Ordering и Barriers
Когда мы имеем дело с синхронизацией процессов или устройств,
иногда возникает необходимость, чтобы операции чтения из памяти и записи в память
шли в определенном порядке.
Когда вы имеете дело с железом , необходимо лишний раз убедиться в том,
что определенный цикл чтения происходит строго по порядку.
В симметричных мульти-процессных системах важно,
чтобы запись осуществлялась в строго определенном порядке.
Как компилятор , так и процессор в состоянии менять порядок чтения-записи.
В процессорах имеются специальные инструкции для этого.
Такие инструкции называются barriers.
Например , на некоторых процессорах в следующем коде
a = 1;
b = 2;
вначале может быть проинициализирована переменная b.
Этот реордеринг компилятором и процессором делается по-разному.
Компилятор делает это статично и раз и навсегда.
Процессор может сделать это динамично по мере необходимости.
Но ежели переменные a и b глобальны , то в коде
a = 1;
b = a;
реордеринг сделан никогда не будет ни тем , ни другим.
Метод rmb() реализует чтение memory barrier.
В момент работы этого метода реордеринг невозможен.
Метод wmb() работает аналогично на запись.
Метод mb() реализует одновременно интерфейс предыдущих двух методов.
Вариант rmb(), read_barrier_depends(),
реализует read barrier, но с высокой частотой загрузки.
На некоторых архитектурах read_barrier_depends() значительно быстрее rmb().
Рассмотрим пример , использующий mb() и rmb().
Начальное значение a равно единице и начальное значение b равно двум.
Thread 1 | Thread 2 |
|---|
a = 3; | - | mb(); | - | b = 4; | c = b; | - | rmb(); | - | d = a; |
Вызов mb() гарантирует , что запись переменных a и b будет сделана именно в этом порядке.
Вызов rmb() гарантирует , что чтение переменных c и d будет сделана именно в этом порядке.
This sort of reordering occurs because modern processors dispatch and commit instructions out of order, to optimize use of their pipelines. What can end up happening in the previous example is that the instructions associated with the loads of b and a occur out of order. The rmb()and wmb() functions correspond to instructions that tell the processor to commit any pending load or store instructions, respectively, before continuing.
Let's look at a similar example, but one that uses read_barrier_depends() instead of rmb(). In this example, initially a is one, b is two, and p is &b.
Thread 1 | THRead 2 |
|---|
a = 3; | - | mb(); | - | p = &a; | pp = p; | - | read_barrier_depends(); | - | b = *pp; |
Again, without memory barriers, it would be possible for b to be set to pp before pp was set to p. The read_barrier_depends(), however, provides a sufficient barrier because the load of *pp depends on the load of p. It would also be sufficient to use rmb() here, but because the reads are data dependent, we can use the potentially faster read_barrier_depends(). Note that in either case, the mb() is required to enforce the intended load/store ordering in the left thread.
The macros smp_rmb(), smp_wmb(), smp_mb(), and smp_read_barrier_depends() provide a useful optimization. On SMP kernels they are defined as the usual memory barriers, whereas on UP kernels they are defined only as a compiler barrier. You can use these SMP variants when the ordering constraints are specific to SMP systems.
The barrier() method prevents the compiler from optimizing loads or stores across the call. The compiler knows not to rearrange stores and loads in ways that would change the effect of the C code and existing data dependencies. It does not have knowledge, however, of events that can occur outside the current context. For example, the compiler cannot know about interrupts that might read the same data you are writing. For this reason, you might want to ensure a store is issued before a load, for example. The previous memory barriers also function as compiler barriers, but a compiler barrier is much lighter in weight than a memory barrier. Indeed, a compiler barrier is practically free, because it simply prevents the compiler from possibly rearranging things.
Table 9.10 has a full listing of the memory and compiler barrier methods provided by all architectures in the Linux kernel.
Table 9.10. Memory and Compiler Barrier MethodsBarrier | Description |
|---|
rmb() | Prevents loads from being reordered across the barrier | read_barrier_depends() | Prevents data-dependent loads from being reordered across the barrier | wmb() | Prevents stores from being reordered across the barrier | mb() | Prevents load or stores from being reordered across the barrier | smp_rmb() | Provides an rmb() on SMP, and on UP provides a barrier() | smp_read_barrier_depends() | Provides a read_barrier_depends() on SMP, and provides a barrier() on UP | smp_wmb() | Provides a wmb() on SMP, and provides a barrier() on UP | smp_mb() | Provides an mb() on SMP, and provides a barrier() on UP | barrier() | Prevents the compiler from optimizing stores or loads across the barrier |
Note that the actual effects of the barriers vary for each architecture. For example, if a machine does not perform out-of-order stores (for example, Intel x86 chips do not) then wmb() does nothing. You can use the appropriate memory barrier for the worst case (that is, the weakest ordering processor) and your code will compile optimally for your architecture.
Synchronization Summarization
This chapter applied the concepts and theories of the last chapter to help you understand the actual methods provided by the Linux kernel for enforcing synchronization and concurrency. We started with the simplest method of ensuring synchronization, atomic operations. We then looked at spin locks, the most common lock in the kernel, which provide a lightweight single-holder lock that busy waits while contended. We also discussed semaphores, a sleeping lock, and less common more specialized locking primitives such as completion variables and seq locks. We poked fun at the BKL, looked at preemption disabling, and tackled barriers. It has been a wild ride.
Armed with this chapter's arsenal of synchronization methods, you can now write kernel code that prevents race conditions and ensures the desired synchronization, with luck picking the best tool for the job.
Atomic Operations
Atomic operations provide instructions that execute atomicallywithout interruption. Just as the atom was originally thought to be an indivisible particle, atomic operators are indivisible instructions. For example, as discussed in the previous chapter, an atomic increment can read and increment a variable by one in a single indivisible and uninterruptible step. Instead of the race discussed in the previous chapter, the outcome is always similar to the following (assume i is initially seven):
Thread 1 | Thread 2 |
|---|
atomic increment i (7 -> 8) | - | - | atomic increment i (8 -> 9) |
The resulting value, nine, is correct. It is never possible for the two atomic operations to occur on the same variable concurrently. Therefore, it is not possible for the increments to race.
The kernel provides two sets of interfaces for atomic operationsone that operates on integers and another that operates on individual bits. These interfaces are implemented on every architecture that Linux supports. Most architectures either directly support simple atomic operations or provide an operation to lock the memory bus for a single operation (and thus ensure another operation cannot occur simultaneously). Architectures that cannot easily support primitive atomic operations, such as SPARC, somehow cope. (The only atomic instruction that is guaranteed to exist on all SPARC machines is ldstub.)
Atomic Integer Operations
The atomic integer methods operate on a special data type, atomic_t. This special type is used, as opposed to having the functions work directly on the C int type, for a couple of reasons. First, having the atomic functions accept only the atomic_t type ensures that the atomic operations are used only with these special types. Likewise, it also ensures that the data types are not passed to any other nonatomic functions. Indeed, what good would atomic operations be if they were not consistently used on the data? Next, the use of atomic_t ensures the compiler does not (erroneously but cleverly) optimize access to the valueit is important the atomic operations receive the correct memory address and not an alias. Finally, use of atomic_t can hide any architecture-specific differences in its implementation.
Despite being an integer, and thus 32 bits on all of the machines that Linux supports, developers and their code once had to assume that an atomic_t was no larger than 24 bits in size. The SPARC port in Linux has an odd implementation of atomic operations: A lock was embedded in the lower 8 bits of the 32-bit int (it looked like Figure 9.1). The lock was used to protect concurrent access to the atomic type because the SPARC architecture lacks appropriate support at the instruction level. Consequently, only 24 usable bits were available on SPARC machines. Although code that assumed that the full 32-bit range existed would work on other machines, it would have failed in strange and subtle ways on SPARC machinesand that is just rude. Recently, clever hacks have allowed SPARC to provide a fully usable 32-bit atomic_t, and this limitation is no more. The old 24-bit implementation is still used by some internal SPARC code, however, and lives in SPARC's <asm/atomic.h>.
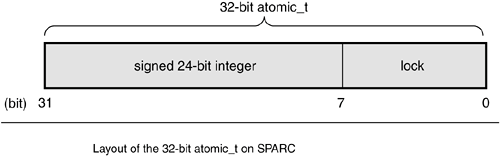
The declarations needed to use the atomic integer operations are in <asm/atomic.h>. Some architectures provide additional methods that are unique to that architecture, but all architectures provide at least a minimum set of operations that are used throughout the kernel. When you write kernel code, you can ensure that these operations are correctly implemented on all architectures.
Defining an atomic_t is done in the usual manner. Optionally, you can set it to an initial value:
atomic_t v; /* define v */
atomic_t u = ATOMIC_INIT(0); /* define u and initialize it to zero */
Operations are all simple:
atomic_set(&v, 4); /* v = 4 (atomically) */
atomic_add(2, &v); /* v = v + 2 = 6 (atomically) */
atomic_inc(&v); /* v = v + 1 = 7 (atomically) */
If you ever need to convert an atomic_t to an int, use atomic_read():
printk("%d\n", atomic_read(&v)); /* will print "7" */
A common use of the atomic integer operations is to implement counters. Protecting a sole counter with a complex locking scheme is silly, so instead developers use atomic_inc() and atomic_dec(), which are much lighter in weight.
Another use of the atomic integer operators is atomically performing an operation and testing the result. A common example is the atomic decrement and test:
int atomic_dec_and_test(atomic_t *v)
This function decrements by one the given atomic value. If the result is zero, it returns true; otherwise, it returns false. A full listing of the standard atomic integer operations (those found on all architectures) is in Table 9.1. All the operations implemented on a specific architecture can be found in <asm/atomic.h>.
Table 9.1. Full Listing of Atomic Integer OperationsAtomic Integer Operation | Description |
|---|
ATOMIC_INIT(int i) | At declaration, initialize an atomic_t to i | int atomic_read(atomic_t *v) | Atomically read the integer value of v | void atomic_set(atomic_t *v, int i) | Atomically set v equal to i | void atomic_add(int i, atomic_t *v) | Atomically add i to v | void atomic_sub(int i, atomic_t *v) | Atomically subtract i from v | void atomic_inc(atomic_t *v) | Atomically add one to v | void atomic_dec(atomic_t *v) | Atomically subtract one from v | int atomic_sub_and_test(int i, atomic_t *v) | Atomically subtract i from v and return true if the result is zero; otherwise false | int atomic_add_negative(int i, atomic_t *v) | Atomically add i to v and return true if the result is negative; otherwise false | int atomic_dec_and_test(atomic_t *v) | Atomically decrement v by one and return true if zero; false otherwise | int atomic_inc_and_test(atomic_t *v) | Atomically increment v by one and return true if the result is zero; false otherwise |
The atomic operations are typically implemented as inline functions with inline assembly (apparently, kernel developers like inlines). In the case where a specific function is inherently atomic, the given function is usually just a macro. For example, on most sane architectures, a word-sized read is always atomic. That is, a read of a single word cannot complete in the middle of a write to that word. The read will always return the word in a consistent state, either before or after the write completes, but never in the middle. Consequently, atomic_read() is usually just a macro returning the integer value of the atomic_t.
|
The preceding discussion on atomic reading begs a discussion on the differences between atomicity and ordering. As discussed, a word-sized read will always occur atomically. It will never interleave with a write to the same word; the read will always return the word in a consistent stateperhaps before the write completed, perhaps after, but never during. For example, if an integer is initially 42 and then set to 365, a read on the integer will always return 42 or 365 and never some commingling of the two values. This is atomicity.
It might be that your code wants something more than this, perhaps for the read to always occur before the pending write. This is not atomicity, but ordering. Atomicity ensures that instructions occur without interruption and that they complete either in their entirety or not at all. Ordering, on the other hand, ensures that the desired order of two or more instructionseven if they are to occur in separate threads of execution or even separate processorsis preserved.
The atomic operations discussed in this section guarantee only atomicity. Ordering is enforced via barrier operations, which we will discuss later in this chapter. |
In your code, it is usually preferred to choose atomic operations over more complicated locking mechanisms. On most architectures, one or two atomic operations incur less overhead and less cache-line thrashing than a more complicated synchronization method. As with any performance-sensitive code, however, testing multiple approaches is always smart.
Atomic Bitwise Operations
In addition to atomic integer operations, the kernel also provides a family of functions that operate at the bit level. Not surprisingly, they are architecture specific and defined in <asm/bitops.h>.
What may be surprising is that the bitwise functions operate on generic memory addresses. The arguments are a pointer and a bit number. Bit zero is the least significant bit of the given address. On 32-bit machines, bit 31 is the most significant bit and bit 32 is the least significant bit of the following word. There are no limitations on the bit number supplied, although most uses of the functions provide a word and, consequently, a bit number between 0 and 31 (or 63, on 64-bit machines).
Because the functions operate on a generic pointer, there is no equivalent of the atomic integer's atomic_t type. Instead, you can work with a pointer to whatever data you desire. Consider an example:
unsigned long word = 0;
set_bit(0, &word); /* bit zero is now set (atomically) */
set_bit(1, &word); /* bit one is now set (atomically) */
printk("%ul\n", word); /* will print "3" */
clear_bit(1, &word); /* bit one is now unset (atomically) */
change_bit(0, &word); /* bit zero is flipped; now it is unset (atomically) */
/* atomically sets bit zero and returns the previous value (zero) */
if (test_and_set_bit(0, &word)) {
/* never true */
}
/* the following is legal; you can mix atomic bit instructions with normal C */
word = 7;
A listing of the standard atomic bit operations is in Table 9.2.
Table 9.2. Listing of Atomic Bitwise OperationsAtomic Bitwise Operation | Description |
|---|
void set_bit(int nr, void *addr) | Atomically set the nr-th bit starting from addr | void clear_bit(int nr, void *addr) | Atomically clear the nr-th bit starting from addr | void change_bit(int nr, void *addr) | Atomically flip the value of the nr-th bit starting from addr | int test_and_set_bit(int nr, void *addr) | Atomically set the nr-th bit starting from addr and return the previous value | int test_and_clear_bit(int nr, void *addr) | Atomically clear the nr-th bit starting from addr and return the previous value | int test_and_change_bit(int nr, void *addr) | Atomically flip the nr-th bit starting from addr and return the previous value | int test_bit(int nr, void *addr) | Atomically return the value of the nr-th bit starting from addr |
Conveniently, nonatomic versions of all the bitwise functions are also provided. They behave identically to their atomic siblings, except they do not guarantee atomicity and their names are prefixed with double underscores. For example, the nonatomic form of test_bit() is __test_bit(). If you do not require atomicity (say, for example, because a lock already protects your data), these variants of the bitwise functions might be faster.
|
On first glance, the concept of a non-atomic bit operation may not make any sense. Only a single bit is involved, thus there is no possibility of inconsistency. So long as one of the operations succeeds, what else could matter? Sure, ordering might be important, but we are talking about atomicity here. At the end of the day, if the bit has a value that was provided by any of the instructions, we should be good to go, right?
Let's jump back to just what atomicity means. Atomicity means that either instructions succeed in their entirety, uninterrupted, or instructions fail to execute at all. Therefore, if you issue two atomic bit operations, you expect two operations to succeed. Sure, the bit needs to have a consistent and correct value (the specified value from the last successful operation, as suggested in the previous paragraph). Moreover, however, if the other operations succeed, then at some point in time the bit needs to have those intermediate values, too.
For example, assume you issue two atomic bit operations: Initially set the bit and then clear the bit. Without atomic operations, the bit may end up cleared, but it may never have been set. The set operation could occur simultaneously with the clear operation and fail. The clear operation would succeed, and the bit would emerge cleared as intended. With atomic operations, however, the set would actually occurthere would be a moment in time when a read would show the bit as setand then the clear would execute and the bit be zero.
This behavior might be important, especially when ordering comes into play. |
The kernel also provides routines to find the first set (or unset) bit starting at a given address:
int find_first_bit(unsigned long *addr, unsigned int size)
int find_first_zero_bit(unsigned long *addr, unsigned int size)
Both functions take a pointer as their first argument and the number of bits in total to search as their second. They return the bit number of the first set or first unset bit, respectively. If your code is searching only a word, the routines __ffs() and ffz(), which take a single parameter of the word in which to search, are optimal.
Unlike the atomic integer operations, code typically has no choice whether to use the bitwise operationsthey are the only portable way to set a specific bit. The only question is whether to use the atomic or nonatomic variants. If your code is inherently safe from race conditions, you can use the nonatomic versions, which might be faster depending on the architecture.
Spin Locks
Although it would be nice if every critical region consisted of code that did nothing more complicated than incrementing a variable, reality is much crueler. In real life, critical regions can span multiple functions. For example, it is often the case that data must be removed from one structure, formatted and parsed, and added to another structure. This entire operation must occur atomically; it must not be possible for other code to read from or write to either structure before its update is done. Because simple atomic operations are clearly incapable of providing the needed protection in such a complex scenario, a more general method of synchronization is neededlocks.
The most common lock in the Linux kernel is the spin lock. A spin lock is a lock that can be held by at most one thread of execution. If a thread of execution attempts to acquire a spin lock while it is contended (already held), the thread busy loopsspinswaiting for the lock to become available. If the lock is not contended, the thread can immediately acquire the lock and continue. The spinning prevents more than one thread of execution from entering the critical region at any one time. Note that the same lock can be used in multiple locationsso all access to a given data structure, for example, can be protected and synchronized.
Going back to the door and key analogy from last chapter, spin locks are akin to sitting outside the door, waiting for the fellow inside to come out and hand you the key. If you reach the door and no one is inside, you can grab the key and enter the room. If you reach the door and someone is currently inside, you must wait outside for the key, effectively checking for its presence repeatedly. When the room is vacated, you can grab the key and go inside. Thanks to the key (read: spin lock), only one person (read: thread of execution) is allowed inside the room (read: critical region) at the same time.
The fact that a contended spin lock causes threads to spin (essentially wasting processor time) while waiting for the lock to become available is important. This behavior is the point of the spin lock. It is not wise to hold a spin lock for a long time. This is the nature of the spin lock: a lightweight single-holder lock that should be held for short durations. An alternative behavior when the lock is contended is to put the current thread to sleep and wake it up when it becomes available. Then the processor can go off and execute other code. This incurs a bit of overheadmost notably the two context switches required to switch out of and back into the blocking thread, which is certainly a lot more code than the handful of lines used to implement a spin lock. Therefore, it is wise to hold spin locks for less than the duration of two context switches. Because most of us have better things to do than measure context switches, just try to hold the lock as little time as possible. The next section covers
semaphores, which provide a lock that makes the waiting thread sleep, rather than spin, when contended.
Spin locks are architecture dependent and implemented in assembly. The architecture-dependent code is defined in <asm/spinlock.h>. The actual usable interfaces are defined in <linux/spinlock.h>. The basic use of a spin lock is
spinlock_t mr_lock = SPIN_LOCK_UNLOCKED;
spin_lock(&mr_lock);
/* critical region */
spin_unlock(&mr_lock);
The lock can be held simultaneously by at most only one thread of execution. Consequently, only one thread is allowed in the critical region at a time. This provides the needed protection from concurrency on multiprocessing machines. On uniprocessor machines, the locks compile away and do not exist. They simply act as markers to disable and enable kernel preemption. If kernel preempt is turned off, the locks compile away entirely.
|
Unlike spin lock implementations in other operating systems and threading libraries, the Linux kernel's spin locks are not recursive. This means that if you attempt to acquire a lock you already hold, you will spin, waiting for yourself to release the lock. But because you are busy spinning, you will never release the lock and you will deadlock. Be careful! |
Spin locks can be used in interrupt handlers, whereas semaphores cannot be used because they sleep. If a lock is used in an interrupt handler, you must also disable local interrupts (interrupt requests on the current processor) before obtaining the lock. Otherwise, it is possible for an interrupt handler to interrupt kernel code while the lock is held and attempt to reacquire the lock. The interrupt handler spins, waiting for the lock to become available. The lock holder, however, does not run until the interrupt handler completes. This is an example of the double-acquire deadlock discussed in the previous chapter. Note that you need to disable interrupts only on the current processor. If an interrupt occurs on a different processor, and it spins on the same lock, it does not prevent the lock holder (which is on a different processor) from eventually releasing the lock.
The kernel provides an interface that conveniently disables interrupts and acquires the lock. Usage is
spinlock_t mr_lock = SPIN_LOCK_UNLOCKED;
unsigned long flags;
spin_lock_irqsave(&mr_lock, flags);
/* critical region ... */
spin_unlock_irqrestore(&mr_lock, flags);
The routine spin_lock_irqsave() saves the current state of interrupts, disables them locally, and then obtains the given lock. Conversely, spin_unlock_irqrestore() unlocks the given lock and returns interrupts to their previous state. This way, if interrupts were initially disabled, your code would not erroneously enable them, but instead keep them disabled. Note that the flags variable is seemingly passed by value. This is because the lock routines are implemented partially as macros.
On uniprocessor systems, the previous example must still disable interrupts to prevent an interrupt handler from accessing the shared data, but the lock mechanism is compiled away. The lock and unlock also disable and enable kernel preemption, respectively.
|
It is important that each lock is clearly associated with what it is locking. More importantly, it is important that you protect data and not code. Despite the examples in this chapter explaining the importance of protecting the critical sections, it is the actual data inside that needs protection and not the code.
Big Fat Rule: Locks that simply wrap code regions are hard to understand and prone to race conditions. Lock data, not code.
Rather than lock code, always associate your shared data with a specific lock. For example, "the struct foo is locked by foo_lock." Whenever you access the data, make sure it is safe. Most likely, this means obtaining the appropriate lock before manipulating the data and releasing the lock when finished. |
If you always know before the fact that interrupts are initially enabled, there is no need to restore their previous state. You can unconditionally enable them on unlock. In those cases, spin_lock_irq() and spin_unlock_irq() are optimal:
spinlock_t mr_lock = SPIN_LOCK_UNLOCKED;
spin_lock_irq(&mr_lock);
/* critical section ... */
spin_unlock_irq(&mr_lock);
As the kernel grows in size and complexity, it is increasingly hard to ensure that interrupts are always enabled in any given code path in the kernel. Use of spin_lock_irq() therefore is not recommended. If you do use it, you had better be positive that interrupts were originally on or people will be upset when they expect interrupts to be off but find them on!
|
The configure option CONFIG_DEBUG_SPINLOCK enables a handful of debugging checks in the spin lock code. For example, with this option the spin lock code checks for the use of uninitialized spin locks and unlocking a lock that is not yet locked. When testing your code, you should always run with spin lock debugging enabled. |
Other Spin Lock Methods
The method spin_lock_init() can be used to initialize a dynamically created spin lock (a spinlock_t that you do not have a direct reference to, just a pointer).
The method spin_trylock() attempts to obtain the given spin lock. If the lock is contended, rather than spin and wait for the lock to be released, the function immedi-ately returns zero. If it succeeds in obtaining the lock, it returns nonzero. Similarly, spin_is_locked() returns nonzero if the given lock is currently acquired. Otherwise, it returns zero. In neither case does this function actually obtain the lock.
See Table 9.3 for a complete list of the standard spin lock methods.
Table 9.3. Listing of Spin Lock MethodsMethod | Description |
|---|
spin_lock() | Acquires given lock | spin_lock_irq() | Disables local interrupts and acquires given lock | spin_lock_irqsave() | Saves current state of local interrupts, disables local interrupts, and acquires given lock | spin_unlock() | Releases given lock | spin_unlock_irq() | Releases given lock and enables local interrupts | spin_unlock_irqrestore() | Releases given lock and restores local interrupts to given previous state | spin_lock_init() | Dynamically initializes given spinlock_t | spin_trylock() | Tries to acquire given lock; if unavailable, returns nonzero | spin_is_locked() | Returns nonzero if the given lock is currently acquired, otherwise it returns zero |
Spin Locks and Bottom Halves
As mentioned in Chapter 7, "Bottom Halves and Deferring Work," certain locking precautions must be taken when working with bottom halves. The function spin_lock_bh() obtains the given lock and disables all bottom halves. The function spin_unlock_bh() performs the inverse.
Because a bottom half may preempt process context code, if data is shared between a bottom half process context, you must protect the data in process context with both a lock and the disabling of bottom halves. Likewise, because an interrupt handler may preempt a bottom half, if data is shared between an interrupt handler and a bottom half, you must both obtain the appropriate lock and disable interrupts.
Recall that two tasklets of the same type do not ever run simultaneously. Thus, there is no need to protect data used only within a single type of tasklet. If the data is shared between two different tasklets, however, you must obtain a normal spin lock before accessing the data in the bottom half. You do not need to disable bottom halves because a tasklet never preempts another running tasklet on the same processor.
With softirqs, regardless of whether it is the same softirq type or not, if data is shared by softirqs it must be protected with a lock. Recall that softirqs, even two of the same type, may run simultaneously on multiple processors in the system. A softirq will never preempt another softirq running on the same processor, however, so disabling bottom halves is not needed.
Reader-Writer Spin Locks
Sometimes, lock usage can be clearly divided into readers and writers. For example, consider a list that is both updated and searched. When the list is updated (written to), it is important that no other threads of execution concurrently write to or read from the list. Writing demands mutual exclusion. On the other hand, when the list is searched (read from), it is only important that nothing else write to the list. Multiple concurrent readers are safe so long as there are no writers. The task list's access patterns (discussed in Chapter 3, "Process Management") fit this description. Not surprisingly, the task list is protected by a reader-writer spin lock.
When a data structure is neatly split into reader/writer paths like this, it makes sense to use a locking mechanism that provides similar semantics. In this case, Linux provides reader-writer spin locks. Reader-writer spin locks provide separate reader and writer variants of the lock. One or more readers can concurrently hold the reader lock. The writer lock, conversely, can be held by at most one writer with no concurrent readers. Reader/writer locks are sometimes called shared/exclusive or concurrent/exclusive locks because the lock is available in a shared (for readers) and an exclusive (for writers) form.
Usage is similar to spin locks. The reader-writer spin lock is initialized via
rwlock_t mr_rwlock = RW_LOCK_UNLOCKED;
Then, in the reader code path:
read_lock(&mr_rwlock);
/* critical section (read only) ... */
read_unlock(&mr_rwlock);
Finally, in the writer code path:
write_lock(&mr_rwlock);
/* critical section (read and write) ... */
write_unlock(&mr_lock);
Normally, the readers and writers are in entirely separate code paths, such as in this example.
Note that you cannot "upgrade" a read lock to a write lock. This code
read_lock(&mr_rwlock);
write_lock(&mr_rwlock);
deadlocks as the write lock spins, waiting for all readers to release the lockincluding yourself. If you ever need to write, obtain the write lock from the very start. If the line between your readers and writers is muddled, it might be an indication that you do not need to use reader-writer locks. In that case, a normal spin lock is optimal.
It is safe for multiple readers to obtain the same lock. In fact, it is safe for the same thread to recursively obtain the same read lock. This lends itself to a useful and common optimization. If you have only readers in interrupt handlers but no writers, you can mix use of the "interrupt disabling" locks. You can use read_lock() instead of read_lock_irqsave() for reader protection. You still need to disable interrupts for write access, a la write_lock_irqsave(), otherwise a reader in an interrupt could deadlock on the held write lock. See Table 9.4 for a full listing of the reader-writer spin lock methods.
Table 9.4. Listing of Reader-Writer Spin Lock MethodsMethod | Description |
|---|
read_lock() | Acquires given lock for reading | read_lock_irq() | Disables local interrupts and acquires given lock for reading | read_lock_irqsave() | Saves the current state of local interrupts, disables local interrupts, and acquires the given lock for reading | read_unlock() | Releases given lock for reading | read_unlock_irq() | Releases given lock and enables local interrupts | read_unlock_irqrestore() | Releases given lock and restores local interrupts to the given previous state | write_lock() | Acquires given lock for writing | write_lock_irq() | Disables local interrupts and acquires the given lock for writing | write_lock_irqsave() | Saves current state of local interrupts, disables local interrupts, and acquires the given lock for writing | write_unlock() | Releases given lock | write_unlock_irq() | Releases given lock and enables local interrupts | write_unlock_irqrestore() | Releases given lock and restores local interrupts to given previous state | write_trylock() | Tries to acquire given lock for writing; if unavailable, returns nonzero | rw_lock_init() | Initializes given rwlock_t | rw_is_locked() | Returns nonzero if the given lock is currently acquired, or else it returns zero |
A final important consideration in using the Linux reader-writer spin locks is that they favor readers over writers. If the read lock is held and a writer is waiting for exclusive access, readers that attempt to acquire the lock will continue to succeed. The spinning writer does not acquire the lock until all readers release the lock. Therefore, a sufficient number of readers can starve pending writers. This is important to keep in mind when designing your locking.
Spin locks provide a very quick and simple lock. The spinning behavior is optimal for short hold times and code that cannot sleep (interrupt handlers, for example). In cases where the sleep time might be long or you potentially need to sleep while holding the lock, the semaphore is a solution.
Semaphores
Semaphores in Linux are sleeping locks. When a task attempts to acquire a semaphore that is already held, the semaphore places the task onto a wait queue and puts the task to sleep. The processor is then free to execute other code. When the processes holding the semaphore release the lock, one of the tasks on the wait queue is awakened so that it can then acquire the semaphore.
Let's jump back to the door and key analogy. When a person reaches the door, he can grab the key and enter the room. The big difference lies in what happens when another dude reaches the door and the key is not available. In this case, instead of spinning, the fellow puts his name on a list and takes a nap. When the person inside the room leaves, he checks the list at the door. If anyone's name is on the list, he goes over to the first name and gives him a playful jab in the chest, waking him up and allowing him to enter the room. In this manner, the key (read: semaphore) continues to ensure that there is only one person (read: thread of execution) inside the room (read: critical region) at one time. If the room is occupied, instead of spinning, the person puts his name on a list (read: wait queue) and takes a nap (read: blocks on the wait queue and goes to sleep), allowing the processor to go off and execute other code. This provides better processor utilization than spin locks because there is no time spent busy looping, but semaphores have much greater overhead than spin locks. Life is always a trade-off.
You can draw some interesting conclusions from the sleeping behavior of semaphores:
Because the contending tasks sleep while waiting for the lock to become available, semaphores are well suited to locks that are held for a long time. Conversely, semaphores are not optimal for locks that are held for very short periods because the overhead of sleeping, maintaining the wait queue, and waking back up can easily outweigh the total lock hold time. Because a thread of execution sleeps on lock contention, semaphores can be obtained only in process context because interrupt context is not schedulable. You can (although you may not want to) sleep while holding a semaphore because you will not deadlock when another process acquires the same semaphore. (It will just go to sleep and eventually let you continue.) You cannot hold a spin lock while you acquire a semaphore, because you might have to sleep while waiting for the semaphore, and you cannot sleep while holding a spin lock.
These facts highlight the uses of semaphores versus spin locks. In most uses of semaphores, there is little choice as to what lock to use. If your code needs to sleep, which is often the case when synchronizing with user-space, semaphores are the sole solution. It is often easier, if not necessary, to use semaphores because they allow you the flexibility of sleeping. When you do have a choice, the decision between semaphore and spin lock should be based on lock hold time. Ideally, all your locks should be held as briefly as possible. With semaphores, however, longer lock hold times are more acceptable. Additionally, unlike spin locks, semaphores do not disable kernel preemption and, consequently, code holding a semaphore can be preempted. This means semaphores do not adversely affect scheduling latency.
A final useful feature of semaphores is that they can allow for an arbitrary number of simultaneous lock holders. Whereas spin locks permit at most one task to hold the lock at a time, the number of permissible simultaneous holders of semaphores can be set at declaration time. This value is called the usage count or simply the count. The most common value is to allow, like spin locks, only one lock holder at a time. In this case, the count is equal to one and the semaphore is called either a binary semaphore (because it is either held by one task or not held at all) or a mutex (because it enforces mutual exclusion). Alternatively, the count can be initialized to a nonzero value greater than one. In this case, the semaphore is called a counting semaphore, and it allows at most count holders of the lock at a time. Counting semaphores are not used to enforce mutual exclusion because they allow multiple threads of execution in the critical region at once. Instead, they are used to enforce limits in certain code. They are not used much in the kernel. If you use a semaphore, you almost assuredly want to use a mutex (a semaphore with a count of one).
Semaphores were formalized by Edsger Wybe Dijkstra in 1968 as a generalized locking mechanism. A semaphore supports two atomic operations, P() and V(), named after the Dutch word Proberen, to test (literally, to probe), and the Dutch word Verhogen, to increment. Later systems called these methods down() and up(), respectively, and so does Linux. The down() method is used to acquire a semaphore by decrementing the count by one. If the new count is zero or greater, the lock is acquired and the task can enter the critical region. If the count is negative, the task is placed on a wait queue and the processor moves on to something else. These names are used as verbs: You down a semaphore to acquire it. The up() method is used to release a semaphore upon completion of a critical region. This is called upping the semaphore. The method increments the count value; if the semaphore's wait queue is not empty, one of the waiting tasks is awakened and allowed to acquire the semaphore.
Creating and Initializing Semaphores
The semaphore implementation is architecture dependent and defined in <asm/semaphore.h>. The struct semaphore type represents semaphores. Statically declared semaphores are created via
static DECLARE_SEMAPHORE_GENERIC(name, count)
where name is the variable's name and count is the usage count of the semaphore. As a shortcut to create the more common mutex, use
static DECLARE_MUTEX(name);
where, again, name is the variable name of the semaphore. More frequently, semaphores are created dynamically, often as part of a larger structure. In this case, to initialize a dynamically created semaphore to which you have only an indirect pointer reference, use
sema_init(sem, count);
where sem is a pointer and count is the usage count of the semaphore. Similarly, to initialize a dynamically created mutex, you can use
init_MUTEX(sem);
I do not know why the "mutex" in init_MUTEX() is capitilized or why the "init" comes first here but second in sema_init(). I do know, however, that it looks dumb and I apologize for the inconsistency. I hope, however, that after you've read Chapter 7, the kernel's symbol naming does not shock anyone.
Using Semaphores
The function down_interruptible() attempts to acquire the given semaphore. If it fails, it sleeps in the TASK_INTERRUPTIBLE state. Recall from Chapter 3 that this process state implies that a task can be awakened with a signal, which is generally a good thing. If the task receives a signal while waiting for the semaphore, it is awakened and down_interruptible() returns -EINTR. Alternatively, the function down() places the task in the TASK_UNINTERRUPTIBLE state if it sleeps. You most likely do not want this because the process waiting for the semaphore does not respond to signals. Therefore, use of down_interruptible() is much more common than down(). Yes, again, the naming is not ideal.
You can use down_trylock() to try to acquire the given semaphore with blocking. If the semaphore is already held, the function immediately returns nonzero. Otherwise, it returns zero and you successfully hold the lock.
To release a given semaphore, call up(). Consider an example:
/* define and declare a semaphore, named mr_sem, with a count of one */
static DECLARE_MUTEX(mr_sem);
/* attempt to acquire the semaphore ... */
if (down_interruptible(&mr_sem)) {
/* signal received, semaphore not acquired ... */
}
/* critical region ... */
/* release the given semaphore */
up(&mr_sem);
A complete listing of the semaphore methods is in Table 9.5.
Reader-Writer Semaphores
Semaphores, like spin locks, also come in a reader-writer flavor. The situations where reader-writer semaphores are preferred over standard semaphores are the same as with reader-writer spin locks versus standard spin locks.
Reader-writer semaphores are represented by the struct rw_semaphore type, which is declared in <linux/rwsem.h>. Statically declared reader-writer semaphores are created via
static DECLARE_RWSEM(name);
where name is the declared name of the new semaphore.
Reader-writer semaphores that are created dynamically are initialized via
init_rwsem(struct rw_semaphore *sem)
All reader-writer semaphores are mutexes (that is, their usage count is one). Any number of readers can concurrently hold the read lock, so long as there are no writers. Conversely, only a sole writer (with no readers) can acquire the write variant of the lock. All reader-writer locks use uninterruptible sleep, so there is only one version of each down(). For example:
static DECLARE_RWSEM(mr_rwsem);
/* attempt to acquire the semaphore for reading ... */
down_read(&mr_rwsem);
/* critical region (read only) ... */
/* release the semaphore */
up_read(&mr_rwsem);
/* ... */
/* attempt to acquire the semaphore for writing ... */
down_write(&mr_rwsem);
/* critical region (read and write) ... */
/* release the semaphore */
up_write(&mr_sem);
As with semaphores, implementations of down_read_trylock() and down_write_trylock() are provided. Each has one parameter: a pointer to a reader-writer semaphore. They both return nonzero if the lock is successfully acquired and zero if it is currently contended. Be careful: For admittedly no good reason, this is the opposite of normal semaphore behavior!
Reader-writer semaphores have a unique method that their reader-writer spin lock cousins do not have: downgrade_writer(). This function atomically converts an acquired write lock to a read lock.
Reader-writer semaphores, as spin locks of the same nature, should not be used unless there is a clear separation between write paths and read paths in your code. Supporting the reader-writer mechanisms has a cost, and it is worthwhile only if your code naturally splits along a reader/writer boundary.
Spin Locks Versus Semaphores
Knowing when to use a spin lock versus a semaphore is important to writing optimal code. In many cases, however, there is little choice. Only a spin lock can be used in interrupt context, whereas only a semaphore can be held while a task sleeps. Table 9.6 reviews the requirements that dictate which lock to use.
Table 9.6. What to Use: Spin Locks Versus SemaphoresRequirement | Recommended Lock |
|---|
Low overhead locking | Spin lock is preferred | Short lock hold time | Spin lock is preferred | Long lock hold time | Semaphore is preferred | Need to lock from interrupt context | Spin lock is required | Need to sleep while holding lock | Semaphore is required |
Completion Variables
Using completion variables is an easy way to synchronize between two tasks in the kernel when one task needs to signal to the other that an event has occurred. One task waits on the completion variable while another task performs some work. When the other task has completed the work, it uses the completion variable to wake up any waiting tasks. If this sounds like a semaphore, you are rightthe idea is much the same. In fact, completion variables merely provide a simple solution to a problem whose answer is otherwise semaphores. For example, the vfork() system call uses completion variables to wake up the parent process when the child process execs or exits.
Completion variables are represented by the struct completion type, which is defined in <linux/completion.h>. A statically created completion variable is created and initialized via
DECLARE_COMPLETION(mr_comp);
A dynamically created completion variable is initialized via init_completion().
On a given completion variable, the tasks that want to wait call wait_for_completion(). After the event has occurred, calling complete() signals all waiting tasks to wake up. Table 9.7 has a listing of the completion variable methods.
Table 9.7. Completion Variables MethodsMethod | Description |
|---|
init_completion(struct completion *) | Initializes the given dynamically created completion variable | wait_for_completion(struct completion *) | Waits for the given completion variable to be signaled | complete(struct completion *) | Signals any waiting tasks to wake up |
For sample usages of completion variables, see kernel/sched.c and kernel/fork.c. A common usage is to have a completion variable dynamically created as a member of a data structure. Kernel code waiting for the initialization of the data structure calls wait_for_completion(). When the initialization is complete, the waiting tasks are awakened via a call to completion().
BKL: The Big Kernel Lock
Welcome to the redheaded stepchild of the kernel. The Big Kernel Lock (BKL) is a global spin lock that was created to ease the transition from Linux's original SMP implementation to fine-grained locking. The BKL has some interesting properties:
You can sleep while holding the BKL. The lock is automatically dropped when the task is unscheduled and reacquired when the task is rescheduled. Of course, this does not mean it is always safe to sleep while holding the BKL, merely that you can and you will not deadlock. The BKL is a recursive lock. A single process can acquire the lock multiple times and not deadlock, as it would with a spin lock. You can use the BKL only in process context. It is evil.
These features helped ease the transition from kernel version 2.0 to 2.2. When SMP support was introduced in kernel version 2.0, only one task could be in the kernel at a time. (Of course, now the kernel is quite finely threadedwe have come a long way.) A goal of 2.2 was to allow multiple processors to execute in the kernel concurrently. The BKL was introduced to help ease the transition to finer grained locking. It was a great aide then; now it is a scalability burden.
Use of the BKL is discouraged. In fact, new code should never introduce locking that uses the BKL. The lock is still fairly well used in parts of the kernel, however. Therefore, understanding the BKL and its interfaces is important. The BKL behaves like a spin lock, with the additions previously discussed. The function lock_kernel() acquires the lock and the function unlock_kernel() releases the lock. A single thread of execution may acquire the lock recursively, but must then call unlock_kernel() an equal number of times to release the lock. On the last unlock call the lock will be released. The function kernel_locked() returns nonzero if the lock is currently held; otherwise, it returns zero. These interfaces are declared in <linux/smp_lock.h>. Here is sample usage:
lock_kernel();
/*
* Critical section, synchronized against all other BKL users...
* Note, you can safely sleep here and the lock will be transparently
* released. When you reschedule, the lock will be transparently
* reacquired. This implies you will not deadlock, but you still do
* not want to sleep if you need the lock to protect data here!
*/
unlock_kernel();
The BKL also disables kernel preemption while it is held. On UP kernels, the BKL code does not actually perform any physical locking. Table 9.8 has a complete list of the BKL functions.
Table 9.8. List of BKL functionsFunction | Description |
|---|
lock_kernel() | Acquires the BKL | unlock_kernel() | Releases the BKL | kernel_locked() | Returns nonzero if the lock is held and zero otherwise (UP always returns nonzero) |
One of the major issues concerning the BKL is determining what the lock is protecting. Too often, the BKL is seemingly associated with code (for example, "it synchronizes callers to foo()") instead of data ("it protects the foo structure"). This makes replacing BKL uses with a spin lock difficult because it is not easy to determine just what is being locked. The replacement is made even harder in that the relationship between all BKL users needs to be determined.
Seq Locks
The seq lock is a new type of lock introduced in the 2.6 kernel. It provides a very simple mechanism for reading and writing shared data. It works by maintaining a sequence counter. Whenever the data in question is written to, a lock is obtained and a sequence number is incremented. Prior to and after reading the data, the sequence number is read. If the values are the same, then a write did not begin in the middle of the read. Further, if the values are even then a write is not underway (grabbing the write lock makes the value odd, whereas releasing it makes it even because the lock starts at zero).
To define a seq lock:
seqlock_t mr_seq_lock = SEQLOCK_UNLOCKED;
The write path is then
write_seqlock(&mr_seq_lock);
/* write lock is obtained... */
write_sequnlock(&mr_seq_lock);
This looks like normal spin lock code. The oddness comes in with the read path, which is quite a bit different:
unsigned long seq;
do {
seq = read_seqbegin(&mr_seq_lock);
/* read data here ... */
} while (read_seqretry(&mr_seq_lock, seq));
Seq locks are useful to provide a very lightweight and scalable lock for use with many readers and a few writers. Seq locks, however, favor writers over readers. The write lock always succeeds in being obtained so long as there are no other writers. Readers do not affect the write lock, as is the case with reader-writer spin locks and semaphores. Furthermore, pending writers continually cause the read loop (the previous example) to repeat, until there are no longer any writers holding the lock.
Preemption Disabling
Because the kernel is preemptive, a process in the kernel can stop running at any instant to allow a process of higher priority to run. This means a task can begin running in the same critical region as a task that was preempted. To prevent this, the kernel preemption code uses spin locks as markers of nonpreemptive regions. If a spin lock is held, the kernel is not preemptive. Because the concurrency issues with kernel preemption and SMP are the same, and the kernel is already SMP-safe, this simple change makes the kernel preempt-safe, too.
Or so we hope. In reality, some situations do not require a spin lock, but do need kernel preemption disabled. The most frequent of these situations is per-processor data. If the data is unique to each processor, there may be no need to protect it with a lock because only that one processor can access the data. If no spin locks are held, the kernel is preemptive, and it would be possible for a newly scheduled task to access this same variable, as shown here:
task A manipulates per-procesor variable foo, which is not protected by a lock
task A is preempted
task B is scheduled
task B manipulates variable foo
task B completes
task A is rescheduled
task A continues manipulating variable foo
Consequently, even if this were a uniprocessor computer, the variable could be accessed pseudo-concurrently by multiple processes. Normally, this variable would require a spin lock (to prevent true concurrency on multiprocessing machines). If this were a per-processor variable, however, it might not require a lock.
To solve this, kernel preemption can be disabled via preempt_disable(). The call is nestable; you may call it any number of times. For each call, a corresponding call to preempt_enable() is required. The final corresponding call to preempt_enable()re-enables preemption. For example:
preempt_disable();
/* preemption is disabled ... */
preempt_enable();
The preemption count stores the number of held locks and preempt_disable() calls. If the number is zero, the kernel is preemptive. If the value is one or greater, the kernel is not preemptive. This count is incredibly usefulit is a great way to do atomicity and sleep debugging. The function preempt_count() returns this value. See Table 9.9 for a listing of kernel preemptionrelated functions.
Table 9.9. Kernel PreemptionRelated FunctionsFunction | Description |
|---|
preempt_disable() | Disables kernel preemption by incrementing the preemption counter | preempt_enable() | Decrement the preemption counter and check and service any pending reschedules if the count is now zero | preempt_enable_no_resched() | Enables kernel preemption but do not check for any pending reschedules | preempt_count() | Returns the preemption count |
As a cleaner solution to per-processor data issues, you can obtain the processor number (which presumably is used to index into the per-processor data) via get_cpu(). This function disables kernel preemption prior to returning the current processor number:
int cpu;
/* disable kernel preemption and set "cpu" to the current processor */
cpu = get_cpu();
/* manipulate per-processor data ... */
/* reenable kernel preemption, "cpu" can change and so is no longer valid */
put_cpu();
Chapter 10. Timers and Time Management
The passing of time is very important to the kernel. A large number of kernel functions are time driven, as opposed to event driven. Some of these functions are periodic, such as balancing the scheduler runqueues or refreshing the screen. They occur on a fixed schedule, such as 100 times per second. The kernel schedules other functions, such as delayed disk I/O, at a relative time in the future. For example, the kernel might schedule work for 500 milliseconds from now. Finally, the kernel must also manage the system uptime and the current date and time.
Note the differences between relative and absolute time. Scheduling an event for five seconds in the future requires no concept of the absolute timeonly the relative time (for example, five seconds from now). Conversely, managing the current time of day requires the kernel to understand not just the passing of time, but also some absolute measurement of it. Both these concepts are crucial to the management of time.
Also note the differences between events that occur periodically and events the kernel schedules for a fixed point in the future. Events that occur periodicallysay, every 10 millisecondsare driven by the system timer. The system timer is a programmable piece of hardware that issues an interrupt at a fixed frequency. The interrupt handler for this timercalled the timer interruptupdates the system time and performs periodic work. The system timer and its timer interrupt are central to Linux, and a large focus of this chapter.
The other focus is dynamic timersthe facility used to schedule events that run once after a specified time has elapsed. For example, the floppy device driver uses a timer to shut off the floppy drive motor after a specified period of inactivity. The kernel can create and destroy timers dynamically. This chapter covers the kernel implementation of dynamic timers, as well as the interface available for their use in your code.
Kernel Notion of Time
Certainly, the concept of time to a computer is a bit obscure. Indeed, the kernel must work with the system's hardware to comprehend and manage time. The hardware provides a system timer that the kernel uses to gauge the passing of time. This system timer works off of an electronic time source, such as a digital clock or the frequency of the processor. The system timer goes off (often called hitting or popping) at a preprogrammed frequency, called the tick rate. When the system timer goes off, it issues an interrupt that the kernel handles via a special interrupt handler.
Because the kernel knows the preprogrammed tick rate, it knows the time between any two successive timer interrupts. This period is called a tick and is equal to one-over-the-tick-rate seconds. This is how the kernel keeps track of both wall time and system uptime. Wall timethe actual time of dayis of most importance to user-space applications. The kernel keeps track of it simply because the kernel controls the timer interrupt. A family of system calls provide the date and time of day to user-space. The system uptimethe relative time since the system bootedis useful to both kernel-space and user-space. A lot of code must be aware of the passing of time. The difference between two uptime readingsnow and thenis a simple measure of this relativity.
The timer interrupt is very important to the management of the operating system. A large number of kernel functions live and die by the passing of time. Some of the work executed periodically by the timer interrupt includes
Updating the system uptime Updating the time of day On an SMP system, ensuring that the scheduler runqueues are balanced, and if not, balancing them (as discussed in Chapter 4, "Process Scheduling") Checking whether the current process has exhausted its timeslice and, if so, causing a reschedule (also discussed in Chapter 4) Running any dynamic timers that have expired Updating resource usage and processor time statistics
Some of this work occurs on every timer interruptthat is, the work is carried out with the frequency of the tick rate. Other functions execute periodically, but only every n timer interrupts. That is, these functions occur at some fraction of the tick rate. The section "The Timer Interrupt Handler" looks at the timer interrupt handler itself.
The Tick Rate: HZ
The frequency of the system timer (the tick rate) is programmed on system boot based on a static preprocessor define, HZ. The value of HZ differs for each supported architecture. In fact, on some supported architectures, it even differs between machine types.
The kernel defines the value in <asm/param.h>. The tick rate has a frequency of HZ hertz and a period of 1/HZ seconds. For example, in include/asm-i386/param.h, the i386 architecture defines:
#define HZ 1000 /* internal kernel time frequency */
Therefore, the timer interrupt on i386 has a frequency of 1000HZ and occurs 1,000 times per second (every one-thousandth of a second, which is every millisecond). Most other architectures have a tick rate of 100. Table 10.1 is a complete listing of the supported architectures and their defined tick rates.
Table 10.1. Frequency of the Timer InterruptArchitecture | Frequency (in Hertz) |
|---|
Alpha | 1024 | Arm | 100 | Cris | 100 | h8300 | 100 | i386 | 1000 | ia64 | 32 or 1024 | m68k | 100 | m68knommu | 50, 100, or 1000 | Mips | 100 | mips64 | 100 or 1000 | Parisc | 100 or 1000 | Ppc | 1000 | ppc64 | 1000 | s390 | 100 | Sh | 100 or 1000 | Sparc | 100 | sparc64 | 1000 | Um | 100 | v850 | 24, 100, or 122 | x86-64 | 1000 |
When writing kernel code, never assume that HZ has any given value. This is not a common mistake these days because so many architectures have varying tick rates. In the past, however, Alpha was the only architecture with a tick rate not equal to 100Hz, and it was common to see code incorrectly hard-code the value 100 when the HZ value should have been used. Examples of using HZ in kernel code are shown later.
The frequency of the timer interrupt is rather important. As you already saw, the timer interrupt performs a lot of work. Indeed, the kernel's entire notion of time derives from the periodicity of the system timer. Picking the right value, like a successful relationship, is all about compromise.
The Ideal HZ Value
Starting with the initial version of Linux, the i386 architecture has had a timer interrupt frequency of 100 Hz. During the 2.5 development series, however, the frequency was raised to 1000 Hz and was (as such things are) controversial. Because so much of the system is dependent on the timer interrupt, changing its frequency has a reasonable impact on the system. Of course, there are pros and cons to larger versus smaller HZ values.
Increasing the tick rate means the timer interrupt runs more frequently. Consequently, the work it performs occurs more often. This has the following benefits:
The timer interrupt has a higher resolution and, consequently, all timed events have a higher resolution The accuracy of timed events improves
The resolution increases by the same factor as the tick rate increases. For example, the granularity of timers with HZ=100 is 10 milliseconds. In other words, all periodic events occur on the timer interrupt's 10 millisecond boundary and no finer precision is guaranteed. With HZ=1000, however, resolution is 1 millisecondten times finer. Although kernel code can create timers with 1-millisecond resolution, there is no guarantee the precision afforded with HZ=100 is sufficient to execute the timer on anything better than 10-millisecond intervals.
Likewise, accuracy improves in the same manner. Assuming the kernel starts timers at random times, the average timer is off by half the period of the timer interrupt because timers might expire at any time, but are executed only on occurrences of the timer interrupt. For example, with HZ=100, the average event occurs +/ 5 milliseconds off from the desired time. Thus, error is 5 milliseconds on average. With HZ=1000, the average error drops to 0.5 millisecondsa tenfold improvement.
This higher resolution and greater accuracy provides multiple advantages:
Kernel timers execute with finer resolution and increased accuracy (this provides a large number of improvements, one of which is the following). System calls such as poll() and select() that optionally employ a timeout value execute with improved precision. Measurements, such as resource usage or the system uptime, are recorded with a finer resolution. Process preemption occurs more accurately.
Some of the most readily noticeable performance benefits come from the improved precision of poll() and select() timeouts. The improvement might be quite large; an application that makes heavy use of these system calls might waste a great deal of time waiting for the timer interrupt, when, in fact, the timeout has actually expired. Remember, the average error (that is, potentially wasted time) is half the period of the timer interrupt.
Another benefit of a higher tick rate is the greater accuracy in process preemption, which results in decreased scheduling latency. Recall from Chapter 4 that the timer interrupt is responsible for decrementing the running process's timeslice count. When the count reaches zero, need_resched is set and the kernel runs the scheduler as soon as possible. Now assume a given process is running and has 2 milliseconds of its timeslice remaining. In 2 milliseconds, the scheduler should preempt the running process and begin executing a new process. Unfortunately, this event does not occur until the next timer interrupt, which might not be in 2 milliseconds. In fact, at worst the next timer interrupt might be 1/HZ of a second away! With HZ=100, a process can get nearly ten extra milliseconds to run. Of course, this all balances out and fairness is preserved, because all tasks receive the same imprecision in schedulingbut that is not the issue. The problem stems from the latency created by the delayed preemption. If the to-be-scheduled task had something time sensitive to do, such as refill an audio buffer, the delay might not be acceptable. Increasing the tick rate to 1000Hz lowers the worst-case scheduling overrun to just 1 millisecond, and the average-case overrun to just 0.5 milliseconds.
Now, there must be some downside to increasing the tick rate or it would have been 1000Hz (or even higher) to start. Indeed, there is one large issue: A higher tick rate implies more frequent timer interrupts, which implies higher overhead, because the processor must spend more time executing the timer interrupt handler. The higher the tick rate, the more time the processor spends executing the timer interrupt. This adds up to not just less processor time available for other work, but also a more frequent thrashing of the processor's cache. The issue of the overhead's impact is debatable. A move from HZ=100 to HZ=1000 clearly brings with it ten times greater overhead. However, how substantial is the overhead to begin with? The final agreement is that, at least on modern systems, HZ=1000 does not create unacceptable overhead and the move to a 1000Hz timer has not hurt performance too much. Nevertheless, it is possible in 2.6 to compile the kernel with a different value for HZ.
|
You might wonder whether an operating system even needs a fixed timer interrupt. Is it possible to design an OS without ticks? Yes, it is possible but it might not be pretty.
There is no absolute need for a fixed timer interrupt. Instead, the kernel can use a dynamically programmed timer for each pending event. This quickly adds a lot of timer overhead, so a better idea is to have just one timer, and program it to occur when the next earliest event is due. When that timer executes, create a timer for the next event and repeat. With this approach, there is no periodic timer interrupt and no HZ value.
Two issues need to be overcome with this approach. The first is how to manage some concept of ticks, at least so the kernel can keep track of relative time. This is not too hard to solve. Solving the second issuehow to overcome the overhead of managing all the dynamic timers, even with an optimized approachis a bit harder. The overhead and complexity is high enough that the Linux kernel does not take this approach. Nonetheless, people have tried and the results are interestingsearch online archives if interested. |
Jiffies
The global variable jiffies holds the number of ticks that have occurred since the system booted. On boot, the kernel initializes the variable to zero, and it is incremented by one during each timer interrupt. Thus, because there are HZ timer interrupts in a second, there are HZ jiffies in a second. The system uptime is therefore jiffies/HZ seconds.
|
The origin of the term jiffy is unknown. Phrases such as in a jiffy are thought to originate from eighteenth-century England. In lay terms, jiffy refers to an indeterminate but very brief period of time.
In scientific applications, jiffy represents various intervals of time, most commonly 10ms. In physics, a jiffy is sometimes used to refer to the time it takes for light to travel some specific distance (usually a foot or a centimeter or across a nucleon).
In computer engineering, a jiffy is often the time between two successive clock cycles. In electrical engineering, a jiffy is the time to complete one AC (alternating current) cycle. In the United States, this is 1/60 of a second.
In operating systems, especially Unix, a jiffy is the time between two successive clock ticks. Historically, this has been 10ms. As we have seen in this chapter, however, a jiffy in Linux can have various values. |
The jiffies variable is declared in <linux/jiffies.h> as
extern unsigned long volatile jiffies;
In the next section, we will look at its actual definition, which is a bit peculiar. For now, let's look at some sample kernel code. The following code converts from seconds to a unit of jiffies:
(seconds * HZ)
Likewise, this code converts from jiffies to seconds:
(jiffies / HZ)
The former is more common. For example, code often needs to set a value for some time in the future, for example:
unsigned long time_stamp = jiffies; /* now */
unsigned long next_tick = jiffies +_1; /* one tick from now */
unsigned long later = jiffies + 5*HZ; /* five seconds from now */
The latter is typically reserved for communicating with user-space, as the kernel itself rarely cares about any sort of absolute time.
Note that the jiffies variable is prototyped as unsigned long and that storing it in anything else is incorrect.
Internal Representation of Jiffies
The jiffies variable has always been an unsigned long, and therefore 32 bits in size on 32-bit architectures and 64-bits on 64-bit architectures. With a tick rate of 100, a 32-bit jiffies variable would overflow in about 497 days. With HZ increased to 1000, however, that overflow now occurs in just 49.7 days! If jiffies were stored in a 64-bit variable on all architectures, then for any reasonable HZ value the jiffies variable would never overflow in anyone's lifetime.
For performance and historical reasonsmainly compatibility with existing kernel codethe kernel developers wanted to keep jiffies an unsigned long. Some smart thinking and a little linker magic saved that day.
As you previously saw, jiffies is defined as an unsigned long:
extern unsigned long volatile jiffies;
A second variable is also defined in <linux/jiffies.h>:
extern u64 jiffies_64;
The ld(1) script used to link the main kernel image (arch/i386/kernel/vmlinux.lds.S on x86) then overlays the jiffies variable over the start of the jiffies_64 variable:
jiffies = jiffies_64;
Thus, jiffies is the lower 32 bits of the full 64-bit jiffies_64 variable. Code can continue to access the jiffies variable exactly as before. Because most code uses jiffies simply to measure elapses in time, most code cares about only the lower 32 bits. The time management code uses the entire 64 bits, however, and thus prevents overflow of the full 64-bit value. Figure 10.1 shows the layout of jiffies and jiffies_64. Code that accesses jiffies simply reads the lower 32 bits of jiffies_64. The function get_jiffies_64() can be used to read the full 64-bit value. Such a need is rare; consequently, most code simply continues to read the lower 32 bits directly via the jiffies variable.
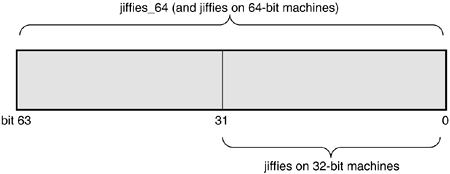
On 64-bit architectures, jiffies_64 and jiffies refer to the same thing. Code can either read jiffies or call get_jiffies_64() because both actions have the same effect.
Jiffies Wraparound
The jiffies variable, like any C integer, experiences overflow when its value is increased beyond its maximum storage limit. For a 32-bit unsigned integer, the maximum value is 232 - 1. Thus, a possible 4294967295 timer ticks can occur before the tick count overflows. When the tick count is equal to this maximum and it is incremented, it wraps around to zero.
Look at an example of a wraparound:
unsigned long timeout = jiffies + HZ/2; /* timeout in 0.5s */
/* do some work ... */
/* then see whether we took too long */
if (timeout > jiffies) {
/* we did not time out, good ... */
} else {
/* we timed out, error ... */
}
The intention of this code snippet is to set a timeout for some time in the futurefor one half second from now, in this example. The code then proceeds to perform some work, presumably poking hardware and waiting for a response. When done, if the whole ordeal took longer than the timeout, the code handles the error as appropriate.
Multiple potential overflow issues are here, but let's study one of them: Consider what happens if jiffies wrapped back to zero after setting timeout. Then the first conditional would fail because the jiffies value would be smaller than timeout despite logically being larger. Conceptually, the jiffies value should be a very large numberlarger than timeout. Because it overflowed its maximum value, however, it is now a very small valueperhaps only a handful of ticks over zero. Because of the wraparound, the results of the if statement are switched. Whoops!
Thankfully, the kernel provides four macros for comparing tick counts that correctly handle wraparound in the tick count. They are in <linux/jiffies.h>:
#define time_after(unknown, known) ((long)(known) - (long)(unknown) < 0)
#define time_before(unknown, known) ((long)(unknown) - (long)(known) < 0)
#define time_after_eq(unknown, known) ((long)(unknown) - (long)(known) >= 0)
#define time_before_eq(unknown, known) ((long)(known) - (long)(unknown) >= 0)
The unknown parameter is typically jiffies and the known parameter is the value against which you want to compare.
The time_after(unknown, known) macro returns true if time unknown is after time known; otherwise, it returns false. The time_before(unknown, known) macro returns true if time unknown is before time known; otherwise, it returns false. The final two macros perform identically to the first two, except they also return true if the parameters are equal.
The timer-wraparound-safe version of the previous example would look like this:
unsigned long timeout = jiffies + HZ/2; /* timeout in 0.5s */
/* ... */
if (time_before(jiffies, timeout)) {
/* we did not time out, good ... */
} else {
/* we timed out, error ... */
}
If you are curious as to why these macros prevent errors because of wraparound, try various values for the two parameters. Then assume one parameter wrapped to zero and see what happens.
User-Space and HZ
In kernels earlier than 2.6, changing the value of HZ resulted in user-space anomalies. This happened because values were exported to user-space in units of ticks-per-second. As these interfaces became permanent, applications grew to rely on a specific value of HZ. Consequently, changing HZ would scale various exported values by some constantwithout user-space knowing! Uptime would read 20 hours when it was in fact two!
To prevent such problems, the kernel needs to scale all exported jiffies values. It does this by defining USER_HZ, which is the HZ value that user-space expects. On x86, because HZ was historically 100, USER_HZ is 100. The macro jiffies_to_clock_t() is then used to scale a tick count in terms of HZ to a tick count in terms of USER_HZ. The macro used depends on whether USER_HZ and HZ are integer multiples of themselves. If so, the macro is rather simple:
#define jiffies_to_clock_t(x) ((x) / (HZ / USER_HZ))
A more complicated algorithm is used if the values are not integer multiples.
Finally, the function jiffies_64_to_clock_t() is provided to convert a 64-bit jiffies value from HZ to USER_HZ units.
These functions are used anywhere a value in ticks-per-seconds needs to be exported to user-space. Example:
unsigned long start;
unsigned long total_time;
start = jiffies;
/* do some work ... */
total_time = jiffies - start;
printk("That took %lu ticks\n", jiffies_to_clock_t(total_time));
User-space expects the previous value as if HZ=USER_HZ. If they are not equivalent, the macro scales as needed and everyone is happy. Of course, this example is silly: It would make more sense to print the message in seconds, not ticks. For example:
printk("That took %lu seconds\n", total_time / HZ);
Hardware Clocks and Timers
Architectures provide two hardware devices to help with time keeping: the system timer, which we have been discussing, and the real-time clock. The actual behavior and implementation of these devices varies between different machines, but the general purpose and design is about the same for each.
Real-Time Clock
The real-time clock (RTC) provides a nonvolatile device for storing the system time. The RTC continues to keep track of time even when the system is off by way of a small battery typically included on the system board. On the PC architecture, the RTC and the CMOS are integrated and a single battery keeps the RTC running and the BIOS settings preserved.
On boot, the kernel reads the RTC and uses it to initialize the wall time, which is stored in the xtime variable. The kernel does not typically read the value again; however, some supported architectures, such as x86, periodically save the current wall time back to the RTC. Nonetheless, the real time clock's primary importance is only during boot, when the xtime variable is initialized.
System Timer
The system timer serves a much more important (and frequent) role in the kernel's timekeeping. The idea behind the system timer, regardless of architecture, is the sameto provide a mechanism for driving an interrupt at a periodic rate. Some architectures implement this via an electronic clock that oscillates at a programmable frequency. Other systems provide a decrementer: A counter is set to some initial value and decrements at a fixed rate until the counter reaches zero. When the counter reaches zero, an interrupt is triggered. In any case, the effect is the same.
On x86, the primary system timer is the programmable interrupt timer (PIT). The PIT exists on all PC machines and has been driving interrupts since the days of DOS. The kernel programs the PIT on boot to drive the system timer interrupt (interrupt zero) at HZ frequency. It is a simple device with limited functionality, but it gets the job done. Other x86 time sources include the local APIC timer and the processor's time stamp counter (TSC).
The Timer Interrupt Handler
Now that we have an understanding of HZ, jiffies, and what the system timer's role is, let's look at the actual implementation of the timer interrupt handler. The timer interrupt is broken into two pieces: an architecture-dependent and an architecture-independent routine.
The architecture-dependent routine is registered as the interrupt handler for the system timer and, thus, runs when the timer interrupt hits. Its exact job depends on the given architecture, of course, but most handlers perform at least the following work:
Obtain the xtime_lock lock, which protects access to jiffies_64 and the wall time value, xtime Acknowledge or reset the system timer as required Periodically save the updated wall time to the real time clock Call the architecture-independent timer routine, do_timer()
The architecture-independent routine, do_timer(), performs much more work:
Increment the jiffies_64 count by one (this is safe, even on 32-bit architectures, because the xtime_lock lock was previously obtained) Update resource usages, such as consumed system and user time, for the currently running process Run any dynamic timers that have expired (discussed in the following section) Execute scheduler_tick(), as discussed in Chapter 4, "Process Scheduling" Update the wall time, which is stored in xtime Calculate the infamous load average
The actual routine is very simple because other functions handle most of the previously discussed work:
void do_timer(struct pt_regs *regs)
{
jiffies_64++;
update_process_times(user_mode(regs));
update_times();
}
The user_mode() macro looks at the state of the processor registers, regs, and returns one if the timer interrupt occurred in user-space and zero if the interrupt occurred in kernel mode. This enables update_process_times() to attribute the previous tick to the proper mode, either user or system:
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id();
int system = user_tick ^ 1;
update_one_process(p, user_tick, system, cpu);
run_local_timers();
scheduler_tick(user_tick, system);
}
The update_one_process() function does the actual updating of the process's times. It is rather elaborate, but note how one of either the user_tick or the system value is equal to one and the other is zero, because of the exclusive-or (XOR). Therefore, updates_one_process() can simply add each value to the corresponding counter without a branch:
/*
* update by one jiffy the appropriate time counter
*/
p->utime += user;
p->stime += system;
The appropriate value is increased by one and the other value remains the same. You might realize that this implies that the kernel credits a process for running the entire previous tick in whatever mode the processor was in when the timer interrupt occurred. In reality, the process might have entered and exited kernel mode many times during the last tick. In fact, the process might not even have been the only process running in the last tick! This granular process accounting is classic Unix, and without much more complex accounting, this is the best the kernel can provide. It is also another reason for a higher frequency tick rate.
Next, the run_local_timers() function marks a softirq (see Chapter 7, "Bottom Halves and Deferring Work") to handle the execution of any expired timers. Timers are covered in a following section, "Timers."
Finally, the scheduler_tick() function decrements the currently running process's timeslice and sets need_resched if needed. On SMP machines, it also balances the per-processor runqueues as needed. This was all discussed in Chapter 4.
When update_process_times() returns, do_timer() calls update_times() to update the wall time:
void update_times(void)
{
unsigned long ticks;
ticks = jiffies - wall_jiffies;
if (ticks) {
wall_jiffies += ticks;
update_wall_time(ticks);
}
last_time_offset = 0;
calc_load(ticks);
}
The ticks value is calculated to be the change in ticks since the last update. In normal cases, this is, of course, one. In rare situations, timer interrupts can be missed and the ticks are said to be lost. This can occur if interrupts are off for a long time. It is not the norm and quite often a bug. The wall_jiffies value is increased by the ticks valuethus, it is equal to the jiffies value of the most recent wall time updateand update_wall_time() is called to update xtime, which stores the wall time. Finally, calc_load() is called to update the load average and update_times() returns.
The do_timer() function returns to the original architecture-dependent interrupt handler, which performs any needed cleanup, releases the xtime_lock lock, and finally returns.
All this occurs every 1/HZ of a second. That is 1000 times per second on your PC.
The Time of Day
The current time of day (the wall time) is defined in kernel/timer.c:
struct timespec xtime;
The timespec data structure is defined in <linux/time.h> as:
struct timespec {
time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
The xtime.tv_sec value stores the number of seconds that have elapsed since January 1, 1970 (UTC). This date is called the epoch. Most Unix systems base their notion of the current wall time as relative to this epoch. The xtime.v_nsec value stores the number of nanoseconds that have elapsed in the last second.
Reading or writing the xtime variable requires the xtime_lock lock, which is not a normal spinlock but a seqlock. Chapter 9, "Kernel Synchronization Methods," discusses seqlocks.
To update xtime, a write seqlock is required:
write_seqlock(&xtime_lock);
/* update xtime ... */
write_sequnlock(&xtime_lock);
Reading xtime requires the use of the read_seqbegin() and read_seqretry() functions:
do {
unsigned long lost;
seq = read_seqbegin(&xtime_lock);
usec = timer->get_offset();
lost = jiffies - wall_jiffies;
if (lost)
usec += lost * (1000000 / HZ);
sec = xtime.tv_sec;
usec += (xtime.tv_nsec / 1000);
} while (read_seqretry(&xtime_lock, seq));
This loop repeats until the reader is assured that it read the data without an intervening write. If the timer interrupt occurred and updated xtime during the loop, the returned sequence number is invalid and the loop repeats.
The primary user-space interface for retrieving the wall time is gettimeofday(), which is implemented as sys_gettimeofday():
asmlinkage long sys_gettimeofday(struct timeval *tv, struct timezone *tz)
{
if (likely(tv)) {
struct timeval ktv;
do_gettimeofday(&ktv);
if (copy_to_user(tv, &ktv, sizeof(ktv)))
return -EFAULT;
}
if (unlikely(tz)) {
if (copy_to_user(tz, &sys_tz, sizeof(sys_tz)))
return -EFAULT;
}
return 0;
}
If the user provided a non-NULL tv value, the architecture-dependent do_gettimeofday() is called. This function primarily performs the xtime read loop previously discussed. Likewise, if tz is non-NULL, the system time zone (stored in sys_tz) is returned to the user. If there were errors copying the wall time or time zone back to user-space, the function returns -EFAULT. Otherwise, it returns zero for success.
The kernel also implements the time() system call, but gettimeofday() largely supersedes it. The C library also provides other wall timerelated library calls, such as ftime() and ctime().
The settimeofday() system call sets the wall time to the specified value. It requires the CAP_SYS_TIME capability.
Other than updating xtime, the kernel does not make nearly as frequent use of the current wall time as user-space does. One notable exception is in the filesystem code, which stores various timestamps (created, accessed, modified, and so on) in inodes.
Timers
Timerssometimes called dynamic timers or kernel timersare essential for managing the flow of time in kernel code. Kernel code often needs to delay execution of some function until a later time. In previous chapters, we looked at using the bottom-half mechanisms, which are great for deferring work until later. Unfortunately, the definition of later is intentionally quite vague. The purpose of bottom halves is not so much to delay work, but simply to not do the work now. What we need is a tool for delaying work a specified amount of timecertainly no less, and with hope, not much longer. The solution is kernel timers.
A timer is very easy to use. You perform some initial setup, specify an expiration time, specify a function to execute upon said expiration, and activate the timer. The given function will run after the timer expires. Timers are not cyclic. The timer is destroyed after it expires. This is one reason for the dynamic nomenclature: Timers are constantly created and destroyed, and there is no limit on the number of timers. Timers are very popular throughout the entire kernel.
Using Timers
Timers are represented by struct timer_list, which is defined in <linux/timer.h>:
struct timer_list {
struct list_head entry; /* entry in linked list of timers */
unsigned long expires; /* expiration value, in jiffies */
spinlock_t lock; /* lock protecting this timer */
void (*function)(unsigned long); /* the timer handler function */
unsigned long data; /* lone argument to the handler */
struct tvec_t_base_s *base; /* internal timer field, do not touch */
};
Fortunately, the usage of timers requires little understanding of this data structure. In fact, toying with it is discouraged to keep code forward compatible with changes. The kernel provides a family of timer-related interfaces to make timer management easy. Everything is declared in <linux/timer.h>. Most of the actual implementation is in kernel/timer.c.
The first step in creating a timer is defining it:
struct timer_list my_timer;
Next, the timer's internal values must be initialized. This is done via a helper function and must be done prior to calling any timer management functions on the timer:
init_timer(&my_timer);
Now you fill out the remaining values as required:
my_timer.expires = jiffies + delay; /* timer expires in delay ticks */
my_timer.data = 0; /* zero is passed to the timer handler */
my_timer.function = my_function; /* function to run when timer expires */
The my_timer.expires value specifies the timeout value in absolute ticks. When the current jiffies count is equal to or greater than my_timer.expires, the handler function my_timer.function is run with the lone argument of my_timer.data. As you can see from the timer_list definition, the function must match this prototype:
void my_timer_function(unsigned long data);
The data parameter enables you to register multiple timers with the same handler, and differentiate between them via the argument. If you do not need the argument, you can simply pass zero (or any other value).
Finally, you activate the timer:
add_timer(&my_timer);
And, voila, the timer is off and running! Note the significance of the expired value. The kernel runs the timer handler when the current tick count is equal to or greater than the specified expiration. Although the kernel guarantees to run no timer handler prior to the timer's expiration, there may be a delay in running the timer. Typically, timers are run fairly close to their expiration; however, they might be delayed until the first timer tick after their expiration. Consequently, timers cannot be used to implement any sort of hard real-time processing.
Sometimes you might need to modify the expiration of an already active timer. The kernel implements a function, mod_timer(), which changes the expiration of a given timer:
mod_timer(&my_timer, jiffies + new_delay); /* new expiration */
The mod_timer() function can operate on timers that are initialized but not active, too. If the timer is inactive, mod_timer() activates it. The function returns zero if the timer was inactive and one if the timer was active. In either case, upon return from mod_timer(), the timer is activated and set to the new expiration.
If you need to deactivate a timer prior to its expiration, use the del_timer() function:
del_timer(&my_timer);
The function works on both active and inactive timers. If the timer is already inactive, the function returns zero; otherwise, the function returns one. Note that you do not need to call this for timers that have expired because they are automatically deactivated.
A potential race condition that must be guarded against exists when deleting timers. When del_timer() returns, it guarantees only that the timer is no longer active (that is, that it will not be executed in the future). On a multiprocessing machine, however, the timer handler might already be executing on another processor. To deactivate the timer and wait until a potentially executing handler for the timer exits, use del_timer_sync():
del_timer_sync(&my_timer);
Unlike del_timer(), del_timer_sync() cannot be used from interrupt context.
Timer Race Conditions
Because timers run asynchronously with respect to the currently executing code, several potential race conditions exist. First, never do the following as a substitute for a mere mod_timer(), because this is unsafe on multiprocessing machines:
del_timer(my_timer)
my_timer->expires = jiffies + new_delay;
add_timer(my_timer);
Second, in almost all cases, you should use del_timer_sync() over del_timer(). Otherwise, you cannot assume the timer is not currently running, and that is why you made the call in the first place! Imagine if, after deleting the timer, the code went on to free or otherwise manipulate resources used by the timer handler. Therefore, the synchronous version is preferred.
Finally, you must make sure to protect any shared data used in the timer handler function. The kernel runs the function asynchronously with respect to other code. Data with a timer should be protected as discussed in Chapters 8 and 9.
The Timer Implementation
The kernel executes timers in bottom-half context, as softirqs, after the timer interrupt completes. The timer interrupt handler runs update_process_times(), which calls run_local_timers():
void run_local_timers(void)
{
raise_softirq(TIMER_SOFTIRQ);
}
The TIMER_SOFTIRQ softirq is handled by run_timer_softirq(). This function runs all the expired timers (if any) on the current processor.
Timers are stored in a linked list. However, it would be unwieldy for the kernel to either constantly traverse the entire list looking for expired timers, or keep the list sorted by expiration value; the insertion and deletion of timers would then become very expensive. Instead, the kernel partitions timers into five groups based on their expiration value. Timers move down through the groups as their expiration time draws closer. The partitioning ensures that, in most executions of the timer softirq, the kernel has to do little work to find the expired timers. Consequently, the timer management code is very efficient.
Delaying Execution
Often, kernel code (especially drivers) needs a way to delay execution for some time without using timers or a bottom-half mechanism. This is usually to allow hardware time to complete a given task. The time is typically quite short. For example, the specifications for a network card might list the time to change Ethernet modes as two microseconds. After setting the desired speed, the driver should wait at least the two microseconds before continuing.
The kernel provides a number of solutions, depending on the semantics of the delay. The solutions have different characteristics. Some hog the processor while delayingeffectively preventingthe accomplishment of any real work. Other solutions do not hog the processor, but offer no guarantee that your code will resume in exactly the required time.
Busy Looping
The simplest solution to implement (although rarely the optimal solution) is busy waiting or busy looping. This technique works only when the time you want to delay is some integer multiple of the tick rate or precision is not very important.
The idea is simple: Spin in a loop until the desired number of clock ticks pass. For example,
unsigned long delay = jiffies + 10; /* ten ticks */
while (time_before(jiffies, delay))
;
The loop continues until jiffies is larger than delay, which will occur only after 10 clock ticks have passed. On x86 with HZ equal to 1000, this results in a wait of 10 milliseconds. Similarly,
unsigned long delay = jiffies + 2*HZ; /* two seconds */
while (time_before(jiffies, delay))
;
This will spin until 2*HZ clock ticks has passed, which is always two seconds regardless of the clock rate.
This approach is not nice to the rest of the system. While your code waits, the processor is tied up spinning in a silly loopno useful work is accomplished! In fact, you rarely want to take this brain-dead approach, and it is shown here because it is a clear and simple method for delaying execution. You might also encounter it in someone else's not-so-pretty code.
A better solution would be to reschedule your process to allow the processor to accomplish other work while your code waits:
unsigned long delay = jiffies + 5*HZ;
while (time_before(jiffies, delay))
cond_resched();
The call to cond_resched() schedules a new process, but only if need_resched is set. In other words, this solution conditionally invokes the scheduler only if there is some more important task to run. Note that because this approach invokes the scheduler, you cannot make use of it from an interrupt handleronly from process context. In fact, all these approaches are best used from process context, because interrupt handlers should execute as quickly as possible (and busy looping does not help accomplish that goal!). Furthermore, delaying execution in any manner, if at all possible, should not occur while a lock is held or interrupts are disabled.
C aficionados might wonder what guarantee is given that the previous loops even work. The C compiler is usually free to perform a given load only once. Normally, no assurance is given that the jiffies variable in the loop's conditional statement is even reloaded on each loop iteration. The kernel requires, however, that jiffies be reread on each iteration, as the value is incremented elsewhere: in the timer interrupt. Indeed, this is why the variable is marked volatile in <linux/jiffies.h>. The volatile keyword instructs the compiler to reload the variable on each access from main memory and never alias the variable's value in a register, guaranteeing that the previous loop completes as expected.
Small Delays
Sometimes, kernel code (again, usually drivers) requires very short (smaller than a clock tick) and rather precise delays. This is often to synchronize with hardware, which again usually lists some minimum time for an activity to completeoften less than a millisecond. It would be impossible to use jiffies-based delays, as in the previous examples, for such a short wait. With a timer interrupt of 100Hz, the clock tick is a rather large 10 milliseconds! Even with a 1000Hz timer interrupt, the clock tick is still one millisecond. Another solution is clearly necessary for smaller, more precise delays.
Thankfully, the kernel provides two functions for microsecond and millisecond delays, both defined in <linux/delay.h>, which do not use jiffies:
void udelay(unsigned long usecs)
void mdelay(unsigned long msecs)
The former function delays execution by busy looping for the specified number of microseconds. The latter function delays execution for the specified number of milliseconds. Recall one second equals 1000 milliseconds, which equals 1,000,000 microseconds. Usage is trivial:
udelay(150); /* delay for 150 µs */
The udelay() function is implemented as a loop that knows how many iterations can be executed in a given period of time. The mdelay() function is then implemented in terms of udelay(). Because the kernel knows how many loops the processor can complete in a second (see the sidebar on BogoMips), the udelay() function simply scales that value to the correct number of loop iterations for the given delay.
|
The BogoMIPS value has always been a source of confusion and humor. In reality, the BogoMIPS calculation has very little to do with the performance of your computer and is primarily used only for the udelay() and mdelay() functions. Its name is a contraction of bogus (that is, fake) and MIPS (million of instructions per second). Everyone is familiar with a boot message similar to the following (this is on a 1GHz Pentium 3):
Detected 1004.932 MHz processor.
Calibrating delay loop... 1990.65 BogoMIPS
The BogoMIPS value is the number of busy loop iterations the processor can perform in a given period. In effect, BogoMIPS are a measurement of how fast a processor can do nothing! This value is stored in the loops_per_jiffy variable and is readable from /proc/cpuinfo. The delay loop functions use the loops_per_jiffy value to figure out (fairly precisely) how many busy loop iterations they need to execute to provide the requisite delay.
The kernel computes loops_per_jiffy on boot via calibrate_delay() in init/main.c. |
The udelay() function should be called only for small delays because larger delays on fast machines might result in overflow. As a rule, do to not use udelay() for delays over one millisecond in duration. For longer durations, mdelay() works fine. Like the other busy waiting solutions for delaying execution, neither of these functions (especially mdelay(), because it is used for such long delays) should be used unless absolutely needed. Remember that it is rude to busy loop with locks held or interrupts disabled because system response and performance will be adversely affected. If you require precise delays, however, these calls are your best bet. Typical uses of these busy waiting functions delay for a very small amount of time, usually in the microsecond range.
schedule_timeout()
A more optimal method of delaying execution is to use schedule_timeout(). This call puts your task to sleep until at least the specified time has elapsed. There is no guarantee that the sleep duration will be exactly the specified timeonly that the duration is at least as long as specified. When the specified time has elapsed, the kernel wakes the task up and places it back on the runqueue. Usage is easy:
/* set task's state to interruptible sleep */
set_current_state(TASK_INTERRUPTIBLE);
/* take a nap and wake up in "s" seconds */
schedule_timeout(s * HZ);
The lone parameter is the desired relative timeout, in jiffies. This example puts the task in interruptible sleep for s seconds. Because the task is marked TASK_INTERRUPTIBLE, it wakes up prematurely if it receives a signal. If the code does not want to process signals, you can use TASK_UNINTERRUPTIBLE instead. The task must be in one of these two states before schedule_timeout() is called or else the task will not go to sleep.
Note that because schedule_timeout() invokes the scheduler, code that calls it must be capable of sleeping. See Chapters 8 and 9 for discussions on atomicity and sleeping. In short, you must be in process context and must not hold a lock.
The schedule_timeout() function is fairly straightforward. Indeed, it is a simple application of kernel timers, so let's take a look at it:
signed long schedule_timeout(signed long timeout)
{
timer_t timer;
unsigned long expire;
switch (timeout)
{
case MAX_SCHEDULE_TIMEOUT:
schedule();
goto out;
default:
if (timeout < 0)
{
printk(KERN_ERR "schedule_timeout: wrong timeout "
"value %lx from %p\n", timeout,
__builtin_return_address(0));
current->state = TASK_RUNNING;
goto out;
}
}
expire = timeout + jiffies;
init_timer(&timer);
timer.expires = expire;
timer.data = (unsigned long) current;
timer.function = process_timeout;
add_timer(&timer);
schedule();
del_timer_sync(&timer);
timeout = expire - jiffies;
out:
return timeout < 0 ? 0 : timeout;
}
The function creates a timer with the original name timer and sets it to expire in timeout clock ticks in the future. It sets the timer to execute the process_timeout() function when the timer expires. It then enables the timer and calls schedule(). Because the task is supposedly marked TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE, the scheduler does not run the task, but instead picks a new one.
When the timer expires, it runs process_timeout():
void process_timeout(unsigned long data)
{
wake_up_process((task_t *) data);
}
This function puts the task in the TASK_RUNNING state and places it back on the runqueue.
When the task reschedules, it returns to where it left off in schedule_timeout() (right after the call to schedule()). In case the task was awakened prematurely (if a signal was received), the timer is destroyed. The function then returns the time slept.
The code in the switch() statement is for special cases and is not part of the general usage of the function. The MAX_SCHEDULE_TIMEOUT check enables a task to sleep indefinitely. In that case, no timer is set (because there is no bound on the sleep duration) and the scheduler is immediately invoked. If you do this, you had better have another method of waking your task up!
Sleeping on a Wait Queue, with a Timeout
Chapter 4 looked at how process context code in the kernel can place itself on a wait queue to wait for a specific event, and then invoke the scheduler to select a new task. Elsewhere, when the event finally occurs, wake_up() is called and the tasks sleeping on the wait queue are awakened and can continue running.
Sometimes it is desirable to wait for a specific event or wait for a specified time to elapsewhichever comes first. In those cases, code might simply call schedule_timeout() instead of schedule() after placing itself on a wait queue. The task wakes up when the desired event occurs or the specified time elapses. The code needs to check why it woke upit might be because of the event occurring, the time elapsing, or a received signaland continue as appropriate.
Out of Time
In this chapter, we looked at the kernel's concept of time and how both wall time and uptime are managed. We contrasted relative time with absolute time and absolute events with periodic events. We then covered time concepts such as the timer interrupt, timer ticks, HZ, and jiffies.
We looked at the implementation of timers and how you can use them in your own kernel code. We finished the chapter with an overview of other methods developers can use to pass time.
Much of the kernel code that you write will require some understanding of time and its passing. With high probabilityespecially if you hack on driversyou will need to deal with kernel timers. Reading this chapter is good for more than just passing the time.
Chapter 11. Memory Management
Memory allocation inside the kernel is not as easy as memory allocation outside the kernel. Many factors contribute to this. Primarily, the kernel simply lacks the luxuries enjoyed by user-space. Unlike user-space, the kernel is not always afforded the capability to easily allocate memory. For example, often the kernel cannot sleep and the kernel cannot easily deal with memory errors. Because of these limitations, and the need for a lightweight memory allocation scheme, getting hold of memory in the kernel is more complicated than in user-space. This is not to say that kernel memory allocations are difficult, however, as you'll see. Just different.
This chapter discusses the methods used to obtain memory inside the kernel. Before you can delve into the actual allocation interfaces, however, you need to understand how the kernel handles memory.
Per-CPU Allocations
Modern SMP-capable operating systems use per-CPU datadata that is unique to a given processorextensively. Typically, per-CPU data is stored in an array. Each item in the array corresponds to a possible processor on the system. The current processor number indexes this array, which is how the 2.4 kernel handles per-CPU data. Nothing is wrong with this approach, so plenty of 2.6 kernel code still uses it. You declare the data as
unsigned long my_percpu[NR_CPUS];
Then you access it as
int cpu;
cpu = get_cpu(); /* get current processor and disable kernel preemption */
my_percpu[cpu]++; /* ... or whatever */
printk("my_percpu on cpu=%d is %lu\n", cpu, my_percpu[cpu]);
put_cpu(); /* enable kernel preemption */
Note that no lock is required because this data is unique to the current processor. So long as no processor touches this data except the current, no concurrency concerns exist, and the current processor can safely access the data without lock.
Kernel preemption is the only concern with per-CPU data. Kernel preemption poses two problems, listed here:
If your code is preempted and reschedules on another processor, the cpu variable is no longer valid because it points to the wrong processor. (In general, code cannot sleep after obtaining the current processor.) If another task preempts your code, it can concurrently access my_percpu on the same processor, which is a race condition.
Any fears are unwarranted, however, because the call get_cpu(), on top of returning the current processor number, also disables kernel preemption. The corresponding call to put_cpu() enables kernel preemption. Note that if you use a call to smp_processor_id() to get the current processor number, kernel preemption is not disabledalways use the aforementioned methods to remain safe.
The New percpu Interface
The 2.6 kernel introduced a new interface, known as percpu, for creating and manipulating per-CPU data. This interface generalizes the previous example. Creation and manipulation of per-CPU data is simplified with this new approach.
The previously discussed method of creating and accessing per-CPU data is still valid and accepted. This new interface, however, grew out of the needs for a simpler and more powerful method for manipulating per-CPU data on large symmetrical multiprocessing computers.
The header <linux/percpu.h> declares all the routines. You can find the actual definitions there, in mm/slab.c, and in <asm/percpu.h>.
Per-CPU Data at Compile-Time
Defining a per-CPU variable at compile-time is quite easy:
DEFINE_PER_CPU(type, name);
This creates an instance of a variable of type type, named name, for each processor on the system. If you need a declaration of the variable elsewhere, to avoid compile warnings, the following macro is your friend:
DECLARE_PER_CPU(type, name);
You can manipulate the variables with the get_cpu_var() and put_cpu_var() routines. A call to get_cpu_var() returns an lvalue for the given variable on the current processor. It also disables preemption, which put_cpu_var() correspondingly enables.
get_cpu_var(name)++; /* increment name on this processor */
put_cpu_var(name); /* done; enable kernel preemption */
You can obtain the value of another processor's per-CPU data, too:
per_cpu(name, cpu)++; /* increment name on the given processor */
You need to be careful with this approach because per_cpu() neither disables kernel preemption nor provides any sort of locking mechanism. The lockless nature of per-CPU data exists only if the current processor is the only manipulator of the data. If other processors touch other processors' data, you need locks. Be careful. Chapter 8, "Kernel Synchronization Introduction," and Chapter 9, "Kernel Synchronization Methods," discuss locking.
Another subtle note: These compile-time per-CPU examples do not work for mod ules because the linker actually creates them in a unique executable section (for the curious, .data.percpu). If you need to access per-CPU data from modules, or if you need to create such data dynamically, there is hope.
Per-CPU Data at Runtime
The kernel implements a dynamic allocator, similar to kmalloc(), for creating per-CPU data. This routine creates an instance of the requested memory for each processor on the systems. The prototypes are in <linux/percpu.h>:
void *alloc_percpu(type); /* a macro */
void *__alloc_percpu(size_t size, size_t align);
void free_percpu(const void *);
The alloc_percpu() macro allocates one instance of an object of the given type for every processor on the system. It is a wrapper around __alloc_percpu(), which takes the actual number of bytes to allocate as a parameter and the number of bytes on which to align the allocation. The alloc_percpu() macro aligns the allocation on a byte boundary that is the natural alignment of the given type. Such alignment is the usual behavior. For example,
struct rabid_cheetah = alloc_percpu(struct rabid_cheetah);
is the same as
struct rabid_cheetah = __alloc_percpu(sizeof (struct rabid_cheetah),
__alignof__ (struct rabid_cheetah));
The __alignof__ construct is a gcc feature that returns the required (or recommended, in the case of weird architectures with no alignment requirements) alignment in bytes for a given type or lvalue. Its syntax is just like that of sizeof. For example,
__alignof__ (unsigned long)
would return four on x86. When given an lvalue, the return value is the largest alignment that the lvalue might have. For example, an lvalue inside a structure could have a greater alignment requirement than if an instance of the same type were created outside of the structure, because of structure alignment requirements. Issues of alignment are further discussed in Chapter 19, "Portability."
A corresponding call to free_percpu() frees the given data on all processors.
A call to alloc_percpu() or __alloc_percpu() returns a pointer, which is used to indirectly reference the dynamically created per-CPU data. The kernel provides two macros to make this easy:
get_cpu_ptr(ptr); /* return a void pointer to this processor's copy of ptr */
put_cpu_ptr(ptr); /* done; enable kernel preemption */
The get_cpu_ptr() macro returns a pointer to the specific instance of the current processor's data. It also disables kernel preemption, which a call to put_cpu_ptr() then enables.
Let's look at a full example of using these functions. Of course, this example is a bit silly because you would normally allocate the memory once (perhaps in some initialization function), use it in various places, and free it once (perhaps in some shutdown function). Nevertheless, this example should make usage quite clear:
void *percpu_ptr;
unsigned long *foo;
percpu_ptr = alloc_percpu(unsigned long);
if (!ptr)
/* error allocating memory .. */
foo = get_cpu_ptr(percpu_ptr);
/* manipulate foo .. */
put_cpu_ptr(percpu_ptr);
Finally, the function per_cpu_ptr() returns a given processor's unique data:
per_cpu_ptr(ptr, cpu);
Again, it does not disable kernel preemptionand if you touch another processor's datakeep in mind that you probably need to implement locking.
Reasons for Using Per-CPU Data
There are a couple benefits to using per-CPU data. The first is the reduction in locking requirements. Depending on the semantics by which processors access the per-CPU data, you might not need any locking at all. Keep in mind that the "only this processor accesses this data" rule is only a programming convention. You need to ensure that the local processor accesses only its unique data. Nothing stops you from cheating.
Second, per-CPU data greatly reduces cache invalidation. This occurs as processors try to keep their caches in sync. If one processor manipulates data held in another processor's cache, that processor must flush or otherwise update its cache. Constant cache invalidation is called thrashing the cache and wreaks havoc on system performance. The use of per-CPU data keeps cache effects to a minimum because processors ideally access only their own data. The percpu interface cache-aligns all data to ensure that accessing one processor's data does not bring in another processor's data on the same cache line.
Consequently, the use of per-CPU data often removes (or at least minimizes) the need for locking. The only safety requirement for the use of per-CPU data is disabling kernel preemption, which is much cheaper than locking, and the interface does so automatically. Per-CPU data can safely be used from either interrupt or process context. Note, however, that you cannot sleep in the middle of accessing per-CPU data (or else you might end up on a different processor).
No one is currently required to use the new per-CPU interface. Doing things manually (with an array as originally discussed) is fine, as long as you disable kernel preemption. The new interface, however, is much easier to use and might gain additional optimizations in the future. If you do decide to use per-CPU data in your kernel code, con sider the new interface. One caveat against its use is that it is not backward compatible with earlier kernels.
Which Allocation Method Should I Use?
If you need contiguous physical pages, use one of the low-level page allocators or kmalloc(). This is the standard manner of allocating memory from within the kernel, and most likely, how you will allocate most of your memory. Recall that the two most common flags given to these functions are GFP_ATOMIC and GFP_KERNEL. Specify the GFP_ATOMIC flag to perform a high priority allocation that will not sleep. This is a requirement of interrupt handlers and other pieces of code that cannot sleep. Code that can sleep, such as process context code that does not hold a spin lock, should use GFP_KERNEL. This flag specifies an allocation that can sleep, if needed, to obtain the requested memory.
If you want to allocate from high memory, use alloc_pages(). The alloc_pages() function returns a struct page, and not a pointer to a logical address. Because high memory might not be mapped, the only way to access it might be via the corresponding struct page structure. To obtain an actual pointer, use kmap() to map the high memory into the kernel's logical address space.
If you do not need physically contiguous pagesonly virtually contiguoususe vmalloc(), although bear in mind the slight performance hit taken with vmalloc() over kmalloc(). The vmalloc() function allocates kernel memory that is virtually contiguous but not, per se, physically contiguous. It performs this feat much as user-space allocations do, by mapping chunks of physical memory into a contiguous logical address space.
If you are creating and destroying many large data structures, consider setting up a slab cache. The slab layer maintains a per-processor object cache (a free list), which might greatly enhance object allocation and deallocation performance. Rather than frequently allocate and free memory, the slab layer stores a cache of already allocated objects for you. When you need a new chunk of memory to hold your data structure, the slab layer often does not need to allocate more memory and instead simply can return an object from the cache.
Pages
The kernel treats physical pages as the basic unit of memory management. Although the processor's smallest addressable unit is usually a word (or even a byte), the memory management unit (MMU, the hardware that manages memory and performs virtual to physical address translations) typically deals in pages. Therefore, the MMU manages the system's page tables with page-sized granularity (hence their name). In terms of virtual memory, pages are the smallest unit that matters.
As you'll see in Chapter 19, "Portability," each architecture enforces its own page size. Many architectures even support multiple page sizes. Most 32-bit architectures have 4KB pages, whereas most 64-bit architectures have 8KB pages. This implies that on a machine with 4KB pages and 1GB of physical memory, physical memory is divided up into 262,144 distinct pages.
The kernel represents every physical page on the system with a struct page structure. This structure is defined in <linux/mm.h>:
struct page {
page_flags_t flags;
atomic_t _count;
atomic_t _mapcount;
unsigned long private;
struct address_space *mapping;
pgoff_t index;
struct list_head lru;
void *virtual;
};
Let's look at the important fields. The flags field stores the status of the page. Such flags include whether the page is dirty or whether it is locked in memory. Bit flags represent the various values, so at least 32 different flags are simultaneously available. The flag values are defined in <linux/page-flags.h>.
The _count field stores the usage count of the pagethat is, how many references there are to this page. When this count reaches negative zero, no one is using the page, and it becomes available for use in a new allocation. Kernel code should not check this field directly but instead use the function page_count(), which takes a page structure as its sole parameter. Although internally _count is negative one when the page is free, page_count() returns zero to indicate free and a positive nonzero integer when the page is in use. A page may be used by the page cache (in which case the mapping field points to the address_space object that is associated with this page), as private data (pointed at by private), or as a mapping in a process's page table.
The virtual field is the page's virtual address. Normally, this is simply the address of the page in virtual memory. Some memory (called high memory) is not permanently mapped in the kernel's address space. In that case, this field is NULL and the page must be dynamically mapped when needed. We'll discuss high memory shortly.
The important point to understand is that the page structure is associated with physical pages, not virtual pages. Therefore, what the structure describes is transient at best. Even if the data contained in the page continues to exist, it might not always be associated with the same page structure because of swapping and so on. The kernel uses this data structure to describe whatever is stored in the associated physical page at that moment. The data structure's goal is to describe physical memory, not the data contained therein.
The kernel uses this structure to keep track of all the pages in the system, because the kernel needs to know whether a page is free (that is, if the page is not allocated). If a page is not free, the kernel needs to know who owns the page. Possible owners include user-space processes, dynamically allocated kernel data, static kernel code, the page cache, and so on.
Developers are often surprised that an instance of this structure is allocated for each physical page in the system. They think, "What a lot of memory used!" Let's look at just how bad (or good) the space consumption is from all these pages. Assume struct page consumes 40 bytes of memory, the system has 4KB physical pages, and the system has 128MB of physical memory. In that case, all the page structures in the system consume slightly more than 1MB of memorynot too high a cost for managing all of the sys tem's physical pages.
Zones
Because of hardware limitations, the kernel cannot treat all pages as identical. Some pages, because of their physical address in memory, cannot be used for certain tasks. Because of this limitation, the kernel divides pages into different zones. The kernel uses the zones to group pages of similar properties. In particular, Linux has to deal with two shortcomings of hardware with respect to memory addressing:
Some hardware devices are capable of performing DMA (direct memory access) to only certain memory addresses. Some architectures are capable of physically addressing larger amounts of memory than they can virtually address. Consequently, some memory is not permanently mapped into the kernel address space.
Because of these constraints, there are three memory zones in Linux:
ZONE_DMA
This zone contains pages that are capable of undergoing DMA.
ZONE_NORMAL
This zone contains normal, regularly mapped, pages.
ZONE_HIGHMEM
This zone contains "high memory," which are pages not permanently mapped into the kernel's address space.
These zones are defined in <linux/mmzone.h>.
The actual use and layout of the memory zones is architecture independent. For example, some architectures have no problem performing DMA into any memory address. In those architectures, ZONE_DMA is empty and ZONE_NORMAL is used for allocations regardless of their use. As a counterexample, on the x86 architecture, ISA devices cannot perform DMA into the full 32-bit address space, because ISA devices can access only the first 16MB of physical memory. Consequently, ZONE_DMA on x86 consists of all memory in the range 016MB.
ZONE_HIGHMEM works in the same regard. What an architecture can and cannot directly map varies. On x86, ZONE_HIGHMEM is all memory above the physical 896MB mark. On other architectures, ZONE_HIGHMEM is empty because all memory is directly mapped. The memory contained in ZONE_HIGHMEM is called high memory. The rest of the system's memory is called low memory.
ZONE_NORMAL tends to be whatever is left over after the previous two zones claim their requisite shares. On x86, for example, ZONE_NORMAL is all physical memory from 16MB to 896MB. On other (more fortunate) architectures, ZONE_NORMAL is all available memory. Table 11.1 is a listing of each zone and its consumed pages on x86.
Table 11.1. Zones on x86Zone | Description | Physical Memory |
|---|
ZONE_DMA | DMA-able pages | < 16MB | ZONE_NORMAL | Normally addressable pages | 16896MB | ZONE_HIGHMEM | Dynamically mapped pages | > 896MB |
Linux partitions the system's pages into zones to have a pooling in place to satisfy allocations as needed. For example, having a ZONE_DMA pool gives the kernel the capability to satisfy memory allocations needed for DMA. If such memory is needed, the kernel can simply pull the required number of pages from ZONE_DMA. Note that the zones do not have any physical relevance; they are simply logical groupings used by the kernel to keep track of pages.
Although some allocations may require pages from a particular zone, the zones are not hard requirements in both directions. Although an allocation for DMA-able memory must originate from ZONE_DMA, a normal allocation can come from ZONE_DMA or ZONE_NORMAL. The kernel prefers to satisfy normal allocations from the normal zone, of course, to save the pages in ZONE_DMA for allocations that need it. But if push comes to shove (say, if memory should get low), the kernel can dip its fingers in whatever zone is available and suitable.
Each zone is represented by struct zone, which is defined in <linux/mmzone.h>:
struct zone {
spinlock_t lock;
unsigned long free_pages;
unsigned long pages_min;
unsigned long pages_low;
unsigned long pages_high;
unsigned long protection[MAX_NR_ZONES];
spinlock_t lru_lock;
struct list_head active_list;
struct list_head inactive_list;
unsigned long nr_scan_active;
unsigned long nr_scan_inactive;
unsigned long nr_active;
unsigned long nr_inactive;
int all_unreclaimable;
unsigned long pages_scanned;
int temp_priority;
int prev_priority;
struct free_area free_area[MAX_ORDER];
wait_queue_head_t *wait_table;
unsigned long wait_table_size;
unsigned long wait_table_bits;
struct per_cpu_pageset pageset[NR_CPUS];
struct pglist_data *zone_pgdat;
struct page *zone_mem_map;
unsigned long zone_start_pfn;
char *name;
unsigned long spanned_pages;
unsigned long present_pages;
};
The structure is big, but there are only three zones in the system and, thus, only three of these structures. Let's look at the more important fields.
The lock field is a spin lock that protects the structure from concurrent access. Note that it protects just the structure, and not all the pages that reside in the zone. A specific lock does not protect individual pages, although parts of the kernel may lock the data that happens to reside in said pages.
The free_pages field is the number of free pages in this zone. The kernel tries to keep at least pages_min pages free (through swapping), if possible.
The name field is, unsurprisingly, a NULL-terminated string representing the name of this zone. The kernel initializes this value during boot in mm/page_alloc.c and the three zones are given the names "DMA," "Normal," and "HighMem."
Getting Pages
Now with an understanding of how the kernel manages memoryvia pages, zones, and so onlet's look at the interfaces the kernel implements to allow you to allocate and free memory within the kernel.
The kernel provides one low-level mechanism for requesting memory, along with several interfaces to access it. All these interfaces allocate memory with page-sized granularity and are declared in <linux/gfp.h>. The core function is
struct page * alloc_pages(unsigned int gfp_mask, unsigned int order)
This allocates 2order (that is, 1 << order) contiguous physical pages and returns a pointer to the first page's page structure; on error it returns NULL. We will look at the gfp_mask parameter in a later section. You can convert a given page to its logical address with the function
void * page_address(struct page *page)
This returns a pointer to the logical address where the given physical page currently resides. If you have no need for the actual struct page, you can call
unsigned long __get_free_pages(unsigned int gfp_mask, unsigned int order)
This function works the same as alloc_pages(), except that it directly returns the logical address of the first requested page. Because the pages are contiguous, the other pages simply follow from the first.
If you need only one page, two functions are implemented as wrappers to save you a bit of typing:
struct page * alloc_page(unsigned int gfp_mask)
unsigned long __get_free_page(unsigned int gfp_mask)
These functions work the same as their brethren but pass zero for the order (20 = one page).
Getting Zeroed Pages
If you need the returned page filled with zeros, use the function
unsigned long get_zeroed_page(unsigned int gfp_mask)
This function works the same as __get_free_page(), except that the allocated page is then zero-filled. This is useful for pages given to user-space because the random garbage in an allocated page is not so randomit might "randomly" contain sensitive data. All data must be zeroed or otherwise cleaned before it is returned to user-space, to ensure system security is not compromised. Table 11.2 is a listing of all the low-level page allocation methods.
Table 11.2. Low-Level Page Allocations MethodsFlag | Description |
|---|
alloc_page(gfp_mask) | Allocate a single page and return a pointer to its page structure | alloc_pages(gfp_mask, order) | Allocate 2order pages and return a pointer to the first page's page structure | __get_free_page(gfp_mask) | Allocate a single page and return a pointer to its logical address | __get_free_pages(gfp_mask, order) | Allocate 2order pages and return a pointer to the first page's logical address | get_zeroed_page(gfp_mask) | Allocate a single page, zero its contents, and return a pointer to its logical address |
Freeing pages
A family of functions allows you to free allocated pages when you no longer need them:
void __free_pages(struct page *page, unsigned int order)
void free_pages(unsigned long addr, unsigned int order)
void free_page(unsigned long addr)
You must be careful to free only pages you allocate. Passing the wrong struct page or address, or the incorrect order, can result in corruption. Remember, the kernel trusts itself. Unlike user-space, the kernel happily hangs itself if you ask it.
Let's look at an example. Here, we want to allocate eight pages:
unsigned long page;
page = __get_free_pages(GFP_KERNEL, 3);
if (!page) {
/* insufficient memory: you must handle this error! */
return ENOMEM;
}
/* 'page' is now the address of the first of eight contiguous pages ... */
free_pages(page, 3);
/*
* our pages are now freed and we should no
* longer access the address stored in 'page'
*/
The GFP_KERNEL parameter is an example of a gfp_mask flag. It is discussed shortly.
Make note of the error checking after the call to __get_free_pages(). A kernel allocation can fail and your code must check for and handle such errors. This might mean unwinding everything you have done thus far. It therefore often makes sense to allocate your memory at the start of the routine, to make handling the error easier. Otherwise, by the time you attempt to allocate memory, it may be rather hard to bail out.
These low-level page functions are useful when you need page-sized chunks of physically contiguous pages, especially if you need exactly a single page or two. For more general byte-sized allocations, the kernel provides kmalloc().
kmalloc()
The kmalloc() function's operation is very similar to that of user-space's familiar malloc() routine, with the exception of the addition of a flags parameter. The kmalloc() function is a simple interface for obtaining kernel memory in byte-sized chunks. If you need whole pages, the previously discussed interfaces might be a better choice. For most kernel allocations, however, kmalloc() is the preferred interface.
The function is declared in <linux/slab.h>:
void * kmalloc(size_t size, int flags)
The function returns a pointer to a region of memory that is at least size bytes in length. The region of memory allocated is physically contiguous. On error, it returns NULL. Kernel allocations always succeed, unless there is an insufficient amount of memory available. Thus, you must check for NULL after all calls to kmalloc() and handle the error appropriately.
Let's look at an example. Assume you need to dynamically allocate enough room for a fictional dog structure:
struct dog *ptr;
ptr = kmalloc(sizeof(struct dog), GFP_KERNEL);
if (!ptr)
/* handle error ... */
If the kmalloc() call succeeds, ptr now points to a block of memory that is at least the requested size. The GFP_KERNEL flag specifies the behavior of the memory allocator while trying to obtain the memory to return to the caller of kmalloc().
gfp_mask Flags
You've seen various examples of allocator flags in both the low-level page allocation functions and kmalloc(). Now it's time to discuss these flags in depth.
The flags are broken up into three categories: action modifiers, zone modifiers, and types. Action modifiers specify how the kernel is supposed to allocate the requested memory. In certain situations, only certain methods can be employed to allocate memory. For example, interrupt handlers must instruct the kernel not to sleep (because interrupt handlers cannot reschedule) in the course of allocating memory. Zone modifiers specify from where to allocate memory. As you saw earlier in this chapter, the kernel divides physical memory into multiple zones, each of which serves a different purpose. Zone modifiers specify from which of these zones to allocate. Type flags specify a combination of action and zone modifiers as needed by a certain type of memory allocation. Type flags simplify specifying numerous modifiers; instead, you generally specify just one type flag. The GFP_KERNEL is a type flag, which is used for code in process context inside the kernel. Let's look at the flags.
Action Modifiers
All the flags, the action modifiers included, are declared in <linux/gfp.h>. The file <linux/slab.h> includes this header, however, so you often need not include it directly. In reality, you will usually use only the type modifiers, which are discussed later. Nonetheless, it is good to have an understanding of these individual flags. Table 11.3 is a list of the action modifiers.
Table 11.3. Action ModifiersFlag | Description |
|---|
__GFP_WAIT | The allocator can sleep. | __GFP_HIGH | The allocator can access emergency pools. | __GFP_IO | The allocator can start disk I/O. | __GFP_FS | The allocator can start filesystem I/O. | __GFP_COLD | The allocator should use cache cold pages. | __GFP_NOWARN | The allocator will not print failure warnings. | __GFP_REPEAT | The allocator will repeat the allocation if it fails, but the allocation can potentially fail. | __GFP_NOFAIL | The allocator will indefinitely repeat the allocation. The allocation cannot fail. | __GFP_NORETRY | The allocator will never retry if the allocation fails. | __GFP_NO_GROW | Used internally by the slab layer. | __GFP_COMP | Add compound page metadata. Used internally by the hugetlb code. |
These allocations can be specified together. For example,
ptr = kmalloc(size, __GFP_WAIT | __GFP_IO | __GFP_FS);
instructs the page allocator (ultimately alloc_pages()) that the allocation can block, perform I/O, and perform filesystem operations, if needed. This allows the kernel great freedom in how it can find the free memory to satisfy the allocation.
Most allocations specify these modifiers, but do so indirectly by way of the type flags we will discuss shortly. Don't worryyou won't have to figure out which of these weird flags to use every time you allocate memory!
Zone Modifiers
Zone modifiers specify from which memory zone the allocation should originate. Normally, allocations can be fulfilled from any zone. The kernel prefers ZONE_NORMAL, however, to ensure that the other zones have free pages when they are needed.
There are only two zone modifiers because there are only two zones other than ZONE_NORMAL (which is where, by default, allocations originate). Table 11.4 is a listing of the zone modifiers.
Table 11.4. Zone ModifiersFlag | Description |
|---|
__GFP_DMA | Allocate only from ZONE_DMA | __GFP_HIGHMEM | Allocate from ZONE_HIGHMEM or ZONE_NORMAL |
Specifying one of these two flags modifies the zone from which the kernel attempts to satisfy the allocation. The __GFP_DMA flag forces the kernel to satisfy the request from ZONE_DMA. This flag says, with an odd accent, I absolutely must have memory into which I can perform DMA. Conversely, the __GFP_HIGHMEM flag instructs the allocator to satisfy the request from either ZONE_NORMAL or (preferentially) ZONE_HIGHMEM. This flag says, I can use high memory, so I can be a doll and hand you back some of that, but normal memory works, too. If neither flag is specified, the kernel fulfills the allocation from either ZONE_DMA or ZONE_NORMAL, with a strong preference to satisfy the allocation from ZONE_NORMAL. No zone flag essentially says, I don't care so long as it behaves normally.
You cannot specify __GFP_HIGHMEM to either __get_free_pages() or kmalloc(). Because these both return a logical address, and not a page structure, it is possible that these functions would allocate memory that is not currently mapped in the kernel's virtual address space and, thus, does not have a logical address. Only alloc_pages() can allocate high memory. The majority of your allocations, however, will not specify a zone modifier because ZONE_NORMAL is sufficient.
Type Flags
The type flags specify the required action and zone modifiers to fulfill a particular type of transaction. Therefore, kernel code tends to use the correct type flag and not specify the myriad of other flags it might need. This is both simpler and less error prone. Table 11.5 is a list of the type flags and Table 11.6 shows which modifiers are associated with each type flag.
Table 11.5. Type FlagsFlag | Description |
|---|
GFP_ATOMIC | The allocation is high priority and must not sleep. This is the flag to use in interrupt handlers, in bottom halves, while holding a spinlock, and in other situations where you cannot sleep. | GFP_NOIO | This allocation can block, but must not initiate disk I/O. This is the flag to use in block I/O code when you cannot cause more disk I/O, which might lead to some unpleasant recursion. | GFP_NOFS | This allocation can block and can initiate disk I/O, if it must, but will not initiate a filesystem operation. This is the flag to use in filesystem code when you cannot start another filesystem operation. | GFP_KERNEL | This is a normal allocation and might block. This is the flag to use in process context code when it is safe to sleep. The kernel will do whatever it has to in order to obtain the memory requested by the caller. This flag should be your first choice. | GFP_USER | This is a normal allocation and might block. This flag is used to allocate memory for user-space processes. | GFP_HIGHUSER | This is an allocation from ZONE_HIGHMEM and might block. This flag is used to allocate memory for user-space processes. | GFP_DMA | This is an allocation from ZONE_DMA. Device drivers that need DMA-able memory use this flag, usually in combination with one of the above. |
Table 11.6. Listing of the Modifiers Behind Each Type FlagFlag | Modifier Flags |
|---|
GFP_ATOMIC | __GFP_HIGH | GFP_NOIO | __GFP_WAIT | GFP_NOFS | (__GFP_WAIT | __GFP_IO) | GFP_KERNEL | (__GFP_WAIT | __GFP_IO | __GFP_FS) | GFP_USER | (__GFP_WAIT | __GFP_IO | __GFP_FS) | GFP_HIGHUSER | (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HIGHMEM) | GFP_DMA | __GFP_DMA |
Let's look at the frequently used flags and when and why you might need them. The vast majority of allocations in the kernel use the GFP_KERNEL flag. The resulting allocation is a normal priority allocation that might sleep. Because the call can block, this flag can be used only from process context that can safely reschedule (that is, no locks are held and so on). Because this flag does not make any stipulations as to how the kernel may obtain the requested memory, the memory allocation has a high probability of succeeding.
On the far other end of the spectrum is the GFP_ATOMIC flag. Because this flag specifies a memory allocation that cannot sleep, the allocation is very restrictive in the memory it can obtain for the caller. If no sufficiently sized contiguous chunk of memory is available, the kernel is not very likely to free memory because it cannot put the caller to sleep. Conversely, the GFP_KERNEL allocation can put the caller to sleep to swap inactive pages to disk, flush dirty pages to disk, and so on. Because GFP_ATOMIC is unable to perform any of these actions, it has less of a chance of succeeding (at least when memory is low) compared to GFP_KERNEL allocations. Nonetheless, the GFP_ATOMIC flag is the only option when the current code is unable to sleep, such as with interrupt handlers, softirqs, and tasklets.
In between these two flags are GFP_NOIO and GFP_NOFS. Allocations initiated with these flags might block, but they refrain from performing certain other operations. A GFP_NOIO allocation does not initiate any disk I/O whatsoever to fulfill the request. On the other hand, GFP_NOFS might initiate disk I/O, but does not initiate filesystem I/O. Why might you need these flags? They are needed for certain low-level block I/O or filesystem code, respectively. Imagine if a common path in the filesystem code allocated memory without the GFP_NOFS flag. The allocation could result in more filesystem operations, which would then beget other allocations and, thus, more filesystem operations! This could continue indefinitely. Code such as this that invokes the allocator must ensure that the allocator also does not execute it, or else the allocation can create a deadlock. Not surprisingly, the kernel uses these two flags only in a handful of places.
The GFP_DMA flag is used to specify that the allocator must satisfy the request from ZONE_DMA. This flag is used by device drivers, which need DMA-able memory for their devices. Normally, you combine this flag with the GFP_ATOMIC or GFP_KERNEL flag.
In the vast majority of the code that you write you will use either GFP_KERNEL or GFP_ATOMIC. Table 11.7 is a list of the common situations and the flags to use. Regardless of the allocation type, you must check for and handle failures.
Table 11.7. Which Flag to Use WhenSituation | Solution |
|---|
Process context, can sleep | Use GFP_KERNEL | Process context, cannot sleep | Use GFP_ATOMIC, or perform your allocations with GFP_KERNEL at an earlier or later point when you can sleep | Interrupt handler | Use GFP_ATOMIC | Softirq | Use GFP_ATOMIC | Tasklet | Use GFP_ATOMIC | Need DMA-able memory, can sleep | Use (GFP_DMA | GFP_KERNEL) | Need DMA-able memory, cannot sleep | Use (GFP_DMA | GFP_ATOMIC), or perform your allocation at an earlier point when you can sleep |
kfree()
The other end of kmalloc() is kfree(), which is declared in <linux/slab.h>:
void kfree(const void *ptr)
The kfree() method frees a block of memory previously allocated with kmalloc(). Calling this function on memory not previously allocated with kmalloc(), or on memory which has already been freed, results in very bad things, such as freeing memory belonging to another part of the kernel. Just as in user-space, be careful to balance your allocations with your deallocations to prevent memory leaks and other bugs. Note, calling kfree(NULL) is explicitly checked for and safe.
Look at an example of allocating memory in an interrupt handler. In this example, an interrupt handler wants to allocate a buffer to hold incoming data. The preprocessor macro BUF_SIZE is the size in bytes of this desired buffer, which is presumably larger than just a couple of bytes.
char *buf;
buf = kmalloc(BUF_SIZE, GFP_ATOMIC);
if (!buf)
/* error allocting memory ! */
Later, when you no longer need the memory, do not forget to free it:
kfree(buf);
vmalloc()
The vmalloc() function works in a similar fashion to kmalloc(), except it allocates memory that is only virtually contiguous and not necessarily physically contiguous. This is how a user-space allocation function works: The pages returned by malloc() are contiguous within the virtual address space of the processor, but there is no guarantee that they are actually contiguous in physical RAM. The kmalloc() function guarantees that the pages are physically contiguous (and virtually contiguous). The vmalloc() function only ensures that the pages are contiguous within the virtual address space. It does this by allocating potentially noncontiguous chunks of physical memory and "fixing up" the page tables to map the memory into a contiguous chunk of the logical address space.
For the most part, only hardware devices require physically contiguous memory allocations. On many architectures, hardware devices live on the other side of the memory management unit and, thus, do not understand virtual addresses. Consequently, any regions of memory that hardware devices work with must exist as a physically contiguous block and not merely a virtually contiguous one. Blocks of memory used only by softwarefor example, process-related buffersare fine using memory that is only virtually contiguous. In your programming, you will never know the difference. All memory appears to the kernel as logically contiguous.
Despite the fact that physically contiguous memory is required in only certain cases, most kernel code uses kmalloc() and not vmalloc() to obtain memory. Primarily, this is for performance. The vmalloc() function, to make nonphysically contiguous pages contiguous in the virtual address space, must specifically set up the page table entries. Worse, pages obtained via vmalloc() must be mapped by their individual pages (because they are not physically contiguous), which results in much greater TLB thrashing than you see when directly mapped memory is used. Because of these concerns, vmalloc() is used only when absolutely necessarytypically, to obtain very large regions of memory. For example, when modules are dynamically inserted into the kernel, they are loaded into memory created via vmalloc().
The vmalloc() function is declared in <linux/vmalloc.h> and defined inmm/vmalloc.c. Usage is identical to user-space's malloc():
void * vmalloc(unsigned long size)
The function returns a pointer to at least size bytes of virtually contiguous memory. On error, the function returns NULL. The function might sleep, and thus cannot be called from interrupt context or other situations where blocking is not permissible.
To free an allocation obtained via vmalloc(), use
void vfree(void *addr)
This function frees the block of memory beginning at addr that was previously allocated via vmalloc(). The function can also sleep and, thus, cannot be called from interrupt context. It has no return value.
Usage of these functions is simple:
char *buf;
buf = vmalloc(16 * PAGE_SIZE); /* get 16 pages */
if (!buf)
/* error! failed to allocate memory */
/*
* buf now points to at least a 16*PAGE_SIZE bytes
* of virtually contiguous block of memory
*/
After you are finished with the memory, make sure to free it by using
vfree(buf);
Slab Layer
Allocating and freeing data structures is one of the most common operations inside any kernel. To facilitate frequent allocations and deallocations of data, programmers often introduce free lists. A free list contains a block of available, already allocated, data structures. When code requires a new instance of a data structure, it can grab one of the structures off the free list rather than allocate the sufficient amount of memory and set it up for the data structure. Later on, when the data structure is no longer needed, it is returned to the free list instead of deallocated. In this sense, the free list acts as an object cache, caching a frequently used type of object.
One of the main problems with free lists in the kernel is that there exists no global control. When available memory is low, there is no way for the kernel to communicate to every free list that it should shrink the sizes of its cache to free up memory. In fact, the kernel has no understanding of the random free lists at all. To remedy this, and to consolidate code, the Linux kernel provides the slab layer (also called the slab allocator). The slab layer acts as a generic data structure-caching layer.
The concept of a slab allocator was first implemented in Sun Microsystem's SunOS 5.4 operating system. The Linux data structurecaching layer shares the same name and basic design.
The slab layer attempts to leverage several basic tenets:
Frequently used data structures tend to be allocated and freed often, so cache them. Frequent allocation and deallocation can result in memory fragmentation (the inability to find large contiguous chunks of available memory). To prevent this, the cached free lists are arranged contiguously. Because freed data structures return to the free list, there is no resulting fragmentation. The free list provides improved performance during frequent allocation and deallocation because a freed object can be immediately returned to the next allocation. If the allocator is aware of concepts such as object size, page size, and total cache size, it can make more intelligent decisions. If part of the cache is made per-processor (separate and unique to each processor on the system), allocations and frees can be performed without an SMP lock. If the allocator is NUMA-aware, it can fulfill allocations from the same memory node as the requestor. Stored objects can be colored to prevent multiple objects from mapping to the same cache lines.
The slab layer in Linux was designed and implemented with these premises in mind.
Design of the Slab Layer
The slab layer divides different objects into groups called caches, each of which stores a different type of object. There is one cache per object type. For example, one cache is for process descriptors (a free list of task_struct structures), whereas another cache is for inode objects (struct inode). Interestingly, the kmalloc() interface is built on top of the slab layer, using a family of general purpose caches.
The caches are then divided into slabs (hence the name of this subsystem). The slabs are composed of one or more physically contiguous pages. Typically, slabs are composed of only a single page. Each cache may consist of multiple slabs.
Each slab contains some number of objects, which are the data structures being cached. Each slab is in one of three states: full, partial, or empty. A full slab has no free objects (all objects in the slab are allocated). An empty slab has no allocated objects (all objects in the slab are free). A partial slab has some allocated objects and some free objects. When some part of the kernel requests a new object, the request is satisfied from a partial slab, if one exists. Otherwise, the request is satisfied from an empty slab. If there exists no empty slab, one is created. Obviously, a full slab can never satisfy a request because it does not have any free objects. This strategy reduces fragmentation.
Let's look at the inode structure as an example, which is the in-memory representation of a disk inode (see Chapter 12). These structures are frequently created and destroyed, so it makes sense to manage them via the slab allocator. Thus, struct inode is allocated from the inode_cachep cache (such a naming convention is standard). This cache is made up of one or more slabsprobably a lot of slabs because there are a lot of objects. Each slab contains as many struct inode objects as possible. When the kernel requests a new inode structure, the kernel returns a pointer to an already allocated, but unused structure from a partial slab or, if there is no partial slab, an empty slab. When the kernel is done using the inode object, the slab allocator marks the object as free. Figure 11.1 diagrams the relationship between caches, slabs, and objects.
Each cache is represented by a kmem_cache_s structure. This structure contains three listsslabs_full, slabs_partial, and slabs_emptystored inside a kmem_list3 structure. These lists contain all the slabs associated with the cache. A slab descriptor, struct slab, represents each slab:
struct slab {
struct list_head list; /* full, partial, or empty list */
unsigned long colouroff; /* offset for the slab coloring */
void *s_mem; /* first object in the slab */
unsigned int inuse; /* allocated objects in the slab */
kmem_bufctl_t free; /* first free object, if any */
};
Slab descriptors are allocated either outside the slab in a general cache or inside the slab itself, at the beginning. The descriptor is stored inside the slab if the total size of the slab is sufficiently small, or if internal slack space is sufficient to hold the descriptor.
The slab allocator creates new slabs by interfacing with the low-level kernel page allocator via __get_free_pages():
static void *kmem_getpages(kmem_cache_t *cachep, int flags, int nodeid)
{
struct page *page;
void *addr;
int i;
flags |= cachep->gfpflags;
if (likely(nodeid == -1)) {
addr = (void*)__get_free_pages(flags, cachep->gfporder);
if (!addr)
return NULL;
page = virt_to_page(addr);
} else {
page = alloc_pages_node(nodeid, flags, cachep->gfporder);
if (!page)
return NULL;
addr = page_address(page);
}
i = (1 << cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
add_page_state(nr_slab, i);
while (i--) {
SetPageSlab(page);
page++;
}
return addr;
}
This function uses __get_free_pages() to allocate memory sufficient to hold the cache. The first parameter to this function points to the specific cache that needs more pages. The second parameter points to the flags given to __get_free_pages(). Note how this value is binary OR'ed against another value. This adds default flags that the cache requires to the flags parameter. The power-of-two size of the allocation is stored in cachep->gfporder. The previous function is a bit more complicated than one might expect because code that makes the allocator NUMA-aware. When nodeid is not negative one, the allocator attempts to fulfill the allocation from the same memory node that requested the allocation. This provides better performance on NUMA systems, where accessing memory outside your node results in a performance penalty.
For educational purposes, we can ignore the NUMA-aware code and write a simple kmem_getpages():
static inline void * kmem_getpages(kmem_cache_t *cachep, unsigned long flags)
{
void *addr;
flags |= cachep->gfpflags;
addr = (void*) __get_free_pages(flags, cachep->gfporder);
return addr;
}
Memory is then freed by kmem_freepages(), which calls free_pages() on the given cache's pages. Of course, the point of the slab layer is to refrain from allocating and freeing pages. In turn, the slab layer invokes the page allocation function only when there does not exist any partial or empty slabs in a given cache. The freeing function is called only when available memory grows low and the system is attempting to free memory, or when a cache is explicitly destroyed.
The slab layer is managed on a per-cache basis through a simple interface, which is exported to the entire kernel. The interface allows the creation and destruction of new caches and the allocation and freeing of objects within the caches. The sophisticated management of caches and the slabs within is entirely handled by the internals of the slab layer. After you create a cache, the slab layer works just like a specialized allocator for the specific type of object.
Slab Allocator Interface
A new cache is created via
kmem_cache_t * kmem_cache_create(const char *name, size_t size,
size_t align, unsigned long flags,
void (*ctor)(void*, kmem_cache_t *, unsigned long),
void (*dtor)(void*, kmem_cache_t *, unsigned long))
The first parameter is a string storing the name of the cache. The second parameter is the size of each element in the cache. The third parameter is the offset of the first object within a slab. This is done to ensure a particular alignment within the page. Normally, zero is sufficient, which results in the standard alignment. The flags parameter specifies optional settings controlling the cache's behavior. It can be zero, specifying no special behavior, or one or more of the following flags OR'ed together:
SLAB_NO_REAP
This flag instructs the slab layer not to automatically reap objects (that is, free the memory backing unused objects) when memory is low. Normally, you do not want to set this flag because your cache could then prevent the system from recovering enough memory to continue operation when memory is low. SLAB_HWCACHE_ALIGN
This flag instructs the slab layer to align each object within a slab to a cache line. This prevents "false sharing" (two or more objects mapping to the same cache line despite existing at different addresses in memory). This improves per formance, but comes at a cost of increased memory footprint because the stricter alignment results in more wasted slack space. How large the increase in memory consumption is depends on the size of the objects and how they naturally align with respect to the system's cache lines. For frequently used caches in performance-critical code, setting this option is a good idea; otherwise, think twice. SLAB_MUST_HWCACHE_ALIGN
If debugging is enabled, it might be infeasible to both perform debugging and cache-align the objects. This flag forces the slab layer to cache-align the objects. Normally, this flag is not needed and the previous is sufficient. Specifying this flag while slab debugging is enabled (it is disabled by default) might result in a large increase in memory consumption. Only objects where cache alignment is critical, such as the process descriptor, should set this flag. SLAB_POISON
This flag causes the slab layer to fill the slab with a known value (a5a5a5a5). This is called poisoning and is useful for catching access to uninitialized memory. SLAB_RED_ZONE
This flag causes the slab layer to insert "red zones" around the allocated memory to help detect buffer overruns. SLAB_PANIC
This flag causes the slab layer to panic if the allocation fails. This flag is useful when the allocation must not fail, as in, say, allocating the VMA structure cache (see Chapter 14, "The Process Address Space") during bootup. SLAB_CACHE_DMA
This flag instructs the slab layer to allocate each slab in DMA-able memory. This is needed if the allocated object is used for DMA and must reside in ZONE_DMA. Otherwise, you do not need this and you should not set it.
The final two parameters, ctor and dtor, are a constructor and destructor for the cache, respectively. The constructor is called whenever new pages are added to the cache. The destructor is called whenever pages are removed from the cache. Having a destructor requires a constructor. In practice, caches in the Linux kernel do not often utilize a constructor or destructor. You can pass NULL for both of these parameters.
On success, kmem_cache_create() returns a pointer to the created cache. Otherwise, it returns NULL. This function must not be called from interrupt context because it can sleep.
To destroy a cache, call
int kmem_cache_destroy(kmem_cache_t *cachep)
As the name implies, this function destroys the given cache. It is generally invoked from module shutdown code in modules that create their own caches. It must not be called from interrupt context because it may sleep. The caller of this function must ensure two conditions are true prior to invoking this function:
All slabs in the cache are empty. Indeed, if an object in one of the slabs were still allocated and in use, how could the cache be destroyed? No one accesses the cache during (and obviously after) a call to kmem_cache_destroy(). The caller must ensure this synchronization.
On success, the function returns zero; it returns nonzero otherwise.
After a cache is created, an object is obtained from the cache via
void * kmem_cache_alloc(kmem_cache_t *cachep, int flags)
This function returns a pointer to an object from the given cache cachep. If no free objects are in any slabs in the cache, and the slab layer must obtain new pages via kmem_getpages(), the value of flags is passed to __get_free_pages(). These are the same flags we looked at earlier. You probably want GFP_KERNEL or GFP_ATOMIC.
To later free an object and return it to its originating slab, use the function
void kmem_cache_free(kmem_cache_t *cachep, void *objp)
This marks the object objp in cachep as free.
Example of Using the Slab Allocator
Let's look at a real-life example that uses the task_struct structure (the process descriptor). This code, in slightly more complicated form, is in kernel/fork.c.
First, the kernel has a global variable that stores a pointer to the task_struct cache:
kmem_cache_t *task_struct_cachep;
During kernel initialization, in fork_init(), the cache is created:
task_struct_cachep = kmem_cache_create("task_struct",
sizeof(struct task_struct),
ARCH_MIN_TASKALIGN,
SLAB_PANIC,
NULL,
NULL);
This creates a cache named task_struct, which stores objects of type struct task_struct. The objects are created with an offset of ARCH_MIN_TASKALIGN bytes within the slab. This preprocessor define is an architecture-specific value. It is usually defined as L1_CACHE_BYTESthe size in bytes of the L1 cache. There is no constructor or destructor. Note that the return value is not checked for NULL, which denotes failure, because the SLAB_PANIC flag was given. If the allocation fails, the slab allocator calls panic(). If you do not provide this flag, you must check the return! The SLAB_PANIC flag is used here because this is a requisite cache for system operation (the machine is not much good without process descriptors).
Each time a process calls fork(), a new process descriptor must be created (recall Chapter 3, "Process Management"). This is done in dup_task_struct(), which is called from do_fork():
struct task_struct *tsk;
tsk = kmem_cache_alloc(task_struct_cachep, GFP_KERNEL);
if (!tsk)
return NULL;
After a task dies, if it has no children waiting on it, its process descriptor is freed and returned to the task_struct_cachep slab cache. This is done in free_task_struct() (where tsk is the exiting task):
kmem_cache_free(task_struct_cachep, tsk);
Because process descriptors are part of the core kernel and always needed, the task_struct_cachep cache is never destroyed. If it were, however, you would destroy the cache via
int err;
err = kmem_cache_destroy(task_struct_cachep);
if (err)
/* error destroying cache */
Easy enough? The slab layer handles all the low-level alignment, coloring, allocations, freeing, and reaping during low-memory conditions. If you are frequently creating many objects of the same type, consider using the slab cache. Definitely do not implement your own free list!
Statically Allocating on the Stack
In user-space, allocations such as some of the examples discussed thus far could have occurred on the stack because we knew the size of the allocation a priori. User-space is afforded the luxury of a very large and dynamically growing stack, whereas the kernel has no such luxurythe kernel's stack is small and fixed. When each process is given a small, fixed stack, memory consumption is minimized and the kernel need not burden itself with stack management code.
The size of the per-process kernel stacks depends on both the architecture and a compile-time option. Historically, the kernel stack has been two pages per process. This is usually 8KB for 32-bit architectures and 16KB for 64-bit architectures because they usually have 4KB and 8KB pages, respectively.
Early in the 2.6 kernel series, however, an option was introduced to move to single-page kernel stacks. When enabled, each process is given only a single page4KB on 32-bit architectures, 8KB on 64-bit architectures. This was done for two reasons. First, it results in a page with less memory consumption per process. Second and most important is that as uptime increases, it becomes increasingly hard to find two physically contiguous unallocated pages. Physical memory becomes fragmented, and the resulting VM pressure from allocating a single new process is expensive.
There is one more complication. Keep with me: We have almost grasped the entire universe of knowledge with respect to kernel stacks. Now, each process's entire call chain has to fit in its kernel stack. Historically, however, interrupt handlers also used the kernel stack of the process they interrupted, thus they too had to fit. This was efficient and simple, but it placed even tighter constraints on the already meager kernel stack. When the stack moved to only a single page, interrupt handlers no longer fit.
To rectify this problem, an additional option was implemented: interrupt stacks. Interrupt stacks provide a single per-processor stack used for interrupt handlers. With this option, interrupt handlers no longer share the kernel stack of the interrupted process. Instead, they use their own stacks. This consumes only a single page per processor.
Summarily, kernel stacks are either one or two pages, depending on compile-time configuration options. The stack can therefore range from 4 to 16KB. Historically, interrupt handlers shared the stack of the interrupted process. When single page stacks are enabled, interrupt handlers are given their own stacks. In any case, unbounded recursion and alloca() are obviously not allowed.
Okay. Got it?
Playing Fair on the Stack
In any given function, you must keep stack usage to a minimum. There is no hard and fast rule, but you should keep the sum of all local (that is, automatic) variables in a particular function to a maximum of a couple hundred bytes. Performing a large static allocation on the stack, such as of a large array or structure, is dangerous. Otherwise, stack allocations are performed in the kernel just as in user-space. Stack overflows occur silently and will undoubtedly result in problems. Because the kernel does not make any effort to manage the stack, when the stack overflows, the excess data simply spills into whatever exists at the tail end of the stack. The first thing to eat it is the tHRead_info structure. (Recall from Chapter 3 that this structure is allocated at the end of each process's kernel stack.) Beyond the stack, any kernel data might lurk. At best, the machine will crash when the stack overflows. At worst, the overflow will silently corrupt data.
Therefore, it is wise to use a dynamic allocation scheme, such as one of those discussed earlier in this chapter for any large memory allocations.
High Memory Mappings
By definition, pages in high memory might not be permanently mapped into the kernel's address space. Thus, pages obtained via alloc_pages() with the __GFP_HIGHMEM flag might not have a logical address.
On the x86 architecture, all physical memory beyond the 896MB mark is high memory and is not permanently or automatically mapped into the kernel's address space, despite x86 processors being capable of physically addressing up to 4GB (64GB with PAE) of physical RAM. After they are allocated, these pages must be mapped into the kernel's logical address space. On x86, pages in high memory are mapped somewhere between the 3 and 4GB mark.
Permanent Mappings
To map a given page structure into the kernel's address space, use
void *kmap(struct page *page)
This function works on either high or low memory. If the page structure belongs to a page in low memory, the page's virtual address is simply returned. If the page resides in high memory, a permanent mapping is created and the address is returned. The function may sleep, so kmap() works only in process context.
Because the number of permanent mappings are limited (if not, we would not be in this mess and could just permanently map all memory), high memory should be unmapped when no longer needed. This is done via
void kunmap(struct page *page)
which unmaps the given page.
Temporary Mappings
For times when a mapping must be created but the current context is unable to sleep, the kernel provides temporary mappings (which are also called atomic mappings). These are a set of reserved mappings that can hold a temporary mapping. The kernel can atomically map a high memory page into one of these reserved mappings. Consequently, a temporary mapping can be used in places that cannot sleep, such as interrupt handlers, because obtaining the mapping never blocks.
Setting up a temporary mapping is done via
void *kmap_atomic(struct page *page, enum km_type type)
The type parameter is one of the following enumerations, which describe the purpose of the temporary mapping. They are defined in <asm/kmap_types.h>:
enum km_type {
KM_BOUNCE_READ,
KM_SKB_SUNRPC_DATA,
KM_SKB_DATA_SOFTIRQ,
KM_USER0,
KM_USER1,
KM_BIO_SRC_IRQ,
KM_BIO_DST_IRQ,
KM_PTE0,
KM_PTE1,
KM_PTE2,
KM_IRQ0,
KM_IRQ1,
KM_SOFTIRQ0,
KM_SOFTIRQ1,
KM_TYPE_NR
};
This function does not block and thus can be used in interrupt context and other places that cannot reschedule. It also disables kernel preemption, which is needed because the mappings are unique to each processor (and a reschedule might change which task is running on which processor).
The mapping is undone via
void kunmap_atomic(void *kvaddr, enum km_type type)
This function also does not block. In fact, in many architectures it does not do anything at all except enable kernel preemption, because a temporary mapping is valid only until the next temporary mapping. Thus, the kernel can just "forget about" the kmap_atomic() mapping, and kunmap_atomic() does not need to do anything special. The next atomic mapping then simply overwrites the previous one.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX 
 Books
Books
