Управление памятью
С помощью сегментации и пэйджинга линукс производит перевод логических адресов в физические.
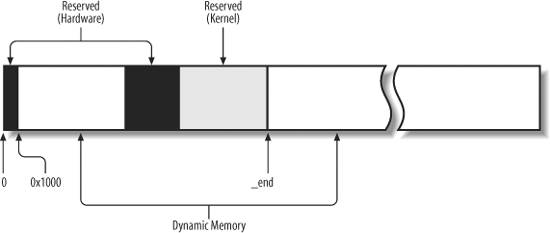
Ядро использует одну и ту же область памяти как для хранения своего кода,
так и для своих статических структур данных.
Остальная часть памяти называется динамической.
Это область памяти нужна не только для создания новых процессов,но и для самого ядра.
Производительность системы зависит от того,насколько эффективно управляется такая память.
Современные операционные системы делают все возможное,
чтобы оптимизировать ее использование.
Рисунок 8-1 показывает использование page frames.
В этой части описано,как ядро выделяет память для своих собственных нужд.
Разделы "Page Frame Management" и
"Memory Area Management"
описывают 2 различных техники для выделения непрерывных цельных кусков памяти,
в то время как секция "Noncontiguous Memory Area Management"
описывает 3-ю технику для управления несмежными областями памяти.
Будут описаны такие темы как memory zones, kernel mappings, buddy system, slab cache, memory pools.
Управление фреймами памяти
We saw in the section "Paging in Hardware" in Chapter 2 how the Intel Pentium processor can use two different page frame sizes: 4 KB and 4 MB (or 2 MB if PAE is enabledsee the section "The Physical Address Extension (PAE) Paging Mechanism" in Chapter 2). Linux adopts the smaller 4 KB page frame size as the standard memory allocation unit. This makes things simpler for two reasons:
The Page Fault
exceptions issued by the paging circuitry are easily interpreted. Either the page requested exists but the process is not allowed to address it, or the page does not exist. In the second case, the memory allocator must find a free
4 KB page frame and assign it to the process. Although both 4 KB and 4 MB are multiples of all disk block sizes, transfers of data between main memory and disks are in most cases more efficient when the smaller size is used.
8.1.1. Page Descriptors
The kernel must keep track of the current status of each page frame. For instance, it must be able to distinguish the page frames that are used to contain pages that belong to processes from those that contain kernel code or kernel data structures. Similarly, it must be able to determine whether a page frame in dynamic memory is free. A page frame in dynamic memory is free if it does not contain any useful data. It is not free when the page frame contains data of a User Mode process, data of a software cache, dynamically allocated kernel data structures, buffered data of a device driver, code of a kernel module, and so on.
State information of a page frame is kept in a page descriptor of type page, whose fields are shown in Table 8-1. All page descriptors
are stored in the mem_map array. Because each descriptor is 32 bytes long, the space required by mem_map is slightly less than 1% of the whole RAM. The virt_to_page(addr) macro yields the address of the page descriptor associated with the linear address addr. The pfn_to_page(pfn) macro yields the address of the page descriptor associated with the page frame having number pfn.
Table 8-1. The fields of the page descriptorType | Name | Description |
|---|
unsigned long | flags | Array of flags (see Table 8-2). Also encodes the zone number to which the page frame belongs. | atomic_t | _count | Page frame's reference counter. | atomic_t | _mapcount | Number of Page Table entries that refer to the page frame (-1 if none). | unsigned long | private | Available to the kernel component that is using the page (for instance, it is a buffer head pointer in case of buffer page; see "Block Buffers and Buffer Heads" in Chapter 15). If the page is free, this field is used by the buddy system (see later in this chapter). | struct address_space * | mapping | Used when the page is inserted into the page cache (see the section "The Page Cache" in Chapter 15), or when it belongs to an anonymous region (see the section "Reverse Mapping for Anonymous Pages" in Chapter 17). | unsigned long | index | Used by several kernel components with different meanings. For instance, it identifies the position of the data stored in the page frame within the page's disk image or within an anonymous region (Chapter 15), or it stores a swapped-out page identifier (Chapter 17). | struct list_head | lru | Contains pointers to the least recently used doubly linked list of pages. |
You don't have to fully understand the role of all fields in the page descriptor right now. In the following chapters, we often come back to the fields of the page descriptor. Moreover, several fields have different meaning, according to whether the page frame is free or what kernel component is using the page frame.
Let's describe in greater detail two of the fields:
_count A usage reference counter for the page. If it is set to -1, the corresponding page frame is free and can be assigned to any process or to the kernel itself. If it is set to a value greater than or equal to 0, the page frame is assigned to one or more processes or is used to store some kernel data structures. The page_count( ) function returns the value of the _count field increased by one, that is, the number of users of the page.
flags Includes up to 32 flags (see Table 8-2) that describe the status of the page frame. For each PG_xyz flag, the kernel defines some macros that manipulate its value. Usually, the PageXyz macro returns the value of the flag, while the SetPageXyz and ClearPageXyz macro set and clear the corresponding bit, respectively.
Table 8-2. Flags describing the status of a page frameFlag name | Meaning |
|---|
PG_locked | The page is locked; for instance, it is involved in a disk I/O operation. | PG_error | An I/O error occurred while transferring the page. | PG_referenced | The page has been recently accessed. | PG_uptodate | This flag is set after completing a read operation, unless a disk I/O error happened. | PG_dirty | The page has been modified (see the section "Implementing the PFRA" in Chapter 17). | PG_lru | The page is in the active or inactive page list (see the section "The Least Recently Used (LRU) Lists" in Chapter 17). | PG_active | The page is in the active page list (see the section "The Least Recently Used (LRU) Lists" in Chapter 17). | PG_slab | The page frame is included in a slab (see the section "Memory Area Management" later in this chapter). | PG_highmem | The page frame belongs to the ZONE_HIGHMEM zone (see the following section "Non-Uniform Memory Access (NUMA)"). | PG_checked | Used by some filesystems such as Ext2 and Ext3 (see Chapter 18). | PG_arch_1 | Not used on the 80 x 86 architecture. | PG_reserved | The page frame is reserved for kernel code or is unusable. | PG_private | The private field of the page descriptor stores meaningful data. | PG_writeback | The page is being written to disk by means of the writepage method (see Chapter 16) . | PG_nosave | Used for system suspend/resume. | PG_compound | The page frame is handled through the extended paging mechanism (see the section "Extended Paging" in Chapter 2). | PG_swapcache | The page belongs to the swap cache (see the section "The Swap Cache" in Chapter 17). | PG_mappedtodisk | All data in the page frame corresponds to blocks allocated on disk. | PG_reclaim | The page has been marked to be written to disk in order to reclaim memory. | PG_nosave_free | Used for system suspend/resume. |
8.1.2. Non-Uniform Memory Access (NUMA)
We are used to thinking of the computer's memory as a homogeneous, shared resource. Disregarding the role of the hardware caches, we expect the time required for a CPU to access a memory location to be essentially the same, regardless of the location's physical address and the CPU. Unfortunately, this assumption is not true in some architectures. For instance, it is not true for some multiprocessor Alpha or MIPS computers.
Linux 2.6 supports the Non-Uniform Memory Access (NUMA) model, in which the access times for different memory locations from a given CPU may vary. The physical memory of the system is partitioned in several nodes
. The time needed by a given CPU to access pages within a single node is the same. However, this time might not be the same for two different CPUs. For every CPU, the kernel tries to minimize the number of accesses to costly nodes by carefully selecting where the kernel data structures that are most often referenced by the CPU are stored.
The physical memory inside each node can be split into several zones, as we will see in the next section. Each node has a descriptor of type pg_data_t, whose fields are shown in Table 8-3. All node descriptors are stored in a singly linked list, whose first element is pointed to by the pgdat_list variable.
Table 8-3. The fields of the node descriptorType | Name | Description |
|---|
struct zone [ ] | node_zones | Array of zone descriptors of the node | struct zonelist [ ] | node_zonelists | Array of zonelist data structures used by the page allocator (see the later section "Memory Zones") | int | nr_zones | Number of zones in the node | struct page * | node_mem_map | Array of page descriptors of the node | struct bootmem_data * | bdata | Used in the kernel initialization phase | unsigned long | node_start_pfn | Index of the first page frame in the node | unsigned long | node_present_pages | Size of the memory node, excluding holes (in page frames) | unsigned long | node_spanned_pages | Size of the node, including holes (in page frames) | int | node_id | Identifier of the node | pg_data_t * | pgdat_next | Next item in the memory node list | wait_queue_head_t | kswapd_wait | Wait queue for the kswapd
pageout daemon (see the section "Periodic Reclaiming" in Chapter 17) | struct task_struct * | kswapd | Pointer to the process descriptor of the kswapd kernel thread | int | kswapd_max_order | Logarithmic size of free blocks to be created by kswapd |
As usual, we are mostly concerned with the 80 x 86 architecture. IBM-compatible PCs use the Uniform Memory Access model (UMA), thus the NUMA support is not really required. However, even if NUMA support is not compiled in the kernel, Linux makes use of a single node that includes all system physical memory. Thus, the pgdat_list variable points to a list consisting of a single elementthe node 0 descriptorstored in the contig_page_data variable.
On the 80 x 86 architecture, grouping the physical memory in a single node might appear useless; however, this approach makes the memory handling code more portable, because the kernel can assume that the physical memory is partitioned in one or more nodes in all architectures.
8.1.3. Memory Zones
In an ideal computer architecture, a page frame is a memory storage unit that can be used for anything: storing kernel and user data, buffering disk data, and so on. Every kind of page of data can be stored in a page frame, without limitations.
However, real computer architectures have hardware constraints that may limit the way page frames can be used. In particular, the Linux kernel must deal with two hardware constraints of the 80 x 86 architecture:
The Direct Memory Access (DMA) processors for old ISA buses have a strong limitation: they are able to address only the first 16 MB of RAM. In modern 32-bit computers with lots of RAM, the CPU cannot directly access all physical memory because the linear address space is too small.
To cope with these two limitations, Linux 2.6 partitions the physical memory of every memory node into three zones. In the 80 x 86 UMA architecture the zones are:
ZONE_DMA Contains page frames of memory below 16 MB
ZONE_NORMAL Contains page frames of memory at and above 16 MB and below 896 MB
ZONE_HIGHMEM Contains page frames of memory at and above 896 MB
The ZONE_DMA zone includes page frames that can be used by old ISA-based devices by means of the DMA. (The section "Direct Memory Access (DMA)" in Chapter 13 gives further details on DMA.)
The ZONE_DMA and ZONE_NORMAL zones include the "normal" page frames that can be directly accessed by the kernel through the linear mapping in the fourth gigabyte of the linear address space (see the section "Kernel Page Tables" in Chapter 2). Conversely, the ZONE_HIGHMEM zone includes page frames that cannot be directly accessed by the kernel through the linear mapping in the fourth gigabyte of linear address space (see the section "Kernel Mappings of High-Memory Page Frames" later in this chapter). The ZONE_HIGHMEM zone is always empty on 64-bit architectures.
Each memory zone has its own descriptor of type zone. Its fields are shown in Table 8-4.
Table 8-4. The fields of the zone descriptorType | Name | Description |
|---|
unsigned long | free_pages | Number of free pages in the zone. | unsigned long | pages_min | Number of reserved pages of the zone (see the section "The Pool of Reserved Page Frames" later in this chapter). | unsigned long | pages_low | Low watermark for page frame reclaiming; also used by the zone allocator as a threshold value (see the section "The Zone Allocator" later in this chapter). | unsigned long | pages_high | High watermark for page frame reclaiming; also used by the zone allocator as a threshold value. | unsigned long [] | lowmem_reserve | Specifies how many page frames in each zone must be reserved for handling low-on-memory critical situations. | struct per_cpu_pageset[] | pageset | Data structure used to implement special caches of single page frames (see the section "The Per-CPU Page Frame Cache" later in this chapter). | spinlock_t | lock | Spin lock protecting the descriptor. | struct free_area [] | free_area | Identifies the blocks of free page frames in the zone (see the section "The Buddy System Algorithm" later in this chapter). | spinlock_t | lru_lock | Spin lock for the active and inactive lists. | struct list head | active_list | List of active pages in the zone (see Chapter 17). | struct list head | inactive_list | List of inactive pages in the zone (see Chapter 17). | unsigned long | nr_scan_active | Number of active pages to be scanned when reclaiming memory (see the section "Low On Memory Reclaiming" in Chapter 17). | unsigned long | nr_scan_inactive | Number of inactive pages to be scanned when reclaiming memory. | unsigned long | nr_active | Number of pages in the zone's active list. | unsigned long | nr_inactive | Number of pages in the zone's inactive list. | unsigned long | pages_scanned | Counter used when doing page frame reclaiming in the zone. | int | all_unreclaimable | Flag set when the zone is full of unreclaimable pages. | int | temp_priority | Temporary zone's priority (used when doing page frame reclaiming). | int | prev_priority | Zone's priority ranging between 12 and 0 (used by the page frame reclaiming algorithm, see the section "Low On Memory Reclaiming" in Chapter 17). | wait_queue_head_t * | wait_table | Hash table of wait queues of processes waiting for one of the pages of the zone. | unsigned long | wait_table_size | Size of the wait queue hash table. | unsigned long | wait_table_bits | Power-of-2 order of the size of the wait queue hash table array. | struct pglist_data * | zone_pgdat | Memory node (see the earlier section "Non-Uniform Memory Access (NUMA)"). | struct page * | zone_mem_map | Pointer to first page descriptor of the zone. | unsigned long | zone_start_pfn | Index of the first page frame of the zone. | unsigned long | spanned_pages | Total size of zone in pages, including holes. | unsigned long | present_pages | Total size of zone in pages, excluding holes. | char * | name | Pointer to the conventional name of the zone: "DMA," "Normal," or "HighMem." |
Many fields of the zone structure are used for page frame reclaiming and will be described in Chapter 17.
Each page descriptor has links to the memory node and to the zone inside the node that includes the corresponding page frame. To save space, these links are not stored as classical pointers; rather, they are encoded as indices stored in the high bits of the flags field. In fact, the number of flags that characterize a page frame is limited, thus it is always possible to reserve the most significant bits of the flags field to encode the proper memory node and zone number. The page_zone( ) function receives as its parameter the address of a page descriptor; it reads the most significant bits of the flags field in the page descriptor, then it determines the address of the corresponding zone descriptor by looking in the zone_table array. This array is initialized at boot time with the addresses of all zone descriptors of all memory nodes.
When the kernel invokes a memory allocation function, it must specify the zones that contain the requested page frames. The kernel usually specifies which zones it's willing to use. For instance, if a page frame must be directly mapped in the fourth gigabyte of linear addresses but it is not going to be used for ISA DMA transfers, then the kernel requests a page frame either in ZONE_NORMAL or in ZONE_DMA. Of course, the page frame should be obtained from ZONE_DMA only if ZONE_NORMAL does not have free page frames. To specify the preferred zones in a memory allocation request, the kernel uses the zonelist data structure, which is an array of zone descriptor pointers.
8.1.4. The Pool of Reserved Page Frames
Memory allocation requests can be satisfied in two different ways. If enough free memory is available, the request can be satisfied immediately. Otherwise, some memory reclaiming must take place, and the kernel control path that made the request is blocked until additional memory has been freed.
However, some kernel control paths cannot be blocked while requesting memorythis happens, for instance, when handling an interrupt or when executing code inside a critical region. In these cases, a kernel control path should issue atomic memory allocation requests (using the GFP_ATOMIC flag; see the later section "The Zoned Page Frame Allocator"). An atomic request never blocks: if there are not enough free pages, the allocation simply fails.
Although there is no way to ensure that an atomic memory allocation request never fails, the kernel tries hard to minimize the likelihood of this unfortunate event. In order to do this, the kernel reserves a pool of page frames for atomic memory allocation requests to be used only on low-on-memory conditions.
The amount of the reserved memory (in kilobytes) is stored in the min_free_kbytes variable. Its initial value is set during kernel initialization and depends on the amount of physical memory that is directly mapped in the kernel's fourth gigabyte of linear addressesthat is, it depends on the number of page frames included in the ZONE_DMA and ZONE_NORMAL memory zones:
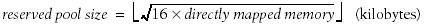
However, initially min_free_kbytes cannot be lower than 128 and greater than 65,536.
The ZONE_DMA and ZONE_NORMAL memory zones contribute to the reserved memory with a number of page frames proportional to their relative sizes. For instance, if the ZONE_NORMAL zone is eight times bigger than ZONE_DMA, seven-eighths of the page frames will be taken from ZONE_NORMAL and one-eighth from ZONE_DMA.
The pages_min field of the zone descriptor stores the number of reserved page frames inside the zone. As we'll see in Chapter 17, this field plays also a role for the page frame reclaiming algorithm, together with the pages_low and pages_high fields. The pages_low field is always set to 5/4 of the value of pages_min, and pages_high is always set to 3/2 of the value of pages_min.
8.1.5. The Zoned Page Frame Allocator
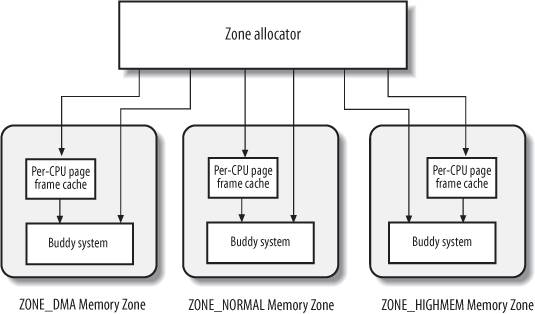
The kernel subsystem that handles the memory allocation requests for groups of contiguous page frames is called the zoned page frame allocator
. Its main components are shown in Figure 8-2.
The component named "zone allocator
" receives the requests for allocation and deallocation of dynamic memory. In the case of allocation requests, the component searches a memory zone that includes a group of contiguous page frames that can satisfy the request (see the later section "The Zone Allocator"). Inside each zone, page frames are handled by a component named "buddy system
" (see the later section "The Buddy System Algorithm"). To get better system performance, a small number of page frames are kept in cache to quickly satisfy the allocation requests for single page frames (see the later section "The Per-CPU Page Frame Cache").
8.1.5.1. Requesting and releasing page frames
Page frames can be requested by using six slightly different functions and macros. Unless otherwise stated, they return the linear address of the first allocated page or return NULL if the allocation failed.
alloc_pages(gfp_mask, order) Macro used to request 2order contiguous page frames. It returns the address of the descriptor of the first allocated page frame or returns NULL if the allocation failed.
alloc_page(gfp_mask) Macro used to get a single page frame; it expands to:
alloc_pages(gfp_mask, 0)
It returns the address of the descriptor of the allocated page frame or returns NULL if the allocation failed.
_ _get_free_pages(gfp_mask, order) Function that is similar to alloc_pages( ), but it returns the linear address of the first allocated page.
_ _get_free_page(gfp_mask) Macro used to get a single page frame; it expands to:
_ _get_free_pages(gfp_mask, 0)
get_zeroed_page(gfp_mask) Function used to obtain a page frame filled with zeros; it invokes:
alloc_pages(gfp_mask | _ _GFP_ZERO, 0)
and returns the linear address of the obtained page frame.
_ _get_dma_pages(gfp_mask, order) Macro used to get page frames suitable for DMA; it expands to:
_ _get_free_pages(gfp_mask | _ _GFP_DMA, order)
The parameter gfp_mask is a group of flags that specify how to look for free page frames. The flags that can be used in gfp_mask are shown in Table 8-5.
Table 8-5. Flag used to request page framesFlag | Description |
|---|
_ _GFP_DMA | The page frame must belong to the ZONE_DMA memory zone. Equivalent to GFP_DMA. | _ _GFP_HIGHMEM | The page frame may belong to the ZONE_HIGHMEM memory zone. | _ _GFP_WAIT | The kernel is allowed to block the current process waiting for free page frames. | _ _GFP_HIGH | The kernel is allowed to access the pool of reserved page frames. | _ _GFP_IO | The kernel is allowed to perform I/O transfers on low memory pages in order to free page frames. | _ _GFP_FS | If clear, the kernel is not allowed to perform filesystem-dependent operations. | _ _GFP_COLD | The requested page frames may be "cold" (see the later section "The Per-CPU Page Frame Cache"). | _ _GFP_NOWARN | A memory allocation failure will not produce a warning message. | _ _GFP_REPEAT | The kernel keeps retrying the memory allocation until it succeeds. | _ _GFP_NOFAIL | Same as _ _GFP_REPEAT. | _ _GFP_NORETRY | Do not retry a failed memory allocation. | _ _GFP_NO_GROW | The slab allocator does not allow a slab cache to be enlarged (see the later section "The Slab Allocator"). | _ _GFP_COMP | The page frame belongs to an extended page (see the section "Extended Paging" in Chapter 2). | _ _GFP_ZERO | The page frame returned, if any, must be filled with zeros. |
In practice, Linux uses the predefined combinations of flag values shown in Table 8-6; the group name is what you'll encounter as the argument of the six page frame allocation functions.
Table 8-6. Groups of flag values used to request page framesGroup name | Corresponding flags |
|---|
GFP_ATOMIC | _ _GFP_HIGH | GFP_NOIO | _ _GFP_WAIT | GFP_NOFS | _ _GFP_WAIT | _ _GFP_IO | GFP_KERNEL | _ _GFP_WAIT | _ _GFP_IO | _ _GFP_FS | GFP_USER | _ _GFP_WAIT | _ _GFP_IO | _ _GFP_FS | GFP_HIGHUSER | _ _GFP_WAIT | _ _GFP_IO | _ _GFP_FS | _ _GFP_HIGHMEM |
The _ _GFP_DMA and _ _GFP_HIGHMEM flags are called zone modifiers
; they specify the zones searched by the kernel while looking for free page frames. The node_zonelists field of the contig_page_data node descriptor is an array of lists of zone descriptors representing the fallback zones: for each setting of the zone modifiers, the corresponding list includes the memory zones that could be used to satisfy the memory allocation request in case the original zone is short on page frames. In the 80 x 86 UMA architecture, the fallback zones are the following:
If the _ _GFP_DMA flag is set, page frames can be taken only from the ZONE_DMA memory zone. Otherwise, if the _ _GFP_HIGHMEM flag is not set, page frames can be taken only from the ZONE_NORMAL and the ZONE_DMA memory zones, in order of preference. Otherwise (the _ _GFP_HIGHMEM flag is set), page frames can be taken from ZONE_HIGHMEM, ZONE_NORMAL, and ZONE_DMA memory zones, in order of preference.
Page frames can be released through each of the following four functions and macros:
_ _free_pages(page, order) This function checks the page descriptor pointed to by page; if the page frame is not reserved (i.e., if the PG_reserved flag is equal to 0), it decreases the count field of the descriptor. If count becomes 0, it assumes that 2order contiguous page frames starting from the one corresponding to page are no longer used. In this case, the function releases the page frames as explained in the later section "The Zone Allocator."
free_pages(addr, order) This function is similar to _ _free_pages( ), but it receives as an argument the linear address addr of the first page frame to be released.
_ _free_page(page) This macro releases the page frame having the descriptor pointed to by page; it expands to:
_ _free_pages(page, 0)
free_page(addr) This macro releases the page frame having the linear address addr; it expands to:
free_pages(addr, 0)
8.1.6. Kernel Mappings of High-Memory Page Frames
The linear address that corresponds to the end of the directly mapped physical memory, and thus to the beginning of the high memory, is stored in the high_memory variable, which is set to 896 MB. Page frames above the 896 MB boundary are not generally mapped in the fourth gigabyte of the kernel linear address spaces, so the kernel is unable to directly access them. This implies that each page allocator function that returns the linear address of the assigned page frame doesn't work for high-memory
page frames, that is, for page frames in the ZONE_HIGHMEM memory zone.
For instance, suppose that the kernel invoked _ _get_free_pages(GFP_HIGHMEM,0) to allocate a page frame in high memory. If the allocator assigned a page frame in high memory, _ _get_free_pages( ) cannot return its linear address because it doesn't exist; thus, the function returns NULL. In turn, the kernel cannot use the page frame; even worse, the page frame cannot be released because the kernel has lost track of it.
This problem does not exist on 64-bit hardware platforms, because the available linear address space is much larger than the amount of RAM that can be installedin short, the ZONE_HIGHMEM zone of these architectures is always empty. On 32-bit platforms such as the 80 x 86 architecture, however, Linux designers had to find some way to allow the kernel to exploit all the available RAM, up to the 64 GB supported by PAE. The approach adopted is the following:
The allocation of high-memory page frames is done only through the alloc_pages( ) function and its alloc_page( ) shortcut. These functions do not return the linear address of the first allocated page frame, because if the page frame belongs to the high memory, such linear address simply does not exist. Instead, the functions return the linear address of the page descriptor of the first allocated page frame. These linear addresses always exist, because all page descriptors are allocated in low memory once and forever during the kernel initialization. Page frames in high memory that do not have a linear address cannot be accessed by the kernel. Therefore, part of the last 128 MB of the kernel linear address space is dedicated to mapping high-memory page frames. Of course, this kind of mapping is temporary, otherwise only 128 MB of high memory would be accessible. Instead, by recycling linear addresses the whole high memory can be accessed, although at different times.
The kernel uses three different mechanisms to map page frames in high memory; they are called permanent kernel mapping, temporary kernel mapping, and noncontiguous memory allocation. In this section, we'll cover the first two techniques; the third one is discussed in the section "Noncontiguous Memory Area Management" later in this chapter.
Establishing a permanent kernel mapping may block the current process; this happens when no free Page Table entries exist that can be used as "windows" on the page frames in high memory. Thus, a permanent kernel mapping cannot be established in interrupt handlers and deferrable functions. Conversely, establishing a temporary kernel mapping never requires blocking the current process; its drawback, however, is that very few temporary kernel mappings can be established at the same time.
A kernel control path that uses a temporary kernel mapping must ensure that no other kernel control path is using the same mapping. This implies that the kernel control path can never block, otherwise another kernel control path might use the same window to map some other high memory page.
Of course, none of these techniques allow addressing the whole RAM simultaneously. After all, less than 128 MB of linear address space are left for mapping the high memory, while PAE supports systems having up to 64 GB of RAM.
8.1.6.1. Permanent kernel mappings
Permanent kernel mappings allow the kernel to establish long-lasting mappings of high-memory page frames into the kernel address space. They use a dedicated Page Table in the master kernel page tables
. The pkmap_page_table variable stores the address of this Page Table, while the LAST_PKMAP macro yields the number of entries. As usual, the Page Table includes either 512 or 1,024 entries, according to whether PAE is enabled or disabled (see the section "The Physical Address Extension (PAE) Paging Mechanism" in Chapter 2); thus, the kernel can access at most 2 or 4 MB of high memory at once.
The Page Table maps the linear addresses starting from PKMAP_BASE. The pkmap_count array includes LAST_PKMAP counters, one for each entry of the pkmap_page_table Page Table. We distinguish three cases:
The counter is 0 The corresponding Page Table entry does not map any high-memory page frame and is usable.
The counter is 1 The corresponding Page Table entry does not map any high-memory page frame, but it cannot be used because the corresponding TLB entry has not been flushed since its last usage.
The counter is n (greater than 1) The corresponding Page Table entry maps a high-memory page frame, which is used by exactly n - 1 kernel components.
To keep track of the association between high memory page frames and linear addresses induced by permanent kernel mappings
, the kernel makes use of the page_address_htable hash table. This table contains one page_address_map data structure for each page frame in high memory that is currently mapped. In turn, this data structure contains a pointer to the page descriptor and the linear address assigned to the page frame.
The page_address( ) function returns the linear address associated with the page frame, or NULL if the page frame is in high memory and is not mapped. This function, which receives as its parameter a page descriptor pointer page, distinguishes two cases:
If the page frame is not in high memory (PG_highmem flag clear), the linear address always exists and is obtained by computing the page frame index, converting it into a physical address, and finally deriving the linear address corresponding to the physical address. This is accomplished by the following code:
_ _va((unsigned long)(page - mem_map) << 12)
If the page frame is in high memory (PG_highmem flag set), the function looks into the page_address_htable hash table. If the page frame is found in the hash table, page_address( ) returns its linear address, otherwise it returns NULL.
The kmap( ) function establishes a permanent kernel mapping. It is essentially equivalent to the following code:
void * kmap(struct page * page)
{
if (!PageHighMem(page))
return page_address(page);
return kmap_high(page);
}
The kmap_high( ) function is invoked if the page frame really belongs to high memory. The function is essentially equivalent to the following code:
void * kmap_high(struct page * page)
{
unsigned long vaddr;
spin_lock(&kmap_lock);
vaddr = (unsigned long) page_address(page);
if (!vaddr)
vaddr = map_new_virtual(page);
pkmap_count[(vaddr-PKMAP_BASE) >> PAGE_SHIFT]++;
spin_unlock(&kmap_lock);
return (void *) vaddr;
}
The function gets the kmap_lock spin lock to protect the Page Table against concurrent accesses in multiprocessor systems. Notice that there is no need to disable the interrupts, because kmap( ) cannot be invoked by interrupt handlers and deferrable functions. Next, the kmap_high( ) function checks whether the page frame is already mapped by invoking page_address( ). If not, the function invokes map_new_virtual( ) to insert the page frame physical address into an entry of pkmap_page_table and to add an element to the page_address_htable hash table. Then kmap_high( ) increases the counter corresponding to the linear address of the page frame to take into account the new kernel component that invoked this function. Finally, kmap_high( ) releases the kmap_lock spin lock and returns the linear address that maps the page frame.
The map_new_virtual( ) function essentially executes two nested loops:
for (;;) {
int count;
DECLARE_WAITQUEUE(wait, current);
for (count = LAST_PKMAP; count > 0; --count) {
last_pkmap_nr = (last_pkmap_nr + 1) & (LAST_PKMAP - 1);
if (!last_pkmap_nr) {
flush_all_zero_pkmaps( );
count = LAST_PKMAP;
}
if (!pkmap_count[last_pkmap_nr]) {
unsigned long vaddr = PKMAP_BASE +
(last_pkmap_nr << PAGE_SHIFT);
set_pte(&(pkmap_page_table[last_pkmap_nr]),
mk_pte(page, _ _pgprot(0x63)));
pkmap_count[last_pkmap_nr] = 1;
set_page_address(page, (void *) vaddr);
return vaddr;
}
}
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue(&pkmap_map_wait, &wait);
spin_unlock(&kmap_lock);
schedule( );
remove_wait_queue(&pkmap_map_wait, &wait);
spin_lock(&kmap_lock);
if (page_address(page))
return (unsigned long) page_address(page);
}
In the inner loop, the function scans all counters in pkmap_count until it finds a null value. The large if block runs when an unused entry is found in pkmap_count. That block determines the linear address corresponding to the entry, creates an entry for it in the pkmap_page_table Page Table, sets the count to 1 because the entry is now used, invokes set_page_address( ) to insert a new element in the page_address_htable hash table, and returns the linear address.
The function starts where it left off last time, cycling through the pkmap_count array. It does this by preserving in a variable named last_pkmap_nr the index of the last used entry in the pkmap_page_table Page Table. Thus, the search starts from where it was left in the last invocation of the map_new_virtual( ) function.
When the last counter in pkmap_count is reached, the search restarts from the counter at index 0. Before continuing, however, map_new_virtual( ) invokes the flush_all_zero_pkmaps( ) function, which starts another scan of the counters, looking for those that have the value 1. Each counter that has a value of 1 denotes an entry in pkmap_page_table that is free but cannot be used because the corresponding TLB entry has not yet been flushed. flush_all_zero_pkmaps( ) resets their counters to zero, deletes the corresponding elements from the page_address_htable hash table, and issues TLB flushes on all entries of pkmap_page_table.
If the inner loop cannot find a null counter in pkmap_count, the map_new_virtual( ) function blocks the current process until some other process releases an entry of the pkmap_page_table Page Table. This is achieved by inserting current in the pkmap_map_wait wait queue, setting the current state to TASK_UNINTERRUPTIBLE, and invoking schedule( ) to relinquish the CPU. Once the process is awakened, the function checks whether another process has mapped the page by invoking page_address( ); if no other process has mapped the page yet, the inner loop is restarted.
The kunmap( ) function destroys a permanent kernel mapping established previously by kmap( ). If the page is really in the high memory zone, it invokes the kunmap_high( ) function, which is essentially equivalent to the following code:
void kunmap_high(struct page * page)
{
spin_lock(&kmap_lock);
if ((--pkmap_count[((unsigned long)page_address(page)
-PKMAP_BASE)>>PAGE_SHIFT]) == 1)
if (waitqueue_active(&pkmap_map_wait))
wake_up(&pkmap_map_wait);
spin_unlock(&kmap_lock);
}
The expression within the brackets computes the index into the pkmap_count array from the page's linear address. The counter is decreased and compared to 1. A successful comparison indicates that no process is using the page. The function can finally wake up processes in the wait queue filled by map_new_virtual( ), if any.
8.1.6.2. Temporary kernel mappings
Temporary kernel mappings are simpler to implement than permanent kernel mappings; moreover, they can be used inside interrupt handlers and deferrable functions, because requesting a temporary kernel mapping never blocks the current process.
Every page frame in high memory can be mapped through a window in the kernel address spacenamely, a Page Table entry that is reserved for this purpose. The number of windows reserved for temporary kernel mappings
is quite small.
Each CPU has its own set of 13 windows, represented by the enum km_type data structure. Each symbol defined in this data structuresuch as KM_BOUNCE_READ, KM_USER0, or KM_PTE0identifies the linear address of a window.
The kernel must ensure that the same window is never used by two kernel control paths at the same time. Thus, each symbol in the km_type structure is dedicated to one kernel component and is named after the component. The last symbol, KM_TYPE_NR, does not represent a linear address by itself, but yields the number of different windows usable by every CPU.
Each symbol in km_type, except the last one, is an index of a fix-mapped linear address (see the section "Fix-Mapped Linear Addresses" in Chapter 2). The enum fixed_addresses data structure includes the symbols FIX_KMAP_BEGIN and FIX_KMAP_END; the latter is assigned to the index FIX_KMAP_BEGIN + (KM_TYPE_NR * NR_CPUS) - 1. In this manner, there are KM_TYPE_NR fix-mapped linear addresses
for each CPU in the system. Furthermore, the kernel initializes the kmap_pte variable with the address of the Page Table entry corresponding to the fix_to_virt(FIX_KMAP_BEGIN) linear address.
To establish a temporary kernel mapping, the kernel invokes the kmap_atomic( ) function, which is essentially equivalent to the following code:
void * kmap_atomic(struct page * page, enum km_type type)
{
enum fixed_addresses idx;
unsigned long vaddr;
current_thread_info( )->preempt_count++;
if (!PageHighMem(page))
return page_address(page);
idx = type + KM_TYPE_NR * smp_processor_id( );
vaddr = fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, 0x063));
_ _flush_tlb_single(vaddr);
return (void *) vaddr;
}
The type argument and the CPU identifier retrieved through smp_processor_id( ) specify what fix-mapped linear address has to be used to map the request page. The function returns the linear address of the page frame if it doesn't belong to high memory; otherwise, it sets up the Page Table entry corresponding to the fix-mapped linear address with the page's physical address and the bits Present, Accessed, Read/Write, and Dirty. Finally, the function flushes the proper TLB entry and returns the linear address.
To destroy a temporary kernel mapping, the kernel uses the kunmap_atomic( ) function. In the 80 x 86 architecture, this function decreases the preempt_count of the current process; thus, if the kernel control path was preemptable right before requiring a temporary kernel mapping, it will be preemptable again after it has destroyed the same mapping. Moreover, kunmap_atomic( ) checks whether the TIF_NEED_RESCHED flag of current is set and, if so, invokes schedule( ).
8.1.7. The Buddy System Algorithm
The kernel must establish a robust and efficient strategy for allocating groups of contiguous page frames. In doing so, it must deal with a well-known memory management problem called external fragmentation: frequent requests and releases of groups of contiguous page frames of different sizes may lead to a situation in which several small blocks of free page frames are "scattered" inside blocks of allocated page frames. As a result, it may become impossible to allocate a large block of contiguous page frames, even if there are enough free pages to satisfy the request.
There are essentially two ways to avoid external fragmentation:
Use the paging circuitry to map groups of noncontiguous free page frames into intervals of contiguous linear addresses. Develop a suitable technique to keep track of the existing blocks of free contiguous page frames, avoiding as much as possible the need to split up a large free block to satisfy a request for a smaller one.
The second approach is preferred by the kernel for three good reasons:
In some cases, contiguous page frames are really necessary, because contiguous linear addresses are not sufficient to satisfy the request. A typical example is a memory request for buffers to be assigned to a DMA processor (see Chapter 13). Because most DMAs ignore the paging circuitry and access the address bus directly while transferring several disk sectors in a single I/O operation, the buffers requested must be located in contiguous page frames. Even if contiguous page frame allocation is not strictly necessary, it offers the big advantage of leaving the kernel paging tables unchanged. What's wrong with modifying the Page Tables? As we know from Chapter 2, frequent Page Table modifications lead to higher average memory access times, because they make the CPU flush the contents of the translation lookaside buffers. Large chunks of contiguous physical memory can be accessed by the kernel through 4 MB pages. This reduces the translation lookaside buffers misses, thus significantly speeding up the average memory access time (see the section "Translation Lookaside Buffers (TLB)" in Chapter 2).
The technique adopted by Linux to solve the external fragmentation problem is based on the well-known buddy system algorithm. All free page frames are grouped into 11 lists of blocks that contain groups of 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, and 1024 contiguous page frames, respectively. The largest request of 1024 page frames corresponds to a chunk of 4 MB of contiguous RAM. The physical address of the first page frame of a block is a multiple of the group sizefor example, the initial address of a 16-page-frame block is a multiple of 16 x 212 (212 = 4,096, which is the regular page size).
We'll show how the algorithm works through a simple example:
Assume there is a request for a group of 256 contiguous page frames (i.e., one megabyte). The algorithm checks first to see whether a free block in the 256-page-frame list exists. If there is no such block, the algorithm looks for the next larger blocka free block in the 512-page-frame list. If such a block exists, the kernel allocates 256 of the 512 page frames to satisfy the request and inserts the remaining 256 page frames into the list of free 256-page-frame blocks. If there is no free 512-page block, the kernel then looks for the next larger block (i.e., a free 1024-page-frame block). If such a block exists, it allocates 256 of the 1024 page frames to satisfy the request, inserts the first 512 of the remaining 768 page frames into the list of free 512-page-frame blocks, and inserts the last 256 page frames into the list of free 256-page-frame blocks. If the list of 1024-page-frame blocks is empty, the algorithm gives up and signals an error condition.
The reverse operation, releasing blocks of page frames, gives rise to the name of this algorithm. The kernel attempts to merge pairs of free buddy blocks of size b together into a single block of size 2b. Two blocks are considered buddies if:
Both blocks have the same size, say b. They are located in contiguous physical addresses. The physical address of the first page frame of the first block is a multiple of 2 x b x 212.
The algorithm is iterative; if it succeeds in merging released blocks, it doubles b and tries again so as to create even bigger blocks.
8.1.7.1. Data structures
Linux 2.6 uses a different buddy system for each zone. Thus, in the 80 x 86 architecture, there are 3 buddy systems: the first handles the page frames suitable for ISA DMA, the second handles the "normal" page frames, and the third handles the high-memory page frames. Each buddy system relies on the following main data structures
:
The mem_map array introduced previously. Actually, each zone is concerned with a subset of the mem_map elements. The first element in the subset and its number of elements are specified, respectively, by the zone_mem_map and size fields of the zone descriptor. An array consisting of eleven elements of type free_area, one element for each group size. The array is stored in the free_area field of the zone descriptor.
Let us consider the kth element of the free_area array in the zone descriptor, which identifies all the free blocks of size 2k. The free_list field of this element is the head of a doubly linked circular list that collects the page descriptors associated with the free blocks of 2k pages. More precisely, this list includes the page descriptors of the starting page frame of every block of 2k free page frames; the pointers to the adjacent elements in the list are stored in the lru field of the page descriptor.
Besides the head of the list, the kth element of the free_area array includes also the field nr_free, which specifies the number of free blocks of size 2k pages. Of course, if there are no blocks of 2k free page frames, nr_free is equal to 0 and the free_list list is empty (both pointers of free_list point to the free_list field itself).
Finally, the private field of the descriptor of the first page in a block of 2k free pages stores the order of the block, that is, the number k. Thanks to this field, when a block of pages is freed, the kernel can determine whether the buddy of the block is also free and, if so, it can coalesce the two blocks in a single block of 2k+1 pages. It should be noted that up to Linux 2.6.10, the kernel used 10 arrays of flags to encode this information.
8.1.7.2. Allocating a block
The _ _rmqueue( ) function is used to find a free block in a zone. The function takes two arguments: the address of the zone descriptor, and order, which denotes the logarithm of the size of the requested block of free pages (0 for a one-page block, 1 for a two-page block, and so forth). If the page frames are successfully allocated, the _ _rmqueue( ) function returns the address of the page descriptor of the first allocated page frame. Otherwise, the function returns NULL.
The _ _rmqueue( ) function assumes that the caller has already disabled local interrupts and acquired the zone->lock spin lock, which protects the data structures of the buddy system. It performs a cyclic search through each list for an available block (denoted by an entry that doesn't point to the entry itself), starting with the list for the requested order and continuing if necessary to larger orders:
struct free_area *area;
unsigned int current_order;
for (current_order=order; current_order<11; ++current_order) {
area = zone->free_area + current_order;
if (!list_empty(&area->free_list))
goto block_found;
}
return NULL;
If the loop terminates, no suitable free block has been found, so _ _rmqueue( ) returns a NULL value. Otherwise, a suitable free block has been found; in this case, the descriptor of its first page frame is removed from the list and the value of free_ pages in the zone descriptor is decreased:
block_found:
page = list_entry(area->free_list.next, struct page, lru);
list_del(&page->lru);
ClearPagePrivate(page);
page->private = 0;
area->nr_free--;
zone->free_pages -= 1UL << order;
If the block found comes from a list of size curr_order greater than the requested size order, a while cycle is executed. The rationale behind these lines of codes is as follows: when it becomes necessary to use a block of 2k page frames to satisfy a request for 2h page frames (h < k), the program allocates the first 2h page frames and iteratively reassigns the last 2k - 2h page frames to the free_area lists that have indexes between h and k:
size = 1 << curr_order;
while (curr_order > order) {
area--;
curr_order--;
size >>= 1;
buddy = page + size;
/* insert buddy as first element in the list */
list_add(&buddy->lru, &area->free_list);
area->nr_free++;
buddy->private = curr_order;
SetPagePrivate(buddy);
}
return page;
Because the _ _rmqueue( ) function has found a suitable free block, it returns the address page of the page descriptor associated with the first allocated page frame.
8.1.7.3. Freeing a block
The _ _free_pages_bulk( ) function implements the buddy system strategy for freeing page frames. It uses three basic input parameters:
page The address of the descriptor of the first page frame included in the block to be released
zone The address of the zone descriptor
order The logarithmic size of the block
The function assumes that the caller has already disabled local interrupts and acquired the zone->lock spin lock, which protects the data structure of the buddy system. _ _free_pages_bulk( ) starts by declaring and initializing a few local variables:
struct page * base = zone->zone_mem_map;
unsigned long buddy_idx, page_idx = page - base;
struct page * buddy, * coalesced;
int order_size = 1 << order;
The page_idx local variable contains the index of the first page frame in the block with respect to the first page frame of the zone.
The order_size local variable is used to increase the counter of free page frames in the zone:
zone->free_pages += order_size;
The function now performs a cycle executed at most 10- order times, once for each possibility for merging a block with its buddy. The function starts with the smallest-sized block and moves up to the top size:
while (order < 10) {
buddy_idx = page_idx ^ (1 << order);
buddy = base + buddy_idx;
if (!page_is_buddy(buddy, order))
break;
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
ClearPagePrivate(buddy);
buddy->private = 0;
page_idx &= buddy_idx;
order++;
}
In the body of the loop, the function looks for the index buddy_idx of the block, which is buddy to the one having the page descriptor index page_idx. It turns out that this index can be easily computed as:
buddy_idx = page_idx ^ (1 << order);
In fact, an Exclusive OR (XOR) using the (1<<order) mask switches the value of the order-th bit of page_idx. Therefore, if the bit was previously zero, buddy_idx is equal to page_idx+ order_size; conversely, if the bit was previously one, buddy_idx is equal to page_idx - order_size.
Once the buddy block index is known, the page descriptor of the buddy block can be easily obtained as:
buddy = base + buddy_idx;
Now the function invokes page_is_buddy() to check if buddy describes the first page of a block of order_size free page frames.
int page_is_buddy(struct page *page, int order)
{
if (PagePrivate(buddy) && page->private == order &&
!PageReserved(buddy) && page_count(page) ==0)
return 1;
return 0;
}
As you see, the buddy's first page must be free ( _count field equal to -1), it must belong to the dynamic memory (PG_reserved bit clear), its private field must be meaningful (PG_private bit set), and finally the private field must store the order of the block being freed.
If all these conditions are met, the buddy block is free and the function removes the buddy block from the list of free blocks of order order, and performs one more iteration looking for buddy blocks twice as big.
If at least one of the conditions in page_is_buddy( ) is not met, the function breaks out of the cycle, because the free block obtained cannot be merged further with other free blocks. The function inserts it in the proper list and updates the private field of the first page frame with the order of the block size:
coalesced = base + page_idx;
coalesced->private = order;
SetPagePrivate(coalesced);
list_add(&coalesced->lru, &zone->free_area[order].free_list);
zone->free_area[order].nr_free++;
8.1.8. The Per-CPU Page Frame Cache
As we will see later in this chapter, the kernel often requests and releases single page frames. To boost system performance, each memory zone defines a per-CPU page frame cache. Each per-CPU cache includes some pre-allocated page frames to be used for single memory requests issued by the local CPU.
Actually, there are two caches for each memory zone and for each CPU: a hot cache
, which stores page frames whose contents are likely to be included in the CPU's hardware cache, and a cold cache
.
Taking a page frame from the hot cache is beneficial for system performance if either the kernel or a User Mode process will write into the page frame right after the allocation. In fact, every access to a memory cell of the page frame will result in a line of the hardware cache being "stolen" from another page frameunless, of course, the hardware cache already includes a line that maps the cell of the "hot" page frame just accessed.
Conversely, taking a page frame from the cold cache is convenient if the page frame is going to be filled with a DMA operation. In this case, the CPU is not involved and no line of the hardware cache will be modified. Taking the page frame from the cold cache preserves the reserve of hot page frames for the other kinds of memory allocation requests.
The main data structure implementing the per-CPU page frame cache is an array of per_cpu_pageset data structures stored in the pageset field of the memory zone descriptor. The array includes one element for each CPU; this element, in turn, consists of two per_cpu_pages descriptors, one for the hot cache and the other for the cold cache. The fields of the per_cpu_pages descriptor are listed in Table 8-7.
Table 8-7. The fields of the per_cpu_pages descriptorType | Name | Description |
|---|
int | count | Number of pages frame in the cache | int | low | Low watermark for cache replenishing | int | high | High watermark for cache depletion | int | batch | Number of page frames to be added or subtracted from the cache | struct list_head | list | List of descriptors of the page frames included in the cache |
The kernel monitors the size of the both the hot and cold caches by using two watermarks: if the number of page frames falls below the low watermark, the kernel replenishes the proper cache by allocating batch single page frames from the buddy system; otherwise, if the number of page frames rises above the high watermark, the kernel releases to the buddy system batch page frames in the cache. The values of batch, low, and high essentially depend on the number of page frames included in the memory zone.
8.1.8.1. Allocating page frames through the per-CPU page frame caches
The buffered_rmqueue( ) function allocates page frames in a given memory zone. It makes use of the per-CPU page frame caches to handle single page frame requests.
The parameters are the address of the memory zone descriptor, the order of the memory allocation request order, and the allocation flags gfp_flags. If the _ _GFP_COLD flag is set in gfp_flags, the page frame should be taken from the cold cache, otherwise it should be taken from the hot cache (this flag is meaningful only for single page frame requests). The function essentially executes the following operations:
If order is not equal to 0, the per-CPU page frame cache cannot be used: the function jumps to step 4. Checks whether the memory zone's local per-CPU cache identified by the value of the _ _GFP_COLD flag has to be replenished (the count field of the per_cpu_pages descriptor is lower than or equal to the low field). In this case, it executes the following substeps: Allocates batch single page frames from the buddy system by repeatedly invoking the _ _rmqueue( ) function. Inserts the descriptors of the allocated page frames in the cache's list. Updates the value of count by adding the number of page frames actually allocated.
If count is positive, the function gets a page frame from the cache's list, decreases count, and jumps to step 5. (Observe that a per-CPU page frame cache could be empty; this happens when the _ _rmqueue( ) function invoked in step 2a fails to allocate any page frames.) Here, the memory request has not yet been satisfied, either because the request spans several contiguous page frames, or because the selected page frame cache is empty. Invokes the _ _rmqueue( ) function to allocate the requested page frames from the buddy system. If the memory request has been satisfied, the function initializes the page descriptor of the (first) page frame: clears some flags, sets the private field to zero, and sets the page frame reference counter to one. Moreover, if the _ _GPF_ZERO flag in gfp_flags is set, it fills the allocated memory area with zeros. Returns the page descriptor address of the (first) page frame, or NULL if the memory allocation request failed.
8.1.8.2. Releasing page frames to the per-CPU page frame caches
In order to release a single page frame to a per-CPU page frame cache, the kernel makes use of the free_hot_page( ) and free_cold_page( ) functions. Both of them are simple wrappers for the free_hot_cold_page( ) function, which receives as its parameters the descriptor address page of the page frame to be released and a cold flag specifying either the hot cache or the cold cache.
The free_hot_cold_page( ) function executes the following operations:
Gets from the page->flags field the address of the memory zone descriptor including the page frame (see the earlier section "Non-Uniform Memory Access (NUMA)"). Gets the address of the per_cpu_pages descriptor of the zone's cache selected by the cold flag. Checks whether the cache should be depleted: if count is higher than or equal to high, invokes the free_pages_bulk( ) function, passing to it the zone descriptor, the number of page frames to be released (batch field), the address of the cache's list, and the number zero (for 0-order page frames). In turn, the latter function invokes repeatedly the _ _free_pages_bulk( ) function to releases the specified number of page framestaken from the cache's listto the buddy system of the memory zone. Adds the page frame to be released to the cache's list, and increases the count field.
It should be noted that in the current version of the Linux 2.6 kernel, no page frame is ever released to the cold cache: the kernel always assumes the freed page frame is hot with respect to the hardware cache. Of course, this does not mean that the cold cache is empty: the cache is replenished by buffered_rmqueue( ) when the low watermark has been reached.
8.1.9. The Zone Allocator
The zone allocator
is the frontend of the kernel page frame allocator. This component must locate a memory zone that includes a number of free page frames large enough to satisfy the memory request. This task is not as simple as it could appear at a first glance, because the zone allocator must satisfy several goals:
It should protect the pool of reserved page frames (see the earlier section "The Pool of Reserved Page Frames"). It should trigger the page frame reclaiming algorithm (see Chapter 17) when memory is scarce and blocking the current process is allowed; once some page frames have been freed, the zone allocator will retry the allocation. It should preserve the small, precious ZONE_DMA memory zone, if possible. For instance, the zone allocator should be somewhat reluctant to assign page frames in the ZONE_DMA memory zone if the request was for ZONE_NORMAL or ZONE_HIGHMEM page frames.
We have seen in the earlier section "The Zoned Page Frame Allocator" that every request for a group of contiguous page frames is eventually handled by executing the alloc_pages macro. This macro, in turn, ends up invoking the _ _alloc_pages( ) function, which is the core of the zone allocator. It receives three parameters:
gfp_mask The flags specified in the memory allocation request (see earlier Table 8-5)
order The logarithmic size of the group of contiguous page frames to be allocated
zonelist Pointer to a zonelist data structure describing, in order of preference, the memory zones suitable for the memory allocation
The _ _alloc_pages( ) function scans every memory zone included in the zonelist data structure. The code that does this looks like the following:
for (i = 0; (z=zonelist->zones[i]) != NULL; i++) {
if (zone_watermark_ok(z, order, ...)) {
page = buffered_rmqueue(z, order, gfp_mask);
if (page)
return page;
}
}
For each memory zone, the function compares the number of free page frames with a threshold value that depends on the memory allocation flags, on the type of current process, and on how many times the zone has already been checked by the function. In fact, if free memory is scarce, every memory zone is typically scanned several times, each time with lower threshold on the minimal amount of free memory required for the allocation. The previous block of code is thus replicated several timeswith minor variationsin the body of the _ _alloc_pages( ) function. The buffered_rmqueue( ) function has been described already in the earlier section "The Per-CPU Page Frame Cache:" it returns the page descriptor of the first allocated page frame, or NULL if the memory zone does not include a group of contiguous page frames of the requested size.
The zone_watermark_ok( ) auxiliary function receives several parameters, which determine a threshold min on the number of free page frames in the memory zone. In particular, the function returns the value 1 if the following two conditions are met:
Besides the page frames to be allocated, there are at least min free page frames in the memory zone, not including the page frames in the low-on-memory reserve (lowmem_reserve field of the zone descriptor). Besides the page frames to be allocated, there are at least 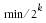 free page frames in blocks of order at least k, for each k between 1 and the order of the allocation. Therefore, if order is greater than zero, there must be at least min/2 free page frames in blocks of size at least 2; if order is greater than one, there must be at least min/4 free page frames in blocks of size at least 4; and so on. free page frames in blocks of order at least k, for each k between 1 and the order of the allocation. Therefore, if order is greater than zero, there must be at least min/2 free page frames in blocks of size at least 2; if order is greater than one, there must be at least min/4 free page frames in blocks of size at least 4; and so on.
The value of the threshold min is determined by zone_watermark_ok( ) as follows:
The base value is passed as a parameter of the function and can be one of the pages_min, pages_low, and pages_high zone's watermarks (see the section "The Pool of Reserved Page Frames" earlier in this chapter). The base value is divided by two if the gfp_high flag passed as parameter is set. Usually, this flag is equal to one if the _ _GFP_HIGHMEM flag is set in the gfp_mask, that is, if the page frames can be allocated from high memory. The threshold value is further reduced by one-fourth if the can_try_harder flag passed as parameter is set. This flag is usually equal to one if either the _ _GFP_WAIT flag is set in gfp_mask, or if the current process is a real-time process and the memory allocation is done in process context (outside of interrupt handlers and deferrable functions).
The _ _alloc_pages( ) function essentially executes the following steps:
Performs a first scanning of the memory zones (see the block of code shown earlier). In this first scan, the min threshold value is set to z->pages_low, where z points to the zone descriptor being analyzed (the can_try_harder and gfp_high parameters are set to zero). If the function did not terminate in the previous step, there is not much free memory left: the function awakens the kswapd
kernel threads to start reclaiming page frames asynchronously (see Chapter 17). Performs a second scanning of the memory zones, passing as base threshold the value z->pages_min. As explained previously, the actual threshold is determined also by the can_try_harder and gfp_high flags. This step is nearly identical to step 1, except that the function is using a lower threshold. If the function did not terminate in the previous step, the system is definitely low on memory. If the kernel control path that issued the memory allocation request is not an interrupt handler or a deferrable function and it is trying to reclaim page frames (either the PF_MEMALLOC flag or the PF_MEMDIE flag of current is set), the function then performs a third scanning of the memory zones, trying to allocate the page frames ignoring the low-on-memory thresholdsthat is, without invoking zone_watermark_ok( ). This is the only case where the kernel control path is allowed to deplete the low-on-memory reserve of pages specified by the lowmem_reserve field of the zone descriptor. In fact, in this case the kernel control path that issued the memory request is ultimately trying to free page frames, thus it should get what it has requested, if at all possible. If no memory zone includes enough page frames, the function returns NULL to notify the caller of the failure. Here, the invoking kernel control path is not trying to reclaim memory. If the _ _GFP_WAIT flag of gfp_mask is not set, the function returns NULL to notify the kernel control path of the memory allocation failure: in this case, there is no way to satisfy the request without blocking the current process. Here the current process can be blocked: invokes cond_resched() to check whether some other process needs the CPU. Sets the PF_MEMALLOC flag of current, to denote the fact that the process is ready to perform memory reclaiming. Invokes TRy_to_free_pages( ) to look for some page frames to be reclaimed (see the section "Low On Memory Reclaiming" in Chapter 17). The latter function may block the current process. Once that function returns, _ _alloc_pages( ) resets the PF_MEMALLOC flag of current and invokes once more cond_resched(). If the previous step has freed some page frames, the function performs yet another scanning of the memory zones equal to the one performed in step 3. If the memory allocation request cannot be satisfied, the function determines whether it should continue scanning the memory zone: if the _ _GFP_NORETRY flag is clear and either the memory allocation request spans up to eight page frames, or one of the _ _GFP_REPEAT and _ _GFP_NOFAIL flags is set, the function invokes blk_congestion_wait( ) to put the process asleep for awhile (see Chapter 14), and it jumps back to step 6. Otherwise, the function returns NULL to notify the caller that the memory allocation failed. If no page frame has been freed in step 9, the kernel is in deep trouble, because free memory is dangerously low and it was not possible to reclaim any page frame. Perhaps the time has come to take a crucial decision. If the kernel control path is allowed to perform the filesystem-dependent operations needed to kill a process (the _ _GFP_FS flag in gfp_mask is set) and the _ _GFP_NORETRY flag is clear, performs the following substeps: Scans once again the memory zones with a threshold value equal to z->pages_high.
Because the watermark used in step 11a is much higher than the watermarks used in the previous scannings, that step is likely to fail. Actually, step 11a succeeds only if another kernel control path is already killing a process to reclaim its memory. Thus, step 11a avoids that two innocent processes are killed instead of one.
8.1.9.1. Releasing a group of page frames
The zone allocator also takes care of releasing page frames; thankfully, releasing memory is a lot easier than allocating it.
All kernel macros and functions that release page framesdescribed in the earlier section "The Zoned Page Frame Allocator"rely on the _ _free_pages( ) function. It receives as its parameters the address of the page descriptor of the first page frame to be released (page), and the logarithmic size of the group of contiguous page frames to be released (order). The function executes the following steps:
Checks that the first page frame really belongs to dynamic memory (its PG_reserved flag is cleared); if not, terminates. Decreases the page->_count usage counter; if it is still greater than or equal to zero, terminates. If order is equal to zero, the function invokes free_hot_page( ) to release the page frame to the per-CPU hot cache of the proper memory zone (see the earlier section "The Per-CPU Page Frame Cache"). If order is greater than zero, it adds the page frames in a local list and invokes the free_pages_bulk( ) function to release them to the buddy system of the proper memory zone (see step 3 in the description of free_hot_cold_page( ) in the earlier section "The Per-CPU Page Frame Cache").
|
8.2. Memory Area Management
This section deals with memory areas
that is, with sequences of memory cells having contiguous physical addresses and an arbitrary length.
The buddy system algorithm adopts the page frame as the basic memory area. This is fine for dealing with relatively large memory requests, but how are we going to deal with requests for small memory areas, say a few tens or hundreds of bytes?
Clearly, it would be quite wasteful to allocate a full page frame to store a few bytes. A better approach instead consists of introducing new data structures that describe how small memory areas are allocated within the same page frame. In doing so, we introduce a new problem called internal fragmentation. It is caused by a mismatch between the size of the memory request and the size of the memory area allocated to satisfy the request.
A classical solution (adopted by early Linux versions) consists of providing memory areas whose sizes are geometrically distributed; in other words, the size depends on a power of 2 rather than on the size of the data to be stored. In this way, no matter what the memory request size is, we can ensure that the internal fragmentation is always smaller than 50 percent. Following this approach, the kernel creates 13 geometrically distributed lists of free memory areas whose sizes range from 32 to 131, 072 bytes. The buddy system is invoked both to obtain additional page frames needed to store new memory areas and, conversely, to release page frames that no longer contain memory areas. A dynamic list is used to keep track of the free memory areas contained in each page frame.
8.2.1. The Slab Allocator
Running a memory area allocation algorithm on top of the buddy algorithm is not particularly efficient. A better algorithm is derived from the slab allocator
schema that was adopted for the first time in the Sun Microsystems Solaris
2.4 operating system. It is based on the following premises:
The type of data to be stored may affect how memory areas are allocated; for instance, when allocating a page frame to a User Mode process, the kernel invokes the get_zeroed_page( ) function, which fills the page with zeros. The concept of a slab allocator expands upon this idea and views the memory areas as objects consisting of both a set of data structures and a couple of functions or methods called the constructor and destructor. The former initializes the memory area while the latter deinitializes it. To avoid initializing objects repeatedly, the slab allocator does not discard the objects that have been allocated and then released but instead saves them in memory. When a new object is then requested, it can be taken from memory without having to be reinitialized. The kernel functions tend to request memory areas of the same type repeatedly. For instance, whenever the kernel creates a new process, it allocates memory areas for some fixed size tables such as the process descriptor, the open file object, and so on (see Chapter 3). When a process terminates, the memory areas used to contain these tables can be reused. Because processes are created and destroyed quite frequently, without the slab allocator, the kernel wastes time allocating and deallocating the page frames containing the same memory areas repeatedly; the slab allocator allows them to be saved in a cache and reused quickly. Requests for memory areas can be classified according to their frequency. Requests of a particular size that are expected to occur frequently can be handled most efficiently by creating a set of special-purpose objects that have the right size, thus avoiding internal fragmentation. Meanwhile, sizes that are rarely encountered can be handled through an allocation scheme based on objects in a series of geometrically distributed sizes (such as the power-of-2 sizes used in early Linux versions), even if this approach leads to internal fragmentation. There is another subtle bonus in introducing objects whose sizes are not geometrically distributed: the initial addresses of the data structures are less prone to be concentrated on physical addresses whose values are a power of 2. This, in turn, leads to better performance by the processor hardware cache. Hardware cache performance creates an additional reason for limiting calls to the buddy system allocator as much as possible. Every call to a buddy system function "dirties" the hardware cache, thus increasing the average memory access time. The impact of a kernel function on the hardware cache is called the function footprint; it is defined as the percentage of cache overwritten by the function when it terminates. Clearly, large footprints lead to a slower execution of the code executed right after the kernel function, because the hardware cache is by now filled with useless information.
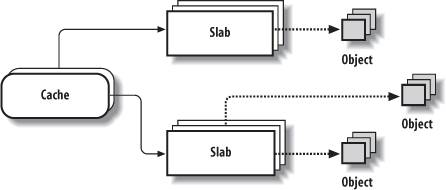
The slab allocator groups objects into caches
. Each cache is a "store" of objects of the same type. For instance, when a file is opened, the memory area needed to store the corresponding "open file" object is taken from a slab allocator cache named filp (for "file pointer").
The area of main memory that contains a cache is divided into slabs
; each slab consists of one or more contiguous page frames that contain both allocated and free objects (see Figure 8-3).
As we'll see in Chapter 17, the kernel periodically scans the caches and releases the page frames corresponding to empty slabs.
8.2.2. Cache Descriptor
Each cache is described by a structure of type kmem_cache_t (which is equivalent to the type struct kmem_cache_s), whose fields are listed in Table 8-8. We omitted from the table several fields used for collecting statistical information and for debugging.
Table 8-8. The fields of the kmem_cache_t descriptorType | Name | Description |
|---|
struct array_cache * [] | array | Per-CPU array of pointers to local caches of free objects (see the section "Local Caches of Free Slab Objects" later in this chapter). | unsigned int | batchcount | Number of objects to be transferred in bulk to or from the local caches. | unsigned int | limit | Maximum number of free objects in the local caches. This is tunable. | struct kmem_list3 | lists | See next table. | unsigned int | objsize | Size of the objects included in the cache. | unsigned int | flags | Set of flags that describes permanent properties of the cache. | unsigned int | num | Number of objects packed into a single slab. (All slabs of the cache have the same size.) | unsigned int | free_limit | Upper limit of free objects in the whole slab cache. | spinlock_t | spinlock | Cache spin lock. | unsigned int | gfporder | Logarithm of the number of contiguous page frames included in a single slab. | unsigned int | gfpflags | Set of flags passed to the buddy system function when allocating page frames. | size_t | colour | Number of colors for the slabs (see the section "Slab Coloring" later in this chapter). | unsigned int | colour_off | Basic alignment offset in the slabs. | unsigned int | colour_next | Color to use for the next allocated slab. | kmem_cache_t * | slabp_cache | Pointer to the general slab cache containing the slab descriptors (NULL if internal slab descriptors are used; see next section). | unsigned int | slab_size | The size of a single slab. | unsigned int | dflags | Set of flags that describe dynamic properties of the cache. | void * | ctor | Pointer to constructor method associated with the cache. | void * | dtor | Pointer to destructor method associated with the cache. | const char * | name | Character array storing the name of the cache. | struct list_head | next | Pointers for the doubly linked list of cache descriptors. |
The lists field of the kmem_cache_t descriptor, in turn, is a structure whose fields are listed in Table 8-9.
Table 8-9. The fields of the kmem_list3 structureType | Name | Description |
|---|
struct list_head | slabs_partial | Doubly linked circular list of slab descriptors with both free and nonfree objects | struct list_head | slabs_full | Doubly linked circular list of slab descriptors with no free objects | struct list_head | slabs_free | Doubly linked circular list of slab descriptors with free objects only | unsigned long | free_objects | Number of free objects in the cache | int | free_touched | Used by the slab allocator's page reclaiming algorithm (see Chapter 17) | unsigned long | next_reap | Used by the slab allocator's page reclaiming algorithm (see Chapter 17) | struct array_cache * | shared | Pointer to a local cache shared by all CPUs (see the later section "Local Caches of Free Slab Objects") |
8.2.3. Slab Descriptor
Each slab of a cache has its own descriptor of type slab illustrated in Table 8-10.
Table 8-10. The fields of the slab descriptorType | Name | Description |
|---|
struct list_head | list | Pointers for one of the three doubly linked list of slab descriptors
(either the slabs_full, slabs_partial, or slabs_free list in the kmem_list3 structure of the cache descriptor) | unsigned long | colouroff | Offset of the first object in the slab (see the section "Slab Coloring" later in this chapter) | void * | s_mem | Address of first object (either allocated or free) in the slab | unsigned int | inuse | Number of objects in the slab that are currently used (not free) | unsigned int | free | Index of next free object in the slab, or BUFCTL_END if there are no free objects left (see the section "Object Descriptor" later in this chapter) |
Slab descriptors can be stored in two possible places:
External slab descriptor Stored outside the slab, in one of the general caches
not suitable for ISA DMA pointed to by cache_sizes (see the next section).
Internal slab descriptor Stored inside the slab, at the beginning of the first page frame assigned to the slab.
The slab allocator chooses the second solution when the size of the objects is smaller than 512MB or when internal
fragmentation leaves enough space for the slab descriptor and the object descriptors (as described later)inside the slab. The CFLGS_OFF_SLAB flag in the flags field of the cache descriptor is set to one if the slab descriptor is stored outside the slab; it is set to zero otherwise.
Figure 8-4 illustrates the major relationships between cache and slab descriptors. Full slabs, partially full slabs, and free slabs are linked in different lists.
8.2.4. General and Specific Caches
Caches are divided into two types: general and specific. General caches are used only by the slab allocator for its own purposes, while specific caches
are used by the remaining parts of the kernel.
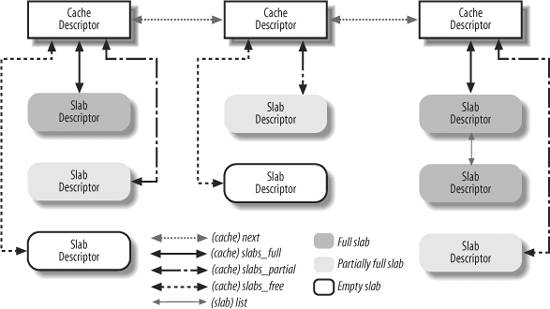
The general caches are:
A first cache called kmem_cache whose objects are the cache descriptors of the remaining caches used by the kernel. The cache_cache variable contains the descriptor of this special cache. Several additional caches contain general purpose memory areas. The range of the memory area sizes typically includes 13 geometrically distributed sizes. A table called malloc_sizes (whose elements are of type cache_sizes) points to 26 cache descriptors associated with memory areas of size 32, 64, 128, 256, 512, 1,024, 2,048, 4,096, 8,192, 16,384, 32,768, 65,536, and 131,072 bytes. For each size, there are two caches: one suitable for ISA DMA allocations and the other for normal allocations.
The kmem_cache_init( ) function is invoked during system initialization to set up the general caches.
Specific caches are created by the kmem_cache_create( ) function. Depending on the parameters, the function first determines the best way to handle the new cache (for instance, whether to include the slab descriptor inside or outside of the slab). It then allocates a cache descriptor for the new cache from the cache_cache general cache and inserts the descriptor in the cache_chain list of cache descriptors (the insertion is done after having acquired the cache_chain_sem semaphore that protects the list from concurrent accesses).
It is also possible to destroy a cache and remove it from the cache_chain list by invoking kmem_cache_destroy( ). This function is mostly useful to modules that create their own caches when loaded and destroy them when unloaded. To avoid wasting memory space, the kernel must destroy all slabs before destroying the cache itself. The kmem_cache_shrink( ) function destroys all the slabs in a cache by invoking slab_destroy( ) iteratively (see the later section "Releasing a Slab from a Cache").
The names of all general and specific caches can be obtained at runtime by reading /proc/slabinfo; this file also specifies the number of free objects and the number of allocated objects in each cache.
8.2.5. Interfacing the Slab Allocator with the Zoned Page Frame Allocator
When the slab allocator creates a new slab, it relies on the zoned page frame allocator to obtain a group of free contiguous page frames. For this purpose, it invokes the kmem_getpages( ) function, which is essentially equivalent, on a UMA system, to the following code fragment:
void * kmem_getpages(kmem_cache_t *cachep, int flags)
{
struct page *page;
int i;
flags |= cachep->gfpflags;
page = alloc_pages(flags, cachep->gfporder);
if (!page)
return NULL;
i = (1 << cache->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
while (i--)
SetPageSlab(page++);
return page_address(page);
}
The two parameters have the following meaning:
cachep Points to the cache descriptor of the cache that needs additional page frames (the number of required page frames is determined by the order in the cachep->gfporder field).
flags Specifies how the page frame is requested (see the section "The Zoned Page Frame Allocator" earlier in this chapter). This set of flags is combined with the specific cache allocation flags stored in the gfpflags field of the cache descriptor.
The size of the memory allocation request is specified by the gfporder field of the cache descriptor, which encodes the size of a slab in the cache. If the slab cache has been created with the SLAB_RECLAIM_ACCOUNT flag set, the page frames assigned to the slabs are accounted for as reclaimable pages when the kernel checks whether there is enough memory to satisfy some User Mode requests. The function also sets the PG_slab flag in the page descriptors of the allocated page frames.
In the reverse operation, page frames assigned to a slab can be released (see the section "Releasing a Slab from a Cache" later in this chapter) by invoking the kmem_freepages( ) function:
void kmem_freepages(kmem_cache_t *cachep, void *addr)
{
unsigned long i = (1<<cachep->gfporder);
struct page *page = virt_to_page(addr);
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += i;
while (i--)
ClearPageSlab(page++);
free_pages((unsigned long) addr, cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_sub(1<<cachep->gfporder, &slab_reclaim_pages);
}
The function releases the page frames, starting from the one having the linear address addr, that had been allocated to the slab of the cache identified by cachep. If the current process is performing memory reclaiming (current->reclaim_state field not NULL), the reclaimed_slab field of the reclaim_state structure is properly increased, so that the pages just freed can be accounted for by the page frame reclaiming algorithm (see the section "Low On Memory Reclaiming" in Chapter 17). Moreover, if the SLAB_RECLAIM_ACCOUNT flag is set (see above), the slab_reclaim_pages variable is properly decreased.
8.2.6. Allocating a Slab to a Cache
A newly created cache does not contain a slab and therefore does not contain any free objects. New slabs are assigned to a cache only when both of the following are true:
Under these circumstances, the slab allocator assigns a new slab to the cache by invoking cache_grow( ). This function calls kmem_ getpages( ) to obtain from the zoned page frame allocator the group of page frames needed to store a single slab; it then calls alloc_slabmgmt( ) to get a new slab descriptor. If the CFLGS_OFF_SLAB flag of the cache descriptor is set, the slab descriptor is allocated from the general cache pointed to by the slabp_cache field of the cache descriptor; otherwise, the slab descriptor is allocated in the first page frame of the slab.
The kernel must be able to determine, given a page frame, whether it is used by the slab allocator and, if so, to derive quickly the addresses of the corresponding cache and slab descriptors. Therefore, cache_ grow( ) scans all page descriptors of the page frames assigned to the new slab, and loads the next and prev subfields of the lru fields in the page descriptors with the addresses of, respectively, the cache descriptor and the slab descriptor. This works correctly because the lru field is used by functions of the buddy system only when the page frame is free, while page frames handled by the slab allocator functions have the PG_slab flag set and are not free as far as the buddy system is concerned. The opposite questiongiven a slab in a cache, which are the page frames that implement it?can be answered by using the s_mem field of the slab descriptor and the gfporder field (the size of a slab) of the cache descriptor.
Next, cache_grow( ) calls cache_init_objs( ), which applies the constructor method (if defined) to all the objects contained in the new slab.
Finally, cache_ grow( ) calls list_add_tail( ) to add the newly obtained slab descriptor *slabp at the end of the fully free slab list of the cache descriptor *cachep, and updates the counter of free objects in the cache:
list_add_tail(&slabp->list, &cachep->lists->slabs_free);
cachep->lists->free_objects += cachep->num;
8.2.7. Releasing a Slab from a Cache
Slabs can be destroyed in two cases:
There are too many free objects in the slab cache (see the later section "Releasing a Slab from a Cache"). A timer function invoked periodically determines that there are fully unused slabs that can be released (see Chapter 17).
In both cases, the slab_destroy( ) function is invoked to destroy a slab and release the corresponding page frames to the zoned page frame allocator:
void slab_destroy(kmem_cache_t *cachep, slab_t *slabp)
{
if (cachep->dtor) {
int i;
for (i = 0; i < cachep->num; i++) {
void* objp = slabp->s_mem+cachep->objsize*i;
(cachep->dtor)(objp, cachep, 0);
}
}
kmem_freepages(cachep, slabp->s_mem - slabp->colouroff);
if (cachep->flags & CFLGS_OFF_SLAB)
kmem_cache_free(cachep->slabp_cache, slabp);
}
The function checks whether the cache has a destructor method for its objects (the dtor field is not NULL), in which case it applies the destructor to all the objects in the slab; the objp local variable keeps track of the currently examined object. Next, it calls kmem_freepages( ), which returns all the contiguous page frames used by the slab to the buddy system. Finally, if the slab descriptor is stored outside of the slab, the function releases it from the cache of slab descriptors
.
Actually, the function is slightly more complicated. For example, a slab cache can be created with the SLAB_DESTROY_BY_RCU flag, which means that slabs should be released in a deferred way by registering a callback with the call_rcu( ) function (see the section "Read-Copy Update (RCU)" in Chapter 5). The callback function, in turn, invokes kmem_freepages() and, possibly, the kmem_cache_free(), as in the main case shown above.
8.2.8. Object Descriptor
Each object has a short descriptor of type kmem_bufctl_t. Object descriptors are stored in an array placed right after the corresponding slab descriptor. Thus, like the slab descriptors themselves, the object descriptors of a slab can be stored in two possible ways that are illustrated in Figure 8-5.
External object descriptors Stored outside the slab, in the general cache pointed to by the slabp_cache field of the cache descriptor. The size of the memory area, and thus the particular general cache used to store object descriptors, depends on the number of objects stored in the slab (num field of the cache descriptor).
Internal object descriptors Stored inside the slab, right before the objects they describe.
The first object descriptor in the array describes the first object in the slab, and so on. An object descriptor is simply an unsigned short integer, which is meaningful only when the object is free. It contains the index of the next free object in the slab, thus implementing a simple list of free objects inside the slab. The object descriptor of the last element in the free object list is marked by the conventional value BUFCTL_END (0xffff).
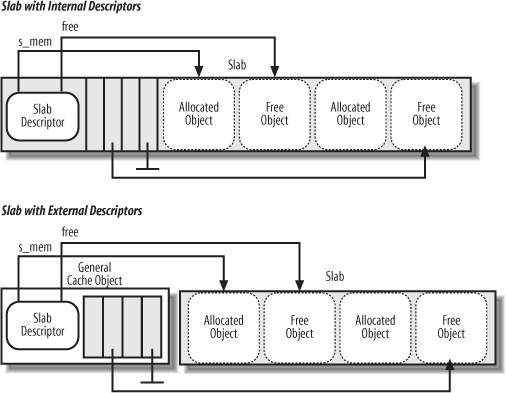
8.2.9. Aligning Objects in Memory
The objects managed by the slab allocator are aligned in memorythat is, they are stored in memory cells whose initial physical addresses are multiples of a given constant, which is usually a power of 2. This constant is called the alignment factor.
The largest alignment factor allowed by the slab allocator is 4,096the page frame size. This means that objects can be aligned by referring to either their physical addresses or their linear addresses. In both cases, only the 12 least significant bits of the address may be altered by the alignment.
Usually, microcomputers access memory cells more quickly if their physical addresses are aligned with respect to the word size (that is, to the width of the internal memory bus of the computer). Thus, by default, the kmem_cache_create( ) function aligns objects according to the word size specified by the BYTES_PER_WORD macro. For 80 x 86 processors, the macro yields the value 4 because the word is 32 bits long.
When creating a new slab cache, it's possible to specify that the objects included in it be aligned in the first-level hardware cache. To achieve this, the kernel sets the SLAB_HWCACHE_ALIGN cache descriptor flag. The kmem_cache_create( ) function handles the request as follows:
If the object's size is greater than half of a cache line, it is aligned in RAM to a multiple of L1_CACHE_BYTESthat is, at the beginning of the line. Otherwise, the object size is rounded up to a submultiple of L1_CACHE_BYTES; this ensures that a small object will never span across two cache lines.
Clearly, what the slab allocator is doing here is trading memory space for access time; it gets better cache performance by artificially increasing the object size, thus causing additional internal fragmentation.
8.2.10. Slab Coloring
We know from Chapter 2 that the same hardware cache line maps many different blocks of RAM. In this chapter, we have also seen that objects of the same size end up being stored at the same offset within a cache. Objects that have the same offset within different slabs will, with a relatively high probability, end up mapped in the same cache line. The cache hardware might therefore waste memory cycles transferring two objects from the same cache line back and forth to different RAM locations, while other cache lines go underutilized. The slab allocator tries to reduce this unpleasant cache behavior by a policy called slab coloring
: different arbitrary values called colors are assigned to the slabs.
Before examining slab coloring, we have to look at the layout of objects in the cache. Let's consider a cache whose objects are aligned in RAM. This means that the object address must be a multiple of a given positive value, say aln. Even taking the alignment constraint into account, there are many possible ways to place objects inside the slab. The choices depend on decisions made for the following variables:
num Number of objects that can be stored in a slab (its value is in the num field of the cache descriptor).
osize Object size, including the alignment bytes.
dsize Slab descriptor size plus all object descriptors size, rounded up to the smallest multiple of the hardware cache line size. Its value is equal to 0 if the slab and object descriptors are stored outside of the slab.
free Number of unused bytes (bytes not assigned to any object) inside the slab.
The total length in bytes of a slab can then be expressed as:
slab length = (num x osize) + dsize+ free
free is always smaller than osize, because otherwise, it would be possible to place additional objects inside the slab. However, free could be greater than aln.
The slab allocator takes advantage of the free unused bytes to color the slab. The term "color" is used simply to subdivide the slabs and allow the memory allocator to spread objects out among different linear addresses. In this way, the kernel obtains the best possible performance from the microprocessor's hardware cache.
Slabs having different colors store the first object of the slab in different memory locations, while satisfying the alignment constraint. The number of available colors is free/aln (this value is stored in the colour field of the cache descriptor). Thus, the first color is denoted as 0 and the last one is denoted as (free / aln)-1. (As a particular case, if free is lower than aln, colour is set to 0, nevertheless all slabs use color 0, thus really the number of colors is one.)
If a slab is colored with color col, the offset of the first object (with respect to the slab initial address) is equal to colx aln + dsize bytes. Figure 8-6 illustrates how the placement of objects inside the slab depends on the slab color. Coloring essentially leads to moving some of the free area of the slab from the end to the beginning.
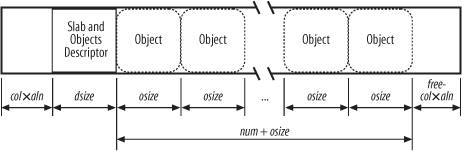
Coloring works only when free is large enough. Clearly, if no alignment is required for the objects or if the number of unused bytes inside the slab is smaller than the required alignment (free < aln), the only possible slab coloring is the one that has the color 0the one that assigns a zero offset to the first object.
The various colors are distributed equally among slabs of a given object type by storing the current color in a field of the cache descriptor called colour_next. The cache_ grow( ) function assigns the color specified by colour_next to a new slab and then increases the value of this field. After reaching colour, it wraps around again to 0. In this way, each slab is created with a different color from the previous one, up to the maximum available colors. The cache_grow( ) function, moreover, gets the value aln from the colour_off field of the cache descriptor, computes dsize according to the number of objects inside the slab, and finally stores the value colx aln + dsize in the colouroff field of the slab descriptor.
8.2.11. Local Caches of Free Slab Objects
The Linux 2.6 implementation of the slab allocator for multiprocessor systems
differs from that of the original Solaris
2.4. To reduce spin lock contention among processors and to make better use of the hardware caches, each cache of the slab allocator includes a per-CPU data structure consisting of a small array of pointers to freed objects called the slab local cache
. Most allocations and releases of slab objects affect the local cache only; the slab data structures get involved only when the local cache underflows or overflows. This technique is quite similar to the one illustrated in the section "The Per-CPU Page Frame Cache" earlier in this chapter.
The array field of the cache descriptor is an array of pointers to array_cache data structures, one element for each CPU in the system. Each array_cache data structure is a descriptor of the local cache of free objects, whose fields are illustrated in Table 8-11.
Table 8-11. The fields of the array_cache structureType | Name | Description |
|---|
unsigned int | avail | Number of pointers to available objects in the local cache. The field also acts as the index of the first free slot in the cache. | unsigned int | limit | Size of the local cachethat is, the maximum number of pointers in the local cache. | unsigned int | batchcount | Chunk size for local cache refill or emptying. | unsigned int | touched | Flag set to 1 if the local cache has been recently used. |
Notice that the local cache descriptor does not include the address of the local cache itself; in fact, the local cache is placed right after the descriptor. Of course, the local cache stores the pointers to the freed objects, not the object themselves, which are always placed inside the slabs of the cache.
When creating a new slab cache, the kmem_cache_create( ) function determines the size of the local caches (storing this value in the limit field of the cache descriptor), allocates them, and stores their pointers into the array field of the cache descriptor.
When creating a new slab cache, the kmem_cache_create( ) function determines the size of the local caches (storing this value in the limit field of the cache descriptor), allocates them, and stores their pointers into the array field of the cache descriptor. The size depends on the size of the objects stored in the slab cache, and ranges from 1 for very large objects to 120 for small ones. Moreover, the initial value of the batchcount field, which is the number of objects added or removed in a chunk from a local cache, is initially set to half of the local cache size.
In multiprocessor systems, slab caches for small objects also sport an additional local cache, whose address is stored in the lists.shared field of the cache descriptor. The shared local cache
is, as the name suggests, shared among all CPUs, and it makes the task of migrating free objects from a local cache to another easier (see the following section). Its initial size is equal to eight times the value of the batchcount field.
8.2.12. Allocating a Slab Object
New objects may be obtained by invoking the kmem_cache_alloc( ) function. The parameter cachep points to the cache descriptor from which the new free object must be obtained, while the parameter flag represents the flags to be passed to the zoned page frame allocator functions, should all slabs of the cache be full.
The function is essentially equivalent to the following:
void * kmem_cache_alloc(kmem_cache_t *cachep, int flags)
{
unsigned long save_flags;
void *objp;
struct array_cache *ac;
local_irq_save(save_flags);
ac = cache_p->array[smp_processor_id()];
if (ac->avail) {
ac->touched = 1;
objp = ((void **)(ac+1))[--ac->avail];
} else
objp = cache_alloc_refill(cachep, flags);
local_irq_restore(save_flags);
return objp;
}
The function tries first to retrieve a free object from the local cache. If there are free objects, the avail field contains the index in the local cache of the entry that points to the last freed object. Because the local cache array is stored right after the ac descriptor, ((void**)(ac+1))[--ac->avail] gets the address of that free object and decreases the value of ac->avail. The cache_alloc_refill( ) function is invoked to repopulate the local cache and get a free object when there are no free objects in the local cache.
The cache_alloc_refill( ) function essentially performs the following steps:
Stores in the ac local variable the address of the local cache descriptor:
ac = cachep->array[smp_processor_id()];
Gets the cachep->spinlock. If the slab cache includes a shared local cache, and if the shared local cache includes some free objects, it refills the CPU's local cache by moving up to ac->batchcount pointers from the shared local cache. Then, it jumps to step 6. Tries to fill the local cache with up to ac->batchcount pointers to free objects included in the slabs of the cache: Looks in the slabs_partial and slabs_free lists of the cache descriptor, and gets the address slabp of a slab descriptor whose corresponding slab is either partially filled or empty. If no such descriptor exists, the function goes to step 5. For each free object in the slab, the function increases the inuse field of the slab descriptor, inserts the object's address in the local cache, and updates the free field so that it stores the index of the next free object in the slab:
slabp->inuse++;
((void**)(ac+1))[ac->avail++] =
slabp->s_mem + slabp->free * cachep->obj_size;
slabp->free = ((kmem_bufctl_t*)(slabp+1))[slabp->free];
Inserts, if necessary, the depleted slab in the proper list, either the slab_full or the slab_partial list.
At this point, the number of pointers added to the local cache is stored in the ac->avail field: the function decreases the free_objects field of the kmem_list3 structure of the same amount to specify that the objects are no longer free. Releases the cachep->spinlock. If the ac->avail field is now greater than 0 (some cache refilling took place), it sets the ac->touched field to 1 and returns the free object pointer that was last inserted in the local cache:
return ((void**)(ac+1))[--ac->avail];
Otherwise, no cache refilling took place: invokes cache_grow() to get a new slab, and thus new free objects. If cache_grow() fails, it returns NULL; otherwise it goes back to step 1 to repeat the procedure.
8.2.13. Freeing a Slab Object
The kmem_cache_free( ) function releases an object previously allocated by the slab allocator to some kernel function. Its parameters are cachep, the address of the cache descriptor, and objp, the address of the object to be released:
void kmem_cache_free(kmem_cache_t *cachep, void *objp)
{
unsigned long flags;
struct array_cache *ac;
local_irq_save(flags);
ac = cachep->array[smp_processor_id()];
if (ac->avail == ac->limit)
cache_flusharray(cachep, ac);
((void**)(ac+1))[ac->avail++] = objp;
local_irq_restore(flags);
}
The function checks first whether the local cache has room for an additional pointer to a free object. If so, the pointer is added to the local cache and the function returns. Otherwise it first invokes cache_flusharray( ) to deplete the local cache and then adds the pointer to the local cache.
The cache_flusharray( ) function performs the following operations:
Acquires the cachep->spinlock spin lock. If the slab cache includes a shared local cache, and if the shared local cache is not already full, it refills the shared local cache by moving up to ac->batchcount pointers from the CPU's local cache. Then, it jumps to step 4. Invokes the free_block( ) function to give back to the slab allocator up to ac->batchcount objects currently included in the local cache. For each object at address objp, the function executes the following steps: Increases the lists.free_objects field of the cache descriptor. Determines the address of the slab descriptor containing the object:
slabp = (struct slab *)(virt_to_page(objp)->lru.prev);
(Remember that the lru.prev field of the descriptor of the slab page points to the corresponding slab descriptor.) Removes the slab descriptor from its slab cache list (either cachep->lists.slabs_partial or cachep->lists.slabs_full). Computes the index of the object inside the slab:
objnr = (objp - slabp->s_mem) / cachep->objsize;
Stores in the object descriptor the current value of the slabp->free, and puts in slabp->free the index of the object (the last released object will be the first object to be allocated again):
((kmem_bufctl_t *)(slabp+1))[objnr] = slabp->free;
slabp->free = objnr;
Decreases the slabp->inuse field. If slabp->inuse is equal to zeroall objects in the slab are freeand the number of free objects in the whole slab cache (cachep->lists.free_objects) is greater than the limit stored in the cachep->free_limit field, then the function releases the slab's page frame(s) to the zoned page frame allocator:
cachep->lists.free_objects -= cachep->num;
slab_destroy(cachep, slabp);
The value stored in the cachep->free_limit field is usually equal to cachep->num+ (1+N) x cachep->batchcount, where N denotes the number of CPUs of the system. Otherwise, if slab->inuse is equal to zero but the number of free objects in the whole slab cache is less than cachep->free_limit, it inserts the slab descriptor in the cachep->lists.slabs_free list. Finally, if slab->inuse is greater than zero, the slab is partially filled, so the function inserts the slab descriptor in the cachep->lists.slabs_partial list.
Releases the cachep->spinlock spin lock. Updates the avail field of the local cache descriptor by subtracting the number of objects moved to the shared local cache or released to the slab allocator. Moves all valid pointers in the local cache at the beginning of the local cache's array. This step is necessary because the first object pointers have been removed from the local cache, thus the remaining ones must be moved up.
8.2.14. General Purpose Objects
As stated earlier in the section "The Buddy System Algorithm," infrequent requests for memory areas are handled through a group of general caches whose objects have geometrically distributed sizes ranging from a minimum of 32 to a maximum of 131,072 bytes.
Objects of this type are obtained by invoking the kmalloc( ) function, which is essentially equivalent to the following code fragment:
void * kmalloc(size_t size, int flags)
{
struct cache_sizes *csizep = malloc_sizes;
kmem_cache_t * cachep;
for (; csizep->cs_size; csizep++) {
if (size > csizep->cs_size)
continue;
if (flags & _ _GFP_DMA)
cachep = csizep->cs_dmacachep;
else
cachep = csizep->cs_cachep;
return kmem_cache_alloc(cachep, flags);
}
return NULL;
}
The function uses the malloc_sizes table to locate the nearest power-of-2 size to the requested size. It then calls kmem_cache_alloc( ) to allocate the object, passing to it either the cache descriptor for the page frames usable for ISA DMA or the cache descriptor for the "normal" page frames, depending on whether the caller specified the _ _GFP_DMA flag.
Objects obtained by invoking kmalloc( ) can be released by calling kfree( ):
void kfree(const void *objp)
{
kmem_cache_t * c;
unsigned long flags;
if (!objp)
return;
local_irq_save(flags);
c = (kmem_cache_t *)(virt_to_page(objp)->lru.next);
kmem_cache_free(c, (void *)objp);
local_irq_restore(flags);
}
The proper cache descriptor is identified by reading the lru.next subfield of the descriptor of the first page frame containing the memory area. The memory area is released by invoking kmem_cache_free( ).
8.2.15. Memory Pools
Memory pools are a new feature of Linux 2.6. Basically, a memory pool allows a kernel componentsuch as the block device subsystemto allocate some dynamic memory to be used only in low-on-memory emergencies.
Memory pools should not be confused with the reserved page frames described in the earlier section "The Pool of Reserved Page Frames." In fact, those page frames can be used only to satisfy atomic memory allocation requests issued by interrupt handlers or inside critical regions. Instead, a memory pool is a reserve of dynamic memory that can be used only by a specific kernel component, namely the "owner" of the pool. The owner does not normally use the reserve; however, if dynamic memory becomes so scarce that all usual memory allocation requests are doomed to fail, the kernel component can invoke, as a last resort, special memory pool functions that dip in the reserve and get the memory needed. Thus, creating a memory pool is similar to keeping a reserve of canned foods on hand and using a can opener only when no fresh food is available.
Often, a memory pool is stacked over the slab allocatorthat is, it is used to keep a reserve of slab objects. Generally speaking, however, a memory pool can be used to allocate every kind of dynamic memory, from whole page frames to small memory areas allocated with kmalloc(). Therefore, we will generically refer to the memory units handled by a memory pool as "memory elements."
A memory pool is described by a mempool_t object, whose fields are shown in Table 8-12.
Table 8-12. The fields of the mempool_t objectType | Name | Description |
|---|
spinlock_t | lock | Spin lock protecting the object fields | int | min_nr | Maximum number of elements in the memory pool | int | curr_nr | Current number of elements in the memory pool | void ** | elements | Pointer to an array of pointers to the reserved elements | void * | pool_data | Private data available to the pool's owner | mempool_alloc_t * | alloc | Method to allocate an element | mempool_free_t * | free | Method to free an element | wait_queue_head_t | wait | Wait queue used when the memory pool is empty |
The min_nr field stores the initial number of elements in the memory pool. In other words, the value stored in this field represents the number of memory elements that the owner of the memory pool is sure to obtain from the memory allocator. The curr_nr field, which is always lower than or equal to min_nr, stores the number of memory elements currently included in the memory pool. The memory elements themselves are referenced by an array of pointers, whose address is stored in the elements field.
The alloc and free methods interface with the underlying memory allocator to get and release a memory element, respectively. Both methods may be custom functions provided by the kernel component that owns the memory pool.
When the memory elements are slab objects, the alloc and free methods are commonly implemented by the mempool_alloc_slab( ) and mempool_free_slab( ) functions, which just invoke the kmem_cache_alloc( ) and kmem_cache_free( ) functions, respectively. In this case, the pool_data field of the mempool_t object stores the address of the slab cache descriptor.
The mempool_create( ) function creates a new memory pool; it receives the number of memory elements min_nr, the addresses of the functions that implement the alloc and free methods, and an optional value for the pool_data field. The function allocates memory for the mempool_t object and the array of pointers to the memory elements, then repeatedly invokes the alloc method to get the min_nr memory elements. Conversely, the mempool_destroy( ) function releases all memory elements in the pool, then releases the array of elements and the mempool_t object themselves.
To allocate an element from a memory pool, the kernel invokes the mempool_alloc( ) function, passing to it the address of the mempool_t object and the memory allocation flags (see Table 8-5 and Table 8-6 earlier in this chapter). Essentially, the function tries to allocate a memory element from the underlying memory allocator by invoking the alloc method, according to the memory allocation flags specified as parameters. If the allocation succeeds, the function returns the memory element obtained, without touching the memory pool. Otherwise, if the allocation fails, the memory element is taken from the memory pool. Of course, too many allocations in a low-on-memory condition can exhaust the memory pool: in this case, if the _ _GFP_WAIT flag is not set, mempool_alloc() blocks the current process until a memory element is released to the memory pool.
Conversely, to release an element to a memory pool, the kernel invokes the mempool_free( ) function. If the memory pool is not full (curr_min is smaller than min_nr), the function adds the element to the memory pool. Otherwise, mempool_free( ) invokes the free method to release the element to the underlying memory allocator.
8.3. Noncontiguous Memory Area Management
We already know that it is preferable to map memory areas into sets of contiguous page frames, thus making better use of the cache and achieving lower average memory access times. Nevertheless, if the requests for memory areas are infrequent, it makes sense to consider an allocation scheme based on noncontiguous page frames accessed through contiguous linear addresses
. The main advantage of this schema is to avoid external fragmentation, while the disadvantage is that it is necessary to fiddle with the kernel Page Tables. Clearly, the size of a noncontiguous memory area must be a multiple of 4,096. Linux uses noncontiguous memory areas in several ways for instance, to allocate data structures for active swap areas (see the section "Activating and Deactivating a Swap Area" in Chapter 17), to allocate space for a module (see Appendix B), or to allocate buffers to some I/O drivers. Furthermore, noncontiguous memory areas provide yet another way to make use of high memory page frames (see the later section "Allocating a Noncontiguous Memory Area").
8.3.1. Linear Addresses of Noncontiguous Memory Areas
To find a free range of linear addresses, we can look in the area starting from PAGE_OFFSET (usually 0xc0000000, the beginning of the fourth gigabyte). Figure 8-7 shows how the fourth gigabyte linear addresses are used:
The beginning of the area includes the linear addresses that map the first 896 MB of RAM (see the section "Process Page Tables" in Chapter 2); the linear address that corresponds to the end of the directly mapped physical memory is stored in the high_memory variable. The end of the area contains the fix-mapped linear addresses
(see the section "Fix-Mapped Linear Addresses" in Chapter 2). Starting from PKMAP_BASE we find the linear addresses used for the persistent kernel mapping of high-memory page frames (see the section "Kernel Mappings of High-Memory Page Frames" earlier in this chapter). The remaining linear addresses can be used for noncontiguous memory areas. A safety interval of size 8 MB (macro VMALLOC_OFFSET) is inserted between the end of the physical memory mapping and the first memory area; its purpose is to "capture" out-of-bounds memory accesses. For the same reason, additional safety intervals of size 4 KB are inserted to separate noncontiguous memory areas.
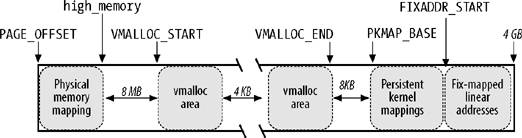
The VMALLOC_START macro defines the starting address of the linear space reserved for noncontiguous memory areas, while VMALLOC_END defines its ending address.
8.3.2. Descriptors of Noncontiguous Memory Areas
Each noncontiguous memory area is associated with a descriptor of type vm_struct, whose fields are listed in Table 8-13.
Table 8-13. The fields of the vm_struct descriptorType | Name | Description |
|---|
void * | addr | Linear address of the first memory cell of the area | unsigned long | size | Size of the area plus 4,096 (inter-area safety interval) | unsigned long | flags | Type of memory mapped by the noncontiguous memory area | struct page ** | pages | Pointer to array of nr_pages pointers to page descriptors
| unsigned int | nr_pages | Number of pages filled by the area | unsigned long | phys_addr | Set to 0 unless the area has been created to map the I/O shared memory of a hardware device | struct vm_struct * | next | Pointer to next vm_struct structure |
These descriptors are inserted in a simple list by means of the next field; the address of the first element of the list is stored in the vmlist variable. Accesses to this list are protected by means of the vmlist_lock read/write spin lock. The flags field identifies the type of memory mapped by the area: VM_ALLOC for pages obtained by means of vmalloc( ), VM_MAP for already allocated pages mapped by means of vmap() (see the next section), and VM_IOREMAP for on-board memory of hardware devices mapped by means of ioremap( ) (see Chapter 13).
The get_vm_area( ) function looks for a free range of linear addresses between VMALLOC_START and VMALLOC_END. This function acts on two parameters: the size (size) in bytes of the memory region to be created, and a flag (flag) specifying the type of region (see above). The steps performed are the following:
Invokes kmalloc( ) to obtain a memory area for the new descriptor of type vm_struct. Gets the vmlist_lock lock for writing and scans the list of descriptors of type vm_struct looking for a free range of linear addresses that includes at least size + 4096 addresses (4096 is the size of the safety interval between the memory areas). If such an interval exists, the function initializes the fields of the descriptor, releases the vmlist_lock lock, and terminates by returning the initial address of the noncontiguous memory area. Otherwise, get_vm_area( ) releases the descriptor obtained previously, releases the vmlist_lock lock, and returns NULL.
8.3.3. Allocating a Noncontiguous Memory Area
The vmalloc( ) function allocates a noncontiguous memory area to the kernel. The parameter size denotes the size of the requested area. If the function is able to satisfy the request, it then returns the initial linear address of the new area; otherwise, it returns a NULL pointer:
void * vmalloc(unsigned long size)
{
struct vm_struct *area;
struct page **pages;
unsigned int array_size, i;
size = (size + PAGE_SIZE - 1) & PAGE_MASK;
area = get_vm_area(size, VM_ALLOC);
if (!area)
return NULL;
area->nr_pages = size >> PAGE_SHIFT;
array_size = (area->nr_pages * sizeof(struct page *));
area->pages = pages = kmalloc(array_size, GFP_KERNEL);
if (!area_pages) {
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
memset(area->pages, 0, array_size);
for (i=0; i<area->nr_pages; i++) {
area->pages[i] = alloc_page(GFP_KERNEL|_ _GFP_HIGHMEM);
if (!area->pages[i]) {
area->nr_pages = i;
fail: vfree(area->addr);
return NULL;
}
}
if (map_vm_area(area, _ _pgprot(0x63), &pages))
goto fail;
return area->addr;
}
The function starts by rounding up the value of the size parameter to a multiple of 4,096 (the page frame size). Then vmalloc( ) invokes get_vm_area( ), which creates a new descriptor and returns the linear addresses assigned to the memory area. The flags field of the descriptor is initialized with the VM_ALLOC flag, which means that the noncontiguous page frames will be mapped into a linear address range by means of the vmalloc( ) function. Then the vmalloc( ) function invokes kmalloc( ) to request a group of contiguous page frames large enough to contain an array of page descriptor pointers. The memset( ) function is invoked to set all these pointers to NULL. Next the alloc_page( ) function is called repeatedly, once for each of the nr_pages of the region, to allocate a page frame and store the address of the corresponding page descriptor in the area->pages array. Observe that using the area->pages array is necessary because the page frames could belong to the ZONE_HIGHMEM memory zone, thus right now they are not necessarily mapped to a linear address.
Now comes the tricky part. Up to this point, a fresh interval of contiguous linear addresses has been obtained and a group of noncontiguous page frames has been allocated to map these linear addresses. The last crucial step consists of fiddling with the page table entries used by the kernel to indicate that each page frame allocated to the noncontiguous memory area is now associated with a linear address included in the interval of contiguous linear addresses yielded by vmalloc( ). This is what map_vm_area( ) does.
The map_vm_area( ) function uses three parameters:
area The pointer to the vm_struct descriptor of the area.
prot The protection bits of the allocated page frames. It is always set to 0x63, which corresponds to Present, Accessed, Read/Write, and Dirty.
pages The address of a variable pointing to an array of pointers to page descriptors (thus, struct page *** is used as the data type!).
The function starts by assigning the linear addresses of the start and end of the area to the address and end local variables, respectively:
address = area->addr;
end = address + (area->size - PAGE_SIZE);
Remember that area->size stores the actual size of the area plus the 4 KB inter-area safety interval. The function then uses the pgd_offset_k macro to derive the entry in the master kernel Page Global Directory related to the initial linear address of the area; it then acquires the kernel Page Table spin lock:
pgd = pgd_offset_k(address);
spin_lock(&init_mm.page_table_lock);
The function then executes the following cycle:
int ret = 0;
for (i = pgd_index(address); i < pgd_index(end-1); i++) {
pud_t *pud = pud_alloc(&init_mm, pgd, address);
ret = -ENOMEM;
if (!pud)
break;
next = (address + PGDIR_SIZE) & PGDIR_MASK;
if (next < address || next > end)
next = end;
if (map_area_pud(pud, address, next, prot, pages))
break;
address = next;
pgd++;
ret = 0;
}
spin_unlock(&init_mm.page_table_lock);
flush_cache_vmap((unsigned long)area->addr, end);
return ret;
In each cycle, it first invokes pud_alloc( ) to create a Page Upper Directory for the new area and writes its physical address in the right entry of the kernel Page Global Directory. It then calls map_area_pud( ) to allocate all the page tables associated with the new Page Upper Directory. It adds the size of the range of linear addresses spanned by a single Page Upper Directorythe constant 230 if PAE is enabled, 222 otherwiseto the current value of address, and it increases the pointer pgd to the Page Global Directory.
The cycle is repeated until all Page Table entries referring to the noncontiguous memory area are set up.
The map_area_pud( ) function executes a similar cycle for all the page tables that a Page Upper Directory points to:
do {
pmd_t * pmd = pmd_alloc(&init_mm, pud, address);
if (!pmd)
return -ENOMEM;
if (map_area_pmd(pmd, address, end-address, prot, pages))
return -ENOMEM;
address = (address + PUD_SIZE) & PUD_MASK;
pud++;
} while (address < end);
The map_area_pmd( ) function executes a similar cycle for all the Page Tables that a Page Middle Directory points to:
do {
pte_t * pte = pte_alloc_kernel(&init_mm, pmd, address);
if (!pte)
return -ENOMEM;
if (map_area_pte(pte, address, end-address, prot, pages))
return -ENOMEM;
address = (address + PMD_SIZE) & PMD_MASK;
pmd++;
} while (address < end);
The pte_alloc_kernel( ) function (see the section "Page Table Handling" in Chapter 2) allocates a new Page Table and updates the corresponding entry in the Page Middle Directory. Next, map_area_pte( ) allocates all the page frames corresponding to the entries in the Page Table. The value of address is increased by 222the size of the linear address interval spanned by a single Page Tableand the cycle is repeated.
The main cycle of map_area_pte( ) is:
do {
struct page * page = **pages;
set_pte(pte, mk_pte(page, prot));
address += PAGE_SIZE;
pte++;
(*pages)++;
} while (address < end);
The page descriptor address page of the page frame to be mapped is read from the array's entry pointed to by the variable at address pages. The physical address of the new page frame is written into the Page Table by the set_pte and mk_pte macros. The cycle is repeated after adding the constant 4,096 (the length of a page frame) to address.
Notice that the Page Tables of the current process are not touched by map_vm_area( ). Therefore, when a process in Kernel Mode accesses the noncontiguous memory area, a Page Fault occurs, because the entries in the process's Page Tables corresponding to the area are null. However, the Page Fault handler checks the faulty linear address against the master kernel Page Tables (which are init_mm.pgd Page Global Directory and its child page tables; see the section "Kernel Page Tables" in Chapter 2). Once the handler discovers that a master kernel Page Table includes a non-null entry for the address, it copies its value into the corresponding process's Page Table entry and resumes normal execution of the process. This mechanism is described in the section "Page Fault Exception Handler" in Chapter 9.
Beside the vmalloc( ) function, a noncontiguous memory area can be allocated by the vmalloc_32( ) function, which is very similar to vmalloc( ) but only allocates page frames from the ZONE_NORMAL and ZONE_DMA memory zones.
Linux 2.6 also features a vmap( ) function, which maps page frames already allocated in a noncontiguous memory area: essentially, this function receives as its parameter an array of pointers to page descriptors, invokes get_vm_area( ) to get a new vm_struct descriptor, and then invokes map_vm_area( ) to map the page frames. The function is thus similar to vmalloc( ), but it does not allocate page frames.
8.3.4. Releasing a Noncontiguous Memory Area
The vfree( ) function releases noncontiguous memory areas created by vmalloc( ) or vmalloc_32( ), while the vunmap( ) function releases memory areas created by vmap( ). Both functions have one parameterthe address of the initial linear address of the area to be released; they both rely on the _ _vunmap( ) function to do the real work.
The _ _vunmap( ) function receives two parameters: the address addr of the initial linear address of the area to be released, and the flag deallocate_pages, which is set if the page frames mapped in the area should be released to the zoned page frame allocator (vfree( )'s invocation), and cleared otherwise (vunmap( )'s invocation). The function performs the following operations:
Invokes the remove_vm_area( ) function to get the address area of the vm_struct descriptor and to clear the kernel's page table entries corresponding to the linear address in the noncontiguous memory area. If the deallocate_pages flag is set, it scans the area->pages array of pointers to the page descriptor; for each element of the array, invokes the _ _free_page( ) function to release the page frame to the zoned page frame allocator. Moreover, executes kfree(area->pages) to release the array itself. Invokes kfree(area) to release the vm_struct descriptor.
The remove_vm_area( ) function performs the following cycle:
write_lock(&vmlist_lock);
for (p = &vmlist ; (tmp = *p) ; p = &tmp->next) {
if (tmp->addr == addr) {
unmap_vm_area(tmp);
*p = tmp->next;
break;
}
}
write_unlock(&vmlist_lock);
return tmp;
The area itself is released by invoking unmap_vm_area( ). This function acts on a single parameter, namely a pointer area to the vm_struct descriptor of the area. It executes the following cycle to reverse the actions performed by map_vm_area( ):
address = area->addr;
end = address + area->size;
pgd = pgd_offset_k(address);
for (i = pgd_index(address); i <= pgd_index(end-1); i++) {
next = (address + PGDIR_SIZE) & PGDIR_MASK;
if (next <= address || next > end)
next = end;
unmap_area_pud(pgd, address, next - address);
address = next;
pgd++;
}
In turn, unmap_area_pud( ) reverses the actions of map_area_pud( ) in the cycle:
do {
unmap_area_pmd(pud, address, end-address);
address = (address + PUD_SIZE) & PUD_MASK;
pud++;
} while (address && (address < end));
The unmap_area_pmd( ) function reverses the actions of map_area_pmd( ) in the cycle:
do {
unmap_area_pte(pmd, address, end-address);
address = (address + PMD_SIZE) & PMD_MASK;
pmd++;
} while (address < end);
Finally, unmap_area_pte( ) reverses the actions of map_area_pte( ) in the cycle:
do {
pte_t page = ptep_get_and_clear(pte);
address += PAGE_SIZE;
pte++;
if (!pte_none(page) && !pte_present(page))
printk("Whee... Swapped out page in kernel page table\n");
} while (address < end);
In every iteration of the cycle, the page table entry pointed to by pte is set to 0 by the ptep_get_and_clear macro.
As for vmalloc( ), the kernel modifies the entries of the master kernel Page Global Directory and its child page tables (see the section "Kernel Page Tables" in Chapter 2), but it leaves unchanged the entries of the process page tables mapping the fourth gigabyte. This is fine because the kernel never reclaims Page Upper Directories, Page Middle Directories, and Page Tables rooted at the master kernel Page Global Directory.
For instance, suppose that a process in Kernel Mode accessed a noncontiguous memory area that later got released. The process's Page Global Directory entries are equal to the corresponding entries of the master kernel Page Global Directory, thanks to the mechanism explained in the section "Page Fault Exception Handler" in Chapter 9; they point to the same Page Upper Directories, Page Middle Directories, and Page Tables. The unmap_area_pte( ) function clears only the entries of the page tables (without reclaiming the page tables themselves). Further accesses of the process to the released noncontiguous memory area will trigger Page Faults because of the null page table entries. However, the handler will consider such accesses a bug, because the master kernel page tables
do not include valid entries.
Chapter 9. Process Address Space
As seen in the previous chapter, a kernel function gets dynamic memory in a fairly straightforward manner by invoking one of a variety of functions: _ _get_free_pages( ) or alloc_pages( ) to get pages from the zoned page frame allocator, kmem_cache_alloc( ) or kmalloc( ) to use the slab allocator for specialized or general-purpose objects, and vmalloc( ) or vmalloc_32( ) to get a noncontiguous memory area. If the request can be satisfied, each of these functions returns a page descriptor address or a linear address identifying the beginning of the allocated dynamic memory area.
These simple approaches work for two reasons:
The kernel is the highest-priority component of the operating system. If a kernel function makes a request for dynamic memory, it must have a valid reason to issue that request, and there is no point in trying to defer it. The kernel trusts itself. All kernel functions are assumed to be error-free, so the kernel does not need to insert any protection against programming errors.
When allocating memory to User Mode processes, the situation is entirely different:
Process requests for dynamic memory are considered non-urgent. When a process's executable file is loaded, for instance, it is unlikely that the process will address all the pages of code in the near future. Similarly, when a process invokes malloc( ) to get additional dynamic memory, it doesn't mean the process will soon access all the additional memory obtained. Thus, as a general rule, the kernel tries to defer allocating dynamic memory to User Mode processes. Because user programs cannot be trusted, the kernel must be prepared to catch all addressing errors caused by processes in User Mode.
As this chapter describes, the kernel succeeds in deferring the allocation of dynamic memory to processes by using a new kind of resource. When a User Mode process asks for dynamic memory, it doesn't get additional page frames; instead, it gets the right to use a new range of linear addresses, which become part of its address space. This interval is called a "memory region."
In the next section, we discuss how the process views dynamic memory. We then describe the basic components of the process address space in the section "Memory Regions." Next, we examine in detail the role played by the Page Fault
exception handler in deferring the allocation of page frames to processes and illustrate how the kernel creates and deletes whole process address spaces. Last, we discuss the APIs and system calls related to address space management.
9.1. The Process's Address Space
The address space of a process consists of all linear addresses that the process is allowed to use. Each process sees a different set of linear addresses; the address used by one process bears no relation to the address used by another. As we will see later, the kernel may dynamically modify a process address space by adding or removing intervals of linear addresses.
The kernel represents intervals of linear addresses by means of resources called memory regions
, which are characterized by an initial linear address, a length, and some access rights. For reasons of efficiency, both the initial address and the length of a memory region must be multiples of 4,096, so that the data identified by each memory region completely fills up the page frames allocated to it. Following are some typical situations in which a process gets new memory regions:
When the user types a command at the console, the shell process creates a new process to execute the command. As a result, a fresh address space, and thus a set of memory regions, is assigned to the new process (see the section "Creating and Deleting a Process Address Space" later in this chapter; also, see Chapter 20). A running process may decide to load an entirely different program. In this case, the process ID remains unchanged, but the memory regions used before loading the program are released and a new set of memory regions is assigned to the process (see the section "The exec Functions" in Chapter 20). A running process may perform a "memory mapping" on a file (or on a portion of it). In such cases, the kernel assigns a new memory region to the process to map the file (see the section "Memory Mapping" in Chapter 16). A process may keep adding data on its User Mode stack until all addresses in the memory region that map the stack have been used. In this case, the kernel may decide to expand the size of that memory region (see the section "Page Fault Exception Handler" later in this chapter). A process may create an IPC-shared memory region to share data with other cooperating processes. In this case, the kernel assigns a new memory region to the process to implement this construct (see the section "IPC Shared Memory" in Chapter 19). A process may expand its dynamic area (the heap) through a function such as malloc( ). As a result, the kernel may decide to expand the size of the memory region assigned to the heap (see the section "Managing the Heap" later in this chapter).
Table 9-1 illustrates some of the system calls related to the previously mentioned tasks. brk( ) is discussed at the end of this chapter, while the remaining system calls are described in other chapters.
Table 9-1. System calls related to memory region creation and deletionSystem call | Description |
|---|
brk( ) | Changes the heap size of the process | execve( ) | Loads a new executable file, thus changing the process address space | _exit( ) | Terminates the current process and destroys its address space | fork( ) | Creates a new process, and thus a new address space | mmap( ), mmap2( )
| Creates a memory mapping for a file, thus enlarging the process address space | mremap( ) | Expands or shrinks a memory region | remap_file_pages( )
| Creates a non-linear mapping for a file (see Chapter 16) | munmap( ) | Destroys a memory mapping for a file, thus contracting the process address space | shmat( ) | Attaches a shared memory region | shmdt( ) | Detaches a shared memory region |
As we'll see in the later section "Page Fault Exception Handler," it is essential for the kernel to identify the memory regions currently owned by a process (the address space of a process), because that allows the Page Fault exception handler to efficiently distinguish between two types of invalid linear addresses that cause it to be invoked:
Those caused by programming errors. Those caused by a missing page; even though the linear address belongs to the process's address space, the page frame corresponding to that address has yet to be allocated.
The latter addresses are not invalid from the process's point of view; the induced Page Faults are exploited by the kernel to implement demand paging
: the kernel provides the missing page frame and lets the process continue.
|
9.2. The Memory Descriptor
All information related to the process address space is included in an object called the memory descriptor of type mm_struct. This object is referenced by the mm field of the process descriptor. The fields of a memory descriptor are listed in Table 9-2.
Table 9-2. The fields of the memory descriptorType | Field | Description |
|---|
struct vm_area_struct * | mmap | Pointer to the head of the list of memory region objects | struct rb_root | mm_rb | Pointer to the root of the red-black tree of memory region objects | struct vm_area_struct * | mmap_cache | Pointer to the last referenced memory region object | unsigned long (*)( ) | get_unmapped_area | Method that searches an available linear address interval in the process address space | void (*)( ) | unmap_area | Method invoked when releasing a linear address interval | unsigned long | mmap_base | Identifies the linear address of the first allocated anonymous memory region or file memory mapping (see the section "Program Segments and Process Memory Regions" in Chapter 20) | unsigned long | free_area_cache | Address from which the kernel will look for a free interval of linear addresses in the process address space | pgd_t * | pgd | Pointer to the Page Global Directory | atomic_t | mm_users | Secondary usage counter | atomic_t | mm_count | Main usage counter | int | map_count | Number of memory regions | struct rw_semaphore | mmap_sem | Memory regions' read/write semaphore | spinlock_t | page_table_lock | Memory regions' and Page Tables' spin lock | struct list_head | mmlist | Pointers to adjacent elements in the list of memory descriptors | unsigned long | start_code | Initial address of executable code | unsigned long | end_code | Final address of executable code | unsigned long | start_data | Initial address of initialized data | unsigned long | end_data | Final address of initialized data | unsigned long | start_brk | Initial address of the heap | unsigned long | brk | Current final address of the heap | unsigned long | start_stack | Initial address of User Mode stack | unsigned long | arg_start | Initial address of command-line arguments | unsigned long | arg_end | Final address of command-line arguments | unsigned long | env_start | Initial address of environment variables | unsigned long | env_end | Final address of environment variables | unsigned long | rss | Number of page frames allocated to the process | unsigned long | anon_rss | Number of page frames assigned to anonymous memory mappings | unsigned long | total_vm | Size of the process address space (number of pages) | unsigned long | locked_vm | Number of "locked" pages that cannot be swapped out (see Chapter 17) | unsigned long | shared_vm | Number of pages in shared file memory mappings | unsigned long | exec_vm | Number of pages in executable memory mappings | unsigned long | stack_vm | Number of pages in the User Mode stack | unsigned long | reserved_vm | Number of pages in reserved or special memory regions | unsigned long | def_flags | Default access flags of the memory regions | unsigned long | nr_ptes | Number of Page Tables of this process | unsigned long [] | saved_auxv | Used when starting the execution of an ELF program (see Chapter 20) | unsigned int | dumpable | Flag that specifies whether the process can produce a core dump of the memory | cpumask_t | cpu_vm_mask | Bit mask for lazy TLB switches (see Chapter 2) | mm_context_t | context | Pointer to table for architecture-specific information (e.g., LDT's address in 80 86 platforms) | unsigned long | swap_token_time | When this process will become eligible for having the swap token (see the section "The Swap Token" in Chapter 17) | char | recent_pagein | Flag set if a major Page Fault has recently occurred | int | core_waiters | Number of lightweight processes that are dumping the contents of the process address space to a core file (see the section "Deleting a Process Address Space" later in this chapter) | struct completion * | core_startup_done | Pointer to a completion used when creating a core file (see the section "Completions" in Chapter 5) | struct completion | core_done | Completion used when creating a core file | rwlock_t | ioctx_list_lock | Lock used to protect the list of asynchronous I/O contexts (see Chapter 16) | struct kioctx * | ioctx_list | List of asynchronous I/O contexts (see Chapter 16) | struct kioctx | default_kioctx | Default asynchronous I/O context (see Chapter 16) | unsigned long | hiwater_rss | Maximum number of page frames ever owned by the process | unsigned long | hiwater_vm | Maximum number of pages ever included in the memory regions of the process |
All memory descriptors are stored in a doubly linked list. Each descriptor stores the address of the adjacent list items in the mmlist field. The first element of the list is the mmlist field of init_mm, the memory descriptor used by process 0 in the initialization phase. The list is protected against concurrent accesses in multiprocessor systems by the mmlist_lock spin lock.
The mm_users field stores the number of lightweight processes that share the mm_struct data structure (see the section "The clone( ), fork( ), and vfork( ) System Calls" in Chapter 3). The mm_count field is the main usage counter of the memory descriptor; all "users" in mm_users count as one unit in mm_count. Every time the mm_count field is decreased, the kernel checks whether it becomes zero; if so, the memory descriptor is deallocated because it is no longer in use.
We'll try to explain the difference between the use of mm_users and mm_count with an example. Consider a memory descriptor shared by two lightweight processes. Normally, its mm_users field stores the value 2, while its mm_count field stores the value 1 (both owner processes count as one).
If the memory descriptor is temporarily lent to a kernel thread (see the next section), the kernel increases the mm_count field. In this way, even if both lightweight processes die and the mm_users field becomes zero, the memory descriptor is not released until the kernel thread finishes using it because the mm_count field remains greater than zero.
If the kernel wants to be sure that the memory descriptor is not released in the middle of a lengthy operation, it might increase the mm_users field instead of mm_count (this is what the try_to_unuse( ) function does; see the section "Activating and Deactivating a Swap Area" in Chapter 17). The final result is the same because the increment of mm_users ensures that mm_count does not become zero even if all lightweight processes that own the memory descriptor die.
The mm_alloc( ) function is invoked to get a new memory descriptor. Because these descriptors are stored in a slab allocator cache, mm_alloc( ) calls kmem_cache_alloc( ), initializes the new memory descriptor, and sets the mm_count and mm_users field to 1.
Conversely, the mmput( ) function decreases the mm_users field of a memory descriptor. If that field becomes 0, the function releases the Local Descriptor Table, the memory region descriptors (see later in this chapter), and the Page Tables referenced by the memory descriptor, and then invokes mmdrop( ). The latter function decreases mm_count and, if it becomes zero, releases the mm_struct data structure.
The mmap, mm_rb, mmlist, and mmap_cache fields are discussed in the next section.
9.2.1. Memory Descriptor of Kernel Threads
Kernel threads run only in Kernel Mode, so they never access linear addresses below TASK_SIZE (same as PAGE_OFFSET, usually 0xc0000000). Contrary to regular processes, kernel threads
do not use memory regions, therefore most of the fields of a memory descriptor are meaningless for them.
Because the Page Table entries that refer to the linear address above TASK_SIZE should always be identical, it does not really matter what set of Page Tables a kernel thread uses. To avoid useless TLB and cache flushes, a kernel thread uses the set of Page Tables of the last previously running regular process. To that end, two kinds of memory descriptor pointers are included in every process descriptor: mm and active_mm.
The mm field in the process descriptor points to the memory descriptor owned by the process, while the active_mm field points to the memory descriptor used by the process when it is in execution. For regular processes, the two fields store the same pointer. Kernel threads, however, do not own any memory descriptor, thus their mm field is always NULL. When a kernel thread is selected for execution, its active_mm field is initialized to the value of the active_mm of the previously running process (see the section "The schedule( ) Function" in Chapter 7).
There is, however, a small complication. Whenever a process in Kernel Mode modifies a Page Table entry for a "high" linear address (above TASK_SIZE), it should also update the corresponding entry in the sets of Page Tables of all processes in the system. In fact, once set by a process in Kernel Mode, the mapping should be effective for all other processes in Kernel Mode as well. Touching the sets of Page Tables of all processes is a costly operation; therefore, Linux adopts a deferred approach.
We already mentioned this deferred approach in the section "Noncontiguous Memory Area Management" in Chapter 8: every time a high linear address has to be remapped (typically by vmalloc( ) or vfree( )), the kernel updates a canonical set of Page Tables rooted at the swapper_pg_dir master kernel Page Global Directory (see the section "Kernel Page Tables" in Chapter 2). This Page Global Directory is pointed to by the pgd field of a master memory descriptor
, which is stored in the init_mm variable.
Later, in the section "Handling Noncontiguous Memory Area Accesses," we'll describe how the Page Fault handler takes care of spreading the information stored in the canonical Page Tables when effectively needed.
|
9.3. Memory Regions
Linux implements a memory region by means of an object of type vm_area_struct; its fields are shown in Table 9-3.
Table 9-3. The fields of the memory region objectType | Field | Description |
|---|
struct mm_struct * | vm_mm | Pointer to the memory descriptor that owns the region. | unsigned long | vm_start | First linear address inside the region. | unsigned long | vm_end | First linear address after the region. | struct vm_area_struct * | vm_next | Next region in the process list. | pgprot_t | vm_page_prot | Access permissions for the page frames of the region. | unsigned long | vm_flags | Flags of the region. | struct rb_node | vm_rb | Data for the red-black tree (see later in this chapter). | union | shared | Links to the data structures used for reverse mapping (see the section "Reverse Mapping for Mapped Pages" in Chapter 17). | struct list_head | anon_vma_node | Pointers for the list of anonymous memory regions (see the section "Reverse Mapping for Anonymous Pages" in Chapter 17). | struct anon_vma * | anon_vma | Pointer to the anon_vma data structure (see the section "Reverse Mapping for Anonymous Pages" in Chapter 17). | struct vm_operations_struct* | vm_ops | Pointer to the methods of the memory region. | unsigned long | vm_pgoff | Offset in mapped file (see Chapter 16). For anonymous pages, it is either zero or equal to vm_start/PAGE_SIZE (see Chapter 17). | struct file * | vm_file | Pointer to the file object of the mapped file, if any. | void * | vm_private_data | Pointer to private data of the memory region. | unsigned long | vm_truncate_count | Used when releasing a linear address interval in a non-linear file memory mapping. |
Each memory region descriptor identifies a linear address interval. The vm_start field contains the first linear address of the interval, while the vm_end field contains the first linear address outside of the interval; vm_end-vm_start thus denotes the length of the memory region. The vm_mm field points to the mm_struct memory descriptor of the process that owns the region. We will describe the other fields of vm_area_struct as they come up.
Memory regions owned by a process never overlap, and the kernel tries to merge regions when a new one is allocated right next to an existing one. Two adjacent regions can be merged if their access rights match.
As shown in Figure 9-1, when a new range of linear addresses is added to the process address space, the kernel checks whether an already existing memory region can be enlarged (case a). If not, a new memory region is created (case b). Similarly, if a range of linear addresses is removed from the process address space, the kernel resizes the affected memory regions (case c). In some cases, the resizing forces a memory region to split into two smaller ones (case d) .
The vm_ops field points to a vm_operations_struct data structure, which stores the methods of the memory region. Only four methodsillustrated in Table 9-4are applicable to UMA systems.
Table 9-4. The methods to act on a memory regionMethod | Description |
|---|
open | Invoked when the memory region is added to the set of regions owned by a process. | close | Invoked when the memory region is removed from the set of regions owned by a process. | nopage | Invoked by the Page Fault exception handler when a process tries to access a page not present in RAM whose linear address belongs to the memory region (see the later section "Page Fault Exception Handler"). | populate | Invoked to set the page table entries corresponding to the linear addresses of the memory region (prefaulting). Mainly used for non-linear file memory mappings. |
9.3.1. Memory Region Data Structures
All the regions owned by a process are linked in a simple list. Regions appear in the list in ascending order by memory address; however, successive regions can be separated by an area of unused memory addresses. The vm_next field of each vm_area_struct element points to the next element in the list. The kernel finds the memory regions through the mmap field of the process memory descriptor, which points to the first memory region descriptor in the list.
The map_count field of the memory descriptor contains the number of regions owned by the process. By default, a process may own up to 65,536 different memory regions; however, the system administrator may change this limit by writing in the /proc/sys/vm/max_map_count file.
Figure 9-2 illustrates the relationships among the address space of a process, its memory descriptor, and the list of memory regions.
A frequent operation performed by the kernel is to search the memory region that includes a specific linear address. Because the list is sorted, the search can terminate as soon as a memory region that ends after the specific linear address is found.
However, using the list is convenient only if the process has very few memory regionslet's say less than a few tens of them. Searching, inserting elements, and deleting elements in the list involve a number of operations whose times are linearly proportional to the list length.
Although most Linux processes use very few memory regions, there are some large applications, such as object-oriented databases or specialized debuggers for the usage of malloc(), that have many hundreds or even thousands of regions. In such cases, the memory region list management becomes very inefficient, hence the performance of the memory-related system calls degrades to an intolerable point.
Therefore, Linux 2.6 stores memory descriptors in data structures called red-black trees
. In a red-black tree, each element (or node) usually has two children: a left child and a right child. The elements in the tree are sorted. For each node N, all elements of the subtree rooted at the left child of N precede N, while, conversely, all elements of the subtree rooted at the right child of N follow N (see Figure 9-3(a); the key of the node is written inside the node itself. Moreover, a red-black tree must satisfy four additional rules:
Every node must be either red or black. The root of the tree must be black. The children of a red node must be black. Every path from a node to a descendant leaf must contain the same number of black nodes
. When counting the number of black nodes, null pointers are counted as black nodes.
These four rules ensure that every red-black tree with n internal nodes has a height of at most 2 x log(n + 1).
Searching an element in a red-black tree is thus very efficient, because it requires operations whose execution time is linearly proportional to the logarithm of the tree size. In other words, doubling the number of memory regions adds just one more iteration to the operation.
Inserting and deleting an element in a red-black tree is also efficient, because the algorithm can quickly traverse the tree to locate the position at which the element will be inserted or from which it will be removed. Each new node must be inserted as a leaf and colored red. If the operation breaks the rules, a few nodes of the tree must be moved or recolored.
For instance, suppose that an element having the value 4 must be inserted in the red-black tree shown in Figure 9-3(a). Its proper position is the right child of the node that has key 3, but once it is inserted, the red node that has the value 3 has a red child, thus breaking rule 3. To satisfy the rule, the color of nodes that have the values 3, 4, and 7 is changed. This operation, however, breaks rule 4, thus the algorithm performs a "rotation" on the subtree rooted at the node that has the key 19, producing the new red-black tree shown in Figure 9-3(b). This looks complicated, but inserting or deleting an element in a red-black tree requires a small number of operationsa number linearly proportional to the logarithm of the tree size.
Therefore, to store the memory regions of a process, Linux uses both a linked list and a red-black tree. Both data structures contain pointers to the same memory region descriptors. When inserting or removing a memory region descriptor, the kernel searches the previous and next elements through the red-black tree and uses them to quickly update the list without scanning it.
The head of the linked list is referenced by the mmap field of the memory descriptor. Each memory region object stores the pointer to the next element of the list in the vm_next field. The head of the red-black tree is referenced by the mm_rb field of the memory descriptor. Each memory region object stores the color of the node, as well as the pointers to the parent, the left child, and the right child, in the vm_rb field of type rb_node.
In general, the red-black tree is used to locate a region including a specific address, while the linked list is mostly useful when scanning the whole set of regions.
9.3.2. Memory Region Access Rights
Before moving on, we should clarify the relation between a page and a memory region. As mentioned in Chapter 2, we use the term "page" to refer both to a set of linear addresses and to the data contained in this group of addresses. In particular, we denote the linear address interval ranging between 0 and 4,095 as page 0, the linear address interval ranging between 4,096 and 8,191 as page 1, and so forth. Each memory region therefore consists of a set of pages that have consecutive page numbers.
We have already discussed two kinds of flags associated with a page:
The first kind of flag is used by the 80 x 86 hardware to check whether the requested kind of addressing can be performed; the second kind is used by Linux for many different purposes (see Table 8-2).
We now introduce a third kind of flag: those associated with the pages of a memory region. They are stored in the vm_flags field of the vm_area_struct descriptor (see Table 9-5). Some flags
offer the kernel information about all the pages of the memory region, such as what they contain and what rights the process has to access each page. Other flags describe the region itself, such as how it can grow.
Table 9-5. The memory region flagsFlag name | Description |
|---|
VM_READ | Pages can be read | VM_WRITE | Pages can be written | VM_EXEC | Pages can be executed | VM_SHARED | Pages can be shared by several processes | VM_MAYREAD | VM_READ flag may be set | VM_MAYWRITE | VM_WRITE flag may be set | VM_MAYEXEC | VM_EXEC flag may be set | VM_MAYSHARE | VM_SHARE flag may be set | VM_GROWSDOWN | The region can expand toward lower addresses | VM_GROWSUP | The region can expand toward higher addresses | VM_SHM | The region is used for IPC's shared memory | VM_DENYWRITE | The region maps a file that cannot be opened for writing | VM_EXECUTABLE | The region maps an executable file | VM_LOCKED | Pages in the region are locked and cannot be swapped out | VM_IO | The region maps the I/O address space of a device | VM_SEQ_READ | The application accesses the pages sequentially | VM_RAND_READ | The application accesses the pages in a truly random order | VM_DONTCOPY | Do not copy the region when forking a new process | VM_DONTEXPAND | Forbid region expansion through mremap( )
system call | VM_RESERVED | The region is special (for instance, it maps the I/O address space of a device), so its pages must not be swapped out | VM_ACCOUNT | Check whether there is enough free memory for the mapping when creating an IPC shared memory region (see Chapter 19) | VM_HUGETLB | The pages in the region are handled through the extended paging mechanism (see the section "Extended Paging" in Chapter 2) | VM_NONLINEAR | The region implements a non-linear file mapping |
Page access rights included in a memory region descriptor may be combined arbitrarily. It is possible, for instance, to allow the pages of a region to be read but not executed. To implement this protection scheme efficiently, the Read, Write, and Execute access rights associated with the pages of a memory region must be duplicated in all the corresponding Page Table entries, so that checks can be directly performed by the Paging Unit circuitry. In other words, the page access rights dictate what kinds of access should generate a Page Fault
exception. As we'll see shortly, the job of figuring out what caused the Page Fault is delegated by Linux to the Page Fault handler, which implements several page-handling strategies.
The initial values of the Page Table flags (which must be the same for all pages in the memory region, as we have seen) are stored in the vm_ page_ prot field of the vm_area_struct descriptor. When adding a page, the kernel sets the flags in the corresponding Page Table entry according to the value of the vm_ page_ prot field.
However, translating the memory region's access rights into the page protection bits
is not straightforward for the following reasons:
In some cases, a page access should generate a Page Fault exception even when its access type is granted by the page access rights specified in the vm_flags field of the corresponding memory region. For instance, as we'll see in the section "Copy On Write" later in this chapter, the kernel may wish to store two identical, writable private pages (whose VM_SHARE flags are cleared) belonging to two different processes in the same page frame; in this case, an exception should be generated when either one of the processes tries to modify the page. As mentioned in Chapter 2, 80 x 86 processors's Page Tables have just two protection bits, namely the Read/Write and User/Supervisor flags. Moreover, the User/Supervisor flag of every page included in a memory region must always be set, because the page must always be accessible by User Mode processes. Recent Intel Pentium 4 microprocessors with PAE enabled sport a NX (No eXecute) flag in each 64-bit Page Table entry.
If the kernel has been compiled without support for PAE, Linux adopts the following rules, which overcome the hardware limitation of the 80 x 86 microprocessors:
The Read access right always implies the Execute access right, and vice versa. The Write access right always implies the Read access right.
Conversely, if the kernel has been compiled with support for PAE and the CPU has the NX flag, Linux adopts different rules:
Moreover, to correctly defer the allocation of page frames through the "Copy On Write" technique (see later in this chapter), the page frame is write-protected whenever the corresponding page must not be shared by several processes.
Therefore, the 16 possible combinations of the Read, Write, Execute, and Share access rights are scaled down according to the following rules:
If the page has both Write and Share access rights, the Read/Write bit is set. If the page has the Read or Execute access right but does not have either the Write or the Share access right, the Read/Write bit is cleared. If the NX bit is supported and the page does not have the Execute access right, the NX bit is set. If the page does not have any access rights, the Present bit is cleared so that each access generates a Page Fault exception. However, to distinguish this condition from the real page-not-present case, Linux also sets the Page size bit to 1.
The downscaled protection bits corresponding to each combination of access rights are stored in the 16 elements of the protection_map array.
9.3.3. Memory Region Handling
Having the basic understanding of data structures and state information that control memory handling
, we can look at a group of low-level functions that operate on memory region descriptors. They should be considered auxiliary functions that simplify the implementation of do_mmap( ) and do_munmap( ). Those two functions, which are described in the sections "Allocating a Linear Address Interval" and "Releasing a Linear Address Interval" later in this chapter, enlarge and shrink the address space of a process, respectively. Working at a higher level than the functions we consider here, they do not receive a memory region descriptor as their parameter, but rather the initial address, the length, and the access rights of a linear address interval.
9.3.3.1. Finding the closest region to a given address: find_vma( )
The find_vma( ) function acts on two parameters: the address mm of a process memory descriptor and a linear address addr. It locates the first memory region whose vm_end field is greater than addr and returns the address of its descriptor; if no such region exists, it returns a NULL pointer. Notice that the region selected by find_vma( ) does not necessarily include addr because addr may lie outside of any memory region.
Each memory descriptor includes an mmap_cache
field that stores the descriptor address of the region that was last referenced by the process. This additional field is introduced to reduce the time spent in looking for the region that contains a given linear address. Locality of address references in programs makes it highly likely that if the last linear address checked belonged to a given region, the next one to be checked belongs to the same region.
The function thus starts by checking whether the region identified by mmap_cache includes addr. If so, it returns the region descriptor pointer:
vma = mm->mmap_cache;
if (vma && vma->vm_end > addr && vma->vm_start <= addr)
return vma;
Otherwise, the memory regions of the process must be scanned, and the function looks up the memory region in the red-black tree:
rb_node = mm->mm_rb.rb_node;
vma = NULL;
while (rb_node) {
vma_tmp = rb_entry(rb_node, struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;
return vma;
The function uses the rb_entry macro, which derives from a pointer to a node of the red-black tree the address of the corresponding memory region descriptor.
The find_vma_prev( ) function is similar to find_vma( ), except that it writes in an additional pprev parameter a pointer to the descriptor of the memory region that precedes the one selected by the function.
Finally, the find_vma_prepare( ) function locates the position of the new leaf in the red-black tree that corresponds to a given linear address and returns the addresses of the preceding memory region and of the parent node of the leaf to be inserted.
9.3.3.2. Finding a region that overlaps a given interval: find_vma_intersection( )
The find_vma_intersection( ) function finds the first memory region that overlaps a given linear address interval; the mm parameter points to the memory descriptor of the process, while the start_addr and end_addr linear addresses specify the interval:
vma = find_vma(mm,start_addr);
if (vma && end_addr <= vma->vm_start)
vma = NULL;
return vma;
The function returns a NULL pointer if no such region exists. To be exact, if find_vma( ) returns a valid address but the memory region found starts after the end of the linear address interval, vma is set to NULL.
9.3.3.3. Finding a free interval: get_unmapped_area( )
The get_unmapped_area( ) function searches the process address space to find an available linear address interval. The len parameter specifies the interval length, while a non-null addr parameter specifies the address from which the search must be started. If the search is successful, the function returns the initial address of the new interval; otherwise, it returns the error code -ENOMEM.
If the addr parameter is not NULL, the function checks that the specified address is in the User Mode address space and that it is aligned to a page boundary. Next, the function invokes either one of two methods, depending on whether the linear address interval should be used for a file memory mapping or for an anonymous memory mapping. In the former case, the function executes the get_unmapped_area file operation; this is discussed in Chapter 16.
In the latter case, the function executes the get_unmapped_area method of the memory descriptor. In turn, this method is implemented by either the arch_get_unmapped_area( ) function, or the arch_get_unmapped_area_topdown( ) function, according to the memory region layout of the process. As we'll see in the section "Program Segments and Process Memory Regions" in Chapter 20, every process can have two different layouts for the memory regions allocated through the mmap( )
system call: either they start from the linear address 0x40000000 and grow towards higher addresses, or they start right above the User Mode stack and grow towards lower addresses.
Let us discuss the arch_get_unmapped_area( ) function, which is used when the memory regions are allocated moving from lower addresses to higher ones. It is essentially equivalent to the following code fragment:
if (len > TASK_SIZE)
return -ENOMEM;
addr = (addr + 0xfff) & 0xfffff000;
if (addr && addr + len <= TASK_SIZE) {
vma = find_vma(current->mm, addr);
if (!vma || addr + len <= vma->vm_start)
return addr;
}
start_addr = addr = mm->free_area_cache;
for (vma = find_vma(current->mm, addr); ; vma = vma->vm_next) {
if (addr + len > TASK_SIZE) {
if (start_addr == (TASK_SIZE/3+0xfff)&0xfffff000)
return -ENOMEM;
start_addr = addr = (TASK_SIZE/3+0xfff)&0xfffff000;
vma = find_vma(current->mm, addr);
}
if (!vma || addr + len <= vma->vm_start) {
mm->free_area_cache = addr + len;
return addr;
}
addr = vma->vm_end;
}
The function starts by checking to make sure the interval length is within TASK_SIZE, the limit imposed on User Mode linear addresses (usually 3 GB). If addr is different from zero, the function tries to allocate the interval starting from addr. To be on the safe side, the function rounds up the value of addr to a multiple of 4 KB.
If addr is 0 or the previous search failed, the arch_get_unmapped_area( ) function scans the User Mode linear address space looking for a range of linear addresses not included in any memory region and large enough to contain the new region. To speed up the search, the search's starting point is usually set to the linear address following the last allocated memory region. The mm->free_area_cache field of the memory descriptor is initialized to one-third of the User Mode linear address spaceusually, 1 GBand then updated as new memory regions are created. If the function fails in finding a suitable range of linear addresses, the search restarts from the beginningthat is, from one-third of the User Mode linear address space: in fact, the first third of the User Mode linear address space is reserved for memory regions having a predefined starting linear address, typically the text, data, and bss segments of an executable file (see Chapter 20).
The function invokes find_vma( ) to locate the first memory region ending after the search's starting point, then repeatedly considers all the following memory regions. Three cases may occur:
The requested interval is larger than the portion of linear address space yet to be scanned (addr + len > TASK_SIZE): in this case, the function either restarts from one-third of the User Mode address space or, if the second search has already been done, returns -ENOMEM (there are not enough linear addresses to satisfy the request). The hole following the last scanned region is not large enough (vma != NULL && vma->vm_start < addr + len). In this case, the function considers the next region. If neither one of the preceding conditions holds, a large enough hole has been found. In this case, the function returns addr.
9.3.3.4. Inserting a region in the memory descriptor list: insert_vm_struct( )
insert_vm_struct( ) inserts a vm_area_struct structure in the memory region object list and red-black tree of a memory descriptor. It uses two parameters: mm, which specifies the address of a process memory descriptor, and vma, which specifies the address of the vm_area_struct object to be inserted. The vm_start and vm_end fields of the memory region object must have already been initialized. The function invokes the find_vma_prepare( ) function to look up the position in the red-black tree mm->mm_rb where vma should go. Then insert_vm_struct( ) invokes the vma_link( ) function, which in turn:
Inserts the memory region in the linked list referenced by mm->mmap. Inserts the memory region in the red-black tree mm->mm_rb. Increases the mm->map_count counter.
If the region contains a memory-mapped file, the vma_link( ) function performs additional tasks that are described in Chapter 17.
The _ _vma_unlink( ) function receives as its parameters a memory descriptor address mm and two memory region object addresses vma and prev. Both memory regions should belong to mm, and prev should precede vma in the memory region ordering. The function removes vma from the linked list and the red-black tree of the memory descriptor. It also updates mm->mmap_cache, which stores the last referenced memory region, if this field points to the memory region just deleted.
9.3.4. Allocating a Linear Address Interval
Now let's discuss how new linear address intervals
are allocated. To do this, the do_mmap( ) function creates and initializes a new memory region for the current process. However, after a successful allocation, the memory region could be merged with other memory regions defined for the process.
The function uses the following parameters:
file and offset File object pointer file and file offset offset are used if the new memory region will map a file into memory. This topic is discussed in Chapter 16. In this section, we assume that no memory mapping is required and that file and offset are both NULL.
addr This linear address specifies where the search for a free interval must start.
len The length of the linear address interval.
prot This parameter specifies the access rights of the pages included in the memory region. Possible flags are PROT_READ, PROT_WRITE, PROT_EXEC, and PROT_NONE. The first three flags mean the same things as the VM_READ, VM_WRITE, and VM_EXEC flags. PROT_NONE indicates that the process has none of those access rights.
flag This parameter specifies the remaining memory region flags:
MAP_GROWSDOWN, MAP_LOCKED, MAP_DENYWRITE, and MAP_EXECUTABLE Their meanings are identical to those of the flags listed in Table 9-5.
MAP_SHARED and MAP_PRIVATE The former flag specifies that the pages in the memory region can be shared among several processes; the latter flag has the opposite effect. Both flags refer to the VM_SHARED flag in the vm_area_struct descriptor.
MAP_FIXED The initial linear address of the interval must be exactly the one specified in the addr parameter.
MAP_ANONYMOUS No file is associated with the memory region (see Chapter 16).
MAP_NORESERVE The function doesn't have to do a preliminary check on the number of free page frames.
MAP_POPULATE The function should pre-allocate the page frames required for the mapping established by the memory region. This flag is significant only for memory regions that map files (see Chapter 16) and for IPC shared memory regions (see Chapter 19).
MAP_NONBLOCK Significant only when the MAP_POPULATE flag is set: when pre-allocating the page frames, the function must not block.
The do_mmap( ) function performs some preliminary checks on the value of offset and then executes the do_mmap_pgoff( ) function. In this chapter we will suppose that the new interval of linear address does not map a file on diskfile memory mapping is discussed in detail in Chapter 16. Here is a description of the do_mmap_pgoff( ) function for anonymous memory regions:
Checks whether the parameter values are correct and whether the request can be satisfied. In particular, it checks for the following conditions that prevent it from satisfying the request: The linear address interval has zero length or includes addresses greater than TASK_SIZE. The process has already mapped too many memory regionsthat is, the value of the map_count field of its mm memory descriptor exceeds the allowed maximum value. The flag parameter specifies that the pages of the new linear address interval must be locked in RAM, but the process is not allowed to create locked memory regions, or the number of pages locked by the process exceeds the threshold stored in the signal->rlim[RLIMIT_MEMLOCK].rlim_cur field of the process descriptor.
If any of the preceding conditions holds, do_mmap_pgoff( ) terminates by returning a negative value. If the linear address interval has a zero length, the function returns without performing any action. Invokes get_unmapped_area( ) to obtain a linear address interval for the new region (see the previous section "Memory Region Handling"). Computes the flags of the new memory region by combining the values stored in the prot and flags parameters:
vm_flags = calc_vm_prot_bits(prot,flags) |
calc_vm_flag_bits(prot,flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (flags & MAP_SHARED)
vm_flags |= VM_SHARED | VM_MAYSHARE;
The calc_vm_prot_bits( ) function sets the VM_READ, VM_WRITE, and VM_EXEC flags in vm_flags only if the corresponding PROT_READ, PROT_WRITE, and PROT_EXEC flags in prot are set. The calc_vm_flag_bits( ) function sets the VM_GROWSDOWN, VM_DENYWRITE, VM_EXECUTABLE, and VM_LOCKED flags in vm_flags only if the corresponding MAP_GROWSDOWN, MAP_DENYWRITE, MAP_EXECUTABLE, and MAP_LOCKED flags in flags are set. A few other flags are set in vm_flags: VM_MAYREAD, VM_MAYWRITE, VM_MAYEXEC, the default flags for all memory regions in mm->def_flags, and both VM_SHARED and VM_MAYSHARE if the pages of the memory region have to be shared with other processes. Invokes find_vma_prepare( ) to locate the object of the memory region that shall precede the new interval, as well as the position of the new region in the red-black tree:
for (;;) {
vma = find_vma_prepare(mm, addr, &prev, &rb_link, &rb_parent);
if (!vma || vma->vm_start >= addr + len)
break;
if (do_munmap(mm, addr, len))
return -ENOMEM;
}
The find_vma_prepare( ) function also checks whether a memory region that overlaps the new interval already exists. This occurs when the function returns a non-NULL address pointing to a region that starts before the end of the new interval. In this case, do_mmap_pgoff( ) invokes do_munmap( ) to remove the new interval and then repeats the whole step (see the later section "Releasing a Linear Address Interval"). Checks whether inserting the new memory region causes the size of the process address space (mm->total_vm<<PAGE_SHIFT)+len to exceed the threshold stored in the signal->rlim[RLIMIT_AS].rlim_cur field of the process descriptor. If so, it returns the error code -ENOMEM. Notice that the check is done here and not in step 1 with the other checks, because some memory regions could have been removed in step 4. Returns the error code -ENOMEM if the MAP_NORESERVE flag was not set in the flags parameter, the new memory region contains private writable pages, and there are not enough free page frames; this last check is performed by the security_vm_enough_memory( ) function. If the new interval is private (VM_SHARED not set) and it does not map a file on disk, it invokes vma_merge( ) to check whether the preceding memory region can be expanded in such a way to include the new interval. Of course, the preceding memory region must have exactly the same flags as those memory regions stored in the vm_flags local variable. If the preceding memory region can be expanded, vma_merge( ) also tries to merge it with the following memory region (this occurs when the new interval fills the hole between two memory regions and all three have the same flags). In case it succeeds in expanding the preceding memory region, the function jumps to step 12. Allocates a vm_area_struct data structure for the new memory region by invoking the kmem_cache_alloc( ) slab allocator function. Initializes the new memory region object (pointed to by vma):
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = protection_map[vm_flags & 0x0f];
vma->vm_ops = NULL;
vma->vm_pgoff = pgoff;
vma->vm_file = NULL;
vma->vm_private_data = NULL;
vma->vm_next = NULL;
INIT_LIST_HEAD(&vma->shared);
If the MAP_SHARED flag is set (and the new memory region doesn't map a file on disk), the region is a shared anonymous region: invokes shmem_zero_setup( ) to initialize it. Shared anonymous regions are mainly used for interprocess communications; see the section "IPC Shared Memory" in Chapter 19. Invokes vma_link( ) to insert the new region in the memory region list and red-black tree (see the earlier section "Memory Region Handling"). Increases the size of the process address space stored in the total_vm field of the memory descriptor. If the VM_LOCKED flag is set, it invokes make_pages_present( ) to allocate all the pages of the memory region in succession and lock them in RAM:
if (vm_flags & VM_LOCKED) {
mm->locked_vm += len >> PAGE_SHIFT;
make_pages_present(addr, addr + len);
}
The make_pages_present( ) function, in turn, invokes get_user_pages( ) as follows:
write = (vma->vm_flags & VM_WRITE) != 0;
get_user_pages(current, current->mm, addr, len, write, 0, NULL, NULL);
The get_user_pages( ) function cycles through all starting linear addresses of the pages between addr and addr+len; for each of them, it invokes follow_page( ) to check whether there is a mapping to a physical page in the current's Page Tables. If no such physical page exists, get_user_pages( ) invokes handle_mm_fault( ), which, as we'll see in the section "Handling a Faulty Address Inside the Address Space," allocates one page frame and sets its Page Table entry according to the vm_flags field of the memory region descriptor. Finally, it terminates by returning the linear address of the new memory region.
9.3.5. Releasing a Linear Address Interval
When the kernel must delete a linear address interval from the address space of the current process, it uses the do_munmap( ) function. The parameters are: the address mm of the process's memory descriptor, the starting address start of the interval, and its length len. The interval to be deleted does not usually correspond to a memory region; it may be included in one memory region or span two or more regions.
9.3.5.1. The do_munmap( ) function
The function goes through two main phases. In the first phase (steps 16), it scans the list of memory regions owned by the process and unlinks all regions included in the linear address interval from the process address space. In the second phase (steps 712), the function updates the process Page Tables and removes the memory regions identified in the first phase. The function makes use of the split_vma( ) and unmap_region( ) functions, which will be described later. do_munmap( ) executes the following steps:
Performs some preliminary checks on the parameter values. If the linear address interval includes addresses greater than TASK_SIZE, if start is not a multiple of 4,096, or if the linear address interval has a zero length, the function returns the error code -EINVAL. Locates the first memory region mpnt that ends after the linear address interval to be deleted (mpnt->end > start), if any:
mpnt = find_vma_prev(mm, start, &prev);
If there is no such memory region, or if the region does not overlap with the linear address interval, nothing has to be done because there is no memory region in the interval:
end = start + len;
if (!mpnt || mpnt->vm_start >= end)
return 0;
If the linear address interval starts inside the mpnt memory region, it invokes split_vma( ) (described below) to split the mpnt memory region into two smaller regions: one outside the interval and the other inside the interval:
if (start > mpnt->vm_start) {
if (split_vma(mm, mpnt, start, 0))
return -ENOMEM;
prev = mpnt;
}
The prev local variable, which previously stored the pointer to the memory region preceding mpnt, is updated so that it points to mpntthat is, to the new memory region lying outside the linear address interval. In this way, prev still points to the memory region preceding the first memory region to be removed. If the linear address interval ends inside a memory region, it invokes split_vma( ) once again to split the last overlapping memory region into two smaller regions: one inside the interval and the other outside the interval:
last = find_vma(mm, end);
if (last && end > last->vm_start)){
if (split_vma(mm, last, start, end, 1))
return -ENOMEM;
}
Updates the value of mpnt so that it points to the first memory region in the linear address interval. If prev is NULLthat is, there is no preceding memory regionthe address of the first memory region is taken from mm->mmap:
mpnt = prev ? prev->vm_next : mm->mmap;
Invokes detach_vmas_to_be_unmapped( ) to remove the memory regions included in the linear address interval from the process's linear address space. This function essentially executes the following code:
vma = mpnt;
insertion_point = (prev ? &prev->vm_next : &mm->mmap);
do {
rb_erase(&vma->vm_rb, &mm->mm_rb);
mm->map_count--;
tail_vma = vma;
vma = vma->next;
} while (vma && vma->start < end);
*insertion_point = vma;
tail_vma->vm_next = NULL;
mm->map_cache = NULL;
The descriptors of the regions to be removed are stored in an ordered list, whose head is pointed to by the mpnt local variable (actually, this list is just a fragment of the original process's list of memory regions). Gets the mm->page_table_lock spin lock. Invokes unmap_region( ) to clear the Page Table entries covering the linear address interval and to free the corresponding page frames (discussed later):
unmap_region(mm, mpnt, prev, start, end);
Releases the mm->page_table_lock spin lock. Releases the descriptors of the memory regions collected in the list built in step 7:
do {
struct vm_area_struct * next = mpnt->vm_next;
unmap_vma(mm, mpnt);
mpnt = next;
} while (mpnt != NULL);
The unmap_vma( ) function is invoked on every memory region in the list; it essentially executes the following steps: Updates the mm->total_vm and mm->locked_vm fields. Executes the mm->unmap_area method of the memory descriptor. This method is implemented either by arch_unmap_area( ) or by arch_unmap_area_topdown( ), according to the memory region layout of the process (see the earlier section "Memory Region Handling"). In both cases, the mm->free_area_cache field is updated, if needed. Invokes the close method of the memory region, if defined. If the memory region is anonymous, the function removes it from the anonymous memory region list headed at mm->anon_vma. Invokes kmem_cache_free( ) to release the memory region descriptor.
9.3.5.2. The split_vma( ) function
The purpose of the split_vma( ) function is to split a memory region that intersects a linear address interval into two smaller regions, one outside of the interval and the other inside. The function receives four parameters: a memory descriptor pointer mm, a memory area descriptor pointer vma that identifies the region to be split, an address addr that specifies the intersection point between the interval and the memory region, and a flag new_below that specifies whether the intersection occurs at the beginning or at the end of the interval. The function performs the following basic steps:
Invokes kmem_cache_alloc( ) to get an additional vm_area_struct descriptor, and stores its address in the new local variable. If no free memory is available, it returns -ENOMEM. Initializes the fields of the new descriptor with the contents of the fields of the vma descriptor. If the new_below flag is 0, the linear address interval starts inside the vma region, so the new region must be placed after the vma region. Thus, the function sets both the new->vm_start and the vma->vm_end fields to addr. Conversely, if the new_below flag is equal to 1, the linear address interval ends inside the vma region, so the new region must be placed before the vma region. Thus, the function sets both the new->vm_end and the vma->vm_start fields to addr. If the open method of the new memory region is defined, the function executes it. Links the new memory region descriptor to the mm->mmap list of memory regions and to the mm->mm_rb red-black tree. Moreover, the function adjusts the red-black tree to take care of the new size of the memory region vma.
9.3.5.3. The unmap_region( ) function
The unmap_region( ) function walks through a list of memory regions and releases the page frames belonging to them. It acts on five parameters: a memory descriptor pointer mm, a pointer vma to the descriptor of the first memory region being removed, a pointer prev to the memory region preceding vma in the process's list (see steps 2 and 4 in do_munmap()), and two addresses start and end that delimit the linear address interval being removed. The function essentially executes the following steps:
Invokes the tlb_gather_mmu( ) function to initialize a per-CPU variable named mmu_gathers. The contents of mmu_gathers are architecture-dependent: generally speaking, the variable should store all information required for a successful updating of the page table entries of a process. In the 80 x 86 architecture, the tlb_gather_mmu( ) function simply saves the value of the mm memory descriptor pointer in the mmu_gathers variable of the local CPU. Stores the address of the mmu_gathers variable in the tlb local variable. Invokes unmap_vmas( ) to scan all Page Table entries belonging to the linear address interval: if only one CPU is available, the function invokes free_swap_and_cache( ) repeatedly to release the corresponding pages (see Chapter 17); otherwise, the function saves the pointers of the corresponding page descriptors in the mmu_gathers local variable. Invokes free_pgtables(tlb,prev,start,end) to try to reclaim the Page Tables of the process that have been emptied in the previous step. Invokes tlb_finish_mmu(tlb,start,end) to finish the work: in turn, this function: In multiprocessor system, invokes free_pages_and_swap_cache( ) to release the page frames whose pointers have been collected in the mmu_gather data structure. This function is described in Chapter 17.
|
9.4. Page Fault Exception Handler
As stated previously, the Linux Page Fault exception handler
must distinguish exceptions caused by programming errors from those caused by a reference to a page that legitimately belongs to the process address space but simply hasn't been allocated yet.
The memory region descriptors allow the exception handler to perform its job quite efficiently. The do_page_fault( ) function, which is the Page Fault interrupt service routine for the 80 x 86 architecture, compares the linear address that caused the Page Fault against the memory regions of the current process; it can thus determine the proper way to handle the exception according to the scheme that is illustrated in Figure 9-4.
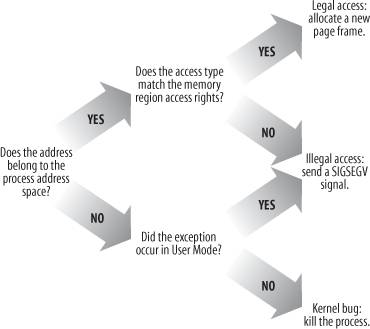
In practice, things are a lot more complex because the Page Fault handler must recognize several particular subcases that fit awkwardly into the overall scheme, and it must distinguish several kinds of legal access. A detailed flow diagram of the handler is illustrated in Figure 9-5.
The identifiers vmalloc_fault, good_area, bad_area, and no_context are labels appearing in do_page_fault( ) that should help you to relate the blocks of the flow diagram to specific lines of code.
The do_ page_fault( ) function accepts the following input parameters:
The regs address of a pt_regs structure containing the values of the microprocessor registers when the exception occurred. A 3-bit error_code, which is pushed on the stack by the control unit when the exception occurred (see "Hardware Handling of Interrupts and Exceptions" in Chapter 4). The bits have the following meanings: If bit 0 is clear, the exception was caused by an access to a page that is not present (the Present flag in the Page Table entry is clear); otherwise, if bit 0 is set, the exception was caused by an invalid access right.
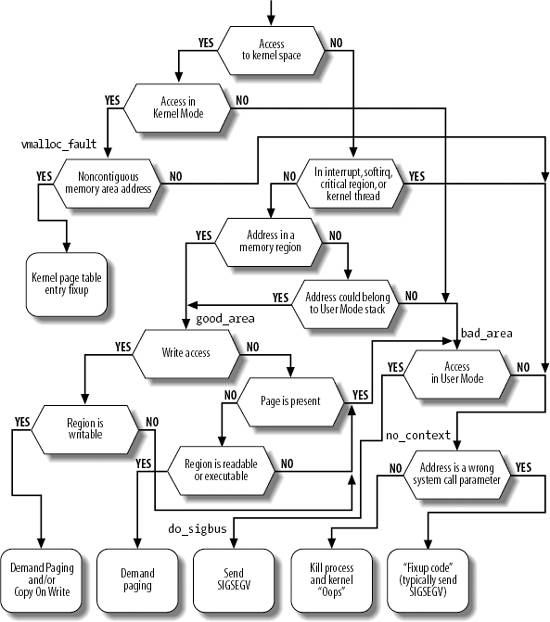 If bit 1 is clear, the exception was caused by a read or execute access; if set, the exception was caused by a write access. If bit 2 is clear, the exception occurred while the processor was in Kernel Mode; otherwise, it occurred in User Mode.
The first operation of do_ page_fault( ) consists of reading the linear address that caused the Page Fault. When the exception occurs, the CPU control unit stores that value in the cr2
control register:
asm("movl %%cr2,%0":"=r" (address));
if (regs->eflags & 0x00020200)
local_irq_enable( );
tsk = current;
The linear address is saved in the address local variable. The function also ensures that local interrupts are enabled if they were enabled before the fault or the CPU was running in virtual-8086 mode, and saves the pointers to the process descriptor of current in the tsk local variable.
As shown at the top of Figure 9-5, do_ page_fault( ) checks whether the faulty linear address belongs to the fourth gigabyte:
info.si_code = SEGV_MAPERR;
if (address >= TASK_SIZE ) {
if (!(error_code & 0x101))
goto vmalloc_fault;
goto bad_area_nosemaphore;
}
If the exception was caused by the kernel trying to access a nonexisting page frame, a jump is made to the code at label vmalloc_fault, which takes care of faults that were likely caused by accessing a noncontiguous memory area in Kernel Mode; we describe this case in the later section "Handling Noncontiguous Memory Area Accesses." Otherwise, a jump is made to the code at the bad_area_nosemaphore label, described in the later section "Handling a Faulty Address Outside the Address Space."
Next, the handler checks whether the exception occurred while the kernel was executing some critical routine or running a kernel thread (remember that the mm field of the process descriptor is always NULL for kernel threads
):
if (in_atomic( ) || !tsk->mm)
goto bad_area_nosemaphore;
The in_atomic( ) macro yields the value one if the fault occurred while either one of the following conditions holds:
If the Page Fault did occur in an interrupt handler, in a deferrable function, in a critical region, or in a kernel thread, do_ page_fault( ) does not try to compare the linear address with the memory regions of current. Kernel threads never use linear addresses below TASK_SIZE. Similarly, interrupt handlers, deferrable functions, and code of critical regions should not use linear addresses below TASK_SIZE because this might block the current process. (See the section "Handling a Faulty Address Outside the Address Space" later in this chapter for information on the info local variable and a description of the code at the bad_area_nosemaphore label.)
Let's suppose that the Page Fault did not occur in an interrupt handler, in a deferrable function, in a critical region, or in a kernel thread. Then the function must inspect the memory regions owned by the process to determine whether the faulty linear address is included in the process address space. In order to this, it must acquire the mmap_sem read/write semaphore of the process:
if (!down_read_trylock(&tsk->mm>mmap_sem)) {
if ((error_code & 4) == 0 &&
!search_exception_table(regs->eip))
goto bad_area_nosemaphore;
down_read(&tsk->mm->mmap_sem);
}
If kernel bugs and hardware malfunctioning can be ruled out, the current process has not already acquired the mmap_sem semaphore for writing when the Page Fault occurs. However, do_page_fault( ) wants to be sure that this is actually true, because otherwise a deadlock would occur. For that reason, the function makes use of down_read_trylock( ) instead of down_read( ) (see the section "Read/Write Semaphores" in Chapter 5). If the semaphore is closed and the Page Fault occurred in Kernel Mode, do_page_fault( ) determines whether the exception occurred while using some linear address that has been passed to the kernel as a parameter of a system call (see the next section "Handling a Faulty Address Outside the Address Space"). In this case, do_page_fault( ) knows for sure that the semaphore is owned by another processbecause every system call service routine carefully avoids acquiring the mmap_sem semaphore for writing before accessing the User Mode address spaceso the function waits until the semaphore is released. Otherwise, the Page Fault is due to a kernel bug or to a serious hardware problem, so the function jumps to the bad_area_nosemaphore label.
Let's assume that the mmap_sem semaphore has been safely acquired for reading. Now do_page_fault( ) looks for a memory region containing the faulty linear address:
vma = find_vma(tsk->mm, address);
if (!vma)
goto bad_area;
if (vma->vm_start <= address)
goto good_area;
If vma is NULL, there is no memory region ending after address, and thus the faulty address is certainly bad. On the other hand, if the first memory region ending after address includes address, the function jumps to the code at label good_area.
If none of the two "if" conditions are satisfied, the function has determined that address is not included in any memory region; however, it must perform an additional check, because the faulty address may have been caused by a push or pusha instruction on the User Mode stack of the process.
Let's make a short digression to explain how stacks are mapped into memory regions. Each region that contains a stack expands toward lower addresses; its VM_GROWSDOWN flag is set, so the value of its vm_end field remains fixed while the value of its vm_start field may be decreased. The region boundaries include, but do not delimit precisely, the current size of the User Mode stack. The reasons for the fuzz factor are:
The region size is a multiple of 4 KB (it must include complete pages) while the stack size is arbitrary. Page frames assigned to a region are never released until the region is deleted; in particular, the value of the vm_start field of a region that includes a stack can only decrease; it can never increase. Even if the process executes a series of pop instructions, the region size remains unchanged.
It should now be clear how a process that has filled up the last page frame allocated to its stack may cause a Page Fault exception: the push refers to an address outside of the region (and to a nonexistent page frame). Notice that this kind of exception is not caused by a programming error; thus it must be handled separately by the Page Fault handler.
We now return to the description of do_ page_fault( ), which checks for the case described previously:
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
if (error_code & 4 /* User Mode */
&& address + 32 < regs->esp)
goto bad_area;
if (expand_stack(vma, address))
goto bad_area;
goto good_area;
If the VM_GROWSDOWN flag of the region is set and the exception occurred in User Mode, the function checks whether address is smaller than the regs->esp stack pointer (it should be only a little smaller). Because a few stack-related assembly language instructions (such as pusha) perform a decrement of the esp register only after the memory access, a 32-byte tolerance interval is granted to the process. If the address is high enough (within the tolerance granted), the code invokes the expand_stack( ) function to check whether the process is allowed to extend both its stack and its address space; if everything is OK, it sets the vm_start field of vma to address and returns 0; otherwise, it returns -ENOMEM.
Note that the preceding code skips the tolerance check whenever the VM_GROWSDOWN flag of the region is set and the exception did not occur in User Mode. These conditions mean that the kernel is addressing the User Mode stack and that the code should always run expand_stack( ).
9.4.1. Handling a Faulty Address Outside the Address Space
If address does not belong to the process address space, do_page_fault( ) proceeds to execute the statements at the label bad_area. If the error occurred in User Mode, it sends a SIGSEGV signal to current (see the section "Generating a Signal" in Chapter 11) and terminates:
bad_area:
up_read(&tsk->mm->mmap_sem);
bad_area_nosemaphore:
if (error_code & 4) { /* User Mode */
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code | (address >= TASK_SIZE);
tsk->thread.trap_no = 14;
info.si_signo = SIGSEGV;
info.si_errno = 0;
info.si_addr = (void *) address;
force_sig_info(SIGSEGV, &info, tsk);
return;
}
The force_sig_info( ) function makes sure that the process does not ignore or block the SIGSEGV signal, and sends the signal to the User Mode process while passing some additional information in the info local variable (see the section "Generating a Signal" in Chapter 11). The info.si_code field is already set to SEGV_MAPERR (if the exception was due to a nonexisting page frame) or to SEGV_ACCERR (if the exception was due to an invalid access to an existing page frame).
If the exception occurred in Kernel Mode (bit 2 of error_code is clear), there are still two alternatives:
The function distinguishes these two alternatives as follows:
no_context:
if ((fixup = search_exception_table(regs->eip)) != 0) {
regs->eip = fixup;
return;
}
In the first case, it jumps to a "fixup code," which typically sends a SIGSEGV signal to current or terminates a system call handler with a proper error code (see the section "Dynamic Address Checking: The Fix-up Code" in Chapter 10).
In the second case, the function prints a complete dump of the CPU registers and of the Kernel Mode stack both on the console and on a system message buffer; it then kills the current process by invoking the do_exit( ) function (see Chapter 20). This is the so-called "Kernel oops" error, named after the message displayed. The dumped values can be used by kernel hackers to reconstruct the conditions that triggered the bug, and thus find and correct it.
9.4.2. Handling a Faulty Address Inside the Address Space
If address belongs to the process address space, do_ page_fault( ) proceeds to the statement labeled good_area:
good_area:
info.si_code = SEGV_ACCERR;
write = 0;
if (error_code & 2) { /* write access */
if (!(vma->vm_flags & VM_WRITE))
goto bad_area;
write++;
} else /* read access */
if ((error_code & 1) || !(vma->vm_flags & (VM_READ | VM_EXEC)))
goto bad_area;
If the exception was caused by a write access, the function checks whether the memory region is writable. If not, it jumps to the bad_area code; if so, it sets the write local variable to 1.
If the exception was caused by a read or execute access, the function checks whether the page is already present in RAM. In this case, the exception occurred because the process tried to access a privileged page frame (one whose User/Supervisor flag is clear) in User Mode, so the function jumps to the bad_area code. If the page is not present, the function also checks whether the memory region is readable or executable.
If the memory region access rights match the access type that caused the exception, the handle_mm_fault( ) function is invoked to allocate a new page frame:
survive:
ret = handle_mm_fault(tsk->mm, vma, address, write);
if (ret == VM_FAULT_MINOR || ret == VM_FAULT_MAJOR) {
if (ret == VM_FAULT_MINOR) tsk->min_flt++; else tsk->maj_flt++;
up_read(&tsk->mm->mmap_sem);
return;
}
The handle_mm_fault( ) function returns VM_FAULT_MINOR or VM_FAULT_MAJOR if it succeeded in allocating a new page frame for the process. The value VM_FAULT_MINOR indicates that the Page Fault has been handled without blocking the current process; this kind of Page Fault is called minor fault. The value VM_FAULT_MAJOR indicates that the Page Fault forced the current process to sleep (most likely because time was spent while filling the page frame assigned to the process with data read from disk); a Page Fault that blocks the current process is called a major fault. The function can also return VM_FAULT_OOM (for not enough memory) or VM_FAULT_SIGBUS (for every other error).
If handle_mm_fault( ) returns the value VM_FAULT_SIGBUS, a SIGBUS signal is sent to the process:
if (ret == VM_FAULT_SIGBUS) {
do_sigbus:
up_read(&tsk->mm->mmap_sem);
if (!(error_code & 4)) /* Kernel Mode */
goto no_context;
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_no = 14;
info.si_signo = SIGBUS;
info.si_errno = 0;
info.si_code = BUS_ADRERR;
info.si_addr = (void *) address;
force_sig_info(SIGBUS, &info, tsk);
}
If handle_mm_fault( ) cannot allocate the new page frame, it returns the value VM_FAULT_OOM; in this case, the kernel usually kills the current process. However, if current is the init process, it is just put at the end of the run queue and the scheduler is invoked; once init resumes its execution, handle_mm_fault( ) is executed again:
if (ret == VM_FAULT_OOM) {
out_of_memory:
up_read(&tsk->mm->mmap_sem);
if (tsk->pid != 1) {
if (error_code & 4) /* User Mode */
do_exit(SIGKILL);
goto no_context;
}
yield();
down_read(&tsk->mm->mmap_sem);
goto survive;
}
The handle_mm_fault( ) function acts on four parameters:
mm A pointer to the memory descriptor of the process that was running on the CPU when the exception occurred
vma A pointer to the descriptor of the memory region, including the linear address that caused the exception
address The linear address that caused the exception
write_access Set to 1 if tsk attempted to write in address and to 0 if tsk attempted to read or execute it
The function starts by checking whether the Page Middle Directory and the Page Table used to map address exist. Even if address belongs to the process address space, the corresponding Page Tables might not have been allocated, so the task of allocating them precedes everything else:
pgd = pgd_offset(mm, address);
spin_lock(&mm->page_table_lock);
pud = pud_alloc(mm, pgd, address);
if (pud) {
pmd = pmd_alloc(mm, pud, address);
if (pmd) {
pte = pte_alloc_map(mm, pmd, address);
if (pte)
return handle_pte_fault(mm, vma, address,
write_access, pte, pmd);
}
}
spin_unlock(&mm->page_table_lock);
return VM_FAULT_OOM;
The pgd local variable contains the Page Global Directory entry that refers to address; pud_alloc( ) and pmd_alloc( ) are invoked to allocate, if needed, a new Page Upper Directory and a new Page Middle Directory, respectively. pte_alloc_map( ) is then invoked to allocate, if needed, a new Page Table. If both operations are successful, the pte local variable points to the Page Table entry that refers to address. The handle_pte_fault( ) function is then invoked to inspect the Page Table entry corresponding to address and to determine how to allocate a new page frame for the process:
If the accessed page is not presentthat is, if it is not already stored in any page framethe kernel allocates a new page frame and initializes it properly; this technique is called demand paging
. If the accessed page is present but is marked read-onlyi.e., if it is already stored in a page framethe kernel allocates a new page frame and initializes its contents by copying the old page frame data; this technique is called Copy On Write.
9.4.3. Demand Paging
The term demand paging denotes a dynamic memory allocation technique that consists of deferring page frame allocation until the last possible momentuntil the process attempts to address a page that is not present in RAM, thus causing a Page Fault exception.
The motivation behind demand paging is that processes do not address all the addresses included in their address space right from the start; in fact, some of these addresses may never be used by the process. Moreover, the program locality principle
(see the section "Hardware Cache" in Chapter 2) ensures that, at each stage of program execution, only a small subset of the process pages are really referenced, and therefore the page frames containing the temporarily useless pages can be used by other processes. Demand paging is thus preferable to global allocation (assigning all page frames to the process right from the start and leaving them in memory until program termination), because it increases the average number of free page frames in the system and therefore allows better use of the available free memory. From another viewpoint, it allows the system as a whole to get better throughput with the same amount of RAM.
The price to pay for all these good things is system overhead: each Page Fault exception induced by demand paging must be handled by the kernel, thus wasting CPU cycles. Fortunately, the locality principle ensures that once a process starts working with a group of pages, it sticks with them without addressing other pages for quite a while. Thus, Page Fault exceptions may be considered rare events.
An addressed page may not be present in main memory either because the page was never accessed by the process, or because the corresponding page frame has been reclaimed by the kernel (see Chapter 17).
In both cases, the page fault handler must assign a new page frame to the process. How this page frame is initialized, however, depends on the kind of page and on whether the page was previously accessed by the process. In particular:
Either the page was never accessed by the process and it does not map a disk file, or the page maps a disk file. The kernel can recognize these cases because the Page Table entry is filled with zerosi.e., the pte_none macro returns the value 1. The page belongs to a non-linear disk file mapping (see the section "Non-Linear Memory Mappings" in Chapter 16). The kernel can recognize this case, because the Present flag is cleared and the Dirty flag is seti.e., the pte_file macro returns the value 1. The page was already accessed by the process, but its content is temporarily saved on disk. The kernel can recognize this case because the Page Table entry is not filled with zeros, but the Present and Dirty flags are cleared.
Thus, the handle_ pte_fault( ) function is able to distinguish the three cases by inspecting the Page Table entry that refers to address:
entry = *pte;
if (!pte_present(entry)) {
if (pte_none(entry))
return do_no_page(mm, vma, address, write_access, pte, pmd);
if (pte_file(entry))
return do_file_page(mm, vma, address, write_access, pte, pmd);
return do_swap_page(mm, vma, address, pte, pmd, entry, write_access);
}
We'll examine cases 2 and 3 in Chapter 16 and in Chapter 17, respectively.
In case 1, when the page was never accessed or the page linearly maps a disk file, the do_no_page( ) function is invoked. There are two ways to load the missing page, depending on whether the page is mapped to a disk file. The function determines this by checking the nopage method of the vma memory region object, which points to the function that loads the missing page from disk into RAM if the page is mapped to a file. Therefore, the possibilities are:
The vma->vm_ops->nopage field is not NULL. In this case, the memory region maps a disk file and the field points to the function that loads the page. This case is covered in the section "Demand Paging for Memory Mapping" in Chapter 16 and in the section "IPC Shared Memory" in Chapter 19. Either the vma->vm_ops field or the vma->vm_ops->nopage field is NULL. In this case, the memory region does not map a file on diski.e., it is an anonymous mapping
. Thus, do_no_ page( ) invokes the do_anonymous_page( ) function to get a new page frame:
if (!vma->vm_ops || !vma->vm_ops->nopage)
return do_anonymous_page(mm, vma, page_table, pmd,
write_access, address);
The do_anonymous_page( ) function handles write and read requests separately:
if (write_access) {
pte_unmap(page_table);
spin_unlock(&mm->page_table_lock);
page = alloc_page(GFP_HIGHUSER | _ _GFP_ZERO);
spin_lock(&mm->page_table_lock);
page_table = pte_offset_map(pmd, addr);
mm->rss++;
entry = maybe_mkwrite(pte_mkdirty(mk_pte(page,
vma->vm_page_prot)), vma);
lru_cache_add_active(page);
SetPageReferenced(page);
set_pte(page_table, entry);
pte_unmap(page_table);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR;
}
The first execution of the pte_unmap macro releases the temporary kernel mapping for the high-memory physical address of the Page Table entry established by pte_offset_map before invoking the handle_pte_fault( ) function (see Table 2-7 in the section "Page Table Handling" in Chapter 2). The following pair or pte_offset_map and pte_unmap macros acquires and releases the same temporary kernel mapping. The temporary kernel mapping has to be released before invoking alloc_page( ), because this function might block the current process.
The function increases the rss field of the memory descriptor to keep track of the number of page frames allocated to the process. The Page Table entry is then set to the physical address of the page frame, which is marked as writable and dirty. The lru_cache_add_active( ) function inserts the new page frame in the swap-related data structures; we discuss it in Chapter 17.
Conversely, when handling a read access, the content of the page is irrelevant because the process is addressing it for the first time. It is safer to give a page filled with zeros to the process rather than an old page filled with information written by some other process. Linux goes one step further in the spirit of demand paging. There is no need to assign a new page frame filled with zeros to the process right away, because we might as well give it an existing page called zero page
, thus deferring further page frame allocation. The zero page is allocated statically during kernel initialization in the empty_zero_page variable (an array of 4,096 bytes filled with zeros).
The Page Table entry is thus set with the physical address of the zero page:
entry = pte_wrprotect(mk_pte(virt_to_page(empty_zero_page),
vma->vm_page_prot));
set_pte(page_table, entry);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR;
Because the page is marked as nonwritable, if the process attempts to write in it, the Copy On Write mechanism is activated. Only then does the process get a page of its own to write in. The mechanism is described in the next section.
9.4.4. Copy On Write
First-generation Unix systems implemented process creation in a rather clumsy way: when a fork( ) system call was issued, the kernel duplicated the whole parent address space in the literal sense of the word and assigned the copy to the child process. This activity was quite time consuming since it required:
Allocating page frames for the Page Tables of the child process Allocating page frames for the pages of the child process Initializing the Page Tables of the child process Copying the pages of the parent process into the corresponding pages of the child process
This way of creating an address space involved many memory accesses, used up many CPU cycles, and completely spoiled the cache contents. Last but not least, it was often pointless because many child processes start their execution by loading a new program, thus discarding entirely the inherited address space (see Chapter 20).
Modern Unix kernels, including Linux, follow a more efficient approach called Copy On Write (COW
). The idea is quite simple: instead of duplicating page frames, they are shared between the parent and the child process. However, as long as they are shared, they cannot be modified. Whenever the parent or the child process attempts to write into a shared page frame, an exception occurs. At this point, the kernel duplicates the page into a new page frame that it marks as writable. The original page frame remains write-protected: when the other process tries to write into it, the kernel checks whether the writing process is the only owner of the page frame; in such a case, it makes the page frame writable for the process.
The _count field of the page descriptor is used to keep track of the number of processes that are sharing the corresponding page frame. Whenever a process releases a page frame or a Copy On Write is executed on it, its _count field is decreased; the page frame is freed only when _count becomes -1 (see the section "Page Descriptors" in Chapter 8).
Let's now describe how Linux implements COW. When handle_ pte_fault( ) determines that the Page Fault exception was caused by an access to a page present in memory, it executes the following instructions:
if (pte_present(entry)) {
if (write_access) {
if (!pte_write(entry))
return do_wp_page(mm, vma, address, pte, pmd, entry);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
set_pte(pte, entry);
flush_tlb_page(vma, address);
pte_unmap(pte);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR;
}
The handle_pte_fault( ) function is architecture-independent: it considers each possible violation of the page access rights. However, in the 80 x 86 architecture, if the page is present, the access was for writing and the page frame is write-protected (see the earlier section "Handling a Faulty Address Inside the Address Space"). Thus, the do_wp_page( ) function is always invoked.
The do_wp_page( ) function starts by deriving the page descriptor of the page frame referenced by the Page Table entry involved in the Page Fault exception. Next, the function determines whether the page must really be duplicated. If only one process owns the page, Copy On Write does not apply, and the process should be free to write the page. Basically, the function reads the _count field of the page descriptor: if it is equal to 0 (a single owner), COW must not be done. Actually, the check is slightly more complicated, because the _count field is also increased when the page is inserted into the swap cache (see the section "The Swap Cache" in Chapter 17) and when the PG_private flag in the page descriptor is set. However, when COW is not to be done, the page frame is marked as writable, so that it does not cause further Page Fault exceptions when writes are attempted:
set_pte(page_table, maybe_mkwrite(pte_mkyoung(pte_mkdirty(pte)),vma));
flush_tlb_page(vma, address);
pte_unmap(page_table);
spin_unlock(&mm->page_table_lock);
return VM_FAULT_MINOR;
If the page is shared among several processes by means of COW, the function copies the content of the old page frame (old_page) into the newly allocated one (new_page). To avoid race conditions, get_page( ) is invoked to increase the usage counter of old_page before starting the copy operation:
old_page = pte_page(pte);
pte_unmap(page_table);
get_page(old_page);
spin_unlock(&mm->page_table_lock);
if (old_page == virt_to_page(empty_zero_page))
new_page = alloc_page(GFP_HIGHUSER | _ _GFP_ZERO);
} else {
new_page = alloc_page(GFP_HIGHUSER);
vfrom = kmap_atomic(old_page, KM_USER0)
vto = kmap_atomic(new_page, KM_USER1);
copy_page(vto, vfrom);
kunmap_atomic(vfrom, KM_USER0);
kunmap_atomic(vto, KM_USER0);
}
If the old page is the zero page, the new frame is efficiently filled with zeros when it is allocated (_ _GFP_ZERO flag). Otherwise, the page frame content is copied using the copy_page( ) macro. Special handling for the zero page is not strictly required, but it improves the system performance, because it preserves the microprocessor hardware cache by making fewer address references.
Because the allocation of a page frame can block the process, the function checks whether the Page Table entry has been modified since the beginning of the function (pte and *page_table do not have the same value). In this case, the new page frame is released, the usage counter of old_page is decreased (to undo the increment made previously), and the function terminates.
If everything looks OK, the physical address of the new page frame is finally written into the Page Table entry, and the corresponding TLB register is invalidated:
spin_lock(&mm->page_table_lock);
entry = maybe_mkwrite(pte_mkdirty(mk_pte(new_page,
vma->vm_page_prot)),vma);
set_pte(page_table, entry);
flush_tlb_page(vma, address);
lru_cache_add_active(new_page);
pte_unmap(page_table);
spin_unlock(&mm->page_table_lock);
The lru_cache_add_active( ) function inserts the new page frame in the swap-related data structures; see Chapter 17 for its description.
Finally, do_wp_page( ) decreases the usage counter of old_page twice. The first decrement undoes the safety increment made before copying the page frame contents; the second decrement reflects the fact that the current process no longer owns the page frame.
9.4.5. Handling Noncontiguous Memory Area Accesses
We have seen in the section "Noncontiguous Memory Area Management" in Chapter 8 that the kernel is quite lazy in updating the Page Table entries corresponding to noncontiguous memory areas. In fact, the vmalloc( ) and vfree( ) functions limit themselves to updating the master kernel Page Tables (i.e., the Page Global Directory init_mm.pgd and its child Page Tables).
However, once the kernel initialization phase ends, the master kernel Page Tables are not directly used by any process or kernel thread. Thus, consider the first time that a process in Kernel Mode accesses a noncontiguous memory area. When translating the linear address into a physical address, the CPU's memory management unit encounters a null Page Table entry and raises a Page Fault. However, the handler recognizes this special case because the exception occurred in Kernel Mode, and the faulty linear address is greater than TASK_SIZE. Thus, the do_page_fault( ) handler checks the corresponding master kernel Page Table entry:
vmalloc_fault:
asm("movl %%cr3
,%0":"=r" (pgd_paddr));
pgd = pgd_index(address) + (pgd_t *) _ _va(pgd_paddr);
pgd_k = init_mm.pgd + pgd_index(address);
if (!pgd_present(*pgd_k))
goto no_context;
pud = pud_offset(pgd, address);
pud_k = pud_offset(pgd_k, address);
if (!pud_present(*pud_k))
goto no_context;
pmd = pmd_offset(pud, address);
pmd_k = pmd_offset(pud_k, address);
if (!pmd_present(*pmd_k))
goto no_context;
set_pmd(pmd, *pmd_k);
pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
goto no_context;
return;
The pgd_paddr local variable is loaded with the physical address of the Page Global Directory of the current process, which is stored in the cr3 register. The pgd local variable is then loaded with the linear address corresponding to pgd_paddr, and the pgd_k local variable is loaded with the linear address of the master kernel Page Global Directory.
If the master kernel Page Global Directory entry corresponding to the faulty linear address is null, the function jumps to the code at the no_context label (see the earlier section "Handling a Faulty Address Outside the Address Space"). Otherwise, the function looks at the master kernel Page Upper Directory entry and at the master kernel Page Middle Directory entry corresponding to the faulty linear address. Again, if either one of these entries is null, a jump is done to the no_context label. Otherwise, the master entry is copied into the corresponding entry of the process's Page Middle Directory. Then the whole operation is repeated with the master Page Table entry.
|
9.5. Creating and Deleting a Process Address Space
Of the six typical cases mentioned earlier in the section "The Process's Address Space," in which a process gets new memory regions, the first oneissuing a fork( ) system callrequires the creation of a whole new address space for the child process. Conversely, when a process terminates, the kernel destroys its address space. In this section, we discuss how these two activities are performed by Linux.
9.5.1. Creating a Process Address Space
In the section "The clone( ), fork( ), and vfork( ) System Calls" in Chapter 3, we mentioned that the kernel invokes the copy_mm( ) function while creating
a new process. This function creates the process address space by setting up all Page Tables and memory descriptors of the new process.
Each process usually has its own address space, but lightweight processes can be created by calling clone( ) with the CLONE_VM flag set. These processes share the same address space; that is, they are allowed to address the same set of pages.
Following the COW approach described earlier, traditional processes inherit the address space of their parent: pages stay shared as long as they are only read. When one of the processes attempts to write one of them, however, the page is duplicated; after some time, a forked process usually gets its own address space that is different from that of the parent process. Lightweight processes, on the other hand, use the address space of their parent process. Linux implements them simply by not duplicating address space. Lightweight processes can be created considerably faster than normal processes, and the sharing of pages can also be considered a benefit as long as the parent and children coordinate their accesses carefully.
If the new process has been created by means of the clone( ) system call and if the CLONE_VM flag of the flag parameter is set, copy_mm( ) gives the clone (tsk) the address space of its parent (current):
if (clone_flags & CLONE_VM) {
atomic_inc(¤t->mm->mm_users);
spin_unlock_wait(¤t->mm->page_table_lock);
tsk->mm = current->mm;
tsk->active_mm = current->mm;
return 0;
}
Invoking the spin_unlock_wait( ) function ensures that, if the page table spin lock of the process is held by some other CPU, the page fault handler does not terminate until that lock is released. In fact, beside protecting the page tables, this spin lock must forbid the creation of new lightweight processes sharing the current->mm descriptor.
If the CLONE_VM flag is not set, copy_mm( ) must create a new address space (even though no memory is allocated within that address space until the process requests an address). The function allocates a new memory descriptor, stores its address in the mm field of the new process descriptor tsk, and copies the contents of current->mm into tsk->mm. It then changes a few fields of the new descriptor:
tsk->mm = kmem_cache_alloc(mm_cachep, SLAB_KERNEL);
memcpy(tsk->mm, current->mm, sizeof(*tsk->mm));
atomic_set(&tsk->mm->mm_users, 1);
atomic_set(&tsk->mm->mm_count, 1);
init_rwsem(&tsk->mm->mmap_sem);
tsk->mm->core_waiters = 0;
tsk->mm->page_table_lock = SPIN_LOCK_UNLOCKED;
tsk->mm->ioctx_list_lock = RW_LOCK_UNLOCKED;
tsk->mm->ioctx_list = NULL;
tsk->mm->default_kioctx = INIT_KIOCTX(tsk->mm->default_kioctx,
*tsk->mm);
tsk->mm->free_area_cache = (TASK_SIZE/3+0xfff)&0xfffff000;
tsk->mm->pgd = pgd_alloc(tsk->mm);
tsk->mm->def_flags = 0;
Remember that the pgd_alloc( ) macro allocates a Page Global Directory for the new process.
The architecture-dependent init_new_context( ) function is then invoked: when dealing with 80 x 86 processors, this function checks whether the current process owns a customized Local Descriptor Table; if so, init_new_context( ) makes a copy of the Local Descriptor Table of current and adds it to the address space of tsk.
Finally, the dup_mmap( ) function is invoked to duplicate both the memory regions and the Page Tables of the parent process. This function inserts the new memory descriptor tsk->mm in the global list of memory descriptors. Then it scans the list of regions owned by the parent process, starting from the one pointed to by current->mm->mmap. It duplicates each vm_area_struct memory region descriptor encountered and inserts the copy in the list of regions and in the red-black tree owned by the child process.
Right after inserting a new memory region descriptor, dup_mmap( ) invokes copy_page_range( ) to create, if necessary, the Page Tables needed to map the group of pages included in the memory region and to initialize the new Page Table entries. In particular, each page frame corresponding to a private, writable page (VM_SHARED flag off and VM_MAYWRITE flag on) is marked as read-only for both the parent and the child, so that it will be handled with the Copy On Write mechanism.
9.5.2. Deleting a Process Address Space
When a process terminates, the kernel invokes the exit_mm( ) function to release the address space owned by that process:
mm_release(tsk, tsk->mm);
if (!(mm = tsk->mm)) /* kernel thread ? */
return;
down_read(&mm->mmap_sem);
The mm_release( ) function essentially wakes up all processes sleeping in the tsk->vfork_done completion (see the section "Completions" in Chapter 5). Typically, the corresponding wait queue is nonempty only if the exiting process was created by means of the vfork( )
system call (see the section "The clone( ), fork( ), and vfork( ) System Calls" in Chapter 3).
If the process being terminated is not a kernel thread, the exit_mm( ) function must release the memory descriptor and all related data structures. First of all, it checks whether the mm->core_waiters flag is set: if it does, then the process is dumping the contents of the memory to a core file. To avoid corruption in the core file, the function makes use of the mm->core_done and mm->core_startup_done completions to serialize the execution of the lightweight processes sharing the same memory descriptor mm.
Next, the function increases the memory descriptor's main usage counter, resets the mm field of the process descriptor, and puts the processor in lazy TLB mode (see "Handling the Hardware Cache and the TLB" in Chapter 2):
atomic_inc(&mm->mm_count);
spin_lock(tsk->alloc_lock);
tsk->mm = NULL;
up_read(&mm->map_sem);
enter_lazy_tlb(mm, current);
spin_unlock(tsk->alloc_lock);
mmput(mm);
Finally, the mmput( ) function is invoked to release the Local Descriptor Table, the memory region descriptors, and the Page Tables. The memory descriptor itself, however, is not released, because exit_mm( ) has increased the main usage counter. The descriptor will be released by the finish_task_switch( ) function when the process being terminated will be effectively evicted from the local CPU (see the section "The schedule( ) Function" in Chapter 7).
|
9.6. Managing the Heap
Each Unix process owns a specific memory region called the heap, which is used to satisfy the process's dynamic memory requests. The start_brk and brk fields of the memory descriptor delimit the starting and ending addresses, respectively, of that region.
The following APIs can be used by the process to request and release dynamic memory:
malloc(size) Requests size bytes of dynamic memory; if the allocation succeeds, it returns the linear address of the first memory location.
calloc(n,size) Requests an array consisting of n elements of size size; if the allocation succeeds, it initializes the array components to 0 and returns the linear address of the first element.
realloc(ptr,size) Changes the size of a memory area previously allocated by malloc( )
or calloc( )
.
free(addr) Releases the memory region allocated by malloc( ) or calloc( ) that has an initial address of addr.
brk(addr) Modifies the size of the heap directly; the addr parameter specifies the new value of current->mm->brk, and the return value is the new ending address of the memory region (the process must check whether it coincides with the requested addr value).
sbrk(incr) Is similar to brk( )
, except that the incr parameter specifies the increment or decrement of the heap size in bytes.
The brk( ) function differs from the other functions listed because it is the only one implemented as a system call. All the other functions are implemented in the C library by using brk( ) and mmap( ).
When a process in User Mode invokes the brk( ) system call, the kernel executes the sys_brk(addr) function. This function first verifies whether the addr parameter falls inside the memory region that contains the process code; if so, it returns immediately because the heap cannot overlap with memory region containing the process's code:
mm = current->mm;
down_write(&mm->mmap_sem);
if (addr < mm->end_code) {
out:
up_write(&mm->mmap_sem);
return mm->brk;
}
Because the brk( ) system call acts on a memory region, it allocates and deallocates whole pages. Therefore, the function aligns the value of addr to a multiple of PAGE_SIZE and compares the result with the value of the brk field of the memory descriptor:
newbrk = (addr + 0xfff) & 0xfffff000;
oldbrk = (mm->brk + 0xfff) & 0xfffff000;
if (oldbrk == newbrk) {
mm->brk = addr;
goto out;
}
If the process asked to shrink the heap, sys_brk( ) invokes the do_munmap( ) function to do the job and then returns:
if (addr <= mm->brk) {
if (!do_munmap(mm, newbrk, oldbrk-newbrk))
mm->brk = addr;
goto out;
}
If the process asked to enlarge the heap, sys_brk( ) first checks whether the process is allowed to do so. If the process is trying to allocate memory outside its limit, the function simply returns the original value of mm->brk without allocating more memory:
rlim = current->signal->rlim[RLIMIT_DATA].rlim_cur;
if (rlim < RLIM_INFINITY && addr - mm->start_data > rlim)
goto out;
The function then checks whether the enlarged heap would overlap some other memory region belonging to the process and, if so, returns without doing anything:
if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))
goto out;
If everything is OK, the do_brk( ) function is invoked. If it returns the oldbrk value, the allocation was successful and sys_brk( ) returns the value addr; otherwise, it returns the old mm->brk value:
if (do_brk(oldbrk, newbrk-oldbrk) == oldbrk)
mm->brk = addr;
goto out;
The do_brk( ) function is actually a simplified version of do_mmap( ) that handles only anonymous memory regions. Its invocation might be considered equivalent to:
do_mmap(NULL, oldbrk, newbrk-oldbrk, PROT_READ|PROT_WRITE|PROT_EXEC,
MAP_FIXED|MAP_PRIVATE, 0)
do_brk( ) is slightly faster than do_mmap( ), because it avoids several checks on the memory region object fields by assuming that the memory region doesn't map a file on disk.
|
|
|
|
|
| |

 LINUX
LINUX 
 Books
Books

 ]
]