Идентификатор в go - это набор символов, букв, символа подчеркивания.
Зарезервированные ключевые слова в go:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
Зарезервированные идентификаторы:
append copy int8 nil true
bool delete int16 panic uint
byte error int32 print uint8
cap false int64 println uint16
close float32 iota real uint32
complex float64 len recover uint64
complex64 imag make rune uintptr
complex128 int new string
Константы декларируются с помощью ключевого слова const.
Переменные можно декларировать с помошью ключевого слова var или без:
const limit = 512 // constant; type-compatible with any number
const top uint16 = 1421 // constant; type: uint16
start := -19 // variable; inferred type: int
end := int64(9876543210) // variable; type: int64
var i int // variable; value 0; type: int
var debug = false // variable; inferred type: bool
checkResults := true // variable; inferred type: bool
stepSize := 1.5 // variable; inferred type: float64
acronym := "FOSS" // variable; inferred type: string
В go два булевских типа true и false.
Бинарные логические операторы - ||(или) и &&(и).
Операторы сравнения - <, <=, ==, !=, >=, >
В Go 11 целочисленных типов, 5 знаковых, 5 беззнаковых, плюс указатель:
byte Synonym for uint8
int The int32 or int64 range depending on the implementation
int8 [−128, 127]
int16 [−32768, 32767]
int32 [−2147483648, 2147483647]
int64 [−9223372036854775808, 9223372036854775807]
rune Synonym for int32
uint The uint32 or uint64 range depending on the implementation
uint8 [0, 255]
uint16 [0, 65535]
uint32 [0, 4294967295]
uint64 [0, 18446744073709551615]
uintptr An unsigned integer capable of storing a pointer value (advanced)
В Go есть два типа чисел с плавающей точкой и два типа комплексных чисел:
float32 ±3.40282346638528859811704183484516925440 х 10^38
float64 ±1.797693134862315708145274237317043567981 х 10^308
complex64 The real and imaginary parts are both of type float32.
complex128 The real and imaginary parts are both of type float64.
Например:
f := 3.2e5 // type: float64
x := -7.3 - 8.9i // type: complex128 (literal)
y := complex64(-18.3 + 8.9i) // type: complex64 (conversion)
z := complex(f, 13.2) // type: complex128 (construction)
fmt.Println(x, real(y), imag(z)) // Prints: (-7.3-8.9i) -18.3 13.2
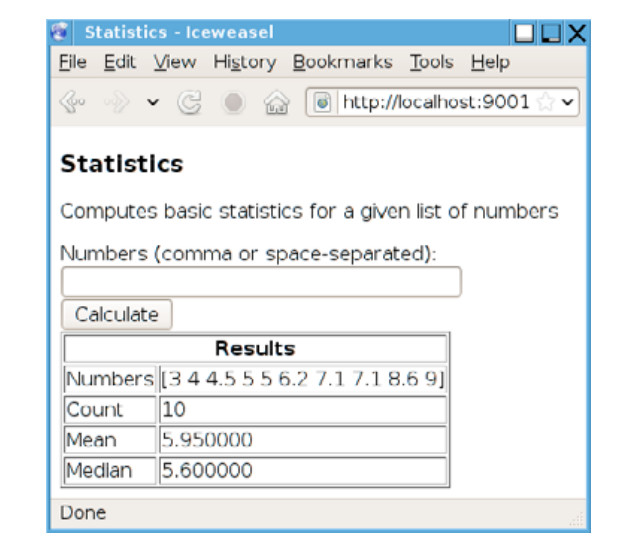
В следующем примере мы создадим локальный веб-сервер, который выведет в броузер страницу статистики:
Создадим базовую структуру:
type statistics struct {
numbers []float64
mean float64
median float64
}
Главная функция запускает локальный веб-сервер на порту 9001:
package main
import (
"fmt"
"log"
"net/http"
"sort"
"strconv"
"strings"
)
const (
pageTop = `<!DOCTYPE HTML><html><head>
<style>.error{color:#FF0000;}</style></head><title>Statistics</title>
<body><h3>Statistics</h3>
<p>Computes basic statistics for a given list of numbers</p>`
form = `<form action="/" method="POST">
<label for="numbers">Numbers (comma or space-separated):</label><br />
<input type="text" name="numbers" size="30"><br />
<input type="submit" value="Calculate">
</form>`
pageBottom = `</body></html>`
anError = `<p class="error">%s</p>`
)
type statistics struct {
numbers []float64
mean float64
median float64
}
func main() {
http.HandleFunc("/", homePage)
if err := http.ListenAndServe(":9001", nil); err != nil {
log.Fatal("failed to start server", err)
}
}
func homePage(writer http.ResponseWriter, request *http.Request) {
err := request.ParseForm() // Must be called before writing response
fmt.Fprint(writer, pageTop, form)
if err != nil {
fmt.Fprintf(writer, anError, err)
} else {
if numbers, message, ok := processRequest(request); ok {
stats := getStats(numbers)
fmt.Fprint(writer, formatStats(stats))
} else if message != "" {
fmt.Fprintf(writer, anError, message)
}
}
fmt.Fprint(writer, pageBottom)
}
func processRequest(request *http.Request) ([]float64, string, bool) {
var numbers []float64
if slice, found := request.Form["numbers"]; found && len(slice) > 0 {
text := strings.Replace(slice[0], ",", " ", -1)
for _, field := range strings.Fields(text) {
if x, err := strconv.ParseFloat(field, 64); err != nil {
return numbers, "'" + field + "' is invalid", false
} else {
numbers = append(numbers, x)
}
}
}
if len(numbers) == 0 {
return numbers, "", false // no data first time form is shown
}
return numbers, "", true
}
func formatStats(stats statistics) string {
return fmt.Sprintf(`<table border="1">
<tr><th colspan="2">Results</th></tr>
<tr><td>Numbers</td><td>%v</td></tr>
<tr><td>Count</td><td>%d</td></tr>
<tr><td>Mean</td><td>%f</td></tr>
<tr><td>Median</td><td>%f</td></tr>
</table>`, stats.numbers, len(stats.numbers), stats.mean, stats.median)
}
func getStats(numbers []float64) (stats statistics) {
stats.numbers = numbers
sort.Float64s(stats.numbers)
stats.mean = sum(numbers) / float64(len(numbers))
stats.median = median(numbers)
return stats
}
func sum(numbers []float64) (total float64) {
for _, x := range numbers {
total += x
}
return total
}
func median(numbers []float64) float64 {
middle := len(numbers) / 2
result := numbers[middle]
if len(numbers)%2 == 0 {
result = (result + numbers[middle-1]) / 2
}
return result
}
Строки в Go - это последовательность байт в кодировке utf-8.
На каждый символ в строке go используется 8 бит - в 2 раза меньше, чем в жабе или питоне.
Строки можно инициализировать с помощью двойных кавычек либо одинарных обратных.
Хотя строки в go immutable, они поддерживают конкатенацию с помощью оператора +=.
Для строк возможны операции:
s += t Appends string t to the end of string s
s + t The concatenation of strings s and t
s[n] The raw byte at index position n (of type uint8) in s
s[n:m] A string taken from s from index positions n to m - 1
s[n:] A string taken from s from index positions n to len(s) - 1
s[:m] A string taken from s from index positions 0 to m - 1
len(s) The number of bytes in string s
len([]rune(s))[] The number of characters in string s—use the faster utf8.
RuneCountInString() instead; see Table 3.10 (➤ 118)
rune(s) Converts string s into a slice of Unicode code points
string(chars) Converts a []rune or []int32 into a string; assumes that the
runes or int32s are Unicode code points
[]byte(s) Converts string s into a slice of raw bytes without copying;
there’s no guarantee that the bytes are valid UTF-8
string(bytes) Converts a []byte or []uint8 into a string without copying;
there’s no guarantee that the bytes are valid UTF-8
string(i) Converts i of any integer type into a string; assumes that i
is a Unicode code point
strconv The string representation of i of type int and an error; e.g.,
Itoa(i) if i is 65, it returns ("65", nil)
fmt.Sprint(x) The string representation of i of type int and an error; e.g.,
if i is 65, it returns ("65", nil);
Go поддерживает в строках срезы так же, как это делается в питоне.
В следующем примере мы имеем строку, состоящую из слов, нужно найти первое и последнее слово в строке:
line := "røde og gule sløjfer"
i := strings.Index(line, " ")
firstWord := line[:i]
j := strings.LastIndex(line, " ")
lastWord := line[j+1:]
fmt.Println(firstWord, lastWord)
Пример работы строковой функции Split:
names := "Niccolò•Noël•Geoffrey•Amélie••Turlough•José"
fmt.Print("|")
for _, name := range strings.Split(names, "•") {
fmt.Printf("%s|", name)
}
fmt.Println()
Строки в Go имеют встроенные функции:
strings.Contains(s, t)
strings.Count(s, t)
strings.EqualFold(s, t)
strings.Fields(s) The []string that results in splitting s on white space
strings.FieldsFunc(s, f) The []string that results in splitting s at every character
where f returns true
strings.HasPrefix(s, t)
strings.HasSuffix(s, t)
strings.Index(s, t) The index of the first occurrence of t in s
strings.IndexAny(s, t) The first index in s of any character that is in t
strings.IndexFunc(s, f) The index of the first character in s for which f returns true
strings.IndexRune(s, char)
strings.Join(xs, t)
strings.LastIndex(s,strings.
LastIndexAny(s, t)
strings.LastIndexFunc(s, f)
strings.Map(mf, t)
strings.NewReader(s)
strings.NewReplacer(...)
strings.Repeat(s, i)
strings.Replace(s,old, new, i)
strings.Split(s, t)
strings.SplitAfter(s, t)
strings.SplitAfterN(s, t, i)
strings.SplitN(s, t, i)
strings.Title(s)
strings.ToLower(s)
strings.ToLowerSpecial(r, s)
strings.ToTitle(s)
strings.ToTitleSpecial(r, s)
strings.ToUpper(s)
strings.ToUpperSpecial(r, s)
strings.Trim(s, t)
strings.TrimFunc(s, f)
strings.TrimLeft(s, t)
strings.TrimLeftFunc(s, f)
strings.TrimRight(s, t)
strings.TrimRightFunc(s, f)
strings.TrimSpace(s)
Пакет Regexp включает следующие функции:
regexp.Match(p, b) true and nil if p matches b of type []byte
regexp.Match-Reader(p, r) true and nil if p matches the text read by r of type io.RuneReader
regexp.Match-String(p, s) true and nil if p matches s
regexp.QuoteMeta(s) A string with all regexp metacharacters safely quoted
regexp.Compile(p) A *regexp.Regexp and nil if p compiles successfully
regexp.Compile-POSIX(p) A *regexp.Regexp and nil if p compiles successfully;
regexp.Must-Compile(p) A *regexp.Regexp if p compiles successfully, otherwise panics
rx.Find(b)
rx.FindAll(b, n)
rx.FindAllIndex(b, n)
rx.FindAllString(s, n)
rx.FindAllString-
Index(s, n)
rx.FindAllStringSubmatch(s, n)
rx.FindAllStringSubmatchIndex(s, n)
rx.FindAllSubmatch(b, n)
rx.FindAllSubmatchIndex(b, n)
rx.FindIndex(b)
rx.FindReaderIndex(r)
rx.FindReaderSubmatchIndex(r)
rx.FindString(s)
rx.FindStringIndex(s)
rx.FindStringSubmatch(s)
rx.FindStringSubmatchIndex(s)
rx.Match(b)
rx.MatchReader(r)
rx.MatchString(s)
rx.NumSubexp()
rx.ReplaceAll(b, br)
rx.ReplaceAllFunc(b, f)
rx.ReplaceAllLiteral(b, br)
В следующем примере приведены три варианта конкатенации строк - от самого медленного до самого быстрого
Пример 1:
for i := 0; i < b.N; i++ {
s1 = s1 + s2
}
Пример 2:
s3 := []byte(s1)
for i := 0; i < b.N; i++ {
s3 = append(s3, s2...)
}
s1 = string(s3)
Пример 3:
var buffer bytes.Buffer
for i := 0; i < b.N; i++ {
buffer.WriteString(s2)
}
s1 := buffer.String()
В следующем примере программа читает плэйлист-файл с расширением .m3u и выводит эквивалентный файл
с расширением .pls. Файл .m3u обычно имеет следующий формат:

 LINUX
LINUX