Системные вызовы
Операционные системы предлагают процессам,выполняемым в User Mode,
набор интерфейсов для общения с железом:ЦПУ,дисками,принтерами и т.д.
Существование подобного слоя между приложениями и железом имеет свои преимущества.
Во-первых,жизнь программиста становится легче,
ибо уже не нужно знать низко-уровневые аспекты.
Во-вторых,это увеличивает стабильность системы,
потому что ядру теперь гораздо проще проконтролировать такие запросы.
В-третьих,такие интерфейсы делают программы портабельными.
Такие интерфейсы еще называются системными вызовами.
POSIX API и системные вызовы
Чем отличаются между собой application programmer interface (API) и системный вызов?
АПИ-это определение функции,которая выполняет какой-то сервис,
а системный вызов-это явный запрос к ядру либо прерыванию.
В юниксе есть различные библиотеки API.
Некоторые из них находятся в libc
и могут фактически являться врапперами самих системных вызовов.
Как правило,каждый системный вызов имеет соответствующий враппер,
который уже непосредственно может быть вызван из приложения.
Случается,что API может и не соответствовать аналогичному системному вызову.
Одна API-функция может выполнить несколько различных системных вызовов.
Более того,несколько различных API могут делать один и тот же системный вызов.
Например,в libc есть следующие API: malloc( )
, calloc( )
, free( )
С точки зрения прикладного программиста,разницы между API и системным вызовом особой и нет.
С точки зрения разработчика ядра эта разница существенна,
ибо системный вызов принадлежит ядру,а API-библиотеке.
Большинство врапперов возвращают целочисленное значение.
Если возвращается -1 , это говорит о том,что ядро не может ответить на системный запрос.
Это может быть вызвано неверными параметрами,недоступными ресурсами.
Ошибка сохраняется в переменной errno.
Каждая ошибка соответствует своему положительному целому числу.
В линуксе они определены в include/asm-i386/errno.h.
Для совместимости также есть хидер include/asm-i386/errno.h.
|
Управление и обслуживание системных вызовов
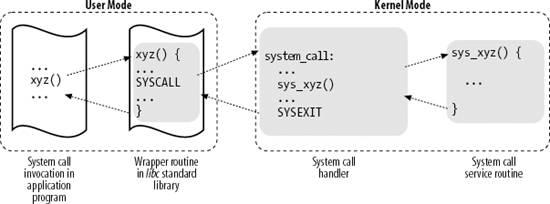
When a User Mode process invokes a system call, the CPU switches to Kernel Mode and starts the execution of a kernel function. As we will see in the next section, in the 80 x 86 architecture a Linux system call can be invoked in two different ways. The net result of both methods, however, is a jump to an assembly language function called the system call handler.
Because the kernel implements many different system calls, the User Mode process must pass a parameter called the system call number to identify the required system call; the eax register is used by Linux for this purpose. As we'll see in the section "Parameter Passing" later in this chapter, additional parameters are usually passed when invoking a system call.
All system calls return an integer value. The conventions for these return values are different from those for wrapper routines. In the kernel, positive or 0 values denote a successful termination of the system call, while negative values denote an error condition. In the latter case, the value is the negation of the error code that must be returned to the application program in the errno variable. The errno variable is not set or used by the kernel. Instead, the wrapper routines handle the task of setting this variable after a return from a system call.
The system call handler, which has a structure similar to that of the other exception handlers, performs the following operations:
Saves the contents of most registers in the Kernel Mode stack (this operation is common to all system calls and is coded in assembly language). Handles the system call by invoking a corresponding C function called the system call service routine. Exits from the handler: the registers are loaded with the values saved in the Kernel Mode stack, and the CPU is switched back from Kernel Mode to User Mode (this operation is common to all system calls and is coded in assembly language).
The name of the service routine associated with the xyz( ) system call is usually sys_xyz( ); there are, however, a few exceptions to this rule.
Figure 10-1 illustrates the relationships between the application program that invokes a system call, the corresponding wrapper routine, the system call handler, and the system call service routine. The arrows denote the execution flow between the functions. The terms "SYSCALL" and "SYSEXIT" are placeholders for the actual assembly language instructions that switch the CPU, respectively, from User Mode to Kernel Mode and from Kernel Mode to User Mode.
To associate each system call number with its corresponding service routine, the kernel uses a system call dispatch table, which is stored in the sys_call_table array and has NR_syscalls entries (289 in the Linux 2.6.11 kernel). The nth entry contains the service routine address of the system call having number n.
The NR_syscalls macro is just a static limit on the maximum number of implementable system calls; it does not indicate the number of system calls actually implemented. Indeed, each entry of the dispatch table may contain the address of the sys_ni_syscall( ) function, which is the service routine of the "nonimplemented" system calls; it just returns the error code -ENOSYS.
|
10.3. Entering and Exiting a System Call
Native applications can invoke a system call in two different ways:
By executing the int
$0x80 assembly language instruction; in older versions of the Linux kernel, this was the only way to switch from User Mode to Kernel Mode. By executing the sysenter
assembly language instruction, introduced in the Intel Pentium II microprocessors; this instruction is now supported by the Linux 2.6 kernel.
Similarly, the kernel can exit from a system callthus switching the CPU back to User Modein two ways:
By executing the iret
assembly language instruction. By executing the sysexit
assembly language instruction, which was introduced in the Intel Pentium II microprocessors together with the sysenter instruction.
However, supporting two different ways to enter the kernel is not as simple as it might look, because:
The kernel must support both older libraries that only use the int $0x80 instruction and more recent ones that also use the sysenter instruction. A standard library that makes use of the sysenter instruction must be able to cope with older kernels that support only the int $0x80 instruction. The kernel and the standard library must be able to run both on older processors that do not include the sysenter instruction and on more recent ones that include it.
We will see in the section "Issuing a System Call via the sysenter Instruction" later in this chapter how the Linux kernel solves these compatibility problems.
10.3.1. Issuing a System Call via the int $0x80 Instruction
The "traditional" way to invoke a system call makes use of the int assembly language instruction, which was discussed in the section "Hardware Handling of Interrupts and Exceptions" in Chapter 4.
The vector 128in hexadecimal, 0x80is associated with the kernel entry point. The trap_init( ) function, invoked during kernel initialization, sets up the Interrupt Descriptor Table entry corresponding to vector 128 as follows:
set_system_gate(0x80, &system_call);
The call loads the following values into the gate descriptor fields (see the section "Interrupt, Trap, and System Gates" in Chapter 4):
Segment Selector The _ _KERNEL_CS Segment Selector of the kernel code segment.
Offset The pointer to the system_call( ) system call handler.
Type Set to 15. Indicates that the exception is a Trap and that the corresponding handler does not disable maskable interrupts.
DPL (Descriptor Privilege Level) Set to 3. This allows processes in User Mode to invoke the exception handler (see the section "Hardware Handling of Interrupts and Exceptions" in Chapter 4).
Therefore, when a User Mode process issues an int $0x80 instruction, the CPU switches into Kernel Mode and starts executing instructions from the system_call address.
10.3.1.1. The system_call( ) function
The system_call( ) function starts by saving the system call number and all the CPU registers that may be used by the exception handler on the stackexcept for eflags, cs, eip, ss, and esp, which have already been saved automatically by the control unit (see the section "Hardware Handling of Interrupts and Exceptions" in Chapter 4). The SAVE_ALL macro, which was already discussed in the section "I/O Interrupt Handling" in Chapter 4, also loads the Segment Selector of the kernel data segment in ds and es:
system_call:
pushl %eax
SAVE_ALL
movl $0xffffe000, %ebx /* or 0xfffff000 for 4-KB stacks */
andl %esp, %ebx
The function then stores the address of the thread_info data structure of the current process in ebx (see the section "Identifying a Process" in Chapter 3). This is done by taking the value of the kernel stack pointer and rounding it up to a multiple of 4 or 8 KB (see the section "Identifying a Process" in Chapter 3).
Next, the system_call( ) function checks whether either one of the TIF_SYSCALL_TRACE and TIF_SYSCALL_AUDIT flags included in the flags field of the thread_info structure is setthat is, whether the system call invocations of the executed program are being traced by a debugger. If this is the case, system_call( ) invokes the do_syscall_trace( ) function twice: once right before and once right after the execution of the system call service routine (as described later). This function stops current and thus allows the debugging process to collect information about it.
A validity check is then performed on the system call number passed by the User Mode process. If it is greater than or equal to the number of entries in the system call dispatch table, the system call handler terminates:
cmpl $NR_syscalls, %eax
jb nobadsys
movl $(-ENOSYS), 24(%esp)
jmp resume_userspace
nobadsys:
If the system call number is not valid, the function stores the -ENOSYS value in the stack location where the eax register has been savedthat is, at offset 24 from the current stack top. It then jumps to resume_userspace (see below). In this way, when the process resumes its execution in User Mode, it will find a negative return code in eax.
Finally, the specific service routine associated with the system call number contained in eax is invoked:
call *sys_call_table(0, %eax, 4)
Because each entry in the dispatch table is 4 bytes long, the kernel finds the address of the service routine to be invoked by multiplying the system call number by 4, adding the initial address of the sys_call_table dispatch table, and extracting a pointer to the service routine from that slot in the table.
10.3.1.2. Exiting from the system call
When the system call service routine terminates, the system_call( ) function gets its return code from eax and stores it in the stack location where the User Mode value of the eax register is saved:
movl %eax, 24(%esp)
Thus, the User Mode process will find the return code of the system call in the eax register.
Then, the system_call( ) function disables the local interrupts and checks the flags in the thread_info structure of current:
cli
movl 8(%ebp), %ecx
testw $0xffff, %cx
je restore_all
The flags field is at offset 8 in the tHRead_info structure; the mask 0xffff selects the bits corresponding to all flags listed in Table 4-15 except TIF_POLLING_NRFLAG. If none of these flags is set, the function jumps to the restore_all label: as described in the section "Returning from Interrupts and Exceptions" in Chapter 4, this code restores the contents of the registers saved on the Kernel Mode stack and executes an iret
assembly language instruction to resume the User Mode process. (You might refer to the flow diagram in Figure 4-6.)
If any of the flags is set, then there is some work to be done before returning to User Mode. If the TIF_SYSCALL_TRACE flag is set, the system_call( ) function invokes for the second time the do_syscall_trace( ) function, then jumps to the resume_userspace label. Otherwise, if the TIF_SYSCALL_TRACE flag is not set, the function jumps to the work_pending label.
As explained in the section "Returning from Interrupts and Exceptions" in Chapter 4, that code at the resume_userspace and work_pending labels checks for rescheduling requests, virtual-8086 mode, pending signals, and single stepping; then eventually a jump is done to the restore_all label to resume the execution of the User Mode process.
10.3.2. Issuing a System Call via the sysenter Instruction
The int assembly language instruction is inherently slow because it performs several consistency and security checks. (The instruction is described in detail in the section "Hardware Handling of Interrupts and Exceptions" in Chapter 4.)
The sysenter instruction, dubbed in Intel documentation as "Fast System Call," provides a faster way to switch from User Mode to Kernel Mode.
10.3.2.1. The sysenter instruction
The sysenter assembly language instruction makes use of three special registers that must be loaded with the following information:
SYSENTER_CS_MSR The Segment Selector of the kernel code segment
SYSENTER_EIP_MSR The linear address of the kernel entry point
SYSENTER_ESP_MSR The kernel stack pointer
When the sysenter instruction is executed, the CPU control unit:
Copies the content of SYSENTER_CS_MSR into cs. Copies the content of SYSENTER_EIP_MSR into eip. Copies the content of SYSENTER_ESP_MSR into esp. Adds 8 to the value of SYSENTER_CS_MSR, and loads this value into ss.
Therefore, the CPU switches to Kernel Mode and starts executing the first instruction of the kernel entry point. As we have seen in the section "The Linux GDT" in Chapter 2, the kernel stack segment coincides with the kernel data segment, and the corresponding descriptor follows the descriptor of the kernel code segment in the Global Descriptor Table; therefore, step 4 loads the proper Segment Selector in the ss register.
The three model-specific registers are initialized by the enable_sep_cpu( ) function, which is executed once by every CPU in the system during the initialization of the kernel. The function performs the following steps:
Writes the Segment Selector of the kernel code (_ _KERNEL_CS) in the SYSENTER_CS_MSR register. Writes in the SYSENTER_CS_EIP register the linear address of the sysenter_entry( ) function described below. Computes the linear address of the end of the local TSS, and writes this value in the SYSENTER_CS_ESP register.
The setting of the SYSENTER_CS_ESP register deserves some comments. When a system call starts, the kernel stack is empty, thus the esp register should point to the end of the 4- or 8-KB memory area that includes the kernel stack and the descriptor of the current process (see Figure 3-2). The User Mode wrapper routine cannot properly set this register, because it does not know the address of this memory area; on the other hand, the value of the register must be set before switching to Kernel Mode. Therefore, the kernel initializes the register so as to encode the address of the Task State Segment of the local CPU. As we have described in step 3 of the _ _switch_to( ) function (see the section "Performing the Process Switch" in Chapter 3), at every process switch the kernel saves the kernel stack pointer of the current process in the esp0 field of the local TSS. Thus, the system call handler reads the esp register, computes the address of the esp0 field of the local TSS, and loads into the same esp register the proper kernel stack pointer.
10.3.2.2. The vsyscall page
A wrapper function in the libc standard library can make use of the sysenter instruction only if both the CPU and the Linux kernel support it.
This compatibility problem calls for a quite sophisticated solution. Essentially, in the initialization phase the sysenter_setup( ) function builds a page frame called vsyscall page
containing a small ELF shared object (i.e., a tiny ELF dynamic library). When a process issues an execve( )
system call to start executing an ELF program, the code in the vsyscall page is dynamically linked to the process address space (see the section "The exec Functions" in Chapter 20). The code in the vsyscall page makes use of the best available instruction to issue a system call.
The sysenter_setup( ) function allocates a new page frame for the vsyscall page and associates its physical address with the FIX_VSYSCALL fix-mapped linear address (see the section "Fix-Mapped Linear Addresses" in Chapter 2). Then, the function copies in the page either one of two predefined ELF shared objects:
If the CPU does not support sysenter, the function builds a vsyscall page that includes the code:
_ _kernel_vsyscall:
int
$0x80
ret
Otherwise, if the CPU does support sysenter, the function builds a vsyscall page that includes the code:
_ _kernel_vsyscall:
pushl %ecx
pushl %edx
pushl %ebp
movl %esp, %ebp
sysenter
When a wrapper routine in the standard library must invoke a system call, it calls the _ _kernel_vsyscall( ) function, whatever it may be.
A final compatibility problem is due to old versions of the Linux kernel that do not support the sysenter instruction; in this case, of course, the kernel does not build the vsyscall page and the _ _kernel_vsyscall( ) function is not linked to the address space of the User Mode processes. When recent standard libraries recognize this fact, they simply execute the int $0x80 instruction to invoke the system calls.
10.3.2.3. Entering the system call
The sequence of steps performed when a system call is issued via the sysenter instruction is the following:
The wrapper routine in the standard library loads the system call number into the eax register and calls the _ _kernel_vsyscall( ) function. The _ _kernel_vsyscall( ) function saves on the User Mode stack the contents of ebp, edx, and ecx (these registers are going to be used by the system call handler), copies the user stack pointer in ebp, then executes the sysenter instruction. The CPU switches from User Mode to Kernel Mode, and the kernel starts executing the sysenter_entry( ) function (pointed to by the SYSENTER_EIP_MSR register). The sysenter_entry( ) assembly language function performs the following steps: Sets up the kernel stack pointer:
movl -508(%esp), %esp
Initially, the esp register points to the first location after the local TSS, which is 512bytes long. Therefore, the instruction loads in the esp register the contents of the field at offset 4 in the local TSS, that is, the contents of the esp0 field. As already explained, the esp0 field always stores the kernel stack pointer of the current process. Enables local interrupts:
sti
Saves in the Kernel Mode stack the Segment Selector of the user data segment, the current user stack pointer, the eflags
register, the Segment Selector of the user code segment, and the address of the instruction to be executed when exiting from the system call:
pushl $(__USER_DS)
pushl %ebp
pushfl
pushl $(__USER_CS)
pushl $SYSENTER_RETURN
Observe that these instructions emulate some operations performed by the int assembly language instruction (steps 5c and 7 in the description of int in the section "Hardware Handling of Interrupts and Exceptions" in Chapter 4). Restores in ebp the original value of the register passed by the wrapper routine:
movl (%ebp), %ebp
This instruction does the job, because _ _kernel_vsyscall( ) saved on the User Mode stack the original value of ebp and then loaded in ebp the current value of the user stack pointer.
10.3.2.4. Exiting from the system call
When the system call service routine terminates, the sysenter_entry( ) function executes essentially the same operations as the system_call( ) function (see previous section). First, it gets the return code of the system call service routine from eax and stores it in the kernel stack location where the User Mode value of the eax register is saved. Then, the function disables the local interrupts and checks the flags in the thread_info structure of current.
If any of the flags is set, then there is some work to be done before returning to User Mode. In order to avoid code duplication, this case is handled exactly as in the system_call( ) function, thus the function jumps to the resume_userspace or work_pending labels (see flow diagram in Figure 4-6 in Chapter 4). Eventually, the iret
assembly language instruction fetches from the Kernel Mode stack the five arguments saved in step 4c by the sysenter_entry( ) function, and thus switches the CPU back to User Mode and starts executing the code at the SYSENTER_RETURN label (see below).
If the sysenter_entry( ) function determines that the flags are cleared, it performs a quick return to User Mode:
movl 40(%esp), %edx
movl 52(%esp), %ecx
xorl %ebp, %ebp
sti
sysexit
The edx and ecx registers are loaded with a couple of the stack values saved by sysenter_entry( ) in step 4c in the previos section: edx gets the address of the SYSENTER_RETURN label, while ecx gets the current user data stack pointer.
10.3.2.5. The sysexit instruction
The sysexit assembly language instruction is the companion of sysenter: it allows a fast switch from Kernel Mode to User Mode. When the instruction is executed, the CPU control unit performs the following steps:
Adds 16 to the value in the SYSENTER_CS_MSR register, and loads the result in the cs register. Copies the content of the edx register into the eip register. Adds 24 to the value in the SYSENTER_CS_MSR register, and loads the result in the ss register. Copies the content of the ecx register into the esp register.
Because the SYSENTER_CS_MSR register is loaded with the Segment Selector of the kernel code, the cs register is loaded with the Segment Selector of the user code, while the ss register is loaded with the Segment Selector of the user data segment (see the section "The Linux GDT" in Chapter 2).
As a result, the CPU switches from Kernel Mode to User Mode and starts executing the instruction whose address is stored in the edx register.
10.3.2.6. The SYSENTER_RETURN code
The code at the SYSENTER_RETURN label is stored in the vsyscall page, and it is executed when a system call entered via sysenter is being terminated, either by the iret instruction or the sysexit instruction.
The code simply restores the original contents of the ebp, edx, and ecx registers saved in the User Mode stack, and returns the control to the wrapper routine in the standard library:
SYSENTER_RETURN:
popl %ebp
popl %edx
popl %ecx
ret
|
10.4. Parameter Passing
Like ordinary functions, system calls often require some input/output parameters, which may consist of actual values (i.e., numbers), addresses of variables in the address space of the User Mode process, or even addresses of data structures including pointers to User Mode functions (see the section "System Calls Related to Signal Handling" in Chapter 11).
Because the system_call( ) and the sysenter_entry( ) functions are the common entry points for all system calls in Linux, each of them has at least one parameter: the system call number passed in the eax register. For instance, if an application program invokes the fork( )
wrapper routine, the eax register is set to 2 (i.e., _ _NR_fork) before executing the int
$0x80 or sysenter assembly language instruction. Because the register is set by the wrapper routines included in the libc library, programmers do not usually care about the system call number.
The fork( ) system call does not require other parameters. However, many system calls do require additional parameters, which must be explicitly passed by the application program. For instance, the mmap( )
system call may require up to six additional parameters (besides the system call number).
The parameters of ordinary C functions are usually passed by writing their values in the active program stack (either the User Mode stack or the Kernel Mode stack). Because system calls are a special kind of function that cross over from user to kernel land, neither the User Mode or the Kernel Mode stacks can be used. Rather, system call parameters are written in the CPU registers before issuing the system call. The kernel then copies the parameters stored in the CPU registers onto the Kernel Mode stack before invoking the system call service routine, because the latter is an ordinary C function.
Why doesn't the kernel copy parameters directly from the User Mode stack to the Kernel Mode stack? First of all, working with two stacks at the same time is complex; second, the use of registers makes the structure of the system call handler similar to that of other exception handlers.
However, to pass parameters in registers, two conditions must be satisfied:
The length of each parameter cannot exceed the length of a register (32 bits). The number of parameters must not exceed six, besides the system call number passed in eax, because 80 x 86 processors have a very limited number of registers.
The first condition is always true because, according to the POSIX standard, large parameters that cannot be stored in a 32-bit register must be passed by reference. A typical example is the settimeofday( ) system call, which must read a 64-bit structure.
However, system calls that require more than six parameters exist. In such cases, a single register is used to point to a memory area in the process address space that contains the parameter values. Of course, programmers do not have to care about this workaround. As with every C function call, parameters are automatically saved on the stack when the wrapper routine is invoked. This routine will find the appropriate way to pass the parameters to the kernel.
The registers used to store the system call number and its parameters are, in increasing order, eax (for the system call number), ebx, ecx, edx, esi, edi, and ebp. As seen before, system_call( ) and sysenter_entry( ) save the values of these registers on the Kernel Mode stack by using the SAVE_ALL macro. Therefore, when the system call service routine goes to the stack, it finds the return address to system_call( ) or to sysenter_entry( ), followed by the parameter stored in ebx (the first parameter of the system call), the parameter stored in ecx, and so on (see the section "Saving the registers for the interrupt handler" in Chapter 4). This stack configuration is exactly the same as in an ordinary function call, and therefore the service routine can easily refer to its parameters by using the usual C-language constructs.
Let's look at an example. The sys_write( ) service routine, which handles the write( ) system call, is declared as:
int sys_write (unsigned int fd, const char * buf, unsigned int count)
The C compiler produces an assembly language function that expects to find the fd, buf, and count parameters on top of the stack, right below the return address, in the locations used to save the contents of the ebx, ecx, and edx registers, respectively.
In a few cases, even if the system call doesn't use any parameters, the corresponding service routine needs to know the contents of the CPU registers right before the system call was issued. For example, the do_fork( ) function that implements fork( ) needs to know the value of the registers in order to duplicate them in the child process thread field (see the section "The thread field" in Chapter 3). In these cases, a single parameter of type pt_regs allows the service routine to access the values saved in the Kernel Mode stack by the SAVE_ALL macro (see the section "The do_IRQ( ) function" in Chapter 4):
int sys_fork (struct pt_regs regs)
The return value of a service routine must be written into the eax register. This is automatically done by the C compiler when a return n; instruction is executed.
10.4.1. Verifying the Parameters
All system call parameters must be carefully checked before the kernel attempts to satisfy a user request. The type of check depends both on the system call and on the specific parameter. Let's go back to the write( )
system call introduced before: the fd parameter should be a file descriptor that identifies a specific file, so sys_write( ) must check whether fd really is a file descriptor of a file previously opened and whether the process is allowed to write into it (see the section "File-Handling System Calls" in Chapter 1). If any of these conditions are not true, the handler must return a negative valuein this case, the error code -EBADF.
One type of checking, however, is common to all system calls. Whenever a parameter specifies an address, the kernel must check whether it is inside the process address space. There are two possible ways to perform this check:
Verify that the linear address belongs to the process address space and, if so, that the memory region including it has the proper access rights. Verify just that the linear address is lower than PAGE_OFFSET (i.e., that it doesn't fall within the range of interval addresses reserved to the kernel).
Early Linux kernels performed the first type of checking. But it is quite time consuming because it must be executed for each address parameter included in a system call; furthermore, it is usually pointless because faulty programs are not very common.
Therefore, starting with Version 2.2, Linux employs the second type of checking. This is much more efficient because it does not require any scan of the process memory region descriptors. Obviously, this is a very coarse check: verifying that the linear address is smaller than PAGE_OFFSET is a necessary but not sufficient condition for its validity. But there's no risk in confining the kernel to this limited kind of check because other errors will be caught later.
The approach followed is thus to defer the real checking until the last possible momentthat is, until the Paging Unit translates the linear address into a physical one. We will discuss in the section "Dynamic Address Checking: The Fix-up Code," later in this chapter, how the Page Fault exception handler
succeeds in detecting those bad addresses issued in Kernel Mode that were passed as parameters by User Mode processes.
One might wonder at this point why the coarse check is performed at all. This type of checking is actually crucial to preserve both process address spaces and the kernel address space from illegal accesses. We saw in Chapter 2 that the RAM is mapped starting from PAGE_OFFSET. This means that kernel routines are able to address all pages present in memory. Thus, if the coarse check were not performed, a User Mode process might pass an address belonging to the kernel address space as a parameter and then be able to read or write every page present in memory without causing a Page Fault
exception.
The check on addresses passed to system calls is performed by the access_ok( ) macro, which acts on two parameters: addr and size. The macro checks the address interval delimited by addr and addr + size - 1. It is essentially equivalent to the following C function:
int access_ok(const void * addr, unsigned long size)
{
unsigned long a = (unsigned long) addr;
if (a + size < a ||
a + size > current_thread_info( )->addr_limit.seg)
return 0;
return 1;
}
The function first verifies whether addr + size, the highest address to be checked, is larger than 232-1; because unsigned long integers and pointers are represented by the GNU C compiler (gcc) as 32-bit numbers, this is equivalent to checking for an overflow condition. The function also checks whether addr + size exceeds the value stored in the addr_limit.seg field of the thread_info structure of current. This field usually has the value PAGE_OFFSET for normal processes and the value 0xffffffff for kernel threads
. The value of the addr_limit.seg field can be dynamically changed by the get_fs and set_fs macros; this allows the kernel to bypass the security checks made by access_ok( ), so that it can invoke system call service routines, directly passing to them addresses in the kernel data segment.
The verify_area( ) function performs the same check as the access_ok( ) macro; although this function is considered obsolete, it is still widely used in the source code.
10.4.2. Accessing the Process Address Space
System call service routines often need to read or write data contained in the process's address space. Linux includes a set of macros that make this access easier. We'll describe two of them, called get_user( ) and put_user( ). The first can be used to read 1, 2, or 4 consecutive bytes from an address, while the second can be used to write data of those sizes into an address.
Each function accepts two arguments, a value x to transfer and a variable ptr. The second variable also determines how many bytes to transfer. Thus, in get_user(x,ptr), the size of the variable pointed to by ptr causes the function to expand into a _ _get_user_1( ), _ _get_user_2( ), or _ _get_user_4( ) assembly language function. Let's consider one of them, _ _get_user_2( ):
_ _get_user_2:
addl $1, %eax
jc bad_get_user
movl $0xffffe000, %edx /* or 0xfffff000 for 4-KB stacks */
andl %esp, %edx
cmpl 24(%edx), %eax
jae bad_get_user
2: movzwl
-1(%eax), %edx
xorl %eax, %eax
ret
bad_get_user:
xorl %edx, %edx
movl $-EFAULT, %eax
ret
The eax register contains the address ptr of the first byte to be read. The first six instructions essentially perform the same checks as the access_ok( ) macro: they ensure that the 2 bytes to be read have addresses less than 4 GB as well as less than the addr_limit.seg field of the current process. (This field is stored at offset 24 in the thread_info structure of current, which appears in the first operand of the cmpl instruction.)
If the addresses are valid, the function executes the movzwl instruction to store the data to be read in the two least significant bytes of edx register while setting the high-order bytes of edx to 0; then it sets a 0 return code in eax and terminates. If the addresses are not valid, the function clears edx, sets the -EFAULT value into eax, and terminates.
The put_user(x,ptr) macro is similar to the one discussed before, except it writes the value x into the process address space starting from address ptr. Depending on the size of x, it invokes either the _ _put_user_asm( ) macro (size of 1, 2, or 4 bytes) or the _ _put_user_u64( ) macro (size of 8 bytes). Both macros return the value 0 in the eax register if they succeed in writing the value, and -EFAULT otherwise.
Several other functions and macros are available to access the process address space in Kernel Mode; they are listed in Table 10-1. Notice that many of them also have a variant prefixed by two underscores (_ _). The ones without initial underscores take extra time to check the validity of the linear address interval requested, while the ones with the underscores bypass that check. Whenever the kernel must repeatedly access the same memory area in the process address space, it is more efficient to check the address once at the start and then access the process area without making any further checks.
Table 10-1. Functions and macros that access the process address spaceFunction | Action |
|---|
get_user _ _get_user | Reads an integer value from user space (1, 2, or 4 bytes) | put_user _ _put_user | Writes an integer value to user space (1, 2, or 4 bytes) | copy_from_user _ _copy_from_user | Copies a block of arbitrary size from user space | copy_to_user _ _copy_to_user | Copies a block of arbitrary size to user space | strncpy_from_user _ _strncpy_from_user | Copies a null-terminated string from user space | strlen_user strnlen_user | Returns the length of a null-terminated string in user space | clear_user _ _clear_user | Fills a memory area in user space with zeros |
10.4.3. Dynamic Address Checking: The Fix-up Code
As seen previously, access_ok( ) makes a coarse check on the validity of linear addresses passed as parameters of a system call. This check only ensures that the User Mode process is not attempting to fiddle with the kernel address space; however, the linear addresses passed as parameters still might not belong to the process address space. In this case, a Page Fault
exception will occur when the kernel tries to use any of such bad addresses.
Before describing how the kernel detects this type of error, let's specify the three cases in which Page Fault exceptions may occur in Kernel Mode. These cases must be distinguished by the Page Fault handler, because the actions to be taken are quite different.
The kernel attempts to address a page belonging to the process address space, but either the corresponding page frame does not exist or the kernel tries to write a read-only page. In these cases, the handler must allocate and initialize a new page frame (see the sections "Demand Paging" and "Copy On Write" in Chapter 9). The kernel addresses a page belonging to its address space, but the corresponding Page Table entry has not yet been initialized (see the section "Handling Noncontiguous Memory Area Accesses" in Chapter 9). In this case, the kernel must properly set up some entries in the Page Tables of the current process. Some kernel functions include a programming bug that causes the exception to be raised when that program is executed; alternatively, the exception might be caused by a transient hardware error. When this occurs, the handler must perform a kernel oops (see the section "Handling a Faulty Address Inside the Address Space" in Chapter 9). The case introduced in this chapter: a system call service routine attempts to read or write into a memory area whose address has been passed as a system call parameter, but that address does not belong to the process address space.
The Page Fault handler can easily recognize the first case by determining whether the faulty linear address is included in one of the memory regions
owned by the process. It is also able to detect the second case by checking whether the corresponding master kernel Page Table entry includes a proper non-null entry that maps the address. Let's now explain how the handler distinguishes the remaining two cases.
10.4.4. The Exception Tables
The key to determining the source of a Page Fault lies in the narrow range of calls that the kernel uses to access the process address space. Only the small group of functions and macros described in the previous section are used to access this address space; thus, if the exception is caused by an invalid parameter, the instruction that caused it must be included in one of the functions or else be generated by expanding one of the macros. The number of the instructions that address user space is fairly small.
Therefore, it does not take much effort to put the address of each kernel instruction that accesses the process address space into a structure called the exception table. If we succeed in doing this, the rest is easy. When a Page Fault exception occurs in Kernel Mode, the do_ page_fault( ) handler examines the exception table: if it includes the address of the instruction that triggered the exception, the error is caused by a bad system call parameter; otherwise, it is caused by a more serious bug.
Linux defines several exception tables
. The main exception table is automatically generated by the C compiler when building the kernel program image. It is stored in the _ _ex_table section of the kernel code segment, and its starting and ending addresses are identified by two symbols produced by the C compiler: _ _start_ _ _ex_table and _ _stop_ _ _ex_table.
Moreover, each dynamically loaded module of the kernel (see Appendix B) includes its own local exception table. This table is automatically generated by the C compiler when building the module image, and it is loaded into memory when the module is inserted in the running kernel.
Each entry of an exception table is an exception_table_entry structure that has two fields:
insn The linear address of an instruction that accesses the process address space
fixup The address of the assembly language code to be invoked when a Page Fault exception triggered by the instruction located at insn occurs
The fixup code consists of a few assembly language instructions that solve the problem triggered by the exception. As we will see later in this section, the fix usually consists of inserting a sequence of instructions that forces the service routine to return an error code to the User Mode process. These instructions, which are usually defined in the same macro or function that accesses the process address space, are placed by the C compiler into a separate section of the kernel code segment called .fixup.
The search_exception_tables( ) function is used to search for a specified address in all exception tables: if the address is included in a table, the function returns a pointer to the corresponding exception_table_entry structure; otherwise, it returns NULL. Thus the Page Fault handler do_page_fault( ) executes the following statements:
if ((fixup = search_exception_tables(regs->eip))) {
regs->eip = fixup->fixup;
return 1;
}
The regs->eip field contains the value of the eip register saved on the Kernel Mode stack when the exception occurred. If the value in the register (the instruction pointer) is in an exception table, do_page_fault( ) replaces the saved value with the address found in the entry returned by search_exception_tables( ). Then the Page Fault handler terminates and the interrupted program resumes with execution of the fixup code
.
10.4.5. Generating the Exception Tables and the Fixup Code
The GNU Assembler .section directive allows programmers to specify which section of the executable file contains the code that follows. As we will see in Chapter 20, an executable file includes a code segment, which in turn may be subdivided into sections. Thus, the following assembly language instructions add an entry into an exception table; the "a" attribute specifies that the section must be loaded into memory together with the rest of the kernel image:
.section _ _ex_table, "a"
.long faulty_instruction_address, fixup_code_address
.previous
The .previous directive forces the assembler to insert the code that follows into the section that was active when the last .section directive was encountered.
Let's consider again the _ _get_user_1( ), _ _get_user_2( ), and _ _get_user_4( ) functions mentioned before. The instructions that access the process address space are those labeled as 1, 2, and 3:
_ _get_user_1:
[...]
1: movzbl (%eax), %edx
[...]
_ _get_user_2:
[...]
2: movzwl -1(%eax), %edx
[...]
_ _get_user_4:
[...]
3: movl -3(%eax), %edx
[...]
bad_get_user:
xorl %edx, %edx
movl $-EFAULT, %eax
ret
.section _ _ex_table,"a"
.long 1b, bad_get_user
.long 2b, bad_get_user
.long 3b, bad_get_user
.previous
Each exception table entry consists of two labels. The first one is a numeric label with a b suffix to indicate that the label is "backward;" in other words, it appears in a previous line of the program. The fixup code is common to the three functions and is labeled as bad_get_user. If a Page Fault
exception is generated by the instructions at label 1, 2, or 3, the fixup code is executed. It simply returns an -EFAULT error code to the process that issued the system call.
Other kernel functions that act in the User Mode address space use the fixup code technique. Consider, for instance, the strlen_user(string) macro. This macro returns either the length of a null-terminated string passed as a parameter in a system call or the value 0 on error. The macro essentially yields the following assembly language instructions:
movl $0, %eax
movl $0x7fffffff, %ecx
movl %ecx, %ebx
movl string, %edi
0: repne; scasb
subl %ecx, %ebx
movl %ebx, %eax
1:
.section .fixup,"ax"
2: xorl %eax, %eax
jmp 1b
.previous
.section _ _ex_table,"a"
.long 0b, 2b
.previous
The ecx and ebx registers are initialized with the 0x7fffffff value, which represents the maximum allowed length for the string in the User Mode address space. The repne;scasb assembly language instructions iteratively scan the string pointed to by the edi register, looking for the value 0 (the end of string \0 character) in eax. Because scasb decreases the ecx register at each iteration, the eax register ultimately stores the total number of bytes scanned in the string (that is, the length of the string).
The fixup code of the macro is inserted into the .fixup section. The "ax" attributes specify that the section must be loaded into memory and that it contains executable code. If a Page Fault exception is generated by the instructions at label 0, the fixup code is executed; it simply loads the value 0 in eaxthus forcing the macro to return a 0 error code instead of the string lengthand then jumps to the 1 label, which corresponds to the instruction following the macro.
The second .section directive adds an entry containing the address of the repne; scasb instruction and the address of the corresponding fixup code in the _ _ex_table section.
|
10.5. Kernel Wrapper Routines
Although system calls are used mainly by User Mode processes, they can also be invoked by kernel threads
, which cannot use library functions. To simplify the declarations of the corresponding wrapper routines
, Linux defines a set of seven macros called _syscall0 through _syscall6.
In the name of each macro, the numbers 0 through 6 correspond to the number of parameters used by the system call (excluding the system call number). The macros are used to declare wrapper routines that are not already included in the libc standard library (for instance, because the Linux system call is not yet supported by the library); however, they cannot be used to define wrapper routines for system calls that have more than six parameters (excluding the system call number) or for system calls that yield nonstandard return values.
Each macro requires exactly 2 + 2 x n parameters, with n being the number of parameters of the system call. The first two parameters specify the return type and the name of the system call; each additional pair of parameters specifies the type and the name of the corresponding system call parameter. Thus, for instance, the wrapper routine of the fork( )
system call may be generated by:
_syscall0(int,fork)
while the wrapper routine of the write( )
system call may be generated by:
_syscall3(int,write,int,fd,const char *,buf,unsigned int,count)
In the latter case, the macro yields the following code:
int write(int fd,const char * buf,unsigned int count)
{
long _ _res;
asm("int $0x80"
: "=a" (_ _res)
: "0" (_ _NR_write), "b" ((long)fd),
"c" ((long)buf), "d" ((long)count));
if ((unsigned long)_ _res >= (unsigned long)-129) {
errno = -_ _res;
_ _res = -1;
}
return (int) _ _res;
}
The _ _NR_write macro is derived from the second parameter of _syscall3; it expands into the system call number of write( ). When compiling the preceding function, the following assembly language code is produced:
write:
pushl %ebx ; push ebx into stack
movl 8(%esp), %ebx ; put first parameter in ebx
movl 12(%esp), %ecx ; put second parameter in ecx
movl 16(%esp), %edx ; put third parameter in edx
movl $4, %eax ; put _ _NR_write in eax
int
$0x80 ; invoke system call
cmpl $-125, %eax ; check return code
jbe .L1 ; if no error, jump
negl %eax ; complement the value of eax
movl %eax, errno ; put result in errno
movl $-1, %eax ; set eax to -1
.L1: popl %ebx ; pop ebx from stack
ret ; return to calling program
Notice how the parameters of the write( ) function are loaded into the CPU registers before the int $0x80 instruction is executed. The value returned in eax must be interpreted as an error code if it lies between -1 and -129 (the kernel assumes that the largest error code defined in include/generic/errno.h is 129). If this is the case, the wrapper routine stores the value of -eax in errno and returns the value -1; otherwise, it returns the value of eax.
|
Chapter 11. Signals
Signals were introduced by the first Unix systems to allow interactions between User Mode processes; the kernel also uses them to notify processes of system events. Signals have been around for 30 years with only minor changes.
The first sections of this chapter examine in detail how signals
are handled by the Linux kernel, then we discuss the system calls that allow processes to exchange signals.
11.1. The Role of Signals
A signal is a very short message that may be sent to a process or a group of processes. The only information given to the process is usually a number identifying the signal; there is no room in standard signals for arguments, a message, or other accompanying information.
A set of macros whose names start with the prefix SIG is used to identify signals; we have already made a few references to them in previous chapters. For instance, the SIGCHLD macro was mentioned in the section "The clone( ), fork( ), and vfork( ) System Calls" in Chapter 3. This macro, which expands into the value 17 in Linux, yields the identifier of the signal that is sent to a parent process when a child stops or terminates. The SIGSEGV macro, which expands into the value 11, was mentioned in the section "Page Fault Exception Handler" in Chapter 9; it yields the identifier of the signal that is sent to a process when it makes an invalid memory reference.
Signals serve two main purposes:
Of course, the two purposes are not mutually exclusive, because often a process must react to some event by executing a specific routine.
Table 11-1 lists the first 31 signals handled by Linux 2.6 for the 80x86 architecture (some signal numbers, such those associated with SIGCHLD or SIGSTOP, are architecture-dependent; furthermore, some signals such as SIGSTKFLT are defined only for specific architectures). The meanings of the default actions are described in the next section.
Table 11-1. The first 31 signals in Linux/i386# | Signal name | Default action | Comment | POSIX |
|---|
1 | SIGHUP | Terminate | Hang up controlling terminal or process | Yes | 2 | SIGINT | Terminate | Interrupt from keyboard | Yes | 3 | SIGQUIT | Dump | Quit from keyboard | Yes | 4 | SIGILL | Dump | Illegal instruction | Yes | 5 | SIGTRAP | Dump | Breakpoint for debugging | No | 6 | SIGABRT | Dump | Abnormal termination | Yes | 6 | SIGIOT | Dump | Equivalent to SIGABRT | No | 7 | SIGBUS | Dump | Bus error | No | 8 | SIGFPE | Dump | Floating-point exception | Yes | 9 | SIGKILL | Terminate | Forced-process termination | Yes | 10 | SIGUSR1 | Terminate | Available to processes | Yes | 11 | SIGSEGV | Dump | Invalid memory reference | Yes | 12 | SIGUSR2 | Terminate | Available to processes | Yes | 13 | SIGPIPE | Terminate | Write to pipe with no readers | Yes | 14 | SIGALRM | Terminate | Real-timerclock | Yes | 15 | SIGTERM | Terminate | Process termination | Yes | 16 | SIGSTKFLT | Terminate | Coprocessor stack error | No | 17 | SIGCHLD | Ignore | Child process stopped or terminated, or got signal if traced | Yes | 18 | SIGCONT | Continue | Resume execution, if stopped | Yes | 19 | SIGSTOP | Stop | Stop process execution | Yes | 20 | SIGTSTP | Stop | Stop process issued from tty | Yes | 21 | SIGTTIN | Stop | Background process requires input | Yes | 22 | SIGTTOU | Stop | Background process requires output | Yes | 23 | SIGURG | Ignore | Urgent condition on socket | No | 24 | SIGXCPU | Dump | CPU time limit exceeded | No | 25 | SIGXFSZ | Dump | File size limit exceeded | No | 26 | SIGVTALRM | Terminate | Virtual timer clock | No | 27 | SIGPROF | Terminate | Profile timer clock | No | 28 | SIGWINCH | Ignore | Window resizing | No | 29 | SIGIO | Terminate | I/O now possible | No | 29 | SIGPOLL | Terminate | Equivalent to SIGIO | No | 30 | SIGPWR | Terminate | Power supply failure | No | 31 | SIGSYS | Dump | Bad system call | No | 31 | SIGUNUSED | Dump | Equivalent to SIGSYS | No |
Besides the regular signals
described in this table, the POSIX standard has introduced a new class of signals denoted as real-time signals
; their signal numbers range from 32 to 64 on Linux. They mainly differ from regular signals because they are always queued so that multiple signals sent will be received. On the other hand, regular signals of the same kind are not queued: if a regular signal is sent many times in a row, just one of them is delivered to the receiving process. Although the Linux kernel does not use real-time signals, it fully supports the POSIX standard by means of several specific system calls.
A number of system calls allow programmers to send signals and determine how their processes respond to the signals they receive. Table 11-2 summarizes these calls; their behavior is described in detail in the later section "System Calls Related to Signal Handling."
Table 11-2. The most significant system calls related to signalsSystem call | Description |
|---|
kill( )
| Send a signal to a thread group | tkill( )
| Send a signal to a process | tgkill( )
| Send a signal to a process in a specific thread group | sigaction( )
| Change the action associated with a signal | signal( )
| Similar to sigaction( ) | sigpending( )
| Check whether there are pending signals | sigprocmask( )
| Modify the set of blocked signals | sigsuspend( )
| Wait for a signal | rt_sigaction( )
| Change the action associated with a real-time signal | rt_sigpending( )
| Check whether there are pending real-time signals | rt_sigprocmask( )
| Modify the set of blocked real-time signals | rt_sigqueueinfo( )
| Send a real-time signal to a thread group | rt_sigsuspend( )
| Wait for a real-time signal | rt_sigtimedwait( )
| Similar to rt_sigsuspend( ) |
An important characteristic of signals is that they may be sent at any time to a process whose state is usually unpredictable. Signals sent to a process that is not currently executing must be saved by the kernel until that process resumes execution. Blocking a signal (described later) requires that delivery of the signal be held off until it is later unblocked, which exacerbates the problem of signals being raised before they can be delivered.
Therefore, the kernel distinguishes two different phases related to signal transmission:
Signal generation The kernel updates a data structure of the destination process to represent that a new signal has been sent.
Signal delivery The kernel forces the destination process to react to the signal by changing its execution state, by starting the execution of a specified signal handler, or both.
Each signal generated can be delivered once, at most. Signals are consumable resources: once they have been delivered, all process descriptor information that refers to their previous existence is canceled.
Signals that have been generated but not yet delivered are called pending signals
. At any time, only one pending signal of a given type may exist for a process; additional pending signals of the same type to the same process are not queued but simply discarded. Real-time signals are different, though: there can be several pending signals of the same type.
In general, a signal may remain pending for an unpredictable amount of time. The following factors must be taken into consideration:
Signals are usually delivered only to the currently running process (that is, to the current process). Signals of a given type may be selectively blocked by a process (see the later section "Modifying the Set of Blocked Signals"). In this case, the process does not receive the signal until it removes the block. When a process executes a signal-handler function, it usually masks the corresponding signali.e., it automatically blocks the signal until the handler terminates. A signal handler therefore cannot be interrupted by another occurrence of the handled signal, and the function doesn't need to be reentrant.
Although the notion of signals is intuitive, the kernel implementation is rather complex. The kernel must:
Remember which signals are blocked by each process. When switching from Kernel Mode to User Mode, check whether a signal for a process has arrived. This happens at almost every timer interrupt (roughly every millisecond). Determine whether the signal can be ignored. This happens when all of the following conditions are fulfilled: The destination process is not traced by another process (the PT_PTRACED flag in the process descriptor ptrace field is equal to 0). The signal is not blocked by the destination process. The signal is being ignored by the destination process (either because the process explicitly ignored it or because the process did not change the default action of the signal and that action is "ignore").
Handle the signal, which may require switching the process to a handler function at any point during its execution and restoring the original execution context after the function returns.
Moreover, Linux must take into account the different semantics for signals adopted by BSD
and System V
; furthermore, it must comply with the rather cumbersome POSIX requirements.
11.1.1. Actions Performed upon Delivering a Signal
There are three ways in which a process can respond to a signal:
Explicitly ignore the signal. Execute the default action associated with the signal (see Table 11-1). This action, which is predefined by the kernel, depends on the signal type and may be any one of the following:
Terminate The process is terminated (killed).
Dump The process is terminated (killed) and a core file containing its execution context is created, if possible; this file may be used for debug purposes.
Ignore The signal is ignored.
Stop The process is stoppedi.e., put in the TASK_STOPPED state (see the section "Process State" in Chapter 3).
Continue If the process was stopped (TASK_STOPPED), it is put into the TASK_RUNNING state.
Catch the signal by invoking a corresponding signal-handler function.
Notice that blocking a signal is different from ignoring it. A signal is not delivered as long as it is blocked; it is delivered only after it has been unblocked. An ignored signal is always delivered, and there is no further action.
The SIGKILL and SIGSTOP signals cannot be ignored, caught, or blocked, and their default actions
must always be executed. Therefore, SIGKILL and SIGSTOP allow a user with appropriate privileges to terminate and to stop, respectively, every process, regardless of the defenses taken by the program it is executing.
A signal is fatal for a given process if delivering the signal causes the kernel to kill the process. The SIGKILL signal is always fatal; moreover, each signal whose default action is "Terminate" and which is not caught by a process is also fatal for that process. Notice, however, that a signal caught by a process and whose corresponding signal-handler function terminates the process is not fatal, because the process chose to terminate itself rather than being killed by the kernel.
11.1.2. POSIX Signals and Multithreaded Applications
The POSIX 1003.1 standard has some stringent requirements for signal handling of multithreaded applications:
Signal handlers must be shared among all threads of a multithreaded application; however, each thread must have its own mask of pending and blocked signals. The kill( )
and sigqueue( )
POSIX library functions (see the later section "System Calls Related to Signal Handling") must send signals to whole multithreaded applications, not to a specific thread. The same holds for all signals (such as SIGCHLD, SIGINT, or SIGQUIT) generated by the kernel. Each signal sent to a multithreaded application will be delivered to just one thread, which is arbitrarily chosen by the kernel among the threads that are not blocking that signal. If a fatal signal is sent to a multithreaded application, the kernel will kill all threads of the applicationnot just the thread to which the signal has been delivered.
In order to comply with the POSIX standard, the Linux 2.6 kernel implements a multithreaded application as a set of lightweight processes belonging to the same thread group (see the section "Processes, Lightweight Processes, and Threads" in Chapter 3).
In this chapter the term "thread group" denotes any thread group, even if it is composed by a single (conventional) process. For instance, when we state that kill( ) can send a signal to a thread group, we imply that this system call can send a signal to a conventional process, too. We will use the term "process" to denote either a conventional process or a lightweight processthat is, a specific member of a thread group.
Furthermore, a pending signal is private if it has been sent to a specific process; it is shared if it has been sent to a whole thread group.
11.1.3. Data Structures Associated with Signals
For each process in the system, the kernel must keep track of what signals are currently pending or masked; the kernel must also keep track of how every thread group is supposed to handle every signal. To do this, the kernel uses several data structures
accessible from the process descriptor. The most significant ones are shown in Figure 11-1.
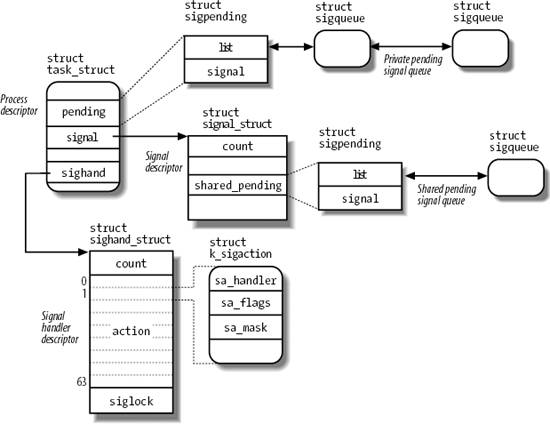
The fields of the process descriptor related to signal handling are listed in Table 11-3.
Table 11-3. Process descriptor fields related to signal handlingType | Name | Description |
|---|
struct signal_struct * | signal | Pointer to the process's signal descriptor | struct sighand_struct * | sighand | Pointer to the process's signal handler descriptor | sigset_t | blocked | Mask of blocked signals | sigset_t | real_blocked | Temporary mask of blocked signals (used by the rt_sigtimedwait( )
system call) | struct sigpending | pending | Data structure storing the private pending signals | unsigned long | sas_ss_sp | Address of alternative signal handler stack | size_t | sas_ss_size | Size of alternative signal handler stack | int (*) (void *) | notifier | Pointer to a function used by a device driver to block some signals of the process | void * | notifier_data | Pointer to data that might be used by the notifier function (previous field of table) | sigset_t * | notifier_mask | Bit mask of signals blocked by a device driver through a notifier function |
The blocked field stores the signals currently masked out by the process. It is a sigset_t array of bits, one for each signal type:
typedef struct {
unsigned long sig[2];
} sigset_t;
Because each unsigned long number consists of 32 bits, the maximum number of signals that may be declared in Linux is 64 (the _NSIG macro specifies this value). No signal can have number 0, so the signal number corresponds to the index of the corresponding bit in a sigset_t variable plus one. Numbers between 1 and 31 correspond to the signals listed in Table 11-1, while numbers between 32 and 64 correspond to real-time signals.
11.1.3.1. The signal descriptor and the signal handler descriptor
The signal field of the process descriptor points to a signal descriptor, a signal_struct structure that keeps track of the shared pending signals. Actually, the signal descriptor also includes fields not strictly related to signal handling, such as the rlim per-process resource limit array (see the section "Process Resource Limits" in Chapter 3), or the pgrp and session fields, which store the PIDs of the group leader and of the session leader of the process, respectively (see the section "Relationships Among Processes" in Chapter 3). In fact, as mentioned in the section "The clone( )
, fork( ), and vfork( ) System Calls" in Chapter 3, the signal descriptor is shared by all processes belonging to the same thread groupthat is, all processes created by invoking the clone( ) system call with the CLONE_THREAD flag setthus the signal descriptor includes the fields that must be identical for every process in the same thread group.
The fields of a signal descriptor somewhat related to signal handling are shown in Table 11-4.
Table 11-4. The fields of the signal descriptor related to signal handlingType | Name | Description |
|---|
atomic_t | count | Usage counter of the signal descriptor | atomic_t | live | Number of live processes in the thread group | wait_queue_head_t | wait_chldexit | Wait queue for the processes sleeping in a wait4( )
system call | struct task_struct * | curr_target | Descriptor of the last process in the thread group that received a signal | struct sigpending | shared_pending | Data structure storing the shared pending signals | int | group_exit_code | Process termination code for the thread group | struct task_struct * | group_exit_task | Used when killing a whole thread group | int | notify_count | Used when killing a whole thread group | int | group_stop_count | Used when stopping a whole thread group | unsigned int | flags | Flags used when delivering signals that modify the status of the process |
Besides the signal descriptor, every process refers also to a signal handler descriptor, which is a sighand_struct structure describing how each signal must be handled by the thread group. Its fields are shown in Table 11-5.
Table 11-5. The fields of the signal handler descriptorType | Name | Description |
|---|
atomic_t | count | Usage counter of the signal handler descriptor | struct k_sigaction [64] | action | Array of structures specifying the actions to be performed upon delivering the signals | spinlock_t | siglock | Spin lock protecting both the signal descriptor and the signal handler descriptor |
As mentioned in the section "The clone( ), fork( ), and vfork( ) System Calls" in Chapter 3, the signal handler descriptor may be shared by several processes by invoking the clone( ) system call with the CLONE_SIGHAND flag set; the count field in this descriptor specifies the number of processes that share the structure. In a POSIX multithreaded application, all lightweight processes in the thread group refer to the same signal descriptor and to the same signal handler descriptor.
11.1.3.2. The sigaction data structure
Some architectures assign properties to a signal that are visible only to the kernel. Thus, the properties of a signal are stored in a k_sigaction structure, which contains both the properties hidden from the User Mode process and the more familiar sigaction structure that holds all the properties a User Mode process can see. Actually, on the 80 x 86 platform, all signal properties are visible to User Mode processes. Thus the k_sigaction structure simply reduces to a single sa structure of type sigaction, which includes the following fields:
sa_handler This field specifies the type of action to be performed; its value can be a pointer to the signal handler, SIG_DFL (that is, the value 0) to specify that the default action is performed, or SIG_IGN (that is, the value 1) to specify that the signal is ignored.
sa_flags This set of flags specifies how the signal must be handled; some of them are listed in Table 11-6.
sa_mask This sigset_t variable specifies the signals to be masked when running the signal handler.
Table 11-6. Flags specifying how to handle a signalFlag Name | Description |
|---|
SA_NOCLDSTOP | Applies only to SIGCHLD; do not send SIGCHLD to the parent when the process is stopped | SA_NOCLDWAIT | Applies only to SIGCHLD; do not create a zombie when the process terminates | SA_SIGINFO | Provide additional information to the signal handler (see the later section "Changing a Signal Action") | SA_ONSTACK | Use an alternative stack for the signal handler (see the later section "Catching the Signal") | SA_RESTART | Interrupted system calls are automatically restarted (see the later section "Reexecution of System Calls") | SA_NODEFER, SA_NOMASK | Do not mask the signal while executing the signal handler | SA_RESETHAND, SA_ONESHOT | Reset to default action after executing the signal handler |
11.1.3.3. The pending signal queues
As we have seen in Table 11-2 earlier in the chapter, there are several system calls that can generate a signal: some of themkill( )
and rt_sigqueueinfo( )
send a signal to a whole thread group, while otherstkill( )
and tgkill( )
send a signal to a specific process.
Thus, in order to keep track of what signals are currently pending, the kernel associates two pending signal queues to each process:
The shared pending signal queue, rooted at the shared_pending field of the signal descriptor, stores the pending signals of the whole thread group. The private pending signal queue, rooted at the pending field of the process descriptor, stores the pending signals of the specific (lightweight) process.
A pending signal queue consists of a sigpending data structure, which is defined as follows:
struct sigpending {
struct list_head list;
sigset_t signal;
}
The signal field is a bit mask specifying the pending signals, while the list field is the head of a doubly linked list containing sigqueue data structures; the fields of this structure are shown in Table 11-7.
Table 11-7. The fields of the sigqueue data structureType | Name | Description |
|---|
struct list_head | list | Links for the pending signal queue's list | spinlock_t * | lock | Pointer to the siglock field in the signal handler descriptor corresponding to the pending signal | int | flags | Flags of the sigqueue data structure | siginfo_t | info | Describes the event that raised the signal | struct user_struct * | user | Pointer to the per-user data structure of the process's owner (see the section "The clone( ), fork( ), and vfork( ) System Calls" in Chapter 3) |
The siginfo_t data structure is a 128-byte data structure that stores information about an occurrence of a specific signal; it includes the following fields:
si_signo The signal number
si_errno The error code of the instruction that caused the signal to be raised, or 0 if there was no error
si_code A code identifying who raised the signal (see Table 11-8)
_sifields A union storing information depending on the type of signal. For instance, the siginfo_t data structure relative to an occurrence of the SIGKILL signal records the PID and the UID
of the sender process here; conversely, the data structure relative to an occurrence of the SIGSEGV signal stores the memory address whose access caused the signal to be raised.
11.1.4. Operations on Signal Data Structures
Several functions and macros are used by the kernel to handle signals. In the following description, set is a pointer to a sigset_t variable, nsig is the number of a signal, and mask is an unsigned long bit mask.
sigemptyset(set) and sigfillset(set) Sets the bits in the sigset_t variable to 0 or 1, respectively.
sigaddset(set,nsig) and sigdelset(set,nsig) Sets the bit of the sigset_t variable corresponding to signal nsig to 1 or 0, respectively. In practice, sigaddset( ) reduces to:
set->sig[(nsig - 1) / 32] |= 1UL << ((nsig - 1) % 32);
and sigdelset( ) to:
set->sig[(nsig - 1) / 32] &= ~(1UL << ((nsig - 1) % 32));
sigaddsetmask(set,mask) and sigdelsetmask(set,mask) Sets all the bits of the sigset_t variable whose corresponding bits of mask are on 1 or 0, respectively. They can be used only with signals that are between 1 and 32. The corresponding functions reduce to:
set->sig[0] |= mask;
and to:
set->sig[0] &= ~mask;
sigismember(set,nsig) Returns the value of the bit of the sigset_t variable corresponding to the signal nsig. In practice, this function reduces to:
return 1 & (set->sig[(nsig-1) / 32] >> ((nsig-1) % 32));
sigmask(nsig) Yields the bit index of the signal nsig. In other words, if the kernel needs to set, clear, or test a bit in an element of sigset_t that corresponds to a particular signal, it can derive the proper bit through this macro.
sigandsets(d,s1,s2), sigorsets(d,s1,s2), and signandsets(d,s1,s2) Performs a logical AND, a logical OR, and a logical NAND, respectively, between the sigset_t variables to which s1 and s2 point; the result is stored in the sigset_t variable to which d points.
sigtestsetmask(set,mask) Returns the value 1 if any of the bits in the sigset_t variable that correspond to the bits set to 1 in mask is set; it returns 0 otherwise. It can be used only with signals that have a number between 1 and 32.
siginitset(set,mask) Initializes the low bits of the sigset_t variable corresponding to signals between 1 and 32 with the bits contained in mask, and clears the bits corresponding to signals between 33 and 63.
siginitsetinv(set,mask) Initializes the low bits of the sigset_t variable corresponding to signals between 1 and 32 with the complement of the bits contained in mask, and sets the bits corresponding to signals between 33 and 63.
signal_pending(p) Returns the value 1 (true) if the process identified by the *p process descriptor has nonblocked pending signals, and returns the value 0 (false) if it doesn't. The function is implemented as a simple check on the TIF_SIGPENDING flag of the process.
recalc_sigpending_tsk(t) and recalc_sigpending( ) The first function checks whether there are pending signals either for the process identified by the process descriptor at *t (by looking at the t->pending->signal field) or for the thread group to which the process belongs (by looking at the t->signal->shared_pending->signal field). The function then sets accordingly the TIF_SIGPENDING flag in t->thread_info->flags. The recalc_sigpending( ) function is equivalent to recalc_sigpending_tsk(current).
rm_from_queue(mask,q) Removes from the pending signal queue q the pending signals corresponding to the bit mask mask.
flush_sigqueue(q) Removes from the pending signal queue q all pending signals.
flush_signals(t) Deletes all signals sent to the process identified by the process descriptor at *t. This is done by clearing the TIF_SIGPENDING flag in t->thread_info->flags and invoking twice flush_sigqueue( ) on the t->pending and t->signal->shared_pending queues.
11.2. Generating a Signal
Many kernel functions generate signals: they accomplish the first phase of signal handlingdescribed earlier in the section "The Role of Signals"by updating one or more process descriptors as needed. They do not directly perform the second phase of delivering the signal but, depending on the type of signal and the state of the destination processes, may wake up some processes and force them to receive the signal.
When a signal is sent to a process, either from the kernel or from another process, the kernel generates it by invoking one of the functions listed in Table 11-9.
Table 11-9. Kernel functions that generate a signal for a processName | Description |
|---|
send_sig( ) | Sends a signal to a single process | send_sig_info( ) | Like send_sig( ), with extended information in a siginfo_t structure | force_sig( ) | Sends a signal that cannot be explicitly ignored or blocked by the process | force_sig_info( ) | Like force_sig( ), with extended information in a siginfo_t structure | force_sig_specific( ) | Like force_sig( ), but optimized for SIGSTOP and SIGKILL signals | sys_tkill( ) | System call handler of tkill( )
(see the later section "System Calls Related to Signal Handling") | sys_tgkill( ) | System call handler of tgkill( )
|
All functions in Table 11-9 end up invoking the specific_send_sig_info( ) function described in the next section.
When a signal is sent to a whole thread group, either from the kernel or from another process, the kernel generates it by invoking one of the functions listed in Table 11-10.
Table 11-10. Kernel functions that generate a signal for a thread groupName | Description |
|---|
send_group_sig_info( ) | Sends a signal to a single thread group identified by the process descriptor of one of its members | kill_pg( ) | Sends a signal to all thread groups in a process group (see the section "Process Management" in Chapter 1) | kill_pg_info( ) | Like kill_pg( ), with extended information in a siginfo_t structure | kill_proc( ) | Sends a signal to a single thread group identified by the PID of one of its members | kill_proc_info( ) | Like kill_proc( ), with extended information in a siginfo_t structure | sys_kill( ) | System call handler of kill( ) (see the later section "System Calls Related to Signal Handling") | sys_rt_sigqueueinfo( ) | System call handler of rt_sigqueueinfo( ) |
All functions in Table 11-10 end up invoking the group_send_sig_info( ) function, which is described in the later section "The group_send_sig_info( ) Function."
11.2.1. The specific_send_sig_info( ) Function
The specific_send_sig_info( ) function sends a signal to a specific process. It acts on three parameters:
sig The signal number.
info Either the address of a siginfo_t table or one of three special values: 0 means that the signal has been sent by a User Mode process, 1 means that it has been sent by the kernel, and 2 means that is has been sent by the kernel and the signal is SIGSTOP or SIGKILL.
t A pointer to the descriptor of the destination process.
The specific_send_sig_info( ) function must be invoked with local interrupts disabled and the t->sighand->siglock spin lock already acquired. The function executes the following steps:
Checks whether the process ignores the signal; in the affirmative case, returns 0 (signal not generated). The signal is ignored when all three conditions for ignoring a signal are satisfied, that is: The process is not being traced (PT_PTRACED flag in t->ptrace clear). The signal is not blocked (sigismember(&t->blocked, sig) returns 0). The signal is either explicitly ignored (the sa_handler field of t->sighand->action[sig-1] is equal to SIG_IGN) or implicitly ignored (the sa_handler field is equal to SIG_DFL and the signal is SIGCONT, SIGCHLD, SIGWINCH, or SIGURG).
Checks whether the signal is non-real-time (sig<32) and another occurrence of the same signal is already pending in the private pending signal queue of the process (sigismember(&t->pending.signal,sig) returns 1): in the affirmative case, nothing has to be done, thus returns 0. Invokes send_signal(sig, info, t, &t->pending) to add the signal to the set of pending signals of the process; this function is described in detail in the next section. If send_signal( ) successfully terminated and the signal is not blocked (sigismember(&t->blocked,sig) returns 0), invokes the signal_wake_up( ) function to notify the process about the new pending signal. In turn, this function executes the following steps: Sets the TIF_SIGPENDING flags in t->tHRead_info->flags. Invokes try_to_wake_up( )see the section "The try_to_wake_up( ) Function" in Chapter 7to awake the process if it is either in TASK_INTERRUPTIBLE state, or in TASK_STOPPED state and the signal is SIGKILL. If try_to_wake_up( ) returned 0, the process was already runnable: if so, it checks whether the process is already running on another CPU and, in this case, sends an interprocessor interrupt to that CPU to force a reschedule of the current process (see the section "Interprocessor Interrupt Handling" in Chapter 4). Because each process checks the existence of pending signals when returning from the schedule( ) function, the interprocessor interrupt ensures that the destination process quickly notices the new pending signal.
Returns 1 (the signal has been successfully generated).
11.2.2. The send_signal( ) Function
The send_signal( ) function inserts a new item in a pending signal queue. It receives as its parameters the signal number sig, the address info of a siginfo_t data structure (or a special code, see the description of specific_send_sig_info( ) in the previous section), the address t of the descriptor of the target process, and the address signals of the pending signal queue.
The function executes the following steps:
If the value of info is 2, the signal is either SIGKILL or SIGSTOP and it has been generated by the kernel via the force_sig_specific( ) function: in this case, it jumps to step 9. The action corresponding to these signals is immediately enforced by the kernel, thus the function may skip adding the signal to the pending signal queue. If the number of pending signals of the process's owner (t->user->sigpending) is smaller than the current process's resource limit (t->signal->rlim[RLIMIT_SIGPENDING].rlim_cur), the function allocates a sigqueue data structure for the new occurrence of the signal:
q = kmem_cache_alloc(sigqueue_cachep, GFP_ATOMIC);
If the number of pending signals of the process's owner is too high or the memory allocation in the previous step failed, it jumps to step 9. Increases the number of pending signals of the owner (t->user->sigpending) and the reference counter of the per-user data structure pointed to by t->user. Adds the sigqueue data structure in the pending signal queue signals:
list_add_tail(&q->list, &signals->list);
Fills the siginfo_t table inside the sigqueue data structure:
if ((unsigned long)info == 0) {
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info._sifields._kill._pid = current->pid;
q->info._sifields._kill._uid = current->uid;
} else if ((unsigned long)info == 1) {
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info._sifields._kill._pid = 0;
q->info._sifields._kill._uid = 0;
} else
copy_siginfo(&q->info, info);
The copy_siginfo( ) function copies the siginfo_t table passed by the caller. Sets the bit corresponding to the signal in the bit mask of the queue:
sigaddset(&signals->signal, sig);
Returns 0: the signal has been successfully appended to the pending signal queue. Here, an item will not be added to the signal pending queue, because there are already too many pending signals, or there is no free memory for the sigqueue data structure, or the signal is immediately enforced by the kernel. If the signal is real-time and was sent through a kernel function that is explicitly required to queue it, the function returns the error code -EAGAIN:
if (sig>=32 && info && (unsigned long) info != 1 &&
info->si_code != SI_USER)
return -EAGAIN;
Sets the bit corresponding to the signal in the bit mask of the queue:
sigaddset(&signals->signal, sig);
Returns 0: even if the signal has not been appended to the queue, the corresponding bit has been set in the bit mask of pending signals.
It is important to let the destination process receive the signal even if there is no room for the corresponding item in the pending signal queue. Suppose, for instance, that a process is consuming too much memory. The kernel must ensure that the kill( )
system call succeeds even if there is no free memory; otherwise, the system administrator doesn't have any chance to recover the system by terminating the offending process.
11.2.3. The group_send_sig_info( ) Function
The group_send_sig_info( ) function sends a signal to a whole thread group. It acts on three parameters: a signal number sig, the address info of a siginfo_t tableor alternatively the special values 0, 1, or 2, as explained in the earlier section "The specific_send_sig_info( ) Function"and the address p of a process descriptor.
The function essentially executes the following steps:
Checks that the parameter sig is correct:
if (sig < 0 || sig > 64)
return -EINVAL;
If the signal is being sent by a User Mode process, it checks whether the operation is allowed. The signal is delivered only if at least one of the following conditions holds: The owner of the sending process has the proper capability (usually, this simply means the signal was issued by the system administrator; see Chapter 20). The signal is SIGCONT and the destination process is in the same login session of the sending process. Both processes belong to the same user.
If the User Mode process is not allowed to send the signal, the function returns the value -EPERM. If the sig parameter has the value 0, it returns immediately without generating any signal:
if (!sig || !p->sighand)
return 0;
Because 0 is not a valid signal number, it is used to allow the sending process to check whether it has the required privileges to send a signal to the destination thread group. The function also returns if the destination process is being killed, indicated by checking whether its signal handler descriptor has been released. Acquires the p->sighand->siglock spin lock and disables local interrupts. Invokes the handle_stop_signal( ) function, which checks for some types of signals that might nullify other pending signals for the destination thread group. The latter function executes the following steps: If the thread group is being killed (SIGNAL_GROUP_EXIT flag in the flags field of the signal descriptor set), it returns. If sig is a SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal, the function invokes the rm_from_queue( ) function to remove the SIGCONT signal from the shared pending signal queue p->signal->shared_pending and from the private queues of all members of the thread group. If sig is SIGCONT, it invokes the rm_from_queue( ) function to remove any SIGSTOP, SIGTSTP, SIGTTIN, and SIGTTOU signal from the shared pending signal queue p->signal->shared_pending; then, removes the same signals from the private pending signal queues of the processes belonging to the thread group, and awakens them:
rm_from_queue(0x003c0000, &p->signal->shared_pending);
t = p;
do {
rm_from_queue(0x003c0000, &t->pending);
try_to_wake_up(t, TASK_STOPPED, 0);
t = next_thread(t);
} while (t != p);
The mask 0x003c0000 selects the four stop signals. At each iteration, the next_thread macro returns the descriptor address of a different lightweight process in the thread group (see the section "Relationships Among Processes" in Chapter 3).
Checks whether the thread group ignores the signal; if so, returns the value 0 (success). The signal is ignored when all three conditions for ignoring a signal that are mentioned in the earlier section "The Role of Signals" are satisfied (see also step 1 in the earlier section "The specific_send_sig_info( ) Function"). Checks whether the signal is non-real-time and another occurrence of the same signal is already pending in the shared pending signal queue of the thread group: if so, nothing has to be done, thus returns the value 0 (success):
if (sig<32 && sigismember(&p->signal->shared_pending.signal,sig))
return 0;
Invokes send_signal( ) to append the signal to the shared pending signal queue (see the previous section "The send_signal( ) Function"). If send_signal( ) returns a nonzero error code, it terminates while returning the same value. Invokes the _ _group_complete_signal( ) function to wake up one lightweight process in the thread group (see below). Releases the p->sighand->siglock spin lock and enables local interrupts.
The _ _group_complete_signal( ) function scans the processes in the thread group, looking for a process that can receive the new signal. A process may be selected if it satisfies all the following conditions:
The process does not block the signal. The process is not in state EXIT_ZOMBIE, EXIT_DEAD, TASK_TRACED, or TASK_STOPPED (as an exception, the process can be in the TASK_TRACED or TASK_STOPPED states if the signal is SIGKILL). The process is not being killedthat is, its PF_EXITING flag is not set. Either the process is currently in execution on a CPU, or its TIF_SIGPENDING flag is not already set. (In fact, there is no point in awakening a process that has pending signals: in general, this operation has been already performed by the kernel control path that set the TIF_SIGPENDING flag. On the other hand, if a process is currently in execution, it should be notified of the new pending signal.)
A thread group might include many processes that satisfy the above conditions. The function selects one of them as follows:
If the process identified by pthe descriptor address passed as parameter of the group_send_sig_info( ) functionsatisfies all the prior rules and can thus receive the signal, the function selects it. Otherwise, the function searches for a suitable process by scanning the members of the thread group, starting from the process that received the last thread group's signal (p->signal->curr_target).
If _ _group_complete_signal( ) succeeds in finding a suitable process, it sets up the delivery of the signal to the selected process. First, the function checks whether the signal is fatal: in this case, the whole thread group is killed by sending SIGKILL signals to each lightweight process in the group. Otherwise, if the signal is not fatal, the function invokes the signal_wake_up( ) function to notify the selected process that it has a new pending signal (see step 4 in the earlier section "The specific_send_sig_info( ) Function").
11.3. Delivering a Signal
We assume that the kernel noticed the arrival of a signal and invoked one of the functions mentioned in the previous sections to prepare the process descriptor of the process that is supposed to receive the signal. But in case that process was not running on the CPU at that moment, the kernel deferred the task of delivering
the signal. We now turn to the activities that the kernel performs to ensure that pending signals of a process are handled.
As mentioned in the section "Returning from Interrupts and Exceptions" in Chapter 4, the kernel checks the value of the TIF_SIGPENDING flag of the process before allowing the process to resume its execution in User Mode. Thus, the kernel checks for the existence of pending signals every time it finishes handling an interrupt or an exception.
To handle the nonblocked pending signals, the kernel invokes the do_signal( ) function, which receives two parameters:
regs The address of the stack area where the User Mode register contents of the current process are saved.
oldset The address of a variable where the function is supposed to save the bit mask array of blocked signals. It is NULL if there is no need to save the bit mask array.
Our description of the do_signal( ) function will focus on the general mechanism of signal delivery; the actual code is burdened with lots of details dealing with race conditions and other special casessuch as freezing the system, generating core dumps, stopping and killing a whole thread group, and so on. We will quietly skip all these details.
As already mentioned, the do_signal( ) function is usually only invoked when the CPU is going to return in User Mode. For that reason, if an interrupt handler invokes do_signal( ), the function simply returns:
if ((regs->xcs & 3) != 3)
return 1;
If the oldset parameter is NULL, the function initializes it with the address of the current->blocked field:
if (!oldset)
oldset = ¤t->blocked;
The heart of the do_signal( ) function consists of a loop that repeatedly invokes the dequeue_signal( ) function until no nonblocked pending signals are left in both the private and shared pending signal queues. The return code of dequeue_signal( ) is stored in the signr local variable. If its value is 0, it means that all pending signals have been handled and do_signal( ) can finish. As long as a nonzero value is returned, a pending signal is waiting to be handled. dequeue_signal( ) is invoked again after do_signal( ) handles the current signal.
The dequeue_signal( ) considers first all signals in the private pending signal queue, starting from the lowest-numbered signal, then the signals in the shared queue. It updates the data structures to indicate that the signal is no longer pending and returns its number. This task involves clearing the corresponding bit in current->pending.signal or current->signal->shared_pending.signal, and invoking recalc_sigpending( ) to update the value of the TIF_SIGPENDING flag.
Let's see how the do_signal( ) function handles each pending signal whose number is returned by dequeue_signal( ). First, it checks whether the current receiver process is being monitored by some other process; in this case, do_signal( ) invokes do_notify_parent_cldstop( ) and schedule( ) to make the monitoring process aware of the signal handling.
Then do_signal( ) loads the ka local variable with the address of the k_sigaction data structure of the signal to be handled:
ka = ¤t->sig->action[signr-1];
Depending on the contents, three kinds of actions may be performed: ignoring
the signal, executing a default action, or executing a signal handler.
When a delivered signal is explicitly ignored, the do_signal( ) function simply continues with a new execution of the loop and therefore considers another pending signal:
if (ka->sa.sa_handler == SIG_IGN)
continue;
In the following two sections we will describe how a default action and a signal handler are executed.
11.3.1. Executing the Default Action for the Signal
If ka->sa.sa_handler is equal to SIG_DFL, do_signal( ) must perform the default action of the signal. The only exception comes when the receiving process is init, in which case the signal is discarded as described in the earlier section "Actions Performed upon Delivering a Signal":
if (current->pid == 1)
continue;
For other processes, the signals whose default action is "ignore" are also easily handled:
if (signr==SIGCONT || signr==SIGCHLD ||
signr==SIGWINCH || signr==SIGURG)
continue;
The signals whose default action is "stop" may stop all processes in the thread group. To do this, do_signal( ) sets their states to TASK_STOPPED and then invokes the schedule( ) function (see the section "The schedule( ) Function" in Chapter 7):
if (signr==SIGSTOP || signr==SIGTSTP ||
signr==SIGTTIN || signr==SIGTTOU) {
if (signr != SIGSTOP &&
is_orphaned_pgrp(current->signal->pgrp))
continue;
do_signal_stop(signr);
}
The difference between SIGSTOP and the other signals is subtle: SIGSTOP always stops the thread group, while the other signals stop the thread group only if it is not in an "orphaned process group." The POSIX standard specifies that a process group is not orphaned as long as there is a process in the group that has a parent in a different process group but in the same session. Thus, if the parent process dies but the user who started the process is still logged in, the process group is not orphaned.
The do_signal_stop( ) function checks whether current is the first process being stopped in the thread group. If so, it activates a "group stop": essentially, the function sets the group_stop_count field in the signal descriptor to a positive value, and awakens each process in the thread group. Each such process, in turn, looks at this field to recognize that a group stop is in progress, changes its state to TASK_STOPPED, and invokes schedule(). The do_signal_stop( ) function also sends a SIGCHLD signal to the parent process of the thread group leader, unless the parent has set the SA_NOCLDSTOP flag of SIGCHLD.
The signals whose default action is "dump" may create a core file in the process working directory; this file lists the complete contents of the process's address space and CPU registers. After do_signal( ) creates the core file, it kills the thread group. The default action of the remaining 18 signals is "terminate," which consists of simply killing the thread group. To kill the whole thread group, the function invokes do_group_exit( ), which executes a clean "group exit" procedure (see the section "Process Termination" in Chapter 3).
11.3.2. Catching the Signal
If a handler has been established for the signal, the do_signal( ) function must enforce its execution. It does this by invoking handle_signal( ):
handle_signal(signr, &info, &ka, oldset, regs);
if (ka->sa.sa_flags & SA_ONESHOT)
ka->sa.sa_handler = SIG_DFL;
return 1;
If the received signal has the SA_ONESHOT flag set, it must be reset to its default action, so that further occurrences of the same signal will not trigger again the execution of the signal handler. Notice how do_signal( ) returns after having handled a single signal. Other pending signals won't be considered until the next invocation of do_signal( ). This approach ensures that real-time signals will be dealt with in the proper order.
Executing a signal handler is a rather complex task because of the need to juggle stacks carefully while switching between User Mode and Kernel Mode. We explain exactly what is entailed here:
Signal handlers are functions defined by User Mode processes and included in the User Mode code segment. The handle_signal( ) function runs in Kernel Mode while signal handlers run in User Mode; this means that the current process must first execute the signal handler in User Mode before being allowed to resume its "normal" execution. Moreover, when the kernel attempts to resume the normal execution of the process, the Kernel Mode stack no longer contains the hardware context of the interrupted program, because the Kernel Mode stack is emptied at every transition from User Mode to Kernel Mode.
An additional complication is that signal handlers may invoke system calls. In this case, after the service routine executes, control must be returned to the signal handler instead of to the normal flow of code of the interrupted program.
The solution adopted in Linux consists of copying the hardware context saved in the Kernel Mode stack onto the User Mode stack of the current process. The User Mode stack is also modified in such a way that, when the signal handler terminates, the sigreturn( )
system call is automatically invoked to copy the hardware context back on the Kernel Mode stack and to restore the original content of the User Mode stack.
Figure 11-2 illustrates the flow of execution of the functions involved in catching
a signal. A nonblocked signal is sent to a process. When an interrupt or exception occurs, the process switches into Kernel Mode. Right before returning to User Mode, the kernel executes the do_signal( ) function, which in turn handles the signal (by invoking handle_signal( )) and sets up the User Mode stack (by invoking setup_frame( ) or setup_rt_frame( )). When the process switches again to User Mode, it starts executing the signal handler, because the handler's starting address was forced into the program counter. When that function terminates, the return code placed on the User Mode stack by the setup_frame( ) or setup_rt_frame( ) function is executed. This code invokes the sigreturn( )
or the rt_sigreturn( )
system call; the corresponding service routines copy the hardware context of the normal program to the Kernel Mode stack and restore the User Mode stack back to its original state (by invoking restore_sigcontext( )). When the system call terminates, the normal program can thus resume its execution.
Let's now examine in detail how this scheme is carried out.
11.3.2.1. Setting up the frame
To properly set the User Mode stack of the process, the handle_signal( ) function invokes either setup_frame( ) (for signals that do not require a siginfo_t table; see the section "System Calls Related to Signal Handling" later in this chapter) or setup_rt_frame( ) (for signals that do require a siginfo_t table). To choose among these two functions, the kernel checks the value of the SA_SIGINFO flag in the sa_flags field of the sigaction table associated with the signal.
The setup_frame( ) function receives four parameters, which have the following meanings:
sig Signal number
ka Address of the k_sigaction table associated with the signal
oldset Address of a bit mask array of blocked signals
regs Address in the Kernel Mode stack area where the User Mode register contents are saved
The setup_frame( ) function pushes onto the User Mode stack a data structure called a frame, which contains the information needed to handle the signal and to ensure the correct return to the sys_sigreturn( ) function. A frame is a sigframe table that includes the following fields (see Figure 11-3):
pretcode Return address of the signal handler function; it points to the code at the _ _kernel_sigreturn label (see below).
sig The signal number; this is the parameter required by the signal handler.
sc S tructure of type sigcontext containing the hardware context of the User Mode process right before switching to Kernel Mode (this information is copied from the Kernel Mode stack of current). It also contains a bit array that specifies the blocked regular signals of the process.
fpstate Structure of type _fpstate that may be used to store the floating point registers of the User Mode process (see the section "Saving and Loading the FPU, MMX, and XMM Registers" in Chapter 3).
extramask Bit array that specifies the blocked real-time signals.
retcode 8-byte code issuing a sigreturn( )
system call. In earlier versions of Linux, this code was effectively executed to return from the signal handler; in Linux 2.6, however, it is used only as a signature, so that debuggers can recognize the signal stack frame.
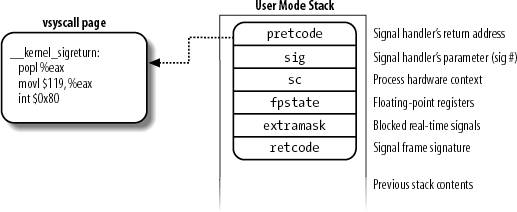
The setup_frame( ) function starts by invoking get_sigframe( ) to compute the first memory location of the frame. That memory location is usually in the User Mode stack, so the function returns the value:
(regs->esp - sizeof(struct sigframe)) & 0xfffffff8
Because stacks grow toward lower addresses, the initial address of the frame is obtained by subtracting its size from the address of the current stack top and aligning the result to a multiple of 8.
The returned address is then verified by means of the access_ok macro; if it is valid, the function repeatedly invokes _ _put_user( ) to fill all the fields of the frame. The pretcode field in the frame is initialized to &_ _kernel_sigreturn, the address of some glue code placed in the vsyscall page (see the section "Issuing a System Call via the sysenter Instruction" in Chapter 10).
Once this is done, the function modifies the regs area of the Kernel Mode stack, thus ensuring that control is transferred to the signal handler when current resumes its execution in User Mode:
regs->esp = (unsigned long) frame;
regs->eip = (unsigned long) ka->sa.sa_handler;
regs->eax = (unsigned long) sig;
regs->edx = regs->ecx = 0;
regs->xds = regs->xes = regs->xss = _ _USER_DS;
regs->xcs = _ _USER_CS;
The setup_frame( ) function terminates by resetting the segmentation registers saved on the Kernel Mode stack to their default value. Now the information needed by the signal handler is on the top of the User Mode stack.
The setup_rt_frame( ) function is similar to setup_frame( ), but it puts on the User Mode stack an extended frame (stored in the rt_sigframe data structure) that also includes the content of the siginfo_t table associated with the signal. Moreover, this function sets the pretcode field so that it points to the _ _kernel_rt_sigreturn code in the vsyscall page.
11.3.2.2. Evaluating the signal flags
After setting up the User Mode stack, the handle_signal( ) function checks the values of the flags associated with the signal. If the signal does not have the SA_NODEFER flag set, the signals in the sa_mask field of the sigaction table must be blocked during the execution of the signal handler:
if (!(ka->sa.sa_flags & SA_NODEFER)) {
spin_lock_irq(¤t->sighand->siglock);
sigorsets(¤t->blocked, ¤t->blocked, &ka->sa.sa_mask);
sigaddset(¤t->blocked, sig);
recalc_sigpending(current);
spin_unlock_irq(¤t->sighand->siglock);
}
As described earlier, the recalc_sigpending( ) function checks whether the process has nonblocked pending signals and sets its TIF_SIGPENDING flag accordingly.
The function returns then to do_signal( ), which also returns immediately.
11.3.2.3. Starting the signal handler
When do_signal( ) returns, the current process resumes its execution in User Mode. Because of the preparation by setup_frame( ) described earlier, the eip register points to the first instruction of the signal handler, while esp points to the first memory location of the frame that has been pushed on top of the User Mode stack. As a result, the signal handler is executed.
11.3.2.4. Terminating the signal handler
When the signal handler terminates, the return address on top of the stack points to the code in the vsyscall page referenced by the pretcode field of the frame:
_ _kernel_sigreturn:
popl %eax
movl $_ _NR_sigreturn, %eax
int $0x80
Therefore, the signal number (that is, the sig field of the frame) is discarded from the stack; the sigreturn( )
system call is then invoked.
The sys_sigreturn( ) function computes the address of the pt_regs data structure regs, which contains the hardware context of the User Mode process (see the section "Parameter Passing" in Chapter 10). From the value stored in the esp field, it can thus derive and check the frame address inside the User Mode stack:
frame = (struct sigframe *)(regs.esp - 8);
if (verify_area(VERIFY_READ, frame, sizeof(*frame)) {
force_sig(SIGSEGV, current);
return 0;
}
Then the function copies the bit array of signals that were blocked before invoking the signal handler from the sc field of the frame to the blocked field of current. As a result, all signals that have been masked for the execution of the signal handler are unblocked. The recalc_sigpending( ) function is then invoked.
The sys_sigreturn( ) function must at this point copy the process hardware context from the sc field of the frame to the Kernel Mode stack and remove the frame from the User Mode stack; it performs these two tasks by invoking the restore_sigcontext( ) function.
If the signal was sent by a system call such as rt_sigqueueinfo( )
that required a siginfo_t table to be associated with the signal, the mechanism is similar. The pretcode field of the extended frame points to the _ _kernel_rt_sigreturn code in the vsyscall page, which in turn invokes the rt_sigreturn( )
system call; the corresponding sys_rt_sigreturn( ) service routine copies the process hardware context from the extended frame to the Kernel Mode stack and restores the original User Mode stack content by removing the extended frame from it.
11.3.3. Reexecution of System Calls
The request associated with a system call cannot always be immediately satisfied by the kernel; when this happens, the process that issued the system call is put in a TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE state.
If the process is put in a TASK_INTERRUPTIBLE state and some other process sends a signal to it, the kernel puts it in the TASK_RUNNING state without completing the system call (see the section "Returning from Interrupts and Exceptions" in Chapter 4). The signal is delivered to the process while switching back to User Mode. When this happens, the system call service routine does not complete its job, but returns an EINTR, ERESTARTNOHAND, ERESTART_RESTARTBLOCK, ERESTARTSYS, or ERESTARTNOINTR error code.
In practice, the only error code a User Mode process can get in this situation is EINTR, which means that the system call has not been completed. (The application programmer may check this code and decide whether to reissue the system call.) The remaining error codes are used internally by the kernel to specify whether the system call may be reexecuted automatically after the signal handler termination.
Table 11-11 lists the error codes related to unfinished system calls and their impact for each of the three possible signal actions. The terms that appear in the entries are defined in the following list:
Terminate The system call will not be automatically reexecuted; the process will resume its execution in User Mode at the instruction following the int
$0x80 or sysenter
one and the eax register will contain the -EINTR value.
Reexecute The kernel forces the User Mode process to reload the eax register with the system call number and to reexecute the int $0x80 or sysenter instruction; the process is not aware of the reexecution and the error code is not passed to it.
Depends The system call is reexecuted only if the SA_RESTART flag of the delivered signal is set; otherwise, the system call terminates with a -EINTR error code.
Table 11-11. Reexecution of system callsError codes and their impact on system call execution |
|---|
Signal Action | EINTR | ERESTARTSYS | ERESTARTNOHAND
ERESTART_RESTARTBLOCKa | ERESTARTNOINTR |
|---|
Default | Terminate | Reexecute | Reexecute | Reexecute | Ignore | Terminate | Reexecute | Reexecute | Reexecute | Catch | Terminate | Depends | Terminate | Reexecute | |
When delivering a signal, the kernel must be sure that the process really issued a system call before attempting to reexecute it. This is where the orig_eax field of the regs hardware context plays a critical role. Let's recall how this field is initialized when the interrupt or exception handler starts:
Interrupt The field contains the IRQ number associated with the interrupt minus 256 (see the section "Saving the registers for the interrupt handler" in Chapter 4).
0x80 exception (also sysenter) The field contains the system call number (see the section "Entering and Exiting a System Call" in Chapter 10).
Other exceptions The field contains the value -1 (see the section "Saving the Registers for the Exception Handler" in Chapter 4).
Therefore, a nonnegative value in the orig_eax field means that the signal has woken up a TASK_INTERRUPTIBLE process that was sleeping in a system call. The service routine recognizes that the system call was interrupted, and thus returns one of the previously mentioned error codes.
11.3.3.1. Restarting a system call interrupted by a non-caught signal
If the signal is explicitly ignored or if its default action is enforced, do_signal( ) analyzes the error code of the system call to decide whether the unfinished system call must be automatically reexecuted, as specified in Table 11-11. If the call must be restarted, the function modifies the regs hardware context so that, when the process is back in User Mode, eip points either to the int $0x80 instruction or to the sysenter instruction, and eax contains the system call number:
if (regs->orig_eax >= 0) {
if (regs->eax == -ERESTARTNOHAND || regs->eax == -ERESTARTSYS ||
regs->eax == -ERESTARTNOINTR) {
regs->eax = regs->orig_eax;
regs->eip -= 2;
}
if (regs->eax == -ERESTART_RESTARTBLOCK) {
regs->eax = _ _NR_restart_syscall;
regs->eip -= 2;
}
}
The regs->eax field is filled with the return code of a system call service routine (see the section "Entering and Exiting a System Call" in Chapter 10). Notice that both the int $0x80 and sysreturn instructions are two bytes long so the function subtracts 2 from eip in order to set it to the instruction that triggers the system call.
The error code ERESTART_RESTARTBLOCK is special, because the eax register is set to the number of the restart_syscall( )
system call; thus, the User Mode process does not restart the same system call that was interrupted by the signal. This error code is only used by time-related system calls that, when restarted, should adjust their User Mode parameters. A typical example is the nanosleep( )
system call (see the section "An Application of Dynamic Timers: the nanosleep( ) System Call" in Chapter 6): suppose that a process invokes it to pause the execution for 20 milliseconds, and that a signal occurs 10 milliseconds later. If the system call would be restarted as usual, the total delay time would exceed 30 milliseconds.
Instead, the service routine of the nanosleep( ) system call fills the restart_block field in the current's thread_info structure with the address of a special service routine to be used when restarting, and returns -ERESTART_RESTARTBLOCK if interrupted. The sys_restart_syscall( ) service routine just executes the special nanosleep( )'s service routine, which adjusts the delay to consider the time elapsed between the invocation of the original system call and its restarting.
11.3.3.2. Restarting a system call for a caught signal
If the signal is caught, handle_signal( ) analyzes the error code and, possibly, the SA_RESTART flag of the sigaction table to decide whether the unfinished system call must be reexecuted:
if (regs->orig_eax >= 0) {
switch (regs->eax) {
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->eax = -EINTR;
break;
case -ERESTARTSYS:
if (!(ka->sa.sa_flags & SA_RESTART)) {
regs->eax = -EINTR;
break;
}
/* fallthrough */
case -ERESTARTNOINTR:
regs->eax = regs->orig_eax;
regs->eip -= 2;
}
}
If the system call must be restarted, handle_signal( ) proceeds exactly as do_signal( ); otherwise, it returns an -EINTR error code to the User Mode process.
11.4. System Calls Related to Signal Handling
As stated in the introduction of this chapter, programs running in User Mode are allowed to send and receive signals. This means that a set of system calls must be defined to allow these kinds of operations. Unfortunately, for historical reasons, several system calls exist that serve essentially the same purpose. As a result, some of these system calls are never invoked. For instance, sys_sigaction( ) and sys_rt_sigaction( ) are almost identical, so the sigaction( )
wrapper function included in the C library ends up invoking sys_rt_sigaction( ) instead of sys_sigaction( ). We will describe some of the most significant system calls in the following sections.
11.4.1. The kill( ) System Call
The kill(pid,sig) system call is commonly used to send signals to conventional processes or multithreaded applications; its corresponding service routine is the sys_kill( ) function. The integer pid parameter has several meanings, depending on its numerical value:
pid > 0 The sig signal is sent to the thread group of the process whose PID is equal to pid.
pid = 0 The sig signal is sent to all thread groups of the processes in the same process group as the calling process.
pid = -1 The signal is sent to all processes, except swapper (PID 0), init (PID 1), and current.
pid < -1 The signal is sent to all thread groups of the processes in the process group -pid.
The sys_kill( ) function sets up a minimal siginfo_t table for the signal, and then invokes kill_something_info( ):
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info._sifields._kill._pid = current->tgid;
info._sifields._kill._uid = current->uid;
return kill_something_info(sig, &info, pid);
The kill_something_info( ) function, in turn, invokes either kill_proc_info( ) (to send the signal to a single thread group via group_send_sig_info( )), or kill_pg_info( ) (to scan all processes in the destination process group and invoke send_sig_info( ) for each of them), or repeatedly group_send_sig_info( ) for each process in the system (if pid is -1).
The kill( ) system call is able to send every signal, even the so-called real-time signals that have numbers ranging from 32 to 64. However, as we saw in the earlier section "Generating a Signal," the kill( ) system call does not ensure that a new element is added to the pending signal queue of the destination process, so multiple instances of pending signals can be lost. Real-time signals should be sent by means of a system call such as rt_sigqueueinfo( )
(see the later section "System Calls for Real-Time Signals").
System V
and BSD
Unix variants also have a killpg( )
system call, which is able to explicitly send a signal to a group of processes. In Linux, the function is implemented as a library function that uses the kill( ) system call. Another variation is raise( )
, which sends a signal to the current process (that is, to the process executing the function). In Linux, raise() is implemented as a library function.
11.4.2. The tkill( ) and tgkill( ) System Calls
The tkill( ) and tgkill( ) system calls send a signal to a specific process in a thread group. The pthread_kill( ) function of every POSIX-compliant pthread library invokes either of them to send a signal to a specific lightweight process.
The tkill( ) system call expects two parameters: the PID pid of the process to be signaled and the signal number sig. The sys_tkill( ) service routine fills a siginfo table, gets the process descriptor address, makes some permission checks (such as those in step 2 in the section "The group_send_sig_info( ) Function"), and invokes specific_send_sig_info( ) to send the signal.
The tgkill( ) system call differs from tkill( ) because it has a third parameter: the thread group ID
(tgid) of the thread group that includes the process to be signaled. The sys_tgkill( ) service routine performs exactly the same operations as sys_tkill( ), but also checks that the process being signaled actually belongs to the thread group tgid. This additional check solves a race condition that occurs when a signal is sent to a process that is being killed: if another multithreaded application is creating lightweight processes fast enough, the signal could be delivered to the wrong process. The tgkill( ) system call solves the problem, because the thread group ID is never changed during the life span of a multithreaded application.
11.4.3. Changing a Signal Action
The sigaction(sig,act,oact) system call allows users to specify an action for a signal; of course, if no signal action is defined, the kernel executes the default action associated with the delivered signal.
The corresponding sys_sigaction( ) service routine acts on two parameters: the sig signal number and the act table of type old_sigaction that specifies the new action. A third oact optional output parameter may be used to get the previous action associated with the signal. (The old_sigaction data structure contains the same fields as the sigaction structure described in the earlier section "Data Structures Associated with Signals," but in a different order.)
The function checks first whether the act address is valid. Then it fills the sa_handler, sa_flags, and sa_mask fields of a new_ka local variable of type k_sigaction with the corresponding fields of *act:
_ _get_user(new_ka.sa.sa_handler, &act->sa_handler);
_ _get_user(new_ka.sa.sa_flags, &act->sa_flags);
_ _get_user(mask, &act->sa_mask);
siginitset(&new_ka.sa.sa_mask, mask);
The function invokes do_sigaction( ) to copy the new new_ka table into the entry at the sig-1 position of current->sig->action ( the number of the signal is one higher than the position in the array because there is no zero signal):
k = ¤t->sig->action[sig-1];
if (act) {
*k = *act;
sigdelsetmask(&k->sa.sa_mask, sigmask(SIGKILL) | sigmask(SIGSTOP));
if (k->sa.sa_handler == SIG_IGN || (k->sa.sa_handler == SIG_DFL &&
(sig==SIGCONT || sig==SIGCHLD || sig==SIGWINCH || sig==SIGURG))) {
rm_from_queue(sigmask(sig), ¤t->signal->shared_pending);
t = current;
do {
rm_from_queue(sigmask(sig), ¤t->pending);
recalc_sigpending_tsk(t);
t = next_thread(t);
} while (t != current);
}
}
The POSIX standard requires that setting a signal action to either SIG_IGN or SIG_DFL when the default action is "ignore" causes every pending signal of the same type to be discarded. Moreover, notice that no matter what the requested masked signals are for the signal handler, SIGKILL and SIGSTOP are never masked.
The sigaction( ) system call also allows the user to initialize the sa_flags field in the sigaction table. We listed the values allowed for this field and the related meanings in Table 11-6 (earlier in this chapter).
Older System V
Unix variants offered the signal( )
system call, which is still widely used by programmers. Recent C libraries implement signal( ) by means of rt_sigaction( )
. However, Linux still supports older C libraries and offers the sys_signal( ) service routine:
new_sa.sa.sa_handler = handler;
new_sa.sa.sa_flags = SA_ONESHOT | SA_NOMASK;
ret = do_sigaction(sig, &new_sa, &old_sa);
return ret ? ret : (unsigned long)old_sa.sa.sa_handler;
11.4.4. Examining the Pending Blocked Signals
The sigpending( )
system call allows a process to examine the set of pending blocked signalsi.e., those that have been raised while blocked. The corresponding sys_sigpending( ) service routine acts on a single parameter, set, namely, the address of a user variable where the array of bits must be copied:
sigorsets(&pending, ¤t->pending.signal,
¤t->signal->shared_pending.signal);
sigandsets(&pending, ¤t->blocked, &pending);
copy_to_user(set, &pending, 4);
11.4.5. Modifying the Set of Blocked Signals
The sigprocmask( )
system call allows processes to modify the set of blocked signals; it applies only to regular (non-real-time) signals. The corresponding sys_sigprocmask( ) service routine acts on three parameters:
oset Pointer in the process address space to a bit array where the previous bit mask must be stored.
set Pointer in the process address space to the bit array containing the new bit mask.
how Flag that may have one of the following values:
SIG_BLOCK The *set bit mask array specifies the signals that must be added to the bit mask array of blocked signals.
SIG_UNBLOCK The *set bit mask array specifies the signals that must be removed from the bit mask array of blocked signals.
SIG_SETMASK The *set bit mask array specifies the new bit mask array of blocked signals.
The function invokes copy_from_user( ) to copy the value pointed to by the set parameter into the new_set local variable and copies the bit mask array of standard blocked signals of current into the old_set local variable. It then acts as the how flag specifies on these two variables:
if (copy_from_user(&new_set, set, sizeof(*set)))
return -EFAULT;
new_set &= ~(sigmask(SIGKILL)|sigmask(SIGSTOP));
old_set = current->blocked.sig[0];
if (how == SIG_BLOCK)
sigaddsetmask(¤t->blocked, new_set);
else if (how == SIG_UNBLOCK)
sigdelsetmask(¤t->blocked, new_set);
else if (how == SIG_SETMASK)
current->blocked.sig[0] = new_set;
else
return -EINVAL;
recalc_sigpending(current);
if (oset && copy_to_user(oset, &old_set, sizeof(*oset)))
return -EFAULT;
return 0;
11.4.6. Suspending the Process
The sigsuspend( )
system call puts the process in the TASK_INTERRUPTIBLE state, after having blocked the standard signals specified by a bit mask array to which the mask parameter points. The process will wake up only when a nonignored, nonblocked signal is sent to it.
The corresponding sys_sigsuspend( ) service routine executes these statements:
mask &= ~(sigmask(SIGKILL) | sigmask(SIGSTOP));
saveset = current->blocked;
siginitset(¤t->blocked, mask);
recalc_sigpending(current);
regs->eax = -EINTR;
while (1) {
current->state = TASK_INTERRUPTIBLE;
schedule( );
if (do_signal(regs, &saveset))
return -EINTR;
}
The schedule( ) function selects another process to run. When the process that issued the sigsuspend( ) system call is executed again, sys_sigsuspend( ) invokes the do_signal( ) function to deliver the signal that has awakened the process. If that function returns the value 1, the signal is not ignored. Therefore the system call terminates by returning the error code -EINTR.
The sigsuspend( ) system call may appear redundant, because the combined execution of sigprocmask( )
and sleep( )
apparently yields the same result. But this is not true: because processes can be interleaved at any time, one must be conscious that invoking a system call to perform action A followed by another system call to perform action B is not equivalent to invoking a single system call that performs action A and then action B.
In this particular case, sigprocmask( ) might unblock a signal that is delivered before invoking sleep( ). If this happens, the process might remain in a TASK_INTERRUPTIBLE state forever, waiting for the signal that was already delivered. On the other hand, the sigsuspend( ) system call does not allow signals to be sent after unblocking and before the schedule( ) invocation, because other processes cannot grab the CPU during that time interval.
11.4.7. System Calls for Real-Time Signals
Because the system calls previously examined apply only to standard signals, additional system calls must be introduced to allow User Mode processes to handle real-time signals
.
Several system calls for
real-time signals (rt_sigaction( )
, rt_sigpending( )
, rt_sigprocmask( )
, and rt_sigsuspend( )
) are similar to those described earlier and won't be discussed further. For the same reason, we won't discuss two other system calls that deal with queues of real-time signals:
rt_sigqueueinfo( ) Sends a real-time signal so that it is added to the shared pending signal queue of the destination process. Usually invoked through the sigqueue( )
standard library function.
rt_sigtimedwait( ) Dequeues a blocked pending signal without delivering it and returns the signal number to the caller; if no blocked signal is pending, suspends the current process for a fixed amount of time. Usually invoked through the sigwaitinfo( )
and sigtimedwait( )
standard library functions.
|
|
|
|
|
|
| |

 LINUX
LINUX 
 Books
Books

 ]
]