JFS
Оригинальный текст можно скачать тут.
JFS - журналируемая файловая система от IBM. В основе ее архитектуры лежат следующие концепции:
Логический том - это может быть физический диск или его часть. Он еще известен как партиция.
Агрегаты и файловые наборы (Aggregates / filesets) - создается утилитой mkfs и представляет из себя
массив дисковых блоков определенного формата, куда входят суперблок и битовая карта свободного пространства.
Созданная партиция и есть агрегат. Файловый набор представляет контрольные структуры, описывающие эту партицию.
Файлы, каталоги, ноды, адресные структуры - файловый набор состоит из файлов и каталогов.
Файлы и каталоги представлены с помощью нод. Нода описывает атрибуты файла/каталога и служат для их
идентификации на диске. Ноды используются и для других обьектов - например для битовых карт.
Файлы включают пользовательские данные, являющиеся байтовым потоком, и нет никаких ограничений на формат файлов.
В нодах используется расширенная адресация.
Логи - присутствуют в каждой партиции и используются для сохранения информации об изменениях при операциях
с мета-данными.
Журналирование - jfs включает улучшенную целостность и восстанавливаемость файловой системы.
Традиционные юниксовые файловые системы типа ext2 требуют запуска специальных утилит (fsck) для поиска
повреждений, которые проверяют всю файловую систему в момент ее монтирования. Журналирование в jfs
реализовано по технологиям баз данных и выполнено на основе атомарных транзакций. Если в файловой системе
происходит сбой, это вызывает откат файловой системы на основе информации из лог-файла.
Время восстановления файловой системы в этом случае значительно меньше.
В jfs логируются операции только над мета-данными, изменения же самих файловых данных не логируется,
т.е. файловые данные после восстановления могут быть утеряны.
Запись в лог в jfs вначале происходило синхронно для каждой ноды или операции в vfs, что тормозило производительность,
особенно на нагруженных серверах. Позднее логирование в jfs стало асинхронным.
Расширенная адресация - расширение (extent) есть последовательная цепочка блоков на диске, выделяемая
для файла, и имеет форму < logical offset, length, physical>. Управляет такой адресацией древовидная структура
B+tree.
Размер блока - в jfs блок может быть размером 512, 1024, 2048, 4096 байт. По умолчанию стоит 4096.
Динамическое выделение нод - выделение, равно как и удаление, происходит динамически. Это снимает ограничения
на количество файлов в партиции.
Организация каталогов - есть 2 варианта: первый - для небольших каталогов (до 8 файлов) содержимое каталога хранится внутри
его ноды; второй - большой каталог представлен именованным деревом B+tree, что кстати ускоряет время поиска и доступа
по сравнению с традиционной юниксовой - не-деревянной - формой организации каталогов.
Разреженные/упакованные файлы (Sparse/dense files) - jfs поддерживает оба этих типа файлов.
Первому типу отводится изначально на диске бОльшее количество блоков, чем он есть на самом деле, и в этом
наборе блоки заполняются произвольным образом.
Ограничения JFS - jfs - 64-битная файловая система, что позволяет поддерживать файлы и партиции большого размера.
Минимальный размер файловой системы - 16 метров. Максимальный размер файловой системы зависит от размера блока.
Он лежит в пределах от 512 терабайт до 4 пета-байт. Максимальный размер файла зависит в свою очередь от
ограничений виртуальной файловой системы.
Утилиты - mkfs - создает jfs-файловую ситему. Есть также утилиты для проверки целостности файловой системы.
Каждая партиция имеет PART_NBlocks - своё число блоков
На следующем рисунке представлена партиция с 2-мя файловыми наборами (filesets):
в начале партиции находится незанятая 32-килобайтная зарезервированная область;
далее идет 1-й суперблок, в котором записан размер партиции, размер выделенных групп, размер блока и т.д;
2-й суперблок является копией первого и пишется на всякий пожарный случай, располагается также в строго фиксированном месте;
за 1-м суперблоком идет 1-я таблица нод, вообщк в этой партиции нет файловой структуры как таковой
далее идет 2-я таблица нод, являющаяся точной копией 1-й таблицы нод
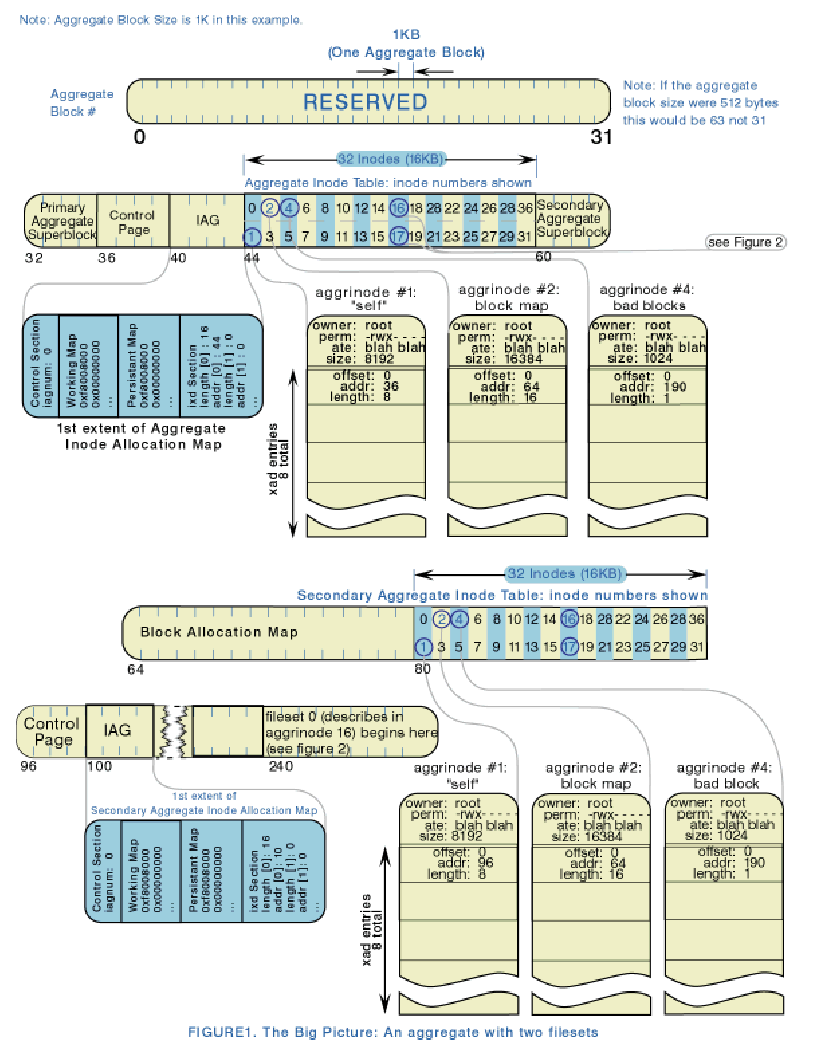
Aggregate Inode Map - битовая карта, которая описывает таблицу нод. Secondary Aggregate Inode Map являяется
копией первой.
Block Allocation Map - карта выделенных блоков.
Первое нодовое расширение (extent) инициализируется на этапе создания партиции. Последующие раширения будут
выделяться динамически.
Ноды в 1-й таблице нод выполянют следующие функции: нулевая нода зарезервирована, первая указывает на себя,
вторая описывает Block Allocation Map, третья описывает лог-файл, четвертая описывает массив "плохих" блоков,
найденных при форматировании, такие блоки маркируются в битовой карте. Ноды 5-15 зарезервированы.
16-я нода описывает контрольные структуры, которые представляют первый файловый набор. В партиции может быть несколько
файловых наборов (fileset).
Выделенные группы (Allocation groups) - они разбивают дисковое пространство на порции, повышая
производительность файловой системы. Дисковые блоки и ноды распределяются не как попало, а по связям,
например файлы внутри одного каталога лучше располагать последовательно.
Максимальное число таких выделенных групп - 128. Минимальный размер такой группы - 8192 блоков.
Filesets - как правило один файловый набор существует в одной партиции, хотя может быть и несколько наборов.
Extents, inodes, B+ trees - расширение есть последовательность блоков. Большие расширения могут распространяться
на несколько выделенных групп. Каждый обьект представлен нодой. Нода включает такую информацию, как время создания,
тип файла и т.д. В ноду входит дерево, которое содержит информацию о расширении.
Для файла выделяется последовательность расширений.
Расширения индексируются с помощью дерева для лучшей производительности. Расширение имеет 2 параметра: длину и адрес.
Если размер блока 512 байт, то максимальный размер расширения - 8 гигов, соответственно для блока в 4 килобайта -
64 гига. Политика выделения расширений в основном сводится к тому, чтобы для одного файла блоки выделялись подряд,
что не всегда возможно. Есть специальная утилита, которая выполняет дефрагментацию расширений.
Нода - имеет размер в 512 байт. Нода содержит 4 главных атрибута: первый - это тип обьекта. Второй
содержит заголовок дерева. Третий содержит дескрипторы расширений.
Структура ноды:
struct dinode {
/*
* I. base area (128 bytes)
* ------------------------
*
* define generic/POSIX attributes
*/
__le32 di_inostamp; /* 4: stamp to show inode belongs to fileset */
__le32 di_fileset; /* 4: fileset number */
__le32 di_number; /* 4: inode number, aka file serial number */
__le32 di_gen; /* 4: inode generation number */
pxd_t di_ixpxd; /* 8: inode extent descriptor */
__le64 di_size; /* 8: size */
__le64 di_nblocks; /* 8: number of blocks allocated */
__le32 di_nlink; /* 4: number of links to the object */
__le32 di_uid; /* 4: user id of owner */
__le32 di_gid; /* 4: group id of owner */
__le32 di_mode; /* 4: attribute, format and permission */
struct timestruc_t di_atime; /* 8: time last data accessed */
struct timestruc_t di_ctime; /* 8: time last status changed */
struct timestruc_t di_mtime; /* 8: time last data modified */
struct timestruc_t di_otime; /* 8: time created */
dxd_t di_acl; /* 16: acl descriptor */
dxd_t di_ea; /* 16: ea descriptor */
__le32 di_next_index; /* 4: Next available dir_table index */
__le32 di_acltype; /* 4: Type of ACL */
/*
* Extension Areas.
*
* Historically, the inode was partitioned into 4 128-byte areas,
* the last 3 being defined as unions which could have multiple
* uses. The first 96 bytes had been completely unused until
* an index table was added to the directory. It is now more
* useful to describe the last 3/4 of the inode as a single
* union. We would probably be better off redesigning the
* entire structure from scratch, but we don't want to break
* commonality with OS/2's JFS at this time.
*/
union {
struct {
/*
* This table contains the information needed to
* find a directory entry from a 32-bit index.
* If the index is small enough, the table is inline,
* otherwise, an x-tree root overlays this table
*/
struct dir_table_slot _table[12]; /* 96: inline */
dtroot_t _dtroot; /* 288: dtree root */
} _dir; /* (384) */
#define di_dirtable u._dir._table
#define di_dtroot u._dir._dtroot
#define di_parent di_dtroot.header.idotdot
#define di_DASD di_dtroot.header.DASD
struct {
union {
u8 _data[96]; /* 96: unused */
struct {
void *_imap; /* 4: unused */
__le32 _gengen; /* 4: generator */
} _imap;
} _u1; /* 96: */
#define di_gengen u._file._u1._imap._gengen
union {
xtpage_t _xtroot;
struct {
u8 unused[16]; /* 16: */
dxd_t _dxd; /* 16: */
union {
__le32 _rdev; /* 4: */
u8 _fastsymlink[128];
} _u;
u8 _inlineea[128];
} _special;
} _u2;
} _file;
#define di_xtroot u._file._u2._xtroot
#define di_dxd u._file._u2._special._dxd
#define di_btroot di_xtroot
#define di_inlinedata u._file._u2._special._u
#define di_rdev u._file._u2._special._u._rdev
#define di_fastsymlink u._file._u2._special._u._fastsymlink
#define di_inlineea u._file._u2._special._inlineea
} u;
};
Нода динамически может быть размещена в любом месте диска и позже перемещена в другое место.
Это удобно например в случае клонирования файлсета, когда копируются только ноды, но не структура каталогов.
Есть и неудобства при динамическом выделении нод: при статическом выделении нодовый слой на диске описывается
гораздо проще.
Нодовое расширение в jfs составляет 32 ноды. При выделении такое расширение не инициализируется до тех пор,
пока нода не начнет использоваться.
Между номером ноды и ее дисковым адресом нет прямой связи. Для нахождения ноды служит Inode Allocation Map.
B+trees - вообще деревья выбраны для того, чтобы повысить производительность файловых расширений.
Деревья имеют эффективный механизм для вставки или добавления файла, для их удаления.
Расширение описывается структурой xad:
struct xad {
unsigned flag:8;
unsigned rsvrd:16;
unsigned off1:8;
uint32 off2;
unsigned len:24;
unsigned addr1:8;
uint32 addr2;
} xad_t;
flag - несет информацию о типе расширения
off1,off2 - логическое смещение первого блока в расширении
len - длина расширения
addr1,addr2 - адреса расширения
Для всех обьектов, кроме каталогов, существует единый древовидный индекс.
На следующем рисунке показана xad-структура, которая связывает логическую организацию байт внутри файла с
физическим расположением этих самых байт на диске:
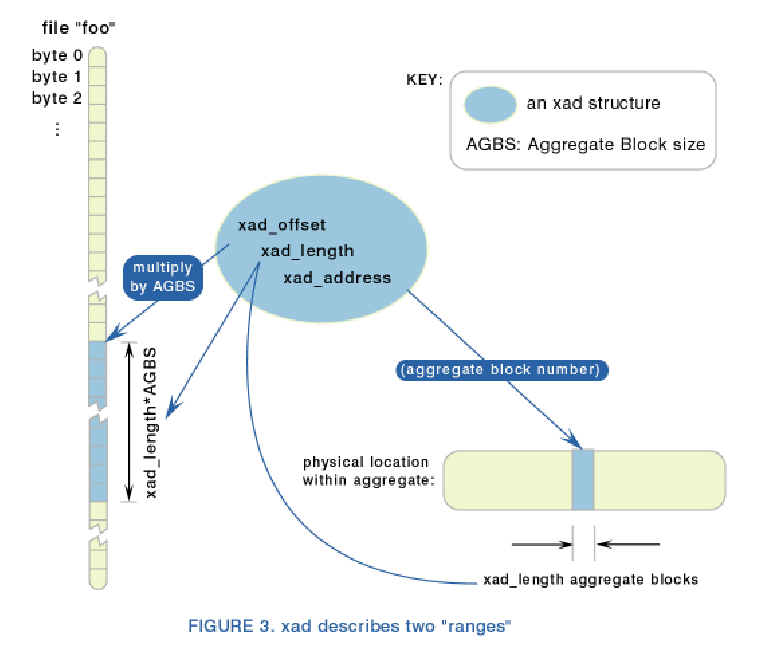
Внутри ноды, во второй ее половине, как уже было сказано, могут находиться данные самого файла, если он
достаточно мал. Если он велик, то внутри ноды располагается рутовая нода бинарного дерева, которое будет управлять
расширениями, в которых будут лежать данные самого файла. В ноде может быть не более 8 xad-структур.
Если размер файла не влезает в 8 структур, xad-структура будет выделена дополнительно как лист в дереве.
При увеличении размера файла бинарное дерево будет разбиваться дальше и добавляться новые ноды. На такую ноду
в дереве выделяется 4 килобайта, в ней может поместиться еще 8 xad-структур
Хидер этого дерева описывается структурой:
typedef union {
struct xtheader {
__le64 next; /* 8: */
__le64 prev; /* 8: */
u8 flag; /* 1: */
u8 rsrvd1; /* 1: */
__le16 nextindex; /* 2: next index = number of entries */
__le16 maxentry; /* 2: max number of entries */
__le16 rsrvd2; /* 2: */
pxd_t self; /* 8: self */
} header; /* (32) */
xad_t xad[XTROOTMAXSLOT]; /* 16 * maxentry: xad array */
} xtpage_t;
В качестве примеров рассмотрим следующие ситуации:
1. Файл размером в 1 метр расположен подряд на диске
2. Файл такого же размера разбит на 3 куска
3. Файл такого же размера имеет "дырки" внутри (sparse file)
4. 16-гигабайтный файл, расположенный последовательно
В первом случае файлу нужна 1000 блоков по 1 килобайту. Для его описания требуется всего одна xad-структура:
flag not discussed here
offset 0 /* the beginning of the file */
length 1017 /* 1017 1KB aggregate blocks */
address xxxxx /* aggregate block # */
1 метр - это как раз тот предел для блока размером в 1 килобайт, при котором для описания файла требуется всего 1 структура xad.
Во втором случае: пусть файл будет разбит на 3 куска размером 495,22 и 500 блоков. Требуются уже 3 xad-структуры:
xad #0:
flag not discussed here
offset 0 /* the beginning of the file */
length 495 /* 495 1KB aggregate blocks */
address xxxxx /* aggregate block # */
xad #1:
flag not discussed here
offset 495 /* the beginning of the file */
length 22 /* 22 1KB aggregate blocks */
address yyyyy /* aggregate block # */
xad #2:
flag not discussed here
offset 517 /* the beginning of the file */
length 500 /* 500 1KB aggregate blocks */
address zzzzz /* aggregate block # */
В третьем случае - представим ситуацию, когда файл получен в результате операции
fd = create ("newfile", blah blah blah);
write (fd, "hi", 2);
lseek (fd, 1041374, 0);
write (fd, " bye" , 3);
У этого файла 2 байта в начале, 3 в конце, а в середине пустота. Так вот jfs не станет выделять столько места
для этого файла - файл будет представлен двумя xad-структурами:
xad #0 :
flag not discussed here
offset 0 /* the beginning of the file */
length 1 /* 1 1KB aggregate blocks */
address xxxxx /* aggregate block # */
xad #1:
flag not discussed here
offset 1016 /* the beginning of the file */
length 1 /* 1 1KB aggregate blocks */
address yyyyy /* aggregate block */
В четвертом случае, когда файл последователен и достаточно велик, ему потребуется много xad-структур -
в данном примере 16-гигабайтный файл начинается с блока 12345 и заканчиввается блоком 16777216:
xad #0:
flag not discussed here
offset 0 /* the beginning of the file */
length 16777215 /* 1 1KB aggregate blocks */
address 12345 /* aggregate block */
xad #1:
flag not discussed here
offset 16777215 /* the beginning of the file */
length 1 /* 1 1KB aggregate blocks */
address 16789560 /* aggregate block # */
Block Allocation Map - битовая карта выделения блоков, представляющая из себя файл, который описывается нодой
номер два. На следующем рисунке показана логическая и физическая структура такой карты. Карта разбита на страницы
по 4 килобайта. В карте есть страницы 3-х типов:
bmap control page
dmap control pages
dmap pages
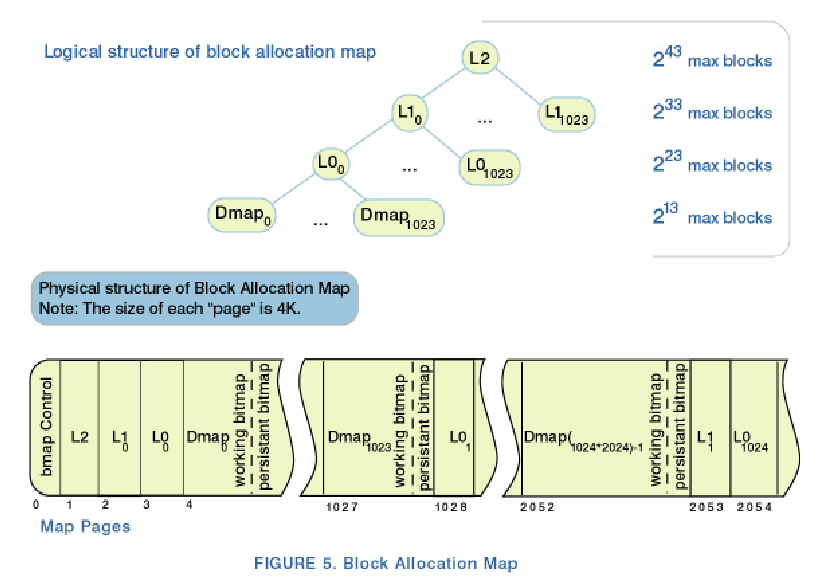
jfs использует дублированные битовые карты для контроля целостности - одна рабочая и одна контрольная.
Первая карта пишет текущее состояние, контрольная пишет коммиты на основе логов и файловых транзакций.
При освобождении блока первой апдэйтится контрольная карта, при выделении - рабочая.
На следующем рисунке показана структура dmap. Хранятся максимальные числа последовательных блоков:
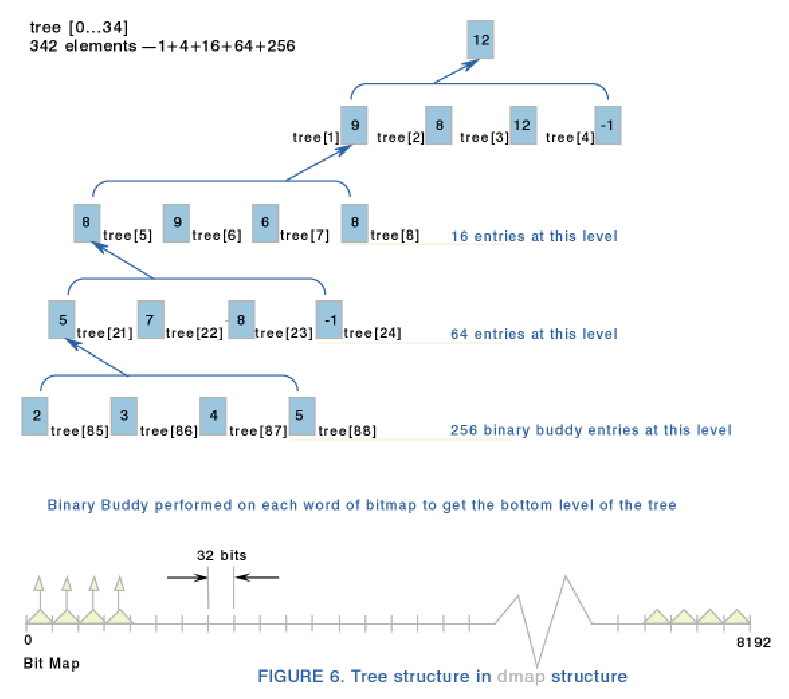
Block Allocation Map представлена структурой dmap:
/*
* dmap summary tree
*
* dmaptree_t must be consistent with dmapctl_t.
*/
typedef struct {
int32 nleafs; /* 4: number of tree leafs */
int32 l2nleafs; /* 4: l2 number of tree leafs */
int32 leafidx; /* 4: index of first tree leaf */
int32 height; /* 4: height of the tree */
int8 budmin; /* 1: min l2 tree leaf value to combine*/
int8 stree[TREESIZE]; /* TREESIZE: tree */
uint8 pad[2]; /* 2: pad to word boundary */
} dmaptree_t; /* - 360 - */
/*
* dmap page per 8K blocks bitmap
*/
typedef struct {
int32 nblocks; /* 4: num blks covered by this dmap */
int32 nfree; /* 4: num of free blks in this dmap */
int64 start; /* 8: starting blkno for this dmap */
dmaptree_t tree; /* 360: dmap tree */
uint8 pad[1672]; /* 1672: pad to 2048 bytes */
uint32 wmap[LPERDMAP]; /* 1024: bits of the working map */
uint32 pmap[LPERDMAP]; /* 1024: bits of the persistent map */
} dmap_t; /* - 4096 - */
|
| 666joy666 | Спасибо, действительно интересная и полезная статья.
2010-06-26 14:02:22 | | am | прикольно
2011-03-31 21:00:06 | |
| 
 LINUX
LINUX