Системные вызовы
Ядро имеет набор интерфейсов , с помощью которых процессы , выполняемые в user-space ,
могут взаимодействовать с системой.
Эти интерфейсы предоставляют доступ к железу и другим ресурсам.
Интерфейс - это что-то вроде мессенджера между приложением и ядром.
Наличие таких интерфейсов гарантирует стабильность системы.
Системный вызов - этой прослойка между железом и процессом пользователя.
Он выполняет 3 задачи.
Первая - он абстрагирует слой железа для пользователя.Например , когда происходит чтение-запись в файл,
приложение не интересует , какой тип у диска или файловой системы.
Второе - системный вызов обеспечивает стабильность и защиту системы.
Третье - обеспечивается виртуальное управление процессами.
Системный вызов - это точечный вход в ядро , и ничего более.
APIs, POSIX, C Library
Обычно в приложениях используется прослойка Application Programming Interface (API),
а не прямые системные вызовы.
API определяет набор программнычх интерфейсов.
Эти интерфейсы могут быть реализованы с помощью одного системного вызова ,
нескольких системных вызовов , или вообще без оных.
Наиболее простые интерфейсы реализованы в юниксе на базе POSIX.
POSIX - прекрасный образец связи между API и системными вызовами.
В большинстве юниксов POSIX API строго коррелированы с соответствующими системными вызовами.
Даже винда и та предпочитает POSIX-совместимые библиотеки.
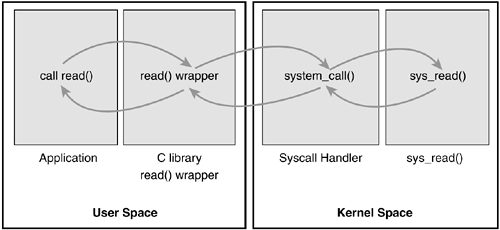
Интерфейс системных вызовов в линуксе реализован с помощью C library.
Эту библиотеку используют все си-шные программисты.
К ней легко приделать враппер из других языков.

С точки зрения программиста , системные вызовы прозрачны ,
поскольку они имеют дело с API.
С точки зрения ядра , оно имеет дело с системными вызовами ,
и до библиотек ядру нет никакого дела.
Реализация системных вызовов сделана в юниксе в т.н. стиле "provide mechanism, not policy."
Другими словами, системные вызовы в юниксе существуют для поддержки узко-специфичных функций,
используемых в широком диапазоне.
Syscalls
System calls (often called syscalls in Linux) are typically accessed via function calls. They can define one or more arguments (inputs) and might result in one or more side effects, for example writing to a file or copying some data into a provided pointer. System calls also provide a return value of type long that signifies success or error. Usually, although not always, a negative return value denotes an error. A return value of zero is usually (but again not always) a sign of success. Unix system calls, on error, write a special error code into the global errno variable. This variable can be translated into human-readable errors via library functions such as perror().
Finally, system calls have a defined behavior. For example, the system call getpid() is defined to return an integer that is the current process's PID. The implementation of this syscall in the kernel is very simple:
asmlinkage long sys_getpid(void)
{
return current->tgid;
}
Note that the definition says nothing of the implementation. The kernel must provide the intended behavior of the system call, but is free to do so with whatever implementation it desires as long as the result is correct. Of course, this system call is as simple as they come and there are not too many other ways to implement it (certainly no simpler method exists).
You can make a couple of observations about system calls even from this simple example. First, note the asmlinkage modifier on the function definition. This is a bit of magic to tell the compiler to look only on the stack for this function's arguments. This is a required modifier for all system calls. Second, note that the getpid() system call is defined as sys_getpid() in the kernel. This is the naming convention taken with all system calls in Linux: System call bar() is implemented in the kernel as function sys_bar().
System Call Numbers
In Linux, each system call is assigned a syscall number. This is a unique number that is used to reference a specific system call. When a user-space process executes a system call, the syscall number delineates which syscall was executed; the process does not refer to the syscall by name.
The syscall number is important; when assigned, it cannot change, or else compiled applications will break. Likewise, if a system call is removed, its system call number cannot be recycled, or else previous compiled code would invoke the system call but in reality call another. Linux provides a "not implemented" system call, sys_ni_syscall(), which does nothing except return -ENOSYS, the error corresponding to an invalid system call. This function is used to "plug the hole" in the rare event that a syscall is removed or otherwise made unavailable.
The kernel keeps a list of all registered system calls in the system call table, stored in sys_call_table. This table is architecture dependent and typically defined in enTRy.S, which for x86 is in arch/i386/kernel/. This table assigns each valid syscall to a unique syscall number.
System Call Performance
System calls in Linux are faster than in many other operating systems. This is partly because of Linux's incredibly fast context switch times; entering and exiting the kernel is a streamlined and simple affair. The other factor is the simplicity of the system call handler and the individual system calls themselves.
System Call Handler
It is not possible for user-space applications to execute kernel code directly. They cannot simply make a function call to a method existing in kernel-space because the kernel exists in a protected memory space. If applications could directly read and write to the kernel's address space, system security and stability would go out the window.
Instead, user-space applications must somehow signal the kernel that they want to execute a system call and have the system switch to kernel mode, where the system call can be executed in kernel-space by the kernel on behalf of the application.
The mechanism to signal the kernel is a software interrupt: Incur an exception and then the system will switch to kernel mode and execute the exception handler. The exception handler, in this case, is actually the system call handler. The defined software interrupt on x86 is the int $0x80 instruction. It triggers a switch to kernel mode and the execution of exception vector 128, which is the system call handler. The system call handler is the aptly named function system_call(). It is architecture dependent and typically implemented in assembly in entry.S. Recently, x86 processors added a feature known as sysenter. This feature provides a faster, more specialized way of trapping into a kernel to execute a system call than using the int interrupt instruction. Support for this feature was quickly added to the kernel. Regardless of how the system call handler is invoked, however, the important notion is that somehow user-space causes an exception or trap to enter the kernel.
Denoting the Correct System Call
Simply entering kernel-space alone is not sufficient because there are multiple system calls, all of which enter the kernel in the same manner. Thus, the system call number must be passed into the kernel. On x86, the syscall number is fed to the kernel via the eax register. Before causing the trap into the kernel, user-space sticks in eax the number corresponding to the desired system call. The system call handler then reads the value from eax. Other architectures do something similar.
The system_call() function checks the validity of the given system call number by comparing it to NR_syscalls. If it is larger than or equal to NR_syscalls, the function returns -ENOSYS. Otherwise, the specified system call is invoked:
call *sys_call_table(,%eax,4)
Because each element in the system call table is 32 bits (four bytes), the kernel multiplies the given system call number by four to arrive at its location in the system call table. See Figure 5.2.
Parameter Passing
In addition to the system call number, most syscalls require that one or more parameters be passed to them. Somehow, user-space must relay the parameters to the kernel during the trap. The easiest way to do this is via the same means that the syscall number is passed: The parameters are stored in registers. On x86, the registers ebx, ecx, edx, esi, and edi contain, in order, the first five arguments. In the unlikely case of six or more arguments, a single register is used to hold a pointer to user-space where all the parameters are stored.
The return value is sent to user-space also via register. On x86, it is written into the eax register.
System Call Implementation
The actual implementation of a system call in Linux does not need to concern itself with the behavior of the system call handler. Thus, adding a new system call to Linux is relatively easy. The hard work lies in designing and implementing the system call; registering it with the kernel is simple. Let's look at the steps involved in writing a new system call for Linux.
The first step in implementing a system call is defining its purpose. What will it do? The syscall should have exactly one purpose. Multiplexing syscalls (a single system call that does wildly different things depending on a flag argument) is discouraged in Linux. Look at ioctl() as an example of what not to do.
What are the new system call's arguments, return value, and error codes? The system call should have a clean and simple interface with the smallest number of arguments possible. The semantics and behavior of a system call are important; they must not change, because existing applications will come to rely on them.
Designing the interface with an eye toward the future is important. Are you needlessly limiting the function? Design the system call to be as general as possible. Do not assume its use today will be the same as its use tomorrow. The purpose of the system call will remain constant but its uses may change. Is the system call portable? Do not make assumptions about an architecture's word size or endianness. Chapter 19, "Portability," discusses these issues. Make sure you are not making poor assumptions that will break the system call in the future. Remember the Unix motto: "provide mechanism, not policy."
When you write a system call, it is important to realize the need for portability and robustness, not just today but in the future. The basic Unix system calls have survived this test of time; most of them are just as useful and applicable today as they were thirty years ago!
Verifying the Parameters
System calls must carefully verify all their parameters to ensure that they are valid and legal. The system call runs in kernel-space, and if the user is able to pass invalid input into the kernel without restraint, the system's security and stability can suffer.
For example, file I/O syscalls must check whether the file descriptor is valid. Process-related functions must check whether the provided PID is valid. Every parameter must be checked to ensure it is not just valid and legal, but correct.
One of the most important checks is the validity of any pointers that the user provides. Imagine if a process could pass any pointer into the kernel, unchecked, with warts and all, even passing a pointer for which it did not have read access! Processes could then trick the kernel into copying data for which they did not have access permission, such as data belonging to another process. Before following a pointer into user-space, the system must ensure that
The pointer points to a region of memory in user-space. Processes must not be able to trick the kernel into reading data in kernel-space on their behalf. The pointer points to a region of memory in the process's address space. The process must not be able to trick the kernel into reading someone else's data. If reading, the memory is marked readable. If writing, the memory is marked writable. The process must not be able to bypass memory access restrictions.
The kernel provides two methods for performing the requisite checks and the desired copy to and from user-space. Note kernel code must never blindly follow a pointer into user-space! One of these two methods must always be used.
For writing into user-space, the method copy_to_user() is provided. It takes three parameters. The first is the destination memory address in the process's address space. The second is the source pointer in kernel-space. Finally, the third argument is the size in bytes of the data to copy.
For reading from user-space, the method copy_from_user() is analogous to copy_to_user(). The function reads from the second parameter into the first parameter the number of bytes specified in the third parameter.
Both of these functions return the number of bytes they failed to copy on error. On success, they return zero. It is standard for the syscall to return -EFAULT in the case of such an error.
Let's consider an example system call that uses both copy_from_user() and copy_to_user(). This syscall, silly_copy(), is utterly worthless; it copies data from its first parameter into its second. This is highly suboptimal in that it involves the intermediate extraneous copy into kernel-space for absolutely no reason. But it helps illustrate the point.
/*
* silly_copy - utterly worthless syscall that copies the len bytes from
* 'src' to 'dst' using the kernel as an intermediary in the copy for no
* good reason. But it makes for a good example!
*/
asmlinkage long sys_silly_copy(unsigned long *src,
unsigned long *dst,
unsigned long len)
{
unsigned long buf;
/* fail if the kernel wordsize and user wordsize do not match */
if (len != sizeof(buf))
return -EINVAL;
/* copy src, which is in the user's address space, into buf */
if (copy_from_user(&buf, src, len))
return -EFAULT;
/* copy buf into dst, which is in the user's address space */
if (copy_to_user(dst, &buf, len))
return -EFAULT;
/* return amount of data copied */
return len;
}
Both copy_to_user() and copy_from_user() may block. This occurs, for example, if the page containing the user data is not in physical memory but swapped to disk. In that case, the process sleeps until the page fault handler can bring the page from the swap file on disk into physical memory.
A final possible check is for valid permission. In older versions of Linux, it was standard for syscalls that require root privilege to use suser(). This function merely checked whether a user was root or not; this is now removed and a finer-grained "capabilities" system is in place. The new system allows specific access checks on specific resources. A call to capable() with a valid capabilities flag returns nonzero if the caller holds the specified capability and zero otherwise. For example, capable(CAP_SYS_NICE) checks whether the caller has the ability to modify nice values of other processes. By default, the superuser possesses all capabilities and non-root possesses none. Here is another worthless system call, this one demonstrating capabilities:
asmlinkage long sys_am_i_popular (void)
{
/* check whether the user possesses the CAP_SYS_NICE capability */
if (!capable(CAP_SYS_NICE))
return EPERM;
/* return zero for success */
return 0;
}
System Call Context
As discussed in Chapter 3, "Process Management," the kernel is in process context during the execution of a system call. The current pointer points to the current task, which is the process that issued the syscall.
In process context, the kernel is capable of sleeping (for example, if the system call blocks on a call or explicitly calls schedule()) and is fully preemptible. These two points are important. First, the capability to sleep means that system calls can make use of the majority of the kernel's functionality. As we will see in Chapter 6, "Interrupts and Interrupt Handlers," the capability to sleep greatly simplifies kernel programming. The fact that process context is preemptible implies that, like user-space, the current task may be preempted by another task. Because the new task may then execute the same system call, care must be exercised to ensure that system calls are reentrant. Of course, this is the same concern that symmetrical multiprocessing introduces. Protecting against reentrancy is covered in Chapter 8, "Kernel Synchronization Introduction," and Chapter 9, "Kernel Synchronization Methods."
When the system call returns, control continues in system_call(), which ultimately switches to user-space and continues the execution of the user process.
Final Steps in Binding a System Call
After the system call is written, it is trivial to register it as an official system call:
First, add an entry to the end of the system call table. This needs to be done for each architecture that supports the system call (which, for most calls, is all the architectures). The position of the syscall in the table, starting at zero, is its system call number. For example, the tenth entry in the list is assigned syscall number nine. For each architecture supported, the syscall number needs to be defined in <asm/unistd.h>. The syscall needs to be compiled into the kernel image (as opposed to compiled as a module). This can be as simple as putting the system call in a relevant file in kernel/, such as sys.c, which is home to miscellaneous system calls.
Let us look at these steps in more detail with a fictional system call, foo(). First, we want to add sys_foo() to the system call table. For most architectures, the table is located in enTRy.S and it looks like this:
ENTRY(sys_call_table)
.long sys_restart_syscall /* 0 */
.long sys_exit
.long sys_fork
.long sys_read
.long sys_write
.long sys_open /* 5 */
...
.long sys_mq_unlink
.long sys_mq_timedsend
.long sys_mq_timedreceive /* 280 */
.long sys_mq_notify
.long sys_mq_getsetattr
The new system call is then appended to the tail of this list:
.long sys_foo
Although it is not explicitly specified, the system call is then given the next subsequent syscall number. In this case, 283. For each architecture you wish to support, the system call must be added to the architecture's system call table. The system call need not receive the same syscall number under each architecture. The system call number is part of the architecture's unique ABI. Usually, you would want to make the system call available to each architecture. Note the convention of placing the number in a comment every five entries; this makes it easy to find out which syscall is assigned which number.
Next, the system call number is added to <asm/unistd.h>, which currently looks somewhat like this:
/*
* This file contains the system call numbers.
*/
#define __NR_restart_syscall 0
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5
...
#define __NR_mq_unlink 278
#define __NR_mq_timedsend 279
#define __NR_mq_timedreceive 280
#define __NR_mq_notify 281
#define __NR_mq_getsetattr 282
The following is then added to the end of the list:
#define __NR_foo 283
Finally, the actual foo() system call is implemented. Because the system call must be compiled into the core kernel image in all configurations, it is put in kernel/sys.c. You should put it wherever the function is most relevant; for example, if the function is related to scheduling, you could put it in kernel/sched.c.
#include <asm/thread_info.h>
/*
* sys_foo everyone's favorite system call.
*
* Returns the size of the per-process kernel stack.
*/
asmlinkage long sys_foo(void)
{
return THREAD_SIZE;
}
That is it! Seriously. Boot this kernel and user-space can invoke the foo() system call.
Accessing the System Call from User-Space
Generally, the C library provides support for system calls. User applications can pull in function prototypes from the standard headers and link with the C library to use your system call (or the library routine that in turn uses your syscall call). If you just wrote the system call, however, it is doubtful that glibc already supports it!
Thankfully, Linux provides a set of macros for wrapping access to system calls. It sets up the register contents and issues the trap instructions. These macros are named _syscalln(), where n is between zero and six. The number corresponds to the number of parameters passed into the syscall because the macro needs to know how many parameters to expect and, consequently, push into registers. For example, consider the system call open(), defined as
long open(const char *filename, int flags, int mode)
The syscall macro to use this system call without explicit library support would be
#define __NR_open 5
_syscall3(long, open, const char *, filename, int, flags, int, mode)
Then, the application can simply call open().
For each macro, there are 2+2xn parameters. The first parameter corresponds to the return type of the syscall. The second is the name of the system call. Next follows the type and name for each parameter in order of the system call. The __NR_open define is in <asm/unistd.h>; it is the system call number. The _syscall3 macro expands into a C function with inline assembly; the assembly performs the steps discussed in the previous section to push the system call number and parameters into the correct registers and issue the software interrupt to trap into the kernel. Placing this macro in an application is all that is required to use the open() system call.
Let's write the macro to use our splendid new foo() system call and then write some test code to show off our efforts.
#define __NR_foo 283
__syscall0(long, foo)
int main ()
{
long stack_size;
stack_size = foo ();
printf ("The kernel stack size is %ld\n", stack_size);
return 0;
}
Why Not to Implement a System Call
With luck, the previous sections have shown that it is easy to implement a new system call, but that in no way should encourage you to do so. Indeed, after my sterling effort to describe how system calls work and how to add new ones, I now suggest caution and unparalleled restraint in adding new syscalls. Often, much more viable alternatives to providing a new system call are available. Let's look at the pros, the cons, and the alternatives.
The pros of implementing a new interface as a syscall are as follows:
The cons:
You need a syscall number, which needs to be officially assigned to you during a developmental kernel series. After the system call is in a stable series kernel, it is written in stone. The interface cannot change without breaking user-space applications. Each architecture needs to separately register the system call and support it. System calls are not easily used from scripts and cannot be accessed directly from the filesystem. For simple exchanges of information, a system call is overkill.
The alternatives:
Implement a device node and read() and write() to it. Use ioctl() to manipulate specific settings or retrieve specific information. Certain interfaces, such as semaphores, can be represented as file descriptors and manipulated as such. Add the information as a file to the appropriate location in sysfs.
For many interfaces, system calls are the correct answer. Linux, however, has tried to avoid simply adding a system call to support each new abstraction that comes along. The result has been an incredibly clean system call layer with very few regrets or deprecations (interfaces no longer used or supported). The slow rate of addition of new system calls is a sign that Linux is a relatively stable and feature-complete operating system.
Chapter 6. Interrupts and Interrupt Handlers
A primary responsibility of the kernel is managing the hardware connected to the machine. As part of this work, the kernel needs to communicate with the machine's individual devices. Given that processors are typically magnitudes faster than the hardware they talk to, it is not ideal for the kernel to issue a request and wait for a response from the potentially slow hardware. Instead, because the hardware is comparatively slow to respond, the kernel must be free to go off, handle other work, and deal with the hardware only after it has actually completed its work. One solution to this problem is polling. Periodically, the kernel can check the status of the hardware in the system and respond accordingly. This incurs overhead, however, regardless of whether the hardware is even active or ready because the polling occurs repeatedly at regular intervals. A better solution is to provide a mechanism for the hardware to signal the kernel when attention is needed. The solution is interrupts.
Interrupts
Interrupts allow hardware to communicate with the processor. For example, as you type, the keyboard controller (the hardware device that manages the keyboard) issues an electrical signal to the processor to alert the operating system to newly available key presses. These electrical signals are interrupts. The processor receives the interrupt and signals the operating system to allow the OS to respond to the new data. Hardware devices generate interrupts asynchronously with respect to the processor clockthey can occur at any time. Consequently, the kernel can be interrupted at any time to process interrupts.
An interrupt is physically produced by electronic signals originating from hardware devices and directed into input pins on an interrupt controller. The interrupt controller, in turn, sends a signal to the processor. The processor detects this signal and interrupts its current execution to handle the interrupt. The processor can then notify the operating system that an interrupt has occurred, and the operating system can handle the interrupt appropriately.
Different devices can be associated with unique interrupts by means of a unique value associated with each interrupt. This way, interrupts from the keyboard are distinct from interrupts from the hard drive. This enables the operating system to differentiate between interrupts and to know which hardware device caused which interrupt. In turn, the operating system can service each interrupt with a unique handler.
These interrupt values are often called interrupt request (IRQ) lines. Typically, they are given a numeric valuefor example, on a PC, IRQ zero is the timer interrupt and IRQ one is the keyboard interrupt. Not all interrupt numbers, however, are so rigidly defined. Interrupts associated with devices on the PCI bus, for example, generally can be dynamically assigned. Other non-PC architectures have similar dynamic assignments for interrupt values. The important notion is that a specific interrupt is associated with a specific device, and the kernel knows this. The hardware then issues interrupts to get the kernel's attention: Hey, I have new key presses waiting; read and process these bad boys!
|
In OS texts, exceptions are often discussed at the same time as interrupts. Unlike interrupts, exceptions occur synchronously with respect to the processor clock. Indeed, they are often called synchronous interrupts . Exceptions are produced by the processor while executing instructions either in response to a programming error (for example, divide by zero) or abnormal conditions that must be handled by the kernel (for example, a page fault). Because many processor architectures handle exceptions in a similar manner to interrupts, the kernel infrastructure for handling the two is similar. Much of the discussion of interrupts (asynchronous interrupts generated by hardware) in this chapter also pertains to exceptions (synchronous interrupts generated by the processor itself).
You are already familiar with one exception: In the previous chapter, you saw how system calls on the x86 architecture are implemented by the issuance of a software interrupt, which traps into the kernel and causes execution of a special system call handler. Interrupts work in a similar way, you shall see, except hardwarenot softwareissues interrupts. |
Interrupt Handlers
The function the kernel runs in response to a specific interrupt is called an interrupt handler or interrupt service routine (ISR). Each device that generates interrupts has an associated interrupt handler. For example, one function handles interrupts from the system timer, while another function handles interrupts generated by the keyboard. The interrupt handler for a device is part of the device's driverthe kernel code that manages the device.
In Linux, interrupt handlers are normal C functions. They match a specific prototype, which enables the kernel to pass the handler information in a standard way, but otherwise they are ordinary functions. What differentiates interrupt handlers from other kernel functions is that the kernel invokes them in response to interrupts and that they run in a special context (discussed later in this chapter) called interrupt context.
Because an interrupt can occur at any time, an interrupt handler can in turn be executed at any time. It is imperative that the handler runs quickly, to resume execution of the interrupted code as soon as possible. Therefore, although it is important to the hardware that the interrupt is serviced immediately, it is important to the rest of the system that the interrupt handler execute in as short a period as possible.
At the very least, an interrupt handler's job is to acknowledge the interrupt's receipt to the hardware: Hey, hardware, I hear ya, now get back to work! Often, however, interrupt handlers have a large amount of work to perform. For example, consider the interrupt handler for a network device. On top of responding to the hardware, the interrupt handler needs to copy networking packets from the hardware into memory, process them, and push the packets down to the appropriate protocol stack or application. Obviously, this can be a lot of work, especially with today's gigabit and ten-gigabit Ethernet cards.
Top Halves Versus Bottom Halves
These two goalsthat an interrupt handler execute quickly and perform a large amount of workare plainly in contrast. Because of these conflicting goals, the processing of interrupts is split into two parts, or halves. The interrupt handler is the top half. It is run immediately upon receipt of the interrupt and performs only the work that is time critical, such as acknowledging receipt of the interrupt or resetting the hardware. Work that can be performed later is delayed until the bottom half. The bottom half runs in the future, at a more convenient time, with all interrupts enabled. Linux provides various mechanisms for implementing bottom halves, and they are all discussed in the next chapter, "
Bottom Halves and Deferring Work."
Let's look at an example of the top half/bottom half split, using our old friend, the network card. When network cards receive incoming packets off the network, they need to alert the kernel to their availability. They want and need to do this immediately, to optimize network throughput and latency and avoid timeouts. Thus, they immediately issue an interrupt: Hey, kernel, I have some fresh packets here! The kernel responds by executing the network card's registered interrupt.
The interrupt runs, acknowledges the hardware, copies the new networking packets into main memory, and readies the network card for more packets. These jobs are the important, time-critical, and hardware-specific work. The rest of the processing and handling of the packets occurs later, in the bottom half. In this chapter, we look at the top half; in the next, the bottom.
 |
Registering an Interrupt Handler
Interrupt handlers are the responsibility of the driver managing the hardware. Each device has one associated driver and, if that device uses interrupts (and most do), then that driver registers one interrupt handler.
Drivers can register an interrupt handler and enable a given interrupt line for handling via the function
/* request_irq: allocate a given interrupt line */
int request_irq(unsigned int irq,
irqreturn_t (*handler)(int, void *, struct pt_regs *),
unsigned long irqflags,
const char *devname,
void *dev_id)
The first parameter, irq, specifies the interrupt number to allocate. For some devices, for example legacy PC devices such as the system timer or keyboard, this value is typically hard-coded. For most other devices, it is probed or otherwise determined programmatically and dynamically.
The second parameter, handler, is a function pointer to the actual interrupt handler that services this interrupt. This function is invoked whenever the operating system receives the interrupt. Note the specific prototype of the handler function: It takes three parameters and has a return value of irqreturn_t. This function is discussed later in this chapter.
The third parameter, irqflags, might be either zero or a bit mask of one or more of the following flags:
SA_INTERRUPT
This flag specifies that the given interrupt handler is a fast interrupt handler. Historically, Linux differentiated between interrupt handlers that were fast versus slow. Fast handlers were assumed to execute quickly, but potentially very often, so the behavior of the interrupt handling was modified to enable them to execute as quickly as possible. Today, there is only one difference: Fast interrupt handlers run with all interrupts disabled on the local processor. This enables a fast handler to complete quickly, without possible interruption from other interrupts. By default (without this flag), all interrupts are enabled except the interrupt lines of any running handlers, which are masked out on all processors. Sans the timer interrupt, most interrupts do not want to enable this flag.
SA_SAMPLE_RANDOM
This flag specifies that interrupts generated by this device should contribute to the kernel entropy pool. The kernel entropy pool provides truly random numbers derived from various random events. If this flag is specified, the timing of interrupts from this device are fed to the pool as entropy. Do not set this if your device issues interrupts at a predictable rate (for example, the system timer) or can be influenced by external attackers (for example, a networking device). On the other hand, most other hardware generates interrupts at nondeterministic times and is, therefore, a good source of entropy. For more information on the kernel entropy pool, see
Appendix B, "Kernel Random Number Generator."
SA_SHIRQ
This flag specifies that the interrupt line can be shared among multiple interrupt handlers. Each handler registered on a given line must specify this flag; otherwise, only one handler can exist per line. More information on shared handlers is provided in a following section.
The fourth parameter, devname, is an ASCII text representation of the device associated with the interrupt. For example, this value for the keyboard interrupt on a PC is "keyboard". These text names are used by /proc/irq and /proc/interrupts for communication with the user, which is discussed shortly.
The fifth parameter, dev_id, is used primarily for shared interrupt lines. When an interrupt handler is freed (discussed later), dev_id provides a unique cookie to allow the removal of only the desired interrupt handler from the interrupt line. Without this parameter, it would be impossible for the kernel to know which handler to remove on a given interrupt line. You can pass NULL here if the line is not shared, but you must pass a unique cookie if your interrupt line is shared (and unless your device is old and crusty and lives on the ISA bus, there is good chance it must support sharing). This pointer is also passed into the interrupt handler on each invocation. A common practice is to pass the driver's device structure: This pointer is unique and might be useful to have within the handlers and the Device Model.
On success, request_irq() returns zero. A nonzero value indicates error, in which case the specified interrupt handler was not registered. A common error is -EBUSY, which denotes that the given interrupt line is already in use (and either the current user or you did not specify SA_SHIRQ).
Note that request_irq() can sleep and therefore cannot be called from interrupt context or other situations where code cannot block. It is a common mistake to call request_irq() when it is unsafe to sleep. This is partly because of why request_irq() can sleep: It is indeed unclear. On registration, an entry corresponding to the interrupt is created in /proc/irq. The function proc_mkdir() is used to create new procfs entries. This function calls proc_create() to set up the new procfs entries, which in turn call kmalloc() to allocate memory. As you will see in
Chapter 11, "Memory Management," kmalloc() can sleep. So there you go!
Anyhow, enough of the nitty gritty. In a driver, requesting an interrupt line and installing a handler is done via request_irq():
if (request_irq(irqn, my_interrupt, SA_SHIRQ, "my_device", dev)) {
printk(KERN_ERR "my_device: cannot register IRQ %d\n", irqn);
return -EIO;
}
In this example, irqn is the requested interrupt line, my_interrupt is the handler, the line can be shared, the device is named "my_device," and we passed dev for dev_id. On failure, the code prints an error and returns. If the call returns zero, the handler has been successfully installed. From that point forward, the handler is invoked in response to an interrupt. It is important to initialize hardware and register an interrupt handler in the proper order to prevent the interrupt handler from running before the device is fully initialized.
Freeing an Interrupt Handler
When your driver unloads, you need to unregister your interrupt handler and potentially disable the interrupt line. To do this, call
void free_irq(unsigned int irq, void *dev_id)
If the specified interrupt line is not shared, this function removes the handler and disables the line. If the interrupt line is shared, the handler identified via dev_id is removed, but the interrupt line itself is disabled only when the last handler is removed. Now you can see why a unique dev_id is important. With shared interrupt lines, a unique cookie is required to differentiate between the multiple handlers that can exist on a single line and allow free_irq() to remove only the correct handler. In either case (shared or unshared), if dev_id is non-NULL, it must match the desired handler.
A call to free_irq() must be made from process context.
Writing an Interrupt Handler
The following is a typical declaration of an interrupt handler:
static irqreturn_t intr_handler(int irq, void *dev_id, struct pt_regs *regs)
Note that this declaration matches the prototype of the handler argument given to request_irq(). The first parameter, irq, is the numeric value of the interrupt line the handler is servicing. This is not entirely useful today, except perhaps in printing log messages. Before the 2.0 kernel, there was not a dev_id parameter and thus irq was used to differentiate between multiple devices using the same driver and therefore the same interrupt handler. As an example of this, consider a computer with multiple hard drive controllers of the same type.
The second parameter, dev_id, is a generic pointer to the same dev_id that was given to request_irq() when the interrupt handler was registered. If this value is unique (which is recommended to support sharing), it can act as a cookie to differentiate between multiple devices potentially using the same interrupt handler. dev_id might also point to a structure of use to the interrupt handler. Because the device structure is both unique to each device and potentially useful to have within the handler, it is typically passed for dev_id.
The final parameter, regs, holds a pointer to a structure containing the processor registers and state before servicing the interrupt. The parameter is rarely used, except for debugging. In fact, current developer interest has hinted that this parameter may not be around forever. Looking at the very small number of users of reg in existing interrupt handlers, few ought to miss it.
The return value of an interrupt handler is the special type irqreturn_t. An interrupt handler can return two special values, IRQ_NONE or IRQ_HANDLED. The former is returned when the interrupt handler detects an interrupt for which its device was not the originator. The latter is returned if the interrupt handler was correctly invoked, and its device did indeed cause the interrupt. Alternatively, IRQ_RETVAL(val) may be used. If val is non-zero, this macro returns IRQ_HANDLED. Otherwise, the macro returns IRQ_NONE. These special values are used to let the kernel know whether devices are issuing spurious (that is, unrequested) interrupts. If all the interrupt handlers on a given interrupt line return IRQ_NONE, then the kernel can detect the problem. Note the curious return type, irqreturn_t, which is simply an int. This value is used to provide backward compatibility with earlier kernels, which did not have this featurebefore 2.6, interrupt handlers returned void. Drivers may simply typedef irqreturn_t to void and define the different return vales to noops and then work in 2.4 without further modification.
The interrupt handler is normally marked static because it is never called directly from another file.
The role of the interrupt handler depends entirely on the device and its reasons for issuing the interrupt. At a minimum, most interrupt handlers need to provide acknowledgment to the device that they received the interrupt. Devices that are more complex need to additionally send and receive data and perform extended work in the interrupt handler. As mentioned, the extended work is pushed as much as possible into the bottom half handler, which is discussed in the next chapter.
|
Interrupt handlers in Linux need not be reentrant. When a given interrupt handler is executing, the corresponding interrupt line is masked out on all processors, preventing another interrupt on the same line from being received. Normally all other interrupts are enabled, so other interrupts are serviced, but the current line is always disabled. Consequently, the same interrupt handler is never invoked concurrently to service a nested interrupt. This greatly simplifies writing your interrupt handler. |
Shared Handlers
A shared handler is registered and executed much like a non-shared handler. There are three main differences:
The SA_SHIRQ flag must be set in the flags argument to request_irq(). The dev_id argument must be unique to each registered handler. A pointer to any per-device structure is sufficient; a common choice is the device structure as it is both unique and potentially useful to the handler. You cannot pass NULL for a shared handler! The interrupt handler must be capable of distinguishing whether its device actually generated an interrupt. This requires both hardware support and associated logic in the interrupt handler. If the hardware did not offer this capability, there would be no way for the interrupt handler to know whether its associated device or some other device sharing the line caused the interrupt.
All drivers sharing the interrupt line must meet the previous requirements. If any one device does not share fairly, none can share the line. When request_irq() is called with SA_SHIRQ specified, the call succeeds only if the interrupt line is currently not registered, or if all registered handlers on the line also specified SA_SHIRQ. Note that in 2.6, unlike the behavior in older kernels, shared handlers can mix usage of SA_INTERRUPT.
When the kernel receives an interrupt, it invokes sequentially each registered handler on the line. Therefore, it is important that the handler be capable of distinguishing whether it generated a given interrupt. The handler must quickly exit if its associated device did not generate the interrupt. This requires the hardware device to have a status register (or similar mechanism) that the handler can check. Most hardware does indeed have such a feature.
A Real-Life Interrupt Handler
Let's look at a real interrupt handler, from the RTC (real-time clock) driver, found in drivers/char/rtc.c. An RTC is found in many machines, including PCs. It is a device, separate from the system timer, which is used to set the system clock, provide an alarm, or supply a periodic timer. On most architectures, the system clock is set by writing the desired time into a specific register or I/O range. Any alarm or periodic timer functionality is normally implemented via interrupt. The interrupt is equivalent to a real-world clock alarm: The receipt of the interrupt is analogous to a buzzing alarm.
When the RTC driver loads, the function rtc_init() is invoked to initialize the driver. One of its duties is to register the interrupt handler:
/* register rtc_interrupt on RTC_IRQ */
if (request_irq(RTC_IRQ, rtc_interrupt, SA_INTERRUPT, "rtc", NULL) {
printk(KERN_ERR "rtc: cannot register IRQ %d\n", RTC_IRQ);
return -EIO;
}
Note in this example that the interrupt line is stored in RTC_IRQ. This is a preprocessor define that specifies the RTC interrupt for a given architecture. On the PC the RTC is always located at IRQ 8. The second parameter is the interrupt handler, rtc_interrupt, which runs with all interrupts disabled, thanks to the SA_INTERRUPT flag. From the fourth parameter, you can see that the driver name is "rtc." Because this device cannot share the interrupt line and the handler has no use for any special value, NULL is passed for dev_id.
Finally, the handler itself:
/*
* A very tiny interrupt handler. It runs with SA_INTERRUPT set,
* but there is a possibility of conflicting with the set_rtc_mmss()
* call (the rtc irq and the timer irq can easily run at the same
* time in two different CPUs). So we need to serialize
* accesses to the chip with the rtc_lock spinlock that each
* architecture should implement in the timer code.
* (See ./arch/XXXX/kernel/time.c for the set_rtc_mmss() function.)
*/
static irqreturn_t rtc_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
/*
* Can be an alarm interrupt, update complete interrupt,
* or a periodic interrupt. We store the status in the
* low byte and the number of interrupts received since
* the last read in the remainder of rtc_irq_data.
*/
spin_lock (&rtc_lock);
rtc_irq_data += 0x100;
rtc_irq_data &= ~0xff;
rtc_irq_data |= (CMOS_READ(RTC_INTR_FLAGS) & 0xF0);
if (rtc_status & RTC_TIMER_ON)
mod_timer(&rtc_irq_timer, jiffies + HZ/rtc_freq + 2*HZ/100);
spin_unlock (&rtc_lock);
/*
* Now do the rest of the actions
*/
spin_lock(&rtc_task_lock);
if (rtc_callback)
rtc_callback->func(rtc_callback->private_data);
spin_unlock(&rtc_task_lock);
wake_up_interruptible(&rtc_wait);
kill_fasync (&rtc_async_queue, SIGIO, POLL_IN);
return IRQ_HANDLED;
}
This function is invoked whenever the machine receives the RTC interrupt. First, note the spin lock calls: The first set ensures that rtc_irq_data is not accessed concurrently by another processor on an SMP machine, and the second set protects rtc_callback from the same. Locks are discussed in
Chapter 9, "Kernel Synchronization Methods."
The rtc_irq_data variable is an unsigned long that stores information about the RTC and is updated on each interrupt to reflect the status of the interrupt.
Next, if an RTC periodic timer is set, it is updated via mod_timer(). Timers are discussed in
Chapter 10, "Timers and Time Management."
The final bunch of code, wrapped with the second set of spin locks, executes a possible preset callback function. The RTC driver enables a callback function to be registered and executed on each RTC interrupt.
Finally, this function returns IRQ_HANDLED to signify that it properly handled this device. Because the interrupt handler does not support sharing, and there is no mechanism for the RTC to detect a spurious interrupt, this handler always returns IRQ_HANDLED.
Interrupt Context
When executing an interrupt handler or bottom half, the kernel is in interrupt context. Recall that process context is the mode of operation the kernel is in while it is executing on behalf of a processfor example, executing a system call or running a kernel thread. In process context, the current macro points to the associated task. Furthermore, because a process is coupled to the kernel in process context, process context can sleep or otherwise invoke the scheduler.
Interrupt context, on the other hand, is not associated with a process. The current macro is not relevant (although it points to the interrupted process). Without a backing process, interrupt context cannot sleephow would it ever reschedule? Therefore, you cannot call certain functions from interrupt context. If a function sleeps, you cannot use it from your interrupt handlerthis limits the functions that one can call from an interrupt handler.
Interrupt context is time critical because the interrupt handler interrupts other code. Code should be quick and simple. Busy looping is discouraged. This is a very important point; always keep in mind that your interrupt handler has interrupted other code (possibly even another interrupt handler on a different line!). Because of this asynchronous nature, it is imperative that all interrupt handlers be as quick and as simple as possible. As much as possible, work should be pushed out from the interrupt handler and performed in a bottom half, which runs at a more convenient time.
The setup of an interrupt handler's stacks is a configuration option. Historically, interrupt handlers did not receive their own stacks. Instead, they would share the stack of the process that they interrupted. The kernel stack is two pages in size; typically, that is 8KB on 32-bit architectures and 16KB on 64-bit architectures. Because in this setup interrupt handlers share the stack, they must be exceptionally frugal with what data they allocate there. Of course, the kernel stack is limited to begin with, so all kernel code should be cautious.
Early in the 2.6 kernel process, an option was added to reduce the stack size from two pages down to one, providing only a 4KB stack on 32-bit systems. This reduced memory pressure because every process on the system previously needed two pages of nonswappable kernel memory. To cope with the reduced stack size, interrupt handlers were given their own stack, one stack per processor, one page in size. This stack is referred to as the interrupt stack. Although the total size of the interrupt stack is half that of the original shared stack, the average stack space available is greater because interrupt handlers get the full page of memory to themselves.
Your interrupt handler should not care what stack setup is in use or what the size of the kernel stack is. Always use an absolute minimum amount of stack space.
Implementation of Interrupt Handling
Perhaps not surprising, the implementation of the interrupt handling system in Linux is very architecture dependent. The implementation depends on the processor, the type of interrupt controller used, and the design of the architecture and machine itself.
Figure 6.1 is a diagram of the path an interrupt takes through hardware and the kernel.
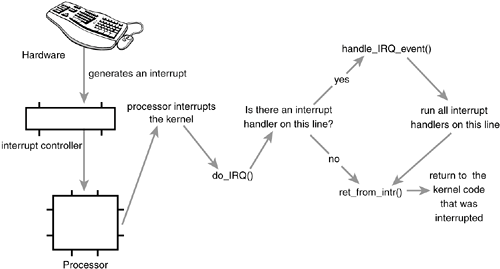
A device issues an interrupt by sending an electric signal over its bus to the interrupt controller. If the interrupt line is enabled (they can be masked out), the interrupt controller sends the interrupt to the processor. In most architectures, this is accomplished by an electrical signal that is sent over a special pin to the processor. Unless interrupts are disabled in the processor (which can also happen), the processor immediately stops what it is doing, disables the interrupt system, and jumps to a predefined location in memory and executes the code located there. This predefined point is set up by the kernel and is the entry point for interrupt handlers.
The interrupt's journey in the kernel begins at this predefined entry point, just as system calls enter the kernel through a predefined exception handler. For each interrupt line, the processor jumps to a unique location in memory and executes the code located there. In this manner, the kernel knows the IRQ number of the incoming interrupt. The initial entry point simply saves this value and stores the current register values (which belong to the interrupted task) on the stack; then the kernel calls do_IRQ(). From here onward, most of the interrupt handling code is written in Chowever, it is still architecture dependent.
The do_IRQ() function is declared as
unsigned int do_IRQ(struct pt_regs regs)
Because the C calling convention places function arguments at the top of the stack, the pt_regs structure contains the initial register values that were previously saved in the assembly entry routine. Because the interrupt value was also saved, do_IRQ() can extract it. The x86 code is
int irq = regs.orig_eax & 0xff;
After the interrupt line is calculated, do_IRQ() acknowledges the receipt of the interrupt and disables interrupt delivery on the line. On normal PC machines, these operations are handled by mask_and_ack_8259A(), which do_IRQ() calls.
Next, do_IRQ() ensures that a valid handler is registered on the line, and that it is enabled and not currently executing. If so, it calls handle_IRQ_event() to run the installed interrupt handlers for the line. On x86, handle_IRQ_event() is
asmlinkage int handle_IRQ_event(unsigned int irq, struct pt_regs *regs,
struct irqaction *action)
{
int status = 1;
int retval = 0;
if (!(action->flags & SA_INTERRUPT))
local_irq_enable();
do {
status |= action->flags;
retval |= action->handler(irq, action->dev_id, regs);
action = action->next;
} while (action);
if (status & SA_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
local_irq_disable();
return retval;
}
First, because the processor disabled interrupts, they are turned back on unless SA_INTERRUPT was specified during the handler's registration. Recall that SA_INTERRUPT specifies that the handler must be run with interrupts disabled. Next, each potential handler is executed in a loop. If this line is not shared, the loop terminates after the first iteration. Otherwise, all handlers are executed. After that, add_interrupt_randomness() is called if SA_SAMPLE_RANDOM was specified during registration. This function uses the timing of the interrupt to generate entropy for the random number generator.
Appendix B, "Kernel Random Number Generator," has more information on the kernel's random number generator. Finally, interrupts are again disabled (do_IRQ() expects them still to be off) and the function returns. Back in do_IRQ(), the function cleans up and returns to the initial entry point, which then jumps to ret_from_intr().
The routine ret_from_intr() is, as with the initial entry code, written in assembly. This routine checks whether a reschedule is pending (recall from
Chapter 4, "Process Scheduling," that this implies that need_resched is set). If a reschedule is pending, and the kernel is returning to user-space (that is, the interrupt interrupted a user process), schedule() is called. If the kernel is returning to kernel-space (that is, the interrupt interrupted the kernel itself), schedule() is called only if the preempt_count is zero (otherwise it is not safe to preempt the kernel). After schedule() returns, or if there is no work pending, the initial registers are restored and the kernel resumes whatever was interrupted.
On x86, the initial assembly routines are located in arch/i386/kernel/entry.S and the C methods are located in arch/i386/kernel/irq.c. Other supported architectures are similar.
/proc/interrupts
Procfs is a virtual filesystem that exists only in kernel memory and is typically mounted at /proc. Reading or writing files in procfs invokes kernel functions that simulate reading or writing from a real file. A relevant example is the /proc/interrupts file, which is populated with statistics related to interrupts on the system. Here is sample output from a uniprocessor PC:
CPU0
0: 3602371 XT-PIC timer
1: 3048 XT-PIC i8042
2: 0 XT-PIC cascade
4: 2689466 XT-PIC uhci-hcd, eth0
5: 0 XT-PIC EMU10K1
12: 85077 XT-PIC uhci-hcd
15: 24571 XT-PIC aic7xxx
NMI: 0
LOC: 3602236
ERR: 0
The first column is the interrupt line. On this system, interrupts numbered 02, 4, 5, 12, and 15 are present. Handlers are not installed on lines not displayed. The second column is a counter of the number of interrupts received. A column is present for each processor on the system, but this machine has only one processor. As you can see, the timer interrupt has received 3,602,371 interrupts, whereas the sound card (EMU10K1) has received none (which is an indication that it has not been used since the machine booted). The third column is the interrupt controller handling this interrupt. XT-PIC corresponds to the standard PC programmable interrupt controller. On systems with an I/O APIC, most interrupts would list IO-APIC-level or IO-APIC-edge as their interrupt controller. Finally, the last column is the device associated with this interrupt. This name is supplied by the devname parameter to request_irq(), as discussed previously. If the interrupt is shared, as is the case with interrupt number four in this example, all the devices registered on the interrupt line are listed.
For the curious, procfs code is located primarily in fs/proc. The function that provides /proc/interrupts is, not surprisingly, architecture dependent and named show_interrupts().
Interrupt Control
The Linux kernel implements a family of interfaces for manipulating the state of interrupts on a machine. These interfaces enable you to disable the interrupt system for the current processor or mask out an interrupt line for the entire machine. These routines are all very architecture dependent and can be found in <asm/system.h> and <asm/irq.g>. See
Table 6.2, later in this chapter, for a complete listing of the interfaces.
Table 6.2. Listing of Interrupt Control MethodsFunction | Description |
|---|
local_irq_disable() | Disable local interrupt delivery | local_irq_enable() | Enable local interrupt delivery | local_irq_save() | Save the current state of local interrupt delivery and then disable it | local_irq_restore() | Restore local interrupt delivery to the given state | disable_irq() | Disable the given interrupt line and ensure no handler on the line is executing before returning | disable_irq_nosync() | Disable the given interrupt line | enable_irq() | Enable the given interrupt line | irqs_disabled() | Returns nonzero if local interrupt delivery is disabled; otherwise returns zero | in_interrupt() | Returns nonzero if in interrupt context and zero if in process context | in_irq() | Returns nonzero if currently executing an interrupt handler and zero otherwise |
Reasons to control the interrupt system generally boil down to needing to provide synchronization. By disabling interrupts, you can guarantee that an interrupt handler will not preempt your current code. Moreover, disabling interrupts also disables kernel preemption. Neither disabling interrupt delivery nor disabling kernel preemption provides any protection from concurrent access from another processor, however. Because Linux supports multiple processors, kernel code more generally needs to obtain some sort of lock to prevent another processor from accessing shared data simultaneously. These locks are often obtained in conjunction with disabling local interrupts. The lock provides protection against concurrent access from another processor, whereas disabling interrupts provides protection against concurrent access from a possible interrupt handler.
Chapters 8 and 9 discuss the various problems of synchronization and their solutions. Nevertheless, understanding the kernel interrupt control interfaces is important.
Disabling and Enabling Interrupts
To disable interrupts locally for the current processor (and only the current processor) and then later reenable them, do the following
local_irq_disable();
/* interrupts are disabled .. */
local_irq_enable();
These functions are usually implemented as a single assembly operation (of course, this depends on the architecture). Indeed, on x86, local_irq_disable() is a simple cli and local_irq_enable() is a simple sti instruction. For non-x86 hackers, cli and sti are the assembly calls to clear and set the allow interrupts flag, respectively. In other words, they disable and enable interrupt delivery on the issuing processor.
The local_irq_disable() routine is dangerous if interrupts were already disabled prior to its invocation. The corresponding call to local_irq_enable() unconditionally enables interrupts, despite the fact that they were off to begin with. Instead, a mechanism is needed to restore interrupts to a previous state. This is a common concern because a given code path in the kernel can be reached both with and without interrupts enabled, depending on the call chain. For example, imagine the previous code snippet is part of a larger function. Imagine that this function is called by two other functions, one which disables interrupts and one which does not. Because it is becoming harder as the kernel grows in size and complexity to know all the code paths leading up to a function, it is much safer to save the state of the interrupt system before disabling it. Then, when you are ready to reenable interrupts, you simply restore them to their original state:
unsigned long flags;
local_irq_save(flags); /* interrupts are now disabled */
/* ... */
local_irq_restore(flags); /* interrupts are restored to their previous state */
Note that these methods are implemented at least in part as macros, so the flags parameter (which must be defined as an unsigned long) is seemingly passed by value. This parameter contains architecture-specific data containing the state of the interrupt systems. Because at least one supported architecture incorporates stack information into the value (ahem, SPARC), flags cannot be passed to another function (specifically, it must remain on the same stack frame). For this reason, the call to save and the call to restore interrupts must occur in the same function.
All the previous functions can be called from both interrupt and process context.
|
The kernel formerly provided a method to disable interrupts on all processors in the system. Furthermore, if another processor called this method, it would have to wait until interrupts were enabled before continuing. This function was named cli() and the corresponding enable call was named sti()very x86-centric, despite existing for all architectures. These interfaces were removed during 2.5, and consequently all interrupt synchronization must now use a combination of local interrupt control and spin locks (discussed in
Chapter 9). This means that code that previously only had to disable interrupts globally to ensure mutual exclusive access to shared data now needs to do a bit more work.
Previously, driver writers could assume a cli() used in their interrupt handlers and anywhere else the shared data was accessed would provide mutual exclusion. The cli() call would ensure that no other interrupt handlers (and thus their specific handler) would run. Furthermore, if another processor entered a cli() protected region, it would not continue until the original processor exited its cli() protected region with a call to sti().
Removing the global cli() has a handful of advantages. First, it forces driver writers to implement real locking. A fine-grained lock with a specific purpose is faster than a global lock, which is effectively what cli() is. Second, the removal streamlined a lot of code in the interrupt system and removed a bunch more. The result is simpler and easier to comprehend. |
Disabling a Specific Interrupt Line
In the previous section, we looked at functions that disable all interrupt delivery for an entire processor. In some cases, it is useful to disable only a specific interrupt line for the entire system. This is called masking out an interrupt line. As an example, you might want to disable delivery of a device's interrupts before manipulating its state. Linux provides four interfaces for this task:
void disable_irq(unsigned int irq);
void disable_irq_nosync(unsigned int irq);
void enable_irq(unsigned int irq);
void synchronize_irq(unsigned int irq);
The first two functions disable a given interrupt line in the interrupt controller. This disables delivery of the given interrupt to all processors in the system. Additionally, the disable_irq() function does not return until any currently executing handler completes. Thus, callers are assured not only that new interrupts will not be delivered on the given line, but also that any already executing handlers have exited. The function disable_irq_nosync() does not wait for current handlers to complete.
The function synchronize_irq() waits for a specific interrupt handler to exit, if it is executing, before returning.
Calls to these functions nest. For each call to disable_irq() or disable_irq_nosync() on a given interrupt line, a corresponding call to enable_irq() is required. Only on the last call to enable_irq() is the interrupt line actually enabled. For example, if disable_irq() is called twice, the interrupt line is not actually reenabled until the second call to enable_irq().
All three of these functions can be called from interrupt or process context and do not sleep. If calling from interrupt context, be careful! You do not want, for example, to enable an interrupt line while you are handling it. (Recall that the interrupt line of a handler is masked out while it is being serviced.)
It would be rather rude to disable an interrupt line that is shared among multiple interrupt handlers. Disabling the line disables interrupt delivery for all devices on the line. Therefore, drivers for newer devices tend not to use these interfaces. Because PCI devices have to support interrupt line sharing by specification, they should not use these interfaces at all. Thus, disable_irq() and friends are found more often in drivers for older legacy devices, such as the PC parallel port.
Status of the Interrupt System
It is often useful to know the state of the interrupt system (for example, whether interrupts are enabled or disabled) or whether you are currently executing in interrupt context.
The macro irqs_disabled(), defined in <asm/system.h>, returns nonzero if the interrupt system on the local processor is disabled. Otherwise, it returns zero.
Two macros, defined in <asm/hardirg.h>, provide an interface to check the kernel's current context. They are
in_interrupt()
in_irq()
The most useful is the first: It returns nonzero if the kernel is in interrupt context. This includes either executing an interrupt handler or a bottom half handler. The macro in_irq() returns nonzero only if the kernel is specifically executing an interrupt handler.
More often, you want to check whether you are in process context. That is, you want to ensure you are not in interrupt context. This is often the case because code wants to do something that can only be done from process context, such as sleep. If in_interrupt() returns zero, the kernel is in process context.
Yes, the names are confusing and do little to impart their meaning. Table 6.2 is a summary of the interrupt control methods and their description.
Don't Interrupt Me; We're Almost Done!
This chapter looked at interrupts, a hardware resource used by devices to asynchronously signal the processor. Interrupts, in effect, are used by hardware to interrupt the operating system.
Most modern hardware uses interrupts to communicate with operating systems. The device driver that manages a given piece of hardware registers an interrupt handler to respond to and process interrupts issued from their associated hardware. Work performed in interrupts includes acknowledging and resetting hardware, copying data from the device to main memory and vice versa, processing hardware requests, and sending out new hardware requests.
The kernel provides interfaces for registering and unregistering interrupt handlers, disabling interrupts, masking out interrupt lines, and checking the status of the interrupt system.
Table 6.2 provided an overview of many of these functions.
Because interrupts interrupt other executing code (processes, the kernel itself, and even other interrupt handlers), they must execute quickly. Often, however, there is a lot of work to do. To balance the large amount of work with the need for quick execution, the kernel divides the work of processing interrupts into two halves. The interrupt handler, the top half, was discussed in this chapter. Now, let's look at the bottom half.
Chapter 7. Bottom Halves and Deferring Work
The previous chapter looked at interrupt handlers as the kernel mechanism for dealing with interrupts. Interrupt handlers are a usefulindeed, requiredpart of any operating system kernel. Because of various limitations, however, interrupt handlers can form only the first half of the interrupt processing solution. The limitations include the following:
Interrupt handlers run asynchronously and thus interrupt other potentially important code, including other interrupt handlers. Therefore, to avoid stalling the interrupted code for too long, interrupt handlers need to run as quickly as possible. Interrupt handlers run with the current interrupt level disabled at best (if SA_INTERRUPT is unset), and at worst (if SA_INTERRUPT is set) with all interrupts on the current processor disabled. Again, interrupt handlers need to run as quickly as possible. Interrupt handlers are often very timing critical because they deal with hardware. Interrupt handlers do not run in process context, therefore they cannot block. This limits what they can do.
It should now be obvious that interrupt handlers are only a piece of the whole solution to managing hardware interrupts. We certainly need a quick, asynchronous, simple handler for immediately responding to hardware and performing any time-critical actions. Interrupt handlers serve this function well; but other, less critical work should be deferred to a later point when interrupts are enabled.
Consequently, managing interrupts is divided into two parts, or halves. The first part, interrupt handlers (top halves), are executed by the kernel asynchronously in immediate response to a hardware interrupt, as discussed in the previous chapter. This chapter looks at the second part of the interrupt solution, bottom halves.
Bottom Halves
The job of bottom halves is to perform any interrupt-related work not performed by the interrupt handler itself. In an ideal world, this is nearly all the work because you want the interrupt handler to perform as little work (and in turn be as fast) as possible. The goal is simply to have interrupt handlers return as quickly as possible.
Nonetheless, the interrupt handler must perform some of the work. For example, the interrupt handler almost assuredly needs to acknowledge the receipt of the interrupt with the hardware. It might also need to copy data to or from the hardware. This work is timing sensitive, so it makes sense to perform it in the interrupt handler itself.
Almost anything else is fair game for performing in the bottom half. For example, if you copy data from the hardware into memory in the top half, it certainly makes sense to process it in the bottom half. Unfortunately, no hard and fast rules exist about what work to perform wherethe decision is left entirely up to the device driver author. Although no arrangement is wrong, an arrangement can easily be suboptimal. Remember, interrupt handlers run asynchronously, with at least the current interrupt line disabled. Minimizing their duration is important. No strict rules about how to divide the work between the top and bottom half exist, but a couple of useful tips might help:
If the work is time sensitive, perform it in the interrupt handler. If the work is related to the hardware itself, perform it in the interrupt handler. If the work needs to ensure that another interrupt (particularly the same interrupt) does not interrupt it, perform it in the interrupt handler. For everything else, consider performing the work in the bottom half.
When attempting to write your own device driver, looking at other interrupt handlers and their corresponding bottom halves will help. When deciding how to divide your interrupt processing work between the top and bottom half, ask yourself what has to be in the top half and what can be in the bottom half. Generally, the quicker the interrupt handler executes, the better.
Why Bottom Halves?
It is crucial to understand why to defer work, and when exactly to defer it. You want to limit the amount of work you perform in an interrupt handler because interrupt handlers run with the current interrupt line disabled on all processors. Worse, handlers that register with SA_INTERRUPT run with all local interrupts disabled (plus the local interrupt line globally disabled). Minimizing the time spent with interrupts disabled is important to system response and performance. Add to this the fact that interrupt handlers run asynchronously with respect to other codeeven other interrupt handlersand then it is clear that you should work to minimize how long interrupt handlers run. The solution is to defer some of the work until later.
But when is "later"? The important thing to realize is that later is often simply not now. The point of a bottom half is not to do work at some specific point in the future, but simply to defer work until any point in the future when the system is less busy and interrupts are again enabled. Often, bottom halves run immediately after the interrupt returns. The key is that they run with all interrupts enabled.
Not just Linux, but many operating systems separate the processing of hardware interrupts into two parts. The top half is quick and simple and runs with some or all interrupts disabled. The bottom half (however it is implemented) runs later with all interrupts enabled. This design keeps system response time low by running with interrupts disabled for as little time as necessary.
A World of Bottom Halves
Unlike the top half, which is implemented entirely via the interrupt handler, multiple mechanisms are available for implementing a bottom half. These mechanisms are different interfaces and subsystems that enable you to implement bottom halves. Whereas the previous chapter looked at just a single way of implementing interrupt handlers, this chapter looks at multiple methods of implementing bottom halves. In fact, over the course of Linux's history there have been many bottom-half mechanisms. Confusingly, some of these mechanisms have similar or even really dumb names. It requires a special type of programmer to name bottom halves.
This chapter discusses both the design and implementation of the bottom-half mechanisms that exist in 2.6. We also discuss how to use them in the kernel code you write. The old, but long since removed, bottom-half mechanisms are historically significant, and so they are mentioned when relevant.
In the beginning, Linux provided only the "bottom half" for implementing bottom halves. This name was logical because at the time that was the only means available for deferring work. The infrastructure was also known as "BH," which is what we will call it to avoid confusion with the generic term "bottom half." The BH interface was very simple, like most things in those good old days. It provided a statically created list of 32 bottom halves. The top half could mark whether the bottom half would run by setting a bit in a 32-bit integer. Each BH was globally synchronized. No two could run at the same time, even on different processors. This was easy to use, yet inflexible; simple, yet a bottleneck.
Later on, the kernel developers introduced task queues both as a method of deferring work and as a replacement for the BH mechanism. The kernel defined a family of queues. Each queue contained a linked list of functions to call. The queued functions were run at certain times, depending on which queue they were in. Drivers could register their bottom halves in the appropriate queue. This worked fairly well, but it was still too inflexible to replace the BH interface entirely. It also was not lightweight enough for performance-critical subsystems, such as networking.
During the 2.3 development series, the kernel developers introduced softirqs and tasklets. With the exception of compatibility with existing drivers, softirqs and tasklets were capable of completely replacing the BH interface. Softirqs are a set of 32 statically defined bottom halves that can run simultaneously on any processoreven two of the same type can run concurrently. Tasklets, which have an awful and confusing name, are flexible, dynamically created bottom halves that are built on top of softirqs. Two different tasklets can run concurrently on different processors, but two of the same type of tasklet cannot run simultaneously. Thus, tasklets are a good tradeoff between performance and ease of use. For most bottom-half processing, the tasklet is sufficient. Softirqs are useful when performance is critical, such as with networking. Using softirqs requires more care, however, because two of the same softirq can run at the same time. In addition, softirqs must be registered statically at compile-time. Conversely, code can dynamically register tasklets.
To further confound the issue, some people refer to all bottom halves as software interrupts or softirqs. In other words, they call both the softirq mechanism and bottom halves in general softirqs. Ignore those people. They run with the same crowd that named the BH and tasklet mechanisms.
While developing the 2.5 kernel, the BH interface was finally tossed to the curb as all BH users were converted to the other bottom-half interfaces. Additionally, the task queue interface was replaced by the work queue interface. Work queues are a very simple yet useful method of queueing work to later be performed in process context. We will get to them later.
Consequently, today 2.6 has three bottom-half mechanisms in the kernel: softirqs, tasklets, and work queues. The kernel used to have the BH and task queue interfaces, but today they are mere memories.
|
Another mechanism for deferring work is kernel timers. Unlike the mechanisms discussed in the chapter thus far, timers defer work for a specified amount of time. That is, although the tools discussed in this chapter are useful to defer work to any time but now, you use timers to defer work until at least a specific time has elapsed.
Therefore, timers have different uses than the general mechanisms discussed in this chapter. A full discussion of timers is given in
Chapter 10, "Timers and Time Management." |
Bottom Half Confusion
This is some seriously confusing stuff, but really it involves just naming issues. Let's go over it again.
"Bottom half" is a generic operating system term referring to the deferred portion of interrupt processing, so named because it represents the second, or bottom, half of the interrupt processing solution. In Linux, the term currently has this meaning, too. All the kernel's mechanisms for deferring work are "bottom halves." Some people also confusingly call all bottom halves "softirqs," but they are just being annoying.
"Bottom half" also refers to the original deferred work mechanism in Linux. This mechanism is also known as a "BH," so we call it by that name now and leave the former as a generic description. The BH mechanism was deprecated a while back and fully removed in 2.5.
Currently, there are three methods for deferring work: softirqs, tasklets, and work queues. Tasklets are built on softirqs and work queues are entirely different. Table 7.1 presents a history of bottom halves.
Table 7.1. Bottom Half StatusBottom Half | Status |
|---|
BH | Removed in 2.5 | Task queues | Removed in 2.5 | Softirq | Available since 2.3 | Tasklet | Available since 2.3 | Work queues | Available since 2.5 |
With this naming confusion settled, let's look at the individual mechanisms.
Softirqs
The place to start this discussion of the actual bottom half methods is with softirqs. Softirqs are rarely used; tasklets are a much more common form of bottom half. Nonetheless, because tasklets are built on softirqs we'll cover them first. The softirq code lives in kernel/softirq.c.
Implementation of Softirqs
Softirqs are statically allocated at compile-time. Unlike tasklets, you cannot dynamically register and destroy softirqs. Softirqs are represented by the softirq_action structure, which is defined in <linux/interrupt.h>:
/*
* structure representing a single softirq entry
*/
struct softirq_action {
void (*action)(struct softirq_action *); /* function to run */
void *data; /* data to pass to function */
};
A 32-entry array of this structure is declared in kernel/softirq.c:
static struct softirq_action softirq_vec[32];
Each registered softirq consumes one entry in the array. Consequently, there can be a maximum of 32 registered softirqs. Note that this cap is fixedthe maximum number of registered softirqs cannot be dynamically changed. In the current kernel, however, only 6 of the 32 entries are used.
The Softirq Handler
The prototype of a softirq handler, action, looks like:
void softirq_handler(struct softirq_action *)
When the kernel runs a softirq handler, it executes this action function with a pointer to the corresponding softirq_action structure as its lone argument. For example, if my_softirq pointed to an entry in the softirq_vec array, the kernel would invoke the softirq handler function as
my_softirq->action(my_softirq)
It seems a bit odd that the kernel passes the entire structure, and not just the data value, to the softirq handler. This trick allows future additions to the structure without requiring a change in every softirq handler. Softirq handlers can retrieve the data value, if they need to, simply by dereferencing their argument and reading the data member.
A softirq never preempts another softirq. In fact, the only event that can preempt a softirq is an interrupt handler. Another softirqeven the same onecan run on another processor, however.
Executing Softirqs
A registered softirq must be marked before it will execute. This is called raising the softirq. Usually, an interrupt handler marks its softirq for execution before returning. Then, at a suitable time, the softirq runs. Pending softirqs are checked for and executed in the following places:
In the return from hardware interrupt code In the ksoftirqd kernel thread In any code that explicitly checks for and executes pending softirqs, such as the networking subsystem
Regardless of the method of invocation, softirq execution occurs in do_softirq(). The function is really quite simple. If there are pending softirqs, do_softirq() loops over each one, invoking its handler. Let's look at a simplified variant of the important part of do_softirq():
u32 pending = softirq_pending(cpu);
if (pending) {
struct softirq_action *h = softirq_vec;
softirq_pending(cpu) = 0;
do {
if (pending & 1)
h->action(h);
h++;
pending >>= 1;
} while (pending);
}
This snippet is the heart of softirq processing. It checks for, and executes, any pending softirqs. Specifically,
It sets the pending local variable to the value returned by the softirq_pending() macro. This is a 32-bit mask of pending softirqsif bit n is set, the nth softirq is pending. Now that the pending bitmask of softirqs is saved, it clears the actual bitmask. The pointer h is set to the first entry in the softirq_vec. If the first bit in pending is set, h->action(h) is called. The pointer h is incremented by one so that it now points to the second entry in the softirq_vec array. The bitmask pending is right-shifted by one. This tosses the first bit away, and moves all other bits one place to the right. Consequently, the second bit is now the first (and so on). The pointer h now points to the second entry in the array and the pending bitmask now has the second bit as the first. Repeat the previous steps. Continue repeating until pending is zero, at which point there are no more pending softirqs and the work is done. Note, this check is sufficient to ensure h always points to a valid entry in softirq_vec because pending has at most 32 set bits and thus this loop executes at most 32 times.
Using Softirqs
Softirqs are reserved for the most timing-critical and important bottom-half processing on the system. Currently, only two subsystemsnetworking and SCSIdirectly use softirqs. Additionally, kernel timers and tasklets are built on top of softirqs. If you are adding a new softirq, you normally want to ask yourself why using a tasklet is insufficient. Tasklets are dynamically created and are simpler to use because of their weaker locking requirements, and they still perform quite well. Nonetheless, for timing-critical applications that are able to do their own locking in an efficient way, softirqs might be the correct solution.
Assigning an Index
You declare softirqs statically at compile-time via an enum in <linux/interrupt.h>. The kernel uses this index, which starts at zero, as a relative priority. Softirqs with the lowest numerical priority execute before those with a higher numerical priority.
Creating a new softirq includes adding a new entry to this enum. When adding a new softirq you might not want to simply add your entry to the end of the list, as you would elsewhere. Instead, you need to insert the new entry depending on the priority you want to give it. Historically, HI_SOFTIRQ is always the first and TASKLET_SOFTIRQ is always the last entry. A new entry probably belongs somewhere after the network entries, but prior to TASKLET_SOFTIRQ. Table 7.2 contains a list of the existing tasklet types.
Table 7.2. Listing of Tasklet TypesTasklet | Priority | Softirq Description |
|---|
HI_SOFTIRQ | 0 | High-priority tasklets | TIMER_SOFTIRQ | 1 | Timer bottom half | NET_TX_SOFTIRQ | 2 | Send network packets | NET_RX_SOFTIRQ | 3 | Receive network packets | SCSI_SOFTIRQ | 4 | SCSI bottom half | TASKLET_SOFTIRQ | 5 | Tasklets |
Registering Your Handler
Next, the softirq handler is registered at run-time via open_softirq(), which takes three parameters: the softirq's index, its handler function, and a value for the data field. The networking subsystem, for example, registers its softirqs like this:
open_softirq(NET_TX_SOFTIRQ, net_tx_action, NULL);
open_softirq(NET_RX_SOFTIRQ, net_rx_action, NULL);
The softirq handlers run with interrupts enabled and cannot sleep. While a handler runs, softirqs on the current processor are disabled. Another processor, however, can execute other softirqs. In fact, if the same softirq is raised again while it is executing, another processor can run it simultaneously. This means that any shared dataeven global data used only within the softirq handler itselfneeds proper locking (as discussed in the next two chapters). This is an important point, and it is the reason tasklets are usually preferred. Simply preventing your softirqs from running concurrently is not ideal. If a softirq obtained a lock to prevent another instance of itself from running simultaneously, there would be no reason to use a softirq. Consequently, most softirq handlers resort to per-processor data (data unique to each processor and thus not requiring locking) or some other tricks to avoid explicit locking and provide excellent scalability.
The raison d'ètre to softirqs is scalability. If you do not need to scale to infinitely many processors, then use a tasklet. Tasklets are ultimately softirqs where multiple instances of the same handler do not run concurrently on multiple processors.
Raising Your Softirq
After a handler is added to the enum list and registered via open_softirq(), it is ready to run. To mark it pending, so that it is run at the next invocation of do_softirq(), call raise_softirq(). For example, the networking subsystem would call
raise_softirq(NET_TX_SOFTIRQ);
This raises the NET_TX_SOFTIRQ softirq. Its handler, net_tx_action(), runs the next time the kernel executes softirqs. This function disables interrupts prior to actually raising the softirq, and then restores them to their previous state. If interrupts are already off, the function raise_softirq_irqoff() can be used as a minor optimization. For example:
/*
* interrupts must already be off!
*/
raise_softirq_irqoff(NET_TX_SOFTIRQ);
Tasklets
Tasklets are a bottom-half mechanism built on top of softirqs. As already mentioned, they have nothing to do with tasks. Tasklets are similar in nature and work in a similar manner to softirqs; however, they have a simpler interface and relaxed locking rules.
The decision between whether to use softirqs versus tasklets is simple: You usually want to use tasklets. As we saw in the previous section, you can count on one hand the users of softirqs. Softirqs are required only for very high-frequency and highly threaded uses. Tasklets, on the other hand, see much greater use. Tasklets work just fine for the vast majority of cases and they are very easy to use.
Implementation of Tasklets
Because tasklets are implemented on top of softirqs, they are softirqs. As discussed, tasklets are represented by two softirqs: HI_SOFTIRQ and TASKLET_SOFTIRQ. The only real difference in these types is that the HI_SOFTIRQ-based tasklets run prior to the TASKLET_SOFTIRQ tasklets.
The Tasklet Structure
Tasklets are represented by the tasklet_struct structure. Each structure represents a unique tasklet. The structure is declared in <linux/interrupt.h>:
struct tasklet_struct {
struct tasklet_struct *next; /* next tasklet in the list */
unsigned long state; /* state of the tasklet */
atomic_t count; /* reference counter */
void (*func)(unsigned long); /* tasklet handler function */
unsigned long data; /* argument to the tasklet function */
};
The func member is the tasklet handler (the equivalent of action to a softirq) and it receives data as its sole argument.
The state member is one of zero, TASKLET_STATE_SCHED, or TASKLET_STATE_RUN. TASKLET_STATE_SCHED denotes a tasklet that is scheduled to run and TASKLET_STATE_RUN denotes a tasklet that is running. As an optimization, TASKLET_STATE_RUN is used only on multiprocessor machines because a uniprocessor machine always knows whether the tasklet is running (it is either the currently executing code, or not).
The count field is used as a reference count for the tasklet. If it is nonzero, the tasklet is disabled and cannot run; if it is zero, the tasklet is enabled and can run if marked pending.
Scheduling Tasklets
Scheduled tasklets (the equivalent of raised softirqs) are stored in two per-processor structures: tasklet_vec (for regular tasklets) and tasklet_hi_vec (for high-priority tasklets). Both of these structures are linked lists of tasklet_struct structures. Each tasklet_struct structure in the list represents a different tasklet.
Tasklets are scheduled via the tasklet_schedule() and tasklet_hi_schedule() functions, which receive a pointer to the tasklet's tasklet_struct as their lone argument. The two functions are very similar (the difference being that one uses TASKLET_SOFTIRQ and one uses HI_SOFTIRQ). Writing and using tasklets is covered in the next section. For now, let's look at the details of tasklet_schedule():
Check whether the tasklet's state is TASKLET_STATE_SCHED. If it is, the tasklet is already scheduled to run and the function can immediately return. Save the state of the interrupt system, and then disable local interrupts. This ensures that nothing on this processor will mess with the tasklet code while tasklet_schedule() is manipulating the tasklets. Add the tasklet to be scheduled to the head of the tasklet_vec or tasklet_hi_vec linked list, which is unique to each processor in the system. Raise the TASKLET_SOFTIRQ or HI_SOFTIRQ softirq, so do_softirq() will execute this tasklet in the near future. Restore interrupts to their previous state and return.
At the next earliest convenience, do_softirq() is run as discussed in the previous section. Because most tasklets and softirqs are marked pending in interrupt handlers, do_softirq() most likely runs when the last interrupt returns. Because TASKLET_SOFTIRQ or HI_SOFTIRQ is now raised, do_softirq() executes the associated handlers. These handlers, tasklet_action() and tasklet_hi_action(), are the heart of tasklet processing. Let's look at what they do:
Disable local interrupt delivery (there is no need to first save their state because the code here is always called as a softirq handler and interrupts are always enabled) and retrieve the tasklet_vec or tasklet_hi_vec list for this processor. Clear the list for this processor by setting it equal to NULL. Enable local interrupt delivery. Again, there is no need to restore them to their previous state because this function knows that they were always originally enabled. Loop over each pending tasklet in the retrieved list. If this is a multiprocessing machine, check whether the tasklet is running on another processor by checking the TASKLET_STATE_RUN flag. If it is currently running, do not execute it now and skip to the next pending tasklet (recall, only one tasklet of a given type may run concurrently). If the tasklet is not currently running, set the TASKLET_STATE_RUN flag, so another processor will not run it. Check for a zero count value, to ensure that the tasklet is not disabled. If the tasklet is disabled, skip it and go to the next pending tasklet. We now know that the tasklet is not running elsewhere, is marked as running so it will not start running elsewhere, and has a zero count value. Run the tasklet handler. After the tasklet runs, clear the TASKLET_STATE_RUN flag in the tasklet's state field. Repeat for the next pending tasklet, until there are no more scheduled tasklets waiting to run.
The implementation of tasklets is simple, but rather clever. As you saw, all tasklets are multiplexed on top of two softirqs, HI_SOFTIRQ and TASKLET_SOFTIRQ. When a tasklet is scheduled, the kernel raises one of these softirqs. These softirqs, in turn, are handled by special functions that then run any scheduled tasklets. The special functions ensure that only one tasklet of a given type is running at the same time (but other tasklets can run simultaneously). All this complexity is then hidden behind a clean and simple interface.
Using Tasklets
In most cases, tasklets are the preferred mechanism with which to implement your bottom half for a normal hardware device. Tasklets are dynamically created, easy to use, and very quick. Moreover, although their name is mind-numbingly confusing, it grows on you: It is cute.
Declaring Your Tasklet
You can create tasklets statically or dynamically. What option you choose depends on whether you have (or want) a direct or indirect reference to the tasklet. If you are going to statically create the tasklet (and thus have a direct reference to it), use one of two macros in <linux/interrupt.h>:
DECLARE_TASKLET(name, func, data)
DECLARE_TASKLET_DISABLED(name, func, data);
Both these macros statically create a struct tasklet_struct with the given name. When the tasklet is scheduled, the given function func is executed and passed the argument data. The difference between the two macros is the initial reference count. The first macro creates the tasklet with a count of zero, and the tasklet is enabled. The second macro sets count to one, and the tasklet is disabled. Here is an example:
DECLARE_TASKLET(my_tasklet, my_tasklet_handler, dev);
This line is equivalent to
struct tasklet_struct my_tasklet = { NULL, 0, ATOMIC_INIT(0),
my_tasklet_handler, dev };
This creates a tasklet named my_tasklet that is enabled with tasklet_handler as its handler. The value of dev is passed to the handler when it is executed.
To initialize a tasklet given an indirect reference (a pointer) to a dynamically created struct tasklet_struct, t, call tasklet_init():
tasklet_init(t, tasklet_handler, dev); /* dynamically as opposed to statically */
Writing Your Tasklet Handler
The tasklet handler must match the correct prototype:
void tasklet_handler(unsigned long data)
As with softirqs, tasklets cannot sleep. This means you cannot use semaphores or other blocking functions in a tasklet. Tasklets also run with all interrupts enabled, so you must take precautions (for example, disable interrupts and obtain a lock) if your tasklet shares data with an interrupt handler. Unlike softirqs, however, two of the same tasklets never run concurrentlyalthough two different tasklets can run at the same time on two different processors. If your tasklet shares data with another tasklet or softirq, you need to use proper locking (see
Chapter 8, "Kernel Synchronization Introduction," and
Chapter 9, "Kernel Synchronization Methods").
Scheduling Your Tasklet
To schedule a tasklet for execution, tasklet_schedule() is called and passed a pointer to the relevant tasklet_struct:
tasklet_schedule(&my_tasklet); /* mark my_tasklet as pending */
After a tasklet is scheduled, it runs once at some time in the near future. If the same tasklet is scheduled again, before it has had a chance to run, it still runs only once. If it is already running, for example on another processor, the tasklet is rescheduled and runs again. As an optimization, a tasklet always runs on the processor that scheduled itmaking better use of the processor's cache, you hope.
You can disable a tasklet via a call to tasklet_disable(), which disables the given tasklet. If the tasklet is currently running, the function will not return until it finishes executing. Alternatively, you can use tasklet_disable_nosync(), which disables the given tasklet but does not wait for the tasklet to complete prior to returning. This is usually not safe because you cannot assume the tasklet is not still running. A call to tasklet_enable() enables the tasklet. This function also must be called before a tasklet created with DECLARE_TASKLET_DISABLED() is usable. For example:
tasklet_disable(&my_tasklet); /* tasklet is now disabled */
/* we can now do stuff knowing that the tasklet cannot run .. */
tasklet_enable(&my_tasklet); /* tasklet is now enabled */
You can remove a tasklet from the pending queue via tasklet_kill(). This function receives a pointer as a lone argument to the tasklet's tasklet_struct. Removing a scheduled tasklet from the queue is useful when dealing with a tasklet that often reschedules itself. This function first waits for the tasklet to finish executing and then it removes the tasklet from the queue. Nothing stops some other code from rescheduling the tasklet, of course. This function must not be used from interrupt context because it sleeps.
ksoftirqd
Softirq (and thus tasklet) processing is aided by a set of per-processor kernel threads. These kernel threads help in the processing of softirqs when the system is overwhelmed with softirqs.
As already described, the kernel processes softirqs in a number of places, most commonly on return from handling an interrupt. Softirqs might be raised at very high rates (such as during intense network traffic). Further, softirq functions can reactivate themselves. That is, while running, a softirq can raise itself so that it runs again (indeed, the networking subsystem does this). The possibility of a high frequency of softirqs in conjunction with their capability to remark themselves active can result in user-space programs being starved of processor time. Not processing the reactivated softirqs in a timely manner, however, is unacceptable. When softirqs were first designed, this caused a dilemma that needed fixing, and neither obvious solution was a good one. First, let's look at each of the two obvious solutions.
The first solution is simply to keep processing softirqs as they come in and to recheck and reprocess any pending softirqs before returning. This ensures that the kernel processes softirqs in a timely manner and, most importantly, that any reactivated softirqs are also immediately processed. The problem lies in high load environments, in which many softirqs occur, that continually reactivate themselves. The kernel might continually service softirqs without accomplishing much else. User-space is neglectedindeed, nothing but softirqs and interrupt handlers run and, in turn, the system's users get mad. This approach might work fine if the system is never under intense load; if the system experiences even moderate interrupt levels this solution is not acceptable. User-space cannot be starved for significant periods.
The second solution is not to handle reactivated softirqs. On return from interrupt, the kernel merely looks at all pending softirqs and executes them as normal. If any softirqs reactivate themselves, however, they will not run until the next time the kernel handles pending softirqs. This is most likely not until the next interrupt occurs, which can equate to a lengthy amount of time before any new (or reactivated) softirqs are executed. Worse, on an otherwise idle system it is beneficial to process the softirqs right away. Unfortunately, this approach is oblivious to which processes may or may not be runnable. Therefore, although this method prevents starving user-space, it does starve the softirqs, and it does not take good advantage of an idle system.
In designing softirqs, the developers realized that some sort of compromise was needed. The solution ultimately implemented in the kernel is to not immediately process reactivated softirqs. Instead, if the number of softirqs grows excessive, the kernel wakes up a family of kernel threads to handle the load. The kernel threads run with the lowest possible priority (nice value of 19), which ensures they do not run in lieu of anything important. This concession prevents heavy softirq activity from completely starving user-space of processor time. Conversely, it also ensures that "excess" softirqs do run eventually. Finally, this solution has the added property that on an idle system, the softirqs are handled rather quickly (because the kernel threads will schedule immediately).
There is one thread per processor. The threads are each named ksoftirqd/n where n is the processor number. On a two-processor system, you would have ksoftirqd/0 and ksoftirqd/1. Having a thread on each processor ensures an idle processor, if available, is always able to service softirqs. After the threads are initialized, they run a tight loop similar to this:
for (;;) {
if (!softirq_pending(cpu))
schedule();
set_current_state(TASK_RUNNING);
while (softirq_pending(cpu)) {
do_softirq();
if (need_resched())
schedule();
}
set_current_state(TASK_INTERRUPTIBLE);
}
If any softirqs are pending (as reported by softirq_pending()), ksoftirqd calls do_softirq() to handle them. Note that it does this repeatedly to handle any reactivated softirqs, too. After each iteration, schedule() is called if needed, to allow more important processes to run. After all processing is complete, the kernel thread sets itself TASK_INTERRUPTIBLE and invokes the scheduler to select a new runnable process.
The softirq kernel threads are awakened whenever do_softirq() detects an executed kernel thread reactivating itself.
The Old BH Mechanism
Although the old BH interface, thankfully, is no longer present in 2.6, it was around for a long timesince the earliest versions of the kernel. Seeing as it had immense staying power, it certainly carries some historical significance that requires more than a passing look. Nothing in this brief section actually pertains to 2.6, but the history is important.
The BH interface is ancient, and it showed. Each BH must be statically defined, and there are a maximum of 32. Because the handlers must all be defined at compile-time, modules could not directly use the BH interface. They could piggyback off an existing BH, however. Over time, this static requirement and the maximum of 32 bottom halves became a major hindrance to their use.
All BH handlers are strictly serializedno two BH handlers, even of different types, can run concurrently. This made synchronization easy, but it wasn't a good thing for multiprocessor scalability. Performance on large SMP machines was sub par. A driver using the BH interface did not scale well to multiple processors. The networking layer, in particular, suffered.
Other than these attributes, the BH mechanism is similar to tasklets. In fact, the BH interface was implemented on top of tasklets in 2.4. The 32 possible bottom halves were represented by constants defined in <linux/interrupt.h>. To mark a BH as pending, the function mark_bh() was called and passed the number of the BH. In 2.4, this in turn scheduled the BH tasklet, bh_action(), to run. Before the 2.4 kernel, the BH mechanism was independently implemented and did not rely on any lower-level bottom-half mechanism, much as softirqs are implemented today.
Because of the shortcomings of this form of bottom half, kernel developers introduced task queues to replace bottom halves. Task queues never accomplished this goal, although they did win many new users. In 2.3, the softirq and tasklet mechanisms were introduced to put an end to the BH. The BH mechanism was reimplemented on top of tasklets. Unfortunately, it was complicated to port bottom halves from the BH interface to tasklets or softirqs because of the weaker inherent serialization of the new interfaces. During 2.5, however, the conversion did occur when timers and SCSIthe remaining BH usersfinally moved over to softirqs. The kernel developers summarily removed the BH interface. Good riddance, BH!
Work Queues
Work queues are a different form of deferring work from what we have looked at so far. Work queues defer work into a kernel threadthis bottom half always runs in process context. Thus, code deferred to a work queue has all the usual benefits of process context. Most importantly, work queues are schedulable and can therefore sleep.
Normally, it is easy to decide between using work queues and softirqs/tasklets. If the deferred work needs to sleep, work queues are used. If the deferred work need not sleep, softirqs or tasklets are used. Indeed, the usual alternative to work queues is kernel threads. Because the kernel developers frown upon creating a new kernel thread (and, in some locales, it is a punishable offense), work queues are strongly preferred. They are really easy to use, too.
If you need a schedulable entity to perform your bottom-half processing, you need work queues. They are the only bottom-half mechanisms that run in process context, and thus, the only ones that can sleep. This means they are useful for situations where you need to allocate a lot of memory, obtain a semaphore, or perform block I/O. If you do not need a kernel thread to handle your deferred work, consider a tasklet instead.
Implementation of Work Queues
In its most basic form, the work queue subsystem is an interface for creating kernel threads to handle work that is queued from elsewhere. These kernel threads are called worker threads. Work queues let your driver create a special worker thread to handle deferred work. The work queue subsystem, however, implements and provides a default worker thread for handling work. Therefore, in its most common form, a work queue is a simple interface for deferring work to a generic kernel thread.
The default worker threads are called events/n where n is the processor number; there is one per processor. For example, on a uniprocessor system there is one thread, events/0. A dual processor system would additionally have an events/1 tHRead. The default worker thread handles deferred work from multiple locations. Many drivers in the kernel defer their bottom-half work to the default thread. Unless a driver or subsystem has a strong requirement for creating its own thread, the default thread is preferred.
Nothing stops code from creating its own worker thread, however. This might be advantageous if you are performing large amounts of processing in the worker thread. Processor-intense and performance-critical work might benefit from its own thread. This also lightens the load on the default threads, which prevents starving the rest of the queued work.
Data Structures Representing the Threads
The worker threads are represented by the workqueue_struct structure:
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
struct workqueue_struct {
struct cpu_workqueue_struct cpu_wq[NR_CPUS];
const char *name;
struct list_head list;
};
This structure, defined in kernel/workqueue.c, contains an array of struct cpu_workqueue_struct, one per possible processor on the system. Because the worker threads exist on each processor in the system, there is one of these structures per worker thread, per processor, on a given machine. The cpu_workqueue_struct is the core data structure and is also defined in kernel/workqueue.c:
struct cpu_workqueue_struct {
spinlock_t lock; /* lock protecting this structure */
long remove_sequence; /* least-recently added (next to run) */
long insert_sequence; /* next to add */
struct list_head worklist; /* list of work */
wait_queue_head_t more_work;
wait_queue_head_t work_done;
struct workqueue_struct *wq; /* associated workqueue_struct */
task_t *thread; /* associated thread */
int run_depth; /* run_workqueue() recursion depth */
};
Note that each type of worker thread has one workqueue_struct associated to it. Inside, there is one cpu_workqueue_struct for every thread and, thus, every processor, because there is one worker thread on each processor.
Data Structures Representing the Work
All worker threads are implemented as normal kernel threads running the worker_thread()function. After initial setup, this function enters an infinite loop and goes to sleep. When work is queued, the thread is awakened and processes the work. When there is no work left to process, it goes back to sleep.
The work is represented by the work_struct structure, defined in <linux/workqueue.h>:
struct work_struct {
unsigned long pending; /* is this work pending? */
struct list_head entry; /* link list of all work */
void (*func)(void *); /* handler function */
void *data; /* argument to handler */
void *wq_data; /* used internally */
struct timer_list timer; /* timer used by delayed work queues */
};
These structures are strung into a linked list, one for each type of queue on each processor. For example, there is one list of deferred work for the generic thread, per processor. When a worker thread wakes up, it runs any work in its list. As it completes work, it removes the corresponding work_struct enTRies from the linked list. When the list is empty, it goes back to sleep.
Let's look at the heart of worker_thread(), simplified:
for (;;) {
set_task_state(current, TASK_INTERRUPTIBLE);
add_wait_queue(&cwq->more_work, &wait);
if (list_empty(&cwq->worklist))
schedule();
else
set_task_state(current, TASK_RUNNING);
remove_wait_queue(&cwq->more_work, &wait);
if (!list_empty(&cwq->worklist))
run_workqueue(cwq);
}
This function performs the following functions, in an infinite loop:
The thread marks itself sleeping (the task's state is set to TASK_INTERRUPTIBLE) and adds itself to a wait queue. If the linked list of work is empty, the thread calls schedule() and goes to sleep. If the list is not empty, the thread does not go to sleep. Instead, it marks itself TASK_RUNNING and removes itself from the wait queue. If the list is nonempty, the thread calls run_workqueue() to perform the deferred work.
run_workqueue()
The function run_workqueue(), in turn, actually performs the deferred work:
while (!list_empty(&cwq->worklist)) {
struct work_struct *work;
void (*f)(void *);
void *data;
work = list_entry(cwq->worklist.next, struct work_struct, entry);
f = work->func;
data = work->data;
list_del_init(cwq->worklist.next);
clear_bit(0, &work->pending);
f(data);
}
This function loops over each entry in the linked list of pending work and executes the func member of the workqueue_struct for each entry in the linked list:
While the list is not empty, it grabs the next entry in the list. It retrieves the function that should be called, func, and its argument, data. It removes this entry from the list and clears the pending bit in the structure itself.
Excuse Me?
The relationship between the different data structures is admittedly a bit convoluted. Figure 7.1 provides a graphical example, which should bring it all together.
At the highest level, there are worker threads. There can be multiple types of worker threads. There is one worker thread per processor of a given type. Parts of the kernel can create worker threads as needed. By default, there is the events worker thread. Each worker thread is represented by the cpu_workqueue_struct structure. The workqueue_struct structure represents all the worker threads of a given type.
For example, assume that in addition to the generic events worker type, I also create a falcon worker type. Also, assume I have a four-processor computer. Then there are four events threads (and thus four cpu_workqueue_struct structures) and four falcon threads (and thus another four cpu_workqueue_struct structures). There is one workqueue_struct for the events type and one for the falcon type.
Now, let's approach from the lowest level, which starts with work. Your driver creates work, which it wants to defer to later. The work_struct structure represents this work. Among other things, this structure contains a pointer to the function that will handle the deferred work. The work is submitted to a specific worker threadin this case, a specific falcon thread. The worker thread then wakes up and performs the queued work.
Most drivers use the existing default worker threads, named events. They are easy and simple. Some more serious situations, however, demand their own worker threads. The XFS file system, for example, creates two new types of worker threads.
Using Work Queues
Using work queues is easy. We cover the default events queue first, and then look at creating new worker threads.
Creating Work
The first step is actually creating some work to defer. To create the structure statically at run-time, use DECLARE_WORK:
DECLARE_WORK(name, void (*func)(void *), void *data);
This statically creates a work_struct structure named name with handler function func and argument data.
Alternatively, you can create work at run-time via a pointer:
INIT_WORK(struct work_struct *work, void (*func)(void *), void *data);
This dynamically initializes the work queue pointed to by work with handler function func and argument data.
Your Work Queue Handler
The prototype for the work queue handler is
void work_handler(void *data)
A worker thread executes this function, and thus, the function runs in process context. By default, interrupts are enabled and no locks are held. If needed, the function can sleep. Note that, despite running in process context, the work handlers cannot access user-space memory because there is no associated user-space memory map for kernel threads. The kernel can access user memory only when running on behalf of a user-space process, such as when executing a system call. Only then is user memory mapped in.
Locking between work queues or other parts of the kernel is handled just as with any other process context code. This makes writing work handlers much easier. The next two chapters cover locking.
Scheduling Work
Now that the work is created, we can schedule it. To queue a given work's handler function with the default events worker threads, simply call
schedule_work(&work);
The work is scheduled immediately and is run as soon as the events worker thread on the current processor wakes up.
Sometimes you do not want the work to execute immediately, but instead after some delay. In those cases, you can schedule work to execute at a given time in the future:
schedule_delayed_work(&work, delay);
In this case, the work_struct represented by &work will not execute for at least delay timer ticks into the future. Using ticks as a unit of time is covered in Chapter 10.
Flushing Work
Queued work is executed when the worker thread next wakes up. Sometimes, you need to ensure that a given batch of work has completed before continuing. This is especially important for modules, which almost certainly want to call this function before unloading. Other places in the kernel also might need to make certain no work is pending, to prevent race conditions.
For these needs, there is a function to flush a given work queue:
void flush_scheduled_work(void);
This function waits until all entries in the queue are executed before returning. While waiting for any pending work to execute, the function sleeps. Therefore, you can call it only from process context.
Note that this function does not cancel any delayed work. That is, any work that was scheduled via schedule_delayed_work(), and whose delay is not yet up, is not flushed via flush_scheduled_work(). To cancel delayed work, call
int cancel_delayed_work(struct work_struct *work);
This function cancels the pending work, if any, associated with the given work_struct.
Creating New Work Queues
If the default queue is insufficient for your needs, you can create a new work queue and corresponding worker threads. Because this creates one worker thread per processor, you should create unique work queues only if your code really needs the performance of a unique set of threads.
You create a new work queue and the associated worker threads via a simple function:
struct workqueue_struct *create_workqueue(const char *name);
The parameter name is used to name the kernel threads. For example, the default events queue is created via
struct workqueue_struct *keventd_wq;
keventd_wq = create_workqueue("events");
This function creates all the worker threads (one for each processor in the system) and prepares them to handle work.
Creating work is handled in the same manner regardless of the queue type. After the work is created, the following functions are analogous to schedule_work() and schedule_delayed_work(), except that they work on the given work queue and not the default events queue.
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
int queue_delayed_work(struct workqueue_struct *wq,
struct work_struct *work,
unsigned long delay)
Finally, you can flush a wait queue via a call to the function
flush_workqueue(struct workqueue_struct *wq)
As previously discussed, this function works identically to flush_scheduled_work(), except that it waits for the given queue to empty before returning.
The Old Task Queue Mechanism
Like the BH interface, which gave way to softirqs and tasklets, the work queue interface grew out of shortcomings in the task queue interface. The task queue interface (often called simply tq in the kernel), like tasklets, also has nothing to do with tasks in the process sense
[7]. The users of the task queue interface were ripped in half during the 2.5 development kernel. Half of the users were converted to tasklets, whereas the other half continued using the task queue interface. What was left of the task queue interface then became the work queue interface. Briefly looking at task queues, which were around for some time, is a useful historical exercise.
Task queues work by defining a bunch of queues. The queues have names, such as the scheduler queue, the immediate queue, or the timer queue. Each queue is run at a specific point in the kernel. A kernel thread, keventd, ran the work associated with the scheduler queue. This was the precursor to the full work queue interface. The timer queue was run at each tick of the system timer and the immediate queue was run in a handful of different places to ensure it was run "immediately" (hack!). There were other queues, too. Additionally, you could dynamically create new queues.
All this might sound useful, but the reality is that the task queue interface was a mess. All the queues were essentially arbitrary abstractions, scattered about the kernel as if thrown in the air and kept where they landed. The only meaningful queue was the scheduler queue, which provided the only way to defer work to process context.
The other good thing about task queues was the brain-dead simple interface. Despite the myriad of queues and the arbitrary rules about when they ran, the interface was as simple as possible. But that's about itthe rest of task queues needed to go.
The various task queue users were converted to other bottom-half mechanisms. Most of them switched to tasklets. The scheduler queue users stuck around. Finally, the keventd code was generalized into the excellent work queue mechanism we have today and task queues were finally ripped out of the kernel.
Which Bottom Half Should I Use?
The decision over which bottom half to use is important. In the current 2.6 kernel, there are three choices: softirqs, tasklets, and work queues. Tasklets are built on softirqs and, therefore, both are similar. The work queue mechanism is an entirely different creature and is built on kernel threads.
Softirqs, by design, provide the least serialization. This requires softirq handlers to go through extra steps to ensure that shared data is safe because two or more softirqs of the same type may run concurrently on different processors. If the code in question is already highly threaded, such as in a networking subsystem that is chest-deep in per-processor variables, softirqs make a good choice. They are certainly the fastest alternative for timing-critical and high-frequency uses. Tasklets make more sense if the code is not finely threaded. They have a simpler interface and, because two tasklets of the same type might not run concurrently, they are easier to implement. Tasklets are effectively softirqs that do not run concurrently. A driver developer should always choose tasklets over softirqs, unless prepared to utilize per-processor variables or similar magic to ensure that the softirq can safely run concurrently on multiple processors.
If your deferred work needs to run in process context, your only choice of the three is work queues. If process context is not a requirementspecifically, if you have no need to sleepsoftirqs or tasklets are perhaps better suited. Work queues involve the highest overhead because they involve kernel threads and, therefore, context switching. This is not to say that they are inefficient, but in light of thousands of interrupts hitting per second (as the networking subsystem might experience), other methods make more sense. For most situations, however, work queues are sufficient.
In terms of ease of use, work queues take the crown. Using the default events queue is child's play. Next come tasklets, which also have a simple interface. Coming in last are softirqs, which need to be statically created and require careful thinking with their implementation.
Table 7.3 is a comparison between the three bottom-half interfaces.
Table 7.3. Bottom Half ComparisonBottom Half | Context | Inherent Serialization |
|---|
Softirq | Interrupt | None | Tasklet | Interrupt | Against the same tasklet | Work queues | Process | None (scheduled as process context) |
In short, normal driver writers have two choices. First, do you need a schedulable entity to perform your deferred work fundamentally, do you need to sleep for any reason? Then work queues are your only option. Otherwise, tasklets are preferred. Only if scalability becomes a concern do you investigate softirqs.
Locking Between the Bottom Halves
We have not discussed locking yet, which is such a fun and expansive topic that we devote the next two chapters to it. Nonetheless, it is important to understand that it is crucial to protect shared data from concurrent access while using bottom halves, even on a single processor machine. Remember, a bottom half can run at virtually any moment. You might want to come back to this section after reading the next two chapters if the concept of locking is foreign to you.
One of the benefits of tasklets is that they are serialized with respect to themselves: The same tasklet will not run concurrently, even on two different processors. This means you do not have to worry about intratasklet[8] concurrency issues. Intertasklet concurrency (that is, when two different tasklets share the same data) requires proper locking.
Because softirqs provide no serialization, (even two instances of the same softirq might run simultaneously), all shared data needs an appropriate lock.
If process context code and a bottom half share data, you need to disable bottom-half processing and obtain a lock before accessing the data. Doing both ensures local and SMP protection and prevents a deadlock.
If interrupt context code and a bottom half share data, you need to disable interrupts and obtain a lock before accessing the data. This also ensures both local and SMP protection and prevents a deadlock.
Any shared data in a work queue requires locking, too. The locking issues are no different from normal kernel code because work queues run in process context.
Chapter 8 covers the magic behind locking, and Chapter 9 covers the kernel locking primitives. These chapters cover how to protect data that bottom halves use.
Disabling Bottom Halves
Normally, it is not sufficient to only disable bottom halves. More often, to safely protect shared data, you need to obtain a lock and disable bottom halves. Such methods, which you might use in a driver, are covered in Chapter 9. If you are writing core kernel code, however, you might need to disable just the bottom halves.
To disable all bottom-half processing (specifically, all softirqs and thus all tasklets), call local_bh_disable(). To enable bottom-half processing, call local_bh_enable(). Yes, the function is misnamed; no one bothered to change the name when the BH interface gave way to softirqs. Table 7.4 is a summary of these functions.
Table 7.4. Listing of Bottom Half Control MethodsMethod | Description |
|---|
void local_bh_disable() | Disable softirq and tasklet processing on the local processor | void local_bh_enable() | Enable softirq and tasklet processing on the local processor |
The calls can be nestedonly the final call to local_bh_enable() actually enables bottom halves. For example, the first time local_bh_disable() is called, local softirq processing is disabled. If local_bh_disable() is called three more times, local processing remains disabled. Processing is not reenabled until the fourth call to local_bh_enable().
The functions accomplish this by maintaining a per-task counter via the preempt_count (interestingly, the same counter used by kernel preemption). When the counter reaches zero, bottom-half processing is possible. Because bottom halves were disabled, local_bh_enable() also checks for any pending bottom halves and executes them.
The functions are unique to each supported architecture and are usually written as complicated macros in <asm/softirq.h>. The following are close C representations for the curious:
/*
* disable local bottom halves by incrementing the preempt_count
*/
void local_bh_disable(void)
{
struct thread_info *t = current_thread_info();
t->preempt_count += SOFTIRQ_OFFSET;
}
/*
* decrement the preempt_count - this will 'automatically' enable
* bottom halves if the count returns to zero
*
* optionally run any bottom halves that are pending
*/
void local_bh_enable(void)
{
struct thread_info *t = current_thread_info();
t->preempt_count -= SOFTIRQ_OFFSET;
/*
* is preempt_count zero and are any bottom halves pending?
* if so, run them
*/
if (unlikely(!t->preempt_count && softirq_pending(smp_processor_id())))
do_softirq();
}
The Bottom of Bottom-Half Processing
In this chapter, we covered the three mechanisms used to defer work in the Linux kernel: softirqs, tasklets, and work queues. We went over their design and implementation. We discussed how to use them in your own code and we insulted their poorly conceived names. For historical completeness, we also looked at the bottom-half mechanisms that existed in previous versions of the Linux kernel: BH's and task queues.
We talked a lot in this chapter about synchronization and concurrency because such topics apply quite a bit to bottom halves. We even wrapped up the chapter with a discussion on disabling bottom halves for reasons of concurrency protection. It is now time to dive head first into these topics. The next chapter discusses kernel synchronization and concurrency in the abstract, providing a foundation for understanding the very issues at the heart of the problem. The subsequent chapter discusses the specific interfaces provided by our beloved kernel to solve these problems. Armed with the next two chapters, the world is your oyster.
Chapter 8. Kernel Synchronization Introduction
In a shared memory application, care must be taken to ensure that shared resources are protected from concurrent access. The kernel is no exception. Shared resources require protection from concurrent access because if multiple threads of execution access and manipulate the data at the same time, the threads may overwrite each other's changes or access data while it is in an inconsistent state. Concurrent access of shared data is a recipe for instability that often proves very hard to track down and debuggetting it right off the bat is important.
Properly protecting shared resources can be tough. Years ago, before Linux supported symmetrical multiprocessing, preventing concurrent access of data was simple. Because only a single processor was supported, the only way data could have been accessed concurrently was if an interrupt occurred or if kernel code explicitly rescheduled and allowed another task to run. Back in those days, life was simple.
Those days are over. Symmetrical multiprocessing support was introduced in the 2.0 kernel and has been continually enhanced ever since. Multiprocessing support implies that kernel code can simultaneously run on two or more processors. Consequently, without protection, code in the kernel, running on two different processors, can simultaneously access shared data at exactly the same time. With the introduction of the 2.6 kernel, the Linux kernel is preemptive. This implies that (again, in the absence of protection) the scheduler can preempt kernel code at virtually any point and reschedule another task. Today, a number of scenarios allow for concurrency inside the kernel and they all require protection.
This chapter discusses the issues of concurrency and synchronization, as they exist in an operating system kernel. The next chapter details the mechanisms and interfaces that the Linux kernel provides to solve these synchronization issues and prevent race conditions.
Critical Regions and Race Conditions
Code paths that access and manipulate shared data are called critical regions. It is usually unsafe for multiple threads of execution to access the same resource simultaneously. To prevent concurrent access during critical regions, the programmer must ensure that the code executes atomicallythat is, the code completes without interruption as if the entire critical region were one indivisible instruction. It is a bug if it is possible for two threads of execution to be simultaneously in the same critical region. When this actually occurs, we call it a race condition (named because the threads raced to get there). Note how rare this could bedebugging race conditions is often very hard because they are not easily reproducible. Ensuring that unsafe concurrency is prevented and that race conditions do not occur is called synchronization.
Why Do We Need Protection?
To best identify race conditions, let's look at just how ubiquitous critical regions are. For a first example, let's consider a real world case: an ATM (Automated Teller Machine, called a cash machine, cashpoint, or ABM outside of the United States).
One of the most common functions performed by cash machines is withdrawing money from a person's personal bank account. A person walks up to the machine, inserts an ATM card, types in a PIN providing a modicum of authentication, selects Withdrawal, inputs a pecuniary amount, hits OK, takes the money, and mails it to me.
After the user has asked for a specific amount of money, the cash machine needs to ensure that the money actually exists in that user's account. If the money exists, it then needs to deduct the withdrawal from the total funds available. The code to implement this would look something like
int total = get_total_from_account(); /* total funds in account */
int withdrawal = get_withdrawal_amount(); /* amount user asked to withdrawal */
/* check whether the user has enough funds in her account */
if (total < withdrawal)
error("You do not have that much money!")
/* OK, the user has enough money: deduct the withdrawal amount from her total */
total -= withdrawal;
update_total_funds(total);
/* give the user their money */
spit_out_money(withdrawal);
Now, let's presume that another deduction in the user's funds is happening at the same time. It does not matter how the simultaneous deduction is happening: Assume that the user's spouse is initiating another withdrawal at another ATM, or electronically transferring funds out of the account, or the bank is deducting a fee from the account (as banks these days are so wont to do), or whatever.
Both systems performing the withdrawal would have code similar to what we just looked at: first check whether the deduction is possible, then compute the new total funds, and finally execute the physical deduction. Now let's make up some numbers. Presume that the first deduction is a withdrawal from an ATM for $100 and that the second deduction is the bank applying a fee of $10 because the customer walked into the bank, (which is not allowed, you must use the ATM, we do not want to see you). Assume the customer has a total of $105 in the bank. Obviously, one of these transactions cannot correctly complete without sending the account into the red.
What you would expect is something like this: The fee transaction happens first. Ten dollars is less than $105, so ten is subtracted from 105 to get a new total of 95, and $10 is pocketed by the bank. Then the ATM withdrawal comes along and fails because $95 is less than $100.
Life can be much more interesting. Assume that the two transactions are initiated at roughly the same time. Both transactions verify that sufficient funds exist: $105 is more than both $100 and $10, so all is good. Then the withdrawal process subtracts $100 from $105, yielding $5. The fee transaction then does the same, subtracting $10 from $105 and getting $95. The withdrawal process then updates the user's new total available funds to $5. Now the fee transaction also updates the new total, resulting in $95. Free money!
Clearly, financial institutions must ensure that this can never happen. They must lock the account during certain operations, making each transaction atomic with respect to any other transaction. Such transactions must occur in their entirety, without interruption, or not occur at all.
The Single Variable
Now, let's look at a specific computing example. Consider a very simple shared resource, a single global integer, and a very simple critical region, the operation of merely incrementing it:
i++;
This might translate into machine instructions to the computer's processor that resemble the following:
get the current value of i and copy it into a register
add one to the value stored in the register
write back to memory the new value of i
Now, assume that there are two threads of execution, both enter this critical region, and the initial value of i is seven. The desired outcome is then similar to the following (with each row representing a unit of time):
Thread 1 | Thread 2 |
|---|
get i (7) | - | increment i (7 -> 8) | - | write back i (8) | - | - | get i (8) | - | increment i (8 -> 9) | - | write back i (9) |
As expected, seven incremented twice is nine.A possible outcome, however, is the following:
Thread 1 | Thread 2 |
|---|
get i (7) | get i (7) | increment i (7 -> 8) | - | - | increment i (7 -> 8) | write back i (8) | - | - | write back i (8) |
If both threads of execution read the initial value of i before it is incremented, both threads will increment and save the same value. As a result, the variable i contains the value eight when, in fact, it should now contain nine. This is one of the simplest examples of a critical region. Thankfully, the solution is equally as simple: We merely need a way to perform these operations in one indivisible step. Most processors provide an instruction to atomically read, increment, and write back a single variable. Using this atomic instruction, the only possible outcome is
Thread 1 | Thread 2 |
|---|
increment i (7 -> 8) | - | - | increment i (8 -> 9) |
Or:
Thread 1 | Thread 2 |
|---|
- | increment i (7 -> 8) | increment i (8 -> 9) | - |
It would never be possible for the two atomic operations to interleave. The processor would physically ensure that it was impossible. Using such an instruction would alleviate the problem. The kernel provides a set of interfaces that implement these atomic instructions; they are discussed in the next chapter.
Locking
Now, let's consider a more complicated race condition that requires a more complicated solution. Assume you have a queue of requests that need to be serviced. How you implement the queue is irrelevant, but you can assume it is a linked list, where each node represents a request. Two functions manipulate the queue. One function adds a new request to the tail of the queue. Another function removes a request from the head of the queue and does something useful with the request. Various parts of the kernel invoke these two functions; thus, requests are continually being added, removed, and serviced. Manipulating the request queues certainly requires multiple instructions. If one thread attempts to read from the queue while another is in the middle of manipulating it, the reading thread will find the queue in an inconsistent state. It should be apparent the sort of damage that could occur if access to the queue could occur concurrently. Often, when the shared resource is a complex data structure, the result of a race condition is corruption of the data structure.
The previous scenario, at first, might not have a clear solution. How can you prevent one processor from reading from the queue while another processor is updating it? Although it is feasible for a particular architecture to implement simple instructions, such as arithmetic and comparison, atomically it is ludicrous for architectures to provide instructions to support the indefinitely sized critical regions that would exist in the previous example. What is needed is a way of making sure that only one thread manipulates the data structure at a timeor, lockingaccess to it while another thread of execution is in the marked region.
A lock provides such a mechanism; it works much like a lock on a door. Imagine the room beyond the door as the critical region. Inside the room, only one thread of execution can be present at a given time. When a thread enters the room, it locks the door behind it. When the thread is finished manipulating the shared data, it leaves the room and unlocks the door. If another thread reaches the door while it is locked, it must wait for the thread inside to exit the room and unlock the door before it can enter. Threads hold locks; locks protect data.
In the previous request queue example, a single lock could have been used to protect the queue. Whenever there was a new request to add to the queue, the thread would first obtain the lock. Then it could safely add the request to the queue and ultimately release the lock. When a thread wanted to remove a request from the queue, it too would obtain the lock. Then it could read the request and remove it from the queue. Finally, it would release the lock. Any other access to the queue would similarly need to obtain the lock. Because the lock can be held by only one thread at a time, only a single thread can manipulate the queue at a time. If a thread comes along while another thread is already updating it, the second thread has to wait for the first to release the lock before it can continue. The lock prevents concurrency and protects the queue from race conditions.
Any code that accesses the queue first needs to obtain the relevant lock. If another thread of execution comes along, the lock prevents concurrency:
Thread 1 | Thread 2 |
|---|
TRy to lock the queue | try to lock the queue | succeeded: acquired lock | failed: waiting... | access queue... | waiting... | unlock the queue | waiting... | ... | succeeded: acquired lock | | | access queue... | | | unlock the queue |
Notice that locks are advisory and voluntary. Locks are entirely a programming construct that the programmer must take advantage of. Nothing prevents you from writing code that manipulates the fictional queue without the appropriate lock. Such a practice, of course, would eventually result in a race condition and corruption.
Locks come in various shapes and sizesLinux alone implements a handful of different locking mechanisms. The most significant difference between the various mechanisms is the behavior when the lock is contended (already in use)some locks simply busy wait, whereas other locks put the current task to sleep until the lock becomes available. The next chapter discusses the behavior of the different locks in Linux and their interfaces.
Astute readers are now screaming. The lock does not solve the problem; it simply shrinks the critical region down to just the lock and unlock code: probably much smaller, sure, but still a potential race! Fortunately, locks are implemented using atomic operations that ensure no race exists. A single instruction can verify whether the key is taken and, if not, seize it. How this is done is very architecture-specific, but almost all processors implement an atomic test and set instruction that tests the value of an integer and sets it to a new value only if it is zero. A value of zero means unlocked.
What Causes Concurrency, Anyway?
In user-space, the need for synchronization stems from the fact that programs are scheduled preemptively by the will of the scheduler. Because a process can be preempted at any time and another process can be scheduled onto the processor, it is possible for a process to be involuntarily preempted in the middle of accessing a critical region. If the newly scheduled process then enters the same critical region (say, if the two processes are threads and they access the same shared memory), a race can occur. The same problem can occur with multiple single-threaded processes sharing files, or within a single program with signals, because signals can occur asynchronously. This type of concurrencywhere two things do not actually happen at the same time, but interleave with each other such that they might as wellis called pseudo-concurrency.
If you have a symmetrical multiprocessing machine, two processes can actually be executed in a critical region at the exact same time. That is called true concurrency. Although the causes and semantics of true versus pseudo concurrency are different, they both result in the same race conditions and require the same sort of protection.
The kernel has similar causes of concurrency. They are
Interrupts
An interrupt can occur asynchronously at almost any time, interrupting the currently executing code.
Softirqs and tasklets
The kernel can raise or schedule a softirq or tasklet at almost any time, interrupting the currently executing code.
Kernel preemption
Because the kernel is preemptive, one task in the kernel can preempt another.
Sleeping and synchronization with user-space
A task in the kernel can sleep and thus invoke the scheduler, resulting in the running of a new process.
Symmetrical multiprocessing
Two or more processors can be executing kernel code at exactly the same time.
It is important that all kernel developers understand and prepare for these causes of concurrency. It is a major bug if an interrupt occurs in the middle of code that is manipulating a resource and the interrupt handler can access the same resource. Similarly, it is a bug if kernel code can be preempted while it is accessing a shared resource. Likewise, it is a bug if code in the kernel sleeps while in the middle of a critical section. Finally, two processors should never be able to simultaneously access the same shared data. With a clear picture of what data needs protection, it is not hard to provide the locking to keep the world safe. Rather, the hard part is identifying these conditions and realizing that to prevent concurrency, you need some form of protection. Let us reiterate this point, because it is quite important. Implementing the actual locking in your code to protect shared data is not hard, especially when done early on while designing the code. The tricky part is identifying the actual shared data and the corresponding critical sections. This is why designing locking into your code from the get-go, and not as an afterthought, is of paramount importance. It can be very hard to go in, after the fact, and identify what needs locking and retrofit locking into the existing code. The result is usually not pretty, either. The moral of this is to always design proper locking into your code from the beginning.
Code that is safe from concurrent access from an interrupt handler is said to be interrupt-safe. Code that is safe from concurrency on symmetrical multiprocessing machines is SMP-safe. Code that is safe from concurrency with kernel preemption is preempt-safe. The actual mechanisms used to provide synchronization and protect against race conditions in all these cases is covered in the next chapter.
So, How Do I Know What Needs Protecting?
Identifying what data specifically needs protection is vital. Because any data that can be accessed concurrently probably needs protection, it is often easier to identify what data does not need protection and work from there. Obviously, any data that is local to one particular thread of execution does not need protection, because only that thread can access the data. For example, local automatic variables (and dynamically allocated data structures whose address is stored only on the stack) do not need any sort of locking because they exist solely on the stack of the executing thread. Likewise, data that is accessed by only a specific task does not require locking (because a process can execute on only one processor at a time).
What does need locking? Most global kernel data structures do. A good rule of thumb is that if another thread of execution can access the data, the data needs some sort of locking; if anyone else can see it, lock it. Remember to lock data, not code.
|
Because the Linux kernel is configurable at compile-time, it makes sense that you can tailor the kernel specifically for a given machine. Most importantly, the CONFIG_SMP configure option controls whether the kernel supports SMP. Many locking issues disappear on uniprocessor machines; consequently, when CONFIG_SMP is unset, unnecessary code is not compiled into the kernel image. For example, such configuration enables uniprocessor machines to forego the overhead of spin locks. The same trick applies to CONFIG_PREEMPT (the configure option enabling kernel preemption). This was an excellent design decisionthe kernel maintains one clean source base, and the various locking mechanisms are used as needed. Different combinations of CONFIG_SMP and CONFIG_PREEMPT on different architectures compile in varying lock support.
In your code, provide appropriate protection for the most pessimistic case, SMP with kernel preemption, and all scenarios will be covered. |
Whenever you write kernel code, you should ask yourself these questions:
Is the data global? Can a thread of execution other than the current one access it? Is the data shared between process context and interrupt context? Is it shared between two different interrupt handlers? If a process is preempted while accessing this data, can the newly scheduled process access the same data? Can the current process sleep (block) on anything? If it does, in what state does that leave any shared data? What prevents the data from being freed out from under me? What happens if this function is called again on another processor? What am I going to do about it?
In short, nearly all global and shared data in the kernel requires some form of the synchronization methods, discussed in the next chapter.
Deadlocks
A deadlock is a condition involving one or more threads of execution and one or more resources, such that each thread is waiting for one of the resources, but all the resources are already held. The threads are all waiting for each other, but they will never make any progress toward releasing the resources that they already hold. Therefore, none of the threads can continue, which means we have a deadlock.
A good analogy is a four-way traffic stop. If each car at the stop decides to wait for the other cars before going, no car will ever go and we have a traffic deadlock.
The simplest example of a deadlock is the self-deadlock: If a thread of execution attempts to acquire a lock it already holds, it has to wait for the lock to be released.
But it will never release the lock, because it is busy waiting for the lock, and the result is deadlock:
acquire lock
acquire lock, again
wait for lock to become available
...
Similarly, consider n threads and n locks. If each thread holds a lock that the other thread wants, all threads block while waiting for their respective locks to become available. The most common example is with two threads and two locks, which is often called the deadly embrace or the ABBA deadlock:
Thread 1 | Thread 2 |
|---|
acquire lock A | acquire lock B | TRy to acquire lock B | try to acquire lock A | wait for lock B | wait for lock A |
Each thread is waiting for the other and neither thread will ever release its original lock; therefore, neither lock will ever become available.
Prevention of deadlock scenarios is important. Although it is difficult to prove that code is free of deadlocks, it is possible to write deadlock-free code. A few simple rules go a long way:
Lock ordering is vital. Nested locks must always be obtained in the same order. This prevents the deadly embrace deadlock. Document the lock ordering so others will follow it. Prevent starvation. Ask, does this code always finish? If foo does not occur, will bar wait forever? Do not double acquire the same lock. Complexity in your locking scheme invites deadlocks, so design for simplicity.
The first point is important, and worth stressing. If two or more locks are ever acquired at the same time, they must always be acquired in the same order. Let's assume you have the cat, dog, and fox lock that protect data structures of the same name. Now assume you have a function that needs to work on all three of these data structures simultaneouslyperhaps to copy data between them. Whatever the case, the data structures require locking to ensure safe access. If one function acquires the locks in the order cat, dog, and then fox, then every other function must obtain these locks (or a subset of them) in this same order. For example, it is a potential deadlock (and hence a bug) to first obtain the fox lock, and then obtain the dog lock (because the dog lock must always be acquired prior to the fox lock). Once more, here is an example where this would cause a deadlock:
Thread 1 | Thread 2 |
|---|
acquire lock cat | acquire lock fox | acquire lock dog | try to acquire lock dog | try to acquire lock fox | wait for lock dog | wait for lock fox | - |
Thread one is waiting for the fox lock, which thread two holds, while thread two is waiting for the dog lock, which thread one holds. Neither ever releases its lock and hence both wait foreverbam, deadlock. If the locks were always obtained in the same order, a deadlock in this manner would not be possible.
Whenever locks are nested within other locks, a specific ordering must be obeyed. It is good practice to place the ordering in a comment above the lock. Something like the following is a good idea:
/*
* cat_lock - always obtain before the dog lock
*/
Note that the order of unlock does not matter with respect to deadlock, although it is common practice to release the locks in an order inverse to that in which they were acquired.
Preventing deadlocks is very important. The Linux kernel has some basic debugging facilities for detecting deadlock scenarios in a running kernel. These features are discussed in the next chapter.
|
Contention and Scalability
The term lock contention, or simply contention, is used to describe a lock that is currently in use, but that another thread is trying to acquire. A lock that is highly contended often has threads waiting to acquire it. High contention can occur because a lock is frequently obtained, held for a long time, or both. Because a lock's job is to serialize access to a resource, it comes as no surprise that locks can slow down a system's performance. A highly contended lock can become a bottleneck in the system, quickly limiting its performance. Of course, the locks are also required to prevent the system from tearing itself to shreds, so a solution to high contention must continue to provide the necessary concurrency protection.
Scalability is a measurement of how well a system can be expanded. In operating systems, we talk of the scalability with a large number of processes, a large number of processors, or large amounts of memory. We can discuss scalability in relation to virtually any component of a computer to which we can attach a quantity. Ideally, doubling the number of processors should result in a doubling of the system's processor performance. This, of course, is never the case.
The scalability of Linux on a large number of processors has increased dramatically in the time since multiprocessing support was introduced in the 2.0 kernel. In the early days of Linux multiprocessing support, only one task could execute in the kernel at a time. During 2.2, this limitation was removed as the locking mechanisms grew more fine-grained. Through 2.4 and onward, kernel locking became even finer grained. Today, in the 2.6 Linux kernel, kernel locking is very fine-grained and scalability is very good.
The granularity of locking is a description of the size or amount of data that a lock protects. A very coarse lock protects a large amount of datafor example, an entire subsystem's set of data structures. On the other hand, a very fine-grained lock protects a very small amount of datasay, only a single element in a larger structure. In reality, most locks fall somewhere in between these two extremes, protecting neither an entire subsystem nor an individual element, but perhaps a single structure or list of structures. Most locks start off fairly coarse, and are made more fine-grained as lock contention proves to be a problem.
One example of evolving to finer-grained locking is the scheduler runqueues, discussed in Chapter 4, "Process Scheduling." In 2.4 and prior kernels, the scheduler had a single runqueue (recall, a runqueue is the list of runnable processes). In 2.6, the O(1) scheduler introduced per-processor runqueues, each with a unique lock. The locking evolved from a single global lock to separate locks for each processor. This was an important optimization, because the runqueue lock was highly contended on large machines, essentially serializing the entire scheduling process down to a single processor executing in the scheduler at a time.
Generally, this scalability improvement is a very good thing because it improves Linux's performance on larger and more powerful systems. Rampant scalability "improvements" can lead to a decrease in performance on smaller SMP and UP machines, however, because smaller machines may not need such fine-grained locking, but will nonetheless have to put up with the increased complexity and overhead. Consider a linked list. An initial locking scheme would provide a single lock for the entire list. In time, this single lock might prove to be a scalability bottleneck on very large multiprocessor machines that frequently access this linked list. In response, the single lock could be broken up into one lock per node in the linked list. For each node that you wanted to read or write, you obtained the node's unique lock. Now there is only lock contention when multiple processors are accessing the same exact node. What if there is still lock contention, however? Do you provide a lock for each element in each node? Each bit of each element? The answer is no. Seriously, even though this very fine-grained locking might ensure excellent scalability on very large SMP machines, how does it perform on dual processor machines? The overhead of all those extra locks is wasted if a dual processor machine does not see significant lock contention to begin with.
Nonetheless, scalability is an important consideration. Designing your locking from the beginning to scale well is important. Coarse locking of major resources can easily become a bottleneck on even small machines. There is a thin line between too-coarse locking and too-fine locking. Locking that is too coarse results in poor scalability if there is high lock contention, whereas locking that is too fine results in wasteful overhead if there is little lock contention. Both scenarios equate to poor performance. Start simple and grow in complexity only as needed. Simplicity is key.
Locking and Your Code
Making your code SMP-safe is not something that can be added as an afterthought. Proper synchronizationlocking that is free of deadlocks, scalable, and cleanrequires design decisions from start through finish. Whenever you write kernel code, whether it is a new system call or a rewritten driver, protecting data from concurrent access needs to be a primary concern.
Provide sufficient protection for every scenarioSMP, kernel preemption, and so onand rest assured the data will be safe on any given machine and configuration. The next chapter discusses just how to do this.
With the fundamentals and the theories of synchronization, concurrency, and locking behind us, let's now dive into the actual tools that the Linux kernel provides to ensure that your code is race and deadlock free.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |

 LINUX
LINUX 
 Books
Books
