Ядро Linux® : реализация для x86
Open Source-технологии вносят революционные изменения в компьютерный мир.
Реализована масса широко-масштабных проектов , таких как Apache, MySQL.
Postgres, с использованием таких языков как Perl, Python, PHP.
Эти технологии используются во многих линуксовых-юниксовых системах,майнфреймах.
Эта книга написана для того,чтобы вы освоили эти технологии.
В книге даны практические примеры кода,используемого в Open Source проектах.
Современные операционные системы становятся все сложнее.
Число подсистем и интерфейсов становится все больше.
Замечательно,что ядро системы нам доступно в исходниках.
В этой книге вы сможете познакомиться с различными компонентами ядра,
как они работают и взаимодействуют друг с другом.
К концу книги вы станете еще ближе к пониманию , что такое ядро.
Обзор ядра
Ядро состоит из различных компонентов.
В этой книге мы будем использовать слова компонент
и подсистема
поочередно для ссылки на различные функции ядра.
Мы рассмотрим компоненты , из которых состоят файловые системы , процессы , шедулер , драйвера.
И это неполный список того , что попадет в поле нашего зрения.
Пользовательский интерфейс
Пользователи взаимодействуют с системой с помощью программ.
Вначале пользователь входит в систему с помощью терминала или
виртуального терминала.
В линуксе программа , названная mingetty
для виртуальных терминалов или agetty
для серийных терминалов, позволяет пользователю набрать пароль.
Пользователь набирает свой аккаунт с помощью getty , которая вызывает другую программу -
login ,
которая уже ожидает ввода пароля, анализирует и либо пускает пользователя , либо нет.
После аутентификации , пользователю нужен диалог с системой.
Программа login вызывает другую программу - shell.
shell - это первичный пользовательский интерфейс к операционной системе.
shell - это командный интерпретатор и включает в себя список процессов.
Shell выводит prompt и ожидает ввода от пользователя.
Программы , которые может вызвать пользователь - это исполняемые файлы , лежащие в файловой системе
При вызове такой программы shell создает child process.
Этот процесс может делать системные вызовы.
После return такой процесс прибивается, и shell опять ожидает ввода команд.
Идентификация пользователя
Пользователь набирает уникальное имя.
Оно ассоциируется с уникальным user ID (UID).
Ядро использует этот UID для наделения пользователя правами на файловую систему.
Пользователю предоставляется доступ к его домашней директории -
home directory, здесь он может создавать,модифицировать и удалять файлы.
Это важно для многопользовательских систем, для того чтобы предотвратить доступ к данным со стороны других пользователей.
Пользователь superuser или root
- особый пользователь с неограниченными правами; его UID = 0.
Пользователь может быть членом одной или нескольких групп,
каждая из которых имеет свой уникальный group ID (GID).
При создании пользователя он становится автоматически членом , имя которой идентично его имени.
Пользователь вручную может быть добавлен к любой другой группе админом.
Любой файл или исполняемый файл всегда ассоциирован с правами конкретного пользователя или группы.
Любой пользователь вправе решать , кто имеет доступ к его файлам . а кто нет.
Файл связан с конкретным UID и конкретным GID.
Файлы и файловые системы
Файловые данные обеспечивают хранение и организацию данных.
Линукс поддерживает концепцию файла как последовательность байт , не зависящих от устройства.
Этим устройством может быть диск , лента , и т.д.
Файлы сгруппированы внутри контейнера , названного директорией.
Поскольку директории могут быть вложенными , файловая система имеет иерархическую древовидную структуру.
Корневая папка находится на вершине - обозначается как слеш (/).
Файловая система находится внутри дисковой партиции.
Директории , файлы , путь
Каждый файл в дереве имеет путь , в который входит его имя и расположение.
Путь относительно текущего каталога или домашнего каталога пользователя называется относительным путем.
Абсолютный путь - путь , который начинается от корня файловой системы.
На рисунке 1.2 абсолютный путь пользователя paul для файла file.c есть
/home/paul/src/file.c.
Относительный путь есть просто src/file.c.
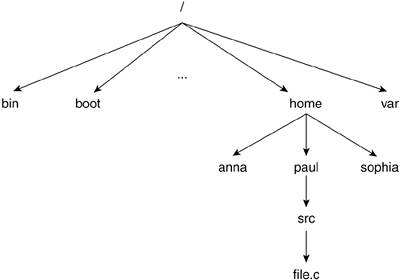
The concepts of absolute versus relative pathnames come into play because the kernel associates processes with the current working directory and with a root directory. The current working directory is the directory from which the process was called and is identified by a . (pronounced "dot"). As an aside, the parent directory is the directory that contains the working directory and is identified by a .. (pronounced "dot dot"). Recall that when a user logs in, she is "located" in her home directory. If Anna tells the shell to execute a particular program, such as ls, as soon as she logs in, the process that executes ls has /home/anna as its current working directory (whose parent directory is /home) and / will be its root directory. The root is always its own parent.
1.9.3.2. Filesystem Mounting
In Linux, as in all UNIX-like systems, a filesystem is only accessible if it has been mounted. A filesystem is mounted with the mount system call and is unmounted with the umount system call. A filesystem is mounted on a mount point, which is a directory used as the root access to the mounted filesystem. A directory mount point should be empty. Any files originally located in the directory used as a mount point are inaccessible after the filesystem is mounted and remains so until the filesystem is unmounted. The /etc/mtab file holds the table of mounted filesystems while /etc/fstab holds the filesystem table, which is a table listing all the system's filesystems and their attributes. /etc/mtab lists the device of the mounted filesystem and associates it with its mount point and any options with which it was mounted.
1.9.3.3. File Protection and Access Rights
Files have access permissions to provide some degree of privacy and security. Access rights or permissions are stored as they apply to three distinct categories of users: the user himself, a designated group, and everyone else. The three types of users can be granted varying access rights as applied to the three types of access to a file: read, write, and execute. When we execute a file listing with an ls al, we get a view of the file permissions:
lkp :~# ls al /home/sophia
drwxr-xr-x 22 sophia sophia 4096 Mar 14 15:13 .
drwxr-xr-x 24 root root 4096 Mar 7 18:47 ..
drwxrwx--- 3 sophia department 4096 Mar 4 08:37 sources
The first entry lists the access permissions of sophia's home directory. According to this, she has granted everyone the ability to enter her home directory but not to edit it. She herself has read, write, and execute permission. The second entry indicates the access rights of the parent directory /home. /home is owned by root but it allows everyone to read and execute. In sophia's home directory, she has a directory called sources, which she has granted read, write, and execute permissions to herself, members of the group called department, and no permissions to anyone else.
1.9.3.4. File Modes
In addition to access rights, a file has three additional modes: sticky, suid, and sgid. Let's look at each mode more closely.
sticky
A file with the sticky bit enabled has a "t" in the last character of the mode field (for example, -rwx-----t). Back in the day when disk accesses were slower than they are today, when memory was not as large, and when demand-based methodologies hadn't been conceived, an executable file could have the sticky bit enabled and ensure that the kernel would keep it in memory despite its state of execution. When applied to a program that was heavily used, this could increase performance by reducing the amount of time spent accessing the file's information from disk.
When the sticky bit is enabled in a directory, it prevents the removal or renaming of files from users who have write permission in that directory (with exception of root and the owner of the file).
suid
An executable with the suid bit set has an "s" where the "x" character goes for the user-permission bits (for example, -rws------). When a user executes an executable file, the process is associated with the user who called it. If an executable has the suid bit set, the process inherits the UID of the file owner and thus access to its set of access rights. This introduces the concepts of the real user ID as opposed to the effective user ID. As we soon see when we look at processes in the "Processes" section, a process' real UID corresponds to that of the user that started the process. The effective UID is often the same as the real UID unless the setuid bit was set in the file. In that case, the effective UID holds the UID of the file owner.
suid has been exploited by hackers who call executable files owned by root with the suid bit set and redirect the program operations to execute instructions that they would otherwise not be allowed to execute with root permissions.
sgid
An executable with the sgid bit set has an "s" where the "x" character goes for the group permission bits (for example, -rwxrws---). The sgid bit acts just like the suid bit but as applied to the group. A process also has a real group ID and an effective group ID that holds the GID of the user and the GID of the file group, respectively.
1.9.3.5. File Metadata
File metadata is all the information about a file that does not include its content. For example, metadata includes the type of file, the size of the file, the UID of the file owner, the access rights, and so on. As we soon see, some file types (devices, pipes, and sockets) contain no data, only metadata. All file metadata, with the exception of the filename, is stored in an inode or index node. An inode is a block of information, and every file has its own inode. A file descriptor is an internal kernel data structure that manages the file data. File descriptors are obtained when a process accesses a file.
1.9.3.6. Types of Files
UNIX-like systems have various file types.
Regular File
A regular file is identified by a dash in the first character of the mode field (for example, -rw-rw-rw-). A regular file can contain ASCII data or binary data if it is an executable file. The kernel does not care what type of data is stored in a file and thus makes no distinctions between them. User programs, however, might care. Regular files have their data stored in zero or more data blocks.
Directory
A directory file is identified by a "d" in the first character of the mode field (for example, drwx------). A directory is a file that holds associations between filenames and the file inodes. A directory consists of a table of entries, each pertaining to a file that it contains. ls ai lists all the contents of a directory and the ID of its associated inode.
Block Devices
A block device is identified by a "b" in the first character of the mode field (for example, brw-------). These files represent a hardware device on which I/O is performed in discretely sized blocks in powers of 2. Block devices include disk and tape drives and are accessed through the /dev directory in the filesystem. Disk accesses can be time consuming; therefore, data transfer for block devices is performed by the kernel's buffer cache, which is a method of storing data temporarily to reduce the number of costly disk accesses. At certain intervals, the kernel looks at the data in the buffer cache that has been updated and synchronizes it with the disk. This provides great increases in performance; however, a computer crash can result in loss of the buffered data if it had not yet been written to disk. Synchronization with the disk drive can be forced with a call to the sync, fsync, or fdatasync system calls, which take care of writing buffered data to disk. A block device does not use any data blocks because it stores no data. Only an inode is required to hold its information.
Character Devices
A character device is identified by a "c" in the first character of the mode field (for example, crw-------). These files represent a hardware device that is not block structured and on which I/O occurs in streams of bytes and is transferred directly between the device driver and the requesting process. These devices include terminals and serial devices and are accessed through the /dev directory in the filesystem. Pseudo devices or device drivers that do not represent hardware but instead perform some unrelated kernel side function can also be character devices. These devices are also known as raw devices because of the fact that there is no intermediary cache to hold the data. Similar to a block device, a character device does not use any data blocks because it stores no data. Only an inode is required to hold its information.
Link
A link device is identified by an "l" in the first character of the mode field (for example, lrw-------). A link is a pointer to a file. This type of file allows there to be multiple references to a particular file while only one copy of the file and its data actually exists in the filesystem. There are two types of links: hard link and symbolic, or soft, link. Both are created through a call to ln. A hard link has limitations that are absent in the symbolic link. These include being limited to linking files within the same filesystem, being unable to link to directories, and being unable to link to non-existing files. Links reflect the permissions of the file to which it is pointing.
Named Pipes
A pipe file is identified by a "p" in the first character of the mode field (for example, prw-------). A pipe is a file that facilitates communication between programs by acting as data pipes; data is written into them by one program and read by another. The pipe essentially buffers its input data from the first process. Named pipes are also known as FIFOs because they relay the information to the reading program in a first in, first out basis. Much like the device files, no data blocks are used by pipe files, only the inode.
Sockets
A socket is identified by an "s" in the first character of the mode field (for example, srw-------). Sockets are special files that also facilitate communication between two processes. One difference between pipes and sockets is that sockets can facilitate communication between processes on different computers connected by a network. Socket files are also not associated with any data blocks. Because this book does not cover networking, we do not go over the internals of sockets.
1.9.3.7. Types of Filesystems
Linux filesystems support an interface that allows various filesystem types to coexist. A filesystem type is determined by the way the block data is broken down and manipulated in the physical device and by the type of physical device. Some examples of types of filesystems include network mounted, such as NFS, and disk based, such as ext3, which is one of the Linux default filesystems. Some special filesystems, such as /proc, provide access to kernel data and address space.
1.9.3.8. File Control
When a file is accessed in Linux, control passes through a number of stages. First, the program that wants to access the file makes a system call, such as open(), read(), or write(). Control then passes to the kernel that executes the system call. There is a high-level abstraction of a filesystem called VFS, which determines what type of specific filesystem (for example, ext2, minix, and msdos) the file exists upon, and control is then passed to the appropriate filesystem driver.
The filesystem driver handles the management of the file upon a given logical device. A hard drive could have msdos and ext2 partitions. The filesystem driver knows how to interpret the data stored on the device and keeps track of all the metadata associated with a file. Thus, the filesystem driver stores the actual file data and incidental information such as the timestamp, group and user modes, and file permissions (read/write/execute).
The filesystem driver then calls a lower-level device driver that handles the actual reading of the data off of the device. This lower-level driver knows about blocks, sectors, and all the hardware information that is necessary to take a chunk of data and store it on the device. The lower-level driver passes the information up to the filesystem driver, which interprets and formats the raw data and passes the information to the VFS, which finally transfers the data back to the originating program.
1.9.4. Processes
If we consider the operating system to be a framework that developers can build upon, we can consider processes to be the basic unit of activity undertaken and managed by this framework. More specifically, a process is a program that is in execution. A single program can be executed multiple times so there might be more than one process associated with a particular program.
The concept of processes became significant with the introduction of multiuser systems in the 1960s. Consider a single-user operating system where the CPU executes only a single process. In this case, no other program can be executed until the currently running process is complete. When multiple users are introduced (or if we want the ability to perform multiple tasks concurrently), we need to define a way to switch between the tasks.
The process model makes the execution of multiple tasks possible by defining execution contexts. In Linux, each process operates as though it were the only process. The operating system then manages these contexts by assigning the processor to work on one or the other according to a predefined set of rules. The scheduler defines and executes these rules. The scheduler tracks the length of time the process has run and switches it off to ensure that no one process hogs the CPU.
The execution context consists of all the parts associated with the program such as its data (and the memory address space it can access), its registers, its stack and stack pointer, and the program counter value. Except for the data and the memory addressing, the rest of the components of a process are transparent to the programmer. However, the operating system needs to manage the stack, stack pointer, program counter, and machine registers. In a multiprocess system, the operating system must also be responsible for the context switch between processes and the management of system resources that processes contend for.
1.9.4.1. Process Creation and Control
A process is created from another process with a call to the fork() system call. When a process calls fork(), we say that the process spawned a new process, or that it forked. The new process is considered the child process and the original process is considered the parent process. All processes have a parent, with the exception of the init process. All processes are spawned from the first process, init, which comes about during the bootstrapping phase. This is discussed further in the next section.
As a result of this child/parent model, a system has a process tree that can define the relationships between all the running processes. Figure 1.3 illustrates a process tree.
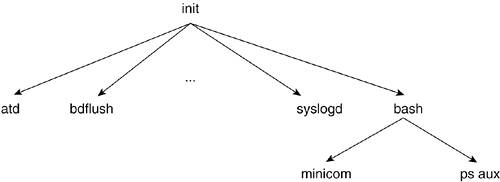
When a child process is created, the parent process might want to know when it is finished. The wait() system call is used to pause the parent process until its child has exited.
A process can also replace itself with another process. This is done, for example, by the mingetty() functions previously described. When a user requests access into the system, the mingetty() function requests his username and then replaces itself with a process executing login() to which it passes the username parameter. This replacement is done with a call to one of the exec() system calls.
1.9.4.2. Process IDs
Every process has a unique identifier know as the process ID (PID). A PID is a non-negative integer. Process IDs are handed out in incrementing sequential order as processes are created. When the maximum PID value is hit, the values wrap and PIDs are handed out starting at the lowest available number greater than 1. There are two special processes: process 0 and process 1. Process 0 is the process that is responsible for system initialization and for spawning off process 1, which is also known as the init process. All processes in a running Linux system are descendants of process 1. After process 0 executes, the init process becomes the idle cycle.
Chapter 8, "Booting the Kernel," discusses this process in "
The Beginning: start_kernel()" section.
Two system calls are used to identify processes. The getpid() system call retrieves the PID of the current process, and the getppid() system call retrieves the PID of the process' parent.
1.9.4.3. Process Groups
A process can be a member of a process group by sharing the same group ID. A process group facilitates associating a set of processes. This is something you might want to do, for example, if you want to ensure that otherwise unrelated processes receive a kill signal at the same time. The process whose PID is identical to the group ID is considered the group leader. Process group IDs can be manipulated by calling the getpgid() and setpgid() system calls, which retrieve and set the process group ID of the indicated process, respectively.
1.9.4.4. Process States
Processes can be in different states depending on the scheduler and the availability of the system resources for which the process contends. A process might be in a runnable state if it is currently being executed or in a run queue, which is a structure that holds references to processes that are in line to be executed. A process can be sleeping if it is waiting for a resource or has yielded to anther process, dead if it has been killed, and defunct or zombie if a process has exited before its parent was able to call wait() on it.
1.9.4.5. Process Descriptor
Each process has a process descriptor that contains all the information describing it. The process descriptor contains such information as the process state, the PID, the command used to start it, and so on. This information can be displayed with a call to ps (process status). A call to ps might yield something like this:
lkp:~#ps aux | more
USER PID TTY STAT COMMAND
root 1 ? S init [3]
root 2 ? SN [ksoftirqd/0]
...
root 10 ? S< [aio/0]
...
root 2026 ? Ss /sbin/syslogd -a /var/lib/ntp/dev/log
root 2029 ? Ss /sbin/klogd -c 1 -2 x
...
root 3324 tty2 Ss+ /sbin/mingetty tty2
root 3325 tty3 Ss+ /sbin/mingetty tty3
root 3326 tty4 Ss+ /sbin/mingetty tty4
root 3327 tty5 Ss+ /sbin/mingetty tty5
root 3328 tty6 Ss+ /sbin/mingetty tty6
root 3329 ttyS0 Ss+ /sbin/agetty -L 9600 ttyS0 vt102
root 14914 ? Ss sshd: root@pts/0
...
root 14917 pts/0 Ss -bash
root 17682 pts/0 R+ ps aux
root 17683 pts/0 R+ more
The list of process information shows the process with PID 1 to be the init process. This list also shows the mingetty() and agetty() programs listening in on the virtual and serial terminals, respectively. Notice how they are all children of the previous one. Finally, the list shows the bash session on which the ps aux | more command was issued. Notice that the | used to indicate a pipe is not a process in itself. Recall that we said pipes facilitate communication between processes. The two processes are ps aux and more.
As you can see, the STAT column indicates the state of the process, with S referring to sleeping processes and R to running or runnable processes.
1.9.4.6. Process Priority
In single-processor computers, we can have only one process executing at a time. Processes are assigned priorities as they contend with each other for execution time. This priority is dynamically altered by the kernel based on how much a process has run and what its priority has been until that moment. A process is allotted a timeslice to execute after which it is swapped out for another process by the scheduler, as we describe next.
Higher priority processes are executed first and more often. The user can set a process priority with a call to nice(). This call refers to the niceness of a process toward another, meaning how much the process is willing to yield. A high priority has a negative value, whereas a low priority has a positive value. The higher the value we pass nice, the more we are willing to yield to another process.
1.9.5. System Calls
System calls are the main mechanism by which user programs communicate with the kernel. Systems calls are generally wrapped inside library calls that manage the setup of the registers and data that each system call needs before executing. The user programs then link in the library with the appropriate routines to make the kernel request.
System calls generally apply to specific subsystems. This means that a user space program can interact with any particular kernel subsystem by means of these system calls. For example, files have file-handling system calls, and processes have process-specific system calls. Throughout this book, we identify the system calls associated with particular kernel subsystems. For example, when we talk about filesystems, we look at the read(), write(), open(), and close() system calls. This provides you with a view of how filesystems are implemented and managed within the kernel.
1.9.6. Linux Scheduler
The Linux scheduler handles the task of moving control from one process to another. With the inclusion of kernel pre-emption in Linux 2.6, any process, including the kernel, can be interrupted at nearly any time and control passed to a new process.
For example, when an interrupt occurs, Linux must stop executing the current process and handle the interrupt. In addition, a multitasking operating system, such as Linux, ensures that no one process hogs the CPU for an extended time. The scheduler handles both of these tasks: On one hand, it swaps the current process with a new process; on the other hand, it keeps track of processes' usage of the CPU and indicates that they be swapped if they have run too long.
How the Linux scheduler determines which process to give control of the CPU is explained in depth in Chapter 7, "Scheduling and Kernel Synchronization"; however, a quick summary is that the scheduler determines priority based on past performance (how much CPU the process has used before) and on the criticality of the process (interrupts are more critical than the log system).
The Linux scheduler also manages how processes execute on multiprocessor machines (SMP). There are some interesting features for load balancing across multiple CPUs as well as the ability to tie processes to a specific CPU. That being said, the basic scheduling functionality operates identically across CPUs.
1.9.7. Linux Device Drivers
Device drivers are how the kernel interfaces with hard disks, memory, sound cards, Ethernet cards, and many other input and output devices.
The Linux kernel usually includes a number of these drivers in a default installation; Linux wouldn't be of much use if you couldn't enter any data via your keyboard. Device drivers are encapsulated in a module. Although Linux is a monolithic kernel, it achieves a high degree of modularization by allowing each device driver to be dynamically loaded. Thus, a default kernel can be kept relatively small and slowly extended based upon the actual configuration of the system on which Linux runs.
In the 2.6 Linux kernel, device drivers have two major ways of displaying their status to a user of the system: the /proc and /sys filesystems. In a nutshell, /proc is usually used to debug and monitor devices and /sys is used to change settings. For example, if you have an RF tuner on an embedded Linux device, the default tuner frequency could be visible, and possibly changeable, under the devices entry in sysfs.
In Chapters 5, "Input/Output," and 10, "Adding Your Code to the Kernel," we closely look at device drivers for both character and block devices. More specifically, we tour the /dev/random device driver and see how it gathers entropy information from other devices on the Linux system.
|
2.1. Common Kernel Datatypes
The Linux kernel has many objects and structures of which to keep track. Examples include memory pages, processes, and interrupts. A timely way to reference one of these objects among many is a major concern if the operating system is run efficiently. Linux uses linked lists and binary search trees (along with a set of helper routines) to first group these objects into a single container and, second, to find a single element in an efficient manner.
2.1.1. Linked Lists
Linked lists are common datatypes in computer science and are used throughout the Linux kernel. Linked lists are often implemented as circular doubly linked lists within the Linux kernel. (See Figure 2.1.) Thus, given any node in a list, we can go to the next or previous node. All the code for linked lists can be viewed in include/linux/list.h. This section deals with the major features of linked lists.

A linked list is initialized by using the LIST_HEAD and INIT_ LIST_HEAD macros:
-----------------------------------------------------------------------------
include/linux/list.h
27
28 struct list_head {
29 struct list_head *next, *prev;
30 };
31
32 #define LIST_HEAD_INIT(name) { &(name), &(name) }
33
34 #define LIST_HEAD(name) \
35 struct list_head name = LIST_HEAD_INIT(name)
36
37 #define INIT_LIST_HEAD(ptr) do { \
38 (ptr)->next = (ptr); (ptr)->prev = (ptr); \
39 } while (0)
-----------------------------------------------------------------------------
Line 34
The LIST_HEAD macro creates the linked list head specified by name.
Line 37
The INIT_LIST_HEAD macro initializes the previous and next pointers within the structure to reference the head itself. After both of these calls, name contains an empty doubly linked list.
Simple stacks and queues can be implemented by the list_add() or list_add_tail() functions, respectively. A good example of this being used is in the work queue code:
-----------------------------------------------------------------------------
kernel/workqueue.c
330 list_add(&wq->list, &workqueues);
-----------------------------------------------------------------------------
The kernel adds wq->list to the system-wide list of work queues, workqueues. workqueues is thus a stack of queues.
Similarly, the following code adds work->entry to the end of the list cwq->worklist. cwq->worklist is thus being treated as a queue:
-----------------------------------------------------------------------------
kernel/workqueue.c
84 list_add_tail(&work->entry, &cwq->worklist);
-----------------------------------------------------------------------------
When deleting an element from a list, list_del() is used. list_del() takes the list entry as a parameter and deletes the element simply by modifying the entry's next and previous nodes to point to each other. For example, when a work queue is destroyed, the following code removes the work queue from the system-wide list of work queues:
-----------------------------------------------------------------------------
kernel/workqueue.c
382 list_del(&wq->list);
-----------------------------------------------------------------------------
One extremely useful macro in include/linux/list.h is the list_for_each_entry macro:
-----------------------------------------------------------------------------
include/linux/list.h
349 /**
350 * list_for_each_entry - iterate over list of given type
351 * @pos: the type * to use as a loop counter.
352 * @head: the head for your list.
353 * @member: the name of the list_struct within the struct.
354 */
355 #define list_for_each_entry(pos, head, member)
356 for (pos = list_entry((head)->next, typeof(*pos), member),
357 prefetch(pos->member.next);
358 &pos->member != (head);
359 pos = list_entry(pos->member.next, typeof(*pos), member),
360 prefetch(pos->member.next))
-----------------------------------------------------------------------------
This function iterates over a list and operates on each member within the list. For example, when a CPU comes online, it wakes a process for each work queue:
-----------------------------------------------------------------------------
kernel/workqueue.c
59 struct workqueue_struct {
60 struct cpu_workqueue_struct cpu_wq[NR_CPUS];
61 const char *name;
62 struct list_head list; /* Empty if single thread */
63 };
...
466 case CPU_ONLINE:
467 /* Kick off worker threads. */
468 list_for_each_entry(wq, &workqueues, list)
469 wake_up_process(wq->cpu_wq[hotcpu].thread);
470 break;
-----------------------------------------------------------------------------
The macro expands and uses the list_head list within the workqueue_struct wq to traverse the list whose head is at work queues. If this looks a bit confusing remember that we do not need to know what list we're a member of in order to traverse it. We know we've reached the end of the list when the value of the current entry's next pointer is equal to the list's head. See Figure 2.2 for an illustration of a work queue list.
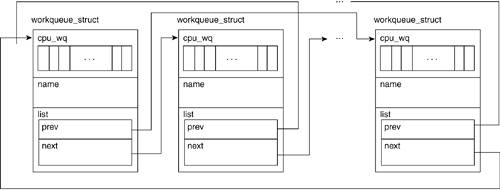
A further refinement of the linked list is an implementation where the head of the list has only a single pointer to the first element. This contrasts the double pointer head discussed in the previous section. Used in hash tables (which are introduced in Chapter 4, "Memory Management"), the single pointer head does not have a back pointer to reference the tail element of the list. This is thought to be less wasteful of memory because the tail pointer is not generally used in a hash search:
-----------------------------------------------------------------------------
include/linux/list.h
484 struct hlist_head {
485 struct hlist_node *first;
486 };
488 struct hlist_node {
489 struct hlist_node *next, **pprev;
490 };
492 #define HLIST_HEAD_INIT { .first = NULL }
493 #define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
-----------------------------------------------------------------------------
Line 492
The HLIST_HEAD_INIT macro sets the pointer first to the NULL pointer.
Line 493
The HLIST_HEAD macro creates the linked list by name and sets the pointer first to the NULL pointer.
These list constructs are used throughout the Linux kernel code in work queues, as we've seen in the scheduler, the timer, and the module-handling routines.
2.1.2. Searching
The previous section explored grouping elements in a list. An ordered list of elements is sorted based on a key value within each element (for example, each element having a key value greater than the previous element). If we want to find a particular element (based on its key), we start at the head and increment through the list, comparing the value of its key with the value we were searching for. If the value was not equal, we move on to the next element until we find the matching key. In this example, the time it takes to find a given element in the list is directly proportional to the value of the key. In other words, this linear search takes longer as more elements are added to the list.
|
For a searching algorithm, big-O notation is the theoretical measure of the execution of an algorithm usually in time needed to find a given key. It represents the worst-case search time for a given number (n) elements. The big-O notation for a linear search is O(n/2), which indicates that, on average, half of the list is searched to find a given key.
Source:
National Institute of Standards and Technology (www.nist.gov). |
With large lists of elements, faster methods of storing and locating a given piece of data are required if the operating system is to be prevented from grinding to a halt. Although many methods (and their derivatives) exist, the other major data structure Linux uses for storage is the tree.
2.1.3. Trees
Used in Linux memory management, the tree allows for efficient access and manipulation of data. In this case, efficiency is measured in how fast we can store and retrieve a single piece of data among many. Basic trees, and specifically red black trees, are presented in this section and, for the specific Linux implementation and helper routines, see Chapter 6, "Filesystems." Rooted trees in computer science consist of nodes and edges (see Figure 2.3). The node represents the data element and the edges are the paths between the nodes. The first, or top, node in a rooted tree is the root node. Relationships between nodes are expressed as parent, child, and sibling, where each child has exactly one parent (except the root), each parent has one or more children, and siblings have the same parent. A node with no children is termed as a leaf. The height of a tree is the number of edges from the root to the most distant leaf. Each row of descendants across the tree is termed as a level. In Figure 2.3, b and c are one level below a, and d, e, and f are two levels below a. When looking at the data elements of a given set of siblings, ordered trees have the left-most sibling being the lowest value ascending in order to the right-most sibling. Trees are generally implemented as linked lists or arrays and the process of moving through a tree is called traversing the tree.
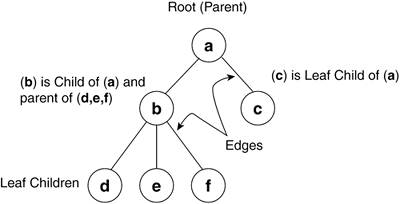
2.1.3.1. Binary Trees
Previously, we looked at finding a key using a linear search, comparing our key with each iteration. What if we could rule out half of the ordered list with every comparison?
A binary tree, unlike a linked list, is a hierarchical, rather than linear, data structure. In the binary tree, each element or node points to a left or right child node, and in turn, each child points to a left or right child, and so on. The main rule for ordering the nodes is that the child on the left has a key value less than the parent, and the child on the right has a value equal to or greater than the parent. As a result of this rule, we know that for a key value in a given node, the left child and all its descendants have a key value less than that given node and the right child and all its descendants have a key value greater than or equal to the given node.
When storing data in a binary tree, we reduce the amount of data to be searched by half during each iteration. In big-O notation, this yields a performance (with respect to the number of items searched) of O log(n). Compare this to the linear search big-O of O(n/2).
The algorithm used to traverse a binary tree is simple and hints of a recursive implementation because, at every node, we compare our key value and either descend left or right into the tree. The following is a discussion on the implementation, helper functions, and types of binary trees.
As just mentioned, a node in a binary tree can have one left child, one right child, a left and right child, or no children. The rule for an ordered binary tree is that for a given node value (x), the left child (and all its descendants) have values less than x and the right child (and all its descendants) have values greater than x. Following this rule, if an ordered set of values were inserted into a binary tree, it would end up being a linear list, resulting in a relatively slow linear search for a given value. For example, if we were to create a binary tree with the values [0,1,2,3,4,5,6], 0 would become the root; 1, being greater than 0, would become the right child; 2, being greater than 1, would become its right child; 3 would become the right child of 2; and so on.
A height-balanced binary tree is where no leaf is some number farther from the root than any other. As nodes are added to the binary tree, it needs to be rebalanced for efficient searching; this is accomplished through rotation. If, after an insertion, a given node (e), has a left child with descendants that are two levels greater than any other leaf, we must right-rotate node e. As shown in Figure 2.4, e becomes the parent of h, and the right child of e becomes the left child of h. If rebalancing is done after each insertion, we are guaranteed that we need at most one rotation. This rule of balance (no child shall have a leaf distance greater than one) is known as an AVL-tree (after G. M. Adelson-Velskii and E. M. Landis).
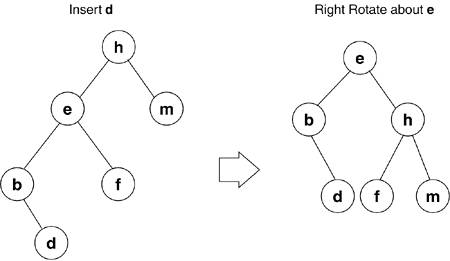
2.1.3.2. Red Black Trees
The red black tree used in Linux memory management is similar to an AVL tree. A red black tree is a balanced binary tree in which each node has a red or black color attribute.
Here are the rules for a red black tree:
All nodes are either red or black. If a node is red, both its children are black. All leaf nodes are black. When traversing from the root node to a leaf, each path contains the same number of black nodes.
Both AVL and red black trees have a big-O of O log(n), and depending on the data being inserted (sorted/unsorted) and searched, each can have their strong points. (Several papers on performance of binary search trees [BSTs] are readily available on the Web and make for interesting reading.)
As previously mentioned, many other data structures and associated search algorithms are used in computer science. This section's goal was to assist you in your exploration by introducing the concepts of the common structures used for organizing data in the Linux kernel. Having a basic understanding of the list and tree structures help you understand the more complex operations, such as memory management and queues, which are discussed in later chapters.
|
2.2. Assembly
Linux is an operating system. As such, sections of it are closely bound to the processor on which it is running. The Linux authors have done a great job of keeping the processor- (or architecture-) specific code to a minimum, striving for the maximum reuse of code across all the supported architectures. In this section, we look at the following:
This section's goal is to cover enough of the basics so you can trace through the architecture-specific kernel code having enough understanding so as not to get lost. We leave advanced assembly-language programming to other books. We also cover some of the trickiest architecture-specific code: inline assembler.
To discuss freely PPC and x86 assembly languages, let's look at the architectures of each processor.
2.2.1. PowerPC
The PowerPC is a Reduced Instruction Set Computing (RISC) architecture. The goal of RISC architecture is to improve performance by having a simple instruction set that executes in as few processor cycles as possible. Because they take advantage of the parallel instruction (superscalar) attributes of the hardware, some of these instructions, as we soon see, are far from simple. IBM, Motorola, and Apple jointly defined the PowerPC architecture. Table 2.1 lists the user set of registers for the PowerPC.
Table 2.1. PowerPC User Register SetRegister Name | Width for Arch. | Function | Number of Regs |
|---|
| | 32 Bit | 64 Bit | | | CR | 32 | 32 | Condition register | 1 | LR | 32 | 64 | Link register | 1 | CTR | 32 | 64 | Count register | 1 | GPR[0..31] | 32 | 64 | General-purpose register | 32 | XER | 32 | 64 | Fixed-point exception register | 1 | FPR[0..31] | 64 | 64 | Floating-point register | 32 | FPSCR | 32 | 64 | Floating-point status control register | 1 |
Table 2.2 illustrates the Application Binary Interface usage of the general and floating-point registers. Volatile registers are for use any time, dedicated registers have specific assigned uses, and non-volatile registers can be used but must be preserved across function calls.
Table 2.2. ABI Register UsageRegister | Type | Use |
|---|
r0 | Volatile | Prologue/epilogue, language specific | r1 | Dedicated | Stack pointer | r2 | Dedicated | TOC | r3-r4 | Volatile | Parameter passing, in/out | r5-r10 | Volatile | Parameter passing | r11 | Volatile | Environment pointer | r12 | Volatile | Exception handling | r13 | Non-volatile | Must be preserved across calls | r14-r31 | Non-volatile | Must be preserved across calls | f0 | Volatile | Scratch | f1 | Volatile | 1st FP parm, 1st FP scalar return | f2-f4 | Volatile | 2nd4th FP parm, FP scalar return | f5-f13 | Volatile | 5th13th FP parm | f14-f31 | Non-volatile | Must be preserved across calls |
|
An ABI is a set of conventions that allows a linker to combine separately compiled modules into one unit without recompilation, such as calling conventions, machine interface, and operating-system interface. Among other things, an ABI defines the binary interface between these units. Several PowerPC ABI variations are in existence. They are often related to the target operating system and/or hardware. These variations or supplements are documents based on the UNIX System V Application Binary Interface, originally from AT&T and later from the Santa Cruz Operation (SCO). The benefits of conforming to an ABI are that it allows linking object files compiled by different compilers. |
The 32-bit PowerPC architecture uses instructions that are 4 bytes long and word aligned. It operates on byte, half-word, word, and double-word accesses. Instructions are categorized into branch, fixed-point, and floating-point.
2.2.1.1. Branch Instructions
The condition register (CR) is integral to all branch operations. It is broken down into eight 4-bit fields that can be set explicitly by a move instruction, implicitly, as the result of an instruction, or most common, as the result of a compare instruction.
The link register (LR) is used by certain forms of the branch instruction to provide the target address and the return address after a branch.
The count register (CTR) holds a loop count decremented by specific branch instructions. The CTR can also hold the target address for certain branch instructions.
In addition to the CTR and LR above, PowerPC branch instructions can jump to a relative or absolute address. Using Extended Mnemonics, there are many forms of conditional branches along with the unconditional branch.
2.2.1.2. Fixed-Point Instructions
The PPC has no computational instructions that modify storage. All work must be brought into one or more of the 32 general-purpose registers (GPRs). Storage access instructions access byte, half-word, word, and double-word data in Big Endian ordering. With Extended Mnemonics, there are many load, store, arithmetic, and logical fixed-point instructions, as well as special instructions to move to/from system registers.
2.2.1.3. Floating-Point Instructions
Floating-point instructions can be broken down into two categories: computational, which includes arithmetic, rounding, conversion, and comparison; and non-computational, which includes move to/from storage or another register. There are 32 general-purpose floating-point registers; each can contain data in double-precision floating-point format.
|
In processor architecture, Endianness refers to byte ordering and operations. The PowerPC is said to be Big Endian, that is, the most significant byte is at the lower address and the least significant byte is 3 bytes later (for 32-bit words). Little Endian, adopted by the x86 architecture, is just the opposite. The least-significant byte is at the lower address and the most significant is 3 bytes later. Let's examine the representation of 0x12345678 (see Figure 2.5):

Discussion on which system is better is beyond the scope of this book, but it is important to know which system you are working with when writing and debugging code. An example pitfall to Endianness is writing a device driver using one architecture for a PCI device based on the other.
The terms Big Endian and Little Endian originate from Jonathan Swift's Gulliver's Travels. In the story, Gulliver comes to find two nations at war over which way to eat a boiled eggfrom the big end or the little end. |
2.2.2. x86
The x86 architecture is a Complex Instruction Set Computing (CISC) architecture. Instructions are variable length, depending on their function. Three kinds of registers exist in the Pentium class x86 architecture: general purpose, segment, and status/control. The basic user set is as follows.
Here are the eight general-purpose registers and their conventional uses:
EAX.
General purpose accumulator
EBX.
Pointer to data
ECX.
Counter for loop operations
EDX.
I/O pointer
ESI.
Pointer to data in DS segment
EDI.
Pointer to data in ES segment
ESP.
Stack pointer
EBP.
Pointer to data on the stack
These six segment registers are used in real mode addressing where memory is accessed in blocks. A given byte of memory is then referenced by an offset from this segment (for example, ES:EDI references memory in the ES (extra segment) with an offset of the value in the EDI):
The EFLAGS register indicates processor status after each instruction. This can hold results such as zero, overflow, or carry. The EIP is a dedicated pointer register that indicates an offset to the current instruction to the processor. This is generally used with the code segment register to form a complete address (for example, CS:EIP):
EFLAGS.
Status, control, and system flags
EIP.
The instruction pointer, contains an offset from CS
Data ordering in x86 architecture is in Little Endian. Memory access is in byte (8 bit), word (16 bit), double word (32 bit), and quad word (64 bit). Address translation (and its associated registers) is discussed in Chapter 4, but for this section, it should be enough to know the usual registers for code and data instructions in the x86 architecture can be broken down into three categories: control, arithmetic, and data.
2.2.2.1. Control Instructions
Control instructions, similar to branch instructions in PPC, alter program flow. The x86 architecture uses various "jump" instructions and labels to selectively execute code based on the values in the EFLAGS register. Although many variations exist, Table 2.3 has some of the most common uses. The condition codes are set according to the outcome of certain instructions. For example, when the cmp (compare) instruction evaluates two integer operands, it modifies the following flags in the EFLAGS register: OF (overflow), SF (sine flag), ZF (zero flag), PF (parity flag), and CF (carry flag). Thus, if the cmp instruction evaluated two equal operands, the zero flag would be set.
Table 2.3. Common Forms of the Jump InstructionInstruction | Function | EFLAGS Condition Codes |
|---|
je | Jump if equal | ZF=1 | jg | Jump if greater | ZF=0 and SF=OF | jge | Jump if greater or equal | SF=OF | jl | Jump if less | SF!=OF | jle | Jump if less or equal | ZF=1 | jmp | Unconditional jump | unconditional |
In x86 assembly code, labels consist of a unique name followed by a colon. Labels can be used anywhere in an assembly program and have the same address as the line of code immediately following it. The following code uses a conditional jump and a label:
-----------------------------------------------------------------------
100 pop eax
101 loop2:
102 pop ebx
103 cmp eax, ebx
104 jge loop2
-----------------------------------------------------------------------
Line 100
Get the value from the top of the stack and put it in eax.
Line 101
This is the label named loop2.
Line 102
Get the value from the top of the stack and put it in ebx.
Line 103
Compare the values in eax and ebx.
Line 104
Jump if eax is greater than or equal to ebx.
Another method of transferring program control is with the call and ret instructions. Referring to the following line of assembly code:
-----------------------------------------------------------------------
call my_routine
-----------------------------------------------------------------------
The call instruction transfers program control to the label my_routine, while pushing the address of the instruction immediately following the call instruction on the stack. The ret instruction (executed from within my_routine) then pops the return address and jumps to that location.
2.2.2.2. Arithmetic Instructions
Popular arithmetic instructions include add, sub, imul (integer multiply), idiv (integer divide), and the logical operators and, or, not, and xor.
x86 floating-point instructions and their associated registers move beyond the scope of this book. Recent extensions to Intel and AMD architectures, such as MMX, SSE, 3DNow, SIMD, and SSE2/3, greatly enhance math-intensive applications, such as graphics and audio. You are directed to the programming manuals for their respective architectures.
2.2.2.3. Data Instructions
Data can be moved between registers, between registers and memory, and from a constant to a register or memory, but not from one memory location to another. Examples of these are as follows:
-----------------------------------------------------------------------
100 mov eax,ebx
101 mov eax,WORD PTR[data3]
102 mov BYTE PTR[char1],al
103 mov eax,0xbeef
104 mov WORD PTR [my_data],0xbeef
-----------------------------------------------------------------------
Line 100
Move 32 bits of data from ebx to eax.
Line 101
Move 32 bits of data from memory variable data3 to eax.
Line 102
Move 8 bits of data from memory variable char1 to al.
Line 103
Move the constant value 0xbeef to eax.
Line 104
Move the constant value 0xbeef to the memory variable my_data.
As seen in previous examples, push, pop, and the long versions pushl and popl move data to and from the stack (pointed to by SS:ESP). Similar to the mov instruction, the push and pop operations can be used with registers, data, and constants.
|
2.3. Assembly Language Example
We can now create a simple program to see how the different architectures produce assembly language for the same C code. For this experiment, we use the gcc compiler that came with Red Hat 9 and the gcc cross compiler for PowerPC. We present the C program and then, for comparison, the x86 code and the PPC code.
It might startle you to see how much assembly code is generated with just a few lines of C. Because we are just compiling from C to assembler, we are not linking in any environment code, such as the C runtime libraries or local stack creation/destruction, so the size is much smaller than an actual ELF executable.
Note that with assembler, you are closest to seeing exactly what the processor is fetching from cycle to cycle. Another way to look at it is that you have complete control of your code and the system. It is important to mention that even though instructions are fetched from memory in order, they might not always be executed in exactly the same order read in. Some architectures order load and store operations separately.
Here is the example C code:
-----------------------------------------------------------------------
count.c
1 int main()
2 {
3 int i,j=0;
4
5 for(i=0;i<8;i++)
6 j=j+i;
7
8 return 0;
9 }
-----------------------------------------------------------------------
Line 1
This is the function definition main.
Line 3
This line initializes the local variables i and j to 0.
Line 5
The for loop: While i takes values from 0 to 7, set j equal to j plus i.
Line 8
The return marks the jump back to the calling program.
2.3.1. x86 Assembly Example
Here is the code generated for x86 by entering gcc S count.c on the command line. Upon entering the code, the base of the stack is pointed to by ss:ebp. The code is produced in "AT&T" format, in which registers are prefixed with a % and constants are prefixed with a $. The assembly instruction samples previously provided in this section should have prepared you for this simple program, but one variant of indirect addressing should be discussed before we go further.
When referencing a location in memory (for example, stack), the assembler uses a specific syntax for indexed addressing. By putting a base register in parentheses and an index (or offset) just outside the parentheses, the effective address is found by adding the index to the value in the register. For example, if %ebp was assigned the value 20, the effective address of 8(%ebp) would be (8) + (20)= 12:
-----------------------------------------------------------------------
count.s
1 .file "count.c"
2 .version "01.01"
3 gcc2_compiled.:
4 .text
5 .align 4
6 .globl main
7 .type main,@function
8 main:
#create a local memory area of 8 bytes for i and j.
9 pushl %ebp
10 movl %esp, %ebp
11 subl $8, %esp
#initialize i (ebp-4) and j (ebp-8) to zero.
12 movl $0, -8(%ebp)
13 movl $0, -4(%ebp)
14 .p2align 2
15 .L3:
#This is the for-loop test
16 cmpl $7, -4(%ebp)
17 jle .L6
18 jmp .L4
19 .p2align 2
20 .L6:
#This is the body of the for-loop
21 movl -4(%ebp), %eax
22 leal -8(%ebp), %edx
23 addl %eax, (%edx)
24 leal -4(%ebp), %eax
25 incl (%eax)
26 jmp .L3
27 .p2align 2
28 .L4:
#Setup to exit the function
29 movl $0, %eax 30 leave 31 ret
-----------------------------------------------------------------------
Line 9
Push stack base pointer onto the stack.
Line 10
Move the stack pointer into the base pointer.
Line 11
Get 8 bytes of stack mem starting at ebp.
Line 12
Move 0 into address ebp8 (j).
Line 13
Move 0 into address ebp4 (i).
Line 14
This is an assembler directive that indicates the instruction should be half-word aligned.
Line 15
This is an assembler-created label called .L3.
Line 16
This instruction compares the value of i to 7.
Line 17
Jump to label .L6 if 4(%ebp) is less than or equal to 7.
Line 18
Otherwise, jump to label .L4.
Line 19
Align.
Line 20
Label .L6.
Line 21
Move i into eax.
Line 22
Load the address of j into edx.
Line 23
Add i to the address pointed to by edx (j).
Line 24
Move the new value of i into eax.
Line 25
Increment i.
Line 26
Jump back to the for loop test.
Line 27
Align as described in Line 14 code commentary.
Line 28
Label .L4.
Line 29
Set the return code in eax.
Line 30
Release the local memory area.
Line 31
Pop any variable off stack, pop the return address, and jump back to the caller.
2.3.2. PowerPC Assembly Example
The following is the resulting PPC assembly code for the C program. If you are familiar with assembly language (and acronyms), the function of many PPC instructions is clear. There are, however, several derivative forms of the basic instructions that we must discuss here:
stwu RS, D(RA) (Store Word with Update).
This instruction takes the value in (GPR) register RS and stores it into the effective address formed by RA+D. The (GPR) register RA is then updated with this new effective address.
li RT, RS, SI (Load Immediate).
This is an extended mnemonic for a fixed-point load instruction. It is equivalent to adding RT, RS, S1, where the sum of (GPR) RS and S1, the 16-bit 2s complement integer is stored in RT. If RS is (GPR) R0, the value SI is stored in RT. Note that the value being only 16 bit has to do with the fact that the opcode, registers, and value must all be encoded into a 32-bit instruction.
lwz RT, D(RA) (Load Word and Zero).
This instruction forms an effective address as in stwu and loads a word of data from memory into (GPR) RT. The "and Zero" indicates that the upper 32 bits of the calculated effective address are set to 0 if this is a 64-bit implementation running in 32-bit mode. (See the PowerPC Architecture Book I for more on implementations.)
blr (Branch to Link Register).
This instruction is an unconditional branch to the 32-bit address in the link register. When calling a function, the caller puts the return address into the link register. Similar to the x86 ret instruction, blr is the common method of returning from a function.
The following code was generated by entering gcc S count.c on the command line:
-----------------------------------------------------------------------
countppc.s
1 .file "count.c"
2 .section ".text"
3 .align 2
4 .globl main
5 .type main,@function
6 main:
#Create 32 byte memory area from stack space and initialize i and j.
7 stwu 1,-32(1) #Store stack ptr (r1) 32 bytes into the stack
8 stw 31,28(1) #Store word r31 into lower end of memory area
9 mr 31,1 #Move contents of r1 into r31
10 li 0,0 #Load 0 into r0
11 stw 0,12(31) #Store word r0 into effective address 12(r31), var j
12 li 0,0 #Load 0 into r0
13 stw 0,8(31) #Store word r0 into effective address 8(r31) , var i
14 .L2:
#For-loop test
15 lwz 0,8(31) #Load i into r0
16 cmpwi 0,0,7 #Compare word immediate r0 with integer value 7
17 ble 0,.L5 #Branch if less than or equal to label .L5
18 b .L3 #Branch unconditional to label .L3
19 .L5:
#The body of the for-loop
20 lwz 9,12(31) #Load j into r9
21 lwz 0,8(31) #Load i into r0
22 add 0,9,0 #Add r0 to r9 and put result in r0
23 stw 0,12(31) #Store r0 into j
24 lwz 9,8(31) #load i into r9
25 addi 0,9,1 #Add 1 to r9 and store in r0
26 stw 0,8(31) #Store r0 into i
27 b .L2
28 .L3:
29 li 0,0 #Load 0 into r0
30 mr 3,0 #move r0 to r3
31 lwz 11,0(1) #load r1 into r11
32 lwz 31,-4(11) #Restore r31
33 mr 1,11 #Restore r1
34 blr #Branch to Link Register contents
--------------------------------------------------------------------
Line 7
Store stack ptr (r1) 32 bytes into the stack.
Line 8
Store word r31 into the lower end of the memory area.
Line 9
Move the contents of r1 into r31.
Line 10
Load 0 into r0.
Line 11
Store word r0 into effective address 12(r31), var j.
Line 12
Load 0 into r0.
Line 13
Store word r0 into effective address 8(r31), var i.
Line 14
Label .L2:.
Line 15
Load i into r0.
Line 16
Compare word immediate r0 with integer value 7.
Line 17
Branch to label .L5 if r0 is less than or equal to 7.
Line 18
Branch unconditional to label .L3.
Line 19
Label .L5:.
Line 20
Load j into r9.
Line 21
Load i into r0.
Line 22
Add r0 to r9 and put the result in r0.
Line 23
Store r0 into j.
Line 24
Load i into r9.
Line 25
Add 1 to r9 and store in r0.
Line 26
Store r0 into i.
Line 27
This is an unconditional branch to label .L2.
Line 28
Label .L3:.
Line 29
Load 0 into r0.
Line 30
Move r0 to r3.
Line 31
Load r1 into r11.
Line 32
Restore r31.
Line 33
Restore r1.
Line 34
This is an unconditional branch to the location indicated by Link Register contents.
Contrasting the two assembler files, they have nearly the same number of lines. Upon further inspection, you can see that the RISC (PPC) processor is characteristically using many load and store instructions while the CISC (x86) tends to use the mov instruction more often.
|
2.4. Inline Assembly
Another form of coding allowed with the gcc compiler is the ability to do inline assembly code. As its name implies, inline assembly does not require a call to a separately compiled assembler program. By using certain constructs, we can tell the compiler that code blocks are to be assembled rather than compiled. Although this makes for an architecture-specific file, the readability and efficiency of a C function can be greatly increased.
Here is the inline assembler construct:
-----------------------------------------------------------------------
1 asm (assembler instruction(s)
2 : output operands (optional)
3 : input operands (optional)
4 : clobbered registers (optional)
5 );
-----------------------------------------------------------------------
For example, in its most basic form,
asm ("movl %eax, %ebx");
could also be written as
asm ("movl %eax, %ebx" :::);
We would be lying to the compiler because we are indeed clobbering ebx. Read on.
What makes this form of inline assembly so versatile is the ability to take in C expressions, modify them, and return them to the program, all the while making sure that the compiler is aware of our changes. Let's further explore the passing of parameters.
2.4.1. Ouput Operands
On line 2, following the colon, the output operands are a list of C expressions in parentheses preceded by a "constraint." For output operands, the constraint usually has the = modifier, which indicates that this is write-only. The & modifier shows that this is an "early clobber" operand, which means that this operand is clobbered before the instruction is finished using it. Each operand is separated by a comma.
2.4.2. Input Operands
The input operands on line 3 follow the same syntax as the output operands except for the write-only modifier.
2.4.3. Clobbered Registers (or Clobber List)
In our assembly statements, we can modify various registers and memory. For gcc to know that these items have been modified, we list them here.
2.4.4. Parameter Numbering
Each parameter is given a positional number starting with 0. For example, if we have one output parameter and two input parameters, %0 references the output parameter and %1 and %2 reference the input parameters.
2.4.5. Constraints
Constraints indicate how an operand can be used. The GNU documentation has the complete listing of simple constraints and machine constraints. Table 2.4 lists the most common constraints for the x86.
Table 2.4. Simple and Machine Constraints for x86Constraint | Function |
|---|
a | eax register. | b | ebx register. | c | ecx register. | d | edx register. | S | esi register. | D | edi register. | I | Constant value (0…31). | q | Dynamically allocates a register from eax, ebx, ecx, edx. | r | Same as q + esi, edi. | m | Memory location. | A | Same as a + b. eax and ebx are allocated together to form a 64-bit register. |
2.4.6. asm
In practice (especially in the Linux kernel), the keyword asm might cause errors at compile time because of other constructs of the same name. You often see this expression written as __asm__, which has the same meaning.
2.4.7. __volatile__
Another commonly used modifier is __volatile__. This modifier is important to assembly code. It tells the compiler not to optimize the inline assembly routine. Often, with hardware-level software, the compiler thinks we are being redundant and wasteful and attempts to rewrite our code to be as efficient as possible. This is useful for application-level programming, but at the hardware level, it can be counterproductive.
For example, say we are writing to a memory-mapped register represented by the reg variable. Next, we initiate some action that requires us to poll reg. The compiler simply sees this as consecutive reads to the same memory location and eliminates the apparent redundancy. Using __volatile__, the compiler now knows not to optimize accesses using this variable. Likewise, when you see asm volatile (...) in a block of inline assembler code, the compiler should not optimize this block.
Now that we have the basics of assembly and gcc inline assembly, we can turn our attention to some actual inline assembly code. Using what we just learned, we first explore a simple example and then a slightly more complex code block.
Here's the first code example in which we pass variables to an inline block of code:
-----------------------------------------------------------------------
6 int foo(void)
7 {
8 int ee = 0x4000, ce = 0x8000, reg;
9 __asm__ __volatile__("movl %1, %%eax";
10 "movl %2, %%ebx";
11 "call setbits" ;
12 "movl %%eax, %0"
13 : "=r" (reg) // reg [param %0] is output
14 : "r" (ce), "r"(ee) // ce [param %1], ee [param %2] are inputs
15 : "%eax" , "%ebx" // %eax and % ebx got clobbered
16 )
17 printf("reg=%x",reg);
18 }
-----------------------------------------------------------------------
Line 6
This line is the beginning of the C routine.
Line 8
ee, ce, and req are local variables that will be passed as parameters to the inline assembler.
Line 9
This line is the beginning of the inline assembler routine. Move ce into eax.
Line 10
Move ee into ebx.
Line 11
Call some function from assembler.
Line 12
Return value in eax, and copy it to reg.
Line 13
This line holds the output parameter list. The parm reg is write only.
Line 14
This line is the input parameter list. The parms ce and ee are register variables.
Line 15
This line is the clobber list. The regs eax and ebx are changed by this routine. The compiler knows not to use the values after this routine.
Line 16
This line marks the end of the inline assembler routine.
This second example uses the switch_to() function from include/ asm-i386/system.h. This function is the heart of the Linux context switch. We explore only the mechanics of its inline assembly in this chapter. Chapter 9, "Building the Linux Kernel," covers how switch_to() is used:
-----------------------------------------------------------------------
include/asm-i386/system.h
012 extern struct task_struct * FASTCALL(__switch_to(struct task_struct *prev, struct
 task_struct *next));
...
015 #define switch_to(prev,next,last) do {
016 unsigned long esi,edi;
017 asm volatile("pushfl\n\t"
018 "pushl %%ebp\n\t"
019 "movl %%esp,%0\n\t" /* save ESP */
020 "movl %5,%%esp\n\t" /* restore ESP */
021 "movl $1f,%1\n\t" /* save EIP */
022 "pushl %6\n\t" /* restore EIP */
023 "jmp __switch_to\n"
023 "1:\t"
024 "popl %%ebp\n\t"
025 "popfl"
026 :"=m" (prev->thread.esp),"=m" (prev->thread.eip),
027 "=a" (last),"=S" (esi),"=D" (edi)
028 :"m" (next->thread.esp),"m" (next->thread.eip),
029 "2" (prev), "d" (next));
030 } while (0)
----------------------------------------------------------------------- task_struct *next));
...
015 #define switch_to(prev,next,last) do {
016 unsigned long esi,edi;
017 asm volatile("pushfl\n\t"
018 "pushl %%ebp\n\t"
019 "movl %%esp,%0\n\t" /* save ESP */
020 "movl %5,%%esp\n\t" /* restore ESP */
021 "movl $1f,%1\n\t" /* save EIP */
022 "pushl %6\n\t" /* restore EIP */
023 "jmp __switch_to\n"
023 "1:\t"
024 "popl %%ebp\n\t"
025 "popfl"
026 :"=m" (prev->thread.esp),"=m" (prev->thread.eip),
027 "=a" (last),"=S" (esi),"=D" (edi)
028 :"m" (next->thread.esp),"m" (next->thread.eip),
029 "2" (prev), "d" (next));
030 } while (0)
-----------------------------------------------------------------------
Line 12
FASTCALL tells the compiler to pass parameters in registers.
The asmlinkage tag tells the compiler to pass parameters on the stack.
Line 15
do { statements...} while(0) is a coding method to allow a macro to appear more like a function to the compiler. In this case, it allows the use of local variables.
Line 16
Don't be confused; these are just local variable names.
Line 17
This is the inline assembler; do not optimize.
Line 23
Parameter 1 is used as a return address.
Lines 1724
\n\t has to do with the compiler/assembler interface. Each assembler instruction should be on its own line.
Line 26
prev->thread.esp and prev->thread.eip are the output parameters:
[ %0]= (prev->thread.esp), is write-only memory
[%1]= (prev->thread.eip), is write-only memory
Line 27
[%2]=(last) is write only to register eax:
[%3]=(esi), is write-only to register esi
[%4]=(edi), is write-only to register edi
Line 28
Here are the input parameters:
[%5]= (next->thread.esp), is memory
[%6]= (next->thread.eip), is memory
Line 29
[%7]= (prev), reuse parameter "2" (register eax) as an input:
[%8]= (next), is an input assigned to register edx.
Note that there is no clobber list.
The inline assembler for PowerPC is nearly identical in construct to x86. The simple constraints, such as "m" and "r," are used along with a PowerPC set of machine constraints. Here is a routine to exchange a 32-bit pointer. Note how similar the inline assembler syntax is to x86:
-----------------------------------------------------------------------
include/asm-ppc/system.h
103 static __inline__ unsigned long
104 xchg_u32(volatile void *p, unsigned long val)
105 {
106 unsigned long prev;
107
108 __asm__ __volatile__ ("\n\
109 1: lwarx %0,0,%2 \n"
110
111 " stwcx. %3,0,%2 \n\
112 bne- 1b"
113 : "=&r" (prev), "=m" (*(volatile unsigned long *)p)
114 : "r" (p), "r" (val), "m" (*(volatile unsigned long *)p)
115 : "cc", "memory");
116
117 return prev;
118 }
-----------------------------------------------------------------------
Line 103
This subroutine is expanded in place; it will not be called.
Line 104
Routine names with parameters p and val.
Line 106
This is the local variable prev.
Line 108
This is the inline assembler. Do not optimize.
Lines 109111
lwarx, along with stwcx, form an "atomic swap." lwarx loads a word from memory and "reserves" the address for a subsequent store from stwcx.
Line 112
Branch if not equal to label 1 (b = backward).
Line 113
Here are the output operands:
[%0]= (prev), write-only, early clobber
[%1]= (*(volatile unsigned long *)p), write-only memory operand
Line 114
Here are the input operands:
[%2]= (p), register operand
[%3]= (val), register operand
[%4]= (*(volatile unsigned long *)p), memory operand
Line 115
Here are the clobber operands:
[%5]= Condition code register is altered
[%6]= memory is clobbered
This closes our discussion on assembly language and how the Linux 2.6 kernel uses it. We have seen how the PPC and x86 architectures differ and how general ASM programming techniques are used regardless of platform. We now turn our attention to the programming language C, in which the majority of the Linux kernel is written, and examine some common problems programmers encounter when using C.
2.5. Quirky C Language Usage
Within the Linux kernel are a number of conventions that can require lots of searching and reading to discover their ultimate meaning and intent. This section clarifies some of the obscure or misleading usage of C, with a specific focus on common C conventions that are used throughout the 2.6 Linux kernel.
2.5.1. asmlinkage
asmlinkage tells the compiler to pass parameters on the local stack. This is related to the FASTCALL macro, which resolves to tell the (architecture-specific) compiler to pass parameters in the general-purpose registers. Here are the macros from include/asm/linkage.h:
-----------------------------------------------------------------------
include/asm/linkage.h
4 #define asmlinkage CPP_ASMLINKAGE __attribute__((regparm(0)))
5 #define FASTCALL(x) x __attribute__((regparm(3)))
6 #define fastcall __attribute__((regparm(3)))
-----------------------------------------------------------------------
An example of asmlinkage is as follows:
asmlinkage long sys_gettimeofday(struct timeval __user *tv, struct timezone __user *tz)
2.5.2. UL
UL is commonly appended to the end of a numerical constant to mark an "unsigned long." UL (or L for long) is necessary because it tells the compiler to treat the value as a long value. This prevents certain architectures from overflowing the bounds of their datatypes. For example, a 16-bit integer can represent numbers between 32,768 and +32,767; an unsigned integer can represent numbers up to 65,535. Using UL allows you to write architecturally independent code for large numbers or long bitmasks.
Some kernel code examples include the following:
-----------------------------------------------------------------------
include/linux/hash.h
18 #define GOLDEN_RATIO_PRIME 0x9e370001UL
-----------------------------------------------------------------------
include/linux/kernel.h
23 #define ULONG_MAX (~0UL)
-----------------------------------------------------------------------
include/linux/slab.h
39 #define SLAB_POISON 0x00000800UL /* Poison objects */
-----------------------------------------------------------------------
2.5.3. inline
The inline keyword is intended to optimize the execution of functions by integrating the code of the function into the code of its callers. The Linux kernel uses mainly inline functions that are also declared as static. A "static inline" function results in the compiler attempting to incorporate the function's code into all its callers and, if possible, it discards the assembly code of the function. Occasionally, the compiler cannot discard the assembly code (in the case of recursion), but for the most part, functions declared as static inline are directly incorporated into the callers.
The point of this incorporation is to eliminate any overhead from having a function call. The #define statement can also eliminate function call overhead and is typically used for portability across compilers and within embedded systems.
So, why not always use inline? The drawback to using inline is an increased binary image and, possibly, a slow down when accessing the CPU's cache.
2.5.4. const and volatile
These two keywords are the bane of many an emerging programmer. The const keyword must not be thought of as constant, but rather read only. For example, const int *x is a pointer to a const integer. Thus, the pointer can be changed but the integer cannot. However, int const *x is a const pointer to an integer, and the integer can change but the pointer cannot. Here is an example of const:
-----------------------------------------------------------------------
include/asm-i386/processor.h
628 static inline void prefetch(const void *x)
629 {
630 __asm__ __volatile__ ("dcbt 0,%0" : : "r" (x));
631 }
-----------------------------------------------------------------------
The volatile keyword marks variables that could change without warning. volatile informs the compiler that it needs to reload the marked variable every time it encounters it rather than storing and accessing a copy. Some good examples of variables that should be marked as volatile are ones that deal with interrupts, hardware registers, or variables that are shared between concurrent processes. Here is an example of how volatile is used:
-----------------------------------------------------------------------
include/linux/spinlock.h
51 typedef struct {
...
volatile unsigned int lock;
...
58 } spinlock_t;
-----------------------------------------------------------------------
Given that const should be interpreted as read only, we see that certain variables can be both const and volatile (for example, a variable holding the contents of a read-only hardware register that changes regularly).
This quick overview puts the prospective Linux kernel hacker on the right track for reading through the kernel sources.
2.6. A Quick Tour of Kernel Exploration Tools
After successfully compiling and building your Linux kernel, you might want to peer into its internals before, after, or even during its operation. This section quickly overviews the tools commonly used to explore various files in the Linux kernel.
2.6.1. objdump/readelf
The objdump and readelf utilities display any of the information within object files (for objdump), or within ELF files (for readelf). THRough command-line arguments, you can use the command to look at the headers, size, or architecture of a given object file. For example, here is a dump of the ELF header for a simple C program (a.out) using the h flag of readelf:
Lwp> readelf h a.out
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x8048310
Start of program headers: 52 (bytes into file)
Start of section headers: 10596 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 6
Size of section headers: 40 (bytes)
Number of section headers: 29
Section header string table index: 26
Here is a dump of the program headers using the l flag of readelf:
Lwp> readelf l a.out
Elf file type is EXEC (Executable file)
Entry point 0x8048310
There are 6 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000034 0x08048034 0x08048034 0x000c0 0x000c0 R E 0x4
INTERP 0x0000f4 0x080480f4 0x080480f4 0x00013 0x00013 R 0x1
[Requesting program interpreter: /lib/ld-linux.so.2]
LOAD 0x000000 0x08048000 0x08048000 0x00498 0x00498 R E 0x1000
LOAD 0x000498 0x08049498 0x08049498 0x00108 0x00120 RW 0x1000
DYNAMIC 0x0004ac 0x080494ac 0x080494ac 0x000c8 0x000c8 RW 0x4
NOTE 0x000108 0x08048108 0x08048108 0x00020 0x00020 R 0x4
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .hash .dynsym .dynstr .gnu.version .gnu.version_r .rel.dyn .rel
.plt .init .plt .text .fini .rodata
03 .data .eh_frame .dynamic .ctors .dtors .got .bss
04 .dynamic
05 .note.ABI-tag
2.6.2. hexdump
The hexdump command displays the contents of a given file in hexadecimal, ASCII, or octal format. (Note that, on older versions of Linux, od (octal dump) was also used. Most systems now use hexdump instead.)
For example, to look at the first 64 bytes of the ELF file a.out in hex, you could type the following:
Lwp> hexdump x n 64 a.out
0000000 457f 464c 0101 0001 0000 0000 0000 0000
0000010 0002 0003 0001 0000 8310 0804 0034 0000
0000020 2964 0000 0000 0000 0034 0020 0006 0028
0000030 001d 001a 0006 0000 0034 0000 8034 0804
0000040
Note the (byte-swapped) ELF header magic number at address 0x0000000.
This is extremely useful in debugging activities; when a hardware device dumps its state to a file, a normal text editor usually interprets the file as containing numerous control characters. hexdump allows you to peek at what is actually contained in the file without intervening editor translation. hexedit is an editor that enables you to directly modify the files without translating the contents into ASCII (or Unicode).
2.6.3. nm
The nm utility lists the symbols that reside within a specified object file. It displays the symbols value, type, and name. This utility is not as useful as other utilities, but it can be helpful when debugging library files.
2.6.4. objcopy
Use the objcopy command when you want to copy an object file but omit or change certain aspects of it. A common use of objcopy is to strip debugging symbols from a tested and working object file. This results in a reduced object file size and is routinely done on embedded systems.
2.6.5. ar
The ar (or archive) command helps maintain the indexed libraries that the linker uses. The ar command combines one or more object files into one library. It can also separate object files from a single library. The ar command is more likely to be seen in a Make file. It is often used to combine commonly used functions into a single library file. For example, you might have a routine that parses a command file and extracts certain data or a call to extract information from a specific register in the hardware. These routines might be needed by several executable programs. Archiving these routines into a single library file allows for better version control by having a central location.
2.7. Kernel Speak: Listening to Kernel Messages
When your Linux system is up and running, the kernel itself logs messages and provides information about its status throughout its operation. This section gives a few of the most common ways the Linux kernel speaks to an end user.
2.7.1. printk()
One of the most basic kernel messaging systems is the printk() function. The kernel uses printk() as opposed to printf() because the standard C library is not linked to the kernel. printk() uses the same interface as printf() does and displays up to 1,024 characters to the console. The printk() function operates by trying to grab the console semaphore, place the output into the console's log buffer, and then call the console driver to flush the buffer. If printk() cannot grab the console semaphore, it places the output into the log buffer and relies on the process that has the console semaphore to flush the buffer. The log-buffer lock is taken before printk() places any data into the log buffer, so concurrent calls to printk() do not trample each other. If the console semaphore is being held, numerous calls to printk() can occur before the log buffer is flushed. So, do not rely on printk() statements to indicate any program timing.
2.7.2. dmesg
The Linux kernel stores its logs, or messages, in a variety of ways. sysklogd() is a combination of syslogd() and klogd(). (More in-depth information can be found in the man page of these commands, but we can quickly summarize the system.) The Linux kernel sends its messages through klogd(), which tags them with appropriate warning levels, and all levels of messages are placed in /proc/kmsg. dmesg is a command-line tool to display the buffer stored in /proc/kmsg and, optionally, filter the buffer based on the message level.
2.7.3. /var/log/messages
This location on a Linux system is where a majority of logged system messages reside. The syslogd() program reads information in /etc/syslogd.conf for specific locations on where to store received messages. Depending on the entries in syslogd.conf, which can vary among Linux distributions, log messages can be stored in numerous files. However, /var/log/messages is usually the standard location.
2.8. Miscellaneous Quirks
This section serves as a catch-all for quirks that plagued the authors when they began to traipse through the kernel code. We include them here to give you an edge on Linux internals.
2.8.1. __init
The __init macro tells the compiler that the associate function or variable is used only upon initialization. The compiler places all code marked with __init into a special memory section that is freed after the initialization phase ends:
----------------------------------------------------------------------
drivers/char/random.c
679 static int __init batch_entropy_init(int size, struct entropy_store *r)
-----------------------------------------------------------------------
As an example, the random device driver initializes a pool of entropy upon being loaded. While the driver is loaded, different functions are used to increase or decrease the size of the entropy pool. This practice of device driver initialization being marked with __init is common, if not a standard.
Similarly, if there is data that is used only during initialization, the data needs to be marked with __initdata. Here, we can see how __initdata is used in the ESP device driver:
-----------------------------------------------------------------------
drivers/char/esp.c
107 static char serial_name[] __initdata = "ESP serial driver";
108 static char serial_version[] __initdata = "2.2";
-----------------------------------------------------------------------
Also, the __exit and __exitdata macros are to be used only in the exit or shutdown routines. These are commonly used when a device driver is unregistered.
2.8.2. likely() and unlikely()
likely() and unlikely() are macros that Linux kernel developers use to give hints to the compiler and chipset. Modern CPUs have extensive branch-prediction heuristics that attempt to predict incoming commands in order to optimize speed. The likely() and unlikely() macros allow the developer to tell the CPU, through the compiler, that certain sections of code are likely, and thus should be predicted, or unlikely, so they shouldn't be predicted.
The importance of branch prediction can be seen with some understanding of instruction pipelining. Modern processors do anticipatory fetchingthat is, they anticipate the next few instructions that will be executed and load them into the processor. Within the processor, these instructions are examined and dispatched to the various units within the processor (integer, floating point, and so on) depending on how they can best be executed. Some instructions might be stalled in the processor, waiting for an intermediate result from a previous instruction. Now, imagine in the instruction stream, a branch instruction is loaded. The processor now has two instruction streams from which to continue its prefetching. If the processor often chooses poorly, it spends too much time reloading the pipeline of instructions that need execution. What if the processor had a hint of which way the branch was going to go? A simple method of branch prediction, in some architectures, is to examine the target address of the branch. If the value is previous to the current address, there's a good chance that this branch is at the end of a loop construct where it loops back many times and only falls through once.
Software is allowed to override the architectural branch prediction with special mnemonics. This ability is surfaced by the compiler by the __builtin_expect() function, which is the foundation of the likely() and unlikely() macros.
As previously mentioned, branch prediction and processor pipelining is complicated and beyond the scope of this book, but the ability to "tune" the code where we think we can make a difference is always a performance plus. Consider the following code block:
-----------------------------------------------------------------------
kernel/time.c
90 asmlinkage long sys_gettimeofday(struct timeval __user *tv, struct timezone __user *tz)
91 {
92 if (likely(tv != NULL)) {
93 struct timeval ktv;
94 do_gettimeofday(&ktv);
95 if (copy_to_user(tv, &ktv, sizeof(ktv)))
96 return -EFAULT;
97 }
98 if (unlikely(tz != NULL)) {
99 if (copy_to_user(tz, &sys_tz, sizeof(sys_tz)))
100 return -EFAULT;
101 }
102 return 0;
103 }
-----------------------------------------------------------------------
In this code, we see that a syscall to get the time of day is likely to have a timeval structure that is not null (lines 9296). If it were null, we couldn't fill in the requested time of day! It is also unlikely that the timezone is not null (lines 98100). To put it another way, the caller rarely asks for the timezone and usually asks for the time.
The specific implementation of likely() and unlikely() are specified as follows:
-----------------------------------------------------------------------
include/linux/compiler.h
45 #define likely(x) __builtin_expect(!!(x), 1)
46 #define unlikely(x) __builtin_expect(!!(x), 0)
-----------------------------------------------------------------------
2.8.3. IS_ERR and PTR_ERR
The IS_ERR macro encodes a negative error number into a pointer, while the PTR_ERR macro retrieves the error number from the pointer.
Both macros are defined in include/linux/err.h.
2.8.4. Notifier Chains
The notifier-chain mechanism is provided for the kernel to register its interest in being informed regarding the occurrence of variable asynchronous events. This generic interface extends its usability to all subsystems or components of the kernel.
A notifier chain is a simply linked list of notifier_block objects:
-----------------------------------------------------------------------
include/linux/notifier.h
14 struct notifier_block
15 {
16 int(*notifier_call)(struct notifier_block *self, unsigned long, void *);
17 struct notifier_block *next;
18 int priority;
19 };
-----------------------------------------------------------------------
notifier_block contains a pointer to a function (notifier_call) to be called when the event comes to pass. This function's parameters include a pointer to the notifier_block holding the information, a value corresponding to event codes or flags, and a pointer to a datatype specific to the subsystem.
The notifier_block struct also contains a pointer to the next notifier_block in the chain and a priority declaration.
The routines notifier_chain_register() and notifier_chain_unregister() register or unregister a notifier_block object in a specific notifier chain.
|
Project: Hellomod
This section introduces the basic concepts necessary to understand other Linux concepts and structures discussed later in the book. Our projects center on the creation of a loadable module using the new 2.6 driver architecture and building on that module for subsequent projects. Because device drivers can quickly become complex; our goal here is only to introduce the basic constructs of a Linux module. We will be developing on this driver in later projects. This module runs in both PPC and x86.
Step 1: Writing the Linux Module Skeleton
The first module we write is the basic "hello world" character device driver. First, we look at the basic code for the module, and then show how to compile with the new 2.6 Makefile system (this is discussed in detail in Chapter 9), and finally, we attach and remove our module to the kernel using the insmod and rmmod commands respectively:
-----------------------------------------------------------------------
hellomod.c
001
// hello world driver for Linux 2.6
004 #include <linux/module.h>
005 #include <linux/kernel.h>
006 #include <linux/init.h>
007 #MODULE_LICENCE("GPL"); //get rid of taint message
009 static int __init lkp_init( void )
{
printk("<1>Hello,World! from the kernel space...\n");
return 0;
013 }
015 static void __exit lkp_cleanup( void )
{
printk("<1>Goodbye, World! leaving kernel space...\n");
018 }
020 module_init(lkp_init);
021 module_exit(lkp_cleanup);
-----------------------------------------------------------------------
Line 4
All modules use the module.h header file and must be included.
Line 5
The kernel.h header file contains often used kernel functions.
Line 6
The init.h header file contains the __init and __exit macros. These macros allow kernel memory to be freed up. A quick read of the code and comments in this file are recommended.
Line 7
To warn of a possible non-GNU public license, several macros were developed starting in the 2.4 kernel. (For more information, see modules.h.)
Lines 912
This is our module initialization function. This function should, for example, contain code to build and initialize structures. On line 11, we are able to send out a message from the kernel with printk(). More on where we read this message when we load our module.
Lines 1518
This is our module exit or cleanup function. Here, we would do any housekeeping associated with our driver being terminated.
Line 20
This is the driver initialization entry point. The kernel calls here at boot time for a built-in module or at insertion-time for a loadable module.
Line 21
For a loadable module, the kernel calls the cleanup_module() function. For a built-in module, this has no effect.
We can have only one initialization (module_init) point and one cleanup (module_exit) point in our driver. These functions are what the kernel is looking for when we load and unload our module.
Step 2: Compiling the Module
If you are used to the older methods of building kernel modules (for example, those that started with #define MODULE), the new method is quite a change. For those whose 2.6 modules are their first, this might seem rather simple. The basic Makefile for our single module is as follows:
Makefile
002 # Makefile for Linux Kernel Primer module skeleton (2.6.7)
006 obj-m += hellomod.o
Notice that we specify to the build system that this be compiled as a loadable module. The command-line invocation of this Makefile wrapped in a bash script called doit is as follows:
----------------------------------------------------------------------------doit
001 make -C /usr/src/linux-2.6.7 SUBDIRS=$PWD modules
--------------------------------------------------------------------------------
Line 1
The C option tells make to change to the Linux source directory (in our case, /usr/src/linux-2.6.7) before reading the Makefiles or doing anything else.
Upon executing ./doit, you should get similar to the following output:
Lkp# ./doit
make: Entering directory '/usr/src/linux-2.6.7'
CC [M] /mysource/hellomod.o
Building modules, stage 2
MODPOST
CC /mysource/hellomod.o
LD [M] /mysource/hellomod.ko
make: Leaving directory '/usr/src/linux-2.6.7'
lkp# _
For those who have compiled or created Linux modules with earlier Linux versions, notice that we now have a linking step LD and that our output module is hellomod.ko.
Step 3: Running the Code
We are now ready to insert our new module into the kernel. We do this using the insmod command, as follows:
lkp# insmod hellomod.ko
To check that the module was inserted properly, you can use the lsmod command, as follows:
lkp# lsmod
Module Size Used by
hellomod 2696 0
lkp#
The output of our module is generated by printk(). This function prints to the system file /var/log/messages by default. To quickly view this, type the following:
lkp# tail /var/log/messages
This prints the last 10 lines of the log file. You should see our initialization message:
...
...
Mar 6 10:35:55 lkp1 kernel: Hello,World! from the kernel space...
To remove our module (and see our exit message), use the rmmod command followed by the module name as seen from the insmod command. For our program, this would look like the following:
lkp# rmmod hellomod
Again, your output should go to the log file and look like the following:
...
...
Mar 6 12:00:05 lkp1 kernel: Hello,World! from the kernel space...
Depending on how your X-system is configured or if you are at a basic command line, the printk output should go to your console, as well as the log file. In our next project, we touch on this again when we look at system task variables.
|
|
|
|
|
| |

 LINUX
LINUX