|
Один из фундаментальных вопросов сетевого программирования
- это различие между протоколами, требующими установления логического соединения
(connection-oriented protocols), и протоколами, не требующими этого (connectionless
protocols). Хотя ничего сложного в таком делении нет, но начинающие их часто
путают. Частично проблема кроется в выборе слов. Очевидно, что два компьютера
должны быть как-то «соединены», если необходимо наладить обмен данными между
ними. Тогда что означает «отсутствие логического соединения»?
О наличии и отсутствии логического соединения говорят
применительно к протоколам. Иными словами, речь идет о способе передачи данных
по физическому носителю, а не о самом физическом носителе. Протоколы, требующие
и не требующие логического соединения, могут одновременно разделять общий физический
носитель; на практике обычно так и бывает.
Но если это деление не имеет ничего общего с физическим
носителем, по которому передаются данные, то что же лежит в его основе? Главное
различие в том, что в протоколах, не требующих соединения, каждый пакет передается
независимо от остальных. Тогда как протоколы, устанавливающие соединение, поддерживают
информацию о состоянии, которая позволяет следить за последовательностью пакетов.
При работе с протоколом, не требующим соединения,
каждый пакет, именуемый оатаграммой, адресуется и посылается приложением индивидуально
(совет 30).С точки зрения протокола каждая датаграмма - это независимая единица,
не имеющая ничего общего с другими датаграммами, которыми обмениваются приложения.
Примечание: Это не означает, что датаграммы
независимы с точки зрения приложения. Если приложение реализует нечто более
сложное, чем простой протокол запрос - ответ (клиент посылает серверу одиночный
запрос и ожидает одиночного ответа на него), то, скорее всего, придется отслеживать
состояние. Но суть в том, что приложение, а не протокол, отвечает за поддержание
информации о состоянии. Пример сервера, который не требует установления соединения,
но следит за последовательностью датаграмм, приведен в листинге 3.6.
Обычно это означает, что клиент и сервер не ведут
сложного диалога, - клиент посылает запрос, а сервер отвечает на него. Если
позже клиент посылает новый запрос, то с точки зрения протокола это новая транзакция,
не связанна с предыдущей.
Кроме того, протокол не обязательно надежен, то
есть сеть предпримет все возможное для доставки каждой датаграммы, но нет гарантий,
что ни одна не будет потеряна, задержана или доставлена не в том порядке.
С другой стороны, протоколы, требующие установления
соединения, самостоятельно отслеживают состояние пакетов, поэтому они используются
в приложениях, ведущих развитый диалог. Сохраняемая информация о состоянии позволяет
протоколу обеспечить надежную доставку. Например, отправитель запоминает, когда
и какие данные послал, но они еще не подтверждены. Если подтверждение не приходит
в течение определенного времени, отправитель повторяет передачу. Получатель
запоминает, какие данные уже принял, и отбрасывает пакеты-дубликаты. Если пакет
поступает не в порядке очередности, то получатель может «придержать» его, пока
не придут логически предшествующие пакеты.
У типичного протокола, требующего наличия соединения,
есть три фазы. Сначала устанавливается соединение между двумя приложениями.
Затем происходит обмен данными. И, наконец, когда оба приложения завершили обмен
данными, соединение разрывается.
Обычно такой протокол сравнивают с телефонным разговором,
а протокол, не требующий соединения, - с отправкой письма. Каждое письмо запечатывается
в отдельный конверт, на котором пишется адрес. При этом все письма оказываются
самостоятельными сущностями. Каждое письмо обрабатывается на почте независимо
от других посланий двух данных корреспондентов. Почта не отслеживает историю
переписки, то есть состояние последовательности писем. Кроме того, не гарантируется,
что письма не затеряются, не задержатся и будут доставлены в правильном порядке.
Это соответствует отправке датаграммы протоколом, не требующим установления
соединения.
Примечание: Хаверлок [Haverlock 2000] отмечает,
что более правильная аналогия - не письмо, а почтовая открытка, так как письмо
с неправильным адресом возвращается отправителю, а почтовая открытка - никогда
(как и в типичном протоколе, не требующем наличия соединения).
А теперь посмотрим, что происходит, когда вы не
посылаете письмо другу, а звоните по телефону. Для начала набираете его номер.
Друг отвечает. Некоторое время вы разговариваете, потом прощаетесь и вешаете
трубки. Так же обстоит дел и в протоколе, требующем соединения. В ходе процедуры
установления соединения одна из сторон связывается с другой, стороны обмениваются
«приветствиями» (на этом этапе они «договариваются» о тех параметрах и соглашениях,
кот рым будут следовать далее), и соединение вступает в фазу обмена данными.
Во время телефонного разговора звонящий знает своего
собеседника. И перед каждой фразой не нужно снова набирать номер телефона -
соединение установлено. Алогично в фазе передачи данных протокола, требующего
наличия соединения, надо передавать свой адрес или адрес другой стороны. Эти
адреса - часть информации о состоянии, хранящейся вместе с логическим соединением.
Остается только посылать данные, не заботясь ни об адресации, ни о других деталях,
связанных с протоколом.
Как и в разговоре по телефону, каждая сторона,
заканчивая передачу данных, формирует об этом собеседника. Когда обе стороны
договорились о завершении, они выполняют строго определенную процедуру разрыва
соединения.
Примечание: Хотя указанная аналогия полезна,
но она все же не точна. В телефонной сети устанавливается физическое соединение.
А приводимое «соединение» целиком умозрительно, оно состоит лишь из хранящейся
на обоих концах информации о состоянии. Что - бы должным образом понять
это, подумайте, что произойдет, если хост на одном конце соединения аварийно
остановится и начнет перезагружаться. Соединение все еще есть? По отношению
к перезагрузившемуся хосту — конечно, нет. Все соединения установлены в его
«прошлой жизни». Но для его бывшего «собеседника» соединение по-прежнему существует,
так коку него все еще хранится информация о состоянии, и не произошло ничего
такого, что сделало бы ее недействительной.
В связи с многочисленными недостатками протоколов,
не требующих соединения, возникает закономерный вопрос: зачем вообще нужен такой
вид протоколов? Позже вы узнаете, что часто встречаются ситуации, когда для
создания приложения использование именно такого протокола оправдано. Например,
протокол без соединения может легко поддерживать связь одного хоста со многими
и наоборот. Между тем протоколы, устанавливающие соединение, должны обычно организовать
по одному соединению между каждой парой хостов. Важно, что протоколы, не требующие
наличия соединения, - это фундамент, на котором строятся более сложные протоколы.
Рассмотрим набор протоколов TCP/IP. В совете 14 говорится, что TCP/IP - это
четырехуровневый стек протоколов (рис. 2.1).

Рис.2.1 Упрощенное представление стека
протоколов TCP/IP
Внизу стека находится интерфейсный уровень, который
связан непосредственно с аппаратурой. Наверху располагаются такие приложения,
как telnet, ftp и другие стандартные и пользовательские программы. Как видно
из рис. 2.1, TCP и UDP построены поверх IP. Следовательно, IP - это фундамент,
на котором возведено все здание TCP/IP. Но IP представляет лишь ненадежный сервис,
не требующий установления соединения. Этот протокол принимает пакеты с выше
расположенных приложенных уровней, обертывает их в IP-пакет и направляет подходящему
аппаратному интерфейсу для отправки в сеть. Послав пакет, IP, как и все протоколы,
не устанавливающие соединения, не сохраняет информацию о нем.
В этой простоте и заключается главное достоинство
протокола IP. Поскольку IP не делает никаких предположений о физической среде
передачи данных, он может работать с любым носителем, способным передавать пакеты.
Так, IP работает на простых последовательных линиях связи, в локальных сетях
на базе технологий Ethernet и Token Ring, в глобальных сетях на основе протоколов
Х.25 и ATM (Asynchronous Transfer Mode - асинхронный режим передачи), в беспроводных
сетях CDPD (Cellular Digital Packet Data - сотовая система передачи пакетов
цифровых данных) и во многих других средах. Хотя эти технологии принципиально
различны, с точки зрения IP они не отличаются друг от друга, поскольку способны
передавать пакеты. Отсюда следует важнейший вывод: раз IP может работать в любой
сети с коммутацией пакетов, то это относится и ко всему набору протоколов TCP/IP.
А теперь посмотрим, как протокол TCP пользуется
этим простым сервисом, чтобы организовать надежный сервис с поддержкой логических
соединений. Поскольку TCP-пакеты (они называются сегментами) посылаются в составе
1Р-датаграмм, у TCP нет информации, дойдут ли они до адреса, не говоря о возможности
искажения данных или о доставке в правильном порядке. Чтобы обеспечить надежность,
TCP добавляет к базовому IP-сервису три параметра. Во-первых, в ТСР-сегмент
включена контрольная сумма содержащихся в нем данных. Это позволяет в пункте
назначения убедиться, что переданные данные не повреждены сетью во время транспортировки.
Во-вторых, TCP присваивает каждому байту порядковый номер, так что даже если
данные прибывают в пункт назначения не в том порядке, в котором были отправлены,
то получатель сможет собрать из них исходное сообщение.
Примечание: Разумеется, TCP не передает
порядковый номер вместе с каждым байтом. Просто в заголовке каждого TCP-сегмента
хранится порядковый номер первого байта. Тогда порядковые номера остальных байтов
можно вычислить.
В-третьих, в TCP имеется механизм подтверждения
и повторной передачи. который гарантирует, что каждый сегмент когда-то будет
доставлен.
Из трех упомянутых выше добавлений механизм подтверждения/повторной
передачи самый сложный, поэтому рассмотрим подробнее его работу.
Примечание: Здесь опускаются некоторые детали.
Это обсуждение поверхностно затрагивает многие тонкости протокола TCP и их применение
для обеспечения надежного и отказоустойчивого транспортного механизма. Более
доступное и подробное изложение вы можете найти в RFC 793 [Pastel 1981b] и RFC
1122 [Braden1989], в книге [Stevens 1994]. В RFC 813 [Clark 1982] обсуждается
механизм окон и подтверждений TCP.
На каждом конце TCP-соединения поддерживается окно
приема, представляющее собой диапазон порядковых номеров байтов, который получатель
готов принят отправителя. Наименьшее значение, соответствующее левому краю окна,
- это порядковый номер следующего ожидаемого байта. Наибольшее значение, соответствующее
правому краю окна, - это порядковый номер последнего байта, для косого у TCP
есть место в буфере. Использование окна приема (вместо посылки только номера
следующего ожидаемого байта) повышает надежность протокола счет предоставления
средств управления потоком. Механизм управления потоком предотвращает переполнение
буфера TCP.
Когда прибывает TCP-сегмент, все байты, порядковые
номера которых оказываются вне окна приема, отбрасываются. Это касается как
ранее принятых данных (с порядковым номерами левее окна приема), так и данных,
для которых нет места в буфере (с порядковым номерами правее окна приема). Если
первый допустимый байт в сегменте не является следующим ожидаемым, значит, сегмент
прибыл не по порядку. В большинстве реализаций TCP такой сегмент помещается
в очередь и находится в ней, пока не придут пропущенные данные. Если же номер
первого допустимого байта совпадает со следующим ожидаемым, то данные становятся
доступными для приложения, а порядковый номер следующего ожидаемого байта увеличивается
на число байтов в сегменте. В этом случае считается, что окно сдвигается вправо
на число принятых байтов. Наконец, TCP посылает отправителю подтверждение (сегмент
АСК), содержащее порядковый номер следующего ожидаемого байта.
Например, на рис. 2.2а окно приема обведено пунктиром.
Вы видите, что порядковый номер следующего ожидаемого байта равен 4, и TCP готов
принять 9 байт (с 4 по 12). На рис. 2.26 показано окно приема после поступления
байтов с номерами 4-7. Окно сдвинулось вправо на четыре номера, а в сегменте
АСК, который пошлет TCP, номер следующего ожидаемого байта будет равен 8.
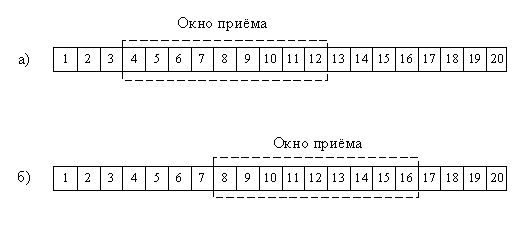
Рис. 2.2. Окно приема TCP
Теперь рассмотрим эту же ситуацию с точки зрения
протокола TCP на посылающем конце. Помимо окна приема, TCP поддерживает окно
передачи, разделенное на две части. В одной из них расположены байты, которые
уже отосланы, но еще не подтверждены, а в другой – байты, которые еще не
отправлены. Предполагается, что на байты 1-3 уже пришло подтверждение, поэтому
на рис. 2.3а изображено окно передачи, соответствующее окну приема на рис. 2.2а.
на рис. 2.3б вы видите окно передачи после пересылки байтов 4-7, но до прихода
подтверждения. TCP еще может послать байты 8-12, не дожидаясь подтверждения
от получателя. После отправки байтов 4-7 TCP начинает отсчет тайм – аута
ретрансмиссии (retransmission timeout - RTO). Если до срабатывания таймера
не пришло подтверждение на все четыре байта, TCP считает, что они потерялись,
и посылает их повторно.
Примечание: Поскольку в многих реализациях
не происходит отслеживания того, какие байты были посланы в конкретном сегменте,
может случиться, что повторно переданный сегмент содержит больше байтов, чем
первоначальный. Например, если байты 8 и 9 были посланы до срабатывания RTO-таймера,
то такие реализации повторно передадут байты с 4 по 9.
Обратите внимание, что срабатывание RTO-таймера
не означает, что исходные данные не дошли до получателя. Например, может потеряться
АСК - сегмент с подтверждением или исходный сегмент задержаться в сети
на время, большее чем тайм-аут ретрансмиссии. Но ничего страшного в этом нет,
так как если первоначально отправленные данные все-таки прибудут, то повторно
переданные окажутся вне окна приема TCP и будут отброшены.
После получения подтверждения на байты 4-7 передающий
TCP «забывает» про них и сдвигает окно передачи вправо, как показано на рис.
2.3в
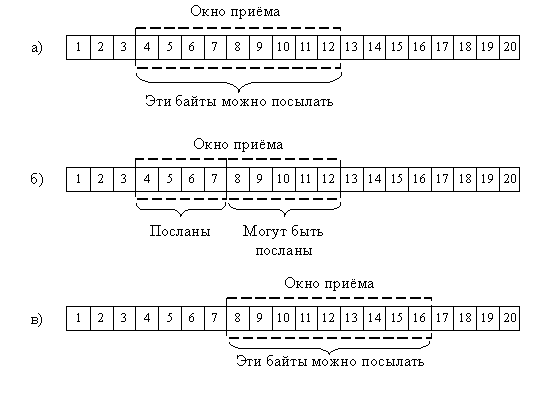
Рис. 2.3. Окно передачи TCP
TCP обеспечивает прикладного программиста надежным
протоколом, требующим установления логических соединений. О таком протоколе
рассказываете в совете 9.
С другой стороны, UDP предоставляет программисту
ненадежный сервис, не требующий соединения. Фактически UDP добавляет лишь два
параметра к протоколу IP, поверх которого он построен. Во-первых, необязательную
контрольную сумму для обнаружения искаженных данных. Хотя у самого протокола
IP тоже есть контрольная сумма, но вычисляется она только для заголовка IP-пакета,
поэтому TCP и UDP также включают контрольные суммы для защиты собственных заголовков
и данных. Во-вторых, UDP добавляет к IP понятие порта. Для отправки IP-датаграммы
конкретному хосту используются IP-адреса, то есть адреса, которые обычно приводятся
в стандартной десятичной нотации Internet (совет 2). Но по прибытии на хост
назначения датаграмму еще необходимо доставить нужному приложению. Например,
один UDP-пакет может быть предназначен для сервиса эхо - контроля, а другой
- для сервиса «время дня». Порты как раз и дают способ направления данных нужному
приложению (этот процесс называют демультиплексированием). С каждым TCP и UDP-сокетом
ассоциирован номер порта. Приложение может явно указать этот номер путем обращения
к системному вызову bind или поручить операционной системе выбор порта. Когда
пакет прибывает, ядро «ищет» в списке сокетов тот, который ассоциирован с протоколом,
парой адресов и парой номеров портов, указанных в пакете. Если сокет найден,
то данные обрабатываются соответствующим протоколом (в примерах TCP или UDP)
и передаются тем приложениям, которые этот сокет открыли.
Примечание: Если сокет открыт несколькими
процессами или потоками (thread), то данные может считывать только один из них,
и остальным они будут недоступны.
Возвращаясь к аналогии с телефонными переговорами
и письмами, можно сказать, что сетевой адрес в TCP-соединении подобен номеру
телефона офисной АТС, а номер порта - это добавочный номер конкретного телефона
в офисе. Точно так же UDP-адрес можно представить как адрес многоквартирного
дома, а номер порта - как отдельный почтовый ящик в его подъезде.
В этом разделе обсуждены различия между протоколами,
которые требуют и не требуют установления логического соединения. Вы узнали,
что ненадежные протоколы, в которых происходит обмен датаграммами без установления
соединения, - это фундамент, на котором строятся надежные протоколы на базе
соединений. Попутно было кратко изложено, как надежный протокол TCP строится
на основе ненадежного протокола IP.
Также отмечалось, что понятие «соединение» в TCP
носит умозрительный характер. Оно состоит из хранящейся информации о состоянии
на обоих концах; никакого «физического» соединения, как при телефонном разговоре,
не существует.
Длина IP -адреса (в версии IPv4) составляет
32 бита. Адреса принято записывать в десятичной нотации - каждый из четырех
байт представляется одним десятичным числом, которые отделяются друг от друга
точками. Так, адрес 0x11345678 записывается в виде 17.52.86.120. При записи
адресов нужно учитывать, что в некоторых реализациях TCP/IP принято стандартное
для языка C соглашение о том, что числа, начинающиеся с нуля, записываются в
восьмеричной системе. В таком случае 17.52.86.120 - это не то же самое,
что 017.52.86.120. В первом примере адреcе сети равен 17, а во втором - 15.
По традиции все IP-адреса подразделены на пять
классов, показанных на рис. 2.4. Адреса класса D используются для группового
вещания, а класс Е зарезервирован для будущих расширений. Остальные классы -
А, В и С – предназначены для адресации отдельных сетей и хостов.

Рис. 2.4. Классы IP - адресов
Класс адреса определяется числом начальных единичных
битов. У адресов класса А вообще нет бита 1 в начале, у адресов класса В - один
такой бит, у адресов класса С - два и т.д. Идентификация класса адреса чрезвычайно
важна, поскольку от этого зависит интерпретация остальных битов адреса.
Остальные биты любого адреса классов А, В и С разделены
на две группы. Первая часть любого адреса представляет собой идентификатор сети,
вторая -идентификатор хоста внутри этой сети.
Примечание: Биты идентификации класса также
считаются частью идентификатора сети. Так, 130.50.10.200 - это адрес класса
В, в котором идентификатор сети равен 0x8232.
Смысл разбивки адресного пространства на классы
в том, чтобы обеспечить необходимую гибкость, не теряя адресов. Например, класс
А позволяет адресовать сети с огромным (16777214) количеством хостов.
Примечание: Существует 224, или 16777216
возможных идентификаторов хостов, но адрес 0 и адрес, состоящий из одних единиц,
имеют специальный смысл. Адрес из одних единиц - это широковещательный адрес.
IP-датаграммы, посланные по этому адресу, доставляются всем хостам в сети. Адрес
0 означает «этот хост»и используется хостом как адрес источника, которому в
ходе процедуры начальной загрузки необходимо определить свой истиннный сетевой
адрес. Поэтому число хостов в сети всегда равно 2^n - 2, где n - число
бит в части адреса, относящейся к хосту.
Поскольку в адресах класса А под идентификатор сети
отводятся 7 бит, то всего существует 128 сетей класса А.
Примечание: Как и в случае идентификаторов
хостов, два из этих адресов зарезервированы. Адрес 0 означает «эта сеть» и,
аналогично хосту 0, используется для определения адреса сети в ходе начальной
Р загрузки. Адрес 127 - это адрес «собственной» сети хоста. Датаграммы, адресованные
сети 127, не должны покидать хост отправитель. Часто этот адрес называют «возвратным»
(loopback) адресом, поскольку отправленные по нему датаграммы «возвращаются»
на тот же самый хост.
На другом полюсе располагаются сети класса С. Их
очень много, но в каждой может быть не более 254 хостов. Таким образом, адреса
класса А предназначены для немногих гигантских сетей с миллионами хостов, тогда
как адреса класса С - для миллионов сетей с небольшим количеством хостов.
В табл. 2.1 показано, сколько сетей и хостов может
существовать в каждом классе, а также диапазоны допустимых адресов. Будем считать,
что сеть 127 принадлежит классу А, хотя на самом деле она, конечно, недоступна
для адресации.
Таблица 2.1. Число сетей, хостов и диапазоны адресов
для классов А, В и С
|
Класс
|
Сети
|
Хосты
|
Диапазон адресов
|
|
A
|
127
|
16777214
|
0.0.0.1-127.255.255.255
|
|
B
|
16384
|
65534
|
128.0.0.0-191.255.255.255
|
|
C
|
2097252
|
254
|
192.0.0.0-223.255.255.255
|
Первоначально проектировщики набора протоколов
TCP/IP полагали, что сети будут исчисляться сотнями, а хосты - тысячами.
Примечание: В действительности, как отмечается
в работе [Huitema 1995], в исходном проекте фигурировали только адреса, которые
теперь относятся к классу А. Подразделение на три класса былосделано позже,
чтобы иметь более 256 сетей
Появление дешевых, повсеместно применяемых персональных
компьютеров привело к значительному росту числа сетей и хостов. Нынешний размер
Internet намного превосходит ожидания его проектировщиков.
Такой рост выявил некоторые недостатки классов адресов.
Прежде всего, число хостов в классах А и В слишком велико. Вспомним, что идентификатор
сети, как предполагалось, относится к физической сети, например локальной. Но
никто не станет строить физическую сеть из 65000 хостов, не говоря уже о 16000000.
Вместо этого большие сети разбиваются на сегменты, взаимосвязанные маршрутизаторами.
В качестве простого примера рассмотрим два сегмента
сети, изображенной
на рис. 2.5.
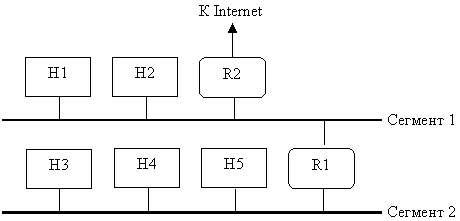
Рис. 2.5. Сеть из двух сегментов
Если хосту H1 нужно обратиться к хосту Н2, то он
получает физический адрес, соответствующий IP-адресу Н2 (используя для этого
метод, свойственный данной реализации физической сети), и помещает датаграмму
«на провод».
А если хосту H1 необходимо обратиться к хосту Н3?
Напрямую послать датаграмму невозможно, даже если известен физический адрес
получателя, поскольку H1 и Н3 находятся в разных сетях. Поэтому H1 должен отправить
датаграмму через маршрутизатор R1. Если у двух сегментов разные идентификаторы
сетей, то H1 по своей маршрутной таблице определяет, что пакеты, адресованные
сегменту 2, обрабатываются маршрутизатором R1, и отправляет ему датаграмму в
предположении, что тот переправит ее хосту Н3.
Итак, можно назначить двум сегментам различные
идентификаторы сети. Но есть и другие решения в рамках системы адресных классов.
Во-первых, маршрутная таблица хоста H1 может содержать по одному элементу для
каждого хоста в сегменте 2, который определит следующего получателя на пути
к этому хосту - R1. Такая же таблица должна размещаться на каждом хосте
в сегменте 1. Аналогичные таблицы, описывающие достижимость хостов из сегмента
1, следует поместить на каждом хосте из сегмента 2. Очевидно, такое решение
плохо масштабируется при значительном количестве хостов. Кроме того, маршрутные
таблицы придется вести вручную, что очень скоро станет непосильной задачей для
администратора. Поэтому на практике такое решение почти никогда не применяется
Во-вторых, можно реализовать ARP-прокси (proxy
ARP) таким образом, что - бы R1 казался для хостов из сегмента 1 одновременно
Н3, Н4 и Н5, а для хостов из сегмента 2 – H1, H2 и R2.
Примечание: Агента ARP в англоязычной литературе
еще называют promiscuous ARP (пропускающий ARP) или ARP hack (трюк ARP).
Это решение годится только в случае, когда в физической
сети используется протокол ARP (Address Resolution Protocol - протокол разрешения
адресов) для отображения IP-адресов на физические адреса. В соответствии с ARP
хост, которому нужно получить физический адрес, согласующийся с некоторым IP-адресом,
должен послать широковещательное сообщение с просьбой хосту, обладающему данным
IP-адресом, выслать свой физический адрес. ARP-запрос получают все хосты в сети,
но отвечает только тот, IP-адрес которого совпадает с запрошенным.
Если применяется агент ARP, то в случае, когда
хосту H1 необходимо послать IP-датаграмму НЗ, физический адрес которого неизвестен,
он посылает ARP-запрос физического адреса Н3. Но Н3 этот запрос не получит,
поскольку находится в другой сети. Поэтому на запрос отвечает его агент - R1,
сообщая свой собственный адрес. Когда R1 получает датаграмму, адресованную Н3,
он переправляет ее конечному адресату. Все происходит так, будто Н3 и H1 находятся
в одной сети.
Как уже отмечалось, агент ARP может работать только
в сетях, которые используют протокол ARP и к тому же имеют сравнительно простую
топологию. Подумайте, что случится при наличии нескольких маршрутизаторов, соединяющих
сегменты 1 и 2.
Из вышесказанного следует, что общий способ организовать
сети с несколькими сегментами - это назначить каждому сегменту свой идентификатор
сети. Но у этого решения есть недостатки. Во-первых, при этом возможна потеря
многих адресов в каждой сети. Так, если у любого сегмента сети имеется свой
адрес класса В, то большая часть IP-адресов просто не будет использоваться.
Во-вторых, маршрутная таблица любого узла, который
направляет датаграммы напрямую в комбинированную сеть, должна содержать по одной
записи для каждого сегмента. В указанном примере это не так страшно. Но вообразите
сеть из нескольких сотен сегментов, а таких сетей может быть много. Понятно,
что размеры маршрутных таблиц станут громадными.
Примечание: Эта проблема более серьезна,
чем может показаться на первый взгляд. Объем памяти маршрутизаторов обычно ограничен,
и нередко маршрутные таблицы размещаются в памяти специального назначения на
сетевых картах. Реальные примеры отказа маршрутизаторов из-за роста маршрутных
таблиц рассматриваются в работе [Huitema 1995].
Обратите внимание, что эти проблемы не возникают
при наличии хотя бы одного идентификатора сети. IP-адреса не остаются неиспользованными,
поскольку при потребности в новых хостах можно всегда добавить новый сегмент.
С другой стороны, так как имеется лишь один идентификатор сети, в любой маршрутной
таблице необходима всего одна запись для отправки датаграмм любому хосту в этой
сети.
Мне хотелось найти решение, сочетающее два достоинства:
во-первых, небольшие маршрутные таблицы и эффективное использование адресного
пространства, обеспечиваемые единым идентификатором сети, во-вторых, простота
маршрутизации, характерная для сетей, имеющих сегменты с разными идентификаторами
сети. Желательно, чтобы внешние хосты «видели» только одну сеть, а внутренние
- несколько сетей, по одной для каждого сегмента.
Это достигается с помощью механизма подсетей. Идея
очень проста. Поскольку внешние хосты для принятия решения о выборе маршрута
используют только идентификатор сети, администратор может распределять идентификаторы
хостов по своему усмотрению. Таким образом, идентификатор хоста - это закрытая
структура, не имеющая вне данной сети интерпретации.
Разделение на подсети осуществляется по следующему
принципу. Одна часть идентификатора хоста служит для определения сегмента (то
есть подсети), в состав которого входит хост, а другая - для идентификации конкретного
хоста. Рассмотрим, например, сеть класса B с адресом 190.50.0.0. Можно считать,
что третий байт адреса - это идентификатор подсети, а четвертый байт - номер
хоста в этой подсети. На рис. 2.6а приведена структура адреса с точки зрения
внешнего компьютера. Идентификатор хоста - это поле с заранее неизвестной
структурой. На рис. 2.6б показано, как эта структура выглядит изнутри сети.
Вы видите, что она состоит из идентификатора подсети и номера хоста.

Рис. 2.6. Два взгляда на адрес сети
класса B с подсетями
В приведенном примере взят адрес класса В, и поле
номера хоста выделено по границе байта. Но это необязательно. На подсети можно
разбивать сети классов А, В и С и часто не по границе байта. С каждой подсетью
ассоциируется маска подсети, которой определяется, какая часть адреса отведена
под идентификаторы сети I и подсети, а какая - под номер хоста. Так, маска
подсети для примера, показанного на рис. 2.6б, будет 0xffffff00. В основном
маска записывается в десятичной нотации (255.255.255.0), но если разбивка проходит
не по границе байта, то удобнее первая форма.
Примечание: Обратите внимание, что, хотя
говорится о маске подсети, фактически она выделяет части, относящиеся как к
сети, так и к подсети, то есть все, кроме номера хоста.
Предположим, что для иде
нтификатора подсети отведено 10 бит, а для номера хоста - 6 бит. Тогда
маска подсети будет 255.255.255.192 (0xffffffc0). Как следует из рис. 2.7, в
результате наложения этой маски на адрес 190.50.7.75 получается номер сети/подсети,
равный 190.70.7.64.
Для проверки убедитесь, что адрес 190.50.7.75 принадлежит
хосту 11 в подсети 29 сети 190.50.0.0. Важно не забывать, что эта интерпретация
имеет смысл только внутри сети. Для внешнего мира адрес интерпретируется как
хост 1867 в сети 190.50.0.0.
Теперь следует выяснить, как маршрутизаторы на
рис. 2.5 могут воспользоваться структурой идентификатора хоста для рассылки
датаграмм внутри сети. Предположим, что есть сеть класса В с адресом 190.5.0.0
и маска подсети равна 255.255.255.0. Такая структура показана на рис. 2.6б.

Рис. 2.7. Наложение маски подсети с
помощью операции AND для выделения сетевой части IP - адреса
На рис. 2.8 первому сегменту назначен идентификатор
подсети 1, а второму - идентификатор подсети 2. Рядом с сетевым интерфейсом
каждого хоста указан его IP -адрес. Обратите внимание, что третий байт
каждого адреса - это номер подсети, которой принадлежит интерфейс. Однако
внешнему компьютеру эта интерпретация неизвестна.
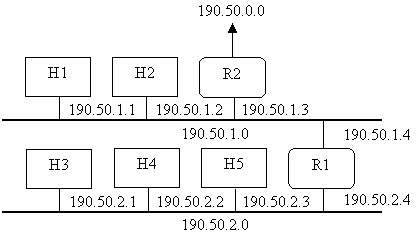
Рис. 2.8. Сеть с подсетями
Возвращаясь к вышесказанному, следует выяснить,
что происходит, когда хосту H1 нужно обратиться к хосту Н3. H1 берет адрес Н3
(190.50.2.1) и накладывает на него маску подсети (255.255.255.0), получая в
результате 190.5.2.0. Поскольку H1 находится в подсети 190.5.1.0, то Н3 напрямую
недоступен, поэтому он сверяется со своей маршрутной таблицей и обнаруживает,
что следующий адрес на пути к Н3 - это R1.
Примечание: Во многих реализациях эти два
шага объединены за счет помещения в маршрутную таблицу обеих подсетей. При поиске
маршрута IP выявляет одно из двух: либо целевая сеть доступна непосредственно,
либо датаграмму надо отослать промежуточному маршрутизатору.
Затем H1 отображает IP - адрес R1 на его физический
адрес (например, с помощью протокола ARP) и посылает R1 датаграмму. R1 ищет
адрес назначения в своей маршрутной таблице, пользуясь той же маской подсети,
и определяет местонахождение НЗ в подсети, соединенной с его интерфейсом 190.50.2.4.
После чего R1 доставляет датаграмму хосту НЗ, получив предварительно его физический
адрес по IP-адресу, - для этого достаточно передать датаграмму сетевому интерфейсу
190.50.2.4.
А теперь предположим, что H1 необходимо отправить
датаграмму Н2. При наложении маски подсети на адрес Н2 (190.5.1.2) получается
190.50.1.0, то есть та же подсеть, в которой находится сам хост H1. Поэтому
H1 нужно только получить физический адрес Н2 и отправить ему датаграмму напрямую.
Далее разберемся, что происходит, когда хосту Е
из внешней сети нужно отправить датаграмму Н3. Поскольку 190.50.2.1 - адрес
класса В, то маршрутизатору на границе сети хоста Е известно, что Н3 находится
в сети 190.50.0.0. Так как шлюзом в эту сеть является R2, рано или поздно датаграмма
от хоста Е дойдет до этого маршрутизатора. С этого момента все совершается так
же, как при отправке датаграммы хостом H1: R2 накладывает маску, выделяет адрес
подсети 190.50.2.0, определяет R1 в качестве следующего узла на пути к Н3 и
посылает R1 датаграмму, которую тот переправляет Н3. Заметьте, что хосту Е неизвестна
внутренняя топология сети 190.50.0.0. Он просто посылает датаграмму шлюзу R2.
Только R2 и другие хосты внутри сети определяют существование подсетей и маршруты
доступа к ним.
Важный момент, который нужно помнить, - маска
подсети ассоциируется с сетевым интерфейсом и, следовательно, с записью в маршрутной
таблице. Это означает, что разные подсети в принципе могут иметь разные маски.
Предположим, что адрес класса В 190.50.0.0 принадлежит
университетской сети, а каждому факультету выделена подсеть с маской 255.255.255.0
(на рис. 2.8 показана только часть всей сети). Администратор факультета информатики,
которому назначена подсеть 5, решает выделить один сегмент сети Ethernet компьютерному
классу, а другой - всем остальным факультетским компьютерам. Он мог бы
потребовать у администрации университета еще один номер подсети, но в компьютерном
классе всего несколько машин, так что нет смысла выделять ему адресное пространство,
эквивалентное целой подсети класса С. Вместо этого он предпочел разбить свою
подсеть на два сегмента, то есть создать подсеть внутри подсети.
Для этого он увеличивает длину поля подсети до
10 бит и использует маску 255.255.255.192. В результате структура адреса выглядит,
как показано на рис. 2.9.
Старшие 8 бит идентификатора подсети всегда равны
0000 0101 (5), поскольку основная сеть адресует всю подсеть как подсеть 5. Биты
X и Y определяют, какой Ethernet-сегмент внутри подсети 190.50.5.0 адресуется.
Из рис. 2.10 видно, что если XY = 10, то адресуется подсеть в компьютерном классе,
а если XY = 01 - оставшаяся часть сети. Частично топология подсети 190.50.5.0
изображена на рис. 2.10.

Рис. 2.9. Структура адреса для подсети
190.50.5.0
В верхнем сегменте (подсеть 190.50.1.0) на рис.
2.10 расположен маршрутизатор R2, обеспечивающий выход во внешний мир, такой
же, как на рис. 2.8. Под сеть 190.50.2.0 здесь не показана. Средний сегмент
(подсеть 190.50.5.128) - это локальная сеть Ethernet в компьютерном классе.
Нижний сегмент (подсеть 190.50.5.64) - это сеть Ethernet, объединяющая
остальные факультетские компьютеры. Для упрощения номер хоста каждой машины
один и тот же для всех ее сетевых интерфейсов и совпадает с числом внутри прямоугольника,
представляющего хост или маршрутизатор.
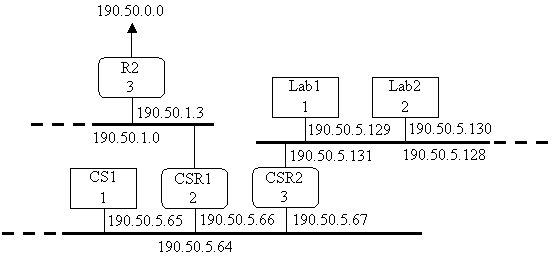
Рис. 2.10. Подсеть внутри подсети
Маска подсети для интерфейсов, подсоединенных к
подсетям 190.50.5.64 и 190.50.5.128, равна 255.255.255.192, а к подсети 190.50.1.0 -
255.255.255.0.
Эта ситуация в точности аналогична предыдущей,
которая рассматривалась для рис. 2.8. Так же, как хостам вне сети 190.50.0.0
неизвестно то, что третий байт адреса определяет подсеть, так и хосты в сети
190.50.0.0, но вне подсети 190.50.5.0, не могут определить, что первые два бита
четвертого байта задают подсеть подсети 190.50.5.0.
Теперь кратко остановимся на широковещательных
адресах. При использовании подсетей существует четыре типа таких адресов для
вещания: ограниченный, на сеть, на подсеть и на все подсети.
Адрес для ограниченного вещания - 255.255.255.255.
Вещание называется ограниченным, поскольку датаграммы, посланные на этот адрес,
не уходят дальше маршрутизатора. Они ограничены локальным кабелем. Такое широковещание
применяется, главным образом, во время начальной загрузки, если хосту неизвестен
свой IP-адрес или маска своей подсети.
Процесс передачи широковещательной датаграммы хостом,
имеющим несколько сетевых интерфейсов, зависит от реализации. Во многих реализациях
датаграмма отправляется только по одному интерфейсу. Чтобы приложение отправил
широковещательную датаграмму по нескольким интерфейсам, ему необходим узнать
у операционной системы, какие интерфейсы сконфигурированы для поддержки широковещания.
В адресе для вещания на сеть идентификатор сети
определяет адрес этой сети, а идентификатор хоста состоит из одних единиц. Например,
для вещания на сет 190.50.0.0 используется адрес 190.50.255.255. Датаграммы,
посылаемые на такой адрес, доставляются всем хостам указанной сети.
Требования к машрутизаторам (RFC 1812) [Baker 1995]
предусматривают по умолчанию пропуск маршрутизатором сообщений, вещаемых на
сеть, но эту возможность можно отключить. Во избежание атак типа «отказ от обслуживания»
(denial of service), которые используют возможности, предоставляемые направленным
широковещанием, во многих маршрутизаторах пропуск таких датаграмм, скорее всего,
будет заблокирован.
В адресе для вещания на все подсети идентификаторы
сети и подсети определяют соответствующие адреса, а идентификатор хоста состоит
из одних единиц. Не зная маски подсети, невозможно определить, является ли данный
адрес адресом для вещания на подсеть. Например, адрес 190.50.1.255 можно трактовать
как адрес для вещания на подсеть только при условии, если маршрутизатор имеет
информацию, что маска подсети равна 255.255.255.0. Если же известно, что маска
подсети равна 255.255.0.0, то это адрес не считается широковещательным.
При использовании бесклассовой междоменной маршрутизации
(CIDR), которая будет рассмотрена ниже, широковещательный адрес этого типа такой
же, как и адрес вещания на сеть; RFC 1812 предлагает трактовать их одинаково.
В адресе для вещания на все подсети задан идентификатор
сети, а адреса подсети и хоста состоят из одних единиц. Как и при вещании на
подсеть, для опознания такого адреса необходимо знать маску подсети.
К сожалению, применение адреса для вещания на все
подсети сопряжено с н которыми проблемами, поэтому этот режим не внедрен. При
использовали CIDR этот вид широковещания не нужен и, по RFC 1812, «отправлен
на свалку истории».
Ни один из описанных широковещательных адресов
нельзя использовать в качестве адреса источника IP-датаграммы. И, наконец, следует
отметить, что в некоторых ранних реализациях TCP/IP, например в системе 4.2BSD,
для выделения широковещательного адреса в поле идентификатора хоста ставились
не единицы, а нули.
Теперь вам известно, как организация подсетей решает
одну из проблем, связанных с классами адресов: переполнение маршрутных таблиц.
Хотя и в меньшей степени, подсети все же позволяют справиться и с проблемой
истощения IP - адресов за счет лучшего использования пула идентификаторов
хостов в пределах одной сети.
Еще одна серьезная проблема - это недостаток сетей
класса В. Как показано на рис. 2.5, существует менее 17000 таких сетей. Поскольку
большинство средних и крупных организаций нуждается в количестве IP-адресов,
превышающем возможности сети класса С, им выделяется идентификатор сети класса
В.
В условиях дефицита сетей класса В организациям
приходилось выделять блоки адресов сетей класса С, но при этом вновь возникает
проблема, которую пытались решить с помощью подсетей, - растут маршрутные таблицы.
Бесклассовая междоменная маршрутизация (CIDR) решает
эту проблему, вывернув принцип организации подсетей «наизнанку». Вместо увеличения
CIDR уменьшает длину идентификатора сети в IP-адресе.
Предположим, некоторой организации нужно 1000 IP-адресов.
Ей выделяют четыре соседних идентификатора сетей класса С с общим префиксом
от 200.10.4.0 до 200.10.7.0. Первые 22 бита этих идентификаторов одинаковы и
представляют номер агрегированной сети, в данном случае 200.10.4.0. Как и для
подсетей, для идентификации сетевой части IP-адреса используется маска сети.
В приведенном здесь примере она равна 255.255.252.0 (0xfffffc00).
Но в отличие от подсетей эта маска сети не расширяет
сетевую часть адреса, а укорачивает ее. Поэтому CIDR называют также суперсетями.
Кроме того, маска сети в отличие от маски подсети экспортируется во внешний
мир. Она становится частью любой записи маршрутной таблицы, ссылающейся на данную
сеть.
Допустим, внешнему маршрутизатору R надо переправить
датаграмму по адресу 200.10.5.33, который принадлежит одному из хостов в агрегированной
сети. Он просматривает записи в своей маршрутной таблице, в каждой из которых
хранятся маска сети, и сравнивает замаскированную часть адреса 200.10.5.33 с
хранящимся в записи значением. Если в таблице есть запись для сети, то в ней
будет храниться адрес 200.10.4.0 и маска сети 255.255.252.0. Когда выполняется
операция побитового AND между адресом 200.10.5.33 и этой маской, получается
значение 200.10.4.0. Это значение совпадает с хранящимся в записи номером подсети,
так что маршрутизатору известно, что именно по этому адресу следует переправить
датаграмму.
Если возникает неоднозначность, то берется самое
длинное соответствие. Например, в маршрутной таблице может быть также запись
с адресом 200.10.0.0 и маской сети 255.255.0.0. Эта запись также соответствует
адресу 200.10.5.33, но, поскольку для нее совпадают только 16 бит, а не 22,
как в первом случае, то предпочтение отдается первой записи.
Примечание: Может случиться так, что Internet
сервис - провайдер (ISP) «владеет» всеми IP-адресами с префиксом 200.10.
В соответствии со второй из рассмотренных выше записей маршрутизатор отправил
бы этому провайдеру все датаграммы, адрес назначения которых начинается с 200.10.
Тогда провайдер смог бы указать более точный маршрут, чтобы избежать лишних
звеньев в маршруте или по какой-то иной причине.
В действительности механизм CIDR более общий. Он
называется «бесклассовым», так как понятие «класса» в нем полностью отсутствует.
Таким образом, каждая запись в маршрутной таблице содержит маску сети, определяющую
сетевую часть IP-адреса. Если принять, что адрес принадлежит некоторому классу,
то эта маска может укоротить или удлинить сетевую часть адреса. Но поскольку
в CIDR понятия «класса» нет, то можно считать, что сетевая маска выделяет сетевую
часть адреса без изменения ее длины.
В действительности, маска - это всего лишь число,
называемое префиксом, которое определяет число бит в сетевой части адреса. Например,
для выше упомянутой агрегированной сети префикс равен 22, и адрес этой сети
следовало бы записать как 200.10.4.0/22, где /22 обозначает префикс. С этой
точки зрения адресацию на основе классов можно считать частным случаем CIDR,
когда имеется всего четыре (или пять) возможных префиксов, закодированных в
старших битах адреса.
Гибкость, с которой CIDR позволяет задавать размер
адреса сети, позволяет эффективно распределять IP-адреса блоками, размер которых
оптимально соответствует потребностям сети. Вы уже видели, как можно использовать
CIDR для агрегирования нескольких сетей класса С в одну большую сеть. А для
организации маленькой сети из нескольких хостов можно выделить лишь часть адресов
сети класса С. Например, сервис - провайдер выделяет небольшой компании
с единственной ЛВС адрес сети 200.50.17.128/26. В такой сети может существовать
до 62 хостов (2^6-2).
В RFC 1518 [Rekhter и Li 1993] при обсуждении вопроса
об агрегировании адресов и его влиянии на размер маршрутных таблиц рекомендуется
выделять префиксы IP-адресов (то есть сетевые части адреса) иерархически.
Примечание: Иерархическое агрегирование
адресов можно сравнить с иерархической файловой системой вроде тех, что используют
в UNIX и Windows. Так же, как каталог верхнего уровня содержит информацию о
своих подкаталогах, но не имеет сведений о находящихся в них файлах, доменам
маршрутизации верхнего уровня известно лишь о промежуточных доменах, а не о
конкретных сетях внутри них. Предположим, что региональный провайдер обеспечивает
весь трафик для префикса 200/8, а к нему подключены три локальных провайдера
с префиксами 200.1/16,200.2/16 и 200.3/16. У каждого провайдера есть несколько
клиентов, которым выделены части располагаемого адресного пространства (200.1.5/24
и т.д.). Маршрутизаторы, внешние по отношению к региональному провайдеру, должны
хранить в своих таблицах только одну запись - 200/8. Этого достаточно для
достижения любого хоста в данном диапазоне адресов. Решения о выборе маршрута
можно принимать, даже не зная о разбиении адресного пространства 200/8. Маршрутизатор
регионального провайдера должен хранить в своей таблице только три записи: по
одной для каждого локального провайдера. На самом нижнем уровне локальный провайдер
хранит записи для каждого своего клиента. Этот простой пример позволяет видеть
суть агрегирования.
Почитать RFC 1518 очень полезно, поскольку в этом
документе демонстрируются преимущества использования CIDR. В RFC 1519 [Fuller
et al. 1993] описаны CIDR и ее логическое обоснование, а также приведены подробный
анализ затрат, связанных с CIDR, и некоторые изменения, которые придется внести
в протоколы междоменной маршрутизации.
Подсети в том виде, в каком они описаны в RFC 950
[Mogul and Postel 1985], -это часть Стандартного протокола (Std. 5). Это
означает, что каждый хост, на котором установлен стек TCP/IP, обязан поддерживать
подсети.
CIDR (RFC 1517 [Hinden 1993], RFC 1518, RFC 1519) -
часть предложений к стандартному протоколу, и потому не является обязательной.
Тем не менее CIDR применяется в Internet почти повсеместно, и все новые адреса
выделяются этим способом. Группа по перспективным разработкам в Internet (IESG
- Internet Engineering Steering Group) выбрала CIDR как промежуточное временное
решение проблемы роста маршрутных таблиц.
В перспективе обе проблемы - исчерпания адресов
и роста маршрутных таблиц - предполагается решать с помощью версии 6 протокола
IP. IPv6 имеет большее адресное пространство (128 бит) и изначально поддерживает
иерархию. Такое адресное пространство (включая 64 бита для идентификатора интерфейса)
гарантирует, что вскоре IP-адресов будет достаточно. Иерархия IРv6-адресов позволяет
держать размер маршрутных таблиц в разумных пределах.
В этом разделе рассмотрены подсети и бесклассовая
междоменная маршрутизация (CIDR). Вы узнали, как они применяются для решения
двух проблем, свойственных адресации на основе классов. Подсети позволяют предотвратить
рост маршрутных таблиц, обеспечивая в то же время гибкую адресацию. CIDR служит
эффективного выделения IP-адресов и способствует их иерархическому назначению.
Раньше, когда доступ в Internet еще не был повсеместно
распространен, организации выбирали произвольный блок IP-адресов для своих сетей.
Считалось, что сеть не подключена и «никогда не будет подключена» к внешним
сетям, hostomv выбор IP-адресов не имеет значения. Но жизнь не стоит на месте,
и в настоящее время очень мало сетей, которые не имеют выхода в Internet.
Теперь необязательно выбирать для частной сети
произвольный блок IP-адресов. В RFC 1918 [Rekhter, Moskowitz et al. 1996] специфицированы
три блока адресов, которые не будут выделяться:
- 10.0.0.0-10.255.255.255 (префикс 10/8);
- 172.16.0.0-172.31.255.255 (префикс 172.16/12);
- 192.168.0.0-192.168.255.255 (префикс 192.168/16).
Если использовать для своей сети один из этих блоков,
то любой хост сможет обратиться к другому хосту в этой же сети, не опасаясь
конфликта с глобально выделенным IP-адресом. Разумеется, пока сеть не имеет
выхода во внешние сети, выбор адресов не имеет значения. Но почему бы сразу
не воспользоваться одним из блоков частных адресов и не застраховаться тем самым
от неприятностей, которые могут произойти, когда внешний выход все-таки появится?
Что случится, когда сеть получит внешний выход?
Как хост с частным IP-адресом сможет общаться с другим хостом в Internet или
другой внешней сети? Самый распространенный ответ - нужно воспользоваться преобразованием
сетевых адресов (Network Address Translation - NAT). Есть несколько типов устройств,
поддерживающих NAT. Среди них маршрутизаторы, межсетевые экраны (firewalls)
и автономные устройства с поддержкой NAT. Принцип работы NAT заключается в преобразовании
между частными сетевыми адресами и одним или несколькими глобально выделенными
IP-адресами. Большинство устройств с поддержкой NAT можно сконфигурировать в
трех режимах:
- статический. Адреса всех или некоторых
хостов в частной сети отображаются на один и тот же фиксированный, глобально
выделенный адрес;
- выбор из пула. Устройство с поддержкой
NAT имеет пул глобально выделенных IP-адресов и динамически назначает один
из них хосту, которому нужно связаться с хостом во внешней сети;
- РАТ, или преобразование адресов портов
(port address translation). Этот метод применяется, когда есть единственный
глобально выделенный адрес (рис. 2.11). При этом каждый частный адрес отображается
на один и тот ж внешний адрес, но номер порта исходящего пакета заменяется
уникальным значением, которое в дальнейшем используется для ассоциирования
входящих пакетов с частным сетевым адресом.
На рис. 2.11 представлена небольшая сеть с тремя
хостами, для которой и пользуется блок адресов 10/8. Имеется также маршрутизатор,
помеченный NAT у которого есть адрес в частной сети и адрес в Internet.
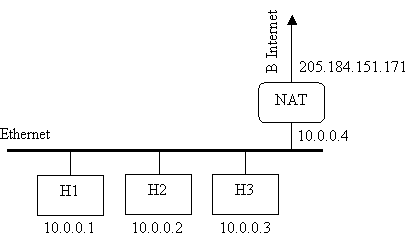
Рис. 2.11. Частная сеть с маршрутизатором,
который поддерживает NAT
Поскольку показан только один глобальный адрес,
ассоциированный с NAT, предположим, что маршрутизатор сконфигурирован с возможностью
использования метода РАТ. Статический режим и режим выбора из пула аналогичны
методу РАТ, но проще его, поскольку не нужно преобразовывать еще и номера портов.
Допустим, что хосту Н2 надо отправить SYN-сегмент
TCP по адресу 204.71.200.69 -на один из Web-серверов www.yahoo.com. - чтобы
открыть соединение. На рис. 2.12а видно, что у сегмента, покидающего Н2, адрес
получателя равен 204.71.200.69.80, а адрес отправителя - 10.0.0.2.9600.
Примечание: Здесь использована стандартная
нотация, согласно которой адрес, записанный в форме A.B.C.D.P означает IP-адресA.B.C.D
и порт Р.
В этом нет ничего особенного, за исключением того,
что адрес отправителя принадлежит частной сети. Когда этот сегмент доходит до
маршрутизатора, NAT Должен заменить адрес отправителя на 205.184.151.171, чтобы
Web-сервер на сайте Yahoo знал, куда посылать сегмент SYN/ACK и последующие.
Поскольку во всех пакетах, исходящих от других хостов в частной сети, адрес
отправителя также будет заменен на 205.184.151.171, NAT необходимо изменить
еще и номер пора некоторое уникальное значение, чтобы потом определять, какому
хосту следует переправлять входящие пакеты. Исходящий порт 9600 преобразуется
в 5555. Таким образом, у сегмента, доставленного на сайт Yahoo, адрес получателя
будет 204.71.200.69.80, а адрес отправителя - 205.184.151.171.5555.
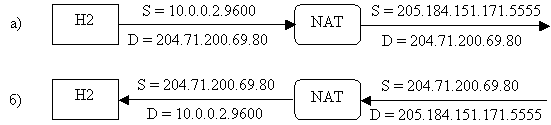
Рис. 2.12. Преобразование адресов портов
Из рис. 2.12б видно также, что в дошедшем до маршрутизатора
ответе Yahoo адрес получателя равен 205.184.151.171.5555. NAT ищет этот номер
порта в своей внутренней таблице и обнаруживает, что порт 5555 соответствует
адресу 10.0.0.1.9600, так что после получения от маршрутизатора этого пакета
в хосте Н2 появится информация, что адрес отправителя равен 204.71.200.69.80,
а адрес получателя - 10.0.0.1.9600.
Описанный здесь метод PAT выглядит довольно примитивно,
но есть много усложняющих его деталей. Например, при изменении адреса отправителя
или но мера исходящего порта меняются как контрольная сумма заголовка IР -
датаграммы так и контрольная сумма TCP-сегмента, поэтому их необходимо скорректировать.
В качестве другого примера возможных осложнений
рассмотрим протокол передачи файлов FTP (File Transfer Protocol) [Reynolds and
Postel 1985]. Когда FTP-клиенту нужно отправить файл или принять его от FTP-сервера,
серверу посылается команда PORT с указанием адреса и номера порта, по которому
будет ожидаться соединение (для передачи данных) от сервера. При этом NAT нужно
распознать TCP-сегмент, содержащий команду PORT протокола FTP, и подменить в
ней адрес и порт. В команде PORT адрес и номер порта представлены в виде ASCII-строк,
поэтому при их подмене может измениться размер сегмента. А это, в свою очередь,
повлечет изменение порядковых номеров байтов. Так что NAT должен за этим следить,
чтобы вовремя скорректировать порядковые номера в сегменте подтверждения АСК,
а также в последующих сегментах с того же хоста.
Несмотря на все эти сложности, NAT работает неплохо
и широко распространен. В частности, PAT - это естественный способ подключения
небольших сетей к Internet в ситуации, когда имеется только одна точка выхода.
В этом разделе показано, как схема NAT позволяет
использовать один из блоков частных сетевых адресов для внутренних хостов, сохраняя
при этом возможность выхода в Internet. Метод PAT, в частности, особенно полезен
для небольших сетей, у которых есть только один глобально выделенный IP-адрес.
К сожалению, поскольку PAT изменяет номер порта в исходящих пакетах, он может
оказаться несовместимым с нестандартными протоколами, которые передают информацию
о номерах портов в теле сообщения.
Большинство приложений TCP/IP попадают в одну из
четырех категорий:
- TCP-сервер;
- TCP-клиент;
- UDP-сервер;
- UDP-клиент.
В приложениях одной категории обычно встречается
почти одинаковый «стартовый» код, который инициализирует все, что связано с
сетью. Например,TCP - сервер должен поместить в поля структуры sockaddr_in
адрес и порт получателя, получить от системы сокет типа SOCK_STREAM, привязать
к нему выбранный адрес и номер порта, установить опцию сокета SO_REUSEADDR (совет
23), вызвать listen, а затем быть готовым к приему соединения (или нескольких
соединений) с помощью системного вызова accept.
На каждом из этих этапов следует проверять код
возврата. А часть программы, занимающаяся преобразованием адресов, должна иметь
дело как с числом так и с символическими адресами и номерами портов. Таким образом,
в любом TCP-сервере есть порядка 100 почти одинаковых строк кода для выявления
всех перечисленных выше задач. Один из способов решения этой проблемы -
поместить стартовый код в одну или несколько библиотечных функций которые приложение
может вызвать. Эта стратегия использована в книге. Но иногда приложению нужна
слегка видоизмененная последовательность инициализации. В таком случае придется
либо написать ее с нуля, либо извлечь нужный фрагмент кода из библиотеки и подправить
его.
Чтобы справиться и с такими ситуациями, можно построить
каркас приложения, в котором уже есть весь необходимый код. Затем скопировать
этот каркас, внести необходимые изменения, после чего заняться логикой самого
приложения. Не имея каркаса, легко поддаться искушению и срезать некоторые углы,
например, жестко «зашить» в приложение адреса (совет 29) или сделать еще что-то
сомнительное. Разработав каркас, вы сможете убрать все типичные функции в библиотеку,
а каркас оставить только для необычных задач.
Чтобы сделать программы переносимыми, следует определить
несколько макросов, в которых скрыть различия между API систем UNIX и Windows.
Например, в UNIX системный вызов для закрытия сокета называется close, а в Windows -
closesocket. Версии этих макросов для UNIX показаны в листинге 2.1. Версии для
Windows аналогичны, приведены в приложении 2. Доступ к этим макросам из каркасов
осуществляется путем включения файла skel.h.
Листинг 2.1. Заголовочный файл skel.h
skel.h
1 #ifndef __SKEL_H__
2 #define __SKEL_H__
3 /*версия для UNIX */
4 #define INIT() ( program_name = \
5 strrchr ( argv[ 0 ], '/'
) ) ? \
6 program_name++ : \
7 ( program_name = argv[ 0 ]
)
8 #define EXIT(s) exit( s )
9 #define CLOSE(s) if ( close( s ) ) error(
1, errno, \
10 "ошибка close "
)
11 #define set_errno(e) errno = ( e )
12 #define isvalidsock(s) ( ( s ) >= 0 )
13 typedef int SOCKET;
14 #endif /* __SKEL_H__ */
Начнем с каркаса TCP-сервера. Затем можно приступить
к созданию библиотеки, поместив в нее фрагменты кода из каркаса. В листинге
2.2 показана функция main.
Листинг 2.2. Функция main из каркаса tcpserver.skel
tcpserver.skel
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <stdarg.h>
5 #include <string.h>
6 #include <errno.h>
7 #include <netdb.h>
8 #include <fcntl.h>
9 #include <sys/time.h>
10 #include <sys/socket.h>
11 #include <netinet/in.h>
12 #include <arpa/inet.h>
13 #include "skel.h"
14 char *program_name;
15 int main( int argc, char **argv )
17 struct sockaddr_in local;
18 struct sockaddr_in peer;
19 char *hname;
20 char *sname;
21 int peerlen;
22 SOCKET s1;
23 SOCKET s;
24 const int on = 1;
25 INIT ();
26 if ( argc == 2 )
27 {
28 hname = NULL;
29 sname = argv[ 1 ];
30 }
31 else
32 {
33 hname = argv[ 1 ];
34 sname = argv[ 2 ];
35 }
36 set_address( hname, sname, &local, "tcp"
);
37 s = socket( AF_INET, SOCK_STREAM, 0 );
38 if ( !isvalidsock( s ) )
39 error ( 1, errno, "ошибка вызова socket"
);
40 if ( setsockopt( s, SOL_SOCKET, SO_REUSEADDR,
&on,
41 sizeof( on ) ) )
42 error( 1, errno, "ошибка вызова setsockopt"
);
43 if ( bind( s, ( struct sockaddr * ) klocal,
44 sizeof( local ) ) )
45 error( 1, errno, "ошибка вызова bind"
);
46 if ( listen ( s, NLISTEN ) )
47 error( 1, errno, "ошибка вызова listen"
);
48 do
49 {
50 peerlen = sizeof( peer );
51 s1 = accept( s, ( struct sockaddr * )&peer,
&peerlen );
52 if ( !isvalidsock( s1 ) )
53 error( 1, errno, "ошибка вызова accept"
);
54 server( s1, &peer );
55 CLOSE( s1 );
56 } while ( 1 );
57 EXIT( 0 );
58 }
Включаемые файлы и глобальные переменные
1-14 Включаем заголовочные файлы, содержащие объявления
используемых стандартных функций.
25 Макрос INIT выполняет стандартную инициализацию,
в частности, установку глобальной переменной program_name для функции error
и вызов функции WSAStartup при работе на платформе Windows.
Функция main
26-35 Предполагается, что при вызове сервера ему
будут переданы адрес и номер порта или только номер порта. Если адрес не указан,
то привязываем к сокету псевдоадрес INADDR_ANY, разрешающий прием соединений
по любому сетевому интерфейсу. В настоящем приложении в командной строке могут,
конечно, быть и другие аргументы, обрабатывать их надо именно в этом месте.
36 Функция set_address записывает в поля переменной
local типа sockaddr_in указанные адрес и номер порта. Функция set_address показана
в листинге 2.3.
37-45 Получаем сокет, устанавливаем в нем опцию
SO_REUSEADDR (совет 23) и привязываем к нему хранящиеся в переменной local адрес
и номер порта.
46-47 Вызываем listen, чтобы сообщить ядру о готовности
принимать соединения от клиентов.
48-56Принимаем соединения и для каждого из них
вызываем функцию server. Она может самостоятельно обслужить соединение или создать
Для этого новый процесс. В любом случае после возврата из функции server соединение
закрывается. Странная, на первый взгляд конструкция do-while позволяет легко
изменить код сервера так, чтоб завершался после обслуживания первого соединения.
Для этого достаточно вместо
while ( 1 );
написать
while ( 0 );
Далее обратимся к функции set__address. Она будет
использована во всех каркасах. Это естественная кандидатура на помещение в библиотеку
стандартных функций.
Листинг 2.3. Функция set_address
tcpserver.skel
1 static void set_address(char *hname, char *sname,
2 struct sockaddr_in *sap, char *protocol)
3 {
4 struct servant *sp;
5 struct hostent *hp;
6 char *endptr;
7 short port;
8 bzero (sap, sizeof(*sap));
9 sap->sin_family = AF_INET;
10 if (hname != NULL)
11 {
12 if (!inet_aton (hname, &sap->sin_addr))
13 {
14 hp = gethostbyname(hname);
15 if ( hp == NULL )
16 error( 1, 0, "неизвестный хост: %s\n",
hname );
17 sap->sin_addr = *( struct in_addr *
)hp->h_addr;
18 }
19 }
20 else
21 sap->sin_addr.s_addr = htonl( INADDR_ANY
);
22 port = strtol( sname, &endptr, 0 );
23 if ( *endptr == '\0' )
24 sap->sin_port = htons( port );
25 else
26 {
27 sp = getservbyname( sname, protocol );
28 if ( sp == NULL )
29 error( 1, 0, "неизвестный сервис:
%s\n", sname );
30 sap->sin_port = sp->s_port;
31 }
32 }
set_address
8-9 Обнулив структуру sockaddr_in, записываем в
поле адресного семейства AF_INET.
10-19 Если hname не NULL, то предполагаем, что это
числовой адрес в стандартной десятичной нотации. Преобразовываем его с помощью
функции inet_aton, если inet_aton возвращает код ошибки, - пытаемся преобразовать
hname в адрес с помощью gethostbyname. Если и это не получается, то печатаем
диагностическое сообщение и завершаем программу.
20-21 Если вызывающая программа не указала ни имени,
ни адреса хоста, устанавливаем адрес INADDR_ANY.
22-24 Преобразовываем sname в целое число. Если
это удалось, то записываем номер порта в сетевом порядке (совет 28).
27-30 В противном случае предполагаем, что это
символическое название ервиса и вызываем getservbyname для получения соответствующего
номера порта. Если сервис неизвестен, печатаем диагностическое сообщение и завершаем
программу. Заметьте, что getservbyname уже возвращает номер порта в сетевом
порядке.
Поскольку иногда приходится вызывать функцию set_address
напрямую, лесь приводится ее прототип:
#include "etcp.h"
void set_address(char *host, char *port,
struct sockaddr_in *sap, char *protocol);
Последняя функция - error - показана в листинге
2.4. Это стандартная диагностическая процедура.
#include "etcp.h"
void error(int status,
int err, char *format,...);
Если status не равно 0, то error завершает программу
после печати диагностического сообщения; в противном случае она возвращает управление.
Если err не равно 0, то считается, что это значение системной переменной errno.
При этом в конце сообщения дописывается соответствующая этому значению строка
и числовое значение кода ошибки.
Далее в примерах постоянно используется функция
error, поэтому добавим в библиотеку.
Листинг2.4. Функция error
tcpserver.skel
1 void error( int status, int err, char *fmt,
... )
2 {
3 va_list ap;
4 va_start ( ар, fmt );
5 fprintf (stderr, "%s: ", program_name
);
6 vfprintf( stderr, fmt, ap ) ;
7 va_end( ap ) ;
8 if ( err )
9 fprintf( stderr, ": %s (%d)\n",
strerror( err ), err);
10 if ( status )
11 EXIT( status );
12 }
В каркас включена также заглушка для функции server:
static void server(SOCKET s, struct sockaddr_in *peerp)
{
}
Каркас можно превратить в простое приложение, добавив
код внутрь этой заглушки. Например, если скопировать файл tcpserver.skel в
hello.с и заменить заглушку кодом
static void server(SOCKET s, struct sockaddr_in
*peerp)
{
send( s, "hello, world\n", 13, 0);
}
то получим сетевую версию известной программы на
языке С. Если откомпилировать и запустить эту программу, а затем подсоединиться
к ней с помощью программы telnet, то получится вполне ожидаемый результат:
bsd: $ hello 9000
[1] 1163
bsd: $ telnet localhost 9000
Trying 127 .0.0.1...
Connected to localhost
Escape character '^]'.
hello, world
Connection closed by foreign host.
Поскольку каркас tcpserver. skel описывает типичную
для TCP-сервера ситуацию, поместим большую часть кода main в библиотечную функцию
tcp_serv показанную в листинге 2.5. Ее прототип выглядит следующим образом:
#include "etcp.h"
SOCKET tcp_server( char *host, char *port );
Возвращаемое значение: сокет в режиме прослушивания (в случае ошибки
завершает программу).
Параметр host указывает на строку, которая содержит
либо имя, либо IP – адрес хоста, а параметр port - на строку с символическим
именем сервиса или номером порта, записанным в виде ASCII-строки.
Далее будем пользоваться функцией tcp_server, если
не возникнет необхомо модифицировать каркас кода.
Листинг 2.5. Функция tcp_server
tcp_server.с
1 SОСКЕТ tcp_server( char *hname, char *sname
)
2 {
3 struct sockaddr_in local;
4 SOCKET s;
5 const int on = 1;
6 set_address( hname, sname, &local, "tcp"
);
7 s = socket( AF_INET, SOCK_STREAM, 0 );
8 if ( !isvalidsock( s ) )
9 error( 1, errno, "ошибка вызова socket"
);
10 if ( setsockopt ( s, SOL_SOCKET, SO_REUSEADDR,
11 ( char * )&on, sizeoff on ) ) )
12 error( 1, errno, "ошибка вызова setsockopt"
);
13 if ( bind( s, ( struct sockaddr * } &local,
14 sizeof( local ) ) )
15 error( 1, errno, "ошибка вызова bind"
);
16 if ( listen( s, NLISTEN ) )
17 error( 1, errno, "ошибка вызова listen"
);
18 return s;
19 }
Рассмотрим каркас приложения TCP-клиента (листинг
2.6). Если не считать Функции main и замены заглушки server заглушкой client,
то код такой же, как для каркаса TCP-сервера.
Листинг 2.6. Функция main из каркаса tcpclientskel
tcpclient. skel
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in peer;
4 SOCKET s;
5 INIT ( ) ;
6 set_address(argv[ 1 ], argv[ 2 ], &peer,
"tcp");
7 s = socket( AF_INET, SOCK_STREAM, 0 );
8 if ( !isvalidsock( s ) )
9 error( 1, errno, "ошибка вызова socket"
);
10 if ( connect( s, ( struct sockaddr * )&peer;
11 sizeof( peer ) ) )
12 error ( 1, errno, "ошибка вызова connect"
);
13 client ( s, &peer );
14 EXIT ( 0 );
15 }
tcp_dient.skel
6-9 Как и в случае tcpserver.skel, записываем в
поля структуры sockaddr_in указанные адрес и номер порта, после чего получаем
сокет.
10-11 Вызываем connect для установления соединения
с сервером.
13 После успешного возврата из connect вызываем
заглушку client передавая ей соединенный сокет и структуру с адресом сервера.
Протестировать клиент можно, скопировав каркас
в файл helloc.с и дописав в заглушку следующий код:
static void client ( SOCKET s, struct sockaddr_in
*peerp )
{
int rc;
char buf[120];
for ( ; ; )
{
rc = recv( s, buf, sizeof( buf ), 0 );
if ( rc <= 0 )
break;
write( 1, buf, rc );
}
}
Этот клиент читает из сокета данные и выводит их
на стандартный вывод до тех пор, пока сервер не пошлет конец файла (EOF). Подсоединившись
к серверу hello, получаете:
bsd: $
hello localhost 9000
hello, world
bsd: $
Поместим фрагменты кода tcpclient.skel в библиотеку,
так же, как поступили с каркасом tcpclient.skel. Новая функция - tcp_client,
приведенная в листинге 2.7, имеет следующий прототип:
#include "etcp.h"
SOCKET tcp_client( char *host, char *port );
Возвращаемое значение: соединенный сокет (в случае ошибки завершает
программу).
Как и в случае tcp_server, параметр host содержит
либо имя, либо IР-адрес хоста, а параметр port - символическое имя сервиса или
номер порта в виде ASCII-строки.
Листинг 2.7. Функция tcp_client
tcp_client.с
1 SOCKET tcp_client( char *hname, char *sname
)
2 {
3 struct sockaddr_in peer;
4 SOCKET s;
5 set_address( hname, sname, &peer, "tcp"
);
6 s = socket( AF_INET, SOCK_STREAM, 0 );
7 if ( !isvalidsock( s ) )
8 error( 1, errno, "ошибка вызова socket"
);
9 if ( connect( s, ( struct sockaddr * )&peer,
10 sizeof( peer ) ) )
11 error( 1, errno, "ошибка вызова connect"
);
12 return s;
13 }
Каркас UDP-сервера в основном похож на каркас TCP-сервера.
Его отличительная особенность - не нужно устанавливать опцию сокета SO_REUSEADDR
и обращаться к системным вызовам accept и listen, поскольку UDL - это протокол,
не требующий логического соединения (совет 1). Функция main из каркаса [приведена
в листинге 2.8.
Листинг 2.8. Функция main из каркаса udpserver.skel
udpserver.skel
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in local;
4 char *hname;
5 char *sname;
6 SOCKET s;
7 INIT();
8 if ( argc == 2 )
9 {
10 hname = NULL;
11 sname = argv[ 1 ];
12 }
13 else
14 {
15 hname = argv[ 1 ];
16 sname = argv[ 2 ];
17 }
18 set_address( hname, sname, &local, "udp"
);
19 s = socket( AF_INET, SOCK_DGRAM, 0 );
20 if ( !isvalidsock( s ) )
21 error ( 1, errno, "ошибка вызова socket"
);
22 if ( bind( s, ( struct sockaddr * ) &local,
23 sizeoff local ) ) )
24 error( 1, errno, "ошибка вызова bind"
);
25 server( s, &local );
26 EXIT( 0 ) ;
27 }
udpserver.skel
18 Вызываем функцию set_address для записи в поля
переменнойlocal типа sockaddr_in адреса и номера порта, по которому сервер будет
принимать датаграммы. Обратите внимание, что вместо "tcp" задается
третьим параметром " udp".
19-24 Получаем сокет типа SOCK_DGRAM и привязываем
к нему адрес и нон» порта, хранящиеся в переменной local.
25 Вызываем заглушку server, которая будет ожидать
входящие датаграммы.
Чтобы получить UDP-версию программы «hello world»,
следует скопировать каркас в файл udphelloc.с и вместо заглушки вставить следующий
код:
static void server( SOCKET s, struct sockaddr_in
*localp )
{
struct sockaddr_in peer;
int peerlen;
char buf [ 1 ];
for ( ; ; )
{
peerlen = sizeof( peer );
if ( recvfrom( s, buf, sizeof( buf ), 0,
( struct sockaddr * )&peer, &peerlen
) < 0 )
error( 1, errno, "ошибка вызова recvfrom"
);
if ( sendto( s, "hello, world\n", 13,
0,
( struct sockaddr * )&peer, peerlen ) < 0 )
error( 1, errno, "ошибка вызова sendto"
);
}
}
Прежде чем тестировать этот сервер, нужно разработать
каркас UDP-клиента (листинг 2.10). Но сначала нужно вынести последнюю часть
main в библиотечную функцию udp_server:
#include "etcp.h"
SOCKET udp_server( char *host, char *port );
Возвращаемое значение:
UDP-сокет, привязанный к хосту host и порту port (в случае ошибки завершает
программу).
Как обычно, параметры host и port указывают на
строки, содержащие соответственно имя или IP-адрес хоста и имя сервиса либо
номер порта в виде ASCII-строки.
Листинг 2.9. Функция udpjserver
udp_server.с
1 SOCKET udp_server( char *hname, char *sname
)
2 {
3 SOCKET s;
4 struct sockaddr_in local;
5 set_address( hname, sname, &local, "udp"
);
6 s = socket( AF_INET, SOCK_DGRAM, 0 );
7 if ( !isvalidsock( s ) )
8 error( 1, errno, "ошибка вызова socket"
);
9 if ( bind( s, ( struct sockaddr * ) &local,
10 sizeof( local ) ) )
11 error( 1, errno, "ошибка вызова bind"
);
12 return s;
13 }
Функция main в каркасе UDP-клиента выполняет в
основном запись в поля переменной peer указанных адреса и номера порта сервера
и получает сокет типа SOCK_DGRAM. Она показана в листинге 2.10. Весь остальной
код каркаса такой же, как для udpserver. skel.
Листинг 2.10. Функция main из каркаса udpclient.skel
udpclient.skel
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in peer;
4 SOCKET s;
5 INIT();
6 set_address( argv[ 1 ], argv[ 2 ], &peer,
"udp" );
7 s = socket( AF_INET, SOCK_DGRAM, 0 );
8 if ( !isvalidsock( s ) )
9 error( 1, errno, "ошибка вызова socket"
) ;
10 client( s, &peer ) ;
11 exit( 0 ) :
12 }
Теперь можно протестировать одновременно этот каркас
и программу udphello, для чего необходимо скопировать udpclient.skel в файл
udphelloc.с и вместо клиентской заглушки подставить такой код:
static void client( SOCKET s, struct sockaddr_in
*peerp )
{
int rc;
int peerlen;
char buff [ 120 ];
peerlen = sizeof( *peerp );
if ( sendto( s, "", 1, 0, ( struct sockaddr
* )peerp,
peerlen ) < 0 )
error( 1, errno, "ошибка вызова sendto"
);
rc= recvfrom( s, buf, sizeof( buf ), 0,
( struct sockaddr * )peerp, &peerlen );
if ( rc >= 0 )
write ( 1, buf, rc );
else
error( 1, errno, "ошибка вызова recvfrom"
);
}
Функция client посылает серверу нулевой байт, читает
возвращенную датаграмму, выводит ее в стандартное устройство вывода и завершает
программу. Функции recvfrom в коде udphello вполне достаточно одного нулевого
байта. После его приема она возвращает управление основной программе, которая
и посылает ответную датаграмму.
При одновременном запуске обеих программ выводится
обычное приветствий
bsd: $ udphello 9000 &
[1] 448
bsd: $ updhelloc localhost 9000
hello, world
bsd: $
Как всегда, следует вынести стартовый код из main
в библиотеку. Обратите внимание, что библиотечной функции, которой дано имя
udp_client (листинг 2.11), передается третий аргумент - адрес структуры sockaddr_in;
в нее будет помещен адрес и номер порта, переданные в двух первых аргументах.
#include "etcp.h"
SOCKET udp_client( char
*host, char *port,
struct sockaddr_in *sap );
Возвращаемое значение: UDP-сокет и заполненная структура sockaddr_in
(в случае ошибки завершает программу).
Листинг 2.11. Функция udp_client
udp_client.c
1 SOCKET udp_client( char *hname, char *sname,
2 struct sockaddr_in *sap )
3 {
4 SOCKET s;
5 set_address( hname, sname, sap, "udp"
);
6 s = socket( AF_INET, SOCK_DGRAM, 0 );
7 if ( !isvalidsockt ( s ) )
8 error( 1, errno, "ошибка вызова socket"
);
9 return s;
10 }
Прочитав данный раздел, вы узнали, как просто создать
целый арсенал каркасов и библиотечных функций. Все построенные каркасы очень
похожи и различаются только несколькими строками в стартовом коде внутри функции
main. Таким образом, после написания первого каркаса пришлось лишь скопировать
код и подправить эти несколько строк. Эта методика очень проста. Поэтому, чтобы
создать несколько элементарных клиентов и серверов, потребовалось только вставить
содержательный код вместо заглушек.
Использование каркасов и написание библиотечных функций закладывает тот фундамент,
на котором далее легко строить приложения и небольшие тестовые программки для
их проверки.
Совет 5. Предпочитайте интерфейс сокетов интерфейсу XTI/TLI
В мире UNIX в качестве интерфейса к коммуникационным
протоколам, в частности к TCP/IP, в основном используются следующие два API:
- шкеты Беркли;
- транспортный интерфейс XTI(X/Open Transport
Interface).
Интерфейс сокетов разработан в Университете г.
Беркли штата Калифорния и вошел в состав созданной там же версии операционной
системы UNIX. Он получил широкое распространение вместе с версией 4.2BSD (1983),
затем был усовершенствован в версии 4.3BSD Reno (1990) и теперь включается практически
во все версии UNIX. API сокетов присутствует и в других операционных системах.
Так, Winsock API популярной в мире Microsoft Windows основан на сокетах из BSD
[Winsock Group 1997].
API интерфейса XTI - это расширение интерфейса
к транспортному уровню (Transport Layer Interface - TLI), который впервые появился
в системе UNIX System V Release 3.0 (SVR3) компании AT&T. TLI задумывался
как интерфейс, не зависящий, от протокола, так как он сравнительно легко поддерживает
новые протоколы, На его дизайн оказала значительное влияние модель протоколов
OSI (совет 14). В то время многие полагали, что эти протоколы вскоре придут
на смену TCP/IP И поэтому, с точки зрения программиста TCP/IP, дизайн этого
интерфейса далек от оптимального. Кроме того, хотя имена функций TLI очень похожи
на используемые в API сокетов (только они начинаются с t_), их семантика в ряде
случаев кардинально отличается.
Тот факт, что интерфейс TLI все еще популярен,
возможно, объясняется en использованием с протоколами Internetwork Packet Exchange/Sequenced
Packe Exchange (IPX/SPX) в системах фирмы Novell. Поэтому при переносе программ
написанных для IPX/SPX, под TCP/IP проще было воспользоваться тем же интерфейсом
TLI [Kacker 1999].
В четвертой части первого тома книги «UNIX Network
Programming» [Stevens 1998] имеется прекрасное введение в программирование XTI
и подсистем STREAMS. Представить, насколько отличается семантика XTI и сокетов,
можно хотя бы по тому, что обсуждению XTI посвящено более 100 страниц.
Надеясь, что протоколы OSI все-таки заменят TCP/IP,
многие производители UNIX-систем рекомендовали писать новые приложения с использованием
ТМ API. Одна фирма-производитель даже заявила, что интерфейс сокетов не будет
поддерживаться в следующих версиях. Но такие прогнозы оказались несколько преждевременными.
Протоколы OSI можно считать устаревшими, но TLI
и последовавший за ним XTI все еще поставляются в составе UNIX-систем, производных
от System V. Поэтому при программировании для UNIX встает вопрос: что лучше
использовать - сокеты или XTI?
Здесь необходимо напомнить, почему указанные протоколы
называются интерфейсами. Для программиста TCP/IP это всего лишь разные способы
доступа к стеку TCP/IP. Поскольку именно этот стек реализует коммуникационные
протоколы, не имеет значения, какой API использует его клиент. Это означает,
что приложение, написанное с помощью сокетов, может обмениваться данными с приложением
на базе XTI. В системах типа SVR4 оба интерфейса обычно реализуются в виде библиотек,
осуществляющих доступ к стеку TCP/IP с помощью подсистемы STREAMS.
Рассмотрим сначала интерфейс XTI. У него есть своя
ниша в сетевом программировании. Поскольку он не зависит от протокола, с его
помощью можно добавить в систему UNIX новый протокол, не имея доступа к коду
ядра. Проектировщику протокола необходимо лишь реализовать транспортный провайдер
в виде STREAMS-мультиплексора, связать его с ядром, а потом обращаться к нему
через XTI.
Примечание: О том, как писать модули STREAMS,
а также о программировании TLI и STREAMS вы можете прочесть в книге [Rago 199^
Обратите внимание, насколько специфична ситуация:
нужно реализовать отсутствующий в системе протокол, когда нет доступа к исходным
текстам ядра.
Примечание: Кроме того, этот протокол нужно
разработать для сиcтемы SVR4 или любой другой, поддерживающей STREAMS и XTI/1
Начиная с версии Solaris 2.6, фирма Sun предоставляет такую же функциональность
с помощью API сокетов.
Иногда утверждают, что проще писать не зависящий
от протокола код с мощью XTI/TLI [Rago 1993]. Конечно, «простота» - понятие
субъективное, но в разделе 11.9 книги «UNIX Network Programming» Стивенс с помощью
сокетов реализовал простой, не зависящий от протокола сервер времени дня, который
поддерживает IP версии 4, IP версии 6 и сокеты в адресном домене UNIX.
И, наконец, говорят, что при поддержке обоих интерфейсов
сокеты обычно реализуются поверх TLI/XTI, так что TLI/XTI более эффективен.
Это не так. Как отмечалось выше, в системах на базе SVR4 оба интерфейса обычно
реализованы в виде библиотек, напрямую общающихся с подсистемой STREAMS. Фактически
с версии Solaris 2.6 (Solaris - это версии SVR4, созданные фирмой Sun) сокеты
реализованы непосредственно в ядре; обращение к ним происходит через вызовы
системы.
Большое преимущество сокетов - переносимость. Поскольку
сокеты есть практически во всех системах с XTI/TLI, их использование гарантирует
максимальную переносимость. Даже если ваше приложение будет работать только
под UNIX, так как большинство операционных систем, поддерживающих TCP/IP, предоставляет
интерфейс сокетов. И лишь немногие системы, не принадлежащие к UNIX, содержат
интерфейс XTI/TLI (если вообще такие существуют). Например, создание приложения,
переносимого между UNIX и Microsoft Windows, - сравнительно несложная задача,
так как Windows поддерживает спецификацию Winsock, в которой реализован API
сокетов.
Еще одно преимущество сокетов в том, что этот интерфейс
проще использовать, чем XTI/TLI. Поскольку XTI/TLI проектировался в основном
как общий интерфейс (имеются в виду протоколы OSI), программисту приходится
при его использовании писать больше кода, чем при работе с сокетами. Даже сторонники
XTI/TLI согласны с тем, что для создания приложений TCP/IP следует предпочесть
интерфейс сокетов.
Руководство «Введение в библиотеку подпрограмм»,
поставляемое в составе Solaris 2.6, дает такой совет по выбору API: «При всех
обстоятельствах рекомендуется использовать API сокетов, а не XTI и TLI. Если
требуется переносимость на Другие системы, удовлетворяющие спецификации XPGV4v2,
то следует использовать интерфейсы из библиотеки libxnet. Если же переносимость
необязательна, то рекомендуется интерфейс сокетов из библиотек libsocket и libnsl,
а не из libxnet. Если выбирать между XTI и TLI, то лучше пользоваться интерфейсом
XTI (доступным через libxnet), а не TLI (доступным через libnsl)».
В обычных ситуациях нет смысла использовать интерфейс
XTI/TLI при программировании TCP/IP. Интерфейс сокетов проще и обладает большей
переносимостью, а возможности обоих интерфейсов почти одинаковы.
TСР - потоковый протокол. Это означает, что данные
доставляются получателю в виде потока байтов, в котором нет понятий «сообщения»
или «границы сообщения». В этом отношении чтение данных по протоколу TCP похоже
на чтение из последовательного порта - заранее не известно, сколько байтов будет
возвращено после обращения к функции чтения.
Представим, например, что имеется TCP-соединение
между приложения на хостах А и В. Приложение на хосте А посылает сообщения хосту
В. Допустим, что у хоста А есть два сообщения, для отправки которых он дважды
вызывает send - по разу для каждого сообщения. Естественно, эти сообщения передаются
от хоста А к хосту В в виде раздельных блоков, каждое в своем пакете, как показано
на рис. 2.13.
К сожалению, реальная передача данных вероятнее
всего будет происходить, не так. Приложение на хосте А вызывает send, и вроде
бы данные сразу же передаются на хост В. На самом деле send обычно просто копирует
данные в буфер стека TCP/IP на хосте А и тут же возвращает управление. TCP самостоятельно
определяет, сколько данных нужно передать немедленно. В частности, он может
вообще отложить передачу до более благоприятного момента. Принятие такого решения
зависит от многих факторов, например: окна передачи (объем данных, которые хост
В готов принять), окна перегрузки (оценка загруженности сети), максимального
размера передаваемого блока вдоль пути (максимально допустимый объем данных
для передачи в одном блоке на пути от А к В) и количества данных в выходной
очереди соединения. Подробнее это рассматривается в совете 15. На рис. 2.14
показано только четыре возможных способа разбиения двух сообщений по пакетам.
Здесь М11 и М12 - первая и вторая части сообщения М1, а М21 и М22 - соответственно
части М2. Как видно из рисунка, TCP не всегда посылает все сообщение в одном
пакете.

Рис. 2.13. Неправильная модель отправки
двух сообщений
Рис.2.14. Четыре возможных способа
разбиения двух сообщений по пакетам
А теперь посмотрим на эту ситуацию с точки зрения
приложения на хосте В. В общем случае оно не имеет информации относительно количества
возвращаемых TCP данных при обращении к системному вызову recv. Например, когда
приложение на хосте В в первый раз читает данные, возможны следующие варианты:
- данных еще нет, и приложение либо блокируется
операционной системой, либо recv возвращает индикатор отсутствия данных. Это
зависит от того, был ли сокет помечен как блокирующий и какую семантику вызова
гесv поддерживает операционная система;
- приложение получает лишь часть данных из
сообщения М1 если TCP посланы пакеты так, как показано на рис. 2.14г;
- приложение получает все сообщение М1, если
TCP отправлены пакеты, как изображено на рис. 2.14а;
- приложение получает все сообщение M1 и
часть или все сообщение М2, как представлено на рис. 2.14в.
Примечание: В действительности таких вариантов
больше, так как здесь не учитывается возможность ошибки и получения конца файла.
Кроме того, предполагается, что приложение читает все доступные данные.
Значительную роль здесь играет время. Если приложением
на хосте В первое сообщение прочитано не сразу после его отправки, а спустя
некоторое время после того, как хост А послал второе, то будут прочитаны оба
сообщения. Как видите, количество данных, доступных приложению в данный момент,
- величина неопределенная.
Еще раз следует подчеркнуть, что TCP - потоковый
протокол и, хотя данные передаются в IP-пакетах, размер пакета напрямую не связан
с количеством данных, переданных TCP при вызове send. У принимающего приложения
нет надежного способа определить, как именно данные распределены по пакетам,
поскольку между соседними вызовами recv может прийти несколько пакетов.
Примечание: Это может произойти, даже если
принимающее приложение реагирует очень быстро. Например, если один пакет потерян
(вполне обычная ситуация в Internet, см. совет 12), а последующие пришли нормально,
то TCP «придерживает» поступившие данные, пока не будет повторно передан и корректно
принят пропавший пакет. В этот момент приложение получает данные из всех поступивших
пакетов.
TCP следит за количеством посланных и подтвержденных
байтов, но не за их распределением по пакетам. В действительности, одни реализации
при повторной передаче потерянного пакета посылают больше данных, другие - меньше.
Все это настолько важно, что заслуживает выделения: Для TCP-приложения нет понятия
«пакет». Если приложение хоть как-то зависит от того, как TCP распределяет данные
по пакетам, то его нужно перепроектировать.
Так как количество возвращаемых в результате чтения
данных непредсказуемо, вы должны быть готовы к обработке этой ситуации. Часто
проблемы вообще не возникает. Допустим, вы пользуетесь для чтения данных стандартной
библиотечной функцией fgets. При этом она сама будет разбивать поток байтов
на строки (листинг 3.3). Иногда границы сообщений бывают важны, тогда приходится
реализовывать их сохранение на прикладном уровне.
Самый простой случай - это сообщения фиксированной
длины. Тогда вам нужно прочесть заранее известное число байтов из потока. В
соответствии с вышесказанным, для этого недостаточно выполнить простое однократное
чтение:
recv( s, msg, sizeof( msg ), 0 );
поскольку при этом можно получить меньше, чем sizеоf
( msg ) байт (рис. 2.14г). Стандартный способ решения этой проблемы показан
в листинге 2.12
Листинг 2.12. Функция readn
readn.с
1 int readn( SOCKET fd, char *bp, size_t len)
2 {
3 int cnt;
4 int rc;
5 cnt = len;
6 while ( cnt > 0 )
7 {
8 rc = recv( fd, bp, cnt, 0 );
9 if ( rc < 0 ) /* Ошибка чтения? */
10 {
11 if ( errno == EINTR ) /* Вызов прерван?
*/
12 continue; /* Повторить чтение. */
13 return -1; /* Вернуть код ошибки. */
14 }
15 if ( rc == 0 ) /* Конец файла? */
16 return len - cnt; /* Вернуть неполный счетчик.
*/
17 bр += гс;
18 cnt -= rc;
19 }
20 return len;
21 }
Функция readn используется точно так же, как read,
только она не возвращает управления, пока не будет прочитано len байт или не
получен конец файла или не возникнет ошибка. Ее прототип выглядит следующим
образом:
#include «etcp.h»
int readn ( SOCKET s,
char *buf, size t len );
Возвращаемое значение:
число прочитанных байтов или -1 в случае ошибки.
Неудивительно, что readn использует ту же технику
для чтения заданного числа байтов из последовального порта или иного потокового
устройства, когда количество данных, доступных в данный момент времени, неизвестно.
Обычно readn (с заменой типа SOCKET на int и recv на read) применяется во всех
этих ситуациях.
Оператор if
if ( errno == EINTR )
continue;
в строках 11 и 12 возобновляет выполнение вызова
recv, если он прерван сигналом. Некоторые системы возобновляют прерванные системные
вызовы автоматически, в таком случае эти две строки не нужны. С другой стороны,
они не мешают, так что для обеспечения максимальной переносимости лучше их оставить.
Если приложение должно работать с сообщениями переменной
длины то в вашем распоряжении есть два метода. Во-первых, можно разделять записи
специальными маркерами. Именно так надо поступить, используя стандартную функцию
fgets для разбиения потока на строки. В этом случае естественным разделителем
служит символ новой строки. Если маркер конца записи встретится в теле сообщения,
то приложение-отправитель должно предварительно найти в сообщении все такие
маркеры и экранировать их либо закодировать как-то еще чтобы принимающее приложение
не приняло их по ошибке за конец записи. Например если в качестве признака конца
записи используется символ-разделитель RS то отправитель сначала должен найти
все вхождения этого символа в тело сообщения и экранировать их, например, добавив
перед каждым символ \ Это означает, что данные необходимо сдвинуть вправо, чтобы
освободить место для символа экранирования. Его, разумеется, тоже необходимо
экранировать. Так, если для экранирования используется символ \, то любое его
вхождение в тело сообщения следует заменить на \\.
Рис.2.15. Формат записи переменной длины
Принимающей стороне нужно просмотреть все сообщение,
удалить символы экранирования и найти разделители записей. Поскольку при использовании
маркеров конца записи все сообщение приходится просматривать дважды, этот метод
лучше применять только при наличии «естественного» разделителя, например символа
новой строки, разделяющего строки текста.
Другой метод работы с сообщениями переменной длины
предусматривает снабжение каждого сообщения заголовком, содержащим (как минимум)
длину следующего за ним тела. Этот метод показан на рис. 2.15.
Принимающее приложение читает сообщение в два приема:
сначала заголовок фиксированной длины, и из него извлекается переменная длина
тела сообщения, a затем - само тело. В листинге 2.13 приведен пример для
простого случая, когда в заголовке хранится только длина записи.
Листинг 2.13. Функция для чтения записи переменной
длины
readvrec.с
1 int readvrec( SOCKET fd, char *bp, size_t
len )
2 {
3 u_int32_t reclen;
4 int rc;
5 /* Прочитать длину записи. */
6 rc = readn( fd, ( char * )&reclen, sizeof(
u_int32_t ) );
7 if ( rc != sizeof( u_int32_t ) )
8 return rc < 0 ? -1 : 0;
9 reclen = ntohl( reclen );
10 if ( reclen > len )
11 {
12 /*
13 * He хватает места в буфере для•размещения
данных
14 * отбросить их и вернуть код ошибки.
15 */
16 while ( reclen > 0 )
17 {
18 rc = readn( fd, bp, len );
19 if ( rc != len )
20 return rc < 0 ? -1 : 0;
21 reclen -= len;
22 if ( reclen < len }
23 len = reclen;
24 }
25 set_errno( EMSGSIZE };
26 return -1;
27 }
28 /* Прочитать саму запись */
29 rc = readn( fd, bp, reclen );
30 if ( rc != reclen )
31 return rc < 0 ? -1 : 0;
32 return rc;
33 }
Чтение длины записи
6-8 Длина записи считывается в переменную reclen.
Функция readvrec возвращает 0 (конец файла), если число байтов, прочитанных
readn, не точно совпадает с размером целого, или -1 в случае ошибки. 1
9 Размер записи преобразуется из сетевого порядка
в машинный. Подробнее об этом рассказывается в совете 28.
Проверка того, поместится ли запись в буфер
10-27 Проверяется, достаточна ли длина буфера, предоставленного
вызывающей программой, для размещения в нем всей записи. Если места не хватит,
то данные считываются в буфер частями по 1en байт, то есть, по сути, отбрасываются.
Изъяв из потока отбрасываемые данные, функции присваивает переменной errno значение
EMSGSIZE и возвращает -1.
Считывание записи
29-32 Наконец считывается сама запись, readvrec
возвращает-1, 0 или reclen в зависимости от того, вернула ли readn код ошибки,
неполный счетчик или нормальное значение.
Поскольку readvrec - функция полезная и ей найдется
применение, необходимо записать ее прототип:
#include "etcp.h"
int readvrec( SOCKET
s, char *buf, size_t len );
Возвращаемое значение:
число прочитанных байтов или -1.
В листинге 2.14 дан пример простого сервера, который
читает из ТСР-соединения записи переменной длины с помощью readvrec и записывает
их на стандартный вывод.
Листинг 2.14. vrs - сервер, демонстрирующие применение
функции readvrec
vrs.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 SOCKET s;
6 SOCKET s1;
7 int peerlen = sizeof( peer );
8 int n;
9 char buf[ 10 ] ;
10 INITO;
11 if ( argc == 2 )
12 s = tcp_server( NULL, argv[ 1 ] );
13 else
14 s = tcp_server( argv[ 1 ], argv[ 2 ] );
15 s1 = accept( s, ( struct sockaddr * )&peer,
&peerlen );
16 if ( !isvalidsock( s1 ) )
17 error( 1, errno, "ошибка вызова accept"
);
18 for ( ; ; )
19 {
20 n = readvrec( si, buf, sizeof ( buf ) );
21 if ( n < 0 )
22 error( 0, errno, "readvrec вернула код
ошибки" );
24 error( 1, 0, "клиент отключился\п"
);
25 else
26 write( 1, buf, n );
27 }
28 EXIT( 0 ); /* Сюда не попадаем. */
29 }
10-17 Инициализируем сервер и принимаем только одно
соединение.
20-24 Вызываем readvrec для чтения очередной записи
переменной длины. Если произошла ошибка, то печатается диагностическое сообщение
и читается следующая запись. Если readvrec возвращает EOF, то печатается сообщение
и работа завершается.
26 Выводим записи на stdout.
В листинге 2.15 приведен соответствующий клиент,
который читает сообщения из стандартного ввода, добавляет заголовок с длиной
сообщения и посылает все это серверу.
Листинг 2.15. vrc - клиент, посылающий записи переменной
длины
vrc.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 int n;
6 struct
7 {
8 u_int32_t reclen;
9 char buf [ 128 ];
10 } packet;
11 INIT();
12 s = tcp_client( argvf 1 ], argv[ 2 ] );
13 while ( fgets( packet.buf, sizeof( packet.buf
), stdin )
14 != NULL )
15 {
16 n = strlen( packet.buf );
1'7 packet .reclen = htonl ( n ) ;
18 if ( send( s, ( char * }&packet,
19 n + sizeof( packet.reclen ), 0 ) < 0
)
20 error ( 1, errno, "ошибка вызова send"
);
21 }
22 EXIT( 0 );
23 }
Определение структуры packet
6-10 Определяем структуру packet, в которую будем
помещать сообщение и его длину перед вызовом send. Тип данных u_int32_t - это
беззнаковое 32-разрядное целое. Поскольку в Windows такого типа нет, в версии
заголовочного файла skel.h для Windows приведено соответствующее определение
типа.
Примечание: В этом примере есть одна потенциальная
проблема, о которой следует знать. Предположим, что компилятор упаковывав данные
в структуру, не добавляя никаких символов заполнения. Поскольку второй элемент
— это массив байтов, в большинстве систем это предположение выполняется, но
всегда нужно помнить о возможной недостоверности допущений о способе упаковки
данных в структуру компилятором. Об этом будет рассказано в совете 24 при обсуждении
способов для отправки нескольких элементов информации одновременно.
Connect, read и send
6-10 Клиент соединяется с сервером, вызывая функцию
tcp_client.
13-21 Вызывается f get s для чтения строки из стандартного
ввода. Эта строка помещается в пакет сообщения. С помощью функции strlen определяется
длина строки. Полученное значение преобразуется в сетевой порядок байтов и помещается
в поле reclen пакета. В конце вызывается send для отправки пакета серверу.
Другой способ отправки сообщений, состоящих из
нескольких частей, рассматривается в совете 24.
Протестируем эти программы, запустив сервер на
машине sparc, а клиент - на машине bsd. Поскольку результаты показаны рядом,
видно, что поступает на вход клиенту и что печатает сервер. Чтобы сообщение
строки 4 уместилось на странице, оно разбито на две строчки.
|
bsd: $ vrc spare 8050
123
123456789
1234567890
12
^C
|
spare: $ vrs 8050
123
123456789
vrs: readvrec вернула код ошибки:
Message too long (97)
12
vrs: клиент отключился
|
Поскольку длина буфера сервера равна 10 байт, функция
readvrec возвращает код ошибки, когда отправляется 11байт 1,..., 0,<LF>.
Типичная ошибка, допускаемая начинающими сетевыми
программистами, - в непонимании того, что TCP доставляет поток байтов,
в котором нет понятия «границы записей». В TCP нет видимой пользователю концепции
«пакета». Он просто передает поток байтов, и нельзя точно предсказать, сколько
байтов будет возвращено при очередном чтении. В этом разделе рассмотрено несколько
способов работы в таких условиях.
TCP - это сложный протокол, обеспечивающий базовую
службу доставки IP - датаграмм надежностью и управлением потоком. В то
же время UDP добавляет лишь контрольную сумму. Поэтому может показаться, что
UDP должен быть на порядок быстрее TCP. Исходя из этого предположения, многие
программисты полагают, что с помощью UDP можно достичь максимальной производительности.
Да, действительно, есть ситуации, когда UDP существенно быстрее TCP. Но иногда
использование TCP оказывается эффективнее, чем применение UDP.
В сетевом программировании производительность любого
протокола зависит от сети, приложения, нагрузки и других факторов, из которых
не последнюю роль играет качество реализации. Единственный надежный способ узнать,
какой протокол и алгоритм работают оптимально, - это протестировать их
в предполагаешь условиях работы приложения. На практике это, конечно, не всегда
осуществимо, но часто удается получить представление о производительности, воспользовавшись
каркасами для построения простых программ, моделирующих ожидаемый сетевой трафик.
Перед созданием тестовых примеров необходимо разобраться,
когда и почему производительность UDP больше, чем TCP. Прежде всего, поскольку
TCP сложнее, он выполняет больше вычислений, чем UDP.
Примечание: В работе [Stevens, 1996] сообщается,
что реализация TCP в системе 4.4 BSD содержит примерно 4500 строк кода на языке
С в сравнении с 800 строками для UDP. Естественно, обычно выполняется намного
меньше строк, но эти числа отражают сравнительную сложность кода.
Но в типичной ситуации большая часть времени процессора
в обоих протоколах тратится на копирование данных и вычисление контрольных сумм
(совет 26), поэтому здесь нет большой разницы. В своей работе [Partridge 1993]
Джекобсон описывает экспериментальную версию TCP, в которой для выполнения всего
кода обычно требуется всего 30 машинных инструкций RISC (исключая вычисление
контрольных сумм и копирование данных в буфер пользовательской программы, которые
производятся одновременно).
Нужно отметить, что для обеспечения надежности
TCP должен посылать подтверждения (АСК-сегменты) на каждый принятый пакет. Это
несколько увеличивает объем обработки на обоих концах. Во-первых, принимающая
сторона может включить АСК в состав данных, которые она посылает отправителю.
В действительности во многих реализациях TCP отправка АСК задерживается на несколько
миллисекунд: предполагается, что приложение-получатель вскоре сгенерирует ответ
на пришедший сегмент. Во-вторых, TCP не обязан подтверждать каждый сегмент.
В большинстве реализаций при нормальных условиях АСК посылает только на каждый
второй сегмент.
Примечание: RFC 1122 [Braden 1989] рекомендует
откладывать посылку ACK до 0,5 с при подтверждении каждого второго сегмента.
Еще одно принципиальное отличие между TCP и UDP
в том, что TCP требует логического соединения (совет 1) и, значит, необходимо
заботиться об его установлении и разрыве. Для установления соединения обычно
требуется обмен тремя сегментами. Для разрыва соединения нужно четыре сегмента,
которые, кроме последнего, часто можно скомбинировать с сегментами, содержащими
данные.
Предположим, что время, необходимое для разрыва
соединения в большинстве случаев не расходуется зря, поскольку одновременно
передаются данные. Следует выяснить, что же происходит во время установления
соединения. Как показано на рис. 2.16, клиент начинает процедуру установления
соединения, посылая серверу сегмент SYN (синхронизация). В этом сегменте указывается
порядковый номер, который клиент присвоит первому посланному байту, а также
другие параметры соединения. В частности, максимальный размер сегмента (MSS),
который клиент готов принять, и начальный размер окна приема, Сервер в ответ
посылает свой сегмент SYN, который также содержит подтверждение АСК на сегмент
SYN клиента. И, наконец, клиент отсылает АСК на сегмент SYN сервера. На этом
процедура установления соединения завершается. Теперь клиент может послать свой
первый сегмент данных.
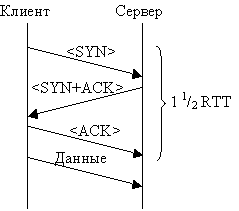
Рис. 2.16. Установление соединения
На рис. 2.16 RTT (round-trip time) - это период
кругового обращения, то есть время, необходимое пакету для прохождения с одного
хоста на другой и обратно. Для установления соединения нужно полтора таких периода.
При длительном соединении между клиентом и сервером
(например, клиент и сервер обмениваются большим объемом данных) указанный период
«размазывается» между всеми передачами данных, так что существенного влияния
на производительность это не оказывает. Однако если речь идет о простой транзакции,
в течение которой клиент посылает запрос, получает ответ и разрывает соединение,
то время инициализации составляет заметную часть от времени всей транзакции.
Таким образом, следует ожидать, что UDP намного превосходит TCP по производительности
именно тогда, когда приложение организует короткие сеансы связи. И, наоборот,
TСР работает быстрее, когда соединение поддерживается в течении длительного
времени при передаче больших объемов данных.
Чтобы протестировать сравнительную производительность
TCP и UDP, а заодно продемонстрировать, как пишутся небольшие тестовые программки,
создадим несколько простых серверов и клиентов. Здесь имеется в виду не полнофункциональная
контрольная задача, а лишь определение производительности двух протоколов при
передаче большого объема данных. Примером такого рода приложения служит протокол
FTP.
В случае UDP клиент посылает нефиксированное количество
датаграмм, которые сервер читает, подсчитывает и отбрасывает. Исходный текст
клиента приведен в листинге 2.16.
Листинг 2.16. UDP-клиент, посылающий произвольное
число датаграмм
udpsource.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 SOCKET s;
6 int rc;
7 int datagrams;
8 int dgramsz = 1440;
9 char buf[ 1440 ];
10 INIT();
11 datagrams = atoi( argv[ 2 ] );
12 if ( argc > 3 )
13 dgramsz = atoi( argv [ 3 ] );
14 s = udp_client( argv[ 1 ], "9000",
&peer );
15 while ( datagrams-- > 0 )
16 {
17 rc = sendto( s, buf, dgramsz, 0,
18 ( struct sockaddr * )&peer, sizeof(
peer ) );
19 if ( rc <= 0 )
20 error( 0, errno, "ошибка вызова sendto"
);
21 }
22 sendto( s, "", 0, 0,
23 ( struct sockaddr * )&peer, sizeof(
peer ) );
24 EXIT( 0 );
25 }
10-14 Читаем из командной строки количество посылаемых
датаграмм и их размер (второй параметр необязателен). Подготавливаем в переменной
peer UDP-сокет с адресом сервера. Вопреки совету 29 номер порта 9000 жестко
«зашит» в код.
15-21 Посылаем указанное количество датаграмм серверу.
22-23 Посылаем серверу последнюю датаграмму, содержащую
нулевой байт. Для сервера она выполняет роль конца файла.
Текст сервера в листинге 2.17 еще проще.
Листинг 2.17. Приемник датаграмм
udpsink.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 int rc;
6 int datagrams = 0;
7 int rcvbufsz = 5000 * 1440;
8 char buf[ 1440 ];
9 INIT();
10 s = udp_server( NULL, "9000" );
11 setsockopt ( s, SOL_SOCKET, SO_RCVBUF,
12 ( char * )&rcvbufsz, sizeof( int ) )
;
13 for ( ;; )
14 {
15 rc = recv( s, buf, sizeof( buf ), 0 );
16 if ( rc <= 0 )
17 break;
18 datagrams++;
19 }
20 error( 0, 0, "получено датаграмм: %d
\n", datagrams );
21 EXIT( 0 ) ;
22 }
10 Подготавливаем сервер к приему датаграмм из порта
9000 с любого интерфейса.
11-12 Выделяем память для буфера на 5000 датаграмм
длиной до 1440 байт.
Примечание: Здесь устанавливается размер
буфера 7200000 байт, но нет гарантии, что операционная система выделит столько
памяти. Хост, работающий под управлением системы BSD, выделил буфер размером
41600 байт. Этим объясняется потеря датаграмм, которая будет рассмотрена далее.
13-19 Читаем и подсчитываем датаграммы, пока не
придет пустая датаграмма или не произойдет ошибка.
20 Выводим число полученных датаграмм на stdrerr.
В совете 32 объясняется, что повысить производительность
TCP можно за счет выбора правильного размера буферов передачи и приема. Нужно
установить размер буфера приема для сокета сервера и размер буфера передачи
для сокета клиента.
Поскольку в функциях tcp_server и tcp_client используются
размеры буферов по умолчанию, следует воспользоваться не библиотекой, а каркасами
из совета 4. Сообщать TCP размеры буферов нужно во время инициализации соединения,
то есть до вызова listen в сервере и до вызова connect в клиенте. Поэтому невозможно
воспользоваться функциями tcp_server и tcp_client, так как к моменту возврата
из них обращение к listen или connect уже произошло. Начнем с клиента, его код
приведен в листинге 2.18.
Листинг 2.18. Функция main TCP-клиента, играющего
роль источника
tcpsource.с
1 int main ( int argc, char **argv )
2 {
3 struct sockaddr_in peer;
4 char *buf;
5 SOCKET s;
6 int с;
7 int blks = 5000;
8 int sndbufsz = 32 * 1024;
9 int sndsz = 1440; /* MSS для Ethernet по
умолчанию. */
10 INIT();
11 opterr = 0;
12 while ( ( с = getopt( argc, argv, "s:b:c:"
) ) != EOF )
13 {
14 switch ( с )
15 {
16 case "s" :
17 sndsz = atoi( optarg ) ;
18 break;
19 case "b" :
20 sndbufsz = atoi( optarg ) ;
21 break;
22 case "c" :
23 blks = atoi( optarg );
2 4 break;
25 case "?" :
26 error( 1, 0, "некорректный параметр:
%c\n", с );
27 }
28 }
28 if ( argc <= optind )
30 error( 1, 0, "не задано имя хоста\n"
};
31 if ( ( buf = malloc( sndsz ) ) == NULL )
32 error( 1, 0, "ошибка вызова malloc\n"
);
33 set_address( argv[ optind ], "9000",
&peer, "tcp" );
34 s = socket( AF_INET, SOCK_STREAM, 0 );
35 if ( !isvalidsock( s ) )
36 error( 1, errno, "ошибка вызова socket"
);
37 if ( setsockopt( s, SOL_SOCKET, SO_SNDBUF,
38 ( char * )&sndbufsz, sizeof( sndbufsz
) ) )
39 error( 1, errno, "ошибка вызова setsockopt
с опцией SO_SNDBUF" );
40 if ( connect( s, ( struct sockaddr * )&peer,
41 sizeof( peer ) ) )
42 error( 1, errno, "ошибка вызова connect"
);
43 while( blks-- > 0 )
44 send( s, buf, sndsz, 0 );
45 EXIT( 0 );
46 }
12-30 В цикле вызываем getopt для получения и обработки
параметров из командной строки. Поскольку эта программа будет использоваться
и далее, то делаем ее конфигурируемой в большей степени, чем необходимо для
данной задачи. С помощью параметров в командной строке можно задать размер буфера
передачи сокета, количество данных, передаваемых при каждой операции записи
в сокет, и число операций записи.
31-42 Это стандартный код инициализации TCP-клиента,
только добавлено еще обращение к setsockopt для установки размера буфера передачи,
а также с помощью функции malloc выделен буфер запрошенного размера для размещения
данных, посылаемых при каждой операции записи. Обратите внимание, что инициализировать
память, на которую указывает buf, не надо, так как в данном случае безразлично,
какие данные посылать.
43-44 Вызываем функцию send нужное число раз.
Функция main сервера, показанная в листинге 2.19,
взята из стандартного каркаса с добавлением обращения к функции getopt для получения
из командной строки параметра, задающего размер буфера приема сокета, а также
вызов функции getsockopt для установки размера буфера.
Листинг 2.19. Функция main TCP-сервера, играющего
роль приемника
tcpsink.с
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in local;
4 struct sockaddr_in peer;
5 int peerlen;
6 SOCKET s1;
7 SOCKET s;
8 int c;
9 int rcvbufsz = 32 * 1024;
10 const int on = 1;
11 INIT();
12 opterr = 0;
13 while ( ( с = getopt( argc, argv, "b:"
) ) != EOF )
14 {
15 switch ( с )
16 {
17 case "b" :
18 rcvbufsz = atoi( optarg };
19 break;
20 case ".?" :
21 error( 1, 0, "недопустимая опция:
%c\n", с );
22 }
23 }
24 set_address( NULL, "9000", &local,
"tcp" );
25 s = socket( AF_INET, SOCK_STREAM, 0 );
26 if ( !isvalidsock( s ) )
27 error( 1, errno, "ошибка вызова socket"
) ;
28 if ( setsockopt( s, SOL_SOCKET, SO_REUSEADDR,
29 ( char * )&on, sizeof( on ) ) )
30 error( 1, errno, "ошибка вызова setsockopt
SO_REUSEADDR")
31 if ( setsockopt( s, SOL_SOCKET, SO_RCVBUF,
32 ( char * )&rcvbufsz, sizeof( rcvbufsz
) ) )
33 error( 1, errno, "ошибка вызова setsockopt
SO_RCVBUF")
34 if ( bind( s, ( struct sockaddr * ) &local,
35 sizeof( local ) ) )
36. error ( 1, errno, "ошибка вызова bind"
) ;
37 listen( s, 5 );
38 do
39 {
40 peerlen = sizeof( peer );
41 s1 = accept( s, ( struct sockaddr *)&peer,
&peerlen );
42 if ( !isvalidsock( s1 ) )
43 error( 1, errno, "ошибка вызова accept"
);
44 server( s1, rcvbufsz );
45 CLOSE( s1 );
46 } while ( 0 );
47 EXIT( 0 );
48 }
Функция server читает и подсчитывает поступающие
байты, пока не обнаружит конец файла (совет 16) или не возникнет ошибка. Она
выделяет память под буфер того же размера, что и буфер приема сокета, чтобы
прочитать максимальное количество данных за одно обращение к recv. Текст функции
server приведен в листинге 2.20.
Листинг 2.20. Функция server
tcpsink.c
1 static void server( SOCKET s, int rcvbufsz
)
2 {
3 char *buf;
4 int rc;
5 int bytes =0;
6 if ( ( buf = malloc( rcvbufsz ) ) == NULL
)
7 error( 1, 0, "ошибка вызова malloc\n"};
8 for ( ; ; )
9 {
10 rc = recv( s, buf, rcvbufsz, 0 );
11 if ( rc <= 0 )
12 break;
13 bytes += rc;
14 }
15 error( 0, 0, "получено байт: %d\n",
bytes );
16 }
Для измерения сравнительной производительности
протоколов TCP и UDP при передаче больших объемов данных запустим клиента на
машине bsd, а сервер - на localhost. Физически хосты bsd localhost -
это, конечно, одно и то же, но, как вы увидите, результаты работы программы
в значительной степени зависят от того, какое из этих имен использовано. Сначала
запустим клиента и сервер на одной машине, чтобы оценить производительность
TCP и UDP, устранив влияние сети. В обоих случаях сегменты TCP или датаграммы
UDP инкапсулируются в IP-датаграммах и посылаются возвратному интерфейсу 1оО,
который немедленно переправляет их процедуре обработки IP-входа, как показано
на рис. 2.17.
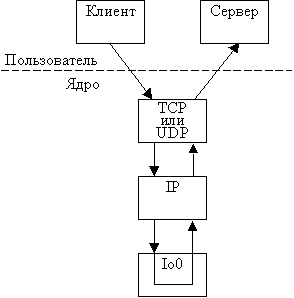
Рис. 2.17. Возвратный интерфейс
Каждый тест был выполнен 50 раз с заданным размером
датаграмм (в случае UDP) или числом передаваемых за один раз байтов (в случае
TCP), равным 1440. Эта величина выбрана потому, что она близка к максимальному
размеру сегмента, который TCP может передать по локальной сети на базе Ethernet.
Примечание: Это число получается так. В
одном фрейме Ethernet может быть передано не более 1500 байт. Каждый заголовок
IP и TCP занимает 20 байт, так что остается 1460. Еще 20 байт резервировано
для опций TCP. В системе BSD TCP посылает 12 байт с опциями, поэтому в этом
случае максимальный размер сегмента составляет 1448 байт.
В табл. 2.2 приведены результаты, усредненные по
50 прогонам. Для каждого протокола указано три времени: по часам - время с момента
запуска до завершения работы клиента; пользовательское - проведенное программой
в режиме пользователя; системное - проведенное программой в режиме ядра. В колонке
«Мб/с» указан результат деления общего числа посланных байтов на время по часам.
В колонке «Потеряно» для UDP приведено среднее число потерянных датаграмм.
Первое, что бросается в глаза, - TCP работает намного
быстрее, когда в качестве имени сервера выбрано localhost, а не bsd. Для UDP
это не так – заметной разницы в производительности нет. Чтобы понять, почему
производительность TCР так возрастает, когда клиент отправляет данные хосту
localhost, запустим программу netstat (совет 38) с опцией -i. Здесь надо
обратить внимание на две строки (ненужная информация опущена):
Name Mtu Network Address
Ed0 1500 172.30 bsd
lo0 16384 127 localhost
Таблица 2.2. Сравнение производительности TCP и
UDP при количестве посылаемых байтов, равном 1440
|
TCP
|
|
Сервер
|
Время по часам
|
Пользовательское время
|
Системное время
|
Мб/с
|
|
bsd
|
2,88
|
0,0292
|
1,4198
|
2,5
|
|
localhost
|
0,9558
|
0,0096
|
0,6316
|
7,53
|
|
sparс
|
7,1882
|
0,016
|
1,6226
|
1,002
|
|
UDP
|
|
Сервер
|
Время по часам
|
Пользовательское время
|
Системное время
|
Мб/с
|
Потеряно
|
|
bsd
|
1,9618
|
0,0316
|
1,1934
|
3,67
|
336
|
|
localhost
|
1,9748
|
0,031
|
1,1906
|
3,646
|
272
|
|
sparс
|
5,8284
|
0,0564
|
0,844
|
1,235
|
440
|
|
|
|
|
|
|
|
Как видите, максимальный размер передаваемого блока
(MTU - maximum transmission unit) для bsd равен 1500, а для localhost - 16384.
Примечание: Такое поведение свойственно
реализациям TCP в системах, производных от BSD. Например, в системе Solaris
это уже не так. При первом построении маршрута к хосту bsd в коде маршрутизации
предполагается, что хост находится в локальной сети, поскольку сетевая часть
IP-адреса совпадает с адресом интерфейса Ethernet. И лишь при первом использовании
маршрута TCP обнаруживает, что он ведет на тот же хост и переключается на возвратный
интерфейс. Однако к этому моменту все метрики маршрута, в том числе и MTU, уже
установлены в соответствии с интерфейсом к локальной сети.
Это означает, что при посылке данных на localhost
TCP может отправлять сегменты длиной до 16384 байт (или 16384 - 20 - 20 - 12
- 16332 байт). Однако при посылке данных на хост bsd число байт в сегменте не
превышает 1448 (как было сказано выше). Но чем больше размер сегментов, тем
меньшее их количество приходится посылать, а это значит, что требуется меньший
объем обработки, и соответственно снижаются накладные расходы на добавление
к каждому сегменту заголовков IP и TCP. А результат налицо - обмен данными с
хостом localhost происходит в три раза быстрее, чем с хостом bsd.
Можно заметить, что на хосте localhost TCP работает
примерно в два раза быстрее, чем UDP. Это также связано с тем, что TCP способен
объединять несколько блоков по 1440 байт в один сегмент, тогда как UDP посылает
отдельно каждую датаграмму длиной 1440 байт.
Следует отметить, что в локальной сети UDP примерно
на 20% быстрее TCP, потеря датаграмм значительнее. Потери имеют место даже тогда,
когда и сервер и клиент работают на одной машине; связаны они с исчерпанием
буферов. Хотя передача 5000 датаграмм на максимально возможной скорости - это
скорее отклонение, чем нормальный режим работы, но все же следует иметь в виду
возможность такого результата. Это означает, что UDP не дает никакой гарантии
относительно доставки данной датаграммы, даже если оба приложения работают на
одной машине.
По результатам сравнения сеансов с хостами localhost
и bsd можно предположить, что на производительность влияет также длина посылаемых
датаграмм. Например, если прогнать те же тесты с блоком длиной 300 байт, то,
как следует из табл. 2.3, TCP работает быстрее UDP и на одной машине, и в локальной
сети.
Из этих примеров следует важный вывод: нельзя строить
априорные предположения о сравнительной производительности TCP и UDP. При изменении
условий, даже очень незначительном, показатели производительности могут очень
резко измениться. Для обоснованного выбора протокола лучше сравнить их производительность
на контрольной задаче (совет 8). Когда это неосуществимо на практике, все же
можно написать небольшие тестовые программы для получения хотя бы приблизительного
представления о том, чего можно ожидать,
Таблица. 2.3. Сравнение производительности TCP и
UDP при количестве посылаемых байтов, равном 300
|
TCP
|
|
Сервер
|
Время по часам
|
Пользовательское время
|
Системное время
|
Мб/с
|
|
bsd
|
1,059
|
0,0124
|
0,445
|
1,416
|
|
sparс
|
1,5552
|
0,0084
|
1,2442
|
0,965
|
|
UDP
|
|
Сервер
|
Время по часам
|
Пользовательское время
|
Системное время
|
Мб/с
|
Потеряно
|
|
bsd
|
1,6324
|
0,0324
|
0,9998
|
0,919
|
212
|
|
sparс
|
1,9118
|
0,0278
|
1,4352
|
0,785
|
306
|
|
|
|
|
|
|
|
Если говорить о практической стороне вопроса, то
современные реализации статочно эффективны. Реально продемонстрировано, что
TCP может работать со скоростью аппаратуры на стомегабитных сетях FDDI. В недавних
экспериментах были достигнуты почти гигабитные скорости при работе на персональном
компьютере [Gallatin et al. 1999].
Примечение: 29 июля 1999 года исследователи
из Университета Дъюка на рабочей станции ХР1000 производства DEC/Compaq на базе
процессора Alpha в сети Myrinet получили скорости передачи порядка гигабита
в секунду. В экспериментах использовался стандартный стек TCP/IP из системы
FreeBSD 4.0, модифицированный по технологии сокетов без копирования (zero-copy
sockets). В том же эксперименте была получена скорость более 800 Мбит/с на персональном
компьютере PII 450 МГц и более ранней версии сети Myrinet. Подробности можно
прочитать на Web-странице http://www.cs.duke.edu/ari/trapeze.
UDP не всегда быстрее, чем TCP. На сравнительную
производительность обоих протоколов влияют разные факторы, и для каждого конкретного
случая желательно проверять быстродействие на контрольных задачах.
Как сказано в совете 7, UDP может быть намного
производительнее TCP в простых приложениях, где есть один запрос и один ответ.
Это наводит на мысль использовать в транзакционных задачах такого рода именно
UDP. Однако протокол UDP не слишком надежен, поэтому эта обязанность лежит на
приложении.
Как минимум, это означает, что приложение должно
позаботиться о тех датаграммах, которые теряются или искажаются при передаче.
Многие начинающие сетевые программисты полагают, что при работе в локальной
сети такая возможность маловероятна, и потому полностью игнорируют ее. Но в
совете 7 было показано, как легко можно потерять датаграммы даже тогда, когда
клиент и север находятся на одной машине. Поэтому не следует забывать о защите
от потери датаграмм.
Если же приложение будет работать в глобальной
сети, то также возможен приход датаграмм не по порядку. Это происходит, когда
между отправителем и получателем было несколько маршрутов.
В свете вышесказанного можно утверждать, что любое
достаточно устойчивое UDP-приложение должно обеспечивать:
- повторную посылку запроса, если ответ не
поступил в течение разумного промежутка времени;
- проверку соответствия между ответами и
запросами.
Первое требование можно удовлетворить, если при
посылке каждого запроса взводить таймер, называемый таймером ретрансмиссии (retransmission
timer), и RTO-таймером. Если таймер срабатывает до получения ответа, то запрос
посылается повторно. В совете 20 будет рассмотрено несколько способов эффективного
решения этой задачи. Второе требование легко реализуется, если в каждый запрос
включить его порядковый номер и обеспечить возврат этого номера сервером вместе
с ответом.
Если приложение будет работать в Internet, то фиксированное
время срабатывания RTO-таймера не годится, поскольку период кругового обращения
(RTT) между двумя хостами может существенно меняться даже за короткий промежуток.
Поэтому хотелось бы корректировать значение RTO-таймера в зависимости от условий
в сети. Кроме того, если RTO-таймер срабатывает, следует увеличить eгo продолжительность
перед повторной передачей, поскольку она, скорее всего была слишком мала. Это
требует некоторой экспоненциальной корректировки. (exponential backoff) RTO
при повторных передачах.
Далее, если приложение реализует что-либо большее,
чем простой протокол запрос - ответ, когда клиент посылает запрос и ждет
ответа, не посылая дополнительных датаграмм, или ответ сервера состоит из нескольких
датаграмм, то необходим какой-то механизм управления потоком. Например, если
сервер - это приложение, работающее с базой данных о кадрах, а клиент просит
послать имена и адреса всех сотрудников конструкторского отдела, то ответ будет
состоять из нескольких записей, каждая из которых посылается в виде отдельной
датаграммы. Если управление потоком отсутствует, то при этом может быть исчерпан
пул буферов клиента. Обычный способ решения этой проблемы - скользящее окно
типа того, что используется в TCP (только подсчитываются не байты, а датаграммы).
И, наконец, если приложение передает подряд несколько
датаграмм, необходимо позаботиться об управлении перегрузкой. В противном случае
такое приложение может легко стать причиной деградации пропускной способности,
которая затронет всех пользователей сети.
Все перечисленные действия, которые должно предпринять
основанное на протоколе UDP приложение для обеспечения надежности, - это, по
сути, вариант TCP. Иногда на это приходится идти. Ведь существуют транзакционные
приложения, в которых накладные расходы, связанные с установлением и разрывом
TCP - соединения, близки или даже превышают затраты на передачу данных.
Примечание: Обычный пример - это система
доменных имен (Domain Name System - DNS), которая используется для отображения
доменного имени хоста на его IP-адрес. Когда вводится имя хоста www. rfс-editor.org
в Web-браузере, реализованный внутри браузера клиент DNS посылает DNS-cepвepy
UDP-датаграмму с запросом IP-адреса, ассоциированного с этим именем. Сервер
в ответ посылает датаграмму, содержащую IP-адрес 128.9.160.27. Подробнее система
DNS обсуждается в совете 29.
Тем менее необходимо тщательно изучить природу
приложения, чтобы понять стоит ли заново реализовывать TCP. Если приложению
требуется надежность TCP, то, быть может, правильное решение - это использование
TCP.
Маловероятно, что функциональность TCP, продублированная
на прикладном уровне, будет реализована столь же эффективно, как в настоящем
TCP. Отчасти это связано с тем, что реализации TCP - это плод многочисленных
экспериментов и научных исследований. С годами TCP эволюционировал по мере того,
как публиковались наблюдения за его работой в различных условиях и сетях в том
числе и Internet.
Кроме того, TCP почти всегда исполняется в контексте
ядра. Чтобы понять, почему это может повлиять на производительность, представьте
себе, что происходит при срабатывании RTO-таймера в вашем приложении. Сначала
ядру нужно «пробудить» приложение, для чего необходимо контекстное переключение
из режима ядра в режим пользователя. Затем приложение должно послать данные.
Для этого требуется еще одно контекстное переключение (на этот раз в режим ядра)
в ходе которого данные из датаграммы копируются в буферы ядра. Ядро выбирает
маршрут следования датаграммы, передает ее подходящему сетевому интерфейсу и
возвращает управление приложению - снова контекстное переключена Приложение
должно заново взвести RTO-таймер, для чего приходится вновь переключаться.
А теперь обсудим, что происходит при срабатывании
RTO-таймера внутри TCP. У ядра уже есть сохраненная копия данных, нет необходимости
повторно копировать их из пространства пользователя. Не нужны и контекстные
переключения. TCP заново посылает данные. Основная работа связана с передачей
данных из буферов ядра сетевому интерфейсу. Повторные вычисления не требуются,
так как TCP сохранил всю информацию в кэше.
Еще одна причина, по которой следует избегать дублирования
функциональности TCP на прикладном уровне, - потеря ответа сервера. Поскольку
клиент не I получил ответа, у него срабатывает таймер, и он посылает запрос
повторно. При этом сервер должен дважды обработать один и тот же запрос, что
может быть нежелательно. Представьте клиент, который «просит» сервер перевести
деньги с одного банковского счета на другой. При использовании TCP логика повторных
попыток реализована вне приложения, так что сервер вообще не определит, повторный
ли это запрос.
Примечание: Здесь не рассматривается возможность
сетевого сбоя или отказа одного из хостов. Подробнее это рассматривается в совете
9
Транзакционные приложения и некоторые проблемы,
связанные с применением в них протоколов TCP и UDP, обсуждаются в RFC 955 [Braden
1985]. В этой работе автор отстаивает необходимость промежуточного протокола
между ненадежным, но не требующим соединений UDP, и надежным, но зависящим от
соединений TCP. Соображения, изложенные в этом RFC, легли в основу предложенной
Брейденом протокола TCP Extensions for Transactions (T/TCP), который рассмотрен
ниже.
Один из способов обеспечить надежность TCP без
установления соединения воспользоваться протоколом Т/ТСР. Это расширение TCP,
позволяющее достичь для транзакций производительности, сравнимой с UDP, за счет
отказа (как правило) от процедуры трехстороннего квитирования в ходе установления
обычного ТСР - соединения и сокращения фазы TIME-WAIT (совет 22) при разрыве
соединения.
Обоснование необходимости Т/ТСР и идеи, лежащие
в основе его реализации, описаны в RFC 1379 [Braden 1992a]. RFC 1644 [Braden
1994] содержит функциональную спецификацию Т/ТСР, а также обсуждение некоторых
вопросов реализации. В работе [Stevens 1996] рассматривается протокол Т/ТСР,
приводятся сравнение его производительности с UDP, изменения в API сокетов,
необходимые для поддержки нового протокола, и его реализация в системе 4.4BSD.
К сожалению, протокол Т/ТСР не так широко распространен,
хотя и реализован в FreeBSD, и существуют дополнения к ядру Linux 2.0.32 и SunOS
4.1.3.
Ричард Стивенс ведет страницу, посвященную Т/ТСР,
на которой есть ссылки на различные посвященные этому протоколу ресурсы. Адрес
Web-страницы – http://www.kohala.com/start/ttcp.html.
Здесь рассмотрены шаги, необходимые для построения
надежного протокола поверх UDP. Хотя и существуют приложения, например, DNS,
в которых это сделано, но для корректного решения такой задачи необходимо практически
заново реализовать TCP. Поскольку маловероятно, что реализованный на базе UDP
протокол будет так же эффективен, как TCP, смысла в этом, как правило, нет.
В этом разделе также кратко обсуждается протокол
Т/ТСР - модификация TCP для оптимизации транзакционных приложений. Хотя
Т/ТСР решает многие проблемы, возникающие при использовании TCP для реализации
транзакций, он пока не получил широкого распространения.
Как уже неоднократно отмечалось, TCP - надежный
протокол. Иногда эту мысль выражают так: «TCP гарантирует доставку отправленных
данных». Хотя эта формулировка часто встречается, ее следует признать исключительно
неудачной.
Предположим, что вы отсоединили хост от сети в
середине передачи данных. В таком случае TCP не сможет доставить оставшиеся
данные. А на практике происходят сбои в сети, аварии серверов, выключение машины
пользователями без Разрыва TCP-соединения. Все это мешает TCP доставить по назначению
данные, преданные приложением.
Но еще важнее психологическое воздействие фразы
о «гарантируемой TCP ставке» на излишне доверчивых сетевых программистов. Разумеется,
никто не считает, что TCP обладает магической способностью доставлять данные
получателю, невзирая на все препятствия. Вера в гарантированную доставку проявляется
в небрежном программировании и, в частности, в легкомысленном отношении к проверке
ошибок.
Прежде чем приступать к рассмотрению ошибок, с
которыми можно столкнутся при работе с TCP, обсудим, что понимается под надежностью
TCP. Если TCP нe гарантирует доставку всех данных, то что же он гарантирует?
Первый вопрос: кому дается гарантия? На рис. 2.18 показан поток данных от приложения
А вниз к стеку TCP/IP на хосте А, через несколько промежуточных маршрутизаторов,
вверх к стеку TCP/IP на хосте В и, наконец, к приложению В. Когда ТСР -
сегмент покидает уровень TCP на хосте А, он «обертывается» в IP-датаграмму для
передачи хосту на другой стороне. По пути он может пройти через несколько маршрутизаторов,
но, как видно из рис. 2.18, маршрутизаторы не имеют уровня TCP,они лишь переправляют
IР - датаграммы.
Рис. 2.18. Сеть с промежуточными маршрутизаторами
Примечание: Некоторые маршрутизаторы в действительности
могут представлять собой компьютеры общего назначения, у которых есть полный
стек TCP/IP, но и в этом случае при выполнении функций маршрутизации не задействуются
ни уровень TCP, ни прикладной уровень.
Поскольку известно, что протокол IP ненадежен,
то первое место в тракте прохождения данных, в связи с которым имеет смысл говорить
о гарантиях, - это уровень TCP хоста В. Когда сегмент оказывается на этом уровне,
единственной, что можно сказать наверняка, - сегмент действительно прибыл. Он
может быть запорчен, оказаться дубликатом, прийти не по порядку или оказаться
неприемлемым еще по каким-то причинам. Обратите внимание, что отправляющий TCP
не может дать никаких гарантий по поводу сегментов, доставленных принимающему
TCP.
Однако принимающий TCP уже готов кое-что гарантировать
отправляющему TCP, а именно - любые данные, которые он подтвердил с помощью
сегмента АСК, а также все предшествующие данные, корректно дошли до уровня TCP.
Поэтому отправляющий TCP может отбросить их копии, которые у него хранятся.
Это не означает, что информация уже доставлена приложению или будет доставлена
в будущем. Например, принимающий хост может аварийно остановиться сразу после
посылки АСК, еще до того, как данные прочитаны приложением. Это стоит подчеркнуть
особо: единственное подтверждение приема данных, которое находите в ведении
TCP, - это вышеупомянутый сегмент АСК. Отправляющее приложение не может,
полагаясь только на TCP, утверждать, что данные были благополучно прочитаны
получателем. Как будет сказано далее, это одна из возможных ошибок при работе
с TCP, о которых разработчик должен знать.
Второе место, в связи с которым имеет смысл говорить
о гарантиях, - это само приложение В. Вы поняли, нет гарантий, что все
данные, отправленные приложением A, дойдут до приложения В. Единственное, что
TCP гарантирует приложению B, -доставленные данные пришли в правильном
порядке и не испорчены.
Примечание: Неискаженностъ данных гарантируется
лишь тем, что ошибку можно обнаружить с помощью контрольной суммы. Поскольку
эта сумма представляет собой 16-разрядное дополнение до единицы суммы двойных
байтов, то она способна обнаружить пакет ошибок в 15 бит или менее [Plummer
1978]. Предполагая равномерное распределение данных, вероятность принятия TCP
ошибочного сегмента за правильный составляет не более 1 / (2^16 - 1). Однако
в работе [Stone et al. 1998] показано, что в реальных данных, встречающихся
в сегментах TCP, частота ошибок, не обнаруживаемых с помощью контрольной суммы,
при некоторых обстоятельствах может быть намного выше.
Вы уже видели одну из потенциальных ошибок при
работе с TCP: не исключено, что подтвержденные TCP данные не дошли до приложения-получателя.
Как и большинство других таких ошибок, это довольно редкая ситуация, и, даже
если она встречается, последствия могут быть не очень печальными. Важно, чтобы
программист знал об этой неприятности и предусматривал защиту при возможном
нежелательном результате. Не думайте, что TCP обо всем позаботится сам, следует
подумать об устойчивости приложения.
Защита от упомянутой ошибки очевидна. Если приложению-отправителю
важно иметь информацию, что сообщение дошло до приложения-получателя, то получатель
должен сам подтвердить факт приема. Часто такое подтверждение присутствует неявно.
Например, если клиент запрашивает у сервера некоторые данные и сервер отвечает,
то сам ответ - это подтверждение получения запроса. Один из возможных способов
организации явных подтверждений обсуждается в совете 19.
Более сложный для клиента вопрос - что делать,
если сервер не подтверждает приема? Это в основном зависит от конкретного приложения,
поэтому готового Решения не существует. Однако стоит отметить, что повторная
посылка запроса не всегда годится; как говорилось в совете 8, вряд ли будет
правильно дважды переводить одну сумму со счета на счет. В системах управления
базами данных для решения такого рода проблем применяется протокол трехфазной
фиксации. Полный подход приемлем и для других приложений, гарантирующих, что
операция выполняется «не более одного раза». Один из примеров - службы параллельности,
фиксации и восстановления (concurrency, commitment, recovery - CCR) – это элемент
прикладного сервиса в протоколах OSI. Протокол CCR обсуждается в работе [Jain
and Agrawala 1993].
TCP - протокол сквозной передачи (end-to-end
protocol), то есть он стремится обеспечить надежный транспортный механизм между
двумя хостами одного ранга. Важно, однако, понимать, что конечные точки - это
уровни TCP на обоих хостах, а не приложения. Программы, которым нужны подтверждения
на прикладном уровне, должны самостоятельно это определить.
Рассмотрим некоторые типичные ошибки. Пока между
двумя хостами существует связь, TCP гарантирует доставку данных по порядку и
без искажений Ошибка может произойти только при разрыве связи. Из-за чего же
связь может разорваться? Есть три причины:
- постоянный или временный сбой в сети;
- отказ принимающего приложения;
- аварийный сбой самого хоста на принимающем
конце.
Каждое из этих событий по-разному отражается на
приложении-отправителе.
Сбои в сети происходят по разным причинам: от потери
связи с маршрутизатором или отрезком опорной сети до выдергивания из разъема
кабеля локальной Ethernet-сети. Сбои, происходящие вне оконечных точек, обычно
временные, поскольку протоколы маршрутизации спроектированы так, чтобы обнаруживать
поврежденные участки и обходить их.
Примечание: Под оконечной точкой понимается
локальная сеть или хост, на котором работает приложение.
Если же ошибка возникает в оконечной точке, то
неисправность будет существовать, пока ее не устранят.
Если промежуточный маршрутизатор не посылает ICMP-сообщение
о том, что хост или сеть назначения недоступны, то ни само приложение, ни стек
TCP/IP на том же хосте не смогут немедленно узнать о сбое в сети (совет 10).
В этом случае у отправителя через некоторое время возникнет тайм-аут, и он повторно
отправит неподтвержденные сегменты. Это будет продолжаться, пока отправляющий
TCP не признает доставку невозможной, после чего он обрывает соединение и сообщает
об ошибке. В системе BSD это произойдет после 12 безуспешных попыток (примерно
9 мин). При наличии у TCP ожидающего запроса на чтение операция возвращает ошибку,
и переменная errno устанавливается в ETIMEDOUT. Если ожидающего запроса на чтение
нет, то следующая операция записи завершится ошибкой. При этом либо будет послан
сигнал SIGPIPE, либо (если этот сигнал перехвачен или игнорируется) в переменную
errno записано значение EPIPE.
Если промежуточный маршрутизатор не может переправить
далее IР-датаграмму, содержащую некоторый сегмент, то он посылает хосту -
отправителю ICMP-сообшение о том, что сеть или хост назначения недоступны. В
этом случае некоторые реализации возвращают в качестве кода ошибки значение
ENETUNREACH или EHOSTUNREACH
А теперь разберемся, что происходит, когда аварийно
или как-либо иначе завершается приложение на другом конце соединения. Прежде
всего следует понимать, что с точки зрения вашего приложения аварийное завершение
другого конца отличается от ситуации, когда приложение на том конце вызывает
функцию close (или closesocket, если речь идет о Windows), а затем exit. В обоих
случаях TCP на другом конце посылает вашему TCP сегмент FIN. FIN выступает в
роли признака конца файла и означает, что у отправившего его приложения нет
больше данных для вас. Это не значит, что приложение на другом конце завершилось
или не хочет принимать данные. Подробнее это рассмотрено в совете 16. Как приложение
уведомляется о приходе FIN (и уведомляется ли вообще), зависит от его действий
в этот момент. Для проработки возможных ситуаций напишем небольшую клиентскую
программу, которая читает строку из стандартного входа, посылает ее серверу,
читает ответ сервера и записывает его на стандартный выход. Исходный текст клиента
приведен в листинге 2.21.
Листинг 2.21. TCP-клиент, который читает и выводит
строки
tcprw.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 int rc;
6 int len;
7 char buf[ 120 ] ;
8 INIT();
9 s = tcp_client( argv[ 1 ], argv[ 2 ] );
10 while ( fgets( buf, sizeof( buf ), stdin ) != NULL
)
11 {
12 len = strlen ( buf );
13 rc = send( s, buf, len, 0 );
14 if ( rc < 0 )
15 error( 1, errno, "ошибка вызова send"
);
16 rc = readline( s, buf, sizeof( buf ) );
17 if ( rc < 0 )
18 error( 1, errno, "ошибка вызова readline"
);
19 else if ( rc == 0 )
20 error( 1, 0, "сервер завершил работу\n"
);
21 else
22 fputs( buf, stdout );
23 }
24 EXIT( 0 ) ;
25 }
8-9 Инициализируем приложение как TCP-клиент и соединяемся
с указанными в командной строке сервером и портом.
10-15 Читаем строки из стандартного входа и посылаем
их серверу, пока не встретится конец файла.
16-20 После отправки данных серверу читается строка
ответа. Функция гeadline получает строку, считывая данные из сокета до символа
новой строки. Текст этой функции приведен в листинге 2.32 в совете 11. Если
readline обнаруживает ошибку или возвращает признак конца файла (совет 16),
то печатаем диагностическое сообщение и завершаем работу
22 В противном случае выводим строку на stdout.
Для тестирования клиента напишем сервер, который
читает в цикле строки поступающие от клиента, и возвращает сообщения о количестве
полученных строк. Для имитации задержки между приемом сообщения и отправкой
ответа сервер пять секунд «спит». Код сервера приведен в листинге 2.22.
Листинг 2.22. Сервер, подсчитывающий сообщения
count.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 SOCKET s1;
6 int rc;
7 int len;
8 int counter = 1;
9 char buf [ 120 ];
10 INIT();
11 s = tcp_server( NULL, argv[ 1 ] );
12 s1 = accept ( s, NULL, NULL );
13 if ( !isvalidsock( s1 ) )
14 error( 1, errno, "ошибка вызова accept"
);
15 while ( ( rc = readline( s1, buf, sizeof(
buf ) ) ) > 0)
16 {
17 sleep ( 5 ) ;
18 len=sprintf(buf, "получено сообщение
%d\n", counter++ );
19 rc = send( s1, buf, len, 0 );
20 if ( rc < 0 )
21 error( 1, errno, "ошибка вызова send"
);
22 }
23 EXIT ( 0 );
24 }
Чтобы увидеть, что происходит при крахе сервера,
сначала запустим сервер и клиент в различных окнах на машине bsd.
bsd: $ tcprw localhost 9000
hello
получено сообщение 1 Это печатается после пятисекундной
задержки
Здесь сервер был остановлен.
hello again
tcprw: ошибка вызова readline: Connection reset
by peer (54)
bsd: $
Серверу посылается одно сообщение, и через 5 с
приходит ожидаемый ответ. Останавливаете серверный процесс, моделируя аварийный
отказ. На стороне клиента ничего не происходит. Клиент блокирован в вызове fgets,
а протокол TCP не может передать клиенту информацию о том, что от другого конца
получен конец файла (FIN). Если ничего не делать, то клиент так и останется
блокированным в ожидании ввода и не узнает о завершении сеанса сервера.
Затем вводите новую строку. Клиент немедленно завершает
работу с сообщением о том' что хост сервера сбросил соединение. Вот что произошло:
функция fgets вернула управление клиенту, которому все еще неизвестно о приходе
признака конца файла от сервера. Поскольку ничто не мешает приложению посылать
данные после прихода FIN, TCP клиента попытался послать серверу вторую строку.
Когда TCP сервера получил эту строку, он послал в ответ сегмент RST (сброс),
поскольку соединения уже не существует, - сервер завершил сеанс. Когда
клиент вызывает readline, ядро возвращает ему код ошибки ECONNRESET, сообщая
тем самым о получении извещения о сбросе. На рис. 2.19 показана хронологическая
последовательность этих событий.
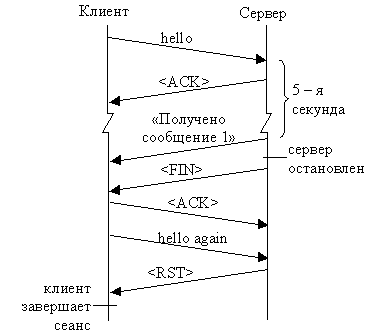
Рис. 2.19. Хронологическая последовательность
событий при крахе сервера
А теперь рассмотрим ситуацию, когда сервер «падает»,
не успев закончить обработку запроса и ответить. Снова запустите сервер и клиент
в разных окнах на машине bsd.
bsd = $ tcprw localhoBt 9000
hello
Здесь сервер был остановлен.
tcprw: сервер завершил работу
bsd: $
Посылаете строку серверу, а затем прерываете его
работу до завершения вызова sleep. Тем самым имитируется крах сервера до завершения
обработки запроса. На этот раз клиент немедленно получает сообщение об ошибке,
говорящее о завершении сервера. В этом примере клиент в момент прихода FIN блокирован
в вызове readline и TCP может уведомить readline сразу, как только будет получен
конец файла. Хронологическая последовательность этих событий изображена на рис.
2.20
Рис. 2.20. Крах сервера в момент, когда
в клиенте происходит чтение
Ошибка также может произойти, если игнорировать
извещение о сбросе соединения и продолжать посылать данные. Чтобы промоделировать
эту ситуацию, следует изменить обращение к функции error после readline -
вывести диагностическое сообщение, но не завершаться. Для этого достаточно вместо
строки 17 в листинге 2.21 написать
error( 0, errno, "ошибка при вызове readline"
);
Теперь еще раз надо прогнать тест:
bsd: $ tcprw localhost 9000
hello.
получено сообщение 1
Здесь сервер был остановлен.
hello again
tcprw: ошибка вызова readline: Connection reset
by peer (54)
Клиент игнорирует ошибку, но
TCP уже разорвал соединение.
hello for the last time
Broken pipe Клиент получает сигнал SIGPlPE
и завершает работу.
bsd: $
Когда вводится вторая строка, клиент, как и раньше,
немедленно извещает ошибке (соединение сброшено сервером), но не завершает сеанс.
Он еще раз обращается к fgets, чтобы получить очередную строку для отправки
серверу стоит внести эту строку, как клиент тут же прекращает работу, и командный
интерпретатор сообщает, что выполнение было прервано сигналом SIGPIPE. В этом
случае при втором обращении к send, как и прежде, TCP послал RST, но вы не обратили
на него внимания. Однако после получения RST клиентский ТСP разорвал соединение,
поэтому при попытке отправить третью строку он немедленно завершает клиента,
посылая ему сигнал SIGPIPE. Хронология такая же как на рис. 2.19. Разница лишь
в том, что клиент «падает» при попытке записи, а не чтения.
Правильно спроектированное приложение, конечно,
не игнорирует ошибки, такая ситуация может иметь место и в корректно написанных
программах. Предположим, что приложение выполняет подряд несколько операций
записи без промежуточного чтения- Типичный пример - FTP. Если приложение на
другом конце «падает», то TCP посылает сегмент FIN. Поскольку данная программа
только пишет, но не читает, в ней не содержится информация о получении этого
FIN. При отправке следующего сегмента TCP на другом конце вернет RST. А в программе
опять не будет никаких сведений об этом, так как ожидающей операции чтения нет.
При второй попытке записи после краха отвечающего конца программа получит сигнал
SIGPIPE, если этот сигнал перехвачен или игнорируется - код ошибки EPIPE.
Такое поведение вполне типично для приложений,
выполняющих многократную запись без чтения, поэтому надо отчетливо представлять
себе последствия. Приложение уведомляется только после второй операции отправки
данных завершившемуся партнеру. Но, так как предшествующая операция привела
к сбросу соединения, посланные ей данные были потеряны.
Поведение зависит от соотношения времен. Например,
если снова прогнать первый тест, запустив сервер на машине spare, а клиента -
на машине bsd, то получается следующее:
bsd: $ tcprw localhost 9000
hello
получено сообщение 1 Это печатается после пятисекундной
задержки.
Здесь сервер был остановлен.
hello again
tcprw: сервер завершил работу
bsd: $
На этот раз клиент обнаружил конец файла, посланный
в результате остановки сервера. RST по-прежнему генерируется при отправке второй
строки, но из-за задержек в сети клиент успевает вызвать readline и обнаружить
конец файла еще до того, как хост bsd получит RST. Если вставить между строками
14 и 15 в листинге 2.21 строчку
sleep( 1 );
с целью имитировать обработку на клиенте или загруженность
системы, то получится тот же результат, что и при запуске клиента и сервера
на одной машине.
Kрax хоста на другом конце соединения
Последняя ошибка, которую следует рассмотреть,
- это аварийный останов хоста на другом конце. Ситуация отличается от краха
хоста, поскольку TCP на другом конце не может с помощью сегмента FIN проинформировать
программу о то, что ее партнер уже не работает.
Пока хост на другом конце не перезагрузят, ситуация
будет выглядеть как сбой в сети - TCP удаленного хоста не отвечает. Как
и при сбое в сети, TCP продолжает повторно передавать неподтвержденные сегменты.
Но в конце концов, если удаленный хост так и не перезагрузится, то TCP вернет
приложению код ошибки ETIMEDOUT.
А что произойдет, если удаленный хост перезагрузится
до того, как TCP Прекратит попытки и разорвет соединение? Тогда повторно передаваемые
вами сегменты дойдут до перезагрузившегося хоста, в котором нет никакой информации
о старых соединениях. В таком случае спецификация TCP [Postel 1981b] требует,
чтобы принимающий хост послал отправителю RST. В результате отправитель оборвет
соединение, и приложение либо получит код ошибки ECONNRESET (если есть ожидающее
чтение), либо следующая операция записи закончится сигналов SIGPIPE или ошибкой
EPIPE.
В этом разделе дано объяснение понятию «надежность
TCP». Вы узнали, что не существует гарантированной доставки, и при работе с
TCP могут встретиться разнообразные ошибки. Ни одна из этих ошибок не фатальна,
но вы должны быть готовы к их обработке.
Программисты, приступающие к изучению семейства
протоколов TCP/IP, но имеющие опыт работы с другими сетевыми технологиями, часто
удивляются, что TCP не посылает приложению немедленного уведомления о потере
связи. Поэтому некоторые даже считают, что TCP не пригоден в качестве универсальной
технологии обмена данными между приложениями. В этом разделе разъясняются причины
отсутствия у TCP средств для уведомления, достоинства и недостатки такого подхода
и способы обнаружения потери связи прикладным программистом.
Как вы узнали в совете 9, сетевой сбой или крах
системы могут прервать сообщение между хостами, но приложения на обоих концах
соединения «узнают» б этом не сразу. Приложение-отправитель остается в неведении
до тех пор пока TCP не исчерпает все попытки. Это продолжается довольно долго,
в системах на базе BSD - примерно 9 мин. Если приложение не посылает данные,
то оно может вообще не получить информации о потере связи. Например, приложение-сервер
ожидает, пока клиент не обратится со следующим запросом. Но, поскольку у клиента
нет связи с сервером, следующий запрос не придет. Даже когда TCP на стороне
клиента прекратит свои попытки и оборвет соединение, серверу об этом будет ничего
не известно.
Другие коммуникационные протоколы, например SNA
или Х.25, извещают приложение о потере связи. Если имеется нечто более сложное,
чем простая двухточечная выделенная линия, то необходим протокол опроса, который
постой проверяет наличие абонента на другом конце соединения. Это может быть
сообщение типа «есть что-нибудь для отправки?» или скрытые фреймы, посылаемые
в фоновом режиме для непрерывного наблюдения за состоянием виртуального канала.
В любом случае, за эту возможность приходится расплачиваться пропускной способностью
сети. Каждое такое опрашивающее сообщение потребляет сетевые ресурсы, которые
могли бы использоваться для увеличения полезной нагрузки.
Очевидно, одна из причин, по которым TCP не уведомляет
о потере связи немедленно, - это нежелание жертвовать полосой пропускания.
Большинству приложений немедленное уведомление и не нужно. Приложение, которому
действительно необходимо срочно узнавать о недоступности другого конца, может
реализовать этой цели собственный механизм. Далее будет показано, как это сделать.
Есть и философское возражение против встраивания
в TCP/IP механизма немедленного уведомления. Один из фундаментальных принципов,
заложенных при проектировании TCP/IP, - это принцип «оконечного разума» [Saltzer
et al. 1984]. В применении к сетям упрощенно подразумевается следующее. «Интеллекту»
нужно находиться как можно ближе к оконечным точкам соединения, а сама сеть
должна быть относительно «неинтеллектуальной». Именно поэтому TCP обрабатывает
ошибки самостоятельно, не полагаясь на сеть. Как сказано в совете 1, протокол
IP (значит, и построенный на его основе TCP) делает очень мало предположений
о свойствах физической сети. Относительно мониторинга наличия связи между приложениями
этот принцип означает, что такой механизм должен реализовываться теми приложениями,
которым это необходимо, а не предоставляться всем приложениям без разбора. В
работе [Huitema 1995] принцип «оконечного разума» интересно обсуждается в применении
к Internet.
Однако веская причина отсутствия у TCP средств
для немедленного уведомления о потере соединения связана с одной из главных
целей его проектирования: способностью поддерживать связь при наличии сбоев
в сети. Протокол TCP - это результат исследований, проведенных при финансовой
поддержке Министерства обороны США, с целью создания надежной технологии связи
между компьютерами. Такая технология могла бы функционировать даже в условиях
обрывов сетей из-за военных действий или природных катастроф. Часто сетевые
сбои быстро устраняются или маршрутизаторы находят другой маршрут для соединения.
Допуская временную потерю связи, TCP часто может справиться со сбоями, не ставя
об этом в известность приложения.
Недостаток такого подхода в том, что код, отслеживающий
наличие связи, необходимо встраивать в каждое приложение (которому это нужно),
а непродуманная реализация может привести к ненужному расходу ресурсов или как-то
иначе повредить пользователям. Но и в этом случае при встраивании мониторинга
в приложение можно осуществить тонкую настройку алгоритма, чтобы он удовлетворял
нуждам приложения и по возможности естественно интегрировался с прикладным протоколом.
В действительности протокол TCP обладает механизмом
обнаружения мертвых соединений - так называемыми контролерами (keep-alive).
Но, как вы вскоре увидите, для приложении подобный механизм часто бесполезен.
Если приложение его активирует, то TCP посылает на другой конец специальный
сегмент, когда по соединению в течение некоторого времени не передавались данные.
Если хост на другом конце доступен и приложение там все еще работает, то TCP
отвечает сегментом ACK. В этом случае TCP, пославший контролера, сбрасывает
время простоя в нуль; приложение не получает извещения о том, что имел место
обмен информацией.
Если хост на другом конце работает, а приложение -
нет, то TCP посылает в ответ сегмент RST. A TCP, отправивший контролер, разрывает
соединение и возвращает приложению код ECONNRESET. Обычно так бывает после перезагрузки
и удаленного хоста, поскольку, как говорилось в совете 9, если бы завершилось
всего лишь приложение на другом конце, то TCP послал сегмент FIN.
Если удаленный хост не посылает в ответ ни АСК,
ни RST, то TCP продолжает посылать контролеров, пока не получит сведений, что
хост недоступен. В этот момент он разрывает соединение и возвращает приложению
код ETIMEDOUT либо, если маршрутизатор прислал ICMP-сообщение о недоступности
хоста или сети, соответственно код EHOSTUNREACH или ENETUNREACH.
Первая проблема, с которой сталкиваются приложения,
нуждающиеся в немедленном уведомлении, при попытке воспользоваться механизмом
контролеров, - это длительность временных интервалов. В соответствии с
RFC 1122 [Braden 1989], если TCP реализует механизм контролеров, то по умолчанию
время простоя должно быть не менее двух часов. И только после этого можно посылать
контролеров. Затем, поскольку АСК, посланный удаленным хостом, доставляется
ненадежно, процесс отправки контролеров необходимо несколько раз повторить;
и лишь тогда можно разрывать соединение. В системе 4.4BSD отправляется девять
контролеров с интервалом 75 с.
Примечание: Точные величины - деталь реализации.
В RFC 1122 не говорится о том, сколько и с каким интервалом нужно посылать контролеры,
прежде чем разорвать соединение. Утверждается лишь, что реализация не должна
интерпретировать отсутствие ответа на посылку одного контролера как индикатор
прекращения соединения.
Таким образом, в реализациях на основе BSD для
обнаружения потери связи потребуется 2 ч 11 мин 15 с. Этот срок приобретает
смысл, если вы понимаете, что назначение контролеров - освободить ресурсы, занятые
уже несуществующими соединениями. Такое возможно, например, если клиент соединяется
с сервером, а затем хост клиента неожиданно отключается. Без механизма дежурных
серверу пришлось бы ждать следующего запроса от клиента вечно, поскольку он
не получит FIN
Примечание: Эта ситуация очень распространена
из-за ошибок пользователей персональных компьютеров, которые просто выключают
компьютер или модем, не завершив корректно работающие приложения.
В некоторых реализациях разрешено изменять один
или оба временных интервала, но это всегда распространяется на систему в целом.
Иными словами, изменение затрагивает все TCP-соединения, установленные данной
системой, и есть основная причина, по которой механизм контролеров почти бесполезен
в качестве средства мониторинга связи. Период, выбранный по умолчанию, слишком
велик, а если его сократить, то контролеры перестанут выполнять свою исходную
задачу - обнаруживать давно «зависшие» соединения.
В последней версии стандарта POSIX появилась новейшая
опция сокета TCP_KEEPALIVE, которая позволяет устанавливать временной интервал
для отдельного соединения, но пока она не получила широкого распространения.
Еще одна проблема, связанная с механизмом контролеров,
состоит в том, что он не просто обнаруживает «мертвые» соединения, а еще и разрывает
их независимо от того, допускает ли это приложение.
Задача проверки наличия соединения, неразрешимая
с помощью механизма контролеров, легко решается путем реализации аналогичного
механизма в самом приложении. Оптимальный метод зависит от приложения. Здесь
вы можете полнее оценить гибкость, которая может быть достигнута при реализации
на прикладном уровне. В качестве примеров рассмотрим два крайних случая:
- клиент и сервер обмениваются сообщениями
разных типов, каждое из которых имеет заголовок, идентифицирующий тип сообщения;
- приложение передает данные в виде потока
байтов без разбиения на записи.
Первый случай сравнительно несложен. Вводится новый
тип сообщения MSG_HEARTBEAT. Получив такое сообщение, приложение возвращает
его отправителю. Такой способ предоставляет большую свободу. Проверять наличие
связи могут одна или обе стороны, причем только одна действительно посылает
контрольное сообщение-пульс.
Сначала рассмотрим заголовочный файл (листинг 2.23),
который используют как клиент, так и сервер.
Листинг 2.23. Заголовочный файл для реализации механизма
пульсации
heartbeat.h
1 #ifndef _HEARTBEAT
2 #define _HEARTBEAT
3 #efine MSG_TYPE1 1 /* Сообщение прикладного
уровня. */
4 #efine MSG_TYPE2 2/* Еще одно. */
5 #efine MSG_HEARTBEAT3 /* Сообщение-пульс.
*/
6 typedef struct/* Структура сообщения.
*/
7 {
8 u_int32_t type; /* MSG_TYPE1, ... */
9 char data[ 2000 ] ;
10 } msg_t;
11 #define Tl 60 /* Время простоя перед
отправкой пульса. */
12 #define T2 10 /* Время ожидания ответа.
*/
13 #endif /* _HEARTBEAT_H_ */
3-5 С помощью этих констант определяются различные
типы сообщений, которыми обмениваются клиент и сервер. Для данного примера нужно
только сообщение MSG_HEARTBEAT.
6-10 Здесь определяется структура сообщений, которыми
обмениваются клиент и сервер. Здесь представляет интерес только поле type. Реальное
приложение могло бы подстроить эту структуру под свои возможности. Подробнее
это рассматривается в замечаниях к листингу 2.15 о смысле типа u_int32_t и об
опасности предположений о способе упаковки структур.
11 Данная константа определяет, сколько времени
может простаивать соединение, прежде чем приложение начнет посылать контрольные
сообщения-пульсы. Здесь произвольно выбрано 60 с, реальное же приложение должно
подобрать значение, наиболее соответствующее потребностям и виду сети.
12 Эта константа определяет, сколько времени клиент
будет ждать ответа на контрольное сообщение.
В листинге 2.24 приведен текст клиента, который
инициирует посылку контрольных сообщений. Такой выбор абсолютно произволен,
в качестве инициатора можно было выбрать сервер.
Листинг 2.24. Клиент, посылающий контрольные сообщения-пульсы
hb_client.c
1 #include "etcp.h"
2 #include "heartbeat.h"
3 int main( int argc, char **argv )
4 {
5 fd_set allfd;
6 fd_set readfd;
7 msg_t msg;
8 struct timeval tv;
9 SOCKET s;
10 int rc;
11 int heartbeats =0;
12 int cnt = sizeof( msg );
13 INIT();
14 s = tcp_client( argv[ 1 ], argv[ 2 ] );
15 FD_ZERO( &allfd } ;
16 FD_SET( s, uallfd );
17 tv.tv_sec = T1;
18 tv.tv_usec =0;
19 for ( ;; )
20 {
21 readfd = allfd;
22 rc = select( s + 1, &readfd, NULL, NULL,
&tv );
23 if ( rc < 0 )
24 error( 1, errno, "ошибка вызова select"
);
25 if ( rc == 0 ) /* Произошел тайм-аут. */
26 {
27 if ( ++ heartbeats > 3 )
28 error( 1, 0, "соединения нет\n"
);
29 error( 0, 0, "посылаю пульс #%d\n"
, heartbeats ) ;
30 msg.type = htonl( MSG_HEARTBEAT );
3! rc = send( s, ( char * )&msg, sizeofl
msg ), 0 );
32 if ( rc < 0 )
33 error( 1, errno, "ошибка вызова send"
) ;
34 tv.tv_sec = T2;
35 continue;
36 )
37 if ( !FD_ISSET( s, &readfd ) )
38 error( 1, 0, "select вернул некорректный
сокет\n" );
39 rc = recv( s, ( char * )&msg + sizeof(
msg ) - cnt,
40 cnt, 0 ) ;
41 if ( rc == 0 )
42 error ( 1, 0, "сервер закончил работу\n"
) ,-
43 if ( rc < 0 )
44 error( 1, errno, "ошибка вызова recv"
);
45 heartbeats = 0;
46 tv.tv_sec = T1;
47 cnt -= rc; /* Встроенный readn. */
48 if ( cnt > 0 )
49 continue;
50 cnt = sizeof( msg );
51 /* Обработка сообщения. */
52 }
53 }
Инициализация
13-14 Выполняем стандартную инициализацию и соединяемся
с сервером, адрес и номер порта которого заданы в командной строке.
15-16 Задаем маску для системного вызова select,
в которой выбран ваш сокет.
17-18 Взводим таймер на Т1 секунд. Если за это время
не было получено никакого сообщения, то select вернет управление с индикацией
срабатывания таймера.
21-22 Устанавливаем маску, выбирающую сокет, из
которого читаем, после чего система блокирует программу в вызове select, пока
не поступят данные либо не сработает таймер.
Обработка тайм-аута
27-28 Если послано подряд более трех контрольных
пульсов и не получено ответа, то считается, что соединение «мертво». В этом
примере просто завершаем работу, но реальное приложение могло бы предпринять
более осмысленные действия.
29-33 Если максимальное число последовательных контрольных
пульсов не достигнуто, посылается новый пульс.
34 -35 Устанавливаем таймер на Т2 секунд. Если за
это время не получен ответ, то либо отправляется новый пульс, либо соединение
признается «мертвым» в зависимости от значения переменной heartbeats.
Обработка сообщения
37-38 Если select вернул сокет, отличный от соединенного
с сервером, to завершаемся с сообщением о фатальной ошибке.
39-40 Вызываем recv для чтения одного сообщения.
Эти строки, а также следующий за ними код, изменяющий значение переменной cnt,
- не что иное, как встроенная версия функции readn. Она не может быть вызвана
напрямую, поскольку заблокировала бы весь процесс на неопределенное время, нарушив
тем самым работу механизма пульсации
41-44 Если получаем признак конца файла или ошибку
чтения, выводим диагностическое сообщение и завершаем сеанс.
45-46 Поскольку только что получен ответ от сервера,
сбрасывается счетчик пульсов в 0 и переустанавливается таймер на Т1 секунд.
47-50 Эти строки завершают встроенный вариант readn.
Уменьшаем переменную cnt на число, равное количеству только что прочитанных
байт. Если прочитано не все, то следует повторить цикл с вызова select. В противном
случае заносится в cnt полная длина сообщения и завершается обработка только
что принятого сообщения.
Листинг 2.25 содержит текст сервера для этого примера.
Здесь предполагается, что сервер также будет следить за состоянием соединения,
но это не обязательно.
Листинг 2.25. Сервер, отвечающий на контрольные
сообщения-пульсы
hb_server.с
1 #include "etcp.h"
2 #include "heartbeat.h"
3 int main( int argc, char **argv )
4 {
5 fd_set allfd;
6 fd_set readfd;
7 msg_t msg;
8 struct timeval tv;
9 SOCKET s;
10 SOCKET s1;
11 int rc;
12 int missed_heartbeats = 0;
13 int cnt = sizeof( msg );
14 INIT();
15 s = tcp_server( NULL, argv[ 1 ] );
16 s1 = accept( s, NULL, NULL ) ;
17 if ( !isvalidsock( s1 ) )
18 error( 1, errno, "ошибка вызова accept"
);
19 tv.tv_sec = T1 + T2;
20 tv.tv_usec = 0;
21 FD_ZERO( fcallfd );
22 FD_SET( si, fiallfd ) ;
23 for ( ;; )
24 {
25 readfd = allfd;
26 rc = select( s1 + 1, &readfd, NULL,
NULL, &tv );
2.7 if ( rc < 0 }
28 error( 1, errno, "ошибка вызова select"
);
29 if ( rc == 0 ) /* Произошел тайм-аут. */
30 {
31 if ( ++missed_heartbeats > 3 )
32 errorf 1, 0, "соединение умерло\n"
);
33 error( 0, 0, "пропущен пульс #%d\n",
34 missed_heartbeats );
35 tv.tv_sec = T2;
35 continue;
37 }
38 if ( !FD_ISSET( s1, &readfd ) )
39 error( 1, 0, "select вернул некорректный
сокет\n" );
40 rc = recv( si, ( char * )&msg + sizeof(
msg ) - cnt,
41 cnt, 0 );
42 if ( rc == 0 )
43 errorf 1, 0, "клиент завершил работу\n"
);
44 if { rc < 0 )
45 error( 1, errno, "ошибка вызова recv"
);
46 missed_heartbeats = 0;
47 tv.tv_sec = T1 + T2;
48 cnt -= rc; /* Встроенный readn. */
49 if ( cnt > 0 )
50 continue;
51 cnt = sizeof ( msg );
52 switch ( ntohl( msg.type ) )
53 {
54 case MSG_TYPE1 :
55 /* обработать сообщение типа TYPE1. */
56 break;
57 case MSG_TYPE2 :
58 /* Обработать сообщение типа TYPE2. */
59 break;
60 case MSG_HEARTBEAT :
61 rc = send( si, ( char * )&msg, sizeof(
msg ), 0 );
62 if ( rc < 0 )
63 error( 1, errno, "ошибка вызова
send" );
64 break;
65 default :
66 error ( 1, 0, "неизвестный тип сообщения
(%d)\n"',
67 ntohl( msg.type ) );
68 }
69 }
70 EXIT( 0 ) ;
71 }
Инициализация
14-18 Выполняем стандартную инициализацию и принимаем
соединение от клиента.
19-20 Взводим таймер на Т1 + Т2 секунд. Поскольку
клиент посылает пульс после Т1 секунд неактивности, следует подождать немного
больше - на Т2 секунд.
21-22 Инициализируем маску для select, указывая
в ней соединенный сокет, из которого происходит чтение.
25-28 Вызываем select и проверяем возвращенное
значение.
Обработка тайм-аута
31-32 Если пропущено более трех пульсов подряд,
то соединение считаете «мертвым» - работа завершается. Как и клиент, реальный
сервер мог бы предпринять в этом случае более осмысленные действия.
35 Взводим таймер на Т2 секунд. К этому моменту
клиент должен был бы посылать пульсы каждые Т2 секунд, так что если за это время
ничего не получено, то необходимо увеличить счетчик пропущенных пульсов.
Обработка сообщения
38-39 Производим ту же проверку корректности сокета,
что и в клиенте.
40-41 Как и в клиенте, встраиваем код функции readn.
42-45 Если recv возвращает признак конца файла или
код ошибки, то печатаем диагностическое сообщение и выходим.
46-47 Поскольку только что получено сообщение от
клиента, соединение все еще живо, так что сбрасываем счетчик пропущенных пульсов
в нуль и взводим таймер на Т1 + Т2 секунд.
48-51 Этот код, такой же, как в клиенте, завершает
встроенную версию readn.
60-64 Если это сообщение-пульс, то возвращаем его
клиенту. Когда клиент получит сообщение, обе стороны будут знать, что соединение
еще есть.
Для тестирования этих программ запустим программу
hb_server на машине spare, а программу hb_client - на машине bsd. После того
как клиент соединится с сервером, отключим spare от сети. Вот что при этом будет
напечатано.
|
spare: $ hb_server 9000
hb_server: пропущен пульс #1
hb_server: пропущен пульс #2
hb_server: пропущен пульс #3
hb_server: соединения нет
spare: $
|
bsd: $ hb_client spare 9000
hb_client: посылаю пульс #1
hb_client: посылаю пульс #2
hb_client: посылаю пульс #3
hb_client: соединения нет
bsd: $
|
Использованная в предыдущем примере модель не совсем
пригодна в ситуации, когда одна сторона посылает другой поток данных, не разбитый
на сообщения. Проблема в том, что посланный пульс оказывается частью потока,
поэтому его идется явно выискивать и, возможно, даже экранировать (совет 6).
Чтобы избежать сложностей, следует воспользоваться другим подходом.
Идея в том, чтобы использовать для контрольных
пульсов отдельное соединение. На первый взгляд, кажется странной возможность
контролировать одно соединение с помощью другого. Но помните, что делается попытка
обнаружить крах оста на другом конце или разрыв в сети. Если это случится, то
пострадают оба соединения. Задачу можно решить несколькими способами. Традиционный
способ - создать отдельный поток выполнения (thread) для управления пульсацией.
Можно также применить универсальный механизм отсчета времени, который разработан
в совете 20. Однако, чтобы не вдаваться в различия между API потоков на платформе
Win32 и библиотекой PThreads в UNIX, модифицируем написанный для предыдущего
примера код с использованием системного вызова select.
Новые версии клиента и сервера очень похожи на
исходные. Основное различие состоит в логике работы select, который теперь должен
следить за двумя сокетами, а также в дополнительном коде для инициализации еще
одного соединения. После соединения клиента с сервером, клиент посылает ему
номер порта, по которому отслеживается пульсация сервера. Это напоминает то,
что делает FТР-сервер, устанавливая соединение для обмена данными с клиентом.
Примечание: Может возникнуть проблема, если
для преобразования частных сетевых адресов в открытые используется механизм
NAT (совет 3). В отличие от ситуации с FTP программное обеспечение NAT не имеет
информации, что нужно подменить указанный номер порта преобразованным. В таком
случае самый простой путь - выделить приложению второй хорошо известный
порт.
Начнем с логики инициализации и установления соединения
на стороне клиента (листинг 2.26).
Листинг 2.26. Код инициализации и установления соединения
на стороне клиента
hb_client2.c
1 #include "etcp.h"
2 #include "heartbeat.h"
3 int main( int argc, char **argv )
4 {
5 fd_set allfd;
6 fd_set readfd;
7 char msg[ 1024 ];
8 struct tirneval tv;
9 struct sockaddr_in hblisten;
10 SOCKET sdata;
11 SOCKET shb;
12 SOCKET slisten;
13 int rc;
14 int hblistenlen = sizeof( hblisten );
15 int heartbeats = 0;
16 int maxfdl;
17 char hbmsg[ 1 ];
18 INIT();
19 slisten = tcp_server( NULL, "0"
) ;
20 rc = getsockname( slisten, ( struct sockaddr
* )&hblisten,
21 &hblistenlen );
23 error( 1, errno, "ошибка вызова getsockname"
);
24 sdata = tcp_client( argv[ 1 ], argv[ 2 ] );
25 rc = send( sdata, ( char * ) &hblisten.
sin__port,
26 sizeof( hblisten.sin_port ), 0 ) ;
27 if ( rc < 0 )
28 error( 1, errno, "ошибка при посылке
номера порта");
29 shb = accept( slisten, NULL, NULL );
30 if ( !isvalidsock( shb ) )
31 error( 1, errno, "ошибка вызова accept"
);
32 FD_ZERO( &allfd ) ;
33 FD_SET( sdata, &allfd );
34 FD_SET( shb, &allfd ) ;
35 maxfdl = ( sdata > shb ? sdata: shb ) +
1;
36 tv.tv_sec = Tl;
37 tv.tv_usec = 0;
Инициализация и соединение
19-23 Вызываем функцию tcp_server с номером порта
0, таким образом заставляя ядро выделить эфемерный порт (совет 18). Затем вызываем
getsockname, чтобы узнать номер этого порта. Это делается потому, что с данным
сервером ассоциирован только один хорошо известный порт.
24-28 Соединяемся с сервером и посылаем ему номер
порта, с которым он должен установить соединение для посылки сообщений-пульсов.
29-31 Вызов accept блокирует программу до тех пор,
пока сервер не установит соединение для пульсации. В промышленной программе,
наверное, стоило бы для этого вызова взвести таймер, чтобы программа не «зависла»,
если сервер не установит соединения. Можно также проверить, что соединение для
пульсации определил именно тот сервер, который запрашивался в строке 24.
32-37 Инициализируем маски для select и взводим
таймер.
Оставшийся код клиента показан в листинге 2.27.
Здесь вы видите обработку содержательных сообщений и контрольных пульсов.
Листинг 2.27. Обработка сообщений клиентом
hb_client2.c
38 for ( ;; )
39 {
40 readfd = allfd;
41 rc = select( maxfdl, &readfd, NULL,
NULL, &tv );
42 if ( rc < 0 )
43 error( 1, errno, "ошибка вызова select"
);
44 if ( rc == 0 ) /* Произошел тайм-аут. */
45 {
46 if ( ++heartbeats > 3 )
47 error( 1, 0, "соединения нет\n"
);
4g error( 0, 0, "посылаю пульс #%d\n",
heartbeats );
49 rc = send( shb, "", 1, 0 ) ;
50 if ( rc < 0 )
51 error( 1, errno, "ошибка вызова send"
);
52 tv.tv_sec = T2;
53 continue;
54 }
55 if ( FD_ISSET( shb, &readfd ) )
56 {
57 rc = recv( shb, hbmsg, 1, 0 );
58 if ( rc == 0 )
59 error( 1, 0, "сервер закончил работу
(shb)\n" );
60 if ( rc < 0 )
61 error( 1, errno, "ошибка вызова recv
для сокета shb");
62 }
63 if ( FD_ISSET( sdata, &readfd ) )
64 {
65 rc = recv( sdata, msg, sizeof( msg ), 0
);
66 if ( rc == 0 )
67 error( 1, 0, "сервер закончил работу
(sdata)\n" );
69 error( 1, errno, "ошибка вызова recv"
);
70 /* Обработка данных. */
71 }
72 heartbeats = 0;
73 tv.tv_sec = T1;
74 }
75 }
Обработка данных и пульсов
40-43 Вызываем функцию select и проверяем код возврата.
44-54 Таймаут обрабатывается так же, как в листинге
2.24, только пульсы посылаются через сокет shb.
55-62 Если через сокет shb пришли данные, читаем
их, но ничего не делаем.
63-71 Если данные пришли через сокет sdata, читаем
столько, сколько сможем, и обрабатываем. Обратите внимание, что теперь производится
работа не с сообщениями фиксированной длины. Поэтому читается не больше, чем
помещается в буфер. Если данных меньше длины буфера, вызов recv вернет все,
что есть, но не заблокирует программу. Если данных больше, то из сокета еще
можно читать. Поэтому следующий вызов select немедленно вернет управление, и
можно будет обработать очередную порцию данных.
72-73 Поскольку только что пришло сообщение от сервера,
сбрасываем переменную heartbeats в 0 и снова взводим таймер.
И в заключение рассмотрим код сервера для этого
примера (листинг 2.28) Как и код клиента, он почти совпадает с исходным сервером
(листинг 2.25) за тем и исключением, что устанавливает два соединения и работает
с двумя сокетами.
Листинг 2.28. Код инициализации и установления соединения
на стороне сервер^!
hb_server2.c
1 #include "etcp.h"
2 #include "heartbeat.h"
3 int main( int argc, char **argv )
4 {
5 fd_set allfd;
6 fd_set readfd;
7 char msg[ 1024 ];
8 struct sockaddr_in peer;
9 struct timeval tv;
10 SOCKET s;
11 SOCKET sdata;
12 SOCKET shb;
13 int rc
14 int maxfdl;
15 int missed_heartbeats = 0;
16 int peerlen = sizeof( peer);
17 char hbmsg[ 1 ];
18 INIT ();
19 s = tcp_server( NULL, argv[ 1 ] );
20 sdata = accept( s, ( struct sockaddr * )&peer,
21 &peerlen );
22 if ( !isvalidsock( sdata ) )
23 error( 1, errno, "accept failed"
);
24 rc = readn( sdata, ( char * )&peer.sin_port,
25 sizeof( peer.sin_port ) );
26 if ( rc < 0 )
27 error( 1, errno, "ошибка при чтении
номера порта" );
28 shb = socket( PF_INET, SOCK_STREAM, 0 );
29 if ( !isvalidsock( shb ) )
30 error ( 1, errno, "ошибка при создании
сокета shb" );
31 rc = connect ( shb, ( struct sockaddr * )&peer,
peerlen );
32 if (rc )
33 error( 1, errno, "ошибка вызова connect
для сокета shb");
34 tv.tv_sec = T1 + T2;
35 tv.tv_usec = 0;
36 FD_ZERO( &allfd ) ;
37 FD_SET( sdata, &allfd );
38 FD_SET( shb, &allfd ) ;
39 maxfdl = ( sdata > shb ? sdata : shb )
+ 1;
Инициализация и соединение
19-23 Слушаем и принимаем соединения от клиента.
Кроме того, сохраняем адрес клиента в переменной peer, чтобы знать, с кем устанавливать
соединение для пульсации.
24-27 Читаем номер порта, который клиент прослушивает
в ожидании соединения для пульсации. Считываем его непосредственно в структуру
peer. О преобразовании порядка байтов с помощью htons или ntohs беспокоиться
не надо, так как порт уже пришел в сетевом порядке. В таком виде его и надо
сохранить в peer.
28-33 Получив сокет shb, устанавливаем соединение
для пульсации.
34-39 Взводим таймер и инициализируем маски для
select.
Оставшаяся часть сервера представлена в листинге
2.29.
Листинг 2.29. Обработка сообщений сервером
hb_server2.с
40 for ( ;; )
41 {
42 readfd = allfd;
43 rc = select( maxfdl, &readfd, NULL,
NULL, &tv );
44 if ( rc < 0 )
45 error( 1, errno, "ошибка вызова select"
);
46 if ( rc == 0 ) /* Произошел тайм-аут. */
47 {
48 if ( ++missed_heartbeats > 3 )
49 error( 1, 0, "соединения нет\n"
);
50 error( 0, 0, "пропущен пульс #%d\n",
51 missed_heartbeats );
52 tv.tv_sec = T2;
53 continue;
54 }
55 if ( FD_ISSET( shb, &readfd ) )
56 {
57 rc = recv( shb, hbmsg, 1, 0 );
58 if ( rc == 0 )
59 error( 1, 0, "клиент завершил работу\n"
);
60 if ( rc < 0 )
61 error( 1, errno, "ошибка вызова recv
для сокета shb" );
62 rc = send( shb, hbmsg, 1, 0 );
63 if ( rc < 0 )
64 error( 1, errno, "ошибка вызова send
для сокета shb" );
65 }
66 if ( FD_ISSET( sdata, &readfd ) )
67 {
68 rc = recv (sdata, msg, sizeof( msg ), 0);
69 if ( rc == 0 )
70 error (1, 0, “клиент завершил работу\n”);
71 if ( rc < 0 )
72 error (1, errno, “ошибка вызова recv”);
73 /*Обработка данных*/
74 }
75 missed_heartbeats = 0;
76 tv.tv_sec = T1 + T2;
77 }
78 EXIT( 0 );
79 }
42-45 Как и в ситуации с клиентом, вызываем select
и проверяем возвращаемое значение.
46-53 Обработка тайм-аута такая же, как и в первом
примере сервера в листинге 2.25.
55-65 Если в сокете shb есть данные для чтения,
то читаем однобайтовый пульс и возвращаем его клиенту.
66-74 Если что-то поступило по соединению для передачи
данных, читаем и обрабатываем данные, проверяя ошибки и признак конца файла.
75-76 Поскольку только что получены данные от клиента,
соединение все еще живо, поэтому сбрасываем в нуль счетчик пропущенных пульсов
и переустанавливаем таймер.
Если запустить клиента и сервер и имитировать сбой
в сети, отсоединив один из хостов, то получим те же результаты, что при запуске
hb_server и hb_client.
Хотя TCP и не предоставляет средств для немедленного
уведомления клиента о потере связи, тем не менее несложно самостоятельно встроить
такой механизм в приложение. Здесь рассмотрены две модели реализации контрольных
сообщений-пульсов. На первый взгляд, это может показаться избыточным, но одна
модель не подходит для всех случаев.
Первый способ применяется, когда приложения обмениваются
между собой сообщениями, содержащими поле идентификатора типа. В этом случае
все очень просто: достаточно добавить еще один тип для сообщений-пульсов. «Родители»
могут спокойно работать - их «дети» под надежным присмотром.
Второй способ применим в ситуации, когда приложения
обмениваются потоком байтов без явно выраженных границ сообщений. В качестве
примера можно назвать передачу последовательности нажатий клавиш. В данном примере
использовано отдельное соединение для приема и передачи пульсов. Разумеется,
тот метод можно было бы применить и в первом случае, но он несколько сложнее,
чем простое добавление нового типа сообщения.
В книге «UNIX Network Programming» [Stevens 1998]
описан еще один метод организации пульсации с помощью механизма срочных данных,
имеющегося в TCP. Это лишний раз демонстрирует, какие разнообразные возможности
иметь в распоряжении прикладного программиста для организации уведомления приложения
о потере связи.
Наконец, следует напомнить, что хотя было сказано
только о протоколе TCP, то же самое верно и в отношении UDP. Представим сервер,
который посылает широковещательные сообщения нескольким клиентам в локальной
сети или организует групповое вещание на глобальную сеть. Поскольку соединения
нет, клиенты имеют информации о крахе сервера, хоста или сбое в сети. Если в
датаграммах есть поле типа, то серверу нужно лишь определить тип для датаграммы-пульса
и посылать ее, когда в сети какое-то время не было других сообщений. Вместо
этого он мог бы рассылать широковещательные датаграммы на отдельный порт, который
клиенты прослушивают.
Часто при написании сетевых приложений не учитывают
возможность возникновения ошибки, считая ее маловероятной. В связи с этим ниже
приведена выдержка из требований к хостам, содержащихся в RFC 1122 [Braden 1989,
стр. 12]: «Программа должна обрабатывать любую возможную ошибку, как бы маловероятна
она ни была; рано или поздно придет пакет именно с такой комбинацией ошибок
и атрибутов, и если программа не готова к этому, то неминуем хаос. Правильнее
всего предположить, что сеть насыщена злонамеренными агентами, которые посылают
пакеты, специально подобранные так, чтобы вызвать максимально разрушительный
эффект. Необходимо думать о том, как защититься, хотя надо признать, что наиболее
серьезные проблемы в сети Internet были вызваны непредвиденными механизмами,
сработавшими в результате сочетания крайне маловероятных событий. Никакой злоумышленник
не додумался бы до такого!»
Сегодня этот совет более актуален, чем во время
написания. Появилось множество реализаций TCP, и некоторые из них содержат грубые
ошибки. К тому же все больше программистов разрабатывают сетевые приложения,
но далеко не у всех есть опыт работы в этой области.
Однако самый серьезный фактор - это лавинообразный
рост числа подключенных к Internet персональных компьютеров. Ранее можно было
предполагать, что у пользователей есть хотя бы минимальная техническая подготовка,
они понимали, к каким последствиям приведет, скажем, выключение компьютера без
предварительного завершения сетевого приложения. Теперь это не так.
Поэтому особенно важно практиковать защитное программирование
и предвидеть все действия, которые может предпринять хост на другом конце, какими
бы маловероятными они ни казались. Эта тема уже затрагивалась в совете 9 при
уяснении потенциальных ошибок при работе с TCP, а также в совете 10, где речь
шла об обнаружении потери связи. В этом разделе будет рассмотрено, какие действия
вашего партнера могут нанести ущерб. Главное - не думайте, что он будет
следовать прикладному протоколу, даже если обе стороны протокола реализовывали
вы сами.
Предположим, что клиент извещает о желании завершить
работу, посыла серверу запрос из одной строки, в которой есть только слово quit.
Допустим далее, что сервер читает строки из входного потока с помощью функции
геаdline (ее текст приведен в листинге 2.32), которая была описана в совете
9. Что произойдет, если клиент завершится (аварийно или нормально) раньше, чем
пошлет команду quit? TCP на стороне клиента отправит сегмент FIN, после чего
операция чтения на сервере вернет признак конца файла. Конечно, это просто обнаружить,
только сервер должен обязательно это сделать. Легко представить себе такой код,
предполагая правильное поведение клиента:
for ( ; ; )
{
if ( readline( s, buf, sizeof( buf ) ) < 0
)
error( 1, errno, "ошибка вызова readline"
);
if ( strcmp( buf, "quit\n" ) == 0)
/* Выполнить функцию завершения клиента. */
else
/* Обработать запрос. */
}
Хотя код выглядит правильным, он не работает, поскольку
будет повторно обрабатывать последний запрос, если клиент завершился, не послав
команду quit.
Предположим, что вы увидели ошибку в предыдущем
фрагменте (или нашли ее после долгих часов отладки) и изменили код так, чтобы
явно обнаруживался признак конца файла:
for ( ;; )
{
rc = readline( s, buf, sizeof( buf ) );
if ( rc < 0 )
error( 1, errno, "ошибка вызова readline"
);
if ( rc == 0 || strcmp( buf, "quit\n"
) == 0)
/* Выполнить функцию завершения клиента. */
else
/* Обработать запрос. */
}
И этот код тоже неправилен, так как в нем не учитывается
случай, когда хост клиента «падает» до того, как клиент послал команду quit
или завершил работу. В этом месте легко принять неверное решение, даже осознавая
проблему. Для проверки краха клиентского хоста надо ассоциировать таймер с вызовом
readline. Потребуется примерно в два раза больше кода, если нужно организовать
обработку «безвременной кончины» клиента. Представив себе, сколько придется
писать, вы решаете, что шансов «грохнуться» хосту клиента мало.
Но проблема в том, что хосту клиента и необязательно
завершаться. Если это ПК, то пользователю достаточно выключить его, не выйдя
из программы. А это очень легко, поскольку клиент мог исполняться в свернутом
окне или в окне, закрытом другими, так что пользователь про него, вероятно,
забыл. Есть и другие возможности. Если соединение между хостами установлено
с помощью модема на клиентском конце (так сегодня выполняется большинство подключений
к Internet), то пользователь может просто выключить модем. Шум в линии также
может привести к обрыву соединения. И все это с точки зрения сервера неотличимо
от краха хоста клиента.
Примечание: При некоторых обстоятельствах
ошибку, связанную с модемом, можно исправить, повторно набрав номер (помните,
что TCP способен восстанавливаться после временных сбоев в сети), но зачастую
IP-адреса обоих оконечных абонентов назначаются динамически сервис - провайдером
при у становлении соединения. В таком случае маловероятно, что будет задан тот
же адрес, и поэтому клиент не сможет оживить соединение.
Для обнаружения потери связи с клиентом необязательно
реализовывать пульсацию, как это делалось в совете 10. Нужно всего лишь установить
тайм-аут для операции чтения. Тогда, если от клиента в течение определенного
времени не поступает запросов, то сервер может предположить, что клиента больше
нет, и разорвать соединение. Так поступают многие FTP-серверы. Это легко сделать,
либо явно установив таймер, либо воспользовавшись возможностями системного вызова
select, как было сделано при реализации пульсации.
Если вы хотите, чтобы сервер не «зависал» навечно,
то можете воспользоваться Механизмом контролеров для разрыва соединения по истечении
контрольного тайм-аута. В листинге 2.30 приведен простой TCP-сервер, который
принимает сообщение от клиента, читает из сокета и пишет результат на стандартный
вывод. Чтобы сервер не «завис», следует задать для сокета опцию SO_KEEPALIVE
с помощью вызова setsockopt. Четвертый аргумент setsockopt должен указывать
на ненулевое целое число, если надо активировать посылку контролеров, или на
нулевое целое, чтобы ее отменить.
Запустите этот сервер на машине bsd, а на другой
машине - программу telnet в качестве клиента. Соединитесь с сервером, отправьте
ему строку «hello», чтобы соединение точно установилось, а затем отключите клиентскую
систему от сети. Сервер напечатает следующее:
bsd: $ keep 9000
hello
Клиент отключился от сети.
…
Спустя 2 ч 11 мин 15 с.
кеер: ошибка вызова recv: Operation timed out (60)
bsd: $
Как и следовало ожидать, TCP на машине bsd разорвал
соединение и вернул серверу код ошибки ETIMEDOUT. В этот момент сервер завершает
работу и освобождает все ресурсы.
Листинг 2.30. Сервер, использующий механизм контролеров
keep.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 SOCKET s1;
6 int on = 1;
7 int rc;
8 char buf[ 128 ] ;
9 INIT();
10 s = tcp_server( NULL, argv[ 1 ] );
11 s1 = accept ( s, NULL, NULL );
12 if ( !isvalidsock( s1 ) )
13 error( 1, errno, "ошибка вызова accept\n"
);
14 if ( setsockopt( si, SOL_SOCKET, SO_KEEPALIVE,
15 ( char * )&on, sizeof ( on ) ) )
16 error( 1, errno, "ошибка вызова setsockopt"
);
17 for ( ;; )
18 {
19 rc = readline( si, buf, sizeof( buf ) );
20 if ( rc == 0 )
21 error( 1, 0, "другой конец отключился\n"
);
22 if ( rc < 0 )
23 error( 1, errno, "ошибка вызова recv"
);
24 write( 1, buf, rc );
25 }
26 }
Что бы вы ни программировали, не думайте, что приложение
будет получать только те данные, на которые рассчитывает. Пренебрежение этим
принципом - пример отсутствия защитного программирования. Хочется надеяться,
что профессиональный программист, разрабатывающий коммерческую программу, всегда
ему следует. Однако часто это правило игнорируют. В работе [Miller et al. 1995]
описывается, как авторы генерировали случайный набор входных данных и подавали
его на вход всевозможных стандартных утилит UNIX от разных производителей. При
этом им удалось «сломать» (с дампом памяти) или «подвесить» (в бесконечном цикле)
от 6 до 43% тестируемых программ (в зависимости от производителя;. В семи исследованных
коммерческих системах частота отказов составила 23%
Вывод ясен: если такие результаты получены при
тестировании зрелых программ, которые принято считать программами «промышленного
качества», то те более необходимо защищаться и подвергать сомнению все места
в программе, где неожиданные входные данные могут привести к нежелательным результатам.
Рассмотрим несколько примеров, когда неожиданные данные оказываются источником
ошибок.
Две самые распространенные причины краха приложений
- это переполнение буфера и сбитые указатели. В вышеупомянутом исследовании
именно эти две ошибки послужили причиной большинства сбоев. Можно сказать, что
в сетевых программах переполнение буфера должно быть редким явлением, так как
при обращении к системным вызовам, выполняющим чтение (read, recv, recvfrom,
readv и readmsg), всегда необходимо указывать размер буфера. Но вы увидите далее
как легко допустить такую ошибку. (Это рассмотрено в замечании к строке 42 программы
shutdown.с в совете 16.)
Чтобы понять, как это происходит, разработаем функцию
readline, использовавшуюся в совете 9. Поставленная задача - написать функцию,
которая считывает из сокета в буфер одну строку, заканчивающуюся символом новой
строки, и дописывает в конец двоичный нуль. На начало буфера указывает параметр
buf.
#include "etcp.h"
int readline( SOCKET
s, char *buf, size_t len );
Возвращаемое значение:
число прочитанных байтов или -1 в случае ошибки.
Первая попытка реализации, которую надо отбросить
сразу, похожа на следующий код:
while ( recv( fd, , &с, 1, 0 ) == 1 )
{
*bufptr++ = с;
if ( с == "\n" )
break;
}
/* Проверка ошибок, добавление завершающего нуля
и т.д. */
Прежде всего, многократные вызовы recv совсем неэффективны,
поскольку при каждом вызове нужно два переключения - в режим ядра и обратно.
Примечание: Но иногда приходится писать
и такой код - смотрите, например, функцию readcrlf в листинге 3.10.
Важнее, однако, то, что нет контроля переполнения
буфера, чтобы понять, как аналогичная ошибка может вкрасться и в более рациональную
реализацию, следует рассмотреть такой фрагмент:
static char *bp;
static int cnt = 0;
static char b[ 1500 ];
char c;
for ( ; ; )
{
if (cnt-- <= 0)
{
cnt = recv( fd, b, sizeof( b ), 0 );
if ( cnt < 0 )
return -1;
if ( cnt == 0 )
return 0;
bp = b;
}
c = *bp++;
*bufptr++ = c;
if ( c ==”\n” )
{
*bufptr = “\0”;
break;
}
}
В этой реализации нет неэффективности первого решения.
Теперь считывается большой блок данных в промежуточный буфер, а затем по одному
копируются байты в окончательный буфер; по ходу производится поиск символа новой
строки. Но при этом в коде присутствует та же ошибка, что и раньше. Не проверяется
переполнение буфера, на который указывает переменная bufptr. Можно было бы и
не писать универсальную функцию чтения строки; такой код - вместе с ошибкой
- легко мог бы быть частью какой-то большей функции.
А теперь напишем настоящую реализацию (листинг
2.31).
Листинг 2.31. Неправильная реализация readline
readline.с
1 int readline( SOCKET fd, char *bufptr, size_t
len )
2 {
3 char *bufx = bufptr;
4 static char *bp;
5 static int cnt = 0;
6 static char b[ 1500 ];
7 char c;
8 while ( --len > 0 )
9 {
10 if ( --cnt <= 0 )
11 {
12 cnt = recv( fd, b, sizeof( b ), 0 );
13 if ( cnt < 0 )
14 return -1;
15 if ( cnt == 0 )
16 return 0;
17 bp = b;
18 }
19 с = *bp++;
20 *bufptr++ = c;
21 if ( с == "\n" )
22 {
23 *bufptr = "\
24 return bufptr - bufx;
25 )
26 }
27 set_errno( EMSGSIZE ) ;
28 return -1;
29 }
На первый взгляд, все хорошо. Размер буфера передается
readline и во внешнем цикле проверяется, не превышен ли он. Если размер превышен,
то переменной errno присваивается значение EMSGSIZE и возвращается -1.
Чтобы понять, в чем ошибка, представьте, что функция
вызывается так:
rc = readline( s, buffer, 10 );
и при этом из сокета читается строка
123456789<nl>
Когда в c записывается символ новой строки, значение
len равно нулю. Это означает, что данный байт последний из тех, что готовы принять.
В строке 20 помещаете символ новой строки в буфер и продвигаете указатель bufptr
за конец буфера. Ошибка возникает в строке 23, где записывается нулевой байт
за границу буфера.
Заметим, что похожая ошибка имеет место и во внутреннем
цикле. Чтобы увидеть ее, представьте, что при входе в функцию readline значение
cnt равно нулю и recv возвращает один байт. Что происходит дальше? Можно назвать
это «опустошением» (underflow) буфера.
Этот пример показывает, как легко допустить ошибки,
связанные с переполнением буфера, даже предполагая, что все контролируется.
В листинге 2.32 приведена окончательная, правильная версия readline.
Листинг 2.32. Окончательная версия readline
readline.с
1 int readline( SOCKET fd, char *bufptr, size_t
len )
2 {
3 char *bufx = bufptr;
4 static char *bp;
5 static int cnt = 0;
6 static char b[ 1500 ];
7 char c;
8 while ( --len > 0 )
9 {
10 if ( --cnt <= 0 )
11 {
12 cnt = recv( fd, b, sizeof ( b ), 0 );
13 if ( cnt < 0 )
14 {
15 if ( errno == EINTR )
16 {
17 len++; /*Уменьшим на 1 в заголовке while.*/
18 continue;
19 }
20 return –1;
21 }
22 if ( cnt == 0)
23 return 0;
24 bp = b;
25 }
26 с = *bp++;
27 *bufptr++ = с;
28 if ( с == "\n" )
29 {
30 *bufptr = "\0";
31 return bufptr - bufx;
32 }
33 }
34 set_errno( EMSGSIZE ) ;
35 return -1;
36 }
Единственная разница между этой и предыдущей версиями
в том, что уменьшаются значения len и cnt до проверки, а не после. Также проверяется,
не вернула ли recv значение EINTR. Если это так, то вызов следует повторить.
При уменьшении len до использования появляется гарантия, что для нулевого байта
всегда останется место. А, уменьшая cnt, можно получить некоторую уверенность,
что данные не будут читаться из пустого буфера.
Вы всегда должны быть готовы к неожиданным действиям
со стороны пользователей и хостов на другом конце соединения. В этом разделе
рассмотрено два примера некорректного поведения другой стороны. Во-первых, нельзя
надеяться на то, что партнер обязательно сообщит вам о прекращении передачи
данных. Во-вторых, продемонстрирована важность проверки правильности входных
данных и разработана функция readline, устойчивая к ошибкам.
Многие сетевые приложения разрабатываются и тестируются
в локальной сети или даже на одной машине. Это просто, удобно и недорого, но
при этом могут остаться незамеченными некоторые ошибки.
Несмотря на возможную потерю данных, показанную
в совете 7, локальная сеть представляет собой среду, в которой датаграммы почти
никогда не теряются, не задерживаются и практически всегда доставляются в правильном
порядке. Однако из этого не следует делать вывод, что приложение, замечательно
работающее в локальной сети, будет также хорошо функционировать и в глобальной
сети или в Internet. Здесь можно столкнуться с проблемами двух типов:
- производительность глобальной сети оказывается
недостаточной из-за дополнительных сетевых задержек;
- некорректный код, работавший в локальной
сети, отказывает в глобальной.
Если вам встречается проблема первого типа, то,
скорее всего, приложение следует перепроектировать.
Чтобы получить представление о такого рода проблемах,
изменим программы hb_server (листинг 2.25) и hb_client (листинг 2.24), задав
Т1, равным 2 с, а Т2 -1 с (листинг 2.23). Тогда пульс будет посылаться каждые
две секунды, и при отсутствии ответа в течение трех секунд приложение завершится.
Сначала запустим эти программы в локальной сети.
Проработав почти семь часов, сервер сообщил о пропуске одного пульса 36 раз,
а о пропуске двух пульсов - один раз. Клиенту пришлось посылать второй пульс
11 из 12139 раз. И клиент, и сервер работали, пока клиент не остановили вручную.
Такие результаты типичны для локальной сети. Если не считать редких и небольших
задержек, сообщения доставляются своевременно.
А теперь запустим те же программы в Internet. Спустя
всего лишь 12 мин клиент сообщает, что послал три пульса, не получив ответа,
и завершает сеанс. Распечатка выходной информации от клиента, частично представленная
ниже, показывает, как развивались события:
spare: $ hb_client 205.184.151.171 9000
hb_client: посылаю пульс: #l
hb_client: посылаю пульс: #2
hb_client: посылаю пульс: #3
hb_client: посылаю пульс: #1
hb_client: посылаю пульс: #2
hb_client: посылаю пульс: #1
Много строк опущено.
hb_client: посылаю пульс: #1
hb_client: посылаю пульс: #2
hb-client: посылаю пульс: #1
hb_client: посылаю пульс: #2
hb_client: посылаю пульс: #3
hb_client: посылаю пульс: #1
hb-client: посылаю пульс: #2
hb_client: Соединение завершается
через
1с после последнего
пульса.
sparc: $
В этот раз клиент послал первый пульс 251 раз,
а второй - 247 раз. Таким образом, он почти ни разу не получил вовремя ответ
на первый пульс. Десять раз клиенту пришлось посылать третий пульс.
Сервер также продемонстрировал значительное падение
производительности. Тайм-аут при ожидании первого пульса происходил 247 раз,
при ожидании второго пульса - 5 и при ожидании третьего пульса - 1
раз.
Этот пример показывает, что приложение, которое
прекрасно работает в условиях локальной сети, может заметно снизить производительность
в глобальной.
В качестве примера проблемы второго типа рассмотрим
основанное на TCP приложение, занимающееся телеметрией. Здесь сервер каждую
секунду принимает от удаленного датчика пакет с результатами измерений. Пакет
может состоять из двух или трех целочисленных значений. В примитивной реализации
подобного сервера мог бы присутствовать такой цикл:
int pkt[ 3 ] ;
for ( ; ; )
{
rc = recv( s, ( char * ) pkt, sizeof( pkt ), 0
);
if (rc != sizeof( int ) * 2 && rc != sizeof(
int ) * 3 )
/* Протоколировать ошибку и выйти. */
else
/* Обработать rc / sizeof( int ) значений. */
}
Из совета 6 вы знаете, что этот код некорректен,
но попробуем провести простое моделирование. Напишем сервер (листинг 2.33),
в котором реализован только что показанный цикл.
Листинг 2.33. Моделирование сервера телеметрии
telemetrys.c
1 #include "etcp.h"
2 #define TWOINTS ( sizeoff int ) * 2 )
3 #define THREEINTS ( sizeof( int ) * 3 )
4 int main( int argc, char **argv )
5 {
6 SOCKET s;
7 SOCKET s1;
8 int rc;
9 int i = 1;
10 int pkt [ 3 ] ;
11 INIT();
12 s = tcp_server( NULL, argv[ 1 ] );
13 s1 = accept( s, NULL, NULL );
14 if ( !isvalidsock( s1 ) )
15 error( 1, errno, "ошибка вызова accept"
);
16 for ( ; ; )
17 {
18 rc = recv( s1, ( char * }pkt, sizeoff pkt
), 0 );
19 if ( rc != TWOINTS && rc != THREEINTS
)
20 error( 1, 0, "recv вернула %d\n",
rc );
21 printf( "Пакет %d содержит %d значений
в %d байтах\n" ,
22 i ++, ntohl pkt[ 0 ] ) , rc );
23 }
24 }
11-15 В этих строках реализована стандартная инициализация
и прием соединения.
16-23 В данном цикле принимаются данные от клиента.
Если получено при чтении не в точности sizeof ( int ) * 2 или sizeof ( int )
* 3 байт, то протоколируем ошибку и выходим. В противном случае байты первого
числа преобразуются в машинный порядок (совет 28), а затем результат и число
прочитанных байтов печатаются на stdout. В листинге 2.34 вы увидите, что клиент
помещает число значений в первое число, посылаемое в пакете. Это поможет разобраться
в том, что происходит. Здесь не используется это число как «заголовок сообщениям,
содержащий его размер (совет 6).
Для тестирования этого сервера также необходим
клиент, который каждую секунду посылает пакет целых чисел, имитируя работу удаленного
датчика. Текст клиента приведен в листинге 2.34.
Листинг 2.34. Имитация клиента для сервера телеметрии
telemetryc.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 int rc;
6 int i;
7 int pkt[ 3 ];
8 INIT();
9 s = tcp_client( argv[ 1 ], argv[ 2 ] );
Ю for ( i = 2;; i = 5 - i )
И {
12 pkt[ 0 ] = htonl( i ) ;
13 rc = send( s, ( char * )pkt, i * sizeof(
int ), 0 );
14 if ( rc < 0 )
15 error( 1, errno, "ошибка вызова send"
);
16 sleep( 1 );
17 }
18 }
8-9 Производим инициализацию и соединяемся с сервером.
10-17 Каждую секунду посылаем пакет из двух или
трех целых чисел. Как говорилось выше, первое число в пакете - это количество
последующих чисел (преобразованное в сетевой порядок байтов).
Для тестирования модели запустим сервер на машине
bsd, а клиента – на машине spare. Сервер печатает следующее:
bsd: $ telemetrys 9000
Пакет 1 содержит 2 значения в 8 байтах
Пакет 2 содержит 3 значения в 12 байтах
Много строк опущено.
Пакет 22104 содержит 3 значения в 12 байтах
Пакет 22105 содержит 2 значения в 8 байтах
Клиент завершил сеанс через 6 ч 8 мин 15 с.
telemetrys: recv вернула 0
bsd: $
Хотя в коде сервера есть очевидная ошибка, он проработал
в локальной сети без сбоев более шести часов, после чего моделирование завершили
с помощью ручной остановки клиента.
Примечание: Протокол сервера проверен с
помощью сценария, написанного на awk - необходимо убедиться, что каждая
операция чтения вернула правильное число байтов.
Однако при запуске того же сервера через Internet
результаты получились совсем другие. Опять запустим клиента на машине spare,
а сервер - на машине bsd, но на этот раз заставим клиента передавать данные
через глобальную сеть, указав ему адрес сетевого интерфейса, подключенного к
Internet. Как видно из последних строк, напечатанных сервером, фатальная ошибка
произошла уже через 15 мин.
Пакет 893 содержит 2 значения в 8 байтах
Пакет 894 содержит 3 значения в 12 байтах
Пакет 895 содержит 2 значения в 12 байтах
Пакет 896 содержит -268436204 значения в 8 байтах
Пакет 897 содержит 2 значения в 12 байтах
Пакет 898 содержит -268436204 значения в 8 байтах
Пакет 899 содержит 2 значения в 12 байтах
Пакет 900 содержит -268436204 значения в 12 байтах
telemetrys: recv вернула 4
bsd: $
Ошибка произошла при обработке пакета 895, когда
нужно было прочесть8 байт, а прочли 12. На рис. 2.21 представлено, что произошло.
Числа слева показывают, сколько байтов было в приемном
буфере TCP на стороне сервера. Числа справа - сколько байтов сервер реально
прочитал. Вы видите, что пакеты 893 и 894 доставлены и обработаны, как и ожидалось.
Но, когда telemetrys вызвал recv для чтения пакета 895, в буфере было 20 байт.
Примечание: Трассировка сетевого трафика,
полученная с помощью программы tcpdump (совет 34), показывает, что в этот момент
были потеряны TCP-сегменты, которыми обменивались два хоста. Вероятно, причиной
послужила временная перегрузка сети, из-за которой промежуточный маршрутизатор
отбросил пакет. Перед доставкой пакета 895 клиент telemetryc yжe подготовил
пакет 896, и оба были доставлены вместе.
В пакете 895 было 8 байт, но, поскольку уже пришел
пакет 896, сервер прочитал пакет 895 и первое число из пакета 896. Поэтому в
распечатке видно, что было прочитано 12 байт, хотя пакет 895 содержит только
два целых. При следующем чтении возвращено два целых из пакета 896, и telemetrys
напечатал мусор вместо числа значений, так как telemetryc не инициализировал
второе значение.

Рис. 2.21. Фатальная ошибка
Как видно из рис. 2.21, то же самое произошло с
пакетами 897 и 898, так что при следующем чтении было доступно уже 28 байт.
Теперь telemetrys читает пакет 899 и первое значение из пакета 900, остаток
пакета 900 и первое значение из пакета 901 и наконец последнее значение из пакета
901. Последняя операция чтения возвращает только 4 байта, поэтому проверка в
строке 19 завершается неудачно, а моделирование - с ошибкой.
К сожалению, на более раннем этапе моделирования
произошло еще худшее:
Пакет 31 содержит 2 значения в 8 байтах
Пакет 32 содержит 3 значения в 12 байтах
Пакет 33 содержит 2 значения в 12 байтах
Пакет 34 содержит -268436204 значения в 8 байтах
Пакет 35 содержит 2 значения в 8 байтах
Пакет 36 содержит 3 значения в 12 байтах
Всего через 33 с после начала моделирования произошла
ошибка, оставшаяся необнаруженной. Как показано на рис. 2.22, когда telemetrys
читал пакет 33 в буфере было 20 байт, поэтому операция чтения вернула 12 байт
вместо 8. Это означает, что пакет с двумя значениями ошибочно был принят за
пакет с тремя значениями, а затем наоборот. Начиная с пакета 35, telemetrys
восстановил синхронизацию, и ошибка прошла незамеченной.
Рис. 2.22. Незамеченная ошибка
Локальная сеть, которая представляет собой почти
идеальную среду, может маскировать проблемы производительности и даже ошибки.
Не думайте, что приложение, работающее в локальной сети, будет также хорошо
работать и в глобальной.
Из-за сетевых задержек приложение, производительность
которого в локальной сети была удовлетворительной, в глобальной сети может работать
неприемлемо медленно. В результате иногда приходится перепроектировать программу.
Из-за перегрузок в интенсивно используемой глобальной
сети, особенно в Internet, данные могут доставляться как внезапно, так и пакетами
неожиданного размера. Это требует от вас особой осторожности в допущениях о
том, сколько данных может прийти в определенный момент и с какой частотой они
поступают.
Хотя в этом разделе говорилось исключительно о протоколе TCP, то же относится
и к UDP, поскольку он не обладает встроенной надежностью, чтобы противостоять
тяжелым условиям в Internet.
В книге [Stevens 1998] автор отмечает, что основные
проблемы в сетевом программировании не имеют отношения ни к программированию,
ни к API. Они возникают из-за непонимания работы сетевых протоколов. Это подтверждают
вопросы, которые задают в конференциях, посвященных сетям (совет 44). Например,
некто, читая справочную документацию на своей UNIX- или Windows-машине обнаруживает,
как отключить алгоритм Нейгла. Но если он не понимает принципов управления потоком,
заложенных в TCP, и роли этого алгоритма, то вряд ли разберется, когда имеет
смысл его отключать, а когда - нет.
Точно так же, отсутствие механизма немедленного
уведомления о потере связи, обсуждавшееся в совете 10, может показаться серьезным
недостатком, если вы не понимаете, почему было принято такое решение. Разобравшись
с причинами, можно без труда организовать обмен сообщениями-пульсами именно
с той частотой которая нужна конкретному приложению.
Есть несколько способов изучить протоколы, и многие
из них будут рассмотрены в главе 4. Основной источник информации о протоколах
TCP/IP - это RFC, который официально определяет, как они должны работать. В
RFC обсуждается широкий спектр вопросов разной степени важности, в том числе
все протоколы из семейства TCP/IP. Все RFC, а также сводный указатель находятся
на следующем сайте: www.rfc-editor.org.
В совете 43 описаны также другие способы получения
RFC.
Поскольку RFC - это плод труда многих авторов,
они сильно различаются доступностью изложения. Кроме того, некоторые вопросы
освещаются в нескольких RFC и не всегда просто составить целостную картину.
Существуют и другие источники информации о протоколах,
более понятные для начинающих. Два из них будут рассмотрены здесь, а остальные
- в главе 4.
В книге [Comer 1995] описываются основные протоколы
TCP/IP и то, как они должны работать, с точки зрения RFC. Здесь содержатся многочисленные
ссылки на RFC, которые облегчают дальнейшее изучение предмета и дают общее представление
об организации RFC. Поэтому некоторые считают эту книгу теоретическим введением
в противоположность книгам [Stevens 1994; Stevens 1995], где представлен подход,
ориентированный в основном на практическое применение.
В книгах Стивенса семейство протоколов TCP/IP исследуется
с точки зрения реализации. Иными словами, показывается, как основные реализации
TCP/IP работают в действительности. В качестве инструмента исследования используются,
главным образом, данные, выдаваемые программой tcpdump (совет 34), и временные
диаграммы типа изображенной на рис. 2.16. В сочетании с детальным изложением
форматов пакетов и небольшими тестовыми программами, призванными прояснить некоторые
аспекты работы обсуждаемых протоколов, это дает возможность ясно представить
себе их функционирование. С помощью формального описания добиться этого было
бы трудно.
Хотя в этих книгах приняты разные подходы к освещению
протоколов TCP/IP следует думать, будто один подход чем-то лучше другого, а
стало быть, отдавать предпочтение только одной книге. Полезность каждой книги
зависит от поставленной перед вами задачи в данный момент. По сути, издания
взаимно дополняют друг друга. И серьезный программист, занимающийся разработкой
сетевых приложений, должен включить эти две книги в свою библиотеку.
В этом разделе обсуждалось, насколько важно разбираться
в функционировании протоколов. Отмечено, что официальной спецификацией TCP/IP
являются RFC и рекомендованы книги Комера и Стивенса в качестве дополнительного
источника информации о протоколах и их работе.
Поскольку задача проектирования и реализации сетевых
протоколов очень сложна, обычно ее разделяют на меньшие части, более простые
для понимания. Традиционно для этого используется концепция уровней. Каждый
уровень предоставляет сервисы уровням выше себя и пользуется сервисами нижележащих
уровней.
Например, на рис. 2.1, где изображен упрощенный
стек протоколов TCP/IP уровень IP предоставляет сервис, именуемый доставкой
датаграмм, уровням TCP и UDP. Чтобы обеспечить такой сервис, IP пользуется сервисами
для передачи датаграмм физическому носителю, которые предоставляет уровень сетевого
интерфейса.
Наверное, самый известный пример многоуровневой
схемы сетевых протоколов - это эталонная модель открытого взаимодействия
систем (Reference Model of Open Systems Interconnection), предложенная Международной
организацией по стандартизации (ISO).
Примечание: Многие ошибочно полагают, что
в модели OSI были впервые введены концепции разбиения на уровни, виртуализации
и многие другие. На самом деле, эти идеи были хорошо известны и активно применялись
разработчиками сети ARPANET, которые создали семейство протоколов TCP/IP задолго
до появления модели OSI. Об истории этого вопроса вы можете узнать в RFC 871
[Padlipsky 1982].
Поскольку в этой модели семь уровней (рис. 2.23),
ее часто называют семиуровневой моделью OSI.

Рис. 2.23. Семиуровневая талонная модель
OSI
Как уже отмечалось, уровень N предоставляет сервисы
уровню N+1 и пользуется сервисами, предоставляемыми уровнем N-1. Кроме того,
каждый уровень может взаимодействовать только со своими непосредственными соседями
сверху и снизу. Это взаимодействие происходит посредством четко определенных
интерфейсов между соседними уровнями, поэтому в принципе реализацию любого уровня
можно заменить при условии, что новая реализация предоставляет в точности те
же сервисы, и это не отразит на остальных уровнях. Одноименные уровни в коммуникационных
стеках обмениваются данными (по сети) с помощью протоколов.
Эти уровни часто упоминаются в литературе по вычислительным
сетям. Каждый из них предоставляет следующие сервисы:
- физический уровень. Этот уровень связан
с аппаратурой. Здесь определяю электрические и временные характеристики интерфейса,
способ передачи битов физическому носителю, кадрирование и даже размеры и
форма разъемов
- канальный уровень. Это программный интерфейс
к физическому уровню. В его задачу входит предоставление надежной связи с
последним. На этом вне находятся драйверы устройств, используемые сетевым
уровнем для общения с физическими устройствами. Кроме того, этот уровень обеспечивает
формирование кадров для канала, проверку контрольных сумм с целью обнаружения
искажения данных и управление совместным доступом к физическому носителю.
Обычно задача интерфейса между сетевым и канальным уровнями - создание
механизма, обеспечивающего независимость от конкретного устройства;
- сетевой уровень. Этот уровень занимается
доставкой пакетов от одного узла другому. Он отвечает за адресацию и маршрутизацию,
фрагментацию и сборку, а также за управление потоком и предотвращение перегрузок;
- транспортный уровень. Реализует надежную
сквозную связь между узлами сети, а также управление потоком и предотвращение
перегрузок. Он компенсирует ненадежность, присущую нижним уровням, за счет
обработки ошибок, которые вызваны искажением данных, потерей пакетов и их
доставкой не по порядку;
- сеансовый уровень. Транспортный уровень
предоставляет надежный полнодуплексный коммуникационный канал между двумя
узлами. Сеансовый уровень добавляет такие сервисы, как организация и уничтожение
сеанса (например, вход в систему и выход из нее), управление диалогом (эмуляция
полудуплексного терминала), синхронизация (создание контрольных точек при
передаче больших файлов) и иные надстройки над надежным протоколом четвертого
уровня;
- уровень представления. Отвечает за представление
данных, например, преобразование форматов (скажем, из кода ASCII в код EBCDIC)
и сжатие;
- прикладной уровень. На нем располагаются
пользовательские программы, использующиеся остальными четырьмя уровнями для
обмена данными. Известные из мира TCP/IP примеры - это telnet, ftp, почтовые
клиенты и Web-браузеры.
Официальное описание семиуровневой модели OSI приведено
в документе International Standards Organization 1984], но оно лишь в общих
чертах декларирует, что должен делать каждый уровень. Детальное описание сервисов,
предоставляемых протоколами на отдельных уровнях, содержится в других документах
ISO. Довольно подробное объяснение модели и ее различных уровней со ссылками
на соответствующие документы ISO можно найти в работе (Jain and Agrawala 1993].
Хотя модель OSI полезна как основа для обсуждения
сетевых архитектур и реализаций, ее нельзя рассматривать как готовый чертеж
для создания любой сетевой архитектуры. Не следует также думать, что размещение
некоторой функции на уровне N в этой модели означает, что только здесь наилучшее
для нее место.
Модель OSI имеет множество недостатков. Хотя, в
конечном итоге, были созданы работающие реализации, протоколы OSI на сегодняшний
день утратили актуальность. Основные проблемы этой модели в том, что, во-первых,
распределение функций между уровнями произвольно и не всегда очевидно, во-вторых,
она была спроектирована (комитетом) без готовой реализации. Вспомните, как разрабатывался
TCP/IP, стандарты которого основаны на результатах экспериментов.
Другая проблема модели OSI - это сложность
и неэффективность. Некоторые функции выполняются сразу на нескольких уровнях.
Так, обнаружение и исправление ошибок происходит на большинстве уровней.
Как отмечено в книге [Tanenbaum 1996], один из
основных дефектов модели OSI состоит в том, что она страдает «коммуникационной
ментальностью». Это относится и к терминологии, отличающейся от общеупотребительной,
и к спецификации примитивов интерфейсов между уровнями, которые более пригодны
для телефонных, а не вычислительных сетей.
Наконец, выбор именно семи уровней продиктован,
скорее, политическими, а не техническими причинами. В действительности сеансовый
уровень и уровень представления редко встречаются в реально работающих сетях.
Сравним модель OSI с моделью TCP/IP. Важно отдавать
себе отчет в том, что модель TCP/IP документирует дизайн семейства протоколов
TCP/IP. Ее не предполагалось представлять в качестве эталона, как модель OSI.
Поэтому никто и не рассматривает ее как основу для проектирования новых сетевых
архитектур. Тем не менее поучительно сравнить две модели и посмотреть, как уровни
TCP/IP отображаются на уровни модели OSI. По крайней мере, это напоминает, что
модель OSI - не единственный правильный путь.
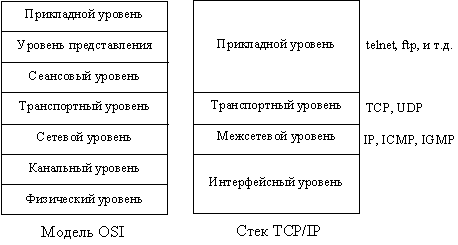
Рис. 2.24. Сравнение модели OSI и стека
TCP/IP
Как видно из рис. 2.24, стек протоколов TCP/IP
состоит из четырех уровней. На прикладном уровне решаются все задачи, свойственные
прикладному уровню, уровню представления и сеансовому уровню модели OSI. Транспортный
уровень аналогичен соответствующему уровню в OSI и занимается сквозной доставкой.
На транспортном уровне определены протоколы TCP и UDP, на межсетевом протоколы
IP, ICMP и IGMP (Internet Group Management Protocol). Он соответствует сетевому
уровню модели OSI.
Примечание: С протоколом IP вы уже знакомы.
ICMP (Internet Control Message Protocol) - это межсетевой протокол контрольных
сообщений, который используется для передачи управляющих сообщений и информации
об ошибках между системами. Например, сообщение «хост недоступен» передается
по протоколу ICMP, равно как запросы и ответы, формируемые утилитой ping. IGMP
(Internet Group Management Protocol) - это межсетевой протокол управления
группами, с помощью которого хосты сообщают маршрутизаторам, поддерживающим
групповое вещание, о принадлежности к локальным группам. Хотя сообщения протоколов
ICMP и IGMP передаются в виде IP-датаграмм, они рассматриваются как неотъемлемая
часть IP, а не как протоколы более высокого уровня.
Интерфейсный уровень отвечает за взаимодействие
между компьютером и физическим сетевым оборудованием. Он приблизительно соответствует
канальному и физическому уровням модели OSI. Интерфейсный уровень по-настоящему
не описан в документации по архитектуре TCP/IP. Там сказано только, что он обеспечивает
доступ к сетевой аппаратуре системно-зависимым способом.
Прежде чем закончить тему уровней в стеке TCP/IP,
рассмотрим, как происходит общение между уровнями стека протоколов в компьютерах
на разных концах сквозного соединения. На рис. 2.25 изображены два стека TCP/IP
на компьютерах, между которыми расположено несколько маршрутизаторов.
Вы знаете, что приложение передает данные стеку
протоколов. Потом они опускаются вниз по стеку, передаются по сети, затем поднимаются
вверх по стеку протоколов компьютера на другом конце и наконец попадают в приложение.
Но три этом каждый уровень стека работает так, будто на другом конце находится
только этот уровень и ничего больше. Например, если в качестве приложения выступает
FTP, то FTP-клиент «говорит» непосредственно с FTP-сервером, не имея сведений
о том, что между ними есть TCP, IP и физическая сеть.
Это верно и для других уровней. Например, если
на транспортном уровне используется протокол TCP, то он общается только с протоколом
TCP на другом конце, не зная, какие еще протоколы и сети используются для поддержания
«беседы». В идеале должно быть так: если уровень N посылает сообщение, то уровень
N на другом конце принимает только его, а все манипуляции, произведенные над
этим сообщением нижележащими уровнями, оказываются невидимыми.
Последнее замечание требует объяснения. На рис.
2.25 вы увидите, что транспортный уровень - самый нижний из сквозных уровней,
то есть таких, связь между которыми устанавливается без посредников. Напротив,
в «разговоре» на межсетевом уровне участвуют маршрутизаторы или полнофункциональные
компьютеры, расположенные на маршруте сообщения.
Примечание: Предполагается наличие промежуточных
маршрутизаторов, то есть сообщение не попадает сразу в конечный пункт.
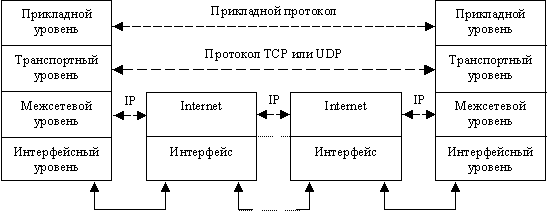
Рис. 2.25. Сквозная сеть
Но промежуточные системы могут изменять некоторые
поля, например, время существования датаграммы (TTL - time to live) в IP-заголовке.
Поэтому межсетевой уровень в пункте назначения может «видеть» не в точности
то же сообщение, что межсетевой уровень, который его послал.
Этот подчеркивает различие между межсетевым и транспортным
уровням. Межсетевой уровень отвечает за доставку сообщений в следующий узел
на маршруте. И он общается с межсетевым уровнем именно этого узла, а не с межсетевым
уровнем в конечной точке. Транспортные же уровни контактируют напрямую, не имея
информации о существовании промежуточных систем.
В этом разделе дано сравнение моделей OSI и TCP/IP.
Вы узнали, что семиуровневая модель OSI нужна как средство описания сетевой
архитектуры, но созданные на ее базе реализации почти не имеют успеха.
| 
 LINUX
LINUX 
 Books
Books
