14.1. Introduction
This chapter covers numerous topics and functions that we lump under the term advanced I/O: nonblocking I/O, record locking, System V STREAMS, I/O multiplexing (the select and poll functions), the readv and writev functions, and memory-mapped I/O (mmap). We need to cover these topics before describing interprocess communication in Chapter 15, Chapter 17, and many of the examples in later chapters.
14.2. Nonblocking I/O
In Section 10.5, we said that the system calls are divided into two categories: the "slow" ones and all the others. The slow system calls are those that can block forever. They include
Reads that can block the caller forever if data isn't present with certain file types (pipes, terminal devices, and network devices) Writes that can block the caller forever if the data can't be accepted immediately by these same file types (no room in the pipe, network flow control, etc.) Opens that block until some condition occurs on certain file types (such as an open of a terminal device that waits until an attached modem answers the phone, or an open of a FIFO for writing-only when no other process has the FIFO open for reading) Reads and writes of files that have mandatory record locking enabled Certain ioctl operations Some of the interprocess communication functions (Chapter 15)
We also said that system calls related to disk I/O are not considered slow, even though the read or write of a disk file can block the caller temporarily.
Nonblocking I/O lets us issue an I/O operation, such as an open, read, or write, and not have it block forever. If the operation cannot be completed, the call returns immediately with an error noting that the operation would have blocked.
There are two ways to specify nonblocking I/O for a given descriptor.
If we call open to get the descriptor, we can specify the O_NONBLOCK flag (Section 3.3). For a descriptor that is already open, we call fcntl to turn on the O_NONBLOCK file status flag (Section 3.14). Figure 3.11 shows a function that we can call to turn on any of the file status flags for a descriptor.
Earlier versions of System V used the flag O_NDELAY to specify nonblocking mode. These versions of System V returned a value of 0 from the read function if there wasn't any data to be read. Since this use of a return value of 0 overlapped with the normal UNIX System convention of 0 meaning the end of file, POSIX.1 chose to provide a nonblocking flag with a different name and different semantics. Indeed, with these older versions of System V, when we get a return of 0 from read, we don't know whether the call would have blocked or whether the end of file was encountered. We'll see that POSIX.1 requires that read return 1 with errno set to EAGAIN if there is no data to read from a nonblocking descriptor. Some platforms derived from System V support both the older O_NDELAY and the POSIX.1 O_NONBLOCK, but in this text, we'll use only the POSIX.1 feature. The older O_NDELAY is for backward compatibility and should not be used in new applications.
4.3BSD provided the FNDELAY flag for fcntl, and its semantics were slightly different. Instead of affecting only the file status flags for the descriptor, the flags for either the terminal device or the socket were also changed to be nonblocking, affecting all users of the terminal or socket, not only the users sharing the same file table entry (4.3BSD nonblocking I/O worked only on terminals and sockets). Also, 4.3BSD returned EWOULDBLOCK if an operation on a nonblocking descriptor could not complete without blocking. Today, BSD-based systems provide the POSIX.1 O_NONBLOCK flag and define EWOULDBLOCK to be the same as EAGAIN. These systems provide nonblocking semantics consistent with other POSIX-compatible systems: changes in file status flags affect all users of the same file table entry, but are independent of accesses to the same device through other file table entries. (Refer to Figures 3.6 and 3.8.)
Example
Let's look at an example of nonblocking I/O. The program in Figure 14.1 reads up to 500,000 bytes from the standard input and attempts to write it to the standard output. The standard output is first set nonblocking. The output is in a loop, with the results of each write being printed on the standard error. The function clr_fl is similar to the function set_fl that we showed in Figure 3.11. This new function simply clears one or more of the flag bits.
If the standard output is a regular file, we expect the write to be executed once:
$ ls -l /etc/termcap print file size
-rw-r--r-- 1 root 702559 Feb 23 2002 /etc/termcap
$ ./a.out < /etc/termcap > temp.file try a regular file first
read 500000 bytes
nwrite = 500000, errno = 0 a single write
$ ls -l temp.file verify size of output file
-rw-rw-r-- 1 sar 500000 Jul 8 04:19 temp.file
But if the standard output is a terminal, we expect the write to return a partial count sometimes and an error at other times. This is what we see:
$ ./a.out < /etc/termcap 2>stderr.out output to terminal
lots of output to terminal ...
$ cat stderr.out
read 500000 bytes
nwrite = 216041, errno = 0
nwrite = -1, errno = 11 1,497 of these errors
...
nwrite = 16015, errno = 0
nwrite = -1, errno = 11 1,856 of these errors
...
nwrite = 32081, errno = 0
nwrite = -1, errno = 11 1,654 of these errors
...
nwrite = 48002, errno = 0
nwrite = -1, errno = 11 1,460 of these errors
...
and so on ...
nwrite = 7949, errno = 0
On this system, the errno of 11 is EAGAIN. The amount of data accepted by the terminal driver varies from system to system. The results will also vary depending on how you are logged in to the system: on the system console, on a hardwired terminal, on network connection using a pseudo terminal. If you are running a windowing system on your terminal, you are also going through a pseudo-terminal device.
Figure 14.1. Large nonblocking write
#include "apue.h"
#include <errno.h>
#include <fcntl.h>
char buf[500000];
int
main(void)
{
int ntowrite, nwrite;
char *ptr;
ntowrite = read(STDIN_FILENO, buf, sizeof(buf));
fprintf(stderr, "read %d bytes\n", ntowrite);
set_fl(STDOUT_FILENO, O_NONBLOCK); /* set nonblocking */
ptr = buf;
while (ntowrite > 0) {
errno = 0;
nwrite = write(STDOUT_FILENO, ptr, ntowrite);
fprintf(stderr, "nwrite = %d, errno = %d\n", nwrite, errno);
if (nwrite > 0) {
ptr += nwrite;
ntowrite -= nwrite;
}
}
clr_fl(STDOUT_FILENO, O_NONBLOCK); /* clear nonblocking */
exit(0);
}
In this example, the program issues thousands of write calls, even though only between 10 and 20 are needed to output the data. The rest just return an error. This type of loop, called polling, is a waste of CPU time on a multiuser system. In Section 14.5, we'll see that I/O multiplexing with a nonblocking descriptor is a more efficient way to do this.
Sometimes, we can avoid using nonblocking I/O by designing our applications to use multiple threads (see Chapter 11). We can allow individual threads to block in I/O calls if we can continue to make progress in other threads. This can sometimes simplify the design, as we shall see in Chapter 21; sometimes, however, the overhead of synchronization can add more complexity than is saved from using threads.
14.3. Record Locking
What happens when two people edit the same file at the same time? In most UNIX systems, the final state of the file corresponds to the last process that wrote the file. In some applications, however, such as a database system, a process needs to be certain that it alone is writing to a file. To provide this capability for processes that need it, commercial UNIX systems provide record locking. (In Chapter 20, we develop a database library that uses record locking.)
Record locking is the term normally used to describe the ability of a process to prevent other processes from modifying a region of a file while the first process is reading or modifying that portion of the file. Under the UNIX System, the adjective "record" is a misnomer, since the UNIX kernel does not have a notion of records in a file. A better term is byte-range locking, since it is a range of a file (possibly the entire file) that is locked.
History
One of the criticisms of early UNIX systems was that they couldn't be used to run database systems, because there was no support for locking portions of files. As UNIX systems found their way into business computing environments, various groups added support record locking (differently, of course).
Early Berkeley releases supported only the flock function. This function locks only entire files, not regions of a file.
Record locking was added to System V Release 3 through the fcntl function. The lockf function was built on top of this, providing a simplified interface. These functions allowed callers to lock arbitrary byte ranges in a file, from the entire file down to a single byte within the file.
POSIX.1 chose to standardize on the fcntl approach. Figure 14.2 shows the forms of record locking provided by various systems. Note that the Single UNIX Specification includes lockf in the XSI extension.
Figure 14.2. Forms of record locking supported by various UNIX systemsSystem | Advisory | Mandatory | fcntl | lockf | flock |
|---|
SUS | • | | • | XSI | | FreeBSD 5.2.1 | • | | • | • | • | Linux 2.4.22 | • | • | • | • | • | Mac OS X 10.3 | • | | • | • | • | Solaris 9 | • | • | • | • | • |
We describe the difference between advisory locking and mandatory locking later in this section. In this text, we describe only the POSIX.1 fcntl locking.
Record locking was originally added to Version 7 in 1980 by John Bass. The system call entry into the kernel was a function named locking. This function provided mandatory record locking and propagated through many versions of System III. Xenix systems picked up this function, and some Intel-based System V derivatives, such as OpenServer 5, still support it in a Xenix-compatibility library.
fcntl Record Locking
Let's repeat the prototype for the fcntl function from Section 3.14.
#include <fcntl.h>
int fcntl(int filedes, int cmd, ... /* struct
 flock *flockptr */ ); flock *flockptr */ );
| Returns: depends on cmd if OK (see following), 1 on error
|
For record locking, cmd is F_GETLK, F_SETLK, or F_SETLKW. The third argument (which we'll call flockptr) is a pointer to an flock structure.
struct flock {
short l_type; /* F_RDLCK, F_WRLCK, or F_UNLCK */
off_t l_start; /* offset in bytes, relative to l_whence */
short l_whence; /* SEEK_SET, SEEK_CUR, or SEEK_END */
off_t l_len; /* length, in bytes; 0 means lock to EOF */
pid_t l_pid; /* returned with F_GETLK */
};
This structure describes
The type of lock desired: F_RDLCK (a shared read lock), F_WRLCK (an exclusive write lock), or F_UNLCK (unlocking a region) The starting byte offset of the region being locked or unlocked (l_start and l_whence) The size of the region in bytes (l_len) The ID (l_pid) of the process holding the lock that can block the current process (returned by F_GETLK only)
There are numerous rules about the specification of the region to be locked or unlocked.
The two elements that specify the starting offset of the region are similar to the last two arguments of the lseek function (Section 3.6). Indeed, the l_whence member is specified as SEEK_SET, SEEK_CUR, or SEEK_END. Locks can start and extend beyond the current end of file, but cannot start or extend before the beginning of the file. If l_len is 0, it means that the lock extends to the largest possible offset of the file. This allows us to lock a region starting anywhere in the file, up through and including any data that is appended to the file. (We don't have to try to guess how many bytes might be appended to the file.) To lock the entire file, we set l_start and l_whence to point to the beginning of the file and specify a length (l_len) of 0. (There are several ways to specify the beginning of the file, but most applications specify l_start as 0 and l_whence as SEEK_SET.)
We mentioned two types of locks: a shared read lock (l_type of F_RDLCK) and an exclusive write lock (F_WRLCK). The basic rule is that any number of processes can have a shared read lock on a given byte, but only one process can have an exclusive write lock on a given byte. Furthermore, if there are one or more read locks on a byte, there can't be any write locks on that byte; if there is an exclusive write lock on a byte, there can't be any read locks on that byte. We show this compatibility rule in Figure 14.3.
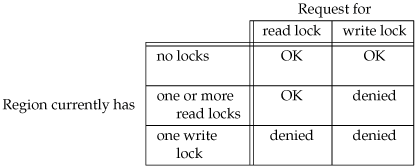
The compatibility rule applies to lock requests made from different processes, not to multiple lock requests made by a single process. If a process has an existing lock on a range of a file, a subsequent attempt to place a lock on the same range by the same process will replace the existing lock with the new one. Thus, if a process has a write lock on bytes 1632 of a file and then tries to place a read lock on bytes 1632, the request will succeed (assuming that we're not racing with any other processes trying to lock the same portion of the file), and the write lock will be replaced by a read lock.
To obtain a read lock, the descriptor must be open for reading; to obtain a write lock, the descriptor must be open for writing.
We can now describe the three commands for the fcntl function.
F_GETLK | Determine whether the lock described by flockptr is blocked by some other lock. If a lock exists that would prevent ours from being created, the information on that existing lock overwrites the information pointed to by flockptr. If no lock exists that would prevent ours from being created, the structure pointed to by flockptr is left unchanged except for the l_type member, which is set to F_UNLCK. | F_SETLK | Set the lock described by flockptr. If we are trying to obtain a read lock (l_type of F_RDLCK) or a write lock (l_type of F_WRLCK) and the compatibility rule prevents the system from giving us the lock (Figure 14.3), fcntl returns immediately with errno set to either EACCES or EAGAIN.
Although POSIX allows an implementation to return either error code, all four implementations described in this text return EAGAIN if the locking request cannot be satisfied.
This command is also used to clear the lock described by flockptr (l_type of F_UNLCK).
| F_SETLKW | This command is a blocking version of F_SETLK. (The W in the command name means wait.) If the requested read lock or write lock cannot be granted because another process currently has some part of the requested region locked, the calling process is put to sleep. The process wakes up either when the lock becomes available or when interrupted by a signal. |
Be aware that testing for a lock with F_GETLK and then trying to obtain that lock with F_SETLK or F_SETLKW is not an atomic operation. We have no guarantee that, between the two fcntl calls, some other process won't come in and obtain the same lock. If we don't want to block while waiting for a lock to become available to us, we must handle the possible error returns from F_SETLK.
Note that POSIX.1 doesn't specify what happens when one process read-locks a range of a file, a second process blocks while trying to get a write lock on the same range, and a third processes then attempts to get another read lock on the range. If the third process is allowed to place a read lock on the range just because the range is already read-locked, then the implementation might starve processes with pending write locks. This means that as additional requests to read lock the same range arrive, the time that the process with the pending write-lock request has to wait is extended. If the read-lock requests arrive quickly enough without a lull in the arrival rate, then the writer could wait for a long time.
When setting or releasing a lock on a file, the system combines or splits adjacent areas as required. For example, if we lock bytes 100 through 199 and then unlock byte 150, the kernel still maintains the locks on bytes 100 through 149 and bytes 151 through 199. Figure 14.4 illustrates the byte-range locks in this situation.
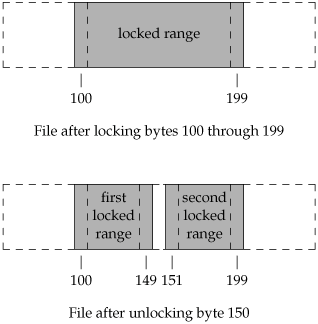
If we were to lock byte 150, the system would coalesce the adjacent locked regions into a single region from byte 100 through 199. The resulting picture would be the first diagram in Figure 14.4, the same as when we started.
ExampleRequesting and Releasing a Lock
To save ourselves from having to allocate an flock structure and fill in all the elements each time, the function lock_reg in Figure 14.5 handles all these details.
Since most locking calls are to lock or unlock a region (the command F_GETLK is rarely used), we normally use one of the following five macros, which are defined in apue.h (Appendix B).
#define read_lock(fd, offset, whence, len) \
lock_reg((fd), F_SETLK, F_RDLCK, (offset), (whence), (len))
#define readw_lock(fd, offset, whence, len) \
lock_reg((fd), F_SETLKW, F_RDLCK, (offset), (whence), (len))
#define write_lock(fd, offset, whence, len) \
lock_reg((fd), F_SETLK, F_WRLCK, (offset), (whence), (len))
#define writew_lock(fd, offset, whence, len) \
lock_reg((fd), F_SETLKW, F_WRLCK, (offset), (whence), (len))
#define un_lock(fd, offset, whence, len) \
lock_reg((fd), F_SETLK, F_UNLCK, (offset), (whence), (len))
We have purposely defined the first three arguments to these macros in the same order as the lseek function.
Figure 14.5. Function to lock or unlock a region of a file
#include "apue.h"
#include <fcntl.h>
int
lock_reg(int fd, int cmd, int type, off_t offset, int whence, off_t len)
{
struct flock lock;
lock.l_type = type; /* F_RDLCK, F_WRLCK, F_UNLCK */
lock.l_start = offset; /* byte offset, relative to l_whence */
lock.l_whence = whence; /* SEEK_SET, SEEK_CUR, SEEK_END */
lock.l_len = len; /* #bytes (0 means to EOF) */
return(fcntl(fd, cmd, &lock));
}
ExampleTesting for a Lock
Figure 14.6 defines the function lock_test that we'll use to test for a lock.
If a lock exists that would block the request specified by the arguments, this function returns the process ID of the process holding the lock. Otherwise, the function returns 0 (false). We normally call this function from the following two macros (defined in apue.h):
#define is_read_lockable(fd, offset, whence, len) \
(lock_test((fd), F_RDLCK, (offset), (whence), (len)) == 0)
#define is_write_lockable(fd, offset, whence, len) \
(lock_test((fd), F_WRLCK, (offset), (whence), (len)) == 0)
Note that the lock_test function can't be used by a process to see whether it is currently holding a portion of a file locked. The definition of the F_GETLK command states that the information returned applies to an existing lock that would prevent us from creating our own lock. Since the F_SETLK and F_SETLKW commands always replace a process's existing lock if it exists, we can never block on our own lock; thus, the F_GETLK command will never report our own lock.
Figure 14.6. Function to test for a locking condition
#include "apue.h"
#include <fcntl.h>
pid_t
lock_test(int fd, int type, off_t offset, int whence, off_t len)
{
struct flock lock;
lock.l_type = type; /* F_RDLCK or F_WRLCK */
lock.l_start = offset; /* byte offset, relative to l_whence */
lock.l_whence = whence; /* SEEK_SET, SEEK_CUR, SEEK_END */
lock.l_len = len; /* #bytes (0 means to EOF) */
if (fcntl(fd, F_GETLK, &lock) < 0)
err_sys("fcntl error");
if (lock.l_type == F_UNLCK)
return(0); /* false, region isn't locked by another proc */
return(lock.l_pid); /* true, return pid of lock owner */
}
ExampleDeadlock
Deadlock occurs when two processes are each waiting for a resource that the other has locked. The potential for deadlock exists if a process that controls a locked region is put to sleep when it tries to lock another region that is controlled by a different process.
Figure 14.7 shows an example of deadlock. The child locks byte 0 and the parent locks byte 1. Then each tries to lock the other's already locked byte. We use the parentchild synchronization routines from Section 8.9 (TELL_xxx and WAIT_xxx) so that each process can wait for the other to obtain its lock. Running the program in Figure 14.7 gives us
$ ./a.out
parent: got the lock, byte 1
child: got the lock, byte 0
child: writew_lock error: Resource deadlock avoided
parent: got the lock, byte 0
When a deadlock is detected, the kernel has to choose one process to receive the error return. In this example, the child was chosen, but this is an implementation detail. On some systems, the child always receives the error. On other systems, the parent always gets the error. On some systems, you might even see the errors split between the child and the parent as multiple lock attempts are made.
Figure 14.7. Example of deadlock detection
#include "apue.h"
#include <fcntl.h>
static void
lockabyte(const char *name, int fd, off_t offset)
{
if (writew_lock(fd, offset, SEEK_SET, 1) < 0)
err_sys("%s: writew_lock error", name);
printf("%s: got the lock, byte %ld\n", name, offset);
}
int
main(void)
{
int fd;
pid_t pid;
/*
* Create a file and write two bytes to it.
*/
if ((fd = creat("templock", FILE_MODE)) < 0)
err_sys("creat error");
if (write(fd, "ab", 2) != 2)
err_sys("write error");
TELL_WAIT();
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid == 0) { /* child */
lockabyte("child", fd, 0);
TELL_PARENT(getppid());
WAIT_PARENT();
lockabyte("child", fd, 1);
} else { /* parent */
lockabyte("parent", fd, 1);
TELL_CHILD(pid);
WAIT_CHILD();
lockabyte("parent", fd, 0);
}
exit(0);
}
Implied Inheritance and Release of Locks
Three rules govern the automatic inheritance and release of record locks.
Locks are associated with a process and a file. This has two implications. The first is obvious: when a process terminates, all its locks are released. The second is far from obvious: whenever a descriptor is closed, any locks on the file referenced by that descriptor for that process are released. This means that if we do
fd1 = open(pathname, ...);
read_lock(fd1, ...);
fd2 = dup(fd1);
close(fd2);
after the close(fd2), the lock that was obtained on fd1 is released. The same thing would happen if we replaced the dup with open, as in
fd1 = open(pathname, ...);
read_lock(fd1, ...);
fd2 = open(pathname, ...)
close(fd2);
to open the same file on another descriptor. Locks are never inherited by the child across a fork. This means that if a process obtains a lock and then calls fork, the child is considered another process with regard to the lock that was obtained by the parent. The child has to call fcntl to obtain its own locks on any descriptors that were inherited across the fork. This makes sense because locks are meant to prevent multiple processes from writing to the same file at the same time. If the child inherited locks across a fork, both the parent and the child could write to the same file at the same time. Locks are inherited by a new program across an exec. Note, however, that if the close-on-exec flag is set for a file descriptor, all locks for the underlying file are released when the descriptor is closed as part of an exec.
FreeBSD Implementation
Let's take a brief look at the data structures used in the FreeBSD implementation. This should help clarify rule 1, that locks are associated with a process and a file.
Consider a process that executes the following statements (ignoring error returns):
fd1 = open(pathname, ...);
write_lock(fd1, 0, SEEK_SET, 1); /* parent write locks byte 0 */
if ((pid = fork()) > 0) { /* parent */
fd2 = dup(fd1);
fd3 = open(pathname, ...);
} else if (pid == 0) {
read_lock(fd1, 1, SEEK_SET, 1); /* child read locks byte 1 */
}
pause();
Figure 14.8 shows the resulting data structures after both the parent and the child have paused.
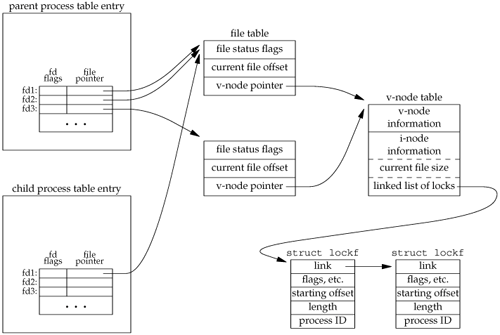
We've shown the data structures that result from the open, fork, and dup earlier (Figures 3.8 and 8.2). What is new are the lockf structures that are linked together from the i-node structure. Note that each lockf structure describes one locked region (defined by an offset and length) for a given process. We show two of these structures: one for the parent's call to write_lock and one for the child's call to read_lock. Each structure contains the corresponding process ID.
In the parent, closing any one of fd1, fd2, or fd3 causes the parent's lock to be released. When any one of these three file descriptors is closed, the kernel goes through the linked list of locks for the corresponding i-node and releases the locks held by the calling process. The kernel can't tell (and doesn't care) which descriptor of the three was used by the parent to obtain the lock.
Example
In the program in Figure 13.6, we saw how a daemon can use a lock on a file to ensure that only one copy of the daemon is running. Figure 14.9 shows the implementation of the lockfile function used by the daemon to place a write lock on a file.
Alternatively, we could define the lockfile function in terms of the write_lock function:
#define lockfile(fd) write_lock((fd), 0, SEEK_SET, 0)
Figure 14.9. Place a write lock on an entire file
#include <unistd.h>
#include <fcntl.h>
int
lockfile(int fd)
{
struct flock fl;
fl.l_type = F_WRLCK;
fl.l_start = 0;
fl.l_whence = SEEK_SET;
fl.l_len = 0;
return(fcntl(fd, F_SETLK, &fl));
}
Locks at End of File
Use caution when locking or unlocking relative to the end of file. Most implementations convert an l_whence value of SEEK_CUR or SEEK_END into an absolute file offset, using l_start and the file's current position or current length. Often, however, we need to specify a lock relative to the file's current position or current length, because we can't call lseek to obtain the current file offset, since we don't have a lock on the file. (There's a chance that another process could change the file's length between the call to lseek and the lock call.)
Consider the following sequence of steps:
writew_lock(fd, 0, SEEK_END, 0);
write(fd, buf, 1);
un_lock(fd, 0, SEEK_END);
write(fd, buf, 1);
This sequence of code might not do what you expect. It obtains a write lock from the current end of the file onward, covering any future data we might append to the file. Assuming that we are at end of file when we perform the first write, that will extend the file by one byte, and that byte will be locked. The unlock that follows has the effect of removing the locks for future writes that append data to the file, but it leaves a lock on the last byte in the file. When the second write occurs, the end of file is extended by one byte, but this byte is not locked. The state of the file locks for this sequence of steps is shown in Figure 14.10
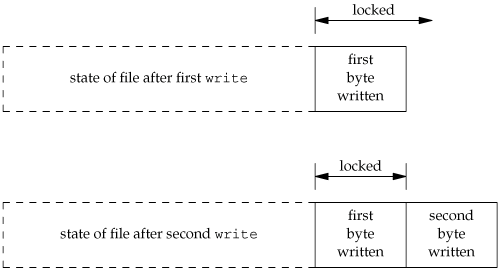
When a portion of a file is locked, the kernel converts the offset specified into an absolute file offset. In addition to specifying an absolute file offset (SEEK_SET), fcntl allows us to specify this offset relative to a point in the file: current (SEEK_CUR) or end of file (SEEK_END). The kernel needs to remember the locks independent of the current file offset or end of file, because the current offset and end of file can change, and changes to these attributes shouldn't affect the state of existing locks.
If we intended to remove the lock covering the byte we wrote in the first write, we could have specified the length as -1. Negative-length values represent the bytes before the specified offset.
Advisory versus Mandatory Locking
Consider a library of database access routines. If all the functions in the library handle record locking in a consistent way, then we say that any set of processes using these functions to access a database are cooperating processes. It is feasible for these database access functions to use advisory locking if they are the only ones being used to access the database. But advisory locking doesn't prevent some other process that has write permission for the database file from writing whatever it wants to the database file. This rogue process would be an uncooperating process, since it's not using the accepted method (the library of database functions) to access the database.
Mandatory locking causes the kernel to check every open, read, and write to verify that the calling process isn't violating a lock on the file being accessed. Mandatory locking is sometimes called enforcement-mode locking.
We saw in Figure 14.2 that Linux 2.4.22 and Solaris 9 provide mandatory record locking, but FreeBSD 5.2.1 and Mac OS X 10.3 do not. Mandatory record locking is not part of the Single UNIX Specification. On Linux, if you want mandatory locking, you need to enable it on a per file system basis by using the -o mand option to the mount command.
Mandatory locking is enabled for a particular file by turning on the set-group-ID bit and turning off the group-execute bit. (Recall Figure 4.12.) Since the set-group-ID bit makes no sense when the group-execute bit is off, the designers of SVR3 chose this way to specify that the locking for a file is to be mandatory locking and not advisory locking.
What happens to a process that tries to read or write a file that has mandatory locking enabled and the specified part of the file is currently read-locked or write-locked by another process? The answer depends on the type of operation (read or write), the type of lock held by the other process (read lock or write lock), and whether the descriptor for the read or write is nonblocking. Figure 14.11 shows the eight possibilities.
Figure 14.11. Effect of mandatory locking on reads and writes by other processesType of existing lock on region held by other process | Blocking descriptor, tries to | Nonblocking descriptor, tries to | read | write | read | write
| read lock | OK | blocks | OK | EAGAIN
| write lock | blocks | blocks | EAGAIN | EAGAIN |
In addition to the read and write functions in Figure 14.11, the open function can also be affected by mandatory record locks held by another process. Normally, open succeeds, even if the file being opened has outstanding mandatory record locks. The next read or write follows the rules listed in Figure 14.11. But if the file being opened has outstanding mandatory record locks (either read locks or write locks), and if the flags in the call to open specify either O_TRUNC or O_CREAT, then open returns an error of EAGAIN immediately, regardless of whether O_NONBLOCK is specified.
Only Solaris treats the O_CREAT flag as an error case. Linux allows the O_CREAT flag to be specified when opening a file with an outstanding mandatory lock. Generating the open error for O_TRUNC makes sense, because the file cannot be truncated if it is read-locked or write-locked by another process. Generating the error for O_CREAT, however, makes little sense; this flag says to create the file only if it doesn't already exist, but it has to exist to be record-locked by another process.
This handling of locking conflicts with open can lead to surprising results. While developing the exercises in this section, a test program was run that opened a file (whose mode specified mandatory locking), established a read lock on an entire file, and then went to sleep for a while. (Recall from Figure 14.11 that a read lock should prevent writing to the file by other processes.) During this sleep period, the following behavior was seen in other typical UNIX System programs.
The same file could be edited with the ed editor, and the results written back to disk! The mandatory record locking had no effect at all. Using the system call trace feature provided by some versions of the UNIX System, it was seen that ed wrote the new contents to a temporary file, removed the original file, and then renamed the temporary file to be the original file. The mandatory record locking has no effect on the unlink function, which allowed this to happen.
Under Solaris, the system call trace of a process is obtained by the truss(1) command. FreeBSD and Mac OS X use the ktrace(1) and kdump(1) commands. Linux provides the strace(1) command for tracing the system calls made by a process.
The vi editor was never able to edit the file. It could read the file's contents, but whenever we tried to write new data to the file, EAGAIN was returned. If we tried to append new data to the file, the write blocked. This behavior from vi is what we expect. Using the Korn shell's > and >> operators to overwrite or append to the file resulted in the error "cannot create." Using the same two operators with the Bourne shell resulted in an error for >, but the >> operator just blocked until the mandatory lock was removed, and then proceeded. (The difference in the handling of the append operator is because the Korn shell opens the file with O_CREAT and O_APPEND, and we mentioned earlier that specifying O_CREAT generates an error. The Bourne shell, however, doesn't specify O_CREAT if the file already exists, so the open succeeds but the next write blocks.)
Results will vary, depending on the version of the operating system you are using. The bottom line with this exercise is to be wary of mandatory record locking. As seen with the ed example, it can be circumvented.
Mandatory record locking can also be used by a malicious user to hold a read lock on a file that is publicly readable. This can prevent anyone from writing to the file. (Of course, the file has to have mandatory record locking enabled for this to occur, which may require the user be able to change the permission bits of the file.) Consider a database file that is world readable and has mandatory record locking enabled. If a malicious user were to hold a read lock on the entire file, the file could not be written to by other processes.
Example
The program in Figure 14.12 determines whether mandatory locking is supported by a system.
This program creates a file and enables mandatory locking for the file. The program then splits into parent and child, with the parent obtaining a write lock on the entire file. The child first sets its descriptor nonblocking and then attempts to obtain a read lock on the file, expecting to get an error. This lets us see whether the system returns EACCES or EAGAIN. Next, the child rewinds the file and tries to read from the file. If mandatory locking is provided, the read should return EACCES or EAGAIN (since the descriptor is nonblocking). Otherwise, the read returns the data that it read. Running this program under Solaris 9 (which supports mandatory locking) gives us
$ ./a.out temp.lock
read_lock of already-locked region returns 11
read failed (mandatory locking works): Resource temporarily unavailable
If we look at either the system's headers or the intro(2) manual page, we see that an errno of 11 corresponds to EAGAIN. Under FreeBSD 5.2.1, we get
$ ./a.out temp.lock
read_lock of already-locked region returns 35
read OK (no mandatory locking), buf = ab
Here, an errno of 35 corresponds to EAGAIN. Mandatory locking is not supported.
Figure 14.12. Determine whether mandatory locking is supported
#include "apue.h"
#include <errno.h>
#include <fcntl.h>
#include <sys/wait.h>
int
main(int argc, char *argv[])
{
int fd;
pid_t pid;
char buf[5];
struct stat statbuf;
if (argc != 2) {
fprintf(stderr, "usage: %s filename\n", argv[0]);
exit(1);
}
if ((fd = open(argv[1], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) < 0)
err_sys("open error");
if (write(fd, "abcdef", 6) != 6)
err_sys("write error");
/* turn on set-group-ID and turn off group-execute */
if (fstat(fd, &statbuf) < 0)
err_sys("fstat error");
if (fchmod(fd, (statbuf.st_mode & ~S_IXGRP) | S_ISGID) < 0)
err_sys("fchmod error");
TELL_WAIT();
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) { /* parent */
/* write lock entire file */
if (write_lock(fd, 0, SEEK_SET, 0) < 0)
err_sys("write_lock error");
TELL_CHILD(pid);
if (waitpid(pid, NULL, 0) < 0)
err_sys("waitpid error");
} else { /* child */
WAIT_PARENT(); /* wait for parent to set lock */
set_fl(fd, O_NONBLOCK);
/* first let's see what error we get if region is locked */
if (read_lock(fd, 0, SEEK_SET, 0) != -1) /* no wait */
err_sys("child: read_lock succeeded");
printf("read_lock of already-locked region returns %d\n",
errno);
/* now try to read the mandatory locked file */
if (lseek(fd, 0, SEEK_SET) == -1)
err_sys("lseek error");
if (read(fd, buf, 2) < 0)
err_ret("read failed (mandatory locking works)");
else
printf("read OK (no mandatory locking), buf = %2.2s\n",
buf);
}
exit(0);
}
Example
Let's return to the first question of this section: what happens when two people edit the same file at the same time? The normal UNIX System text editors do not use record locking, so the answer is still that the final result of the file corresponds to the last process that wrote the file.
Some versions of the vi editor use advisory record locking. Even if we were using one of these versions of vi, it still doesn't prevent users from running another editor that doesn't use advisory record locking.
If the system provides mandatory record locking, we could modify our favorite editor to use it (if we have the sources). Not having the source code to the editor, we might try the following. We write our own program that is a front end to vi. This program immediately calls fork, and the parent just waits for the child to complete. The child opens the file specified on the command line, enables mandatory locking, obtains a write lock on the entire file, and then executes vi. While vi is running, the file is write-locked, so other users can't modify it. When vi terminates, the parent's wait returns, and our front end terminates.
A small front-end program of this type can be written, but it doesn't work. The problem is that it is common for most editors to read their input file and then close it. A lock is released on a file whenever a descriptor that references that file is closed. This means that when the editor closes the file after reading its contents, the lock is gone. There is no way to prevent this in the front-end program.
We'll use record locking in Chapter 20 in our database library to provide concurrent access to multiple processes. We'll also provide some timing measurements to see what effect record locking has on a process.
14.4. STREAMS
The STREAMS mechanism is provided by System V as a general way to interface communication drivers into the kernel. We need to discuss STREAMS to understand the terminal interface in System V, the use of the poll function for I/O multiplexing (Section 14.5.2), and the implementation of STREAMS-based pipes and named pipes (Sections 17.2 and 17.2.1).
Be careful not to confuse this usage of the word stream with our previous usage of it in the standard I/O library (Section 5.2). The streams mechanism was developed by Dennis Ritchie [Ritchie 1984] as a way of cleaning up the traditional character I/O system (c-lists) and to accommodate networking protocols. The streams mechanism was later added to SVR3, after enhancing it a bit and capitalizing the name. Complete support for STREAMS (i.e., a STREAMS-based terminal I/O system) was provided with SVR4. The SVR4 implementation is described in [AT&T 1990d]. Rago [1993] discusses both user-level STREAMS programming and kernel-level STREAMS programming.
STREAMS is an optional feature in the Single UNIX Specification (included as the XSI STREAMS Option Group). Of the four platforms discussed in this text, only Solaris provides native support for STREAMS. A STREAMS subsystem is available for Linux, but you need to add it yourself. It is not usually included by default.
A stream provides a full-duplex path between a user process and a device driver. There is no need for a stream to talk to a hardware device; a stream can also be used with a pseudo-device driver. Figure 14.13 shows the basic picture for what is called a simple stream.
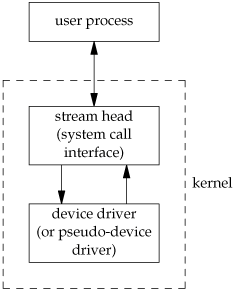
Beneath the stream head, we can push processing modules onto the stream. This is done using an ioctl command. Figure 14.14 shows a stream with a single processing module. We also show the connection between these boxes with two arrows to stress the full-duplex nature of streams and to emphasize that the processing in one direction is separate from the processing in the other direction.
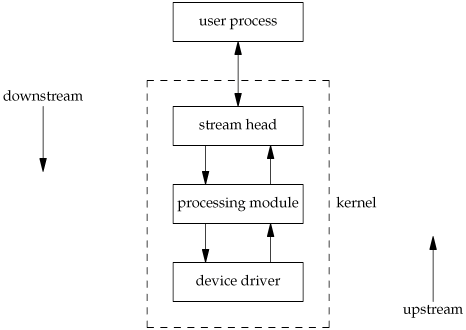
Any number of processing modules can be pushed onto a stream. We use the term push, because each new module goes beneath the stream head, pushing any previously pushed modules down. (This is similar to a last-in, first-out stack.) In Figure 14.14, we have labeled the downstream and upstream sides of the stream. Data that we write to a stream head is sent downstream. Data read by the device driver is sent upstream.
STREAMS modules are similar to device drivers in that they execute as part of the kernel, and they are normally link edited into the kernel when the kernel is built. If the system supports dynamically-loadable kernel modules (as do Linux and Solaris), then we can take a STREAMS module that has not been link edited into the kernel and try to push it onto a stream; however, there is no guarantee that arbitrary combinations of modules and drivers will work properly together.
We access a stream with the functions from Chapter 3: open, close, read, write, and ioctl. Additionally, three new functions were added to the SVR3 kernel to support STREAMS (getmsg, putmsg, and poll), and another two (getpmsg and putpmsg) were added with SVR4 to handle messages with different priority bands within a stream. We describe these five new functions later in this section.
The pathname that we open for a stream normally lives beneath the /dev directory. Simply looking at the device name using ls -l, we can't tell whether the device is a STREAMS device. All STREAMS devices are character special files.
Although some STREAMS documentation implies that we can write processing modules and push them willy-nilly onto a stream, the writing of these modules requires the same skills and care as writing a device driver. Generally, only specialized applications or functions push and pop STREAMS modules.
Before STREAMS, terminals were handled with the existing c-list mechanism. (Section 10.3.1 of Bach [1986] and Section 10.6 of McKusick et al. [1996] describe c-lists in SVR2 and 4.4BSD, respectively.) Adding other character-based devices to the kernel usually involved writing a device driver and putting everything into the driver. Access to the new device was typically through the raw device, meaning that every user read or write ended up directly in the device driver. The STREAMS mechanism cleans up this way of interacting, allowing the data to flow between the stream head and the driver in STREAMS messages and allowing any number of intermediate processing modules to operate on the data.
STREAMS Messages
All input and output under STREAMS is based on messages. The stream head and the user process exchange messages using read, write, ioctl, getmsg, getpmsg, putmsg, and putpmsg. Messages are also passed up and down a stream between the stream head, the processing modules, and the device driver.
Between the user process and the stream head, a message consists of a message type, optional control information, and optional data. We show in Figure 14.15 how the various message types are generated by the arguments to write, putmsg, and putpmsg. The control information and data are specified by strbuf structures:
struct strbuf
int maxlen; /* size of buffer */
int len; /* number of bytes currently in buffer */
char *buf; /* pointer to buffer */
};
Figure 14.15. Type of STREAMS message generated for write, putmsg, and putpmsgFunction | Control? | Data? | band | flag | Message type generated |
|---|
write | N/A | yes | N/A | N/A | M_DATA (ordinary) | putmsg | no | no | N/A | 0 | no message sent, returns 0 | putmsg | no | yes | N/A | 0 | M_DATA (ordinary) | putmsg | yes | yes or no | N/A | 0 | M_PROTO (ordinary) | putmsg | yes | yes or no | N/A | RS_HIPRI | M_PCPROTO (high-priority) | putmsg | no | yes or no | N/A | RS_HIPRI | error, EINVAL
| putpmsg | yes or no | yes or no | 0255 | 0 | error, EINVAL
| putpmsg | no | no | 0255 | MSG_BAND | no message sent, returns 0 | putpmsg | no | yes | 0 | MSG_BAND | M_DATA (ordinary) | putpmsg | no | yes | 1255 | MSG_BAND | M_DATA (priority band) | putpmsg | yes | yes or no | 0 | MSG_BAND | M_PROTO (ordinary) | putpmsg | yes | yes or no | 1255 | MSG_BAND | M_PROTO (priority band) | putpmsg | yes | yes or no | 0 | MSG_HIPRI | M_PCPROTO (high-priority) | putpmsg | no | yes or no | 0 | MSG_HIPRI | error, EINVAL
| putpmsg | yes or no | yes or no | nonzero | MSG_HIPRI | error, EINVAL
|
When we send a message with putmsg or putpmsg, len specifies the number of bytes of data in the buffer. When we receive a message with getmsg or getpmsg, maxlen specifies the size of the buffer (so the kernel won't overflow the buffer), and len is set by the kernel to the amount of data stored in the buffer. We'll see that a zero-length message is OK and that a len of 1 can specify that there is no control or data.
Why do we need to pass both control information and data? Providing both allows us to implement service interfaces between a user process and a stream. Olander, McGrath, and Israel [1986] describe the original implementation of service interfaces in System V. Chapter 5 of AT&T [1990d] describes service interfaces in detail, along with a simple example. Probably the best-known service interface, described in Chapter 4 of Rago [1993], is the System V Transport Layer Interface (TLI), which provides an interface to the networking system.
Another example of control information is sending a connectionless network message (a datagram). To send the message, we need to specify the contents of the message (the data) and the destination address for the message (the control information). If we couldn't send control and data together, some ad hoc scheme would be required. For example, we could specify the address using an ioctl, followed by a write of the data. Another technique would be to require that the address occupy the first N bytes of the data that is written using write. Separating the control information from the data, and providing functions that handle both (putmsg and getmsg) is a cleaner way to handle this.
There are about 25 different types of messages, but only a few of these are used between the user process and the stream head. The rest are passed up and down a stream within the kernel. (These message types are of interest to people writing STREAMS processing modules, but can safely be ignored by people writing user-level code.) We'll encounter only three of these message types with the functions we use (read, write, getmsg, getpmsg, putmsg, and putpmsg):
M_DATA (user data for I/O) M_PROTO (protocol control information) M_PCPROTO (high-priority protocol control information)
Every message on a stream has a queueing priority:
Ordinary messages are simply priority band messages with a band of 0. Priority band messages have a band of 1255, with a higher band specifying a higher priority. High-priority messages are special in that only one is queued by the stream head at a time. Additional high-priority messages are discarded when one is already on the stream head's read queue.
Each STREAMS module has two input queues. One receives messages from the module above (messages moving downstream from the stream head toward the driver), and one receives messages from the module below (messages moving upstream from the driver toward the stream head). The messages on an input queue are arranged by priority. We show in Figure 14.15 how the arguments to write, putmsg, and putpmsg cause these various priority messages to be generated.
There are other types of messages that we don't consider. For example, if the stream head receives an M_SIG message from below, it generates a signal. This is how a terminal line discipline module sends the terminal-generated signals to the foreground process group associated with a controlling terminal.
putmsg and putpmsg Functions
A STREAMS message (control information or data, or both) is written to a stream using either putmsg or putpmsg. The difference in these two functions is that the latter allows us to specify a priority band for the message.
#include <stropts.h>
int putmsg(int filedes, const struct strbuf *ctlptr,
const struct strbuf *dataptr, int flag);
int putpmsg(int filedes, const struct strbuf *ctlptr,
const struct strbuf *dataptr, int band
, int flag);
| Both return: 0 if OK, 1 on error |
We can also write to a stream, which is equivalent to a putmsg without any control information and with a flag of 0.
These two functions can generate the three different priorities of messages: ordinary, priority band, and high priority. Figure 14.15 details the combinations of the arguments to these two functions that generate the various types of messages.
The notation "N/A" means not applicable. In this figure, a "no" for the control portion of the message corresponds to either a null ctlptr argument or ctlptr>len being 1. A "yes" for the control portion corresponds to ctlptr being non-null and ctlptr>len being greater than or equal to 0. The data portion of the message is handled equivalently (using dataptr instead of ctlptr).
STREAMS ioctl Operations
In Section 3.15, we said that the ioctl function is the catchall for anything that can't be done with the other I/O functions. The STREAMS system continues this tradition.
Between Linux and Solaris, there are almost 40 different operations that can be performed on a stream using ioctl. Most of these operations are documented in the streamio(7) manual page. The header <stropts.h> must be included in C code that uses any of these operations. The second argument for ioctl, request, specifies which of the operations to perform. All the requests begin with I_. The third argument depends on the request. Sometimes, the third argument is an integer value; sometimes, it's a pointer to an integer or a structure.
Exampleisastream Function
We sometimes need to determine if a descriptor refers to a stream or not. This is similar to calling the isatty function to determine if a descriptor refers to a terminal device (Section 18.9). Linux and Solaris provide the isastream function.
#include <stropts.h>
int isastream(int filedes);
| Returns: 1 (true) if STREAMS device, 0 (false) otherwise |
Like isatty, this is usually a trivial function that merely tries an ioctl that is valid only on a STREAMS device. Figure 14.16 shows one possible implementation of this function. We use the I_CANPUT ioctl command, which checks if the band specified by the third argument (0 in the example) is writable. If the ioctl succeeds, the stream is not changed.
We can use the program in Figure 14.17 to test this function.
Running this program on Solaris 9 shows the various errors returned by the ioctl function:
$ ./a.out /dev/tty /dev/fb /dev/null /etc/motd
/dev/tty: streams device
/dev/fb: not a stream: Invalid argument
/dev/null: not a stream: No such device or address
/etc/motd: not a stream: Inappropriate ioctl for device
Note that /dev/tty is a STREAMS device, as we expect under Solaris. The character special file /dev/fb is not a STREAMS device, but it supports other ioctl requests. These devices return EINVAL when the ioctl request is unknown. The character special file /dev/null does not support any ioctl operations, so the error ENODEV is returned. Finally, /etc/motd is a regular file, not a character special file, so the classic error ENOTTY is returned. We never receive the error we might expect: ENOSTR ("Device is not a stream").
The message for ENOTTY used to be "Not a typewriter," a historical artifact because the UNIX kernel returns ENOTTY whenever an ioctl is attempted on a descriptor that doesn't refer to a character special device. This message has been updated on Solaris to "Inappropriate ioctl for device."
Figure 14.16. Check if descriptor is a STREAMS device
#include <stropts.h>
#include <unistd.h>
int
isastream(int fd)
{
return(ioctl(fd, I_CANPUT, 0) != -1);
}
Figure 14.17. Test the isastream function
#include "apue.h"
#include <fcntl.h>
int
main(int argc, char *argv[])
{
int i, fd;
for (i = 1; i < argc; i++) {
if ((fd = open(argv[i], O_RDONLY)) < 0) {
err_ret("%s: can't open", argv[i]);
continue;
}
if (isastream(fd) == 0)
err_ret("%s: not a stream", argv[i]);
else
err_msg("%s: streams device", argv[i]);
}
exit(0);
}
Example
If the ioctl request is I_LIST, the system returns the names of all the modules on the streamthe ones that have been pushed onto the stream, including the topmost driver. (We say topmost because in the case of a multiplexing driver, there may be more than one driver. Chapter 12 of Rago [1993] discusses multiplexing drivers in detail.) The third argument must be a pointer to a str_list structure:
struct str_list {
int sl_nmods; /* number of entries in array */
struct str_mlist *sl_modlist; /* ptr to first element of array */
};
We have to set sl_modlist to point to the first element of an array of str_mlist structures and set sl_nmods to the number of entries in the array:
struct str_mlist {
char l_name[FMNAMESZ+1]; /* null terminated module name */
};
The constant FMNAMESZ is defined in the header <sys/conf.h> and is often 8. The extra byte in l_name is for the terminating null byte.
If the third argument to the ioctl is 0, the count of the number of modules is returned (as the value of ioctl) instead of the module names. We'll use this to determine the number of modules and then allocate the required number of str_mlist structures.
Figure 14.18 illustrates the I_LIST operation. Since the returned list of names doesn't differentiate between the modules and the driver, when we print the module names, we know that the final entry in the list is the driver at the bottom of the stream.
If we run the program in Figure 14.18 from both a network login and a console login, to see which STREAMS modules are pushed onto the controlling terminal, we get the following:
$ who
sar console May 1 18:27
sar pts/7 Jul 12 06:53
$ ./a.out /dev/console
#modules = 5
module: redirmod
module: ttcompat
module: ldterm
module: ptem
driver: pts
$ ./a.out /dev/pts/7
#modules = 4
module: ttcompat
module: ldterm
module: ptem
driver: pts
The modules are the same in both cases, except that the console has an extra module on top that helps with virtual console redirection. On this computer, a windowing system was running on the console, so /dev/console actually refers to a pseudo terminal instead of to a hardwired device. We'll return to the pseudo terminal case in Chapter 19.
Figure 14.18. List the names of the modules on a stream
#include "apue.h"
#include <fcntl.h>
#include <stropts.h>
#include <sys/conf.h>
int
main(int argc, char *argv[])
{
int fd, i, nmods;
struct str_list list;
if (argc != 2)
err_quit("usage: %s <pathname>", argv[0]);
if ((fd = open(argv[1], O_RDONLY)) < 0)
err_sys("can't open %s", argv[1]);
if (isastream(fd) == 0)
err_quit("%s is not a stream", argv[1]);
/*
* Fetch number of modules.
*/
if ((nmods = ioctl(fd, I_LIST, (void *) 0)) < 0)
err_sys("I_LIST error for nmods");
printf("#modules = %d\n", nmods);
/*
* Allocate storage for all the module names.
*/
list.sl_modlist = calloc(nmods, sizeof(struct str_mlist));
if (list.sl_modlist == NULL)
err_sys("calloc error");
list.sl_nmods = nmods;
/*
* Fetch the module names.
*/
if (ioctl(fd, I_LIST, &list) < 0)
err_sys("I_LIST error for list");
/*
* Print the names.
*/
for (i = 1; i <= nmods; i++)
printf(" %s: %s\n", (i == nmods) ? "driver" : "module",
list.sl_modlist++->l_name);
exit(0);
}
write to STREAMS Devices
In Figure 14.15 we said that a write to a STREAMS device generates an M_DATA message. Although this is generally true, there are some additional details to consider. First, with a stream, the topmost processing module specifies the minimum and maximum packet sizes that can be sent downstream. (We are unable to query the module for these values.) If we write more than the maximum, the stream head normally breaks the data into packets of the maximum size, with one final packet that can be smaller than the maximum.
The next thing to consider is what happens if we write zero bytes to a stream. Unless the stream refers to a pipe or FIFO, a zero-length message is sent downstream. With a pipe or FIFO, the default is to ignore the zero-length write, for compatibility with previous versions. We can change this default for pipes and FIFOs using an ioctl to set the write mode for the stream.
Write Mode
Two ioctl commands fetch and set the write mode for a stream. Setting request to I_GWROPT requires that the third argument be a pointer to an integer, and the current write mode for the stream is returned in that integer. If request is I_SWROPT, the third argument is an integer whose value becomes the new write mode for the stream. As with the file descriptor flags and the file status flags (Section 3.14), we should always fetch the current write mode value and modify it rather than set the write mode to some absolute value (possibly turning off some other bits that were enabled).
Currently, only two write mode values are defined.
SNDZERO | A zero-length write to a pipe or FIFO will cause a zero-length message to be sent downstream. By default, this zero-length write sends no message. | SNDPIPE | Causes SIGPIPE to be sent to the calling process that calls either write or putmsg after an error has occurred on a stream. |
A stream also has a read mode, and we'll look at it after describing the getmsg and getpmsg functions.
getmsg and getpmsg Functions
STREAMS messages are read from a stream head using read, getmsg, or getpmsg.
Note that flagptr and bandptr are pointers to integers. The integer pointed to by these two pointers must be set before the call to specify the type of message desired, and the integer is also set on return to the type of message that was read.
If the integer pointed to by flagptr is 0, getmsg returns the next message on the stream head's read queue. If the next message is a high-priority message, the integer pointed to by flagptr is set to RS_HIPRI on return. If we want to receive only high-priority messages, we must set the integer pointed to by flagptr to RS_HIPRI before calling getmsg.
A different set of constants is used by getpmsg. We can set the integer pointed to by flagptr to MSG_HIPRI to receive only high-priority messages. We can set the integer to MSG_BAND and then set the integer pointed to by bandptr to a nonzero priority value to receive only messages from that band, or higher (including high-priority messages). If we only want to receive the first available message, we can set the integer pointed to by flagptr to MSG_ANY; on return, the integer will be overwritten with either MSG_HIPRI or MSG_BAND, depending on the type of message received. If the message we retrieved was not a high-priority message, the integer pointed to by bandptr will contain the message's priority band.
If ctlptr is null or ctlptr>maxlen is 1, the control portion of the message will remain on the stream head's read queue, and we will not process it. Similarly, if dataptr is null or dataptr>maxlen is 1, the data portion of the message is not processed and remains on the stream head's read queue. Otherwise, we will retrieve as much control and data portions of the message as our buffers will hold, and any remainder will be left on the head of the queue for the next call.
If the call to getmsg or getpmsg retrieves a message, the return value is 0. If part of the control portion of the message is left on the stream head read queue, the constant MORECTL is returned. Similarly, if part of the data portion of the message is left on the queue, the constant MOREDATA is returned. If both control and data are left, the return value is (MORECTL|MOREDATA).
Read Mode
We also need to consider what happens if we read from a STREAMS device. There are two potential problems.
What happens to the record boundaries associated with the messages on a stream? What happens if we call read and the next message on the stream has control information?
The default handling for condition 1 is called byte-stream mode. In this mode, a read takes data from the stream until the requested number of bytes has been read or until there is no more data. The message boundaries associated with the STREAMS messages are ignored in this mode. The default handling for condition 2 causes the read to return an error if there is a control message at the front of the queue. We can change either of these defaults.
Using ioctl, if we set request to I_GRDOPT, the third argument is a pointer to an integer, and the current read mode for the stream is returned in that integer. A request of I_SRDOPT takes the integer value of the third argument and sets the read mode to that value. The read mode is specified by one of the following three constants:
RNORM | Normal, byte-stream mode (the default), as described previously. | RMSGN | Message-nondiscard mode. A read takes data from a stream until the requested number of bytes have been read or until a message boundary is encountered. If the read uses a partial message, the rest of the data in the message is left on the stream for a subsequent read. | RMSGD | Message-discard mode. This is like the nondiscard mode, but if a partial message is used, the remainder of the message is discarded. |
Three additional constants can be specified in the read mode to set the behavior of read when it encounters messages containing protocol control information on a stream:
RPROTNORM | Protocol-normal mode: read returns an error of EBADMSG. This is the default. | RPROTDAT | Protocol-data mode: read returns the control portion as data. | RPROTDIS | Protocol-discard mode: read discards the control information but returns any data in the message. |
Only one of the message read modes and one of the protocol read modes can be set at a time. The default read mode is (RNORM|RPROTNORM).
Example
The program in Figure 14.19 is the same as the one in Figure 3.4, but recoded to use getmsg instead of read.
If we run this program under Solaris, where both pipes and terminals are implemented using STREAMS, we get the following output:
$ echo hello, world | ./a.out requires STREAMS-based pipes
flag = 0, ctl.len = -1, dat.len = 13
hello, world
flag = 0, ctl.len = 0, dat.len = 0 indicates a STREAMS hangup
$ ./a.out requires STREAMS-based terminals
this is line 1
flag = 0, ctl.len = -1, dat.len = 15
this is line 1
and line 2
flag = 0, ctl.len = -1, dat.len = 11
and line 2
^D type the terminal EOF character
flag = 0, ctl.len = -1, dat.len = 0 tty end of file is not the same as a hangup
$ ./a.out < /etc/motd
getmsg error: Not a stream device
When the pipe is closed (when echo terminates), it appears to the program in Figure 14.19 as a STREAMS hangup, with both the control length and the data length set to 0. (We discuss pipes in Section 15.2.) With a terminal, however, typing the end-of-file character causes only the data length to be returned as 0. This terminal end of file is not the same as a STREAMS hangup. As expected, when we redirect standard input to be a non-STREAMS device, getmsg returns an error.
Figure 14.19. Copy standard input to standard output using getmsg
#include "apue.h"
#include <stropts.h>
#define BUFFSIZE 4096
int
main(void)
{
int n, flag;
char ctlbuf[BUFFSIZE], datbuf[BUFFSIZE];
struct strbuf ctl, dat;
ctl.buf = ctlbuf;
ctl.maxlen = BUFFSIZE;
dat.buf = datbuf;
dat.maxlen = BUFFSIZE;
for ( ; ; ) {
flag = 0; /* return any message */
if ((n = getmsg(STDIN_FILENO, &ctl, &dat, &flag)) < 0)
err_sys("getmsg error");
fprintf(stderr, "flag = %d, ctl.len = %d, dat.len = %d\n",
flag, ctl.len, dat.len);
if (dat.len == 0)
exit(0);
else if (dat.len > 0)
if (write(STDOUT_FILENO, dat.buf, dat.len) != dat.len)
err_sys("write error");
}
}
14.5. I/O Multiplexing
When we read from one descriptor and write to another, we can use blocking I/O in a loop, such as
while ((n = read(STDIN_FILENO, buf, BUFSIZ)) > 0)
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error");
We see this form of blocking I/O over and over again. What if we have to read from two descriptors? In this case, we can't do a blocking read on either descriptor, as data may appear on one descriptor while we're blocked in a read on the other. A different technique is required to handle this case.
Let's look at the structure of the telnet(1) command. In this program, we read from the terminal (standard input) and write to a network connection, and we read from the network connection and write to the terminal (standard output). At the other end of the network connection, the telnetd daemon reads what we typed and presents it to a shell as if we were logged in to the remote machine. The telnetd daemon sends any output generated by the commands we type back to us through the telnet command, to be displayed on our terminal. Figure 14.20 shows a picture of this.

The telnet process has two inputs and two outputs. We can't do a blocking read on either of the inputs, as we never know which input will have data for us.
One way to handle this particular problem is to divide the process in two pieces (using fork), with each half handling one direction of data. We show this in Figure 14.21. (The cu(1) command provided with System V's uucp communication package was structured like this.)

If we use two processes, we can let each process do a blocking read. But this leads to a problem when the operation terminates. If an end of file is received by the child (the network connection is disconnected by the telnetd daemon), then the child terminates, and the parent is notified by the SIGCHLD signal. But if the parent terminates (the user enters an end of file at the terminal), then the parent has to tell the child to stop. We can use a signal for this (SIGUSR1, for example), but it does complicate the program somewhat.
Instead of two processes, we could use two threads in a single process. This avoids the termination complexity, but requires that we deal with synchronization between the threads, which could add more complexity than it saves.
We could use nonblocking I/O in a single process by setting both descriptors nonblocking and issuing a read on the first descriptor. If data is present, we read it and process it. If there is no data to read, the call returns immediately. We then do the same thing with the second descriptor. After this, we wait for some amount of time (a few seconds, perhaps) and then try to read from the first descriptor again. This type of loop is called polling. The problem is that it wastes CPU time. Most of the time, there won't be data to read, so we waste time performing the read system calls. We also have to guess how long to wait each time around the loop. Although it works on any system that supports nonblocking I/O, polling should be avoided on a multitasking system.
Another technique is called asynchronous I/O. To do this, we tell the kernel to notify us with a signal when a descriptor is ready for I/O. There are two problems with this. First, not all systems support this feature (it is an optional facility in the Single UNIX Specification). System V provides the SIGPOLL signal for this technique, but this signal works only if the descriptor refers to a STREAMS device. BSD has a similar signal, SIGIO, but it has similar limitations: it works only on descriptors that refer to terminal devices or networks. The second problem with this technique is that there is only one of these signals per process (SIGPOLL or SIGIO). If we enable this signal for two descriptors (in the example we've been talking about, reading from two descriptors), the occurrence of the signal doesn't tell us which descriptor is ready. To determine which descriptor is ready, we still need to set each nonblocking and try them in sequence. We describe asynchronous I/O briefly in Section 14.6.
A better technique is to use I/O multiplexing. To do this, we build a list of the descriptors that we are interested in (usually more than one descriptor) and call a function that doesn't return until one of the descriptors is ready for I/O. On return from the function, we are told which descriptors are ready for I/O.
Three functionspoll, pselect, and selectallow us to perform I/O multiplexing. Figure 14.22 summarizes which platforms support them. Note that select is defined by the base POSIX.1 standard, but poll is an XSI extension to the base.
Figure 14.22. I/O multiplexing supported by various UNIX systemsSystem | poll | pselect | select | <sys/select.h> |
|---|
SUS | XSI | • | • | • | FreeBSD 5.2.1 | • | • | • | | Linux 2.4.22 | • | • | • | • | Mac OS X 10.3 | • | • | • | | Solaris 9 | • | | • | • |
POSIX specifies that <sys/select> be included to pull the information for select into your program. Historically, however, we have had to include three other header files, and some of the implementations haven't yet caught up to the standard. Check the select manual page to see what your system supports. Older systems require that you include <sys/types.h>, <sys/time.h>, and <unistd.h>.
I/O multiplexing was provided with the select function in 4.2BSD. This function has always worked with any descriptor, although its main use has been for terminal I/O and network I/O. SVR3 added the poll function when the STREAMS mechanism was added. Initially, however, poll worked only with STREAMS devices. In SVR4, support was added to allow poll to work on any descriptor.
14.5.1. select and pselect Functions
The select function lets us do I/O multiplexing under all POSIX-compatible platforms. The arguments we pass to select tell the kernel
Which descriptors we're interested in. What conditions we're interested in for each descriptor. (Do we want to read from a given descriptor? Do we want to write to a given descriptor? Are we interested in an exception condition for a given descriptor?) How long we want to wait. (We can wait forever, wait a fixed amount of time, or not wait at all.)
On the return from select, the kernel tells us
The total count of the number of descriptors that are ready Which descriptors are ready for each of the three conditions (read, write, or exception condition)
With this return information, we can call the appropriate I/O function (usually read or write) and know that the function won't block.
#include <sys/select.h>
int select(int maxfdp1, fd_set *restrict readfds,
fd_set *restrict writefds, fd_set
*restrict exceptfds,
struct timeval *restrict tvptr);
| Returns: count of ready descriptors, 0 on timeout, 1 on error |
Let's look at the last argument first. This specifies how long we want to wait:
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* and microseconds */
};
There are three conditions.
tvptr == NULL
Wait forever. This infinite wait can be interrupted if we catch a signal. Return is made when one of the specified descriptors is ready or when a signal is caught. If a signal is caught, select returns 1 with errno set to EINTR.
tvptr->tv_sec == 0 && tvptr->tv_usec == 0
Don't wait at all. All the specified descriptors are tested, and return is made immediately. This is a way to poll the system to find out the status of multiple descriptors, without blocking in the select function.
tvptr->tv_sec != 0 || tvptr->tv_usec != 0
Wait the specified number of seconds and microseconds. Return is made when one of the specified descriptors is ready or when the timeout value expires. If the timeout expires before any of the descriptors is ready, the return value is 0. (If the system doesn't provide microsecond resolution, the tvptr>tv_usec value is rounded up to the nearest supported value.) As with the first condition, this wait can also be interrupted by a caught signal.
POSIX.1 allows an implementation to modify the timeval structure, so after select returns, you can't rely on the structure containing the same values it did before calling select. FreeBSD 5.2.1, Mac OS X 10.3, and Solaris 9 all leave the structure unchanged, but Linux 2.4.22 will update it with the time remaining if select returns before the timeout value expires.
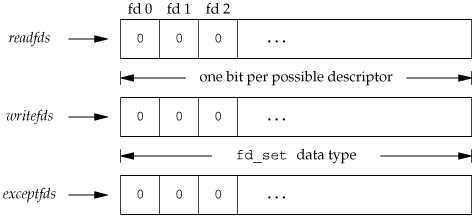
The middle three argumentsreadfds, writefds, and exceptfdsare pointers to descriptor sets. These three sets specify which descriptors we're interested in and for which conditions (readable, writable, or an exception condition). A descriptor set is stored in an fd_set data type. This data type is chosen by the implementation so that it can hold one bit for each possible descriptor. We can consider it to be just a big array of bits, as shown in Figure 14.23.
The only thing we can do with the fd_set data type is allocate a variable of this type, assign a variable of this type to another variable of the same type, or use one of the following four functions on a variable of this type.
#include <sys/select.h>
int FD_ISSET(int fd, fd_set *fdset);
| Returns: nonzero if fd is in set, 0 otherwise |
void FD_CLR(int fd, fd_set *fdset);
void FD_SET(int fd, fd_set *fdset);
void FD_ZERO(fd_set *fdset);
|
These interfaces can be implemented as either macros or functions. An fd_set is set to all zero bits by calling FD_ZERO. To turn on a single bit in a set, we use FD_SET. We can clear a single bit by calling FD_CLR. Finally, we can test whether a given bit is turned on in the set with FD_ISSET.
After declaring a descriptor set, we must zero the set using FD_ZERO. We then set bits in the set for each descriptor that we're interested in, as in
fd_set rset;
int fd;
FD_ZERO(&rset);
FD_SET(fd, &rset);
FD_SET(STDIN_FILENO, &rset);
On return from select, we can test whether a given bit in the set is still on using FD_ISSET:
if (FD_ISSET(fd, &rset)) {
...
}
Any (or all) of the middle three arguments to select (the pointers to the descriptor sets) can be null pointers if we're not interested in that condition. If all three pointers are NULL, then we have a higher precision timer than provided by sleep. (Recall from Section 10.19 that sleep waits for an integral number of seconds. With select, we can wait for intervals less than 1 second; the actual resolution depends on the system's clock.) Exercise 14.6 shows such a function.
The first argument to select, maxfdp1, stands for "maximum file descriptor plus 1." We calculate the highest descriptor that we're interested in, considering all three of the descriptor sets, add 1, and that's the first argument. We could just set the first argument to FD_SETSIZE, a constant in <sys/select.h> that specifies the maximum number of descriptors (often 1,024), but this value is too large for most applications. Indeed, most applications probably use between 3 and 10 descriptors. (Some applications need many more descriptors, but these UNIX programs are atypical.) By specifying the highest descriptor that we're interested in, we can prevent the kernel from going through hundreds of unused bits in the three descriptor sets, looking for bits that are turned on.
As an example, Figure 14.24 shows what two descriptor sets look like if we write
fd_set readset, writeset;
FD_ZERO(&readset);
FD_ZERO(&writeset);
FD_SET(0, &readset);
FD_SET(3, &readset);
FD_SET(1, &writeset);
FD_SET(2, &writeset);
select(4, &readset, &writeset, NULL, NULL);
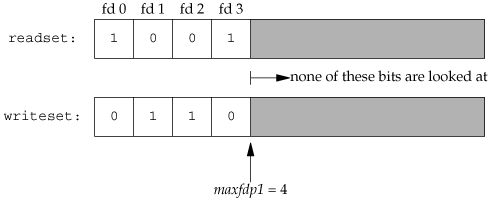
The reason we have to add 1 to the maximum descriptor number is that descriptors start at 0, and the first argument is really a count of the number of descriptors to check (starting with descriptor 0).
There are three possible return values from select.
A return value of 1 means that an error occurred. This can happen, for example, if a signal is caught before any of the specified descriptors are ready. In this case, none of the descriptor sets will be modified. A return value of 0 means that no descriptors are ready. This happens if the time limit expires before any of the descriptors are ready. When this happens, all the descriptor sets will be zeroed out. A positive return value specifies the number of descriptors that are ready. This value is the sum of the descriptors ready in all three sets, so if the same descriptor is ready to be read and written, it will be counted twice in the return value. The only bits left on in the three descriptor sets are the bits corresponding to the descriptors that are ready.
We now need to be more specific about what "ready" means.
A descriptor in the read set (readfds) is considered ready if a read from that descriptor won't block. A descriptor in the write set (writefds) is considered ready if a write to that descriptor won't block. A descriptor in the exception set (exceptfds) is considered ready if an exception condition is pending on that descriptor. Currently, an exception condition corresponds to either the arrival of out-of-band data on a network connection or certain conditions occurring on a pseudo terminal that has been placed into packet mode. (Section 15.10 of Stevens [1990] describes this latter condition.) File descriptors for regular files always return ready for reading, writing, and exception conditions.
It is important to realize that whether a descriptor is blocking or not doesn't affect whether select blocks. That is, if we have a nonblocking descriptor that we want to read from and we call select with a timeout value of 5 seconds, select will block for up to 5 seconds. Similarly, if we specify an infinite timeout, select blocks until data is ready for the descriptor or until a signal is caught.
If we encounter the end of file on a descriptor, that descriptor is considered readable by select. We then call read and it returns 0, the way to signify end of file on UNIX systems. (Many people incorrectly assume that select indicates an exception condition on a descriptor when the end of file is reached.)
POSIX.1 also defines a variant of select called pselect.
#include <sys/select.h>
int pselect(int maxfdp1, fd_set *restrict readfds,
fd_set *restrict writefds, fd_set
*restrict exceptfds,
const struct timespec *restrict tsptr,
const sigset_t *restrict sigmask);
| Returns: count of ready descriptors, 0 on timeout, 1 on error |
The pselect function is identical to select, with the following exceptions.
The timeout value for select is specified by a timeval structure, but for pselect, a timespec structure is used. (Recall the definition of the timespec structure in Section 11.6.) Instead of seconds and microseconds, the timespec structure represents the timeout value in seconds and nanoseconds. This provides a higher-resolution timeout if the platform supports that fine a level of granularity. The timeout value for pselect is declared const, and we are guaranteed that its value will not change as a result of calling pselect. An optional signal mask argument is available with pselect. If sigmask is null, pselect behaves as select does with respect to signals. Otherwise, sigmask points to a signal mask that is atomically installed when pselect is called. On return, the previous signal mask is restored.
14.5.2. poll Function
The poll function is similar to select, but the programmer interface is different. As we'll see, poll is tied to the STREAMS system, since it originated with System V, although we are able to use it with any type of file descriptor.
#include <poll.h>
int poll(struct pollfd fdarray[], nfds_t nfds, int
timeout);
| Returns: count of ready descriptors, 0 on timeout, 1 on error |
With poll, instead of building a set of descriptors for each condition (readability, writability, and exception condition), as we did with select, we build an array of pollfd structures, with each array element specifying a descriptor number and the conditions that we're interested in for that descriptor:
struct pollfd {
int fd; /* file descriptor to check, or <0 to ignore */
short events; /* events of interest on fd */
short revents; /* events that occurred on fd */
};
The number of elements in the fdarray array is specified by nfds.
Historically, there have been differences in how the nfds parameter was declared. SVR3 specified the number of elements in the array as an unsigned long, which seems excessive. In the SVR4 manual [AT&T 1990d], the prototype for poll showed the data type of the second argument as size_t. (Recall the primitive system data types, Figure 2.20.) But the actual prototype in the <poll.h> header still showed the second argument as an unsigned long. The Single UNIX Specification defines the new type nfds_t to allow the implementation to select the appropriate type and hide the details from applications. Note that this type has to be large enough to hold an integer, since the return value represents the number of entries in the array with satisfied events.
The SVID corresponding to SVR4 [AT&T 1989] showed the first argument to poll as struct pollfd fdarray[], whereas the SVR4 manual page [AT&T 1990d] showed this argument as struct pollfd *fdarray. In the C language, both declarations are equivalent. We use the first declaration to reiterate that fdarray points to an array of structures and not a pointer to a single structure.
To tell the kernel what events we're interested in for each descriptor, we have to set the events member of each array element to one or more of the values in Figure 14.25. On return, the revents member is set by the kernel, specifying which events have occurred for each descriptor. (Note that poll doesn't change the events member. This differs from select, which modifies its arguments to indicate what is ready.)
Figure 14.25. The events and revents flags for pollName | Input to events? | Result from revents? | Description |
|---|
POLLIN | • | • | Data other than high priority can be read without blocking (equivalent to POLLRDNORM|POLLRDBAND). | POLLRDNORM | • | • | Normal data (priority band 0) can be read without blocking. | POLLRDBAND | • | • | Data from a nonzero priority band can be read without blocking. | POLLPRI | • | • | High-priority data can be read without blocking. | POLLOUT | • | • | Normal data can be written without blocking. | POLLWRNORM | • | • | Same as POLLOUT. | POLLWRBAND | • | • | Data for a nonzero priority band can be written without blocking. | POLLERR | | • | An error has occurred. | POLLHUP | | • | A hangup has occurred. | POLLNVAL | | • | The descriptor does not reference an open file. |
The first four rows of Figure 14.25 test for readability, the next three test for writability, and the final three are for exception conditions. The last three rows in Figure 14.25 are set by the kernel on return. These three values are returned in revents when the condition occurs, even if they weren't specified in the events field.
When a descriptor is hung up (POLLHUP), we can no longer write to the descriptor. There may, however, still be data to be read from the descriptor.
The final argument to poll specifies how long we want to wait. As with select, there are three cases.
timeout == -1
Wait forever. (Some systems define the constant INFTIM in <stropts.h> as 1.) We return when one of the specified descriptors is ready or when a signal is caught. If a signal is caught, poll returns 1 with errno set to EINTR.
timeout == 0
Don't wait. All the specified descriptors are tested, and we return immediately. This is a way to poll the system to find out the status of multiple descriptors, without blocking in the call to poll.
timeout > 0
Wait timeout milliseconds. We return when one of the specified descriptors is ready or when the timeout expires. If the timeout expires before any of the descriptors is ready, the return value is 0. (If your system doesn't provide millisecond resolution, timeout is rounded up to the nearest supported value.)
It is important to realize the difference between an end of file and a hangup. If we're entering data from the terminal and type the end-of-file character, POLLIN is turned on so we can read the end-of-file indication (read returns 0). POLLHUP is not turned on in revents. If we're reading from a modem and the telephone line is hung up, we'll receive the POLLHUP notification.
As with select, whether a descriptor is blocking or not doesn't affect whether poll blocks.
Interruptibility of select and poll
When the automatic restarting of interrupted system calls was introduced with 4.2BSD (Section 10.5), the select function was never restarted. This characteristic continues with most systems even if the SA_RESTART option is specified. But under SVR4, if SA_RESTART was specified, even select and poll were automatically restarted. To prevent this from catching us when we port software to systems derived from SVR4, we'll always use the signal_intr function (Figure 10.19) if the signal could interrupt a call to select or poll.
None of the implementations described in this book restart poll or select when a signal is received, even if the SA_RESTART flag is used.
14.6. Asynchronous I/O
Using select and poll, as described in the previous section, is a synchronous form of notification. The system doesn't tell us anything until we ask (by calling either select or poll). As we saw in Chapter 10, signals provide an asynchronous form of notification that something has happened. All systems derived from BSD and System V provide some form of asynchronous I/O, using a signal (SIGPOLL in System V; SIGIO in BSD) to notify the process that something of interest has happened on a descriptor.
We saw that select and poll work with any descriptors. But with asynchronous I/O, we now encounter restrictions. On systems derived from System V, asynchronous I/O works only with STREAMS devices and STREAMS pipes. On systems derived from BSD, asynchronous I/O works only with terminals and networks.
One limitation of asynchronous I/O is that there is only one signal per process. If we enable more than one descriptor for asynchronous I/O, we cannot tell which descriptor the signal corresponds to when the signal is delivered.
The Single UNIX Specification includes an optional generic asynchronous I/O mechanism, adopted from the real-time draft standard. It is unrelated to the mechanisms we describe here. This mechanism solves a lot of the limitations that exist with these older asynchronous I/O mechanisms, but we will not discuss it further.
14.6.1. System V Asynchronous I/O
In System V, asynchronous I/O is part of the STREAMS system and works only with STREAMS devices and STREAMS pipes. The System V asynchronous I/O signal is SIGPOLL.
To enable asynchronous I/O for a STREAMS device, we have to call ioctl with a second argument (request) of I_SETSIG. The third argument is an integer value formed from one or more of the constants in Figure 14.26. These constants are defined in <stropts.h>.
Figure 14.26. Conditions for generating SIGPOLL signalConstant | Description |
|---|
S_INPUT | A message other than a high-priority message has arrived. | S_RDNORM | An ordinary message has arrived. | S_RDBAND | A message with a nonzero priority band has arrived. | S_BANDURG | If this constant is specified with S_RDBAND, the SIGURG signal is generated instead of SIGPOLL when a nonzero priority band message has arrived. | S_HIPRI | A high-priority message has arrived. | S_OUTPUT | The write queue is no longer full. | S_WRNORM | Same as S_OUTPUT. | S_WRBAND | We can send a nonzero priority band message. | S_MSG | A STREAMS signal message that contains the SIGPOLL signal has arrived. | S_ERROR | An M_ERROR message has arrived. | S_HANGUP | An M_HANGUP message has arrived. |
In Figure 14.26, whenever we say "has arrived," we mean "has arrived at the stream head's read queue."
In addition to calling ioctl to specify the conditions that should generate the SIGPOLL signal, we also have to establish a signal handler for this signal. Recall from Figure 10.1 that the default action for SIGPOLL is to terminate the process, so we should establish the signal handler before calling ioctl.
14.6.2. BSD Asynchronous I/O
Asynchronous I/O in BSD-derived systems is a combination of two signals: SIGIO and SIGURG. The former is the general asynchronous I/O signal, and the latter is used only to notify the process that out-of-band data has arrived on a network connection.
To receive the SIGIO signal, we need to perform three steps.
1. | Establish a signal handler for SIGIO, by calling either signal or sigaction.
| 2. | Set the process ID or process group ID to receive the signal for the descriptor, by calling fcntl with a command of F_SETOWN ( Section 3.14).
| 3. | Enable asynchronous I/O on the descriptor by calling fcntl with a command of F_SETFL to set the O_ASYNC file status flag ( Figure 3.9).
|
Step 3 can be performed only on descriptors that refer to terminals or networks, which is a fundamental limitation of the BSD asynchronous I/O facility.
For the SIGURG signal, we need perform only steps 1 and 2. SIGURG is generated only for descriptors that refer to network connections that support out-of-band data.
14.7. readv and writev Functions
The readv and writev functions let us read into and write from multiple noncontiguous buffers in a single function call. These operations are called scatter read and gather write.
#include <sys/uio.h>
ssize_t readv(int filedes, const struct iovec *iov
, int iovcnt);
ssize_t writev(int filedes, const struct iovec
*iov, int iovcnt);
| Both return: number of bytes read or written, 1 on error |
The second argument to both functions is a pointer to an array of iovec structures:
struct iovec {
void *iov_base; /* starting address of buffer */
size_t iov_len; /* size of buffer */
};
The number of elements in the iov array is specified by iovcnt. It is limited to IOV_MAX (Recall Figure 2.10). Figure 14.27 shows a picture relating the arguments to these two functions and the iovec structure.
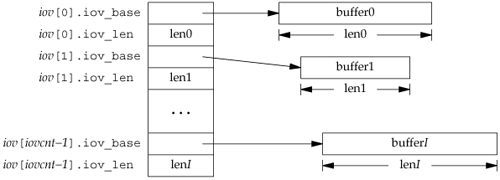
The writev function gathers the output data from the buffers in order: iov[0], iov[1], through iov[iovcnt1]; writev returns the total number of bytes output, which should normally equal the sum of all the buffer lengths.
The readv function scatters the data into the buffers in order, always filling one buffer before proceeding to the next. readv returns the total number of bytes that were read. A count of 0 is returned if there is no more data and the end of file is encountered.
These two functions originated in 4.2BSD and were later added to SVR4. These two functions are included in the XSI extension of the Single UNIX Specification.
Although the Single UNIX Specification defines the buffer address to be a void *, many implementations that predate the standard still use a char * instead.
Example
In Section 20.8, in the function _db_writeidx, we need to write two buffers consecutively to a file. The second buffer to output is an argument passed by the caller, and the first buffer is one we create, containing the length of the second buffer and a file offset of other information in the file. There are three ways we can do this.
Call write twice, once for each buffer. Allocate a buffer of our own that is large enough to contain both buffers, and copy both into the new buffer. We then call write once for this new buffer. Call writev to output both buffers.
The solution we use in Section 20.8 is to use writev, but it's instructive to compare it to the other two solutions.
Figure 14.28 shows the results from the three methods just described.
The test program that we measured output a 100-byte header followed by 200 bytes of data. This was done 1,048,576 times, generating a 300-megabyte file. The test program has three separate casesone for each of the techniques measured in Figure 14.28. We used times (Section 8.16) to obtain the user CPU time, system CPU time, and wall clock time before and after the writes. All three times are shown in seconds.
As we expect, the system time increases when we call write twice, compared to calling either write or writev once. This correlates with the results in Figure 3.5.
Next, note that the sum of the CPU times (user plus system) is less when we do a buffer copy followed by a single write compared to a single call to writev. With the single write, we copy the buffers to a staging buffer at user level, and then the kernel will copy the data to its internal buffers when we call write. With writev, we should do less copying, because the kernel only needs to copy the data directly into its staging buffers. The fixed cost of using writev for such small amounts of data, however, is greater than the benefit. As the amount of data we need to copy increases, the more expensive it will be to copy the buffers in our program, and the writev alternative will be more attractive.
Be careful not to infer too much about the relative performance of Linux to Mac OS X from the numbers shown in Figure 14.28. The two computers were very different: they had different processor architectures, different amounts of RAM, and disks with different speeds. To do an apples-to-apples comparison of one operating system to another, we need to use the same hardware for each operating system.
Figure 14.28. Timing results comparing writev and other techniquesOperation | Linux (Intel x86) | Mac OS X (PowerPC) |
|---|
User | System | Clock | User | System | Clock |
|---|
two writes | 1.29 | 3.15 | 7.39 | 1.60 | 17.40 | 19.84 | buffer copy, then one write | 1.03 | 1.98 | 6.47 | 1.10 | 11.09 | 12.54 | one writev | 0.70 | 2.72 | 6.41 | 0.86 | 13.58 | 14.72 |
In summary, we should always try to use the fewest number of system calls necessary to get the job done. If we are writing small amounts of data, we will find it less expensive to copy the data ourselves and use a single write instead of using writev. We might find, however, that the performance benefits aren't worth the extra complexity cost needed to manage our own staging buffers.
14.8. readn and writen Functions
Pipes, FIFOs, and some devices, notably terminals, networks, and STREAMS devices, have the following two properties.
A read operation may return less than asked for, even though we have not encountered the end of file. This is not an error, and we should simply continue reading from the device. A write operation can also return less than we specified. This may be caused by flow control constraints by downstream modules, for example. Again, it's not an error, and we should continue writing the remainder of the data. (Normally, this short return from a write occurs only with a nonblocking descriptor or if a signal is caught.)
We'll never see this happen when reading or writing a disk file, except when the file system runs out of space or we hit our quota limit and we can't write all that we requested.
Generally, when we read from or write to a pipe, network device, or terminal, we need to take these characteristics into consideration. We can use the following two functions to read or write N bytes of data, letting these functions handle a possible return value that's less than requested. These two functions simply call read or write as many times as required to read or write the entire N bytes of data.
#include "apue.h"
ssize_t readn(int filedes, void *buf, size_t nbytes);
ssize_t writen(int filedes, void *buf, size_t nbytes);
| Both return: number of bytes read or written, 1 on error |
We define these functions as a convenience for later examples, similar to the error-handling routines used in many of the examples in this text. The readn and writen functions are not part of any standard.
We call writen whenever we're writing to one of the file types that we mentioned, but we call readn only when we know ahead of time that we will be receiving a certain number of bytes. Figure 14.29 shows implementations of readn and writen that we will use in later examples.
Figure 14.29. The readn and writen functions
#include "apue.h"
ssize_t /* Read "n" bytes from a descriptor */
readn(int fd, void *ptr, size_t n)
{
size_t nleft;
ssize_t nread;
nleft = n;
while (nleft > 0) {
if ((nread = read(fd, ptr, nleft)) < 0) {
if (nleft == n)
return(-1); /* error, return -1 */
else
break; /* error, return amount read so far */
} else if (nread == 0) {
break; /* EOF */
}
nleft -= nread;
ptr += nread;
}
return(n - nleft); /* return >= 0 */
}
ssize_t /* Write "n" bytes to a descriptor */
writen(int fd, const void *ptr, size_t n)
{
size_t nleft;
ssize_t nwritten;
nleft = n;
while (nleft > 0) {
if ((nwritten = write(fd, ptr, nleft)) < 0) {
if (nleft == n)
return(-1); /* error, return -1 */
else
break; /* error, return amount written so far */
} else if (nwritten == 0) {
break;
}
nleft -= nwritten;
ptr += nwritten;
}
return(n - nleft); /* return >= 0 */
}
Note that if we encounter an error and have previously read or written any data, we return the amount of data transferred instead of the error. Similarly, if we reach end of file while reading, we return the number of bytes copied to the caller's buffer if we already read some data successfully and have not yet satisfied the amount requested.
14.9. Memory-Mapped I/O
Memory-mapped I/O lets us map a file on disk into a buffer in memory so that, when we fetch bytes from the buffer, the corresponding bytes of the file are read. Similarly, when we store data in the buffer, the corresponding bytes are automatically written to the file. This lets us perform I/O without using read or write.
Memory-mapped I/O has been in use with virtual memory systems for many years. In 1981, 4.1BSD provided a different form of memory-mapped I/O with its vread and vwrite functions. These two functions were then removed in 4.2BSD and were intended to be replaced with the mmap function. The mmap function, however, was not included with 4.2BSD (for reasons described in Section 2.5 of McKusick et al. [1996]). Gingell, Moran, and Shannon [1987] describe one implementation of mmap. The mmap function is included in the memory-mapped files option in the Single UNIX Specification and is required on all XSI-conforming systems; most UNIX systems support it.
To use this feature, we have to tell the kernel to map a given file to a region in memory. This is done by the mmap function.
#include <sys/mman.h>
void *mmap(void *addr, size_t len, int prot, int
flag, int filedes,
off_t off );
| Returns: starting address of mapped region if OK, MAP_FAILED on error |
The addr argument lets us specify the address of where we want the mapped region to start. We normally set this to 0 to allow the system to choose the starting address. The return value of this function is the starting address of the mapped area.
The filedes argument is the file descriptor specifying the file that is to be mapped. We have to open this file before we can map it into the address space. The len argument is the number of bytes to map, and off is the starting offset in the file of the bytes to map. (Some restrictions on the value of off are described later.)
The prot argument specifies the protection of the mapped region.
We can specify the protection as either PROT_NONE or the bitwise OR of any combination of PROT_READ, PROT_WRITE, and PROT_EXEC. The protection specified for a region can't allow more access than the open mode of the file. For example, we can't specify PROT_WRITE if the file was opened read-only.
Before looking at the flag argument, let's see what's going on here. Figure 14.31 shows a memory-mapped file. (Recall the memory layout of a typical process, Figure 7.6.) In this figure, "start addr" is the return value from mmap. We have shown the mapped memory being somewhere between the heap and the stack: this is an implementation detail and may differ from one implementation to the next.
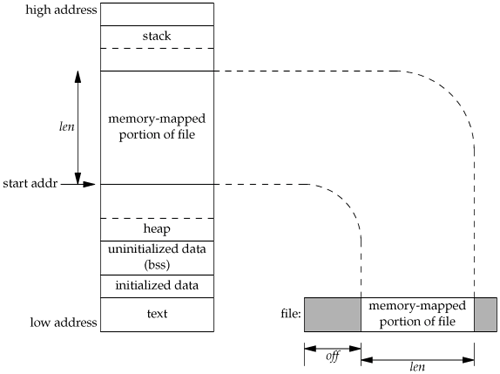
The flag argument affects various attributes of the mapped region.
MAP_FIXED | The return value must equal addr. Use of this flag is discouraged, as it hinders portability. If this flag is not specified and if addr is nonzero, then the kernel uses addr as a hint of where to place the mapped region, but there is no guarantee that the requested address will be used. Maximum portability is obtained by specifying addr as 0.
Support for the MAP_FIXED flag is optional on POSIX-conforming systems, but required on XSI-conforming systems.
| MAP_SHARED | This flag describes the disposition of store operations into the mapped region by this process. This flag specifies that store operations modify the mapped filethat is, a store operation is equivalent to a write to the file. Either this flag or the next (MAP_PRIVATE), but not both, must be specified. | MAP_PRIVATE | This flag says that store operations into the mapped region cause a private copy of the mapped file to be created. All successive references to the mapped region then reference the copy. (One use of this flag is for a debugger that maps the text portion of a program file but allows the user to modify the instructions. Any modifications affect the copy, not the original program file.) |
Each implementation has additional MAP_xxx flag values, which are specific to that implementation. Check the mmap(2) manual page on your system for details.
The value of off and the value of addr (if MAP_FIXED is specified) are required to be multiples of the system's virtual memory page size. This value can be obtained from the sysconf function (Section 2.5.4) with an argument of _SC_PAGESIZE or _SC_PAGE_SIZE. Since off and addr are often specified as 0, this requirement is not a big deal.
Since the starting offset of the mapped file is tied to the system's virtual memory page size, what happens if the length of the mapped region isn't a multiple of the page size? Assume that the file size is 12 bytes and that the system's page size is 512 bytes. In this case, the system normally provides a mapped region of 512 bytes, and the final 500 bytes of this region are set to 0. We can modify the final 500 bytes, but any changes we make to them are not reflected in the file. Thus, we cannot append to a file with mmap. We must first grow the file, as we will see in Figure 14.32.
Figure 14.32. Copy a file using memory-mapped I/O
#include "apue.h"
#include <fcntl.h>
#include <sys/mman.h>
int
main(int argc, char *argv[])
{
int fdin, fdout;
void *src, *dst;
struct stat statbuf;
if (argc != 3)
err_quit("usage: %s <fromfile> <tofile>", argv[0]);
if ((fdin = open(argv[1], O_RDONLY)) < 0)
err_sys("can't open %s for reading", argv[1]);
if ((fdout = open(argv[2], O_RDWR | O_CREAT | O_TRUNC,
FILE_MODE)) < 0)
err_sys("can't creat %s for writing", argv[2]);
if (fstat(fdin, &statbuf) < 0) /* need size of input file */
err_sys("fstat error");
/* set size of output file */
if (lseek(fdout, statbuf.st_size - 1, SEEK_SET) == -1)
err_sys("lseek error");
if (write(fdout, "", 1) != 1)
err_sys("write error");
if ((src = mmap(0, statbuf.st_size, PROT_READ, MAP_SHARED,
fdin, 0)) == MAP_FAILED)
err_sys("mmap error for input");
if ((dst = mmap(0, statbuf.st_size, PROT_READ | PROT_WRITE,
MAP_SHARED, fdout, 0)) == MAP_FAILED)
err_sys("mmap error for output");
memcpy(dst, src, statbuf.st_size); /* does the file copy */
exit(0);
}
Two signals are normally used with mapped regions. SIGSEGV is the signal normally used to indicate that we have tried to access memory that is not available to us. This signal can also be generated if we try to store into a mapped region that we specified to mmap as read-only. The SIGBUS signal can be generated if we access a portion of the mapped region that does not make sense at the time of the access. For example, assume that we map a file using the file's size, but before we reference the mapped region, the file's size is truncated by some other process. If we then try to access the memory-mapped region corresponding to the end portion of the file that was truncated, we'll receive SIGBUS.
A memory-mapped region is inherited by a child across a fork (since it's part of the parent's address space), but for the same reason, is not inherited by the new program across an exec.
We can change the permissions on an existing mapping by calling mprotect.
#include <sys/mman.h>
int mprotect(void *addr, size_t len, int prot);
| Returns: 0 if OK, 1 on error |
The legal values for prot are the same as those for mmap (Figure 14.30). The address argument must be an integral multiple of the system's page size.
Figure 14.30. Protection of memory-mapped regionprot | Description |
|---|
PROT_READ | Region can be read. | PROT_WRITE | Region can be written. | PROT_EXEC | Region can be executed. | PROT_NONE | Region cannot be accessed. |
The mprotect function is included as part of the memory protection option in the Single UNIX Specification, but all XSI-conforming systems are required to support it.
If the pages in a shared mapping have been modified, we can call msync to flush the changes to the file that backs the mapping. The msync function is similar to fsync (Section 3.13), but works on memory-mapped regions.
#include <sys/mman.h>
int msync(void *addr, size_t len, int flags);
| Returns: 0 if OK, 1 on error |
If the mapping is private, the file mapped is not modified. As with the other memory-mapped functions, the address must be aligned on a page boundary.
The flags argument allows us some control over how the memory is flushed. We can specify the MS_ASYNC flag to simply schedule the pages to be written. If we want to wait for the writes to complete before returning, we can use the MS_SYNC flag. Either MS_ASYNC or MS_SYNC must be specified.
An optional flag, MS_INVALIDATE, lets us tell the operating system to discard any pages that are out of sync with the underlying storage. Some implementations will discard all pages in the specified range when we use this flag, but this behavior is not required.
A memory-mapped region is automatically unmapped when the process terminates or by calling munmap directly. Closing the file descriptor filedes does not unmap the region.
#include <sys/mman.h>
int munmap(caddr_t addr, size_t len);
| Returns: 0 if OK, 1 on error
|
munmap does not affect the object that was mappedthat is, the call to munmap does not cause the contents of the mapped region to be written to the disk file. The updating of the disk file for a MAP_SHARED region happens automatically by the kernel's virtual memory algorithm as we store into the memory-mapped region. Modifications to memory in a MAP_PRIVATE region are discarded when the region is unmapped.
Example
The program in Figure 14.32 copies a file (similar to the cp(1) command) using memory-mapped I/O.
We first open both files and then call fstat to obtain the size of the input file. We need this size for the call to mmap for the input file, and we also need to set the size of the output file. We call lseek and then write one byte to set the size of the output file. If we don't set the output file's size, the call to mmap for the output file is OK, but the first reference to the associated memory region generates SIGBUS. We might be tempted to use ftruncate to set the size of the output file, but not all systems extend the size of a file with this function. (See Section 4.13.)
Extending a file with ftruncate works on the four platforms discussed in this text.
We then call mmap for each file, to map the file into memory, and finally call memcpy to copy from the input buffer to the output buffer. As the bytes of data are fetched from the input buffer (src), the input file is automatically read by the kernel; as the data is stored in the output buffer (dst), the data is automatically written to the output file.
Exactly when the data is written to the file is dependent on the system's page management algorithms. Some systems have daemons that write dirty pages to disk slowly over time. If we want to ensure that the data is safely written to the file, we need to call msync with the MS_SYNC flag before exiting.
Let's compare this memory-mapped file copy to a copy that is done by calling read and write (with a buffer size of 8,192). Figure 14.33 shows the results. The times are given in seconds, and the size of the file being copied was 300 megabytes.
For Solaris 9, the total CPU time (user + system) is almost the same for both types of copies: 9.88 seconds versus 9.62 seconds. For Linux 2.4.22, the total CPU time is almost doubled when we use mmap and memcpy (1.06 seconds versus 1.95 seconds). The difference is probably because the two systems implement process time accounting differently.
As far as elapsed time is concerned, the version with mmap and memcpy is faster than the version with read and write. This makes sense, because we're doing less work with mmap and memcpy. With read and write, we copy the data from the kernel's buffer to the application's buffer (read), and then copy the data from the application's buffer to the kernel's buffer (write). With mmap and memcpy, we copy the data directly from one kernel buffer mapped into our address space into another kernel buffer mapped into our address space.
Figure 14.33. Timing results comparing read/write versus mmap/memcpyOperation | Linux 2.4.22 (Intel x86) | Solaris 9 (SPARC) |
|---|
User | System | Clock | User | System | Clock |
|---|
read/write | 0.04 | 1.02 | 39.76 | 0.18 | 9.70 | 41.66 | mmap/memcpy | 0.64 | 1.31 | 24.26 | 1.68 | 7.94 | 28.53 |
Memory-mapped I/O is faster when copying one regular file to another. There are limitations. We can't use it to copy between certain devices (such as a network device or a terminal device), and we have to be careful if the size of the underlying file could change after we map it. Nevertheless, some applications can benefit from memory-mapped I/O, as it can often simplify the algorithms, since we manipulate memory instead of reading and writing a file. One example that can benefit from memory-mapped I/O is the manipulation of a frame buffer device that references a bit-mapped display.
Krieger, Stumm, and Unrau [1992] describe an alternative to the standard I/O library (Chapter 5) that uses memory-mapped I/O.
We return to memory-mapped I/O in Section 15.9, showing an example of how it can be used to provide shared memory between related processes.
15.1. Introduction
In Chapter 8, we described the process control primitives and saw how to invoke multiple processes. But the only way for these processes to exchange information is by passing open files across a fork or an exec or through the file system. We'll now describe other techniques for processes to communicate with each other: IPC, or interprocess communication.
In the past, UNIX System IPC was a hodgepodge of various approaches, few of which were portable across all UNIX system implementations. Through the POSIX and The Open Group (formerly X/Open) standardization efforts, the situation has improved, but differences still exist. Figure 15.1 summarizes the various forms of IPC that are supported by the four implementations discussed in this text.
Figure 15.1. Summary of UNIX System IPCIPC type | SUS | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
half-duplex pipes | • | (full) | • | • | (full) | FIFOs | • | • | • | • | • | full-duplex pipes | allowed | •,UDS | opt, UDS | UDS | •, UDS | named full-duplex pipes | XSI option | UDS | opt, UDS | UDS | •, UDS | message queues | XSI | • | • | | • | semaphores | XSI | • | • | • | • | shared memory | XSI | • | • | • | • | sockets | • | • | • | • | • | STREAMS | XSI option | | opt | | • |
Note that the Single UNIX Specification (the "SUS" column) allows an implementation to support full-duplex pipes, but requires only half-duplex pipes. An implementation that supports full-duplex pipes will still work with correctly written applications that assume that the underlying operating system supports only half-duplex pipes. We use "(full)" instead of a bullet to show implementations that support half-duplex pipes by using full-duplex pipes.
In Figure 15.1, we show a bullet where basic functionality is supported. For full-duplex pipes, if the feature can be provided through UNIX domain sockets (Section 17.3), we show "UDS" in the column. Some implementations support the feature with pipes and UNIX domain sockets, so these entries have both "UDS" and a bullet.
As we mentioned in Section 14.4, support for STREAMS is optional in the Single UNIX Specification. Named full-duplex pipes are provided as mounted STREAMS-based pipes and so are also optional in the Single UNIX Specification. On Linux, support for STREAMS is available in a separate, optional package called "LiS" (for Linux STREAMS). We show "opt" where the platform provides support for the feature through an optional packageone that is not usually installed by default.
The first seven forms of IPC in Figure 15.1 are usually restricted to IPC between processes on the same host. The final two rowssockets and STREAMSare the only two that are generally supported for IPC between processes on different hosts.
We have divided the discussion of IPC into three chapters. In this chapter, we examine classical IPC: pipes, FIFOs, message queues, semaphores, and shared memory. In the next chapter, we take a look at network IPC using the sockets mechanism. In Chapter 17, we take a look at some advanced features of IPC.
15.2. Pipes
Pipes are the oldest form of UNIX System IPC and are provided by all UNIX systems. Pipes have two limitations.
Historically, they have been half duplex (i.e., data flows in only one direction). Some systems now provide full-duplex pipes, but for maximum portability, we should never assume that this is the case. Pipes can be used only between processes that have a common ancestor. Normally, a pipe is created by a process, that process calls fork, and the pipe is used between the parent and the child.
We'll see that FIFOs (Section 15.5) get around the second limitation, and that UNIX domain sockets (Section 17.3) and named STREAMS-based pipes (Section 17.2.2) get around both limitations.
Despite these limitations, half-duplex pipes are still the most commonly used form of IPC. Every time you type a sequence of commands in a pipeline for the shell to execute, the shell creates a separate process for each command and links the standard output of one to the standard input of the next using a pipe.
A pipe is created by calling the pipe function.
#include <unistd.h>
int pipe(int filedes[2]);
| Returns: 0 if OK, 1 on error |
Two file descriptors are returned through the filedes argument: filedes[0] is open for reading, and filedes[1] is open for writing. The output of filedes[1] is the input for filedes[0].
Pipes are implemented using UNIX domain sockets in 4.3BSD, 4.4BSD, and Mac OS X 10.3. Even though UNIX domain sockets are full duplex by default, these operating systems hobble the sockets used with pipes so that they operate in half-duplex mode only.
POSIX.1 allows for an implementation to support full-duplex pipes. For these implementations, filedes[0] and filedes[1] are open for both reading and writing.
Two ways to picture a half-duplex pipe are shown in Figure 15.2. The left half of the figure shows the two ends of the pipe connected in a single process. The right half of the figure emphasizes that the data in the pipe flows through the kernel.
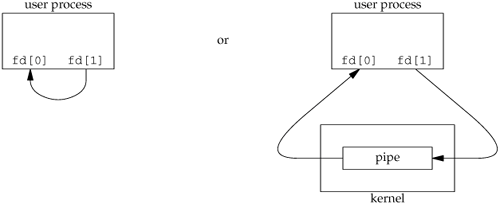
The fstat function (Section 4.2) returns a file type of FIFO for the file descriptor of either end of a pipe. We can test for a pipe with the S_ISFIFO macro.
POSIX.1 states that the st_size member of the stat structure is undefined for pipes. But when the fstat function is applied to the file descriptor for the read end of the pipe, many systems store in st_size the number of bytes available for reading in the pipe. This is, however, nonportable.
A pipe in a single process is next to useless. Normally, the process that calls pipe then calls fork, creating an IPC channel from the parent to the child or vice versa. Figure 15.3 shows this scenario.
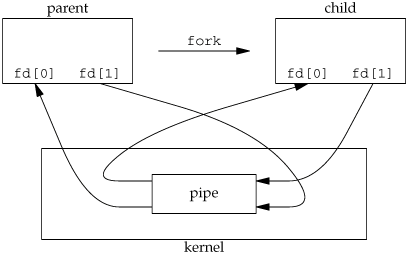
What happens after the fork depends on which direction of data flow we want. For a pipe from the parent to the child, the parent closes the read end of the pipe (fd[0]), and the child closes the write end (fd[1]). Figure 15.4 shows the resulting arrangement of descriptors.
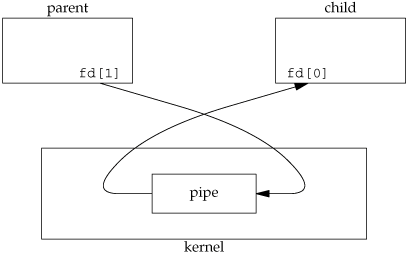
For a pipe from the child to the parent, the parent closes fd[1], and the child closes fd[0].
When one end of a pipe is closed, the following two rules apply.
If we read from a pipe whose write end has been closed, read returns 0 to indicate an end of file after all the data has been read. (Technically, we should say that this end of file is not generated until there are no more writers for the pipe. It's possible to duplicate a pipe descriptor so that multiple processes have the pipe open for writing. Normally, however, there is a single reader and a single writer for a pipe. When we get to FIFOs in the next section, we'll see that often there are multiple writers for a single FIFO.) If we write to a pipe whose read end has been closed, the signal SIGPIPE is generated. If we either ignore the signal or catch it and return from the signal handler, write returns 1 with errno set to EPIPE.
When we're writing to a pipe (or FIFO), the constant PIPE_BUF specifies the kernel's pipe buffer size. A write of PIPE_BUF bytes or less will not be interleaved with the writes from other processes to the same pipe (or FIFO). But if multiple processes are writing to a pipe (or FIFO), and if we write more than PIPE_BUF bytes, the data might be interleaved with the data from the other writers. We can determine the value of PIPE_BUF by using pathconf or fpathconf (recall Figure 2.11).
Example
Figure 15.5 shows the code to create a pipe between a parent and its child and to send data down the pipe.
Figure 15.5. Send data from parent to child over a pipe
#include "apue.h"
int
main(void)
{
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if (pipe(fd) < 0)
err_sys("pipe error");
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) { /* parent */
close(fd[0]);
write(fd[1], "hello world\n", 12);
} else { /* child */
close(fd[1]);
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
exit(0);
}
In the previous example, we called read and write directly on the pipe descriptors. What is more interesting is to duplicate the pipe descriptors onto standard input or standard output. Often, the child then runs some other program, and that program can either read from its standard input (the pipe that we created) or write to its standard output (the pipe).
Example
Consider a program that displays some output that it has created, one page at a time. Rather than reinvent the pagination done by several UNIX system utilities, we want to invoke the user's favorite pager. To avoid writing all the data to a temporary file and calling system to display that file, we want to pipe the output directly to the pager. To do this, we create a pipe, fork a child process, set up the child's standard input to be the read end of the pipe, and exec the user's pager program. Figure 15.6 shows how to do this. (This example takes a command-line argument to specify the name of a file to display. Often, a program of this type would already have the data to display to the terminal in memory.)
Before calling fork, we create a pipe. After the fork, the parent closes its read end, and the child closes its write end. The child then calls dup2 to have its standard input be the read end of the pipe. When the pager program is executed, its standard input will be the read end of the pipe.
When we duplicate a descriptor onto another (fd[0] onto standard input in the child), we have to be careful that the descriptor doesn't already have the desired value. If the descriptor already had the desired value and we called dup2 and close, the single copy of the descriptor would be closed. (Recall the operation of dup2 when its two arguments are equal, discussed in Section 3.12). In this program, if standard input had not been opened by the shell, the fopen at the beginning of the program should have used descriptor 0, the lowest unused descriptor, so fd[0] should never equal standard input. Nevertheless, whenever we call dup2 and close to duplicate a descriptor onto another, we'll always compare the descriptors first, as a defensive programming measure.
Note how we try to use the environment variable PAGER to obtain the name of the user's pager program. If this doesn't work, we use a default. This is a common usage of environment variables.
Figure 15.6. Copy file to pager program
#include "apue.h"
#include <sys/wait.h>
#define DEF_PAGER "/bin/more" /* default pager program */
int
main(int argc, char *argv[])
{
int n;
int fd[2];
pid_t pid;
char *pager, *argv0;
char line[MAXLINE];
FILE *fp;
if (argc != 2)
err_quit("usage: a.out <pathname>");
if ((fp = fopen(argv[1], "r")) == NULL)
err_sys("can't open %s", argv[1]);
if (pipe(fd) < 0)
err_sys("pipe error");
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) { /* parent */
close(fd[0]); /* close read end */
/* parent copies argv[1] to pipe */
while (fgets(line, MAXLINE, fp) != NULL) {
n = strlen(line);
if (write(fd[1], line, n) != n)
err_sys("write error to pipe");
}
if (ferror(fp))
err_sys("fgets error");
close(fd[1]); /* close write end of pipe for reader */
if (waitpid(pid, NULL, 0) < 0)
err_sys("waitpid error");
exit(0);
} else { /* child */
close(fd[1]); /* close write end */
if (fd[0] != STDIN_FILENO) {
if (dup2(fd[0], STDIN_FILENO) != STDIN_FILENO)
err_sys("dup2 error to stdin");
close(fd[0]); /* don't need this after dup2 */
}
/* get arguments for execl() */
if ((pager = getenv("PAGER")) == NULL)
pager = DEF_PAGER;
if ((argv0 = strrchr(pager, '/')) != NULL)
argv0++; /* step past rightmost slash */
else
argv0 = pager; /* no slash in pager */
if (execl(pager, argv0, (char *)0) < 0)
err_sys("execl error for %s", pager);
}
exit(0);
}
Example
Recall the five functions TELL_WAIT, TELL_PARENT, TELL_CHILD, WAIT_PARENT, and WAIT_CHILD from Section 8.9. In Figure 10.24, we showed an implementation using signals. Figure 15.7 shows an implementation using pipes.
We create two pipes before the fork, as shown in Figure 15.8. The parent writes the character "p" across the top pipe when TELL_CHILD is called, and the child writes the character "c" across the bottom pipe when TELL_PARENT is called. The corresponding WAIT_xxx functions do a blocking read for the single character.
Note that each pipe has an extra reader, which doesn't matter. That is, in addition to the child reading from pfd1[0], the parent also has this end of the top pipe open for reading. This doesn't affect us, since the parent doesn't try to read from this pipe.
Figure 15.7. Routines to let a parent and child synchronize
#include "apue.h"
static int pfd1[2], pfd2[2];
void
TELL_WAIT(void)
{
if (pipe(pfd1) < 0 || pipe(pfd2) < 0)
err_sys("pipe error");
}
void
TELL_PARENT(pid_t pid)
{
if (write(pfd2[1], "c", 1) != 1)
err_sys("write error");
}
void
WAIT_PARENT(void)
{
char c;
if (read(pfd1[0], &c, 1) != 1)
err_sys("read error");
if (c != 'p')
err_quit("WAIT_PARENT: incorrect data");
}
void
TELL_CHILD(pid_t pid)
{
if (write(pfd1[1], "p", 1) != 1)
err_sys("write error");
}
void
WAIT_CHILD(void)
{
char c;
if (read(pfd2[0], &c, 1) != 1)
err_sys("read error");
if (c != 'c')
err_quit("WAIT_CHILD: incorrect data");
}
15.3. popen and pclose Functions
Since a common operation is to create a pipe to another process, to either read its output or send it input, the standard I/O library has historically provided the popen and pclose functions. These two functions handle all the dirty work that we've been doing ourselves: creating a pipe, forking a child, closing the unused ends of the pipe, executing a shell to run the command, and waiting for the command to terminate.
#include <stdio.h>
FILE *popen(const char *cmdstring, const char *type);
| Returns: file pointer if OK, NULL on error |
int pclose(FILE *fp);
| Returns: termination status of cmdstring, or 1 on error |
The function popen does a fork and exec to execute the cmdstring, and returns a standard I/O file pointer. If type is "r", the file pointer is connected to the standard output of cmdstring (Figure 15.9).

If type is "w", the file pointer is connected to the standard input of cmdstring, as shown in Figure 15.10.

One way to remember the final argument to popen is to remember that, like fopen, the returned file pointer is readable if type is "r" or writable if type is "w".
The pclose function closes the standard I/O stream, waits for the command to terminate, and returns the termination status of the shell. (We described the termination status in Section 8.6. The system function, described in Section 8.13, also returns the termination status.) If the shell cannot be executed, the termination status returned by pclose is as if the shell had executed exit(127).
The cmdstring is executed by the Bourne shell, as in
sh -c cmdstring
This means that the shell expands any of its special characters in cmdstring. This allows us to say, for example,
fp = popen("ls *.c", "r");
or
fp = popen("cmd 2>&1", "r");
Example
Let's redo the program from Figure 15.6, using popen. This is shown in Figure 15.11.
Using popen reduces the amount of code we have to write.
The shell command ${PAGER:-more} says to use the value of the shell variable PAGER if it is defined and non-null; otherwise, use the string more.
Figure 15.11. Copy file to pager program using popen
#include "apue.h"
#include <sys/wait.h>
#define PAGER "${PAGER:-more}" /* environment variable, or default */
int
main(int argc, char *argv[])
{
char line[MAXLINE];
FILE *fpin, *fpout;
if (argc != 2)
err_quit("usage: a.out <pathname>");
if ((fpin = fopen(argv[1], "r")) == NULL)
err_sys("can't open %s", argv[1]);
if ((fpout = popen(PAGER, "w")) == NULL)
err_sys("popen error");
/* copy argv[1] to pager */
while (fgets(line, MAXLINE, fpin) != NULL) {
if (fputs(line, fpout) == EOF)
err_sys("fputs error to pipe");
}
if (ferror(fpin))
err_sys("fgets error");
if (pclose(fpout) == -1)
err_sys("pclose error");
exit(0);
}
Examplepopen and pclose Functions
Figure 15.12 shows our version of popen and pclose.
Although the core of popen is similar to the code we've used earlier in this chapter, there are many details that we need to take care of. First, each time popen is called, we have to remember the process ID of the child that we create and either its file descriptor or FILE pointer. We choose to save the child's process ID in the array childpid, which we index by the file descriptor. This way, when pclose is called with the FILE pointer as its argument, we call the standard I/O function fileno to get the file descriptor, and then have the child process ID for the call to waitpid. Since it's possible for a given process to call popen more than once, we dynamically allocate the childpid array (the first time popen is called), with room for as many children as there are file descriptors.
Calling pipe and fork and then duplicating the appropriate descriptors for each process is similar to what we did earlier in this chapter.
POSIX.1 requires that popen close any streams that are still open in the child from previous calls to popen. To do this, we go through the childpid array in the child, closing any descriptors that are still open.
What happens if the caller of pclose has established a signal handler for SIGCHLD? The call to waitpid from pclose would return an error of EINTR. Since the caller is allowed to catch this signal (or any other signal that might interrupt the call to waitpid), we simply call waitpid again if it is interrupted by a caught signal.
Note that if the application calls waitpid and obtains the exit status of the child created by popen, we will call waitpid when the application calls pclose, find that the child no longer exists, and return 1 with errno set to ECHILD. This is the behavior required by POSIX.1 in this situation.
Some early versions of pclose returned an error of EINTR if a signal interrupted the wait. Also, some early versions of pclose blocked or ignored the signals SIGINT, SIGQUIT, and SIGHUP during the wait. This is not allowed by POSIX.1.
Figure 15.12. The popen and pclose functions
#include "apue.h"
#include <errno.h>
#include <fcntl.h>
#include <sys/wait.h>
/*
* Pointer to array allocated at run-time.
*/
static pid_t *childpid = NULL;
/*
* From our open_max(), Figure 2.16.
*/
static int maxfd;
FILE *
popen(const char *cmdstring, const char *type)
{
int i;
int pfd[2];
pid_t pid;
FILE *fp;
/* only allow "r" or "w" */
if ((type[0] != 'r' && type[0] != 'w') || type[1] != 0) {
errno = EINVAL; /* required by POSIX */
return(NULL);
}
if (childpid == NULL) { /* first time through */
/* allocate zeroed out array for child pids */
maxfd = open_max();
if ((childpid = calloc(maxfd, sizeof(pid_t))) == NULL)
return(NULL);
}
if (pipe(pfd) < 0)
return(NULL); /* errno set by pipe() */
if ((pid = fork()) < 0) {
return(NULL); /* errno set by fork() */
} else if (pid == 0) { /* child */
if (*type == 'r') {
close(pfd[0]);
if (pfd[1] != STDOUT_FILENO) {
dup2(pfd[1], STDOUT_FILENO);
close(pfd[1]);
}
} else {
close(pfd[1]);
if (pfd[0] != STDIN_FILENO) {
dup2(pfd[0], STDIN_FILENO);
close(pfd[0]);
}
}
/* close all descriptors in childpid[] */
for (i = 0; i < maxfd; i++)
if (childpid[i] > 0)
close(i);
execl("/bin/sh", "sh", "-c", cmdstring, (char *)0);
_exit(127);
}
/* parent continues... */
if (*type == 'r') {
close(pfd[1]);
if ((fp = fdopen(pfd[0], type)) == NULL)
return(NULL);
} else {
close(pfd[0]);
if ((fp = fdopen(pfd[1], type)) == NULL)
return(NULL);
}
childpid[fileno(fp)] = pid; /* remember child pid for this fd */
return(fp);
}
int
pclose(FILE *fp)
{
int fd, stat;
pid_t pid;
if (childpid == NULL) {
errno = EINVAL;
return(-1); /* popen() has never been called */
}
fd = fileno(fp);
if ((pid = childpid[fd]) == 0) {
errno = EINVAL;
return(-1); /* fp wasn't opened by popen() */
}
childpid[fd] = 0;
if (fclose(fp) == EOF)
return(-1);
while (waitpid(pid, &stat, 0) < 0)
if (errno != EINTR)
return(-1); /* error other than EINTR from waitpid() */
return(stat); /* return child's termination status */
}
Note that popen should never be called by a set-user-ID or set-group-ID program. When it executes the command, popen does the equivalent of
execl("/bin/sh", "sh", "-c", command, NULL);
which executes the shell and command with the environment inherited by the caller. A malicious user can manipulate the environment so that the shell executes commands other than those intended, with the elevated permissions granted by the set-ID file mode.
One thing that popen is especially well suited for is executing simple filters to transform the input or output of the running command. Such is the case when a command wants to build its own pipeline.
Example
Consider an application that writes a prompt to standard output and reads a line from standard input. With popen, we can interpose a program between the application and its input to transform the input. Figure 15.13 shows the arrangement of processes.
The transformation could be pathname expansion, for example, or providing a history mechanism (remembering previously entered commands).
Figure 15.14 shows a simple filter to demonstrate this operation. The filter copies standard input to standard output, converting any uppercase character to lowercase. The reason we're careful to fflush standard output after writing a newline is discussed in the next section when we talk about coprocesses.
We compile this filter into the executable file myuclc, which we then invoke from the program in Figure 15.15 using popen.
We need to call fflush after writing the prompt, because the standard output is normally line buffered, and the prompt does not contain a newline.
Figure 15.14. Filter to convert uppercase characters to lowercase
#include "apue.h"
#include <ctype.h>
int
main(void)
{
int c;
while ((c = getchar()) != EOF) {
if (isupper(c))
c = tolower(c);
if (putchar(c) == EOF)
err_sys("output error");
if (c == '\n')
fflush(stdout);
}
exit(0);
}
Figure 15.15. Invoke uppercase/lowercase filter to read commands
#include "apue.h"
#include <sys/wait.h>
int
main(void)
{
char line[MAXLINE];
FILE *fpin;
if ((fpin = popen("myuclc", "r")) == NULL)
err_sys("popen error");
for ( ; ; ) {
fputs("prompt> ", stdout);
fflush(stdout);
if (fgets(line, MAXLINE, fpin) == NULL) /* read from pipe */
break;
if (fputs(line, stdout) == EOF)
err_sys("fputs error to pipe");
}
if (pclose(fpin) == -1)
err_sys("pclose error");
putchar('\n');
exit(0);
}
15.4. Coprocesses
A UNIX system filter is a program that reads from standard input and writes to standard output. Filters are normally connected linearly in shell pipelines. A filter becomes a coprocess when the same program generates the filter's input and reads the filter's output.
The Korn shell provides coprocesses [Bolsky and Korn 1995]. The Bourne shell, the Bourne-again shell, and the C shell don't provide a way to connect processes together as coprocesses. A coprocess normally runs in the background from a shell, and its standard input and standard output are connected to another program using a pipe. Although the shell syntax required to initiate a coprocess and connect its input and output to other processes is quite contorted (see pp. 6263 of Bolsky and Korn [1995] for all the details), coprocesses are also useful from a C program.
Whereas popen gives us a one-way pipe to the standard input or from the standard output of another process, with a coprocess, we have two one-way pipes to the other process: one to its standard input and one from its standard output. We want to write to its standard input, let it operate on the data, and then read from its standard output.
Example
Let's look at coprocesses with an example. The process creates two pipes: one is the standard input of the coprocess, and the other is the standard output of the coprocess. Figure 15.16 shows this arrangement.
The program in Figure 15.17 is a simple coprocess that reads two numbers from its standard input, computes their sum, and writes the sum to its standard output. (Coprocesses usually do more interesting work than we illustrate here. This example is admittedly contrived so that we can study the plumbing needed to connect the processes.)
We compile this program and leave the executable in the file add2.
The program in Figure 15.18 invokes the add2 coprocess after reading two numbers from its standard input. The value from the coprocess is written to its standard output.
Here, we create two pipes, with the parent and the child closing the ends they don't need. We have to use two pipes: one for the standard input of the coprocess and one for its standard output. The child then calls dup2 to move the pipe descriptors onto its standard input and standard output, before calling execl.
If we compile and run the program in Figure 15.18, it works as expected. Furthermore, if we kill the add2 coprocess while the program in Figure 15.18 is waiting for our input and then enter two numbers, the signal handler is invoked when the program writes to the pipe that has no reader. (See Exercise 15.4.)
Recall from Figure 15.1 that not all systems provide full-duplex pipes using the pipe function. In Figure 17.4, we provide another version of this example using a single full-duplex pipe instead of two half-duplex pipes, for those systems that support full-duplex pipes.
Figure 15.17. Simple filter to add two numbers
#include "apue.h"
int
main(void)
{
int n, int1, int2;
char line[MAXLINE];
while ((n = read(STDIN_FILENO, line, MAXLINE)) > 0) {
line[n] = 0; /* null terminate */
if (sscanf(line, "%d%d", &int1, &int2) == 2) {
sprintf(line, "%d\n", int1 + int2);
n = strlen(line);
if (write(STDOUT_FILENO, line, n) != n)
err_sys("write error");
} else {
if (write(STDOUT_FILENO, "invalid args\n", 13) != 13)
err_sys("write error");
}
}
exit(0);
}
Figure 15.18. Program to drive the add2 filter
#include "apue.h"
static void sig_pipe(int); /* our signal handler */
int
main(void)
{
int n, fd1[2], fd2[2];
pid_t pid;
char line[MAXLINE];
if (signal(SIGPIPE, sig_pipe) == SIG_ERR)
err_sys("signal error");
if (pipe(fd1) < 0 || pipe(fd2) < 0)
err_sys("pipe error");
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) { /* parent */
close(fd1[0]);
close(fd2[1]);
while (fgets(line, MAXLINE, stdin) != NULL) {
n = strlen(line);
if (write(fd1[1], line, n) != n)
err_sys("write error to pipe");
if ((n = read(fd2[0], line, MAXLINE)) < 0)
err_sys("read error from pipe");
if (n == 0) {
err_msg("child closed pipe");
break;
}
line[n] = 0; /* null terminate */
if (fputs(line, stdout) == EOF)
err_sys("fputs error");
}
if (ferror(stdin))
err_sys("fgets error on stdin");
exit(0);
} else { /* child */
close(fd1[1]);
close(fd2[0]);
if (fd1[0] != STDIN_FILENO) {
if (dup2(fd1[0], STDIN_FILENO) != STDIN_FILENO)
err_sys("dup2 error to stdin");
close(fd1[0]);
}
if (fd2[1] != STDOUT_FILENO) {
if (dup2(fd2[1], STDOUT_FILENO) != STDOUT_FILENO)
err_sys("dup2 error to stdout");
close(fd2[1]);
}
if (execl("./add2", "add2", (char *)0) < 0)
err_sys("execl error");
}
exit(0);
}
static void
sig_pipe(int signo)
{
printf("SIGPIPE caught\n");
exit(1);
}
Example
In the coprocess add2 (Figure 15.17), we purposely used low-level I/O (UNIX system calls): read and write. What happens if we rewrite this coprocess to use standard I/O? Figure 15.19 shows the new version.
If we invoke this new coprocess from the program in Figure 15.18, it no longer works. The problem is the default standard I/O buffering. When the program in Figure 15.19 is invoked, the first fgets on the standard input causes the standard I/O library to allocate a buffer and choose the type of buffering. Since the standard input is a pipe, the standard I/O library defaults to fully buffered. The same thing happens with the standard output. While add2 is blocked reading from its standard input, the program in Figure 15.18 is blocked reading from the pipe. We have a deadlock.
Here, we have control over the coprocess that's being run. We can change the program in Figure 15.19 by adding the following four lines before the while loop:
if (setvbuf(stdin, NULL, _IOLBF, 0) != 0)
err_sys("setvbuf error");
if (setvbuf(stdout, NULL, _IOLBF, 0) != 0)
err_sys("setvbuf error");
These lines cause fgets to return when a line is available and cause printf to do an fflush when a newline is output (refer back to Section 5.4 for the details on standard I/O buffering). Making these explicit calls to setvbuf fixes the program in Figure 15.19.
If we aren't able to modify the program that we're piping the output into, other techniques are required. For example, if we use awk(1) as a coprocess from our program (instead of the add2 program), the following won't work:
#! /bin/awk -f
{ print $1 + $2 }
The reason this won't work is again the standard I/O buffering. But in this case, we cannot change the way awk works (unless we have the source code for it). We are unable to modify the executable of awk in any way to change the way the standard I/O buffering is handled.
The solution for this general problem is to make the coprocess being invoked (awk in this case) think that its standard input and standard output are connected to a terminal. That causes the standard I/O routines in the coprocess to line buffer these two I/O streams, similar to what we did with the explicit calls to setvbuf previously. We use pseudo terminals to do this in Chapter 19.
Figure 15.19. Filter to add two numbers, using standard I/O
#include "apue.h"
int
main(void)
{
int int1, int2;
char line[MAXLINE];
while (fgets(line, MAXLINE, stdin) != NULL) {
if (sscanf(line, "%d%d", &int1, &int2) == 2) {
if (printf("%d\n", int1 + int2) == EOF)
err_sys("printf error");
} else {
if (printf("invalid args\n") == EOF)
err_sys("printf error");
}
}
exit(0);
}
15.5. FIFOs
FIFOs are sometimes called named pipes. Pipes can be used only between related processes when a common ancestor has created the pipe. (An exception to this is mounted STREAMS-based pipes, which we discuss in Section 17.2.2.) With FIFOs, however, unrelated processes can exchange data.
We saw in Chapter 4 that a FIFO is a type of file. One of the encodings of the st_mode member of the stat structure (Section 4.2) indicates that a file is a FIFO. We can test for this with the S_ISFIFO macro.
Creating a FIFO is similar to creating a file. Indeed, the pathname for a FIFO exists in the file system.
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
| Returns: 0 if OK, 1 on error
|
The specification of the mode argument for the mkfifo function is the same as for the open function (Section 3.3). The rules for the user and group ownership of the new FIFO are the same as we described in Section 4.6.
Once we have used mkfifo to create a FIFO, we open it using open. Indeed, the normal file I/O functions (close, read, write, unlink, etc.) all work with FIFOs.
Applications can create FIFOs with the mknod function. Because POSIX.1 originally didn't include mknod, the mkfifo function was invented specifically for POSIX.1. The mknod function is now included as an XSI extension. On most systems, the mkfifo function calls mknod to create the FIFO.
POSIX.1 also includes support for the mkfifo(1) command. All four platforms discussed in this text provide this command. This allows a FIFO to be created using a shell command and then accessed with the normal shell I/O redirection.
When we open a FIFO, the nonblocking flag (O_NONBLOCK) affects what happens.
In the normal case (O_NONBLOCK not specified), an open for read-only blocks until some other process opens the FIFO for writing. Similarly, an open for write-only blocks until some other process opens the FIFO for reading. If O_NONBLOCK is specified, an open for read-only returns immediately. But an open for write-only returns 1 with errno set to ENXIO if no process has the FIFO open for reading.
As with a pipe, if we write to a FIFO that no process has open for reading, the signal SIGPIPE is generated. When the last writer for a FIFO closes the FIFO, an end of file is generated for the reader of the FIFO.
It is common to have multiple writers for a given FIFO. This means that we have to worry about atomic writes if we don't want the writes from multiple processes to be interleaved. (We'll see a way around this problem in Section 17.2.2.) As with pipes, the constant PIPE_BUF specifies the maximum amount of data that can be written atomically to a FIFO.
There are two uses for FIFOs.
FIFOs are used by shell commands to pass data from one shell pipeline to another without creating intermediate temporary files. FIFOs are used as rendezvous points in clientserver applications to pass data between the clients and the servers.
We discuss each of these uses with an example.
ExampleUsing FIFOs to Duplicate Output Streams
FIFOs can be used to duplicate an output stream in a series of shell commands. This prevents writing the data to an intermediate disk file (similar to using pipes to avoid intermediate disk files). But whereas pipes can be used only for linear connections between processes, a FIFO has a name, so it can be used for nonlinear connections.
Consider a procedure that needs to process a filtered input stream twice. Figure 15.20 shows this arrangement.
With a FIFO and the UNIX program tee(1), we can accomplish this procedure without using a temporary file. (The tee program copies its standard input to both its standard output and to the file named on its command line.)
mkfifo fifo1
prog3 < fifo1 &
prog1 < infile | tee fifo1 | prog2
We create the FIFO and then start prog3 in the background, reading from the FIFO. We then start prog1 and use tee to send its input to both the FIFO and prog2. Figure 15.21 shows the process arrangement.
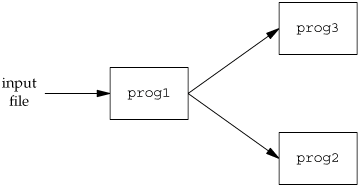
ExampleClientServer Communication Using a FIFO
Another use for FIFOs is to send data between a client and a server. If we have a server that is contacted by numerous clients, each client can write its request to a well-known FIFO that the server creates. (By "well-known" we mean that the pathname of the FIFO is known to all the clients that need to contact the server.) Figure 15.22 shows this arrangement. Since there are multiple writers for the FIFO, the requests sent by the clients to the server need to be less than PIPE_BUF bytes in size. This prevents any interleaving of the client writes.
The problem in using FIFOs for this type of clientserver communication is how to send replies back from the server to each client. A single FIFO can't be used, as the clients would never know when to read their response versus responses for other clients. One solution is for each client to send its process ID with the request. The server then creates a unique FIFO for each client, using a pathname based on the client's process ID. For example, the server can create a FIFO with the name /tmp/serv1.XXXXX, where XXXXX is replaced with the client's process ID. Figure 15.23 shows this arrangement.
This arrangement works, although it is impossible for the server to tell whether a client crashes. This causes the client-specific FIFOs to be left in the file system. The server also must catch SIGPIPE, since it's possible for a client to send a request and terminate before reading the response, leaving the client-specific FIFO with one writer (the server) and no reader. We'll see a more elegant approach to this problem when we discuss mounted STREAMS-based pipes and connld in Section 17.2.2.
With the arrangement shown in Figure 15.23, if the server opens its well-known FIFO read-only (since it only reads from it) each time the number of clients goes from 1 to 0, the server will read an end of file on the FIFO. To prevent the server from having to handle this case, a common trick is just to have the server open its well-known FIFO for readwrite. (See Exercise 15.10.)
15.6. XSI IPC
The three types of IPC that we call XSI IPCmessage queues, semaphores, and shared memoryhave many similarities. In this section, we cover these similar features; in the following sections, we look at the specific functions for each of the three IPC types.
The XSI IPC functions are based closely on the System V IPC functions. These three types of IPC originated in the 1970s in an internal AT&T version of the UNIX System called "Columbus UNIX." These IPC features were later added to System V. They are often criticized for inventing their own namespace instead of using the file system.
Recall from Figure 15.1 that message queues, semaphores, and shared memory are defined as XSI extensions in the Single UNIX Specification.
15.6.1. Identifiers and Keys
Each IPC structure (message queue, semaphore, or shared memory segment) in the kernel is referred to by a non-negative integer identifier. To send or fetch a message to or from a message queue, for example, all we need know is the identifier for the queue. Unlike file descriptors, IPC identifiers are not small integers. Indeed, when a given IPC structure is created and then removed, the identifier associated with that structure continually increases until it reaches the maximum positive value for an integer, and then wraps around to 0.
The identifier is an internal name for an IPC object. Cooperating processes need an external naming scheme to be able to rendezvous using the same IPC object. For this purpose, an IPC object is associated with a key that acts as an external name.
Whenever an IPC structure is being created (by calling msgget, semget, or shmget), a key must be specified. The data type of this key is the primitive system data type key_t, which is often defined as a long integer in the header <sys/types.h>. This key is converted into an identifier by the kernel.
There are various ways for a client and a server to rendezvous at the same IPC structure.
The server can create a new IPC structure by specifying a key of IPC_PRIVATE and store the returned identifier somewhere (such as a file) for the client to obtain. The key IPC_PRIVATE guarantees that the server creates a new IPC structure. The disadvantage to this technique is that file system operations are required for the server to write the integer identifier to a file, and then for the clients to retrieve this identifier later. The IPC_PRIVATE key is also used in a parentchild relationship. The parent creates a new IPC structure specifying IPC_PRIVATE, and the resulting identifier is then available to the child after the fork. The child can pass the identifier to a new program as an argument to one of the exec functions. The client and the server can agree on a key by defining the key in a common header, for example. The server then creates a new IPC structure specifying this key. The problem with this approach is that it's possible for the key to already be associated with an IPC structure, in which case the get function (msgget, semget, or shmget) returns an error. The server must handle this error, deleting the existing IPC structure, and try to create it again. The client and the server can agree on a pathname and project ID (the project ID is a character value between 0 and 255) and call the function ftok to convert these two values into a key. This key is then used in step 2. The only service provided by ftok is a way of generating a key from a pathname and project ID.
#include <sys/ipc.h>
key_t ftok(const char *path, int id);
| Returns: key if OK, (key_t)-1 on error |
The path argument must refer to an existing file. Only the lower 8 bits of id are used when generating the key.
The key created by ftok is usually formed by taking parts of the st_dev and st_ino fields in the stat structure (Section 4.2) corresponding to the given pathname and combining them with the project ID. If two pathnames refer to two different files, then ftok usually returns two different keys for the two pathnames. However, because both i-node numbers and keys are often stored in long integers, there can be information loss creating a key. This means that two different pathnames to different files can generate the same key if the same project ID is used.
The three get functions (msgget, semget, and shmget) all have two similar arguments: a key and an integer flag. A new IPC structure is created (normally, by a server) if either key is IPC_PRIVATE or key is not currently associated with an IPC structure of the particular type and the IPC_CREAT bit of flag is specified. To reference an existing queue (normally done by a client), key must equal the key that was specified when the queue was created, and IPC_CREAT must not be specified.
Note that it's never possible to specify IPC_PRIVATE to reference an existing queue, since this special key value always creates a new queue. To reference an existing queue that was created with a key of IPC_PRIVATE, we must know the associatedidentifier and then use that identifier in the other IPC calls (such as msgsnd and msgrcv), bypassing the get function.
If we want to create a new IPC structure, making sure that we don't reference an existing one with the same identifier, we must specify a flag with both the IPC_CREAT and IPC_EXCL bits set. Doing this causes an error return of EEXIST if the IPC structure already exists. (This is similar to an open that specifies the O_CREAT and O_EXCL flags.)
15.6.2. Permission Structure
XSI IPC associates an ipc_perm structure with each IPC structure. This structure defines the permissions and owner and includes at least the following members:
struct ipc_perm {
uid_t uid; /* owner's effective user id */
gid_t gid; /* owner's effective group id */
uid_t cuid; /* creator's effective user id */
gid_t cgid; /* creator's effective group id */
mode_t mode; /* access modes */
.
.
.
};
Each implementation includes additional members. See <sys/ipc.h> on your system for the complete definition.
All the fields are initialized when the IPC structure is created. At a later time, we can modify the uid, gid, and mode fields by calling msgctl, semctl, or shmctl. To change these values, the calling process must be either the creator of the IPC structure or the superuser. Changing these fields is similar to calling chown or chmod for a file.
The values in the mode field are similar to the values we saw in Figure 4.6, but there is nothing corresponding to execute permission for any of the IPC structures. Also, message queues and shared memory use the terms read and write, but semaphores use the terms read and alter. Figure 15.24 shows the six permissions for each form of IPC.
Figure 15.24. XSI IPC permissionsPermission | Bit |
|---|
user-read | 0400 | user-write (alter) | 0200
| group-read | 0040 | group-write (alter) | 0020 | other-read | 0004 | other-write (alter) | 0002
|
Some implementations define symbolic constants to represent each permission, however, these constants are not standardized by the Single UNIX Specification.
15.6.3. Configuration Limits
All three forms of XSI IPC have built-in limits that we may encounter. Most of these limits can be changed by reconfiguring the kernel. We describe the limits when we describe each of the three forms of IPC.
Each platform provides its own way to report and modify a particular limit. FreeBSD 5.2.1, Linux 2.4.22, and Mac OS X 10.3 provide the sysctl command to view and modify kernel configuration parameters. On Solaris 9, changes to kernel configuration parameters are made by modifying the file /etc/system and rebooting.
On Linux, you can display the IPC-related limits by running ipcs -l. On FreeBSD, the equivalent command is ipcs -T. On Solaris, you can discover the tunable parameters by running sysdef -i.
15.6.4. Advantages and Disadvantages
A fundamental problem with XSI IPC is that the IPC structures are systemwide and do not have a reference count. For example, if we create a message queue, place some messages on the queue, and then terminate, the message queue and its contents are not deleted. They remain in the system until specifically read or deleted by some process calling msgrcv or msgctl, by someone executing the ipcrm(1) command, or by the system being rebooted. Compare this with a pipe, which is completely removed when the last process to reference it terminates. With a FIFO, although the name stays in the file system until explicitly removed, any data left in a FIFO is removed when the last process to reference the FIFO terminates.
Another problem with XSI IPC is that these IPC structures are not known by names in the file system. We can't access them and modify their properties with the functions we described in Chapters 3 and 4. Almost a dozen new system calls (msgget, semop, shmat, and so on) were added to the kernel to support these IPC objects. We can't see the IPC objects with an ls command, we can't remove them with the rm command, and we can't change their permissions with the chmod command. Instead, two new commands ipcs(1) and ipcrm(1)were added.
Since these forms of IPC don't use file descriptors, we can't use the multiplexed I/O functions (select and poll) with them. This makes it harder to use more than one of these IPC structures at a time or to use any of these IPC structures with file or device I/O. For example, we can't have a server wait for a message to be placed on one of two message queues without some form of busywait loop.
An overview of a transaction processing system built using System V IPC is given in Andrade, Carges, and Kovach [1989]. They claim that the namespace used by System V IPC (the identifiers) is an advantage, not a problem as we said earlier, because using identifiers allows a process to send a message to a message queue with a single function call (msgsnd), whereas other forms of IPC normally require an open, write, and close. This argument is false. Clients still have to obtain the identifier for the server's queue somehow, to avoid using a key and calling msgget. The identifier assigned to a particular queue depends on how many other message queues exist when the queue is created and how many times the table in the kernel assigned to the new queue has been used since the kernel was bootstrapped. This is a dynamic value that can't be guessed or stored in a header. As we mentioned in Section 15.6.1, minimally a server has to write the assigned queue identifier to a file for its clients to read.
Other advantages listed by these authors for message queues are that they're reliable, flow controlled, record oriented, and can be processed in other than first-in, first-out order. As we saw in Section 14.4, the STREAMS mechanism also possesses all these properties, although an open is required before sending data to a stream, and a close is required when we're finished. Figure 15.25 compares some of the features of these various forms of IPC.
Figure 15.25. Comparison of features of various forms of IPCIPC type | Connectionless? | Reliable? | Flow control? | Records? | Message types or priorities? |
|---|
message queues | no | yes | yes | yes | yes | STREAMS | no | yes | yes | yes | yes | UNIX domain stream socket | no | yes | yes | no | no | UNIX domain datagram socket | yes | yes | no | yes | no | FIFOs (non-STREAMS) | no | yes | yes | no | no |
(We describe stream and datagram sockets in Chapter 16. We describe UNIX domain sockets in Section 17.3.) By "connectionless," we mean the ability to send a message without having to call some form of an open function first. As described previously, we don't consider message queues connectionless, since some technique is required to obtain the identifier for a queue. Since all these forms of IPC are restricted to a single host, all are reliable. When the messages are sent across a network, the possibility of messages being lost becomes a concern. "Flow control" means that the sender is put to sleep if there is a shortage of system resources (buffers) or if the receiver can't accept any more messages. When the flow control condition subsides, the sender should automatically be awakened.
One feature that we don't show in Figure 15.25 is whether the IPC facility can automatically create a unique connection to a server for each client. We'll see in Chapter 17 that STREAMS and UNIX stream sockets provide this capability.
The next three sections describe each of the three forms of XSI IPC in detail.
15.7. Message Queues
A message queue is a linked list of messages stored within the kernel and identified by a message queue identifier. We'll call the message queue just a queue and its identifier a queue ID.
The Single UNIX Specification includes an alternate IPC message queue implementation in the message-passing option of its real-time extensions. We do not cover the real-time extensions in this text.
A new queue is created or an existing queue opened by msgget. New messages are added to the end of a queue by msgsnd. Every message has a positive long integer type field, a non-negative length, and the actual data bytes (corresponding to the length), all of which are specified to msgsnd when the message is added to a queue. Messages are fetched from a queue by msgrcv. We don't have to fetch the messages in a first-in, first-out order. Instead, we can fetch messages based on their type field.
Each queue has the following msqid_ds structure associated with it:
struct msqid_ds {
struct ipc_perm msg_perm; /* see Section 15.6.2 */
msgqnum_t msg_qnum; /* # of messages on queue */
msglen_t msg_qbytes; /* max # of bytes on queue */
pid_t msg_lspid; /* pid of last msgsnd() */
pid_t msg_lrpid; /* pid of last msgrcv() */
time_t msg_stime; /* last-msgsnd() time */
time_t msg_rtime; /* last-msgrcv() time */
time_t msg_ctime; /* last-change time */
.
.
.
};
This structure defines the current status of the queue. The members shown are the ones defined by the Single UNIX Specification. Implementations include additional fields not covered by the standard.
Figure 15.26 lists the system limits that affect message queues. We show "notsup" where the platform doesn't support the feature. We show "derived" whenever a limit is derived from other limits. For example, the maximum number of messages in a Linux system is based on the maximum number of queues and the maximum amount of data allowed on the queues. If the minimum message size is 1 byte, that would limit the number of messages systemwide to maximum # queues * maximum size of a queue. Given the limits in Figure 15.26, Linux has an upper bound of 262,144 messages with the default configuration. (Even though a message can contain zero bytes of data, Linux treats it as if it contained 1 byte, to limit the number of messages queued.)
Figure 15.26. System limits that affect message queuesDescription | Typical values |
|---|
FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
Size in bytes of largest message we can send | 16,384 | 8,192 | notsup | 2,048 | The maximum size in bytes of a particular queue (i.e., the sum of all the messages on the queue) | 2,048 | 16,384 | notsup | 4,096 | The maximum number of messages queues, systemwide | 40 | 16 | notsup | 50 | The maximum number of messages, systemwide | 40 | derived | notsup | 40 |
Recall from Figure 15.1 that Mac OS X 10.3 doesn't support XSI message queues. Since Mac OS X is based in part on FreeBSD, and FreeBSD supports message queues, it is possible for Mac OS X to support them, too. Indeed, a good Internet search engine will provide pointers to a third-party port of XSI message queues for Mac OS X.
The first function normally called is msgget to either open an existing queue or create a new queue.
#include <sys/msg.h>
int msgget(key_t key, int flag);
| Returns: message queue ID if OK, 1 on error |
In Section 15.6.1, we described the rules for converting the key into an identifier and discussed whether a new queue is created or an existing queue is referenced. When a new queue is created, the following members of the msqid_ds structure are initialized.
The ipc_perm structure is initialized as described in Section 15.6.2. The mode member of this structure is set to the corresponding permission bits of flag. These permissions are specified with the values from Figure 15.24. msg_qnum, msg_lspid, msg_lrpid, msg_stime, and msg_rtime are all set to 0. msg_ctime is set to the current time. msg_qbytes is set to the system limit.
On success, msgget returns the non-negative queue ID. This value is then used with the other three message queue functions.
The msgctl function performs various operations on a queue. This function and the related functions for semaphores and shared memory (semctl and shmctl) are the ioctl-like functions for XSI IPC (i.e., the garbage-can functions).
#include <sys/msg.h>
int msgctl(int msqid, int cmd, struct msqid_ds *buf );
| Returns: 0 if OK, 1 on error |
The cmd argument specifies the command to be performed on the queue specified by msqid.
IPC_STAT | Fetch the msqid_ds structure for this queue, storing it in the structure pointed to by buf. | IPC_SET | Copy the following fields from the structure pointed to by buf to the msqid_ds structure associated with this queue: msg_perm.uid, msg_perm.gid, msg_perm.mode, and msg_qbytes. This command can be executed only by a process whose effective user ID equals msg_perm.cuid or msg_perm.uid or by a process with superuser privileges. Only the superuser can increase the value of msg_qbytes. | IPC_RMID | Remove the message queue from the system and any data still on the queue. This removal is immediate. Any other process still using the message queue will get an error of EIDRM on its next attempted operation on the queue. This command can be executed only by a process whose effective user ID equals msg_perm.cuid or msg_perm.uid or by a process with superuser privileges. |
We'll see that these three commands (IPC_STAT, IPC_SET, and IPC_RMID) are also provided for semaphores and shared memory.
Data is placed onto a message queue by calling msgsnd.
#include <sys/msg.h>
int msgsnd(int msqid, const void *ptr, size_t
nbytes, int flag);
| Returns: 0 if OK, 1 on error |
As we mentioned earlier, each message is composed of a positive long integer type field, a non-negative length (nbytes), and the actual data bytes (corresponding to the length). Messages are always placed at the end of the queue.
The ptr argument points to a long integer that contains the positive integer message type, and it is immediately followed by the message data. (There is no message data if nbytes is 0.) If the largest message we send is 512 bytes, we can define the following structure:
struct mymesg {
long mtype; /* positive message type */
char mtext[512]; /* message data, of length nbytes */
};
The ptr argument is then a pointer to a mymesg structure. The message type can be used by the receiver to fetch messages in an order other than first in, first out.
Some platforms support both 32-bit and 64-bit environments. This affects the size of long integers and pointers. For example, on 64-bit SPARC systems, Solaris allows both 32-bit and 64-bit applications to coexist. If a 32-bit application were to exchange this structure over a pipe or a socket with a 64-bit application, problems would arise, because the size of a long integer is 4 bytes in a 32-bit application, but 8 bytes in a 64-bit application. This means that a 32-bit application will expect that the mtext field will start 4 bytes after the start of the structure, whereas a 64-bit application will expect the mtext field to start 8 bytes after the start of the structure. In this situation, part of the 64-bit application's mtype field will appear as part of the mtext field to the 32-bit application, and the first 4 bytes in the 32-bit application's mtext field will be interpreted as a part of the mtype field by the 64-bit application.
This problem doesn't happen with XSI message queues, however. Solaris implements the 32-bit version of the IPC system calls with different entry points than the 64-bit version of the IPC system calls. The system calls know how to deal with a 32-bit application communicating with a 64-bit application, and treat the type field specially to avoid it interfering with the data portion of the message. The only potential problem is a loss of information when a 64-bit application sends a message with a value in the 8-byte type field that is larger than will fit in a 32-bit application's 4-byte type field. In this case, the 32-bit application will see a truncated type value.
A flag value of IPC_NOWAIT can be specified. This is similar to the nonblocking I/O flag for file I/O (Section 14.2). If the message queue is full (either the total number of messages on the queue equals the system limit, or the total number of bytes on the queue equals the system limit), specifying IPC_NOWAIT causes msgsnd to return immediately with an error of EAGAIN. If IPC_NOWAIT is not specified, we are blocked until there is room for the message, the queue is removed from the system, or a signal is caught and the signal handler returns. In the second case, an error of EIDRM is returned ("identifier removed"); in the last case, the error returned is EINTR.
Note how ungracefully the removal of a message queue is handled. Since a reference count is not maintained with each message queue (as there is for open files), the removal of a queue simply generates errors on the next queue operation by processes still using the queue. Semaphores handle this removal in the same fashion. In contrast, when a file is removed, the file's contents are not deleted until the last open descriptor for the file is closed.
When msgsnd returns successfully, the msqid_ds structure associated with the message queue is updated to indicate the process ID that made the call (msg_lspid), the time that the call was made (msg_stime), and that one more message is on the queue (msg_qnum).
Messages are retrieved from a queue by msgrcv.
#include <sys/msg.h>
ssize_t msgrcv(int msqid, void *ptr, size_t nbytes
, long type, int flag);
| Returns: size of data portion of message if OK, 1 on error |
As with msgsnd, the ptr argument points to a long integer (where the message type of the returned message is stored) followed by a data buffer for the actual message data. nbytes specifies the size of the data buffer. If the returned message is larger than nbytes and the MSG_NOERROR bit in flag is set, the message is truncated. (In this case, no notification is given to us that the message was truncated, and the remainder of the message is discarded.) If the message is too big and this flag value is not specified, an error of E2BIG is returned instead (and the message stays on the queue).
The type argument lets us specify which message we want.
type == 0 | The first message on the queue is returned. | type > 0 | The first message on the queue whose message type equals type is returned. | type < 0 | The first message on the queue whose message type is the lowest value less than or equal to the absolute value of type is returned. |
A nonzero type is used to read the messages in an order other than first in, first out. For example, the type could be a priority value if the application assigns priorities to the messages. Another use of this field is to contain the process ID of the client if a single message queue is being used by multiple clients and a single server (as long as a process ID fits in a long integer).
We can specify a flag value of IPC_NOWAIT to make the operation nonblocking, causing msgrcv to return -1 with errno set to ENOMSG if a message of the specified type is not available. If IPC_NOWAIT is not specified, the operation blocks until a message of the specified type is available, the queue is removed from the system (-1 is returned with errno set to EIDRM), or a signal is caught and the signal handler returns (causing msgrcv to return 1 with errno set to EINTR).
When msgrcv succeeds, the kernel updates the msqid_ds structure associated with the message queue to indicate the caller's process ID (msg_lrpid), the time of the call (msg_rtime), and that one less message is on the queue (msg_qnum).
ExampleTiming Comparison of Message Queues versus Stream Pipes
If we need a bidirectional flow of data between a client and a server, we can use either message queues or full-duplex pipes. (Recall from Figure 15.1 that full-duplex pipes are available through the UNIX domain sockets mechanism (Section 17.3), although some platforms provide a full-duplex pipe mechanism through the pipe function.)
Figure 15.27 shows a timing comparison of three of these techniques on Solaris: message queues, STREAMS-based pipes, and UNIX domain sockets. The tests consisted of a program that created the IPC channel, called fork, and then sent about 200 megabytes of data from the parent to the child. The data was sent using 100,000 calls to msgsnd, with a message length of 2,000 bytes for the message queue, and 100,000 calls to write, with a length of 2,000 bytes for the STREAMS-based pipe and UNIX domain socket. The times are all in seconds.
These numbers show us that message queues, originally implemented to provide higher-than-normal-speed IPC, are no longer that much faster than other forms of IPC (in fact, STREAMS-based pipes are faster than message queues). (When message queues were implemented, the only other form of IPC available was half-duplex pipes.) When we consider the problems in using message queues (Section 15.6.4), we come to the conclusion that we shouldn't use them for new applications.
Figure 15.27. Timing comparison of IPC alternatives on SolarisOperation | User | System | Clock |
|---|
message queue | 0.57 | 3.63 | 4.22 | STREAMS pipe | 0.50 | 3.21 | 3.71 | UNIX domain socket | 0.43 | 4.45 | 5.59 |
15.8. Semaphores
A semaphore isn't a form of IPC similar to the others that we've described (pipes, FIFOs, and message queues). A semaphore is a counter used to provide access to a shared data object for multiple processes.
The Single UNIX Specification includes an alternate set of semaphore interfaces in the semaphore option of its real-time extensions. We do not discuss these interfaces in this text.
To obtain a shared resource, a process needs to do the following:
Test the semaphore that controls the resource. If the value of the semaphore is positive, the process can use the resource. In this case, the process decrements the semaphore value by 1, indicating that it has used one unit of the resource. Otherwise, if the value of the semaphore is 0, the process goes to sleep until the semaphore value is greater than 0. When the process wakes up, it returns to step 1.
When a process is done with a shared resource that is controlled by a semaphore, the semaphore value is incremented by 1. If any other processes are asleep, waiting for the semaphore, they are awakened.
To implement semaphores correctly, the test of a semaphore's value and the decrementing of this value must be an atomic operation. For this reason, semaphores are normally implemented inside the kernel.
A common form of semaphore is called a binary semaphore. It controls a single resource, and its value is initialized to 1. In general, however, a semaphore can be initialized to any positive value, with the value indicating how many units of the shared resource are available for sharing.
XSI semaphores are, unfortunately, more complicated than this. Three features contribute to this unnecessary complication.
A semaphore is not simply a single non-negative value. Instead, we have to define a semaphore as a set of one or more semaphore values. When we create a semaphore, we specify the number of values in the set. The creation of a semaphore (semget) is independent of its initialization (semctl). This is a fatal flaw, since we cannot atomically create a new semaphore set and initialize all the values in the set. Since all forms of XSI IPC remain in existence even when no process is using them, we have to worry about a program that terminates without releasing the semaphores it has been allocated. The undo feature that we describe later is supposed to handle this.
The kernel maintains a semid_ds structure for each semaphore set:
struct semid_ds {
struct ipc_perm sem_perm; /* see Section 15.6.2 */
unsigned short sem_nsems; /* # of semaphores in set */
time_t sem_otime; /* last-semop() time */
time_t sem_ctime; /* last-change time */
.
.
.
};
The Single UNIX Specification defines the fields shown, but implementations can define additional members in the semid_ds structure.
Each semaphore is represented by an anonymous structure containing at least the following members:
struct {
unsigned short semval; /* semaphore value, always >= 0 */
pid_t sempid; /* pid for last operation */
unsigned short semncnt; /* # processes awaiting semval>curval */
unsigned short semzcnt; /* # processes awaiting semval==0 */
.
.
.
};
Figure 15.28 lists the system limits (Section 15.6.3) that affect semaphore sets.
Figure 15.28. System limits that affect semaphoresDescription | Typical values |
|---|
FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
The maximum value of any semaphore | 32,767 | 32,767 | 32,767 | 32,767 | The maximum value of any semaphore's adjust-on-exit value | 16,384 | 32,767 | 16,384 | 16,384 | The maximum number of semaphore sets, systemwide | 10 | 128 | 87,381 | 10 | The maximum number of semaphores, systemwide | 60 | 32,000 | 87,381 | 60 | The maximum number of semaphores per semaphore set | 60 | 250 | 87,381 | 25 | The maximum number of undo structures, systemwide | 30 | 32,000 | 87,381 | 30 | The maximum number of undo entries per undo structures | 10 | 32 | 10 | 10 | The maximum number of operations per semop call | 100 | 32 | 100 | 10 |
The first function to call is semget to obtain a semaphore ID.
#include <sys/sem.h>
int semget(key_t key, int nsems, int flag);
| Returns: semaphore ID if OK, 1 on error |
In Section 15.6.1, we described the rules for converting the key into an identifier and discussed whether a new set is created or an existing set is referenced. When a new set is created, the following members of the semid_ds structure are initialized.
The ipc_perm structure is initialized as described in Section 15.6.2. The mode member of this structure is set to the corresponding permission bits of flag. These permissions are specified with the values from Figure 15.24. sem_otime is set to 0. sem_ctime is set to the current time. sem_nsems is set to nsems.
The number of semaphores in the set is nsems. If a new set is being created (typically in the server), we must specify nsems. If we are referencing an existing set (a client), we can specify nsems as 0.
The semctl function is the catchall for various semaphore operations.
#include <sys/sem.h>
int semctl(int semid, int semnum, int cmd,
... /* union semun arg */);
| Returns: (see following) |
The fourth argument is optional, depending on the command requested, and if present, is of type semun, a union of various command-specific arguments:
union semun {
int val; /* for SETVAL */
struct semid_ds *buf; /* for IPC_STAT and IPC_SET */
unsigned short *array; /* for GETALL and SETALL */
};
Note that the optional argument is the actual union, not a pointer to the union.
The cmd argument specifies one of the following ten commands to be performed on the set specified by semid. The five commands that refer to one particular semaphore value use semnum to specify one member of the set. The value of semnum is between 0 and nsems-1, inclusive.
IPC_STAT | Fetch the semid_ds structure for this set, storing it in the structure pointed to by arg.buf. | IPC_SET | Set the sem_perm.uid, sem_perm.gid, and sem_perm.mode fields from the structure pointed to by arg.buf in the semid_ds structure associated with this set. This command can be executed only by a process whose effective user ID equals sem_perm.cuid or sem_perm.uid or by a process with superuser privileges. | IPC_RMID | Remove the semaphore set from the system. This removal is immediate. Any other process still using the semaphore will get an error of EIDRM on its next attempted operation on the semaphore. This command can be executed only by a process whose effective user ID equals sem_perm.cuid or sem_perm.uid or by a process with superuser privileges. | GETVAL | Return the value of semval for the member semnum. | SETVAL | Set the value of semval for the member semnum. The value is specified by arg.val. | GETPID | Return the value of sempid for the member semnum. | GETNCNT | Return the value of semncnt for the member semnum. | GETZCNT | Return the value of semzcnt for the member semnum. | GETALL | Fetch all the semaphore values in the set. These values are stored in the array pointed to by arg.array. | SETALL | Set all the semaphore values in the set to the values pointed to by arg.array. |
For all the GET commands other than GETALL, the function returns the corresponding value. For the remaining commands, the return value is 0.
The function semop atomically performs an array of operations on a semaphore set.
#include <sys/sem.h>
int semop(int semid, struct sembuf semoparray[],
size_t nops);
| Returns: 0 if OK, 1 on error |
The semoparray argument is a pointer to an array of semaphore operations, represented by sembuf structures:
struct sembuf {
unsigned short sem_num; /* member # in set (0, 1, ..., nsems-1) */
short sem_op; /* operation (negative, 0, or positive) */
short sem_flg; /* IPC_NOWAIT, SEM_UNDO */
};
The nops argument specifies the number of operations (elements) in the array.
The operation on each member of the set is specified by the corresponding sem_op value. This value can be negative, 0, or positive. (In the following discussion, we refer to the "undo" flag for a semaphore. This flag corresponds to the SEM_UNDO bit in the corresponding sem_flg member.)
The easiest case is when sem_op is positive. This case corresponds to the returning of resources by the process. The value of sem_op is added to the semaphore's value. If the undo flag is specified, sem_op is also subtracted from the semaphore's adjustment value for this process. If sem_op is negative, we want to obtain resources that the semaphore controls. If the semaphore's value is greater than or equal to the absolute value of sem_op (the resources are available), the absolute value of sem_op is subtracted from the semaphore's value. This guarantees that the resulting value for the semaphore is greater than or equal to 0. If the undo flag is specified, the absolute value of sem_op is also added to the semaphore's adjustment value for this process. If the semaphore's value is less than the absolute value of sem_op (the resources are not available), the following conditions apply. If IPC_NOWAIT is specified, semop returns with an error of EAGAIN. If IPC_NOWAIT is not specified, the semncnt value for this semaphore is incremented (since the caller is about to go to sleep), and the calling process is suspended until one of the following occurs. The semaphore's value becomes greater than or equal to the absolute value of sem_op (i.e., some other process has released some resources). The value of semncnt for this semaphore is decremented (since the calling process is done waiting), and the absolute value of sem_op is subtracted from the semaphore's value. If the undo flag is specified, the absolute value of sem_op is also added to the semaphore's adjustment value for this process. The semaphore is removed from the system. In this case, the function returns an error of EIDRM. A signal is caught by the process, and the signal handler returns. In this case, the value of semncnt for this semaphore is decremented (since the calling process is no longer waiting), and the function returns an error of EINTR.
If sem_op is 0, this means that the calling process wants to wait until the semaphore's value becomes 0. If the semaphore's value is currently 0, the function returns immediately. If the semaphore's value is nonzero, the following conditions apply. If IPC_NOWAIT is specified, return is made with an error of EAGAIN. If IPC_NOWAIT is not specified, the semzcnt value for this semaphore is incremented (since the caller is about to go to sleep), and the calling process is suspended until one of the following occurs. The semaphore's value becomes 0. The value of semzcnt for this semaphore is decremented (since the calling process is done waiting). The semaphore is removed from the system. In this case, the function returns an error of EIDRM. A signal is caught by the process, and the signal handler returns. In this case, the value of semzcnt for this semaphore is decremented (since the calling process is no longer waiting), and the function returns an error of EINTR.
The semop function operates atomically; it does either all the operations in the array or none of them.
Semaphore Adjustment on exit
As we mentioned earlier, it is a problem if a process terminates while it has resources allocated through a semaphore. Whenever we specify the SEM_UNDO flag for a semaphore operation and we allocate resources (a sem_op value less than 0), the kernel remembers how many resources we allocated from that particular semaphore (the absolute value of sem_op). When the process terminates, either voluntarily or involuntarily, the kernel checks whether the process has any outstanding semaphore adjustments and, if so, applies the adjustment to the corresponding semaphore.
If we set the value of a semaphore using semctl, with either the SETVAL or SETALL commands, the adjustment value for that semaphore in all processes is set to 0.
ExampleTiming Comparison of Semaphores versus Record Locking
If we are sharing a single resource among multiple processes, we can use either a semaphore or record locking. It's interesting to compare the timing differences between the two techniques.
With a semaphore, we create a semaphore set consisting of a single member and initialize the semaphore's value to 1. To allocate the resource, we call semop with a sem_op of -1; to release the resource, we perform a sem_op of +1. We also specify SEM_UNDO with each operation, to handle the case of a process that terminates without releasing its resource.
With record locking, we create an empty file and use the first byte of the file (which need not exist) as the lock byte. To allocate the resource, we obtain a write lock on the byte; to release it, we unlock the byte. The properties of record locking guarantee that if a process terminates while holding a lock, then the lock is automatically released by the kernel.
Figure 15.29 shows the time required to perform these two locking techniques on Linux. In each case, the resource was allocated and then released 100,000 times. This was done simultaneously by three different processes. The times in Figure 15.29 are the totals in seconds for all three processes.
On Linux, there is about a 60 percent penalty in the elapsed time for record locking compared to semaphore locking.
Even though record locking is slower than semaphore locking, if we're locking a single resource (such as a shared memory segment) and don't need all the fancy features of XSI semaphores, record locking is preferred. The reasons are that it is much simpler to use, and the system takes care of any lingering locks when a process terminates.
Figure 15.29. Timing comparison of locking alternatives on LinuxOperation | User | System | Clock |
|---|
semaphores with undo | 0.38 | 0.48 | 0.86 | advisory record locking | 0.41 | 0.95 | 1.36 |
15.9. Shared Memory
Shared memory allows two or more processes to share a given region of memory. This is the fastest form of IPC, because the data does not need to be copied between the client and the server. The only trick in using shared memory is synchronizing access to a given region among multiple processes. If the server is placing data into a shared memory region, the client shouldn't try to access the data until the server is done. Often, semaphores are used to synchronize shared memory access. (But as we saw at the end of the previous section, record locking can also be used.)
The Single UNIX Specification includes an alternate set of interfaces to access shared memory in the shared memory objects option of its real-time extensions. We do not cover the real-time extensions in this text.
The kernel maintains a structure with at least the following members for each shared memory segment:
struct shmid_ds {
struct ipc_perm shm_perm; /* see Section 15.6.2 */
size_t shm_segsz; /* size of segment in bytes */
pid_t shm_lpid; /* pid of last shmop() */
pid_t shm_cpid; /* pid of creator */
shmatt_t shm_nattch; /* number of current attaches */
time_t shm_atime; /* last-attach time */
time_t shm_dtime; /* last-detach time */
time_t shm_ctime; /* last-change time */
.
.
.
};
(Each implementation adds other structure members as needed to support shared memory segments.)
The type shmatt_t is defined to be an unsigned integer at least as large as an unsigned short. Figure 15.30 lists the system limits (Section 15.6.3) that affect shared memory.
Figure 15.30. System limits that affect shared memoryDescription | Typical values |
|---|
FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
The maximum size in bytes of a shared memory segment | 33,554,432 | 33,554,432 | 4,194,304 | 8,388,608 | The minimum size in bytes of a shared memory segment | 1 | 1 | 1 | 1 | The maximum number of shared memory segments, systemwide | 192 | 4,096 | 32 | 100 | The maximum number of shared memory segments, per process | 128 | 4,096 | 8 | 6 |
The first function called is usually shmget, to obtain a shared memory identifier.
#include <sys/shm.h>
int shmget(key_t key, size_t size, int flag);
| Returns: shared memory ID if OK, 1 on error |
In Section 15.6.1, we described the rules for converting the key into an identifier and whether a new segment is created or an existing segment is referenced. When a new segment is created, the following members of the shmid_ds structure are initialized.
The ipc_perm structure is initialized as described in Section 15.6.2. The mode member of this structure is set to the corresponding permission bits of flag. These permissions are specified with the values from Figure 15.24. shm_lpid, shm_nattach, shm_atime, and shm_dtime are all set to 0. shm_ctime is set to the current time. shm_segsz is set to the size requested.
The size parameter is the size of the shared memory segment in bytes. Implementations will usually round up the size to a multiple of the system's page size, but if an application specifies size as a value other than an integral multiple of the system's page size, the remainder of the last page will be unavailable for use. If a new segment is being created (typically in the server), we must specify its size. If we are referencing an existing segment (a client), we can specify size as 0. When a new segment is created, the contents of the segment are initialized with zeros.
The shmctl function is the catchall for various shared memory operations.
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
| Returns: 0 if OK, 1 on error |
The cmd argument specifies one of the following five commands to be performed, on the segment specified by shmid.
IPC_STAT | Fetch the shmid_ds structure for this segment, storing it in the structure pointed to by buf. | IPC_SET | Set the following three fields from the structure pointed to by buf in the shmid_ds structure associated with this shared memory segment: shm_perm.uid, shm_perm.gid, and shm_perm.mode. This command can be executed only by a process whose effective user ID equals shm_perm.cuid or shm_perm.uid or by a process with superuser privileges. | IPC_RMID | Remove the shared memory segment set from the system. Since an attachment count is maintained for shared memory segments (the shm_nattch field in the shmid_ds structure), the segment is not removed until the last process using the segment terminates or detaches it. Regardless of whether the segment is still in use, the segment's identifier is immediately removed so that shmat can no longer attach the segment. This command can be executed only by a process whose effective user ID equals shm_perm.cuid or shm_perm.uid or by a process with superuser privileges. |
Two additional commands are provided by Linux and Solaris, but are not part of the Single UNIX Specification.
SHM_LOCK | Lock the shared memory segment in memory. This command can be executed only by the superuser. | SHM_UNLOCK | Unlock the shared memory segment. This command can be executed only by the superuser. |
Once a shared memory segment has been created, a process attaches it to its address space by calling shmat.
#include <sys/shm.h>
void *shmat(int shmid, const void *addr, int flag);
| Returns: pointer to shared memory segment if OK, 1 on error |
The address in the calling process at which the segment is attached depends on the addr argument and whether the SHM_RND bit is specified in flag.
If addr is 0, the segment is attached at the first available address selected by the kernel. This is the recommended technique. If addr is nonzero and SHM_RND is not specified, the segment is attached at the address given by addr. If addr is nonzero and SHM_RND is specified, the segment is attached at the address given by (addr - (addr modulus SHMLBA)). The SHM_RND command stands for "round." SHMLBA stands for "low boundary address multiple" and is always a power of 2. What the arithmetic does is round the address down to the next multiple of SHMLBA.
Unless we plan to run the application on only a single type of hardware (which is highly unlikely today), we should not specify the address where the segment is to be attached. Instead, we should specify an addr of 0 and let the system choose the address.
If the SHM_RDONLY bit is specified in flag, the segment is attached read-only. Otherwise, the segment is attached readwrite.
The value returned by shmat is the address at which the segment is attached, or 1 if an error occurred. If shmat succeeds, the kernel will increment the shm_nattch counter in the shmid_ds structure associated with the shared memory segment.
When we're done with a shared memory segment, we call shmdt to detach it. Note that this does not remove the identifier and its associated data structure from the system. The identifier remains in existence until some process (often a server) specifically removes it by calling shmctl with a command of IPC_RMID.
#include <sys/shm.h>
int shmdt(void *addr);
| Returns: 0 if OK, 1 on error |
The addr argument is the value that was returned by a previous call to shmat. If successful, shmdt will decrement the shm_nattch counter in the associated shmid_ds structure.
Example
Where a kernel places shared memory segments that are attached with an address of 0 is highly system dependent. Figure 15.31 shows a program that prints some information on where one particular system places various types of data.
Running this program on an Intel-based Linux system gives us the following output:
$ ./a.out
array[] from 804a080 to 8053cc0
stack around bffff9e4
malloced from 8053cc8 to 806c368
shared memory attached from 40162000 to 4017a6a0
Figure 15.32 shows a picture of this, similar to what we said was a typical memory layout in Figure 7.6. Note that the shared memory segment is placed well below the stack.
Figure 15.31. Print where various types of data are stored
#include "apue.h"
#include <sys/shm.h>
#define ARRAY_SIZE 40000
#define MALLOC_SIZE 100000
#define SHM_SIZE 100000
#define SHM_MODE 0600 /* user read/write */
char array[ARRAY_SIZE]; /* uninitialized data = bss */
int
main(void)
{
int shmid;
char *ptr, *shmptr;
printf("array[] from %lx to %lx\n", (unsigned long)&array[0],
(unsigned long)&array[ARRAY_SIZE]);
printf("stack around %lx\n", (unsigned long)&shmid);
if ((ptr = malloc(MALLOC_SIZE)) == NULL)
err_sys("malloc error");
printf("malloced from %lx to %lx\n", (unsigned long)ptr,
(unsigned long)ptr+MALLOC_SIZE);
if ((shmid = shmget(IPC_PRIVATE, SHM_SIZE, SHM_MODE)) < 0)
err_sys("shmget error");
if ((shmptr = shmat(shmid, 0, 0)) == (void *)-1)
err_sys("shmat error");
printf("shared memory attached from %lx to %lx\n",
(unsigned long)shmptr, (unsigned long)shmptr+SHM_SIZE);
if (shmctl(shmid, IPC_RMID, 0) < 0)
err_sys("shmctl error");
exit(0);
}
Recall that the mmap function (Section 14.9) can be used to map portions of a file into the address space of a process. This is conceptually similar to attaching a shared memory segment using the shmat XSI IPC function. The main difference is that the memory segment mapped with mmap is backed by a file, whereas no file is associated with an XSI shared memory segment.
ExampleMemory Mapping of /dev/zero
Shared memory can be used between unrelated processes. But if the processes are related, some implementations provide a different technique.
The following technique works on FreeBSD 5.2.1, Linux 2.4.22, and Solaris 9. Mac OS X 10.3 currently doesn't support the mapping of character devices into the address space of a process.
The device /dev/zero is an infinite source of 0 bytes when read. This device also accepts any data that is written to it, ignoring the data. Our interest in this device for IPC arises from its special properties when it is memory mapped.
An unnamed memory region is created whose size is the second argument to mmap, rounded up to the nearest page size on the system. The memory region is initialized to 0. Multiple processes can share this region if a common ancestor specifies the MAP_SHARED flag to mmap.
The program in Figure 15.33 is an example that uses this special device.
The program opens the /dev/zero device and calls mmap, specifying a size of a long integer. Note that once the region is mapped, we can close the device. The process then creates a child. Since MAP_SHARED was specified in the call to mmap, writes to the memory-mapped region by one process are seen by the other process. (If we had specified MAP_PRIVATE instead, this example wouldn't work.)
The parent and the child then alternate running, incrementing a long integer in the shared memory-mapped region, using the synchronization functions from Section 8.9. The memory-mapped region is initialized to 0 by mmap. The parent increments it to 1, then the child increments it to 2, then the parent increments it to 3, and so on. Note that we have to use parentheses when we increment the value of the long integer in the update function, since we are incrementing the value and not the pointer.
The advantage of using /dev/zero in the manner that we've shown is that an actual file need not exist before we call mmap to create the mapped region. Mapping /dev/zero automatically creates a mapped region of the specified size. The disadvantage of this technique is that it works only between related processes. With related processes, however, it is probably simpler and more efficient to use threads (Chapters 11 and 12). Note that regardless of which technique is used, we still need to synchronize access to the shared data.
Figure 15.33. IPC between parent and child using memory mapped I/O of /dev/zero
#include "apue.h"
#include <fcntl.h>
#include <sys/mman.h>
#define NLOOPS 1000
#define SIZE sizeof(long) /* size of shared memory area */
static int
update(long *ptr)
{
return((*ptr)++); /* return value before increment */
}
int
main(void)
{
int fd, i, counter;
pid_t pid;
void *area;
if ((fd = open("/dev/zero", O_RDWR)) < 0)
err_sys("open error");
if ((area = mmap(0, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED,
fd, 0)) == MAP_FAILED)
err_sys("mmap error");
close(fd); /* can close /dev/zero now that it's mapped */
TELL_WAIT();
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) { /* parent */
for (i = 0; i < NLOOPS; i += 2) {
if ((counter = update((long *)area)) != i)
err_quit("parent: expected %d, got %d", i, counter);
TELL_CHILD(pid);
WAIT_CHILD();
}
} else { /* child */
for (i = 1; i < NLOOPS + 1; i += 2) {
WAIT_PARENT();
if ((counter = update((long *)area)) != i)
err_quit("child: expected %d, got %d", i, counter);
TELL_PARENT(getppid());
}
}
exit(0);
}
ExampleAnonymous Memory Mapping
Many implementations provide anonymous memory mapping, a facility similar to the /dev/zero feature. To use this facility, we specify the MAP_ANON flag to mmap and specify the file descriptor as -1. The resulting region is anonymous (since it's not associated with a pathname through a file descriptor) and creates a memory region that can be shared with descendant processes.
The anonymous memory-mapping facility is supported by all four platforms discussed in this text. Note, however, that Linux defines the MAP_ANONYMOUS flag for this facility, but defines the MAP_ANON flag to be the same value for improved application portability.
To modify the program in Figure 15.33 to use this facility, we make three changes: (a) remove the open of /dev/zero, (b) remove the close of fd, and (c) change the call to mmap to the following:
if ((area = mmap(0, SIZE, PROT_READ | PROT_WRITE,
MAP_ANON | MAP_SHARED, -1, 0)) == MAP_FAILED)
In this call, we specify the MAP_ANON flag and set the file descriptor to -1. The rest of the program from Figure 15.33 is unchanged.
The last two examples illustrate sharing memory among multiple related processes. If shared memory is required between unrelated processes, there are two alternatives. Applications can use the XSI shared memory functions, or they can use mmap to map the same file into their address spaces using the MAP_SHARED flag.
15.10. ClientServer Properties
Let's detail some of the properties of clients and servers that are affected by the various types of IPC used between them. The simplest type of relationship is to have the client fork and exec the desired server. Two half-duplex pipes can be created before the fork to allow data to be transferred in both directions. Figure 15.16 is an example of this. The server that is executed can be a set-user-ID program, giving it special privileges. Also, the server can determine the real identity of the client by looking at its real user ID. (Recall from Section 8.10 that the real user ID and real group ID don't change across an exec.)
With this arrangement, we can build an open server. (We show an implementation of this clientserver in Section 17.5.) It opens files for the client instead of the client calling the open function. This way, additional permission checking can be added, above and beyond the normal UNIX system user/group/other permissions. We assume that the server is a set-user-ID program, giving it additional permissions (root permission, perhaps). The server uses the real user ID of the client to determine whether to give it access to the requested file. This way, we can build a server that allows certain users permissions that they don't normally have.
In this example, since the server is a child of the parent, all the server can do is pass back the contents of the file to the parent. Although this works fine for regular files, it can't be used for special device files, for example. We would like to be able to have the server open the requested file and pass back the file descriptor. Whereas a parent can pass a child an open descriptor, a child cannot pass a descriptor back to the parent (unless special programming techniques are used, which we cover in Chapter 17).
We showed the next type of server in Figure 15.23. The server is a daemon process that is contacted using some form of IPC by all clients. We can't use pipes for this type of clientserver. A form of named IPC is required, such as FIFOs or message queues. With FIFOs, we saw that an individual per client FIFO is also required if the server is to send data back to the client. If the clientserver application sends data only from the client to the server, a single well-known FIFO suffices. (The System V line printer spooler used this form of clientserver arrangement. The client was the lp(1) command, and the server was the lpsched daemon process. A single FIFO was used, since the flow of data was only from the client to the server. Nothing was sent back to the client.)
Multiple possibilities exist with message queues.
A single queue can be used between the server and all the clients, using the type field of each message to indicate the message recipient. For example, the clients can send their requests with a type field of 1. Included in the request must be the client's process ID. The server then sends the response with the type field set to the client's process ID. The server receives only the messages with a type field of 1 (the fourth argument for msgrcv), and the clients receive only the messages with a type field equal to their process IDs. Alternatively, an individual message queue can be used for each client. Before sending the first request to a server, each client creates its own message queue with a key of IPC_PRIVATE. The server also has its own queue, with a key or identifier known to all clients. The client sends its first request to the server's well-known queue, and this request must contain the message queue ID of the client's queue. The server sends its first response to the client's queue, and all future requests and responses are exchanged on this queue. One problem with this technique is that each client-specific queue usually has only a single message on it: a request for the server or a response for a client. This seems wasteful of a limited systemwide resource (a message queue), and a FIFO can be used instead. Another problem is that the server has to read messages from multiple queues. Neither select nor poll works with message queues.
Either of these two techniques using message queues can be implemented using shared memory segments and a synchronization method (a semaphore or record locking).
The problem with this type of clientserver relationship (the client and the server being unrelated processes) is for the server to identify the client accurately. Unless the server is performing a nonprivileged operation, it is essential that the server know who the client is. This is required, for example, if the server is a set-user-ID program. Although all these forms of IPC go through the kernel, there is no facility provided by them to have the kernel identify the sender.
With message queues, if a single queue is used between the client and the server (so that only a single message is on the queue at a time, for example), the msg_lspid of the queue contains the process ID of the other process. But when writing the server, we want the effective user ID of the client, not its process ID. There is no portable way to obtain the effective user ID, given the process ID. (Naturally, the kernel maintains both values in the process table entry, but other than rummaging around through the kernel's memory, we can't obtain one, given the other.)
We'll use the following technique in Section 17.3 to allow the server to identify the client. The same technique can be used with FIFOs, message queues, semaphores, or shared memory. For the following description, assume that FIFOs are being used, as in Figure 15.23. The client must create its own FIFO and set the file access permissions of the FIFO so that only user-read and user-write are on. We assume that the server has superuser privileges (or else it probably wouldn't care about the client's true identity), so the server can still read and write to this FIFO. When the server receives the client's first request on the server's well-known FIFO (which must contain the identity of the client-specific FIFO), the server calls either stat or fstat on the client-specific FIFO. The server assumes that the effective user ID of the client is the owner of the FIFO (the st_uid field of the stat structure). The server verifies that only the user-read and user-write permissions are enabled. As another check, the server should also look at the three times associated with the FIFO (the st_atime, st_mtime, and st_ctime fields of the stat structure) to verify that they are recent (no older than 15 or 30 seconds, for example). If a malicious client can create a FIFO with someone else as the owner and set the file's permission bits to user-read and user-write only, then the system has other fundamental security problems.
To use this technique with XSI IPC, recall that the ipc_perm structure associated with each message queue, semaphore, and shared memory segment identifies the creator of the IPC structure (the cuid and cgid fields). As with the example using FIFOs, the server should require the client to create the IPC structure and have the client set the access permissions to user-read and user-write only. The times associated with the IPC structure should also be verified by the server to be recent (since these IPC structures hang around until explicitly deleted).
We'll see in Section 17.2.2 that a far better way of doing this authentication is for the kernel to provide the effective user ID and effective group ID of the client. This is done by the STREAMS subsystem when file descriptors are passed between processes.
|

 LINUX
LINUX 
 Books
Books
