Базы данных и Perl
Содержание
С базами данных в перле можно работать двумя способами:
вы можете реализовать свою собственную базу
или использовать уже существующую.
Можно использовать стандартный пакет DBM,RDBM.
Perl comes with a set of database management (DBM) library files.
Here's the list of packages that come with the latest version
of Perl (5.002):
- GDBM_File.pm-GNU's database
interface files
- NDBM_File.pm-Berkeley
UNIX compatibility
- ODBM_File.pm-Standard
Perl package
- SDBM_File.pm-Standard
Perl package
- AnyDBM_File.pm-Virtual
classes for any of the above database interfaces
The AnyDBM_File package encapsulates
the rest of the packages. If you use the AnyDBM
file, you'll automatically load one of the standard packages from
the previous list. To use the AnyDBM_File
package, insert the following statement at the start of your Perl
script:
use AnyDBM_File;
There is nothing preventing you from explicitly naming a particular
DBM package to override the defaults used by the AnyDBM_file
package. To use the GDBM_File
explicitly, insert this statement instead:
use GDBM_File;
A DBM, when used with these packages, is a mapping of an associative
array to a file on disk. To map the associative array to disk,
you use dbmopen() to create
or open an existing file, make all the modifications to the associative
array, and then close the file with a call to dmbclose().
I covered how to bind variables to associative arrays and how
to use the tie() function
in Chapter 6, "Binding Variables to
Objects." In the future, most dbmopen()
function calls will be replaced by, or at least internally work
as, tie() function calls.
Basically, a DBM file will be tied to an associative array. Subsequent
updates to the associative array will be reflected in the file
on disk. However, you will come across legacy code that does use
the dbmopen() and dbmclose()
functions, so it's important to see how these work together. Also,
you may find it easier to use these DBM functions to program for
quick prototyping than to have to code the callback functions
required for the tie() function.
After you've read this chapter, you should be able to decide whether
to use DBM functions or write the functions for database access
using the tie() function.
Here's an example to illustrate how the DBM files work. First,
I'll create a small database of some stock symbols and the names
of the companies. The file containing this data sample is called
sym.txt and is partially
shown here:
$ head sym.txt
ASZ AMSCO INTL Inc
AMSR AMSERV HEALTHCARE
ASO AMSOUTH BAncORP
AMTC AMTEch
AMTL AMTROL
AVFC AMVESTORS FIN CORP
AMW AMWEST INSURAncE GROUP
AMLN AMYLIN PHARMACEUTICALS
AAC ANACOMP Inc
Apc ANADARKO PETROLEUM CORP
$
This file contains several lines of records where each record
has two items of data: the first column is the stock ticker symbol
followed by the company name. Note that a company name can contain
one or more space characters.
Now I'll construct a mini-database of all company names indexed
by their stock symbol. To use the DBM utilities for this endeavor,
I would use the script shown in Listing 18.1.
Listing 18.1. Creating a DBM file.
1 #!/usr/bin/perl
2 # --------------------------------------------------------
3 # Sample script to create a DBM repository.
4 # Input file "sym.txt" to the script has the
format:
5 # SYMBOL Company Name
6 # --------------------------------------------------------
7 #
8 # Use the default DBM utilites
9 #
10 use AnyDBM_File;
11 open(SFILE, "sym.txt") || die "\n Cannot open
sym.txt $!\n";
12 #
13 # Open the database "ticker". If it does not exist,
create it.
14 # Map the hash stocks to this database.
15 #
16 dbmopen(%stocks,"ticker",0666);
17 while (<SFILE>) {
18 chop;
19 ($symbol,@name) = split('
',$_);
20
21 $stocks{$symbol} = join(' ',@name);
22 # print " $symbol [ @name ] \n";
23 }
24 #
25 # Close the input file
26 #
27 close(SFILE);
28 #
29 # Commit changes in hash to disk for the next flush.
30 #
31 dbmclose(%stocks);
In Listing 18.1, the AnyDBM_File
package is used at line 10 to get the best available package for
the system. You can override the type by replacing the AnyDBM_File
package with a DBM package of your choice. In line 11, the input
file is opened.
Line 16 creates a DBM called ticker
and maps it onto an associative array called %stocks{}.
Note that you are actually creating two files called ticker.pag.
The file permissions given for this open
are 0666 so that it's possible for all other users to use this
DBM.
In lines 17 through 23, the symbol names are read in, and the
values are assigned to the newly created hash, called stocks.
Lines 18 and 19 simply take the text input from the sym.txt
file and separate it into a symbol and a company name. At line
21 a value is assigned to the associative array using the symbol
as the index into the array. Now that this array has been mapped
to the disk, the data can be kept in the array even after the
script that created this file is long gone.
Note also that the join() function
is used in line 21 to piece together the items of names of the
companies into one string. Had the join()
function not been used, $stocks{$symbol}
would contain the number of items of the @names
array and not the contents.
In line 31 the dbmclose()
function is used to commit the changes to disk. If you do not
use dbmclose(), your DBM
file modifications are not be saved to disk. The dbmclose()
function disconnects (or un-ties) the hash from the file
on disk so that any changes made to the hash after the dbmclose()
function are made as if to an uninitialized associative array.
When the contents of the hash will be flushed to disk depends
on the underlying system. As far as the program is concerned,
the hash connected to the underlying database is not initialized
anymore.
Two files are created with the use of the AnyDBM_File
package. These are the two files that were created by the script
in Listing 18.1 when I ran it:
-rw-r--r-- 2 khusain users 6608
Mar 26 08:08 scripts/ticker.dir
-rw-r--r-- 2 khusain users 6608
Mar 26 08:08 scripts/ticker.pag
Of course, because you do not have access to the original files
that I used in this example, the sizes shown here will be different
for the data file that you use. Just note that the size of both
the files is the same.
If the AnyDBM_File package
had been substituted with the GDBM_File
page, we would only get one file:
-rw-r--r-- 1 khusain users 6608
Mar 26 08:06 scripts/ticker
Again, the size of the ticker
file will be different depending on the input data file that you
use. However, you should note that the size of the ticker file
is the same as that of the two files created by the AnyDBM-File
package.
The database has now been created on disk. Whether it consists
of one file or two is not important in the application that will
access the database because all the internals are hidden with
the DBM function calls.
In order for us to look at the data in the newly created DBM file,
another script needs to be created. The viewing script is shown
in Listing 18.2.
Listing 18.2. Viewing the contents of a DBM file.
1 #!/usr/bin/perl
2 # --------------------------------------------------------
3 # Sample script to list contents of a DBM repository.
4 # --------------------------------------------------------
5 #
6 # Use the default DBM utilites
7 #
8 use AnyDBM_File;
9 #
10 # Open the database "ticker". (If it does not exist,
create it.)
11 # Map the hash stocks to this database.
12 #
13 dbmopen(%stocks,"ticker",0666);
14 while (($symbol,$name) = each(%stocks)) {
15 print "Symbol [$symbol] for [$name]\n";
16 }
17 #
18 # Keep any changes, if any, in hash back on disk.
19 #
20 dbmclose(%stocks);
Line 13 opens the hash as before. Because the file already exists,
there is no need to create it. Lines 14 and 15 are where the contents
of the hash $stocks is printed
out. Line 20 closes the file.
It's relatively simple to add a new symbol to the newly created
database. To see how to add to the database, refer to Listing
18.3.
Listing 18.3. Adding to the DBM array.
1 #!/usr/bin/perl
2 # --------------------------------------------------------
3 # Sample script to add to contents of a DBM repository.
4 # --------------------------------------------------------
5 #
6 # Use the default DBM utilites
7 #
8 use AnyDBM_File;
9 #
10 # Open the database "ticker". (If it does not exist,
create it.)
11 # Map the hash stocks to this database.
12 #
13 dbmopen(%stocks,"ticker",0666);
14 print "\n Symbol: ";
15 # Get the symbol for the company
16 chop ($symbol = <STDIN>);
17 print "\n Company Name: ";
18 # Get the name of the company
19 chop ($name = <STDIN>);
20 $stocks{$symbol} = $name;
21 # Keep any changes, if any, in hash back on disk.
22 #
23 dbmclose(%stocks);
To delete an item from the %stocks{}
associative array, use the delete
command. For example, the code in Listing 18.3 can be modified
to become a deletion command by adding the delete
operator to line 20. The code in line 20 would look like this:
delete $stocks{$symbol};
The contents of a DBM array can be easily searched using Perl's
features. To look for a symbol in an existing DBM, use the Perl
search operation with the =~ //
syntax. Listing 18.5 illustrates this.
Listing 18.5. Searching the DBM array.
1 #!/usr/bin/perl
2 # --------------------------------------------------------
3 # Sample script to search contents of a DBM repository.
4 # --------------------------------------------------------
5 #
6 # Use the default DBM utilites
7 #
8 use AnyDBM_File;
9 #
10 # Open the database "ticker". (If it does not exist,
create it.)
11 # Map the hash stocks to this database.
12 #
13 dbmopen(%stocks,"ticker",0666);
14 print "\n Enter String to Look for: ";
15 $search = <STDIN>;
16 chop $search;
17 printf "\n Searching.\n";
18 $i = 0;
19 while (($symbol,$name) = each(%stocks)) {
20 if ($name =~ /$search/) {
21 $i++;
22 print
"$i. [$symbol] has [$name]\n"
23 }
24 }
25 printf "\n ===> $i Records found.\n ";
26 #
27 # Keep any changes, if any, in hash back on disk.
28 #
29 dbmclose(%stocks);
Lines 19 through 24 contain a while
loop that uses the each command.
The each command is more
efficient than using a for
loop command because both the key and the indexed value are retrieved
with the each command. In
the for loop on the keys
of an associative array, two separate steps must be taken to retrieve
the same information-first to get the key for the loop iteration
with a call to the keys(hash) function, and second to get
the value based on the retrieved key.
Running the program to look for NAL
in the company names produces the following output:
Enter String to Look for: NAL
Searching.
1. [ALOG] has [ANALOGIC CORP]
2. [AATI] has [ANALYSIS & TEchNOLOGY]
3. [ANLY] has [ANALYSTS INTL CORP]
4. [APSG] has [APPLIED SIGNAL TEch]
5. [ADI] has [ANALOG DEVICES]
===> 5 Records found.
The program found all company names with the string NAL
in their name. As you can see, within Perl you have the power
to create a new database, add or delete items from the database,
and list the contents of the database. Using the hash as the map,
you can perform many other operations on the hash and reflect
the results back to disk.
The DBM files are still a flat database; therefore, in order to
create relationships between data items, you still have to do
some shuffling around of indexes, filenames, and files. Fairly
sophisticated data algorithms are not out of reach, however, if
you are careful. For example, the sample $symbol
index can also be used as a filename containing historical data.
Let's say the %stocks{} DBM
array is used as a storage area for the stocks in a portfolio.
It's easy to get historical data from the Internet (for example,
via CompuServe) for a given stock symbol. Listing 18.5 collects
and displays some statistics for the symbols in the sample portfolio.
So that you don't have to type everything via STDIN,
the script is designed to use command-line options with the Getopts::Long
module. See Chapter 16, "Command-Line
Interface with Perl," for more information on how to use
the Getopts::Long.pm module.
In this example, the -s option
is used to specify the stock symbol and the -v
option is used to get a complete listing of all the readings.
Listing 18.4. Using the DBM array.
1 #!/usr/bin/perl
2 # --------------------------------------------------------
3 # Sample script to use the DBM array for indexing.
4 # --------------------------------------------------------
5 #
6 # Use the default DBM utilites
7 #
8 use AnyDBM_File;
9 use Getopt::Long;
10 #
11 # Open the database "ticker". (If it does not exist,
create it.)
12 # Map the hash stocks to this database.
13 #
14 dbmopen(%stocks,"ticker",0666);
15 #print "\n Enter Symbol to Look for: ";
16 #$search = <STDIN>;
17 #chop $search;
18 GetOptions('stock=s','v!');
19 $search = $opt_stock;
20 $i = 0;
21 $highest = 0;
22 $lowest = 10000;
23 if ($stocks{$search}) {
24 if (-e $search) {
25 open(SDATA,$search)
|| die "Cannot open $search $!\n";
26 printf
"\n Historical data for $search \n" if ($opt_v);
27 while
(<SDATA>) {
28
($day,$hi,$lo,$close) = split('\s',$_);
29
$sum += $close;
30
$i++;
31
if ($hi > $highest) { $highest = $hi; }
32
if ($lo < $lowest) { $lowest = $lo; }
33
write if ($opt_v);
34 }
35 close
SDATA;
36 printf "\n
Summay of %d readings on $search", $i;
37 printf
"\n Lowest On File = %f ", $lowest;
38 printf
"\n Highest On File = %f ", $highest;
39 printf
"\n Average Price = %f ", $sum / $i;
40 printf
"\n";
41 }
42 } else {
43 printf "\n Sorry, I do not track
this symbol: $symbol";
44 }
45
46 dbmclose(%stocks);
47 #
48 # Define a clean output format for displaying data
49 #.
50 format STDOUT =
51 @<<<<<< @####.### @####.### @####.###
52 $day, $hi, $lo, $close
53 .
You print the stocks you are tracking by checking to see if the
name exists in the %stocks{}
hash. This is done in line 23 with the following statement:
if ($stocks{$search}) {
Once the file is found to exist with the -e
flag in line 24, it is opened and read from in lines 27 to 35.
The summary is printed in lines 36 through 40. In case the symbol
is not listed in the database, an error message is printed in
the else clause in line 43.
The format for the output via the write
statement in line 33 is defined in lines 50 to 53.
In this example, the historical data for a stock is stored in
a file called AMAT. Therefore,
to invoke the script, use this command:
$ test.pl -s AMAT
Summay of 305 readings on AMAT
Lowest On File = 18.500000
Highest On File = 59.875000
Average Price = 38.879393
As you can see, the output from this script is made a bit more
presentable with the use of the format
statement.
Because it's possible to use the DBM files from within modules,
let's see if the Invest.pm
module (covered in Chapter 5, "Object-Oriented
Programming in Perl") can be updated to include saving and
restoring portfolio information on disk. You will be appending
some functions to the original Invest.pm.
All the new functions will go at the end of the file unless specified
otherwise.
Some changes need to be made to the Invest.pm
module to get it to work with the DBM files. The first change
is to include the following statement before the first executable
line in the Invest.pm file:
require AnyDBM_File;
The @portfolio array is changed
to %portfolio because this
array can be mapped directly to disk via a DBM file. The @portfolio
array contains references to hashes and not the content of the
item in the referenced hash. Therefore, a new scheme has to be
incorporated in order to parse the values and then store them
to disk. After the values are stored to disk, the reverse operation
has to be applied to read them back. Because this sample portfolio
is not a large database, the important values can be stored using
a colon delimited array. If this example were a very large array,
the items could be stored with the pack()
function and thus store only binary values.
A new function has to be created to save the contents of the portfolio
to disk. Add the following function to the end of the Invest.pm
file on or about line 116:
savePortfolio {
my ($this, $filename) = @_;
my %dummy;
my $a;
my ($key, $val);
dbmopen(%dummy,$filename,0666);
while (($key,$val) = each(%portfolio)) {
$a = "$key:" . $val->{'type'}
. ":" .
$val->{'symbol'} . ":" .
$val->{'shares'};
$dummy{$key} = $a;
# Debug: print "\n Writing $dummy{$key}";
}
dbmclose(%dummy);
}
The %dummy hash is used to
map to the disk file. Each item in the portfolio
hash is parsed for storage in the %dummy
hash. The value of $key goes
from 0, 1,
2, and up. One string is
saved to disk per hash item. Here's the format of the string:
$key:$type:$symbol:$shares
$type can be Stock
or Fund. $symbol
is the stock or fund symbol and $shares
is the number of shares of the stock. Keep in mind that this is
only an example-the real data stored would probably have to include
date of purchase, purchase price, and so on. In this event, the
fields could be appended to the string with colons separating
each field. If you want to add purchase price, your field would
look like this:
$key:$type:$symbol:$shares:$purchased
To restore the file back from disk, the Invest.pm
file will have to read back the same portfolio file and restore
all the values in the portfolio array. The function will also
have to recognize the difference between the types of items it
has to re-create. The restoration is done by this function which
is added to the end of the Invest.pm
file at about line 132:
sub restorePortfolio {
my ($this, $filename) = @_;
my %dummy;
my ($key, $val);
my ($ndx,$sec,$sym,$shr);
my $a;
local $i1;
dbmopen(%dummy,$filename,0666);
while (($key,$val) = each(%dummy)) {
$a = $dummy{$key};
($ndx,$sec,$sym,$shr) = split(':',$a);
# print "Read back $ndx,$sec,$sym,$shr
\n";
if ($sec eq 'Fund')
{
$i1 = Invest::Fund::new('Invest::Fund',
'symbol'
=> "$sym", 'shares' => "$shr");
}
else
{
$i1 = Invest::Stock::new('Invest::Stock',
'symbol'
=> "$sym", 'shares' =>"$shr");
}
$this->Invest::AddItem($i1);
$this->Invest::showPortfolio;
}
dbmclose(%dummy);
}
To create the sample portfolio, use the shell script shown in
Listing 18.6. You might want to edit the code shown in Listing
18.6 to print the reported information in a different format than
the one shown here. In this sample script, two stocks are added
and then the contents of the portfolio are printed.
Listing 18.6. Creating a sample portfolio.
1 #!/usr/bin/perl
2
3 push(@Inc,'pwd');
4
5 use Invest;
6 # use Invest::Fund;
7 use Invest::Stock;
8
9 #
10 # Create a new portfolio object
11 #
12 $port = new Invest;
13
14 print "\n -- CREATE PORTFOLIO --";
15 $s1 = new Invest::Stock('symbol' => 'AMAT', 'shares' =>
'400');
16 $s2 = new Invest::Stock('symbol' => 'INTC', 'shares' =>
'200');
17
18 print "\n Adding stocks ";
19 $port->Invest::AddItem($s1);
20 $port->Invest::AddItem($s2);
21
22 $port->Invest::showPortfolio();
23
24 #
25 # SAVE THE DATA HERE in the DBM file called
myStocks
26 #
27 $port->Invest::savePortfolio("myStocks");
To view the contents of the portfolio, you'll have to write another
simple script. This script is shown is Listing 18.7. The file
to recover data from is called myStocks.
You should be able to see this file in your directory.
Listing 18.7. Listing the portfolio.
1 #!/usr/bin/perl
2
3 push(@Inc,'pwd');
4
5 use Invest;
6 use Invest::Fund;
7 use Invest::Stock;
8
9 $port = new Invest;
10
11 print "\n -- LIST PORTFOLIO --";
12
13 $port->Invest::restorePortfolio("myStocks");
14 $port->Invest::showPortfolio();
There are occasions when you'll want to have more than one file
open for DBM access. You can use a unique stock ticker symbol
as the index into several hashes, each of which is then mapped
to its own DBM file. For example, the following database code
could be used to track stock price information in one DBM file
and earnings information in another DBM file. Both DBM files will
be indexed via the stock symbol name. Results of analyzing data
from both DBM files could be printed using code similar to the
following snippet:
foreach $symbol (@listOfsymbols) {
dbmopen(%earnings,$symbol,0666);
dbmopen(%prices,$symbol,0666);
@results = analyzeEarnings(\%earnings,\%prices);
printResults(\@results);
dbmclose(%prices);
dbmclose(%earnings);
}
So far I have only covered the standard DBM utilities that come
with Perl distribution. For most casual users, these DBM files
will be sufficient for their database needs. Unfortunately, when
things get complicated, as in the case of relational databases,
you might want to reconsider your options with other database
solutions. The price tag for DBM utilities is attractive because
they're free. However, you just might want to pay someone to acquire
a commercial Relational Database Management System (RDBMS).
Second, there is an inherent danger in using DBM utilities that
I must warn you about. If you make a mistake in working with your
mapped hash and somehow write it to disk with a dbmclose(),
guess what? You just wiped out your entire database. This type
of faux pas is not hard to do, especially if you are modifying
data. Obliteration of your DBM database is generally only recoverable
from backup.
Commercial databases have a "safer" feel because they
provide you with a safety net by keeping alternate backups. You
are still your own worst enemy, but it's a little bit harder to
destroy all data. In any event, always back up your data.
If you do decide to use a database management system (DBMS) other
than the DBM utilities, all is not lost. You can use RDB (a freeware
relational database) or other Perl front-ends to popular databases.
All of the front packages allow your Perl programs to talk to
different databases via the protocol used by a DBI package.
Listing 18.8 presents the final version of the Invest.pm
file after all the modifications discussed up to now in this chapter
have been made to it.
Listing 18.8. The final version of Invest.pm
with DBM support.
1
2 package Invest;
3
4 push (@Inc,'pwd');
5 require Exporter;
6 require Invest::Stock;
7 require Invest::Fund;
8 require AnyDBM_File;
9 @ISA = (Exporter);
10
11 =head1 NAME
12
13 Invest - Sample module to simulate Bond behaviour
14
15 =head1 SYNOPSIS
16
17 use Invest;
18 use Invest::Fund;
19 use Invest::Stock;
20
21 $port = new Invest::new();
22
23 $i1 = Invest::Fund('symbol' =>
'twcux');
24 $i2 = Invest::Stock('symbol'
=> 'INTC');
25 $i3 = Invest::Stock('symbol'
=> 'MSFT', 'shares' => '10');
26
27 $port->Invest::AddItem($i1);
28 $port->Invest::AddItem($i2);
29 $port->Invest::AddItem($i3);
30
31 $port->showPortfolio();
32 $port->savePortfolio("myStocks");
33
34 =head1 DESCRIPTION
35
36 This module provides a short example of generating a
letter for a
37 friendly neighborbood loan shark.
38
39 The code begins after the "cut" statement.
40 =cut
41
42 @EXPORT = qw( new, AddItem, showPortfolio, savePortfolio,
43 reportPortfolio,
44 restorePortfolio,
PrintMe);
45
46 my %portfolio = {};
47 my $portIndex = 0;
48
49 sub Invest::new {
50 my
$this = shift;
51 my
$class = ref($this) || $this;
52 my
$self = {};
53 bless
$self, $class;
54 $portIndex = 0;
55 # printf "\n Start portfolio";
56 return
$self;
57 }
58
59 sub Invest::AddItem {
60 my ($type,$stock) = @_;
61 $portfolio{$portIndex} = $stock;
62 # print "\nAdded ". $stock->{'shares'}
. " shares of " . $stock->{'symbol'};
63 $portIndex++;
64 }
65
66 sub Invest::showPortfolio {
67 printf "\n Our Portfolio
is:";
68 my ($key, $i);
69 while (($key,$i) = each(%portfolio))
{
70 print
"\n ". $i->{'shares'} . " shares
of " . $i->{'symbol'};
71 }
72 print "\n";
73 }
74
75 sub Invest::reportPortfolio {
76 my $hdrfmt = $~;
77 my $topfmt = $^;
78 my $pageCt = $=;
79 my $lineCt = $-;
80 my $sym;
81 my $shr;
82 my ($key, $i);
83
84 $~ = "PORT_RPT";
85 $^ = "PORT_RPT_TOP";
86
87 format PORT_RPT_TOP =
88
89 Report
90 STOCK SHARES
91 ===== ======
92 .
93
94 format PORT_RPT =
95 @<<<< @<<<<
96 $sym, $shr
97 .
98 # note how the code is intermingled
with the format!
99 while (($key,$i) = each(%portfolio))
{
100 $shr
= $i->{'shares'};
101 $sym
= $i->{'symbol'};
102 write
;
103
104 }
105
106 $= = $pageCt;
107 $- = $lineCt;
108 $~ = $hdrfmt;
109 $^ = $topfmt;
110 }
111
112 sub PrintMe {
113 my $this = shift;
114 print "\n Class : $$this";
115 }
116
117 sub savePortfolio {
118 my ($this, $filename) = @_;
119 my %dummy;
120 my $a;
121 my ($key, $val);
122 dbmopen(%dummy,$filename,0666);
123 while (($key,$val) = each(%portfolio))
{
124 $a =
"$key:" . $val->{'type'} . ":" . $val->{'symbol'}
. ":" . $val->{'shares'};
125 print
"\n Writing $key $a";
126 $dummy{$key}
= $a;
127 print
"\n Writing $dummy{$key}";
128 }
129 dbmclose(%dummy);
130 }
131
132 sub restorePortfolio {
133 my ($this, $filename) = @_;
134 my %dummy;
135 my ($key, $val);
136 my ($ndx,$sec,$sym,$shr);
137 my $a;
138 local $i1;
139 dbmopen(%dummy,$filename,0666);
140 while (($key,$val) = each(%dummy))
{
141 $a =
$dummy{$key};
142 ($ndx,$sec,$sym,$shr)
= split(':',$a);
143 # print
"Read back $ndx,$sec,$sym,$shr \n";
144 if ($sec
eq 'Fund')
145
{
146
$i1 = Invest::Fund::new('Invest::Fund',
147 'symbol'
=> "$sym", 'shares' => "$shr");
148
}
149 else
150
{
151
$i1 = Invest::Stock::new('Invest::Stock',
152 'symbol'
=> "$sym", 'shares' =>"$shr");
153
}
154 $this->Invest::AddItem($i1);
155 $this->Invest::showPortfolio;
156 }
157 dbmclose(%dummy);
158 }
159
160 1;
Line 8 is where the require
statement is used to implement the AnyDBM_FILE
support. Lines 17 through 19 use other packages as well.
The database interface (DBI) package for Perl is the implementation
of the DBI Application Program Interface (API) specification written
by Tim Bunce (Tim.Bunce@ig.co.uk).
The DBI package API is designed specifically for use with Perl.
The set of functions and variables in the DBI package provide
a consistent interface to the application using it. The strong
point of the DBI package API, in addition to its broad set of
available functions, is that it completely isolates the using
application from the internal implementation of the underlying
database.
The DBI specification exists at various sites in the CPAN archives,
but the latest version (v0.6) is not up to date. The best source
of information is to look in the source files for a DBI package
itself. The entire specification is good for getting an idea of
how everything is intended to work together. However, the interface
has changed considerably since the specification was released.
Check out the file dbispec.v06
in compressed form at ftp.demon.co.uk
in the /pub/perl/db directory.
The DBI specification started out as DBperl back in 1992 as a
team effort from several Perl enthusiasts. Here are the initial
contributors to the specification for each type of database:
| infoperl (Informix) | Kurt Andersen (kurt@hpsdid.sdd.hp.com)
|
| interperl (Interbase) | Buzz Moschetti (buzz@fsrg.bear.com)
|
| oraperl (Oracle) | Kevin Stock (kstock@encore.com)
|
| sybperl (Sybperl) | Michael Peppler (mpeppler@itf.ch)
|
| sqlperl/ingperl (Ingres) | Ted Mellon (dbi-users@fugue.com) and Tim Bunce
|
The original DBI specification was edited by Kurt Anderson. In
1994, Tim Bunce took over the editing and maintenance of the specification
in addition to the DBI and DBD::Oracle
package development. The specification and related files are copyrighted
by Tim Bunce.
The original specification was edited by Kurt Anderson from the
discussions on the mailing list. In 1993, Tim Bunce took over
the editing and maintenance of the specification and in 1994 started
the development of the DBI and DBD::Oracle
modules. The DBI specification and modules are copyrighted by
Tim Bunce but are freely available to all with the same terms
as Perl. (Tim is the technical director of the software systems
house, Paul Ingram Group in Surrey, England. Tim can be reached
at Tim.Bunce@ig.co.uk, but
DBI related mail should be sent to the dbi-users@fugue.com
mailing list.)
The DBI is not related to any one specific database because it
serves as an intermediary between a program and one or more DBD::*
driver modules. DBD:: modules
are drivers written to support a specific database back-end. The
DBI:: module manages all
installed DBD:: drivers in
your system. You can load and use more than one DBD::
module at the same time.
DBD:: modules are written
in such a way that they may be copied and customized to suit your
specific needs. For example, the DBD::Oracle
module served as the starting point for Alligator Descartes, another
well-known pioneer in developing database interfaces for Perl,
to develop DBD:: modules
for other databases. He has written two copyrighted documents
on how to develop your own driver from DBD::
modules. These documents are located on the Web site www.hermetica.com
in the technologia/DBI directory.
Some of DBI:: packages available
on the Internet are listed here; you can get the latest versions
of these files from the Internet CPAN sites:
- DBD-Oracle-0.29.tar.gz
for Oracle users
- DBD-Informix-0.20pl0.tar.gz
for Informix database users
- DBD-QBase-0.03.tar.gz
for Quickbase users
- DBD-mSQL-0.60pl9.tar.gz
for mSQL-based databases
- DBI-0.67.tar.gz for the
DBI interface
The interface packages are simply front-ends to the database engine
that you must have installed on your machine. For example, in
order to use the Oracle DBI package, you'll need the Oracle database
engine installed on your system. The installation instructions
are located in the README
files in the packages themselves. You'll need to have Perl 5.002
installed on your system to get some of the packages to work,
especially the DBI module.
The DBI interface is very different than the old, database-specific
interfaces provided by oraperl, ingperl, interperl, and so on.
To simplify the transition to Perl 5, some DBD::
drivers, such as DBD::Oracle,
come with an extra module that emulates the old-style interface.
The DBI interface has never been fully defined because it has
been constantly evolving. This evolution will take a large step
forward with the adoption of the standard ODBC interface as the
core of the DBI. Because this redefinition of the DBI interface
standard is bound to change the DBI interface, Tim Bunce recommends
using stable emulation interfaces, such as oraperl, instead.
The RDB database utilities for Perl deserve an honorable mention.
The RDB package is complete, simple to use, and very easy to set
up. The author of this package is Walt Hobbs; he can be reached
at hobbs@rand.org.
The source and documentation is found in the file RDB-2.5k.tar.Z
in the CPAN modules directories. There is a file named Info.RDB
in the package that provides a short overview of how the RDB package
organizes its data and what commands are available for you to
use. The Info.RDB file also
lists the origins of the RDB package, describes how to use it,
and provides a sample data file.
The operators in the RDB packages are Perl scripts that use standard
I/O for UNIX to operate on ASCII files. The format for databases
in the RDBM package is to store data in rows and columns in text
files. Each row contains items separated by tabs, and each row
is terminated by a newline character. (The field separator is
a tab, and the record separator, therefore, is the newline character.)
Each column in the text file has the items' names and format defined
as the first two rows.
Because the data is stored in such a format, it's easier to access
the data using programs other than those supplied with the RDB
package. You can use Perl or awk scripts to get what you want
if the RDM programs do not give you what you need. The RDB operators
are only Perl scripts that you can use as a basis for writing
your own extensions.
The operators on the package include listing by row, listing by
column, merging tables, and printing reports. All operators in
the RDB package read from standard input and write to standard
output.
Consider the following sample data file. There are four columns
in the data file. Each column has a heading and type of data associated
with it. The comments with #
in the front of the line are ignored. The first uncommented row
contains the name of fields per column. The row immediately after
that stores the type of data. 4N
means that LINE and WORD
are four-digit wide numbers. (S
specifies a string and M
stands for month.) A digit by itself is a string; therefore, NAME
fields are eight characters wide.
#
# Sample data file for Chapter 18
#
LINE WORD BYTE NAME
4N 4N 5N 8
1128 6300 37140 TS03.dat
644 3966 24462 TS04.dat
1175 6573 40280 TS05.dat
968 6042 38088 TS13.dat
687 3972 24383 TS14.dat
741 4653 28100 TS16.dat
1621 8804 58396 TS17.dat
1061 6086 39001 TS20.dat
1107 4782 29440 TS21.dat
846 5839 37442 TS22.dat
1758 8521 54235 TS23.dat
836 4856 30916 TS24.dat
1084 5742 34816 TS27.dat
The commands to operate on are relatively simple. To sort the
table by LINE numbers, you
use this command on the test.data
file:
sorttbl < test.data LINE > out
The resulting output in the out
file is as follows. The format for the output file is an RDB file
itself. You can run other RDB operators on it, too!
#
# Sample data file for Chapter 18
#
LINE WORD BYTE NAME
4N 4N 5N 8
644 3966 24462 TS04.dat
687 3972 24383 TS14.dat
741 4653 28100 TS16.dat
836 4856 30916 TS24.dat
846 5839 37442 TS22.dat
968 6042 38088 TS13.dat
1061 6086 39001 TS20.dat
1084 5742 34816 TS27.dat
1107 4782 29440 TS21.dat
1128 6300 37140 TS03.dat
1175 6573 40280 TS05.dat
1621 8804 58396 TS17.dat
1758 8521 54235 TS23.dat
You can get summary information about columns with the summ
command. For example, to get summary information for the test.data
file for averages, use this command:
summ -m < test.data
Here's the resulting output:
Rows: 13
Min, Avg, Max, Total for LINE: 644, 1050, 1758, 13656
Min, Avg, Max, Total for WORD: 3966, 5856, 8804, 76136
Min, Avg, Max, Total for BYTE: 24383, 36669, 58396, 476699
Min, Avg, Max, Total for NAME: 0, 0, 0, 0
You can join two tables together on a per-column basis to get
a merged table. The command to do this is jointbl.
The -c option does the merge
for you on a per-column basis. Consider the two files p1.dat
and p2.dat with a common
column of NAME in each file.
The merged output is shown with this command:
jointbl -c < p1.dat NAME p2.dat
The use of the jointbl command
is shown in the following input/output example:
$ cat p1.dat
$
$ cat p2.dat
#
# P2
#
LINE NAME
4N 8
1128 TS03.dat
644 TS04.dat
1175 TS05.dat
968 TS13.dat
687 TS14.dat
741 TS16.dat
1621 TS17.dat
1061 TS20.dat
1107 TS21.dat
846 TS22.dat
1758 TS23.dat
836 TS24.dat
1084 TS27.dat
$
$ jointbl -c < p1.dat NAME p2.dat
#
# P1
#
#
# P2
#
NAME BYTE LINE
8 5N 4N
TS03.dat 37140 1128
TS04.dat 24462 644
TS05.dat 40280 1175
TS13.dat 38088 968
TS14.dat 24383 687
TS16.dat 28100 741
TS17.dat 58396 1621
TS20.dat 39001 1061
TS21.dat 29440 1107
TS22.dat 37442
846
TS23.dat 54235 1758
TS24.dat 30916
836
TS27.dat 34816 1084
Other more powerful features of this RDB package are listed in
the RDB.ps PostScript file.
It prints out to a 72-page manual with examples and details on
all of the commands available for you. If you do not feel like
killing a tree, you can use ghostview
to view the file.
Perl supplies a flat database package in the DBM utilities. The
modules allow Perl scripts to map hashes to disk files for storage.
For most users, storing data with DBM utilities is sufficient.
Some DBD:: and DBI::
modules are available as front-ends to commercial databases such
as Oracle, Sybase, Informix, and Quickbase. You need the specific
database and database engine installed on your machine in order
for the DBD:: code to work.
The RDB package provides a text file-based relational database
management system. Utilities in the RDB package are a set of Perl
programs that operate on rows and columns of data files.
Chapter 20
Introduction to Web Pages and CGI
CONTENTS
This chapter offers a brief introduction to the HyperText Markup
Language (HTML) and the Common Gateway Interface (CGI). The information
in this chapter provides the basis for the rest of the chapters
about Web pages in this book, especially for the topic of writing
CGI scripts in Perl. This chapter assumes that you have a cursory
knowledge of what the World Wide Web (WWW) is about and how to
use a browser.
I also assume you're somewhat familiar with HTML code. Going into
more detail about HTML programming would cause us to move too
far away from the scope of the book: Perl programming. Therefore,
I stick to the very basic HTML elements for text formatting and
listing items rather than covering a lot of HTML programming issues.
Reading this one chapter won't make you a Webmaster, but you'll
learn enough to create Web pages you can subsequently use in conjunction
with Perl scripts. With these basics, you'll be able to easily
incorporate other HTML page-layout elements in your documents.
If you are not familiar with HTML or would like more information,
don't worry. There are several documents on the Internet that
describe how to write HTML pages. For up-to-date documentation
on HTML, conduct a search on the keywords HTMLPrimer and
html-primer in the Internet search areas.
For more information via printed text books, you might want to
consult these titles:
- Teach Yourself Web Publishing with HTML 3.0 in a Week,
Laura Lemay, Sams.net Publishing, 1-57521-064-9, 1996.
- HTML & CGI Unleashed, John December and Mark Ginsberg,
Sams.net Publishing, 0-672-30745-6, 1995.
- Using HTML, Neil Randall, Que, 0-7897-0622-9, 1995.
HTML is the de facto standard language for writing Web pages on
the Internet. HTML documents are written as text files and are
meant to be interpreted by a Web browser. A Web browser displays
the data in HTML pages by reading in the tags around the data.
Web browsers reside on client machines, and Web server daemons
run on Web servers. The protocol used by Web servers and clients
to talk to each other is called the HyperText Transfer Protocol
(HTTP).
An HTML page contains uniform resource locators (URLs) in addition
to the tags. A URL tells the browser where to get certain data.
URLs can point to other Web documents, FTP sites, Gopher sites,
and even executable programs on the server side. The Common Gateway
Interface (CGI) is the standard used to run programs for a client
on the server.
A Web server gets a request for action from the browser when the
user selects the URL. The request is processed by the server by
running a program. The program is often referred to as a CGI script
because a lot of programs for handling CGI requests are Perl scripts.
The results of the CGI script are sent back to the browser making
the request. The browser displays the results back to the user.
Results can be in plain text, binary data, or HTML documents.
The browser reading the output from the CGI script has to know
the type of input it is receiving. The type of information is
sent back as a multipurpose Internet mail-extension (MIME) header.
For example, to send back plain text, you use "Content-Type:
text/plain\n\n" at the start of the document.
To send back HTML data, you use "Content-type:
text/html\n\n".
| Note |
Using two carriage returns after the type of data is very important. The HTML standard requires a blank line after the Content-type string. This is why we have "\n\n"
appended to Content-type. In most cases, the "\n\n" will work as intended to produce a blank line for a browser. Sometimes this will not work, and the data being sent back
to the browser will not be shown because the server will be handling carriage-returns/line-feeds using the "\r\n" string instead of "\n". To allow for
inconsistencies in the way operating systems handle carriage-return/line-feed pairs, you should use the string "\r\n\r\n".
|
An HTML document uses markup tags to specify special areas of
the text. The format of an HTML document is as follows:
<HTML>
<HEAD>
<TITLE>Title of the page</TITLE>
</HEAD>
<BODY>
The
body of the document.
</BODY>
</HTML>
All text for the HTML document is shown between the <HTML>
and </HTML> tags. There
can be only two pairs of elements, one pair of <BODY>
and </BODY> tags to
store the text matter for the HTML document, and the other pair
of <HEAD> and </HEAD>
tags. The <HEAD> and
</HEAD> tags show the
document title in the heading section of a viewer. The <TITLE>
and </TITLE> tags hold
the string for text in the title bar for your browser and are
the only required element within the <HEAD>
and </HEAD> tags.
Both the <HEAD> and
<TITLE> tags are optional.
However, for compatibility with some browsers, you should include
them. The <BODY> and
</BODY> tags are required
in all cases. Most HTML tags are paired. So if you have <HEAD>,
then you should have </HEAD>.
There are exceptions to this rule. For example, the paragraph
tag <P> and the line
break <BR> tag are
used by themselves and do not require any accompanying </P>
or </BR> tags. (The
</P> tag is sometimes
used to terminate a paragraph, but the </BR>
tag does not exist.)
Tags are not case sensitive, and any formatting in between the
tags is almost always ignored. Therefore, the tag <html>
is the same as <HtMl>
and <HTML>.
It's the presence of <HTML>,
<HEAD>, and <BODY>
tags in the page that distinguishes an HTML page from a simple
text page. Figure 20.1 presents a sample text page which does
not have any formatting on it whatsoever being loaded into an
HTML browser.
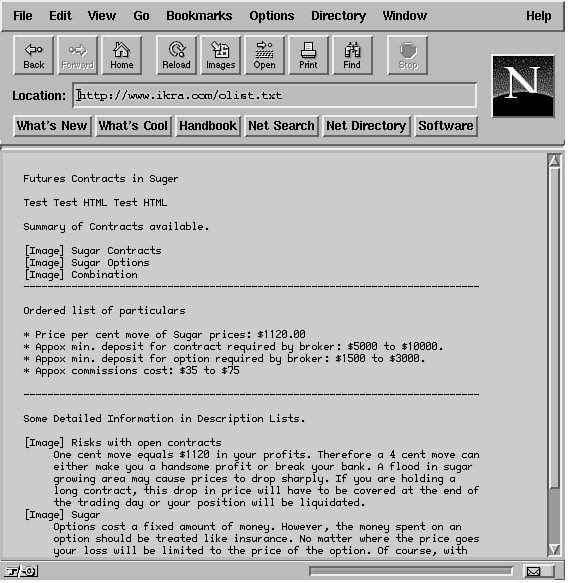 Figure 20.1: An unformatted document. Figure 20.1: An unformatted document.
All the text shown in Figure 20.1 is aligned in the way that the
original text document was set up. In some cases, the text would
have been clumped in one long paragraph. Here is the text for
the document shown in Figure 20.1:
Futures Contracts in Sugar
Test Test HTML Test HTML
Summary of Contracts available.
[Image] Sugar Contracts
[Image] Sugar Options
[Image] Combination
----------------------------------------------------------------------------
Ordered list of particulars
* Price per cent move of Sugar prices: $1120.00
* Appox min. deposit for contract required by broker: $5000 to
$10000.
* Appox min. deposit for option required by broker: $1500 to $3000.
* Appox commissions cost: $35 to $75
----------------------------------------------------------------------------
Some Detailed Information in Description Lists.
[Image] Risks with open contracts
One cent move equals $1120 in your profits.
Therefore a 4 cent move can
either make you a handsome profit or break your bank. A flood
in sugar
growing area may cause prices to drop
sharply. If you are holding a
long contract, this drop in price will have to be covered at the
end of
the trading day or your position will
be liquidated.
[Image] Sugar
Options cost a fixed amount of money.
However, the money spent on an
option should be treated like insurance. No matter where the price
goes
your loss will be limited to the price
of the option. Of course, with
limiting risk you are also limiting profits.
To make the text more presentable, you can add some HTML tags
to the document, as shown in Listing 20.1. First, we'll delimit
the paragraphs with a <P>
tag and then add some headings to it. HTML provides six levels
of headings, numbered H1
through H6. H1
is the top-level heading in a document's hierarchy and H6
is the bottom. Generally, you use H2
headers inside H1 headers,
H3 headers inside H2
headers, and so on. Do not skip heading levels unless you have
a compelling reason to switch heading styles. Use the tags <H1>Text
for heading</H1> for defining a heading.
A sample HTML page is shown in Listing 20.1. See the output in
Figure 20.2.
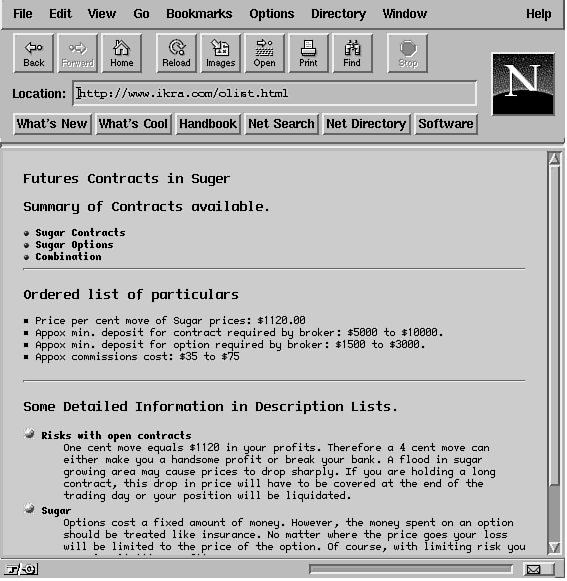 Figure 20.2:Using tags to enhance the appearance of HTML documents. Figure 20.2:Using tags to enhance the appearance of HTML documents.
Listing 20.1. Formatted text.
1 <HTML>
2 <HEAD><TITLE>Using Lists</TITLE>
3 </HEAD>
4 <BODY><P>
5 <P>
6 <H1>Futures Contracts in Sugar</H1>
7 <P>
8 <A HREF="../cgi-bin/testing.pl"> Test</A>
9 <A HREF="query.pl"> Test HTML</A>
10 <A HREF="../cgi-bin/query.pl"> Test HTML</A>
11 <H2>Summary of Contracts available.</H2>
12 <IMG SRC="red-ball-small.gif"> <B>Sugar
Contracts</B><BR>
13 <IMG SRC="red-ball-small.gif"> <B>Sugar
Options</B><BR>
14 <IMG SRC="red-ball-small.gif"> <B>Combination</B><BR>
15 <HR>
16 <H2> Ordered list of particulars </H2>
17 <UL>
18 <LI> Price per cent move of Sugar prices:
$1120.00
19 <LI> Appox min. deposit for contract required by broker:
$5000 to $10000.
20 <LI> Appox min. deposit for option required by broker:
$1500 to $3000.
21 <LI> Appox commissions cost: $35 to $75
22</UL>
23 <P>
24 <H2> Some Detailed Information in Description Lists. </H2>
25 <P>
26 <DL>
27 <DT><IMG SRC="yellow-ball.gif"> <B>Risks
with open contracts </B>
28 <DD> One cent move equals $1120 in your profits. Therefore
a 4 cent move
29 can either make you a handsome profit or break your bank. A
flood in sugar
30 growing area may cause prices to drop sharply. If you are holding
a long
31 contract, this drop in price will have to be covered at the
end of the
32 trading day or your position will be liquidated.
33 <DT><IMG SRC="yellow-ball.gif"> <B>
Sugar </B>
34 <DD> Options cost a fixed amount of money. However, the
money spent on
35 an option should be treated like insurance. No matter where
the price
36 goes your loss will be limited to the price of the option.
Of course,
37 with limiting risk you are also limiting profits.
38 <DT><IMG SRC="yellow-ball.gif"> <B>
Combination of both <B>
39 </BODY></HTML>
Your browser will show a different font for each header style.
In this listing, we used two heading levels, <H1>
and <H2>, lines 5 and
8. The required <TITLE>
is also shown and terminated with the </TITLE>
keyword in line 1. The <P>
tag is used to start a new paragraph in lines 4, 5, and 7, for
example. If the <P>
tags were not used, the text would follow in one big clump unless
you were beginning a new header or a horizontal line with the
<HR> tag. See Line
15 where the <HR> tag
is used to draw a horizontal line.
Look at lines 12 through 14. Using <BR>
tags, I have created the list of three items using IMG tags.
Note how images are stored and displayed within the document with
the <IMG> tag. Basically,
the IMG tag specifies where an image will be displayed in the
HTML document. The SRC attribute of the IMG tag specifies the
URL for the contents of the image. The URL can be a complete (absolute)
pathname or a relative pathname. An absolute path would describe
the entire URL: http://www.ikra.com/mydirectory/red-ball-small.gif,
whereas the relative pathname will assume the default directory
for images on the server and pick the image called red-ball-small.gif
from that directory. By using image files, you can enhance the
appearance of items in a list and provide your own bullets. Consider
this reference in line 12:
<IMG SRC="red-ball-small.gif">
<B>Sugar Contracts</B><BR>
The file red-ball-small.gif
is shown next to the text Sugar Contracts
using the relative URL scheme.
There are several more attributes to an IMG tag allowing you to
align text around the image, size the image, provide a mapping
of URLs to go to if the user clicks on a section of the image,
and so on. Be sure to check the references provided in the "HTML,
CGI, and MIME" section for more information on how to use
IMG tags.
HTML supports the following types of list formats with which you
can show information:
- Unnumbered lists (items in <UL>
and </UL> tags) where
the items in a list are not numbered.
- Numbered lists (items in <OL>
and </OL> tags) where
each item in a list is numbered.
- Definition lists (items in <DT>
and <DD> tags) where
each item in the list is a term followed by a descriptive paragraph
that applies to that term.
Items in a list are separated by <LI>
tags. The </LI> tag
is not needed to stop one item and start another. In Listing 20.1,
lines 17 to 22 provide an unnumbered list with the use of <UL>
and
</UL> tags. To make
this a numbered list, simply change the <UL>
and </UL> pair to an
<OL> and </OL>
tag, respectively, and all the items in the list will be numbered.
A definition list has two items: a <DT>
tag with a term and the definition of the term with
<DD>. The <LI>
and <DD> items can
contain multiple paragraphs with the use of the <P>
tag. Lines 27 through 38 in Listing 20.1 show how to create a
simple definitions list.
You can even nest lists within lists. Just remember to end each
list completely within the list item of the parent list. See the
sample HTML code in Listing 20.2.
Listing 20.2. Nested lists.
1 <HTML><HEAD><TITLE>Another
Lists Example</TITLE></HEAD>
2 <BODY>
3 <P><H1>This shows Numbered Lists</H1><P>
4 Start of List here.
5 <OL>
6 <LI> Toulouse
7 <UL>
8 <LI> To Barritz
9 <LI> To Bordeaux
10 <LI> To Marseille
11 <LI> To Paris
12 </UL>
13 <LI> Paris
14 <UL>
15 <LI> To Dijon
16 <LI> To Rennes
17 <LI> To Toulouse
18 </UL>
19 <LI> Rennes
20 <UL>
21 <LI> To Paris
22 <LI> To Cherbourg
23 </UL>
24 <LI> Nice
25 <UL>
26 <LI> To Digne
27 <LI> To Menton
28 </UL>
29 </OL>
30 </BODY>
31 </HTML>
The top level numbered list is started at line 5 and ends in line
29. Each item of the numbered list is inserted in lines 6, 13,
19, and 24. Nested lists are shown as unnumbered lists enclosed
in <UL> and </UL>
tags in lines 8 to 12, 14 to 18, 20 to 23, and 25 to 28. Each
<UL> and </UL>
pair is terminated in the space for each item in the top level
numbered list.
The basic set of HTML tags such as the <HEAD>,
<BODY>, and <TITLE>
are almost always supported by all browsers. However, you should
keep in mind that not all tags are supported by all Web browsers.
If a browser does not support a tag, it just ignores it.
You can emphasize text in the document so that it stands out when
displayed by a browser. For example, to underline text, use <U>
and </U> to enclose
the text. For bold text, enclose the text in <B>
and </B> tags. For
italics, use <I> and
</I>. See the sample
HTML code in Listing 20.3.
Listing 20.3. Using HTML tags to change font style.
1 <HTML>
2 <HEAD>
3 <TITLE> IISTV.htmL </TITLE>
4 </HEAD>
5 <BODY>
6 <Center><H1>Time Change for Islam TV Program</H1></Center>
7 <HR>
8 <P>
9 From January 1996, the Islamic Information Service TV
(IISTV)
10 Program, will be broadcast <b>every Sunday at 9.00 A.M.
11 on Channel 67 (KHSH TV)</b> in the <U>Houston Metropolitan
Area</U>.
12 Islam TV is regularly watched in 5000 homes and is a totally
13 viewer supported program and we need your support.<P>
14 The program is also carried on the <EM>International
Cable channel</EM>
15 <STRONG>every Saturday at 9:30 AM.</STRONG>
16 <P>
17 For more information or to send contributions, please contact<P>
18 <hr>
19 <CENTER>
20 <STRONG>
21 ISGH/IIS-TV
<BR>
22 </STRONG>
23 9336-B
Katy Freeway Suite 314<BR>
24
Houston, Texas 77024. <BR>
25 713
827 1827<BR>
26 </CENTER>
27 <hr>
28 </BODY>
29 </HTML>
Line 6 defines a centered line of text with the <Center>
and </Center> tags.
Note how the <H1> and
</H1> tags are enclosed
along with the text being centered. Line 7 draws a horizontal
line. (Remember that HR stands for Horizontal Rule.) The <b>
and </b> tags are used
in lines 10 and 11 to embolden some text. Since HTML is case insensitive,
we could have used the tags <B>
and </B> with no loss
of functionality. Use of the <EM>
and <STRONG> tags is
shown in lines 14 and 15, respectively.
Note that the effect of <B>
remains in effect until the </B>
is seen. So the text being set to a style can be typed in across
several lines. In lines 19 through 26, center several lines.
In HTML documents you should use <STRONG>
and <EM> tags instead
of <B> and <I>
tags, respectively. There are occasions where using even seemingly
innocent tags such as <B>
for bolding text or <I>
for italicizing text may not work. For example, if a browser is
using a font that does not have an italics character set, the
<I>text</I> will
be printed with its codes; that is, it will be as <I>text</I>
and not as text. To
take care of some of these issues, should they arise, HTML authors
prefer to use the <EM></EM>
emphasis tags in place of the <I></I>
tags and the <STRONG></STRONG>
tags in place of the <B></B>.
An HTML document defines only the display style with the use of
markup tags. How a Web browser chooses to display the information
is left to the implementation at the Web browser. So the client's
browser is responsible for rendering this text and may have a
completely different font than what you are using to create the
page. Therefore, what you see on your screen will be different
from what someone else using a different font may see. For best
results, try viewing your HTML page with different browsers. The
font on someone else's browser might be completely different.
For one thing, users can choose whatever font they desire for
their browser. Even if users don't explicitly choose a font, the
browser may default to a font that is different from the one you
use. For example, one user may use the Internet Explorer from
Microsoft with a 10-point font, and another user may use Netscape
Navigator with a 12-point font. Each user will see different
lengths of paragraphs and text layout.
Simple text formatting with the use of carriage returns in HTML
documents does not work. The client browser will implement word
wrapping when it sees text. You can force paragraph and line breaks
with the use of <P>
or <BR> tags. The <BR>
tag creates a line break, and does not start a new paragraph
like the <P> tag. A
<P> tag may be used
to lay out text differently using formats and text alignment on
different types of browsers. A <BR>
tag simply starts a new line without changing the current paragraph
format. Not using these tags causes all white space (including
spaces, tabs, and blank lines) to be collapsed into one white
space. Listings 20.4 and 20.5 provide samples of two HTML files
that produce the same output.
Listing 20.4. Headings in HTML files.
1 <HTML><HEAD>
2 <TITLE>A simple HTML file</TITLE>
3 </HEAD>
4 <BODY>
5 <H1>This is Header Level 1</H1>
6 <H2>This is Header Level 2</H2>
7 <H3>This is Header Level 3</H3>
8 <H4>This is Header Level 4</H4>
9 <H5>This is Header Level 5</H5>
10 <H6>This is Header Level 6</H6>
11 This is line 1
12 This is line 2<P>
13 This is line 3<P>
14 This is a broken line with an <BR><BR> sign.
15 <P>
16 End of File Here.
17 </BODY>
18 </HTML>
Listing 20.5. The second version of the HTML file shown in
Listing 20.4.
1 <HTML><HEAD><TITLE>A
simple HTML file</TITLE>
2 <HEAD>
3 <BODY>
4 <H1>This is Header Level 1</H1> <H2>This
is Header Level 2</H2>
5 <H3>This is Header Level 3</H3> <H4>This
is Header Level 4</H4>
6 <H5>This is Header Level 5</H5> <H6>This
is Header Level 6</H6>
7 This is line 1 This is line 2<P> This is line 3<P>
8 This is a broken line with an <oBR><BR>
sign. <P> End of File Here.
9 </BODY></HTML>
Figure 20.3 shows the output from both listings. Note how heading-level
1 and heading-level 2 are shown in the same font style in this
figure. The example shown here uses Netscape as the browser. The
results on your browser might be different because each browser
displays HTML in the way it chooses. It's a bit like the contents
of a box shifting during transport but the weight of the contents
has not changed.
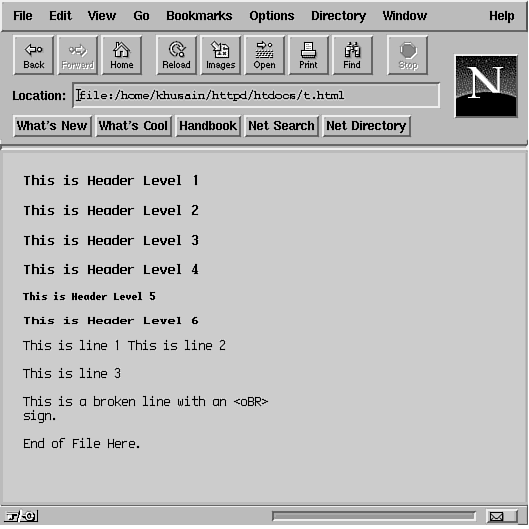 Figure 20.3: Using different heading levels. Figure 20.3: Using different heading levels.
For the sake of readability, it's best to place headings and paragraphs
on separate blank lines along with <P>
tags. You can also specify formatting options for paragraph alignment
in the <P> tag, as
illustrated in Listing 20.5. The format specified for <P>
will continue until the next <P>
tag. To terminate a particular format you can use the </P>
tag.
Listing 20.6. Aligning paragraphs.
1 <html>
2 <body>
3 <TITLE>Aligned Paragraphs</TITLE>
4 <H1>This shows aligned paragraphs</H1>
5 <P ALIGN=CENTER>
6 This line is centered
7 <P ALIGN=LEFT>
8 This is aligned off the left margin
9 <P ALIGN=RIGHT>
10 This is line aligned off the right margin
11 <P>
12 End of File Here.
13 </body>
14 </html>
The output from this listing is shown in Figure 20.4.
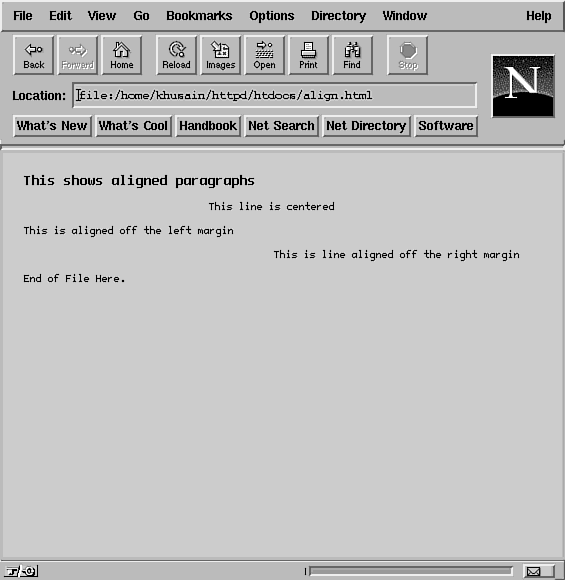 Figure 20.4: Using aligned paragraphs. Figure 20.4: Using aligned paragraphs.
Having the browser format text for you does keep you from a lot
of the hassle of tracking line breaks, paragraph formatting, and
so on. However, when displaying text that is already laid out
(such as source code), the default formatting can wreak havoc
on your source listings. For this reason, HTML documents have
the preformatted (<PRE>)
tag. Using the <PRE>
tag turns off the HTML formatting at the browser. Listing 20.8
contains an HTML file that illustrates using this tag. The output
is shown in Figure 20.5.
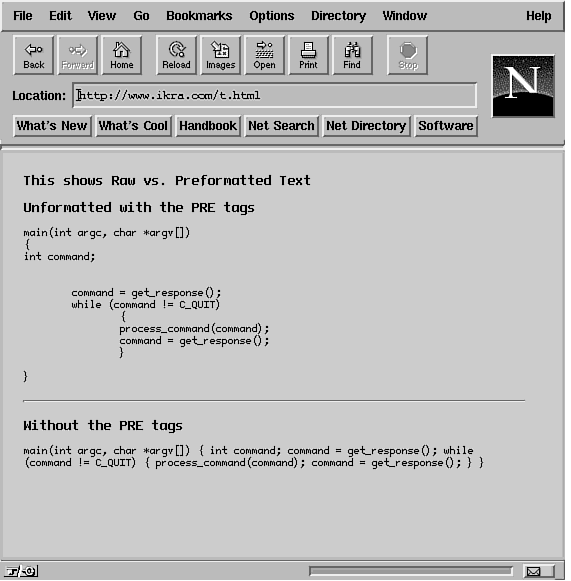 Figure 20.5: Preformatted text. Figure 20.5: Preformatted text.
Listing 20.7. Preformatted text.
1 <html>
2 <body>
3 <TITLE>Yet Another Example</TITLE>
4 <H1>This shows Raw vs. Preformatted Text</H1>
5 <H3>Unformatted with the PRE tags </H3>
6 <PRE>
7 main(int argc, char *argv[])
8 {
9 int command;
10
11 command = get_response();
12 while (command != C_QUIT)
13
{
14
process_command(command);
15
command = get_response();
16
}
17
18 }
19 </PRE>
20 <HR>
21 <H3> Without the PRE tags </H3>
22 <P>
23 main(int argc, char *argv[])
24 {
25 int command;
26
27 command = get_response();
28 while (command != C_QUIT)
29
{
30
process_command(command);
31
command = get_response();
32
}
33
34 }
35
36 </body>
37 </html>
By now you have seen that the greater than symbol and the less
than symbol are used to encode documents. What if you wanted to
include them in text that was not in preformatted tags? There
are several special characters to encode these special symbols
in HTML. In order to include them in a file, you have to enter
their codes in the HTML file. Four of the most common special
characters in HTML and their codes are
- < as the escape
sequence for <.
- > as the escape
sequence for >.
- & as the escape
sequence for the ampersand (&).
- " the escape
sequence for the double quote (").
So, to show this string in an HTML page, <HELLO>,
you would use the text statement <HELLO>
in your code. Note that the semicolon is required in each code.
URL stands for uniform resource locator. Basically, it's
an extension of a file name to include the network address of
a "thing" file and where that "thing" may
be found. The "thing" your URL is pointing to may be
a file, directory, database, image, newsgroup, archive, and so
on, on a machine that is residing anywhere on the Internet. It's
up to the browser to show that data to you.
A URL consists of three parts:
service://sitename[:port]/path/filename
The service part tells you
which service you are trying to access. The sitename
is the Internet address of the machine where the service is
being sought. The port
number is optional, because the default is port 80. The path/filename
is the location of the file relative to the root directory for
the server.
The services your browser can offer will vary. Here are the most
common types of service you can use with a Web browser:
- Http for perusing an
HTML document
- Gopher for starting a
gopher session
- Ftp for starting an ftp
session
- Telnet for starting a
telnet session
- File for getting a local
file
- News for a Usenet newsgroup
Here are some examples of URLs:
- ftp://pop.ikra.com/pub/perl5/VRML.pm This
URL specifies a file to get via ftp
from the /pub/perl5 directory.
- http://www.ikra.com/iistv.html This
URL specifies an HTML document on the node www.ikra.com.
- news://ikra.com/newsgroups/comp.dcom.telecom This
URL specifies a newsgroup to get on ikra.com.
To specify URL links to other documents, use the anchor tags,
<A> and </A>.
Anchor tags are used to provide links to other documents as well
as provide a location in a document that another HTML document
can refer to. Please check the references in this chapter if you
are not familiar with using HTML anchors. Here's the format for
using anchors for creating links to other documents:
<A HREF="URL">Text describing
where the URL points to</A>
The HREF token specifies
the URL to use. The text between the first ending >
and the start of </A>
is shown by the browser in a different color. The space between
<A and HREF
is required.
Here is a sample hypertext reference in an HTML document. For
clarity, I refer to the document that specifies the hyperlink
as the first document, and the location to which the URL points
as the second document. Let's look at the URL:
<A HREF="http://pop.ikra.com/iistv.html">IISTV</A>
The browser showing this link will make the word IISTV
show up in a different color than regular text and the link is
underlined. Clicking on the word IISTV
will cause the browser to get the file iistv.html
from www.ikra.com.
You normally use the absolute pathname of the file in a URL. Pathnames
always use the standard UNIX syntax (/),
not the DOS syntax (\), for
delimiting directory names in a path. Relative pathnames are also
possible if the anchor being specified happens to reside in the
same directory tree on the same machine as the original document.
Use relative links if you are likely to move directories around.
Moving the top-level file's location will move the entire tree
with it. On the other hand, a full pathname makes an explicit
link to the file regardless of where other files are moved to.
Anchors can also be used to move to a particular part within the
same document. Suppose you want to set a link from one document
(index.html) to a section
in another document (text.html).
Therefore, in the index.html
file, define a tag for the topic in the text.html
file like this:
<A NAME = "Daumesnil">Daumesnil
Station</A><P>
The station to go to the Zoo from....
In the index.html file, you
create the anchor to the text.html
file with a named anchor. A named anchor uses the name of the
file, followed by the hash mark (#)
and the location in the file:
Get off on <A HREF = "text.html#Daumesnil">the
Daumesnil stop</A>
and go two stations west to Port Doree.
Now when the user clicks on the words the
Daumesnil stop, the browser loads index.html
and goes to the place where the tag is placed for Daumesnil.
To go to a location within the same file, skip the filename portion
and use only the hash mark with the anchor name.
A request from a client browser at the Web server is handled by
the httpd daemon. If the
request is to run a CGI program, the server will run the program
for you and return the results of the program back to the client
browser. Input to the CGI program being run is sent either via
the command line or through environment variables. The CGI program
can be in any language, but it has to be able to process input
in this way. The output from the program is generally to standard
output. Therefore, a CGI program can be a compiled executable,
or a Perl, shell, or awk script, and so on. Naturally, because
this book is about Perl, the CGI scripts I discuss here will be
in Perl.
CGI scripts are similar to the scripts you would write to handle
the command-line interface but with one glaring exception: You
cannot send command-line options to CGI scripts. CGI uses the
command line for other purposes, so it's impossible to send arguments
to the script via the command line.
CGI uses environment variables to send your CGI program its parameters.
Environment variables are useful in CGI scripts in that any child
processes created by a CGI script also inherit the values of the
parent's environment variables. Some of the main environment variables
used by CGI scripts are listed in Table 20.1. The dagger (†)
indicates that the variable might not be supported on all servers,
so use it with caution.
Table 20.1. CGI environment variables.
| Variable | Description
|
| AUTH_TYPE
| The authorization type |
| CONTENT_LENGTH
| The size in a decimal number of octets (8-bit bytes) of any attached entity
|
| CONTENT_TYPE
| The MIME type of an attached entity |
| DOCUMENT_ROOT
| The root directory for your server's documents†
|
| DOCUMENT_URL
| The URL for your client's document† |
| DOCUMENT_NAME
| *The name of your client's document† |
| DATE_LOCAL
| Local to server |
| DATE_GMT
| Local to server |
| GATEWAY_INTERFACE
| The server's CGI specification version |
| HTTP_(string)
| The client's header data |
| PATH_INFO
| The path to be interpreted by the CGI script
|
| PATH_TRANSLATED
| The virtual to physical mapping of the path
|
| QUERY_STRING
| The URL-encoded search string |
| REMOTE_ADDR
| The IP address of the client |
| REMOTE_HOST
| The full qualified domain name of client |
| REMOTE_IDENT
| The identity data of the client |
| REMOTE_USER
| The user ID sent by the client |
| REQUEST_METHOD
| The request method sent by the client |
| SCRIPT_NAME
| The URL path identifying the CGI script |
| SERVER_NAME
| The server name (the host name of a DNS entry)
|
| SERVER_PORT
| The port at which the request was received
|
| SERVER_ROOT
| *The root directory for CGI binaries at the server
|
| SERVER_PROTOCOL
| A request for protocol name and version number
|
| SERVER_SOFTWARE
| A request for server software name and version number
|
Let's briefly cover some of these environment variables and how
your CGI script uses them. Keep in mind that only a few of these
variables are guaranteed to be set at any one invocation. Not
all of these variables are even set by all servers, so check your
documentation (usually a README
file of sorts) if you do not have the ncSA server. This book deals
with the ncSA server, which pretty much covers most of these variables.
To make things easier, you probably will not even use most of
the environment variables all the time. The most often used ones
tend to be QUERY_STRING,
REQUEST_METHOD, and PATH_INFO.
However, I cover some of the others just so you are aware of them
and what they do.
This variable is set to the number of bytes for the attached data
to a file. If there is no attached data, this is set to NULL.
In Perl, this is interpreted as zero. For example, for a string
of "x=10&y=10",
the variable is set as CONTENT_LENGTH=9.
The CONTENT_TYPE variable
is set to the type of MIME entity (data) being sent to the CGI
script. If there is no data, this variable is set to NULL,
as well. The MIME types are defined in HTTP 1.0 (and later versions).
With MIME types you can represent different types of data: video,
audio, images, or just plain text. Each type of data has its own
format: for example, GIF files are in the GIF format, text files
are in ASCII, and so on. For a GIF file, the CONTENT_TYPE
variable is set as follows:
CONTENT_TYPE = image/gif
A client may specify a list of the types of acceptable media in
its request header. This allows the server some flexibility in
how it returns data. Most types of data are registered with the
Internet Assigned Numbers Authority (IANA). The most common registered
types and subtypes are listed in Table 20.2. Subtypes and types
are not case sensitive-so GIF is equivalent to gif.
Table 20.2. MIME registered content types used by HTTP.
| Type | Subtypes
| Description |
| text |
plain |
ASCII text information |
| image |
jpeg, gif
| Supported formats |
| audio |
basic |
Audio information (includes .au format)
|
| video |
mpeg | Video data
|
| application
| octet-stream
| Application-specific data |
| message
| rfc822, partial,
external-body
| An encapsulated message |
| multipart
| mixed, alternative,
digest, parallel
| Multiple parts of individual data
types
|
The types shown in Table 20.2 are by no means complete. Servers
may support more types and subtypes. The application type describes
transmitted application-specific data. This is generally binary
data that is not interpreted by the server. Here is the usual
setting for such data:
CONTENT_TYPE=application/octet-stream
The text type describes textual data. The primary and default
subtype is plain. Here is
the general setting for this variable:
CONTENT_TYPE=text/plain.
With the introduction of "rich text" as specified by
RFC 1521 it may be necessary to specify the character set being
used. RFC 1521 is the Internet standard for defining internet
MIME formats. For more information on RFC 1521, check out the
HTML page on http://www.cis.ohio-state.edu/htbin/rfc/rfc1521.html.
Therefore, the setting for sending a plain text file via CGI would
be the following:
CONTENT_TYPE=text/plain; charset=us-ascii
A blank like here is manadatory per standard
Note that each content type must be followed by a mandatory blank
line as required by HTML/CGI specifications. The image Content-Type
can also be used to describe image data. The two well-known image
types are JPEG and GIF. The type of format for a GIF would be
CONTENT_TYPE=image/gif
A blank like here is manadatory per standard
The video Content-Type describes
video data in the MPEG format. For audio, the Content-Type
would be in the basic format. In extended subtypes, you'll see
an x in front of the
subtype.
This represents the version of the CGI specification to which
the server complies. This variable is set for all HTTP requests.
This variable represents additional path information. It describes
a resource to be returned by the CGI application once it has completed
its execution. The value of the PATH_INFO
variable can be a URL, a string provided to the CGI script, or
some other client information. It is up to the handling CGI script
as to how to use this information (if the information is needed).
If this information is a valid URL, the server may interpret the
URL before passing it to the CGI application.
The QUERY_STRING variable
is defined as anything that follows the first question mark (?)
in a URL. This information can be added either by an ISINDEX
document or an HTML form (with the GET
action). This string is encoded in the standard URL format of
changing spaces to +, individual
assignments separated by ampersands and encoding special characters
with %XX hexadecimal encoding.
You will need to decode the value of QUERY_STRING
before you can use it.
Assignments to values in an HTML FORM
are done in the form x=value.
Spaces are converted into plus (+)
signs. So an assignment of the form x=hello
world, will be converted to x=hello+world.
Individual assignments are separated by ampersands (&).
The equal (=) sign, the plus
(+) sign, and the ampersand
(&) may only be included
as encoded values (by using the #
operator, for example). Therefore, these assignments, x="hello
world", "a=2"
and "y=I am here",
are encoded as this:
x=hello+world&a=2&y=I+am+here
The server is responsible for packing the data and setting the
environment variables before running the CGI script. Information
being passed to the CGI script can be passed in one of two ways:
as part of STDIN (the Perl
handle for standard input)
or by setting the value in QUERY_STRING.
The results from the execution are sent back from the CGI script
to STDOUT (the default output
file handle for Perl).
When data is passed in via STDIN,
the CONTENT_LENGTH and CONTENT_TYPE
variables are set to reflect the length and type of data, respectively.
This kind of input is the result of the POST
method at the client. For the GET
method of requesting data, the variable QUERY_STRING
is set to the values.
Incoming strings take the form of an input string. Assignments
to values are done in the form x=value.
Spaces are converted into plus (+)
signs. Individual assignments are separated by ampersands (&).
The equal (=) sign, the plus
(+) sign, and the ampersand
(&) may only be included
as encoded values (by using the #
operator, for example). Therefore, two assignments, x=1
and "y=42 and 32",
are encoded as this:
x=1&y=42+and+32
There is a method to send data to a CGI script with the command
line, provided you have the support in the server and your data
traffic is not large. Command-line interfaces tend to be restricted
by the number of bytes available for the interface. The method
of passing data via the environment variables is considered safer
and is the preferred way of passing data.
A CGI script must always return something back to the client.
This is a requirement; otherwise, the client at the other end
might hang for a long time. The standard output from the CGI program
is the output that the script writes to STDOUT.
Output is returned in one of two ways: a nonparsed header output
or a parsed header output. In the nonparsed header output, a complete
HTTP message is sent back. In the parsed header output, an HTML
header and the body of a message is sent with another URL. The
latter method is the preferred way of sending data back from a
server to a browser.
CGI programs can return a number of document types back to the
client. The CGI standard specifies what format of data to expect
at the server via the MIME header. The most common MIME types
are text/html
for HTML, and text/plain
for straight ASCII text.
For example, to send back HTML to the client, your output should
look like the example shown here:
Content-type: text/html
<HTML><HEAD>
<TITLE>HTML Output from test CGI script</TITLE>
</HEAD><BODY>
<H1>Test output</H1>
<P>
Body of text
<P>
</BODY></HTML>
Let's look a test script to see how an HTML file can be sent back.
The CGI script in Listing 20.8 shows how to display information
about the environment variables in use. The best way to learn
is by example-and this sample script will show you how to write
a very basic CGI script in Perl.
Listing 20.8. A sample test script.
1 #!/usr/bin/perl
2 # A very common echo script on just about every
server
3 $| = 1;
4 print "Content-type: text/plain\n\n";
5 print "CGI/1.0 test script report\n\n";
6 if ($ENV{'REQUEST_METHOD'} eq "POST") {
7 $form = <STDIN>;
8 print "$form \n";
9 } else {
10 print "argc is $#ARGV \nargv is ";
11 while (@ARGV) {
12 $ARGV=shift;
13 print "$ARGV ";
14 }
15 }
16 print "\n";
17 #
18 print "SERVER_SOFTWARE = $ENV{'SERVER_SOFTWARE'}\n";
19 print "SERVER_NAME = $ENV{'SERVER_NAME'}\n";
20 print "GATEWAY_INTERFACE = $ENV{'GATEWAY_INTERFACE'}\n";
21 print "SERVER_PROTOCOL = $ENV{'SERVER_PROTOCOL'}\n";
22 print "SERVER_PORT = $ENV{'SERVER_PORT'}\n";
23 print "SERVER_ROOT = $ENV{'SERVER_ROOT'}\n";
24 print "REQUEST_METHOD = $ENV{'REQUEST_METHOD'}\n";
25 print "HTTP_AccEPT = $ENV{'HTTP_AccEPT'}\n";
26 print "PATH_INFO = $ENV{'PATH_INFO'}\n";
27 print "PATH = $ENV{'PATH'}\n";
28 print "PATH_TRANSLATED = $ENV{'PATH_TRANSLATED'}\n";
29 print "SCRIPT_NAME = $ENV{'SCRIPT_NAME'}\n";
30 print "QUERY_STRING = $ENV{'QUERY_STRING'}\n";
31 print "QUERY_STRING_UNESCAPED = $ENV{'QUERY_STRING_UNESCAPED'}\n";
32 print "REMOTE_HOST = $ENV{'REMOTE_HOST'}\n";
33 print "REMOTE_IDENT = $ENV{'REMOTE_IDENT'}\n";
34 print "REMOTE_ADDR = $ENV{'REMOTE_ADDR'}\n";
35 print "REMOTE_USER = $ENV{'REMOTE_USER'}\n";
36 print "AUTH_TYPE = $ENV{'AUTH_TYPE'}\n";
37 print "CONTENT_TYPE = $ENV{'CONTENT_TYPE'}\n";
38 print "CONTENT_LENGTH = $ENV{'CONTENT_LENGTH'}\n";
39 print "DOCUMENT_ROOT = $ENV{'DOCUMENT_ROOT'}\n";
40 print "DOCUMENT_URI = $ENV{'DOCUMENT_URI'}\n";
41 print "DOCUMENT_NAME = $ENV{'DOCUMENT_NAME'}\n";
42 print "DATE_LOCAL = $ENV{'DATE_LOCAL'}\n";
43 print "DATE_GMT = $ENV{'DATE_GMT'}\n";
44 print "LAST_MODIFIED = $ENV{'LAST_MODIFIED'}\n";
Line 3 forces the data written to STDOUT
(the default) to be sent back to the client immediately. Make
it a habit to do this is for all your CGI scripts. Flushing the
output is necessary when processing large amounts of data, because
the inherent caching on the output buffer may delay the transfer
of text from the one shown.
Line 4 returns the MIME type of document back to the client. Note
the two carriage returns at the end of the print
statement. The client expects an extra blank line.
Line 5 simply prints an output header for the text output. Line
6 checks if the input is coming from the standard input (STDIN)
or if it should be gathered from the command line. The command-line
parsing is shown only for use in this example. In Chapter 22,
"Using HTML FORMs,"
and Chapter 23, "HTML with Perl Modules,"
I develop a Perl subroutine to handle this input via the HTML
FORMS. Keep in mind that
the command-line interface is restrictive when large amounts of
data are being passed through. For the moment, this example shows
how the input is set in $ARGC
and the @ARGV array.
Lines 7 and 8 extract the input stream from <STDIN>,
whereas lines 11 through 14 extract incoming arguments from the
command-line interface. The rest of the script echoes the values
of the environment variables set at the time the shell script
is executed. Let's look at the variables in the output shown in
Figure 20.6. Note that the output is in text.
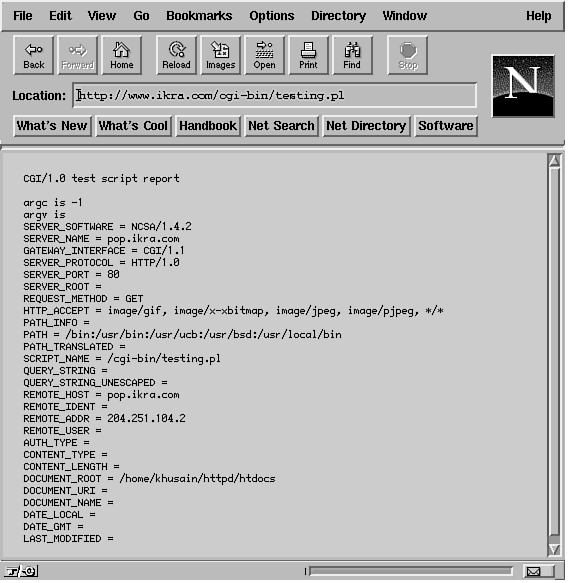 Figure 20.6: Environment variables from the test script. Figure 20.6: Environment variables from the test script.
The output in Figure 20.6 does not look very pretty does it? We
can send back an HTML document, too. Look at Listing 20.9, where
we send back an HTML document. In this listing, the content type
is set to "text/HTML"
because we are sending back an HTML document. The rest of the
script is basically echoing an HTML document back to the client.
Listing 20.9. Echo environment variables with HTML output.
1 #!/usr/bin/perl
2 print "Content-type: text/html\n\n";
3 print <<"HTML";
4 <HTML>
5 <BODY> <TITLE> HTML output </TITLE>
6 <p>
7 <H1> The environment variables </H1>
8 <UL>
9 <LI>AUTH_TYPE = <B> $ENV{'AUTH_TYPE'}</B>
10 <LI>CONTENT_TYPE = <B> $ENV{'CONTENT_TYPE'}</B>
11 <LI>CONTENT_LENGTH = <B> $ENV{'CONTENT_LENGTH'}</B>
12 <LI>DATE_LOCAL = <B> $ENV{'DATE_LOCAL'}</B>
13 <LI>DATE_GMT = <B> $ENV{'DATE_GMT'}</B>
14 <LI>DOCUMENT_ROOT = <B> $ENV{'DOCUMENT_ROOT'}</B>
15 <LI>DOCUGMENT_URI = <B> $ENV{'DOCUMENT_URI'}</B>
16 <LI>DOCUMENT_NAME = <B> $ENV{'DOCUMENT_NAME'}</B>
17 <LI>GATEWAY_INTERFACE = <B> $ENV{'GATEWAY_INTERFACE'}</B>
18 <LI>HTTP_AccEPT = <B> $ENV{'HTTP_AccEPT'}</B>
19 <LI>LAST_MODIFIED = <B> $ENV{'LAST_MODIFIED'}</B>
20 <LI>PATH_INFO = <B> $ENV{'PATH_INFO'}</B>
21 <LI>PATH = <B> $ENV{'PATH'}</B>
22 <LI>PATH_TRANSLATED = <B> $ENV{'PATH_TRANSLATED'}</B>
23 <LI>QUERY_STRING = <B> $ENV{'QUERY_STRING'}</B>
24 <LI>QUERY_STRING_UNESCAPED = <B> $ENV{'QUERY_STRING_UNESCAPED'}</B>
25 <LI>REMOTE_HOST = <B> $ENV{'REMOTE_HOST'}</B>
26 <LI>REMOTE_IDENT = <B> $ENV{'REMOTE_IDENT'}</B>
27 <LI>REMOTE_ADDR = <B> $ENV{'REMOTE_ADDR'}</B>
28 <LI>REMOTE_USER = <B> $ENV{'REMOTE_USER'}</B>
29 <LI>REQUEST_METHOD = <B> $ENV{'REQUEST_METHOD'}</B>
30 <LI>SCRIPT_NAME = <B> $ENV{'SCRIPT_NAME'}</B>
31 <LI>SERVER_NAME = <B> $ENV{'SERVER_NAME'}</B>
32 <LI>SERVER_SOFTWARE = <B> $ENV{'SERVER_SOFTWARE'}</B>
33 <LI>SERVER_PORT = <B> $ENV{'SERVER_PORT'}</B>
34 <LI>SERVER_PROTOCOL = <B> $ENV{'SERVER_PROTOCOL'}</B>
35 <LI>SERVER_ROOT = <B> $ENV{'SERVER_ROOT'}</B>
36 </UL>
37 </BODY>
38 </HTML>
The output is shown in Figure 20.7. I cover sending and receiving
data using these environment variables using Perl in Chapters 22
and 23 in greater detail.
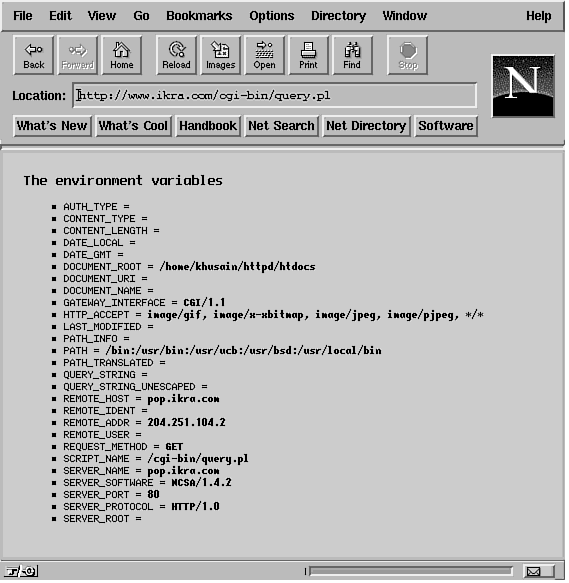 Figure 20.7: HTML equivalent output from Listing 20.9. Figure 20.7: HTML equivalent output from Listing 20.9.
The Netscape browser allows you to use frames to define scrollable
portions on your screen, as illustrated in Figure 20.8. The main
file for this page is shown in Listing 20.10.
 Figure 20.8: Using HTML FRAME tags. Figure 20.8: Using HTML FRAME tags.
For more information on frames, look at the Web site for Netscape,
the folks who came up with frames, at this address:
http://www.netscape.com/assist/net_sites/frames.html
Listing 20.10. Using FRAMEs.
1 <HTML><HEAD><TITLE>Kamran's
Home Page </TITLE>
2 </HEAD>
3 <BODY>
4 <FRAMESET ROWS="22%,78%">
5 <FRAME NAME="TOPICS"
SRC="topics.html">
6 <FRAME NAME="INDEX"
SRC="index.html">
7 </FRAMESET>
8 <NOFRAME>
9 <P>
10 For more information, please contact <address>Kamran
Husain</address>
11 <a href="mailto:khusain@ikra.com">khusain@ikra.com</a>
</BODY></HTML>
The names of the two FRAMEs
in Listing 20.10 are set as TOPICS
and INDEX. The area that
these tags use up on the screen in specified in the FRAMESET
tags. The ROWS attribute
of the FRAMESET specifies
the percentage of screen space that is to be used when rendering
each page. For example, the line
<FRAMESET ROWS="22%,78%">
sets aside 22% of the top
of the screen for the first frame to be laid out and 78%
for the other frame. Had we used COLS
instead of ROWS in the specification,
like this:
<FRAMESET COLS="22%,78%">
we would be specifying 22%
of the screen space for the first frame and 78%
for the second frame. More than one frame can be specified as
long as the sum of all the percentages assigned for spaces add
up to 100. For example, to set aside three columnar spaces on
a screen, you could use the following line:
<FRAMESET COLS="22%,22%,*">
The first two frames would be given a column whose width is 22%
each of the total space available. The asterisk in the third column's
space indicates to the browser to use the rest of the available
space for the third column.
Also, like lists, frames can be nested within other frames by
nesting a <FRAMESET></FRAMESET>
tag pair in other FRAMESET
tags. For more information on using FRAMES,
check out the reference books listed earlier in this chapter.
In Listing 20.10, the TOPICS
frame occupies the 22% top
area, and the INDEX frame
occupies the bottom 78%.
The URLs in the INDEX frame
use the name TOPICS of the
window and the TARGET option
to display text in the TOPICS
window frame. See Listing 20.11.
Listing 20.11. Using TARGET
in FRAMEs.
1 <HTML>
2 <HEAD><TITLE>MPS Inc. Home Page </TITLE>
</HEAD>
3 <P>
4 <H1>Topics to choose from</H1>
5 <ul>
6 <li> <A HREF="mpstrain.html" TARGET="INDEX"
>
7 Training Courses</A>
8 <li> <A HREF="mpsgraph.html" TARGET="INDEX">
9 Graphics Applications with C/C++ </A>
10 <li> <A HREF="mpsprog.html" TARGET="INDEX">
11 UNIX Programming</A>
12 <li> <A HREF="mpsgraph.html#Seismic" TARGET="INDEX">
13 Seismic Exploration Applications></A>
14 </ul>
15 </B></BODY></HTML>
The TARGET attribute sets
the frame that will be used to lay out the contents of what the
HREF attribute points to.
When you click on any of the links defined in the top row of the
HTML page, the contents of the URL are laid out in the bottom
frame. Therefore, the top serves as a table of contents, and the
bottom serves as the viewing area for the HTML page.
This chapter has been a whirlwind introduction to writing HTML
pages and interfacing with CGI scripts. A book devoted to these
topics would probably give you more detailed information. However,
you now have enough information to start writing your own Web
pages. In Chapters 22 and 23
I cover how to use HTML tables and forms with Perl CGI scripts.
CGI scripts are the workhorse behind the HTML pages. Input is
sent from a client via a server to a CGI script and replies are
expected back even if commands are not successful. Replies can
take the form of text, data, images, HTML pages, and so on. Output
from the CGI script is sent to its standard output and is passed
back to the client via the server. Arguments to CGI scripts are
passed via environment variables because this is an easy way to
pass values between child and parent processes. CGI scripts do
not have to be written in Perl, but it's easier to manipulate
strings in Perl than it is in C or other languages.
| 
 LINUX
LINUX 
 Books
Books
