16.1. Introduction
In the previous chapter, we looked at pipes, FIFOs, message queues, semaphores, and shared memory: the classical methods of IPC provided by various UNIX systems. These mechanisms allow processes running on the same computer to communicate with one another. In this chapter, we look at the mechanisms that allow processes running on different computers (connected to a common network) to communicate with one another: network IPC.
In this chapter, we describe the socket network IPC interface, which can be used by processes to communicate with other processes, regardless of where they are running: on the same machine or on different machines. Indeed, this was one of the design goals of the socket interface. The same interfaces can be used for both intermachine communication and intramachine communication. Although the socket interface can be used to communicate using many different network protocols, we will restrict our discussion to the TCP/IP protocol suite in this chapter, since it is the de facto standard for communicating over the Internet.
The socket API as specified by POSIX.1 is based on the 4.4BSD socket interface. Although minor changes have been made over the years, the current socket interface closely resembles the interface when it was originally introduced in 4.2BSD in the early 1980s.
This chapter is only an overview of the socket API. Stevens, Fenner, and Rudoff [2004] discuss the socket interface in detail in the definitive text on network programming in the UNIX System.
16.2. Socket Descriptors
A socket is an abstraction of a communication endpoint. Just as they would use file descriptors to access a file, applications use socket descriptors to access sockets. Socket descriptors are implemented as file descriptors in the UNIX System. Indeed, many of the functions that deal with file descriptors, such as read and write, will work with a socket descriptor.
To create a socket, we call the socket function.
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
| Returns: file (socket) descriptor if OK, 1 on error |
The domain argument determines the nature of the communication, including the address format (described in more detail in the next section). Figure 16.1 summarizes the domains specified by POSIX.1. The constants start with AF_ (for address family) because each domain has its own format for representing an address.
Figure 16.1. Socket communication domainsDomain | Description |
|---|
AF_INET | IPv4 Internet domain | AF_INET6 | IPv6 Internet domain | AF_UNIX | UNIX domain | AF_UNSPEC | unspecified |
We discuss the UNIX domain in Section 17.3. Most systems define the AF_LOCAL domain also, which is an alias for AF_UNIX. The AF_UNSPEC domain is a wildcard that represents "any" domain. Historically, some platforms provide support for additional network protocols, such as AF_IPX for the NetWare protocol family, but domain constants for these protocols are not defined by the POSIX.1 standard.
The type argument determines the type of the socket, which further determines the communication characteristics. The socket types defined by POSIX.1 are summarized in Figure 16.2, but implementations are free to add support for additional types.
Figure 16.2. Socket typesType | Description |
|---|
SOCK_DGRAM | fixed-length, connectionless, unreliable messages | SOCK_RAW | datagram interface to IP (optional in POSIX.1) | SOCK_SEQPACKET | fixed-length, sequenced, reliable, connection-oriented messages | SOCK_STREAM | sequenced, reliable, bidirectional, connection-oriented byte streams |
The protocol argument is usually zero, to select the default protocol for the given domain and socket type. When multiple protocols are supported for the same domain and socket type, we can use the protocol argument to select a particular protocol. The default protocol for a SOCK_STREAM socket in the AF_INET communication domain is TCP (Transmission Control Protocol). The default protocol for a SOCK_DGRAM socket in the AF_INET communication domain is UDP (User Datagram Protocol).
With a datagram (SOCK_DGRAM) interface, no logical connection needs to exist between peers for them to communicate. All you need to do is send a message addressed to the socket being used by the peer process.
A datagram, therefore, provides a connectionless service. A byte stream (SOCK_STREAM), on the other hand, requires that, before you can exchange data, you set up a logical connection between your socket and the socket belonging to the peer you want to communicate with.
A datagram is a self-contained message. Sending a datagram is analogous to mailing someone a letter. You can mail many letters, but you can't guarantee the order of delivery, and some might get lost along the way. Each letter contains the address of the recipient, making the letter independent from all the others. Each letter can even go to different recipients.
In contrast, using a connection-oriented protocol for communicating with a peer is like making a phone call. First, you need to establish a connection by placing a phone call, but after the connection is in place, you can communicate bidirectionally with each other. The connection is a peer-to-peer communication channel over which you talk. Your words contain no addressing information, as a point-to-point virtual connection exists between both ends of the call, and the connection itself implies a particular source and destination.
With a SOCK_STREAM socket, applications are unaware of message boundaries, since the socket provides a byte stream service. This means that when we read data from a socket, it might not return the same number of bytes written by the process sending us data. We will eventually get everything sent to us, but it might take several function calls.
A SOCK_SEQPACKET socket is just like a SOCK_STREAM socket except that we get a message-based service instead of a byte-stream service. This means that the amount of data received from a SOCK_SEQPACKET socket is the same amount as was written. The Stream Control Transmission Protocol (SCTP) provides a sequential packet service in the Internet domain.
A SOCK_RAW socket provides a datagram interface directly to the underlying network layer (which means IP in the Internet domain). Applications are responsible for building their own protocol headers when using this interface, because the transport protocols (TCP and UDP, for example) are bypassed. Superuser privileges are required to create a raw socket to prevent malicious applications from creating packets that might bypass established security mechanisms.
Calling socket is similar to calling open. In both cases, you get a file descriptor that can be used for I/O. When you are done using the file descriptor, you call close to relinquish access to the file or socket and free up the file descriptor for reuse.
Although a socket descriptor is actually a file descriptor, you can't use a socket descriptor with every function that accepts a file descriptor argument. Figure 16.3 summarizes most of the functions we've described so far that are used with file descriptors and describes how they behave when used with a socket descriptor. Unspecified and implementation-defined behavior usually means that the function doesn't work with socket descriptors. For example, lseek doesn't work with sockets, since sockets don't support the concept of a file offset.
Figure 16.3. How file descriptor functions act with socketsFunction | Behavior with socket |
|---|
close (Section 3.3) | deallocates the socket | dup, dup2 (Section 3.12) | duplicates the file descriptor as normal | fchdir (Section 4.22) | fails with errno set to ENOTDIR
| fchmod (Section 4.9) | unspecified | fchown (Section 4.11) | implementation defined | fcntl (Section 3.14) | some commands supported, including F_DUPFD, F_GETFD, F_GETFL, F_GETOWN, F_SETFD, F_SETFL, and F_SETOWN
| fdatasync, fsync (Section 3.13) | implementation defined | fstat (Section 4.2) | some stat structure members supported, but how left up to the implementation | ftruncate (Section 4.13) | unspecified | getmsg, getpmsg (Section 14.4) | works if sockets are implemented with STREAMS (i.e., on Solaris) | ioctl (Section 3.15) | some commands work, depending on underlying device driver | lseek (Section 3.6) | implementation defined (usually fails with errno set to ESPIPE) | mmap (Section 14.9) | unspecified | poll (Section 14.5.2) | works as expected | putmsg, putpmsg (Section 14.4) | works if sockets are implemented with STREAMS (i.e., on Solaris) | read (Section 3.7) and readv (Section 14.7) | equivalent to recv (Section 16.5) without any flags | select (Section 14.5.1) | works as expected | write (Section 3.8) and writev (Section 14.7) | equivalent to send (Section 16.5) without any flags |
Communication on a socket is bidirectional. We can disable I/O on a socket with the shutdown function.
#include <sys/socket.h>
int shutdown (int sockfd, int how);
| Returns: 0 if OK, 1 on error |
If how is SHUT_RD, then reading from the socket is disabled. If how is SHUT_WR, then we can't use the socket for transmitting data. We can use SHUT_RDWR to disable both data transmission and reception.
Given that we can close a socket, why is shutdown needed? There are several reasons. First, close will deallocate the network endpoint only when the last active reference is closed. This means that if we duplicate the socket (with dup, for example), the socket won't be deallocated until we close the last file descriptor referring to it. The shutdown function allows us to deactivate a socket independently of the number of active file descriptors referencing it. Second, it is sometimes convenient to shut a socket down in one direction only. For example, we can shut a socket down for writing if we want the process we are communicating with to be able to determine when we are done transmitting data, while still allowing us to use the socket to receive data sent to us by the process.
16.3. Addressing
In the previous section, we learned how to create and destroy a socket. Before we learn to do something useful with a socket, we need to learn how to identify the process that we want to communicate with. Identifying the process has two components. The machine's network address helps us identify the computer on the network we wish to contact, and the service helps us identify the particular process on the computer.
16.3.1. Byte Ordering
When communicating with processes running on the same computer, we generally don't have to worry about byte ordering. The byte order is a characteristic of the processor architecture, dictating how bytes are ordered within larger data types, such as integers. Figure 16.4 shows how the bytes within a 32-bit integer are numbered.
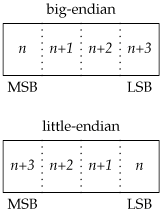
If the processor architecture supports big-endian byte order, then the highest byte address occurs in the least significant byte (LSB). Little-endian byte order is the opposite: the least significant byte contains the lowest byte address. Note that regardless of the byte ordering, the most significant byte (MSB) is always on the left, and the least significant byte is always on the right. Thus, if we were to assign a 32-bit integer the value 0x04030201, the most significant byte would contain 4, and the least significant byte would contain 1, regardless of the byte ordering. If we were then to cast a character pointer (cp) to the address of the integer, we would see a difference from the byte ordering. On a little-endian processor, cp[0] would refer to the least significant byte and contain 1; cp[3] would refer to the most significant byte and contain 4. Compare that to a big-endian processor, where cp[0] would contain 4, referring to the most significant byte, and cp[3] would contain 1, referring to the least significant byte. Figure 16.5 summarizes the byte ordering for the four platforms discussed in this text.
Figure 16.5. Byte order for test platformsOperating system | Processor architecture | Byte order |
|---|
FreeBSD 5.2.1 | Intel Pentium | little-endian | Linux 2.4.22 | Intel Pentium | little-endian | Mac OS X 10.3 | PowerPC | big-endian | Solaris 9 | Sun SPARC | big-endian |
To confuse matters further, some processors can be configured for either little-endian or big-endian operation.
Network protocols specify a byte ordering so that heterogeneous computer systems can exchange protocol information without confusing the byte ordering. The TCP/IP protocol suite uses big-endian byte order. The byte ordering becomes visible to applications when they exchange formatted data. With TCP/IP, addresses are presented in network byte order, so applications sometimes need to translate them between the processor 's byte order and the network byte order. This is common when printing an address in a human-readable form, for example.
Four common functions are provided to convert between the processor byte order and the network byte order for TCP/IP applications.
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostint32);
| Returns: 32-bit integer in network byte order |
uint16_t htons(uint16_t hostint16);
| Returns: 16-bit integer in network byte order |
uint32_t ntohl(uint32_t netint32);
| Returns: 32-bit integer in host byte order |
uint16_t ntohs(uint16_t netint16);
| Returns: 16-bit integer in host byte order |
The h is for "host" byte order, and the n is for "network" byte order. The l is for "long" (i.e., 4-byte) integer, and the s is for "short" (i.e., 2-byte) integer. These four functions are defined in <arpa/inet.h>, although some older systems define them in <netinet/in.h>.
16.3.2. Address Formats
An address identifies a socket endpoint in a particular communication domain. The address format is specific to the particular domain. So that addresses with different formats can be passed to the socket functions, the addresses are cast to a generic sockaddr address structure:
struct sockaddr {
sa_family_t sa_family; /* address family */
char sa_data[]; /* variable-length address */
.
.
.
};
Implementations are free to add additional members and define a size for the sa_data member. For example, on Linux, the structure is defined as
struct sockaddr {
sa_family_t sa_family; /* address family */
char sa_data[14]; /* variable-length address */
};
But on FreeBSD, the structure is defined as
struct sockaddr {
unsigned char sa_len; /* total length */
sa_family_t sa_family; /* address family */
char sa_data[14]; /* variable-length address */
};
Internet addresses are defined in <netinet/in.h>. In the IPv4 Internet domain (AF_INET), a socket address is represented by a sockaddr_in structure:
struct in_addr {
in_addr_t s_addr; /* IPv4 address */
};
struct sockaddr_in {
sa_family_t sin_family; /* address family */
in_port_t sin_port; /* port number */
struct in_addr sin_addr; /* IPv4 address */
};
The in_port_t data type is defined to be a uint16_t. The in_addr_t data type is defined to be a uint32_t. These integer data types specify the number of bits in the data type and are defined in <stdint.h>.
In contrast to the AF_INET domain, the IPv6 Internet domain (AF_INET6) socket address is represented by a sockaddr_in6 structure:
struct in6_addr {
uint8_t s6_addr[16]; /* IPv6 address */
};
struct sockaddr_in6 {
sa_family_t sin6_family; /* address family */
in_port_t sin6_port; /* port number */
uint32_t sin6_flowinfo; /* traffic class and flow info */
struct in6_addr sin6_addr; /* IPv6 address */
uint32_t sin6_scope_id; /* set of interfaces for scope */
};
These are the definitions required by the Single UNIX Specification. Individual implementations are free to add additional fields. For example, on Linux, the sockaddr_in structure is defined as
struct sockaddr_in {
sa_family_t sin_family; /* address family */
in_port_t sin_port; /* port number */
struct in_addr sin_addr; /* IPv4 address */
unsigned char sin_zero[8]; /* filler */
};
where the sin_zero member is a filler field that should be set to all-zero values.
Note that although the sockaddr_in and sockaddr_in6 structures are quite different, they are both passed to the socket routines cast to a sockaddr structure. In Section 17.3, we will see that the structure of a UNIX domain socket address is different from both of the Internet domain socket address formats.
It is sometimes necessary to print an address in a format that is understandable by a person instead of a computer. The BSD networking software included the inet_addr and inet_ntoa functions to convert between the binary address format and a string in dotted-decimal notation (a.b.c.d). These functions, however, work only with IPv4 addresses. Two new functionsinet_ntop and inet_ptonsupport similar functionality and work with both IPv4 and IPv6 addresses.
#include <arpa/inet.h>
const char *inet_ntop(int domain, const void
 *restrict addr,
char *restrict str,
socklen_t size); *restrict addr,
char *restrict str,
socklen_t size);
| Returns: pointer to address string on success, NULL on error |
int inet_pton(int domain, const char *restrict str,
void *restrict addr);
| Returns: 1 on success, 0 if the format is invalid, or 1 on error |
The inet_ntop function converts a binary address in network byte order into a text string; inet_pton converts a text string into a binary address in network byte order. Only two domain values are supported: AF_INET and AF_INET6.
For inet_ntop, the size parameter specifies the size of the buffer (str) to hold the text string. Two constants are defined to make our job easier: INET_ADDRSTRLEN is large enough to hold a text string representing an IPv4 address, and INET6_ADDRSTRLEN is large enough to hold a text string representing an IPv6 address. For inet_pton, the addr buffer needs to be large enough to hold a 32-bit address if domain is AF_INET or large enough to hold a 128-bit address if domain is AF_INET6.
16.3.3. Address Lookup
Ideally, an application won't have to be aware of the internal structure of a socket address. If an application simply passes socket addresses around as sockaddr structures and doesn't rely on any protocol-specific features, then the application will work with many different protocols that provide the same type of service.
Historically, the BSD networking software has provided interfaces to access the various network configuration information. In Section 6.7, we briefly discussed the networking data files and the functions used to access them. In this section, we discuss them in a little more detail and introduce the newer functions used to look up addressing information.
The network configuration information returned by these functions can be kept in a number of places. They can be kept in static files (/etc/hosts, /etc/services, etc.), or they can be managed by a name service, such as DNS (Domain Name System) or NIS (Network Information Service). Regardless of where the information is kept, the same functions can be used to access it.
The hosts known by a given computer system are found by calling gethostent.
#include <netdb.h>
struct hostent *gethostent(void);
| Returns: pointer if OK, NULL on error |
void sethostent(int stayopen);
void endhostent(void);
|
If the host database file isn't already open, gethostent will open it. The gethostent function returns the next entry in the file. The sethostent function will open the file or rewind it if it is already open. The endhostent function will close the file.
When gethostent returns, we get a pointer to a hostent structure which might point to a static data buffer that is overwritten each time we call gethostent. The hostent structure is defined to have at least the following members:
struct hostent {
char *h_name; /* name of host */
char **h_aliases; /* pointer to alternate host name array */
int h_addrtype; /* address type */
int h_length; /* length in bytes of address */
char **h_addr_list; /* pointer to array of network addresses */
.
.
.
};
The addresses returned are in network byte order.
Two additional functionsgethostbyname and gethostbyaddroriginally were included with the hostent functions, but are now considered to be obsolete. We'll see replacements for them shortly.
We can get network names and numbers with a similar set of interfaces.
#include <netdb.h>
struct netent *getnetbyaddr(uint32_t net, int type);
struct netent *getnetbyname(const char *name);
struct netent *getnetent(void);
| All return: pointer if OK, NULL on error |
void setnetent(int stayopen);
void endnetent(void);
|
The netent structure contains at least the following fields:
struct netent {
char *n_name; /* network name */
char **n_aliases; /* alternate network name array pointer */
int n_addrtype; /* address type */
uint32_t n_net; /* network number */
.
.
.
};
The network number is returned in network byte order. The address type is one of the address family constants (AF_INET, for example).
We can map between protocol names and numbers with the following functions.
#include <netdb.h>
struct protoent *getprotobyname(const char *name);
struct protoent *getprotobynumber(int proto);
struct protoent *getprotoent(void);
| All return: pointer if OK, NULL on error |
void setprotoent(int stayopen);
void endprotoent(void);
|
The protoent structure as defined by POSIX.1 has at least the following members:
struct protoent {
char *p_name; /* protocol name */
char **p_aliases; /* pointer to alternate protocol name array */
int p_proto; /* protocol number */
.
.
.
};
Services are represented by the port number portion of the address. Each service is offered on a unique, well-known port number. We can map a service name to a port number with getservbyname, map a port number to a service name with getservbyport, or scan the services database sequentially with getservent.
#include <netdb.h>
struct servent *getservbyname(const char *name,
const char *proto);
struct servent *getservbyport(int port, const char
*proto);
struct servent *getservent(void);
| All return: pointer if OK, NULL on error |
void setservent(int stayopen);
void endservent(void);
|
The servent structure is defined to have at least the following members:
struct servent {
char *s_name; /* service name */
char **s_aliases; /* pointer to alternate service name array */
int s_port; /* port number */
char *s_proto; /* name of protocol */
.
.
.
};
POSIX.1 defines several new functions to allow an application to map from a host name and a service name to an address and vice versa. These functions replace the older gethostbyname and gethostbyaddr functions.
The getaddrinfo function allows us to map a host name and a service name to an address.
#include <sys/socket.h>
#include <netdb.h>
int getaddrinfo(const char *restrict host,
const char *restrict service,
const struct addrinfo *restrict hint,
struct addrinfo **restrict res);
| Returns: 0 if OK, nonzero error code on error |
void freeaddrinfo(struct addrinfo *ai);
|
We need to provide the host name, the service name, or both. If we provide only one name, the other should be a null pointer. The host name can be either a node name or the host address in dotted-decimal notation.
The getaddrinfo function returns a linked list of addrinfo structures. We can use freeaddrinfo to free one or more of these structures, depending on how many structures are linked together using the ai_next field.
The addrinfo structure is defined to include at least the following members:
struct addrinfo {
int ai_flags; /* customize behavior */
int ai_family; /* address family */
int ai_socktype; /* socket type */
int ai_protocol; /* protocol */
socklen_t ai_addrlen; /* length in bytes of address */
struct sockaddr *ai_addr; /* address */
char *ai_canonname; /* canonical name of host */
struct addrinfo *ai_next; /* next in list */
.
.
.
};
We can supply an optional hint to select addresses that meet certain criteria. The hint is a template used for filtering addresses and uses only the ai_family, ai_flags, ai_protocol, and ai_socktype fields. The remaining integer fields must be set to 0, and the pointer fields must be null. Figure 16.6 summarizes the flags we can use in the ai_flags field to customize how addresses and names are treated.
Figure 16.6. Flags for addrinfo structureFlag | Description |
|---|
AI_ADDRCONFIG | Query for whichever address type (IPv4 or IPv6) is configured. | AI_ALL | Look for both IPv4 and IPv6 addresses (used only with AI_V4MAPPED). | AI_CANONNAME | Request a canonical name (as opposed to an alias). | AI_NUMERICHOST | Return the host address in numeric format. | AI_NUMERICSERV | Return the service as a port number. | AI_PASSIVE | Socket address is intended to be bound for listening. | AI_V4MAPPED | If no IPv6 addresses are found, return IPv4 addresses mapped in IPv6 format. |
If getaddrinfo fails, we can't use perror or strerror to generate an error message. Instead, we need to call gai_strerror to convert the error code returned into an error message.
#include <netdb.h>
const char *gai_strerror(int error);
| Returns: a pointer to a string describing the error |
The getnameinfo function converts an address into a host name and a service name.
#include <sys/socket.h>
#include <netdb.h>
int getnameinfo(const struct sockaddr *restrict addr,
socklen_t alen, char *restrict host,
socklen_t hostlen, char *restrict
service,
socklen_t servlen, unsigned int
flags);
| Returns: 0 if OK, nonzero on error |
The socket address (addr) is translated into a host name and a service name. If host is non-null, it points to a buffer hostlen bytes long that will be used to return the host name. Similarly, if service is non-null, it points to a buffer servlen bytes long that will be used to return the service name.
The flags argument gives us some control over how the translation is done. Figure 16.7 summarizes the supported flags.
Figure 16.7. Flags for the getnameinfo functionFlag | Description |
|---|
NI_DGRAM | The service is datagram based instead of stream based. | NI_NAMEREQD | If the host name can't be found, treat this as an error. | NI_NOFQDN | Return only the node name portion of the fully-qualified domain name for local hosts. | NI_NUMERICHOST | Return the numeric form of the host address instead of the name. | NI_NUMERICSERV | Return the numeric form of the service address (i.e., the port number) instead of the name. |
Example
Figure 16.8 illustrates the use of the getaddrinfo function.
This program illustrates the use of the getaddrinfo function. If multiple protocols provide the given service for the given host, the program will print more than one entry. In this example, we print out the address information only for the protocols that work with IPv4 (ai_family equals AF_INET). If we wanted to restrict the output to the AF_INET protocol family, we could set the ai_family field in the hint.
When we run the program on one of the test systems, we get
$ ./a.out harry nfs
flags canon family inet type stream protocol TCP
host harry address 192.168.1.105 port 2049
flags canon family inet type datagram protocol UDP
host harry address 192.168.1.105 port 2049
Figure 16.8. Print host and service information
#include "apue.h"
#include <netdb.h>
#include <arpa/inet.h>
#if defined(BSD) || defined(MACOS)
#include <sys/socket.h>
#include <netinet/in.h>
#endif
void
print_family(struct addrinfo *aip)
{
printf(" family ");
switch (aip->ai_family) {
case AF_INET:
printf("inet");
break;
case AF_INET6:
printf("inet6");
break;
case AF_UNIX:
printf("unix");
break;
case AF_UNSPEC:
printf("unspecified");
break;
default:
printf("unknown");
}
}
void
print_type(struct addrinfo *aip)
{
printf(" type ");
switch (aip->ai_socktype) {
case SOCK_STREAM:
printf("stream");
break;
case SOCK_DGRAM:
printf("datagram");
break;
case SOCK_SEQPACKET:
printf("seqpacket");
break;
case SOCK_RAW:
printf("raw");
break;
default:
printf("unknown (%d)", aip->ai_socktype);
}
}
void
print_protocol(struct addrinfo *aip)
{
printf(" protocol ");
switch (aip->ai_protocol) {
case 0:
printf("default");
break;
case IPPROTO_TCP:
printf("TCP");
break;
case IPPROTO_UDP:
printf("UDP");
break;
case IPPROTO_RAW:
printf("raw");
break;
default:
printf("unknown (%d)", aip->ai_protocol);
}
}
void
print_flags(struct addrinfo *aip)
{
printf("flags");
if (aip->ai_flags == 0) {
printf(" 0");
} else {
if (aip->ai_flags & AI_PASSIVE)
printf(" passive");
if (aip->ai_flags & AI_CANONNAME)
printf(" canon");
if (aip->ai_flags & AI_NUMERICHOST)
printf(" numhost");
#if defined(AI_NUMERICSERV)
if (aip->ai_flags & AI_NUMERICSERV)
printf(" numserv");
#endif
#if defined(AI_V4MAPPED)
if (aip->ai_flags & AI_V4MAPPED)
printf(" v4mapped");
#endif
#if defined(AI_ALL)
if (aip->ai_flags & AI_ALL)
printf(" all");
#endif
}
}
int
main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
struct sockaddr_in *sinp;
const char *addr;
int err;
char abuf[INET_ADDRSTRLEN];
if (argc != 3)
err_quit("usage: %s nodename service", argv[0]);
hint.ai_flags = AI_CANONNAME;
hint.ai_family = 0;
hint.ai_socktype = 0;
hint.ai_protocol = 0;
hint.ai_addrlen = 0;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(argv[1], argv[2], &hint, &ailist)) != 0)
err_quit("getaddrinfo error: %s", gai_strerror(err));
for (aip = ailist; aip != NULL; aip = aip->ai_next) {
print_flags(aip);
print_family(aip);
print_type(aip);
print_protocol(aip);
printf("\n\thost %s", aip->ai_canonname?aip->ai_canonname:"-");
if (aip->ai_family == AF_INET) {
sinp = (struct sockaddr_in *)aip->ai_addr;
addr = inet_ntop(AF_INET, &sinp->sin_addr, abuf,
INET_ADDRSTRLEN);
printf(" address %s", addr?addr:"unknown");
printf(" port %d", ntohs(sinp->sin_port));
}
printf("\n");
}
exit(0);
}
16.3.4. Associating Addresses with Sockets
The address associated with a client's socket is of little interest, and we can let the system choose a default address for us. For a server, however, we need to associate a well-known address with the server's socket on which client requests will arrive. Clients need a way to discover the address to use to contact a server, and the simplest scheme is for a server to reserve an address and register it in /etc/services or with a name service.
We use the bind function to associate an address with a socket.
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr,
socklen_t len);
| Returns: 0 if OK, 1 on error |
There are several restrictions on the address we can use:
The address we specify must be valid for the machine on which the process is running; we can't specify an address belonging to some other machine. The address must match the format supported by the address family we used to create the socket. The port number in the address cannot be less than 1,024 unless the process has the appropriate privilege (i.e., is the superuser). Usually, only one socket endpoint can be bound to a given address, although some protocols allow duplicate bindings.
For the Internet domain, if we specify the special IP address INADDR_ANY, the socket endpoint will be bound to all the system's network interfaces. This means that we can receive packets from any of the network interface cards installed in the system. We'll see in the next section that the system will choose an address and bind it to our socket for us if we call connect or listen without first binding an address to the socket.
We can use the getsockname function to discover the address bound to a socket.
#include <sys/socket.h>
int getsockname(int sockfd, struct sockaddr
*restrict addr,
socklen_t *restrict alenp);
| Returns: 0 if OK, 1 on error |
Before calling getsockname, we set alenp to point to an integer containing the size of the sockaddr buffer. On return, the integer is set to the size of the address returned. If the address won't fit in the buffer provided, the address is silently truncated. If no address is currently bound to the socket, the results are undefined.
If the socket is connected to a peer, we can find out the peer's address by calling the getpeername function.
#include <sys/socket.h>
int getpeername(int sockfd, struct sockaddr
*restrict addr,
socklen_t *restrict alenp);
| Returns: 0 if OK, 1 on error |
Other than returning the peer's address, the getpeername function is identical to the getsockname function.
16.4. Connection Establishment
If we're dealing with a connection-oriented network service (SOCK_STREAM or SOCK_SEQPACKET), then before we can exchange data, we need to create a connection between the socket of the process requesting the service (the client) and the process providing the service (the server). We use the connect function to create a connection.
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr
*addr, socklen_t len);
| Returns: 0 if OK, 1 on error |
The address we specify with connect is the address of the server with which we wish to communicate. If sockfd is not bound to an address, connect will bind a default address for the caller.
When we try to connect to a server, the connect request might fail for several reasons. The machine to which we are trying to connect must be up and running, the server must be bound to the address we are trying to contact, and there must be room in the server's pending connect queue (we'll learn more about this shortly). Thus, applications must be able to handle connect error returns that might be caused by transient conditions.
Example
Figure 16.9 shows one way to handle transient connect errors. This is likely with a server that is running on a heavily loaded system.
This function shows what is known as an exponential backoff algorithm. If the call to connect fails, the process goes to sleep for a short time and then tries again, increasing the delay each time through the loop, up to a maximum delay of about 2 minutes.
Figure 16.9. Connect with retry
#include "apue.h"
#include <sys/socket.h>
#define MAXSLEEP 128
int
connect_retry(int sockfd, const struct sockaddr *addr, socklen_t alen)
{
int nsec;
/*
* Try to connect with exponential backoff.
*/
for (nsec = 1; nsec <= MAXSLEEP; nsec <<= 1) {
if (connect(sockfd, addr, alen) == 0) {
/*
* Connection accepted.
*/
return(0);
}
/*
* Delay before trying again.
*/
if (nsec <= MAXSLEEP/2)
sleep(nsec);
}
return(-1);
}
If the socket descriptor is in nonblocking mode, which we discuss further in Section 16.8, connect will return 1 with errno set to the special error code EINPROGRESS if the connection can't be established immediately. The application can use either poll or select to determine when the file descriptor is writable. At this point, the connection is complete.
The connect function can also be used with a connectionless network service (SOCK_DGRAM). This might seem like a contradiction, but it is an optimization instead. If we call connect with a SOCK_DGRAM socket, the destination address of all messages we send is set to the address we specified in the connect call, relieving us from having to provide the address every time we transmit a message. In addition, we will receive datagrams only from the address we've specified.
A server announces that it is willing to accept connect requests by calling the listen function.
#include <sys/socket.h>
int listen(int sockfd, int backlog);
| Returns: 0 if OK, 1 on error |
The backlog argument provides a hint to the system of the number of outstanding connect requests that it should enqueue on behalf of the process. The actual value is determined by the system, but the upper limit is specified as SOMAXCONN in <sys/socket.h>.
On Solaris, the SOMAXCONN value in <sys/socket.h> is ignored. The particular maximum depends on the implementation of each protocol. For TCP, the default is 128.
Once the queue is full, the system will reject additional connect requests, so the backlog value must be chosen based on the expected load of the server and the amount of processing it must do to accept a connect request and start the service.
Once a server has called listen, the socket used can receive connect requests. We use the accept function to retrieve a connect request and convert that into a connection.
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *restrict addr,
socklen_t *restrict len);
| Returns: file (socket) descriptor if OK, 1 on error |
The file descriptor returned by accept is a socket descriptor that is connected to the client that called connect. This new socket descriptor has the same socket type and address family as the original socket (sockfd). The original socket passed to accept is not associated with the connection, but instead remains available to receive additional connect requests.
If we don't care about the client's identity, we can set the addr and len parameters to NULL. Otherwise, before calling accept, we need to set the addr parameter to a buffer large enough to hold the address and set the integer pointed to by len to the size of the buffer. On return, accept will fill in the client's address in the buffer and update the integer pointed to by len to reflect the size of the address.
If no connect requests are pending, accept will block until one arrives. If sockfd is in nonblocking mode, accept will return 1 and set errno to either EAGAIN or EWOULDBLOCK.
All four platforms discussed in this text define EAGAIN to be the same as EWOULDBLOCK.
If a server calls accept and no connect request is present, the server will block until one arrives. Alternatively, a server can use either poll or select to wait for a connect request to arrive. In this case, a socket with pending connect requests will appear to be readable.
Example
Figure 16.10 shows a function we can use to allocate and initialize a socket for use by a server process.
We'll see that TCP has some strange rules regarding address reuse that make this example inadequate. Figure 16.20 shows a version of this function that bypasses these rules, solving the major drawback with this version.
Figure 16.10. Initialize a socket endpoint for use by a server
#include "apue.h"
#include <errno.h>
#include <sys/socket.h>
int
initserver(int type, const struct sockaddr *addr, socklen_t alen,
int qlen)
{
int fd;
int err = 0;
if ((fd = socket(addr->sa_family, type, 0)) < 0)
return(-1);
if (bind(fd, addr, alen) < 0) {
err = errno;
goto errout;
}
if (type == SOCK_STREAM || type == SOCK_SEQPACKET) {
if (listen(fd, qlen) < 0) {
err = errno;
goto errout;
}
}
return(fd);
errout:
close(fd);
errno = err;
return(-1);
}
16.5. Data Transfer
Since a socket endpoint is represented as a file descriptor, we can use read and write to communicate with a socket, as long as it is connected. Recall that a datagram socket can be "connected" if we set the default peer address using the connect function. Using read and write with socket descriptors is significant, because it means that we can pass socket descriptors to functions that were originally designed to work with local files. We can also arrange to pass the socket descriptors to child processes that execute programs that know nothing about sockets.
Although we can exchange data using read and write, that is about all we can do with these two functions. If we want to specify options, receive packets from multiple clients, or send out-of-band data, we need to use one of the six socket functions designed for data transfer.
Three functions are available for sending data, and three are available for receiving data. First, we'll look at the ones used to send data.
The simplest one is send. It is similar to write, but allows us to specify flags to change how the data we want to transmit is treated.
#include <sys/socket.h>
ssize_t send(int sockfd, const void *buf, size_t
nbytes, int flags);
| Returns: number of bytes sent if OK, 1 on error |
Like write, the socket has to be connected to use send. The buf and nbytes arguments have the same meaning as they do with write.
Unlike write, however, send supports a fourth flags argument. Two flags are defined by the Single UNIX Specification, but it is common for implementations to support additional ones. They are summarized in Figure 16.11.
Figure 16.11. Flags used with send socket callsFlag | Description | POSIX.1 | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
MSG_DONTROUTE | Don't route packet outside of local network. | | • | • | • | • | MSG_DONTWAIT | Enable nonblocking operation (equivalent to using O_NONBLOCK). | | • | • | • | | MSG_EOR | This is the end of record if supported by protocol. | • | • | • | • | | MSG_OOB | Send out-of-band data if supported by protocol (see Section 16.7). | • | • | • | • | • |
If send returns success, it doesn't necessarily mean that the process at the other end of the connection receives the data. All we are guaranteed is that when send succeeds, the data has been delivered to the network drivers without error.
With a protocol that supports message boundaries, if we try to send a single message larger than the maximum supported by the protocol, send will fail with errno set to EMSGSIZE. With a byte-stream protocol, send will block until the entire amount of data has been transmitted.
The sendto function is similar to send. The difference is that sendto allows us to specify a destination address to be used with connectionless sockets.
#include <sys/socket.h>
ssize_t sendto(int sockfd, const void *buf, size_t
nbytes, int flags,
const struct sockaddr *destaddr,
socklen_t destlen);
| Returns: number of bytes sent if OK, 1 on error |
With a connection-oriented socket, the destination address is ignored, as the destination is implied by the connection. With a connectionless socket, we can't use send unless the destination address is first set by calling connect, so sendto gives us an alternate way to send a message.
We have one more choice when transmitting data over a socket. We can call sendmsg with a msghdr structure to specify multiple buffers from which to transmit data, similar to the writev function (Section 14.7).
#include <sys/socket.h>
ssize_t sendmsg(int sockfd, const struct msghdr
*msg, int flags);
| Returns: number of bytes sent if OK, 1 on error |
POSIX.1 defines the msghdr structure to have at least the following members:
struct msghdr {
void *msg_name; /* optional address */
socklen_t msg_namelen; /* address size in bytes */
struct iovec *msg_iov; /* array of I/O buffers */
int msg_iovlen; /* number of elements in array */
void *msg_control; /* ancillary data */
socklen_t msg_controllen; /* number of ancillary bytes */
int msg_flags; /* flags for received message */
.
.
.
};
We saw the iovec structure in Section 14.7. We'll see the use of ancillary data in Section 17.4.2.
The recv function is similar to read, but allows us to specify some options to control how we receive the data.
#include <sys/socket.h>
ssize_t recv(int sockfd, void *buf, size_t nbytes,
int flags);
| Returns: length of message in bytes, 0 if no messages are available and peer has done an orderly shutdown, or 1 on error |
The flags that can be passed to recv are summarized in Figure 16.12. Only three are defined by the Single UNIX Specification.
Figure 16.12. Flags used with recv socket callsFlag | Description | POSIX.1 | FreeBSD 5.2.1 | Linux 5.2.1 | Mac OS X 10.3 | Solaris 9 |
|---|
MSG_OOB | Retrieve out-of-band data if supported by protocol (see Section 16.7). | • | • | • | • | • | MSG_PEEK | Return packet contents without consuming packet. | • | • | • | • | • | MSG_TRUNC | Request that the real length of the packet be returned, even if it was truncated. | | | • | | | MSG_WAITALL | Wait until all data is available (SOCK_STREAM only). | • | • | • | • | • |
When we specify the MSG_PEEK flag, we can peek at the next data to be read without actually consuming it. The next call to read or one of the recv functions will return the same data we peeked at.
With SOCK_STREAM sockets, we can receive less data than we requested. The MSG_WAITALL flag inhibits this behavior, preventing recv from returning until all the data we requested has been received. With SOCK_DGRAM and SOCK_SEQPACKET sockets, the MSG_WAITALL flag provides no change in behavior, because these message-based socket types already return an entire message in a single read.
If the sender has called shutdown (Section 16.2) to end transmission, or if the network protocol supports orderly shutdown by default and the sender has closed the socket, then recv will return 0 when we have received all the data.
If we are interested in the identity of the sender, we can use recvfrom to obtain the source address from which the data was sent.
#include <sys/socket.h>
ssize_t recvfrom(int sockfd, void *restrict buf,
size_t len, int flags,
struct sockaddr *restrict addr,
socklen_t *restrict addrlen);
| Returns: length of message in bytes, 0 if no messages are available and peer has done an orderly shutdown, or 1 on error |
If addr is non-null, it will contain the address of the socket endpoint from which the data was sent. When calling recvfrom, we need to set the addrlen parameter to point to an integer containing the size in bytes of the socket buffer to which addr points. On return, the integer is set to the actual size of the address in bytes.
Because it allows us to retrieve the address of the sender, recvfrom is usually used with connectionless sockets. Otherwise, recvfrom behaves identically to recv.
To receive data into multiple buffers, similar to readv (Section 14.7), or if we want to receive ancillary data (Section 17.4.2), we can use recvmsg.
#include <sys/socket.h>
ssize_t recvmsg(int sockfd, struct msghdr *msg,
int flags);
| Returns: length of message in bytes, 0 if no messages are available and peer has done an orderly shutdown, or 1 on error |
The msghdr structure (which we saw used with sendmsg) is used by recvmsg to specify the input buffers to be used to receive the data. We can set the flags argument to change the default behavior of recvmsg. On return, the msg_flags field of the msghdr structure is set to indicate various characteristics of the data received. (The msg_flags field is ignored on entry to recvmsg). The possible values on return from recvmsg are summarized in Figure 16.13. We'll see an example that uses recvmsg in Chapter 17.
Figure 16.13. Flags returned in msg_flags by recvmsgFlag | Description | POSIX.1 | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
MSG_CTRUNC | Control data was truncated. | • | • | • | • | • | MSG_DONTWAIT | recvmsg was called in nonblocking mode. | | | • | | • | MSG_EOR | End of record was received. | • | • | • | • | • | MSG_OOB | Out-of-band data was received. | • | • | • | • | • | MSG_TRUNC | Normal data was truncated. | • | • | • | • | • |
ExampleConnection-Oriented Client
Figure 16.14 shows a client command that communicates with a server to obtain the output from a system's uptime command. We call this service "remote uptime" (or "ruptime" for short).
This program connects to a server, reads the string sent by the server, and prints the string on the standard output. Since we're using a SOCK_STREAM socket, we can't be guaranteed that we will read the entire string in one call to recv, so we need to repeat the call until it returns 0.
The getaddrinfo function might return more than one candidate address for us to use if the server supports multiple network interfaces or multiple network protocols. We try each one in turn, giving up when we find one that allows us to connect to the service. We use the connect_retry function from Figure 16.9 to establish a connection with the server.
Figure 16.14. Client command to get uptime from server
#include "apue.h"
#include <netdb.h>
#include <errno.h>
#include <sys/socket.h>
#define MAXADDRLEN 256
#define BUFLEN 128
extern int connect_retry(int, const struct sockaddr *, socklen_t);
void
print_uptime(int sockfd)
{
int n;
char buf[BUFLEN];
while ((n = recv(sockfd, buf, BUFLEN, 0)) > 0)
write(STDOUT_FILENO, buf, n);
if (n < 0)
err_sys("recv error");
}
int
main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err;
if (argc != 2)
err_quit("usage: ruptime hostname");
hint.ai_flags = 0;
hint.ai_family = 0;
hint.ai_socktype = SOCK_STREAM;
hint.ai_protocol = 0;
hint.ai_addrlen = 0;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(argv[1], "ruptime", &hint, &ailist)) != 0)
err_quit("getaddrinfo error: %s", gai_strerror(err));
for (aip = ailist; aip != NULL; aip = aip->ai_next) {
if ((sockfd = socket(aip->ai_family, SOCK_STREAM, 0)) < 0)
err = errno;
if (connect_retry(sockfd, aip->ai_addr, aip->ai_addrlen) < 0) {
err = errno;
} else {
print_uptime(sockfd);
exit(0);
}
}
fprintf(stderr, "can't connect to %s: %s\n", argv[1],
strerror(err));
exit(1);
}
ExampleConnection-Oriented Server
Figure 16.15 shows the server that provides the uptime command's output to the client program from Figure 16.14.
To find out its address, the server needs to get the name of the host on which it is running. Some systems don't define the _SC_HOST_NAME_MAX constant, so we use HOST_NAME_MAX in this case. If the system doesn't define HOST_NAME_MAX, we define it ourselves. POSIX.1 states that the minimum value for the host name is 255 bytes, not including the terminating null, so we define HOST_NAME_MAX to be 256 to include the terminating null.
The server gets the host name by calling gethostname and looks up the address for the remote uptime service. Multiple addresses can be returned, but we simply choose the first one for which we can establish a passive socket endpoint. Handling multiple addresses is left as an exercise.
We use the initserver function from Figure 16.10 to initialize the socket endpoint on which we will wait for connect requests to arrive. (Actually, we use the version from Figure 16.20; we'll see why when we discuss socket options in Section 16.6.)
Figure 16.15. Server program to provide system uptime
#include "apue.h"
#include <netdb.h>
#include <errno.h>
#include <syslog.h>
#include <sys/socket.h>
#define BUFLEN 128
#define QLEN 10
#ifndef HOST_NAME_MAX
#define HOST_NAME_MAX 256
#endif
extern int initserver(int, struct sockaddr *, socklen_t, int);
void
serve(int sockfd)
{
int clfd;
FILE *fp;
char buf[BUFLEN];
for (;;) {
clfd = accept(sockfd, NULL, NULL);
if (clfd < 0) {
syslog(LOG_ERR, "ruptimed: accept error: %s",
strerror(errno));
exit(1);
}
if ((fp = popen("/usr/bin/uptime", "r")) == NULL) {
sprintf(buf, "error: %s\n", strerror(errno));
send(clfd, buf, strlen(buf), 0);
} else {
while (fgets(buf, BUFLEN, fp) != NULL)
send(clfd, buf, strlen(buf), 0);
pclose(fp);
}
close(clfd);
}
}
int
main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err, n;
char *host;
if (argc != 1)
err_quit("usage: ruptimed");
#ifdef _SC_HOST_NAME_MAX
n = sysconf(_SC_HOST_NAME_MAX);
if (n < 0) /* best guess */
#endif
n = HOST_NAME_MAX;
host = malloc(n);
if (host == NULL)
err_sys("malloc error");
if (gethostname(host, n) < 0)
err_sys("gethostname error");
daemonize("ruptimed");
hint.ai_flags = AI_CANONNAME;
hint.ai_family = 0;
hint.ai_socktype = SOCK_STREAM;
hint.ai_protocol = 0;
hint.ai_addrlen = 0;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(host, "ruptime", &hint, &ailist)) != 0) {
syslog(LOG_ERR, "ruptimed: getaddrinfo error: %s",
gai_strerror(err));
exit(1);
}
for (aip = ailist; aip != NULL; aip = aip->ai_next) {
if ((sockfd = initserver(SOCK_STREAM, aip->ai_addr,
aip->ai_addrlen, QLEN)) >= 0) {
serve(sockfd);
exit(0);
}
}
exit(1);
}
ExampleAlternate Connection-Oriented Server
Previously, we stated that using file descriptors to access sockets was significant, because it allowed programs that knew nothing about networking to be used in a networked environment. The version of the server shown in Figure 16.16 illustrates this point. Instead of reading the output of the uptime command and sending it to the client, the server arranges to have the standard output and standard error of the uptime command be the socket endpoint connected to the client.
Instead of using popen to run the uptime command and reading the output from the pipe connected to the command's standard output, we use fork to create a child process and then use dup2 to arrange that the child's copy of STDIN_FILENO is open to /dev/null and that both STDOUT_FILENO and STDERR_FILENO are open to the socket endpoint. When we execute uptime, the command writes the results to its standard output, which is connected to the socket, and the data is sent back to the ruptime client command.
The parent can safely close the file descriptor connected to the client, because the child still has it open. The parent waits for the child to complete before proceeding, so that the child doesn't become a zombie. Since it shouldn't take too long to run the uptime command, the parent can afford to wait for the child to exit before accepting the next connect request. This strategy might not be appropriate if the child takes a long time, however.
Figure 16.16. Server program illustrating command writing directly to socket
#include "apue.h"
#include <netdb.h>
#include <errno.h>
#include <syslog.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <sys/wait.h>
#define QLEN 10
#ifndef HOST_NAME_MAX
#define HOST_NAME_MAX 256
#endif
extern int initserver(int, struct sockaddr *, socklen_t, int);
void
serve(int sockfd)
{
int clfd, status;
pid_t pid;
for (;;) {
clfd = accept(sockfd, NULL, NULL);
if (clfd < 0) {
syslog(LOG_ERR, "ruptimed: accept error: %s",
strerror(errno));
exit(1);
}
if ((pid = fork()) < 0) {
syslog(LOG_ERR, "ruptimed: fork error: %s",
strerror(errno));
exit(1);
} else if (pid == 0) { /* child */
/*
* The parent called daemonize (Figure 13.1), so
* STDIN_FILENO, STDOUT_FILENO, and STDERR_FILENO
* are already open to /dev/null. Thus, the call to
* close doesn't need to be protected by checks that
* clfd isn't already equal to one of these values.
*/
if (dup2(clfd, STDOUT_FILENO) != STDOUT_FILENO ||
dup2(clfd, STDERR_FILENO) != STDERR_FILENO) {
syslog(LOG_ERR, "ruptimed: unexpected error");
exit(1);
}
close(clfd);
execl("/usr/bin/uptime", "uptime", (char *)0);
syslog(LOG_ERR, "ruptimed: unexpected return from exec: %s",
strerror(errno));
} else { /* parent */
close(clfd);
waitpid(pid, &status, 0);
}
}
}
int
main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err, n;
char *host;
if (argc != 1)
err_quit("usage: ruptimed");
#ifdef _SC_HOST_NAME_MAX
n = sysconf(_SC_HOST_NAME_MAX);
if (n < 0) /* best guess */
#endif
n = HOST_NAME_MAX;
host = malloc(n);
if (host == NULL)
err_sys("malloc error");
if (gethostname(host, n) < 0)
err_sys("gethostname error");
daemonize("ruptimed");
hint.ai_flags = AI_CANONNAME;
hint.ai_family = 0;
hint.ai_socktype = SOCK_STREAM;
hint.ai_protocol = 0;
hint.ai_addrlen = 0;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(host, "ruptime", &hint, &ailist)) != 0) {
syslog(LOG_ERR, "ruptimed: getaddrinfo error: %s",
gai_strerror(err));
exit(1);
}
for (aip = ailist; aip != NULL; aip = aip->ai_next) {
if ((sockfd = initserver(SOCK_STREAM, aip->ai_addr,
aip->ai_addrlen, QLEN)) >= 0) {
serve(sockfd);
exit(0);
}
}
exit(1);
}
The previous examples have used connection-oriented sockets. But how do we choose the appropriate type? When do we use a connection-oriented socket, and when do we use a connectionless socket? The answer depends on how much work we want to do and what kind of tolerance we have for errors.
With a connectionless socket, packets can arrive out of order, so if we can't fit all our data in one packet, we will have to worry about ordering in our application. The maximum packet size is a characteristic of the communication protocol. Also, with a connectionless socket, the packets can be lost. If our application can't tolerate this loss, we should use connection-oriented sockets.
Tolerating packet loss means that we have two choices. If we intend to have reliable communication with our peer, we have to number our packets and request retransmission from the peer application when we detect a missing packet. We will also have to identify duplicate packets and discard them, since a packet might be delayed and appear to be lost, but show up after we have requested retransmission.
The other choice we have is to deal with the error by letting the user retry the command. For simple applications, this might be adequate, but for complex applications, this usually isn't a viable alternative, so it is generally better to use connection-oriented sockets in this case.
The drawbacks to connection-oriented sockets are that more work and time are needed to establish a connection, and each connection consumes more resources from the operating system.
ExampleConnectionless Client
The program in Figure 16.17 is a version of the uptime client command that uses the datagram socket interface.
The main function for the datagram-based client is similar to the one for the connection-oriented client, with the addition of installing a signal handler for SIGALRM. We use the alarm function to avoid blocking indefinitely in the call to recvfrom.
With the connection-oriented protocol, we needed to connect to the server before exchanging data. The arrival of the connect request was enough for the server to determine that it needed to provide service to a client. But with the datagram-based protocol, we need a way to notify the server that we want it to perform its service on our behalf. In this example, we simply send the server a 1-byte message. The server will receive it, get our address from the packet, and use this address to transmit its response. If the server offered multiple services, we could use this request message to indicate the service we want, but since the server does only one thing, the content of the 1-byte message doesn't matter.
If the server isn't running, the client will block indefinitely in the call to recvfrom. With the connection-oriented example, the connect call will fail if the server isn't running. To avoid blocking indefinitely, we set an alarm clock before calling recvfrom.
Figure 16.17. Client command using datagram service
#include "apue.h"
#include <netdb.h>
#include <errno.h>
#include <sys/socket.h>
#define BUFLEN 128
#define TIMEOUT 20
void
sigalrm(int signo)
{
}
void
print_uptime(int sockfd, struct addrinfo *aip)
{
int n;
char buf[BUFLEN];
buf[0] = 0;
if (sendto(sockfd, buf, 1, 0, aip->ai_addr, aip->ai_addrlen) < 0)
err_sys("sendto error");
alarm(TIMEOUT);
if ((n = recvfrom(sockfd, buf, BUFLEN, 0, NULL, NULL)) < 0) {
if (errno != EINTR)
alarm(0);
err_sys("recv error");
}
alarm(0);
write(STDOUT_FILENO, buf, n);
}
int
main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err;
struct sigaction sa;
if (argc != 2)
err_quit("usage: ruptime hostname");
sa.sa_handler = sigalrm;
sa.sa_flags = 0;
sigemptyset(&sa.sa_mask);
if (sigaction(SIGALRM, &sa, NULL) < 0)
err_sys("sigaction error");
hint.ai_flags = 0;
hint.ai_family = 0;
hint.ai_socktype = SOCK_DGRAM;
hint.ai_protocol = 0;
hint.ai_addrlen = 0;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(argv[1], "ruptime", &hint, &ailist)) != 0)
err_quit("getaddrinfo error: %s", gai_strerror(err));
for (aip = ailist; aip != NULL; aip = aip->ai_next) {
if ((sockfd = socket(aip->ai_family, SOCK_DGRAM, 0)) < 0) {
err = errno;
} else {
print_uptime(sockfd, aip);
exit(0);
}
}
fprintf(stderr, "can't contact %s: %s\n", argv[1], strerror(err));
exit(1);
}
ExampleConnectionless Server
The program in Figure 16.18 is the datagram version of the uptime server.
The server blocks in recvfrom for a request for service. When a request arrives, we save the requester's address and use popen to run the uptime command. We send the output back to the client using the sendto function, with the destination address set to the requester's address.
Figure 16.18. Server providing system uptime over datagrams
#include "apue.h"
#include <netdb.h>
#include <errno.h>
#include <syslog.h>
#include <sys/socket.h>
#define BUFLEN 128
#define MAXADDRLEN 256
#ifndef HOST_NAME_MAX
#define HOST_NAME_MAX 256
#endif
extern int initserver(int, struct sockaddr *, socklen_t, int);
void
serve(int sockfd)
{
int n;
socklen_t alen;
FILE *fp;
char buf[BUFLEN];
char abuf[MAXADDRLEN];
for (;;) {
alen = MAXADDRLEN;
if ((n = recvfrom(sockfd, buf, BUFLEN, 0,
(struct sockaddr *)abuf, &alen)) < 0) {
syslog(LOG_ERR, "ruptimed: recvfrom error: %s",
strerror(errno));
exit(1);
}
if ((fp = popen("/usr/bin/uptime", "r")) == NULL) {
sprintf(buf, "error: %s\n", strerror(errno));
sendto(sockfd, buf, strlen(buf), 0,
(struct sockaddr *)abuf, alen);
} else {
if (fgets(buf, BUFLEN, fp) != NULL)
sendto(sockfd, buf, strlen(buf), 0,
(struct sockaddr *)abuf, alen);
pclose(fp);
}
}
}
int
main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err, n;
char *host;
if (argc != 1)
err_quit("usage: ruptimed");
#ifdef _SC_HOST_NAME_MAX
n = sysconf(_SC_HOST_NAME_MAX);
if (n < 0) /* best guess */
#endif
n = HOST_NAME_MAX;
host = malloc(n);
if (host == NULL)
err_sys("malloc error");
if (gethostname(host, n) < 0)
err_sys("gethostname error");
daemonize("ruptimed");
hint.ai_flags = AI_CANONNAME;
hint.ai_family = 0;
hint.ai_socktype = SOCK_DGRAM;
hint.ai_protocol = 0;
hint.ai_addrlen = 0;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(host, "ruptime", &hint, &ailist)) != 0) {
syslog(LOG_ERR, "ruptimed: getaddrinfo error: %s",
gai_strerror(err));
exit(1);
}
for (aip = ailist; aip != NULL; aip = aip->ai_next) {
if ((sockfd = initserver(SOCK_DGRAM, aip->ai_addr,
aip->ai_addrlen, 0)) >= 0) {
serve(sockfd);
exit(0);
}
}
exit(1);
}
16.6. Socket Options
The socket mechanism provides two socket-option interfaces for us to control the behavior of sockets. One interface is used to set an option, and another interface allows us to query the state of an option. We can get and set three kinds of options:
Generic options that work with all socket types Options that are managed at the socket level, but depend on the underlying protocols for support Protocol-specific options unique to each individual protocol
The Single UNIX Specification defines only the socket-layer options (the first two option types in the preceding list).
We can set a socket option with the setsockopt function.
#include <sys/socket.h>
int setsockopt(int sockfd, int level, int option,
const void *val,
socklen_t len);
| Returns: 0 if OK, 1 on error |
The level argument identifies the protocol to which the option applies. If the option is a generic socket-level option, then level is set to SOL_SOCKET. Otherwise, level is set to the number of the protocol that controls the option. Examples are IPPROTO_TCP for TCP options and IPPROTO_IP for IP options. Figure 16.19 summarizes the generic socket-level options defined by the Single UNIX Specification.
Figure 16.19. Socket optionsOption | Type of val argument | Description |
|---|
SO_ACCEPTCONN | int | Return whether a socket is enabled for listening (getsockopt only). | SO_BROADCAST | int | Broadcast datagrams if *val is nonzero. | SO_DEBUG | int | Debugging in network drivers enabled if *val is nonzero. | SO_DONTROUTE | int | Bypass normal routing if *val is nonzero. | SO_ERROR | int | Return and clear pending socket error (getsockopt only). | SO_KEEPALIVE | int | Periodic keep-alive messages enabled if *val is nonzero. | SO_LINGER | struct linger | Delay time when unsent messages exist and socket is closed. | SO_OOBINLINE | int | Out-of-band data placed inline with normal data if *val is nonzero. | SO_RCVBUF | int | The size in bytes of the receive buffer. | SO_RCVLOWAT | int | The minimum amount of data in bytes to return on a receive call. | SO_RCVTIMEO | struct timeval | The timeout value for a socket receive call. | SO_REUSEADDR | int | Reuse addresses in bind if *val is nonzero. | SO_SNDBUF | int | The size in bytes of the send buffer. | SO_SNDLOWAT | int | The minimum amount of data in bytes to transmit in a send call. | SO_SNDTIMEO | struct timeval | The timeout value for a socket send call. | SO_TYPE | int | Identify the socket type (getsockopt only). |
The val argument points to a data structure or an integer, depending on the option. Some options are on/off switches. If the integer is nonzero, then the option is enabled. If the integer is zero, then the option is disabled. The len argument specifies the size of the object to which val points.
We can find out the current value of an option with the getsockopt function.
#include <sys/socket.h>
int getsockopt(int sockfd, int level, int option,
void *restrict val,
socklen_t *restrict lenp);
| Returns: 0 if OK, 1 on error |
Note that the lenp argument is a pointer to an integer. Before calling getsockopt, we set the integer to the size of the buffer where the option is to be copied. If the actual size of the option is greater than this size, the option is silently truncated. If the actual size of the option is less than or equal to this size, then the integer is updated with the actual size on return.
Example
The function in Figure 16.10 fails to operate properly when the server terminates and we try to restart it immediately. Normally, the implementation of TCP will prevent us from binding the same address until a timeout expires, which is usually on the order of several minutes. Luckily, the SO_REUSEADDR socket option allows us to bypass this restriction, as illustrated in Figure 16.20.
To enable the SO_REUSEADDR option, we set an integer to a nonzero value and pass the address of the integer as the val argument to setsockopt. We set the len argument to the size of an integer to indicate the size of the object to which val points.
Figure 16.20. Initialize a socket endpoint for use by a server with address reuse
#include "apue.h"
#include <errno.h>
#include <sys/socket.h>
int
initserver(int type, const struct sockaddr *addr, socklen_t alen,
int qlen)
{
int fd, err;
int reuse = 1;
if ((fd = socket(addr->sa_family, type, 0)) < 0)
return(-1);
if (setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &reuse,
sizeof(int)) < 0) {
err = errno;
goto errout;
}
if (bind(fd, addr, alen) < 0) {
err = errno;
goto errout;
}
if (type == SOCK_STREAM || type == SOCK_SEQPACKET) {
if (listen(fd, qlen) < 0) {
err = errno;
goto errout;
}
}
return(fd);
errout:
close(fd);
errno = err;
return(-1);
}
16.7. Out-of-Band Data
Out-of-band data is an optional feature supported by some communication protocols, allowing higher-priority delivery of data than normal. Out-of-band data is sent ahead of any data that is already queued for transmission. TCP supports out-of-band data, but UDP doesn't. The socket interface to out-of-band data is heavily influenced by TCP's implementation of out-of-band data.
TCP refers to out-of-band data as "urgent" data. TCP supports only a single byte of urgent data, but allows urgent data to be delivered out of band from the normal data delivery mechanisms. To generate urgent data, we specify the MSG_OOB flag to any of the three send functions. If we send more than one byte with the MSG_OOB flag, the last byte will be treated as the urgent-data byte.
When urgent data is received, we are sent the SIGURG signal if we have arranged for signal generation by the socket. In Sections 3.14 and 14.6.2, we saw that we could use the F_SETOWN command to fcntl to set the ownership of a socket. If the third argument to fcntl is positive, it specifies a process ID. If it is a negative value other than -1, it represents the process group ID. Thus, we can arrange that our process receive signals from a socket by calling
fcntl(sockfd, F_SETOWN, pid);
The F_GETOWN command can be used to retrieve the current socket ownership. As with the F_SETOWN command, a negative value represents a process group ID, and a positive value represents a process ID. Thus, the call
owner = fcntl(sockfd, F_GETOWN, 0);
will return with owner equal to the ID of the process configured to receive signals from the socket if owner is positive and with the absolute value of owner equal to the ID of the process group configured to receive signals from the socket if owner is negative.
TCP supports the notion of an urgent mark : the point in the normal data stream where the urgent data would go. We can choose to receive the urgent data inline with the normal data if we use the SO_OOBINLINE socket option. To help us identify when we have reached the urgent mark, we can use the sockatmark function.
#include <sys/socket.h>
int sockatmark(int sockfd);
| Returns: 1 if at mark, 0 if not at mark, 1 on error |
When the next byte to be read is where the urgent mark is located, sockatmark will return 1.
When out-of-band data is present in a socket's read queue, the select function (Section 14.5.1) will return the file descriptor as having an exception condition pending. We can choose to receive the urgent data inline with the normal data, or we can use the MSG_OOB flag with one of the recv functions to receive the urgent data ahead of any other queue data. TCP queues only one byte of urgent data. If another urgent byte arrives before we receive the current one, the existing one is discarded.
16.8. Nonblocking and Asynchronous I/O
Normally, the recv functions will block when no data is immediately available. Similarly, the send functions will block when there is not enough room in the socket's output queue to send the message. This behavior changes when the socket is in nonblocking mode. In this case, these functions will fail instead of blocking, setting errno to either EWOULDBLOCK or EAGAIN. When this happens, we can use either poll or select to determine when we can receive or transmit data.
The real-time extensions in the Single UNIX Specification include support for a generic asynchronous I/O mechanism. The socket mechanism has its own way of handling asynchronous I/O, but this isn't standardized in the Single UNIX Specification. Some texts refer to the classic socket-based asynchronous I/O mechanism as "signal-based I/O" to distinguish it from the asynchronous I/O mechanism in the real-time extensions.
With socket-based asynchronous I/O, we can arrange to be sent the SIGIO signal when we can read data from a socket or when space becomes available in a socket's write queue. Enabling asynchronous I/O is a two-step process.
Establish socket ownership so signals can be delivered to the proper processes. Inform the socket that we want it to signal us when I/O operations won't block.
We can accomplish the first step in three ways.
Use the F_SETOWN command with fcntl. Use the FIOSETOWN command with ioctl. Use the SIOCSPGRP command with ioctl.
To accomplish the second step, we have two choices.
Use the F_SETFL command with fcntl and enable the O_ASYNC file flag. Use the FIOASYNC command with ioctl.
We have several options, but they are not universally supported. Figure 16.21 summarizes the support for these options provided by the platforms discussed in this text. We show • where support is provided and  where support depends on the particular domain. For example, on Linux, the UNIX domain sockets don't support FIOSETOWN or SIOCSPGRP. where support depends on the particular domain. For example, on Linux, the UNIX domain sockets don't support FIOSETOWN or SIOCSPGRP.
Figure 16.21. Socket asynchronous I/O management commandsMechanism | POSIX.1 | FreeBSD 5.2.1 | Linux 2.4.22 | Mac OS X 10.3 | Solaris 9 |
|---|
fcntl(fd, F_SETOWN, pid) | • | • | • | • | • | ioctl(fd, FIOSETOWN, pid) | | • |
| • | • | ioctl(fd, SIOCSPGRP, pid) | | • |
| • | • | fcntl(fd, F_SETFL, flags|O_ASYNC) | | • | • | • | | ioctl(fd, FIOASYNC, &n); | | • | • | • | • |
17.1. Introduction
In the previous two chapters, we discussed various forms of IPC, including pipes and sockets. In this chapter, we look at two advanced forms of IPCSTREAMS-based pipes and UNIX domain socketsand what we can do with them. With these forms of IPC, we can pass open file descriptors between processes, servers can associate names with their file descriptors, and clients can use these names to rendezvous with the servers. We'll also see how the operating system provides a unique IPC channel per client. Many of the ideas that form the basis for the techniques described in this chapter come from the paper by Presotto and Ritchie [1990].
17.2. STREAMS-Based Pipes
A STREAMS-based pipe ("STREAMS pipe," for short) is a bidirectional (full-duplex) pipe. To obtain bidirectional data flow between a parent and a child, only a single STREAMS pipe is required.
Recall from Section 15.1 that STREAMS pipes are supported by Solaris and are available in an optional add-on package with Linux.
Figure 17.1 shows the two ways to view a STREAMS pipe. The only difference between this picture and Figure 15.2 is that the arrows have heads on both ends; since the STREAMS pipe is full duplex, data can flow in both directions.
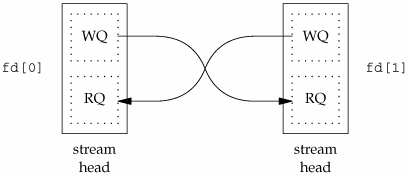
If we look inside a STREAMS pipe (Figure 17.2), we see that it is simply two stream heads, with each write queue (WQ) pointing at the other's read queue (RQ). Data written to one end of the pipe is placed in messages on the other's read queue.
Since a STREAMS pipe is a stream, we can push a STREAMS module onto either end of the pipe to process data written to the pipe (Figure 17.3). But if we push a module on one end, we can't pop it off the other end. If we want to remove it, we need to remove it from the same end on which it was pushed.
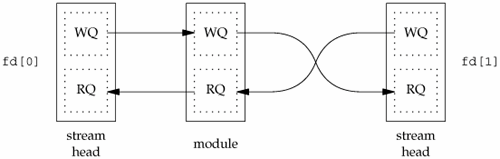
Assuming that we don't do anything fancy, such as pushing modules, a STREAMS pipe behaves just like a non-STREAMS pipe, except that it supports most of the STREAMS ioctl commands described in streamio(7). In Section 17.2.2, we'll see an example of pushing a module on a STREAMS pipe to provide unique connections when we give the pipe a name in the file system.
Example
Let's redo the coprocess example, Figure 15.18, with a single STREAMS pipe. Figure 17.4 shows the new main function. The add2 coprocess is the same (Figure 15.17). We call a new function, s_pipe, to create a single STREAMS pipe. (We show versions of this function for both STREAMS pipes and UNIX domain sockets shortly.)
The parent uses only fd[0], and the child uses only fd[1]. Since each end of the STREAMS pipe is full duplex, the parent reads and writes fd[0], and the child duplicates fd[1] to both standard input and standard output. Figure 17.5 shows the resulting descriptors. Note that this example also works with full-duplex pipes that are not based on STREAMS, because it doesn't make use of any STREAMS features other than the full-duplex nature of STREAMS-based pipes.
Rago [1993] covers STREAMS-based pipes in more detail. Recall from Figure 15.1 that FreeBSD supports full-duplex pipes, but these pipes are not based on the STREAMS mechanism.
Figure 17.4. Program to drive the add2 filter, using a STREAMS pipe
#include "apue.h"
static void sig_pipe(int); /* our signal handler */
int
main(void)
{
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if (signal(SIGPIPE, sig_pipe) == SIG_ERR)
err_sys("signal error");
if (s_pipe(fd) < 0) /* need only a single stream pipe */
err_sys("pipe error");
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid > 0) { /* parent */
close(fd[1]);
while (fgets(line, MAXLINE, stdin) != NULL) {
n = strlen(line);
if (write(fd[0], line, n) != n)
err_sys("write error to pipe");
if ((n = read(fd[0], line, MAXLINE)) < 0)
err_sys("read error from pipe");
if (n == 0) {
err_msg("child closed pipe");
break;
}
line[n] = 0; /* null terminate */
if (fputs(line, stdout) == EOF)
err_sys("fputs error");
}
if (ferror(stdin))
err_sys("fgets error on stdin");
exit(0);
} else { /* child */
close(fd[0]);
if (fd[1] != STDIN_FILENO &&
dup2(fd[1], STDIN_FILENO) != STDIN_FILENO)
err_sys("dup2 error to stdin");
if (fd[1] != STDOUT_FILENO &&
dup2(fd[1], STDOUT_FILENO) != STDOUT_FILENO)
err_sys("dup2 error to stdout");
if (execl("./add2", "add2", (char *)0) < 0)
err_sys("execl error");
}
exit(0);
}
static void
sig_pipe(int signo)
{
printf("SIGPIPE caught\n");
exit(1);
}
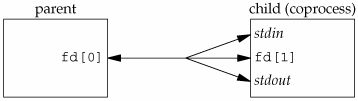
We define the function s_pipe to be similar to the standard pipe function. Both functions take the same argument, but the descriptors returned by s_pipe are open for reading and writing.
ExampleSTREAMS-Based s_pipe Function
Figure 17.6 shows the STREAMS-based version of the s_pipe function. This version simply calls the standard pipe function, which creates a full-duplex pipe.
Figure 17.6. STREAMS version of the s_pipe function
#include "apue.h"
/*
* Returns a STREAMS-based pipe, with the two file descriptors
* returned in fd[0] and fd[1].
*/
int
s_pipe(int fd[2])
{
return(pipe(fd));
}
17.2.1. Naming STREAMS Pipes
Normally, pipes can be used only between related processes: child processes inheriting pipes from their parent processes. In Section 15.5, we saw that unrelated processes can communicate using FIFOs, but this provides only a one-way communication path. The STREAMS mechanism provides a way for processes to give a pipe a name in the file system. This bypasses the problem of dealing with unidirectional FIFOs.
We can use the fattach function to give a STREAMS pipe a name in the file system.
#include <stropts.h>
int fattach(int filedes, const char *path);
| Returns: 0 if OK, 1 on error |
The path argument must refer to an existing file, and the calling process must either own the file and have write permissions to it or be running with superuser privileges.
Once a STREAMS pipe is attached to the file system namespace, the underlying file is inaccessible. Any process that opens the name will gain access to the pipe, not the underlying file. Any processes that had the underlying file open before fattach was called, however, can continue to access the underlying file. Indeed, these processes generally will be unaware that the name now refers to a different file.
Figure 17.7 shows a pipe attached to the pathname /tmp/pipe. Only one end of the pipe is attached to a name in the file system. The other end is used to communicate with processes that open the attached filename. Even though it can attach any kind of STREAMS file descriptor to a name in the file system, the fattach function is most commonly used to give a name to a STREAMS pipe.
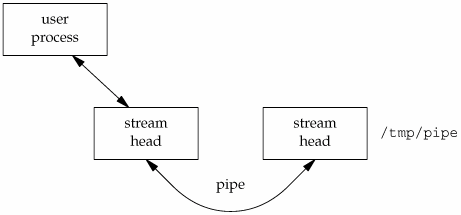
A process can call fdetach to undo the association between a STREAMS file and the name in the file system.
#include <stropts.h>
int fdetach(const char *path);
| Returns: 0 if OK, 1 on error |
After fdetach is called, any processes that had accessed the STREAMS pipe by opening the path will still continue to access the stream, but subsequent opens of the path will access the original file residing in the file system.
17.2.2. Unique Connections
Although we can attach one end of a STREAMS pipe to the file system namespace, we still have problems if multiple processes want to communicate with a server using the named STREAMS pipe. Data from one client will be interleaved with data from the other clients writing to the pipe. Even if we guarantee that the clients write less than PIPE_BUF bytes so that the writes are atomic, we have no way to write back to an individual client and guarantee that the intended client will read the message. With multiple clients reading from the same pipe, we cannot control which one will be scheduled and actually read what we send.
The connld STREAMS module solves this problem. Before attaching a STREAMS pipe to a name in the file system, a server process can push the connld module on the end of the pipe that is to be attached. This results in the configuration shown in Figure 17.8.
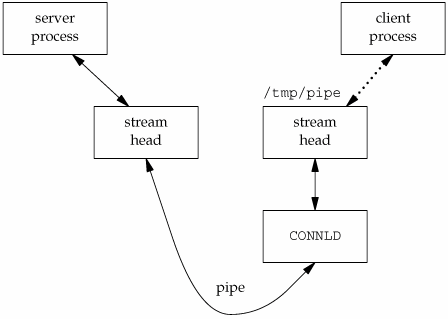
In Figure 17.8, the server process has attached one end of its pipe to the path /tmp/pipe. We show a dotted line to indicate a client process in the middle of opening the attached STREAMS pipe. Once the open completes, we have the configuration shown in Figure 17.9.
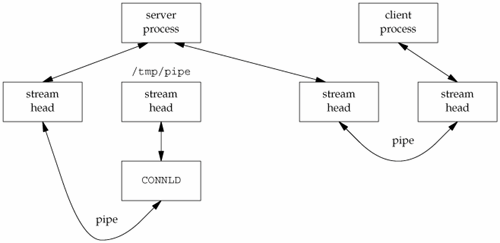
The client process never receives an open file descriptor for the end of the pipe that it opened. Instead, the operating system creates a new pipe and returns one end to the client process as the result of opening /tmp/pipe. The system sends the other end of the new pipe to the server process by passing its file descriptor over the existing (attached) pipe, resulting in a unique connection between the client process and the server process. We'll see the mechanics of passing file descriptors using STREAMS pipes in Section 17.4.1.
The fattach function is built on top of the mount system call. This facility is known as mounted streams. Mounted streams and the connld module were developed by Presotto and Ritchie [1990] for the Research UNIX system. These mechanisms were then picked up by SVR4.
We will now develop three functions that can be used to create unique connections between unrelated processes. These functions mimic the connection-oriented socket functions discussed in Section 16.4. We use STREAMS pipes for the underlying communication mechanism here, but we'll see alternate implementations of these functions that use UNIX domain sockets in Section 17.3.
#include "apue.h"
int serv_listen(const char *name);
| Returns: file descriptor to listen on if OK, negative value on error |
int serv_accept(int listenfd, uid_t *uidptr);
| Returns: new file descriptor if OK, negative value on error |
int cli_conn(const char *name);
| Returns: file descriptor if OK, negative value on error |
The serv_listen function (Figure 17.10) can be used by a server to announce its willingness to listen for client connect requests on a well-known name (some pathname in the file system). Clients will use this name when they want to connect to the server. The return value is the server's end of the STREAMS pipe.
Figure 17.10. The serv_listen function using STREAMS pipes
#include "apue.h"
#include <fcntl.h>
#include <stropts.h>
/* pipe permissions: user rw, group rw, others rw */
#define FIFO_MODE (S_IRUSR|S_IWUSR|S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH)
/*
* Establish an endpoint to listen for connect requests.
* Returns fd if all OK, <0 on error
*/
int
serv_listen(const char *name)
{
int tempfd;
int fd[2];
/*
* Create a file: mount point for fattach().
*/
unlink(name);
if ((tempfd = creat(name, FIFO_MODE)) < 0)
return(-1);
if (close(tempfd) < 0)
return(-2);
if (pipe(fd) < 0)
return(-3);
/*
* Push connld & fattach() on fd[1].
*/
if (ioctl(fd[1], I_PUSH, "connld") < 0) {
close(fd[0]);
close(fd[1]);
return(-4);
}
if (fattach(fd[1], name) < 0) {
close(fd[0]);
close(fd[1]);
return(-5);
}
close(fd[1]); /* fattach holds this end open */
return(fd[0]); /* fd[0] is where client connections arrive */
}
The serv_accept function (Figure 17.11) is used by a server to wait for a client's connect request to arrive. When one arrives, the system automatically creates a new STREAMS pipe, and the function returns one end to the server. Additionally, the effective user ID of the client is stored in the memory to which uidptr points.
Figure 17.11. The serv_accept function using STREAMS pipes
#include "apue.h"
#include <stropts.h>
/*
* Wait for a client connection to arrive, and accept it.
* We also obtain the client's user ID.
* Returns new fd if all OK, <0 on error.
*/
int
serv_accept(int listenfd, uid_t *uidptr)
{
struct strrecvfd recvfd;
if (ioctl(listenfd, I_RECVFD, &recvfd) < 0)
return(-1); /* could be EINTR if signal caught */
if (uidptr != NULL)
*uidptr = recvfd.uid; /* effective uid of caller */
return(recvfd.fd); /* return the new descriptor */
}
A client calls cli_conn (Figure 17.12) to connect to a server. The name argument specified by the client must be the same name that was advertised by the server's call to serv_listen. On return, the client gets a file descriptor connected to the server.
Figure 17.12. The cli_conn function using STREAMS pipes
#include "apue.h"
#include <fcntl.h>
#include <stropts.h>
/*
* Create a client endpoint and connect to a server.
* Returns fd if all OK, <0 on error.
*/
int
cli_conn(const char *name)
{
int fd;
/* open the mounted stream */
if ((fd = open(name, O_RDWR)) < 0)
return(-1);
if (isastream(fd) == 0) {
close(fd);
return(-2);
}
return(fd);
}
We double-check that the returned descriptor refers to a STREAMS device, in case the server has not been started but the pathname still exists in the file system. In Section 17.6, we'll see how these three functions are used.
17.3. UNIX Domain Sockets
UNIX domain sockets are used to communicate with processes running on the same machine. Although Internet domain sockets can be used for this same purpose, UNIX domain sockets are more efficient. UNIX domain sockets only copy data; they have no protocol processing to perform, no network headers to add or remove, no checksums to calculate, no sequence numbers to generate, and no acknowledgements to send.
UNIX domain sockets provide both stream and datagram interfaces. The UNIX domain datagram service is reliable, however. Messages are neither lost nor delivered out of order. UNIX domain sockets are like a cross between sockets and pipes. You can use the network-oriented socket interfaces with them, or you can use the socketpair function to create a pair of unnamed, connected, UNIX domain sockets.
#include <sys/socket.h>
int socketpair(int domain, int type, int protocol,
int sockfd[2]);
| Returns: 0 if OK, 1 on error |
Although the interface is sufficiently general to allow socketpair to be used with arbitrary domains, operating systems typically provide support only for the UNIX domain.
Examples_pipe Function Using UNIX Domain Sockets
Figure 17.13 shows the socket-based version of the s_pipe function previously shown in Figure 17.6. The function creates a pair of connected UNIX domain stream sockets.
Some BSD-based systems use UNIX domain sockets to implement pipes. But when pipe is called, the write end of the first descriptor and the read end of the second descriptor are both closed. To get a full-duplex pipe, we must call socketpair directly.
Figure 17.13. Socket version of the s_pipe function
#include "apue.h"
#include <sys/socket.h>
/*
* Returns a full-duplex "stream" pipe (a UNIX domain socket)
* with the two file descriptors returned in fd[0] and fd[1].
*/
int
s_pipe(int fd[2])
{
return(socketpair(AF_UNIX, SOCK_STREAM, 0, fd));
}
17.3.1. Naming UNIX Domain Sockets
Although the socketpair function creates sockets that are connected to each other, the individual sockets don't have names. This means that they can't be addressed by unrelated processes.
In Section 16.3.4, we learned how to bind an address to an Internet domain socket. Just as with Internet domain sockets, UNIX domain sockets can be named and used to advertise services. The address format used with UNIX domain sockets differs from Internet domain sockets, however.
Recall from Section 16.3 that socket address formats differ from one implementation to the next. An address for a UNIX domain socket is represented by a sockaddr_un structure. On Linux 2.4.22 and Solaris 9, the sockaddr_un structure is defined in the header <sys/un.h> as follows:
struct sockaddr_un {
sa_family_t sun_family; /* AF_UNIX */
char sun_path[108]; /* pathname */
};
On FreeBSD 5.2.1 and Mac OS X 10.3, however, the sockaddr_un structure is defined as
struct sockaddr_un {
unsigned char sun_len; /* length including null */
sa_family_t sun_family; /* AF_UNIX */
char sun_path[104]; /* pathname */
};
The sun_path member of the sockaddr_un structure contains a pathname. When we bind an address to a UNIX domain socket, the system creates a file of type S_IFSOCK with the same name.
This file exists only as a means of advertising the socket name to clients. The file can't be opened or otherwise used for communication by applications.
If the file already exists when we try to bind the same address, the bind request will fail. When we close the socket, this file is not automatically removed, so we need to make sure that we unlink it before our application exits.
Example
The program in Figure 17.14 shows an example of binding an address to a UNIX domain socket.
When we run this program, the bind request succeeds, but if we run the program a second time, we get an error, because the file already exists. The program won't succeed again until we remove the file.
$ ./a.out run the program
UNIX domain socket bound
$ ls -l foo.socket look at the socket file
srwxrwxr-x 1 sar 0 Aug 22 12:43 foo.socket
$ ./a.out try to run the program again
bind failed: Address already in use
$ rm foo.socket remove the socket file
$ ./a.out run the program a third time
UNIX domain socket bound now it succeeds
The way we determine the size of the address to bind is to determine the offset of the sun_path member in the sockaddr_un structure and add to this the length of the pathname, not including the terminating null byte. Since implementations vary in what members precede sun_path in the sockaddr_un structure, we use the offsetof macro from <stddef.h> (included by apue.h) to calculate the offset of the sun_path member from the start of the structure. If you look in <stddef.h>, you'll see a definition similar to the following:
#define offsetof(TYPE, MEMBER) ((int)&((TYPE *)0)->MEMBER)
The expression evaluates to an integer, which is the starting address of the member, assuming that the structure begins at address 0.
Figure 17.14. Binding an address to a UNIX domain socket
#include "apue.h"
#include <sys/socket.h>
#include <sys/un.h>
int
main(void)
{
int fd, size;
struct sockaddr_un un;
un.sun_family = AF_UNIX;
strcpy(un.sun_path, "foo.socket");
if ((fd = socket(AF_UNIX, SOCK_STREAM, 0)) < 0)
err_sys("socket failed");
size = offsetof(struct sockaddr_un, sun_path) + strlen(un.sun_path);
if (bind(fd, (struct sockaddr *)&un, size) < 0)
err_sys("bind failed");
printf("UNIX domain socket bound\n");
exit(0);
}
17.3.2. Unique Connections
A server can arrange for unique UNIX domain connections to clients using the standard bind, listen, and accept functions. Clients use connect to contact the server; after the connect request is accepted by the server, a unique connection exists between the client and the server. This style of operation is the same that we illustrated with Internet domain sockets in Figures 16.14 and 16.15.
Figure 17.15 shows the UNIX domain socket version of the serv_listen function.
Figure 17.15. The serv_listen function for UNIX domain sockets
#include "apue.h"
#include <sys/socket.h>
#include <sys/un.h>
#include <errno.h>
#define QLEN 10
/*
* Create a server endpoint of a connection.
* Returns fd if all OK, <0 on error.
*/
int
serv_listen(const char *name)
{
int fd, len, err, rval;
struct sockaddr_un un;
/* create a UNIX domain stream socket */
if ((fd = socket(AF_UNIX, SOCK_STREAM, 0)) < 0)
return(-1);
unlink(name); /* in case it already exists */
/* fill in socket address structure */
memset(&un, 0, sizeof(un));
un.sun_family = AF_UNIX;
strcpy(un.sun_path, name);
len = offsetof(struct sockaddr_un, sun_path) + strlen(name);
/* bind the name to the descriptor */
if (bind(fd, (struct sockaddr *)&un, len) < 0) {
rval = -2;
goto errout;
}
if (listen(fd, QLEN) < 0) { /* tell kernel we're a server */
rval = -3;
goto errout;
}
return(fd);
errout:
err = errno;
close(fd);
errno = err;
return(rval);
}
First, we create a single UNIX domain socket by calling socket. We then fill in a sockaddr_un structure with the well-known pathname to be assigned to the socket. This structure is the argument to bind. Note that we don't need to set the sun_len field present on some platforms, because the operating system sets this for us using the address length we pass to the bind function.
Finally, we call listen (Section 16.4) to tell the kernel that the process will be acting as a server awaiting connections from clients. When a connect request from a client arrives, the server calls the serv_accept function (Figure 17.16).
Figure 17.16. The serv_accept function for UNIX domain sockets
#include "apue.h"
#include <sys/socket.h>
#include <sys/un.h>
#include <time.h>
#include <errno.h>
#define STALE 30 /* client's name can't be older than this (sec) */
/*
* Wait for a client connection to arrive, and accept it.
* We also obtain the client's user ID from the pathname
* that it must bind before calling us.
* Returns new fd if all OK, <0 on error
*/
int
serv_accept(int listenfd, uid_t *uidptr)
{
int clifd, len, err, rval;
time_t staletime;
struct sockaddr_un un;
struct stat statbuf;
len = sizeof(un);
if ((clifd = accept(listenfd, (struct sockaddr *)&un, &len)) < 0)
return(-1); /* often errno=EINTR, if signal caught */
/* obtain the client's uid from its calling address */
len -= offsetof(struct sockaddr_un, sun_path); /* len of pathname */
un.sun_path[len] = 0; /* null terminate */
if (stat(un.sun_path, &statbuf) < 0) {
rval = -2;
goto errout;
}
#ifdef S_ISSOCK /* not defined for SVR4 */
if (S_ISSOCK(statbuf.st_mode) == 0) {
rval = -3; /* not a socket */
goto errout;
}
#endif
if ((statbuf.st_mode & (S_IRWXG | S_IRWXO)) ||
(statbuf.st_mode & S_IRWXU) != S_IRWXU) {
rval = -4; /* is not rwx------ */
goto errout;
}
staletime = time(NULL) - STALE;
if (statbuf.st_atime < staletime ||
statbuf.st_ctime < staletime ||
statbuf.st_mtime < staletime) {
rval = -5; /* i-node is too old */
goto errout;
}
if (uidptr != NULL)
*uidptr = statbuf.st_uid; /* return uid of caller */
unlink(un.sun_path); /* we're done with pathname now */
return(clifd);
errout:
err = errno;
close(clifd);
errno = err;
return(rval);
}
The server blocks in the call to accept, waiting for a client to call cli_conn. When accept returns, its return value is a brand new descriptor that is connected to the client. (This is somewhat similar to what the connld module does with the STREAMS subsystem.) Additionally, the pathname that the client assigned to its socket (the name that contained the client's process ID) is also returned by accept, through the second argument (the pointer to the sockaddr_un structure). We null terminate this pathname and call stat. This lets us verify that the pathname is indeed a socket and that the permissions allow only user-read, user-write, and user-execute. We also verify that the three times associated with the socket are no older than 30 seconds. (Recall from Section 6.10 that the time function returns the current time and date in seconds past the Epoch.)
If all these checks are OK, we assume that the identity of the client (its effective user ID) is the owner of the socket. Although this check isn't perfect, it's the best we can do with current systems. (It would be better if the kernel returned the effective user ID to accept as the I_RECVFD ioctl command does.)
The client initiates the connection to the server by calling the cli_conn function (Figure 17.17).
Figure 17.17. The cli_conn function for UNIX domain sockets
#include "apue.h"
#include <sys/socket.h>
#include <sys/un.h>
#include <errno.h>
#define CLI_PATH "/var/tmp/" /* +5 for pid = 14 chars */
#define CLI_PERM S_IRWXU /* rwx for user only */
/*
* Create a client endpoint and connect to a server.
* Returns fd if all OK, <0 on error.
*/
int
cli_conn(const char *name)
{
int fd, len, err, rval;
struct sockaddr_un un;
/* create a UNIX domain stream socket */
if ((fd = socket(AF_UNIX, SOCK_STREAM, 0)) < 0)
return(-1);
/* fill socket address structure with our address */
memset(&un, 0, sizeof(un));
un.sun_family = AF_UNIX;
sprintf(un.sun_path, "%s%05d", CLI_PATH, getpid());
len = offsetof(struct sockaddr_un, sun_path) + strlen(un.sun_path);
unlink(un.sun_path); /* in case it already exists */
if (bind(fd, (struct sockaddr *)&un, len) < 0) {
rval = -2;
goto errout;
}
if (chmod(un.sun_path, CLI_PERM) < 0) {
rval = -3;
goto errout;
}
/* fill socket address structure with server's address */
memset(&un, 0, sizeof(un));
un.sun_family = AF_UNIX;
strcpy(un.sun_path, name);
len = offsetof(struct sockaddr_un, sun_path) + strlen(name);
if (connect(fd, (struct sockaddr *)&un, len) < 0) {
rval = -4;
goto errout;
}
return(fd);
errout:
err = errno;
close(fd);
errno = err;
return(rval);
}
We call socket to create the client's end of a UNIX domain socket. We then fill in a sockaddr_un structure with a client-specific name.
We don't let the system choose a default address for us, because the server would be unable to distinguish one client from another. Instead, we bind our own address, a step we usually don't take when developing a client program that uses sockets.
The last five characters of the pathname we bind are made from the process ID of the client. We call unlink, just in case the pathname already exists. We then call bind to assign a name to the client's socket. This creates a socket file in the file system with the same name as the bound pathname. We call chmod to turn off all permissions other than user-read, user-write, and user-execute. In serv_accept, the server checks these permissions and the user ID of the socket to verify the client's identity.
We then have to fill in another sockaddr_un structure, this time with the well-known pathname of the server. Finally, we call the connect function to initiate the connection with the server.
17.4. Passing File Descriptors
The ability to pass an open file descriptor between processes is powerful. It can lead to different ways of designing clientserver applications. It allows one process (typically a server) to do everything that is required to open a file (involving such details as translating a network name to a network address, dialing a modem, negotiating locks for the file, etc.) and simply pass back to the calling process a descriptor that can be used with all the I/O functions. All the details involved in opening the file or device are hidden from the client.
We must be more specific about what we mean by "passing an open file descriptor" from one process to another. Recall Figure 3.7, which showed two processes that have opened the same file. Although they share the same v-node, each process has its own file table entry.
When we pass an open file descriptor from one process to another, we want the passing process and the receiving process to share the same file table entry. Figure 17.18 shows the desired arrangement.
Technically, we are passing a pointer to an open file table entry from one process to another. This pointer is assigned the first available descriptor in the receiving process. (Saying that we are passing an open descriptor mistakenly gives the impression that the descriptor number in the receiving process is the same as in the sending process, which usually isn't true.) Having two processes share an open file table is exactly what happens after a fork (recall Figure 8.2).
What normally happens when a descriptor is passed from one process to another is that the sending process, after passing the descriptor, then closes the descriptor. Closing the descriptor by the sender doesn't really close the file or device, since the descriptor is still considered open by the receiving process (even if the receiver hasn't specifically received the descriptor yet).
We define the following three functions that we use in this chapter to send and receive file descriptors. Later in this section, we'll show the code for these three functions for both STREAMS and sockets.
#include "apue.h"
int send_fd(int fd, int fd_to_send);
int send_err(int fd, int status, const char *errmsg);
| Both return: 0 if OK, 1 on error |
int recv_fd(int fd, ssize_t (*userfunc)(int, const
void *, size_t));
| Returns: file descriptor if OK, negative value on error |
A process (normally a server) that wants to pass a descriptor to another process calls either send_fd or send_err. The process waiting to receive the descriptor (the client) calls recv_fd.
The send_fd function sends the descriptor fd_to_send across using the STREAMS pipe or UNIX domain socket represented by fd.
We'll use the term s-pipe to refer to a bidirectional communication channel that could be implemented as either a STREAMS pipe or a UNIX domain stream socket.
The send_err function sends the errmsg using fd, followed by the status byte. The value of status must be in the range 1 through 255.
Clients call recv_fd to receive a descriptor. If all is OK (the sender called send_fd), the non-negative descriptor is returned as the value of the function. Otherwise, the value returned is the status that was sent by send_err (a negative value in the range 1 through -255). Additionally, if an error message was sent by the server, the client's userfunc is called to process the message. The first argument to userfunc is the constant STDERR_FILENO, followed by a pointer to the error message and its length. The return value from userfunc is the number of bytes written or a negative number on error. Often, the client specifies the normal write function as the userfunc.
We implement our own protocol that is used by these three functions. To send a descriptor, send_fd sends two bytes of 0, followed by the actual descriptor. To send an error, send_err sends the errmsg, followed by a byte of 0, followed by the absolute value of the status byte (1 through 255). The recv_fd function reads everything on the s-pipe until it encounters a null byte. Any characters read up to this point are passed to the caller's userfunc. The next byte read by recv_fd is the status byte. If the status byte is 0, a descriptor was passed; otherwise, there is no descriptor to receive.
The function send_err calls the send_fd function after writing the error message to the s-pipe. This is shown in Figure 17.19.
Figure 17.19. The send_err function
#include "apue.h"
/*
* Used when we had planned to send an fd using send_fd(),
* but encountered an error instead. We send the error back
* using the send_fd()/recv_fd() protocol.
*/
int
send_err(int fd, int errcode, const char *msg)
{
int n;
if ((n = strlen(msg)) > 0)
if (writen(fd, msg, n) != n) /* send the error message */
return(-1);
if (errcode >= 0)
errcode = -1; /* must be negative */
if (send_fd(fd, errcode) < 0)
return(-1);
return(0);
}
In the next two sections, we'll look at the implementation of the send_fd and recv_fd functions.
17.4.1. Passing File Descriptors over STREAMS-Based Pipes
With STREAMS pipes, file descriptors are exchanged using two ioctl commands: I_SENDFD and I_RECVFD. To send a descriptor, we set the third argument for ioctl to the actual descriptor. This is shown in Figure 17.20.
Figure 17.20. The send_fd function for STREAMS pipes
#include "apue.h"
#include <stropts.h>
/*
* Pass a file descriptor to another process.
* If fd<0, then -fd is sent back instead as the error status.
*/
int
send_fd(int fd, int fd_to_send)
{
char buf[2]; /* send_fd()/recv_fd() 2-byte protocol */
buf[0] = 0; /* null byte flag to recv_fd() */
if (fd_to_send < 0) {
buf[1] = -fd_to_send; /* nonzero status means error */
if (buf[1] == 0)
buf[1] = 1; /* -256, etc. would screw up protocol */
} else {
buf[1] = 0; /* zero status means OK */
}
if (write(fd, buf, 2) != 2)
return(-1);
if (fd_to_send >= 0)
if (ioctl(fd, I_SENDFD, fd_to_send) < 0)
return(-1);
return(0);
}
When we receive a descriptor, the third argument for ioctl is a pointer to a strrecvfd structure:
struct strrecvfd {
int fd; /* new descriptor */
uid_t uid; /* effective user ID of sender */
gid_t gid; /* effective group ID of sender */
char fill[8];
};
The recv_fd function reads the STREAMS pipe until the first byte of the 2-byte protocol (the null byte) is received. When we issue the I_RECVFD ioctl command, the next message on the stream head's read queue must be a descriptor from an I_SENDFD call, or we get an error. This function is shown in Figure 17.21.
Figure 17.21. The recv_fd function for STREAMS pipes
#include "apue.h"
#include <stropts.h>
/*
* Receive a file descriptor from another process (a server).
* In addition, any data received from the server is passed
* to (*userfunc)(STDERR_FILENO, buf, nbytes). We have a
* 2-byte protocol for receiving the fd from send_fd().
*/
int
recv_fd(int fd, ssize_t (*userfunc)(int, const void *, size_t))
{
int newfd, nread, flag, status;
char *ptr;
char buf[MAXLINE];
struct strbuf dat;
struct strrecvfd recvfd;
status = -1;
for ( ; ; ) {
dat.buf = buf;
dat.maxlen = MAXLINE;
flag = 0;
if (getmsg(fd, NULL, &dat, &flag) < 0)
err_sys("getmsg error");
nread = dat.len;
if (nread == 0) {
err_ret("connection closed by server");
return(-1);
}
/*
* See if this is the final data with null & status.
* Null must be next to last byte of buffer, status
* byte is last byte. Zero status means there must
* be a file descriptor to receive.
*/
for (ptr = buf; ptr < &buf[nread]; ) {
if (*ptr++ == 0) {
if (ptr != &buf[nread-1])
err_dump("message format error");
status = *ptr & 0xFF; /* prevent sign extension */
if (status == 0) {
if (ioctl(fd, I_RECVFD, &recvfd) < 0)
return(-1);
newfd = recvfd.fd; /* new descriptor */
} else {
newfd = -status;
}
nread -= 2;
}
}
if (nread > 0)
if ((*userfunc)(STDERR_FILENO, buf, nread) != nread)
return(-1);
if (status >= 0) /* final data has arrived */
return(newfd); /* descriptor, or -status */
}
}
17.4.2. Passing File Descriptors over UNIX Domain Sockets
To exchange file descriptors using UNIX domain sockets, we call the sendmsg(2) and recvmsg(2) functions (Section 16.5). Both functions take a pointer to a msghdr structure that contains all the information on what to send or receive. The structure on your system might look similar to the following:
struct msghdr {
void *msg_name; /* optional address */
socklen_t msg_namelen; /* address size in bytes */
struct iovec *msg_iov; /* array of I/O buffers */
int msg_iovlen; /* number of elements in array */
void *msg_control; /* ancillary data */
socklen_t msg_controllen; /* number of ancillary bytes */
int msg_flags; /* flags for received message */
};
The first two elements are normally used for sending datagrams on a network connection, where the destination address can be specified with each datagram. The next two elements allow us to specify an array of buffers (scatter read or gather write), as we described for the readv and writev functions (Section 14.7). The msg_flags field contains flags describing the message received, as summarized in Figure 16.13.
Two elements deal with the passing or receiving of control information. The msg_control field points to a cmsghdr (control message header) structure, and the msg_controllen field contains the number of bytes of control information.
struct cmsghdr {
socklen_t cmsg_len; /* data byte count, including header */
int cmsg_level; /* originating protocol */
int cmsg_type; /* protocol-specific type */
/* followed by the actual control message data */
};
To send a file descriptor, we set cmsg_len to the size of the cmsghdr structure, plus the size of an integer (the descriptor). The cmsg_level field is set to SOL_SOCKET, and cmsg_type is set to SCM_RIGHTS, to indicate that we are passing access rights. (SCM stands for socket-level control message.) Access rights can be passed only across a UNIX domain socket. The descriptor is stored right after the cmsg_type field, using the macro CMSG_DATA to obtain the pointer to this integer.
Three macros are used to access the control data, and one macro is used to help calculate the value to be used for cmsg_len.
#include <sys/socket.h>
unsigned char *CMSG_DATA(struct cmsghdr *cp);
| Returns: pointer to data associated with cmsghdr structure |
struct cmsghdr *CMSG_FIRSTHDR(struct msghdr *mp);
| Returns: pointer to first cmsghdr structure associated
with the msghdr structure, or NULL if none exists |
struct cmsghdr *CMSG_NXTHDR(struct msghdr *mp,
struct cmsghdr *cp);
| Returns: pointer to next cmsghdr structure associated with
the msghdr structure given the current cmsghdr
structure, or NULL if we're at the last one |
unsigned int CMSG_LEN(unsigned int nbytes);
| Returns: size to allocate for data object nbytes large |
The Single UNIX Specification defines the first three macros, but omits CMSG_LEN.
The CMSG_LEN macro returns the number of bytes needed to store a data object of size nbytes, after adding the size of the cmsghdr structure, adjusting for any alignment constraints required by the processor architecture, and rounding up.
The program in Figure 17.22 is the send_fd function for UNIX domain sockets.
Figure 17.22. The send_fd function for UNIX domain sockets
#include "apue.h"
#include <sys/socket.h>
/* size of control buffer to send/recv one file descriptor */
#define CONTROLLEN CMSG_LEN(sizeof(int))
static struct cmsghdr *cmptr = NULL; /* malloc'ed first time */
/*
* Pass a file descriptor to another process.
* If fd<0, then -fd is sent back instead as the error status.
*/
int
send_fd(int fd, int fd_to_send)
{
struct iovec iov[1];
struct msghdr msg;
char buf[2]; /* send_fd()/recv_fd() 2-byte protocol */
iov[0].iov_base = buf;
iov[0].iov_len = 2;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
if (fd_to_send < 0) {
msg.msg_control = NULL;
msg.msg_controllen = 0;
buf[1] = -fd_to_send; /* nonzero status means error */
if (buf[1] == 0)
buf[1] = 1; /* -256, etc. would screw up protocol */
} else {
if (cmptr == NULL && (cmptr = malloc(CONTROLLEN)) == NULL)
return(-1);
cmptr->cmsg_level = SOL_SOCKET;
cmptr->cmsg_type = SCM_RIGHTS;
cmptr->cmsg_len = CONTROLLEN;
msg.msg_control = cmptr;
msg.msg_controllen = CONTROLLEN;
*(int *)CMSG_DATA(cmptr) = fd_to_send; /* the fd to pass */
buf[1] = 0; /* zero status means OK */
}
buf[0] = 0; /* null byte flag to recv_fd() */
if (sendmsg(fd, &msg, 0) != 2)
return(-1);
return(0);
}
In the sendmsg call, we send both the protocol data (the null and the status byte) and the descriptor.
To receive a descriptor (Figure 17.23), we allocate enough room for a cmsghdr structure and a descriptor, set msg_control to point to the allocated area, and call recvmsg. We use the CMSG_LEN macro to calculate the amount of space needed.
We read from the socket until we read the null byte that precedes the final status byte. Everything up to this null byte is an error message from the sender. This is shown in Figure 17.23.
Figure 17.23. The recv_fd function for UNIX domain sockets
#include "apue.h"
#include <sys/socket.h> /* struct msghdr */
/* size of control buffer to send/recv one file descriptor */
#define CONTROLLEN CMSG_LEN(sizeof(int))
static struct cmsghdr *cmptr = NULL; /* malloc'ed first time */
/*
* Receive a file descriptor from a server process. Also, any data
* received is passed to (*userfunc)(STDERR_FILENO, buf, nbytes).
* We have a 2-byte protocol for receiving the fd from send_fd().
*/
int
recv_fd(int fd, ssize_t (*userfunc)(int, const void *, size_t))
{
int newfd, nr, status;
char *ptr;
char buf[MAXLINE];
struct iovec iov[1];
struct msghdr msg;
status = -1;
for ( ; ; ) {
iov[0].iov_base = buf;
iov[0].iov_len = sizeof(buf);
msg.msg_iov = iov;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
if (cmptr == NULL && (cmptr = malloc(CONTROLLEN)) == NULL)
return(-1);
msg.msg_control = cmptr;
msg.msg_controllen = CONTROLLEN;
if ((nr = recvmsg(fd, &msg, 0)) < 0) {
err_sys("recvmsg error");
} else if (nr == 0) {
err_ret("connection closed by server");
return(-1);
}
/*
* See if this is the final data with null & status. Null
* is next to last byte of buffer; status byte is last byte.
* Zero status means there is a file descriptor to receive.
*/
for (ptr = buf; ptr < &buf[nr]; ) {
if (*ptr++ == 0) {
if (ptr != &buf[nr-1])
err_dump("message format error");
status = *ptr & 0xFF; /* prevent sign extension */
if (status == 0) {
if (msg.msg_controllen != CONTROLLEN)
err_dump("status = 0 but no fd");
newfd = *(int *)CMSG_DATA(cmptr);
} else {
newfd = -status;
}
nr -= 2;
}
}
if (nr > 0 && (*userfunc)(STDERR_FILENO, buf, nr) != nr)
return(-1);
if (status >= 0) /* final data has arrived */
return(newfd); /* descriptor, or -status */
}
}
Note that we are always prepared to receive a descriptor (we set msg_control and msg_controllen before each call to recvmsg), but only if msg_controllen is nonzero on return did we receive a descriptor.
When it comes to passing file descriptors, one difference between UNIX domain sockets and STREAMS pipes is that we get the identity of the sending process with STREAMS pipes. Some versions of UNIX domain sockets provide similar functionality, but their interfaces differ.
FreeBSD 5.2.1 and Linux 2.4.22 provide support for sending credentials over UNIX domain sockets, but they do it differently. Mac OS X 10.3 is derived in part from FreeBSD, but has credential passing disabled. Solaris 9 doesn't support sending credentials over UNIX domain sockets.
With FreeBSD, credentials are transmitted as a cmsgcred structure:
#define CMGROUP_MAX 16
struct cmsgcred {
pid_t cmcred_pid; /* sender's process ID */
uid_t cmcred_uid; /* sender's real UID */
uid_t cmcred_euid; /* sender's effective UID */
gid_t cmcred_gid; /* sender's real GID */
short cmcred_ngroups; /* number of groups */
gid_t cmcred_groups[CMGROUP_MAX]; /* groups */
};
When we transmit credentials, we need to reserve space only for the cmsgcred structure. The kernel will fill it in for us to prevent an application from pretending to have a different identity.
On Linux, credentials are transmitted as a ucred structure:
struct ucred {
uint32_t pid; /* sender's process ID */
uint32_t uid; /* sender's user ID */
uint32_t gid; /* sender's group ID */
};
Unlike FreeBSD, Linux requires that we initialize this structure before transmission. The kernel will ensure that applications either use values that correspond to the caller or have the appropriate privilege to use other values.
Figure 17.24 shows the send_fd function updated to include the credentials of the sending process.
Figure 17.24. Sending credentials over UNIX domain sockets
#include "apue.h"
#include <sys/socket.h>
#if defined(SCM_CREDS) /* BSD interface */
#define CREDSTRUCT cmsgcred
#define SCM_CREDTYPE SCM_CREDS
#elif defined(SCM_CREDENTIALS) /* Linux interface */
#define CREDSTRUCT ucred
#define SCM_CREDTYPE SCM_CREDENTIALS
#else
#error passing credentials is unsupported!
#endif
/* size of control buffer to send/recv one file descriptor */
#define RIGHTSLEN CMSG_LEN(sizeof(int))
#define CREDSLEN CMSG_LEN(sizeof(struct CREDSTRUCT))
#define CONTROLLEN (RIGHTSLEN + CREDSLEN)
static struct cmsghdr *cmptr = NULL; /* malloc'ed first time */
/*
* Pass a file descriptor to another process.
* If fd<0, then -fd is sent back instead as the error status.
*/
int
send_fd(int fd, int fd_to_send)
{
struct CREDSTRUCT *credp;
struct cmsghdr *cmp;
struct iovec iov[1];
struct msghdr msg;
char buf[2]; /* send_fd/recv_ufd 2-byte protocol */
iov[0].iov_base = buf;
iov[0].iov_len = 2;
msg.msg_iov = iov;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_flags = 0;
if (fd_to_send < 0) {
msg.msg_control = NULL;
msg.msg_controllen = 0;
buf[1] = -fd_to_send; /* nonzero status means error */
if (buf[1] == 0)
buf[1] = 1; /* -256, etc. would screw up protocol */
} else {
if (cmptr == NULL && (cmptr = malloc(CONTROLLEN)) == NULL)
return(-1);
msg.msg_control = cmptr;
msg.msg_controllen = CONTROLLEN;
cmp = cmptr;
cmp->cmsg_level = SOL_SOCKET;
cmp->cmsg_type = SCM_RIGHTS;
cmp->cmsg_len = RIGHTSLEN;
*(int *)CMSG_DATA(cmp) = fd_to_send; /* the fd to pass */
cmp = CMSG_NXTHDR(&msg, cmp);
cmp->cmsg_level = SOL_SOCKET;
cmp->cmsg_type = SCM_CREDTYPE;
cmp->cmsg_len = CREDSLEN;
credp = (struct CREDSTRUCT *)CMSG_DATA(cmp);
#if defined(SCM_CREDENTIALS)
credp->uid = geteuid();
credp->gid = getegid();
credp->pid = getpid();
#endif
buf[1] = 0; /* zero status means OK */
}
buf[0] = 0; /* null byte flag to recv_ufd() */
if (sendmsg(fd, &msg, 0) != 2)
return(-1);
return(0);
}
Note that we need to initialize the credentials structure only on Linux.
The function in Figure 17.25 is a modified version of recv_fd, called recv_ufd, that returns the user ID of the sender through a reference parameter.
Figure 17.25. Receiving credentials over UNIX domain sockets
#include "apue.h"
#include <sys/socket.h> /* struct msghdr */
#include <sys/un.h>
#if defined(SCM_CREDS) /* BSD interface */
#define CREDSTRUCT cmsgcred
#define CR_UID cmcred_uid
#define CREDOPT LOCAL_PEERCRED
#define SCM_CREDTYPE SCM_CREDS
#elif defined(SCM_CREDENTIALS) /* Linux interface */
#define CREDSTRUCT ucred
#define CR_UID uid
#define CREDOPT SO_PASSCRED
#define SCM_CREDTYPE SCM_CREDENTIALS
#else
#error passing credentials is unsupported!
#endif
/* size of control buffer to send/recv one file descriptor */
#define RIGHTSLEN CMSG_LEN(sizeof(int))
#define CREDSLEN CMSG_LEN(sizeof(struct CREDSTRUCT))
#define CONTROLLEN (RIGHTSLEN + CREDSLEN)
static struct cmsghdr *cmptr = NULL; /* malloc'ed first time */
/*
* Receive a file descriptor from a server process. Also, any data
* received is passed to (*userfunc)(STDERR_FILENO, buf, nbytes).
* We have a 2-byte protocol for receiving the fd from send_fd().
*/
int
recv_ufd(int fd, uid_t *uidptr,
ssize_t (*userfunc)(int, const void *, size_t))
{
struct cmsghdr *cmp;
struct CREDSTRUCT *credp;
int newfd, nr, status;
char *ptr;
char buf[MAXLINE];
struct iovec iov[1];
struct msghdr msg;
const int on = 1;
status = -1;
newfd = -1;
if (setsockopt(fd, SOL_SOCKET, CREDOPT, &on, sizeof(int)) < 0) {
err_ret("setsockopt failed");
return(-1);
}
for ( ; ; ) {
iov[0].iov_base = buf;
iov[0].iov_len = sizeof(buf);
msg.msg_iov = iov;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
if (cmptr == NULL && (cmptr = malloc(CONTROLLEN)) == NULL)
return(-1);
msg.msg_control = cmptr;
msg.msg_controllen = CONTROLLEN;
if ((nr = recvmsg(fd, &msg, 0)) < 0) {
err_sys("recvmsg error");
} else if (nr == 0) {
err_ret("connection closed by server");
return(-1);
}
/*
* See if this is the final data with null & status. Null
* is next to last byte of buffer; status byte is last byte.
* Zero status means there is a file descriptor to receive.
*/
for (ptr = buf; ptr < &buf[nr]; ) {
if (*ptr++ == 0) {
if (ptr != &buf[nr-1])
err_dump("message format error");
status = *ptr & 0xFF; /* prevent sign extension */
if (status == 0) {
if (msg.msg_controllen != CONTROLLEN)
err_dump("status = 0 but no fd");
/* process the control data */
for (cmp = CMSG_FIRSTHDR(&msg);
cmp != NULL; cmp = CMSG_NXTHDR(&msg, cmp)) {
if (cmp->cmsg_level != SOL_SOCKET)
continue;
switch (cmp->cmsg_type) {
case SCM_RIGHTS:
newfd = *(int *)CMSG_DATA(cmp);
break;
case SCM_CREDTYPE:
credp = (struct CREDSTRUCT *)CMSG_DATA(cmp);
*uidptr = credp->CR_UID;
}
}
} else {
newfd = -status;
}
nr -= 2;
}
}
if (nr > 0 && (*userfunc)(STDERR_FILENO, buf, nr) != nr)
return(-1);
if (status >= 0) /* final data has arrived */
return(newfd); /* descriptor, or -status */
}
}
On FreeBSD, we specify SCM_CREDS to transmit credentials; on Linux, we use SCM_CREDENTIALS.
17.5. An Open Server, Version 1
Using file descriptor passing, we now develop an open server: a program that is executed by a process to open one or more files. But instead of sending the contents of the file back to the calling process, the server sends back an open file descriptor. This lets the server work with any type of file (such as a device or a socket) and not simply regular files. It also means that a minimum of information is exchanged using IPC: the filename and open mode from the client to the server, and the returned descriptor from the server to the client. The contents of the file are not exchanged using IPC.
There are several advantages in designing the server to be a separate executable program (either one that is executed by the client, as we develop in this section, or a daemon server, which we develop in the next section).
The server can easily be contacted by any client, similar to the client calling a library function. We are not hard coding a particular service into the application, but designing a general facility that others can reuse. If we need to change the server, only a single program is affected. Conversely, updating a library function can require that all programs that call the function be updated (i.e., relinked with the link editor). Shared libraries can simplify this updating (Section 7.7). The server can be a set-user-ID program, providing it with additional permissions that the client does not have. Note that a library function (or shared library function) can't provide this capability.
The client process creates an s-pipe (either a STREAMS-based pipe or a UNIX domain socket pair) and then calls fork and exec to invoke the server. The client sends requests across the s-pipe, and the server sends back responses across the s-pipe.
We define the following application protocol between the client and the server.
The client sends a request of the form "open <pathname> <openmode>\0" across the s-pipe to the server. The <openmode> is the numeric value, in ASCII decimal, of the second argument to the open function. This request string is terminated by a null byte. The server sends back an open descriptor or an error by calling either send_fd or send_err.
This is an example of a process sending an open descriptor to its parent. In Section 17.6, we'll modify this example to use a single daemon server, where the server sends a descriptor to a completely unrelated process.
We first have the header, open.h (Figure 17.26), which includes the standard headers and defines the function prototypes.
Figure 17.26. The open.h header
#include "apue.h"
#include <errno.h>
#define CL_OPEN "open" /* client's request for server */
int csopen(char *, int);
The main function (Figure 17.27) is a loop that reads a pathname from standard input and copies the file to standard output. The function calls csopen to contact the open server and return an open descriptor.
Figure 17.27. The client main function, version 1
#include "open.h"
#include <fcntl.h>
#define BUFFSIZE 8192
int
main(int argc, char *argv[])
{
int n, fd;
char buf[BUFFSIZE], line[MAXLINE];
/* read filename to cat from stdin */
while (fgets(line, MAXLINE, stdin) != NULL) {
if (line[strlen(line) - 1] == '\n')
line[strlen(line) - 1] = 0; /* replace newline with null */
/* open the file */
if ((fd = csopen(line, O_RDONLY)) < 0)
continue; /* csopen() prints error from server */
/* and cat to stdout */
while ((n = read(fd, buf, BUFFSIZE)) > 0)
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error");
if (n < 0)
err_sys("read error");
close(fd);
}
exit(0);
}
The function csopen (Figure 17.28) does the fork and exec of the server, after creating the s-pipe.
Figure 17.28. The csopen function, version 1
#include "open.h"
#include <sys/uio.h> /* struct iovec */
/*
* Open the file by sending the "name" and "oflag" to the
* connection server and reading a file descriptor back.
*/
int
csopen(char *name, int oflag)
{
pid_t pid;
int len;
char buf[10];
struct iovec iov[3];
static int fd[2] = { -1, -1 };
if (fd[0] < 0) { /* fork/exec our open server first time */
if (s_pipe(fd) < 0)
err_sys("s_pipe error");
if ((pid = fork()) < 0) {
err_sys("fork error");
} else if (pid == 0) { /* child */
close(fd[0]);
if (fd[1] != STDIN_FILENO &&
dup2(fd[1], STDIN_FILENO) != STDIN_FILENO)
err_sys("dup2 error to stdin");
if (fd[1] != STDOUT_FILENO &&
dup2(fd[1], STDOUT_FILENO) != STDOUT_FILENO)
err_sys("dup2 error to stdout");
if (execl("./opend", "opend", (char *)0) < 0)
err_sys("execl error");
}
close(fd[1]); /* parent */
}
sprintf(buf, " %d", oflag); /* oflag to ascii */
iov[0].iov_base = CL_OPEN " "; /* string concatenation */
iov[0].iov_len = strlen(CL_OPEN) + 1;
iov[1].iov_base = name;
iov[1].iov_len = strlen(name);
iov[2].iov_base = buf;
iov[2].iov_len = strlen(buf) + 1; /* +1 for null at end of buf */
len = iov[0].iov_len + iov[1].iov_len + iov[2].iov_len;
if (writev(fd[0], &iov[0], 3) != len)
err_sys("writev error");
/* read descriptor, returned errors handled by write() */
return(recv_fd(fd[0], write));
}
The child closes one end of the pipe, and the parent closes the other. For the server that it executes, the child also duplicates its end of the pipe onto its standard input and standard output. (Another option would have been to pass the ASCII representation of the descriptor fd[1] as an argument to the server.)
The parent sends to the server the request containing the pathname and open mode. Finally, the parent calls recv_fd to return either the descriptor or an error. If an error is returned by the server, write is called to output the message to standard error.
Now let's look at the open server. It is the program opend that is executed by the client in Figure 17.28. First, we have the opend.h header (Figure 17.29), which includes the standard headers and declares the global variables and function prototypes.
Figure 17.29. The opend.h header, version 1
#include "apue.h"
#include <errno.h>
#define CL_OPEN "open" /* client's request for server */
extern char errmsg[]; /* error message string to return to client */
extern int oflag; /* open() flag: O_xxx ... */
extern char *pathname; /* of file to open() for client */
int cli_args(int, char **);
void request(char *, int, int);
The main function (Figure 17.30) reads the requests from the client on the s-pipe (its standard input) and calls the function request.
Figure 17.30. The server main function, version 1
#include "opend.h"
char errmsg[MAXLINE];
int oflag;
char *pathname;
int
main(void)
{
int nread;
char buf[MAXLINE];
for ( ; ; ) { /* read arg buffer from client, process request */
if ((nread = read(STDIN_FILENO, buf, MAXLINE)) < 0)
err_sys("read error on stream pipe");
else if (nread == 0)
break; /* client has closed the stream pipe */
request(buf, nread, STDOUT_FILENO);
}
exit(0);
}
The function request in Figure 17.31 does all the work. It calls the function buf_args to break up the client's request into a standard argv-style argument list and calls the function cli_args to process the client's arguments. If all is OK, open is called to open the file, and then send_fd sends the descriptor back to the client across the s-pipe (its standard output). If an error is encountered, send_err is called to send back an error message, using the clientserver protocol that we described earlier.
Figure 17.31. The request function, version 1
#include "opend.h"
#include <fcntl.h>
void
request(char *buf, int nread, int fd)
{
int newfd;
if (buf[nread-1] != 0) {
sprintf(errmsg, "request not null terminated: %*.*s\n",
nread, nread, buf);
send_err(fd, -1, errmsg);
return;
}
if (buf_args(buf, cli_args) < 0) { /* parse args & set options */
send_err(fd, -1, errmsg);
return;
}
if ((newfd = open(pathname, oflag)) < 0) {
sprintf(errmsg, "can't open %s: %s\n", pathname,
strerror(errno));
send_err(fd, -1, errmsg);
return;
}
if (send_fd(fd, newfd) < 0) /* send the descriptor */
err_sys("send_fd error");
close(newfd); /* we're done with descriptor */
}
The client's request is a null-terminated string of white-space-separated arguments. The function buf_args in Figure 17.32 breaks this string into a standard argv-style argument list and calls a user function to process the arguments. We'll use the buf_args function later in this chapter. We use the ISO C function strtok to tokenize the string into separate arguments.
Figure 17.32. The buf_args function
#include "apue.h"
#define MAXARGC 50 /* max number of arguments in buf */
#define WHITE " \t\n" /* white space for tokenizing arguments */
/*
* buf[] contains white-space-separated arguments. We convert it to an
* argv-style array of pointers, and call the user's function (optfunc)
* to process the array. We return -1 if there's a problem parsing buf,
* else we return whatever optfunc() returns. Note that user's buf[]
* array is modified (nulls placed after each token).
*/
int
buf_args(char *buf, int (*optfunc)(int, char **))
{
char *ptr, *argv[MAXARGC];
int argc;
if (strtok(buf, WHITE) == NULL) /* an argv[0] is required */
return(-1);
argv[argc = 0] = buf;
while ((ptr = strtok(NULL, WHITE)) != NULL) {
if (++argc >= MAXARGC-1) /* -1 for room for NULL at end */
return(-1);
argv[argc] = ptr;
}
argv[++argc] = NULL;
/*
* Since argv[] pointers point into the user's buf[],
* user's function can just copy the pointers, even
* though argv[] array will disappear on return.
*/
return((*optfunc)(argc, argv));
}
The server's function that is called by buf_args is cli_args (Figure 17.33). It verifies that the client sent the right number of arguments and stores the pathname and open mode in global variables.
Figure 17.33. The cli_args function
#include "opend.h"
/*
* This function is called by buf_args(), which is called by
* request(). buf_args() has broken up the client's buffer
* into an argv[]-style array, which we now process.
*/
int
cli_args(int argc, char **argv)
{
if (argc != 3 || strcmp(argv[0], CL_OPEN) != 0) {
strcpy(errmsg, "usage: <pathname> <oflag>\n");
return(-1);
}
pathname = argv[1]; /* save ptr to pathname to open */
oflag = atoi(argv[2]);
return(0);
}
This completes the open server that is invoked by a fork and exec from the client. A single s-pipe is created before the fork and is used to communicate between the client and the server. With this arrangement, we have one server per client.
17.6. An Open Server, Version 2
In the previous section, we developed an open server that was invoked by a fork and exec by the client, demonstrating how we can pass file descriptors from a child to a parent. In this section, we develop an open server as a daemon process. One server handles all clients. We expect this design to be more efficient, since a fork and exec are avoided. We still use an s-pipe between the client and the server and demonstrate passing file descriptors between unrelated processes. We'll use the three functions serv_listen, serv_accept, and cli_conn introduced in Section 17.2.2. This server also demonstrates how a single server can handle multiple clients, using both the select and poll functions from Section 14.5.
The client is similar to the client from Section 17.5. Indeed, the file main.c is identical (Figure 17.27). We add the following line to the open.h header (Figure 17.26):
#define CS_OPEN "/home/sar/opend" /* server's well-known name */
The file open.c does change from Figure 17.28, since we now call cli_conn instead of doing the fork and exec. This is shown in Figure 17.34.
Figure 17.34. The csopen function, version 2
#include "open.h"
#include <sys/uio.h> /* struct iovec */
/*
* Open the file by sending the "name" and "oflag" to the
* connection server and reading a file descriptor back.
*/
int
csopen(char *name, int oflag)
{
int len;
char buf[10];
struct iovec iov[3];
static int csfd = -1;
if (csfd < 0) { /* open connection to conn server */
if ((csfd = cli_conn(CS_OPEN)) < 0)
err_sys("cli_conn error");
}
sprintf(buf, " %d", oflag); /* oflag to ascii */
iov[0].iov_base = CL_OPEN " "; /* string concatenation */
iov[0].iov_len = strlen(CL_OPEN) + 1;
iov[1].iov_base = name;
iov[1].iov_len = strlen(name);
iov[2].iov_base = buf;
iov[2].iov_len = strlen(buf) + 1; /* null always sent */
len = iov[0].iov_len + iov[1].iov_len + iov[2].iov_len;
if (writev(csfd, &iov[0], 3) != len)
err_sys("writev error");
/* read back descriptor; returned errors handled by write() */
return(recv_fd(csfd, write));
}
The protocol from the client to the server remains the same.
Next, we'll look at the server. The header opend.h (Figure 17.35) includes the standard headers and declares the global variables and the function prototypes.
Figure 17.35. The opend.h header, version 2
#include "apue.h"
#include <errno.h>
#define CS_OPEN "/home/sar/opend" /* well-known name */
#define CL_OPEN "open" /* client's request for server */
extern int debug; /* nonzero if interactive (not daemon) */
extern char errmsg[]; /* error message string to return to client */
extern int oflag; /* open flag: O_xxx ... */
extern char *pathname; /* of file to open for client */
typedef struct { /* one Client struct per connected client */
int fd; /* fd, or -1 if available */
uid_t uid;
} Client;
extern Client *client; /* ptr to malloc'ed array */
extern int client_size; /* # entries in client[] array */
int cli_args(int, char **);
int client_add(int, uid_t);
void client_del(int);
void loop(void);
void request(char *, int, int, uid_t);
Since this server handles all clients, it must maintain the state of each client connection. This is done with the client array declared in the opend.h header. Figure 17.36 defines three functions that manipulate this array.
Figure 17.36. Functions to manipulate client array
#include "opend.h"
#define NALLOC 10 /* # client structs to alloc/realloc for */
static void
client_alloc(void) /* alloc more entries in the client[] array */
{
int i;
if (client == NULL)
client = malloc(NALLOC * sizeof(Client));
else
client = realloc(client, (client_size+NALLOC)*sizeof(Client));
if (client == NULL)
err_sys("can't alloc for client array");
/* initialize the new entries */
for (i = client_size; i < client_size + NALLOC; i++)
client[i].fd = -1; /* fd of -1 means entry available */
client_size += NALLOC;
}
/*
* Called by loop() when connection request from a new client arrives.
*/
int
client_add(int fd, uid_t uid)
{
int i;
if (client == NULL) /* first time we're called */
client_alloc();
again:
for (i = 0; i < client_size; i++) {
if (client[i].fd == -1) { /* find an available entry */
client[i].fd = fd;
client[i].uid = uid;
return(i); /* return index in client[] array */
}
}
/* client array full, time to realloc for more */
client_alloc();
goto again; /* and search again (will work this time) */
}
/*
* Called by loop() when we're done with a client.
*/
void
client_del(int fd)
{
int i;
for (i = 0; i < client_size; i++) {
if (client[i].fd == fd) {
client[i].fd = -1;
return;
}
}
log_quit("can't find client entry for fd %d", fd);
}
The first time client_add is called, it calls client_alloc, which calls malloc to allocate space for ten entries in the array. After these ten entries are all in use, a later call to client_add causes realloc to allocate additional space. By dynamically allocating space this way, we have not limited the size of the client array at compile time to some value that we guessed and put into a header. These functions call the log_ functions (Appendix B) if an error occurs, since we assume that the server is a daemon.
The main function (Figure 17.37) defines the global variables, processes the command-line options, and calls the function loop. If we invoke the server with the -d option, the server runs interactively instead of as a daemon. This is used when testing the server.
Figure 17.37. The server main function, version 2
#include "opend.h"
#include <syslog.h>
int debug, oflag, client_size, log_to_stderr;
char errmsg[MAXLINE];
char *pathname;
Client *client = NULL;
int
main(int argc, char *argv[])
{
int c;
log_open("open.serv", LOG_PID, LOG_USER);
opterr = 0; /* don't want getopt() writing to stderr */
while ((c = getopt(argc, argv, "d")) != EOF) {
switch (c) {
case 'd': /* debug */
debug = log_to_stderr = 1;
break;
case '?':
err_quit("unrecognized option: -%c", optopt);
}
}
if (debug == 0)
daemonize("opend");
loop(); /* never returns */
}
The function loop is the server's infinite loop. We'll show two versions of this function. Figure 17.38 shows one version that uses select; Figure 17.39 shows another version that uses poll.
Figure 17.38. The loop function using select
#include "opend.h"
#include <sys/time.h>
#include <sys/select.h>
void
loop(void)
{
int i, n, maxfd, maxi, listenfd, clifd, nread;
char buf[MAXLINE];
uid_t uid;
fd_set rset, allset;
FD_ZERO(&allset);
/* obtain fd to listen for client requests on */
if ((listenfd = serv_listen(CS_OPEN)) < 0)
log_sys("serv_listen error");
FD_SET(listenfd, &allset);
maxfd = listenfd;
maxi = -1;
for ( ; ; ) {
rset = allset; /* rset gets modified each time around */
if ((n = select(maxfd + 1, &rset, NULL, NULL, NULL)) < 0)
log_sys("select error");
if (FD_ISSET(listenfd, &rset)) {
/* accept new client request */
if ((clifd = serv_accept(listenfd, &uid)) < 0)
log_sys("serv_accept error: %d", clifd);
i = client_add(clifd, uid);
FD_SET(clifd, &allset);
if (clifd > maxfd)
maxfd = clifd; /* max fd for select() */
if (i > maxi)
maxi = i; /* max index in client[] array */
log_msg("new connection: uid %d, fd %d", uid, clifd);
continue;
}
for (i = 0; i <= maxi; i++) { /* go through client[] array */
if ((clifd = client[i].fd) < 0)
continue;
if (FD_ISSET(clifd, &rset)) {
/* read argument buffer from client */
if ((nread = read(clifd, buf, MAXLINE)) < 0) {
log_sys("read error on fd %d", clifd);
} else if (nread == 0) {
log_msg("closed: uid %d, fd %d",
client[i].uid, clifd);
client_del(clifd); /* client has closed cxn */
FD_CLR(clifd, &allset);
close(clifd);
} else { /* process client's request */
request(buf, nread, clifd, client[i].uid);
}
}
}
}
}
This function calls serv_listen to create the server's endpoint for the client connections. The remainder of the function is a loop that starts with a call to select. Two conditions can be true after select returns.
The descriptor listenfd can be ready for reading, which means that a new client has called cli_conn. To handle this, we call serv_accept and then update the client array and associated bookkeeping information for the new client. (We keep track of the highest descriptor number for the first argument to select. We also keep track of the highest index in use in the client array.) An existing client's connection can be ready for reading. This means that the client has either terminated or sent a new request. We find out about a client termination by read returning 0 (end of file). If read returns a value greater than 0, there is a new request to process, which we handle by calling request.
We keep track of which descriptors are currently in use in the allset descriptor set. As new clients connect to the server, the appropriate bit is turned on in this descriptor set. The appropriate bit is turned off when the client terminates.
We always know when a client terminates, whether the termination is voluntary or not, since all the client's descriptors (including the connection to the server) are automatically closed by the kernel. This differs from the XSI IPC mechanisms.
The loop function that uses poll is shown in Figure 17.39.
Figure 17.39. The loop function using poll
#include "opend.h"
#include <poll.h>
#if !defined(BSD) && !defined(MACOS)
#include <stropts.h>
#endif
void
loop(void)
{
int i, maxi, listenfd, clifd, nread;
char buf[MAXLINE];
uid_t uid;
struct pollfd *pollfd;
if ((pollfd = malloc(open_max() * sizeof(struct pollfd))) == NULL)
err_sys("malloc error");
/* obtain fd to listen for client requests on */
if ((listenfd = serv_listen(CS_OPEN)) < 0)
log_sys("serv_listen error");
client_add(listenfd, 0); /* we use [0] for listenfd */
pollfd[0].fd = listenfd;
pollfd[0].events = POLLIN;
maxi = 0;
for ( ; ; ) {
if (poll(pollfd, maxi + 1, -1) < 0)
log_sys("poll error");
if (pollfd[0].revents & POLLIN) {
/* accept new client request */
if ((clifd = serv_accept(listenfd, &uid)) > 0)
log_sys("serv_accept error: %d", clifd);
i = client_add(clifd, uid);
pollfd[i].fd = clifd;
pollfd[i].events = POLLIN;
if (i > maxi)
maxi = i;
log_msg("new connection: uid %d, fd %d", uid, clifd);
}
for (i = 1; i <= maxi; i++) {
if ((clifd = client[i].fd) < 0)
continue;
if (pollfd[i].revents & POLLHUP) {
goto hungup;
} else if (pollfd[i].revents & POLLIN) {
/* read argument buffer from client */
if ((nread = read(clifd, buf, MAXLINE)) < 0) {
log_sys("read error on fd %d", clifd);
} else if (nread == 0) {
hungup:
log_msg("closed: uid %d, fd %d",
client[i].uid, clifd);
client_del(clifd); /* client has closed conn */
pollfd[i].fd = -1;
close(clifd);
} else { /* process client's request */
request(buf, nread, clifd, client[i].uid);
}
}
}
}
}
To allow for as many clients as there are possible open descriptors, we dynamically allocate space for the array of pollfd structures. (Recall the open_max function from Figure 2.16.)
We use the first entry (index 0) of the client array for the listenfd descriptor. That way, a client's index in the client array is the same index that we use in the pollfd array. The arrival of a new client connection is indicated by a POLLIN on the listenfd descriptor. As before, we call serv_accept to accept the connection.
For an existing client, we have to handle two different events from poll: a client termination is indicated by POLLHUP, and a new request from an existing client is indicated by POLLIN. Recall from Exercise 15.7 that the hang-up message can arrive at the stream head while there is still data to be read from the stream. With a pipe, we want to read all the data before processing the hangup. But with this server, when we receive the hangup from the client, we can close the connection (the stream) to the client, effectively throwing away any data still on the stream. There is no reason to process any requests still on the stream, since we can't send any responses back.
As with the select version of this function, new requests from a client are handled by calling the request function (Figure 17.40). This function is similar to the earlier version (Figure 17.31). It calls the same function, buf_args (Figure 17.32), that calls cli_args (Figure 17.33), but since it runs from a daemon process, it logs error messages instead of printing them on the standard error stream.
Figure 17.40. The request function, version 2
#include "opend.h"
#include <fcntl.h>
void
request(char *buf, int nread, int clifd, uid_t uid)
{
int newfd;
if (buf[nread-1] != 0) {
sprintf(errmsg,
"request from uid %d not null terminated: %*.*s\n",
uid, nread, nread, buf);
send_err(clifd, -1, errmsg);
return;
}
log_msg("request: %s, from uid %d", buf, uid);
/* parse the arguments, set options */
if (buf_args(buf, cli_args) < 0) {
send_err(clifd, -1, errmsg);
log_msg(errmsg);
return;
}
if ((newfd = open(pathname, oflag)) < 0) {
sprintf(errmsg, "can't open %s: %s\n",
pathname, strerror(errno));
send_err(clifd, -1, errmsg);
log_msg(errmsg);
return;
}
/* send the descriptor */
if (send_fd(clifd, newfd) < 0)
log_sys("send_fd error");
log_msg("sent fd %d over fd %d for %s", newfd, clifd, pathname);
close(newfd); /* we're done with descriptor */
}
This completes the second version of the open server, using a single daemon to handle all the client requests.
| 
 LINUX
LINUX 
 Books
Books
