Глава 7. Процессы и потоки
Строго говоря, главной задачей операционной системы является создание среды для выполнения программ. По терминологии Unix выполняющаяся программа называется процессом. Ядро Linux, подобно ядру всех вариантов Unix, является многозадачным; оно может распределять время между несколькими процессами, создавая впечатление, будто все они выполняются одновременно. При этом, как и всегда, ядро регулирует доступ к ресурсам. А в данном случае ресурсом является время центрального процессора.
Традиционно процесс имеет единый контекст выполнения. Проще говоря, в ходе процесса одновременно выполняется только одно действие. В каждый данный момент времени можно точно сказать, какая часть кода выполняется. Но иногда было бы желательно, чтобы единый процесс одновременно выполнял более одного действия. Например, может возникнуть потребность, чтобы Web-браузер загружал и отображал Web-страницу, продолжая отслеживать, не щелкает ли пользователь по кнопке Stop. Запуск совершенно новой программы лишь для того, чтобы отслеживать состояние кнопки Stop — явное излишество, но Web-браузеру не всегда удобно делить свое время. В этом случае ему пришлось бы загрузить часть страницы, проверить состояние кнопки Stop, загрузить еще часть страницы, снова проверить состояние кнопки Stop и т.д.
Популярным решением этой проблемы является поток (thread). Концептуально, потоки — это отдельные контексты выполнения внутри одного и того же процесса. Проще говоря, они обеспечивают возможность единому процессу одновременно выполнять более одного действия, как если бы процесс был самостоятельной миниатюрной многозадачной операционной системой. Потоки внутри группы совместно используют все свои глобальные переменные и имеют одну и ту же кучу; таким образом, память, выделенная оператором malloc одному потоку внутри группы, доступна для чтения и записи другим потокам. Но при этом они имеют различные стеки (они не используют совместно локальные переменные) и могут выполняться одновременно в различных местах внутри кода процесса. Таким образом, Web-браузер может иметь один поток, занимающийся загрузкой и отображением страницы, пока другой поток следит за состоянием кнопки Stop и прерывает первый поток в случае щелчка по этой кнопке.
Эквивалентное представление потоков, используемое ядром Linux, заключается в том, что потоки — это процессы, которые совместно используют одну и ту глобальную область памяти. Это означает, что ядро не должно применять к потокам совершенно новый механизм, который по существу дублировал бы код, созданный для обработки процессов, и что данное описание процессов в значительной степени применимо и к потокам.
Конечно, приведенные рассуждения применимы только к потокам области ядра. Существуют также потоки области пользователя, которые позволяют достичь этого же эффекта, но реализуются на уровне приложений. Потоки области пользователя имеют свои преимущества и недостатки по сравнению с потоками области ядра, но эти вопросы выходят за рамки данной книги. Словно для того, чтобы еще больше запутать дело, существует функция ядра kernel_thread (строка 2426), которая не имеет ничего общего с потоками области ядра в обычном понимании этого термина.
Частично по историческим причинам, а частично потому, что ядро Linux в действительности не различает концепции процессов и потоков, в коде ядра ссылка и на процессы, и на потоки осуществляется под общим названием «задача». В соответствии с этим подходом в данной книге термины «задача» и «процесс» используются один взамен другого.
Планирование и временные кванты
Регулирование доступа к центральному процессору называется планированием. Качественное планирование учитывает приоритеты, присвоенные пользователем, и создает достоверное впечатление одновременного выполнения всех процессов. Некачественное планирование приводит к тому, что операционная система кажется перегруженной и медленной. Это одна из причин, по которой планировщик Linux в высшей степени оптимизирован.
С точки зрения концептуальных представлений планирование делит время на «кванты» и по определенному алгоритму выделяет кванты процессам. Эти кванты времени называются временными квантами (timeslices).
Процессы реального времени
Linux предоставляет три алгоритма планирования: традиционный планировщик Unix и два планировщика «реального времени», определяемые стандартом операционной системы POSIX.lb (ранее известного под названием POSIX.4). Соответственно, в книге иногда упоминаются процессы реального времени (в отличие от процессов не реального времени (nonrealtime processes), хотя по мнению автора с технической точки зрения более подходящим является термин «unreal time»). Однако термин «реальное время» не должен вводить в заблуждение — применительно к оборудованию он означает, что пользователь получает определенные гарантии в отношении производительности операционной системы, такие как задержки прерываний, которые не обеспечиваются алгоритмами планирования реального времени операционной системы Linux. В действительности алгоритмы планирования Linux являются алгоритмами «мягкого реального времени». Т.е., они предоставляют центральный процессор процессу реального времени, если это требуется любому процессу реального времени, и наоборот, они позволяют центральному процессору выделять время для процессов не реального времени.
Некоторые варианты Linux обеспечивают «жесткое реальное время», если это свойство действительно требуется. Но в рассматриваемом ядре Linux — и, соответственно, в этой главе — «реальное время» всегда означает «мягкое реальное время».
Приоритеты
Процессы не реального времени имеют два различных вида приоритетов: статический приоритет и динамический приоритет. Процессы реального времени добавляют третий вид приоритета — приоритет реального времени. Приоритеты — это просто целочисленные значения, выражающие относительный вес, который должен быть присвоен процессу при определении того, какому процессу должно быть выделено определенное время центрального процессора. Чем выше приоритет процесса, тем выше его шансы получить доступ к процессору.
- Статический приоритет. Этот приоритет называется статическим, поскольку не изменяется с течением времени и может быть изменен только явно пользователем. Он указывает максимальный размер временного кванта, который может быть выделен процессу, прежде чем другим процессам будет разрешено конкурировать за доступ к процессору. (По каким-либо другим причинам процесс может быть вынужден освободить процессор и до истечения этого интервала.)
- Динамический приоритет. Этот приоритет снижается с течением времени, пока процесс используется время процессора; когда его значение падает ниже 0, процесс помечается для повторного планирования. Это значение указывает остаток времени данного временного кванта.
- Приоритет реального времени. Этот приоритет показывает, какие другие процессы данный процесс побеждает в соревновании за время центрального процессора: более высокие значения всегда побеждают более низкие. Поскольку приоритет реального времени для процесса, который не является процессом реального времени, равен 0, любой процесс реального времени всегда побеждает любой процесс не реального времени. (Это утверждение не совсем верно; как будет описано далее в этой главе, процессы реального времени могут явно освобождать центральный процессор, и могут быть вынуждены делать это, ожидая выполнения операций ввода/вывода. Ранее приведенное описание применимо только к процессам, которые готовы к взаимодействию с центральным процессором.)
Идентификаторы процессов (PID)
Традиционно каждый процесс Unix имеет уникальный идентификатор — целое число в диапазоне от 0 до 32767, которое называется идентификатором процесса (process identifier, PID). Идентификаторы процессов PID 0 и 1 имеют для системы специальной значение; все остальные идентификаторы присваиваются «обычным» процессам. В ходе рассмотрения get_pid далее в этой главе будет показано, как PID генерируются и присваиваются.
В Linux PID не обязательно должны быть уникальными — обычно, это так, но две задачи могут совместно использовать общий PID. Это — побочный эффект поддержки операционной системой Linux потоков, которые должны совместно использовать PID, поскольку они являются частью одного и того же процесса. В среде Linux можно было бы создать две задачи, которые не используют совместно ничего, кроме своего PID — в действительности они не были бы потоками в каком-либо разумном смысле, но, тем не менее, имели бы одинаковый PID. Это было бы лишено особого смысла, но при желании система Linux позволила бы сделать это.
Подсчет ссылок
Подсчет ссылок — широко используемая технология совместного использования несколькими объектами общей информации. Говоря в целом, один или более «объектов-владельцев» содержат указатель на совместно используемый объект данных, который включает в себя целое значение, называемое счетчиком ссылок; значение этого счетчика ссылок равно числу объектов-владельцев, которые совместно используют данные. Новому объекту-владельцу, который желает совместно использовать данные, присваивается указатель на эту же структуру, а значение счетчика ссылок увеличивается на единицу.
Когда объект-владелец удаляется, счетчик ссылок совместно используемого объекта данных уменьшается на единицу, а «выходящий последним гасит свет» — т.е., когда значение счетчика ссылок уменьшается до 0, объект-владелец освобождает объект совместного использования. Эта технология иллюстрируется на рис. 7.1.
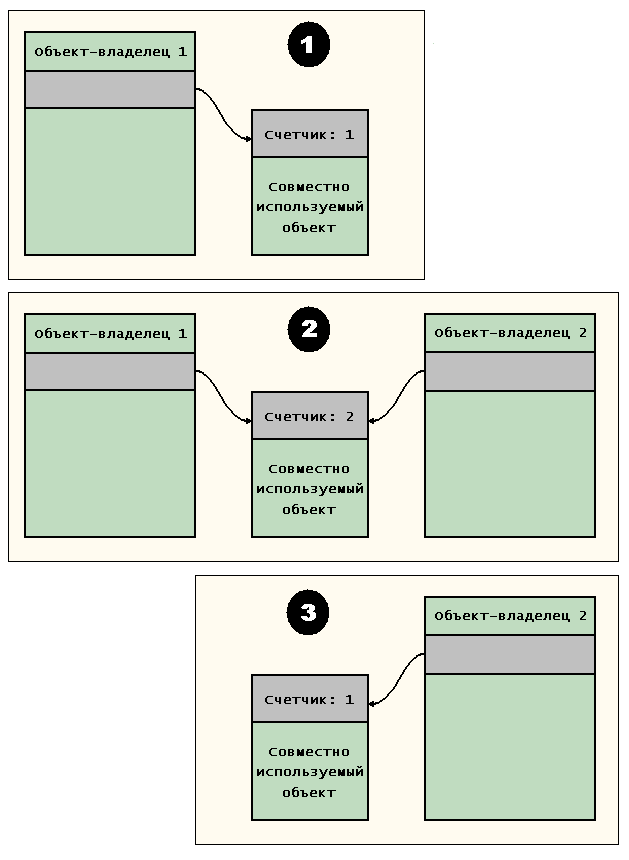
Рис. 7.1. Подсчет ссылок
Как будет показано далее, Linux использует подсчет ссылок для совместного использования общих данных потоками.
Возможности
На заре развития Unix пользователь являлся либо привилегированным (root), либо обычным. Привилегированный пользователь мог делать почти все, даже если в действительности это было не очень хорошей идеей, например, удалением всех файлов на системном загрузочном диске. Обычный же пользователь не мог особенно повредить системе, но и не мог выполнять какие-либо существенные задачи администрирования.
К сожалению, с точки зрения обеспечения безопасности системы множество приложений занимают промежуточное положение между этими двумя крайними ситуациями. Например, изменение системного времени относилось к задачам, которые мог выполнять только привилегированный пользователь, и поэтому программы, делавшие это, должны были запускаться в качестве привилегированных. Но поскольку он выполнялся в качестве привилегированного, процесс, изменяющий системное время, мог выполнять и любые другие задачи, доступные привилегированному процессу. Корректно написанные программы не создавали проблем, но тем не менее, существовала вероятность случайного или умышленного внесения беспорядка в систему. (Неисчислимое множество компьютерных атак было связано с некоторыми внешне заслуживающими доверия исполняемыми программами, которые в действительности проделывали грязные трюки.)
Некоторые из этих проблем можно было обойти посредством правильного использования групп или с помощью таких программ, как sudo, но это получалось не всегда. Для выполнения некоторых важных операций все же приходилось предоставлять процессам общий привилегированный доступ, даже когда в действительности нужно было разрешить им выполнить всего одну-две привилегированные операции. Linux решает эту проблему посредством воплощения идеи, заимствованной из уже не существующего проектного стандарта POSIX — возможностей.
Возможности позволяют более точно указывать, что разрешается делать привилегированному процессу. Например, процессу можно предоставить возможность изменять системное время, не предоставляя ему возможность прерывать любые другие процессы в системе, удалять все файлы и вообще совершать какие-либо безумные действия. Кроме того, в качестве предупреждения случайных злоупотреблений привилегиями долговременный процесс может получать ту или иную возможность временно, только на время выполнения конкретной задачи, а затем, по завершении выполнения, утрачивать ее.
В настоящее время разработка возможностей продолжается. Для полного использования потенциальных преимуществ возможностей некоторые новые функции все еще ждут своей реализации; например, ядро все еще не обеспечивает поддержку присоединения к самому файлу требуемых программе возможностей. В результате, иногда система Linux продолжает проверять, выполняется ли процесс в качестве привилегированного, вместо того, чтобы проверять наличие конкретных возможностей, требуемых процессу. Но даже уже сделанное является достаточно полезным.
Представление процессов в ядре
Для отслеживания процессов ядро использует несколько структур данных; некоторые из них связанны с представлением самого процесса, а некоторые являются отдельными. Эти структуры данных показаны на рис. 7.2 и подробно описаны далее в этой главе.
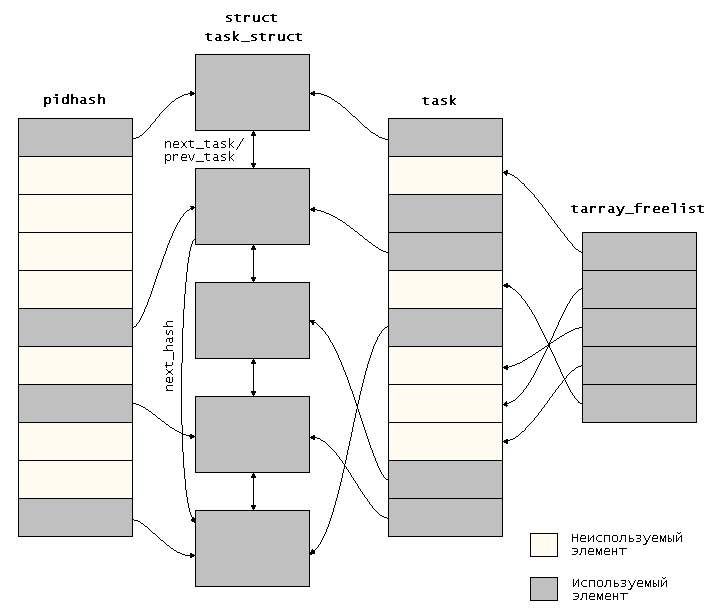
Рис. 7.2. Структуры данных ядра, предназначенные для управления задачами
16325: Процесс представляется структурой данных ядра struct task_struct. Советуем по крайней мере просмотреть определение этой структуры. Она достаточно велика, но логически организована в виде отдельных модулей, смысл которых станет понятен по мере прочтения этой главы. А пока, обратите внимание, что многие составные части этой структуры являются указателями на другие структуры; это пригодится, когда дочерней и родительской структурам потребуется совместно использовать указываемую информацию — многие указатели указывают на информацию, для которой выполняется подсчет ссылок.
16350: Сами задачи образуют циклический, дважды связанный список, называемый списком задач, использующий члены next_task и prev_task структуры struct task_struct. Да, это так, не смотря на то, что они уже доступны в центральном массиве task (который вскоре будет описан). Вначале это может показаться странным, но в действительности имеет большой смысл, поскольку позволяет коду ядра осуществлять итерации по всем существующим задачам — т.е. всем заполненным слотам в массиве task — не тратя время на явный пропуск пустых слотов. Действительно, эта итерация требуется столь часто, что для нее существует макрос: for_each_task в строке 16898.
Хотя он содержит всего одну строку, макрос for_each_task имеет несколько заслуживающих внимания особенностей. Во-первых, обратите внимание, что он использует член init_task в качестве начала и конца итерации. Это совершенно безопасно, поскольку init_task никогда не осуществляет выход; следовательно, он всегда доступен для использования в качестве маркера. Однако обратите внимание, что сам член init_task не посещается во время итерации, что иногда желательно во время использования макроса. Обратите также внимание, что посредством использования члена next_task в списке всегда выполняется продвижение вперед; не существует никакого макроса для перемещения назад. Это и не нужно — член prev_task требуется только для эффективного удаления задачи из списка.
16351: Linux поддерживает еще один циклический, дважды связанный список задач, аналогичный описанному перед этим. Этот список использует члены prev_run и next_run структуры struct task_struct и в целом обрабатывается как очередь (gesundheight); по этой причине данный список обычно называется текущей очередью. Как и в случае с членом prev_task, член prev_run нужен только для эффективного удаления задачи из очереди; итерация по списку всегда выполняется в прямом направлении посредством использования члена next_run. Кроме того, как и в случае обычного списка задач, член init_task используется для отметки начала и конца очереди.
Задачи добавляются в очередь с помощью функции add_to_runqueue (строка 26276) и удаляются с помощью функции del_from_runqueue (строка 26287). Иногда они также перемещаются в начало или в конец очереди соответственно с помощью функций move_first_runqueue (строка 26318) и move_last_runqueue (строка 26300). Обратите внимание, что все эти функции являются локальными для kernel/sched.c, а поля prev_run и next_run не используются ни в каких других файлах (за исключением файла kernel/fork.c во время процесса создания); это достаточно оправдано, поскольку текущая очередь требуется только для планирования.
16370: На основе этого задачи образуют граф, структура которого выражает родственные взаимосвязи между задачами; поскольку я не знаю никакого общепринятого термина для этого графа, я называю его графом процессов. Граф практически не зависит от связи next_task/prev_task в которой позиция задачи почти не имеет смысла — так уж сложилось исторически. Каждая структура struct task_struct поддерживает пять указателей самой позиции внутри графа процессов. Эти пять указателей объявляются в строках 16370 – 16371:
- p_opptr указывает на исходный родительский процесс данного процесса; обычно он равен указателю p_pptr.
- p_pptr указывает на текущий родительский процесс данного процесса.
- p_cptr указывает на самый младший (наиболее недавний) дочерний процесс данного процесса.
- p_ysptr указывает на следующий более младший (следующий более недавний) родственный процесс данного процесса.
- p_osptr указывает на следующий более старший (следующий менее недавний) родственный процесс данного процесса.
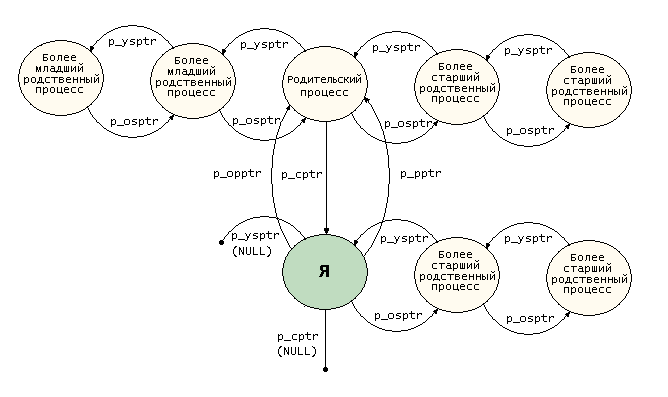
Рис. 7.3. Граф процессов
Эти взаимосвязи показаны на рис. 7.3 (полный набор связей показан только для узла, обозначенного Я). Этот набор указателей обеспечивает еще один способ перемещения по набору процессов в системе; совершено очевидно, что указатели наиболее полезны при таких перемещениях, как поиск родительского процесса или перемещение по списку дочерних процессов данного процесса. Указатели поддерживаются двумя макросами:
- REMOVE_LINKS (строка 16876) удаляет процесс из графа.
- SET_LINKS (строка 16887) вставляет процесс в граф.
Оба эти макроса также настраивают связи next_task/prev_task. Если вы внимательно исследуете макросы, то увидите, что они могут добавлять или удалять только процессы-листья, но не процессы, имеющие дочерние процессы.
16517: task определяется как массив указателей на структуру struct task_structs. Каждая задача в системе представляется записью в этом массиве. Массив имеет размер NR_TASKS (в строке 18320 это значение установлено равным 512), устанавливая верхний предел количества задач, которые могут выполняться одновременно. Поскольку существует 32768 возможных PID, этот массив явно недостаточно велик, чтобы непосредственно индексировать все задачи в системе по их PID. (Т.е. элемент массива task[i] не обязательно будет задачей, имеющей PID i.) Вместо этого Linux использует другие структуры данных, помогающие в управлении этим ограниченным ресурсом.
16519: Список свободных слотов tarray_freelist поддерживает список (в действительности являющийся стеком) свободных позиций в массиве task. Он инициализируется в строках 27966 и 27967, а затем манипулирование им осуществляется с помощью двух внутренних функций, определенных в строках с 16522 по 16542. В SMP доступ к списку tarray_freelist должен ограничиваться блокировкой taskslot_lock (строка 23475). (Блокировки подробно описаны в главе 10.)
16546: Массив pidhash помогает отображать PID указателями на структуру struct task_structs. pidhash инициализируется в строках 27969 и 27970, после чего манипулирование им осуществляется с помощью набора макросов и внутренних функций, определенных в строках с 16548 по 16580. Тем самым просто реализуется лишенная коллизий хэш-таблица. Обратите внимание, что функции, поддерживающие pidhash, используют два члена в самой структуре struct task_struct — pidhash_next (строка 16374) и pidhash_pprev (строка 16375) — для поддержания областей хеша. С помощью pidhash ядро может эффективно находить задачу по ее PID, хотя эта операция выполняется и не так быстро, как могла бы выполняться при непосредственном поиске.
Просто ради развлечения, убедитесь, что функция хеша — pid_hashfh в строке 16548 — обеспечивает равномерное распределение по своей области от 0 до 32767 (по всем допустимым PID). Если читатели имеют иное представление о развлечении, что ж, так тому и быть.
Эти структуры данных обеспечивают массу информации о действующей системе, но это не дается даром: все эти структуры должны корректно поддерживаться при каждом добавлении или удалении процессов; в противном случае порядок в системе будет нарушен. Трудность этого является одной из причин, по которой процессы создаются (функцией do_fork, которая описана далее в этой главе) и удаляются (функцией release, также описанной далее) в одном месте.
Эту сложность можно было бы уменьшить, по крайней мере частично, если просто сделать task массивом 32768 структур struct task_structs, по одной для каждого возможного PID. Но это значительно увеличило бы требования к объему памяти ядра. Единственная структура struct task_structs занимает 964 байта в однопроцессорной и 1212 байт в SMP-системе — округленно, около 1 Кб. Для хранения 32768 структур массиву task потребовалась бы память объемом 32768 Кб или 32 Мб! (В действительности все гораздо хуже: дополнительная память, связанная с поддержкой задач, которая еще не была освещена, увеличивает эту цифру в 8 раз — т.е. до 256 Мб — и все это еще без действительного выполнения какой-либо из задач.) Кроме того, аппаратная часть системы управления памятью х86 ограничивает количество активных задач приблизительно до 4000; эта тема освещена в следующей главе. Таким образом, большая часть ячеек в таком массиве неизбежно расходовалась бы напрасно.
По существу task — это всего лишь 512 4-разрядных указателей, которые занимают всего 2 Кб памяти, если ни одна из задач не выполняется. Все вспомогательные структуры данных занимают небольшой дополнительный объем памяти, но это все же значительно меньше 32 Мб. Даже в случае заполнения всех слотов в массиве task и при резервировании памяти для всех структур struct task_struct общий объем занятой памяти составляет всего около 512 Кб. В случае кармана приложений картина меняется.
Состояния процессов
В любой конкретный момент времени процесс находится в одном из шести состояний, как описано в следующих комментариях. Текущее состояние процесса отслеживается в члене state структуры struct task_struct (строка 16328).
16188: TASK_RUNNING означает, что процесс готов к запуску. Даже в однопроцессорных системах в состоянии TASK_RUNNING одновременно может находиться более одной задачи — состояние TASK_RUNNING не означает, что процесс уже сейчас находится в центральном процессоре (хотя и может там находиться); просто он готов обратиться к процессору, как только тот будет доступен.
16189: TASK_INTERRUPTIBLE является одним из двух ждущих состояний — это состояние означает, что процесс ожидает события, но его можно прервать соответствующим сигналом.
16190: TASK_UNINTERRUPTIBLE является вторым ждущим состоянием. Это состояние означает, что процесс ожидает выполнения определенного условия в отношении оборудования и не должен прерываться сигналом.
16191: TASK_ZOMBIE означает, что процесс завершился (или был прерван), но представляющая его структура task_struct еще не была удалена. Это позволяет родительскому процессу осведомляться о состоянии его более не существующего дочернего процесса даже после того, как дочерний процесс был завершен. Эта ситуация будет подробнее описана далее в этой главе.
16192: TASK_STOPPED означает, что процесс был остановлен. В основном это означает, что он получил один из сигналов SIGSTOP, SIGSTP, SIGTTIN или SIGTTOU, но может также означать, что процесс отслеживается (например, что он выполняется под управлением отладчика, и пользователь выполняет пошаговую проверку кода).
16193: TASK_SWAPPING предположительно означает, что процесс выполняет подкачку на диск или с диска. Однако, похоже, что это состояние не используется — идентификатор появляется в нескольких местах ядра, но его значение никогда не присваивается члену state процесса. Это состояние еще только разрабатывается.
Происхождение процессов: fork и __clone
Традиционные реализации Unix предоставляют только один способ создания новых процессов после того, как система запущена: системный вызов fork. (Если читателей интересует происхождение первого процесса, то оно описано в главе 4.) Когда процесс вызывает функцию fork, он делится на два — подобно развилке дороги — после чего родительский и дочерний процессы вольны следовать различными путями. Непосредственно после выполнения функции fork родительский и дочерний процессы почти идентичны — все их переменные имеют одинаковые значения, у них открыты одни и те же файлы и т.п. Но если родительский процесс изменяет значение переменной, дочерний процесс не видит этого изменения и наоборот. Дочерний процесс — это копия родительского процесса (по крайней мере, вначале), но они не используют ресурсы совместно.
В Linux сохранена традиционная функция fork и добавлена более общая функция __clone. (Два символа подчеркивания говорят о том, что обычный код приложения не должен вызывать функцию __clone непосредственно, а вместо этого должен вызывать функции из библиотек потоков, построенные на основе __clone.) В то время как fork создает новый дочерний процесс, являющийся копией родительского процесса, но не использующий совместно с ним никакие ресурсы, функция __clone позволяет указывать, какие ресурсы родительский и дочерний процессы должны использовать совместно. Если функции __clone не будет передан ни один из пяти распознаваемых ею флагов, дочерний процесс не будет ничего использовать совместно с родительским процессом. Если передать все пять флагов, дочерний процесс будет использовать все совместно с родительским процессом, подобно обычному потоку. Остальные комбинации флагов создают промежуточные ситуации.
Попутно следует отметить, что с помощь функции kernel_thread (строка 2426) ядро создает несколько задач для собственного использования. Пользователи никогда не вызывают эту функцию — в действительности они и не могут это сделать; она предназначена исключительно для создания специальных процессов, таких как kswapd (он освещен в главе 8), которые по существу являются частями ядра, для удобства обрабатываемыми в качестве задач. Создаваемые функцией kernel_thread задачи имеют некоторые необычные свойства, которые не будут подробно освещаться (например, они не могут быть предварительно освобождены), но на данном этапе главное запомнить, что функция kernel_thread использует подпрограмму do_fork для выполнения всей рутинной работы. Таким образом, строго говоря, на практике даже эти специальные процессы создаются так же, как обычные.
do_fork
23953: do_fork — это подпрограмма ядра, реализующая обе функции: и fork, и __clone.
23963: Выделяет структуру struct task_struct для представления нового процесса.
23967: Присваивает новой структуре struct task_struct ее начальное значение, скопированное непосредственно из текущего процесса. Остальная часть работы, выполняемой подпрограммой do_fork, в основном заключается в создании новых копий любой информации, которая не будет использоваться родительским и дочерни процессами совместно, (current, присутствующий в этой и других строках программы ядра, — это макрос, который вычисляет значение указателя на структуру struct task_struct, представляющую выполняющийся в текущий момент процесс. Этот макрос определяется в строке 10285, но это всего лишь вызов функции get_current, которая определена в строке 10277.)
23981: Новому процессу требуется слот в массиве task; этот слот отыскивается посредством функции find_empty_process (строка 23598; эта функция принципиально зависит от функции get_free_taskslot, определенной в строке 16532). Однако, работа этих функций несколько запутанна: значения не используемых членов массива task устанавливаются равными не NULL, а значению следующего элемента свободного списка (с помощью функции add_free_taskslot, в строке 16523). Следовательно, неиспользуемые записи массива task указывают на другие неиспользуемые записи массива task в связанном списке, a tarray_freelist просто указывает на заголовок этого списка. Таким образом, возврат свободной позиции — просто вопрос возврата заголовка списка (и, естественно, распространение указателя заголовка на следующий элемент). Для управления этой информацией было бы удобнее использовать отдельную структуру данных, но в ядре основное внимание всегда уделяется минимизации используемого объема памяти.
23999: PID присваивается новой задаче (подробности этого процесса вскоре будут освещены).
24045: Эта и несколько следующих строк, в которых используются вспомогательные функции, определенные где-либо в другом месте файла, создают для дочернего процесса его собственные копии выбранных фрагментов структуры родительского процесса, исходя из значения переданного аргумента clone_flags. Этот аргумент показывает, что важные фрагменты должны использоваться совместно вместо того, чтобы быть скопированы; в этом случае вспомогательная функция просто увеличивает значение счетчика ссылок и осуществляет возврат; в противном случае она создает новую копию, принадлежащую новому процессу.
24078: На данный момент все собственные структуры данных процесса установлены, но большинство структур данных ядра, которые отслеживают процессы, еще не установлены. Установка начинается с добавления процессов в граф процессов.
24079: Посредством вызова функции hash_pid вводит новый процесс в таблицу pidhash.
24088: Помещает новый процесс в состояние TASK_RUNNING и посредством вызова функции wake_up_process вводит его в текущую очередь (строка 26356).
Обратите внимание, что теперь не только заполнена структура struct task_struct, но и все важные структуры данных — список свободных слотов, список задач, граф процессов, текущая очередь и хеш PID — правильно изменены с учетом нового процесса. Можете себя поздравить!
Выделение PID
PID генерируются функцией get_pid (строка 23611), которая возвращает еще не используемый PID. В качестве начального эта функция использует last_pid (строка 23464) — последний выделенный PID.
Используемая в программе ядра версия функции get_pid служит примером часто применяемых в ядре компромиссов между простотой и быстродействием; в данном случае преимущество отдано быстродействию. Функция get_pid в высшей степени оптимизирована — она гораздо сложнее, чем могла бы быть простая ее реализация, но она и работает гораздо быстрее. Наиболее простая реализация выполняла бы просмотр всего списка задач — как правило состоящего из десятков, а иногда и сотен, записей — для каждого возможного PID, пока не было бы найдено подходящее значение. Иногда анализируемая версия вынуждена просматривать весь список, но в большинстве случаев может его пропускать. Целью такого подхода является ускорение создания процесса — операции, малая скорость которой в Unix общеизвестна.
Если требуется всего лишь быстро вычислить целочисленное значение, отличающееся для каждого выполняющегося процесса, то такое значение уже существует: достаточно получить индекс процесса в массиве task. В среднем это наверняка было бы быстрее, чем прибегать к использованию функции get_pid — в конце концов, при этом никогда не пришлось бы просматривать весь список задач. К сожалению, многие существующие приложения исходят из предположения, что до использования PID должно пройти некоторое время. Такое допущение в любом случае является ненадежным, но, вероятно, не стоит заставлять ядро спорить с такими программами. Существующая стратегия выделения PID все же обеспечивает очень высокое быстродействие и имеет то преимущество, что редко позволяет, если вообще позволяет, проявляться скрытым ошибкам в таких приложениях (если, конечно, считать это преимуществом).
get_pid
23613: Переменная предназначена для ускорения работы; она отслеживает следующего наименьшего кандидата в PID, который может быть зарезервирован. (Более точным ее именем было бы next_unsafe.) Когда значение last_pid увеличивается выше этого предела, весь список задач должен быть проверен на предмет того, является ли кандидат в PID все еще зарезервированным (процесс, который первоначально зарезервировал его, может уже завершиться), поскольку просмотр всего списка может быть очень медленным, по возможности его следует избегать. Таким образом, выполняя просмотр, функция get_pid повторно вычисляет переменную next_safe — если какой-либо процесс завершился, это значение теперь может быть выше, и, следовательно, функция get_pid может быть в состоянии избежать некоторых будущих просмотров списка задач. (Переменная next_safe является статической и поэтому ее значение будет запомнено, когда функции get_pid в следующий раз потребуется выделить PID.)
23616: Если новый процесс должен использовать PID совместно с его родительским процессом, возвращается PID родительского процесса.
23620: Начинает поиск среди кандидатов в PID на предмет неиспользуемого значения. Поразрядный оператор AND лишь проверяет, не превышает ли новое значение переменной last_pid 32767 (максимальный допустимый PID), проверяя, не равен ли единице любой, кроме младших 15-и разрядов. Сомнительно, что разработчики ядра действительно нуждались в столь незначительном ускорении работы, но утверждать это трудно; по крайней мере, на момент написания этих строк gcc был недостаточно разумным, чтобы заметить эквивалентность и выбрать несколько более быструю форму, использованную в коде.
23621: Если значение переменной last_pid превышает максимальное допустимое для нее значение, оно устанавливается равным 300. Это число лишено какого-либо особого смысла и является всего лишь еще одной попыткой ускорения работы. Идея заключается в том, что PID с низкими номерами как правило принадлежат долговременным «демонам», создаваемым во время начального запуска и никогда не прерывающимся. Поскольку они всегда занимают PID с низкими номерами, неиспользуемый PID будет найден быстрее, если несколько сот начальных значений никогда не будут считаться доступными для повторного использования. Поскольку количество допустимых PID в 64 раза превосходит максимальное количество задач, допускаемых одновременно (512), напрасная трата нескольких из них вполне оправдана во имя повышения быстродействия.
23622: Поскольку значение last_pid превосходит максимальный допустимый PID, оно должно также превосходить значение next_safe; следовательно, следующая проверка if может быть пропущена.
23622: Если значение переменной last_pid все же меньше значения переменной next_safe, ее новое значение доступно для использования. В противном случае необходимо проверить список задач.
23633: Если текущее значение переменной last_pid принято, оно просто увеличивается, при необходимости устанавливаясь равным 300, и цикл запускается снова. На первый взгляд кажется, что этот цикл мог бы продолжаться вечно — что если все PID уже используются? Но недолгие размышления заставляют отмести такую возможность: максимальный размер списка задач равен максимальному количеству одновременно выполняющихся задач, а количество допустимых PID значительно больше этого числа. Следовательно, со временем цикл должен найти допустимый PID; это всего лишь вопрос времени.
23651: Функция get_pid находит незанятый PID, который и возвращается.
Запуск новой программы
Если бы можно было выполнять только программу fork (или __clone), можно было бы только снова и снова создавать копии одного и того же процесса — система Linux могла бы запускать копии первого когда-либо созданного в ней процесса пользователя — init. Этот процесс полезен, но не настолько, желательно иметь возможность делать и что-нибудь еще.
После появления нового процесса он становится тем, что называется exec, (exec — это не одна функция, а скорее общий термин, относящийся к семейству функций, которые все по существу выполняют одно и то же, но принимают несколько различные аргументы.)
Таким образом, создание «действительно» нового процесса, который из родительской программы запускает образ другой программы, состоит из двух этапов: одного для fork и второго — для exec, приводя к следующей знакомой структуре кода С:
/* Возможность возникновения ошибки в следующих
строках программы игнорируется. */
if (fork()) {
/* Я - родительская программа; продолжаю
обычную работу. */
} else {
/* Я - дочерняя программа */
/* Становлюсь /some/other/program. */
execl("/some/other/program",
"/some/other/program")
}
(execl — одна из нескольких функций семейства exec.)
Основополагающей функцией ядра, реализующей все функции в семействе exec является do_execve, определенная в строках с 10079 по 10141. Функция do_execve выполняет три задачи:
- Считывает некоторую основную информацию из выполняемого файла в память. (do_execve перепоручает эту задачу функции prepare_binprm.)
- Готовит новые аргументы и среду — т.е. то, что приложения С будут видеть как переменные argc, argv и envp.
- Выделяет обработчик двоичных файлов, готовый анализировать исполняемый файл, и предоставляет ему выполнить остальную часть работы по изменению структур данных ядра.
Помня об этих задачах, давайте начнем подробное рассмотрение функции do_execve.
do_execve
10082: Тип, представляющий всю информацию, которая должна отслеживаться преобразуемым в exec процессом, является struct linux_binprm (см. строку 13786) — скорее всего, binprm является аббревиатурой слов «binary parameters» («двоичные параметры»). do_execve выполняет свою задачу и осуществляет обмен данными с другими функциями, которым она делегировала часть своей работы посредством переменной bprm. Обратите внимание, что переменная bprm освобождается, когда функция do_execve выполняет возврат — эта переменная требуется только во время создания exec, а не в течение всего времени существования процесса.
10087: do_execve начинается с инициализации миниатюрной таблицы страниц (см. главу 8), которая отслеживает страницы памяти, выделенные для аргументов и среды нового процесса. Для этого она выделяет MAX_ARG_PAGES страниц (в строке 13780 это значение определятся равным 32); на платформе х86 размер каждой страницы памяти равен 4 Кб, следовательно, общий доступный для аргументов и среды объем памяти составляет 32 х 4 Кб = 128 Кб. Лично я был весьма рад узнать об этом, поскольку иногда превышал этот предел — обычно, когда запускал команду типа cat * >/tmp/joined в каталоге, содержащем тысячи файлов; все эти имена файлов, будучи объединены, вполне могут занять более 128 Кб. Обычно я обхожу эту проблему, используя программу xargs, но, возможно, со временем я перекомпилирую ядро, установив более высокий предел для MAX_ARG_PAGES. По крайней мере, теперь я знаю как повысить этот предел, если он действительно начинает доставлять беспокойство. (Возможно некоторые решительные читатели решат вообще удалить этот жестко запрограммированный предел.) Всегда приятно иметь исходный код.
10091: Следующий шаг — открытие выполняемого файла. Он еще не считывается — в настоящее время следует убедиться, что файл существует, чтобы функция do_execve знала, следует ли продолжать работу. В некоторых случаях функция do_execve была бы значительно более эффективной, если бы этот шаг был первым, вместо заполнения таблицы страниц bprm — если это не удается, время, затраченное на инициализацию таблицы страниц, оказывается потраченным зря. Однако это помогает, только если файл не существует — этот случай встречается слишком редко, чтобы для него стоило выполнять оптимизацию.
10096: Продолжает заполнять bprm, в частности его члены argc и envc. Для заполнения этих членов функция do_execve использует функцию count (строка A ="part1_15.htm#l9480">9480), которая пошагово просматривает переданные массивы argv и envp, подсчитывая отличные от NULL указатели. Первый же указатель, имеющий значение NULL, прерывает список, в результате чего возвращается количество найденных до этого момента отличных от NULL указателей. Вначале это кажется еще одним возможным местом некоторого снижения эффективности: иногда программа, вызывающая функцию do_execve, уже знает длину массивов argv и envp. Следовательно, функцию do_execve можно было бы расширить для приема целочисленных аргументов argc и envc, которые, если не являются отрицательными, указывали бы длину соответствующих массивов. Но все не так просто: count также все время выполняет в сканируемом массиве проверку в поисках ошибок при доступе к памяти. Принуждение программы, вызывающей функцию do_execve (или точнее, доверие ей этого), выполнять такую проверку было ошибочным. Лучше оставить все так, как есть.
10115: Копирует аргументы и среду в новый процесс, в основном посредством использования функции copy_strings (строка 9519). Эта функция кажется очень сложной, но ее задача достаточно проста: копировать строки в область памяти нового процесса, при необходимости выделяя страницы. Ее сложность проистекает из необходимости управлять таблицей страниц и пересекать границы областей ядра и пользователя, как подробнее освещено в главе 8.
10126: Если до сих пор все в порядке, последним шагом является отыскание обработчика двоичных файлов для нового выполняемого файла. Если функция search_binary_handler находит такой обработчик и завершается успешно, для указания успеха возвращается неотрицательное значение.
10134: Если достигнута эта точка, значит в одном из предшествующих шагов имела место ошибка. Любые страницы, выделенные для аргументов и среды программы, должны быть освобождены, после чего для сообщения об ошибке вызывающей программе должно быть возвращено отрицательное значение.
prepare_binprm
9832: prepare_binprm заполняет значительные области структуры bprm функции do_execve.
9839: С этой строки начинается ряд профилактических проверок, таких, как проверка того, что предпринимается попытка выполнить файл, а не каталог, и что разряд выполнения файла установлен.
9858: Учитывает разряды setuid и setgid, если они установлены, отмечая, что новый процесс должен обрабатывать выполняющего пользователя в качестве другого пользователя (если установлен разряд setuid) и/или члена другой группы (если установлен разряд setgid).
9933: И наконец, функция prepare_binprm считывает первые 128 байт файла (а не первые 512 байт, как утверждается в заглавном комментарии функции) в член buf структуры bprm.
Попутно отметим здесь возможное осложнение поддержки: в строке 13787 член buf структуры struct linux_binprm был объявлен имеющим длину 128 байт, а в строке 9933 128 байт были считаны. Но в обоих местах используется литеральная константа 128 — никакое выражение #define не утверждает, что оба числа должны быть одинаковыми; следовательно, одно из них могло бы измениться без соответствующего изменения второго, внося путаницу. Не хочется быть педантом, но это упущение трудно оправдать повышением эффективности — как, впрочем, и как-либо иначе.
Здесь читателям предоставляется возможность внести небольшой, но полезный вклад в исходный код: замените 128 новым значением #define (или чем-либо вроде sizeof(bprm->buf)) везде, где оно используется для этой цели; существует всего несколько таких случаев, но я предоставляю читателям самим их найти. Попытавшись сделать это, читатели поймут, почему в этом случае лучше использовать #define, а не sizeof. (А еще лучше было бы выявить и исправить все подобные повторяющиеся магические числа. Но выполнить такое глобальное исправление не так просто, поскольку точное выявление всех совпадений — весьма трудоемкий процесс; начните с малого, постепенно расширяя задачу.)
search_binary_handler
Обработчик двоичных файлов — это механизм ядра Linux, предназначенный для единообразной обработки различных двоичных форматов, потребность в котором связана с тем, что не все программы хранятся в одном и том же файловом формате. Хорошим примером служат файлы .class Java. Java определяет независимый от платформы формат двоичных исполняемых файлов — сами файлы остаются неизменными, независимо от платформы, на которой они выполняются — поэтому ясно, что они не могут быть структурированы так же, как собственные исполняемые файлы Linux. Тем не менее, благодаря использованию соответствующего обработчика двоичных файлов Linux может обрабатывать их, как если бы они были собственными исполняемыми файлами.
Обработчики двоичных файлов будут подробно описаны далее, но теперь читатели знают о них достаточно, чтобы понять, как функция do_execve находит подходящий обработчик. Она делегирует эту задачу функции search_binary_handler (строка 9996).
10037: Начинает итерационный просмотр связанного списка обработчиков двоичных файлов ядра, поочередно передавая каждому из них bprm. (В данный момент аргумент regs нас не интересует.) Точнее говоря, каждый элемент связанного списка обработчиков двоичных файлов содержит набор указателей на функции, которые вместе обеспечивают поддержку единого двоичного формата. (Состав функций приведен в определении структуры struct linux_binfmt в строке 13803; интерес представляют следующие компоненты: предназначенный для загрузки двоичных файлов, load_binary; предназначенный для загрузки библиотеки совместного использования, load_shlib; и предназначенный для создания дампа ядра, core_dump.) Функция search_binary_handler просто вызывает каждую из функций load_binary, пока одна из них не вернет неотрицательное значение, показывающее, что она распознала и успешно загрузила файл. Функция search_binary_handler возвращает отрицательное значение для указания ошибки, в том числе невозможности найти подходящий обработчик двоичных файлов.
10070: Если циклу, который был начат в строке 10037, не удается найти подходящий обработчик двоичных файлов, эта строка предпринимает попытку загрузить новый двоичный формат, который должен привести к успеху при второй попытке. Следовательно все это входит в двухпроходный цикл, начинающийся в строке 10036.
Форматы исполняемых файлов
Как упоминалось в предшествующем разделе, не все программы хранятся в одинаковом файловом формате, и чтобы абстрагироваться от различий Linux использует обработчики двоичных файлов.
Текущим «собственным» форматом исполняемых файлов Linux (если термин «собственный» действительно применим к системе с равно хорошей поддержкой такого большого количества форматов) является Executable and Linking Format (ELF). Формат ELF почти полностью заменил собой более ранний, так называемый формат a.out, который был далеко не столь гибок — среди прочих недостатков формат a.out плохо подходил для динамического связывания, затрудняя реализацию библиотек совместного использования. Linux по прежнему сохраняет обработчик двоичных файлов для формата a.out, но ELF является предпочтительным.
Как правило, обработчики двоичных файлов распознают файлы по каким-либо «магическим последовательностям» (специальным последовательностям байтов), внедренным в начало файла, а иногда — по какому-либо свойству имени файла. Например, обработчик Java убеждается, что имя файла заканчивается символами .class и что первыми четырьмя байтами (в шестнадцатиричном формате) являются 0xcafebabe, как определено стандартом Java.
Ядро версии 2.2 обеспечивает следующие обработчики двоичных файлов (в системе на базе процессора Intel; порты Linux для других платформ, таких как PowerPC и SPARC, обеспечивают дополнительные обработчики):
- a.out (в файле fs/binfmt_aout.c). Для двоичных файлов в старом формате Linux. Этот обработчик все еще требуется для обратной совместимости в некоторых системах, но в целом, формат a.out быстро отмирает.
- ELF (в файле fs/binfmt_elf.c). Для двоичных файлов в новом формате Linux. Этот формат широко используется как для исполняемых файлов, так и для библиотек совместного использования. Большинство современных систем Linux (например, Red Hat 5.2) поставляются только с двоичными файлами в формате ELF, хотя, как правило, они поддерживают также загрузку двоичных файлов в формате a.out, на тот случай, если пользователь решит их установить. Обратите внимание, что несмотря на то, что формат ELF считается собственным форматом Linux, он использует обработчик двоичных файлов, подобно остальным форматам — ядро не оказывает предпочтение ни одному из форматов. Исключение особых случаев способствует упрощению кода ядра.
- ЕМ86 (в файле fs/binfmt_em86.c). Помогает выполнять двоичные файлы Intel Linux на компьютерах Alpha, как если бы они были собственными двоичными файлами Alpha.
- Java (в файле fs/binfmt_java.c). Позволяет выполнять файлы .class Java без явного указания интерпретатора байт-кода Java. При этом используется механизм, аналогичный используемому для сценариев; обработчик запускает интерпретатор байт-кода, передавая ему имя файла .class в качестве аргумента. С точки зрения пользователя двоичные файлы Java обрабатываются как собственные исполняемые файлы. Этот обработчик будет рассмотрен подробнее далее в этой главе.
- Misc (в файле fs/binfmt_misc.c). Наиболее разумный на данный момент из обработчиков двоичных файлов, этот обработчик может распознавать ряд двоичных форматов по специальным внедренным цифрам или по суффиксам имен файлов; но его главное преимущество заключается в том, что он может конфигурироваться во время выполнения, а не только во время компиляции. Следовательно поддержку новых форматов двоичных файлов можно добавлять «на лету», не выполняя перекомпиляцию ядра и перезагрузку. (Это действительно прекрасная идея!). Комментарии в исходном файле указывают, что со временем обработчики двоичных файлов Java и ЕМ86 будут заменены этим обработчиком.
- Scripts (в файле fs/binfmt_script.c). Предназначен для сценариев оболочки, сценариев Perl и т.п. Допуская некоторую вольность, можно сказать, что любой исполняемый файл, первыми двумя символами которого являются #!, обрабатываются этим обработчиком двоичных файлов.
Из всех этих обработчиков двоичных файлов только обработчики Java и ELF приведены в этой книге (начиная со строк 9083 и 7656, соответственно). Это связано с тем, что основное внимание уделено тому, как ядро справляется с различиями между различными форматами, а не обработке каждого отдельного двоичного формата (хотя эта тема и сама по себе представляет интерес).
Пример: обработчик двоичных файлов Java
Как было показано ранее, функция do_execve пошагово просматривает связанный список структур struct linux_binfmt, представляющий обработчики двоичных файлов, вызывая функцию указываемую членом load_binary для каждого элемента struct, пока один из форматов не подойдет (или, естественно, пока не закончится список поддерживаемых форматов). Но откуда берутся эти структуры, и как реализованы функции load_binary? Чтобы ответить на эти вопросы, обратимся к файлу fs/binfmt_java.c.
Посредством использования функции java_format (строка 9236) и связанных с ней функций этот модуль обрабатывает двоичные файлы Java, которые не являются апплетами, разработанными для выполнения в среде Web-браузера. Апплеты обрабатываются с помощью функции applet_format (строка 9254) и связанных с ней функций. Остальная часть этого раздела будет посвящена файлам, не являющимся апплетами; поддержка апплетов осуществляется совершенно так же.
Функции в файле fs/binfmt_java.c можно было бы улучшить, переписав их для объединения значительной части кода, общего для функций обработки апплетов и не-апплетов. Однако, поскольку вскоре предвидится замена этого обработчика обработчиком двоичных файлов misc, это было бы напрасной тратой времени.
do_load_java
9108: Эта функция выполняет всю реальную работу по загрузке файла .class Java.
9117: Начинается с проверки наличия специальной последовательности шестнадцатиричных цифр 0xcafebabe, поскольку в соответствии со стандартом Java все допустимые файлы класса должны начинаться с этой последовательности байтов. Профилактические проверки продолжаются вплоть до строки 9124, подтверждая отсутствие рекурсивных вызовов.
9148: К этому моменту все профилактические проверки уже выполнены. Теперь функция do_load_java принимает базовое имя фала, помещает его и имя интерпретатора байт-кода Java в область программы и предпринимает попытку выполнить интерпретатор байт-кода Java.
9165: Интерпретатор выполняется, используя процедуру, которая во многом аналогична используемой в функции do_execve. В частности, он ищет обработчик двоичных файлов для интерпретатора, используя функцию search_binary_handler, совершено так же, как была найдена сама функция do_load_java. (На практике, вероятно, им будет обработчик двоичных файлов ELF, хотя это и не обязательно.) Помните, что другой обработчик не будет выделять новую структуру struct task_struct — это уже было сделано при выполнении подпрограммы fork. Другой обработчик всего лишь изменяет структуру struct task_struct существующего процесса. Если желаете выяснить все подробности этого процесса, начните с функции do_load_elf_binary (строка 8072) — наиболее интересная часть кода начинается со строки 8273.
load_java
9226: Для внешнего мира загрузка файла .class Java выполняется функцией load_java. Она увеличивает, а в последствии уменьшает значение счетчика, используемого ее модулем ядра (эта функция компилируется в качестве модуля ядра), но в действительности она делегирует всю реальную работу функции do_load_java (строка 9108).
java_format
9236: Сравнив инициализацию функции java_format с определением структуры struct linux_binfmt (строка 13803), можно видеть, что этот модуль не обеспечивает поддержку библиотек совместного использования или дампов ядра, а поддерживает только загрузку исполняемых файлов; и эта поддержка обеспечивается посредством функции load_java.
init_java_binfmt
9262: Точкой входа этого модуля является функция init_java_binfmt, которая выталкивает адреса двух статических структур struct linux_binfmt, java_format и applet_format, в список системы. Функция init_java_binfmt вызывается из строки 9355, если поддержка двоичных файлов Java скомпилирована в ядро, или задачей kmod, если эта поддержка скомпилирована в качестве модуля ядра.
Планирование: посмотрите, как они выполняются!
После того, как приложение загружено, ему должен быть предоставлен доступ к центральному процессору. В этом состоит задача планировщика. В основном, планировщики операционных систем можно отнести к одной из следующих категорий:
- Комплексные планировщики — При работе занимают сравнительно длительное время, но существует надежда скомпенсировать этот недостаток путем повышения общей производительности системы.
- Быстрые черновые планировщики — Стараются всего лишь умеренно качественно справится с задачей и поскорее отойти в сторону, чтобы сами процессы имели доступ к процессору как можно дольше.
Планировщик Linux относится ко второй категории. Однако не следует пренебрежительно относится к определению «быстрый черновой»: в целом, при оценке технических характеристик планировщик Linux вполне выдерживает соревнование как с коммерческими, так и некомерческими аналогами.
Функции и политики планирования
Основная функция планирования ядра удачно называется schedule и начинается в строке 26686. В действительности, это очень простая функция, более простая чем кажется, хотя ее значение слегка сбивает с толку, поскольку объединяет три алгоритма планирования. Кроме того, некоторым усложнением она обязана своей поддержке SMT, рассмотрение которой будет отложено до главы 10.
Используемый в конкретном случае алгоритм планирования зависит от процесса. Алгоритм планирования, используемый для данного процесса, называется его политикой планирования и отражается в члене policy структуры struct task_struct процесса. Обычно в члене policy установлен только один из разрядов SCHED_OTHER, SCHED_FIFO или SCHED_RR. Но кроме того может быть установлен и разряд SCHED_YIELD, если процесс решит освободить центральный процессор — например, вызвав системную функцию sched_yield (см. sys_sched_yield в строке 27757).
Константы SCHED_XXX определяются посредством оператора #define в строках с 16196 по 16202.
16196: SCHED_OTHER означает, что применяется традиционное планирование Unix — данный процесс не является процессом реального времени.
16197: SCHED_FIFO означает, что этот процесс является процессом реального времени и объектом для планировщика FIFO (first in, first out — первым зашел, первым вышел) POSIX.1b. Он должен продолжаться до тех пор, пока не заблокирует ввод/вывод, явным образом не освободит процессор, либо не будет вытеснен другим процессом реального времени с более высоким приоритетом rt_priority. В реализации Linux процессы SCHED_FIFO имеют выделенные для них временные кванты — просто они не обязаны освобождать процессор, когда их временной квант заканчивается. Следовательно, как диктуется POSIX.1b, такой процесс действует, как если бы он не имел временного кванта. То, что процесс в любом случае отслеживает временной квант, это просто вопрос удобства реализации, поэтому не обязательно засорять код конструкцией
if (!(current->policy & SCHED_FIFO)) { ... }
Кроме того, вероятно, так он работает быстрее — другие политики действительно вынуждены отслеживать временные кванты, а постоянная проверка необходимости такого отслеживания была бы медленней простого отслеживания.
16198: SCHED_RR означает, что этот процесс является процессом реального времени и объектом планировщика RR (round-robin) POSIX.lb. Это аналогично SCHED_FIFO, за исключением того, что временные кванты имеют значение. Когда временной квант процесса SCHED_RR истекает, он перемещается в конец списка процессов SCHED_FIFO и SCHED_RR с таким же приоритетом rt_priority.
SCHED_YIELD является не политикой планирования, а дополнительным разрядом, который пресекает политики планирования. Как уже было сказано ранее, этот разряд указывает планировщику освободить процессор, если тот требуется кому-либо другому. В частности, обратите внимание, что это приведет даже к тому, что процесс реального времени освободит процессор для процесса не реального времени.
schedule
26689: prev и next будут установлены для двух процессов, которые представляют для schedule наибольший интерес: для одного, который выполнялся во время вызова schedule (prev), и для второго, которому центральный процессор должен быть предоставлен следующим (next). Имейте в виду, что prev и next могут быть одинаковыми — schedule может повторно запланировать процесс, который уже имел доступ к процессору.
26706: Как уже упоминалось в главе 6, здесь выполняются «нижние половины» обработчиков прерываний.
26715: Реализует часть планировщика реального времени (SCHED_RR), перемещая «исчерпавшийся» процесс RR — уже полностью использовавший свой временной квант — в конец очереди, чтобы другие процессы RR с таким же приоритетом могли сделать свой ход. Одновременно это обновляет временной квант исчерпавшегося процесса. Важно, чтобы такое обновление не выполнялось для SCHED_FIFO, чтобы последующие процессы не были вынуждены освобождать процессор при истечении отведенных им временных квантов.
26720: schedule часто используется потому, что какой-то другой фрагмент программы пришел к заключению о необходимости перемещения процесса в или из состояния TASK_RUNNING — например, при выполнении аппаратного условия, которого дожидался процесс; поэтому данный переключатель при необходимости изменяет состояние процесса. Если процесс уже находится в состоянии TASK_RUNNING, он остается неизменным. Если он был прерываемым (дожидающимся сигнала) и сигнал пришел, процесс возвращается в состояние TASK_RUNNING. Во всех остальных случаях (например, если процесс переходит в состояние TASK_UNINTERRUPTIBLE) процесс долен быть удален из текущей очереди.
26735: Инициализирует значением, соответствующим первой задаче в текущей очереди; р выполнит циклический просмотр всех задач в очереди.
26736: с отслеживает наибольшую адекватность (goodness) всех процессов в текущей очереди — наиболее адекватный процесс — тот, который имеет наибольшие требования к процессору. (Функция goodness будет вскоре рассмотрена.) Чем выше адекватность, тем лучше; причем значение адекватности процесса никогда не бывает отрицательным, в отличие от непонятной ситуации, ставшей привычной для пользователей Unix, когда более высокий приоритет (обычно называемый более высоким уровнем правильности (niceness)) приводит к тому, что процессу будет выделен меньший интервал времени процессора. (По крайней мере, это имеет смысл внутри ядра.)
26757: Начинает просмотр списка задач, отслеживая процесс с наилучшим значением адекватности. Обратите внимание, что это изменяет представление о наилучшем процессе только когда текущая запись прервана, а не когда она просто привязана. Следовательно, связи разрываются в интересах первого процесса в очереди.
26758: В этом цикле рассматриваются только те процессы, которые могут быть запланированы. Реализация SMP-макроса can_schedule приведена в строке 26568; его определение заставляет ядро SMP рассматривать планирование задач в этом центральном процессоре только если задача еще не выполняется в нем. (В этом заключен большой смысл — было бы расточительным без необходимости перетасовывать задачи.) однопроцессорная версия приведена в строке 26573 и это значение всегда истинно — другими словами, в однопроцессорной системе все процессы в текущей очереди соревнуются за получение доступа к центральному процессору.
26767: Значение адекватности, равное 0, означает, что процесс полностью использовал свой лимит временного кванта, или что он был вынужден освободить процессор. Если все процессы в текущей очереди имеют значение адекватности, равное 0, в конце цикла с равно 0, В этом случае schedule повторно вычисляет счетчики процессов; новое значение счетчика равно половине старого значения плюс значение статического приоритета процесса — и поскольку старое значение равно 0, если только процесс не освободил процессор, обычно schedule всего лишь повторно инициализирует счетчики значениями их статического приоритета. (Встретившийся в этом цикле процесс, мог бы также быть добавлен обработчиком прерываний или подпрограммой fork другого процессора, пока функция schedule искала наивысшее значение адекватности; поэтому значение его счетчика могло быть ненулевым. Однако, такой случай встречается редко.) Тем не менее, планировщик не утруждает себя повторным вычислением того, какой процесс обладает наивысшей адекватностью в данный момент; он лишь планирует процесс, первым встретившийся ему в предыдущем цикле. На тот момент этот процесс был первым найденным им, который имел наилучшее на тот момент значение адекватности (0), поэтому функция schedule заключает, что пока все сделано, и что программа будет успешно работать в течение длительного времени. (Помните, что речь идет о мышлении в стиле «быстро и приблизительно».)
26801: Если schedule решила запланировать другой процесс из тех, что выполнялись ранее, она должна подавить старый процесс и позволить выполняться новому. Это выполняется с помощью функции switch_to, которая будет исследована следующей. Один важный результат работы функции switch_to может показаться очень странным разработчикам приложений: обращение к функции schedule не выполняет возврат. По крайней мере, не сразу; функция осуществляет возврат, когда система снова переключается на текущую задачу. Особым случаем вызова schedule является случай, когда она вызывается потому, что задача осуществляет выход; в этом случае вызов schedule никогда не возвращает значение — поскольку ядро никогда не переключается на задачу, которая осуществила выход. Еще один особый случай — когда функция schedule не запланировала другой процесс — т.е., если значения next и prev равны по окончании работы schedule — и, следовательно, переключение контекста не выполняется, а schedule действительно возвращает значение немедленно.
26809: В однопроцессорных системах функции __schedule_tail и reacquire_kernel_lock в конце функции schedule не представляют собой ничего особенного, поэтому мы закончим исследование ядра планировщика. При случае, чтобы убедиться в правильном понимании кода, попытайтесь доказать следующее свойство: если текущая очередь пуста, следующей будет запланирована простаивающая задача.
switch_to
switch_to обрабатывает переключение с одного процесса на другой, что называется переключением контекста; это функция самого нижнего уровня, которая обрабатывается по разному в различных процессорах. Интересно отметить, что на платформе х86 разработчики ядра решили обрабатывать большую часть переключений контекста программно, отказавшись от некоторой части аппаратной поддержки. Причины этого изложены в заглавном комментарии над функцией __switch_to (строка 2638), которая вместе с макросом switch_to (строка 12939) обрабатывает переключение контекста.
Поскольку переключение контекста в значительной степени зависит от понимания того, как ядро работает с памятью, что подробно описано лишь начиная со следующей главы, в этой главе бегло освещается эта тема. При переключении контекста главное помнить, где мы находились, и что делали — т.е. текущий контекст нужно сохранить, и лишь затем переключаться на другой контекст, сохраненный ранее. Используя незначительную постороннюю помощь, макрос switch_to сохраняет два важных фрагмента контекста, описанные далее.
12945: Во-первых, макрос switch_to сохраняет регистр ESP, который указывает на текущий стек процесса. Стек подробно описан в следующей главе; а пока, достаточно знать, что стек содержит локальные переменные и информацию о вызовах функций. Макрос switch_to сохраняет также регистр EIP, который является указателем текущей инструкции процесса — адресом следующей инструкции, которую он должен был бы выполнить, если бы ему было разрешено продолжать выполняться.
12948: Выталкивает next->tss.eip — указатель сохраненной инструкции — в стек возврата, делая его адресом возврата, если немедленный последующий переход jmp к функции __switch_to осуществляет возврат. Побочным эффектом возврата из функции __switch_to является получение нового процесса.
12949: Вызывает функцию __switch_to (строка 2638), которая выполняет работу по сохранению и восстановлению сегментных регистров и таблиц страниц. Это станет более понятным после прочтения главы 8.
12955: tss означает task-state segment (сегмент состояния задачи). Этот термин был введен компанией Intel для обозначения функции процессора, которая поддерживает аппаратное переключение контекстов. Вместо этого в коде ядра переключение контекстов выполняется программным путем, но разработчики продолжают использовать TSS для отслеживания состояния процесса. Член tss структуры struct task_struct имеет тип struct thread_struct, описание которого было опущено для экономии места в книге. Члены этой структуры всего лишь соответствуют TSS системы х86 — существуют члены для регистров EIP и ESP, и т.д.
Вычисление адекватности процесса
Адекватность (goodness) процесса вычисляется функцией goodness (строка 26388). Эта функция возвращает значение, относящееся к одному из двух классов: менее 1000 и свыше 1000. Значения от 1000 и выше присваиваются только процессам «реального времени», а значения от 0 до 999 — только «обычным» процессам. В действительности значения адекватности для обычных процессов занимают только самую нижнюю часть этого диапазона от 0 до 41 (или от 0 до 56 для SMP, поскольку режим SMP предоставляет процессу дополнительную возможность оставаться в используемом процессоре). И для SMP, и для однопроцессорной системы значения адекватности процессов реального времени изменяются в диапазоне от 1001 до 1099.
Главная особенность такого разделения на классы заключается в том, что диапазон значений для процессов реального времени располагается над диапазоном значений, выделенным для процессов не реального времени (таким образом, смещение могло бы быть равным 100, а не 1000). Стандарт POSIX.1b делает ядро ответственным за то, чтобы процессам реального времени всегда отдавалось предпочтение перед процессами не реального времени, когда они конкурируют за доступ к процессору. Поскольку планировщик всегда выбирает процесс с наивысшим значением адекватности, и поскольку значение адекватности любого процесса реального времени, который еще не освободил процессор, всегда превосходит значение любого процесса не реального времени, позицию Linux в этом вопросе легко продемонстрировать.
Несмотря на заглавный комментарий над функцией goodness, эта функция никогда не возвращает значение –1000, ни какое-либо иное отрицательное значение. Бездействующий процесс имеет отрицательное значение переменной counter, поэтому функция goodness вернула бы отрицательное значение, если бы была вызвана с бездействующим процессом в качестве аргумента; но это никогда не происходит.
goodness — достаточно простая функция, хотя и является важной частью планировщика Linux. Она вызывается для каждого процесса в текущей очереди при каждом выполнении функции schedule и поэтому должна работать быстро. Но если она принимает неудачное решение, страдает вся система. Учитывая эти противоречия, думается, было бы трудно добиться лучшего результата, чем уже имеющийся.
goodness
26394: Возвращает 0, если процесс освободил процессор (после очистки разряда SCHED_YIELD, поскольку процесс готов освободить процессор только однажды, и сейчас как раз такой случай).
26402: Если это — процесс реального времени, функция goodness возвращает значение, помещая его в верхний класс; точное значение зависит от его значения rt_priority.
26411: К этому моменту коду известно, что данный процесс является процессом не реального времени. Он инициализирует адекватность процесса (которая внутри функции называется weight (вес)) его текущим значением counter, чтобы снизить вероятность получения процессом доступа к процессору, если он уже занимал его в течение некоторого времени, или имел низкое начальное значение приоритета.
26412: Если значение weight равно 0, используется счетчик процесса, чтобы функция goodness не добавляла никаких весовых факторов. Остальные процессы также должны получить шанс.
26418: Добавляет максимальное дополнительное значение для продолжения занимания этого же процессора (только в режиме SMP — подумайте о смысле этого при одновременном выполнении трех процессов в двухпроцессорной системе).
26423: Добавляет небольшое дополнительное значение для задержки текущего процесса или внутри текущего потока; это способствует полному использованию кэша и исключению частых переключений контекстов MMU.
26425: Добавляет значение приоритета priority процесса. Так функция goodness (и, следовательно, планировщик) сможет отдать предпочтение процессам с более высоким приоритетом перед процессами с более низким приоритетом, даже если первые уже частично использовали свои временные кванты.
26428: Возвращает вычисленное значение адекватности.
Приоритеты не реального времени
Каждый процесс Linux имеет определенный приоритет — целочисленное значение в диапазоне от 1 до 40, которое хранится в члене priority структуры struct task_struct. (Для процессов реального времени применяется также дополнительный член rt_priority структуры struct task_struct. Вскоре это будет рассмотрено подробнее.) Теоретически этот диапазон ограничивается значениями переменных PRIO_MIN (которое определяется оператором #define в строке 16094) и PRIO_MAX (определяется одной строкой ниже). К сожалению, функции, управляющие приоритетом — sys_setpriority и sys_nice — в действительности не обращают никакого внимания на эти объявленные константы, предпочитая им жестко закодированные значения. (Кроме того, они используют максимальное значение правильности (niceness), равное 19, а не 20.) Если уж на то пошло, константы PRIO_MIN и PRIO_MAX вообще нигде не используются. Что ж, это еще одна возможность привлечь читателей к улучшению кода.
Поскольку согласно документации функция sys_nice (строка 27562) вот-вот устареет — предположительно она должна быть реализована заново в стиле функции sys_setpriority — давайте пропустим первую функцию и исследуем вторую.
sys_setpriority
29213: Функция sys_setpriority принимает три аргумента — which, who и niceval. Аргументы which и who обеспечивают способ указания отдельного процесса, группы процессов или всех процессов, принадлежащих данному пользователю. В зависимости от значения аргумента which аргумент who интерпретируется по-разному; он будет считываться в качестве идентификатора процесса, идентификатора группы процессов или идентификатора пользователя.
29220: Это профилактическая проверка того, что значение which является допустимым. Полагаю, что она выполняется излишне сложно. Вместо
if (which > 2 || which < 0)
лучше было бы написать
if (which != PRIO_PROCESS &&
which != PRIO_PGRP &&
which != PRIO_USER)
или, по крайней мере
if (which > PRIO_USER || which < PRIO_PGRP)
Между прочим, это же справедливо по отношению к строке 29270.
29226: niceval указывается в интервале пользователя — т.е. в диапазоне от –20 до 19 (или, по крайней мере, так предполагается), а не в диапазоне от 1 до 40, который является предпочтительным для внутренней структуры ядра. Как следует из названия, это значение «требовательности», а не приоритета. Таким образом, функция sys_setpriority вынуждена пропустить несколько значений, чтобы выполнить соглашение, одновременно усекая значения аргумента niceval, выходящие за пределы допустимого диапазона. Признаю, что был сбит с толку сложностью этого кода. При действительно используемом значении переменной DEF_PRIORITY равном 20, следующий гораздо более простой код явно дал бы такой же результат:
if (niceval < -19)
priority = 40;
else if (niceval > 19)
priority = 1;
else
priority = 20 - niceval;
Эта версия также могла бы учитывать значение DEF_PRIORITY, оставаясь более простой, чем код в функции sys_setpriority. Таким образом, либо я чего-то не понял, либо имеющийся код действительно излишне сложен.
29241: Выполняет цикл по всем задачам в списке задач системы, выполняя разрешенные изменения. proc_sel (строка 29190) сообщает, удовлетворяет ли данный процесс значениям аргументов which и who, которые используются для выбора процесса; эта функция вынесена за пределы функции sys_setpriority, поскольку она используется также и функцией sys_getpriority.
И sys_setpriority, и sys_getpriority (которая имеет аналогичный внутренний цикл, начинающийся в строке 29274) можно было бы несколько ускорить для общего случая получения или установки приоритета единственного процесса (по крайней мере, путем более раннего прерывания цикла for_each_task). Функция sys__setpriority вызывается не очень часто, но sys_getpriority может быть достаточно распространенной, чтобы оправдать приложенные усилия.
update_process_times
Функция влияет только на член priority процесса — т.е. на его статический приоритет. Вспомните, что процессы имеют также динамические приоритеты, представленные членом counter, который был рассмотрен при рассмотрении функций schedule и goodness. Мы уже видели, что функция schedule периодически пополняет динамический приоритет каждого процесса, исходя из его статического приоритета, когда планировщик видит, что значение counter равно 0. Но еще не было показано, где значение counter уменьшается. Каким образом оно достигает 0?
Для однопроцессорной системы ответ заключается в функции update_process_times (строка 27382). (Освещение этой функции отложено до главы 10.) Функция update_process_times вызывается как часть функции update_times (строка 27412), которая, в свою очередь, является частью прерывания таймера, освещенного в главе 6. В результате, эта функция вызывается достаточно часто — 100 раз за секунду. (Конечно, это часто только с человеческой точки зрения, а для процессора такая частота является чрезвычайно малой.) При каждом вызове эта функция уменьшает значение counter текущего процесса на количество «тиков» (сотые доли секунды — см. главу 6), произошедших с момента последнего вызова. Обычно, это только один тик, но ядро может пропускать тики таймера, если, например, он занят обслуживанием прерывания. Когда значение счетчика падает ниже 0, функция update_process_times устанавливает флаг need_resched, показывающий, что этот процесс нуждается в повторном планировании.
Теперь, поскольку приоритет процесса, установленный по умолчанию (в терминах приоритетов ядра, а не значений требовательности процесса (niceness) области пользователя) равен 20, процесс по умолчанию получает 21-тиковый временной квант. (Да, именно 21 тик, а не 20, поскольку процесс не помечается для повторного планирования до тех пор, пока его динамический приоритет не упадет ниже 0.) Один тик равен одной сотой секунды или 10 миллисекундам, и таким образом временной квант, устанавливаемый по умолчанию, равен 210 миллисекундам — около одной пятой секунды — как и задокументировано в строке 16466.
Меня этот результат удивил, поскольку я был уверен, что для отзывчивой системы должен был бы требоваться гораздо меньший временной квант — я на столько был уверен в этом, что вначале заподозрил наличие ошибки в документации. Однако теперь мне ясно, что удивляться не следовало. В конце концов, процессы часто не полностью используют выделенные им временные кванты, поскольку они должны часто блокироваться для выполнения ввода/вывода. А когда несколько процессов обращаются к процессору, слишком частое переключение между ними оказывается бессмысленным. (Особенно в такой архитектуре, как х86, где переключения контекстов обходятся сравнительно дорого.) В конечном счете я вынужден был признать, что никогда не замечал в своем компьютере, работающем под управлением Linux, никаких задержек ответа и поэтому пришел к выводу, что 210-миллисекундный временной квант является удачным выбором — несмотря на то, что вначале этот интервал казался удивительно длинным.
Если по какой-либо причине требуются временные кванты, превышающие по длительности даже текущий максимум (410 миллисекунд, когда значения приоритетов повышаются до 40), можно просто воспользоваться политикой планирования SCHED_FIFO и освободить процессор, когда будете готовы к этому (или переписать функции sys_setpriority и sys_nice).
Приоритеты реального времени
Процессы реального времени Linux добавляют новый уровень к схеме приоритетов. Приоритет реального времени хранится в члене rt_priority структуры struct task_struct и является целым числом в диапазоне от 0 до 99. (Значение, равное 0, означает, что процесс не является процессом реального времени, и в этом случае его членом policy должен быть SCHED_OTHER.)
Задачи реального времени используют тот же член counter, что и их аналоги не реального времени, и поэтому их динамические приоритеты обрабатываются таким же образом. Задачи реального времени даже используют член priority для той же цели, что и задачи не реального времени — в качестве значения, посредством которого они пополняют значение counter, когда оно полностью использовано. Для ясности, следует отметить, что член priority используется только для ранжирования процессов реального относительно друг друга — в остальном они обрабатываются идентично процессам не реального времени.
rt_priority процесса устанавливается в качестве части определения его политики планирования с помощью стандартизованных POSIX.1b функций sched_setscheduler и sched_setparam (которые, обычно, имеет право вызывать только привилегированный пользователь, как будет показано при рассмотрении возможностей). Это означает, что политика планирования процесса может изменяться во время его существования, если, конечно, процесс имеет разрешение выполнять изменение.
Системные вызовы, реализующие эти функции POSIX sched_setscheduler (строка 27688) и sched_setparam (строка 27694), делегируют всю реальную работу функции setscheduler (строка 27618), которую мы теперь и исследуем.
setscheduler
27618: Тремя аргументами этой функции являются целевой процесс pid (значение 0 означает текущий процесс), новая политика планирования policy и param, структура, содержащая дополнительную информацию — новое значение rt_priority.
27630: Выполняя некоторые профилактические проверки, функция setscheduler копирует переданную структуру struct sched_param из области пользователя. Эта структура, определенная в строке 16204, имеет только один член sched_priority, который является затребованным вызывающей функцией значением rt_priority\ для целевого процесса.
27639: Находит целевой процесс, используя функцию find_process_by_pid (строка 27608), которая возвращает либо указатель на текущую задачу (если pid равен 0), либо указатель на процесс с заданным PID (если таковой существует), либо NULL (если не существует ни одного процесса с этим PID).
27645: Если аргумент policy был отрицательным, текущая политика планирования сохраняется. В противном случае она принимается временно, если ее значение допустимо.
27657: Убеждается, что приоритет находится в допустимом диапазоне. Это достигается несколько сложным путем. Данная строка — всего лишь первый шаг, подтверждающий, что переданное значение не слишком выходит за рамки диапазона.
27659: Теперь известно, что приоритет реального времени лежит в диапазоне между 0 и 99, включая крайние значения. Если значением policy является SCHED_OTHER, но новый приоритет реального времени не равен 0, этот тест не пройдет. Тест не пройдет, также, если policy определяет один из планировщиков реального времени, но новый приоритет реального времени равен 0 (если он не равен 0, значит, он имеет значение от 1 до 99, как и должно быть). В противном случае тест будет успешным. Эта конструкция не очень понятна, но она верна, максимально минимизирована и (как мне кажется) работает быстро. Однако, я не уверен, что в данном случае требуется особенно высокая скорость работы — в конце концов, как часто процесс устанавливает свой планировщик? Следующая конструкция была бы более читабельной и наверняка не на много более медленной:
if (policy == SCHED_OTHER) {
if (lp.sched_priority != 0)
goto out_unlock;
} else { /* SCHED_FIFO или SCHED_RR */
if ((lp.sched_priority < 1) ||
(lp.sched_priority > 99))
goto out_unlock;
}
27663: He каждому процессу должно быть разрешено устанавливать собственную политику планирования или политику планирования другого процесса. Если бы было можно, любой процесс мог бы узурпировать центральный процессор, по существу блокируя систему, просто устанавливая свою политику планирования в значение SCHED_FIFO и входя в бесконечный цикл. Естественно, это нельзя допустить. Поэтому функция setscheduler позволяет процессу устанавливать собственную политику планирования, только если он имеет возможность сделать это. Возможности подробнее освещены в следующем разделе.
27666: Следуя этой же логике, нежелательно, чтобы кто угодно мог изменять политику планирования процессов любых других пользователей; как правило, пользователю должно разрешаться изменять политику планирования только собственных процессов. Поэтому setscheduler убеждается, что пользователь либо устанавливает планировщик собственного процесса, либо имеет возможность устанавливать политику планирования любых пользователей.
27672: Именно здесь функция setscheduler наконец берется за дело, устанавливая поля policy и priority в структуре struct task_struct целевого процесса. И, если процесс находится в текущей очереди (что проверяется путем проверки того, что значение его члена next_run не является NULL), он перемещается в ее начало — это несколько странно; возможно, это было сделано, чтобы помочь процессу SCHED_FIFO получить доступ к процессору. Процесс помечается для повторного планирования, а функция setscheduler осуществляет уборку и выход.
Учет ограничений
Ядро часто должно решать, позволять ли процессу выполнять ту или иную операцию. Процессу просто запрещается выполнять определенные операции, а другие операции ему разрешается выполнять только при определенных обстоятельствах; в основном, эти права выражаются возможностями и/или определяются исходя из идентификаторов пользователя и группы. В других случаях процессу разрешается делать что-либо, но только ограниченным образом — например, время использования им центрального процессора может быть ограничено.
Возможности
В предшествующем разделе был приведен пример проверки возможностей — фактически, одна и та же возможность проверялась дважды. Этой возможностью была CAP_SYS_NICE (строка 14104), которая управляет тем, должно ли быть позволено процессу устанавливать приоритеты (уровни требовательности) или политики планирования. Поскольку возможность CAP_SYS_NICE применяется не только к уровням требовательности, ее название не совсем правильно — хотя понятно, что установка планировщика — весьма близкое понятие, и что, скорее всего, вряд-ли одна возможность потребуется без другой.
Каждый процесс имеет три набора возможностей, хранящиеся в структуре struct task_struct (и определенные в строках с 16400 по 16401):
- cap_effective — действующий набор;
- cap_permitted — разрешенный набор;
- cap_iheritable — наследуемый набор.
Действующий набор возможностей процесса — набор действий, которые ему разрешено выполнять в настоящее время; этот набор проверяется широко используемой функцией capable, которая определяется в строке 16738.
Разрешенный набор ограничивает возможности, которые могут быть предоставлены процессу в обычных условиях. Обычно этот набор не увеличивается, за одним исключением: если процесс имеет возможность CAP_SETPCAP, он может предоставить другим процессам любую возможность из своего разрешенного набора, даже если целевой процесс еще не имеет ее.
Если возможность находится в разрешенном наборе, но не находится в действующем наборе, процесс не имеет данную возможность непосредственно сейчас, но может получить ее, сделав запрос. К чему такое различие? Что ж, при первом освещении возможностей в начале этой главы мы кратко рассмотрели пример долговременного процесса, которому возможность требовалась только периодически, а не постоянно. Для того, чтобы процесс случайно не злоупотребил возможностью, он может дождаться, когда она ему потребуется, запросить ее, выполнить привилегированную операцию, а затем снова утратить возможность. Такой подход гораздо безопасней.
Наследуемый набор — не совсем то, что можно было бы предположить. Это не набор возможностей, которые родительский процесс передает дочерним процессам во время выполнения подпрограммы fork — в действительности в момент создания (т.е. непосредственно после выполнения fork) все три набора возможностей дочернего процесса совпадают с наборами родительского процесса. Наследуемый процесс выступает на сцену во время выполнения exec. Непосредственно перед вызовом exec наследуемый набор процесса помогает определить разрешенный и наследуемый наборы, которые процесс сохранит после выполнения exec — для более подробного ознакомления с этим процессом обратитесь к функции compute_creds (строка 9948). Обратите внимание, что сохранение возможности после выполнения exec лишь частично зависит от наследуемого набора процесса; это зависит также от разрядов возможностей, установленных в самом файле (или, по крайней мере, так планируется — это свойство реализовано еще не полностью).
Попутно отметим, что разрешенный набор всегда должен быть включать действующий и наследуемый наборы (или же совпадать с ними). (Строго говоря, это справедливо только по отношению к действующему набору. Один процесс может расширить наследуемый набор другого процесса так, что он больше не будет поднабором его разрешенного набора, но, насколько можно судить, это было бы бессмысленным, поэтому пока мы не будем рассматривать такую возможность.) Однако в отличие от того, что можно было бы предположить, действующий набор не обязательно должен включать наследуемый набор (или совпадать с ним). Т.е., после выполнения exec процесс может иметь возможность, которую он не имел до этого (хотя возможность должна входить в его разрешенный набор — т.е. она должна являться возможностью, которую оригинал мог бы получить для себя). Полагаю, что частично это связано с тем, что процессу не нужно временно получать возможность, которую ему негде использовать, разве что он может выполнить программу, которая в ней нуждается.
Возможности показаны на рис. 7.4. На этом рисунке показаны три набора возможностей для гипотетического процесса, причем разряды нумеруются справа налево. Процессу разрешено получить возможность CAP_KILL, которая позволяет ему прервать любой другой процесс, независимо от его владельца; но процесс пока не имеет этой возможности и не будет получать ее автоматически во время выполнения exec. В настоящий момент он имеет возможность вставлять и удалять модули ядра (используя CAP_SYS_MODULE), но также не будет получать ее во время выполнения exec. Процесс мог бы получить возможность CAP_SYS_NICE и будет получать ее во время выполнения exec (при условии, что соответствующие разряды возможностей файла установлены). И наконец, непосредственно сейчас процесс может изменить системное время (CAP_SYS_TIME) и будет сохранять эту возможность после выполнения exec (опять таки, при условии, что соответствующие разряды возможностей файла установлены). Ни этот процесс, ни один из тех, которые он может запустить с помощью функции exec, не может получить иные возможности, если только они не обеспечиваются каким-либо другим процессом, имеющим возможность CAP_SETPCAP.

Рис. 7.4. Наборы возможностей
Код, поддерживающий все эти свойства, в основном размещается в файле kernel/capability.c, начинающемся со строки 22460. Двумя основными функциями являются sys_capget (строка 22480), которая считывает возможности, и sys_capset (строка 22592), которая их устанавливает; эти функции освещаются далее в этом разделе. Как уже отмечалось, наследование возможностей после выполнения exec обеспечивается функцией compute_creds файла fs/exec.c (строка 9948).
Конечно, как правило, привилегированный процесс располагает всеми возможностями. Функция возможностей ядра обеспечивает привилегированный процесс структурированным способом избирательно предоставлять данному процессу только необходимые возможности, независимо от того, выполняется ли процесс в качестве привилегированного.
Интересное свойство возможностей состоит в том, что они могут использоваться для изменения «оттенка» системы. Например, установка возможности CAP_SYS_NICE для всех процессов позволила бы всем процессам поднимать свои приоритеты (и устанавливать свои планировщики, и т.п.). При изменении способа использования системы всеми процессами изменяется и сама система. Можете сами придумать новые возможности ядра, которые позволяют полнее использовать систему.
Одно, почти неуловимое преимущество возможностей заключается в том, что они проясняют исходный код. При проверке того, нужно ли разрешать текущему процессу устанавливать системное время, необходимость запрашивать вместо этого, будет ли текущий процесс запускаться привилегированным процессом — не слишком очевидный подход. Возможности позволяют более точно выразить, что имеется в виду. Существование возможностей даже помогает прояснить код, который запрашивает о идентификаторе пользователя или группы процесса, поскольку выполняющий это код предположительно интересует ответ на данный вопрос, а не возможные из него выводы. В противном случае, используя возможности, код запросил бы конкретно интересующие его данные. По мере дальнейшей интеграции возможностей в код ядра Linux это свойство станет более надежным.
13916: Здесь ядро распознает начало возможностей. Поскольку операторы #define снабжены развернутыми комментариями, мы не станем подробно останавливаться на каждом из них.
14153: Каждой возможности были просто присвоены последовательные целые числа, но поскольку они используются для адресации разрядов внутри целого значения без знака, с помощью макроса CAP_TO_MASK они преобразуются в степени числа 2.
14154: В основе установки и проверки возможностей лежит всего лишь набор простых манипуляций разрядами; некоторые макросы и встроенные функции, представленные в строках от этой до конца файла include/linux/capability.h, служат для прояснения манипуляций с разрядами.
sys_capget
22480: sys_capget принимает два аргумента: header типа cap_user_header_t (строка 13878) является указателем на структуру, определяющую версию используемых возможностей и обеспечивающую PID целевого процесса, dataptr типа cap_user_data_t (строка 13884) также является указателем на структуру — эта структура содержит действующий, разрешенный и наследуемый наборы. Посредством второго указателя sys_capget возвращает информацию.
22492: В случае несоответствия версий посредством указателя header sys_capget возвращает используемую версию, а затем — ошибку EINVAL (или EFAULT, если ей не удалось скопировать информацию о версии в область вызывающей функции).
22509: Идентифицирует процесс, о возможностях которого хочет узнать вызывающая функция; если pid не равен 0 или PID текущего процесса, sys_capget ищет его.
22520: Если ей удалось обнаружить целевой процесс, она копирует его возможности во временную переменную data.
22530: Если до сих пор все шло хорошо, она копирует возможности обратно в область пользователя в адрес, переданный аргументом dataptr. После этого она возвращает переменную error — как обычно, это 0, если все нормально, или, в противном случае — номер ошибки.
sys_capset
22592: Аргументы sys_capset почти полностью аналогичны аргументам функции sys_capget. Различие состоит в том, что теперь переменная data (которая больше не называется dataptr) является константой const. Подозреваю, что это было сделано для того, чтобы помешать изменению объекта, на который указывает data, но в действительности это предотвращает изменение самой переменной data, чтобы она не могла указывать на что-либо другое.
22600: Как и в случае с функцией sys_capget, функция sys_capset убеждается, что ядро и вызывающий процесс используют совместимые версии системы возможностей. Если это не так, она отклоняет попытку.
22613: Если значение pid является ненулевым, показывая, что вызывающий процесс желает установить возможности другого процесса, в большинстве случаев попытка должна быть отклонена. sys_capset разрешает попытку в любом случае, если вызывающий процесс имеет возможность CAP_SETPCAP и, следовательно, ему разрешается устанавливать возможности любого процесса. Первая часть этой проверки несколько слишком строга: она должна была бы также принимать pid, если он равен pid текущего процесса.
22616: Копирует новые возможности из области пользователя и возвращает ошибку, если это не удается.
22627: Аналогично коду sys_capget, начинающемуся в строке 22509, sys_capset идентифицирует процесс, о возможностях которого хочет узнать вызывающий процесс. Различие состоит в том, что в данном случае допускаются отрицательные значения pid для указания групп процессов (или же –1 указывает все процессы). В таком случае target по прежнему устанавливается в значение current, чтобы в последующих вычислениях использовались возможности текущего процесса.
22642: Теперь функция должна убедиться, что новые наборы возможностей принимают допустимые и внутренне непротиворечивые значения. Эта проверка удостоверяет, что наследуемый набор нового процесса не содержит ничего нового, если только новое свойство не входит в разрешенный набор вызывающего процесса. Таким образом, функция не пропускает никакие возможности, отсутствующие в вызывающем процессе.
22650: Аналогично, функция sys_capset убеждается, что разрешенный набор целевого процесса не содержит ничего, что в него не входило ранее, если только вызывающий процесс также не располагает этой возможностью. Таким образом, функция снова не пропускает никакие возможности, отсутствующие в вызывающем процессе.
22658: Вспомните, что действующий набор процесса должен быть поднабором его разрешенного набора. Это свойство поддерживается здесь.
22666: Теперь функция sys_capset готова выполнить запрошенные изменения. Отрицательное значение pid означает, что функция изменяет возможности более чем для одного процесса — для всех процессов, если значение pid равно –1; или для всех процессов в группе процессов, если pid имеет любое другое отрицательное значение. В этих случаях работа выполняется функциями cap_set_all (строка 22561) или cap_set_pg (строка 22539), соответственно; эти функции просто выполняют цикл по соответствующим наборам процессов, перезаписывая наборы возможностей для каждого из них так же, как для единственного процесса.
22676: Если pid имеет положительное значение (или 0, означающее текущий процесс), наборы возможностей присваиваются только целевому процессу.
Идентификаторы пользователей и групп
Столь же полезные и мощные, как возможности, в арсенале ядра идентификаторы служат не только средством управления доступом. В некоторых обстоятельствах нужно знать, кто запускает процесс или от чьего лица выполняется процесс. Пользователи идентифицируются по целочисленным идентификаторам пользователей; пользователь также принадлежит к одной или нескольким группам, каждая из которых имеет свой целочисленный идентификатор.
Существует две разновидности идентификаторов пользователей и групп: реальные и эффективные. Говоря в общем, реальный идентификатор пользователя (или группы) сообщает, кто создал процесс, а эффективный идентификатор пользователя (или группы) сообщает от чьего лица выполняется процесс, если эта информация изменяется. Поскольку решения по ограничению доступа в большей степени зависят от того, от чьего имени выполняется процесс, чем от того, кем он был создан, ядро проверяет эффективные идентификаторы пользователей (или групп) чаще, чем реальные — во всяком случае в коде, с которым мы ознакомились к этому моменту. Соответствующими членами структуры struct task_struct являются uid, euid, gid и egid (строки с 16396 по 16397). Обратите внимание, что идентификатор пользователя отличается от имени пользователя; первый — целое число, а второе — текстовая строка. Сопоставление этих параметров выполняется в файле /etc/passwd.
Давайте еще раз вернемся к функции sys_setpriority и подробней рассмотрим код, пропущенный ранее, в строках 29244 и 29245. Функция sys_setpriority должна позволять любому пользователю понижать приоритет его процессов, но не процессов каких-либо других пользователей — если только пользователь не имеет возможность CAP_SYS_NICE. Таким образом, первые два термина в выражении if проверяют, соответствует ли идентификатор целевого процесса реальному либо эффективному идентификатору процесса, вызывающего функцию sys_setpriority. Если он не соответствует ни одному из них, и если возможность CAP_SYS_NICE не установлена, функция sys_setpriority корректно отклоняет попытку.
Процессы могут изменять собственные идентификаторы пользователей и групп — если это разрешено — с помощью функций sys_setuid и sys_setgid (строки 29578 и 29445) и ряда других. Идентификаторы пользователей и групп могут также быть изменены посредством выполнения функции exec применительно к исполняемым файлам setuid или setgid.
Ограничения ресурсов
Ядру может быть указано ограничить использование процессом различных ресурсов, в том числе памяти и времени центрального процессора. Это делается с помощью функции sys_setrlimit (строка 30057). Представление о поддерживаемых ограничениях можно получить, взглянув на struct rusage (строка 16068). Специфичные для процесса ограничения отслеживаются в структуре struct task_struct; взгляните на член массива rlim в строке 16404.
Результат нарушения ограничения различен для различных ограничений. Например, для RLIMIT_NPROC (это ограничение не включено в исходный код, приведенный в данной книге) — ограничения количества процессов, которые может иметь пользователь — результатом его нарушения является просто неудача процедуры fork, как видно из строки 23974.
Последствия нарушения других ограничений могут быть более серьезными для процесса: например, превышение лимита времени процессора приводит к прерыванию процесса (см. строку 27333). Процесс может спросить о конкретном ограничении, воспользовавшись функцией sys_getrlimit (строка 30046), или о ресурсах, использовавшихся им до сих пор, воспользовавшись функцией sys_getrusage (строка 30143).
В строке 30067 обратите внимание, что процесс может произвольно понижать собственные значения ограничений, но повышать свои значения ограничений он может только до максимального значения, которое может устанавливаться независимо для каждого ограничения.
Следовательно, текущее и максимальное значения ограничений ресурсов отслеживаются независимо (посредством использования членов rlim_cur и rlim_max структуры struct rlimit, определенных в строке 16089). Однако, процессы с возможностью CAP_SYS_RESOURCE могут перезаписывать максимальные значения.
Это отличается от правил, действующих для приоритетов: процессу разрешается понижать свой приоритет, но ему требуется специальное разрешение для повышения своего приоритета, даже если он понижает приоритет, а затем немедленно хочет его повысить. Пара представлений о текущем и максимальном значениях ограничения ресурсов не имеет аналога в схеме приоритетов ядра.
Кроме того, один процесс может изменять приоритет другого процесса (естественно, при наличии соответствующего разрешения), но процесс может изменять только собственные ограничения ресурсов.
Все хорошее когда-то кончается — а теперь, как это делается
Мы увидели, как процессы рождаются и как они получают свои сроки жизни. Теперь пора узнать, как они умирают.
exit
Процесс можно прервать против его желания, послав ему сигнал 9, как было описано в главе 6, но добровольное завершение является более распространенным. Процессы завершаются добровольно, вызывая системную функцию exit, которая реализована в ядре функцией sys_exit (строка 23322). (Кстати, когда программа на С осуществляет возврат из main, она косвенно вызывает exit.)
Когда процесс осуществляет выход, ядро должно освободить все ресурсы, выделенные процессу — память, файлы и т.п. — и, конечно, прекратить предоставлять в его распоряжение центральный процессор.
Однако, ядро не сразу освобождает структуру struct task_struct, представляющую процесс, поскольку родительский процесс данного процесса должен быть в состоянии запросить о состоянии выхода дочернего процесса с помощью системного вызова wait. Функция wait возвращает PID дочернего процесса, о завершении которого она докладывает, поскольку приложения могли бы быть введены в заблуждение, если бы PID более не существующего дочернего процесса был повторно выделен прежде, чем родительский процесс получил ответ wait. (Кроме всего прочего, один и тот же родительский процесс мог бы получить два дочерних процесса с одним и тем же PID — один действующий и один не существующий — не знал бы, какой из них завершил работу). Следовательно, ядро должно резервировать PID не существующего дочернего процесса до тех пор, пока не будет выполнена функция wait — это делается автоматически путем сохранения соответствующей структуры struct task_struct; код, выполняющий выделение PID просто не запрашивает, существуют ли найденные им в списке задач процессы.
Процессы в этом промежуточном состоянии — уже не существующие, но еще и не завершившиеся полностью — называются зомби. Таким образом, задача функции sys_exit заключается в превращении действующих процессов в зомби.
Сама по себе функция sys_exit тривиальна; она просто преобразует код выхода в формат, ожидаемый функцией do_exit, а затем вызывает функцию, которая выполняет реальную работу (do_exit вызывается также в качестве части отправки сигналов, как было описано в главе 6.)
do_exit
23267: do_exit принимает код выхода в качестве аргумента и содержит необычный символ NORET_TYPE перед возвращаемым ею типом. Хотя в настоящий момент NORET_TYPE (строка 14955) определяется в качестве пустого комментария — т.е. он не оказывает никакого действия — обычно он определяется как __volatile__, что указывает gcc что функция не выполнила возврат. В свете этого gcc выполняет некоторую дополнительную оптимизацию и подавляет предупреждение о том, что функция не выполнила возврат. Получив новое определение, NORET_TYPE больше не оказывает никакого влияния на работу компилятора, но при том сохраняется, поскольку по прежнему доносит полезную информацию до читателя.
23285: Освобождает свои семафоры и другие структуры System V IPC, которые освещены в главе 9.
23286: Освобождает свою выделенную память, что освещается в главе 8.
23290: Освобождает свои выделенные файлы, как вскоре будет описано.
23291: Освобождает свои данные файловой системы, что выходит за рамки этой книги.
23292: Освобождает свою таблицу обработчика сигналов, что освещено в главе 6.
23294: Выполняющая выход задача теперь входит в состояние TASK_ZOMBIE и ее код выхода запоминается родительским процессом для использования в будущем.
23296: Вызывает функцию exit_notify (строка 23198), которая предупреждает родительский процесс завершающейся задачи и членов ее группы процессов о том, что этот процесс завершается.
23304: Вызывает функцию schedule (строка 26686) для освобождения процессора. Это обращение к schedule никогда не выполняет возврат, поскольку оно переключает контекст на другой процесс и никогда не выполняет обратного переключения; поэтому это последний раз, когда завершающийся процесс получает доступ к процессору.
__exit_files
Способ взаимодействия процессов с файлами не является главной темой этой книги. Но следует кратко рассмотреть функцию __exit_files (строка 23109), поскольку это поможет получить более полное представление о функции __clone. Ранее мы уже рассматривали функцию __clone, которая позволяет родительском и дочернему процессам совместно использовать определенную информацию. Один из компонентов, которые родительский и дочерний процессы могут использовать совместно — их список открытых файлов. Как уже упоминалось, Linux использует схему подсчета ссылок, чтобы процессы могли корректно выполнить после себя уборку. Что ж, вот удачный пример такой уборки.
23115: Предполагая, что процесс имел какие-либо открытые файлы (это справедливо почти всегда), __exit_files уменьшит значение счетчика ссылок, которое первоначально хранилось в tsk->files->count. Элементарные операции, такие как atomic_dec_and_test подробно освещены в главе 10; а пока достаточно сказать, что atomic_dec_and_test (строка 10249) уменьшает свой аргумент и возвращает значение true, когда новое значение аргумента равно 0. Следовательно, возвращаемое значение истинно, когда ссылка tsk на интересующую структуру struct files_struct была последней. (Если бы эта копия была закрытой, а не используемой совместно с другим процессом, первоначально значение счетчика ссылок было бы равно 1 и обязательно уменьшилось бы до 0.)
23116: Перед освобождением памяти, которая отслеживает открытые файлы процесса, все файлы должны быть закрыты, что делается посредством вызова функции close_files (строка 23081).
23118: Освобождает память, содержащую массив дескрипторов файлов процесса, fd, что является субполем поля files. Максимальное число открытых файлов (NR_OPEN, определенное значением 1024 в строке 15067) выбирается так, чтобы проверка if в этой строке дала результат true — массив fd должен полностью помещаться на одной странице памяти. В основном это связано с тем, что при этом выделение (и освобождение) его памяти будет выполняться быстрее; в противном случае функция __exit_files будет вынуждена прибегнуть к более общим, но и более медленным функциям памяти ядра. Подробнее это решение будет обосновано в следующей главе.
23122: В последнюю очередь функция __exit_files освобождает сами файлы.
В основе остальных функций __exit_xxx лежит аналогичная концепция: они уменьшают значение собственного счетчика ссылок на потенциально общую с другими процессами информацию задачи, и если это была последняя ссылка, делают все необходимое для полного ее освобождения.
wait
Подобно exec, wait представляет собой семейство функций, а не отдельную функцию. (Однако, в отличие от exec, семейство функций wait действительно содержит член с именем wait.) Все функции семейства wait обязательно реализуются в ядре посредством единственной системной функции sys_wait4 (строка 23327), имя которой отражает тот факт, что она реализует наиболее общую функцию в семействе wait, wait4. Реализации стандартной библиотеки С libc должны реорганизовывать аргументы вызовов других функций wait и вызывать функцию sys_wait4. (Что ж, это еще не все: по историческим причинам порт Alpha ядра также обеспечивает функцию sys_waitpid. Но даже sys_waitpid вызывает функцию sys_wait4.)
Кроме всего прочего, sys_wait4 — только она — наконец отсылает зомби в могилу. Однако, с точки зрения приложения wait и связанные с ней функции озабочены проверкой дочернего процесса: они смотрят, умер ли кто-нибудь, и если да, то кто и как.
sys_wait4
23327: Как и надлежит очень общей функции, sys_wait4 имеет множество параметров, некоторые из которых необязательны, pid, как всегда, представляет PID целевого процесса; нулевое и отрицательные значения имеют специальный смысл, как будет вскоре показано. stat_addr если его значением является не NULL, представляет адрес, в который должно быть скопировано состояние выхода прерванного дочернего процесса, options — это набор флагов, которые могут изменить поведение функции sys_wait4. ru, если его значением является не NULL, — это адрес, в который должна быть скопирована информация об использовании ресурсов прерванного дочернего процесса.
23335: Если ей переданы любые недопустимые параметры, sys_wait4 возвращает код ошибки. Это решение кажется несколько грубым; вполне можно было бы просто игнорировать не имеющие важного значения флаги. Аргументы за выполнение этой задачи именно таким образом естественно заключаются в том, что если вызывающий процесс включает разряды, которые не собирался включать, он может столкнуться с неожиданным для себя поведением — в любом случае это означает, что вызывающий процесс ошибся и в этом случае лучше сообщить об ошибке, чем молча проигнорировать ошибку вызывающего процесса.
23342: Выполняет цикл по всем непосредственным дочерним процессам данного процесса (но не по внучатым процессам и т.д.). Как упоминалось ранее в этой главе, самый младший (наиболее недавно созданный) дочерний процесс доступен посредством члена p_cptr структуры struct task_struct, а список более старших братьев этого самого младшего дочернего процесса — посредством его члена p_osptr; таким образом, функция sys_wait4 проходит по всем дочерним процессам родительского процесса, начиная с самого младшего дочернего процесса, циклически переходя к все более старшим его братьям.
23343: Отфильтровывает неподходящие PID, исходя из значения аргумента pid. Обратите внимание, как будет обрабатываться аргумент pid равный –1 который позволяет выбрать любой процесс: значение этого pid не пройдет тесты в строках 23343, 23346 и 23349, поэтому он никогда не будет отклонен. Следовательно, это приводит к тому, что будет рассматриваться каждый дочерний процесс.
23376: Именно этот случай нас интересует в настоящее время — родительский процесс дожидается прерванного дочернего процесса. Именно здесь зомби наконец умирает окончательно. Все начинается с обновления представления родительского процесса о пользователе и системном времени, использованном его дочерними процессами (посредством системной функции sys_times, строка 29772), поскольку дочерний процесс больше не должен участвовать в вычислениях.
23382: Собирается информация об использовании других ресурсов (если она была запрошена), и состояние выхода дочернего процесса передается по указанному адресу (если оно было запрошено).
23387: Отправляет retval идентификатору PID завершившегося дочернего процесса, подлежащего удалению. Это конец; retval больше не будет меняться.
23388: Если текущий родительский процесс завершившегося процесса не является его исходным родительским процессом, процесс удаляет себя из текущей позиции в графе процессов (посредством REMOVE_LINKS, строка 16876), переустанавливает себя под исходным родительским процессом (посредством SET_LINKS, строка 16887), а затем отправляет своему родительскому процессу сигнал SIGCHLD, чтобы родительский процесс знал о выходе его дочернего процесса. Уведомление доставляется посредством notify_parent, описанной в главе 6 (строка 28548).
23396: Иначе — в обычном случае — может быть наконец вызвана функция release (строка 22951) для освобождения структуры struct task_struct завершившегося дочернего процесса. (Функция release будет рассмотрена через несколько минут, по завершении рассмотрения sys_wait4.)
23400: Теперь дочерний процесс успешно завершен, поэтому функции sys_wait4 остается только вернуть успех; она переходит к строке 23418, где возвращает значение retval (PID завершившегося дочернего процесса).
23401: Обратите внимание на необычное управление потоком; цикл for, который начался в строке 23342, продолжается в ветви default. Поскольку ветвь достигается только для процессов, которые не являются ни остановленными, ни зомби, это управление потоком является корректным, но его легко пропустить при первом чтении. Однако, в любом случае это излишне; и без этой ветви цикл вел бы себя так же.
23406: Если эта точка достигнута, цикл for пришел к завершению — вызывающий процесс просмотрел весь список дочерних процессов, так и не найдя процесс подлежащий, завершению — и вычисление находится в одном из трех состояний. Либо ни один дочерний процесс еще не завершился, либо ни один из дочерних процессов не совпал с переданным аргументом pid, либо (это особый случай предшествующей ситуации) задача вообще не имела дочерних процессов.
23408: Если значение flag ненулевое, во время цикла for была достигнута строка 23358, а значит по меньшей мере один дочерний процесс совпал с переданным аргументом pid — он просто не был зомби или остановленным, и поэтому не мог быть удален. В этом случае, если параметр WHOHANG был передан — т.е. вызывающий процесс не хочет ждать, раз ни один дочерний процесс не может быть удален — осуществляется переход к концу с возвратом нуля.
23411: Если был получен сигнал, выполняется выход с ошибкой. Этим сигналом не был SIGCHLD — если бы это было так, мертвый дочерний процесс не был бы найден, и, следовательно, эта точка не была бы достигнута.
23413: В противном случае все в порядке; вызывающему процессу нужно только дождаться выхода дочернего процесса. Таким образом, состояние процесса устанавливается равным TASK_INTERRUPTIBLE и для передачи процессора другому процессу вызывается функция schedule, которая не выполнит возврат до тех пор, пока ожидающий процесс не получит еще один доступ к процессору, во время которого он снова проверит наличие мертвого дочернего процесса (перейдя обратно к метке repeat в строке 23339). Вспомните, что в состоянии TASK_INTERRUPTIBLE процесс дожидается пробуждения сигналом — в данном случае он специально дожидается сигнала SIGCHLD, показывающего, что дочерний процесс выполнил выход, но ни один сигнал не смог прибыть.
23417: flag имел значение 0, поскольку либо процесс не имел дочерних процессов, либо переданный аргумент pid не совпал ни с одним из его дочерних процессов — в любом случае, функция sys_wait4 возвращает вызывающему процессу ошибку ECHILD.
release
22951: Единственным аргументом функции release является указатель на структуру struct task_struct, подлежащую освобождению.
22953: Убеждается, что задача не пытается освободить самое себя — невероятная ситуация, которая указывала бы на логическую ошибку в ядре.
22969: Код для однопроцессорной системы начинается вызовом функции free_uid (строка 23532), которая освобождает потенциально совместно используемую структуру struct user_struct, которая, кроме всего прочего, помогает процедуре fork убедиться, что единственный пользователь не владеет всеми процессами.
22970: Уменьшает значение системного счетчика общего количества выполняющихся задач и освобождает слот завершающегося процесса в массиве tarray_freelist.
22974: PID завершающегося процесса также освобожден и с помощью REMOVE_LINKS (строка 16876) он удален из графа процессов и из списка задач. Обратите внимание, что поскольку здесь структуры данных ядра должны быть исправлены, запись процесса в массиве task не нуждается в установке в NULL; достаточно добавления его слота в список свободных слотов.
22979: Значения счетчиков ошибок младшей страницы, ошибок старшей страницы и количества выполненных подкачек процесса добавлены к значениям соответствующих «дочерних счетчиков» текущего процесса — что совершено правильно; функция release вызывается только функцией sys_wait4, которая разрешает процессам освобождать только собственные дочерние процессы. Следовательно, текущий процесс должен быть родительским процессом завершающегося процесса.
22982: И наконец, пора освободить структуру struct task_struct завершившегося процесса, что выполняется посредством вызова функции free_task_struct (строка 2391). Эта функция просто освобождает страницы, на которых хранилась структура. И теперь, наконец, процесс полностью завершен.
|

 LINUX
LINUX 
 Books
Books
