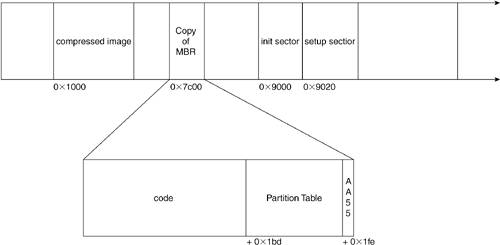
8.5. The Beginning: start_kernel()
This discussion begins with the jump to the start_kernel() (init/main.c) function, the first architecture-independent part of the code to be called.
With the jump to start_kernel(), we execute Process 0, which is otherwise known as the root thread. Process 0 spawns off Process 1, known as the init process. Process 0 then becomes the idle thread for the CPU. When /sbin/init is called, we have only those two processes running:
----------------------------------------------------------------------
init/main.c
396 asmlinkage void __init start_kernel(void)
397 {
398 char * command_line;
399 extern char saved_command_line[];
400 extern struct kernel_param __start___param[], __stop___param[];
...
405 lock_kernel();
406 page_address_init();
407 printk(linux_banner);
408 setup_arch(&command_line);
409 setup_per_cpu_areas();
...
415 smp_prepare_boot_cpu();
...
422 sched_init();
423
424 build_all_zonelists();
425 page_alloc_init();
426 printk("Kernel command line: %s\n", saved_command_line);
427 parse_args("Booting kernel", command_line, __start___param,
428 __stop___param - __start___param,
429 &unknown_bootoption);
430 sort_main_extable();
431 trap_init();
432 rcu_init();
433 init_IRQ();
434 pidhash_init();
435 init_timers();
436 softirq_init();
437 time_init();
...
444 console_init();
445 if (panic_later)
446 panic(panic_later, panic_param) ;
447 profile_init();
448 local_irq_enable();
449 #ifdef CONFIG_BLK_DEV_INITRD
450 if (initrd_start && !initrd_below_start_ok &&
451 initrd_start < min_low_pfn << PAGE_SHIFT) {
452 printk(KERN_CRIT "initrd overwritten (0x%08lx < 0x%08lx) - "
453 "disabling it.\n",initrd_start,min_low_pfn << PAGE_SHIFT);
454 initrd_start = 0;
455 }
456 #endif
457 mem_init();
458 kmem_cache_init();
459 if (late_time_init)
460 late_time_init();
461 calibrate_delay();
462 pidmap_init();
463 pgtable_cache_init();
464 prio_tree_init();
465 anon_vma_init();
466 #ifdef CONFIG_X86
467 if (efi_enabled)
468 efi_enter_virtual_mode();
469 #endif
470 fork_init(num_physpages);
471 proc_caches_init();
472 buffer_init();
473 unnamed_dev_init();
474 security_scaffolding_startup();
475 vfs_caches_init(num_physpages);
476 radix_tree_init();
477 signals_init();
478 /* rootfs populating might need page-writeback */
479 page_writeback_init();
480 #ifdef CONFIG_PROC_FS
481 proc_root_init();
482 #endif
483 check_bugs();
...
490 init_idle(current, smp_processor_id());
...
493 rest_init();
494 }
-----------------------------------------------------------------------
8.5.1. The Call to lock_kernel()
Line 405
In the 2.6 Linux kernel, the default configuration is to have a preemptible kernel. A preemptible kernel means that the kernel itself can be interrupted by a higher priority task, such as a hardware interrupt, and control is passed to the higher priority task. The kernel must save enough state so that it can return to executing when the higher priority task finishes.
Early versions of Linux implemented kernel preemption and SMP locking by using the Big Kernel Lock (BKL). Later versions of Linux correctly abstracted preemption into various calls, such as preempt_disable(). The BKL is still with us in the initialization process. It is a recursive spinlock that can be taken several times by a given CPU. A side effect of using the BKL is that it disables preemption, which is an important side effect during initialization.
Locking the kernel prevents it from being interrupted or preempted by any other task. Linux uses the BKL to do this. When the kernel is locked, no other process can execute. This is the antithesis of a preemptible kernel that can be interrupted at any point. In the 2.6 Linux kernel, we use the BKL to lock the kernel upon startup and initialize the various kernel objects without fear of being interrupted. The kernel is unlocked on line 493 within the rest_init() function. Thus, all of start_kernel() occurs with the kernels locked. Let's look at what happens in lock_kernel():
----------------------------------------------------------------------
include/linux/smp_lock.h
42 static inline void lock_kernel(void)
43 {
44 int depth = current->lock_depth+1;
45 if (likely(!depth))
46 get_kernel_lock();
47 current->lock_depth = depth;
48 }
-----------------------------------------------------------------------
Lines 4448
The init task has a special lock_depth of -1. This ensures that in multi-processor systems, different CPUs do not attempt to simultaneously grab the kernel lock. Because only one CPU runs the init task, only it can grab the big kernel lock because depth is 0 only for init (otherwise, depth is greater than 0). A similar trick is used in unlock_kernel() where we test (--current->lock_depth < 0). Let's see what happens in get_kernel_lock():
----------------------------------------------------------------------
include/linux/smp_lock.h
10 extern spinlock_t kernel_flag;
11
12 #define kernel_locked() (current->lock_depth >= 0)
13
14 #define get_kernel_lock() spin_lock(&kernel_flag)
15 #define put_kernel_lock() spin_unlock(&kernel_flag)
...
59 #define lock_kernel() do { } while(0)
60 #define unlock_kernel() do { } while(0)
61 #define release_kernel_lock(task) do { } while(0)
62 #define reacquire_kernel_lock(task) do { } while(0)
63 #define kernel_locked() 1
-----------------------------------------------------------------------
Lines 1015
These macros describe the big kernel locks that use standard spinlock routines. In multiprocessor systems, it is possible that two CPUs might try to access the same data structure. Spinlocks, which are explained in
Chapter 7, prevent this kind of contention.
Lines 5963
In the case where the kernel is not preemptible and not operating over multiple CPUs, we simply do nothing for lock_kernel() because nothing can interrupt us anyway.
The kernel has now seized the BKL and will not let go of it until the end of start_kernel(); as a result, all the following commands cannot bepreempted.
8.5.2. The Call to page_address_init()
Line 406
The call to page_address_init() is the first function that is involved with the initialization of the memory subsystem in this architecture-dependent portion of the code. The definition of page_address_init() varies according to three different compile-time parameter definitions. The first two result in page_address_init() being stubbed out to do nothing by defining the body of the function to be do { } while (0), as shown in the following code. The third is the operation we explore here in more detail. Let's look at the different definitions and discuss when they are enabled:
----------------------------------------------------------------------
include/linux/mm.h
376 #if defined(WANT_PAGE_VIRTUAL)
382 #define page_address_init() do { } while(0)
385 #if defined(HASHED_PAGE_VIRTUAL)
388 void page_address_init(void);
391 #if !defined(HASHED_PAGE_VIRTUAL) && !defined(WANT_PAGE_VIRTUAL)
394 #define page_address_init() do { } while(0)
----------------------------------------------------------------------
The #define for WANT_PAGE_VIRTUAL is set when the system has direct memory mapping, in which case simply calculating the virtual address of the memory location is sufficient to access the memory location. In cases where all of RAM is not mapped into the kernel address space (as is often the case when himem is configured), we need a more involved way to acquire the memory address. This is why the initialization of page addressing is defined only in the case where HASHED_PAGE_VIRTUAL is set.
We now look at the case where the kernel has been told to use HASHED_PAGE_VIRTUAL and where we need to initialize the virtual memory that the kernel is using. Keep in mind that this happens only if himem has been configured; that is, the amount of RAM the kernel can access is larger than that mapped by the kernel address space (generally 4GB).
In the process of following the function definition, various kernel objects are introduced and revisited. Table 8.2 shows the kernel objects introduced during the process of exploring page_address_init().
Table 8.2. Objects Introduced During the Call to page_address_init()Object Name | Description |
|---|
page_address_map | Struct | page_address_slot | Struct | page_address_pool | Global variable | page_address_maps | Global variable | page_address_htable | Global variable |
----------------------------------------------------------------------
mm/highmem.c
510 static struct page_address_slot {
511 struct list_head lh;
512 spinlock_t lock;
513 } ____cacheline_aligned_in_smp page_address_htable[1<<PA_HASH_ORDER];
...
591 static struct page_address_map page_address_maps[LAST_PKMAP];
592
593 void __init page_address_init(void)
594 {
595 int i;
596
597 INIT_LIST_HEAD(&page_address_pool);
598 for (i = 0; i < ARRAY_SIZE(page_address_maps); i++)
599 list_add(&page_address_maps[i].list, &page_address_pool) ;
600 for (i = 0; i < ARRAY_SIZE(page_address_htable); i++) {
601 INIT_LIST_HEAD(&page_address_htable[i].lh);
602 spin_lock_init(&page_address_htable[i].lock);
603 }
604 spin_lock_init(&pool_lock);
605 }
----------------------------------------------------------------------
Line 597
The main purpose of this line is to initialize the page_address_pool global variable, which is a struct of type list_head and point to a list of free pages allocated from page_address_maps (line 591). Figure 8.11 illustrates page_address_pool.
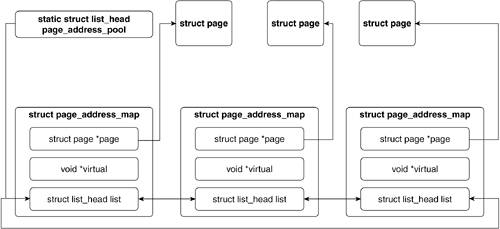
Lines 598599
We add each list of pages in page_address_maps to the doubly linked list headed by page_address_pool. We describe the page_address_map structure in detail next.
Lines 600603
We initialize each page address hash table's list_head and spinlock. The page_address_htable variable holds the list of entries that hash to the same bucket. Figure 8.12 illustrates the page address hash table.
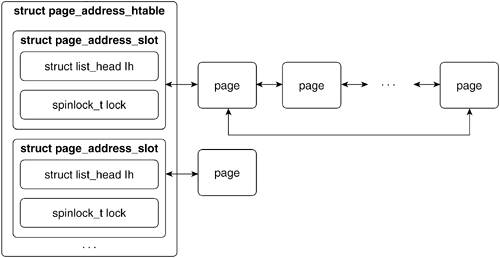
Line 604
We initialize the page_address_pool's spinlock.
Let's look at the page_address_map structure to better understand the lists we just saw initialized. This structure's main purpose is to maintain the association with a page and its virtual address. This would be wasteful if the page had a linear association with its virtual address. This becomes necessary only if the addressing is hashed:
----------------------------------------------------------------------
mm/highmem.c
490 struct page_address_map {
491 struct page *page;
492 void *virtual;
493 struct list_head list;
494 };
-----------------------------------------------------------------------
As you can see, the object keeps a pointer to the page structure that's associated with this page, a pointer to the virtual address, and a list_head struct to maintain its position in the doubly linked list of the page address list it is in.
8.5.3. The Call to printk(linux_banner)
Line 407
This call is responsible for the first console output made by the Linux kernel. This introduces the global variable linux_banner:
----------------------------------------------------------------------
init/version.c
31 const char *linux_banner =
32 "Linux version " UTS_RELEASE " (" LINUX_COMPILE_BY "@"
LINUX_COMPILE_HOST ") (" LINUX_COMPILER ") " UTS_VERSION "\n";
-----------------------------------------------------------------------
The version.c file defines linux_banner as just shown. This string provides the user with a reference of the Linux kernel version, the gcc version it was compiled with, and the release.
8.5.4. The Call to setup_arch
Line 408
The setup_arch() function in arch/i386/kernel/setup.c is cast to the __init type (refer to
Chapter 2 for a description of __init) where it runs only once at system initialization time. The setup_arch() function takes in a pointer to any Linux command-line data entered at boot time and initializes many of the architecture-specific subsystems, such as memory, I/O, processors, and consoles:
----------------------------------------------------------------------
arch/i386/kernel/setup.c
1083 void __init setup_arch(char **cmdline_p)
1084 {
1085 unsigned long max_low_pfn;
1086
1087 memcpy(&boot_cpu_data, &new_cpu_data, sizeof(new_cpu_data));
1088 pre_setup_arch_hook();
1089 early_cpu_init();
1090
1091 /*
1092 * FIXME: This isn't an official loader_type right
1093 * now but does currently work with elilo.
1094 * If we were configured as an EFI kernel, check to make
1095 * sure that we were loaded correctly from elilo and that
1096 * the system table is valid. If not, then initialize normally.
1097 */
1098 #ifdef CONFIG_EFI
1099 if ((LOADER_TYPE == 0x50) && EFI_SYSTAB)
1100 efi_enabled = 1;
1101 #endif
1102
1103 ROOT_DEV = old_decode_dev(ORIG_ROOT_DEV);
1104 drive_info = DRIVE_INFO;
1105 screen_info = SCREEN_INFO;
1106 edid_info = EDID_INFO;
1107 apm_info.bios = APM_BIOS_INFO;
1108 ist_info = IST_INFO;
1109 saved_videomode = VIDEO_MODE;
1110 if( SYS_DESC_TABLE.length != 0 ) {
1111 MCA_bus = SYS_DESC_TABLE.table[3] &0x2;
1112 machine_id = SYS_DESC_TABLE.table[0];
1113 machine_submodel_id = SYS_DESC_TABLE.table[1];
1114 BIOS_revision = SYS_DESC_TABLE.table[2];
1115 }
1116 aux_device_present = AUX_DEVICE_INFO;
1117
1118 #ifdef CONFIG_BLK_DEV_RAM
1119 rd_image_start = RAMDISK_FLAGS & RAMDISK_IMAGE_START_MASK;
1120 rd_prompt = ((RAMDISK_FLAGS & RAMDISK_PROMPT_FLAG) != 0);
1121 rd_doload = ((RAMDISK_FLAGS & RAMDISK_LOAD_FLAG) != 0);
1122 #endif
1123 ARCH_SETUP
1124 if (efi_enabled)
1125 efi_init();
1126 else
1127 setup_memory_region();
1128
1129 copy_edd();
1130
1131 if (!MOUNT_ROOT_RDONLY)
1132 root_mountflags &= ~MS_RDONLY;
1133 init_mm.start_code = (unsigned long) _text;
1134 init_mm.end_code = (unsigned long) _etext;
1135 init_mm.end_data = (unsigned long) _edata;
1136 init_mm.brk = init_pg_tables_end + PAGE_OFFSET;
1137
1138 code_resource.start = virt_to_phys(_text);
1139 code_resource.end = virt_to_phys(_etext)-1;
1140 data_resource.start = virt_to_phys(_etext);
1141 data_resource.end = virt_to_phys(_edata)-1;
1142
1143 parse_cmdline_early(cmdline_p);
1144
1145 max_low_pfn = setup_memory();
1146
1147 /*
1148 * NOTE: before this point _nobody_ is allowed to allocate
1149 * any memory using the bootmem allocator.
1150 */
1152 #ifdef CONFIG_SMP
1153 smp_alloc_memory(); /* AP processor realmode stacks in low memory*/
1154 #endif
1155 paging_init();
1156
1157 #ifdef CONFIG_EARLY_PRINTK
1158 {
1159 char *s = strstr(*cmdline_p, "earlyprintk=");
1160 if (s) {
1161 extern void setup_early_printk(char *);
1162
1163 setup_early_printk(s);
1164 printk("early console enabled\n");
1165 }
1166 }
1167 #endif
...
1170 dmi_scan_machine();
1171
1172 #ifdef CONFIG_X86_GENERICARCH
1173 generic_apic_probe(*cmdline_p);
1174 #endif
1175 if (efi_enabled)
1176 efi_map_memmap();
1177
1178 /*
1179 * Parse the ACPI tables for possible boot-time SMP configuration.
1180 */
1181 acpi_boot_init();
1182
1183 #ifdef CONFIG_X86_LOCAL_APIC
1184 if (smp_found_config)
1185 get_smp_config();
1186 #endif
1187
1188 register_memory(max_low_pfn);
1188
1190 #ifdef CONFIG_VT
1191 #if defined(CONFIG_VGA_CONSOLE)
1192 if (!efi_enabled || (efi_mem_type(0xa0000) != EFI_CONVENTIONAL_MEMORY))
1193 conswitchp = &vga_con;
1194 #elif defined(CONFIG_DUMMY_CONSOLE)
1195 conswitchp = &dummy_con;
1196 #endif
1197 #endif
1198 }
-----------------------------------------------------------------------
Line 1087
Get boot_cpu_data, which is a pointer to the cpuinfo_x86 struct filled in at boot time. This is similar for PPC.
Line 1088
Activate any machine-specific identification routines. This can be found in arch/xxx/machine-default/setup.c.
Line 1089
Identify the specific processor.
Lines 11031116
Get the system boot parameters.
Lines 11181122
Get RAM disk if set in arch/<arch>/defconfig.
Lines 11241127
Initialize Extensible Firmware Interface (if set in /defconfig) or just print out the BIOS memory map.
Line 1129
Save off Enhanced Disk Drive parms from boot time.
Lines 11331141
Initialize memory-management structs from the BIOS-provided memory map.
Line 1143
Begin parsing out the Linux command line. (See arch/<arch>/kernel/ setup.c.)
Line 1145
Initializes/reserves boot memory. (See arch/i386/kernel/setup.c.)
Lines 11531155
Get a page for SMP initialization or initialize paging beyond the 8M that's already initialized in head.S. (See arch/i386/mm/init.c.)
Lines 11571167
Get printk() running even though the console is not fully initialized.
Line 1170
This line is the Desktop Management Interface (DMI), which gathers information about the specific system-hardware configuration from BIOS. (See arch/i386/kernel/dmi_scan.c.)
Lines 11721174
If the configuration calls for it, look for the APIC given on the command line. (See arch/i386/machine-generic/probe.c.)
Lines 11751176
If using Extensible Firmware Interface, remap the EFI memory map. (See arch/i386/kernel/efi.c.)
Line 1181
Look for local and I/O APICs. (See arch/i386/kernel/acpi/boot.c.) Locate and checksum System Description Tables. (See drivers/acpi/tables.c.) For a better understanding of ACPI, go to the ACPI4LINUX project on the Web.
Lines 11831186
Scan for SMP configuration. (See arch/i386/kernel/mpparse.c.) This section can also use ACPI for configuration information.
Line 1188
Request I/O and memory space for standard resources. (See arch/i386/kernel/std_resources.c for an idea of how resources are registered.)
Lines 11901197
Set up the VGA console switch structure. (See drivers/video/console/vgacon.c.)
A similar but shorter version of setup_arch() can be found in arch/ppc/kernel/setup.c for the PowerPC. This function initializes a large part of the ppc_md structure. A call to pmac_feature_init() in arch/ppc/platforms/pmac_feature.c does an initial probe and initialization of the pmac hardware.
8.5.5. The Call to setup_per_cpu_areas()
Line 409
The routine setup_per_cpu_areas() exists for the setup of a multiprocessing environment. If the Linux kernel is compiled without SMP support, setup_per_cpu_areas() is stubbed out to do nothing, as follows:
----------------------------------------------------------------------
init/main.c
317 static inline void setup_per_cpu_areas(void) { }
-----------------------------------------------------------------------
If the Linux kernel is compiled with SMP support, setup_per_cpu_areas() is defined as follows:
----------------------------------------------------------------------
init/main.c
327 static void __init setup_per_cpu_areas(void)
328 {
329 unsigned long size, i;
330 char *ptr;
331 /* Created by linker magic */
332 extern char __per_cpu_start[], __per_cpu_end[];
333
334 /* Copy section for each CPU (we discard the original) */
335 size = ALIGN(__per_cpu_end - __per_cpu_start, SMP_CACHE_BYTES);
336 #ifdef CONFIG_MODULES
337 if (size < PERCPU_ENOUGH_ROOM)
338 size = PERCPU_ENOUGH_ROOM;
339 #endif
340
341 ptr = alloc_bootmem(size * NR_CPUS);
342
343 for (i = 0; i < NR_CPUS; i++, ptr += size) {
344 __per_cpu_offset[i] = ptr - __per_cpu_start;
345 memcpy(ptr, __per_cpu_start, __per_cpu_end - __per_cpu_start);
346 }
347 }
-----------------------------------------------------------------------
Lines 329332
The variables for managing a consecutive block of memory are initialized. The "linker magic" variables are defined during linking in the appropriate architecture's kernel directory (for example, arch/i386/kernel/vmlinux.lds.S).
Lines 334341
We determine the size of memory a single CPU requires and allocate that memory for each CPU in the system as a single contiguous block of memory.
Lines 343346
We cycle through the newly allocated memory, initializing each CPU's chunk of memory. Conceptually, we have taken a chunk of data that's valid for a single CPU (__per_cpu_start to __per_cpu_end) and copied it for each CPU on the system. This way, each CPU has its own data with which to play.
8.5.6. The Call to smp_prepare_boot_cpu()
Line 415
Similar to smp_per_cpu_areas(), smp_prepare_boot_cpu() is stubbed out when the Linux kernel does not support SMP:
----------------------------------------------------------------------
include/linux/smp.h
106 #define smp_prepare_boot_cpu() do {} while (0)
-----------------------------------------------------------------------
However, if the Linux kernel is compiled with SMP support, we need to allow the booting CPU to access its console drivers and the per-CPU storage that we just initialized. Marking CPU bitmasks achieves this.
A CPU bitmask is defined as follows:
----------------------------------------------------------------------
include/asm-generic/cpumask.h
10 #if NR_CPUS > BITS_PER_LONG && NR_CPUS != 1
11 #define CPU_ARRAY_SIZE BITS_TO_LONGS(NR_CPUS)
12
13 struct cpumask
14 {
15 unsigned long mask[CPU_ARRAY_SIZE];
16 };
-----------------------------------------------------------------------
This means that we have a platform-independent bitmask that contains the same number of bits as the system has CPUs.
smp_prepare_boot_cpu() is implemented in the architecture-dependent section of the Linux kernel but, as we soon see, it is the same for i386 and PPC systems:
----------------------------------------------------------------------
arch/i386/kernel/smpboot.c
66 /* bitmap of online cpus */
67 cpumask_t cpu_online_map;
...
70 cpumask_t cpu_callout_map;
...
1341 void __devinit smp_prepare_boot_cpu(void)
1342 {
1343 cpu_set(smp_processor_id(), cpu_online_map);
1344 cpu_set(smp_processor_id(), cpu_callout_map);
1345 }
-----------------------------------------------------------------------
----------------------------------------------------------------------
arch/ppc/kernel/smp.c
49 cpumask_t cpu_online_map;
50 cpumask_t cpu_possible_map;
...
331 void __devinit smp_prepare_boot_cpu(void)
332 {
333 cpu_set(smp_processor_id(), cpu_online_map);
334 cpu_set(smp_processor_id(), cpu_possible_map);
335 }
-----------------------------------------------------------------------
In both these functions, cpu_set() simply sets the bit smp_processor_id() in the cpumask_t bitmap. Setting a bit implies that the value of the set bit is 1.
8.5.7. The Call to sched_init()
Line 422
The call to sched_init() marks the initialization of all objects that the scheduler manipulates to manage the assignment of CPU time among the system's processes. Keep in mind that, at this point, only one process exists: the init process that currently executes sched_init():
----------------------------------------------------------------------
kernel/sched.c
3896 void __init sched_init(void)
3897 {
3898 runqueue_t *rq;
3899 int i, j, k;
3900
...
3919 for (i = 0; i < NR_CPUS; i++) {
3920 prio_array_t *array;
3921
3922 rq = cpu_rq(i);
3923 spin_lock_init(&rq->lock);
3924 rq->active = rq->arrays;
3925 rq->expired = rq->arrays + 1;
3926 rq->best_expired_prio = MAX_PRIO;
...
3938 for (j = 0; j < 2; j++) {
3939 array = rq->arrays + j;
3940 for (k = 0; k < MAX_PRIO; k++) {
3941 INIT_LIST_HEAD(array->queue + k);
3942 __clear_bit(k, array->bitmap);
3943 }
3944 // delimiter for bitsearch
3945 __set_bit(MAX_PRIO, array->bitmap);
3946 }
3947 }
3948 /*
3949 * We have to do a little magic to get the first
3950 * thread right in SMP mode.
3951 */
3952 rq = this_rq();
3953 rq->curr = current;
3954 rq->idle = current;
3955 set_task_cpu(current, smp_processor_id());
3956 wake_up_forked_process(current);
3957
3958 /*
3959 * The boot idle thread does lazy MMU switching as well:
3960 */
3961 atomic_inc(&init_mm.mm_count);
3962 enter_lazy_tlb(&init_mm, current);
3963 }
-----------------------------------------------------------------------
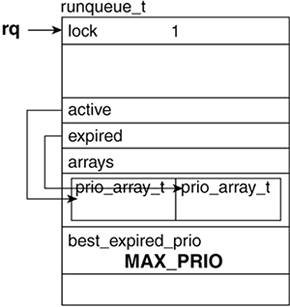
Lines 39193926
Each CPU's run queue is initialized: The active queue, expired queue, and spinlock are all initialized in this segment. Recall from
Chapter 7 that spin_lock|_init() sets the spinlock to 1, which indicates that the data object is unlocked.
Figure 8.13 illustrates the initialized run queue.
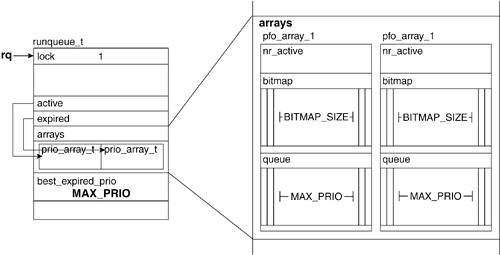
Lines 39383947
For each possible priority, we initialize the list associated with the priority and clear all bits in the bitmap to show that no process is on that queue. (If all this is confusing, refer to Figure 8.14. Also, see
Chapter 7 for an overview of how the scheduler manages its run queues.) This code chunk just ensures that everything is ready for the introduction of a process. As of line 3947, the scheduler is in the position to know that no processes exist; it ignores the current and idle processes for now.
Lines 39523956
We add the current process to the current CPU's run queue and call wake_up_forked_process() on ourselves to initialize current into the scheduler. Now, the scheduler knows that exactly one process exists: the init process.
Lines 39613962
When lazy MMU switching is enabled, it allows a multiprocessor Linux system to perform context switches at a faster rate. A TLB is a transaction lookaside buffer that contains the recent page translation addresses. It takes a long time to flush the TLB, so we swap it if possible. enter_lazy_tlb() ensures that the mm_struct init_mm isn't being used across multiple CPUs and can be lazily switched. On a uniprocessor system, this becomes a NULL function.
The sections that were omitted in the previous code deal with initialization of SMP machines. As a quick overview, those sections bootstrap each CPU to the default settings necessary to allow for load balancing, group scheduling, and thread migration. They are omitted here for clarity and brevity.
8.5.8. The Call to build_all_zonelists()
Line 424
The build_all_zonelists()function splits up the memory according to the zone types ZONE_DMA, ZONE_NORMAL, and ZONE_HIGHMEM. As mentioned in
Chapter 6, "Filesystems," zones are linear separations of physical memory that are used mainly to address hardware limitations. Suffice it to say that this is the function where these memory zones are built. After the zones are built, pages are stored in page frames that fall within zones.
The call to build_all_zonelists() introduces numnodes and NODE_DATA. The global variable numnodes holds the number of nodes (or partitions) of physical memory.
The partitions are determined according to CPU access time. Note that, at this point, the page tables have already been fully set up:
----------------------------------------------------------------------
mm/page_alloc.c
1345 void __init build_all_zonelists(void)
1346 {
1347 int i;
1348
1349 for(i = 0 ; i < numnodes ; i++)
1350 build_zonelists(NODE_DATA(i));
1351 printk("Built %i zonelists\n", numnodes);
1352 }
----------------------------------------------------------------------
build_all_zonelists() calls build_zonelists() once for each node and finishes by printing out the number of zonelists created. This book does not go into more detail regarding nodes. Suffice it to say that, in our one CPU example, numnodes are equivalent to 1, and each node can have all three types of zones. The NODE_DATA macro returns the node's descriptor from the node descriptor list.
8.5.9. The Call to page_alloc_init
Line 425
The function page_alloc_init() simply registers a function in a notifier chain. The function-registered page_alloc_cpu_notify() is a page-draining function associated with dynamic CPU configuration.
Dynamic CPU configuration refers to bringing up and down CPUs during the running of the Linux system, an event referred to as "hotplugging the CPU." Although technically, CPUs are not physically inserted and removed during machine operation, they can be turned on and off in some systems, such as the IBM p-Series 690. Let's look at the function:
----------------------------------------------------------------------
mm/page_alloc.c
1787 #ifdef CONFIG_HOTPLUG_CPU
1788 static int page_alloc_cpu_notify(struct notifier_block *self,
1789 unsigned long action, void *hcpu)
1790 {
1791 int cpu = (unsigned long)hcpu;
1792 long *count;
1793
if (action == CPU_DEAD) {
...
1796 count = &per_cpu(nr_pagecache_local, cpu);
1797 atomic_add(*count, &nr_pagecache);
1798 *count = 0;
1799 local_irq_disable();
1800 __drain_pages(cpu);
1801 local_irq_enable();
1802 }
1803 return NOTIFY_OK;
1804 }
1805 #endif /* CONFIG_HOTPLUG_CPU */
1806
1807 void __init page_alloc_init(void)
1808 {
1809 hotcpu_notifier(page_alloc_cpu_notify, 0);
1810 }
-----------------------------------------------------------------------
Line 1809
This line is the registration of the page_alloc_cpu_notify() routine into the hotcpu_notifier notifier chain. The hotcpu_notifier() routine creates a notifier_block that points to the page_alloc_cpu_notify() function and, with a priority of 0, then registers the object in the cpu_chain notifier chain(kernel/cpu.c).
Line 1788
page_alloc_cpu_notify() has the parameters that correspond to a notifier call, as
Chapter 2 explained. The system-specific pointer points to an integer that specifies the CPU number.
Lines 17941802
If the CPU is dead, free up its pages. The variable action is set to CPU_DEAD when a CPU is brought down. (See drain_pages() in this same file.)
8.5.10. The Call to parse_args()
Line 427
The parse_args() function parses the arguments passed to the Linux kernel.
For example, nfsroot is a kernel parameter that sets the NFS root filesystem for systems without disks. You can find a complete list of kernel parameters in Documentation/kernel-parameters.txt:
----------------------------------------------------------------------
kernel/params.c
116 int parse_args(const char *name,
117 char *args,
118 struct kernel_param *params,
119 unsigned num,
120 int (*unknown)(char *param, char *val))
121 {
122 char *param, *val;
123
124 DEBUGP("Parsing ARGS: %s\n", args);
125
126 while (*args) {
127 int ret;
128
129 args = next_arg(args, ¶m, &val);
130 ret = parse_one(param, val, params, num, unknown);
131 switch (ret) {
132 case -ENOENT:
133 printk(KERN_ERR "%s: Unknown parameter '%s'\n",
134 name, param);
135 return ret;
136 case -ENOSPC:
137 printk(KERN_ERR
138 "%s: '%s' too large for parameter '%s'\n",
139 name, val ?: "", param);
140 return ret;
141 case 0:
142 break;
143 default:
144 printk(KERN_ERR
145 "%s: '%s' invalid for parameter '%s'\n",
146 name, val ?: "", param);
147 return ret;
148 }
149 }
150
151 /* All parsed OK. */
152 return 0;
153 }
-----------------------------------------------------------------------
Lines 116125
The parameters passed to parse_args() are the following:
name.
A character string to be displayed if any errors occur while the kernel attempts to parse the kernel parameter arguments. In standard operation, this means that an error message, "Booting Kernel: Unknown parameter X," is displayed.
args.
The kernel parameter list of form foo=bar,bar2 baz=fuz wix.
params.
Points to the kernel parameter structure that holds all the valid parameters for the specific kernel. Depending on how a kernel was compiled, some parameters might exist and others might not.
num.
The number of kernel parameters in this specific kernel, not the number of arguments in args.
unknown.
Points to a function to call if a kernel parameter is specified that is not recognized.
Lines 126153
We loop through the string args, set param to point to the first parameter, and set val to the first value (if any, val could be null). This is done via next_args() (for example, the first call to next_args() with args being foo=bar,bar2 baz=fuz wix). We set param to foo and val to bar, bar2. The space after bar2 is overwritten with a \0 and args is set to point at the beginning character of baz.
We pass our pointers param and val into parse_one(), which does the work of setting the actual kernel parameter data structures:
----------------------------------------------------------------------
kernel/params.c
46 static int parse_one(char *param,
47 char *val,
48 struct kernel_param *params,
49 unsigned num_params,
50 int (*handle_unknown)(char *param, char *val))
51 {
52 unsigned int i;
53
54 /* Find parameter */
55 for (i = 0; i < num_params; i++) {
56 if (parameq(param, params[i].name)) {
57 DEBUGP("They are equal! Calling %p\n",
58 params[i].set);
59 return params[i].set(val, ¶ms[i]);
60 }
61 }
62
63 if (handle_unknown) {
64 DEBUGP("Unknown argument: calling %p\n", handle_unknown);
65 return handle_unknown(param, val);
66 }
67
68 DEBUGP("Unknown argument '%s'\n", param);
69 return -ENOENT;
70 }
-----------------------------------------------------------------------
Lines 4654
These parameters are the same as those described under parse_args() with param and val pointing to a subsection of args.
Lines 5561
We loop through the defined kernel parameters to see if any match param. If we find a match, we use val to call the associated set function. Thus, the set function handles multiple, or null, arguments.
Lines 6266
If the kernel parameter was not found, we call the handle_unknown() function that was passed in via parse_args().
After parse_one() is called for each parameter-value combination specified in args, we have set the kernel parameters and are ready to continue starting the Linux kernel.
8.5.11. The Call to trap_init()
Line 431
In Chapter 3, we introduced exceptions and interrupts. The function TRap_init() is specific to the handling of interrupts in x86 architecture. Briefly, this function initializes a table referenced by the x86 hardware. Each element in the table has a function to handle kernel or user-related issues, such as an invalid instruction or reference to a page not currently in memory. Although the PowerPC can have these same issues, its architecture handles them in a somewhat different manner. (Again, all this is discussed in Chapter 3.)
8.5.12. The Call to rcu_init()
Line 432
The rcu_init() function initializes the Read-Copy-Update (RCU) subsystem of the Linux 2.6 kernel. RCU controls access to critical sections of code and enforces mutual exclusion in systems where the cost of acquiring locks becomes significant in comparison to the chip speed. The Linux implementation of RCU is beyond the scope of this book. We occasionally mention calls to the RCU subsystem in our code analysis, but the specifics are left out. For more information on the Linux RCU subsystem, consult the Linux Scalability Effort pages at http://lse.sourceforge.net/locking/rcupdate.html:
----------------------------------------------------------------------
kernel/rcupate.c
297 void __init rcu_init(void)
298 {
299 rcu_cpu_notify(&rcu_nb, CPU_UP_PREPARE,
300 (void *)(long)smp_processor_id());
301 /* Register notifier for non-boot CPUs */
302 register_cpu_notifier(&rcu_nb);
303 }
-----------------------------------------------------------------------
8.5.13. The Call to init_IRQ()
Line 433
The function init_IRQ() in arch/i386/kernel/i8259.c initializes the hardware interrupt controller, the interrupt vector table and, if on x86, the system timer.
Chapter 3 includes a thorough discussion of interrupts for both x86 and PPC, where the Real-Time Clock is used as an interrupt example:
----------------------------------------------------------------------
arch/i386/kernel/i8259.c
410 void __init init_IRQ(void)
411 {
412 int i;
...
422 for (i = 0; i < (NR_VECTORS - FIRST_EXTERNAL_VECTOR); i++) {
423 int vector = FIRST_EXTERNAL_VECTOR + i;
424 if (i >= NR_IRQS)
425 break;
...
430 if (vector != SYSCALL_VECTOR)
431 set_intr_gate(vector, interrupt[i]);
432 }
...
437 intr_init_hook();
...
443 setup_timer();
...
449 if (boot_cpu_data.hard_math && !cpu_has_fpu)
450 setup_irq(FPU_IRQ, &fpu_irq);
451 }
-----------------------------------------------------------------------
Lines 422432
Initialize the interrupt vectors. This associates the x86 (hardware) IRQs with the appropriate handling code.
Line 437
Set up machine-specific IRQs, such as the Advanced Programmable Interrupt Controller (APIC).
Line 443
Initialize the timer clock.
Lines 449450
Set up for FPU if needed.
The following code is the PPC implementation of init_IRQ():
----------------------------------------------------------------------
arch/ppc/kernel/irq.c
700 void __init init_IRQ(void)
701 {
702 int i;
703
704 for (i = 0; i < NR_IRQS; ++i)
705 irq_affinity[i] = DEFAULT_CPU_AFFINITY;
706
707 ppc_md.init_IRQ();
708 }
-----------------------------------------------------------------------
Line 704
In multiprocessor systems, an interrupt can have an affinity for a specific processor.
Line 707
For a PowerMac platform, this routine is found in arch/ppc/platforms/ pmac_pic.c. It sets up the Programmable Interrupt Controller (PIC) portion of the I/O controller.
8.5.14. The Call to softirq_init()
Line 436
The softirq_init() function prepares the boot CPU to accept notifications from tasklets. Let's look at the internals of softirq_init():
----------------------------------------------------------------------
kernel/softirq.c
317 void __init softirq_init(void)
318 {
319 open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
320 open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);
321 }
...
327 void __init softirq_init(void)
328 {
329 open_softirq(TASKLET_SOFTIRQ, tasklet_action, NULL);
330 open_softirq(HI_SOFTIRQ, tasklet_hi_action, NULL);
331 tasklet_cpu_notify(&tasklet_nb, (unsigned long)CPU_UP_PREPARE,
332 (void *)(long)smp_processor_id());
333 register_cpu_notifier(&tasklet_nb);
334 }
-----------------------------------------------------------------------
Lines 319320
We initialize the actions to take when we get a TASKLET_SOFTIRQ or HI_SOFTIRQ interrupt. As we pass in NULL, we are telling the Linux kernel to call tasklet_action(NULL) and tasklet_hi_action(NULL) (in the cases of Line 319 and Line 320, respectively). The following implementation of open_softirq() shows how the Linux kernel stores the tasklet initialization information:
----------------------------------------------------------------------
kernel/softirq.c
177 void open_softirq(int nr, void (*action)(struct softirq_action*),
void * data)
178 {
179 softirq_vec[nr].data = data;
180 softirq_vec[nr].action = action;
181 }
----------------------------------------------------------------------
8.5.15. The Call to time_init()
Line 437
The function time_init() selects and initializes the system timer. This function, like TRap_init(), is very architecture dependent;
Chapter 3 covered this when we explored timer interrupts. The system timer gives Linux its temporal view of the world, which allows it to schedule when a task should run and for how long. The High Performance Event Timer (HPET) from Intel will be the successor to the 8254 PIT and RTC hardware. The HPET uses memory-mapped I/O, which means that the HPET control registers are accessed as if they were memory locations. Memory must be configured properly to access I/O regions. If set in arch/i386/defconfig.h, time_init() needs to be delayed until after mem_init() has set up memory regions. See the following code:
----------------------------------------------------------------------
arch/i386/kernel/time.c
376 void __init time_init(void)
377 {
...
378 #ifdef CONFIG_HPET_TIMER
379 if (is_hpet_capable()) {
380 late_time_init = hpet_time_init;
381 return;
382 }
...
387 #endif
388 xtime.tv_sec = get_cmos_time();
389 wall_to_monotonic.tv_sec = -xtime.tv_sec;
390 xtime.tv_nsec = (INITIAL_JIFFIES % HZ) * (NSEC_PER_SEC / HZ);
391 wall_to_monotonic.tv_nsec = -xtime.tv_nsec;
392
393 cur_timer = select_timer();
394 printk(KERN_INFO "Using %s for high-res timesource\n",cur_timer->name);
395
396 time_init_hook();
397 }
-----------------------------------------------------------------------
Lines 379387
If the HPET is configured, time_init() must run after memory has been initialized. The code for late_time_init() (on lines 358373) is the same as time_init().
Lines 388391
Initialize the xtime time structure used for holding the time of day.
Line 393
Select the first timer that initializes. This can be overridden. (See arch/i386/ kernel/timers/timer.c.)
8.5.16. The Call to console_init()
Line 444
A computer console is a device where the kernel (and other parts of a system) output messages. It also has login capabilities. Depending on the system, the console can be on the monitor or through a serial port. The function console_init() is an early call to initialize the console device, which allows for boot-time reporting of status:
----------------------------------------------------------------------
drivers/char/tty_io.c
2347 void __init console_init(void)
2348 {
2349 initcall_t *call;
...
2352 (void) tty_register_ldisc(N_TTY, &tty_ldisc_N_TTY);
...
2358 #ifdef CONFIG_EARLY_PRINTK
2359 disable_early_printk();
2360 #endif
...
2366 call = &__con_initcall_start;
2367 while (call < &__con_initcall_end) {
2368 (*call)();
2369 call++;
2370 }
2371 }
-----------------------------------------------------------------------
Line 2352
Set up the line discipline.
Line 2359
Keep the early printk support if desired. Early printk support allows the system to report status during the boot process before the system console is fully initialized. It specifically initializes a serial port (ttyS0, for example) or the system's VGA to a minimum functionality. Early printk support is started in setup_arch(). (For more information, see the code discussion on line 408 in this section and the files /kernel/printk.c and /arch/i386/kernel/ early_printk.c.)
Line 2366
Initialize the console.
8.5.17. The Call to profile_init()
Line 447
profile_init() allocates memory for the kernel to store profiling data in. Profiling is the term used in computer science to describe data collection during program execution. Profiling data is used to analyze performance and otherwise study the program being executed (in our case, the Linux kernel itself):
----------------------------------------------------------------------
kernel/profile.c
30 void __init profile_init(void)
31 {
32 unsigned int size;
33
34 if (!prof_on)
35 return;
36
37 /* only text is profiled */
38 prof_len = _etext - _stext;
39 prof_len >>= prof_shift;
40
41 size = prof_len * sizeof(unsigned int) + PAGE_SIZE - 1;
42 prof_buffer = (unsigned int *) alloc_bootmem(size);
43 }
-----------------------------------------------------------------------
Lines 3435
Don't do anything if kernel profiling is not enabled.
Lines 3839
_etext and _stext are defined in kernel/head.S. We determine the profile length as delimited by _etext and _stext and then shift the value by prof_shift, which was defined as a kernel parameter.
Lines 4142
We allocate a contiguous block of memory for storing profiling data of the size requested by the kernel parameters.
8.5.18. The Call to local_irq_enable()
Line 448
The function local_irq_enable() allows interrupts on the current CPU. It is usually paired with local_irq_disable(). In previous kernel versions, the sti(), cli() pair were used for this purpose. Although these macros still resolve to sti() and cli(), the keyword to note here is local. These affect only the currently running processor:
----------------------------------------------------------------------
include\asm-i386\system.h
446 #define local_irq_disable() _asm__ __volatile__("cli": : :"memory")
447 #define local_irq_enable() __asm__ __volatile__("sti": : :"memory")
----------------------------------------------------------------------
Lines 446447
Referring to the "
Inline Assembly" section in
Chapter 2, the item in the quotes is the assembly instruction and memory is on the clobber list.
8.5.19. initrd Configuration
Lines 449456
This #ifdef statement is a sanity check on initrdthe initial RAM disk.
A system using initrd loads the kernel and mounts the initial RAM disk as the root filesystem. Programs can run from this RAM disk and, when the time comes, a new root filesystem, such as the one on a hard drive, can be mounted and the initial RAM disk unmounted.
This operation simply checks to ensure that the initial RAM disk specified is valid. If it isn't, we set initrd_start to 0, which tells the kernel to not use an initial RAM disk.
8.5.20. The Call to mem_init()
Line 457
For both x86 and PPC, the call to mem_init() finds all free pages and sends that information to the console. Recall from
Chapter 4 that the Linux kernel breaks available memory into zones. Currently, Linux has three zones:
Zone_DMA.
Memory less than 16MB.
Zone_Normal.
Memory starting at 16MB but less than 896MB. (The kernel uses the last 128MB.)
Zone_HIGHMEM.
Memory greater than 1GB.
The function mem_init() finds the total number of free page frames in all the memory zones. This function prints out informational kernel messages regarding the beginning state of the memory. This function is architecture dependent because it manages early memory allocation data. Each architecture supplies its own function, although they all perform the same tasks. We first look at how x86 does it and follow it up with PPC:
----------------------------------------------------------------------
arch/i386/mm/init
445 void __init mem_init(void)
446 {
447 extern int ppro_with_ram_bug(void);
448 int codesize, reservedpages, datasize, initsize;
449 int tmp;
450 int bad_ppro;
...
459 #ifdef CONFIG_HIGHMEM
460 if (PKMAP_BASE+LAST_PKMAP*PAGE_SIZE >= FIXADDR_START) {
461 printk(KERN_ERR "fixmap and kmap areas overlap - this will crash\n");
462 printk(KERN_ERR "pkstart: %lxh pkend:%lxh fixstart %lxh\n",
463 PKMAP_BASE, PKMAP_BASE+LAST_PKMAP*PAGE_SIZE, FIXADDR_START);
464 BUG();
465 }
466 #endif
467
468 set_max_mapnr_init();
...
476 /* this will put all low memory onto the freelists */
477 totalram_pages += __free_all_bootmem();
478
479
480 reservedpages = 0;
481 for (tmp = 0; tmp < max_low_pfn; tmp++)
...
485 if (page_is_ram(tmp) && PageReserved(pfn_to_page(tmp)))
486 reservedpages++;
487
488 set_highmem_pages_init(bad_ppro);
490 codesize = (unsigned long) &_etext - (unsigned long) &_text;
491 datasize = (unsigned long) &_edata - (unsigned long) &_etext;
492 initsize = (unsigned long) &__init_end - (unsigned long) &__init_begin;
493
494 kclist_add(&kcore_mem, __va(0), max_low_pfn << PAGE_SHIFT);
495 kclist_add(&kcore_vmalloc, (void *)VMALLOC_START,
496 VMALLOC_END-VMALLOC_START);
497
498 printk(KERN_INFO "Memory: %luk/%luk available (%dk kernel code, %dk reserved, %dk
 data, %dk init, %ldk highmem)\n",
499 (unsigned long) nr_free_pages() << (PAGE_SHIFT-10),
500 num_physpages << (PAGE_SHIFT-10),
501 codesize >> 10,
502 reservedpages << (PAGE_SHIFT-10),
503 datasize >> 10,
504 initsize >> 10,
505 (unsigned long) (totalhigh_pages << (PAGE_SHIFT-10))
506 );
...
521 #ifndef CONFIG_SMP
522 zap_low_mappings();
523 #endif
524 }
----------------------------------------------------------------------- data, %dk init, %ldk highmem)\n",
499 (unsigned long) nr_free_pages() << (PAGE_SHIFT-10),
500 num_physpages << (PAGE_SHIFT-10),
501 codesize >> 10,
502 reservedpages << (PAGE_SHIFT-10),
503 datasize >> 10,
504 initsize >> 10,
505 (unsigned long) (totalhigh_pages << (PAGE_SHIFT-10))
506 );
...
521 #ifndef CONFIG_SMP
522 zap_low_mappings();
523 #endif
524 }
-----------------------------------------------------------------------
Line 459
This line is a straightforward error check so that fixed map and kernel map do not overlap.
Line 469
The function set_max_mapnr_init() (arch/i386/mm/init.c) simply sets the value of num_physpages, which is a global variable (defined in mm/memory.c) that holds the number of available page frames.
Line 477
The call to __free_all_bootmem() marks the freeing up of all low-memory pages. During boot time, all pages are reserved. At this late point in the bootstrapping phase, the available low-memory pages are released. The flow of the function calls are seen in Figure 8.15.

Let's look at the core portion of free_all_bootmem_core() to understand what is happening:
----------------------------------------------------------------------
mm/bootmem.c
257 static unsigned long __init free_all_bootmem_core(pg_data_t *pgdat)
258 {
259 struct page *page;
260 bootmem_data_t *bdata = pgdat->bdata;
261 unsigned long i, count, total = 0;
...
295 page = virt_to_page(bdata->node_bootmem_map);
296 count = 0;
297 for (i = 0; i < ((bdata->node_low_pfn-(bdata->node_boot_start >> PAGE_SHIFT))/8 +
PAGE_SIZE-1)/PAGE_SIZE; i++,page++) {
298 count++;
299 ClearPageReserved(page);
300 set_page_count(page, 1);
301 __free_page(page);
302 }
303 total += count;
304 bdata->node_bootmem_map = NULL;
305
306 return total;
307 }
-----------------------------------------------------------------------
For all the available low-memory pages, we clear the PG_reserved flag in the flags field of the page struct. Next, we set the count field of the page struct to 1 to indicate that it is in use and call __free_page(), thus passing it to the buddy allocator. If you recall from
Chapter 4's explanation of the buddy system, we explain that this function releases a page and adds it to a free list.
The function __free_all_bootmem() returns the number of low memory pages available, which is added to the running count of totalram_pages (an unsigned long defined in mm/page_alloc.c).
Lines 480486
These lines update the count of reserved pages.
Line 488
The call to set_highmem_pages_init() marks the initialization of high-memory pages. Figure 8.16 illustrates the calling hierarchy of set_highmem_pages_init().
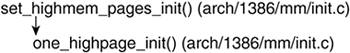
Let's look at the bulk of the code performed in one_highpage_init():
----------------------------------------------------------------------
arch/i386/mm/init.c
253 void __init one_highpage_init(struct page *page, int pfn, int bad_ppro)
254 {
255 if (page_is_ram(pfn) && !(bad_ppro && page_kills_ppro(pfn))) {
256 ClearPageReserved(page);
257 set_bit(PG_highmem, &page->flags);
258 set_page_count(page, 1);
259 __free_page(page);
260 totalhigh_pages++;
261 } else
262 SetPageReserved(page);
263 }
----------------------------------------------------------------------
Much like __free_all_bootmem(), all high-memory pages have their page struct flags field cleared of the PG_reserved flag, have PG_highmem set, and have their count field set to 1. __free_page() is also called to add these pages to the free lists and the totalhigh_pages counter is incremented.
Lines 490506
This code block gathers and prints out information regarding the size of memory areas and the number of available pages.
Lines 521523
The function zap_low_mappings flushes the initial TLBs and PGDs in low memory.
The function mem_init() marks the end of the boot phase of memory allocation and the beginning of the memory allocation that will be used throughout the system's life.
The PPC code for mem_init() finds and initializes all pages for all zones:
----------------------------------------------------------------------
arch/ppc/mm/init.c
393 void __init mem_init(void)
394 {
395 unsigned long addr;
396 int codepages = 0;
397 int datapages = 0;
398 int initpages = 0;
399 #ifdef CONFIG_HIGHMEM
400 unsigned long highmem_mapnr;
402 highmem_mapnr = total_lowmem >> PAGE_SHIFT;
403 highmem_start_page = mem_map + highmem_mapnr;
404 #endif /* CONFIG_HIGHMEM */
405 max_mapnr = total_memory >> PAGE_SHIFT;
407 high_memory = (void *) __va(PPC_MEMSTART + total_lowmem);
408 num_physpages = max_mapnr; /* RAM is assumed contiguous */
410 totalram_pages += free_all_bootmem();
412 #ifdef CONFIG_BLK_DEV_INITRD
413 /* if we are booted from BootX with an initial ramdisk,
414 make sure the ramdisk pages aren't reserved. */
415 if (initrd_start) {
416 for (addr = initrd_start; addr < initrd_end; addr += PAGE_SIZE)
417 ClearPageReserved(virt_to_page(addr));
418 }
419 #endif /* CONFIG_BLK_DEV_INITRD */
421 #ifdef CONFIG_PPC_OF
422 /* mark the RTAS pages as reserved */
423 if ( rtas_data )
424 for (addr = (ulong)__va(rtas_data);
425 addr < PAGE_ALIGN((ulong)__va(rtas_data)+rtas_size) ;
426 addr += PAGE_SIZE)
427 SetPageReserved(virt_to_page(addr));
428 #endif
429 #ifdef CONFIG_PPC_PMAC
430 if (agp_special_page)
431 SetPageReserved(virt_to_page(agp_special_page));
432 #endif
433 if ( sysmap )
434 for (addr = (unsigned long)sysmap;
435 addr < PAGE_ALIGN((unsigned long)sysmap+sysmap_size) ;
436 addr += PAGE_SIZE)
437 SetPageReserved(virt_to_page(addr));
439 for (addr = PAGE_OFFSET; addr < (unsigned long)high_memory;
440 addr += PAGE_SIZE) {
441 if (!PageReserved(virt_to_page(addr)))
442 continue;
443 if (addr < (ulong) etext)
444 codepages++;
445 else if (addr >= (unsigned long)&__init_begin
446 && addr < (unsigned long)&__init_end)
447 initpages++;
448 else if (addr < (ulong) klimit)
449 datapages++;
450 }
452 #ifdef CONFIG_HIGHMEM
453 {
454 unsigned long pfn;
456 for (pfn = highmem_mapnr; pfn < max_mapnr; ++pfn) {
457 struct page *page = mem_map + pfn;
459 ClearPageReserved(page);
460 set_bit(PG_highmem, &page->flags);
461 set_page_count(page, 1);
462 __free_page(page);
463 totalhigh_pages++;
464 }
465 totalram_pages += totalhigh_pages;
466 }
467 #endif /* CONFIG_HIGHMEM */
469 printk("Memory: %luk available (%dk kernel code, %dk data, %dk init, %ldk highmem)\n",
470 (unsigned long)nr_free_pages()<< (PAGE_SHIFT-10),
471 codepages<< (PAGE_SHIFT-10), datapages<< (PAGE_SHIFT-10),
472 initpages<< (PAGE_SHIFT-10),
473 (unsigned long) (totalhigh_pages << (PAGE_SHIFT-10)));
474 if (sysmap)
475 printk("System.map loaded at 0x%08x for debugger, size: %ld bytes\n",
476 (unsigned int)sysmap, sysmap_size);
477 #ifdef CONFIG_PPC_PMAC
478 if (agp_special_page)
479 printk(KERN_INFO "AGP special page: 0x%08lx\n", agp_special_page);
480 #endif
482 /* Make sure all our pagetable pages have page->mapping
483 and page->index set correctly. */
484 for (addr = KERNELBASE; addr != 0; addr += PGDIR_SIZE) {
485 struct page *pg;
486 pmd_t *pmd = pmd_offset(pgd_offset_k(addr), addr);
487 if (pmd_present(*pmd)) {
488 pg = pmd_page(*pmd);
489 pg->mapping = (void *) &init_mm;
490 pg->index = addr;
491 }
492 }
493 mem_init_done = 1;
494 }
-----------------------------------------------------------------------
Lines 399410
These lines find the amount of memory available. If HIGHMEM is used, those pages are also counted. The global variable totalram_pages is modified to reflect this.
Lines 412419
If used, clear any pages that the boot RAM disk used.
Lines 421432
Depending on the boot environment, reserve pages for the Real-Time Abstraction Services and AGP (video), if needed.
Lines 433450
If required, reserve some pages for system map.
Lines 452467
If using HIGHMEM, clear any reserved pages and modify the global variable totalram_pages.
Lines 469480
Print memory information to the console.
Lines 482492
Loop through page directory and initialize each mm_struct and index.
8.5.21. The Call to late_time_init()
Lines 459460
The function late_time_init() uses HPET (refer to the discussion under "The Call to time_init" section). This function is used only with the Intel architecture and HPET. This function has essentially the same code as time_init(); it is just called after memory initialization to allow the HPET to be mapped into physical memory.
8.5.22. The Call to calibrate_delay()
Line 461
The function calibrate_delay() in init/main.c calculates and prints the value of the much celebrated "BogoMips," which is a measurement that indicates the number of delay() iterations your processor can perform in a clock tick. calibrate_delay() allows delays to be approximately the same across processors of different speeds. The resulting valueat most an indicator of how fast a processor is runningis stored in loop_pre_jiffy and the udelay() and mdelay() functions use it to set the number of delay() iterations to perform:
----------------------------------------------------------------------
init/main.c
void __init calibrate_delay(void)
{
unsigned long ticks, loopbit;
int lps_precision = LPS_PREC;
186 loops_per_jiffy = (1<<12);
printk("Calibrating delay loop... ");
189 while (loops_per_jiffy <<= 1) {
/* wait for "start of" clock tick */
ticks = jiffies;
while (ticks == jiffies)
/* nothing */;
/* Go .. */
ticks = jiffies;
__delay(loops_per_jiffy);
ticks = jiffies - ticks;
if (ticks)
break;
200 }
/* Do a binary approximation to get loops_per_jiffy set to equal one clock
(up to lps_precision bits) */
204 loops_per_jiffy >>= 1;
loopbit = loops_per_jiffy;
206 while ( lps_precision-- && (loopbit >>= 1) ) {
loops_per_jiffy |= loopbit;
ticks = jiffies;
while (ticks == jiffies);
ticks = jiffies;
__delay(loops_per_jiffy);
if (jiffies != ticks) /* longer than 1 tick */
loops_per_jiffy &= ~loopbit;
214 }
/* Round the value and print it */
217 printk("%lu.%02lu BogoMIPS\n",
loops_per_jiffy/(500000/HZ),
219 (loops_per_jiffy/(5000/HZ)) % 100);
}
----------------------------------------------------------------------
Line 186
Start at 0x800.
Lines 189200
Keep doubling loops_per_jiffy until the amount of time it takes the function delay(loops_per_jiffy) to exceed one jiffy.
Line 204
Divide loops_per_jiffy by 2.
Lines 206214
Successively add descending powers of 2 to loops_per_jiffy until tick equals jiffy.
Lines 217219
Print the value out as if it were a float.
8.5.23. The Call to pgtable_cache_init()
Line 463
The key function in this x86 code block is the system function kmem_cache_create(). This function creates a named cache. The first parameter is a string used to identify it in /proc/slabinfo:
----------------------------------------------------------------------
arch/i386/mm/init.c
529 kmem_cache_t *pgd_cache;
530 kmem_cache_t *pmd_cache;
531
532 void __init pgtable_cache_init(void)
533 {
534 if (PTRS_PER_PMD > 1) {
535 pmd_cache = kmem_cache_create("pmd",
536 PTRS_PER_PMD*sizeof(pmd_t),
537 0, 538 SLAB_HWCACHE_ALIGN | SLAB_MUST_H WCACHE_ALIGN,
539 pmd_ctor,
540 NULL);
541 if (!pmd_cache)
542 panic("pgtable_cache_init(): cannot create pmd c ache");
543 }
544 pgd_cache = kmem_cache_create("pgd",
545 PTRS_PER_PGD*sizeof(pgd_t),
546 0,
547 SLAB_HWCACHE_ALIGN | SLAB_MUST_HWCACHE_A LIGN,
548 pgd_ctor,
549 PTRS_PER_PMD == 1 ? pgd_dtor : NULL);
550 if (!pgd_cache)
551 panic("pgtable_cache_init(): Cannot create pgd cache");
552 }
----------------------------------------------------------------------
----------------------------------------------------------------------
arch/ppc64/mm/init.c
976 void pgtable_cache_init(void)
977 {
978 zero_cache = kmem_cache_create("zero",
979 PAGE_SIZE,
980 0,
981 SLAB_HWCACHE_ALIGN | SLAB_MUST_HWCACHE_A LIGN,
982 zero_ctor,
983 NULL);
984 if (!zero_cache)
985 panic("pgtable_cache_init(): could not create zero_cache !\n");
986 }
----------------------------------------------------------------------
Lines 532542
Create the pmd cache.
Lines 544551
Create the pgd cache.
On the PPC, which has hardware-assisted hashing, pgtable_cache_init() is a no-op:
----------------------------------------------------------------------
include\asmppc\pgtable.h
685 #define pgtable_cache_init() do { } while (0)
8.5.24. The Call to buffer_init()
Line 472
The buffer_init() function in fs/buffer.c holds data from filesystem devices:
----------------------------------------------------------------------
fs/buffer.c
3031 void __init buffer_init(void)
{
int i;
int nrpages;
3036 bh_cachep = kmem_cache_create("buffer_head",
sizeof(struct buffer_head), 0,
0, init_buffer_head, NULL);
3039 for (i = 0; i < ARRAY_SIZE(bh_wait_queue_heads); i++)
init_waitqueue_head(&bh_wait_queue_heads[i].wqh);
3044 nrpages = (nr_free_buffer_pages() * 10) / 100;
max_buffer_heads = nrpages * (PAGE_SIZE / sizeof(struct buffer_head));
hotcpu_notifier(buffer_cpu_notify, 0);
3048 }
----------------------------------------------------------------------
Line 3036
Allocate the buffer cache hash table.
Line 3039
Create a table of buffer hash wait queues.
Line 3044
Limit low-memory occupancy to 10 percent.
8.5.25. The Call to security_scaffolding_startup()
Line 474
The 2.6 Linux kernel contains code for loading kernel modules that implement various security features. security_scaffolding_startup() simply verifies that a security operations object exists, and if it does, calls the security module's initialization functions.
How security modules can be created and what kind of issues a writer might face are beyond the scope of this text. For more information, consult Linux Security Modules (http://lsm.immunix.org/) and the Linux-security-module mailing list (http://mail.wirex.com/mailman/listinfo/linux-security-module).
8.5.26. The Call to vfs_caches_init()
Line 475
The VFS subsystem depends on memory caches, called SLAB caches, to hold the structures it manages.
Chapter 4 discusses SLAB caches detail. The vfs_caches_init() function initializes the SLAB caches that the subsystem uses. Figure 8.17 shows the overview of the main function hierarchy called from vfs_caches_init(). We explore in detail each function included in this call hierarchy. You can refer to this hierarchy to keep track of the functions as we look at each of them.
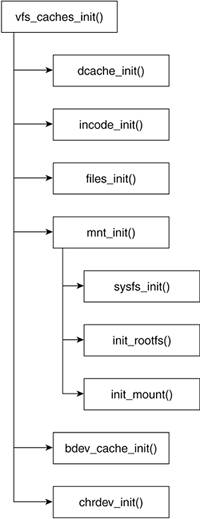
Table 8.3 summarizes the objects introduced by the vfs_caches_init() function or by one of the functions it calls.
----------------------------------------------------------------------
fs/dcache.c
1623 void __init vfs_caches_init(unsigned long mempages)
1624 {
1625 names_cachep = kmem_cache_create("names_cache",
1626 PATH_MAX, 0,
1627 SLAB_HWCACHE_ALIGN, NULL, NULL);
1628 if (!names_cachep)
1629 panic("Cannot create names SLAB cache");
1630
1631 filp_cachep = kmem_cache_create("filp",
1632 sizeof(struct file), 0,
1633 SLAB_HWCACHE_ALIGN, filp_ctor, filp_dtor);
1634 if(!filp_cachep)
1635 panic("Cannot create filp SLAB cache");
1636
1637 dcache_init(mempages);
1638 inode_init(mempages);
1639 files_init(mempages);
1640 mnt_init(mempages);
1641 bdev_cache_init();
1642 chrdev_init();
1643 }
-----------------------------------------------------------------------
Table 8.3. Objects Introduced by vfs_caches_initObject Name | Description |
|---|
names_cachep | Global variable | filp_cachep | Global variable | inode_cache | Global variable | dentry_cache | Global variable | mnt_cache | Global variable | namespace | Struct | mount_hashtable | Global variable | root_fs_type | Global variable | file_system_type | Struct (discussed in
Chapter 6) | bdev_cachep | Global variable |
Line 1623
The routine takes in the global variable num_physpages (whose value is calculated during mem_init()) as a parameter that holds the number of physical pages available in the system's memory. This number influences the creation of SLAB caches, as we see later.
Lines 16251629
The next step is to create the names_cachep memory area.
Chapter 4 describes the kmem_cache_create() function in detail. This memory area holds objects of size PATH_MAX, which is the maximum allowable number of characters a pathname is allowed to have. (This value is set in linux/limits.h as 4,096.) At this point, the cache that has been created is empty of objects, or memory areas of size PATH_MAX. The actual memory areas are allocated upon the first and potentially subsequent calls to getname().
As discussed in
Chapter 6 the getname() routine is called at the beginning of some of the file-related system calls (for example, sys_open()) to read the file pathname from the process address space. Objects are freed from the cache with the putname() routine.
If the names_cache cache cannot be created, the kernel jumps to the panic routine, exiting the function's flow of control.
Lines 16311635
The filp_cachep cache is created next, with objects the size of the file structure. The object holding the file structure is allocated by the get_empty_filp() (fs/file_table.c) routine, which is called, for example, upon creation of a pipe or the opening of a file. The file descriptor object is deallocated by a call to the file_free() (fs/file_table.c) routine.
Line 1637
The dcache_init() (fs/dcache.c) routine creates the SLAB cache that holds dentry descriptors. The cache itself is called the dentry_cache. The dentry descriptors themselves are created for each hierarchical component in pathnames referred by processes when accessing a file or directory. The structure associates the file or directory component with the inode that represents it, which further facilitates requests to that component for a speedier association with its corresponding inode.
Line 1638
The inode_init() (fs/inode.c) routine initializes the inode hash table and the wait queue head array used for storing hashed inodes that the kernel wants to lock. The wait queue heads (wait_queue_head_t) for hashed inodes are stored in an array called i_wait_queue_heads. This array gets initialized at this point of the system's startup process.
The inode_hashtable gets created at this point. This table speeds up the searches on inode. The last thing that occurs is that the SLAB cache used to hold inode objects gets created. It is called inode_cache. The memory areas for this cache are allocated upon calls to alloc_inode (fs/inode.c) and freed upon calls to destroy_inode() (fs/inode.c).
Line 1639
The files_init() routine is called to determine the maximum amount of memory allowed for files per process. The max_files field of the files_stat structure is set. This is then referenced upon file creation to determine if there is enough memory to open the file. Let's look at this routine:
----------------------------------------------------------------------
fs/file_table.c
292 void __init files_init(unsigned long mempages)
293 {
294 int n;
...
299 n = (mempages * (PAGE_SIZE / 1024)) / 10;
300 files_stat.max_files = n;
301 if (files_stat.max_files < NR_FILE)
302 files_stat.max_files = NR_FILE;
303 }
----------------------------------------------------------------------
Line 299
The page size is divided by the amount of space that a file (along with associated inode and cache) will roughly occupy (in this case, 1K). This value is then multiplied by the number of pages to get the total amount of "blocks" that can be used for files. The division by 10 shows that the default is to limit the memory usage for files to no more than 10 percent of the available memory.
Lines 301302
The NR_FILE (include/linux/fs.h) is set to 8,192.
Line 1640
The next routine, called mnt_init(), creates the cache that will hold the vfsmount objects the VFS uses for mounting filesystems. The cache is called mnt_cache. The routine also creates the mount_hashtable array, which stores references to objects in mnt_cache for faster access. It then issues calls to initialize the sysfs filesystem and mounts the root filesystem. Let's closely look at the creation of the hash table:
----------------------------------------------------------------------
fs/namespace.c
1137 void __init mnt_init(unsigned long mempages)
{
1139 struct list_head *d;
1140 unsigned long order;
1141 unsigned int nr_hash;
1142 int i;
...
1149 order = 0;
1150 mount_hashtable = (struct list_head *)
1151 __get_free_pages(GFP_ATOMIC, order);
1152
1153 if (!mount_hashtable)
1154 panic("Failed to allocate mount hash table\n");
...
1161 nr_hash = (1UL << order) * PAGE_SIZE / sizeof(struct list_head);
1162 hash_bits = 0;
1163 do {
1164 hash_bits++;
1165 } while ((nr_hash >> hash_bits) != 0);
1166 hash_bits--;
...
1172 nr_hash = 1UL << hash_bits;
1173 hash_mask = nr_hash-1;
1174
1175 printk("Mount-cache hash table entries: %d (order: %ld, %ld bytes)\n", nr_hash,
order, (PAGE_SIZE << order));
...
1179 d = mount_hashtable;
1180 i = nr_hash;
1181 do {
1182 INIT_LIST_HEAD(d);
1183 d++;
1184 i--;
1185 } while (i);
..
1189 }
----------------------------------------------------------------------
Lines 11391144
The hash table array consists of a full page of memory.
Chapter 4 explains in detail how the routine __get_free_pages() works. In a nutshell, this routine returns a pointer to a memory area of size 2 order pages. In this case, we allocate one page to hold the hash table.
Lines 11611173
The next step is to determine the number of entries in the table. nr_hash is set to hold the order (power of two) number of list heads that can fit into the table. hash_bits is calculated as the number of bits needed to represent the highest power of two in nr_hash. Line 1172 then redefines nr_hash as being composed of the single leftmost bit. The bitmask can then be calculated from the new nr_hash value.
Lines 11791185
Finally, we initialize the hash table through a call to the INIT_LIST_HEAD macro, which takes in a pointer to the memory area where a new list head is to be initialized. We do this nr_hash times (or the number of entries that the table can hold).
Let's walk through an example: We assume a PAGE_SIZE of 4KB and a struct list_head of 8 bytes. Because order is equal to 0, the value of nr_hash becomes 500; that is, up to 500 list_head structs can fit in one 4KB table. The (1UL << order) becomes the number of pages that have been allocated. For example, if the order had been 1 (meaning we had requested 21 pages allocated to the hash table), 0000 0001 bit-shifted once to the left becomes 0000 0010 (or 2 in decimal notation). Next, we calculate the number of bits the hash key will need. Walking through each iteration of the loop, we get the following:
Beginning values are hash_bits = 0 and nr_hash = 500.
Iteration 1:
hash_bits = 1, and (500 >> 1) ! = 0 (0001 1111 0100 >> 1) = 0000 1111 1010
Iteration 2:
hash_bits = 2, and (500 >> 2) ! = 0 (0001 1111 1010 >> 2) = 0000 0111 1110
Iteration3:
hash_bits = 3, and (500 >> 3) ! = 0 (0001 1111 1010 >> 3) = 0000 0011 1111
Iteration 4:
hash_bits = 4, and (500 >> 4) ! = 0 (0001 1111 1010 >> 4) = 0000 0001 1111
Iteration 5:
hash_bits = 5, and (500 >> 5) ! = 0 (0001 1111 1010 >> 5) = 0000 0000 1111
Iteration 6:
hash_bits = 6, and (500 >> 6) ! = 0 (0001 1111 1010 >> 6) = 0000 0000 0111
Iteration 7:
hash_bits = 7, and (500 >> 7) ! = 0 (0001 1111 1010 >> 7) = 0000 0000 0011
Iteration 8:
hash_bits = 8, and (500 >> 8) ! = 0 (0001 1111 1010 >> 8) = 0000 0000 0001
Iteration 9:
hash_bits = 9, and (500 >> 9) ! = 0 (0001 1111 1010 >> 9) = 0000 0000 0000
After breaking out of the while loop, hash_bits is decremented to 8, nr_hash is set to 0001 0000 0000, and the hash_mask is set to 0000 1111 1111.
After the mnt_init() routine initializes mount_hashtable and creates mnt_cache, it issues three calls:
----------------------------------------------------------------------
fs/namespace.c
...
1189 sysfs_init();
1190 init_rootfs();
1191 init_mount_tree();
1192 }
----------------------------------------------------------------------
sysfs_init() is responsible for the creation of the sysfs filesystem. init_rootfs() and init_mount_tree() are together responsible for mounting the root filesystem. We closely look at each routine in turn.
----------------------------------------------------------------------
init_rootfs()
fs/ramfs/inode.c
218 static struct file_system_type rootfs_fs_type = {
219 .name = "rootfs",
220 .get_sb = rootfs_get_sb,
221 .kill_sb = kill_litter_super,
222 };
...
237 int __init init_rootfs(void)
238 {
239 return register_filesystem(&rootfs_fs_type);
240 }
----------------------------------------------------------------------
The rootfs filesystem is an initial filesystem the kernel mounts. It is a simple and quite empty directory that becomes overmounted by the real filesystem at a later point in the kernel boot-up process.
Lines 218222
This code block is the declaration of the rootfs_fs_type file_system_type struct. Only the two methods for getting and killing the associated superblock are defined.
Lines 237240
The init_rootfs() routine merely register this rootfs with the kernel. This makes available all the information regarding the type of filesystem (information stored in the file_system_type struct) within the kernel.
----------------------------------------------------------------------
init_mount_tree()
fs/namespace.c
1107 static void __init init_mount_tree(void)
1108 {
1109 struct vfsmount *mnt;
1110 struct namespace *namespace;
1111 struct task_struct *g, *p;
1112
1113 mnt = do_kern_mount("rootfs", 0, "rootfs", NULL);
1114 if (IS_ERR(mnt))
1115 panic("Can't create rootfs");
1116 namespace = kmalloc(sizeof(*namespace), GFP_KERNEL);
1117 if (!namespace)
1118 panic("Can't allocate initial namespace");
1119 atomic_set(&namespace->count, 1);
1120 INIT_LIST_HEAD(&namespace->list);
1121 init_rwsem(&namespace->sem);
1122 list_add(&mnt->mnt_list, &namespace->list);
1123 namespace->root = mnt;
1124
1125 init_task.namespace = namespace;
1126 read_lock(&tasklist_lock);
1127 do_each_thread(g, p) {
1128 get_namespace(namespace);
1129 p->namespace = namespace;
1130 } while_each_thread(g, p);
1131 read_unlock(&tasklist_lock);
1132
1133 set_fs_pwd(current->fs, namespace->root,
namespace->root->mnt_root);
1134 set_fs_root(current->fs, namespace->root,
namespace->root->mnt_root);
1135 }
-----------------------------------------------------------------------
Lines 11161123
Initialize the process namespace. This structure keeps pointers to the mount tree-related structures and the corresponding dentry. The namespace object is allocated, the count set to 1, the list field of type list_head is initialized, the semaphore that locks the namespace (and the mount tree) is initialized, and the root field corresponding to the vfsmount structure is set to point to our newly allocated vfsmount.
Line 1125
The current task's (the init task's) process descriptor namespace field is set to point at the namespace object we just allocated and initialized. (The current process is Process 0.)
Lines 11341135
The following two routines set the values of four fields in the fs_struct associated with our process. fs_struct holds field for the root and current working directory entries set by these two routines.
We just finished exploring what happens in the mnt_init function. Let's continue exploring vfs_mnt_init.
----------------------------------------------------------------------
1641 bdev_cache_init()
fs/block_dev.c
290 void __init bdev_cache_init(void)
291 {
292 int err;
293 bdev_cachep = kmem_cache_create("bdev_cache",
294 sizeof(struct bdev_inode),
295 0,
296 SLAB_HWCACHE_ALIGN|SLAB_RECLAIM_ACCOUNT,
297 init_once,
298 NULL);
299 if (!bdev_cachep)
300 panic("Cannot create bdev_cache SLAB cache");
301 err = register_filesystem(&bd_type);
302 if (err)
303 panic("Cannot register bdev pseudo-fs");
304 bd_mnt = kern_mount(&bd_type);
305 err = PTR_ERR(bd_mnt);
306 if (IS_ERR(bd_mnt))
307 panic("Cannot create bdev pseudo-fs");
308 blockdev_superblock = bd_mnt->mnt_sb; /* For writeback */
309 }
----------------------------------------------------------------------
Lines 293298
Create the bdev_cache SLAB cache, which holds bdev_inodes.
Line 301
Register the bdev special filesystem. It has been defined as follows:
----------------------------------------------------------------------
fs/block_dev.c
294 static struct file_system_type bd_type = {
295 .name = "bdev",
296 .get_sb = bd_get_sb,
297 .kill_sb = kill_anon_super,
298 };
----------------------------------------------------------------------
As you can see, the file_system_type struct of the bdev special filesystem has only two routines defined: one for fetching the filesystem's superblock and the other for removing/freeing the superblock. At this point, you might wonder why block devices are registered as filesystems. In
Chapter 6, we saw that systems that are not technically filesystems can use filesystem kernel structures; that is, they do not have mount points but can make use of the VFS kernel structures that support filesystems. Block devices are one instance of a pseudo filesystem that makes use of the VFS filesystem kernel structures. As with bdev, these special filesystems generally define only a limited number of fields because not all of them make sense for the particular application.
Lines 304308
The call to kern_mount() sets up all the mount-related VFS structures and returns the vfsmount structure. (See
Chapter 6 for more information on setting the global variables bd_mnt to point to the vfsmount structure and blockdev_superblock to point to the vfsmount superblock.)
This function initializes the character device objects that surround the driver model:
----------------------------------------------------------------------
1642 chrdev_init
fs/char_dev.c
void __init chrdev_init(void)
{
433 subsystem_init(&cdev_subsys);
434 cdev_map = kobj_map_init(base_probe, &cdev_subsys);
435 }
----------------------------------------------------------------------
8.5.27. The Call to radix_tree_init()
Line 476
The 2.6 Linux kernel uses a radix tree to manage pages within the page cache. Here, we simply initialize a contiguous section of kernel space for storing the page cache radix tree:
----------------------------------------------------------------------
lib/radix-tree.c
798 void __init radix_tree_init(void)
799 {
800 radix_tree_node_cachep = kmem_cache_create("radix_tree_node",
801 sizeof(struct radix_tree_node), 0,
802 SLAB_PANIC, radix_tree_node_ctor, NULL);
803 radix_tree_init_maxindex();
804 hotcpu_notifier(radix_tree_callback, 0);
-----------------------------------------------------------------------
----------------------------------------------------------------------
lib/radix-tree.c
768 static __init void radix_tree_init_maxindex(void)
769 {
770 unsigned int i;
771
772 for (i = 0; i < ARRAY_SIZE(height_to_maxindex); i++)
773 height_to_maxindex[i] = __maxindex(i);
774 }
-----------------------------------------------------------------------
Notice how radix_tree_init() allocates the page cache space and radix_tree_init_maxindex() configures the radix tree data store, height_to_maxindex[].
hotcpu_notifier() (on line 804) refers to Linux 2.6's capability to hotswap CPUs. When a CPU is hotswapped, the kernel calls radix_tree_callback(), which attempts to cleanly free the parts of the page cache that were linked to the hotswapped CPU.
8.5.28. The Call to signals_init()
Line 477
The signals_init() function in kernel/signal.c initializes the kernel signal queue:
----------------------------------------------------------------------
fs/buffer.c
2565 void __init signals_init(void)
2566 {
2567 sigqueue_cachep =
2568 kmem_cache_create("sigqueue",
2569 sizeof(struct sigqueue),
2570 __alignof__(struct sigqueue),
2571 0, NULL, NULL);
2572 if (!sigqueue_cachep)
2573 panic("signals_init(): cannot create sigqueue SLAB cache");
2574 }
-----------------------------------------------------------------------
Lines 25672571
Allocate SLAB memory for sigqueue.
8.5.29. The Call to page_writeback_init()
Line 479
The page_writeback_init() function initializes the values controlling when a dirty page is written back to disk. Dirty pages are not immediately written back to disk; they are written after a certain amount of time passes or a certain number or percent of the pages in memory are marked as dirty. This init function attempts to determine the optimum number of pages that must be dirty before triggering a background write and a dedicated write. Background dirty-page writes take up much less processing power than dedicated dirty-page writes:
----------------------------------------------------------------------
mm/page-writeback.c
488 /*
489 * If the machine has a large highmem:lowmem ratio then scale back the default
490 * dirty memory thresholds: allowing too much dirty highmem pins an excessive
491 * number of buffer_heads.
492 */
493 void __init page_writeback_init(void)
494 {
495 long buffer_pages = nr_free_buffer_pages();
496 long correction;
497
498 total_pages = nr_free_pagecache_pages();
499
500 correction = (100 * 4 * buffer_pages) / total_pages;
501
502 if (correction < 100) {
503 dirty_background_ratio *= correction;
504 dirty_background_ratio /= 100;
505 vm_dirty_ratio *= correction;
506 vm_dirty_ratio /= 100;
507 }
508 mod_timer(&wb_timer, jiffies + (dirty_writeback_centisecs * HZ) / 100);
509 set_ratelimit();
510 register_cpu_notifier(&ratelimit_nb);
511 }
-----------------------------------------------------------------------
Lines 495507
If we are operating on a machine with a large page cache compared to the number of buffer pages, we lower the dirty-page writeback thresholds. If we choose not to lower the threshold, which raises the frequency of writebacks, at each writeback, we would use an inordinate amount of buffer_heads. (This is the meaning of the comment before page_writeback().)
The default background writeback, dirty_background_ratio, starts when 10 percent of the pages are dirty. A dedicated writeback, vm_dirty_ratio, starts when 40 percent of the pages are dirty.
Line 508
We modify the writeback timer, wb_timer, to be triggered periodically (every 5 seconds by default).
Line 509
set_ratelimit() is called, which is documented excellently. I defer to these inline comments:
----------------------------------------------------------------------
mm/page-writeback.c
450 /*
451 * If ratelimit_pages is too high then we can get into dirty-data overload
452 * if a large number of processes all perform writes at the same time.
453 * If it is too low then SMP machines will call the (expensive)
454 * get_writeback_state too often.
455 *
456 * Here we set ratelimit_pages to a level which ensures that when all CPUs are
457 * dirtying in parallel, we cannot go more than 3% (1/32) over the dirty memory
458 * thresholds before writeback cuts in.
459 *
460 * But the limit should not be set too high. Because it also controls the
461 * amount of memory which the balance_dirty_pages() caller has to write back.
462 * If this is too large then the caller will block on the IO queue all the
463 * time. So limit it to four megabytes - the balance_dirty_pages() caller
464 * will write six megabyte chunks, max.
465 */
466
467 static void set_ratelimit(void)
468 {
469 ratelimit_pages = total_pages / (num_online_cpus() * 32);
470 if (ratelimit_pages < 16)
471 ratelimit_pages = 16;
472 if (ratelimit_pages * PAGE_CACHE_SIZE > 4096 * 1024)
473 ratelimit_pages = (4096 * 1024) / PAGE_CACHE_SIZE;
474 }
-----------------------------------------------------------------------
Line 510
The final command of page_writeback_init() registers the ratelimit notifier block, ratelimit_nb, with the CPU notifier. The ratelimit notifier block calls ratelimit_handler() when notified, which in turn, calls set_ratelimit(). The purpose of this is to recalculate ratelimit_pages when the number of online CPUs changes:
----------------------------------------------------------------------
mm/page-writeback.c
483 static struct notifier_block ratelimit_nb = {
484 .notifier_call = ratelimit_handler,
485 .next = NULL,
486 };
-----------------------------------------------------------------------
Finally, we need to examine what happens when the wb_timer (from Line 508) goes off and calls wb_time_fn():
----------------------------------------------------------------------
mm/page-writeback.c
414 static void wb_timer_fn(unsigned long unused)
415 {
416 if (pdflush_operation(wb_kupdate, 0) < 0)
417 mod_timer(&wb_timer, jiffies + HZ); /* delay 1 second */
418 }
-----------------------------------------------------------------------
Lines 416417
When the timer goes off, the kernel triggers pdflush_operation(), which awakens one of the pdflush threads to perform the actual writeback of dirty pages to disk. If pdflush_operation() cannot awaken any pdflush thread, it tells the writeback timer to trigger again in 1 second to retry awakening a pdflush tHRead. See Chapter 9, "Building the Linux Kernel," for more information on pdflush.
8.5.30. The Call to proc_root_init()
Lines 480482
As
Chapter 2 explained, the CONFIG_* #define refers to a compile-time variable. If, at compile time, the proc filesystem is selected, the next step in initialization is the call to proc_root_init():
----------------------------------------------------------------------
fs/proc/root.c
40 void __init proc_root_init(void)
41 {
42 int err = proc_init_inodecache();
43 if (err)
44 return;
45 err = register_filesystem(&proc_fs_type);
46 if (err)
47 return;
48 proc_mnt = kern_mount(&proc_fs_type);
49 err = PTR_ERR(proc_mnt);
50 if (IS_ERR(proc_mnt)) {
51 unregister_filesystem(&proc_fs_type);
52 return;
53 }
54 proc_misc_init();
55 proc_net = proc_mkdir("net", 0);
56 #ifdef CONFIG_SYSVIPC
57 proc_mkdir("sysvipc", 0);
58 #endif
59 #ifdef CONFIG_SYSCTL
60 proc_sys_root = proc_mkdir("sys", 0);
61 #endif
62 #if defined(CONFIG_BINFMT_MISC) || defined(CONFIG_BINFMT_MISC_MODULE)
63 proc_mkdir("sys/fs", 0);
64 proc_mkdir("sys/fs/binfmt_misc", 0);
65 #endif
66 proc_root_fs = proc_mkdir("fs", 0);
67 proc_root_driver = proc_mkdir("driver", 0);
68 proc_mkdir("fs/nfsd", 0); /* somewhere for the nfsd filesystem to be mounted */
69 #if defined(CONFIG_SUN_OPENPROMFS) || defined(CONFIG_SUN_OPENPROMFS_MODULE)
70 /* just give it a mountpoint */
71 proc_mkdir("openprom", 0);
72 #endif
73 proc_tty_init();
74 #ifdef CONFIG_PROC_DEVICETREE
75 proc_device_tree_init();
76 #endif
77 proc_bus = proc_mkdir("bus", 0);
78 }
-----------------------------------------------------------------------
Line 42
This line initializes the inode cache that holds the inodes for this filesystem.
Line 45
The file_system_type structure proc_fs_type is registered with the kernel. Let's closely look at the structure:
----------------------------------------------------------------------
fs/proc/root.c
33 static struct file_system_type proc_fs_type = {
34 .name = "proc",
35 .get_sb = proc_get_sb,
36 .kill_sb = kill_anon_super,
37 };
----------------------------------------------------------------------
The file_system_type structure, which defines the filesystem's name simply as proc, has the routines for retrieving and freeing the superblock structures.
Line 48
We mount the proc filesystem. See the sidebar on kern_mount for more details as to what happens here.
Lines 5478
The call to proc_misc_init() is what creates most of the entries you see in the /proc filesystem. It creates entries with calls to create_proc_read_entry(), create_proc_entry(), and create_proc_seq_entry(). The remainder of the code block consists of calls to proc_mkdir for the creation of directories under /proc/, the call to the proc_tty_init() routine to create the tree under /proc/tty, and, if the config time value of CONFIG_PROC_DEVICETREE is set, then the call to the proc_device_tree_init() routine to create the /proc/device-tree subtree.
8.5.31. The Call to init_idle()
Line 490
init_idle() is called near the end of start_kernel() with parameters current and smp_processor_id() to prepare start_kernel() for rescheduling:
----------------------------------------------------------------------
kernel/sched.c
2643 void __init init_idle(task_t *idle, int cpu)
2644 {
2645 runqueue_t *idle_rq = cpu_rq(cpu), *rq = cpu_rq(task_cpu(idle));
2646 unsigned long flags;
2647
2648 local_irq_save(flags);
2649 double_rq_lock(idle_rq, rq);
2650
2651 idle_rq->curr = idle_rq->idle = idle;
2652 deactivate_task(idle, rq);
2653 idle->array = NULL;
2654 idle->prio = MAX_PRIO;
2655 idle->state = TASK_RUNNING;
2656 set_task_cpu(idle, cpu);
2657 double_rq_unlock(idle_rq, rq);
2658 set_tsk_need_resched(idle);
2659 local_irq_restore(flags);
2660
2661 /* Set the preempt count _outside_ the spinlocks! */
2662 #ifdef CONFIG_PREEMPT
2663 idle->thread_info->preempt_count = (idle->lock_depth >= 0);
2664 #else
2665 idle->thread_info->preempt_count = 0;
2666 #endif
2667 }
-----------------------------------------------------------------------
Line 2645
We store the CPU request queue of the CPU that we're on and the CPU request queue of the CPU that the given task idle is on. In our case, with current and smp_processor_id(), these request queues will be equal.
Line 26482649
We save the IRQ flags and obtain the lock on both request queues.
Line 2651
We set the current task of the CPU request queue of the CPU that we're on to the task idle.
Lines 26522656
These statements remove the task idle from its request queue and move it to the CPU request queue of cpu.
Lines 26572659
We release the request queue locks on the run queues that we previously locked. Then, we mark task idle for rescheduling and restore the IRQs that we previously saved. We finally set the preemption counter if kernel preemption is configured.
8.5.32. The Call to rest_init()
Line 493
The rest_init() routine is fairly straightforward. It essentially creates what we call the init thread, removes the initialization kernel lock, and calls the idle tHRead:
----------------------------------------------------------------------
init/main.c
388 static void noinline rest_init(void)
389 {
390 kernel_thread(init, NULL, CLONE_FS | CLONE_SIGHAND);
391 unlock_kernel();
392 cpu_idle();
393 }
-----------------------------------------------------------------------
Line 388
You might have noticed that this is the first routine start_kernel() calls that is not __init. If you recall from
Chapter 2, we said that when a function is preceded by __init, it is because all the memory used to maintain the function variables and the like will be memory that is cleared/freed once initialization nears completion. This is done through a call to free_initmem(), which we see in a moment when we explore what happens in init(). The reason why rest_init() is not an __init function is because it calls the init thread before its completion (meaning the call to cpu_idle). Because the init tHRead executes the call to free_initmem(), there is the possibility of a race condition occurring whereby free_initmem() is called before rest_init() (or the root thread) is finished.
Line 390
This line is the creation of the init thread, which is also referred to as the init process or process 1. For brevity, all we say here is that this thread shares all kernel data structures with the calling process. The kernel thread calls the init() functions, which we look at in the next section.
Line 391
The unlock_kernel() routine does nothing if only a single processor exists. Otherwise, it releases the BKL.
Line 392
The call to cpu_idle() is what turns the root thread into the idle thread. This routine yields the processor to the scheduler and is returned to when the scheduler has no other pending process to run.
At this point, we have completed the bulk of the Linux kernel initialization. We now briefly look at what happens in the call to init().
| 
 LINUX
LINUX 
 Books
Books