The Linux Kernel / David A Rusling
The Linux Kernel
David A Rusling
Данное руководство основывается на версии ядра 2.0.33 .
Hardware Basics
В 1975 году была опубликована схема процессора Altair 8080 . Его можно было купить за $397
и затем прогаммировать на асме . Энтузиасты сразу начали писать софт для него .
В 1982 году появилась IBM PC , с процессором Intel 8088 , 64К памяти и CGA-видео-адаптером.
В 1983 появилась IBM PC-XT c 10-метровым хардом . Нынешний Pentium Pro основан на том , что
при старте использует режим адресации от 8086 .
Процессор имеет таймер,который генерирует циклы. За 1 цикл может выполняться не более 1 инструкции.
Процессор на 100 мегагерц производит 100,000,000 циклов каждую секунду .
Процессор имеет регистры для временного хранения и обработки данных .
Память различается на быструю и медленную . Быстрая память - это кеш , который может быть встроен
в процессор . Например , у альфа-процессора имеется 2 кеша - один для данных и один для кода .
Различные компоненты взаимодействуют друг с другом с помощью шины . Шины бывают адрессные,контрольные
и для данных . Шина данных двунаправленная-она позволяет читать данные из память и загоняь их
обратно . Контрольная шина управляет сигналами . Память можно разделить на общую и I/O .
Управление памятью-одна из важнейших функций системы.Памяти всегда не хватает , а жить как-то надо,
вот программисты м придумали виртуальную память . Модель виртуальной памяти позволяет манипулировать
существующей физической так , что при ее недостатке специальные механизмы позволяют изыскивать
память там , где ее по идее не хватает по определению . Виртуальная память может быть больше
физической . Каждый процесс имеет свое собственное виртуальное пространство . Виртуальная память
может быть расшарена для нескольких экземпляров одного приложения , например bash .
Процессор читает инструкции из памяти и выполняет их , при этом он может читать какие-то данные
и сохранять их в память . В виртуальной памяти все адреса виртуальные и переводятся в реальные
физические с помощью специальных таблиц . Механизм перевода реализован с помощью страниц памяти .
На альфе эти страницы 8-килобайтные, на интеле - 4-килобайтные . У каждой такой страницы есть
свой уникальный номер - page frame number - PFN .
Виртуальный адрес разбит на 2 части - собственно адрес и смещение . Первые 11 бит этого адреса
есть смещение и все , начиная с 12 бита , и есть сам адрес . Т.е. процессор при чтении виртуального
адреса сначала должен разделить его на 2 части , затем переводит виртуальный адрес в физический
и затем добавляет смещение - так получается физический адрес . Для этого используются т.н.
page tables . У каждого процесса своя собственная page tables .
Каждая строка такой таблицы имеет
специальный флаг для определения того , валиден ли данный адрес
физический PFN , соответствующий виртуальному
информация об access control на чтение/запись
Виртуальный адрес - это его же индекс в его же page table .
Если виртуальный адрес засвопен на диск , он грузится , это критическая операция , и в это время
должен выполняться какой-то параллельный процесс .
В отличие от пользовательских процессов , ядро залинковано напрямую на физические адреса и не имеет
виртуальных адресов .
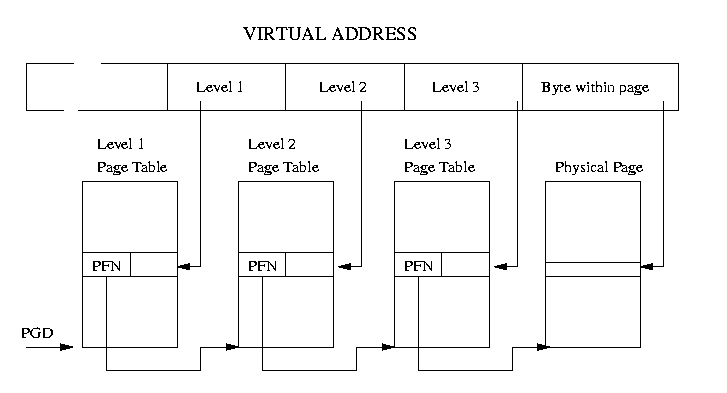
В линуксе 2.0 3-уровневая модель page tables , которая показана на картинке :
|
|
Page Table включает в себя PFN - page frame number для Page Table следующего уровня.
Процессор берет содержимое level 1 из виртуального адреса , которое фактически является
индексом-смещением для page table 1 уровня . Затем процессор делает то же самое для 2 и 3 уровня.
В результате из 3-х слагаемых получается адрес реальной адрес физической страницы , к которому
добавляется байтовой смещение внутри страницы .
Структура для страницы называется mem_map , и она входит в список структур mem_map_t ,
который инициализируется при старте системы .
Одна mem_map_t описывает 1 физическую страницу . Поля структуры :
count - число пользователей страницы
age - на его основе решается вопрос о своппинге страницы
map_nr - PFN страницы
При выделении страниц используется алгоритм Buddy . Страницы выделяются блоками , блок кратен 2 .
Т.е. выделение блоками возможно для 1,2,4 и т.д. страниц за 1 раз . free_area ищет для этого ресурсы
и выделенные в физической памяти pfn сохраняет.
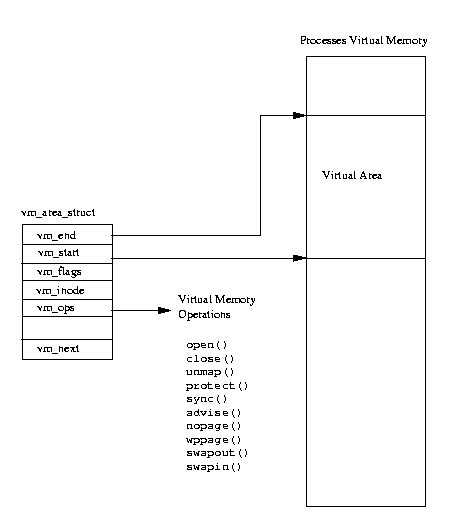
Когда загружается пользовательская программа , под нее выделяется виртуальное адресное пространство :
|
|
Привязка к виртуальным адресам называется memory mapping . Базовая структура - mm_struct ,
к которой привязаны все процессы . Когда в память загружается пользовательская программа ,
она порождает несколько vm_area_struct , из которых одна относится к коду , другая к данным ,
и т.д.
Когда физической памяти становится недостаточно,Linux должен пытаться освобождать физические страницы.
Эта задачу выполняет демон kswapd . Тип этого процесса kernel thread.
Он выполняется в режиме ядра и не привязан к виртуальным адресам . Он стартует в kernel init .
С определенной периодичностью он проверяет количество свободных страниц . Он ничего не делает ,
пока это число больше чем free_pages_high . Как только оно становится меньше , этот демон
пытается уменьшить число страниц , используемых в системе . Это достигается несколькими
путями :
уменьшение буфера и page cache
своппинг виртуальных расшаренных страниц
Если число свободных страниц в системе упало ниже free_pages_low , при каждом последующем цикле
демон будет пытаться освободить 6 страниц , либо 3 . После освобождения достаточного числа страниц ,
он засыпает .
Page cache и buffer cache - прежде всего сюда демон смотрит для освобождения памяти.
Демон проверяет массив mem_map и проверяет , закеширована ли страница в одном из них.
Если ее там нет , она освобождается . Если она присутствует в кеше , она удаляется из кеша
и потом освобождается .
Расшаренная память предназначена для меж-процессорного взаимодействия . Ее описывает структура
shmid_ds . Процесс описан в vm_area_struct , в котором имеются указатели vm_next_shared и vm_prev_shared .
Процессы
Каждый процесс представлен структурой task_struct , которые собраны в массиве task .
Указатель на текущий процесс называется current . Максимальное число процессов для 2.0 - 512 .
Поля структуры task_struct :
1. state - состояние : Running , Waiting , Stopped , Zombie
2. Scheduling Information -
policy
priority
rt_priority
counter
3. Identifiers - набор уникальных чисел
uid - идентификатор пользователя
gid - идентификатор группы пользователей
4. Inter-Process Communication -
5. Links - в линуксе нет изолированных процессов , всё связано ,
связи можно посмотреть ,выполнив команду pstree
6. Times , Timers
7. File system
8. Virtual memory
9. Processor Specific Context -
он используется каждый раз , когда процесс просыпается
из спячки и запускается шедулером
Когда процесс выполняет системный вызов , например чтение файла с диска , в этот момент
как правило шедулер , выполняя этот вызов , параллельно переключается на другой процесс ,
а после вызова возвращает управление первому процессу .
В 2.0 установлен интервал т.н. time-slice , который равен 200 мс , по истечение которого
автоматически происходит переключение на другой процесс .
Процессы можно разделить на 2 группы - нормальные и real time . real time имеют более
высокий приоритет .
ELF (Executable and Linkable Format) - формат исполняемых файлов,разработанный в юниксе.
Такой файл включает код и данные . Статически слинкованный образ линкуется ld .
В файл входит таблица ,в которой прописаны виртуальные адреса , по покоторым загружается код .
При этом сам образ исполняемого файла в память не загружается . Вместо этого строится древовидная
структура vm_area_struct и page table , и по мере исполнения нужные куски подкачиваются .
Динамически слинкованные файлы не включают в себя весь код , который прикручивается динамически
в run time с помощью ld.so.1, libc.so.1, ld-linux.so.1. При динамической линковке бинарнику
нужно больше ресурсов , потому что бинарные page tables существенно разрастаются .
Процессы взаимодействуют между собой и с ядром . В линуксе несколько механизмов такого взаимодействия -
Inter-Process Communication (IPC) .
Сигналы - наиболее древняя юниксовая форма меж-процессорного взаимодейтвия , имеет асинхронный характер.
Сигнал может быть сгенерирован прерыванием , ошибкой , другим процессом .
Вызвать список системных сигналов можно командой
kill -l
Вот список для 2.0 :
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGIOT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 17) SIGCHLD
18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN
22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO
30) SIGPWR
2 сигнала не могут быть проигнорированы никаким процессом : SIGSTOP и SIGKILL .
Остальные сигналы процесс может блокировать . Обработка сигналов выполняется последовательно .
Число сигналов ограничено размером dword процессора . Все сигналы собраны в массиве sigaction .
Для того , чтобы послать сигнал любому другому сигналу , надо иметь рутовые права .
Обычный процесс может послать сигнал процессам со своими uid и gid .
При генерации сигнала устанавливается бит signal в структуре task_struct.
Второй способ межпроцессорного взаимодействия - пайпы - pipes .
Рассмотрим команду :
ls | pr | lpr
Вывод команды ls передается команде pr , которая в свою очередь , обработав его , передает
команде lpr , которая печатает . Пайпы - байтовый поток . Перенаправлением этого потока
занимается шелл . Пайп реализован как 2 структуры типа file , одна на чтение , другая на запись .
Существуют именованные пайпы , которые хранятся не в памяти , а в файловой системе .
Существует еще один тип взаимодействия между процессами - System V IPC .
Он включает в себя очереди и семафоры . Доступ дается на основе аутентификации .
Очереди состоят из сообщений , которые могут приходить от нескольких процессов .
Очередей может быть несколько , массив очередей называется msgque .
Простейшим примером семафора может быть ячейка памяти , которую могут изменять более одного процесса .
Изменение этого состояния есть атомарный процесс . Состояние одного процесса может зависеть
от состояние семафора и от того , что этот семафор может быть изменен другим процессом .
Допустим , есть некий файл данных , с которым в режиме чтение-запись работают много процессов .
Чтобы скоординировать доступ к этому файлу , можно использовать семафоры.
Основная проблема у семафоров - deadlocks , возникает тогда , когда процесс , работающий с
семафором , терпит крах , и состояние семафора не восстанавливается к исходному .
Для предотвращения этого служит структура sem_undo , в которой хранятся исходные значения семафоров .
Device Drivers
Каждое периферийное устройство имеет собственный контроллер . Для клавиатуры это SuperIO ,
для дисков это IDE-контроллер . Каждый контроллер имеет свой собственный регистр CSRs .
Работой контролера управляет device driver , который для 2.0 как правило является частью ядра .
Драйвер функционирует как обычный файл - его можно открыть , произвести запись . Каждый драйвер
представлен в системе device special file , как например /dev/hda . Блочные или дисковые устройства
содаются командой mknod . Сетевые устройства создаются после того , как будут обнаружены .
Линукс поддерживает 3 типа устройств :
character - чтение и запись напрямую , без буферизации
block - чтение и запись поблочная , порциями по 512 1024 байт
network - работают через сокет-интерфейс
По функциональности драйвера можно разделить на следующие группы :
kernel code
Kernel interfaces
Kernel mechanisms and services
Загрузочные
Конфигурационные
Существуют 2 метода опроса драйверов - пулинг - polling - и прерывания . Пулинг использует
системный таймер для постоянного контроля . В каталоге /proc/interrupts можно найти частотную
таблицу для различных типов прерываний :
0: 727432 timer
1: 20534 keyboard
2: 0 cascade
3: 79691 + serial
4: 28258 + serial
5: 1 sound blaster
11: 20868 + aic7xxx
13: 1 math error
14: 247 + ide0
15: 170 + ide1
Каждое прерывание имеет свой номер , например у флоппи это 6 . Ядро ведет опрос прерываний в специальном
режиме , и если одновременно приходят несколько прерываний , они становятся в очередь .
DMA controller - Direct Memory Access - созданы для того , чтобы передавать от устройств большие
обьемы данных с высокой скоростью . Общение с памятью происходит без участия процессора .
У контролера есть 8 каналов , у каждого канала есть 16-битный регистр . У ДМА есть несколько особенностей-
они работают с физической памятью , а не с виртуальной . Вторая особенность - они работают только
с нижними 16 М памяти . Некоторые устройства жестко прикреплены к фиксированным каналам .
В линуксе базовая дма-структура называется dma_chan.
Драйвер может быть подключен как на этапе загрузки с помощью скриптов , так и после , динамически .
Каждый драйвер представлен структурой device_struct в массиве chrdevs .
Сетевые устройства получают и посылают пакеты данных . Сетевое устройство представлено структурой
device . Их инициализация происходит при загрузке . Пакеты представлены структурой sk_buff , в которой
представлены информация :
Name - /dev/ethN
Bus Information
Interface Flags - IFF_UP , IFF_BROADCAST ...
Protocol Information - mtu , Family , Type , Addresses
Packet Queue
Support Functions
|
| paristit | pase umi dolci
2016-06-01 23:42:35 | |
|
|

 LINUX
LINUX