BTRFS
Btrfs (B-tree FS)- новая файловая система, устойчивая к отказам и легкая в администрировании.
Разработана в Oracle, лицензирована под GPL, полностью открыта.
Автор btrfs - Chris Mason - при разработке отталкивался от не-безизвестной reiserfs:
Что касается ZFS, то сам Мэйсон говорит: Я еще не делал никаких сравнений производительности,
при том, что у наших систем есть некоторые общие свойства, общий дизайн их обеих совершенно разный.
Btrfs имеет следующие фичи: встроенная поддержка RAID, снэпшоты, сжатие, криптование.
Нужно сказать, что классические линуксовые файловые системы - ext или xfs - не решают многих насущных проблем,
например, таких, как добавление диска к уже существующему тому или фоновое увеличение рабочей партиции.
В btrfs это решается одной командой:
btrfs device add < device > < file system >
B-tree
Все метаданные в btrfs разбросаны по нескольким бинарным деревьям. Такое дерево состоит из нод и листьев
и может содержать один или более уровней. В ноде содержится ключ и адрес листа или следующей ноды.
В листьях хранятся данные:
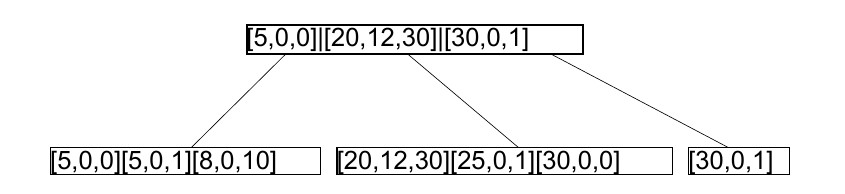
Каждый ключ в такой ноде имеет 3 значения: objectID, тип, и смещение. В данном примере [30,0,0] меньше, чем [30,0,1].
В листе хранятся ключи и данные:

item включают в себя ключ, размер и смещение внутри листа. item-ы растут от начала листа, данные растут в обратном порядке - от конца.
Снэпшоты
Снэпшот - это копия любой директории, он позволяет с помощью стандартной команды cd войти в него и работать как с обычным каталогом.
По умолчанию, все снэпшоты перезаписываемы, но можно всегда создать и снэпшот только на чтение. Последние хороши для создания
бэкапов - мгновенных снимков файловой системы. Записываемые снэпшоты хороши, например, тем, что перед тем, как вы делаете какой-то
критический апдэйт системы, вы сначала предварительно создаете снэпшот, а в случае краха после апдэйта откатываетесь.
При создании файловой системы btrfs рутовая директория также является и под-томом - subvolume.
Снэпшот можно делать только по отношению к таким под-томам. Создать под-том /home:
btrfs subvolume create /home
Создать снэпшот для домашнего каталога:
btrfs subvolume snapshot /home/ /home-snap
Удалить снэпшот:
btrfs subvolume delete /home-snap/
Вывести полный список снэпшотов:
btrfs subvolume list /mnt/btrfs-test/
btrfs везде, где только можно, использует 64-битные идентификаторы. Это означает, что она может управлять числом под-томов,
равным 2 в 64-й степени. Число нод потенциально возрастает до 2-х в 128-й степени.
Это позволяет создавать практически неограниченное число под-томов внутри одной файловой системы.
Можно адресовать адресное пространство на диске размером 8 exabytes.
Директории
Файловая система ext при создании партиции под нодовую таблицу выделяет все место сразу, т.е. максимальное количество
файлов ограничено. В btrfs таких ограничений нет. Если вы в ext удалите каталог c несколькими тысячами файлов,
а затем выполните команду ls, вы неожиданно обнаружите, что скорость ее работы не увеличивается.
При массированном удалении ext сразу ничего не делает с дырами, которые у нее образуются, от этого увеличивается дефрагментация.
В btrfs шринкование (уничтожение дыр) происходит автоматически в результате штатной операции в дереве.
В btrfs имя файла хешируется, и вместо поиска по файлу, мы ищем по числовому индексу, что быстрее.
Дисковое пространство
Также реализовано отложенное выделение дискового пространства, т.е. фактическое выделение происходит в последний момент,
когда операционная система сбрасывает данные на диск. Файловая система откусывает порции от диска размером в 1 гигабайт
для данных и 256 мегабайт для метаданных, причем эти два типа данных не смешиваются. Например, если у вас RAID,
и вы хотите метаданные зеркалировать, а данные распределять (stripe), при задании параметров файловой системы
вы можете определить RAID1 для метаданных и RAID0 для данных.
Контрольные суммы
Btrfs вычисляет контрольные суммы для всех данных. Для этого используются отдельные потоки, работающие в фоновом режиме.
Это делается как при чтении, так и при записи. Контрольные суммы позволяют управлять целостностью данных.
Для RAID при записи система автоматически проверяет синхронизацию данных по зеркалам с помощью контрольных сумм.
Компрессия
Btrfs поддерживает 2 типа сжатия - zlib и lzo, последняя по умолчанию. Если примонтировать диск с параметром:
mount -o compress
то все последующие записи будут сжиматься.
SSD
Для ssd накопителей дефрагментация теряет актуальность. Btrfs этот факт учитывает и выполняет другой алгоритм выделения
свободного дискового пространства - просто выделется следующее за только что выделенным.
Также поддерживается TRIM.
Целостность данных
Традиционные линуксовые файловые системы типа ext или xfs имеют механизм журналирования данных.
Это означает, что данные пишутся дважды - сначала в журнал, а потом уже окончательно.
В btrfs главенствует другой прицип - COW - copy on write. Это значит, что если мы модифицируем какой-то блок с данными,
мы на диске выделяем для него новое место, делаем его модификацию и пишем его на это новое место, а старое освобождаем.
При этом отпадает необходимость в ведении журнала.
Производительность
Но не все хорошо в датском королевстве. У btrfs тоже есть темные пятна - в частности, рандомная частичная модификация
файла. Тут возникают проблемы с фрагментацией и чтением кеша. Здесь может помочь такая опция, как авто-дефрагментация.
Также большие энтерпрайзные базы ведут себя на btrfs похуже, нежели на ext или xfs.
Но работа кипит, и не за горами то время, когда btrfs займет место дефолтной файловой системы в линуксе.
**********************
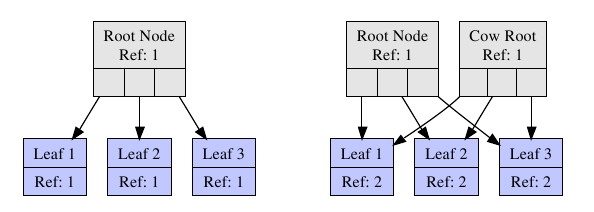
Файловая система btrfs построена по принципу copy-on-write (COW): т.е. если на диске нужно модифицировать какой-то блок,
то создается его копия, с которой продолжается работа.
Принцип copy-on-write демонстрирует следующая картинка:
Базовые структуры файловой системы:
Ноды
Нода хранится в структуре btrfs_inode_items и имеет тип, равный 1. Нода хранит стандартную мета-информацию
для файлов и каталогов. В ноде нет самих данных, а также расширенных атрибутов.
Файлы и каталоги
Небольшие файлы размером менее одного блока могут быть упакованы в дереве.
Структура btrfs_item хранит размер самого файла.
Большие файлы хранятся в расширениях. Структура btrfs_file_extent_item хранит указатель на это расширение
и число блоков файловой системы, отведенных на хранение файла, а также карту распределения свободных участков,
что позволяет эффективно использовать дисковое пространство внутри расширения
struct btrfs_file_extent_item {
/*
* transaction id that created this extent
*/
__le64 generation;
/*
* max number of bytes to hold this extent in ram
* when we split a compressed extent we can't know how big
* each of the resulting pieces will be. So, this is
* an upper limit on the size of the extent in ram instead of
* an exact limit.
*/
__le64 ram_bytes;
/*
* 32 bits for the various ways we might encode the data,
* including compression and encryption. If any of these
* are set to something a given disk format doesn't understand
* it is treated like an incompat flag for reading and writing,
* but not for stat.
*/
u8 compression;
u8 encryption;
__le16 other_encoding; /* spare for later use */
/* are we inline data or a real extent? */
u8 type;
/*
* disk space consumed by the extent, checksum blocks are included
* in these numbers
*/
__le64 disk_bytenr;
__le64 disk_num_bytes;
/*
* the logical offset in file blocks (no csums)
* this extent record is for. This allows a file extent to point
* into the middle of an existing extent on disk, sharing it
* between two snapshots (useful if some bytes in the middle of the
* extent have changed
*/
__le64 offset;
/*
* the logical number of file blocks (no csums included)
*/
__le64 num_bytes;
} __attribute__ ((__packed__));
Контрольные файловые суммы хранятся в структуре btrfs_csum_item.
Счетчики ссылок (Reference Count)
Это основа для создания снепшотов. Для каждого расширения в структуре btrfs_extent_item хранится
число ссылок. Деревья, хранящие эти ссылки, занимаются политикой выделения свободных блоков:
struct btrfs_extent_item {
__le64 refs;
__le64 generation;
__le64 flags;
} __attribute__ ((__packed__));
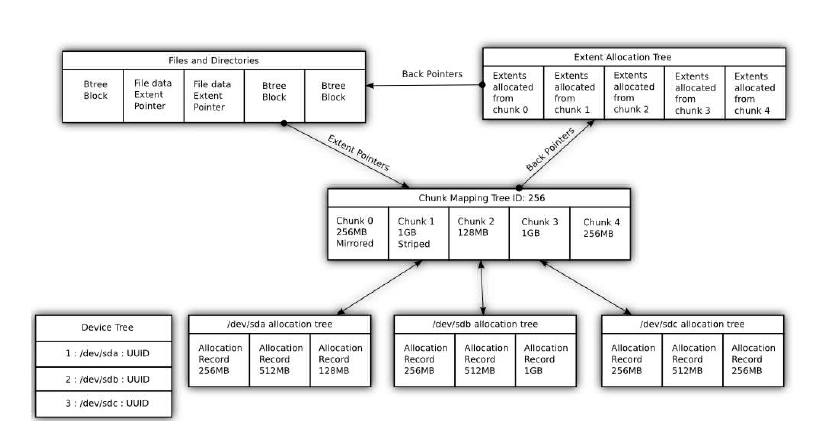
Extent Block Groups
Это основа для оптимизации использования диска за счет разбиения его на порции по 256 метров.
Для каждой такой порции всегда известно число свободных блоков. Каждая такая блоковая группа имеет флаг,
который указывает на ее тип - хранятся ли там данные или метаданные, хотя данные в принципе могут быть и смешаны.
Утилита mkfs разбивает диск в соотношении: 33% на метаданные и 66% на сами данные.
Snapshots и Subvolumes
Том - имя дерева, которое хранит файлы и каталоги. Том может иметь своего владельца, квоты на дисковое пространство.
В файловой системе может быть 2^64 томов. Снепшот - это то же самое, что и том, с той лишь разницей, что
его рутовый блок находится в другом томе. При создании снепшота счетчик ссылок на этот рутовый блок будет увеличен.
Btree Roots
Существуют 3 базовых типа деревьев, которые появляются на этапе генерации файловой системы:
рутовое дерево
дерево расширений
дерево тома по умолчанию
Рутовой дерево хранит ссылки на собственный рутовый блок, а также на рутовые блоки для каждого тома и снепшота.
Рутовое дерево - это каталог всех остальных деревьев, в котором хранятся имена всех томов и снепшотов.
Каждый снепшот или том имеет свою структуру btrfs_root_item:
struct btrfs_root_item {
struct btrfs_inode_item inode;
__le64 generation;
__le64 root_dirid;
__le64 bytenr;
__le64 byte_limit;
__le64 bytes_used;
__le64 last_snapshot;
__le64 flags;
__le32 refs;
struct btrfs_disk_key drop_progress;
u8 drop_level;
u8 level;
} __attribute__ ((__packed__));
Расширенные деревья используются для выделения свободного дискового пространства и могут создаваться в соответствии
с политикой прав и уменьшения дисковых блокировок.
Базовая структура btrfs - copy-on-write B-tree - впервые была анонсирована Огад Rodeh из IBM в 2007 г.
Он предложил добавить механизм reference counts для балансировки деревьев, что повышает их
производительность/параллелизм.
Структура btrfs (для 3 различных устройств):
Основные фичи btrfs:
расширенная емкость (до 2^64 max file size)
эффективное использование дискового пространства для малых файлов
эффективное использование дискового пространства при индексации каталогов
динамическое выделение нод
снэпшоты
вложенные тома (внутренне разбиение на несколько рутов)
контрольные суммы для данных и метаданных
компрессия
поддержка raid
бэкап, зеркалирование, дефрагментация
В btrfs имеется несколько типов деревьев:
Root tree
File system tree
Extent allocation tree
Checksum tree
Log tree
Chunk and device trees
Data relocation tree
Каждая файловая система формата btrfs состоит из нескольких корней B-деревьев.
Как уже было сказано, только что созданная ФС имеет корни для:
Дерева корней
Дерева выделенных экстентов
Дерева defaultсубтома
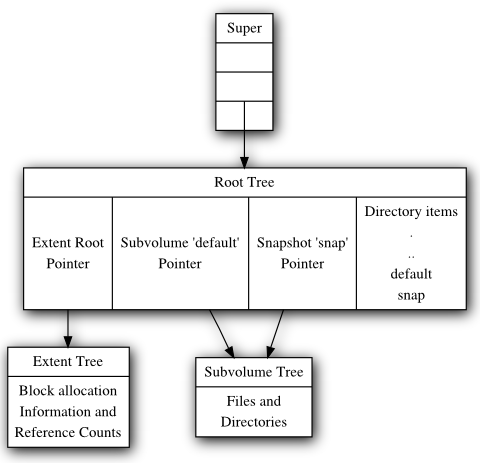
Дерево корней содержит корневые блоки для дерева экстентов, а также
корневые блоки и имена деревьев для каждого субтома и снапшота в ФС.
При фиксации транзакции указатели на корневые блоки обновляются по
COWсемантике в этом дереве, и его новый корневой блок записывается в суперблок
btrfs.
Root tree - родитель для всех остальных деревьев, которые вложены в нем, его object id = 1.
Остальные типы деревьев могут иметь по несколько инстансов, каждый из которых имеет свой object ID.
File system tree - в нем хранятся файлы и каталоги. Каждый файл или директория имеют свою ноду.
Директории проиндексированы для быстрого поиска. Файлы имеют ссылку на родителя. Сами данные файлов хранятся
за пределами деревьев в расширениях, расширение имеет размер в 4 КБ,
Extent allocation tree - хранятся ссылки на расширения, в которых хранятся сами данные. Расширения не имеют
своих ID, они используют байтовые смещения в ключах. Расширения имеют обратные ссылки на ноды, что позволяет
оптимально быстро делать перемещения по диску. Преимущество btrfs по сравнению с той же ext3 в том, что
последняя в случае большого файла хранит его более хаотично на диске, в то время как btrfs хранит большой файл
более упорядоченно, что увеличивает скорость доступа.
Checksum tree - хранятся контрольные суммы как для данных, так и для метаданных.
Это позволяет на лету определять ошибки в файловой системе и исправлять их.
Log tree - для того чтобы избежать постоянных коммитов и сбросов данных на диск, это дерево создает промежуточный
журнал транзакций.
Все метаданные хранятся в дереве - btree. Дерево хранит пару ключ/значение - key/item. Ключ служит для
идентификации и сортировки значений внутри дерева. Ключ разбит на 3 части: objectid, type, offset.
В качестве значения может быть данные произвольного типа.
Подтома (Subvolume) - именованные деревья, хранящие файлы и каталоги. Каждый снэпшот представляет из себя
такой Subvolume. Вложенный том - это как вложенная отдельная партиция, созданная без дополнительного разбиения
диска. Это позволяет делать снэпшоты - снимки файловой системы на момент времени, что в свою очередь может
избавить от необходимости в журналировании. Логика создания снэпшота следующая: создается - причем мгновенно -
копия файловой системы, вернее ее файловой структуры, а сами данные не копируются сразу, а лишь тогда,
когда происходит их модификация. таким образом поддерживается атомарность данных, т.е. неблокировка данных
для других операций.
Btrfs использует новый тип блокировок, которые могут работать в обоих режимах
(и их можно переключать между режимами). Один и тот же код будет использовать мьютексы в контексте задачи
и спин-блокировки в режиме прерывания.
Суперблок:
struct btrfs_super_block {
u8 csum[BTRFS_CSUM_SIZE]; /* контрольная сумма */
u8 fsid[16]; /* UUID файловой системы */
__le64 bytenr; /* номер этого блока */
__le64 flags;
__le64 magic; /* 8 байт, "_B5RfS_M" */
__le64 generation; /* ID последней удачной транзакции */
__le64 root; /* указатель на дерево корней */
__le64 chunk_root; /* указатель на дерево сегментов */
__le64 total_bytes; /* размер ФС в байтах */
__le64 bytes_used; /* использовано байт */
__le64 root_dir_objectid; /* objectid корневого каталога */
__le64 num_devices; /* количество устройств в пуле */
__le32 sectorsize; /* размер сектора */
__le32 nodesize; /* размер узла дерева */
__le32 leafsize; /* размер листа дерева */
__le32 stripesize;
__le32 sys_chunk_array_size;
u8 root_level; /* глубина основного дерева ФС */
u8 chunk_root_level; /* глубина дерева сегментов */
struct btrfs_dev_item dev_item; /* дескриптор этого устройства */
char label[BTRFS_LABEL_SIZE]; /* символьная метка ФС */
u8 sys_chunk_array[BTRFS_SYSTEM_CHUNK_ARRAY_SIZE];
};
Реализация Bдерева btrfs - это классическое B+ дерево с данными в листьях
и указателями в узлах.
Базовые структуры - ключ, значение, заголовок блока:
struct btrfs_header {
u8 csum[32];
u8 fsid[16];
__le64 blocknr;
__le64 flags;
u8 chunk_tree_uid[16];
__le64 generation;
__le64 owner;
__le32 nritems;
u8 level;
}
struct btrfs_disk_key {
__le64 objectid;
u8 type;
__le64 offset;
}
struct btrfs_item {
struct btrfs_disk_key key;
__le32 offset;
__le32 size;
}
Заголовок блока дерева содержит контрольную сумму содержимого блока,
UUID (Universally Unique Identifier — универсальный уникальный идентификатор
стандарта OSF DCE) файловой системы, которой принадлежит блок, уровень
блока в дереве и смещение, по которому блок располагается на диске.
Поле generation соответствует ID транзакции, в рамках которой был размещен
или переразмещен данный блок. Оно позволяет легко поддерживать
инкреметальные бэкапы (снапшоты) и подсистему COWтранзакций — совершенно
так же, как это сделано в ZFS.
Inodes хранятся в структуре btrfs_inode_item (ctree.h), поле offset ключа inode
итема всегда равно нулю, поле type - единице.
struct btrfs_inode_item {
__le64 generation; /* ID транзакции создания файла */
__le64 size; /* Размер файла в байтах */
__le64 nblocks; /* Количество занимаемых блоков */
__le64 block_group; /* Предпочитаемая группа блоков */
__le32 nlink; /* Счетчик ссылок на файл */
__le32 uid; /* UID владельца */
__le32 gid; /* GID владельца */
__le32 mode; /* Маска типа и прав доступа */
__le64 rdev; /* [minor:major] для устройств */
__le16 flags; /* Флаги */
__le16 compat_flags; /* Флаги совместимости */
struct btrfs_timespec atime; /* Времена доступа, модификации, и т.д. */
struct btrfs_timespec ctime;
struct btrfs_timespec mtime;
struct btrfs_timespec otime;
};
Дерево изнутри представляет из себя набор нод, каждая из которых состоит из комбинации ключ / блоковый хидер.
Ключ указывает, где искать данные - items, а хидер указывает на следующую ноду в дереве.
Листья хранят в себе значения - items - которые представляют из себя комбинацию ключей и данных.
Эти значения и сами данные упакованы внутри блока в следующем порядке: это позволяет одновременно убивать
2-х зайцев - время поиска и компактное использование дискового пространства

Предыдущие файловые системы организовывали данные следующим образом:
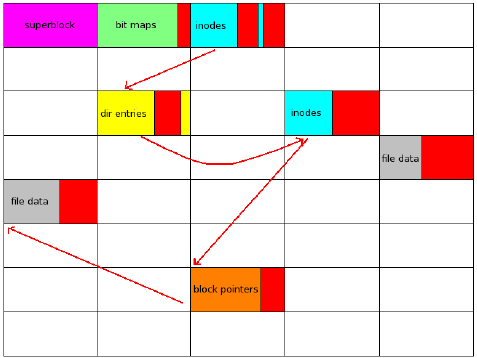
В btrfs это делается по другому:
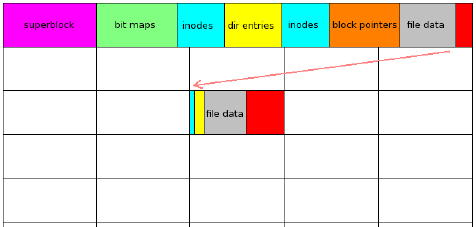
Блоки красного цвета на обоих диаграммах указывают неиспользуемое дисковое пространство.
Метаданные и данные в файловой системе хранятся как часть item. Если еще раз вернуться к структуре
struct btrfs_disk_key {
__le64 objectid;
u8 type;
__le64 offset;
}
Каждый обьект в файловой системе имеет уникальный objectid, это эквивалентно номеру ноды.
Пара гарантировано группирует вместе связанные данные, в отличие от.
Поле type указывает на тип - это может быть файловая нода, каталог, сами данные файла.
Такая схема позволяет эффективно использовать дисковое пространство, уменьшая дефрагментацию.
Родительская нода включает ключ и указатель на блок. Дочерние ноды разбиты на 2 секции и включают
массив значений фиксированного размера, а также область, где хранятся данные.
| Item 0 ... |
Item N |
Free Space |
... |
Free Space |
Data for itemN ... |
Data for Item 0 |
Блоковый заголовок включает контрольную сумму для контента, его владельца, уровень блока в дереве, номер блока.
Контрольная сумма проверяется перед записью блока на диск.
Каждый обьект в файловой системе имеет свой ID.
Ноды хранятся в структуре btrfs_inode_item, в ней хранится мета-информация, атрибуты хранятся в другом месте.
Маленькие файлы, размером меньшие одного блока, могут быть упакованы,
Большие файлы хранятся в расширениях. Структура btrfs_file_extent_item хранит пару (стартовый блок -
количество блоков)
Контрольные суммы для файлов хранятся в специальном дереве с помощью структуры btrfs_csum_item.
Директории проиндексированы двумя вариантами: первый вариант используется для поиска
| Directory Objectid |
BTRFS_DIR_ITEM_KEY |
64 bit filename hash |
Второй вариант используется для получения данных по нодовому номеру:
| Directory Objectid |
BTRFS_DIR_INDEX_KEY |
Inode Sequence number |
Возможности, появившиеся в файловой системе, начиная с версии 0.16 :
- Полностью распределенное блокирование B-дерева. При поиске в B-дереве блокировка узлов теперь спускается вместе с курсором; узлы на верхних уровнях освобождаются по мере необходимости. С блокированием при выделении экстентов все еще есть проблемы, которые должны быть решены в будущем;
- Усовершенствование журналирования данных (режим data=ordered). В режиме data=ordered btrfs будет записывать грязные блоки пользовательских данных до фиксации транзакции. Теперь журналирование данных затрагивает только сами блоки данных и относящиеся к ним экстент-итемы B-дерева. Остальные метаданные транзакции могут сбрасываться на диск параллельно с записью блоков данных (раньше приходилось ожидать сброса пользовательских блоков).
- Поддержка ACL. ACL реализованы и включены по умолчанию.
- Предотвращение потери файлов. Слой Linux VFS и POSIX API заставляют файловую систему разрывать связь между файлом и каталогом до его удаления из ФС (т.е. освобождения его блоков и inode). В случае краха ФС между разрывом связи и удалением этот файл остается на диске, но не имеет имени. Теперь btrfs отслеживает такие случаи и гарантирует полное освобождение всех занимаемых файлом ресурсов в случае краха ФС.
- Новый формат индекса каталога. Btrfs индексирует каталоги двумя способами: первый оптимизирован для быстрого поиска имен, второй возвращает inodes в порядке, близком к их расположению в B-дереве, что важно для высокой производительности при создании полных бэкапов ФС. Теперь в btrfs для элементов каждого каталога введён sequence-номер, с помощью которого устраняются некоторые наихудшие случаи второго способа индексирования для файлов, имеющих множество имен (жестких ссылок) в одном каталоге.
- Уменьшенное время размонтирования. Раньше btrfs ожидала удаления всех старых транзакций перед размонтированием ФС. В новой версии введен кэш учёта ссылок, существенно снижающий нагрузку на диск и улучшающий производительность ФС на всех режимах.
- Улучшения в потоковых записи и чтении. Новый код журналирования данных улучшил производительность потоковой записи. Потоковое чтение усовершенствовано за счет оптимизации пула потоков (threads), занимающихся проверкой контрольный сумм после прочтения данных. Теперь, на машинах с достаточно мощным CPU, производительность режимов datasum и nondatasum практически сравнялась.
Примеры команд по работе с btrfs
Создание файловой системы:
mkfs.btrfs
Управление томами, подтомами, снимками; проверка целостности файловой системы:
btrfsctl
Сканирование в поисках файловых систем btrfs:
btrfsctl -a
btrfsctl -A /dev/sda2
Создание снимков и подтомов:
mount -t btrfs -o subvol=. /dev/sda2 /mnt
btrfsctl -s new_subvol_name /mnt
btrfsctl -s snapshot_of_default /mnt/default
btrfsctl -s snapshot_of_new_subvol /mnt/new_subvol_name
btrfsctl -s snapshot_of_a_snapshot /mnt/snapshot_of_new_subvol
ls /mnt
Проверка extent-деревьев файловой системы:
btrfsck
Вывести метаданные в текстовой форме:
debug-tree
debug-tree /dev/sda2 >& big_output_file
|
| Коммент | а можно ли из snapshot восстановить систему, типа откат к определённому снапшоту?
2011-11-12 20:54:33 | | Яковлев Сергей | Можно:
делаем снэпшот:
btrfs subvolume snapshot mnt@ mnt@_snapshot
откатить снэпшот:
mv mnt@ mnt@_badroot
mv mnt@_snapshot mnt@
2011-11-12 22:23:18 | | debil | а можно тоже самое с пояснениями для домохозяек
2011-11-13 16:09:43 | |
|

 LINUX
LINUX