Дескриптор процесса
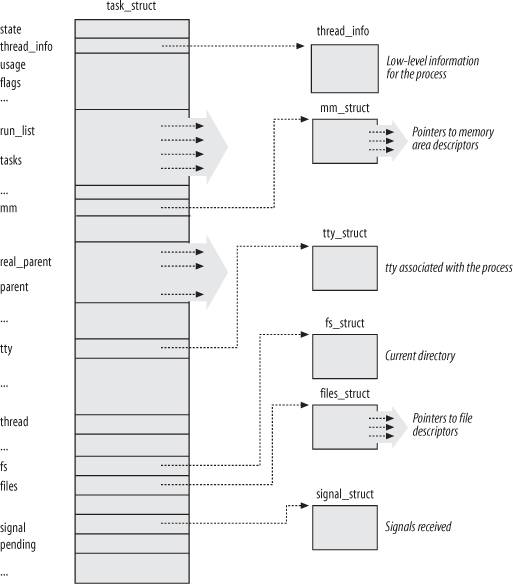
To manage processes, the kernel must have a clear picture of what each process is doing. It must know, for instance, the process's priority, whether it is running on a CPU or blocked on an event, what address space has been assigned to it, which files it is allowed to address, and so on. This is the role of the process descriptor a task_struct type structure whose fields contain all the information related to a single process. As the repository of so much information, the process descriptor is rather complex. In addition to a large number of fields containing process attributes, the process descriptor contains several pointers to other data structures that, in turn, contain pointers to other structures. Figure 3-1 describes the Linux process descriptor schematically.
The six data structures on the right side of the figure refer to specific resources owned by the process. Most of these resources will be covered in future chapters. This chapter focuses on two types of fields that refer to the process state and to process parent/child relationships.
3.2.1. Process State
As its name implies, the state field of the process descriptor describes what is currently happening to the process. It consists of an array of flags, each of which describes a possible process state. In the current Linux version, these states are mutually exclusive, and hence exactly one flag of state always is set; the remaining flags are cleared. The following are the possible process states:
TASK_RUNNING The process is either executing on a CPU or waiting to be executed.
TASK_INTERRUPTIBLE The process is suspended (sleeping) until some condition becomes true. Raising a hardware interrupt, releasing a system resource the process is waiting for, or delivering
a signal are examples of conditions that might wake up the process (put its state back to TASK_RUNNING).
TASK_UNINTERRUPTIBLE Like TASK_INTERRUPTIBLE, except that delivering a signal to the sleeping process leaves its state unchanged. This process state is seldom used. It is valuable, however, under certain specific conditions in which a process must wait until a given event occurs without being interrupted. For instance, this state may be used when a process opens a device file and the corresponding device driver starts probing for a corresponding hardware device. The device driver must not be interrupted until the probing is complete, or the hardware device could be left in an unpredictable state.
TASK_STOPPED Process execution has been stopped; the process enters this state after receiving a SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal.
TASK_TRACED Process execution has been stopped by a debugger. When a process is being monitored by another (such as when a debugger executes a ptrace( ) system call to monitor a test program), each signal may put the process in the TASK_TRACED state.
Two additional states of the process can be stored both in the state field and in the exit_state field of the process descriptor; as the field name suggests, a process reaches one of these two states only when its execution is terminated:
EXIT_ZOMBIE Process execution is terminated, but the parent process has not yet issued a wait4( )
or waitpid( )
system call to return information about the dead process. Before the wait( )-like call is issued, the kernel cannot discard the data contained in the dead process descriptor because the parent might need it. (See the section "Process Removal" near the end of this chapter.)
EXIT_DEAD The final state: the process is being removed by the system because the parent process has just issued a wait4( ) or waitpid( ) system call for it. Changing its state from EXIT_ZOMBIE to EXIT_DEAD avoids race conditions due to other threads of execution that execute wait( )-like calls on the same process (see Chapter 5).
The value of the state field is usually set with a simple assignment. For instance:
p->state = TASK_RUNNING;
The kernel also uses the set_task_state and set_current_state macros: they set the state of a specified process and of the process currently executed, respectively. Moreover, these macros ensure that the assignment operation is not mixed with other instructions by the compiler or the CPU control unit. Mixing the instruction order may sometimes lead to catastrophic results (see Chapter 5).
3.2.2. Identifying a Process
As a general rule, each execution context that can be independently scheduled must have its own process descriptor; therefore, even lightweight processes, which share a large portion of their kernel data structures, have their own task_struct structures.
The strict one-to-one correspondence between the process and process descriptor makes the 32-bit address of the task_struct structure a useful means for the kernel to identify processes. These addresses are referred to as process descriptor pointers. Most of the references to processes that the kernel makes are through process descriptor pointers.
On the other hand, Unix-like operating systems allow users to identify processes by means of a number called the Process ID (or PID), which is stored in the pid field of the process descriptor. PIDs are numbered sequentially: the PID of a newly created process is normally the PID of the previously created process increased by one. Of course, there is an upper limit on the PID values; when the kernel reaches such limit, it must start recycling the lower, unused PIDs. By default, the maximum PID number is 32,767 (PID_MAX_DEFAULT - 1); the system administrator may reduce this limit by writing a smaller value into the /proc
/sys/kernel/pid_max file (/proc is the mount point of a special filesystem, see the section "Special Filesystems" in Chapter 12). In 64-bit architectures, the system administrator can enlarge the maximum PID number up to 4,194,303.
When recycling PID numbers, the kernel must manage a pidmap_array bitmap that denotes which are the PIDs currently assigned and which are the free ones. Because a page frame contains 32,768 bits, in 32-bit architectures the pidmap_array bitmap is stored in a single page. In 64-bit architectures, however, additional pages can be added to the bitmap when the kernel assigns a PID number too large for the current bitmap size. These pages are never released.
Linux associates a different PID with each process or lightweight process in the system. (As we shall see later in this chapter, there is a tiny exception on multiprocessor systems.) This approach allows the maximum flexibility, because every execution context in the system can be uniquely identified.
On the other hand, Unix programmers expect threads in the same group to have a common PID. For instance, it should be possible to a send a signal specifying a PID that affects all threads in the group. In fact, the POSIX 1003.1c standard states that all threads of a multithreaded application must have the same PID.
To comply with this standard, Linux makes use of thread groups. The identifier shared by the threads is the PID of the thread group leader
, that is, the PID of the first lightweight process in the group; it is stored in the tgid field of the process descriptors. The getpid( )
system call returns the value of tgid relative to the current process instead of the value of pid, so all the threads of a multithreaded application share the same identifier. Most processes belong to a thread group consisting of a single member; as thread group leaders, they have the tgid field equal to the pid field, thus the getpid( ) system call works as usual for this kind of process.
Later, we'll show you how it is possible to derive a true process descriptor pointer efficiently from its respective PID. Efficiency is important because many system calls such as kill( ) use the PID to denote the affected process.
3.2.2.1. Process descriptors handling
Processes are dynamic entities whose lifetimes range from a few milliseconds to months. Thus, the kernel must be able to handle many processes at the same time, and process descriptors are stored in dynamic memory
rather than in the memory area permanently assigned to the kernel. For each process, Linux packs two different data structures in a single per-process memory area: a small data structure linked to the process descriptor, namely the thread_info structure, and the Kernel Mode process stack. The length of this memory area is usually 8,192 bytes (two page frames). For reasons of efficiency the kernel stores the 8-KB memory area in two consecutive page frames with the first page frame aligned to a multiple of 213; this may turn out to be a problem when little dynamic memory is available, because the free memory may become highly fragmented (see the section "The Buddy System Algorithm" in Chapter 8). Therefore, in the 80x86 architecture the kernel can be configured at compilation time so that the memory area including stack and tHRead_info structure spans a single page frame (4,096 bytes).
In the section "Segmentation in Linux" in Chapter 2, we learned that a process in Kernel Mode accesses a stack contained in the kernel data segment, which is different from the stack used by the process in User Mode. Because kernel control paths
make little use of the stack, only a few thousand bytes of kernel stack are required. Therefore, 8 KB is ample space for the stack and the tHRead_info structure. However, when stack and thread_info structure are contained in a single page frame, the kernel uses a few additional stacks to avoid the overflows caused by deeply nested interrupts and exceptions (see Chapter 4).
Figure 3-2 shows how the two data structures are stored in the 2-page (8 KB) memory area. The thread_info structure resides at the beginning of the memory area, and the stack grows downward from the end. The figure also shows that the tHRead_info structure and the task_struct structure are mutually linked by means of the fields task and tHRead_info, respectively.
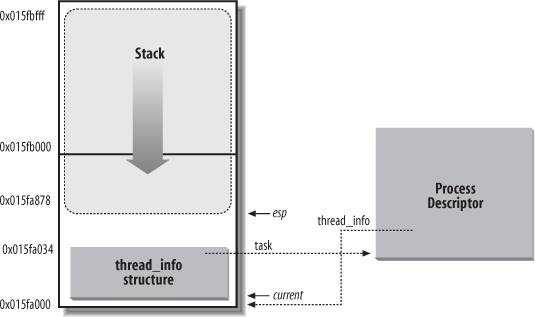
The esp register is the CPU stack pointer, which is used to address the stack's top location. On 80x86 systems, the stack starts at the end and grows toward the beginning of the memory area. Right after switching from User Mode to Kernel Mode, the kernel stack of a process is always empty, and therefore the esp register points to the byte immediately following the stack.
The value of the esp is decreased as soon as data is written into the stack. Because the thread_info structure is 52 bytes long, the kernel stack can expand up to 8,140 bytes.
The C language allows the tHRead_info structure and the kernel stack of a process to be conveniently represented by means of the following union construct:
union thread_union {
struct thread_info thread_info;
unsigned long stack[2048]; /* 1024 for 4KB stacks */
};
The tHRead_info structure shown in Figure 3-2 is stored starting at address 0x015fa000, and the stack is stored starting at address 0x015fc000. The value of the esp register points to the current top of the stack at 0x015fa878.
The kernel uses the alloc_thread_info and free_thread_info macros to allocate and release the memory area storing a thread_info structure and a kernel stack.
3.2.2.2. Identifying the current process
The close association between the thread_info structure and the Kernel Mode stack just described offers a key benefit in terms of efficiency: the kernel can easily obtain the address of the thread_info structure of the process currently running on a CPU from the value of the esp register. In fact, if the thread_union structure is 8 KB (213 bytes) long, the kernel masks out the 13 least significant bits of esp to obtain the base address of the thread_info structure; on the other hand, if the thread_union structure is 4 KB long, the kernel masks out the 12 least significant bits of esp. This is done by the current_thread_info( ) function, which produces assembly language instructions like the following:
movl $0xffffe000,%ecx /* or 0xfffff000 for 4KB stacks */
andl %esp,%ecx
movl %ecx,p
After executing these three instructions, p contains the tHRead_info structure pointer of the process running on the CPU that executes the instruction.
Most often the kernel needs the address of the process descriptor rather than the address of the thread_info structure. To get the process descriptor pointer of the process currently running on a CPU, the kernel makes use of the current macro, which is essentially equivalent to current_thread_info( )->task and produces assembly language instructions like the following:
movl $0xffffe000,%ecx /* or 0xfffff000 for 4KB stacks */
andl %esp,%ecx
movl (%ecx),p
Because the task field is at offset 0 in the thread_info structure, after executing these three instructions p contains the process descriptor pointer of the process running on the CPU.
The current macro often appears in kernel code as a prefix to fields of the process descriptor. For example, current->pid returns the process ID of the process currently running on the CPU.
Another advantage of storing the process descriptor with the stack emerges on multiprocessor systems: the correct current process for each hardware processor can be derived just by checking the stack, as shown previously. Earlier versions of Linux did not store the kernel stack and the process descriptor together. Instead, they were forced to introduce a global static variable called current to identify the process descriptor of the running process. On multiprocessor systems, it was necessary to define current as an arrayone element for each available CPU.
3.2.2.3. Doubly linked lists
Before moving on and describing how the kernel keeps track of the various processes in the system, we would like to emphasize the role of special data structures that implement doubly linked lists.
For each list, a set of primitive operations must be implemented: initializing the list, inserting and deleting an element, scanning the list, and so on. It would be both a waste of programmers' efforts and a waste of memory to replicate the primitive operations for each different list.
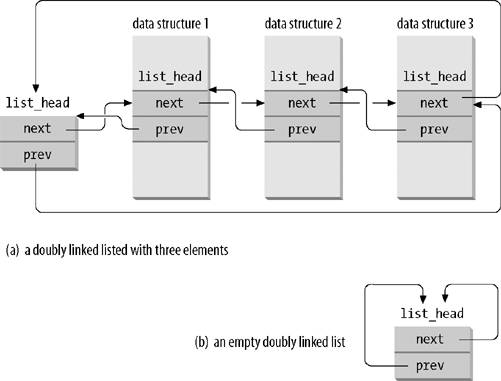
Therefore, the Linux kernel defines the list_head data structure, whose only fields next and prev represent the forward and back pointers of a generic doubly linked list element, respectively. It is important to note, however, that the pointers in a list_head field store the addresses of other list_head fields rather than the addresses of the whole data structures in which the list_head structure is included; see Figure 3-3 (a).
A new list is created by using the LIST_HEAD(list_name) macro. It declares a new variable named list_name of type list_head, which is a dummy first element that acts as a placeholder for the head of the new list, and initializes the prev and next fields of the list_head data structure so as to point to the list_name variable itself; see Figure 3-3 (b).
Several functions and macros implement the primitives, including those shown in Table Table 3-1.
Table 3-1. List handling functions and macrosName | Description |
|---|
list_add(n,p) | Inserts an element pointed to by n right after the specified element pointed to by p. (To insert n at the beginning of the list, set p to the address of the list head.) | list_add_tail(n,p) | Inserts an element pointed to by n right before the specified element pointed to by p. (To insert n at the end of the list, set p to the address of the list head.) | list_del(p) | Deletes an element pointed to by p. (There is no need to specify the head of the list.) | list_empty(p) | Checks if the list specified by the address p of its head is empty. | list_entry(p,t,m) | Returns the address of the data structure of type t in which the list_head field that has the name m and the address p is included. | list_for_each(p,h) | Scans the elements of the list specified by the address h of the head; in each iteration, a pointer to the list_head structure of the list element is returned in p. | list_for_each_entry(p,h,m) | Similar to list_for_each, but returns the address of the data structure embedding the list_head structure rather than the address of the list_head structure itself. |
The Linux kernel 2.6 sports another kind of doubly linked list, which mainly differs from a list_head list because it is not circular; it is mainly used for hash tables, where space is important, and finding the the last element in constant time is not. The list head is stored in an hlist_head data structure, which is simply a pointer to the first element in the list (NULL if the list is empty). Each element is represented by an hlist_node data structure, which includes a pointer next to the next element, and a pointer pprev to the next field of the previous element. Because the list is not circular, the pprev field of the first element and the next field of the last element are set to NULL. The list can be handled by means of several helper functions and macros similar to those listed in Table 3-1: hlist_add_head( ), hlist_del( ), hlist_empty( ), hlist_entry, hlist_for_each_entry, and so on.
3.2.2.4. The process list
The first example of a doubly linked list we will examine is the process list, a list that links together all existing process descriptors. Each task_struct structure includes a tasks field of type list_head whose prev and next fields point, respectively, to the previous and to the next task_struct element.
The head of the process list is the init_task task_struct descriptor; it is the process descriptor of the so-called process 0 or swapper (see the section "Kernel Threads" later in this chapter). The tasks->prev field of init_task points to the tasks field of the process descriptor inserted last in the list.
The SET_LINKS and REMOVE_LINKS macros are used to insert and to remove a process descriptor in the process list, respectively. These macros also take care of the parenthood relationship of the process (see the section "How Processes Are Organized" later in this chapter).
Another useful macro, called for_each_process, scans the whole process list. It is defined as:
#define for_each_process(p) \
for (p=&init_task; (p=list_entry((p)->tasks.next, \
struct task_struct, tasks) \
) != &init_task; )
The macro is the loop control statement after which the kernel programmer supplies the loop. Notice how the init_task process descriptor just plays the role of list header. The macro starts by moving past init_task to the next task and continues until it reaches init_task again (thanks to the circularity of the list). At each iteration, the variable passed as the argument of the macro contains the address of the currently scanned process descriptor, as returned by the list_entry macro.
3.2.2.5. The lists of TASK_RUNNING processes
When looking for a new process to run on a CPU, the kernel has to consider only the runnable processes (that is, the processes in the TASK_RUNNING state).
Earlier Linux versions put all runnable processes in the same list called runqueue. Because it would be too costly to maintain the list ordered according to process priorities, the earlier schedulers were compelled to scan the whole list in order to select the "best" runnable process.
Linux 2.6 implements the runqueue differently. The aim is to allow the scheduler to select the best runnable process in constant time, independently of the number of runnable processes. We'll defer to Chapter 7 a detailed description of this new kind of runqueue, and we'll provide here only some basic information.
The trick used to achieve the scheduler speedup consists of splitting the runqueue in many lists of runnable processes, one list per process priority. Each task_struct descriptor includes a run_list field of type list_head. If the process priority is equal to k (a value ranging between 0 and 139), the run_list field links the process descriptor into the list of runnable processes having priority k. Furthermore, on a multiprocessor system, each CPU has its own runqueue, that is, its own set of lists of processes. This is a classic example of making a data structures more complex to improve performance: to make scheduler operations more efficient, the runqueue list has been split into 140 different lists!
As we'll see, the kernel must preserve a lot of data for every runqueue in the system; however, the main data structures of a runqueue are the lists of process descriptors belonging to the runqueue; all these lists are implemented by a single prio_array_t data structure, whose fields are shown in Table 3-2.
Table 3-2. The fields of the prio_array_t data structureType | Field | Description |
|---|
int | nr_active | The number of process descriptors linked into the lists | unsigned long [5] | bitmap | A priority bitmap: each flag is set if and only if the corresponding priority list is not empty | struct list_head [140] | queue | The 140 heads of the priority lists |
The enqueue_task(p,array) function inserts a process descriptor into a runqueue list; its code is essentially equivalent to:
list_add_tail(&p->run_list, &array->queue[p->prio]);
__set_bit(p->prio, array->bitmap);
array->nr_active++;
p->array = array;
The prio field of the process descriptor stores the dynamic priority of the process, while the array field is a pointer to the prio_array_t data structure of its current runqueue. Similarly, the dequeue_task(p,array) function removes a process descriptor from a runqueue list.
3.2.3. Relationships Among Processes
Processes created by a program have a parent/child relationship. When a process creates multiple children
, these children have sibling
relationships. Several fields must be introduced in a process descriptor to represent these relationships; they are listed in Table 3-3 with respect to a given process P. Processes 0 and 1 are created by the kernel; as we'll see later in the chapter, process 1 (init) is the ancestor of all other processes.
Table 3-3. Fields of a process descriptor used to express parenthood relationshipsField name | Description |
|---|
real_parent | Points to the process descriptor of the process that created P or to the descriptor of process 1 (init) if the parent process no longer exists. (Therefore, when a user starts a background process and exits the shell, the background process becomes the child of init.) | parent | Points to the current parent of P (this is the process that must be signaled when the child process terminates); its value usually coincides with that of real_parent. It may occasionally differ, such as when another process issues a ptrace( ) system call requesting that it be allowed to monitor P (see the section "Execution Tracing" in Chapter 20). | children | The head of the list containing all children created by P. | sibling | The pointers to the next and previous elements in the list of the sibling processes, those that have the same parent as P. |
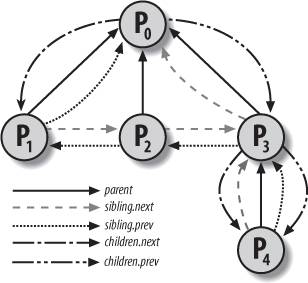
Figure 3-4 illustrates the parent and sibling relationships of a group of processes. Process P0 successively created P1, P2, and P3. Process P3, in turn, created process P4.
Furthermore, there exist other relationships among processes: a process can be a leader of a process group or of a login session (see "Process Management" in Chapter 1), it can be a leader of a thread group (see "Identifying a Process" earlier in this chapter), and it can also trace the execution of other processes (see the section "Execution Tracing" in Chapter 20). Table 3-4 lists the fields of the process descriptor that establish these relationships between a process P and the other processes.
Table 3-4. The fields of the process descriptor that establish non-parenthood relationshipsField name | Description |
|---|
group_leader | Process descriptor pointer of the group leader of P | signal->pgrp | PID of the group leader of P | tgid | PID of the thread group leader of P | signal->session | PID of the login session leader of P | ptrace_children | The head of a list containing all children of P being traced by a debugger | ptrace_list | The pointers to the next and previous elements in the real parent's list of traced processes (used when P is being traced) |
3.2.3.1. The pidhash table and chained lists
In several circumstances, the kernel must be able to derive the process descriptor pointer corresponding to a PID. This occurs, for instance, in servicing the kill( ) system call. When process P1 wishes to send a signal to another process, P2, it invokes the kill( ) system call specifying the PID of P2 as the parameter. The kernel derives the process descriptor pointer from the PID and then extracts the pointer to the data structure that records the pending signals
from P2's process descriptor.
Scanning the process list sequentially and checking the pid fields of the process descriptors is feasible but rather inefficient. To speed up the search, four hash tables have been introduced. Why multiple hash tables? Simply because the process descriptor includes fields that represent different types of PID (see Table 3-5), and each type of PID requires its own hash table.
Table 3-5. The four hash tables and corresponding fields in the process descriptorHash table type | Field name | Description |
|---|
PIDTYPE_PID | pid | PID of the process | PIDTYPE_TGID | tgid | PID of thread group leader process | PIDTYPE_PGID | pgrp | PID of the group leader process | PIDTYPE_SID | session | PID of the session leader process |
The four hash tables are dynamically allocated during the kernel initialization phase, and their addresses are stored in the pid_hash array. The size of a single hash table depends on the amount of available RAM; for example, for systems having 512 MB of RAM, each hash table is stored in four page frames and includes 2,048 entries.
The PID is transformed into a table index using the pid_hashfn macro, which expands to:
#define pid_hashfn(x) hash_long((unsigned long) x, pidhash_shift)
The pidhash_shift variable stores the length in bits of a table index (11, in our example). The hash_long( ) function is used by many hash functions; on a 32-bit architecture it is essentially equivalent to:
unsigned long hash_long(unsigned long val, unsigned int bits)
{
unsigned long hash = val * 0x9e370001UL;
return hash >> (32 - bits);
}
Because in our example pidhash_shift is equal to 11, pid_hashfn yields values ranging between 0 and 211 - 1 = 2047.
|
You might wonder where the 0x9e370001 constant (= 2,654,404,609) comes from. This hash function is based on a multiplication of the index by a suitable large number, so that the result overflows and the value remaining in the 32-bit variable can be considered as the result of a modulus operation. Knuth suggested that good results are obtained when the large multiplier is a prime approximately in golden ratio to 232 (32 bit being the size of the 80x86's registers). Now, 2,654,404,609 is a prime near to  that can also be easily multiplied by additions and bit shifts, because it is equal to that can also be easily multiplied by additions and bit shifts, because it is equal to 
|
As every basic computer science course explains, a hash function does not always ensure a one-to-one correspondence between PIDs and table indexes. Two different PIDs that hash into the same table index are said to be colliding.
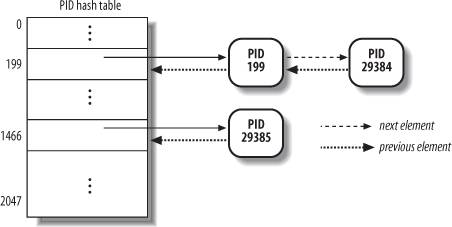
Linux uses chaining to handle colliding PIDs; each table entry is the head of a doubly linked list of colliding process descriptors. Figure 3-5 illustrates a PID hash table with two lists. The processes having PIDs 2,890 and 29,384 hash into the 200th element of the table, while the process having PID 29,385 hashes into the 1,466th element of the table.
Hashing with chaining is preferable to a linear transformation from PIDs to table indexes because at any given instance, the number of processes in the system is usually far below 32,768 (the maximum number of allowed PIDs). It would be a waste of storage to define a table consisting of 32,768 entries, if, at any given instance, most such entries are unused.
The data structures used in the PID hash tables are quite sophisticated, because they must keep track of the relationships between the processes. As an example, suppose that the kernel must retrieve all processes belonging to a given thread group, that is, all processes whose tgid field is equal to a given number. Looking in the hash table for the given thread group number returns just one process descriptor, that is, the descriptor of the thread group leader. To quickly retrieve the other processes in the group, the kernel must maintain a list of processes for each thread group. The same situation arises when looking for the processes belonging to a given login session or belonging to a given process group.
The PID hash tables' data structures solve all these problems, because they allow the definition of a list of processes for any PID number included in a hash table. The core data structure is an array of four pid structures embedded in the pids field of the process descriptor; the fields of the pid structure are shown in Table 3-6.
Table 3-6. The fields of the pid data structuresType | Name | Description |
|---|
int | nr | The PID number | struct hlist_node | pid_chain | The links to the next and previous elements in the hash chain list | struct list_head | pid_list | The head of the per-PID list |
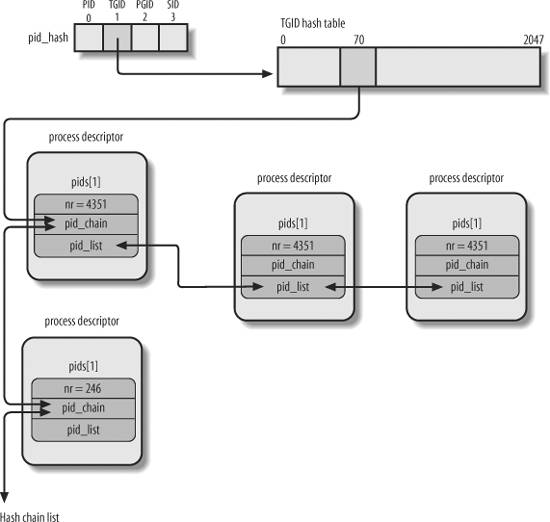
Figure 3-6 shows an example based on the PIDTYPE_TGID hash table. The second entry of the pid_hash array stores the address of the hash table, that is, the array of hlist_head structures representing the heads of the chain lists. In the chain list rooted at the 71st entry of the hash table, there are two process descriptors corresponding to the PID numbers 246 and 4,351 (double-arrow lines represent a couple of forward and backward pointers). The PID numbers are stored in the nr field of the pid structure embedded in the process descriptor (by the way, because the thread group number coincides with the PID of its leader, these numbers also are stored in the pid field of the process descriptors). Let us consider the per-PID list of the thread group 4,351: the head of the list is stored in the pid_list field of the process descriptor included in the hash table, while the links to the next and previous elements of the per-PID list also are stored in the pid_list field of each list element.
The following functions and macros are used to handle the PID hash tables:
do_each_task_pid(nr, type, task)
while_each_task_pid(nr, type, task) Mark begin and end of a do-while loop that iterates over the per-PID list associated with the PID number nr of type type; in any iteration, task points to the process descriptor of the currently scanned element.
find_task_by_pid_type(type, nr) Looks for the process having PID nr in the hash table of type type. The function returns a process descriptor pointer if a match is found, otherwise it returns NULL.
find_task_by_pid(nr) Same as find_task_by_pid_type(PIDTYPE_PID, nr).
attach_pid(task, type, nr) Inserts the process descriptor pointed to by task in the PID hash table of type type according to the PID number nr; if a process descriptor having PID nr is already in the hash table, the function simply inserts task in the per-PID list of the already present process.
detach_pid(task, type) Removes the process descriptor pointed to by task from the per-PID list of type type to which the descriptor belongs. If the per-PID list does not become empty, the function terminates. Otherwise, the function removes the process descriptor from the hash table of type type; finally, if the PID number does not occur in any other hash table, the function clears the corresponding bit in the PID bitmap, so that the number can be recycled.
next_thread(task) Returns the process descriptor address of the lightweight process that follows task in the hash table list of type PIDTYPE_TGID. Because the hash table list is circular, when applied to a conventional process the macro returns the descriptor address of the process itself.
3.2.4. How Processes Are Organized
The runqueue lists group all processes in a TASK_RUNNING state. When it comes to grouping processes in other states, the various states call for different types of treatment, with Linux opting for one of the choices shown in the following list.
Processes in a TASK_STOPPED, EXIT_ZOMBIE, or EXIT_DEAD state are not linked in specific lists. There is no need to group processes in any of these three states, because stopped, zombie, and dead processes are accessed only via PID or via linked lists of the child processes for a particular parent. Processes in a TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE state are subdivided into many classes, each of which corresponds to a specific event. In this case, the process state does not provide enough information to retrieve the process quickly, so it is necessary to introduce additional lists of processes. These are called wait queues
and are discussed next.
3.2.4.1. Wait queues
Wait queues have several uses in the kernel, particularly for interrupt handling, process synchronization, and timing. Because these topics are discussed in later chapters, we'll just say here that a process must often wait for some event to occur, such as for a disk operation to terminate, a system resource to be released, or a fixed interval of time to elapse. Wait queues implement conditional waits on events: a process wishing to wait for a specific event places itself in the proper wait queue and relinquishes control. Therefore, a wait queue represents a set of sleeping processes, which are woken up by the kernel when some condition becomes true.
Wait queues are implemented as doubly linked lists whose elements include pointers to process descriptors. Each wait queue is identified by a wait queue head, a data structure of type wait_queue_head_t:
struct _ _wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct _ _wait_queue_head wait_queue_head_t;
Because wait queues are modified by interrupt handlers as well as by major kernel functions, the doubly linked lists must be protected from concurrent accesses, which could induce unpredictable results (see Chapter 5). Synchronization is achieved by the lock spin lock in the wait queue head. The task_list field is the head of the list of waiting processes.
Elements of a wait queue list are of type wait_queue_t:
struct _ _wait_queue {
unsigned int flags;
struct task_struct * task;
wait_queue_func_t func;
struct list_head task_list;
};
typedef struct _ _wait_queue wait_queue_t;
Each element in the wait queue list represents a sleeping
process, which is waiting for some event to occur; its descriptor address is stored in the task field. The task_list field contains the pointers that link this element to the list of processes waiting for the same event.
However, it is not always convenient to wake up all sleeping processes
in a wait queue. For instance, if two or more processes are waiting for exclusive access to some resource to be released, it makes sense to wake up just one process in the wait queue. This process takes the resource, while the other processes continue to sleep. (This avoids a problem known as the "thundering herd," with which multiple processes are wakened only to race for a resource that can be accessed by one of them, with the result that remaining processes must once more be put back to sleep.)
Thus, there are two kinds of sleeping processes: exclusive processes
(denoted by the value 1 in the flags field of the corresponding wait queue element) are selectively woken up by the kernel, while nonexclusive processes
(denoted by the value 0 in the flags field) are always woken up by the kernel when the event occurs. A process waiting for a resource that can be granted to just one process at a time is a typical exclusive process. Processes waiting for an event that may concern any of them are nonexclusive. Consider, for instance, a group of processes that are waiting for the termination of a group of disk block transfers: as soon as the transfers complete, all waiting processes must be woken up. As we'll see next, the func field of a wait queue element is used to specify how the processes sleeping in the wait queue should be woken up.
3.2.4.2. Handling wait queues
A new wait queue head may be defined by using the DECLARE_WAIT_QUEUE_HEAD(name) macro, which statically declares a new wait queue head variable called name and initializes its lock and task_list fields. The init_waitqueue_head( ) function may be used to initialize a wait queue head variable that was allocated dynamically.
The init_waitqueue_entry(q,p ) function initializes a wait_queue_t structure q as follows:
q->flags = 0;
q->task = p;
q->func = default_wake_function;
The nonexclusive process p will be awakened by default_wake_function( ), which is a simple wrapper for the TRy_to_wake_up( ) function discussed in Chapter 7.
Alternatively, the DEFINE_WAIT macro declares a new wait_queue_t variable and initializes it with the descriptor of the process currently executing on the CPU and the address of the autoremove_wake_function( ) wake-up function. This function invokes default_wake_function( ) to awaken the sleeping process, and then removes the wait queue element from the wait queue list. Finally, a kernel developer can define a custom awakening function by initializing the wait queue element with the init_waitqueue_func_entry( ) function.
Once an element is defined, it must be inserted into a wait queue. The add_wait_queue( ) function inserts a nonexclusive process in the first position of a wait queue list. The add_wait_queue_exclusive( ) function inserts an exclusive process in the last position of a wait queue list. The remove_wait_queue( ) function removes a process from a wait queue list. The waitqueue_active( ) function checks whether a given wait queue list is empty.
A process wishing to wait for a specific condition can invoke any of the functions shown in the following list.
The sleep_on( ) function operates on the current process:
void sleep_on(wait_queue_head_t *wq)
{
wait_queue_t wait;
init_waitqueue_entry(&wait, current);
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue(wq,&wait); /* wq points to the wait queue head */
schedule( );
remove_wait_queue(wq, &wait);
}
The function sets the state of the current process to TASK_UNINTERRUPTIBLE and inserts it into the specified wait queue. Then it invokes the scheduler, which resumes the execution of another process. When the sleeping process is awakened, the scheduler resumes execution of the sleep_on( ) function, which removes the process from the wait queue. The interruptible_sleep_on( ) function is identical to sleep_on( ), except that it sets the state of the current process to TASK_INTERRUPTIBLE instead of setting it to TASK_UNINTERRUPTIBLE, so that the process also can be woken up by receiving a signal. The sleep_on_timeout( ) and interruptible_sleep_on_timeout( ) functions are similar to the previous ones, but they also allow the caller to define a time interval after which the process will be woken up by the kernel. To do this, they invoke the schedule_timeout( ) function instead of schedule( ) (see the section "An Application of Dynamic Timers: the nanosleep( ) System Call" in Chapter 6). The prepare_to_wait( ), prepare_to_wait_exclusive( ), and finish_wait( ) functions, introduced in Linux 2.6, offer yet another way to put the current process to sleep in a wait queue. Typically, they are used as follows:
DEFINE_WAIT(wait);
prepare_to_wait_exclusive(&wq, &wait, TASK_INTERRUPTIBLE);
/* wq is the head of the wait queue */
...
if (!condition)
schedule();
finish_wait(&wq, &wait);
The prepare_to_wait( ) and prepare_to_wait_exclusive( ) functions set the process state to the value passed as the third parameter, then set the exclusive flag in the wait queue element respectively to 0 (nonexclusive) or 1 (exclusive), and finally insert the wait queue element wait into the list of the wait queue head wq. As soon as the process is awakened, it executes the finish_wait( ) function, which sets again the process state to TASK_RUNNING (just in case the awaking condition becomes true before invoking schedule( )), and removes the wait queue element from the wait queue list (unless this has already been done by the wake-up function). The wait_event and wait_event_interruptible macros put the calling process to sleep on a wait queue until a given condition is verified. For instance, the wait_event(wq,condition) macro essentially yields the following fragment:
DEFINE_WAIT(_ _wait);
for (;;) {
prepare_to_wait(&wq, &_ _wait, TASK_UNINTERRUPTIBLE);
if (condition)
break;
schedule( );
}
finish_wait(&wq, &_ _wait);
A few comments on the functions mentioned in the above list: the sleep_on( )-like functions cannot be used in the common situation where one has to test a condition and atomically put the process to sleep when the condition is not verified; therefore, because they are a well-known source of race conditions, their use is discouraged. Moreover, in order to insert an exclusive process into a wait queue, the kernel must make use of the prepare_to_wait_exclusive( ) function (or just invoke add_wait_queue_exclusive( ) directly); any other helper function inserts the process as nonexclusive. Finally, unless DEFINE_WAIT or finish_wait( ) are used, the kernel must remove the wait queue element from the list after the waiting process has been awakened.
The kernel awakens processes in the wait queues, putting them in the TASK_RUNNING state, by means of one of the following macros: wake_up, wake_up_nr, wake_up_all, wake_up_interruptible, wake_up_interruptible_nr, wake_up_interruptible_all, wake_up_interruptible_sync, and wake_up_locked. One can understand what each of these nine macros does from its name:
All macros take into consideration sleeping processes in the TASK_INTERRUPTIBLE state; if the macro name does not include the string "interruptible," sleeping processes in the TASK_UNINTERRUPTIBLE state also are considered. All macros wake all nonexclusive processes having the required state (see the previous bullet item). The macros whose name include the string "nr" wake a given number of exclusive processes having the required state; this number is a parameter of the macro. The macros whose names include the string "all" wake all exclusive processes having the required state. Finally, the macros whose names don't include "nr" or "all" wake exactly one exclusive process that has the required state. The macros whose names don't include the string "sync" check whether the priority of any of the woken processes is higher than that of the processes currently running in the systems and invoke schedule( ) if necessary. These checks are not made by the macro whose name includes the string "sync"; as a result, execution of a high priority process might be slightly delayed. The wake_up_locked macro is similar to wake_up, except that it is called when the spin lock in wait_queue_head_t is already held.
For instance, the wake_up macro is essentially equivalent to the following code fragment:
void wake_up(wait_queue_head_t *q)
{
struct list_head *tmp;
wait_queue_t *curr;
list_for_each(tmp, &q->task_list) {
curr = list_entry(tmp, wait_queue_t, task_list);
if (curr->func(curr, TASK_INTERRUPTIBLE|TASK_UNINTERRUPTIBLE,
0, NULL) && curr->flags)
break;
}
}
The list_for_each macro scans all items in the q->task_list doubly linked list, that is, all processes in the wait queue. For each item, the list_entry macro computes the address of the corresponding wait_queue_t variable. The func field of this variable stores the address of the wake-up function, which tries to wake up the process identified by the task field of the wait queue element. If a process has been effectively awakened (the function returned 1) and if the process is exclusive (curr->flags equal to 1), the loop terminates. Because all nonexclusive processes are always at the beginning of the doubly linked list and all exclusive processes are at the end, the function always wakes the nonexclusive processes and then wakes one exclusive process, if any exists.
3.2.5. Process Resource Limits
Each process has an associated set of resource limits
, which specify the amount of system resources it can use. These limits keep a user from overwhelming the system (its CPU, disk space, and so on). Linux recognizes the following resource limits illustrated in Table 3-7.
The resource limits for the current process are stored in the current->signal->rlim field, that is, in a field of the process's signal descriptor (see the section "Data Structures Associated with Signals" in Chapter 11). The field is an array of elements of type struct rlimit, one for each resource limit:
struct rlimit {
unsigned long rlim_cur;
unsigned long rlim_max;
};
Table 3-7. Resource limitsField name | Description |
|---|
RLIMIT_AS | The maximum size of process address space, in bytes. The kernel checks this value when the process uses malloc( ) or a related function to enlarge its address space (see the section "The Process's Address Space" in Chapter 9). | RLIMIT_CORE | The maximum core dump file size, in bytes. The kernel checks this value when a process is aborted, before creating a core file in the current directory of the process (see the section "Actions Performed upon Delivering a Signal" in Chapter 11). If the limit is 0, the kernel won't create the file. | RLIMIT_CPU | The maximum CPU time for the process, in seconds. If the process exceeds the limit, the kernel sends it a SIGXCPU signal, and then, if the process doesn't terminate, a SIGKILL signal (see Chapter 11). | RLIMIT_DATA | The maximum heap size, in bytes. The kernel checks this value before expanding the heap of the process (see the section "Managing the Heap" in Chapter 9). | RLIMIT_FSIZE | The maximum file size allowed, in bytes. If the process tries to enlarge a file to a size greater than this value, the kernel sends it a SIGXFSZ signal. | RLIMIT_LOCKS | Maximum number of file locks (currently, not enforced). | RLIMIT_MEMLOCK | The maximum size of nonswappable memory, in bytes. The kernel checks this value when the process tries to lock a page frame in memory using the mlock( ) or mlockall( ) system calls (see the section "Allocating a Linear Address Interval" in Chapter 9). | RLIMIT_MSGQUEUE | Maximum number of bytes in POSIX message queues
(see the section "POSIX Message Queues" in Chapter 19). | RLIMIT_NOFILE | The maximum number of open file descriptors
. The kernel checks this value when opening a new file or duplicating a file descriptor (see Chapter 12). | RLIMIT_NPROC | The maximum number of processes that the user can own (see the section "The clone( ), fork( ), and vfork( ) System Calls" later in this chapter). | RLIMIT_RSS | The maximum number of page frames owned by the process (currently, not enforced). | RLIMIT_SIGPENDING | The maximum number of pending signals for the process (see Chapter 11). | RLIMIT_STACK | The maximum stack size, in bytes. The kernel checks this value before expanding the User Mode stack of the process (see the section "Page Fault Exception Handler" in Chapter 9). |
The rlim_cur field is the current resource limit for the resource. For example, current->signal->rlim[RLIMIT_CPU].rlim_cur represents the current limit on the CPU time of the running process.
The rlim_max field is the maximum allowed value for the resource limit. By using the getrlimit( ) and setrlimit( ) system calls, a user can always increase the rlim_cur limit of some resource up to rlim_max. However, only the superuser (or, more precisely, a user who has the CAP_SYS_RESOURCE capability) can increase the rlim_max field or set the rlim_cur field to a value greater than the corresponding rlim_max field.
Most resource limits contain the value RLIM_INFINITY (0xffffffff), which means that no user limit is imposed on the corresponding resource (of course, real limits exist due to kernel design restrictions, available RAM, available space on disk, etc.). However, the system administrator may choose to impose stronger limits on some resources. Whenever a user logs into the system, the kernel creates a process owned by the superuser, which can invoke setrlimit( ) to decrease the rlim_max and rlim_cur fields for a resource. The same process later executes a login shell and becomes owned by the user. Each new process created by the user inherits the content of the rlim array from its parent, and therefore the user cannot override the limits enforced by the administrator.
3.3. Process Switch
To control the execution of processes, the kernel must be able to suspend the execution of the process running on the CPU and resume the execution of some other process previously suspended. This activity goes variously by the names process switch, task switch, or context switch. The next sections describe the elements of process switching in Linux.
3.3.1. Hardware Context
While each process can have its own address space, all processes have to share the CPU registers. So before resuming the execution of a process, the kernel must ensure that each such register is loaded with the value it had when the process was suspended.
The set of data that must be loaded into the registers before the process resumes its execution on the CPU is called the hardware context
. The hardware context is a subset of the process execution context, which includes all information needed for the process execution. In Linux, a part of the hardware context of a process is stored in the process descriptor, while the remaining part is saved in the Kernel Mode stack.
In the description that follows, we will assume the prev local variable refers to the process descriptor of the process being switched out and next refers to the one being switched in to replace it. We can thus define a process switch as the activity consisting of saving the hardware context of prev and replacing it with the hardware context of next. Because process switches
occur quite often, it is important to minimize the time spent in saving and loading hardware contexts.
Old versions of Linux took advantage of the hardware support offered by the 80x86 architecture and performed a process switch through a far jmp
instruction to the selector of the Task State Segment Descriptor of the next process. While executing the instruction, the CPU performs a hardware context switch by automatically saving the old hardware context and loading a new one. But Linux 2.6 uses software to perform a process switch for the following reasons:
Step-by-step switching performed through a sequence of mov instructions allows better control over the validity of the data being loaded. In particular, it is possible to check the values of the ds and es segmentation registers, which might have been forged by a malicious user. This type of checking is not possible when using a single far jmp instruction. The amount of time required by the old approach and the new approach is about the same. However, it is not possible to optimize a hardware context switch, while there might be room for improving the current switching code.
Process switching occurs only in Kernel Mode. The contents of all registers used by a process in User Mode have already been saved on the Kernel Mode stack before performing process switching (see Chapter 4). This includes the contents of the ss and esp pair that specifies the User Mode stack pointer address.
3.3.2. Task State Segment
The 80x86 architecture includes a specific segment type called the Task State Segment (TSS), to store hardware contexts. Although Linux doesn't use hardware context switches, it is nonetheless forced to set up a TSS for each distinct CPU in
the system. This is done for two main reasons:
When an 80x86 CPU switches from User Mode to Kernel Mode, it fetches the address of the Kernel Mode stack from the TSS (see the sections "Hardware Handling of Interrupts and Exceptions" in Chapter 4 and "Issuing a System Call via the sysenter Instruction" in Chapter 10). When a User Mode process attempts to access an I/O port by means of an in or out
instruction, the CPU may need to access an I/O Permission Bitmap stored in the TSS to verify whether the process is allowed to address the port. More precisely, when a process executes an in or out I/O instruction in User Mode, the control unit performs the following operations: It checks the 2-bit IOPL field in the eflags
register. If it is set to 3, the control unit executes the I/O instructions. Otherwise, it performs the next check. It accesses the tr
register to determine the current TSS, and thus the proper I/O Permission Bitmap. It checks the bit of the I/O Permission Bitmap corresponding to the I/O port specified in the I/O instruction. If it is cleared, the instruction is executed; otherwise, the control unit raises a "General protection
" exception.
The tss_struct structure describes the format of the TSS. As already mentioned in Chapter 2, the init_tss array stores one TSS for each CPU on the system. At each process switch, the kernel updates some fields of the TSS so that the corresponding CPU's control unit may safely retrieve the information it needs. Thus, the TSS reflects the privilege of the current process on the CPU, but there is no need to maintain TSSs for processes when they're not running.
Each TSS has its own 8-byte Task State Segment Descriptor (TSSD). This descriptor includes a 32-bit Base field that points to the TSS starting address and a 20-bit Limit field. The S flag of a TSSD is cleared to denote the fact that the corresponding TSS is a System Segment (see the section "Segment Descriptors" in Chapter 2).
The Type field is set to either 9 or 11 to denote that the segment is actually a TSS. In the Intel's original design, each process in the system should refer to its own TSS; the second least significant bit of the Type field is called the Busy bit; it is set to 1 if the process is being executed by a CPU, and to 0 otherwise. In Linux design, there is just one TSS for each CPU, so the Busy bit is always set to 1.
The TSSDs created by Linux are stored in the Global Descriptor Table (GDT), whose base address is stored in the gdtr
register of each CPU. The tr register of each CPU contains the TSSD Selector of the corresponding TSS. The register also includes two hidden, nonprogrammable fields: the Base and Limit fields of the TSSD. In this way, the processor can address the TSS directly without having to retrieve the TSS address from the GDT.
3.3.2.1. The thread field
At every process switch, the hardware context of the process being replaced must be saved somewhere. It cannot be saved on the TSS, as in the original Intel design, because Linux uses a single TSS for each processor, instead of one for every process.
Thus, each process descriptor includes a field called thread of type thread_struct, in which the kernel saves the hardware context whenever the process is being switched out. As we'll see later, this data structure includes fields for most of the CPU registers, except the general-purpose registers such as eax, ebx, etc., which are stored in the Kernel Mode stack.
3.3.3. Performing the Process Switch
A process switch may occur at just one well-defined point: the schedule( ) function, which is discussed at length in Chapter 7. Here, we are only concerned with how the kernel performs a process switch.
Essentially, every process switch consists of two steps:
Switching the Page Global Directory to install a new address space; we'll describe this step in Chapter 9. Switching the Kernel Mode stack and the hardware context, which provides all the information needed by the kernel to execute the new process, including the CPU registers.
Again, we assume that prev points to the descriptor of the process being replaced, and next to the descriptor of the process being activated. As we'll see in Chapter 7, prev and next are local variables of the schedule( ) function.
3.3.3.1. The switch_to macro
The second step of the process switch is performed by the switch_to macro. It is one of the most hardware-dependent routines of the kernel, and it takes some effort to understand what it does.
First of all, the macro has three parameters, called prev, next, and last. You might easily guess the role of prev and next: they are just placeholders for the local variables prev and next, that is, they are input parameters that specify the memory locations containing the descriptor address of the process being replaced and the descriptor address of the new process, respectively.
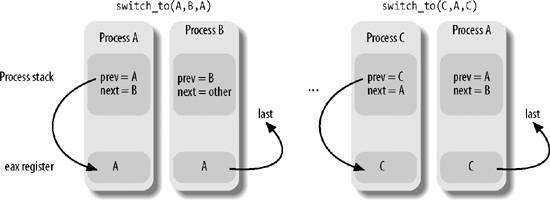
What about the third parameter, last? Well, in any process switch three processes are involved, not just two. Suppose the kernel decides to switch off process A and to activate process B. In the schedule( ) function, prev points to A's descriptor and next points to B's descriptor. As soon as the switch_to macro deactivates A, the execution flow of A freezes.
Later, when the kernel wants to reactivate A, it must switch off another process C (in general, this is different from B) by executing another switch_to macro with prev pointing to C and next pointing to A. When A resumes its execution flow, it finds its old Kernel Mode stack, so the prev local variable points to A's descriptor and next points to B's descriptor. The scheduler, which is now executing on behalf of process A, has lost any reference to C. This reference, however, turns out to be useful to complete the process switching (see Chapter 7 for more details).
The last parameter of the switch_to macro is an output parameter that specifies a memory location in which the macro writes the descriptor address of process C (of course, this is done after A resumes its execution). Before the process switching, the macro saves in the eax CPU register the content of the variable identified by the first input parameter prevthat is, the prev local variable allocated on the Kernel Mode stack of A. After the process switching, when A has resumed its execution, the macro writes the content of the eax CPU register in the memory location of A identified by the third output parameter last. Because the CPU register doesn't change across the process switch, this memory location receives the address of C's descriptor. In the current implementation of schedule( ), the last parameter identifies the prev local variable of A, so prev is overwritten with the address of C.
The contents of the Kernel Mode stacks of processes A, B, and C are shown in Figure 3-7, together with the values of the eax register; be warned that the figure shows the value of the prev local variable before its value is overwritten with the contents of the eax register.
The switch_to macro is coded in extended inline assembly language
that makes for rather complex reading: in fact, the code refers to registers by means of a special positional notation that allows the compiler to freely choose the general-purpose registers to be used. Rather than follow the cumbersome extended inline assembly language, we'll describe what the switch_to macro typically does on an 80x86 microprocessor by using standard assembly language:
Saves the values of prev and next in the eax and edx registers, respectively:
movl prev, %eax
movl next, %edx
Saves the contents of the eflags
and ebp registers in the prev Kernel Mode stack. They must be saved because the compiler assumes that they will stay unchanged until the end of switch_to:
pushfl
pushl %ebp
Saves the content of esp in prev->thread.esp so that the field points to the top of the prev Kernel Mode stack:
movl %esp,484(%eax)
The 484(%eax) operand identifies the memory cell whose address is the contents of eax plus 484. Loads next->thread.esp in esp. From now on, the kernel operates on the Kernel Mode stack of next, so this instruction performs the actual process switch from prev to next. Because the address of a process descriptor is closely related to that of the Kernel Mode stack (as explained in the section "Identifying a Process" earlier in this chapter), changing the kernel stack means changing the current process:
movl 484(%edx), %esp
Saves the address labeled 1 (shown later in this section) in prev->thread.eip. When the process being replaced resumes its execution, the process executes the instruction labeled as 1:
movl $1f, 480(%eax)
On the Kernel Mode stack of next, the macro pushes the next->thread.eip value, which, in most cases, is the address labeled as 1:
pushl 480(%edx)
Jumps to the _ _switch_to( ) C function (see next):
jmp _ _switch_to
Here process A that was replaced by B gets the CPU again: it executes a few instructions that restore the contents of the eflags and ebp registers. The first of these two instructions is labeled as 1:
1:
popl %ebp
popfl
Notice how these pop instructions refer to the kernel stack of the prev process. They will be executed when the scheduler selects prev as the new process to be executed on the CPU, thus invoking switch_to with prev as the second parameter. Therefore, the esp register points to the prev's Kernel Mode stack. Copies the content of the eax register (loaded in step 1 above) into the memory location identified by the third parameter last of the switch_to macro:
movl %eax, last
As discussed earlier, the eax register points to the descriptor of the process that has just been replaced.
3.3.3.2. The _ _switch_to ( ) function
The _ _switch_to( ) function does the bulk of the process switch started by the switch_to( ) macro. It acts on the prev_p and next_p parameters that denote the former process and the new process. This function call is different from the average function call, though, because _ _switch_to( ) takes the prev_p and next_p parameters from the eax and edx registers (where we saw they were stored), not from the stack like most functions. To force the function to go to the registers for its parameters, the kernel uses the _ _attribute_ _ and regparm keywords, which are nonstandard extensions of the C language implemented by the gcc compiler. The _ _switch_to( ) function is declared in the include /asm-i386 /system.h header file as follows:
_ _switch_to(struct task_struct *prev_p,
struct task_struct *next_p)
_ _attribute_ _(regparm(3));
The steps performed by the function are the following:
Executes the code yielded by the _ _unlazy_fpu( ) macro (see the section "Saving and Loading the FPU
, MMX, and XMM Registers" later in this chapter) to optionally save the contents of the FPU, MMX, and XMM registers
of the prev_p process.
_ _unlazy_fpu(prev_p);
Executes the smp_processor_id( ) macro to get the index of the local CPU
, namely the CPU that executes the code. The macro gets the index from the cpu field of the tHRead_info structure of the current process and stores it into the cpu local variable. Loads next_p->thread.esp0 in the esp0 field of the TSS relative to the local CPU; as we'll see in the section "Issuing a System Call via the sysenter Instruction
" in Chapter 10, any future privilege level change from User Mode to Kernel Mode raised by a sysenter assembly instruction will copy this address in the esp register:
init_tss[cpu].esp0 = next_p->thread.esp0;
Loads in the Global Descriptor Table of the local CPU the Thread-Local Storage (TLS) segments used by the next_p process; the three Segment Selectors are stored in the tls_array array inside the process descriptor (see the section "Segmentation in Linux" in Chapter 2).
cpu_gdt_table[cpu][6] = next_p->thread.tls_array[0];
cpu_gdt_table[cpu][7] = next_p->thread.tls_array[1];
cpu_gdt_table[cpu][8] = next_p->thread.tls_array[2];
Stores the contents of the fs and gs segmentation registers in prev_p->thread.fs and prev_p->thread.gs, respectively; the corresponding assembly language instructions are:
movl %fs, 40(%esi)
movl %gs, 44(%esi)
The esi register points to the prev_p->thread structure. If the fs or the gs segmentation register have been used either by the prev_p or by the next_p process (i.e., if they have a nonzero value), loads into these registers the values stored in the thread_struct descriptor of the next_p process. This step logically complements the actions performed in the previous step. The main assembly language instructions are:
movl 40(%ebx),%fs
movl 44(%ebx),%gs
The ebx register points to the next_p->thread structure. The code is actually more intricate, as an exception might be raised by the CPU when it detects an invalid segment register value. The code takes this possibility into account by adopting a "fix-up" approach (see the section "Dynamic Address Checking: The Fix-up Code" in Chapter 10). Loads six of the dr0,..., dr7 debug registers
with the contents of the next_p->thread.debugreg array. This is done only if next_p was using the debug registers when it was suspended (that is, field next_p->thread.debugreg[7] is not 0). These registers need not be saved, because the prev_p->thread.debugreg array is modified only when a debugger wants to monitor prev:
if (next_p->thread.debugreg[7]){
loaddebug(&next_p->thread, 0);
loaddebug(&next_p->thread, 1);
loaddebug(&next_p->thread, 2);
loaddebug(&next_p->thread, 3);
/* no 4 and 5 */
loaddebug(&next_p->thread, 6);
loaddebug(&next_p->thread, 7);
}
Updates the I/O bitmap in the TSS, if necessary. This must be done when either next_p or prev_p has its own customized I/O Permission Bitmap:
if (prev_p->thread.io_bitmap_ptr || next_p->thread.io_bitmap_ptr)
handle_io_bitmap(&next_p->thread, &init_tss[cpu]);
Because processes seldom modify the I/O Permission Bitmap, this bitmap is handled in a "lazy" mode: the actual bitmap is copied into the TSS of the local CPU only if a process actually accesses an I/O port in the current timeslice. The customized I/O Permission Bitmap of a process is stored in a buffer pointed to by the io_bitmap_ptr field of the tHRead_info structure. The handle_io_bitmap( ) function sets up the io_bitmap field of the TSS used by the local CPU for the next_p process as follows: If the next_p process does not have its own customized I/O Permission Bitmap, the io_bitmap field of the TSS is set to the value 0x8000. If the next_p process has its own customized I/O Permission Bitmap, the io_bitmap field of the TSS is set to the value 0x9000.
The io_bitmap field of the TSS should contain an offset inside the TSS where the actual bitmap is stored. The 0x8000 and 0x9000 values point outside of the TSS limit and will thus cause a "General protection
" exception whenever the User Mode process attempts to access an I/O port (see the section "Exceptions" in Chapter 4). The do_general_protection( ) exception handler will check the value stored in the io_bitmap field: if it is 0x8000, the function sends a SIGSEGV signal to the User Mode process; otherwise, if it is 0x9000, the function copies the process bitmap (pointed to by the io_bitmap_ptr field in the tHRead_info structure) in the TSS of the local CPU, sets the io_bitmap field to the actual bitmap offset (104), and forces a new execution of the faulty assembly language instruction. Terminates. The _ _switch_to( ) C function ends by means of the statement:
return prev_p;
The corresponding assembly language instructions generated by the compiler are:
movl %edi,%eax
ret
The prev_p parameter (now in edi) is copied into eax, because by default the return value of any C function is passed in the eax register. Notice that the value of eax is thus preserved across the invocation of _ _switch_to( ); this is quite important, because the invoking switch_to macro assumes that eax always stores the address of the process descriptor being replaced. The ret assembly language instruction loads the eip program counter with the return address stored on top of the stack. However, the _ _switch_to( ) function has been invoked simply by jumping into it. Therefore, the ret instruction finds on the stack the address of the instruction labeled as 1, which was pushed by the switch_to macro. If next_p was never suspended before because it is being executed for the first time, the function finds the starting address of the ret_from_fork( ) function (see the section "The clone( ), fork( ), and vfork( ) System Calls" later in this chapter).
3.3.4. Saving and Loading the FPU, MMX, and XMM Registers
Starting with the Intel 80486DX, the arithmetic floating-point unit (FPU) has been integrated into the CPU. The name mathematical coprocessor continues to be used in memory of the days when floating-point computations were executed by an expensive special-purpose chip. To maintain compatibility with older models, however, floating-point arithmetic functions are performed with ESCAPE instructions
, which are instructions with a prefix byte ranging between 0xd8 and 0xdf. These instructions act on the set of floating-point registers included in the CPU. Clearly, if a process is using ESCAPE instructions, the contents of the floating-point registers belong to its hardware context and should be saved.
In later Pentium models, Intel introduced a new set of assembly language instructions into its microprocessors. They are called MMX instructions
and are supposed to speed up the execution of multimedia applications. MMX instructions act on the floating-point registers of the FPU. The obvious disadvantage of this architectural choice is that programmers cannot mix floating-point instructions and MMX instructions. The advantage is that operating system designers can ignore the new instruction set, because the same facility of the task-switching code for saving the state of the floating-point unit can also be relied upon to save the MMX state.
MMX instructions speed up multimedia applications, because they introduce a single-instruction multiple-data (SIMD) pipeline inside the processor. The Pentium III model extends that SIMD capability: it introduces the SSE extensions (Streaming SIMD Extensions), which adds facilities for handling floating-point values contained in eight 128-bit registers called the XMM registers
. Such registers do not overlap with the FPU and MMX registers
, so SSE and FPU/MMX instructions may be freely mixed. The Pentium 4 model introduces yet another feature: the SSE2 extensions, which is basically an extension of SSE supporting higher-precision floating-point values. SSE2 uses the same set of XMM registers as SSE.
The 80x86 microprocessors do not automatically save the FPU, MMX, and XMM registers in the TSS. However, they include some hardware support that enables kernels to save these registers only when needed. The hardware support consists of a TS (Task-Switching) flag in the cr0
register, which obeys the following rules:
Every time a hardware context switch is performed, the TS flag is set. Every time an ESCAPE, MMX, SSE, or SSE2 instruction is executed when the TS flag is set, the control unit raises a "Device not available
" exception (see Chapter 4).
The TS flag allows the kernel to save and restore the FPU, MMX, and XMM registers only when really needed. To illustrate how it works, suppose that a process A is using the mathematical coprocessor. When a context switch occurs from A to B, the kernel sets the TS flag and saves the floating-point registers into the TSS of process A. If the new process B does not use the mathematical coprocessor, the kernel won't need to restore the contents of the floating-point registers. But as soon as B tries to execute an ESCAPE or MMX instruction, the CPU raises a "Device not available" exception, and the corresponding handler loads the floating-point registers with the values saved in the TSS of process B.
Let's now describe the data structures introduced to handle selective loading of the FPU, MMX, and XMM registers. They are stored in the thread.i387 subfield of the process descriptor, whose format is described by the i387_union union:
union i387_union {
struct i387_fsave_struct fsave;
struct i387_fxsave_struct fxsave;
struct i387_soft_struct soft;
};
As you see, the field may store just one of three different types of data structures. The i387_soft_struct type is used by CPU models without a mathematical coprocessor; the Linux kernel still supports these old chips by emulating the coprocessor via software. We don't discuss this legacy case further, however. The i387_fsave_struct type is used by CPU models with a mathematical coprocessor and, optionally, an MMX unit. Finally, the i387_fxsave_struct type is used by CPU models featuring SSE and SSE2 extensions.
The process descriptor includes two additional flags:
The TS_USEDFPU flag, which is included in the status field of the thread_info descriptor. It specifies whether the process used the FPU, MMX, or XMM registers in the current execution run. The PF_USED_MATH flag, which is included in the flags field of the task_struct descriptor. This flag specifies whether the contents of the thread.i387 subfield are significant. The flag is cleared (not significant) in two cases, shown in the following list. When the process starts executing a new program by invoking an execve( ) system call (see Chapter 20). Because control will never return to the former program, the data currently stored in thread.i387 is never used again. When a process that was executing a program in User Mode starts executing a signal handler procedure (see Chapter 11). Because signal handlers are asynchronous with respect to the program execution flow, the floating-point registers could be meaningless to the signal handler. However, the kernel saves the floating-point registers in thread.i387 before starting the handler and restores them after the handler terminates. Therefore, a signal handler is allowed to use the mathematical coprocessor.
3.3.4.1. Saving the FPU registers
As stated earlier, the _ _switch_to( ) function executes the _ _unlazy_fpu macro, passing the process descriptor of the prev process being replaced as an argument. The macro checks the value of the TS_USEDFPU flags of prev. If the flag is set, prev has used an FPU, MMX, SSE, or SSE2 instructions; therefore, the kernel must save the relative hardware context:
if (prev->thread_info->status & TS_USEDFPU)
save_init_fpu(prev);
The save_init_fpu( ) function, in turn, executes essentially the following operations:
Dumps the contents of the FPU registers in the process descriptor of prev and then reinitializes the FPU. If the CPU uses SSE/SSE2 extensions, it also dumps the contents of the XMM registers and reinitializes the SSE/SSE2 unit. A couple of powerful extended inline assembly language instructions take care of everything, either:
asm volatile( "fxsave
%0 ; fnclex"
: "=m" (prev->thread.i387.fxsave) );
if the CPU uses SSE/SSE2 extensions, or otherwise:
asm volatile( "fnsave
%0 ; fwait"
: "=m" (prev->thread.i387.fsave) );
Resets the TS_USEDFPU flag of prev:
prev->thread_info->status &= ~TS_USEDFPU;
Sets the CW flag of cr0
by means of the stts( ) macro, which in practice yields assembly language instructions like the following:
movl %cr0, %eax
orl $8,%eax
movl %eax, %cr0
3.3.4.2. Loading the FPU registers
The contents of the floating-point registers are not restored right after the next process resumes execution. However, the TS flag of cr0 has been set by _ _unlazy_fpu( ). Thus, the first time the next process tries to execute an ESCAPE, MMX, or SSE/SSE2 instruction, the control unit raises a "Device not available" exception, and the kernel (more precisely, the exception handler involved by the exception) runs the math_state_restore( ) function. The next process is identified by this handler as current.
void math_state_restore( )
{
asm volatile ("clts"); /* clear the TS flag of cr0 */
if (!(current->flags & PF_USED_MATH))
init_fpu(current);
restore_fpu(current);
current->thread.status |= TS_USEDFPU;
}
The function clears the CW flags of cr0, so that further FPU, MMX, or SSE/SSE2 instructions executed by the process won't trigger the "Device not available" exception. If the contents of the thread.i387 subfield are not significant, i.e., if the PF_USED_MATH flag is equal to 0, init_fpu() is invoked to reset the tHRead.i387 subfield and to set the PF_USED_MATH flag of current to 1. The restore_fpu( ) function is then invoked to load the FPU registers with the proper values stored in the thread.i387 subfield. To do this, either the fxrstor
or the frstor
assembly language instructions are used, depending on whether the CPU supports SSE/SSE2 extensions. Finally, math_state_restore( ) sets the TS_USEDFPU flag.
3.3.4.3. Using the FPU, MMX, and SSE/SSE2 units in Kernel Mode
Even the kernel can make use of the FPU, MMX, or SSE/SSE2 units. In doing so, of course, it should avoid interfering with any computation carried on by the current User Mode process. Therefore:
Before using the coprocessor, the kernel must invoke kernel_fpu_begin( ), which essentially calls save_init_fpu( ) to save the contents of the registers if the User Mode process used the FPU (TS_USEDFPU flag), and then resets the TS flag of the cr0 register. After using the coprocessor, the kernel must invoke kernel_fpu_end( ), which sets the TS flag of the cr0 register.
Later, when the User Mode process executes a coprocessor instruction, the math_state_restore( ) function will restore the contents of the registers, just as in process switch handling.
It should be noted, however, that the execution time of kernel_fpu_begin( ) is rather large when the current User Mode process is using the coprocessor, so much as to nullify the speedup obtained by using the FPU, MMX, or SSE/SSE2 units. As a matter of fact, the kernel uses them only in a few places, typically when moving or clearing large memory areas or when computing checksum functions.
|
3.4. Creating Processes
Unix operating systems rely heavily on process creation to satisfy user requests. For example, the shell creates a new process that executes another copy of the shell whenever the user enters a command.
Traditional Unix systems treat all processes in the same way: resources owned by the parent process are duplicated in the child process. This approach makes process creation very slow and inefficient, because it requires copying the entire address space of the parent process. The child process rarely needs to read or modify all the resources inherited from the parent; in many cases, it issues an immediate execve( ) and wipes out the address space that was so carefully copied.
Modern Unix kernels solve this problem by introducing three different mechanisms:
The Copy On Write technique allows both the parent and the child to read the same physical pages. Whenever either one tries to write on a physical page, the kernel copies its contents into a new physical page that is assigned to the writing process. The implementation of this technique in Linux is fully explained in Chapter 9. Lightweight processes allow both the parent and the child to share many per-process kernel data structures, such as the paging tables (and therefore the entire User Mode address space), the open file tables, and the signal dispositions. The vfork( ) system call creates a process that shares the memory address space of its parent. To prevent the parent from overwriting data needed by the child, the parent's execution is blocked until the child exits or executes a new program. We'll learn more about the vfork( ) system call in the following section.
3.4.1. The clone( ), fork( ), and vfork( ) System Calls
Lightweight processes are created in Linux by using a function named clone( ), which uses the following parameters:
fn Specifies a function to be executed by the new process; when the function returns, the child terminates. The function returns an integer, which represents the exit code for the child process.
arg Points to data passed to the fn( ) function.
flags Miscellaneous information. The low byte specifies the signal number to be sent to the parent process when the child terminates; the SIGCHLD signal is generally selected. The remaining three bytes encode a group of clone flags, which are shown in Table 3-8.
child_stack Specifies the User Mode stack pointer to be assigned to the esp register of the child process. The invoking process (the parent) should always allocate a new stack for the child.
tls Specifies the address of a data structure that defines a Thread Local Storage segment for the new lightweight process (see the section "The Linux GDT" in Chapter 2). Meaningful only if the CLONE_SETTLS flag is set.
ptid Specifies the address of a User Mode variable of the parent process that will hold the PID of the new lightweight process. Meaningful only if the CLONE_PARENT_SETTID flag is set.
ctid Specifies the address of a User Mode variable of the new lightweight process that will hold the PID of such process. Meaningful only if the CLONE_CHILD_SETTID flag is set.
Table 3-8. Clone flagsFlag name | Description |
|---|
CLONE_VM | Shares the memory descriptor and all Page Tables (see Chapter 9). | CLONE_FS | Shares the table that identifies the root directory and the current working directory, as well as the value of the bitmask used to mask the initial file permissions of a new file (the so-called file umask
). | CLONE_FILES | Shares the table that identifies the open files (see Chapter 12). | CLONE_SIGHAND | Shares the tables that identify the signal handlers and the blocked and pending signals (see Chapter 11). If this flag is true, the CLONE_VM flag must also be set. | CLONE_PTRACE | If traced, the parent wants the child to be traced too. Furthermore, the debugger may want to trace the child on its own; in this case, the kernel forces the flag to 1. | CLONE_VFORK | Set when the system call issued is a vfork( ) (see later in this section). | CLONE_PARENT | Sets the parent of the child (parent and real_parent fields in the process descriptor) to the parent of the calling process. | CLONE_THREAD | Inserts the child into the same thread group of the parent, and forces the child to share the signal descriptor of the parent. The child's tgid and group_leader fields are set accordingly. If this flag is true, the CLONE_SIGHAND flag must also be set. | CLONE_NEWNS | Set if the clone needs its own namespace, that is, its own view of the mounted filesystems (see Chapter 12); it is not possible to specify both CLONE_NEWNS and CLONE_FS. | CLONE_SYSVSEM | Shares the System V IPC undoable semaphore operations (see the section "IPC Semaphores" in Chapter 19). | CLONE_SETTLS | Creates a new Thread Local Storage (TLS) segment for the lightweight process; the segment is described in the structure pointed to by the tls parameter. | CLONE_PARENT_SETTID | Writes the PID of the child into the User Mode variable of the parent pointed to by the ptid parameter. | CLONE_CHILD_CLEARTID | When set, the kernel sets up a mechanism to be triggered when the child process will exit or when it will start executing a new program. In these cases, the kernel will clear the User Mode variable pointed to by the ctid parameter and will awaken any process waiting for this event. | CLONE_DETACHED | A legacy flag ignored by the kernel. | CLONE_UNTRACED | Set by the kernel to override the value of the CLONE_PTRACE flag (used for disabling tracing of kernel threads
; see the section "Kernel Threads" later in this chapter). | CLONE_CHILD_SETTID | Writes the PID of the child into the User Mode variable of the child pointed to by the ctid parameter. | CLONE_STOPPED | Forces the child to start in the TASK_STOPPED state. |
clone( ) is actually a wrapper function defined in the C library (see the section "POSIX APIs and System Calls" in Chapter 10), which sets up the stack of the new lightweight process and invokes a clone( ) system call hidden to the programmer. The sys_clone( ) service routine that implements the clone( ) system call does not have the fn and arg parameters. In fact, the wrapper function saves the pointer fn into the child's stack position corresponding to the return address of the wrapper function itself; the pointer arg is saved on the child's stack right below fn. When the wrapper function terminates, the CPU fetches the return address from the stack and executes the fn(arg) function.
The traditional fork( ) system call is implemented by Linux as a clone( ) system call whose flags parameter specifies both a SIGCHLD signal and all the clone flags cleared, and whose child_stack parameter is the current parent stack pointer. Therefore, the parent and child temporarily share the same User Mode stack. But thanks to the Copy On Write mechanism, they usually get separate copies of the User Mode stack as soon as one tries to change the stack.
The vfork( ) system call, introduced in the previous section, is implemented by Linux as a clone( ) system call whose flags parameter specifies both a SIGCHLD signal and the flags CLONE_VM and CLONE_VFORK, and whose child_stack parameter is equal to the current parent stack pointer.
3.4.1.1. The do_fork( ) function
The do_fork( ) function, which handles the clone( ), fork( ), and vfork( ) system calls, acts on the following parameters:
clone_flags Same as the flags parameter of clone( )
stack_start Same as the child_stack parameter of clone( )
regs Pointer to the values of the general purpose registers saved into the Kernel Mode stack when switching from User Mode to Kernel Mode (see the section "The do_IRQ( ) function" in Chapter 4)
stack_size Unused (always set to 0)
parent_tidptr, child_tidptr Same as the corresponding ptid and ctid parameters of clone()
do_fork( ) makes use of an auxiliary function called copy_process( ) to set up the process descriptor and any other kernel data structure required for child's execution. Here are the main steps performed by do_fork( ):
Allocates a new PID for the child by looking in the pidmap_array bitmap (see the earlier section "Identifying a Process"). Checks the ptrace field of the parent (current->ptrace): if it is not zero, the parent process is being traced by another process, thus do_fork( ) checks whether the debugger wants to trace the child on its own (independently of the value of the CLONE_PTRACE flag specified by the parent); in this case, if the child is not a kernel thread (CLONE_UNTRACED flag cleared), the function sets the CLONE_PTRACE flag. Invokes copy_process() to make a copy of the process descriptor. If all needed resources are available, this function returns the address of the task_struct descriptor just created. This is the workhorse of the forking procedure, and we will describe it right after do_fork( ). If either the CLONE_STOPPED flag is set or the child process must be traced, that is, the PT_PTRACED flag is set in p->ptrace, it sets the state of the child to TASK_STOPPED and adds a pending SIGSTOP signal to it (see the section "The Role of Signals" in Chapter 11). The state of the child will remain TASK_STOPPED until another process (presumably the tracing process or the parent) will revert its state to TASK_RUNNING, usually by means of a SIGCONT signal. If the CLONE_STOPPED flag is not set, it invokes the wake_up_new_task( ) function, which performs the following operations: Adjusts the scheduling parameters of both the parent and the child (see "The Scheduling Algorithm" in Chapter 7). If the child will run on the same CPU as the parent, and parent and child do not share the same set of page tables (CLONE_VM flag cleared), it then forces the child to run before the parent by inserting it into the parent's runqueue right before the parent. This simple step yields better performance if the child flushes its address space and executes a new program right after the forking. If we let the parent run first, the Copy On Write mechanism would give rise to a series of unnecessary page duplications. Otherwise, if the child will not be run on the same CPU as the parent, or if parent and child share the same set of page tables (CLONE_VM flag set), it inserts the child in the last position of the parent's runqueue.
If the CLONE_STOPPED flag is set, it puts the child in the TASK_STOPPED state. If the parent process is being traced, it stores the PID of the child in the ptrace_message field of current and invokes ptrace_notify( ), which essentially stops the current process and sends a SIGCHLD signal to its parent. The "grandparent" of the child is the debugger that is tracing the parent; the SIGCHLD signal notifies the debugger that current has forked a child, whose PID can be retrieved by looking into the current->ptrace_message field. If the CLONE_VFORK flag is specified, it inserts the parent process in a wait queue and suspends it until the child releases its memory address space (that is, until the child either terminates or executes a new program). Terminates by returning the PID of the child.
3.4.1.2. The copy_process( ) function
The copy_process( ) function sets up the process descriptor and any other kernel data structure required for a child's execution. Its parameters are the same as do_fork( ), plus the PID of the child. Here is a description of its most significant steps:
Checks whether the flags passed in the clone_flags parameter are compatible. In particular, it returns an error code in the following cases: Both the flags CLONE_NEWNS and CLONE_FS are set. The CLONE_THREAD flag is set, but the CLONE_SIGHAND flag is cleared (lightweight processes in the same thread group must share signals). The CLONE_SIGHAND flag is set, but the CLONE_VM flag is cleared (lightweight processes sharing the signal handlers must also share the memory descriptor).
Performs any additional security checks by invoking security_task_create( ) and, later, security_task_alloc( ). The Linux kernel 2.6 offers hooks for security extensions that enforce a security model stronger than the one adopted by traditional Unix. See Chapter 20 for details. Invokes dup_task_struct( ) to get the process descriptor for the child. This function performs the following actions: Invokes _ _unlazy_fpu( ) on the current process to save, if necessary, the contents of the FPU, MMX, and SSE/SSE2 registers in the thread_info structure of the parent. Later, dup_task_struct( ) will copy these values in the thread_info structure of the child. Executes the alloc_task_struct( ) macro to get a process descriptor (task_struct structure) for the new process, and stores its address in the tsk local variable. Executes the alloc_thread_info macro to get a free memory area to store the thread_info structure and the Kernel Mode stack of the new process, and saves its address in the ti local variable. As explained in the earlier section "Identifying a Process," the size of this memory area is either 8 KB or 4 KB. Copies the contents of the current's process descriptor into the task_struct structure pointed to by tsk, then sets tsk->thread_info to ti. Copies the contents of the current's thread_info descriptor into the structure pointed to by ti, then sets ti->task to tsk. Sets the usage counter of the new process descriptor (tsk->usage) to 2 to specify that the process descriptor is in use and that the corresponding process is alive (its state is not EXIT_ZOMBIE or EXIT_DEAD). Returns the process descriptor pointer of the new process (tsk).
Checks whether the value stored in current->signal->rlim[RLIMIT_NPROC].rlim_cur is smaller than or equal to the current number of processes owned by the user. If so, an error code is returned, unless the process has root privileges. The function gets the current number of processes owned by the user from a per-user data structure named user_struct. This data structure can be found through a pointer in the user field of the process descriptor. Increases the usage counter of the user_struct structure (tsk->user->_ _count field) and the counter of the processes owned by the user (tsk->user->processes). Checks that the number of processes in the system (stored in the nr_threads variable) does not exceed the value of the max_threads variable. The default value of this variable depends on the amount of RAM in the system. The general rule is that the space taken by all tHRead_info descriptors and Kernel Mode stacks cannot exceed 1/8 of the physical memory. However, the system administrator may change this value by writing in the /proc/sys/kernel/threads-max file. If the kernel functions implementing the execution domain and the executable format (see Chapter 20) of the new process are included in kernel modules, it increases their usage counters (see Appendix B). Sets a few crucial fields related to the process state: Initializes the big kernel lock
counter tsk->lock_depth to -1 (see the section "The Big Kernel Lock" in Chapter 5). Initializes the tsk->did_exec field to 0: it counts the number of execve( )
system calls issued by the process. Updates some of the flags included in the tsk->flags field that have been copied from the parent process: first clears the PF_SUPERPRIV flag, which indicates whether the process has used any of its superuser privileges, then sets the PF_FORKNOEXEC flag, which indicates that the child has not yet issued an execve( ) system call.
Stores the PID of the new process in the tsk->pid field. If the CLONE_PARENT_SETTID flag in the clone_flags parameter is set, it copies the child's PID into the User Mode variable addressed by the parent_tidptr parameter. Initializes the list_head data structures and the spin locks included in the child's process descriptor, and sets up several other fields related to pending signals, timers, and time statistics. Invokes copy_semundo( ), copy_files( ), copy_fs( ), copy_sighand( ), copy_signal( ), copy_mm( ), and copy_namespace( ) to create new data structures and copy into them the values of the corresponding parent process data structures, unless specified differently by the clone_flags parameter. Invokes copy_thread( ) to initialize the Kernel Mode stack of the child process with the values contained in the CPU registers when the clone( ) system call was issued (these values have been saved in the Kernel Mode stack of the parent, as described in Chapter 10). However, the function forces the value 0 into the field corresponding to the eax register (this is the child's return value of the fork() or clone( ) system call). The tHRead.esp field in the descriptor of the child process is initialized with the base address of the child's Kernel Mode stack, and the address of an assembly language function (ret_from_fork( )) is stored in the thread.eip field. If the parent process makes use of an I/O Permission Bitmap, the child gets a copy of such bitmap. Finally, if the CLONE_SETTLS flag is set, the child gets the TLS segment specified by the User Mode data structure pointed to by the tls parameter of the clone( ) system call. If either CLONE_CHILD_SETTID or CLONE_CHILD_CLEARTID is set in the clone_flags parameter, it copies the value of the child_tidptr parameter in the tsk->set_chid_tid or tsk->clear_child_tid field, respectively. These flags specify that the value of the variable pointed to by child_tidptr in the User Mode address space of the child has to be changed, although the actual write operations will be done later. Turns off the TIF_SYSCALL_TRACE flag in the tHRead_info structure of the child, so that the ret_from_fork( ) function will not notify the debugging process about the system call termination (see the section "Entering and Exiting a System Call" in Chapter 10).
(The system call tracing of the child is not disabled, because it is controlled by the PTRACE_SYSCALL flag in tsk->ptrace.) Initializes the tsk->exit_signal field with the signal number encoded in the low bits of the clone_flags parameter, unless the CLONE_THREAD flag is set, in which case initializes the field to -1. As we'll see in the section "Process Termination" later in this chapter, only the death of the last member of a thread group (usually, the thread group leader) causes a signal notifying the parent of the thread group leader. Invokes sched_fork( ) to complete the initialization of the scheduler data structure of the new process. The function also sets the state of the new process to TASK_RUNNING and sets the preempt_count field of the tHRead_info structure to 1, thus disabling kernel preemption (see the section "Kernel Preemption" in Chapter 5). Moreover, in order to keep process scheduling fair, the function shares the remaining timeslice of the parent between the parent and the child (see "The scheduler_tick( ) Function" in Chapter 7). Sets the cpu field in the thread_info structure of the new process to the number of the local CPU returned by smp_processor_id( ). Initializes the fields that specify the parenthood relationships. In particular, if CLONE_PARENT or CLONE_THREAD are set, it initializes tsk->real_parent and tsk->parent to the value in current->real_parent; the parent of the child thus appears as the parent of the current process. Otherwise, it sets the same fields to current. If the child does not need to be traced (CLONE_PTRACE flag not set), it sets the tsk->ptrace field to 0. This field stores a few flags used when a process is being traced by another process. In such a way, even if the current process is being traced, the child will not. Executes the SET_LINKS macro to insert the new process descriptor in the process list. If the child must be traced (PT_PTRACED flag in the tsk->ptrace field set), it sets tsk->parent to current->parent and inserts the child into the trace list of the debugger. Invokes attach_pid( ) to insert the PID of the new process descriptor in the pidhash[PIDTYPE_PID] hash table. If the child is a thread group leader (flag CLONE_THREAD cleared): Initializes tsk->tgid to tsk->pid. Initializes tsk->group_leader to tsk. Invokes three times attach_pid( ) to insert the child in the PID hash tables of type PIDTYPE_TGID, PIDTYPE_PGID, and PIDTYPE_SID.
Otherwise, if the child belongs to the thread group of its parent (CLONE_THREAD flag set): Initializes tsk->tgid to tsk->current->tgid. Initializes tsk->group_leader to the value in current->group_leader. Invokes attach_pid( ) to insert the child in the PIDTYPE_TGID hash table (more specifically, in the per-PID list of the current->group_leader process).
A new process has now been added to the set of processes: increases the value of the nr_threads variable. Increases the total_forks variable to keep track of the number of forked processes. Terminates by returning the child's process descriptor pointer (tsk).
Let's go back to what happens after do_fork() terminates. Now we have a complete child process in the runnable state. But it isn't actually running. It is up to the scheduler to decide when to give the CPU to this child. At some future process switch, the schedule bestows this favor on the child process by loading a few CPU registers with the values of the thread field of the child's process descriptor. In particular, esp is loaded with thread.esp (that is, with the address of child's Kernel Mode stack), and eip is loaded with the address of ret_from_fork( ). This assembly language function invokes the schedule_tail( ) function (which in turn invokes the finish_task_switch( ) function to complete the process switch; see the section "The schedule( ) Function" in Chapter 7), reloads all other registers with the values stored in the stack, and forces the CPU back to User Mode. The new process then starts its execution right at the end of the fork( ), vfork( ), or clone( ) system call. The value returned by the system call is contained in eax: the value is 0 for the child and equal to the PID for the child's parent. To understand how this is done, look back at what copy_thread() does on the eax register of the child's process (step 13 of copy_process()).
The child process executes the same code as the parent, except that the fork returns a 0 (see step 13 of copy_process( )). The developer of the application can exploit this fact, in a manner familiar to Unix programmers, by inserting a conditional statement in the program based on the PID value that forces the child to behave differently from the parent process.
3.4.2. Kernel Threads
Traditional Unix systems delegate some critical tasks to intermittently running processes, including flushing disk caches, swapping out unused pages, servicing network connections, and so on. Indeed, it is not efficient to perform these tasks in strict linear fashion; both their functions and the end user processes get better response if they are scheduled in the background. Because some of the system processes run only in Kernel Mode, modern operating systems delegate their functions to kernel threads
, which are not encumbered with the unnecessary User Mode context. In Linux, kernel threads differ from regular processes in the following ways:
Kernel threads run only in Kernel Mode, while regular processes run alternatively in Kernel Mode and in User Mode. Because kernel threads run only in Kernel Mode, they use only linear addresses greater than PAGE_OFFSET. Regular processes, on the other hand, use all four gigabytes of linear addresses, in either User Mode or Kernel Mode.
3.4.2.1. Creating a kernel thread
The kernel_thread( ) function creates a new kernel thread. It receives as parameters the address of the kernel function to be executed (fn), the argument to be passed to that function (arg), and a set of clone flags (flags). The function essentially invokes do_fork( ) as follows:
do_fork(flags|CLONE_VM|CLONE_UNTRACED, 0, pregs, 0, NULL, NULL);
The CLONE_VM flag avoids the duplication of the page tables of the calling process: this duplication would be a waste of time and memory, because the new kernel thread will not access the User Mode address space anyway. The CLONE_UNTRACED flag ensures that no process will be able to trace the new kernel thread, even if the calling process is being traced.
The pregs parameter passed to do_fork( ) corresponds to the address in the Kernel Mode stack where the copy_thread( ) function will find the initial values of the CPU registers for the new thread. The kernel_thread( ) function builds up this stack area so that:
The ebx and edx registers will be set by copy_thread() to the values of the parameters fn and arg, respectively. The eip register will be set to the address of the following assembly language fragment:
movl %edx,%eax
pushl %edx
call *%ebx
pushl %eax
call do_exit
Therefore, the new kernel thread starts by executing the fn(arg) function. If this function terminates, the kernel thread executes the _exit( )
system call passing to it the return value of fn( ) (see the section "Destroying Processes" later in this chapter).
3.4.2.2. Process 0
The ancestor of all processes, called process 0, the idle process, or, for historical reasons, the swapper process, is a kernel thread created from scratch during the initialization phase of Linux (see Appendix A). This ancestor process uses the following statically allocated data structures (data structures for all other processes are dynamically allocated):
A process descriptor stored in the init_task variable, which is initialized by the INIT_TASK macro. A thread_info descriptor and a Kernel Mode stack stored in the init_thread_union variable and initialized by the INIT_THREAD_INFO macro. The following tables, which the process descriptor points to: init_mm init_fs init_files init_signals init_sighand
The tables are initialized, respectively, by the following macros: INIT_MM INIT_FS INIT_FILES INIT_SIGNALS INIT_SIGHAND
The master kernel Page Global Directory stored in swapper_pg_dir (see the section "Kernel Page Tables" in Chapter 2).
The start_kernel( ) function initializes all the data structures needed by the kernel, enables interrupts, and creates another kernel thread, named process 1 (more commonly referred to as the init process
):
kernel_thread(init, NULL, CLONE_FS|CLONE_SIGHAND);
The newly created kernel thread has PID 1 and shares all per-process kernel data structures with process 0. When selected by the scheduler, the init process starts executing the init( ) function.
After having created the init process, process 0 executes the cpu_idle( ) function, which essentially consists of repeatedly executing the hlt
assembly language instruction with the interrupts enabled (see Chapter 4). Process 0 is selected by the scheduler only when there are no other processes in the TASK_RUNNING state.
In multiprocessor systems there is a process 0 for each CPU. Right after the power-on, the BIOS of the computer starts a single CPU while disabling the others. The swapper process running on CPU 0 initializes the kernel data structures, then enables the other CPUs and creates the additional swapper processes by means of the copy_process( ) function passing to it the value 0 as the new PID. Moreover, the kernel sets the cpu field of the tHRead_info descriptor of each forked process to the proper CPU index.
3.4.2.3. Process 1
The kernel thread created by process 0 executes the init( ) function, which in turn completes the initialization of the kernel. Then init( ) invokes the execve( )
system call to load the executable program init. As a result, the init kernel thread becomes a regular process having its own per-process kernel data structure (see Chapter 20). The init process stays alive until the system is shut down, because it creates and monitors the activity of all processes that implement the outer layers of the operating system.
3.4.2.4. Other kernel threads
Linux uses many other kernel threads. Some of them are created in the initialization phase and run until shutdown; others are created "on demand," when the kernel must execute a task that is better performed in its own execution context.
A few examples of kernel threads (besides process 0 and process 1) are:
keventd (also called events) Executes the functions in the keventd_wq workqueue (see Chapter 4).
kapmd Handles the events related to the Advanced Power Management (APM).
kswapd Reclaims memory, as described in the section "Periodic Reclaiming" in Chapter 17.
pdflush Flushes "dirty" buffers to disk to reclaim memory, as described in the section "The pdflush Kernel Threads" in Chapter 15.
kblockd Executes the functions in the kblockd_workqueue workqueue. Essentially, it periodically activates the block device drivers, as described in the section "Activating the Block Device Driver" in Chapter 14.
ksoftirqd Runs the tasklets (see section "Softirqs and Tasklets" in Chapter 4); there is one of these kernel threads for each CPU in the system.
|
3.5. Destroying Processes
Most processes "die" in the sense that they terminate the execution of the code they were supposed to run. When this occurs, the kernel must be notified so that it can release the resources owned by the process; this includes memory, open files, and any other odds and ends that we will encounter in this book, such as semaphores.
The usual way for a process to terminate is to invoke the exit( ) library function, which releases the resources allocated by the C library, executes each function registered by the programmer, and ends up invoking a system call that evicts the process from the system. The exit( )
library function may be inserted by the programmer explicitly. Additionally, the C compiler always inserts an exit( ) function call right after the last statement of the main( ) function.
Alternatively, the kernel may force a whole thread group to die. This typically occurs when a process in the group has received a signal that it cannot handle or ignore (see Chapter 11) or when an unrecoverable CPU exception has been raised in Kernel Mode while the kernel was running on behalf of the process (see Chapter 4).
3.5.1. Process Termination
In Linux 2.6 there are two system calls that terminate a User Mode application:
The exit_group( )
system call, which terminates a full thread group, that is, a whole multithreaded application. The main kernel function that implements this system call is called do_group_exit( ). This is the system call that should be invoked by the exit() C library function. The _exit( )
system call, which terminates a single process, regardless of any other process in the thread group of the victim. The main kernel function that implements this system call is called do_exit( ). This is the system call invoked, for instance, by the pthread_exit( )
function of the LinuxThreads library.
3.5.1.1. The do_group_exit( ) function
The do_group_exit( ) function kills all processes belonging to the thread group of current. It receives as a parameter the process termination
code, which is either a value specified in the exit_group( ) system call (normal termination) or an error code supplied by the kernel (abnormal termination). The function executes the following operations:
Checks whether the SIGNAL_GROUP_EXIT flag of the exiting process is not zero, which means that the kernel already started an exit procedure for this thread group. In this case, it considers as exit code the value stored in current->signal->group_exit_code, and jumps to step 4. Otherwise, it sets the SIGNAL_GROUP_EXIT flag of the process and stores the termination code in the current->signal->group_exit_code field. Invokes the zap_other_threads( ) function to kill the other processes in the thread group of current, if any. In order to do this, the function scans the per-PID list in the PIDTYPE_TGID hash table corresponding to current->tgid; for each process in the list different from current, it sends a SIGKILL signal to it (see Chapter 11). As a result, all such processes will eventually execute the do_exit( ) function, and thus they will be killed. Invokes the do_exit( ) function passing to it the process termination code. As we'll see below, do_exit( ) kills the process and never returns.
3.5.1.2. The do_exit( ) function
All process terminations are handled by the do_exit( ) function, which removes most references to the terminating process from kernel data structures. The do_exit( ) function receives as a parameter the process termination code and essentially executes the following actions:
Sets the PF_EXITING flag in the flag field of the process descriptor to indicate that the process is being eliminated. Removes, if necessary, the process descriptor from a dynamic timer queue via the del_timer_sync( ) function (see Chapter 6). Detaches from the process descriptor the data structures related to paging, semaphores, filesystem, open file descriptors, namespaces, and I/O Permission Bitmap, respectively, with the exit_mm( ), exit_sem( ), _ _exit_files( ), _ _exit_fs(), exit_namespace( ), and exit_thread( ) functions. These functions also remove each of these data structures if no other processes are sharing them. If the kernel functions implementing the execution domain and the executable format (see Chapter 20) of the process being killed are included in kernel modules, the function decreases their usage counters. Sets the exit_code field of the process descriptor to the process termination code. This value is either the _exit( ) or exit_group( ) system call parameter (normal termination), or an error code supplied by the kernel (abnormal termination). Invokes the exit_notify( ) function to perform the following operations: Updates the parenthood relationships of both the parent process and the child processes. All child processes created by the terminating process become children of another process in the same thread group, if any is running, or otherwise of the init process. Checks whether the exit_signal process descriptor field of the process being terminated is different from -1, and whether the process is the last member of its thread group (notice that these conditions always hold for any normal process; see step 16 in the description of copy_process( ) in the earlier section "
The clone( ), fork( ), and vfork( ) System Calls"). In this case, the function sends a signal (usually SIGCHLD) to the parent of the process being terminated to notify the parent about a child's death. Otherwise, if the exit_signal field is equal to -1 or the thread group includes other processes, the function sends a SIGCHLD signal to the parent only if the process is being traced (in this case the parent is the debugger, which is thus informed of the death of the lightweight process). If the exit_signal process descriptor field is equal to -1 and the process is not being traced, it sets the exit_state field of the process descriptor to EXIT_DEAD, and invokes release_task( ) to reclaim the memory of the remaining process data structures and to decrease the usage counter of the process descriptor (see the following section). The usage counter becomes equal to 1 (see step 3f in the copy_process( ) function), so that the process descriptor itself is not released right away. Otherwise, if the exit_signal process descriptor field is not equal to -1 or the process is being traced, it sets the exit_state field to EXIT_ZOMBIE. We'll see what happens to zombie processes in the following section. Sets the PF_DEAD flag in the flags field of the process descriptor (see the section "
The schedule( ) Function" in
Chapter 7).
Invokes the schedule( ) function (see Chapter 7) to select a new process to run. Because a process in an EXIT_ZOMBIE state is ignored by the scheduler, the process stops executing right after the switch_to macro in schedule( ) is invoked. As we'll see in Chapter 7, the scheduler will check the PF_DEAD flag and will decrease the usage counter in the descriptor of the zombie process being replaced to denote the fact that the process is no longer alive.
3.5.2. Process Removal
The Unix operating system allows a process to query the kernel to obtain the PID of its parent process or the execution state of any of its children. A process may, for instance, create a child process to perform a specific task and then invoke some wait( )-like library function to check whether the child has terminated. If the child has terminated, its termination code will tell the parent process if the task has been carried out successfully.
To comply with these design choices, Unix kernels are not allowed to discard data included in a process descriptor field right after the process terminates. They are allowed to do so only after the parent process has issued a wait( )-like system call that refers to the terminated process. This is why the EXIT_ZOMBIE state has been introduced: although the process is technically dead, its descriptor must be saved until the parent process is notified.
What happens if parent processes terminate before their children? In such a case, the system could be flooded with zombie processes whose process descriptors would stay forever in RAM. As mentioned earlier, this problem is solved by forcing all orphan processes to become children of the init process. In this way, the init process will destroy the zombies while checking for the termination of one of its legitimate children through a wait( )-like system call.
The release_task( ) function detaches the last data structures from the descriptor of a zombie process; it is applied on a zombie process in two possible ways: by the do_exit( ) function if the parent is not interested in receiving signals from the child, or by the wait4( )
or waitpid( )
system calls after a signal has been sent to the parent. In the latter case, the function also will reclaim the memory used by the process descriptor, while in the former case the memory reclaiming will be done by the scheduler (see Chapter 7). This function executes the following steps:
Decreases the number of processes belonging to the user owner of the terminated process. This value is stored in the user_struct structure mentioned earlier in the chapter (see step 4 of copy_process( )). If the process is being traced, the function removes it from the debugger's ptrace_children list and assigns the process back to its original parent. Invokes _ _exit_signal() to cancel any pending signal and to release the signal_struct descriptor of the process. If the descriptor is no longer used by other lightweight processes, the function also removes this data structure. Moreover, the function invokes exit_itimers( ) to detach any POSIX interval timer from the process. Invokes _ _exit_sighand() to get rid of the signal handlers. Invokes _ _unhash_process( ), which in turn: Decreases by 1 the nr_threads variable. Invokes detach_pid( ) twice to remove the process descriptor from the pidhash hash tables of type PIDTYPE_PID and PIDTYPE_TGID. If the process is a thread group leader, invokes again detach_pid( ) twice to remove the process descriptor from the PIDTYPE_PGID and PIDTYPE_SID hash tables. Uses the REMOVE_LINKS macro to unlink the process descriptor from the process list.
If the process is not a thread group leader, the leader is a zombie, and the process is the last member of the thread group, the function sends a signal to the parent of the leader to notify it of the death of the process. Invokes the sched_exit( ) function to adjust the timeslice of the parent process (this step logically complements step 17 in the description of copy_process( )) Invokes put_task_struct() to decrease the process descriptor's usage counter; if the counter becomes zero, the function drops any remaining reference to the process: Decreases the usage counter (_ _count field) of the user_struct data structure of the user that owns the process (see step 5 of copy_process( )), and releases that data structure if the usage counter becomes zero. Releases the process descriptor and the memory area used to contain the tHRead_info descriptor and the Kernel Mode stack.
|
Chapter 4. Interrupts and Exceptions
An interrupt is usually defined as an event that alters the sequence of instructions executed by a processor. Such events correspond to electrical signals
generated by hardware circuits both inside and outside the CPU chip.
Interrupts are often divided into synchronous and asynchronous interrupts
:
Synchronous interrupts are produced by the CPU control unit while executing instructions and are called synchronous because the control unit issues them only after terminating the execution of an instruction. Asynchronous interrupts are generated by other hardware devices at arbitrary times with respect to the CPU clock signals.
Intel microprocessor manuals designate synchronous and asynchronous interrupts
as exceptions
and interrupts, respectively. We'll adopt this classification, although we'll occasionally use the term "interrupt signal" to designate both types together (synchronous as well as asynchronous).
Interrupts are issued by interval timers and I/O devices; for instance, the arrival of a keystroke from a user sets off an interrupt.
Exceptions, on the other hand, are caused either by programming errors or by anomalous conditions that must be handled by the kernel. In the first case, the kernel handles the exception by delivering to the current process one of the signals familiar to every Unix programmer. In the second case, the kernel performs all the steps needed to recover from the anomalous condition, such as a Page Fault or a requestvia an assembly language instruction such as int
or sysenter
for a kernel service.
We start by describing in the next section the motivation for introducing such signals. We then show how the well-known IRQs (Interrupt ReQuests) issued by I/O devices give rise to interrupts, and we detail how 80 x 86 processors handle interrupts and exceptions at the hardware level. Then we illustrate, in the section "Initializing the Interrupt Descriptor Table," how Linux initializes all the data structures required by the 80x86 interrupt architecture. The remaining three sections describe how Linux handles interrupt signals at the software level.
One word of caution before moving on: in this chapter, we cover only "classic" interrupts common to all PCs; we do not cover the nonstandard interrupts of some architectures.
|
4.1. The Role of Interrupt Signals
As the name suggests, interrupt signals provide a way to divert the processor to code outside the normal flow of control. When an interrupt signal arrives, the CPU must stop what it's currently doing and switch to a new activity; it does this by saving the current value of the program counter (i.e., the content of the eip and cs registers) in the Kernel Mode stack and by placing an address related to the interrupt type into the program counter.
There are some things in this chapter that will remind you of the context switch described in the previous chapter, carried out when a kernel substitutes one process for another. But there is a key difference between interrupt handling and process switching: the code executed by an interrupt or by an exception handler is not a process. Rather, it is a kernel control path that runs at the expense of the same process that was running when the interrupt occurred (see the later section "Nested Execution of Exception and Interrupt Handlers"). As a kernel control path, the interrupt handler is lighter than a process (it has less context and requires less time to set up or tear down).
Interrupt handling is one of the most sensitive tasks performed by the kernel, because it must satisfy the following constraints:
Interrupts can come anytime, when the kernel may want to finish something else it was trying to do. The kernel's goal is therefore to get the interrupt out of the way as soon as possible and defer as much processing as it can. For instance, suppose a block of data has arrived on a network line. When the hardware interrupts the kernel, it could simply mark the presence of data, give the processor back to whatever was running before, and do the rest of the processing later (such as moving the data into a buffer where its recipient process can find it, and then restarting the process). The activities that the kernel needs to perform in response to an interrupt are thus divided into a critical urgent part that the kernel executes right away and a deferrable part that is left for later. Because interrupts can come anytime, the kernel might be handling one of them while another one (of a different type) occurs. This should be allowed as much as possible, because it keeps the I/O devices busy (see the later section "Nested Execution of Exception and Interrupt Handlers"). As a result, the interrupt handlers must be coded so that the corresponding kernel control paths
can be executed in a nested manner. When the last kernel control path terminates, the kernel must be able to resume execution of the interrupted process or switch to another process if the interrupt signal has caused a rescheduling activity. Although the kernel may accept a new interrupt signal while handling a previous one, some critical regions exist inside the kernel code where interrupts must be disabled. Such critical regions must be limited as much as possible because, according to the previous requirement, the kernel, and particularly the interrupt handlers, should run most of the time with the interrupts enabled.
|
4.2. Interrupts and Exceptions
The Intel documentation classifies interrupts and exceptions as follows:
Interrupts:
Maskable interrupts All Interrupt Requests (IRQs) issued by I/O devices give rise to maskable interrupts
. A maskable interrupt can be in two states: masked or unmasked; a masked interrupt is ignored by the control unit as long as it remains masked.
Nonmaskable interrupts Only a few critical events (such as hardware failures) give rise to nonmaskable interrupts
. Nonmaskable interrupts are always recognized by the CPU.
Exceptions:
Processor-detected exceptions Generated when the CPU detects an anomalous condition while executing an instruction. These are further divided into three groups, depending on the value of the eip register that is saved on the Kernel Mode stack when the CPU control unit raises the exception.
Faults Can generally be corrected; once corrected, the program is allowed to restart with no loss of continuity. The saved value of eip is the address of the instruction that caused the fault, and hence that instruction can be resumed when the exception handler terminates. As we'll see in the section "Page Fault Exception Handler" in Chapter 9, resuming the same instruction is necessary whenever the handler is able to correct the anomalous condition that caused the exception.
Traps Reported immediately following the execution of the trapping instruction; after the kernel returns control to the program, it is allowed to continue its execution with no loss of continuity. The saved value of eip is the address of the instruction that should be executed after the one that caused the trap. A trap is triggered only when there is no need to reexecute the instruction that terminated. The main use of traps is for debugging purposes. The role of the interrupt signal in this case is to notify the debugger that a specific instruction has been executed (for instance, a breakpoint has been reached within a program). Once the user has examined the data provided by the debugger, she may ask that execution of the debugged program resume, starting from the next instruction.
Aborts A serious error occurred; the control unit is in trouble, and it may be unable to store in the eip register the precise location of the instruction causing the exception. Aborts are used to report severe errors, such as hardware failures and invalid or inconsistent values in system tables. The interrupt signal sent by the control unit is an emergency signal used to switch control to the corresponding abort exception handler. This handler has no choice but to force the affected process to terminate.
Programmed exceptions Occur at the request of the programmer. They are triggered by int
or int3
instructions; the into
(check for overflow) and bound
(check on address bound) instructions also give rise to a programmed exception when the condition they are checking is not true. Programmed exceptions are handled by the control unit as traps; they are often called software interrupts
. Such exceptions have two common uses: to implement system calls and to notify a debugger of a specific event (see Chapter 10).
Each interrupt or exception is identified by a number ranging from 0 to 255; Intel calls this 8-bit unsigned number a vector. The vectors
of nonmaskable interrupts and exceptions are fixed, while those of maskable interrupts can be altered by programming the Interrupt Controller (see the next section).
4.2.1. IRQs and Interrupts
Each hardware device controller capable of issuing interrupt requests usually has a single output line designated as the Interrupt ReQuest (IRQ) line. All existing IRQ lines are connected to the input pins of a hardware circuit called the Programmable Interrupt Controller, which performs the following actions:
Monitors the IRQ lines, checking for raised signals. If two or more IRQ lines are raised, selects the one having the lower pin number. If a raised signal occurs on an IRQ line: Converts the raised signal received into a corresponding vector. Stores the vector in an Interrupt Controller I/O port, thus allowing the CPU to read it via the data bus. Sends a raised signal to the processor INTR pinthat is, issues an interrupt. Waits until the CPU acknowledges the interrupt signal by writing into one of the Programmable Interrupt Controllers (PIC) I/O ports; when this occurs, clears the INTR line.
The IRQ lines are sequentially numbered starting from 0; therefore, the first IRQ line is usually denoted as IRQ 0. Intel's default vector associated with IRQ n is n+32. As mentioned before, the mapping between IRQs and vectors can be modified by issuing suitable I/O instructions to the Interrupt Controller ports.
Each IRQ line can be selectively disabled. Thus, the PIC can be programmed to disable IRQs. That is, the PIC can be told to stop issuing interrupts
that refer to a given IRQ line, or to resume issuing them. Disabled interrupts are not lost; the PIC sends them to the CPU as soon as they are enabled again. This feature is used by most interrupt handlers, because it allows them to process IRQs of the same type serially.
Selective enabling/disabling of IRQs is not the same as global masking/unmasking of maskable interrupts. When the IF flag of the eflags register is clear, each maskable interrupt issued by the PIC is temporarily ignored by the CPU. The cli
and sti
assembly language instructions, respectively, clear and set that flag.
Traditional PICs are implemented by connecting "in cascade" two 8259A-style external chips. Each chip can handle up to eight different IRQ input lines. Because the INT output line of the slave PIC is connected to the IRQ 2 pin of the master PIC, the number of available IRQ lines is limited to 15.
4.2.1.1. The Advanced Programmable Interrupt Controller (APIC)
The previous description refers to PICs designed for uniprocessor systems. If the system includes a single CPU, the output line of the master PIC can be connected in a straightforward way to the INTR pin the CPU. However, if the system includes two or more CPUs, this approach is no longer valid and more sophisticated PICs are needed.
Being able to deliver interrupts to each CPU in the system is crucial for fully exploiting the parallelism of the SMP
architecture. For that reason, Intel introduced starting with Pentium III a new component designated as the I/O Advanced Programmable Interrupt Controller (I/O APIC). This chip is the advanced version of the old 8259A Programmable Interrupt Controller; to support old operating systems, recent motherboards include both types of chip. Moreover, all current 80 x 86 microprocessors include a local APIC. Each local APIC has 32-bit registers, an internal clock; a local timer device; and two additional IRQ lines, LINT 0 and LINT 1, reserved for local APIC interrupts. All local APICs are connected to an external I/O APIC, giving rise to a multi-APIC system.
Figure 4-1 illustrates in a schematic way the structure of a multi-APIC system. An APIC bus connects the "frontend" I/O APIC to the local APICs. The IRQ lines coming from the devices are connected to the I/O APIC, which therefore acts as a router with respect to the local APICs. In the motherboards of the Pentium III and earlier processors, the APIC bus was a serial three-line bus; starting with the Pentium 4, the APIC bus is implemented by means of the system bus. However, because the APIC bus and its messages are invisible to software, we won't give further details.
The I/O APIC consists of a set of 24 IRQ lines, a 24-entry Interrupt Redirection Table, programmable registers, and a message unit for sending and receiving APIC messages over the APIC bus. Unlike IRQ pins of the 8259A, interrupt priority is not related to pin number: each entry in the Redirection Table can be individually programmed to indicate the interrupt vector and priority, the destination processor, and how the processor is selected. The information in the Redirection Table is used to translate each external IRQ signal into a message to one or more local APIC units via the APIC bus.
Interrupt requests coming from external hardware devices can be distributed among the available CPUs in two ways:
Static distribution The IRQ signal is delivered to the local APICs listed in the corresponding Redirection Table entry. The interrupt is delivered to one specific CPU, to a subset of CPUs, or to all CPUs at once (broadcast mode).
Dynamic distribution The IRQ signal is delivered to the local APIC of the processor that is executing the process with the lowest priority.
Every local APIC has a programmable task priority register (TPR), which is used to compute the priority of the currently running process. Intel expects this register to be modified in an operating system kernel by each process switch.
If two or more CPUs share the lowest priority, the load is distributed between them using a technique called arbitration
. Each CPU is assigned a different arbitration priority ranging from 0 (lowest) to 15 (highest) in the arbitration priority register of the local APIC.
Every time an interrupt is delivered to a CPU, its corresponding arbitration priority is automatically set to 0, while the arbitration priority of any other CPU is increased. When the arbitration priority register becomes greater than 15, it is set to the previous arbitration priority of the winning CPU increased by 1. Therefore, interrupts are distributed in a round-robin fashion among CPUs with the same task priority.
Besides distributing interrupts among processors, the multi-APIC system allows CPUs to generate interprocessor interrupts
. When a CPU wishes to send an interrupt to another CPU, it stores the interrupt vector and the identifier of the target's local APIC in the Interrupt Command Register (ICR) of its own local APIC. A message is then sent via the APIC bus to the target's local APIC, which therefore issues a corresponding interrupt to its own CPU.
Interprocessor interrupts (in short, IPIs) are a crucial component of the SMP
architecture. They are actively used by Linux to exchange messages among CPUs (see later in this chapter).
Many of the current uniprocessor systems include an I/O APIC chip, which may be configured in two distinct ways:
As a standard 8259A-style external PIC connected to the CPU. The local APIC is disabled and the two LINT 0 and LINT 1 local IRQ lines are configured, respectively, as the INTR and NMI pins. As a standard external I/O APIC. The local APIC is enabled, and all external interrupts are received through the I/O APIC.
4.2.2. Exceptions
The 80x86 microprocessors issue roughly 20 different exceptions
. The kernel must provide a dedicated exception handler for each exception type. For some exceptions, the CPU control unit also generates a hardware error code and pushes it on the Kernel Mode stack before starting the exception handler.
The following list gives the vector, the name, the type, and a brief description of the exceptions found in 80x86 processors. Additional information may be found in the Intel technical documentation.
0 - "Divide error" (fault) Raised when a program issues an integer division by 0.
1- "Debug" (trap or fault) Raised when the TF flag of eflags
is set (quite useful to implement single-step execution
of a debugged program) or when the address of an instruction or operand falls within the range of an active debug register (see the section "Hardware Context" in Chapter 3).
2 - Not used Reserved for nonmaskable interrupts (those that use the NMI pin).
3 - "Breakpoint" (trap) Caused by an int3
(breakpoint) instruction (usually inserted by a debugger).
4 - "Overflow" (trap) An into
(check for overflow) instruction has been executed while the OF (overflow) flag of eflags is set.
5 - "Bounds check" (fault) A bound
(check on address bound) instruction is executed with the operand outside of the valid address bounds.
6 - "Invalid opcode" (fault) The CPU execution unit has detected an invalid opcode (the part of the machine instruction that determines the operation performed).
7 - "Device not available" (fault) An ESCAPE, MMX, or SSE/SSE2 instruction has been executed with the TS flag of cr0
set (see the section "Saving and Loading the FPU, MMX, and XMM Registers" in Chapter 3).
8 - "Double fault" (abort) Normally, when the CPU detects an exception while trying to call the handler for a prior exception, the two exceptions can be handled serially. In a few cases, however, the processor cannot handle them serially, so it raises this exception.
9 - "Coprocessor segment overrun" (abort) Problems with the external mathematical coprocessor (applies only to old 80386 microprocessors).
10 - "Invalid TSS" (fault) The CPU has attempted a context switch to a process having an invalid Task State Segment.
11 - "Segment not present" (fault) A reference was made to a segment not present in memory (one in which the Segment-Present flag of the Segment Descriptor was cleared).
12 - "Stack segment fault" (fault) The instruction attempted to exceed the stack segment limit, or the segment identified by ss is not present in memory.
13 - "General protection" (fault) One of the protection rules in the protected mode of the 80x86 has been violated.
14 - "Page Fault" (fault) The addressed page is not present in memory, the corresponding Page Table entry is null, or a violation of the paging protection mechanism has occurred.
15 - Reserved by Intel
16 - "Floating-point error" (fault) The floating-point unit integrated into the CPU chip has signaled an error condition, such as numeric overflow or division by 0.
17 - "Alignment check" (fault) The address of an operand is not correctly aligned (for instance, the address of a long integer is not a multiple of 4).
18 - "Machine check" (abort) A machine-check mechanism has detected a CPU or bus error.
19 - "SIMD floating point exception" (fault) The SSE or SSE2 unit integrated in the CPU chip has signaled an error condition on a floating-point operation.
The values from 20 to 31 are reserved by Intel for future development. As illustrated in Table 4-1, each exception is handled by a specific exception handler (see the section "Exception Handling" later in this chapter), which usually sends a Unix signal to the process that caused the exception.
Table 4-1. Signals sent by the exception handlers# | Exception | Exception handler | Signal |
|---|
0 | Divide error | divide_error( ) | SIGFPE | 1 | Debug | debug( ) | SIGTRAP | 2 | NMI | nmi( ) | None | 3 | Breakpoint | int3( ) | SIGTRAP | 4 | Overflow | overflow( ) | SIGSEGV | 5 | Bounds check | bounds( ) | SIGSEGV | 6 | Invalid opcode | invalid_op( ) | SIGILL | 7 | Device not available | device_not_available( ) | None | 8 | Double fault | doublefault_fn( ) | None | 9 | Coprocessor segment overrun | coprocessor_segment_overrun( ) | SIGFPE | 10 | Invalid TSS | invalid_TSS( ) | SIGSEGV | 11 | Segment not present | segment_not_present( ) | SIGBUS | 12 | Stack segment fault | stack_segment( ) | SIGBUS | 13 | General protection | general_protection( ) | SIGSEGV | 14 | Page Fault | page_fault( ) | SIGSEGV | 15 | Intel-reserved | None | None | 16 | Floating-point error | coprocessor_error( ) | SIGFPE | 17 | Alignment check | alignment_check( ) | SIGBUS | 18 | Machine check | machine_check( ) | None | 19 | SIMD floating point | simd_coprocessor_error( ) | SIGFPE |
4.2.3. Interrupt Descriptor Table
A system table called Interrupt Descriptor Table (IDT
) associates each interrupt or exception vector with the address of the corresponding interrupt or exception handler. The IDT must be properly initialized before the kernel enables interrupts.
The IDT format is similar to that of the GDT and the LDTs examined in Chapter 2. Each entry corresponds to an interrupt or an exception vector and consists of an 8-byte descriptor. Thus, a maximum of 256 x 8 = 2048 bytes are required to store the IDT.
The idtr
CPU register allows the IDT to be located anywhere in memory: it specifies both the IDT base physical address and its limit (maximum length). It must be initialized before enabling interrupts by using the lidt
assembly language instruction.
The IDT may include three types of descriptors; Figure 4-2 illustrates the meaning of the 64 bits included in each of them. In particular, the value of the Type field encoded in the bits 4043 identifies the descriptor type.
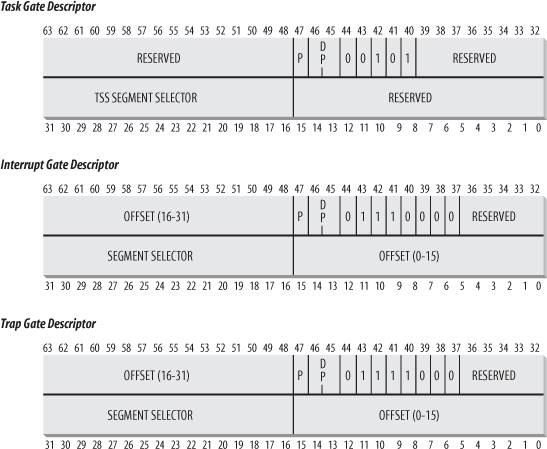
The descriptors are:
Task gate Includes the TSS selector of the process that must replace the current one when an interrupt signal occurs.
Interrupt gate Includes the Segment Selector and the offset inside the segment of an interrupt or exception handler. While transferring control to the proper segment, the processor clears the IF flag, thus disabling further maskable interrupts.
Trap gate Similar to an interrupt gate, except that while transferring control to the proper segment, the processor does not modify the IF flag.
As we'll see in the later section "Interrupt, Trap, and System Gates," Linux uses interrupt gates
to handle interrupts and trap gates
to handle exceptions.
4.2.4. Hardware Handling of Interrupts and Exceptions
We now describe how the CPU control unit handles interrupts and exceptions. We assume that the kernel has been initialized, and thus the CPU is operating in Protected Mode.
After executing an instruction, the cs and eip pair of registers contain the logical address of the next instruction to be executed. Before dealing with that instruction, the control unit checks whether an interrupt or an exception occurred while the control unit executed the previous instruction. If one occurred, the control unit does the following:
Determines the vector i (0  i 255) associated with the interrupt or the exception. i 255) associated with the interrupt or the exception. Reads the i th entry of the IDT referred by the idtr register (we assume in the following description that the entry contains an interrupt or a trap gate). Gets the base address of the GDT from the gdtr
register and looks in the GDT to read the Segment Descriptor identified by the selector in the IDT entry. This descriptor specifies the base address of the segment that includes the interrupt or exception handler. Makes sure the interrupt was issued by an authorized source. First, it compares the Current Privilege Level (CPL), which is stored in the two least significant bits of the cs register, with the Descriptor Privilege Level (DPL
) of the Segment Descriptor included in the GDT. Raises a "General protection
" exception if the CPL is lower than the DPL, because the interrupt handler cannot have a lower privilege than the program that caused the interrupt. For programmed exceptions, makes a further security check: compares the CPL with the DPL of the gate descriptor included in the IDT and raises a "General protection" exception if the DPL is lower than the CPL. This last check makes it possible to prevent access by user applications to specific trap or interrupt gates. Checks whether a change of privilege level is taking place that is, if CPL is different from the selected Segment Descriptor's DPL. If so, the control unit must start using the stack that is associated with the new privilege level. It does this by performing the following steps: Reads the tr
register to access the TSS segment of the running process. Loads the ss and esp registers with the proper values for the stack segment and stack pointer associated with the new privilege level. These values are found in the TSS (see the section "Task State Segment" in Chapter 3). In the new stack, it saves the previous values of ss and esp, which define the logical address of the stack associated with the old privilege level.
If a fault has occurred, it loads cs and eip with the logical address of the instruction that caused the exception so that it can be executed again. Saves the contents of eflags
, cs, and eip in the stack. If the exception carries a hardware error code, it saves it on the stack. Loads cs and eip, respectively, with the Segment Selector and the Offset fields of the Gate Descriptor stored in the i th entry of the IDT. These values define the logical address of the first instruction of the interrupt or exception handler.
The last step performed by the control unit is equivalent to a jump to the interrupt or exception handler. In other words, the instruction processed by the control unit after dealing with the interrupt signal is the first instruction of the selected handler.
After the interrupt or exception is processed, the corresponding handler must relinquish control to the interrupted process by issuing the iret
instruction, which forces the control unit to:
Load the cs, eip, and eflags registers with the values saved on the stack. If a hardware error code has been pushed in the stack on top of the eip contents, it must be popped before executing iret. Check whether the CPL of the handler is equal to the value contained in the two least significant bits of cs (this means the interrupted process was running at the same privilege level as the handler). If so, iret concludes execution; otherwise, go to the next step. Load the ss and esp registers from the stack and return to the stack associated with the old privilege level. Examine the contents of the ds, es, fs, and gs segment registers; if any of them contains a selector that refers to a Segment Descriptor whose DPL value is lower than CPL, clear the corresponding segment register. The control unit does this to forbid User Mode programs that run with a CPL equal to 3 from using segment registers previously used by kernel routines (with a DPL equal to 0). If these registers were not cleared, malicious User Mode programs could exploit them in order to access the kernel address space.
4.3. Nested Execution of Exception and Interrupt Handlers
Every interrupt or exception gives rise to a kernel control path or separate sequence of instructions that execute in Kernel Mode on behalf of the current process. For instance, when an I/O device raises an interrupt, the first instructions of the corresponding kernel control path are those that save the contents of the CPU registers in the Kernel Mode stack, while the last are those that restore the contents of the registers.
Kernel control paths may be arbitrarily nested; an interrupt handler may be interrupted by another interrupt handler, thus giving rise to a nested execution of
kernel control paths
, as shown in Figure 4-3. As a result, the last instructions of a kernel control path that is taking care of an interrupt do not always put the current process back into User Mode: if the level of nesting is greater than 1, these instructions will put into execution the kernel control path that was interrupted last, and the CPU will continue to run in Kernel Mode.
The price to pay for allowing nested kernel control paths is that an interrupt handler must never block, that is, no process switch can take place until an interrupt handler is running. In fact, all the data needed to resume a nested kernel control path is stored in the Kernel Mode stack, which is tightly bound to the current process.
Assuming that the kernel is bug free, most exceptions can occur only while the CPU is in User Mode. Indeed, they are either caused by programming errors or triggered by debuggers. However, the "Page Fault
" exception may occur in Kernel Mode. This happens when the process attempts to address a page that belongs to its address space but is not currently in RAM. While handling such an exception, the kernel may suspend the current process and replace it with another one until the requested page is available. The kernel control path that handles the "Page Fault" exception resumes execution as soon as the process gets the processor again.
Because the "Page Fault" exception handler never gives rise to further exceptions, at most two kernel control paths associated with exceptions (the first one caused by a system call invocation, the second one caused by a Page Fault) may be stacked, one on top of the other.
In contrast to exceptions, interrupts issued by I/O devices do not refer to data structures specific to the current process, although the kernel control paths that handle them run on behalf of that process. As a matter of fact, it is impossible to predict which process will be running when a given interrupt occurs.
An interrupt handler may preempt both other interrupt handlers and exception handlers. Conversely, an exception handler never preempts an interrupt handler. The only exception that can be triggered in Kernel Mode is "Page Fault," which we just described. But interrupt handlers never perform operations that can induce page faults, and thus, potentially, a process switch.
Linux interleaves kernel control paths for two major reasons:
To improve the throughput of programmable interrupt controllers and device controllers. Assume that a device controller issues a signal on an IRQ line: the PIC transforms it into an external interrupt, and then both the PIC and the device controller remain blocked until the PIC receives an acknowledgment from the CPU. Thanks to kernel control path interleaving, the kernel is able to send the acknowledgment even when it is handling a previous interrupt. To implement an interrupt model without priority levels. Because each interrupt handler may be deferred by another one, there is no need to establish predefined priorities among hardware devices. This simplifies the kernel code and improves its portability.
On multiprocessor systems, several kernel control paths may execute concurrently. Moreover, a kernel control path associated with an exception may start executing on a CPU and, due to a process switch, migrate to another CPU.
|
4.4. Initializing the Interrupt Descriptor Table
Now that we understand what the 80x86 microprocessors do with interrupts and exceptions at the hardware level, we can move on to describe how the Interrupt Descriptor Table is initialized.
Remember that before the kernel enables the interrupts, it must load the initial address of the IDT table into the idtr
register and initialize all the entries of that table. This activity is done while initializing
the system (see Appendix A).
The int
instruction allows a User Mode process to issue an interrupt signal that has an arbitrary vector ranging from 0 to 255. Therefore, initialization of the IDT must be done carefully, to block illegal interrupts and exceptions simulated by User Mode processes via int instructions. This can be achieved by setting the DPL field of the particular Interrupt or Trap Gate Descriptor to 0. If the process attempts to issue one of these interrupt signals, the control unit checks the CPL value against the DPL field and issues a "General protection
" exception.
In a few cases, however, a User Mode process must be able to issue a programmed exception. To allow this, it is sufficient to set the DPL field of the corresponding Interrupt or Trap Gate Descriptors to 3 that is, as high as possible.
Let's now see how Linux implements this strategy.
4.4.1. Interrupt, Trap, and System Gates
As mentioned in the earlier section "Interrupt Descriptor Table," Intel provides three types of interrupt descriptors
: Task, Interrupt, and Trap Gate Descriptors. Linux uses a slightly different breakdown and terminology from Intel when classifying the interrupt descriptors included in the Interrupt Descriptor Table:
Interrupt gate An Intel interrupt gate that cannot be accessed by a User Mode process (the gate's DPL field is equal to 0). All Linux interrupt handlers are activated by means of interrupt gates
, and all are restricted to Kernel Mode.
System gate An Intel trap gate that can be accessed by a User Mode process (the gate's DPL field is equal to 3). The three Linux exception handlers associated with the vectors 4, 5, and 128 are activated by means of system gates
, so the three assembly language instructions into
, bound
, and int
$0x80 can be issued in User Mode.
System interrupt gate An Intel interrupt gate that can be accessed by a User Mode process (the gate's DPL field is equal to 3). The exception handler associated with the vector 3 is activated by means of a system interrupt gate, so the assembly language instruction int3
can be issued in User Mode.
Trap gate An Intel trap gate that cannot be accessed by a User Mode process (the gate's DPL field is equal to 0). Most Linux exception handlers are activated by means of trap gates
.
Task gate An Intel task gate that cannot be accessed by a User Mode process (the gate's DPL field is equal to 0). The Linux handler for the "Double fault
" exception is activated by means of a task gate.
The following architecture-dependent functions are used to insert gates in the IDT:
set_intr_gate(n,addr) Inserts an interrupt gate in the n th IDT entry. The Segment Selector inside the gate is set to the kernel code's Segment Selector. The Offset field is set to addr, which is the address of the interrupt handler. The DPL field is set to 0.
set_system_gate(n,addr) Inserts a trap gate in the n th IDT entry. The Segment Selector inside the gate is set to the kernel code's Segment Selector. The Offset field is set to addr, which is the address of the exception handler. The DPL field is set to 3.
set_system_intr_gate(n,addr) Inserts an interrupt gate in the n th IDT entry. The Segment Selector inside the gate is set to the kernel code's Segment Selector. The Offset field is set to addr, which is the address of the exception handler. The DPL field is set to 3.
set_trap_gate(n,addr) Similar to the previous function, except the DPL field is set to 0.
set_task_gate(n,gdt) Inserts a task gate in the n th IDT entry. The Segment Selector inside the gate stores the index in the GDT of the TSS containing the function to be activated. The Offset field is set to 0, while the DPL field is set to 3.
4.4.2. Preliminary Initialization of the IDT
The IDT is initialized and used by the BIOS routines while the computer still operates in Real Mode. Once Linux takes over, however, the IDT is moved to another area of RAM and initialized a second time, because Linux does not use any BIOS routine (see Appendix A).
The IDT is stored in the idt_table table, which includes 256 entries. The 6-byte idt_descr variable stores both the size of the IDT and its address and is used in the system initialization phase when the kernel sets up the idtr register with the lidt
assembly language instruction.
During kernel initialization, the setup_idt( ) assembly language function starts by filling all 256 entries of idt_table with the same interrupt gate, which refers to the ignore_int( ) interrupt handler:
setup_idt:
lea ignore_int, %edx
movl $(_ _KERNEL_CS << 16), %eax
movw %dx, %ax /* selector = 0x0010 = cs */
movw $0x8e00, %dx /* interrupt gate, dpl=0, present */
lea idt_table, %edi
mov $256, %ecx
rp_sidt:
movl %eax, (%edi)
movl %edx, 4(%edi)
addl $8, %edi
dec %ecx
jne rp_sidt
ret
The ignore_int( ) interrupt handler, which is in assembly language, may be viewed as a null handler that executes the following actions:
Saves the content of some registers in the stack. Invokes the printk( ) function to print an "Unknown interrupt" system message. Restores the register contents from the stack. Executes an iret
instruction to restart the interrupted program.
The ignore_int( ) handler should never be executed. The occurrence of "Unknown interrupt" messages on the console or in the log files denotes either a hardware problem (an I/O device is issuing unforeseen interrupts) or a kernel problem (an interrupt or exception is not being handled properly).
Following this preliminary initialization, the kernel makes a second pass in the IDT to replace some of the null handlers with meaningful trap and interrupt handlers. Once this is done, the IDT includes a specialized interrupt, trap, or system gate for each different exception issued by the control unit and for each IRQ recognized by the interrupt controller.
The next two sections illustrate in detail how this is done for exceptions and interrupts.
4.6. Interrupt Handling
As we explained earlier, most exceptions are handled simply by sending a Unix signal to the process that caused the exception. The action to be taken is thus deferred until the process receives the signal; as a result, the kernel is able to process the exception quickly.
This approach does not hold for interrupts, because they frequently arrive long after the process to which they are related (for instance, a process that requested a data transfer) has been suspended and a completely unrelated process is running. So it would make no sense to send a Unix signal to the current process.
Interrupt handling depends on the type of interrupt. For our purposes, we'll distinguish three main classes of interrupts:
I/O interrupts An I/O device requires attention; the corresponding interrupt handler must query the device to determine the proper course of action. We cover this type of interrupt in the later section "I/O Interrupt Handling."
Timer interrupts Some timer, either a local APIC timer or an external timer, has issued an interrupt; this kind of interrupt tells the kernel that a fixed-time interval has elapsed. These interrupts are handled mostly as I/O interrupts; we discuss the peculiar characteristics of timer interrupts in Chapter 6.
Interprocessor interrupts A CPU issued an interrupt to another CPU of a multiprocessor system. We cover such interrupts in the later section "Interprocessor Interrupt Handling."
4.6.1. I/O Interrupt Handling
In general, an I/O interrupt handler must be flexible enough to service several devices at the same time. In the PCI bus architecture, for instance, several devices may share the same IRQ line. This means that the interrupt vector alone does not tell the whole story. In the example shown in Table 4-3, the same vector 43 is assigned to the USB port and to the sound card. However, some hardware devices found in older PC architectures (such as ISA) do not reliably operate if their IRQ line is shared with other devices.
Interrupt handler flexibility is achieved in two distinct ways, as discussed in the following list.
IRQ sharing The interrupt handler executes several interrupt service routines
(ISRs). Each ISR is a function related to a single device sharing the IRQ line. Because it is not possible to know in advance which particular device issued the IRQ, each ISR is executed to verify whether its device needs attention; if so, the ISR performs all the operations that need to be executed when the device raises an interrupt.
IRQ dynamic allocation An IRQ line is associated with a device driver at the last possible moment; for instance, the IRQ line of the floppy device is allocated only when a user accesses the floppy disk device. In this way, the same IRQ vector may be used by several hardware devices even if they cannot share the IRQ line; of course, the hardware devices cannot be used at the same time. (See the discussion at the end of this section.)
Not all actions to be performed when an interrupt occurs have the same urgency. In fact, the interrupt handler itself is not a suitable place for all kind of actions. Long noncritical operations should be deferred, because while an interrupt handler is running, the signals on the corresponding IRQ line are temporarily ignored. Most important, the process on behalf of which an interrupt handler is executed must always stay in the TASK_RUNNING state, or a system freeze can occur. Therefore, interrupt handlers cannot perform any blocking procedure such as an I/O disk operation. Linux divides the actions to be performed following an interrupt into three classes:
Critical Actions such as acknowledging an interrupt to the PIC, reprogramming the PIC or the device controller, or updating data structures accessed by both the device and the processor. These can be executed quickly and are critical, because they must be performed as soon as possible. Critical actions are executed within the interrupt handler immediately, with maskable interrupts disabled.
Noncritical Actions such as updating data structures that are accessed only by the processor (for instance, reading the scan code after a keyboard key has been pushed). These actions can also finish quickly, so they are executed by the interrupt handler immediately, with the interrupts enabled.
Noncritical deferrable Actions such as copying a buffer's contents into the address space of a process (for instance, sending the keyboard line buffer to the terminal handler process). These may be delayed for a long time interval without affecting the kernel operations; the interested process will just keep waiting for the data. Noncritical deferrable actions are performed by means of separate functions that are discussed in the later section "Softirqs and Tasklets."
Regardless of the kind of circuit that caused the interrupt, all I/O interrupt handlers perform the same four basic actions:
Save the IRQ value and the register's contents on the Kernel Mode stack. Send an acknowledgment to the PIC that is servicing the IRQ line, thus allowing it to issue further interrupts. Execute the interrupt service routines (ISRs) associated with all the devices that share the IRQ. Terminate by jumping to the ret_from_intr( ) address.
Several descriptors are needed to represent both the state of the IRQ lines and the functions to be executed when an interrupt occurs. Figure 4-4 represents in a schematic way the hardware circuits and the software functions used to handle an interrupt. These functions are discussed in the following sections.
4.6.1.1. Interrupt vectors
As illustrated in Table 4-2, physical IRQs may be assigned any vector in the range 32-238. However, Linux uses vector 128 to implement system calls.
The IBM-compatible PC architecture requires that some devices be statically connected to specific IRQ lines. In particular:
The interval timer device must be connected to the IRQ 0 line (see Chapter 6). The slave 8259A PIC must be connected to the IRQ 2 line (although more advanced PICs are now being used, Linux still supports 8259A-style PICs).
 The external mathematical coprocessor must be connected to the IRQ 13 line (although recent 80 x 86 processors no longer use such a device, Linux continues to support the hardy 80386 model). In general, an I/O device can be connected to a limited number of IRQ lines. (As a matter of fact, when playing with an old PC where IRQ sharing is not possible, you might not succeed in installing a new card because of IRQ conflicts with other already present hardware devices.)
Table 4-2. Interrupt vectors in LinuxVector range | Use |
|---|
019 (0x0-0x13) | Nonmaskable interrupts and exceptions | 2031 (0x14-0x1f) | Intel-reserved | 32127 (0x20-0x7f) | External interrupts (IRQs) | 128 (0x80) | Programmed exception for system calls (see Chapter 10) | 129238 (0x81-0xee) | External interrupts (IRQs) | 239 (0xef) | Local APIC timer interrupt (see Chapter 6) | 240 (0xf0) | Local APIC thermal interrupt (introduced in the Pentium 4 models) | 241250 (0xf1-0xfa) | Reserved by Linux for future use | 251253 (0xfb-0xfd) | Interprocessor interrupts (see the section "Interprocessor Interrupt Handling" later in this chapter) | 254 (0xfe) | Local APIC error interrupt (generated when the local APIC detects an erroneous condition) | 255 (0xff) | Local APIC spurious interrupt (generated if the CPU masks an interrupt while the hardware device raises it) |
There are three ways to select a line for an IRQ-configurable device:
By setting hardware jumpers (only on very old device cards). By a utility program shipped with the device and executed when installing it. Such a program may either ask the user to select an available IRQ number or probe the system to determine an available number by itself. By a hardware protocol executed at system startup. Peripheral devices declare which interrupt lines they are ready to use; the final values are then negotiated to reduce conflicts as much as possible. Once this is done, each interrupt handler can read the assigned IRQ by using a function that accesses some I/O ports of the device. For instance, drivers for devices that comply with the Peripheral Component Interconnect (PCI) standard use a group of functions such as pci_read_config_byte( ) to access the device configuration space.
Table 4-3 shows a fairly arbitrary arrangement of devices and IRQs, such as those that might be found on one particular PC.
Table 4-3. An example of IRQ assignment to I/O devicesIRQ | INT | Hardware device |
|---|
0 | 32 | Timer | 1 | 33 | Keyboard | 2 | 34 | PIC cascading | 3 | 35 | Second serial port | 4 | 36 | First serial port | 6 | 38 | Floppy disk | 8 | 40 | System clock | 10 | 42 | Network interface | 11 | 43 | USB port, sound card | 12 | 44 | PS/2 mouse | 13 | 45 | Mathematical coprocessor | 14 | 46 | EIDE disk controller's first chain | 15 | 47 | EIDE disk controller's second chain |
The kernel must discover which I/O device corresponds to the IRQ number before enabling interrupts. Otherwise, for example, how could the kernel handle a signal from a SCSI disk without knowing which vector corresponds to the device? The correspondence is established while initializing each device driver (see Chapter 13).
4.6.1.2. IRQ data structures
As always, when discussing complicated operations involving state transitions, it helps to understand first where key data is stored. Thus, this section explains the data structures that support interrupt handling and how they are laid out in various descriptors. Figure 4-5 illustrates schematically the relationships between the main descriptors that represent the state of the IRQ lines. (The figure does not illustrate the data structures needed to handle softirqs and tasklets; they are discussed later in this chapter.)
Every interrupt vector has its own irq_desc_t descriptor, whose fields are listed in Table 4-4. All such descriptors are grouped together in the irq_desc array.
Table 4-4. The irq_desc_t descriptorField | Description |
|---|
handler | Points to the PIC object (hw_irq_controller descriptor) that services the IRQ line. | handler_data | Pointer to data used by the PIC methods. | action | Identifies the interrupt service routines
to be invoked when the IRQ occurs. The field points to the first element of the list of irqaction descriptors associated with the IRQ. The irqaction descriptor is described later in the chapter. | status | A set of flags describing the IRQ line status (see Table 4-5). | depth | Shows 0 if the IRQ line is enabled and a positive value if it has been disabled at least once. | irq_count | Counter of interrupt occurrences on the IRQ line (for diagnostic use only). | irqs_unhandled | Counter of unhandled interrupt occurrences on the IRQ line (for diagnostic use only). | lock | A spin lock used to serialize the accesses to the IRQ descriptor and to the PIC (see Chapter 5). |
An interrupt is unexpected
if it is not handled by the kernel, that is, either if there is no ISR associated with the IRQ line, or if no ISR associated with the line recognizes the interrupt as raised by its own hardware device. Usually the kernel checks the number of unexpected interrupts received on an IRQ line, so as to disable the line in case a faulty hardware device keeps raising an interrupt over and over. Because the IRQ line can be shared among several devices, the kernel does not disable the line as soon as it detects a single unhandled
interrupt. Rather, the kernel stores in the irq_count and irqs_unhandled fields of the irq_desc_t descriptor the total number of interrupts and the number of unexpected interrupts, respectively; when the 100,000th interrupt is raised, the kernel disables the line if the number of unhandled interrupts is above 99,900 (that is, if less than 101 interrupts over the last 100,000 received are expected interrupts from hardware devices sharing the line).
The status of an IRQ line is described by the flags listed in Table 4-5.
Table 4-5. Flags describing the IRQ line statusFlag name | Description |
|---|
IRQ_INPROGRESS | A handler for the IRQ is being executed. | IRQ_DISABLED | The IRQ line has been deliberately disabled by a device driver. | IRQ_PENDING | An IRQ has occurred on the line; its occurrence has been acknowledged to the PIC, but it has not yet been serviced by the kernel. | IRQ_REPLAY | The IRQ line has been disabled but the previous IRQ occurrence has not yet been acknowledged to the PIC. | IRQ_AUTODETECT | The kernel is using the IRQ line while performing a hardware device probe. | IRQ_WAITING | The kernel is using the IRQ line while performing a hardware device probe; moreover, the corresponding interrupt has not been raised. | IRQ_LEVEL | Not used on the 80 x 86 architecture. | IRQ_MASKED | Not used. | IRQ_PER_CPU | Not used on the 80 x 86 architecture. |
The depth field and the IRQ_DISABLED flag of the irq_desc_t descriptor specify whether the IRQ line is enabled or disabled. Every time the disable_irq( ) or disable_irq_nosync( ) function is invoked, the depth field is increased; if depth is equal to 0, the function disables the IRQ line and sets its IRQ_DISABLED flag. Conversely, each invocation of the enable_irq( ) function decreases the field; if depth becomes 0, the function enables the IRQ line and clears its IRQ_DISABLED flag.
During system initialization, the init_IRQ( ) function sets the status field of each IRQ main descriptor to IRQ _DISABLED. Moreover, init_IRQ( ) updates the IDT by replacing the interrupt gates set up by setup_idt( ) (see the section "Preliminary Initialization of the IDT," earlier in this chapter) with new ones. This is accomplished through the following statements:
for (i = 0; i < NR_IRQS; i++)
if (i+32 != 128)
set_intr_gate(i+32,interrupt[i]);
This code looks in the interrupt array to find the interrupt handler addresses that it uses to set up the interrupt gates
. Each entry n of the interrupt array stores the address of the interrupt handler for IRQ n (see the later section "Saving the registers for the interrupt handler"). Notice that the interrupt gate corresponding to vector 128 is left untouched, because it is used for the system call's programmed exception.
In addition to the 8259A chip that was mentioned near the beginning of this chapter, Linux supports several other PIC circuits such as the SMP IO-APIC, Intel PIIX4's internal 8259 PIC, and SGI's Visual Workstation Cobalt (IO-)APIC. To handle all such devices in a uniform way, Linux uses a PIC object, consisting of the PIC name and seven PIC standard methods. The advantage of this object-oriented approach is that drivers need not to be aware of the kind of PIC installed in the system. Each driver-visible interrupt source is transparently wired to the appropriate controller. The data structure that defines a PIC object is called hw_interrupt_type (also called hw_irq_controller).
For the sake of concreteness, let's assume that our computer is a uniprocessor with two 8259A PICs, which provide 16 standard IRQs. In this case, the handler field in each of the 16 irq_desc_t descriptors points to the i8259A_irq_type variable, which describes the 8259A PIC. This variable is initialized as follows:
struct hw_interrupt_type i8259A_irq_type = {
.typename = "XT-PIC",
.startup = startup_8259A_irq,
.shutdown = shutdown_8259A_irq,
.enable = enable_8259A_irq,
.disable = disable_8259A_irq,
.ack = mask_and_ack_8259A,
.end = end_8259A_irq,
.set_affinity = NULL
};
The first field in this structure, "XT-PIC", is the PIC name. Next come the pointers to six different functions used to program the PIC. The first two functions start up and shut down an IRQ line of the chip, respectively. But in the case of the 8259A chip, these functions coincide with the third and fourth functions, which enable and disable the line. The mask_and_ack_8259A( ) function acknowledges the IRQ received by sending the proper bytes to the 8259A I/O ports. The end_8259A_irq( ) function is invoked when the interrupt handler for the IRQ line terminates. The last set_affinity method is set to NULL: it is used in multiprocessor systems to declare the "affinity" of CPUs for specified IRQs that is, which CPUs are enabled to handle specific IRQs.
As described earlier, multiple devices can share a single IRQ. Therefore, the kernel maintains irqaction descriptors (see Figure 4-5 earlier in this chapter), each of which refers to a specific hardware device and a specific interrupt. The fields included in such descriptor are shown in Table 4-6, and the flags are shown in Table 4-7.
Table 4-6. Fields of the irqaction descriptorField name | Description |
|---|
handler | Points to the interrupt service routine for an I/O device. This is the key field that allows many devices to share the same IRQ. | flags | This field includes a few fields that describe the relationships between the IRQ line and the I/O device (see Table 4-7). | mask | Not used. | name | The name of the I/O device (shown when listing the serviced IRQs by reading the /proc/interrupts file). | dev_id | A private field for the I/O device. Typically, it identifies the I/O device itself (for instance, it could be equal to its major and minor numbers; see the section "
Device Files"
in Chapter 13), or it points to the device driver's data. | next | Points to the next element of a list of irqaction descriptors. The elements in the list refer to hardware devices that share the same IRQ. | irq | IRQ line. | dir | Points to the descriptor of the /proc/irq/n directory associated with the IRQn. |
Table 4-7. Flags of the irqaction descriptorFlag name | Description |
|---|
SA_INTERRUPT | The handler must execute with interrupts disabled. | SA_SHIRQ | The device permits its IRQ line to be shared with other devices. | SA_SAMPLE_RANDOM | The device may be considered a source of events that occurs randomly; it can thus be used by the kernel random number generator. (Users can access this feature by taking random numbers from the /dev/random and /dev/urandom device files.) |
Finally, the irq_stat array includes NR_CPUS entries, one for every possible CPU in the system. Each entry of type irq_cpustat_t includes a few counters and flags used by the kernel to keep track of what each CPU is currently doing (see Table 4-8).
Table 4-8. Fields of the irq_cpustat_t structureField name | Description |
|---|
_ _softirq_pending | Set of flags denoting the pending softirqs (see the section "Softirqs" later in this chapter) | idle_timestamp | Time when the CPU became idle (significant only if the CPU is currently idle) | _ _nmi_count | Number of occurrences of NMI interrupts
| apic_timer_irqs | Number of occurrences of local APIC timer interrupts (see
Chapter 6) |
4.6.1.3. IRQ distribution in multiprocessor systems
Linux sticks to the Symmetric Multiprocessing model (SMP
); this means, essentially, that the kernel should not have any bias toward one CPU with respect to the others. As a consequence, the kernel tries to distribute the IRQ signals coming from the hardware devices in a round-robin fashion among all the CPUs. Therefore, all the CPUs should spend approximately the same fraction of their execution time servicing I/O interrupts.
In the earlier section "The Advanced Programmable Interrupt Controller (APIC)," we said that the multi-APIC system has sophisticated mechanisms to dynamically distribute the IRQ signals among the CPUs.
During system bootstrap, the booting CPU executes the setup_IO_APIC_irqs( ) function to initialize the I/O APIC chip. The 24 entries of the Interrupt Redirection Table of the chip are filled, so that all IRQ signals from the I/O hardware devices can be routed to each CPU in the system according to the "lowest priority" scheme (see the earlier section "IRQs and Interrupts"). During system bootstrap, moreover, all CPUs execute the setup_local_APIC( ) function, which takes care of initializing the local APICs. In particular, the task priority register (TPR) of each chip is initialized to a fixed value, meaning that the CPU is willing to handle every kind of IRQ signal, regardless of its priority. The Linux kernel never modifies this value after its initialization.
All task priority registers contain the same value, thus all CPUs always have the same priority. To break a tie, the multi-APIC system uses the values in the arbitration priority registers of local APICs, as explained earlier. Because such values are automatically changed after every interrupt, the IRQ signals are, in most cases, fairly distributed among all CPUs.
In short, when a hardware device raises an IRQ signal, the multi-APIC system selects one of the CPUs and delivers the signal to the corresponding local APIC, which in turn interrupts its CPU. No other CPUs are notified of the event.
All this is magically done by the hardware, so it should be of no concern for the kernel after multi-APIC system initialization. Unfortunately, in some cases the hardware fails to distribute the interrupts among the microprocessors in a fair way (for instance, some Pentium 4-based SMP motherboards have this problem). Therefore, Linux 2.6 makes use of a special kernel thread called kirqd
to correct, if necessary, the automatic assignment of IRQs to CPUs.
The kernel thread exploits a nice feature of multi-APIC systems, called the IRQ affinity
of a CPU: by modifying the Interrupt Redirection Table entries of the I/O APIC, it is possible to route an interrupt signal to a specific CPU. This can be done by invoking the set_ioapic_affinity_irq( ) function, which acts on two parameters: the IRQ vector to be rerouted and a 32-bit mask denoting the CPUs that can receive the IRQ. The IRQ affinity of a given interrupt also can be changed by the system administrator by writing a new CPU bitmap mask into the /proc/irq/n/smp_affinity file (n being the interrupt vector).
The kirqd kernel thread periodically executes the do_irq_balance( ) function, which keeps track of the number of interrupt occurrences received by every CPU in the most recent time interval. If the function discovers that the IRQ load imbalance between the heaviest loaded CPU and the least loaded CPU is significantly high, then it either selects an IRQ to be "moved" from a CPU to another, or rotates all IRQs among all existing CPUs.
4.6.1.4. Multiple Kernel Mode stacks
As mentioned in the section "Identifying a Process"
in Chapter 3, the thread_info descriptor of each process is coupled with a Kernel Mode stack in a thread_union data structure composed by one or two page frames, according to an option selected when the kernel has been compiled. If the size of the tHRead_union structure is 8 KB, the Kernel Mode stack of the current process is used for every type of kernel control path: exceptions, interrupts, and deferrable functions (see the later section "Softirqs and Tasklets"). Conversely, if the size of the thread_union structure is 4 KB, the kernel makes use of three types of Kernel Mode stacks:
The exception stack
is used when handling exceptions (including system calls). This is the stack contained in the per-process thread_union data structure, thus the kernel makes use of a different exception stack for each process in the system. The hard IRQ stack
is used when handling interrupts. There is one hard IRQ stack for each CPU in the system, and each stack is contained in a single page frame. The soft IRQ stack
is used when handling deferrable functions (softirqs or tasklets; see the later section "Softirqs and Tasklets"). There is one soft IRQ stack for each CPU in the system, and each stack is contained in a single page frame.
All hard IRQ stacks are contained in the hardirq_stack array, while all soft IRQ stacks are contained in the softirq_stack array. Each array element is a union of type irq_ctx that span a single page. At the bottom of this page is stored a thread_info structure, while the spare memory locations are used for the stack; remember that each stack grows towards lower addresses. Thus, hard IRQ stacks and soft IRQ stacks are very similar to the exception stacks described in the section "
Identifying a Process" in
Chapter 3; the only difference is that the tHRead_info structure coupled with each stack is associated with a CPU rather than a process.
The hardirq_ctx and softirq_ctx arrays allow the kernel to quickly determine the hard IRQ stack and soft IRQ stack of a given CPU, respectively: they contain pointers to the corresponding irq_ctx elements.
4.6.1.5. Saving the registers for the interrupt handler
When a CPU receives an interrupt, it starts executing the code at the address found in the corresponding gate of the IDT (see the earlier section "
Hardware Handling of Interrupts and Exceptions").
As with other context switches, the need to save registers leaves the kernel developer with a somewhat messy coding job, because the registers have to be saved and restored using assembly language code. However, within those operations, the processor is expected to call and return from a C function. In this section, we describe the assembly language task of handling registers; in the next, we show some of the acrobatics required in the C function that is subsequently invoked.
Saving registers is the first task of the interrupt handler. As already mentioned, the address of the interrupt handler for IRQ n is initially stored in the interrupt[n] enTRy and then copied into the interrupt gate included in the proper IDT entry.
The interrupt array is built through a few assembly language instructions in the arch/i386/kernel/entry.S
file. The array includes NR_IRQS elements, where the NR_IRQS macro yields either the number 224 if the kernel supports a recent I/O APIC chip, or the number 16 if the kernel uses the older 8259A PIC chips. The element at index n in the array stores the address of the following two assembly language instructions:
pushl $n-256
jmp common_interrupt
The result is to save on the stack the IRQ number associated with the interrupt minus 256. The kernel represents all IRQs through negative numbers, because it reserves positive interrupt numbers to identify system calls (see
Chapter 10). The same code for all interrupt handlers can then be executed while referring to this number. The common code starts at label common_interrupt and consists of the following assembly language macros and instructions:
common_interrupt:
SAVE_ALL
movl %esp,%eax
call do_IRQ
jmp ret_from_intr
The SAVE_ALL macro expands to the following fragment:
cld
push %es
push %ds
pushl %eax
pushl %ebp
pushl %edi
pushl %esi
pushl %edx
pushl %ecx
pushl %ebx
movl $ _ _USER_DS,%edx
movl %edx,%ds
movl %edx,%es
SAVE_ALL saves all the CPU registers that may be used by the interrupt handler on the stack, except for eflags
, cs, eip, ss, and esp, which are already saved automatically by the control unit (see the earlier section "
Hardware Handling of Interrupts and Exceptions"). The macro then loads the selector of the user data segment into ds and es.
After saving the registers, the address of the current top stack location is saved in the eax register; then, the interrupt handler invokes the do_IRQ( ) function. When the ret instruction of do_IRQ( ) is executed (when that function terminates) control is transferred to ret_from_intr( ) (see the later section "
Returning from Interrupts and Exceptions").
4.6.1.6. The do_IRQ( ) function
The do_IRQ( ) function is invoked to execute all interrupt service routines
associated with an interrupt. It is declared as follows:
_ _attribute_ _((regparm(3))) unsigned int do_IRQ(struct pt_regs *regs)
The regparm keyword instructs the function to go to the eax register to find the value of the regs argument; as seen above, eax points to the stack location containing the last register value pushed on by SAVE_ALL.
The do_IRQ( ) function executes the following actions:
Executes the irq_enter( ) macro, which increases a counter representing the number of nested interrupt handlers. The counter is stored in the preempt_count field of the tHRead_info structure of the current process (see
Table 4-10 later in this chapter). If the size of the thread_union structure is 4 KB, it switches to the hard IRQ stack.In particular, the function performs the following substeps: Executes the current_thread_info( ) function to get the address of the tHRead_info descriptor associated with the Kernel Mode stack addressed by the esp register (see the section "
Identifying a Process" in
Chapter 3). Compares the address of the tHRead_info descriptor obtained in the previous step with the address stored in hardirq_ctx[smp_processor_id( )], that is, the address of the thread_info descriptor associated with the local CPU. If the two addresses are equal, the kernel is already using the hard IRQ stack, thus jumps to step 3. This happens when an IRQ is raised while the kernel is still handling another interrupt. Here the Kernel Mode stack has to be switched. Stores the pointer to the current process descriptor in the task field of the tHRead_info descriptor in irq_ctx union of the local CPU. This is done so that the current macro works as expected while the kernel is using the hard IRQ stack (see the section "
Identifying a Process" in
Chapter 3). Stores the current value of the esp stack pointer register in the previous_esp field of the thread_info descriptor in the irq_ctx union of the local CPU (this field is used only when preparing the function call trace for a kernel oops). Loads in the esp stack register the top location of the hard IRQ stack of the local CPU (the value in hardirq_ctx[smp_processor_id( )] plus 4096); the previous value of the esp register is saved in the ebx register.
Invokes the _ _do_IRQ( ) function passing to it the pointer regs and the IRQ number obtained from the regs->orig_eax field (see the following section). If the hard IRQ stack has been effectively switched in step 2e above, the function copies the original stack pointer from the ebx register into the esp register, thus switching back to the exception stack or soft IRQ stack that were in use before. Executes the irq_exit( ) macro, which decreases the interrupt counter and checks whether deferrable kernel functions are waiting to be executed (see the section "
Softirqs and Tasklets" later in this chapter). Terminates: the control is transferred to the ret_from_intr( ) function (see the later section "
Returning from Interrupts and Exceptions").
4.6.1.7. The _ _do_IRQ( ) function
The _ _do_IRQ( ) function receives as its parameters an IRQ number (through the eax register) and a pointer to the pt_regs structure where the User Mode register values have been saved (through the edx register).
The function is equivalent to the following code fragment:
spin_lock(&(irq_desc[irq].lock));
irq_desc[irq].handler->ack(irq);
irq_desc[irq].status &= ~(IRQ_REPLAY | IRQ_WAITING);
irq_desc[irq].status |= IRQ_PENDING;
if (!(irq_desc[irq].status & (IRQ_DISABLED | IRQ_INPROGRESS))
&& irq_desc[irq].action) {
irq_desc[irq].status |= IRQ_INPROGRESS;
do {
irq_desc[irq].status &= ~IRQ_PENDING;
spin_unlock(&(irq_desc[irq].lock));
handle_IRQ_event(irq, regs, irq_desc[irq].action);
spin_lock(&(irq_desc[irq].lock));
} while (irq_desc[irq].status & IRQ_PENDING);
irq_desc[irq].status &= ~IRQ_INPROGRESS;
}
irq_desc[irq].handler->end(irq);
spin_unlock(&(irq_desc[irq].lock));
Before accessing the main IRQ descriptor, the kernel acquires the corresponding spin lock. We'll see in
Chapter 5 that the spin lock protects against concurrent accesses by different CPUs. This spin lock is necessary in a multiprocessor system, because other interrupts of the same kind may be raised, and other CPUs might take care of the new interrupt occurrences. Without the spin lock, the main IRQ descriptor would be accessed concurrently by several CPUs. As we'll see, this situation must be absolutely avoided.
After acquiring the spin lock, the function invokes the ack method of the main IRQ descriptor. When using the old 8259A PIC, the corresponding mask_and_ack_8259A( ) function acknowledges the interrupt on the PIC and also disables the IRQ line. Masking the IRQ line ensures that the CPU does not accept further occurrences of this type of interrupt until the handler terminates. Remember that the _ _do_IRQ( ) function runs with local interrupts disabled; in fact, the CPU control unit automatically clears the IF flag of the eflags
register because the interrupt handler is invoked through an IDT's interrupt gate. However, we'll see shortly that the kernel might re-enable local interrupts before executing the interrupt service routines of this interrupt.
When using the I/O APIC, however, things are much more complicated. Depending on the type of interrupt, acknowledging the interrupt could either be done by the ack method or delayed until the interrupt handler terminates (that is, acknowledgement could be done by the end method). In either case, we can take for granted that the local APIC doesn't accept further interrupts of this type until the handler terminates, although further occurrences of this type of interrupt may be accepted by other CPUs.
The _ _do_IRQ( ) function then initializes a few flags of the main IRQ descriptor. It sets the IRQ_PENDING flag because the interrupt has been acknowledged (well, sort of), but not yet really serviced; it also clears the IRQ_WAITING and IRQ_REPLAY flags (but we don't have to care about them now).
Now _ _do_IRQ( ) checks whether it must really handle the interrupt. There are three cases in which nothing has to be done. These are discussed in the following list.
IRQ_DISABLED is set A CPU might execute the _ _do_IRQ( ) function even if the corresponding IRQ line is disabled; you'll find an explanation for this nonintuitive case in the later section "Reviving a lost interrupt." Moreover, buggy motherboards may generate spurious interrupts even when the IRQ line is disabled in the PIC.
IRQ_INPROGRESS is set In a multiprocessor system, another CPU might be handling a previous occurrence of the same interrupt. Why not defer the handling of this occurrence to that CPU? This is exactly what is done by Linux. This leads to a simpler kernel architecture because device drivers' interrupt service routines need not to be reentrant (their execution is serialized). Moreover, the freed CPU can quickly return to what it was doing, without dirtying its hardware cache; this is beneficial to system performance. The IRQ_INPROGRESS flag is set whenever a CPU is committed to execute the interrupt service routines of the interrupt; therefore, the _ _do_IRQ( ) function checks it before starting the real work.
irq_desc[irq].action is NULL This case occurs when there is no interrupt service routine associated with the interrupt. Normally, this happens only when the kernel is probing a hardware device.
Let's suppose that none of the three cases holds, so the interrupt has to be serviced. The _ _do_IRQ( ) function sets the IRQ_INPROGRESS flag and starts a loop. In each iteration, the function clears the IRQ_PENDING flag, releases the interrupt spin lock, and executes the interrupt service routines by invoking handle_IRQ_event( ) (described later in the chapter). When the latter function terminates, _ _do_IRQ( ) acquires the spin lock again and checks the value of the IRQ_PENDING flag. If it is clear, no further occurrence of the interrupt has been delivered to another CPU, so the loop ends. Conversely, if IRQ_PENDING is set, another CPU has executed the do_IRQ( ) function for this type of interrupt while this CPU was executing handle_IRQ_event( ). Therefore, do_IRQ( ) performs another iteration of the loop, servicing the new occurrence of the interrupt.
Our _ _do_IRQ( ) function is now going to terminate, either because it has already executed the interrupt service routines or because it had nothing to do. The function invokes the end method of the main IRQ descriptor. When using the old 8259A PIC, the corresponding end_8259A_irq( ) function reenables the IRQ line (unless the interrupt occurrence was spurious). When using the I/O APIC, the end method acknowledges the interrupt (if not already done by the ack method).
Finally, _ _do_IRQ( ) releases the spin lock: the hard work is finished!
4.6.1.8. Reviving a lost interrupt
The _ _do_IRQ( ) function is small and simple, yet it works properly in most cases. Indeed, the IRQ_PENDING, IRQ_INPROGRESS, and IRQ_DISABLED flags ensure that interrupts are correctly handled even when the hardware is misbehaving. However, things may not work so smoothly in a multiprocessor system.
Suppose that a CPU has an IRQ line enabled. A hardware device raises the IRQ line, and the multi-APIC system selects our CPU for handling the interrupt. Before the CPU acknowledges the interrupt, the IRQ line is masked out by another CPU; as a consequence, the IRQ_DISABLED flag is set. Right afterwards, our CPU starts handling the pending interrupt; therefore, the do_IRQ( ) function acknowledges the interrupt and then returns without executing the interrupt service routines because it finds the IRQ_DISABLED flag set. Therefore, even though the interrupt occurred before the IRQ line was disabled, it gets lost.
To cope with this scenario, the enable_irq( ) function, which is used by the kernel to enable an IRQ line, checks first whether an interrupt has been lost. If so, the function forces the hardware to generate a new occurrence of the lost interrupt:
spin_lock_irqsave(&(irq_desc[irq].lock), flags);
if (--irq_desc[irq].depth == 0) {
irq_desc[irq].status &= ~IRQ_DISABLED;
if (irq_desc[irq].status & (IRQ_PENDING | IRQ_REPLAY))
== IRQ_PENDING) {
irq_desc[irq].status |= IRQ_REPLAY;
hw_resend_irq(irq_desc[irq].handler,irq);
}
irq_desc[irq].handler->enable(irq);
}
spin_lock_irqrestore(&(irq_desc[irq].lock), flags);
The function detects that an interrupt was lost by checking the value of the IRQ_PENDING flag. The flag is always cleared when leaving the interrupt handler; therefore, if the IRQ line is disabled and the flag is set, then an interrupt occurrence has been acknowledged but not yet serviced. In this case the hw_resend_irq( ) function raises a new interrupt. This is obtained by forcing the local APIC to generate a self-interrupt (see the later section "Interprocessor Interrupt Handling"). The role of the IRQ_REPLAY flag is to ensure that exactly one self-interrupt is generated. Remember that the _ _do_IRQ( ) function clears that flag when it starts handling the interrupt.
4.6.1.9. Interrupt service routines
As mentioned previously, an interrupt service routine handles an interrupt by executing an operation specific to one type of device. When an interrupt handler must execute the ISRs, it invokes the handle_IRQ_event( ) function. This function essentially performs the following steps:
Enables the local interrupts with the sti
assembly language instruction if the SA_INTERRUPT flag is clear. Executes each interrupt service routine of the interrupt through the following code:
retval = 0;
do {
retval |= action->handler(irq, action->dev_id, regs);
action = action->next;
} while (action);
At the start of the loop, action points to the start of a list of irqaction data structures that indicate the actions to be taken upon receiving the interrupt (see Figure 4-5 earlier in this chapter). Disables local interrupts with the cli
assembly language instruction. Terminates by returning the value of the retval local variable, that is, 0 if no interrupt service routine has recognized interrupt, 1 otherwise (see next).
All interrupt service routines act on the same parameters (once again they are passed through the eax, edx, and ecx registers, respectively):
irq The IRQ number
dev_id The device identifier
regs A pointer to a pt_regs structure on the Kernel Mode (exception) stack containing the registers saved right after the interrupt occurred. The pt_regs structure consists of 15 fields:
The first nine fields are the register values pushed by SAVE_ALL The tenth field, referenced through a field called orig_eax, encodes the IRQ number The remaining fields correspond to the register values pushed on automatically by the control unit
The first parameter allows a single ISR to handle several IRQ lines, the second one allows a single ISR to take care of several devices of the same type, and the last one allows the ISR to access the execution context of the interrupted kernel control path. In practice, most ISRs do not use these parameters.
Every interrupt service routine returns the value 1 if the interrupt has been effectively handled, that is, if the signal was raised by the hardware device handled by the interrupt service routine (and not by another device sharing the same IRQ); it returns the value 0 otherwise. This return code allows the kernel to update the counter of unexpected interrupts mentioned in the section "IRQ data structures" earlier in this chapter.
The SA_INTERRUPT flag of the main IRQ descriptor determines whether interrupts must be enabled or disabled when the do_IRQ( ) function invokes an ISR. An ISR that has been invoked with the interrupts in one state is allowed to put them in the opposite state. In a uniprocessor system, this can be achieved by means of the cli (disable interrupts) and sti (enable interrupts) assembly language instructions.
The structure of an ISR depends on the characteristics of the device handled. We'll give a couple of examples of ISRs in
Chapter 6 and
Chapter 13.
4.6.1.10. Dynamic allocation of IRQ lines
As noted in section "Interrupt vectors," a few vectors are reserved for specific devices, while the remaining ones are dynamically handled. There is, therefore, a way in which the same IRQ line can be used by several hardware devices even if they do not allow IRQ sharing. The trick is to serialize the activation of the hardware devices so that just one owns the IRQ line at a time.
Before activating a device that is going to use an IRQ line, the corresponding driver invokes request_irq( ). This function creates a new irqaction descriptor and initializes it with the parameter values; it then invokes the setup_irq( ) function to insert the descriptor in the proper IRQ list. The device driver aborts the operation if setup_irq( ) returns an error code, which usually means that the IRQ line is already in use by another device that does not allow interrupt sharing. When the device operation is concluded, the driver invokes the free_irq( ) function to remove the descriptor from the IRQ list and release the memory area.
Let's see how this scheme works on a simple example. Assume a program wants to address the /dev/fd0 device file, which corresponds to the first floppy disk on the system. The program can do this either by directly accessing /dev/fd0 or by mounting a filesystem on it. Floppy disk controllers are usually assigned IRQ 6; given this, a floppy driver may issue the following request:
request_irq(6, floppy_interrupt,
SA_INTERRUPT|SA_SAMPLE_RANDOM, "floppy", NULL);
As can be observed, the floppy_interrupt( ) interrupt service routine must execute with the interrupts disabled (SA_INTERRUPT flag set) and no sharing of the IRQ (SA_SHIRQ flag missing). The SA_SAMPLE_RANDOM flag set means that accesses to the floppy disk are a good source of random events to be used for the kernel random number generator. When the operation on the floppy disk is concluded (either the I/O operation on /dev/fd0 terminates or the filesystem is unmounted), the driver releases IRQ 6:
free_irq(6, NULL);
To insert an irqaction descriptor in the proper list, the kernel invokes the setup_irq( ) function, passing to it the parameters irq _nr, the IRQ number, and new (the address of a previously allocated irqaction descriptor). This function:
Checks whether another device is already using the irq _nr IRQ and, if so, whether the SA_SHIRQ flags in the irqaction descriptors of both devices specify that the IRQ line can be shared. Returns an error code if the IRQ line cannot be used. Adds *new (the new irqaction descriptor pointed to by new) at the end of the list to which irq _desc[irq _nr]->action points. If no other device is sharing the same IRQ, the function clears the IRQ _DISABLED, IRQ_AUTODETECT, IRQ_WAITING, and IRQ _INPROGRESS flags in the flags field of *new and invokes the startup method of the irq_desc[irq_nr]->handler PIC object to make sure that IRQ signals are enabled.
Here is an example of how setup_irq( ) is used, drawn from system initialization. The kernel initializes the irq0 descriptor of the interval timer device by executing the following instructions in the time_init( ) function (see
Chapter 6):
struct irqaction irq0 =
{timer_interrupt, SA_INTERRUPT, 0, "timer", NULL, NULL};
setup_irq(0, &irq0);
First, the irq0 variable of type irqaction is initialized: the handler field is set to the address of the timer_interrupt( ) function, the flags field is set to SA_INTERRUPT, the name field is set to "timer", and the fifth field is set to NULL to show that no dev_id value is used. Next, the kernel invokes setup_irq( ) to insert irq0 in the list of irqaction descriptors associated with IRQ 0.
4.6.2. Interprocessor Interrupt Handling
Interprocessor interrupts allow a CPU to send interrupt signals to any other CPU in the system. As explained in the section "The Advanced Programmable Interrupt Controller (APIC)Ы" earlier in this chapter, an interprocessor interrupt (IPI) is delivered not through an IRQ line, but directly as a message on the bus that connects the local APIC of all CPUs (either a dedicated bus in older motherboards, or the system bus in the Pentium 4-based motherboards).
On multiprocessor systems, Linux makes use of three kinds of interprocessor interrupts (see also Table 4-2):
CALL_FUNCTION_VECTOR (vector 0xfb) Sent to all CPUs but the sender, forcing those CPUs to run a function passed by the sender. The corresponding interrupt handler is named call_function_interrupt( ). The function (whose address is passed in the call_data global variable) may, for instance, force all other CPUs to stop, or may force them to set the contents of the Memory Type Range Registers (MTRRs). Usually this interrupt is sent to all CPUs except the CPU executing the calling function by means of the smp_call_function( ) facility function.
RESCHEDULE_VECTOR (vector 0xfc) When a CPU receives this type of interrupt, the corresponding handler named reschedule_interrupt( ) limits itself to acknowledging the interrupt. Rescheduling is done automatically when returning from the interrupt (see the section "
Returning from Interrupts and Exceptions" later in this chapter).
INVALIDATE_TLB_VECTOR (vector 0xfd) Sent to all CPUs but the sender, forcing them to invalidate their Translation Lookaside Buffers. The corresponding handler, named invalidate_interrupt( ), flushes some TLB entries of the processor as described in the section "
Handling the Hardware Cache and the TLB" in
Chapter 2.
The assembly language code of the interprocessor interrupt handlers is generated by the BUILD_INTERRUPT macro: it saves the registers, pushes the vector number minus 256 on the stack, and then invokes a high-level C function having the same name as the low-level handler preceded by smp_. For instance, the high-level handler of the CALL_FUNCTION_VECTOR interprocessor interrupt that is invoked by the low-level call_function_interrupt( ) handler is named smp_call_function_interrupt( ). Each high-level handler acknowledges the interprocessor interrupt on the local APIC and then performs the specific action triggered by the interrupt.
Thanks to the following group of functions, issuing interprocessor interrupts (IPIs) becomes an easy task:
send_IPI_all( ) Sends an IPI to all CPUs (including the sender)
send_IPI_allbutself( ) Sends an IPI to all CPUs except the sender
send_IPI_self( ) Sends an IPI to the sender CPU
send_IPI_mask( ) Sends an IPI to a group of CPUs specified by a bit mask
4.7. Softirqs and Tasklets
We mentioned earlier in the section "Interrupt Handling" that several tasks among those executed by the kernel are not critical: they can be deferred for a long period of time, if necessary. Remember that the interrupt service routines of an interrupt handler are serialized, and often there should be no occurrence of an interrupt until the corresponding interrupt handler has terminated. Conversely, the deferrable tasks can execute with all interrupts enabled. Taking them out of the interrupt handler helps keep kernel response time small. This is a very important property for many time-critical applications that expect their interrupt requests to be serviced in a few milliseconds.
Linux 2.6 answers such a challenge by using two kinds of non-urgent interruptible kernel functions: the so-called deferrable functions (softirqs
and tasklets
), and those executed by means of some work queues (we will describe them in the section "Work Queues" later in this chapter).
Softirqs and tasklets are strictly correlated, because tasklets are implemented on top of softirqs. As a matter of fact, the term "softirq," which appears in the kernel source code, often denotes both kinds of deferrable functions. Another widely used term is interrupt context
: it specifies that the kernel is currently executing either an interrupt handler or a deferrable function.
Softirqs are statically allocated (i.e., defined at compile time), while tasklets can also be allocated and initialized at runtime (for instance, when loading a kernel module). Softirqs can run concurrently on several CPUs, even if they are of the same type. Thus, softirqs are reentrant functions and must explicitly protect their data structures with spin locks. Tasklets do not have to worry about this, because their execution is controlled more strictly by the kernel. Tasklets of the same type are always serialized: in other words, the same type of tasklet cannot be executed by two CPUs at the same time. However, tasklets of different types can be executed concurrently on several CPUs. Serializing the tasklet simplifies the life of device driver developers, because the tasklet function needs not be reentrant.
Generally speaking, four kinds of operations can be performed on deferrable functions:
Initialization Defines a new deferrable function; this operation is usually done when the kernel initializes itself or a module is loaded.
Activation Marks a deferrable function as "pending" to be run the next time the kernel schedules a round of executions of deferrable functions. Activation can be done at any time (even while handling interrupts).
Masking Selectively disables a deferrable function so that it will not be executed by the kernel even if activated. We'll see in the section "Disabling and Enabling Deferrable Functions" in Chapter 5 that disabling deferrable functions is sometimes essential.
Execution Executes a pending deferrable function together with all other pending deferrable functions of the same type; execution is performed at well-specified times, explained later in the section "Softirqs."
Activation and execution are bound together: a deferrable function that has been activated by a given CPU must be executed on the same CPU. There is no self-evident reason suggesting that this rule is beneficial for system performance. Binding the deferrable function to the activating CPU could in theory make better use of the CPU hardware cache. After all, it is conceivable that the activating kernel thread accesses some data structures that will also be used by the deferrable function. However, the relevant lines could easily be no longer in the cache when the deferrable function is run because its execution can be delayed a long time. Moreover, binding a function to a CPU is always a potentially "dangerous" operation, because one CPU might end up very busy while the others are mostly idle.
4.7.1. Softirqs
Linux 2.6 uses a limited number of softirqs
. For most purposes, tasklets are good enough and are much easier to write because they do not need to be reentrant.
As a matter of fact, only the six kinds of softirqs listed in Table 4-9 are currently defined.
Table 4-9. Softirqs used in Linux 2.6Softirq | Index (priority) | Description |
|---|
HI_SOFTIRQ | 0 | Handles high priority tasklets | TIMER_SOFTIRQ | 1 | Tasklets related to timer interrupts | NET_TX_SOFTIRQ | 2 | Transmits packets to network cards | NET_RX_SOFTIRQ | 3 | Receives packets from network cards | SCSI_SOFTIRQ | 4 | Post-interrupt processing of SCSI commands | TASKLET_SOFTIRQ | 5 | Handles regular tasklets |
The index of a sofirq determines its priority: a lower index means higher priority because softirq functions will be executed starting from index 0.
4.7.1.1. Data structures used for softirqs
The main data structure used to represent softirqs is the softirq_vec array, which includes 32 elements of type softirq_action. The priority of a softirq is the index of the corresponding softirq_action element inside the array. As shown in Table 4-9, only the first six entries of the array are effectively used. The softirq_action data structure consists of two fields: an action pointer to the softirq function and a data pointer to a generic data structure that may be needed by the softirq function.
Another critical field used to keep track both of kernel preemption
and of nesting of kernel control paths
is the 32-bit preempt_count field stored in the tHRead_info field of each process descriptor (see the section "
Identifying a Process" in
Chapter 3). This field encodes three distinct counters plus a flag, as shown in Table 4-10.
Table 4-10. Subfields of the preempt_count field (continues)Bits | Description |
|---|
07 | Preemption counter (max value = 255) | 815 | Softirq counter (max value = 255). | 1627 | Hardirq counter (max value = 4096) | 28 | PREEMPT_ACTIVE flag |
The first counter keeps track of how many times kernel preemption has been explicitly disabled on the local CPU; the value zero means that kernel preemption has not been explicitly disabled at all. The second counter specifies how many levels deep the disabling of deferrable functions is (level 0 means that deferrable functions are enabled). The third counter specifies the number of nested interrupt handlers on the local CPU (the value is increased by irq_enter( ) and decreased by irq_exit( ); see the section "
I/O Interrupt Handling" earlier in this chapter).
There is a good reason for the name of the preempt_count field: kernel preemptability has to be disabled either when it has been explicitly disabled by the kernel code (preemption counter not zero) or when the kernel is running in interrupt context. Thus, to determine whether the current process can be preempted, the kernel quickly checks for a zero value in the preempt_count field. Kernel preemption will be discussed in depth in the section "
Kernel Preemption" in
Chapter 5.
The in_interrupt( ) macro checks the hardirq and softirq counters in the current_thread_info( )->preempt_count field. If either one of these two counters is positive, the macro yields a nonzero value, otherwise it yields the value zero. If the kernel does not make use of multiple Kernel Mode stacks, the macro always looks at the preempt_count field of the thread_info descriptor of the current process. If, however, the kernel makes use of multiple Kernel Mode stacks, the macro might look at the preempt_count field in the tHRead_info descriptor contained in a irq_ctx union associated with the local CPU. In this case, the macro returns a nonzero value because the field is always set to a positive value.
The last crucial data structure for implementing the softirqs is a per-CPU 32-bit mask describing the pending softirqs; it is stored in the _ _softirq_pending field of the irq_cpustat_t data structure (recall that there is one such structure per each CPU in the system; see Table 4-8). To get and set the value of the bit mask, the kernel makes use of the local_softirq_pending( ) macro that selects the softirq bit mask of the local CPU.
4.7.1.2. Handling softirqs
The open_softirq( ) function takes care of softirq initialization. It uses three parameters: the softirq index, a pointer to the softirq function to be executed, and a second pointer to a data structure that may be required by the softirq function. open_softirq( ) limits itself to initializing the proper entry of the softirq_vec array.
Softirqs are activated by means of the raise_softirq( ) function. This function, which receives as its parameter the softirq index nr, performs the following actions:
Executes the local_irq_save macro to save the state of the IF flag of the eflags
register and to disable interrupts on the local CPU. Marks the softirq as pending by setting the bit corresponding to the index nr in the softirq bit mask of the local CPU. If in_interrupt() yields the value 1, it jumps to step 5. This situation indicates either that raise_softirq( ) has been invoked in interrupt context, or that the softirqs are currently disabled. Otherwise, invokes wakeup_softirqd() to wake up, if necessary, the ksoftirqd
kernel thread of the local CPU (see later). Executes the local_irq_restore macro to restore the state of the IF flag saved in step 1.
Checks for active (pending) softirqs should be perfomed periodically, but without inducing too much overhead. They are performed in a few points of the kernel code. Here is a list of the most significant points (be warned that number and position of the softirq checkpoints change both with the kernel version and with the supported hardware architecture):
When the kernel invokes the local_bh_enable( ) function to enable softirqs on the local CPU When the do_IRQ( ) function finishes handling an I/O interrupt and invokes the irq_exit( ) macro If the system uses an I/O APIC, when the smp_apic_timer_interrupt( ) function finishes handling a local timer interrupt (see the section "
Timekeeping Architecture in Multiprocessor Systems" in
Chapter 6) In multiprocessor systems, when a CPU finishes handling a function triggered by a CALL_FUNCTION_VECTOR interprocessor interrupt When one of the special ksoftirqd/n kernel threads is awakened (see later)
4.7.1.3. The do_softirq( ) function
If pending softirqs are detected at one such checkpoint (local_softirq_pending() is not zero), the kernel invokes do_softirq( ) to take care of them. This function performs the following actions:
If in_interrupt( ) yields the value one, this function returns. This situation indicates either that do_softirq( ) has been invoked in interrupt context or that the softirqs are currently disabled. Executes local_irq_save to save the state of the IF flag and to disable the interrupts on the local CPU. If the size of the thread_union structure is 4 KB, it switches to the soft IRQ stack, if necessary. This step is very similar to step 2 of do_IRQ( ) in the earlier section "
I/O Interrupt Handling;" of course, the softirq_ctx array is used instead of hardirq_ctx. Invokes the _ _do_softirq( ) function (see the following section). If the soft IRQ stack has been effectively switched in step 3 above, it restores the original stack pointer into the esp register, thus switching back to the exception stack that was in use before. Executes local_irq_restore to restore the state of the IF flag (local interrupts enabled or disabled) saved in step 2 and returns.
4.7.1.4. The _ _do_softirq( ) function
The _ _do_softirq( ) function reads the softirq bit mask of the local CPU and executes the deferrable functions corresponding to every set bit. While executing a softirq function, new pending softirqs might pop up; in order to ensure a low latency time for the deferrable funtions, _ _do_softirq( ) keeps running until all pending softirqs have been executed. This mechanism, however, could force _ _do_softirq( ) to run for long periods of time, thus considerably delaying User Mode processes. For that reason, _ _do_softirq( ) performs a fixed number of iterations and then returns. The remaining pending softirqs, if any, will be handled in due time by the ksoftirqd kernel thread described in the next section. Here is a short description of the actions performed by the function:
Initializes the iteration counter to 10. Copies the softirq bit mask of the local CPU (selected by local_softirq_pending( )) in the pending local variable. Invokes local_bh_disable( ) to increase the softirq counter. It is somewhat counterintuitive that deferrable functions should be disabled before starting to execute them, but it really makes a lot of sense. Because the deferrable functions mostly run with interrupts enabled, an interrupt can be raised in the middle of the _ _do_softirq( ) function. When do_IRQ( ) executes the irq_exit( ) macro, another instance of the _ _do_softirq( ) function could be started. This has to be avoided, because deferrable functions must execute serially on the CPU. Thus, the first instance of _ _do_softirq( ) disables deferrable functions, so that every new instance of the function will exit at step 1 of do_softirq( ). Clears the softirq bitmap of the local CPU, so that new softirqs can be activated (the value of the bit mask has already been saved in the pending local variable in step 2). Executes local_irq_enable( ) to enable local interrupts. For each bit set in the pending local variable, it executes the corresponding softirq function; recall that the function address for the softirq with index n is stored in softirq_vec[n]->action. Executes local_irq_disable() to disable local interrupts. Copies the softirq bit mask of the local CPU into the pending local variable and decreases the iteration counter one more time. If pending is not zeroat least one softirq has been activated since the start of the last iterationand the iteration counter is still positive, it jumps back to step 4. If there are more pending softirqs, it invokes wakeup_softirqd( ) to wake up the kernel thread that takes care of the softirqs for the local CPU (see next section). Subtracts 1 from the softirq counter, thus reenabling the deferrable functions.
4.7.1.5. The ksoftirqd kernel threads
In recent kernel versions, each CPU has its own ksoftirqd/n kernel thread (where n is the logical number of the CPU). Each ksoftirqd/n kernel thread runs the ksoftirqd( ) function, which essentially executes the following loop:
for(;;) {
set_current_state(TASK_INTERRUPTIBLE );
schedule( );
/* now in TASK_RUNNING state */
while (local_softirq_pending( )) {
preempt_disable();
do_softirq( );
preempt_enable();
cond_resched( );
}
}
When awakened, the kernel thread checks the local_softirq_pending() softirq bit mask and invokes, if necessary, do_softirq( ). If there are no softirqs pending, the function puts the current process in the TASK_INTERRUPTIBLE state and invokes then the cond_resched() function to perform a process switch if required by the current process (flag TIF_NEED_RESCHED of the current thread_info set).
The ksoftirqd/n kernel threads represent a solution for a critical trade-off problem.
Softirq functions may reactivate themselves; in fact, both the networking softirqs and the tasklet softirqs do this. Moreover, external events, such as packet flooding on a network card, may activate softirqs at very high frequency.
The potential for a continuous high-volume flow of softirqs creates a problem that is solved by introducing kernel threads. Without them, developers are essentially faced with two alternative strategies.
The first strategy consists of ignoring new softirqs that occur while do_softirq( ) is running. In other words, the do_softirq( ) function could determine what softirqs are pending when the function is started and then execute their functions. Next, it would terminate without rechecking the pending softirqs. This solution is not good enough. Suppose that a softirq function is reactivated during the execution of do_softirq( ). In the worst case, the softirq is not executed again until the next timer interrupt, even if the machine is idle. As a result, softirq latency time is unacceptable for networking developers.
The second strategy consists of continuously rechecking for pending softirqs. The do_softirq( ) function could keep checking the pending softirqs and would terminate only when none of them is pending. While this solution might satisfy networking developers, it can certainly upset normal users of the system: if a high-frequency flow of packets is received by a network card or a softirq function keeps activating itself, the do_softirq( ) function never returns, and the User Mode programs are virtually stopped.
The ksoftirqd/n kernel threads try to solve this difficult trade-off problem. The do_softirq( ) function determines what softirqs are pending and executes their functions. After a few iterations, if the flow of softirqs does not stop, the function wakes up the kernel thread and terminates (step 10 of _ _do_softirq( )). The kernel thread has low priority, so user programs have a chance to run; but if the machine is idle, the pending softirqs are executed quickly.
4.7.2. Tasklets
Tasklets are the preferred way to implement deferrable functions in I/O drivers. As already explained, tasklets
are built on top of two softirqs named HI_SOFTIRQ and TASKLET_SOFTIRQ. Several tasklets may be associated with the same softirq, each tasklet carrying its own function. There is no real difference between the two softirqs, except that do_softirq( ) executes HI_SOFTIRQ's tasklets before TASKLET_SOFTIRQ's tasklets.
Tasklets and high-priority tasklets are stored in the tasklet_vec and tasklet_hi_vec arrays, respectively. Both of them include NR_CPUS elements of type tasklet_head, and each element consists of a pointer to a list of tasklet descriptors. The tasklet descriptor is a data structure of type tasklet_struct, whose fields are shown in Table 4-11.
Table 4-11. The fields of the tasklet descriptorField name | Description |
|---|
next | Pointer to next descriptor in the list | state | Status of the tasklet | count | Lock counter | func | Pointer to the tasklet function | data | An unsigned long integer that may be used by the tasklet function |
The state field of the tasklet descriptor includes two flags:
TASKLET_STATE_SCHED When set, this indicates that the tasklet is pending (has been scheduled for execution); it also means that the tasklet descriptor is inserted in one of the lists of the tasklet_vec and tasklet_hi_vec arrays.
TASKLET_STATE_RUN When set, this indicates that the tasklet is being executed; on a uniprocessor system this flag is not used because there is no need to check whether a specific tasklet is running.
Let's suppose you're writing a device driver and you want to use a tasklet: what has to be done? First of all, you should allocate a new tasklet_struct data structure and initialize it by invoking tasklet_init( ); this function receives as its parameters the address of the tasklet descriptor, the address of your tasklet function, and its optional integer argument.
The tasklet may be selectively disabled by invoking either tasklet_disable_nosync( ) or tasklet_disable( ). Both functions increase the count field of the tasklet descriptor, but the latter function does not return until an already running instance of the tasklet function has terminated. To reenable the tasklet, use tasklet_enable( ).
To activate the tasklet, you should invoke either the tasklet_schedule( ) function or the tasklet_hi_schedule( ) function, according to the priority that you require for the tasklet. The two functions are very similar; each of them performs the following actions:
Checks the TASKLET_STATE_SCHED flag; if it is set, returns (the tasklet has already been scheduled). Invokes local_irq_save to save the state of the IF flag and to disable local interrupts. Adds the tasklet descriptor at the beginning of the list pointed to by tasklet_vec[n] or tasklet_hi_vec[n], where n denotes the logical number of the local CPU. Invokes raise_softirq_irqoff( ) to activate either the TASKLET_SOFTIRQ or the HI_SOFTIRQ softirq (this function is similar to raise_softirq( ), except that it assumes that local interrupts are already disabled). Invokes local_irq_restore to restore the state of the IF flag.
Finally, let's see how the tasklet is executed. We know from the previous section that, once activated, softirq functions are executed by the do_softirq( ) function. The softirq function associated with the HI_SOFTIRQ softirq is named tasklet_hi_action( ), while the function associated with TASKLET_SOFTIRQ is named tasklet_action( ). Once again, the two functions are very similar; each of them:
Disables local interrupts. Gets the logical number n of the local CPU. Stores the address of the list pointed to by tasklet_vec[n] or tasklet_hi_vec[n] in the list local variable. Puts a NULL address in tasklet_vec[n] or tasklet_hi_vec[n], thus emptying the list of scheduled tasklet descriptors. Enables local interrupts. For each tasklet descriptor in the list pointed to by list: In multiprocessor systems, checks the TASKLET_STATE_RUN flag of the tasklet. If it is set, a tasklet of the same type is already running on another CPU, so the function reinserts the task descriptor in the list pointed to by tasklet_vec[n] or tasklet_hi_vec[n] and activates the TASKLET_SOFTIRQ or HI_SOFTIRQ softirq again. In this way, execution of the tasklet is deferred until no other tasklets of the same type are running on other CPUs. Otherwise, the tasklet is not running on another CPU: sets the flag so that the tasklet function cannot be executed on other CPUs.
Checks whether the tasklet is disabled by looking at the count field of the tasklet descriptor. If the tasklet is disabled, it clears its TASKLET_STATE_RUN flag and reinserts the task descriptor in the list pointed to by tasklet_vec[n] or tasklet_hi_vec[n]; then the function activates the TASKLET_SOFTIRQ or HI_SOFTIRQ softirq again. If the tasklet is enabled, it clears the TASKLET_STATE_SCHED flag and executes the tasklet function.
Notice that, unless the tasklet function reactivates itself, every tasklet activation triggers at most one execution of the tasklet function.
4.8. Work Queues
The work queues
have been introduced in Linux 2.6 and replace a similar construct called "task queue" used in Linux 2.4. They allow kernel functions to be activated (much like deferrable functions) and later executed by special kernel threads
called worker threads
.
Despite their similarities, deferrable functions and work queues are quite different. The main difference is that deferrable functions run in interrupt context while functions in work queues run in process context. Running in process context is the only way to execute functions that can block (for instance, functions that need to access some block of data on disk) because, as already observed in the section "
Nested Execution of Exception and Interrupt Handlers" earlier in this chapter, no process switch can take place in interrupt context. Neither deferrable functions nor functions in a work queue can access the User Mode address space of a process. In fact, a deferrable function cannot make any assumption about the process that is currently running when it is executed. On the other hand, a function in a work queue is executed by a kernel thread, so there is no User Mode address space to access.
4.8.1.
4.8.1.1. Work queue data structures
The main data structure associated with a work queue is a descriptor called workqueue_struct, which contains, among other things, an array of NR_CPUS elements, the maximum number of CPUs in the system. Each element is a descriptor of type cpu_workqueue_struct, whose fields are shown in Table 4-12.
Table 4-12. The fields of the cpu_workqueue_struct structureField name | Description |
|---|
lock | Spin lock used to protect the structure | remove_sequence | Sequence number used by flush_workqueue( ) | insert_sequence | Sequence number used by flush_workqueue( ) | worklist | Head of the list of pending functions | more_work | Wait queue where the worker thread waiting for more work to be done sleeps | work_done | Wait queue where the processes waiting for the work queue to be flushed sleep | wq | Pointer to the workqueue_struct structure containing this descriptor | tHRead | Process descriptor pointer of the worker thread of the structure | run_depth | Current execution depth of run_workqueue( ) (this field may become greater than one when a function in the work queue list blocks) |
The worklist field of the cpu_workqueue_struct structure is the head of a doubly linked list collecting the pending functions of the work queue. Every pending function is represented by a work_struct data structure, whose fields are shown in Table 4-13.
Table 4-13. The fields of the work_struct structureField name | Description |
|---|
pending | Set to 1 if the function is already in a work queue list, 0 otherwise | entry | Pointers to next and previous elements in the list of pending functions | func | Address of the pending function | data | Pointer passed as a parameter to the pending function | wq_data | Usually points to the parent cpu_workqueue_struct descriptor | timer | Software timer used to delay the execution of the pending function |
4.8.1.2. Work queue functions
The create_workqueue("foo" ) function receives as its parameter a string of characters and returns the address of a workqueue_struct descriptor for the newly created work queue. The function also creates n worker threads (where n is the number of CPUs effectively present in the system), named after the string passed to the function: foo/0, foo/1, and so on. The create_singlethread_workqueue( ) function is similar, but it creates just one worker thread, no matter what the number of CPUs in the system is. To destroy a work queue the kernel invokes the destroy_workqueue( ) function, which receives as its parameter a pointer to a workqueue_struct array.
queue_work( ) inserts a function (already packaged inside a work_struct descriptor) in a work queue; it receives a pointer wq to the workqueue_struct descriptor and a pointer work to the work_struct descriptor. queue_work( ) essentially performs the following steps:
Checks whether the function to be inserted is already present in the work queue (work->pending field equal to 1); if so, terminates. Adds the work_struct descriptor to the work queue list, and sets work->pending to 1. If a worker thread is sleeping in the more_work wait queue of the local CPU's cpu_workqueue_struct descriptor, the function wakes it up.
The queue_delayed_work( ) function is nearly identical to queue_work( ), except that it receives a third parameter representing a time delay in system ticks (see
Chapter 6). It is used to ensure a minimum delay before the execution of the pending function. In practice, queue_delayed_work( ) relies on the software timer in the timer field of the work_struct descriptor to defer the actual insertion of the work_struct descriptor in the work queue list. cancel_delayed_work( ) cancels a previously scheduled work queue function, provided that the corresponding work_struct descriptor has not already been inserted in the work queue list.
Every worker thread continuously executes a loop inside the worker_thread( ) function; most of the time the thread is sleeping and waiting for some work to be queued. Once awakened, the worker thread invokes the run_workqueue( ) function, which essentially removes every work_struct descriptor from the work queue list of the worker thread and executes the corresponding pending function. Because work queue functions can block, the worker thread can be put to sleep and even migrated to another CPU when resumed.
Sometimes the kernel has to wait until all pending functions in a work queue have been executed. The flush_workqueue( ) function receives a workqueue_struct descriptor address and blocks the calling process until all functions that are pending in the work queue terminate. The function, however, does not wait for any pending function that was added to the work queue following flush_workqueue( ) invocation; the remove_sequence and insert_sequence fields of every cpu_workqueue_struct descriptor are used to recognize the newly added pending functions.
4.8.1.3. The predefined work queue
In most cases, creating a whole set of worker threads in order to run a function is overkill. Therefore, the kernel offers a predefined work queue called events, which can be freely used by every kernel developer. The predefined work queue is nothing more than a standard work queue that may include functions of different kernel layers and I/O drivers; its workqueue_struct descriptor is stored in the keventd_wq array. To make use of the predefined work queue, the kernel offers the functions listed in Table 4-14.
Table 4-14. Helper functions for the predefined work queuePredefined work queue function | Equivalent standard work queue function |
|---|
schedule_work(w) | queue_work(keventd_wq,w) | schedule_delayed_work(w,d) | queue_delayed_work(keventd_wq,w,d) (on any CPU) | schedule_delayed_work_on(cpu,w,d) | queue_delayed_work(keventd_wq,w,d) (on a given CPU) | flush_scheduled_work( ) | flush_workqueue(keventd_wq) |
The predefined work queue saves significant system resources when the function is seldom invoked. On the other hand, functions executed in the predefined work queue should not block for a long time: because the execution of the pending functions in the work queue list is serialized on each CPU, a long delay negatively affects the other users of the predefined work queue.
In addition to the general events queue, you'll find a few specialized work queues in Linux 2.6. The most significant is the kblockd work queue used by the block device layer (see
Chapter 14).
|
4.9. Returning from Interrupts and Exceptions
We will finish the chapter by examining the termination phase
of interrupt and exception handlers. (Returning from a system call is a special case, and we shall describe it in
Chapter 10.) Although the main objective is clear namely, to resume execution of some program several issues must be considered before doing it:
Number of kernel control paths being concurrently executed If there is just one, the CPU must switch back to User Mode.
Pending process switch requests If there is any request, the kernel must perform process scheduling; otherwise, control is returned to the current process.
Pending signals If a signal is sent to the current process, it must be handled.
Single-step mode If a debugger is tracing the execution of the current process, single-step mode must be restored before switching back to User Mode.
Virtual-8086 mode If the CPU is in virtual-8086 mode, the current process is executing a legacy Real Mode program, thus it must be handled in a special way.
A few flags are used to keep track of pending process switch requests, of pending signals
, and of single step execution; they are stored in the flags field of the thread_info descriptor. The field stores other flags as well, but they are not related to returning from interrupts and exceptions. See Table 4-15 for a complete list of these flags.
Table 4-15. The flags field of the thread_info descriptor (continues)Flag name | Description |
|---|
TIF_SYSCALL_TRACE | System calls are being traced | TIF_NOTIFY_RESUME | Not used in the 80 x 86 platform | TIF_SIGPENDING | The process has pending signals | TIF_NEED_RESCHED | Scheduling must be performed | TIF_SINGLESTEP | Restore single step execution on return to User Mode | TIF_IRET | Force return from system call via iret rather than sysexit | TIF_SYSCALL_AUDIT | System calls are being audited | TIF_POLLING_NRFLAG | The idle process is polling the TIF_NEED_RESCHED flag | TIF_MEMDIE | The process is being destroyed to reclaim memory (see the section "
The Out of Memory Killer" in
Chapter 17) |
The kernel assembly language code that accomplishes all these things is not, technically speaking, a function, because control is never returned to the functions that invoke it. It is a piece of code with two different entry points: ret_from_intr( ) and ret_from_exception( ). As their names suggest, the kernel enters the former when terminating an interrupt handler, and it enters the latter when terminating an exception handler. We shall refer to the two entry points as functions, because this makes the description simpler.
The general flow diagram with the corresponding two entry points is illustrated in Figure 4-6. The gray boxes refer to assembly language instructions that implement kernel preemption (see
Chapter 5); if you want to see what the kernel does when it is compiled without support for kernel preemption, just ignore the gray boxes. The ret_from_exception( ) and ret_from_intr( ) enTRy points look quite similar in the flow diagram. A difference exists only if support for kernel preemption has been selected as a compilation option: in this case, local interrupts are immediately disabled when returning from exceptions.
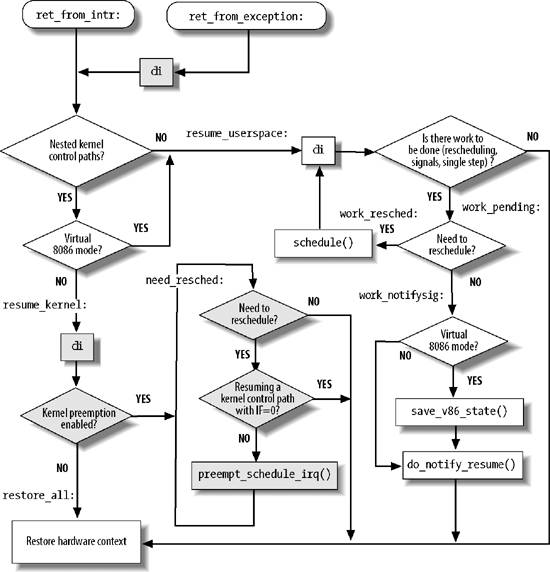
The flow diagram gives a rough idea of the steps required to resume the execution of an interrupted program. Now we will go into detail by discussing the assembly language code.
4.9.1.
4.9.1.1. The entry points
The ret_from_intr( ) and ret_from_exception( ) entry points are essentially equivalent to the following assembly language code:
ret_from_exception:
cli ; missing if kernel preemption is not supported
ret_from_intr:
movl $-8192, %ebp ; -4096 if multiple Kernel Mode stacks are used
andl %esp, %ebp
movl 0x30(%esp), %eax
movb 0x2c(%esp), %al
testl $0x00020003, %eax
jnz resume_userspace
jpm resume_kernel
Recall that when returning from an interrupt, the local interrupts are disabled (see step 3 in the earlier description of handle_IRQ_event( )); thus, the cli
assembly language instruction is executed only when returning from an exception.
The kernel loads the address of the tHRead_info descriptor of current in the ebp register (see "
Identifying a Process" in
Chapter 3).
Next, the values of the cs and eflags
registers, which were pushed on the stack when the interrupt or the exception occurred, are used to determine whether the interrupted program was running in User Mode, or if the VM flag of eflags was set. In either case, a jump is made to the resume_userspace label. Otherwise, a jump is made to the resume_kernel label.
4.9.1.2. Resuming a kernel control path
The assembly language code at the resume_kernel label is executed if the program to be resumed is running in Kernel Mode:
resume_kernel:
cli ; these three instructions are
cmpl $0, 0x14(%ebp) ; missing if kernel preemption
jz need_resched ; is not supported
restore_all:
popl %ebx
popl %ecx
popl %edx
popl %esi
popl %edi
popl %ebp
popl %eax
popl %ds
popl %es
addl $4, %esp
iret
If the preempt_count field of the tHRead_info descriptor is zero (kernel preemption enabled), the kernel jumps to the need_resched label. Otherwise, the interrupted program is to be restarted. The function loads the registers with the values saved when the interrupt or the exception started, and the function yields control by executing the iret instruction.
4.9.1.3. Checking for kernel preemption
When this code is executed, none of the unfinished kernel control paths is an interrupt handler, otherwise the preempt_count field would be greater than zero. However, as stated in "
Nested Execution of Exception and Interrupt Handlers" earlier in this chapter, there could be up to two kernel control paths associated with exceptions (beside the one that is terminating).
need_resched:
movl 0x8(%ebp), %ecx
testb $(1<<TIF_NEED_RESCHED), %cl
jz restore_all
testl $0x00000200,0x30(%esp)
jz restore_all
call preempt_schedule_irq
jmp need_resched
If the TIF_NEED_RESCHED flag in the flags field of current->thread_info is zero, no process switch is required, thus a jump is made to the restore_all label. Also a jump to the same label is made if the kernel control path that is being resumed was running with the local interrupts disabled. In this case a process switch could corrupt kernel data structures (see the section "
When Synchronization Is Necessary" in
Chapter 5 for more details).
If a process switch is required, the preempt_schedule_irq( ) function is invoked: it sets the PREEMPT_ACTIVE flag in the preempt_count field, temporarily sets the big kernel lock counter to -1 (see the section "
The Big Kernel Lock" in
Chapter 5), enables the local interrupts, and invokes schedule( ) to select another process to run. When the former process will resume, preempt_schedule_irq( ) restores the previous value of the big kernel lock counter, clears the PREEMPT_ACTIVE flag, and disables local interrupts. The schedule( ) function will continue to be invoked as long as the TIF_NEED_RESCHED flag of the current process is set.
4.9.1.4. Resuming a User Mode program
If the program to be resumed was running in User Mode, a jump is made to the resume_userspace label:
resume_userspace:
cli
movl 0x8(%ebp), %ecx
andl $0x0000ff6e, %ecx
je restore_all
jmp work_pending
After disabling the local interrupts, a check is made on the value of the flags field of current->thread_info. If no flag except TIF_SYSCALL_TRACE, TIF_SYSCALL_AUDIT, or TIF_SINGLESTEP is set, nothing remains to be done: a jump is made to the restore_all label, thus resuming the User Mode program.
4.9.1.5. Checking for rescheduling
The flags in the thread_info descriptor state that additional work is required before resuming the interrupted program.
work_pending:
testb $(1<<TIF_NEED_RESCHED), %cl
jz work_notifysig
work_resched:
call schedule
cli
jmp resume_userspace
If a process switch request is pending, schedule( ) is invoked to select another process to run. When the former process will resume, a jump is made back to resume_userspace.
4.9.1.6. Handling pending signals, virtual-8086 mode, and single stepping
There is other work to be done besides process switch requests:
work_notifysig:
movl %esp, %eax
testl $0x00020000, 0x30(%esp)
je 1f
work_notifysig_v86:
pushl %ecx
call save_v86_state
popl %ecx
movl %eax, %esp
1:
xorl %edx, %edx
call do_notify_resume
jmp restore_all
If the VM control flag in the eflags
register of the User Mode program is set, the save_v86_state( ) function is invoked to build up the virtual-8086 mode data structures in the User Mode address space. Then the do_notify_resume( ) function is invoked to take care of pending signals and single stepping. Finally, a jump is made to the restore_all label to resume the interrupted program.
|
|
|
|
|
|

 LINUX
LINUX 
 Books
Books

 ]
]