File handling in the Linux kernel
Оригинал лежит на
http://www.kevinboone.com/linuxfile.html
Будет рассмотрен механизм управления файлами в ядре в следующем порядке слоев :
1 application layer
2 VFS layer
3 filesystem layer
4 generic device layer
5 device driver layer
File handling in the Linux kernel: application layer
Архитектура слоев
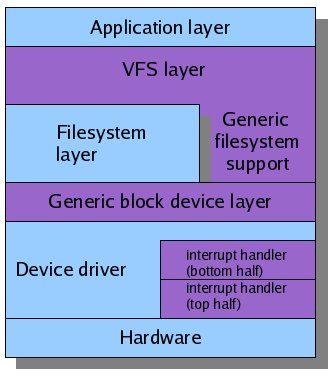 Ядро линукса можно рассматривать в разрезе слоев.
Наверху эти слои наиболее абстрагированы ,
а внизу лежит слой железа - disk, IO, DMA-контроллеры и т.д.
Модель слоев - сильно упрощенная модель.
В идеале , каждый слой вызывает сервис , который лежит ниже ,
и сам обслуживает выше-стоящий слой.
В таком иделаьном мире зависимость между слоями минимизирована ,
и модификация одного слоя не должна приводить к сбоям в работе других слоев.
Ядро линукса можно рассматривать в разрезе слоев.
Наверху эти слои наиболее абстрагированы ,
а внизу лежит слой железа - disk, IO, DMA-контроллеры и т.д.
Модель слоев - сильно упрощенная модель.
В идеале , каждый слой вызывает сервис , который лежит ниже ,
и сам обслуживает выше-стоящий слой.
В таком иделаьном мире зависимость между слоями минимизирована ,
и модификация одного слоя не должна приводить к сбоям в работе других слоев.
Linux kernel в этом смысле не идеален.
На то есть причины . Первая : ядро строится многими людьми на протяжении многих лет.
Целые куски кода в ядре исчезают бесследно , на их место приходят другие.
Вторая : помимо вертикальных слоев , существуют также горизонтальные.
Под этим я понимаю подсистемы , которые имеют одинаковый уровень абстракции.
Слои , которые рассмотрены в этой статье , не являются общепринятыми по умолчанию
в самом ядре.
Будет описан каждый слой и разговор начнется со слоев верхнего уровня.
Начнем мы со слоя приложения.
Итак , слои :
- Слой приложения. Это может быть код приложения: C,
C++, Java, и т.д.
- Библиотечный слой.
Приложения не работают напрямую с ядром .
Для этого есть GNU C library (`glibc').
Это касается не только непосредственно приложений , написанных на си ,
но также и tcl, и java, и т.д.
- VFS . VFS - верхняя , наиболее абстрактная часть ядра
управления файлами.
VFS включает набор API для поддержки стандартного функционала - open, read, write, и т.д.
VFS работает не только с файлами , но также и с pipes, sockets, character devices, и т.д.
В основном код VFS лежит в каталоге
fs/ ядра.
- Файловая система .
Файловая система конвертирует высокоуровневые операции VFS -- reading, writing --
в низко-уровневые операции с дисковыми блоками.
Поскольку в большинстве своем файловые системы похожи друг на друга ,
код VFS по их управлению универсален.
Часть кода VFS можно найти в
mm/ .
- The generic block device layer.
Файловая система не обязательно имеет блочную систему.
Например
/proc не хранится на диске.
VFS не волнует , как реализована файловая система.
Модель блочного устройства построена на последовательности блоков данных фиксированного размера.
Код лежит в drivers/block.
В основном этот код обслуживает базовые функции любых типов блочных устройств ,
в частности обслуживает буфер и очереди.
- The device driver.
Это нижний уровень, наименее абстрактный , напрямую взаимодействующий с драйверами.
Он работает с портами IO, memory-mapped IO, DMA, прерываниями.
Большинство линуксовых драйверов написано на си .
Не все драйвера обслуживают прерывания ,
их можно разделить на 2 группы , в нижней части находятся например
дисковые и SCSI контроллеры.
Такая архитектура имеет свои преимущества.
Различные файловые системы - ext2, ISO9660,UDF -
ничего не знают о драйверах , но могут управлять любым блочным устройством.
В слое драйверов имеется поддержка для SCSI, IDE, MFM, и других контроллеров.
Эти драйвера могут быть использованы для любых файловых систем.
В данной статье рассматривается пример с приложением , написанном на C,
слинкованном с GNU C library.
Файловая система - ext2, диск - IDE.
Приложение
Рассмотрим простое приложение , которое открывает файл , читает данные и закрывает файл :
char buff[5000];
int f = open ("/foo/bar", O_RDONLY);
read (f, &buff, sizeof(buff));
close (f);
Рассмотрим системные вызовы open()и read()
и все , что происходит при этом по пути к контролеру диска.
Код приложения отличается от ядра тем , что на него наложены многие ограничения ,
Фаза `application mode' плавно переходит в `kernel mode' и назад -
и все это в одном потоке.
Библиотека
Функции open() и read()
реализованы в GNU C library (`glibc').
Исполняемый код такой библиотеки обычно лежит в /lib/libc-XXX.so,
где `XXX' - номер версии.
Реализация этих функций такова , что при этом будет неминуемо сделан системный вызов -
и следовательно , будет выполнен код ядра.
Так , при вызове функции open() будет загружен системный вызов под номером 5 ,
который будет загружен в регистр esp , после чего будет выполнена инструкция
int 0x80
Это прерывание попадает в ядро , в векторную таблицу прерываний ,
определенную в arch/i386/kernel/entry.S.
Далее системный номер используется как смещение в таблице системных вызовов там же ,
в entry.S и которая называется sys_call_table.
Эта функция будет называться внутри ядра как sys_open, и определена она в
fs/open.c.
Приложений может быть много , а дисковый контролер один , и ядро должно предусмотреть его блокировку
на тот период , пока он будет обслуживать данный вызов.
Такая блокировка происходит на нижних уровнях ядра , и прикладному программисту нет нужды заботиться об этом.
File handling in the Linux kernel: VFS layer
VFS
Функции sys_open , sys_read,
sys_write лежат в слое кода , называемом VFS.
Эти функции архитектурно-независимы по следующим причинам
- независимость от типа файловой системы - ext2, NFS и т.д.
- независимость от железа - IDE , SATA и т.д..
Мы можем разместить ext2 на SCSI,или UFS на IDE.
Но мы не можем разместить NFS на диске - всему есть разумный предел ,
и сетевая файловая система не может быть размещена на локальном диске.
VFS кроме обычных операций с файлами также имеет дело с монтированием файловых систем
и приаттачиванием блочных устройств в точках монтирования.
Функция sys_open выглядит примерно так :
int sys_open (const char *name, int flags, int mode)
{
int fd = get_unused_fd();
struct file *f = filp_open(name, flags, mode);
fd_install(fd, f);
return fd;
}
Функция get_unused_fd() пытается найти открытый слот
в таблице файловых дескрипторов для текущего процесса.
Если их слишком много , может случиться fail.
В случае успеха вызывается функция filp_open() ; в случае успеха
вернется структура file с файловым дескриптором ,
который будет назначен fd_install().
sys_open вызывает filp_open() ,
вызов которой назначается файловому дескриптору.
filp_open() определен в open.c, и выглядит примерно так :
struct file *filp_open
(const char *name, int flags, int mode)
{
struct nameidata nd;
open_namei (filename, namei_flags, mode, &nd);
return dentry_open(nd.dentry, nd.mnt, flags);
}
filp_open срабатывает в 2 приема.
Сначала вызывается open_namei ( fs/namei.c)
для генерации структуры nameidata.
Эта структура делает линк на файловую ноду.
Далее делается вызов dentry_open(),
передавая информацию из структуры nameidata.
Рассмотрим подробнее структуры
inode, dentry, file.
Концепция ноды - одна из самых древних в юниксе.
Нода - блок данных , который хранит информацию о файле ,
такую как права доступа , размер , путь.
В юниксе различные файловые имена могут указывать на один файл - линки,
но каждый файл имеет только одну ноду.
Директория - разновидность файла и имеет аналогичную ноду.
Нода в завуалированном виде представлена на уровне приложения структурой stat,
в которой есть информация о группе , владельце , размере и т.д.
Поскольку над одним файлом могут трудиться несколько процессов ,
нужно разграничить права доступа для них на этот файл.
В линуксе это реализовано с помощью структуры file.
Она включает информацию о файле применительно к ктекущему процессу.
Структура file содержит косвенную ссылку на ноду.
VFS кеширует ноды в памяти , этот кеш управляется с помощью связанного списка ,
состоящего из структур dentry. Каждая такая dentry
включает ссылку на ноду и имя файла.
Нода - это представление файла , который может быть расшарен;
структура file есть представление файла в конкретном процессе ,
dentry - структура для кеширования нод в памяти .
Вернемся к filp_open().
Она вызывает open_namei(), которая ищет dentry
для данного файла.
Вычисляется путь относительно рута с помощью слеша .
Путь может состоять из нескольких компонентов , и если эти компоненты закешированы
в качестве dentry, вычисление пути проходит быстрее.
Если файл не был в доступе , его нода наверняка не закеширована.
В этом случае она читается слоем файловой системы и кешируется.
open_namei() инициализирует структуру nameidata:
struct nameidata
{
struct dentry *dentry;
struct vfsmount *mnt;
//...
}
dentry включает ссылку на закешированную ноду ,
vfsmount - ссылка на файловую систему , в которой находится файл.
Утилита mount регистрирует эту структуру vfsmount на уровне ядра .
Функция filp_open вычислили нужную dentry,
в том числе и нужную ноду , а также структуру vfsmount .
open() сам по себе не ссылается на vfsmount.
Структура vfsmount хранится в структуре file для будущего использования.
filp_open вызывает dentry_open(), которая выглядит так :
struct file *dentry_open
(struct dentry *dentry, struct vfsmount *mnt, int flags)i
{
struct file * f = // get an empty file structure;
f->f_flags = flags;
// ...populate other file structure elements
// Get the inode for the file
struct inode = dentry->d_inode;
// Call open() through the inode
f->f_op = fops_get(inode->i_fop);
f->f_op->open(inode, f);
}
Здесь определяется адрес функции в файловом слое.
Он может быть найден в самой ноде.
Поддержка mount() в VFS
Мы рассмотрели , как происходит реализация библиотечных вызовов
типа open() и read() на уровне VFS.
Работа VFS не зависит от типа файловой системы и типа устройства.
Ниже VFS находится слой файловой системы , ниже файловой системы находятся устройства.
Процесс монтирования является мостом между ними и VFS.
Под словом -файловая система- понимается конкретный тип файловой системы -
например ext3,
и иногда означает конкретно примонтированный инстанс этой системы.
Для того , чтобы получить список поддерживаемых файловых систем , можно набрать :
cat /proc/filesystems
Как минимум линукс обязан поддерживать ext2
и iso9660 (CDROM) типы.
Некоторые файловые системы вкомпилированы в ядро - например
proc , которая поддерживает одноименный каталог,
который позволяет пользовательским приложениям взаимодействовать с ядром и драйверами.
Т.е. в линуксе файловая система не обязательно соответствует физическому носителю.
В данном случае /proc существует в памяти и динамически генерируется.
Некоторые файловые системы поддерживаются через загружаемые модули ,
поскольку не используются постоянно.
Например , поддержка FAT или VFAT может быть модульной .
Хэндлер файловой системы должен себя зарегистрировать в ядре.
Обычно это делается с помощью register_filesystem(), которая определена
в fs/super.c :
int register_filesystem(struct file_system_type *fs)
{
struct file_system_type ** p =
find_filesystem(fs->name);
if (*p)
return -EBUSY;
else
{ *p = fs; return 0; }
}
Эта функция проверяет - а зарегистрирован ли данный тип файловой системы ,
и если нет , то сохраняетт структуру file_system_type в таблице фйловых систем ядра.
Хэндлер файловой системы , который инициализирует
структуру struct file_system_type,
выглядит так :
struct file_system_type
{
const char *name;
struct super_block *(*read_super)
(struct super_block *, void *, int);
//...
}
Структура включает имя файловой системы
(например ext3), и адрес функции
read_super.
Эта функция будет вызвана . когда файловая система будет монтироваться.
Задача read_super - инициализация структуры
struct super_block,
содержание которой похоже на содержимое суперблока физического диска.
Суперблок включает базовую информацию о файловой системе,
такую например , как максимальный размер файла.
Структура super_block также включает указатели на блоковые операции.
С точки зрения пользователя , для доступа к файловой системе ее нужно примонтировать командой
mount.
Команда mount вызывает функцию mount(),
которая определена в libc-XXX.so.
Происходит вызов функции VFS sys_mount(),
определенной в fs/namespace.h,
sys_mount() проверяет таблицу монтирования :
/*
sys_mount arguments:
dev_name - name of the block special file, e.g., /dev/hda1
dir_name - name of the mount point, e.g., /usr
fstype - name of the filesystem type, e.g., ext3
flags - mount flags, e.g., read-only
data - filesystem-specific data
*/
long sys_mount
(char *dev_name, char *dir_name, char *fstype,
int flags, char *name, void *data)
{
// Get a dentry for the mount point directory
struct nameidata nd_dir;
path_lookup (dir_name, /*...*/, ∓nd_dir);
// Get a dentry from the block special file that
// represents the disk hardware (e.g., /dev/hda)
struct nameidata nd_dev;
path_lookup (dev_name, /*...*/, ∓nd_dev);
// Get the block device structure which was allocated
// when loading the dentry for the block special file.
// This contains the major and minor device numbers
struct block_device *bdev = nd_dev->inode->i_bdev;
// Get these numbers into a packed k_dev_t (see later)
k_dev_t dev = to_kdev_t(bdev->bd_dev);
// Get the file_system_type struct for the given
// filesystem type name
struct file_system_type *type = get_fs_type(fstype);
struct super_block *sb = // allocate space
// Store the block device information in the sb
sb->s_dev = dev;
// ... populate other generate sb fields
// Ask the filesystem type handler to populate the
// rest of the superblock structure
type->read_super(s, data, flags & MS_VERBOSE));
// Now populate a vfsmount structure from the superblock
struct vfsmount *mnt = // allocate space
mnt->mnt_sb = sb;
//... Initialize other vfsmount elements from sb
// Finally, attach the vfsmount structure to the
// mount point's dentry (in `nd_dir')
graft_tree (mnt, nd_dir);
}
Приведенный код упрощен по сравнению с реальным , в частности пропущена обработка ошибок .
некоторые файловые системы могут обслуживать несколько точек монтирования и т.д.
Как ядро выполняет начальное чтение диска при загрузке ?
В ядре есть специальный тип файловой системы - rootfs.
Она инициализируется при загрузке , и берет информацию не от ноды с диска ,
а от параметра загрузчика.
Во время загрузки будет смонтирована как обычная система.
При наборе команды
% mount
сначала появляется строка
/dev/hda1 on / type ext2 (rw)
раньше чем `type rootfs'.
Функция sys_mount() создает пустую структуру
superblock , и сохраняет в ней структуру блочного устройства.
Хэндлер файловой системы регистрируется с помощью register_filesystem(),
прописывая имя файловой системы и адрес функции read_super().
Когда sys_mount() проинициализирует структуру super_block,
вызывается функция read_super().
Хэндлер прочтет физический суперблок с диска и проверит его.
Будет также проинициализирована структура super_operations,
и будет добавлен указатель на поле s_op
в структуре super_block . super_operations
включает набор указателей на функции базовых файловых операций ,
таких как создание или удаление файла.
Когда структура super_block будет проинициализирована ,
будет заполнена другая структура vfsmount данными из суперблока,
после чего vfsmount будет приаттачена к dentry .
Это будет сигнал к тому , что данная директория - не просто каталог , а точка монтирования.
Открытие файла
Когда приложение пытается открыть файл,
вызывается sys_open() ,
которая пытается найти в кеше ноду для файла.
Для этого просматривается список dentry.
Если ноды нет в dentry ,
тогда функция начинает шерстить диск .
Вначале загружается в память рутовый каталог ('/') ,
для этого просто читается нода с номером 2.
Предположим , что нужно прочитать файл `/home/fred/test'.
Может оказаться так , что каталог '/home' будет лежать в файловой системе
совсем другого типа и на другом физическом диске.
Каждя нода , загружаемая в кеш , наследуется от своих предков , вплоть до точки монтирования.
VFS находит структуру vfsmount , которая хранитсяв dentry ,
читает структуру super_operations ,
затем вызывает функцию для открытия ноды в точке монтирования ,
а от нее вниз до самого файла.
Нода для найденного файла кешируется , в ней будет указатель на функции файловых операций.
При открытии файла VFS выполняет примерно следующий код :
// Call open() through the inode
f->f_op = fops_get(inode->i_fop);
f->f_op->open(inode, f);
что вызовет функцию для открытия файла .
File handling in the Linux kernel: filesystem layer
Into the filesystem layer
In the previous article in this series, we traced the execution
from the entry point to the VFS layer, to the inode
structure for a particular
file. This was a long and convoluted process, and before we describe
the filesystem layer, it might be worth recapping it briefly.
- The application code calls
open() in libc-XXX.so.
libc-XXX.so traps into the kernel, in a way that is
architecture-dependent.
- The kernel's trap handler (which is architecture dependant)
calls
sys_open.
sys_open finds the dentry for
the file which, we hope, is cached.
- The file's
inode structure is retrieved from the
dentry.
- The VFS code calls the
open function in the inode,
which is a pointer to a function provided by the handler for
the filesystem type. This handler was installed at boot time, or
by loading a kernel module,
and made a available by being attached to the mount point during
the VFS mount process. The mounted filesystem is represented as
a vfsmount structure, which contains a pointer
to the filesystem's superblock, which in turn contains a pointer to the
block device that handles the physical hardware.
The purpose of the filesystem layer is, in outline, to convert
operations on files, to operations on disk blocks. It is the way in
which file operations are converted to block operations that distinguishes
one filesystem type from another. Since we have to use some sort of
example, in the following I will concetrate on the ext2
filesystem type that we have all come to know and love.
We have seen
how the VFS layer calls open through the inode which
was created by the filesystem handler for the requested file. As well
as open(), a large number of other operations
is exposed in the inode structure.
Looking at the definition of struct inode (in
include/linux/fs.h), we have:
struct inode
{
unsigned long i_ino;
umode_t i_mode;
nlink_t i_nlink;
uid_t i_uid;
gid_t i_gid;
// ... many other data fields
struct inode_operations *i_op;
struct file_operations *i_fop;
}
The interface for manipulating the file is provided by the i_op
and i_fop structures. These structures contain the pointers to the
functions that do the real work; these functions are provided by the
filesytem handler. For example, file_operations, contains the
following pointers:
struct file_operations
{
int (*open) (struct inode *, struct file *);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*release) (struct inode *, struct file *);
// ... and many more
}
You can see that the interface is clean -- there are no references to
lower-level structures, such as disk block lists, and there is nothing
in the interface that presupposes a particular type of low-level hardware.
This clean interface should, in principle, make it easy to understand
the interaction between the VFS layer and the filesystem handlers.
Conceptually, for example, a file read operation ought to look
like this:
- The application asks the VFS layer to
read a file.
- The VFS layer finds the inode and calls the
read()
function.
- The filesystem handler finds which disk blocks correspond to the
part of the file requested by the application via VFS.
- The filesystem handler asks the block device to read those
blocks from disk.
No doubt in some very simple filesystems, the sequence of operations that
comprise a disk read is
just like this.
But in most cases the interaction between VFS and the filesystem
is far from straightforward. To understand
why, we need to consider in more detail what
goes on at the filesystem level.
The pointers in struct file_operations and
struct inode_operations
are hooks into the filesytem handler, and we can expect
each handler to implement them slightly differently. Or can we? It's
worth thinking, for example, about exactly what happens in the filesystem
layer when an application opens or reads a file. Consider the `open'
operation first. What exactly is meant by `opening' a file at the filesystem
level? To the application programmer, `opening' has connotations of
checking that file exists, checking that the requested access mode is
allowed, creating the file if necessary, and marking it as open. At the
filesystem layer, by the time we call open() in
struct file_operations() all of this has been done. It was
done on the cached dentry for the file, and if the file did
not exist, or had the wrong permissions, we would have found out before now.
So the open() operation is more-or-less a no-brainer,
on most filesystem types. What about
the read()
operation? This operation will involve doing
some real work, won't it? Well, possibly not. If we're lucky, the
requested file region will have been read already in the
not-too-distant
past, and will be in a cache somewhere. If we're very lucky, then
it will be available in a cache even if it hasn't been read recently.
This is because disk drives work most effectively when they can read
in a continuous stream. If we have just read physical block 123, for
example, from the disk, there is an excellent chance that the
application will need block 124 shortly. So the kernel will try to
`read ahead' and load disk blocks
into cache before they are actually requested. Similar considerations
apply to disk write operations: writes will normally be performed on
memory
buffers, which will be flushed periodically to the hardware.
Now, this disk caching, buffering, and read-ahead support is, for the
most part filesystem-independent. Of the huge amount of work
that goes on when the application reads data from a file, the only
part that is file-system specific is the mapping of logical
file offsets to physical disk blocks. Everything else is generic.
Now, if it is generic, it can be considered part of VFS, along with
all the other generic file operations, right? Well, no actually.
I would suggest that conceptually the generic filesystem
stuff forms a separate architectural layer,
sitting between the individual filesystem handlers and the block devices.
Whatever the merits of this argument, the Linux
kernel is not structured like this. You'll see, in fact, that the
code is split between two subsystems: the VFS subsystem
(in the fs directory of the kernel source),
and the memory management subsystem
(in the mm directory). There is a reason for this, but it
is rather convoluted, and you may not need to understand it to make
sense of the rest of the disk access procedure which I will describe
later. But, if you are interested, it's like this.
A digression: memory mapped files
Recent linux kernels make use of the concept of `memory mapped files'
for abstracting away low-level file operations, even within the kernel.
To use a memory-mapped file, the kernel maps a contiguous region
of virtual memory to a file. Suppose, for example, the kernel
was manipulating a file
100 megabytes long. The kernel sets up 100 megabytes of virtual
memory, at some particular point in its address space. Then, in order
to read from some particular offset within the file, it reads from
the corresponding offset into virtual memory. On some occassions, the
requested data will be in physical memory, having been read from disk.
On others, the data will not be there when it is read. After all,
we aren't really going to read a hundred megabyte file all at once, and
then find we only need ten bytes of it. When the kernel tries to read
from the file region that does not exist in physical memory, a page
fault is generated, which traps into the virtual memory management system.
This system then allocates physical memory, then
schedules a file read to bring the data into memory.
You may be wondering
what advantage this memory mapping offers over the simplistic view of
disk access I described above, where VFS asks for the data, the
filesystem converts the file region into blocks, and the block
device reads
those blocks. Well, apart from being a convenient abstraction, the
kernel will have a memory-mapped file infrastructure anyway. It must
have, even if it doesn't use that particular term. The ability to
swap physical memory with backing store (disk, usually), when particular
regions of virtual memory are requested, is a fundamental part of
memory management on all modern operating systems. If we couldn't do this,
the total virtual memory available to the system would be limited to the
size of physical memory. There could be no demand paging. So, the argument
goes, if we have to have a memory-mapped file concept, with all the complex
infrastructure that entails, we may as well use it to support ordinary
files, as well as paging to and from a swap file. Consequently, most
(all?) file operations carried out in the Linux kernel make use of
the memory-mapped file infrastructure.
The ext2 filesystem handler
In the following, I am using ext2 as an example of a
filesystem handler but, as should be clear by now, we don't lose a lot
of generality. Most of the filesystem infrastructure is generic
anyway. I ought to point out, for the sake of completeness, that
none of what follows is mandatory for a filesystem handler.
So long as the handler implements the functions defined in
struct file_operations and struct inode_operations,
the VFS layer couldn't care less what goes on inside the handler. In practice,
most filesystem type handlers do work the way I am about to described,
with minor variations.
Let's dispose of the open() operation first, as this is
trivial (remember that VFS has done all the hard work by the time
the filesystem handler is invoked). VFS calls
open() in the struct file_operations provided
by the filesystem handler. In the ext2 handler,
this structure is initialized like this (fs/ext2/file.c):
struct file_operations ext2_file_operations =
{
llseek: generic_file_llseek,
read: generic_file_read,
write: generic_file_write,
ioctl: ext2_ioctl,
mmap: generic_file_mmap,
open: generic_file_open,
release: ext2_release_file,
fsync: ext2_sync_file,
};
Notice that most of the file operations are simply delegated to the
generic filesystem infrastructure. open() maps onto
generic_file_open(), which is defined in fs/open.c:
int generic_file_open
(struct inode * inode, struct file * filp)
{
if (!(filp->f_flags & O_LARGEFILE) &&
inode->i_size > MAX_NON_LFS)
return -EFBIG;
return 0;
}
Not very interesting, it it? All this function does is to check
whether we have requested
an operation with large file support on a filesystem that can't accomodate
it. All the hard work has already been done by this point.
The read() operation is more interesting. This function
results in a call on generic_file_read(), which is defined
in mm/filemap.c (remember, file reads are part of
the memory management infrastructure!). The logic is fairly complex,
but for our purposes -- talking about file management, not memory
management -- can be distilled down to something like this:
/*
arguments to generic_file_read:
filp - the file structure from VFS
buf - buffer to read into
count - number of bytes to read
ppos - offset into file at which to read
*/
ssize_t generic_file_read (struct file * filp,
char * buf, size_t count, loff_t *ppos)
{
struct address_space *mapping =
filp->f_dentry->d_inode->i_mapping;
// Use the inode to convert the file offset and byte
// count into logical disk blocks. Work out the number of
// memory pages this corresponds to. Then loop until we
// have all the required pages
while (more_to_read)
{
if (is_page_in_cache)
{
// add cached page to buffer
}
else
{
struct page *page = page_cache_alloc(mapping);
// Ask the filesystem handler for the logical page.
// This operation is non-blocking
mapping->a_ops->readpage(filp, page);
// Schedule a look-ahead read if possible
generic_file_readahead(...);
// Wait for request page to be delivered from the IO subsystem
wait_on_page(page);
// Add page to buffer
// Mark new page as clean in cache
}
}
}
In this code we can see (in outline) the caching and read-ahead
logic.
It's important to remember that because
the generic_file_read code is part of the memory management
subsystem, its operations are expressed in terms of (virtual memory)
pages, not disk blocks. Ultimately we will be reading disk blocks,
but not here. In practice, disk blocks will often be 1kB, and
pages 4kB. So we will have four block reads for each page read.
generic_read_file can't get real data from a real filesystem,
either in blocks or in pages,
because only the filesystem knows where the logical blocks in the file
are located on the disk.
So, for this discussion, the most important
feature of the above code is the call:
mapping->a_ops->readpage(filp, page);
This is a call through the inode of the file, back into the filesystem
handler. It is expected to schedule the read of a page of data, which
may encompass multiple disk blocks. In reality, reading a page
is also a generic operation -- it is only reading blocks that is
filesystem-specific. A page read just works out the number of
blocks that constitute a page, and then calls another function to
read each block. So, in the ext2 filesystem example,
the readpage function pointer points to
ext2_readpage() (in fs/ext2/inode.c),
which simply calls back into the generic VFS layer like this:
static int ext2_readpage
(struct file *file, struct page *page)
{
return block_read_full_page(page,ext2_get_block);
}
block_read_full_page() (in fs/buffer.c)
calls the ext2_get_block() function once
for each block in the page. This function does
not do any IO itself, or even delegate it to the block device.
Instead, it determines the location on disk of the requested
logical block, and returns this information in a
buffer_head structure (of which, more later).
The ext2
handler does know the block device (because this information
is stored in the inode object that has been passed
all the way down from the VFS layer). So it could quite happily
ask the device to do a read. It doesn't, and the reason for this
is quite subtle. Disk devices generally work most efficiently
when they are reading or writing continuously. They don't work
so well if the disk head is constantly switching tracks. So for
best performance, we want to try to arrange the disk blocks to be
read sequentially, even if that means that they are not read
or written in the order they are requested. The code to do this
is likely to be the same for most, if not all, disk devices. So
disk drivers typically make use of the generic request management
code in the block device layer, rather than scheduling IO operations
themselves.
So, in short, the filesystem handler does not do any IO, it merely fills
in a buffer_head structure for each block required.
The salient parts of the structure are:
struct buffer_head
{
struct buffer_head *b_next; /* Next buffer in list */
unsigned long b_blocknr; /* Block number */
kdev_t b_dev; /* Device */
struct page *page; /* Memory this block is mapped to */
void (*b_end_io)(struct buffer_head *bh, int uptodate);
// ... and lots more
}
You can see that the structure contains a block number, an identifier
for the device (b_dev),
and a reference to the memory into which the disk
contents should be read. kdev_t is an integer containing
the major and minor device numbers packed together.
buffer_head therefore contains everything the IO
subsystem needs to do the real read. It also defines a function
called b_end_io that the block device layer will call
when it has loaded the requested block (remember this operation
is asynchronous). However,
the VFS generic filesystem infrastructure does not hand off
this structure to the IO subsystem immediately it is returned from
the filesystem handler. Instead, as the
filesystem handler populates buffer_head objects, VFS
builds them into a queue (a linked list), and then submits the whole queue
to the block device layer. A filesystem handler can implement its
own b_end_io function or, more commonly, make using of
the generic end-of-block processing found in the generic block device
layer, which we will consider next.
File handling in the Linux kernel: generic device layer
Into the block generic device layer
In the previous article we traced the flow of execution from the VFS layer,
down into the filesystem handler, and from there into the generic
filesystem handling code. Before we examine the kernel's
generic block device layer, which provides the general functionality
that most block devices will require, let's have a quick
recap of what goes on in the filesystem layer.
When the application manipulates a file, the kernel's
VFS layer
finds the file's dentry structure in memory, and
calls the file operations open(), read(),
etc., through the file's inode structure.
The inode contains pointers into
the filesystem handler for the particular filesystem on which the file
is located. The handler delegates most of its work
to the generic filesystem support code, which is split between
the VFS subsystem and the memory management subsystem. The generic
VFS code attempts to find the requested blocks in the
buffer cache but, if it can't,
it calls back into the filesystem handler to determine the physical
blocks that correspond to the logical blocks that VFS has asked it
to read or write. The filesystem handler populates buffer_head
structures containing
the block numbers and device numbers, which are then built into a
queue of IO requests. The queue of requests is
then passed to the generic block device layer.
Device drivers, special files, and modules
Before we look at what goes on in the block device layer, we need to
consider how the VFS layer (or the filesystem handler in some cases)
knows how to find the driver implementation that supports a particular block device.
After all, the system could be supporting IDE disks, SCSI disks,
RAMdisks, loopback devices, and any number of other things. An
ext2 filesystem will look much the same whichever of
these things it is installed on, but naturally the hardware operations
will be quite different. Underneath each block device, that is,
each block special file of the form /dev/hdXX will
be a driver. The same driver can, and often does, support mutliple
block devices, and each block device can, in principle, support multiple
hardware units. The driver code may be compiled directly into
the core kernel, or made available as a loadable module.
Each block special file is indentified by two
numbers - a major device number and a minor device number. In
practice, a block special file is not a real file, and does not take
any space on disk. The device numbers typically live in
the file's inode; however, this is filesystem-dependant.
Conventionally the major device number identifies either a particular
driver or a particular hardware controller, while the minor number
identifies a particular device attached to that controller.
There have been some significant changes to the way that Linux
handles block special files and drivers in the last year or so.
One of the problems that these changes attempt to solve is that
major and minor numbers are, and always will be, 8-bit integers.
If we assume loosely that each specific hardware controller attached
to the system has its own major number (and that's a fair approximation)
then we could have 200 or so different controllers attached (we
have to leave some numbers free for things like /dev/null).
However, the mapping between controller types and major numbers has
traditionally always been static. What this means is that
the Linux designers decided in advance what numbers should be assigned to
what controllers. So, on an x86 system, major 3 is the primary IDE
controller (/dev/hda and /dev/hdb), major 22 is the secondary IDE controller (/dev/hdc and /dev/hdc),
major 8 is for the first 16 SCSI hard disks (/dev/sda...),
and so on. In fact, most of the major numbers have been pre-allocated,
so it's hard to find numbers for new devices.
In more recent Linux kernels, we have the ability to mount /dev
as a filesystem, in much the same way that /proc works.
Under this system, device numbers get allocated dynmically, so we can have
200-odd devices per system, rather 200-odd for the whole world.
This issue of device number allocation may seen to be off-topic,
but I am mentioning it because the system I about to describe assumes
that we are using the old-fashioned (static major numbers) system, and
may be out-of-date by the time you read this. However, the basic
principles remain the same.
You should be aware also that block devices have been with Linux for a long
time, and kernel support for driver implementers has developed
significantly over the years. In 2.2-series kernels, for example,
driver writers typically took advantage of a set of macros defined
in kernel header files, to simplify the structure of the driver. For a
good example of this style of driver authoring, look at
drivers/ide/legacy/hd.c, the PC-AT legacy hard-disk driver.
There are, in consequence, a number of different ways of implementing
even a simple block device driver. In what follows, I will describe only
the technique that seems to be most widely used in the latest 2.4.XX
kernels. As ever, the principles are the same in all versions, but the
mechanics are different.
Finding the device numbers for a filesystem
There's one more thing to consider before we look at how the filesystem
layer interacts with the block device layer, and that is how the
filesystem layer knows which driver to use for a given filesystem.
If you think back to the mount operation described above,
you may remember that sys_mount took the name of
the block special file as an argument; this argument will usually have
come from the command-line to the mount command.
sys_mount then descends the filesystem to find the
inode for the block special file:
path_lookup (dev_name, /*...*/, ∓nd_dev);
and from that inode it extracts the major and minor numbers, among
other things, and stores them in the superblock structure for the
filesystem. The superblock is then stored in a vfsmount
structure, and the vfsmount attached to the dentry
of the directory on which the filesystem is mounted. So, in short,
as VFS descends the pathname of a requested file, it can determine the
major and minor device numbers from the closest vfsmount above
the desired file. Then, if we have the major number, we can
ask the kernel for the struct block_device_operations
that supports it, which was stored by the kernel when the driver was
registered.
Registering the driver
We have seen that each device, or group of devices, is assigned
a major device number, which identifies the driver to be invoked
when requests are issued on that device. We now need to consider how
the kernel knows which driver to invoke, when an IO request is queued for
a specific major device number.
It is the responsibility of the block device driver to register
itself with the
kernel's device manager. It does this by making a call to
register_blkdev() (or devfs_register_blkdev()
in modern practice).
This call will usually be in the driver's initialization section,
and therefore be invoked at boot time (if the driver is compiled in)
or when the driver's module is loaded. Let's assume for now that
the filesystem is hosted on an IDE disk partition, and will be handled
by the ide-disk driver. When the IDE subsystem
is initialized it probes for IDE controllers, and for each one it
finds it executes (drivers/ide/ide-probe.c):
devfs_register_blkdev (hwif->major, hwif->name, ide_fops));
ide_fops is a structure of type block_device_operations, which contains pointers to functions implemented in the driver for
doing the various low-level operations. We'll come back to this later.
devfs_register_blkdev adds the driver to the kernel'
s driver table, assigning
it a particular name, and a particular major number (the code for
this is in fs/block_dev.c, but it's not particularly
interesting). What the call really does is map a major device number
to a block_device_operations structure. This structure
is defined in include/linux/fs.h like this:
struct block_device_operations
{
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
int (*ioctl) (struct inode *, struct file *, unsigned, unsigned long);
// ... and a few more
}
Each of these elements is a pointer to a function defined in the driver.
For example, when the IDE driver is initialized, if its bus probe reveals
that the attached device is a hard disk, then it points the
open function at idedisk_open() (in
drivers/ide/ide-disk.c). All this function does is
signal to the kernel that the driver is now in use and, if the
drive supports removeable media, locks the drive door.
In the code extract above there were not read() or
write() functions. That's not because I left them out,
but because they don't exist. Unlike a character device, block devices
don't expose read and write functionality directly to the layer above;
instead they expose a function that handles requests delivered to
a request queue.
Request queue management
We have seen that the filesystem layer builds a queue of
requests for blocks to read or write. It then typically submits
that queue to the block device layer by a call to
submit_bh() (in drivers/block/ll_rw_block.c).
This function does some checks on
the requests submitted, and then calls the request handling
function registered by the driver (see below for details).
The driver can either
directly specify a request handler in its own code, or make
use of the generic request handler in the block device layer.
The latter is usually preferred, for the following reason.
Most block devices, disk drives in particular, work most efficiently
when asked to read or write a contiguous region of data.
Suppose that the filesystem handler is asked to provide a list of the
physical blocks that comprise a particular file, and that list
turns out to be blocks 10, 11, 12, 1, 2, 3, and 4.
Now, we could ask the block device driver
to load the blocks in that order, but this would involve
seven short reads, probably with a repositioning of the disk head
between the third and fourth block.
It would be more effecient to ask the hardware to load blocks
10-12, which it could do in a continuous read, and then 1-4, which
are also contiguous. In addition, it would probably be more efficient to
re-order the reads so that blocks 1-4 get done first, then 10-12.
These processes are refered to in the kernel documentation as
`coalescing' and `sorting'.
Now, coalescing and sorting themselves require a certain amount of
CPU time, and not all devices will benefit. In particular, if the
block device offers true random access -- a ramdisk, for example --
the overheads of sorting and coalescing may well outweigh the benefits.
Consequently, the implementer of a block device driver can choose whether
to make use of the request queue management features or not.
If the driver should receive
requests one-at-a-time as they are delivered from the filesystem layer,
it can use the function
void blk_queue_make_request
(request_queue_t *q, make_request_fn *mrf);
This takes two arguments: the queue in the kernel to which requests
are delivered by the filesystem (of which, more later), and the
function to call when each request arrives. An example of the use
of this function might be:
#define MAJOR = NNN; // Our major number
/*
my_request_fn() will be called whenever a request is ready
to be serviced. Requests are delivered in no particular
order
*/
static int my_request_fn
(request_queue_t *q, int rw, struct buffer_head *rbh)
{
// read or write the buffer specified in rbh
// ...
}
// Initialization section
blk_queue_make_request(BLK_DEFAULT_QUEUE(MAJOR), my_request_fn);
The kernel's block device manager maintains a default queue for
each device, and in this example we have simply attached a
request handler to that default queue.
If the driver is taking advantage of the kernel's request ordering
and coalescing functions, then it register's itself using the function
void blk_init_queue
(request_queue_t * q, request_fn_proc * rfn);
(also defined in drivers/block/ll_rw_blk.c).
The second argument to this function is a pointer to a function
that will be invoked when a sorted queue of requests is available
to be processed. The driver might use this function like this:
/*
my_request_fn() will be called whenever a queue of requests
is ready to be serviced. Requests are delivered ordered and
coalesced
*/
static int my_request_fn
(request_queue_t *q)
{
// read or write the queue of buffer specified in *q
// ...
}
// Initialization section
blk_init_q(BLK_DEFAULT_QUEUE(MAJOR), my_request_fn);
So we have seen how the device registers itself with the generic
block device layer, so that it can accept requests to read or write blocks.
We must now consider
what happens when these requests have been completed.
You may remember that the interface between the filesystem layer and
the block device layer is asynchronous. When the filesystem handler added
the specifications of blocks to load into the buffer_head
structure, it could also write a pointer to the function to call to indicate
that the block had been read. This function was stored in the
field b_end_io. In practice, when the filesystem layer
submits a queue of blocks to read to the submit_bh()
function in the block device layer, submit_bh()
ultimately sets
b_end_io to a generic end-of-block handler.
This is the function end_buffer_io_sync
(in fs/buffer.c). This generic handler simply marks
the buffer complete and unlocks its memory. As the interface between
the filesystem layer and the generic block device layer is asynchronous,
the interface between the generic block device layer and the driver
itself is also asynchronous. The request handling functions
described above (named my_request_fn in the code
snippets) are expected not to block. Instead, these
methods should schedule an IO request on the hardware, then notify
the block device layer by calling b_end_io on each block
when it is completed. In practice, device drivers typically make use
of utility functions in the generic block device layer, which combine
this notification of completion with the manipulation of the queue.
If the driver registers itself using blk_init_q(),
its request handler can expected to be passed a pointed to a
queue whenever there are requests available to be serviced. It uses
utility functions to iterate through the queue, and to notify the
block device layer everytime a block is completed. We will look at
these functions in more detail in the next section.
Device driver interface
So, in summary, a specific block device driver has two interfaces
with the generic block device layer. First, it provides functions
to open, close, and manage the device, and registers them by calling
register_blkdev(). Second, it provides a function that
handles incoming requests, or incoming request queues, and registers
that function by the appropriate kernel API call:
blk_queue_make_request()
or blk_init_queue. Having registered a queue handler, the
device driver typically uses utility functions in the generic block device
layer to retrieve requests from the queue, and issue notifications when
hardware operations are complete.
In concept, then, a block device driver
is relatively simple. Most of the work will be done in its request
handling method, which will schedule hardware operations, then call
notification functions when these operations complete.
In reality, hardware device drivers have to contend with the complexities
of interrupts, DMA, spinlocks, and IO, and are consequently
much more
complex that the simple interface between the device driver and the
kernel would suggest. In the next, and final, installment, we will
consider some of these low-level issues, using the IDE disk driver as an
example.
File handling in the Linux kernel: device driver layer
Into the device driver
In the previous article I described how requests to read or write
files ended up as queues of requests to read or right blocks on
a storage device. When the device driver is initialized, it supplies
the address either of a function that can read or write a single block
to the device, or of a function that can read or write queues of
requests. The latter is the more usual. I also pointed out that
the generic block device layer provides various utility functions
that drivers can use to simplify queue management and notification.
It's time to look in more detail at what goes on inside a typical
block driver, using the IDE disk driver as an example. Of course,
the details will vary with the hardware type and, to a certain
extent, the platform, but the principles will be similar in most
cases. Before we do that, we need to stop for a while and think
about hardware interfacing in general: interrupts, ports, and
DMA.
Interrupts in Linux
The problem with hardware access is that it's slow. Dead slow. Even
a trivial operation like move a disk head a couple of tracks takes
an age in CPU terms. Now, Linux is a multitasking system, and it would
be a shame to make all the processes on the system stop and wait
while a hardware operation completes. There are really only two strategies
for getting around this problem, both of which are supported by the
Linux kernel.
The first strategy is the `poll-and-sleep' approach. The kernel thread
that
is interacting with the hardware checks whether the operation has
finished;
if it hasn't, it puts itself to sleep for a short time. While it is
asleep,
other processes can get a share of the CPU. Poll-and-sleep is easy to
implement but it has a significant problem. The problem is that most
hardware operations don't take predictable times to complete. So when
the
disk controller tells the disk to read a block, it may get the results
almost immediately, or it may have to wait will the disk spins up and
repositions the head. The final wait time could be anywhere between
a microsecond and a second. So, how long should the process sleep
between polls? If it sleeps for a second, then little CPU time is
wasted, but every disk
operation will take at least a second. If it sleeps for a microsecond,
then
there will be a faster response, but perhaps up to a million wasted
polls. This is far from ideal. However, polling can work reasonably
well
for hardware that responds in a predictable time.
The other strategy, and the one that is most widely used, is to use
hardware interrupts. When the CPU receives an interrupt,
provided interrupts haven't
been disabled or masked out, and there isn't another interrupt of
the same type currently
in service, then the CPU will stop what it's doing, and execute a piece of
code called the interrupt handler. In Unix, interrupts are conceptually
similar to signals, but interrupts typically jump right into the kernel.
In the x86 world, hardware interrupts are generally called IRQs, and
you'll see both the terms `interrupt' and `IRQ' used in the names of
kernel APIs.
When the interrupt handler is finished, execution resumes at the point
at which it was broken off. So, what the driver can do is to tell the hardware to
do a particular operation, and then put itself to sleep until the
hardware generates an interrupt to say that it's finished. The driver can
then finish up the operation and return the data to the caller.
Most hardware devices that are attached to a computer are capable of
generating interrupts. Different architectures support different numbers
of interrupts, and have different sharing capabilities. Until recently
there was a significant chance that you would have more hardware than
you had interrupts for, at least in the PC world. However, Linux
now supports `interrupt sharing', at least on compatible hardware.
On the laptop PC I am using to write this, the interrupt 9 is
shared by the ACPI (power management) system, the USB interfaces (two of
them) and the FireWire interface. Interrupt allocations can be found
by doing
%cat /proc/interrupts
So, what a typical harddisk driver will usually do, when asked to
read or write one or more blocks of data, will be to write to the
hardware registers of the controller whatever is needed to start
the operation, then wait for an interrupt.
In Linux, interrupt handlers can usually be written in C. This
works because the real interrupt handler is in the kernel's
IO subsystem - all interrupts actually come to the same place.
The kernel then calls the registered handler for the interrupt.
The kernel takes care of matters like saving the CPU register
contents before calling the handler, so we don't need to do
that stuff in C.
An interrupt handler is defined and registered like this:
void my_handler (int irq, void *data,
struct pt_regs *regs)
{
// Handle the interrupt here
}
int irq = 9; // IRQ number
int flags = SA_INTERRUPT | SA_SHIRQ; // For example
char *name = "myhardware";
char *data = // any data needed by the handler
request_irq(irq, my_handler, flags, data);
request_irq takes the IRQ number (1-15 on x86),
some flags, a pointer to the handler, and a name. The name is
nothing more than the text that appears in /proc/interrupts.
The flags dictate two important things -- whether the interrupt
is `fast' (SA_INTERRUPT, see below) and whether it is shareable (SA_SHIRQ).
If the interrupt is not available, or is available but only to a driver
that supports sharing, then request_irq returns a non-zero
status. The last argument to the function is a pointer to an arbitrary
block of data. This will be made available to the handler when the
interrupt arrives, and is a nice way to supply data to the handler.
However, this is relatively new thing in Linux, and not all the
existing drivers use it.
The interrupt handler is invoked with the number of the
IRQ, the registers that were saved by the interrupt service routine
in the kernel, and the block of data passed when the handler was
registered.
An important historical distinction in Linux was
between `fast' and `slow' interrupt handlers, and because this continues
to
confuse developers and arouse heated debate, it might merit a brief
mention here.
. In the early days (1.x kernels), the Linux
architecture supported two types of interrupt handler - a `fast' and
a `slow' handler. A fast handler was invoked without the stack
being fully formatted, and without all the registers preserved.
It was intended for handlers that were genuinely fast, and didn't do much.
They couldn't do much, because they weren't set up to.
In order to avoid the complexity of interacting with the interrupt
controller, which would have been been necessary to prevent other instances
of the same interrupt entering the handler re-entrantly and breaking it,
a fast
handler was entered with interrupts completely disabled. This was
a satisfactory approach when the interrupts really had to be fast.
As hardware got faster, the benefit of servicing an interrupt with an
incompletely formatted stack became less obvious. In addition, the
technique was developed of allowing the handler to be constructed of
two parts: a `top half' and a `bottom half'. The `top half' was the part of the
handler that had to complete immediately. The top half would do the minimum
amount of work, then schedule the `bottom half' to execute when the
interrupt was finished. Because the bottom half could be pre-empted, it
did not hold up other processes. The meaning of
a `fast' interrupt handler therefore changed: a fast handler completed
all its work within the main handler, and did not need to schedule
a bottom half.
In modern (2.4.x and later) kernels, all these historical features are
gone. Any interrupt handler can register a bottom half and, if it
does, the bottom half will be scheduled to run in normal time when
the interrupt handler returns. You can use the macro mark_bh
to schedule a bottom half; doing so requires a knowledge of kernel
tasklets, which are beyond the scope of this article
(read the comments in include/linux/interrupt.h in the
first instance). The only thing that the `fast handler' flag
SA_INTERRUPT now does is to cause the handler to be
invoked with interrupts disabled. If the flag is ommitted, interrupts
are enabled, but only for IRQs different to the one currently being
serviced. One type of interrupt can still interrupt a different type.
Port IO in Linux
Interrupts allow the hardware to wake up the device driver when it
is ready, but we need something else to send and receive data
to and from the device. In some computer architectures, peripherals
are commonly mapped into the CPU's ordinary address space. In such a
system, reading
and writing a peripheral is identical to reading and writing memory,
except that region of `memory' is fixed. Most architectures on
which Linux runs do support the `memory mapping' strategy, although
it is no longer widely used.
In a sense, DMA (direct memory access) is perhaps a more subtle way
of achieving the same effect. Most architectures provide separate
address spaces for IO devices (`ports') and for memory, and most
perhiperals are constructed to make use of this form of addressing.
Typically the IO address
space is smaller than the memory address space -- 64 kBytes is quite
a common figure. Different CPU instructions are used to read and write
IO ports, compared to memory. To make port IO as portable as possible,
the kernel source code provides macros for use in C that expand into
the appropriate assembler code for the platform. So we have, for
example, outb to output a byte value to a port, and
inl to input a long (32-bit) value from a port.
Device drivers are encouraged to use the function request_region
to reserve a block of IO ports. For example:
if (!request_region (0x300, 8, "mydriver"))
{ printk ("Can't allocate ports\n"); }
This prevents different drivers trying to control the same devices. Ports
allocated this way appear in /proc/ioports. Note that some
architectures allow port numbers to be dynamically allocated at boot time, while
others are largely static. In the PC world, most systems now support
dynamic allocation, which makes drivers somewhat more complicated to
code, but gives users and administrators an easier time.
DMA in Linux
The use of DMA in Linux is a big subject in its own right, and one whose
details are highly architecture-dependent. I only intend to deal with it
in outline here. In short, DMA (direct memory access) provides a
mechanism by which peripheral devices can read or write main memory
independently of the CPU. DMA is usually much faster than a scheme were
the CPU iterates over the data to be transferred, and moves it byte-by-byte
into memory (`programmed IO').
In the PC world, there are two main forms of DMA. The
earlier form, which has been around since the PC-AT days, uses a dedicated
DMA controller to do the data transfer. The IO device and the memory are
essentially passive. This scheme was considered very fast in the early 1990s,
but worked only over the ISA bus. These days, many peripheral devices
that can take part in DMA use bus mastering. In bus mastering DMA,
it is the peripheral that takes control of the DMA process, and a specific
DMA controller is not required.
A block device driver that uses DMA is usually not very different from
one that does not. DMA, although faster than programmed IO, is unlikely
to be instantaneous. Consequently, the driver will still have to schedule
an operation, then receive an interrupt when it has completed.
The IDE disk driver
We are now in a position to look at what goes on inside the IDE disk
driver. IDE disks are not very smart -- they need a lot of help from
the driver. Each read or write operation will go through various stages,
and these stages are coordinated by the driver. You should also remember
that a disk drive has to do more than simply read and write, but I
won't discuss the other operations here.
When the driver is initialized, it probes the hardware and, for each
controller found, initializes a block device, a request queue
handler, and an interrupt handler for each controller
(ide-probe.c). In outline, the
initialization code for the first IDE controller
looks like this:
// Register the device driver with the kernel. For
// first controller, major number is 3. The name
// `ide0' will appear in /proc/devices. ide_fops is a
// structure that contains pointers to the open,
// close, and ioctl functions (see previous article).
devfs_register_blkdev (3, "ide0", ide_fops)
// Initialize the request queue and point it to the
// request handler. Note that we aren't using the
// kernel's default queue this time
request *q = // create a queue
blk_dev[3].queue = q; // install it in kernel
blk_init_queue(q, do_ide_request);
// Register an interrupt handler
// The real driver works out the IRQ number, but it's
// usually 14 for the first controller on PCs
// ide_intr is the handler
// SA_INTERRUPT means call with interrupts disabled
request_irq(14, &ide_intr, SA_INTERRUPT, "ide0",
/*... some drive-related data */)
// Request the relevant block of IO ports; again
// 0x1F0 is common on PCs.
request_region (0x01F0, 8, "ide0");
}
The interrupt handler ide_intr()
is quite straightforward, because it delegates the
processing to a function defined by the pointer
handler:
void ide_intr (int irq, void *data, struct pt_regs *regs)
{
// Check that an interrupt is expected
// Various other checks, and eventually...
handler();
}
We will see how handler gets set shortly.
When requests are delivered to the driver, the method
do_ide_request is invoked. This
determines the type of the request, and whether the
driver is in a position to service the request. If it
is not, it puts itself to sleep for a while. If the
request can be serviced, then
do_ide_request() calls the appropriate
function for that type of request. For a read or write request,
the function is
__do_rw_disk() (in
drivers/ide/ide-disk.c).
__do_rw_disk()
tells the IDE
controller which blocks to read, by calculating the
drive parameters and outputing them to the control
registers. It is a fairly long and complex function,
but the part that is important for
this discussion looks (rather simplified) looks like this:
int block = // block to read, from the request
outb(block, IDE_SECTOR_REG);
outb(block>>=8, IDE_LCYL_REG);
outb(block>>=8, IDE_HCYL_REG);
// etc., and eventually set the address of the
// function that will be invoked on the next
// interrupt, and schedule the operation on the drive
if (rq->cmd == READ)
{
handler = &read_intr;
outb(WIN_READ, IDE_COMMAND_REG); // start the read
}
The outb function outputs bytes of data
to the control registers IDE_SECTOR_REG, etc.
These are defined in
include/linux/ide.h,
and expand to the IO port addresses of
the control registers for specific IDE disks.
If the IDE controller supports bus-mastering DMA, then
the driver will intialize a DMA channel for it to use.
read_intr is the function that will be
invoked on the next interrupt; its address is stored
in the pointer handler, so it gets
invoked by ide_intr, the registered interrupt handler.
void read_intr(ide_drive_t *drive)
{
// Extract working data from the drive structure
// passed by the interrupt handler
struct request *rq = //... request queue
int nsect = //... number of sectors expected
char *name = //...name of device
// Get the buffer from the first request in the
// queue
char *to = ide_map_buffer(rq, /*...*/);
// in ide-taskfile.c
// And store the data in the buffer
// This will either be done by reading ports, or it
// will already have been done by the DMA transfer
taskfile_input_data(drive, to, nsect * SECTOR_WORDS);
// in ide-taskfile.c
// Now shuffle the request queue, so the next
// request becomes the head of the queue
if (end_that_request_first(rq, 1, name))
{
// All requests done on this queue
// So reset, and wake up anybody who is listening
end_that_request_last (rq);
}
}
The convenience functions
end_that_request_first() and
end_that_request_last() are defined in
devices/block/ll_rw_blk.c
end_that_request_first()
shuffles the next request to the head or
the queue, so it is available to be processed, and
then calls b_end_io on the request that
was just finished.
int end_that_request_first(structure request *req,
int uptdate, char *name)
{
struct buffer_head *bh = req->bh;
bh->b_end_io (bh, uptodate);
// Adjust buffer to make next request current
if (/* all requests done */) return 1;
return 0;
}
bh->b_end_io points to
end_buffer_io_sync (in
fs/buffer.c) which just marks
the buffer complete, and wakes up any threads that are
sleeping in wait for it to complete.
Summary
So that's it. We've seen how a file read operation
travels all the way from the application program,
through the standard library, into the kernel's VFS
layer, through the filesystem handler, and into the
block device infrastructure. We've even seen how the
block device interracts with the physical hardware.
Of course, I've left a great deal out in this
discussion. If you look at all the functions I've
mentioned in passing, you'll see that they amount to
about 20,000 lines of code. Probably about half of
that volume is concerned with handling errors and
unexpected situations. All the same, I hope my
description of the basic principles has been helpful.
|

 LINUX
LINUX 
 Kernels
Kernels
