Дескриптор процесса
В ядре дескриптором процесса является структура под названием task_struct,
которая хранит атрибуты процесса и информацию о нем.
Процесс взаимодействует со многими аспектами ядра , такими как управление памятью и шедулер.
Все структуры всех выполняемых процессов ядро хранит в связанном списке , называемом task_list.
Также имеется ссылка на текущий выполняемый процесс и соответственную task_struct ,
которая называется current.
Процесс может иметь один или несколько тредов.
Каждый тред имеет свою собственную task_struct , в которой имеется уникальный id-шник этого треда.
Треды живут в адресном пространстве процесса.
К важнейшим категориям дескриптора процесса относятся :
Посмотрим на саму структуру task_struct.
Она определена в файлк include/linux/sched.h:
-----------------------------------------------------------------------
include/linux/sched.h
384 struct task_struct {
385 volatile long state;
386 struct thread_info *thread_info;
387 atomic_t usage;
388 unsigned long flags;
389 unsigned long ptrace;
390
391 int lock_depth;
392
393 int prio, static_prio;
394 struct list_head run_list;
395 prio_array_t *array;
396
397 unsigned long sleep_avg;
398 long interactive_credit;
399 unsigned long long timestamp;
400 int activated;
401
302 unsigned long policy;
403 cpumask_t cpus_allowed;
404 unsigned int time_slice, first_time_slice;
405
406 struct list_head tasks;
407 struct list_head ptrace_children;
408 struct list_head ptrace_list;
409
410 struct mm_struct *mm, *active_mm;
...
413 struct linux_binfmt *binfmt;
414 int exit_code, exit_signal;
415 int pdeath_signal;
...
419 pid_t pid;
420 pid_t tgid;
...
426 struct task_struct *real_parent;
427 struct task_struct *parent;
428 struct list_head children;
429 struct list_head sibling;
430 struct task_struct *group_leader;
...
433 struct pid_link pids[PIDTYPE_MAX];
434
435 wait_queue_head_t wait_chldexit;
436 struct completion *vfork_done;
437 int __user *set_child_tid;
438 int __user *clear_child_tid;
439
440 unsigned long rt_priority;
441 unsigned long it_real_value, it_prof_value, it_virt_value;
442 unsigned long it_real_incr, it_prof_incr, it_virt_incr;
443 struct timer_list real_timer;
444 unsigned long utime, stime, cutime, cstime;
445 unsigned long nvcsw, nivcsw, cnvcsw, cnivcsw;
446 u64 start_time;
...
450 uid_t uid,euid,suid,fsuid;
451 gid_t gid,egid,sgid,fsgid;
452 struct group_info *group_info;
453 kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
454 int keep_capabilities:1;
455 struct user_struct *user;
...
457 struct rlimit rlim[RLIM_NLIMITS];
458 unsigned short used_math;
459 char comm[16];
...
461 int link_count, total_link_count;
...
467 struct fs_struct *fs;
...
469 struct files_struct *files;
...
509 unsigned long ptrace_message;
510 siginfo_t *last_siginfo;
...
516 };
-----------------------------------------------------------------------
Атрибуты процесса
The process attribute category is a catch-all category we defined for task characteristics related to the state and identification of a task. Examining these fields' values at any time gives the kernel hacker an idea of the current status of a process. Figure 3.2 illustrates the process attributerelated fields of the task_struct.
3.2.1.1. state
The state field keeps track of the state a process finds itself in during its execution lifecycle. Possible values it can hold are TASK_RUNNING, TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_ZOMBIE, TASK_STOPPED, and TASK_DEAD (see the "Process Lifespan" section in this chapter for more detail).
3.2.1.2. pid
In Linux, each process has a unique process identifier (pid). This pid is stored in the task_struct as a type pid_t. Although this type can be traced back to an integer type, the default maximum value of a pid is 32,768 (the value pertaining to a short int).
3.2.1.3. flags
Flags define special attributes that belong to the task. Per process flags are defined in include/linux/sched.h and include those flags listed in
Table 3.1. The flag's value provides the kernel hacker with more information regarding what the task is undergoing.
Table 3.1. Selected task_struct Flag's Field ValuesFlag Name | When Set |
|---|
PF_STARTING | Set when the process is being created. | PF_EXITING | Set during the call to do_exit(). | PF_DEAD | Set during the call to exit_notify() in the process of exiting. At this point, the state of the process is either TASK_ZOMBIE or TASK_DEAD. | PF_FORKNOEXEC | The parent upon forking sets this flag. |
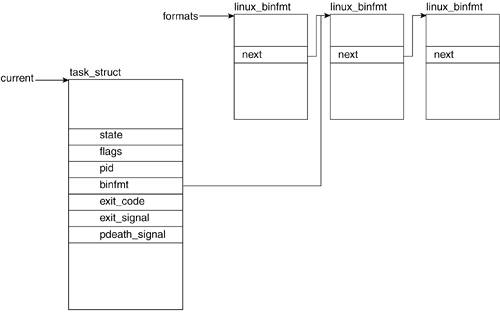
3.2.1.4. binfmt
Linux supports a number of executable formats. An executable format is what defines the structure of how your program code is to be loaded into memory.
Figure 3.2 illustrates the association between the task_struct and the linux_binfmt struct, the structure that contains all the information related to a particular binary format (see
Chapter 9 for more detail).
3.2.1.5. exit_code and exit_signal
The exit_code and exit_signal fields hold a task's exit value and the terminating signal (if one was used). This is the way a child's exit value is passed to its parent.
3.2.1.6. pdeath_signal
pdeath_signal is a signal sent upon the parent's death.
3.2.1.7. comm
A process is often created by means of a command-line call to an executable. The comm field holds the name of the executable as it is called on the command line.
3.2.1.8. ptrace
ptrace is set when the ptrace() system call is called on the process for performance measurements. Possible ptrace() flags are defined in include/ linux/ptrace.h.
3.2.2. Scheduling Related Fields
A process operates as though it has its own virtual CPU. However, in reality, it shares the CPU with other processes. To sustain the switching between process executions, each process closely interrelates with the scheduler (see
Chapter 7 for more detail).
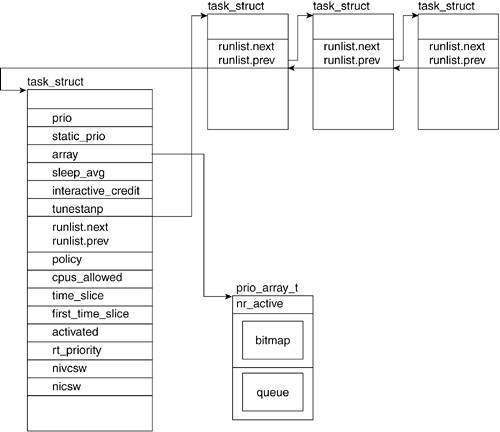
However, to understand some of these fields, you need to understand a few basic scheduling concepts. When more than one process is ready to run, the scheduler decides which one runs first and for how long. The scheduler achieves fairness and efficiency by allotting each process a timeslice and a priority. The timeslice defines the amount of time the process is allowed to execute before it is switched off for another process. The priority of a process is a value that defines the relative order in which it will be allowed to be executed with respect to other waiting processesthe higher the priority, the sooner it is scheduled to run. The fields shown in
Figure 3.3 keep track of the values necessary for scheduling purposes.
3.2.2.1. prio
In Chapter 7, we see that the dynamic priority of a process is a value that depends on the processes' scheduling history and the specified nice value. (See the following sidebar for more information about nice values.) It is updated at sleep time, which is when the process is not being executed and when timeslice is used up. This value, prio, is related to the value of the static_prio field described next. The prio field holds +/- 5 of the value of static_prio, depending on the process' history; it will get a +5 bonus if it has slept a lot and a -5 handicap if it has been a processing hog and used up its timeslice.
3.2.2.2. static_prio
static_prio is equivalent to the nice value. The default value of static_prio is MAX_PRIO-20. In our kernel, MAX_PRIO defaults to 140.
|
The nice() system call allows a user to modify the static scheduling priority of a process. The nice value can range from 20 to 19. The nice() function then calls set_user_nice() to set the static_prio field of the task_struct. The static_prio value is computed from the nice value by way of the PRIO_TO_NICE macro. Likewise, the nice value is computed from the static_prio value by means of a call to NICE_TO_PRIO.
---------------------------------------kernel/sched.c
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + nice + 20)
#define PRIO_TO_NICE(prio) ((prio MAX_RT_PRIO 20)
-----------------------------------------------------
|
3.2.2.3. run_list
The run_list field points to the runqueue. A runqueue holds a list of all the processes to run. See the "
Basic Structure" section for more information on the runqueue struct.
3.2.2.4. array
The array field points to the priority array of a runqueue. The "
Keeping Track of Processes: Basic Scheduler Construction" section in this chapter explains this array in detail.
3.2.2.5. sleep_avg
The sleep_avg field is used to calculate the effective priority of the task, which is the average amount of clock ticks the task has spent sleeping.
3.2.2.6. timestamp
The timestamp field is used to calculate the sleep_avg for when a task sleeps or yields.
3.2.2.7. interactive_credit
The interactive_credit field is used along with the sleep_avg and activated fields to calculate sleep_avg.
3.2.2.8. policy
The policy determines the type of process (for example, time sharing or real time). The type of a process heavily influences the priority scheduling. For more information on this field, see
Chapter 7.
3.2.2.9. cpus_allowed
The cpus_allowed field specifies which CPUs might handle a task. This is one way in which we can specify which CPU a particular task can run on when in a multiprocessor system.
3.2.2.10. time_slice
The time_slice field defines the maximum amount of time the task is allowed to run.
3.2.2.11. first_time_slice
The first_time_slice field is repeatedly set to 0 and keeps track of the scheduling time.
3.2.2.12. activated
The activated field keeps track of the incrementing and decrementing of sleep averages. If an uninterruptible task gets woken, this field gets set to -1.
3.2.2.13. rt_priority
rt_priority is a static value that can only be updated through schedule(). This value is necessary to support real-time tasks.
3.2.2.14. nivcsw and nvcsw
Different kinds of context switches exist. The kernel keeps track of these for profiling reasons. A global switch count gets set to one of the four different context switch counts, depending on the kind of transition involved in the context switch (see
Chapter 7 for more information on context switch). These are the counters for the basic context switch:
The nivcsw field (number of involuntary context switches) keeps count of kernel preemptions applied on the task. It gets incremented only upon a task's return from a kernel preemption where the switch count is set to nivcsw. The nvcsw field (number of voluntary context switches) keeps count of context switches that are not based on kernel preemption. The switch count gets set to nvcsw if the previous state was not an active preemption.
3.2.3. Process RelationsRelated Fields
The following fields of the task_struct are those related to process relationships. Each task or process p has a parent that created it. Process p can also create processes and, therefore, might have children. Because p's parent could have created more than one process, it is possible that process p might have siblings.
Figure 3.4 illustrates how the task_structs of all these processes relate.
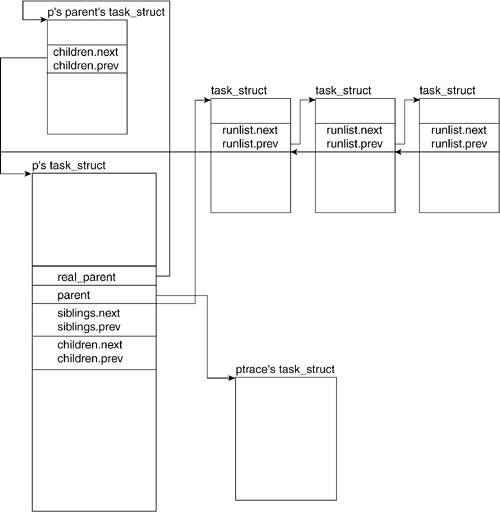
3.2.3.1. real_parent
real_parent points to the current process' parent's description. It will point to the process descriptor of init() if the original parent of our current process has been destroyed. In previous kernels, this was known as p_opptr.
3.2.3.2. parent
parent is a pointer to the descriptor of the parent process. In
Figure 3.4, we see that this points to the ptrace task_struct. When ptrace is run on a process, the parent field of task_struct points to the ptrace process.
3.2.3.3. children
children is the struct that points to the list of our current process' children.
3.2.3.4. sibling
sibling is the struct that points to the list of the current process' siblings.
3.2.3.5. group_leader
A process can be a member of a group of processes, and each group has one process defined as the group leader. If our process is a member of a group, group_leader is a pointer to the descriptor of the leader of that group. A group leader generally owns the tty from which the process was created, called the controlling terminal.
3.2.4. Process CredentialsRelated Fields
In multiuser systems, it is necessary to distinguish among processes that are created by different users. This is necessary for the security and protection of user data. To this end, each process has credentials that help the system determine what it can and cannot access.
Figure 3.5 illustrates the fields in the task_struct related to process credentials.
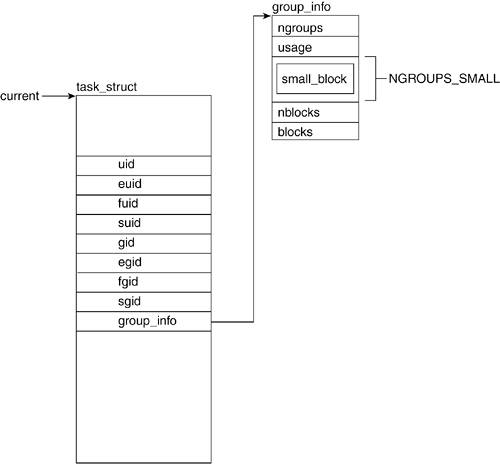
3.2.4.1. uid and gid
The uid field holds the user ID number of the user who created the process. This field is used for protection and security purposes. Likewise, the gid field holds the group ID of the group who owns the process. A uid or gid of 0 corresponds to the root user and group.
3.2.4.2. euid and egid
The effective user ID usually holds the same value as the user ID field. This changes if the executed program has the set UID (SUID) bit on. In this case, the effective user ID is that of the owner of the program file. Generally, this is used to allow any user to run a particular program with the same permissions as another user (for example, root). The effective group ID works in much the same way, holding a value different from the gid field only if the set group ID (SGID) bit is on.
3.2.4.3. suid and sgid
suid (saved user ID) and sgid (saved group ID) are used in the setuid() system calls.
3.2.4.4. fsuid and fsgid
The fsuid and fsgid values are checked specifically for filesystem checks. They generally hold the same values as uid and gid except for when a setuid() system call is made.
3.2.4.5. group_info
In Linux, a user may be part of more than one group. These groups may have varying permissions with respect to system and data accesses. For this reason, the processes need to inherit this credential. The group_info field is a pointer to a structure of type group_info, which holds all the information regarding the various groups of which the process can be a member.
The group_info structure allows a process to associate with a number of groups that is bound by available memory. In
Figure 3.5, you can see that a field of group_info called small_block is an array of NGROUPS_SMALL (in our case, 32) gid_t units. If a task belongs to more than 32 groups, the kernel can allocate blocks or pages that hold the necessary number of gid_ts beyond NGROUPS_SMALL. The field nblocks holds the number of blocks allocated, while ngroups holds the value of units in the small_block array that hold a gid_t value.
3.2.5. Process CapabilitiesRelated Fields
Traditionally, UNIX systems offer process-related protection of certain accesses and actions by defining any given process as privileged (super user or UID = 0) or unprivileged (any other process). In Linux, capabilities were introduced to partition the activities previously available only to the superuser; that is, capabilities are individual "privileges" that may be conferred upon a process independently of each other and of its UID. In this manner, particular processes can be given permission to perform particular administrative tasks without necessarily getting all the privileges or having to be owned by the superuser. A capability is thus defined as a given administrative operation.
Figure 3.6 shows the fields that are related to process capabilities.
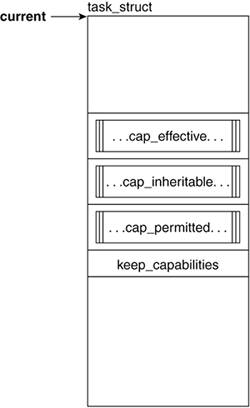
3.2.5.1. cap_effective, cap_inheritable, cap_permitted, and keep_capabilities
The structure used to support the capabilities model is defined in include/linux/security.h as an unsigned 32-bit value. Each 32-bit mask corresponds to a capability set; each capability is assigned a bit in each of:
cap_effective.
The capabilities that can be currently used by the process.
cap_inheritable.
The capabilities that are passed through a call to execve.
cap_permitted.
The capabilities that can be made either effective or inheritable. One way to understand the distinction between these three types is to consider the permitted capabilities to be similar to a trivialized gene pool made available by one's parents. Of the genetic qualities made available by one's parents, we can display a subset of them (effective qualities) and/or pass them on (inheritable). Permitted capabilities constitute more of a potentiality whereas effective capabilities are an actuality. Therefore, cap_effective and cap_inheritable are always subsets of cap_permitted.
keep_capabilities.
Keeps track of whether the process will drop or maintain its capabilities on a call to setuid().
Table 3.2 lists some of the supported capabilities that are defined in include/linux/capability.h.
Table 3.2. Selected CapabilitiesCapability | Description |
|---|
CAP_CHOWN | Ignores the restrictions imposed by chown() | CAP_FOWNER | Ignores file-permission restrictions | CAP_FSETID | Ignores setuid and setgid restrictions on files | CAP_KILL | Ignores ruid and euids when sending signals | CAP_SETGID | Ignores group-related permissions checks | CAP_SETUID | Ignores uid-related permissions checks | CAP_SETCAP | Allows a process to set its capabilities |
The kernel checks if a particular capability is set with a call to capable() passing as a parameter the capability variable. Generally, the function checks to see whether the capability bit is set in the cap_effective set; if so, it sets current->flags to PF_SUPERPRIV, which indicates that the capability is granted. The function returns a 1 if the capability is granted and 0 if capability is not granted.
Three system calls are associated with the manipulation of capabilities: capget(), capset(), and prctl(). The first two allow a process to get and set its capabilities, while the prctl() system call allows manipulation of current->keep_capabilities.
3.2.6. Process LimitationsRelated Fields
A task uses a number of the resources made available by hardware and the scheduler. To keep track of how they are used and any limitations that might be applied to a process, we have the following fields.
3.2.6.1. rlim
The rlim field holds an array that provides for resource control and accounting by maintaining resource limit values. Figure 3.7 illustrates the rlim field of the task_struct.
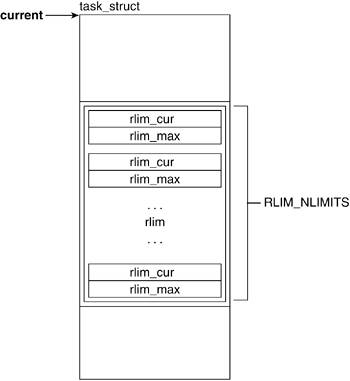
Linux recognizes the need to limit the amount of certain resources that a process is allowed to use. Because the kinds and amounts of resources processes might use varies from process to process, it is necessary to keep this information on a per process basis. What better place than to keep a reference to it in the process descriptor?
The rlimit descriptor (include/linux/resource.h) has the fields rlim_cur and rlim_max, which are the current and maximum limits that apply to that resource. The limit "units" vary by the kind of resource to which the structure refers.
-----------------------------------------------------------------------
include/linux/resource.h
struct rlimit {
unsigned long rlim_cur;
unsigned long rlim_max;
};
-----------------------------------------------------------------------
Table 3.3 lists the resources upon which their limits are defined in include/asm/resource.h. However, both x86 and PPC have the same resource limits list and default values.
Table 3.3. Resource Limits ValuesRL Name | Description | Default rlim_cur | Default rlim_max |
|---|
RLIMIT_CPU | The amount of CPU time in seconds this process may run. | RLIM_INFINITY | RLIM_INFINITY | RLIMIT_FSIZE | The size of a file in 1KB blocks. | RLIM_INFINITY | RLIM_INFINITY | RLIMIT_DATA | The size of the heap in bytes. | RLIM_INFINITY | RLIM_INFINITY | RLIMIT_STACK | The size of the stack in bytes. | _STK_LIM | RLIM_INFINITY | RLIMIT_CORE | The size of the core dump file. | 0 | RLIM_INFINITY | RLIMIT_RSS | The maximum resident set size (real memory). | RLIM_INFINITY | RLIM_INFINITY | RLIMIT_NPROC | The number of processes owned by this process. | 0 | 0 | RLIMIT_NOFILE | The number of open files this process may have at one time. | INR_OPEN | INR_OPEN | RLIMIT_MEMLOCK | Physical memory that can be locked (not swapped). | RLIM_INFINITY | RLIM_INFINITY | RLIMIT_AS | Size of process address space in bytes. | RLIM_INFINITY | RLIM_INFINITY | RLIMIT_LOCKS | Number of file locks. | RLIM_INFINITY | RLIM_INFINITY |
When a value is set to RLIM_INFINITY, the resource is unlimited for that process.
The current limit (rlim_cur) is a soft limit that can be changed via a call to setrlimit(). The maximum limit is defined by rlim_max and cannot be exceeded by an unprivileged process. The geTRlimit() system call returns the value of the resource limits. Both setrlimit() and getrlimit() take as parameters the resource name and a pointer to a structure of type rlimit.
3.2.7. Filesystem- and Address SpaceRelated Fields
Processes can be heavily involved with files throughout their lifecycle, performing tasks such as opening, closing, reading, and writing. The task_struct has two fields that are associated with file- and filesystem-related data: fs and files (see
Chapter 6, "Filesystems," for more detail). The two fields related to address space are active_mm and mm (see
Chapter 4, "Memory Management," for more detail on mm_struct).
Figure 3.8 shows the filesystem- and address spacerelated fields of the task_struct.
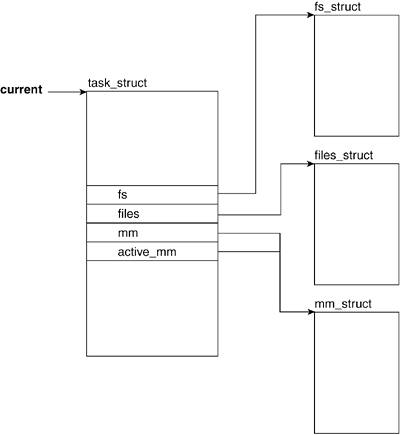
3.2.7.1. fs
The fs field holds a pointer to filesystem information.
3.2.7.2. files
The files field holds a pointer to the file descriptor table for the task. This file descriptor holds pointers to files (more specifically, to their descriptors) that the task has open.
3.2.7.3. mm
mm points to address-space and memory-managementrelated information.
3.2.7.4. active_mm
active_mm is a pointer to the most recently accessed address space. Both the mm and active_mm fields start pointing at the same mm_struct.
Evaluating the process descriptor gives us an idea of the type of data that a process is involved with throughout its lifetime. Now, we can look at what happens throughout the lifespan of a process. The following sections explain the various stages and states of a process and go through the sample program line by line to explain what happens in the kernel.
3.3. Process Creation: fork(), vfork(), and clone() System Calls
After the sample code is compiled into a file (in our case, an ELF executable), we call it from the command line. Look at what happens when we press the Return key. We already mentioned that any given process is created by another process. The operating system provides the functionality to do this by means of the fork(), vfork(), and clone() system calls.
The C library provides three functions that issue these three system calls. The prototypes of these functions are declared in <unistd.h>.
Figure 3.9 shows how a process that calls fork() executes the system call sys_fork(). This figure describes how kernel code performs the actual process creation. In a similar manner, vfork() calls sys_fork(), and clone() calls sys_clone().
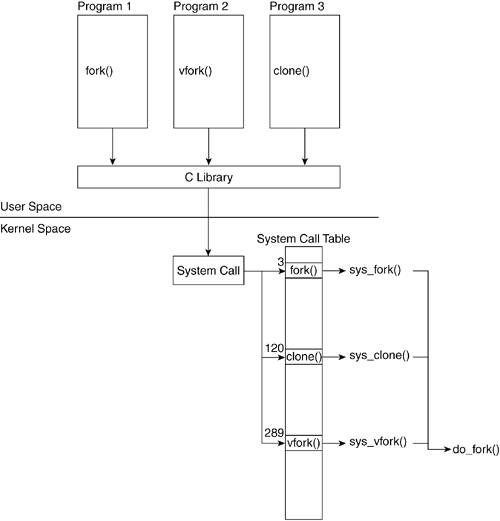
All three of these system calls eventually call do_fork(), which is a kernel function that performs the bulk of the actions related to process creation. You might wonder why three different functions are available to create a process. Each function slightly differs in how it creates a process, and there are specific reasons why one would be chosen over the other.
When we press Return at the shell prompt, the shell creates the new process that executes our program by means of a call to fork(). In fact, if we type the command ls at the shell and press Return, the pseudocode of the shell at that moment looks something like this:
if( (pid = fork()) == 0 )
execve("foo");
else
waitpid(pid);
We can now look at the functions and trace them down to the system call. Although our program calls fork(), it could just as easily have called vfork() or clone(), which is why we introduced all three functions in this section. The first function we look at is fork(). We delve through the calls fork(), sys_fork(), and do_fork(). We follow that with vfork() and finally look at clone() and trace them down to the do_fork() call.
3.3.1. fork() Function
The fork() function returns twice: once in the parent and once in the child process. If it returns in the child process, fork() returns 0. If it returns in the parent, fork() returns the child's PID. When the fork() function is called, the function places the necessary information in the appropriate registers, including the index into the system call table where the pointer to the system call resides. The processor we are running on determines the registers into which this information is placed.
At this point, if you want to continue the sequential ordering of events, look at the "
Interrupts" section in this chapter to see how sys_fork() is called. However, it is not necessary to understand how a new process gets created.
Let's now look at the sys_fork() function. This function does little else than call the do_fork() function. Notice that the sys_fork() function is architecture dependent because it accesses function parameters passed in through the system registers.
-----------------------------------------------------------------------
arch/i386/kernel/process.c
asmlinkage int sys_fork(struct pt_regs regs)
{
return do_fork(SIGCHLD, regs.esp, ®s, 0, NULL, NULL);
}
-----------------------------------------------------------------------
-----------------------------------------------------------------------
arch/ppc/kernel/process.c
int sys_fork(int p1, int p2, int p3, int p4, int p5, int p6,
struct pt_regs *regs)
{
CHECK_FULL_REGS(regs);
return do_fork(SIGCHLD, regs->gpr[1], regs, 0, NULL, NULL);
}
-----------------------------------------------------------------------
The two architectures take in different parameters to the system call. The structure pt_regs holds information such as the stack pointer. The fact that gpr[1] holds the stack pointer in PPC, whereas %esp holds the stack pointer in x86, is known by convention.
3.3.2. vfork() Function
The vfork() function is similar to the fork() function with the exception that the parent process is blocked until the child calls exit() or exec().
sys_vfork()
arch/i386/kernel/process.c
asmlinkage int sys_vfork(struct pt_regs regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs.ep, ®s, 0, NULL, NULL);
}
-----------------------------------------------------------------------
arch/ppc/kernel/process.c
int sys_vfork(int p1, int p2, int p3, int p4, int p5, int p6,
struct pt_regs *regs)
{
CHECK_FULL_REGS(regs);
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->gpr[1],
regs, 0, NULL, NULL);
}
-----------------------------------------------------------------------
The only difference between the calls to sys_fork() in sys_vfork() and sys_fork() are the flags that do_fork() is passed. The presence of these flags are used later to determine if the added behavior just described (of blocking the parent) will be executed.
3.3.3. clone() Function
The clone() library function, unlike fork() and vfork(), takes in a pointer to a function along with its argument. The child process created by do_fork()calls this function as soon as it gets created.
-----------------------------------------------------------------------
sys_clone()
arch/i386/kernel/process.c
asmlinkage int sys_clone(struct pt_regs regs)
{
unsigned long clone_flags;
unsigned long newsp;
int __user *parent_tidptr, *child_tidptr;
clone_flags = regs.ebx;
newsp = regs.ecx;
parent_tidptr = (int __user *)regs.edx;
child_tidptr = (int __user *)regs.edi;
if (!newsp)
newsp = regs.esp;
return do_fork(clone_flags & ~CLONE_IDLETASK, newsp, ®s, 0, parent_tidptr,
 child_tidptr);
}
-----------------------------------------------------------------------
-----------------------------------------------------------------------
arch/ppc/kernel/process.c
int sys_clone(unsigned long clone_flags, unsigned long usp,
int __user *parent_tidp, void __user *child_thread\
ptr,
int __user *child_tidp, int p6,
struct pt_regs *regs)
{
CHECK_FULL_REGS(regs);
if (usp == 0)
usp = regs->gpr[1]; /* stack pointer for chi\
ld */
return do_fork(clone_flags & ~CLONE_IDLETASK, usp, regs,\
0,
parent_tidp, child_tidp);
}
----------------------------------------------------------------------- child_tidptr);
}
-----------------------------------------------------------------------
-----------------------------------------------------------------------
arch/ppc/kernel/process.c
int sys_clone(unsigned long clone_flags, unsigned long usp,
int __user *parent_tidp, void __user *child_thread\
ptr,
int __user *child_tidp, int p6,
struct pt_regs *regs)
{
CHECK_FULL_REGS(regs);
if (usp == 0)
usp = regs->gpr[1]; /* stack pointer for chi\
ld */
return do_fork(clone_flags & ~CLONE_IDLETASK, usp, regs,\
0,
parent_tidp, child_tidp);
}
-----------------------------------------------------------------------
As Table 3.4 shows, the only difference between fork(), vfork(), and clone() is which flags are set in the subsequent calls to do_fork().
Table 3.4. Flags Passed to do_fork by fork(), vfork(), and clone()| | fork() | vfork() | clone() |
|---|
SIGCHLD | X | X | | CLONE_VFORK | | X | | CLONE_VM | | X | |
Finally, we get to do_fork(), which performs the real process creation. Recall that up to this point, we only have the parent executing the call to fork(), which then enables the system call sys_fork(); we still do not have a new process. Our program foo still exists as an executable file on disk. It is not running or in memory.
3.3.4. do_fork() Function
We follow the kernel side execution of do_fork() line by line as we describe the details behind the creation of a new process.
-----------------------------------------------------------------------
kernel/fork.c
1167 long do_fork(unsigned long clone_flags,
1168 unsigned long stack_start,
1169 struct pt_regs *regs,
1170 unsigned long stack_size,
1171 int __user *parent_tidptr,
1172 int __user *child_tidptr)
1173 {
1174 struct task_struct *p;
1175 int trace = 0;
1176 long pid;
1177
1178 if (unlikely(current->ptrace)) {
1179 trace = fork_traceflag (clone_flags);
1180 if (trace)
1181 clone_flags |= CLONE_PTRACE;
1182 }
1183
1184 p = copy_process(clone_flags, stack_start, regs, stack_size, parent_tidptr,
child_tidptr);
-----------------------------------------------------------------------
Lines 11781183
The code begins by verifying if the parent wants the new process ptraced. ptracing references are prevalent within functions dealing with processes. This book explains only the ptrace references at a high level. To determine whether a child can be traced, fork_traceflag() must verify the value of clone_flags. If CLONE_VFORK is set in clone_flags, if SIGCHLD is not to be caught by the parent, or if the current process also has PT_TRACE_FORK set, the child is traced, unless the CLONE_UNTRACED or CLONE_IDLETASK flags have also been set.
Line 1184
This line is where a new process is created and where the values in the registers are copied out. The copy_process() function performs the bulk of the new process space creation and descriptor field definition. However, the start of the new process does not take place until later. The details of copy_process() make more sense when the explanation is scheduler-centric. See the "
Keeping Track of Processes: Basic Scheduler Construction" section in this chapter for more detail on what happens here.
-----------------------------------------------------------------------
kernel/fork.c
...
1189 pid = IS_ERR(p) ? PTR_ERR(p) : p->pid;
1190
1191 if (!IS_ERR(p)) {
1192 struct completion vfork;
1193
1194 if (clone_flags & CLONE_VFORK) {
1195 p->vfork_done = &vfork;
1196 init_completion(&vfork);
1197 }
1198
1199 if ((p->ptrace & PT_PTRACED) || (clone_flags & CLONE_STOPPED)) {
...
1203 sigaddset(&p->pending.signal, SIGSTOP);
1204 set_tsk_thread_flag(p, TIF_SIGPENDING);
1205 }
...
-----------------------------------------------------------------------
Line 1189
This is a check for pointer errors. If we find a pointer error, we return the pointer error without further ado.
Lines 11941197
At this point, check if do_fork() was called from vfork(). If it was, enable the wait queue involved with vfork().
Lines 11991205
If the parent is being traced or the clone is set to CLONE_STOPPED, the child is issued a SIGSTOP signal upon startup, thus starting in a stopped state.
-----------------------------------------------------------------------
kernel/fork.c
1207 if (!(clone_flags & CLONE_STOPPED)) {
...
1222 wake_up_forked_process(p);
1223 } else {
1224 int cpu = get_cpu();
1225
1226 p->state = TASK_STOPPED;
1227 if (!(clone_flags & CLONE_STOPPED))
1228 wake_up_forked_process(p); /* do this last */
1229 ++total_forks;
1230
1231 if (unlikely (trace)) {
1232 current->ptrace_message = pid;
1233 ptrace_notify ((trace << 8) | SIGTRAP);
1234 }
1235
1236 if (clone_flags & CLONE_VFORK) {
1237 wait_for_completion(&vfork);
1238 if (unlikely (current->ptrace & PT_TRACE_VFORK_DONE))
1239 ptrace_notify ((PTRACE_EVENT_VFORK_DONE << 8) | SIGTRAP);
1240 } else
...
1248 set_need_resched();
1249 }
1250 return pid;
1251 }
-----------------------------------------------------------------------
Lines 12261229
In this block, we set the state of the task to TASK_STOPPED. If the CLONE_STOPPED flag was not set in clone_flags, we wake up the child process; otherwise, we leave it waiting for its wakeup signal.
Lines 12311234
If ptracing has been enabled on the parent, we send a notification.
Lines 12361239
If this was originally a call to vfork(), this is where we set the parent to blocking and send a notification to the trace if enabled. This is implemented by the parent being placed in a wait queue and remaining there in a TASK_UNINTERRUPTIBLE state until the child calls exit() or execve().
Line 1248
We set need_resched in the current task (the parent). This allows the child process to run first.
|
3.4. Process Lifespan
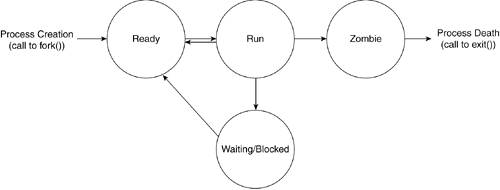
Now that we have seen how a process is created, we need to look at what happens during the course of its lifespan. During this time, a process can find itself in various states. The transition between these states depends on the actions that the process performs and on the nature of the signals sent to it. Our example program has found itself in the TASK_INTERRUPTIBLE state and in TASK_RUNNING (its current state).
The first state a process state is set to is TASK_INTERRUPTIBLE. This occurs during process creation in the copy_process() routine called by do_fork(). The second state a process finds itself in is TASK_RUNNING, which is set prior to exiting do_fork(). These two states are guaranteed in the life of the process. Following those two states, many variables come into play that determine what states the process will find itself in. The last state a process is set to is TASK_ZOMBIE, during the call to do_exit(). Let's look at the various process states and the manner in which the transitions from one state to the next occur. We point out how our process proceeds from one state to another.
3.4.1. Process States
When a process is running, it means that its context has been loaded into the CPU registers and memory and that the program that defines this context is being executed. At any particular time, a process might be unable to run for a number of reasons. A process might be unable to continue running because it is waiting for input that is not present or the scheduler may have decided it has run the maximum amount of time units allotted and that it must yield to another process. A process is considered ready when it's not running but is able to run (as with the rescheduling) or blocked when waiting for input.
Figure 3.10 shows the abstract process states and underlies the possible Linux task states that correspond to each abstract state. Table 3.5 outlines the four transitions and how it is brought about. Table 3.6 associates the abstract states with the values used in the Linux kernel to identify those states.
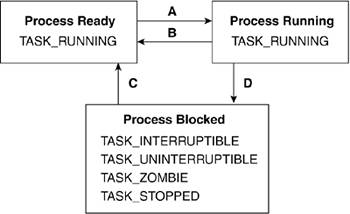
Table 3.5. Summary of TransitionsTransition | Agent of Transition |
|---|
Ready to Running (A) | Selected by scheduler | Running to Ready (B) | Timeslice ends (inactive)
Process yields (active) | Blocked to Ready (C ) | Signal comes in
Resource becomes available | Running to Blocked (D) | Process sleeps or waits on something |
Table 3.6. Association of Linux Flags with Abstract Process StatesAbstract State | Linux Task States |
|---|
Ready | TASK_RUNNING | Running | TASK_RUNNING | Blocked | TASK_INTERRUPTIBLE
TASK_UNINTERRUPTIBLE
TASK_ZOMBIE
TASK_STOPPED |
NOTE
The set_current_state() process state can be set if access to the task struct is available by a direct assignment setting such as current->state= TASK_INTERRUPTIBLE. A call to set_current_state(TASK_INTERRUPTIBLE) will perform the same effect.
3.4.2. Process State Transitions
We now look at the kinds of events that would cause a process to go from one state to another. The abstract process transitions (refer to Table 3.5) include the transition from the ready state to the running state, the transition from the running state to the ready state, the transitions from the blocked state to the ready state, and the transition from the running state to the blocked state. Each transition can translate into more than one transition between different Linux task states. For example, going from blocked to running could translate to going from any one of TASK_ INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_ZOMBIE, or TASK_STOPPED to TASK_RUNNING. Figure 3.11 and Table 3.7 describe these transitions.

Table 3.7. Summary of Task TransitionsStart Linux Task State | End Linux Task State | Agent of Transition |
|---|
TASK_RUNNING | TASK_UNINTERRUPTIBLE | Process enters wait queue. | TASK_RUNNING | TASK_INTERRUPTIBLE | Process enters wait queue. | TASK_RUNNING | TASK_STOPPED | Process receives SIGSTOP signal or process is being traced. | TASK_RUNNING | TASK_ZOMBIE | Process is killed but parent has not called sys_wait4(). | TASK_INTERRUPTIBLE | TASK_STOPPED | During signal receipt. | TASK_UNINTERRUPTIBLE | TASK_STOPPED | During waking up. | TASK_UNINTERRUPTIBLE | TASK_RUNNING | Process has received the resource it was waiting for. | TASK_INTERRUPTIBLE | TASK_RUNNING | Process has received the resource it was waiting for or has been set to running as a result of a signal it received. | TASK_RUNNING | TASK_RUNNING | Moved in and out by the scheduler. |
We now explain the various state transitions detailing the Linux task state transitions under the general process transition categories.
3.4.2.1. Ready to Running
The abstract process state transition of "ready to running" does not correspond to an actual Linux task state transition because the state does not actually change (it stays as TASK_RUNNING). However, the process goes from being in a queue of ready to run tasks (or run queue) to actually being run by the CPU.
TASK_RUNNING to TASK_RUNNING
Linux does not have a specific state for the task that is currently using the CPU, and the task retains the state of TASK_RUNNING even though the task moves out of a queue and its context is now executing. The scheduler selects the task from the run queue.
Chapter 7 discusses how the scheduler selects the next task to set to running.
3.4.2.2. Running to Ready
In this situation, the task state does not change even though the task itself undergoes a change. The abstract process state transition helps us understand what is happening. As previously stated, a process goes from running to being ready to run when it transitions from being run by the CPU to being placed in the run queue.
TASK_RUNNING to TASK_RUNNING
Because Linux does not have a separate state for the task whose context is being executed by the CPU, the task does not suffer an explicit Linux task state transition when this occurs and stays in the TASK_RUNNING state. The scheduler selects when to switch out a task from being run to being placed in the run queue according to the time it has spent executing and the task's priority (
Chapter 7 covers this in detail).
3.4.2.3. Running to Blocked
When a process gets blocked, it can be in one of the following states: TASK_INTERRUPTIBLE, TASK_UNINTERRUPTIBLE, TASK_ZOMBIE, or TASK_STOPPED. We now describe how a task gets to be in each of these states from TASK_RUNNING, as detailed in Table 3.7.
TASK_RUNNING to TASK_INTERRUPTIBLE
This state is usually called by blocking I/O functions that have to wait on an event or resource. What does it mean for a task to be in the TASK_INTERRUPTIBLE state? Simply that it is not on the run queue because it is not ready to run. A task in TASK_INTERRUPTIBLE wakes up if its resource becomes available (time or hardware) or if a signal comes in. The completion of the original system call depends on the implementation of the interrupt handler. In the code example, the child process accesses a file that is on disk. The disk driver is in charge of knowing when the device is ready for the data to be accessed. Hence, the driver will have code that looks something like this:
while(1)
{
if(resource_available)
break();
set_current_state(TASK_INTERRUPTIBLE);
schedule();
}
set_current_state(TASK_RUNNING);
The example process enters the TASK_INTERRUPTIBLE state at the time it performs the call to open(). At this point, it is removed from being the running process by the call to schedule(), and another process that the run queue selects becomes the running process. After the resource becomes available, the process breaks out of the loop and sets the process' state to TASK_RUNNING, which puts it back on the run queue. It then waits until the scheduler determines that it is the process' turn to run.
The following listing shows the function interruptible_sleep_on(), which can set a task in the TASK_INTERRUPTIBLE state:
-----------------------------------------------------------------------
kernel/sched.c
2504 void interruptible_sleep_on(wait_queue_head_t *q)
2505 {
2506 SLEEP_ON_VAR
2507
2508 current->state = TASK_INTERRUPTIBLE;
2509
2510 SLEEP_ON_HEAD
2511 schedule();
2512 SLEEP_ON_TAIL
2513 }
-----------------------------------------------------------------------
The SLEEP_ON_HEAD and the SLEEP_ON_TAIL macros take care of adding and removing the task from the wait queue (see the "
Wait Queues" section in this chapter). The SLEEP_ON_VAR macro initializes the task's wait queue entry for addition to the wait queue.
TASK_RUNNING to TASK_UNINTERRUPTIBLE
The TASK_UNINTERRUPTIBLE state is similar to TASK_INTERRUPTIBLE with the exception that processes do not heed signals that come in while it is in kernel mode. This state is also the default state into which a task is set when it is initialized during creation in do_fork(). The sleep_on() function is called to set a task in the TASK_UNINTERRUPTIBLE state.
-----------------------------------------------------------------------
kernel/sched.c
2545 long fastcall __sched sleep_on(wait_queue_head_t *q)
2546 {
2547 SLEEP_ON_VAR
2548
2549 current->state = TASK_UNINTERRUPTIBLE;
2550
2551 SLEEP_ON_HEAD
2552 schedule();
2553 SLEEP_ON_TAIL
2554
2555 return timeout;
2556 }
-----------------------------------------------------------------------
This function sets the task on the wait queue, sets its state, and calls the scheduler.
TASK_RUNNING to TASK_ZOMBIE
A process in the TASK_ZOMBIE state is called a zombie process. Each process goes through this state in its lifecycle. The length of time a process stays in this state depends on its parent. To understand this, realize that in UNIX systems, any process may retrieve the exit status of a child process by means of a call to wait() or waitpid() (see the "
Parent Notification and sys_wait4()" section). Hence, minimal information needs to be available to the parent, even once the child terminates. It is costly to keep the process alive just because the parent needs to know its state; hence, the zombie state is one in which the process' resources are freed and returned but the process descriptor is retained.
This temporary state is set during a process' call to sys_exit() (see the "
Process Termination" section for more information). Processes in this state will never run again. The only state they can go to is the TASK_STOPPED state.
If a task stays in this state for too long, the parent task is not reaping its children. A zombie task cannot be killed because it is not actually alive. This means that no task exists to kill, merely the task descriptor that is waiting to be released.
TASK_RUNNING to TASK_STOPPED
This transition will be seen in two cases. The first case is processes that a debugger or a trace utility is manipulating. The second is if a process receives SIGSTOP or one of the stop signals.
TASK_UNINTERRUPTIBLE or TASK_INTERRUPTIBLE to TASK_STOPPED
TASK_STOPPED manages processes in SMP systems or during signal handling. A process is set to the TASK_STOPPED state when the process receives a wake-up signal or if the kernel specifically needs the process to not respond to anything (as it would if it were set to TASK_INTERRUPTIBLE, for example).
Unlike a task in state TASK_ZOMBIE, a process in state TASK_STOPPED is still able to receive a SIGKILL signal.
3.4.2.4. Blocked to Ready
The transition of a process from blocked to ready occurs upon acquisition of the data or hardware on which the process was waiting. The two Linux-specific transitions that occur under this category are TASK_INTERRUPTIBLE to TASK_RUNNING and TASK_UNINTERRUPTIBLE to TASK_RUNNING.
3.5. Process Termination
A process can terminate voluntarily and explicitly, voluntarily and implicitly, or involuntarily. Voluntary termination can be attained in two ways:
Returning from the main() function (implicit) Calling exit() (explicit)
Executing a return from the main() function literally translates into a call to exit(). The linker introduces the call to exit() under these circumstances.
Involuntary termination can be attained in three ways:
The process might receive a signal that it cannot handle. An exception might be raised during its kernel mode execution. The process might have received the SIGABRT or other termination signal.
The termination of a process is handled differently depending on whether the parent is alive or dead. A process can
In the first case, the child is turned into a zombie process until the parent makes the call to wait/waitpid(). In the second case, the child's parent status will have been inherited by the init() process. We see that when any process terminates, the kernel reviews all the active processes and verifies whether the terminating process is parent to any process that is still alive and active. If so, it changes that child's parent PID to 1.
Let's look at the example again and follow it through its demise. The process explicitly calls exit(0). (Note that it could have just as well called _exit(), return(0), or fallen off the end of main with neither call.) The exit() C library function then calls the sys_exit() system call. We can review the following code to see what happens to the process from here onward.
We now look at the functions that terminate a process. As previously mentioned, our process foo calls exit(), which calls the first function we look at, sys_exit(). We delve through the call to sys_exit() and into the details of do_exit().
3.5.1. sys_exit() Function
-----------------------------------------------------------------------
kernel/exit.c
asmlinkage long sys_exit(int error_code)
{
do_exit((error_code&0xff)<<8);
}
-----------------------------------------------------------------------
sys_exit() does not vary between architectures, and its job is fairly straightforwardall it does is call do_exit() and convert the exit code into the format required by the kernel.
3.5.2. do_exit() Function
-----------------------------------------------------------------------
kernel/exit.c
707 NORET_TYPE void do_exit(long code)
708 {
709 struct task_struct *tsk = current;
710
711 if (unlikely(in_interrupt()))
712 panic("Aiee, killing interrupt handler!");
713 if (unlikely(!tsk->pid))
714 panic("Attempted to kill the idle task!");
715 if (unlikely(tsk->pid == 1))
716 panic("Attempted to kill init!");
717 if (tsk->io_context)
718 exit_io_context();
719 tsk->flags |= PF_EXITING;
720 del_timer_sync(&tsk->real_timer);
721
722 if (unlikely(in_atomic()))
723 printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n",
724 current->comm, current->pid,
725 preempt_count());
-----------------------------------------------------------------------
Line 707
The parameter code comprises the exit code that the process returns to its parent.
Lines 711716
Verify against unlikely, but possible, invalid circumstances. These include the following:
Making sure we are not inside an interrupt handler. Ensure we are not the idle task (PID0=0) or the init task (PID=1). Note that the only time the init process is killed is upon system shutdown.
Line 719
Here, we set PF_EXITING in the flags field of the processes' task struct. This indicates that the process is shutting down. For example, this is used when creating interval timers for a given process. The process flags are checked to see if this flag is set and thus helps prevent wasteful processing.
-----------------------------------------------------------------------
kernel/exit.c
...
727 profile_exit_task(tsk);
728
729 if (unlikely(current->ptrace & PT_TRACE_EXIT)) {
730 current->ptrace_message = code;
731 ptrace_notify((PTRACE_EVENT_EXIT << 8) | SIGTRAP);
732 }
733
734 acct_process(code);
735 __exit_mm(tsk);
736
737 exit_sem(tsk);
738 __exit_files(tsk);
739 __exit_fs(tsk);
740 exit_namespace(tsk);
741 exit_thread();
...
-----------------------------------------------------------------------
Lines 729732
If the process is being ptraced and the PT_TRACE_EXIT flag is set, we pass the exit code and notify the parent process.
Lines 735742
These lines comprise the cleaning up and reclaiming of resources that the task has been using and will no longer need. __exit_mm() frees the memory allocated to the process and releases the mm_struct associated with this process. exit_sem() disassociates the task from any IPC semaphores. __exit_files() releases any files the task allocated and decrements the file descriptor counts. __exit_fs() releases all file system data.
-----------------------------------------------------------------------
kernel/exit.c
...
744 if (tsk->leader)
745 disassociate_ctty(1);
746
747 module_put(tsk->thread_info->exec_domain->module);
748 if (tsk->binfmt)
749 module_put(tsk->binfmt->module);
...
-----------------------------------------------------------------------
Lines 744745
If the process is a session leader, it is expected to have a controlling terminal or tty. This function disassociates the task leader from its controlling tty.
Lines 747749
In these blocks, we decrement the reference counts for the module:
-----------------------------------------------------------------------
kernel/exit.c
...
751 tsk->exit_code = code;
752 exit_notify(tsk);
753
754 if (tsk->exit_signal == -1 && tsk->ptrace == 0)
755 release_task(tsk);
756
757 schedule();
758 BUG();
759 /* Avoid "noreturn function does return". */
760 for (;;) ;
761 }
...
-----------------------------------------------------------------------
Line 751
Set the task's exit code in the task_struct field exit_code.
Line 752
Send the SIGCHLD signal to parent and set the task state to TASK_ZOMBIE. exit_notify() notifies the relations of the impending task's death. The parent is informed of the exit code while the task's children have their parent set to the init process. The only exception to this is if another existing process exists within the same process group: In this case, the existing process is used as a surrogate parent.
Line 754
If exit_signal is -1 (indicating an error) and the process is not being ptraced, the kernel calls on the scheduler to release the process descriptor of this task and to reclaim its timeslice.
Line 757
Yield the processor to a new process. As we see in
Chapter 7, the call to schedule() will not return. All code past this point catches impossible circumstances or avoids compiler warnings.
3.5.3. Parent Notification and sys_wait4()
When a process is terminated, its parent is notified. Prior to this, the process is in a zombie state where all its resources have been returned to the kernel, but the process descriptor remains. The parent task (for example, the Bash shell) receives the signal SIGCHLD that the kernel sends to it when the child process terminates. In the example, the shell calls wait() when it wants to be notified. A parent process can ignore the signal by not implementing an interrupt handler and can instead choose to call wait() (or waitpid()) at any point.
The wait family of functions serves two general roles:
Our parent program can choose to call one of the four functions in the wait family:
pid_t wait(int *status) pid_t waitpid(pid_t pid, int *status, int options) pid_t wait3(int *status, int options, struct rusage *rusage) pid_t wait4(pid_t pid, int *status, int options, struct rusage *rusage)
Each function will in turn call sys_wait4(), which is where the bulk of the notification occurs.
A process that calls one of the wait functions is blocked until one of its children terminates or returns immediately if the child has terminated (or if the parent is childless). The sys_wait4() function shows us how the kernel manages this notification:
-----------------------------------------------------------------------
kernel/exit.c
1031 asmlinkage long sys_wait4(pid_t pid,unsigned int * stat_addr,
int options, struct rusage * ru)
1032 {
1033 DECLARE_WAITQUEUE(wait, current);
1034 struct task_struct *tsk;
1035 int flag, retval;
1036
1037 if (options & ~(WNOHANG|WUNTRACED|__WNOTHREAD|__WCLONE|__WALL))
1038 return -EINVAL;
1039
1040 add_wait_queue(¤t->wait_chldexit,&wait);
1041 repeat:
1042 flag = 0;
1043 current->state = TASK_INTERRUPTIBLE;
1044 read_lock(&tasklist_lock);
...
-----------------------------------------------------------------------
Line 1031
The parameters include the PID of the target process, the address in which the exit status of the child should be placed, flags for sys_wait4(), and the address in which the resource usage information of the child should be placed.
Lines 1033 and 1040
Declare a wait queue and add the process to it. (This is covered in more detail in the "
Wait Queues" section.)
Line 10371038
This code mostly checks for error conditions. The function returns a failure code if the system call is passed options that are invalid. In this case, the error EINVAL is returned.
Line 1042
The flag variable is set to 0 as an initial value. This variable is changed once the pid argument is found to match one of the calling task's children.
Line 1043
This code is where the calling process is set to blocking. The state of the task is moved from TASK_RUNNING to TASK_INTERRUPTIBLE.
-----------------------------------------------------------------------
kernel/exit.c
...
1045 tsk = current;
1046 do {
1047 struct task_struct *p;
1048 struct list_head *_p;
1049 int ret;
1050
1051 list_for_each(_p,&tsk->children) {
1052 p = list_entry(_p,struct task_struct,sibling);
1053
1054 ret = eligible_child(pid, options, p);
1055 if (!ret)
1056 continue;
1057 flag = 1;
1058 switch (p->state) {
1059 case TASK_STOPPED:
1060 if (!(options & WUNTRACED) &&
1061 !(p->ptrace & PT_PTRACED))
1062 continue;
1063 retval = wait_task_stopped(p, ret == 2,
1064 stat_addr, ru);
1065 if (retval != 0) /* He released the lock. */
1066 goto end_wait4;
1067 break;
1068 case TASK_ZOMBIE:
...
1072 if (ret == 2)
1073 continue;
1074 retval = wait_task_zombie(p, stat_addr, ru);
1075 if (retval != 0) /* He released the lock. */
1076 goto end_wait4;
1077 break;
1078 }
1079 }
...
1091 tsk = next_thread(tsk);
1092 if (tsk->signal != current->signal)
1093 BUG();
1094 } while (tsk != current);
...
-----------------------------------------------------------------------
Lines 1046 and 1094
The do while loop iterates once through the loop while looking at itself, then continues while looking at other tasks.
Line 1051
Repeat the action on every process in the task's children list. Remember that this is the parent process that is waiting on its children's exit. The process is currently in TASK_INTERRUPTIBLE and iterating over its children list.
Line 1054
Determine if the pid parameter passed is unreasonable.
Line 10581079
Check the state of each of the task's children. Actions are performed only if a child is stopped or if it is a zombie. If a task is sleeping, ready, or running (the remaining states), nothing is done. If a child is in TASK_STOPPED and the UNtrACED option has been used (which means that the task wasn't stopped because of a process trace), we verify if the status of that child has been reported and return the child's information. If a child is in TASK_ZOMBIE, it is reaped.
-----------------------------------------------------------------------
kernel/exit.c
...
1106 retval = -ECHILD;
1107 end_wait4:
1108 current->state = TASK_RUNNING;
1109 remove_wait_queue(¤t->wait_chldexit,&wait);
1110 return retval;
1111 }
-----------------------------------------------------------------------
Line 1106
If we have gotten to this point, the PID specified by the parameter is not a child of the calling process. ECHILD is the error used to notify us of this event.
Line 11071111
At this point, the children list has been processed, and any children that needed to be reaped have been reaped. The parent's block is removed and its state is set to TASK_RUNNING once again. Finally, the wait queue is removed.
At this point, you should be familiar with the various stages that a process goes through during its lifecycle, the kernel functions that make all this happen, and the structures the kernel uses to keep track of all this information. Now, we look at how the scheduler manipulates and manages processes to create the effect of a multithreaded system. We also see in more detail how processes go from one state to another.
3.6. Keeping Track of Processes: Basic Scheduler Construction
Until this point, we kept the concepts of the states and the transitions process-centric. We have not spoken about how the transition is managed, nor have we spoken about the kernel infrastructure, which performs the running and stopping of processes. The scheduler handles all these details. Having finished the exploration of the process lifecycle, we now introduce the basics of the scheduler and how it interacts with the do_fork() function during process creation.
3.6.1. Basic Structure
The scheduler operates on a structure called a run queue. There is one run queue per CPU on the system. The core data structures within a run queue are two priority-ordered arrays. One of these contains active tasks and the other contains expired tasks. In general, an active task runs for a set amount of time, the length of its timeslice or quantum, and is then inserted into the expired array to wait for more CPU time. When the active array is empty, the scheduler swaps the two arrays by exchanging the active and expired pointers. The scheduler then begins executing tasks on the new active array.
Figure 3.12 illustrates the priority arrays within the run queue. The definition of the priority array structure is as follows:
-----------------------------------------------------------------------
kernel/sched.c
192 struct prio_array {
193 int nr_active;
194 unsigned long bitmap[BITMAP_SIZE];
195 struct list_head queue[MAX_PRIO];
196 };
-----------------------------------------------------------------------
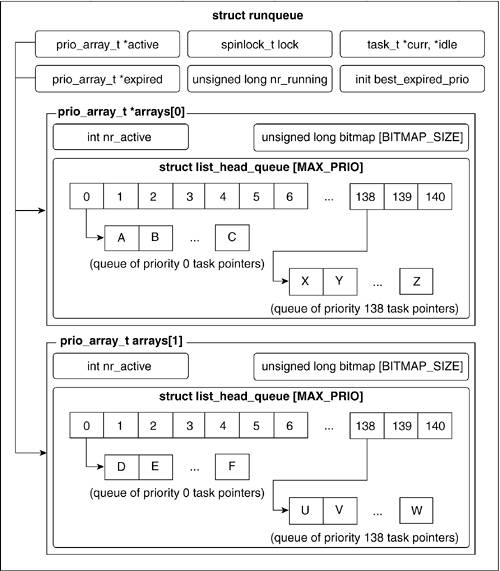
The fields of the prio_array struct are as follows:
nr_active.
A counter that keeps track of the number of tasks held in the priority array.
bitmap.
This keeps track of the priorities within the array. The actual length of bitmap depends on the size of unsigned longs on the system. It will always be enough to store MAX_PRIO bits, but it could be longer.
queue.
An array that stores lists of tasks. Each list holds tasks of a certain priority. Thus, queue[0] holds a list of all tasks of priority 0, queue[1] holds a list of all tasks of priority 1, and so on.
With this basic understanding of how a run queue is organized, we can now embark on following a task through the scheduler on a single CPU system.
3.6.2. Waking Up from Waiting or Activation
Recall that when a process calls fork(), a new process is made. As previously mentioned, the process calling fork() is called the parent, and the new process is called the child. The newly created process needs to be scheduled for access to the CPU. This occurs via the do_fork() function.
Two important lines deal with the scheduler in do_fork() related to waking up processes. copy_process(), called on line 1184 of linux/kernel/fork.c, calls the function sched_fork(), which initializes the process for an impending insertion into the scheduler's run queue. wake_up_forked_process(), called on line 1222 of linux/kernel/fork.c, takes the initialized process and inserts it into the run queue. Initialization and insertion have been separated to allow for the new process to be killed, or otherwise terminated, before being scheduled. The process will only be scheduled if it is created, initialized successfully, and has no pending signals.
3.6.2.1. sched_fork(): Scheduler Initialization for Newly Forked Process
The sched_fork()function performs the infrastructure setup the scheduler requires for a newly forked process:
-----------------------------------------------------------------------
kernel/sched.c
719 void sched_fork(task_t *p)
720 {
721 /*
722 * We mark the process as running here, but have not actually
723 * inserted it onto the runqueue yet. This guarantees that
724 * nobody will actually run it, and a signal or other external
725 * event cannot wake it up and insert it on the runqueue either.
726 */
727 p->state = TASK_RUNNING;
728 INIT_LIST_HEAD(&p->run_list);
729 p->array = NULL;
730 spin_lock_init(&p->switch_lock);
-----------------------------------------------------------------------
Line 727
The process is marked as running by setting the state attribute in the task structure to TASK_RUNNING to ensure that no event can insert it on the run queue and run the process before do_fork() and copy_process() have verified that the process was created properly. When that verification passes, do_fork() adds it to the run queue via wake_up_forked_process().
Line 728730
The process' run_list field is initialized. When the process is activated, its run_list field is linked into the queue structure of a priority array in the run queue. The process' array field is set to NULL to represent that it is not part of either priority array on a run queue. The next block of sched_fork(), lines 731 to 739, deals with kernel preemption. (Refer to Chapter 7 for more information on preemption.)
-----------------------------------------------------------------------
kernel/sched.c
740 /*
741 * Share the timeslice between parent and child, thus the
742 * total amount of pending timeslices in the system doesn't change,
743 * resulting in more scheduling fairness.
744 */
745 local_irq_disable();
746 p->time_slice = (current->time_slice + 1) >> 1;
747 /*
748 * The remainder of the first timeslice might be recovered by
749 * the parent if the child exits early enough.
750 */
751 p->first_time_slice = 1;
752 current->time_slice >>= 1;
753 p->timestamp = sched_clock();
754 if (!current->time_slice) {
755 /*
756 * This case is rare, it happens when the parent has only
757 * a single jiffy left from its timeslice. Taking the
758 * runqueue lock is not a problem.
759 */
760 current->time_slice = 1;
761 preempt_disable();
762 scheduler_tick(0, 0);
763 local_irq_enable();
764 preempt_enable();
765 } else
766 local_irq_enable();
767 }
-----------------------------------------------------------------------
Lines 740753
After disabling local interrupts, we divide the parent's timeslice between the parent and the child using the shift operator. The new process' first timeslice is set to 1 because it hasn't been run yet and its timestamp is initialized to the current time in nanosec units.
Lines 754767
If the parent's timeslice is 1, the division results in the parent having 0 time left to run. Because the parent was the current process on the scheduler, we need the scheduler to choose a new process. This is done by calling scheduler_tick() (on line 762). Preemption is disabled to ensure that the scheduler chooses a new current process without being interrupted. Once all this is done, we enable preemption and restore local interrupts.
At this point, the newly created process has had its scheduler-specific variables initialized and has been given an initial timeslice of half the remaining timeslice of its parent. By forcing a process to sacrifice a portion of the CPU time it's been allocated and giving that time to its child, the kernel prevents processes from seizing large chunks of processor time. If processes were given a set amount of time, a malicious process could spawn many children and quickly become a CPU hog.
After a process has been successfully initialized, and that initialization verified, do_fork() calls wake_up_forked_process():
-----------------------------------------------------------------------
kernel/sched.c
922 /*
923 * wake_up_forked_process - wake up a freshly forked process.
924 *
925 * This function will do some initial scheduler statistics housekeeping
926 * that must be done for every newly created process.
927 */
928 void fastcall wake_up_forked_process(task_t * p)
929 {
930 unsigned long flags;
931 runqueue_t *rq = task_rq_lock(current, &flags);
932
933 BUG_ON(p->state != TASK_RUNNING);
934
935 /*
936 * We decrease the sleep average of forking parents
937 * and children as well, to keep max-interactive tasks
938 * from forking tasks that are max-interactive.
939 */
940 current->sleep_avg = JIFFIES_TO_NS(CURRENT_BONUS(current) *
941 PARENT_PENALTY / 100 * MAX_SLEEP_AVG / MAX_BONUS);
942
943 p->sleep_avg = JIFFIES_TO_NS(CURRENT_BONUS(p) *
944 CHILD_PENALTY / 100 * MAX_SLEEP_AVG / MAX_BONUS);
945
946 p->interactive_credit = 0;
947
948 p->prio = effective_prio(p);
949 set_task_cpu(p, smp_processor_id());
950
951 if (unlikely(!current->array))
952 __activate_task(p, rq);
953 else {
954 p->prio = current->prio;
955 list_add_tail(&p->run_list, ¤t->run_list);
956 p->array = current->array;
957 p->array->nr_active++;
958 rq->nr_running++;
959 }
960 task_rq_unlock(rq, &flags);
961 }
-----------------------------------------------------------------------
Lines 930934
The first thing that the scheduler does is lock the run queue structure. Any modifications to the run queue must be made with the lock held. We also throw a bug notice if the process isn't marked as TASK_RUNNING, which it should be thanks to the initialization in sched_fork() (see Line 727 in kernel/sched.c shown previously).
Lines 940947
The scheduler calculates the sleep average of the parent and child processes. The sleep average is the value of how much time a process spends sleeping compared to how much time it spends running. It is incremented by the amount of time the process slept, and it is decremented on each timer tick while it's running. An interactive, or I/O bound, process spends most of its time waiting for input and normally has a high sleep average. A non-interactive, or CPU-bound, process spends most of its time using the CPU instead of waiting for I/O and has a low sleep average. Because users want to see results of their input, like keyboard strokes or mouse movements, interactive processes are given more scheduling advantages than non-interactive processes. Specifically, the scheduler reinserts an interactive process into the active priority array after its timeslice expires. To prevent an interactive process from creating a non-interactive child process and thereby seizing a disproportionate share of the CPU, these formulas are used to lower the parent and child sleep averages. If the newly forked process is interactive, it soon sleeps enough to regain any scheduling advantages it might have lost.
Line 948
The function effective_prio() modifies the process' static priority. It returns a priority between 100 and 139 (MAX_RT_PRIO to MAX__PRIO-1). The process' static priority can be modified by up to 5 in either direction based on its previous CPU usage and time spent sleeping, but it always remains in this range. From the command line, we talk about the nice value of a process, which can range from +19 to -20 (lowest to highest priority). A nice priority of 0 corresponds to a static priority of 120.
Line 749
The process has its CPU attribute set to the current CPU.
Lines 951960
The overview of this code block is that the new process, or child, copies the scheduling information from its parent, which is current, and then inserts itself into the run queue in the appropriate place. We have finished our modifications of the run queue, so we unlock it. The following paragraph and Figure 3.13 discuss this process in more detail.
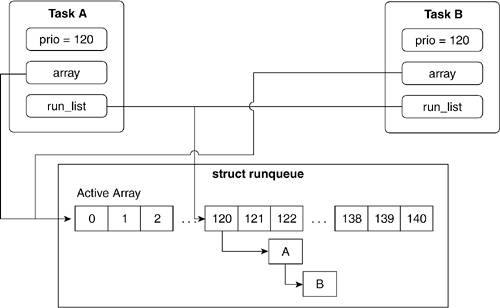
The pointer array points to a priority array in the run queue. If the current process isn't pointing to a priority array, it means that the current process has finished or is asleep. In that case, the current process' runlist field is not in the queue of the run queue's priority array, which means that the list_add_tail() operation (on line 955) would fail. Instead, we insert the newly created process using __activate_task(), which adds the new process to the queue without referring to its parent.
In the normal case, when the current process is waiting for CPU time on a run queue, the process is added to the queue residing at slot p->prio in the priority array. The array that the process was added to has its process counter, nr_active, incremented and the run queue has its process counter, nr_running, incremented. Finally, we unlock the run queue lock.
The case where the current process doesn't point to a priority array on the run queue is useful in seeing how the scheduler manages the run queue and priority array attributes.
-----------------------------------------------------------------------
kernel/sched.c
366 static inline void __activate_task(task_t *p, runqueue_t *rq)
367 {
368 enqueue_task(p, rq->active);
369 rq->nr_running++;
370 }
-----------------------------------------------------------------------
__activate_task() places the given process p on to the active priority array on the run queue rq and increments the run queue's nr_running field, which is the counter for total number of processes that are on the run queue.
-----------------------------------------------------------------------
kernel/sched.c
311 static void enqueue_task(struct task_struct *p, prio_array_t *array)
312 {
313 list_add_tail(&p->run_list, array->queue + p->prio);
314 __set_bit(p->prio, array->bitmap);
315 array->nr_active++;
316 p->array = array;
317 }
-----------------------------------------------------------------------
Lines 311312
enqueue_task() takes a process p and places it on priority array array, while initializing aspects of the priority array.
Line 313
The process' run_list is added to the tail of the queue located at p->prio in the priority array.
Line 314
The priority array's bitmap at priority p->prio is set so when the scheduler runs, it can see that there is a process to run at priority p->prio.
Line 315
The priority array's process counter is incremented to reflect the addition of the new process.
Line 316
The process' array pointer is set to the priority array to which it was just added.
To recap, the act of adding a newly forked process is fairly straightforward, even though the code can be confusing because of similar names throughout the scheduler. A process is placed at the end of a list in a run queue's priority array at the slot specified by the process' priority. The process then records the location of the priority array and the list it's located in within its structure.
|
3.7. Wait Queues
We discussed the process transition between the states of TASK_RUNNING and TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE. Now, we look at another structure that's involved in this transition. When a process is waiting on an external event to occur, it is removed from the run queue and placed on a wait queue. Wait queues are doubly linked lists of wait_queue_t structures. The wait_queue_t structure is set up to hold all the information required to keep track of a waiting task. All tasks waiting on a particular external event are placed in a wait queue. The tasks on a given wait queue are woken up, at which point the tasks verify the condition they are waiting for and either resume sleep or remove themselves from the wait queue and set themselves back to TASK_RUNNING. You might recall that sys_wait4() system calls use wait queues when a parent requests status of its forked child. Note that a task waiting for an external event (and therefore is no longer on the run queue) is either in the TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE states.
A wait queue is a doubly linked list of wait_queue_t structures that hold pointers to the process task structures of the processes that are blocking. Each list is headed up by a wait_queue_head_t structure, which marks the head of the list and holds the spinlock to the list to prevent wait_queue_t additional race conditions. Figure 3.14 illustrates wait queue implementation. We now look at the wait_queue_t and the wait_queue_head_t structures:
-----------------------------------------------------------------------
include/linux/wait.h
19 typedef struct __wait_queue wait_queue_t;
...
23 struct __wait_queue {
24 unsigned int flags;
25 #define WQ_FLAG_EXCLUSIVE 0x01
26 struct task_struct * task;
27 wait_queue_func_t func;
28 struct list_head task_list;
29 };
30
31 struct __wait_queue_head {
32 spinlock_t lock;
33 struct list_head task_list;
34 };
35 typedef struct __wait_queue_head wait_queue_head_t;
-----------------------------------------------------------------------
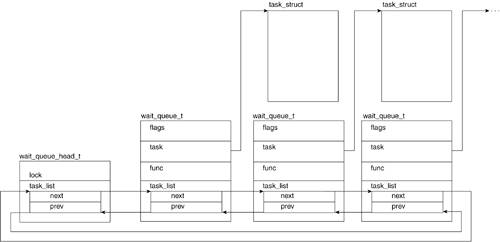
The wait_queue_t structure is comprised of the following fields:
flags.
Can hold the value WQ_FLAG_EXCLUSIVE, which is set to 1, or ~WQ_FLAG_EXCLUSIVE, which would be 0. The WQ_FLAG_EXCLUSIVE flag marks this process as an exclusive process. Exclusive and non-exclusive processes are discussed in the next section.
task.
The pointer to the task descriptor of the process being placed on the wait queue.
func.
A structure holding a function used to wake the task on the wait queue. This field uses as default default_wake_function(), which is covered in detail in the section, "
Waiting on the Event." wait_queue_func_t is defined as follows:
------------------------------------------------------------------
include/linux/wait.h
typedef int (*wait_queue_func_t)(wait_queue_t *wait,
unsigned mode, int sync);
------------------------------------------------------------------
where wait is the pointer to the wait queue, mode is either TASK_ INTERRUPTIBLE or TASK_UNINTERRUPTIBLE, and sync specifies if the wakeup should be synchronous.
task_list.
The structure that holds pointers to the previous and next elements in the wait queue.
The structure __wait_queue_head is the head of a wait queue list and is comprised of the following fields:
The "Wait Queues" section in Chapter 10, "Adding Your Code to the Kernel," describes an example implementation of a wait queue. In general, the way in which a process puts itself to sleep involves a call to one of the wait_event* macros (which is discussed shortly) or by executing the following steps, as in the example shown in Chapter 10:
1. | By declaring the wait queue, the process sleeps on by way of DECLARE_WAITQUEUE_HEAD.
| 2. | Adding itself to the wait queue by way of add_wait_queue() or add_wait_queue_exclusive().
| 3. | Changing its state to TASK_INTERRUPTIBLE or TASK_ UNINTERRUPTIBLE.
| 4. | Testing for the external event and calling schedule(), if it has not occurred yet.
| 5. | After the external event occurs, setting itself to the TASK_RUNNING state.
| 6. | Removing itself from the wait queue by calling remove_wait_queue().
|
The waking up of a process is handled by way of a call to one of the wake_up macros. These wake up all processes that belong to a particular wait queue. This places the task in the TASK_RUNNING state and places it back on the run queue.
Let's look at what happens when we call the add_wait_queue() functions.
3.7.1. Adding to the Wait Queue
Two different functions are used to add sleeping processes into a wait queue: add_wait_queue() and add_wait_queue_exclusive(). The two functions exist to accommodate the two types of sleeping processes. Non-exclusive waiting processes are those that wait for the return of a condition that is not shared by other waiting processes. Exclusive waiting processes are waiting for a condition that another waiting process might be waiting on, which potentially generates a race condition.
The add_wait_queue() function inserts a non-exclusive process into the wait queue. A non-exclusive process is one which will, under any circumstance, be woken up by the kernel when the event it is waiting for comes to fruition. The function sets the flags field of the wait queue struct, which represents the sleeping process to 0, sets the wait queue lock to avoid interrupts accessing the same wait queue from generating a race condition, adds the structure to the wait queue list, and restores the lock from the wait queue to make it available to other processes:
-----------------------------------------------------------------------
kernel/fork.c
93 void add_wait_queue(wait_queue_head_t *q, wait_queue_t * wait)
94 {
95 unsigned long flags;
96
97 wait->flags &= ~WQ_FLAG_EXCLUSIVE;
98 spin_lock_irqsave(&q->lock, flags);
99 __add_wait_queue(q, wait);
100 spin_unlock_irqrestore(&q->lock, flags);
101 }
-----------------------------------------------------------------------
The add_wait_queue_exclusive() function inserts an exclusive process into the wait queue. The function sets the flags field of the wait queue struct to 1 and proceeds in much the same manner as add_wait_queue() exclusive, with the exception that it adds exclusive processes into the queue from the tail end. This means that in a particular wait queue, the non-exclusive processes are at the front and the exclusive processes are at the end. This comes into play with the order in which the processes in a wait queue are woken up, as we see when we discuss waking up sleeping processes:
-----------------------------------------------------------------------
kernel/fork.c
105 void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t * wait)
106 {
107 unsigned long flags;
108
109 wait->flags |= WQ_FLAG_EXCLUSIVE;
110 spin_lock_irqsave(&q->lock, flags);
111 __add_wait_queue_tail(q, wait);
112 spin_unlock_irqrestore(&q->lock, flags);
113 }
-----------------------------------------------------------------------
3.7.2. Waiting on the Event
The sleep_on(), sleep_on_timeout(), and interruptible_sleep_on() interfaces, although still supported in 2.6, will be removed for the 2.7 release. Therefore, we cover only the wait_event*() interfaces that are to replace the sleep_on*() interfaces.
The wait_event*() interfaces include wait_event(), wait_event_ interruptible(), and wait_event_interruptible_timeout(). Figure 3.15 shows the function skeleton calling routing.
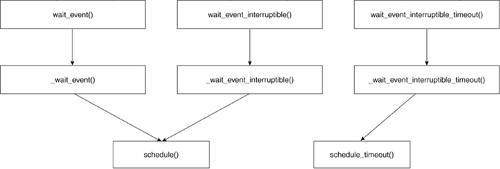
We go through and describe the interfaces related to wait_event() and mention what the differences are with respect to the other two functions. The wait_event() interface is a wrapper around the call to __wait_event() with an infinite loop that is broken only if the condition being waited upon returns. wait_event_interruptible_timeout() passes a third parameter called ret of type int, which is used to pass the timeout time.
wait_event_interruptible() is the only one of the three interfaces that returns a value. This return value is ERESTARTSYS if a signal broke the waiting event, or 0 if the condition was met:
-----------------------------------------------------------------------
include/linux/wait.h
137 #define wait_event(wq, condition)
138 do {
139 if (condition)
140 break;
141 __wait_event(wq, condition);
142 } while (0)
-----------------------------------------------------------------------
The __wait_event() interface does all the work around the process state change and the descriptor manipulation:
-----------------------------------------------------------------------
include/linux/wait.h
121 #define __wait_event(wq, condition)
122 do {
123 wait_queue_t __wait;
124 init_waitqueue_entry(&__wait, current);
125
126 add_wait_queue(&wq, &__wait);
127 for (;;) {
128 set_current_state(TASK_UNINTERRUPTIBLE);
129 if (condition)
130 break;
131 schedule();
132 }
133 current->state = TASK_RUNNING;
134 remove_wait_queue(&wq, &__wait);
135 } while (0)
-----------------------------------------------------------------------
Line 124126
Initialize the wait queue descriptor for the current process and add the descriptor entry to the wait queue that was passed in. Up to this point, __wait_event_interruptible and __wait_event_interruptible_timeout look identical to __wait_event.
Lines 127132
This code sets up an infinite loop that will only be broken out of if the condition is met. Before blocking on the condition, we set the state of the process to TASK_INTERRUPTIBLE by using the set_current_state macro. Recall that this macro references the pointer to the current process so we do not need to pass in the process information. Once it blocks, it yields the CPU to the next process by means of a call to the scheduler(). __wait_event_interruptible() differs in one large respect at this point; it sets the state field of the process to TASK_ UNINTERRUPTIBLE and waits on a signal_pending call to the current process. __wait_event_interruptible_timeout is much like __wait_event_ interruptible except for its call to schedule_timeout() instead of the call to schedule() when calling the scheduler. schedule_timeout takes as a parameter the timeout length passed in to the original wait_event_interruptible_ timeout interface.
Lines 133134
At this point in the code, the condition has been met or, in the case of the other two interfaces, a signal might have been received or the timeout reached. The state field of the process descriptor is now set back to TASK_RUNNING (the scheduler places this in the run queue). Finally, the entry is removed from the wait queue. The remove_wait_queue() function locks the wait queue before removing the entry, and then it restores the lock before returning.
3.7.3. Waking Up
A process must be woken up to verify whether its condition has been met. Note that a process might put itself to sleep, but it cannot wake itself up. Numerous macros can be used to wake_up tasks in a wait queue but only three main "wake_up" functions exist. The macros wake_up, wake_up_nr, wake_up_all, wake_up_ interruptible, wake_up_interruptible_nr, and wake_up_ interruptible_all all call __wake_up() with different parameters. The macros wake_up_all_sync and wake_up_interruptible_sync both call __wake_ up_sync() with different parameters. Finally, the wake_up_locked macro defaults to the __wake_up_locked() function:
-----------------------------------------------------------------------
include/linux/wait.h
116 extern void FASTCALL(__wake_up(wait_queue_head_t *q, unsigned int mode, int nr));
117 extern void FASTCALL(__wake_up_locked(wait_queue_head_t *q, unsigned int mode));
118 extern void FASTCALL(__wake_up_sync(wait_queue_head_t *q, unsigned int mode, int
nr));
119
120 #define wake_up(x) __wake_up((x),TASK_UNINTERRUPTIBLE | TASK_INTERRUPTIBLE, 1)
121 #define wake_up_nr(x, nr) __wake_up((x),TASK_UNINTERRUPTIBLE | TASK_INTERRUPTIBLE, nr)
122 #define wake_up_all(x) __wake_up((x),TASK_UNINTERRUPTIBLE | TASK_INTERRUPTIBLE, 0)
123 #define wake_up_all_sync(x) __wake_up_sync((x),TASK_UNINTERRUPTIBLE |
TASK_INTERRUPTIBLE, 0)
124 #define wake_up_interruptible(x) __wake_up((x),TASK_INTERRUPTIBLE, 1)
125 #define wake_up_interruptible_nr(x, nr) __wake_up((x),TASK_INTERRUPTIBLE, nr)
126 #define wake_up_interruptible_all(x) __wake_up((x),TASK_INTERRUPTIBLE, 0)
127 #define wake_up_locked(x) __wake_up_locked((x), TASK_UNINTERRUPTIBLE |
TASK_INTERRUPTIBLE)
128 #define wake_up_interruptible_sync(x) __wake_up_sync((x),TASK_INTERRUPTIBLE, 1
129 )
-----------------------------------------------------------------------
Let's look at __wake_up():
-----------------------------------------------------------------------
kernel/sched.c
2336 void fastcall __wake_up(wait_queue_head_t *q, unsigned int mode, int nr_exclusive)
2337 {
2338 unsigned long flags;
2339
2340 spin_lock_irqsave(&q->lock, flags);
2341 __wake_up_common(q, mode, nr_exclusive, 0);
2342 spin_unlock_irqrestore(&q->lock, flags);
2343 }
-----------------------------------------------------------------------
Line 2336
The parameters passed to __wake_up include q, the pointer to the wait queue; mode, the indicator of the type of thread to wake up (this is identified by the state of the thread); and nr_exclusive, which indicates whether it's an exclusive or non-exclusive wakeup. An exclusive wakeup (when nr_exclusive = 0) wakes up all the tasks in the wait queue (both exclusive and non-exclusive), whereas a non-exclusive wakeup wakes up all the non-exclusive tasks and only one exclusive task.
Lines 2340, 2342
These lines set and unset the wait queue's spinlock. Set the lock before calling __wake_up_common()to ensure no race condition comes up.
Line 2341
The function __wake_up_common() performs the bulk of the wakeup function:
-----------------------------------------------------------------------
kernel/sched.c
2313 static void __wake_up_common(wait_queue_head_t *q,
unsigned int mode, int nr_exclusive, int sync)
2314 {
2315 struct list_head *tmp, *next;
2316
2317 list_for_each_safe(tmp, next, &q->task_list) {
2318 wait_queue_t *curr;
2319 unsigned flags;
2320 curr = list_entry(tmp, wait_queue_t, task_list);
2321 flags = curr->flags;
2322 if (curr->func(curr, mode, sync) &&
2323 (flags & WQ_FLAG_EXCLUSIVE) &&
2324 !--nr_exclusive)
2325 break;
2326 }
2327 }
-----------------------------------------------------------------------
Line 2313
The parameters passed to __wake_up_common are q, the pointer to the wait queue; mode, the type of thread to wake up; nr_exclusive, the type of wakeup previously shown; and sync, which states whether the wakeup should be synchronous.
Line 2315
Here, we set temporary pointers for list-entry manipulation.
Line 2317
The list_for_each_safe macro scans each item of the wait queue. This is the beginning of our loop.
Line 2320
The list_entry macro returns the address of the wait queue structure held by the tmp variable.
Line 2322
The wait_queue_t's func field is called. By default, this calls default_wake_function(), which is shown here:
-----------------------------------------------------------------------
kernel/sched.c
2296 int default_wake_function(wait_queue_t *curr, unsigned mode,
int sync)
2297 {
2298 task_t *p = curr->task;
2299 return try_to_wake_up(p, mode, sync);
2300 }
-----------------------------------------------------------------------
This function calls try_to_wake_up() (kernel/sched.c) on the task pointed to by the wait_queue_t structure. This function performs the bulk of the work of waking up a process, including putting it on the run queue.
Lines 23222325
The loop terminates if the process being woken up is the first exclusive process. This makes sense if we realize that all the exclusive processes are queued at the end of the wait queue. After we encounter the first exclusive task in the wait queue all remaining tasks will also be exclusive so we do not want to wake them and we break out of the loop.
3.8. Asynchronous Execution Flow
We mentioned that processes can transition from one state to another by means of interrupts, for instance going from TASK_INTERRUPTIBLE to TASK_RUNNING. One of the ways this is attained is by means of asynchronous execution which includes exceptions and interrupts. We have mentioned that processes move in and out of user and kernel mode. We will now go into a description of how exceptions work and follow it up with an explanation of how interrupts work.
3.8.1. Exceptions
Exceptions, also known as synchronous interrupts, are events that occur entirely within the processor's hardware. These events are synchronous to the execution of the processor; that is, they occur not during but after the execution of a code instruction. Examples of processor exceptions include the referencing of a virtual memory location, which is not physically there (known as a page fault) and a calculation that results in a divide by 0. The important thing to note with exceptions (sometimes called soft irqs) is that they typically happen after an intruction's execution. This differentiates them from external or asynchronous events, which are discussed later in Section 3.8.2, "Interrupts."
Most modern processors (the x86 and the PPC included) allow the programmer to initiate an exception by executing certain instructions. These instructions can be thought of as hardware-assisted subroutine calls. An example of this is the system call.
3.8.1.1. System Calls
Linux provides user mode programs with entry points into the kernel by which services or hardware access can be requested from the kernel. These entry points are standardized and predefined in the kernel. Many of the C library routines available to user mode programs, such as the fork() function in Figure 3.9, bundle code and one or more system calls to accomplish a single function. When a user process calls one of these functions, certain values are placed into the appropriate processor registers and a software interrupt is generated. This software interrupt then calls the kernel entry point. Although not recommended, system calls (syscalls) can also be accessed from kernel code. From where a syscall should be accessed is the source of some discussion because syscalls called from the kernel can have an improvement in performance. This improvement in performance is weighed against the added complexity and maintainability of the code. In this section, we explore the "traditional" syscall implementation where syscalls are called from user space.
Syscalls have the ability to move data between user space and kernel space. Two functions are provided for this purpose: copy_to_user() and copy_from_user(). As in all kernel programming, validation (of pointers, lengths, descriptors, and permissions) is critical when moving data. These functions have the validation built in. Interestingly, they return the number of bytes not transferred.
By its nature, the implementation of the syscall is hardware specific. Traditionally, with Intel architecture, all syscalls have used software interrupt 0x80.
Parameters of the syscall are passed in the general registers with the unique syscall number in %eax. The implementation of the system call on the x86 architecture limits the number of parameters to 5. If more than 5 are required, a pointer to a block of parameters can be passed. Upon execution of the assembler instruction int 0x80, a specific kernel mode routine is called by way of the exception-handling capabilities of the processor. Let's look at an example of how a system call entry is initialized:
set_system_gate(SYSCALL_VECTOR,&system_call);
This macro creates a user privilege descriptor at entry 128 (SYSCALL_VECTOR), which points to the address of the syscall handler in entry.S (system_call).
As we see in the next section on interrupts, PPC interrupt routines are "anchored" to certain memory locations; the external interrupt handler is anchored to address 0x500, the system timer is anchored to address 0x900, and so on. The system call instruction sc vectors to address 0xc00. Let's explore the code segment from head.S where the handler is set for the PPC system call:
-----------------------------------------------------------------------
arch/ppc/kernel/head.S
484 /* System call */
485 . = 0xc00
486 SystemCall:
487 EXCEPTION_PROLOG
488 EXC_XFER_EE_LITE(0xc00, DoSyscall)
-----------------------------------------------------------------------
Line 485
The anchoring of the address. This line tells the loader that the next instruction is located at address 0xc00. Because labels follow similar rules, the label SystemCall along with the first line of code in the macro EXCEPTION_PROLOG both start at address 0xc00.
Line 488
This macro dispatches the DoSyscall() handler.
For both architectures, the syscall number and any parameters are stored in the processor's registers.
When the x86 exception handler processes the int 0x80, it indexes into the system call table. The file arch/i386/kernel/entry.S contains low-level interrupt handling routines and the system call table, sys_call_table. Likewise for the PPC, the syscall low-level routines are in arch/ppc/kernel/entry.S and the sys_call_table is in arch/ppc/kernel/misc.S.
The syscall table is an assembly code implementation of an array in C with 4-byte entries. Each entry is initialized to the address of a function. By convention, we must prepend the name of our function with "sys_." Because the position in the table determines the syscall number, we must add the name of our function to the end of the list. Even with different assembly languages, the tables are nearly identical between the architectures. However, the PPC table has only 255 entries at the time of this writing, while the x86 table has 275.
The files include/asm-i386/unistd.h and include/asm-ppc/unistd.h associate the system calls with their positional numbers in the sys_call_table. The "sys_" is replaced with a "__NR_" in this file. This file also has macros to assist the user program in loading the registers with parameters. (See the assembly programming section in Chapter 2, "Exploration Toolkit," for a crash course in C and assembler variables and inline assembler.)
Let's look at how we would add a system call named sys_ourcall. The system call must be added to the sys_call_table. The addition of our system call into the x86 sys_call_table is shown here:
-----------------------------------------------------------------------
arch/i386/kernel/entry.S
607 .data
608 ENTRY(sys_call_table)
609 .long sys_restart_syscall /* 0 - old "setup()" system call, used for restarting*/
...
878 .long sys_tgkill /* 270 */
879 .long sys_utimes
880 .long sys_fadvise64_64
881 .long sys_ni_syscall /* sys_vserver */
882 .long sys_ourcall /* our syscall will be 274 */
883
884 nr_syscalls=(.-sys_call_table)/4
-----------------------------------------------------------------------
In x86, our system call would be number 274. If we were to add a syscall named sys_ourcall in PPC, the entry would be number 255. Here, we show how it would look when we introduce the association of our system call with its positional number into include/asm-ppc/unistd.h. __NR_ourcall is number-entry number 255 at the end of the table:
-----------------------------------------------------------------------
include/asm-ppc/unistd.h
/*
* This file contains the system call numbers.
*/
#define __NR_restart_syscall 0
#define __NR_exit 1
#define __NR_fork 2
...
#define __NR_utimes 271
#define __NR_fadvise64_64 272
#define __NR_vserver 273
#define __NR_ourcall 274
/* #define NR_syscalls 274 this is the old value before our syscall */
#define NR_syscalls 275
-----------------------------------------------------------------------
The next section discusses interrupts and the hardware involved to alert the kernel to the need for handling them. Where exceptions as a group diverge somewhat is what their handler does in response to being called. Although exceptions travel the same route as interrupts at handling time, exceptions tend to send signals back to the current process rather than work with hardware devices.
3.8.2. Interrupts
Interrupts are asynchronous to the execution of the processor, which means that interrupts can happen in between instructions. The processor receives notification of an interrupt by way of an external signal to one of its pins (INTR or NMI). This signal comes from a hardware device called an interrupt controller. Interrupts and interrupt controllers are hardware and system specific. From architecture to architecture, many differences exist in how interrupt controllers are designed. This section touches on the major hardware differences and functions tracing the kernel code from the architecture-independent to the architecture-dependent parts.
An interrupt controller is needed because the processor must be in communication with one of several peripheral devices at any given moment. Older x86 computers used a cascaded pair of Intel 8259 interrupt controllers configured in such a way that the processor was able to discern between 15 discrete interrupt lines (IRQ) (see Figure 3.16).When the interrupt controller has a pending interrupt (for example, when you press a key), it asserts its INT line, which is connected to the processor. The processor then acknowledges this signal by asserting its acknowledge line connected to the INTA line on the interrupt controller. At this moment, the interrupt controller transfers the IRQ data to the processor. This sequence is known as an interrupt-acknowledge cycle.
Newer x86 processors have a local Advanced Programmable Interrupt Controller (APIC). The local APIC (which is built into the processor package) receives interrupt signals from the following:
Processor's interrupt pins (LINT0, LINT1) Internal timer Internal performance monitor Internal temperature sensor Internal APIC error Another processor (inter-processor interrupts) An external I/O APIC (via an APIC bus on multiprocessor systems)
After the APIC receives an interrupt signal, it routes the signal to the processor core (internal to the processor package). The I/O APIC shown in Figure 3.17 is part of a processor chipset and is designed to receive 24 programmable interrupt inputs.
The x86 processors with local APIC can also be configured with 8259 type interrupt controllers instead of the I/O APIC architecture (or the I/O APIC can be configured to interface to an 8259 controller). To find out if a system is using the I/O APIC architecture, enter the following on the command line:
lkp:~# cat /proc/interrupts
If you see I/O-APIC listed, it is in use. Otherwise, you see XT-PIC, which means it is using the 8259 type architecture.
The PowerPC interrupt controllers for the Power Mac G4 and G5 are integrated into the Key Largo and K2 I/O controllers. Entering this on the command line:
lkp:~# cat /proc/interrupts
on a G4 machine yields OpenPIC, which is an Open Programmable Interrupt Controller standard initiated by AMD and Cyrix in 1995 for multiprocessor systems. MPIC is the IBM implementation of OpenPIC, and is used in several of their CHRP designs. Old-world Apple machines had an in-house interrupt controller and, for the 4xx embedded processors, the interrupt controller core is integrated into the ASIC chip.
Now that we have had the necessary discussion of how, why, and when interrupts are delivered to the kernel by the hardware, we can analyze a real-world example of the kernel handling the Hardware System Timer interrupt and expand on where the interrupt is delivered. As we go through the System Timer code, we see that at interrupt time, the hardware-to-software interface is implemented in both the x86 and PPC architectures with jump tables that select the proper handler code for a given interrupt.
Each interrupt of the x86 architecture is assigned a unique number or vector. At interrupt time, this vector is used to index into the Interrupt Descriptor Table (IDT). (See the Intel Programmer's Reference for the format of the x86 gate descriptor.) The IDT allows the hardware to assist the software with address resolution and privilege checking of handler code at interrupt time. The PPC architecture is somewhat different in that it uses an interrupt table created at compile time to execute the proper interrupt handler. (Later in this section, there is more on the software aspects of initialization and use of the jump tables, when we compare x86 and PPC interrupt handling for the system timer.) The next section discusses interrupt handlers and their implementation. We follow that with a discussion of the system timer as an example of the Linux implementation of interrupts and their associated handlers.
We now talk about the different kinds of interrupt handlers.
3.8.2.1. Interrupt Handlers
Interrupt and exception handlers look much like regular C functions. They mayand often docall hardware-specific assembly routines. Linux interrupt handlers are broken into a high-performance top half and a low-performance bottom half:
Top half.
Must execute as quickly as possible. Top-half handlers, depending on how they are registered, can run with all local (to a given processor) interrupts disabled (a fast handler). Code in a top-half handler needs to be limited to responding directly to the hardware and/or performing time-critical tasks. To remain in the top-half handler for a prolonged period of time could significantly impact system performance. To keep performance high and latency (which is the time it takes to acknowledge a device) low, the bottom-half architecture was introduced.
Bottom half.
Allows the handler writer to delay the less critical work until the kernel has more time. Remember, the interrupt came in asynchronously with the execution of the system; the kernel might have been doing something more time critical at that moment. With the bottom-half architecture, the handler writer can have the kernel run the less critical handler code at a later time.
Table 3.8 illustrates the four most common methods of bottom-half interrupt handling.
Table 3.8. Bottom-Half Interrupt Handling Methods"Old" bottom halves | These pre-SMP handlers are being phased out because of the fact that only one bottom half can run at a time regardless of the number of processors. This system has been removed in the 2.6 kernel and is mentioned only for reference. | Work queues | The top-half code is said to run in interrupt context, which means it is not associated with any process. With no process association, the code cannot sleep or block. Work queues run in process context and have the abilities of any kernel thread. Work queues have a rich set of functions for creation, scheduling, canceling, and so on. For more information on work queues, see the "Work Queues and Interrupts" section in
Chapter 10. | Softirqs | Softirqs run in interrupt context and are similar to bottom halves except that softirqs of the same type can run on multiple processors simultaneously. Only 32 softirqs are available in the system. The system timer uses softirqs. | Tasklets | Similar to softirqs except that no limit exists. All tasklets are funneled through one softirq, and the same tasklet cannot run simultaneously on multiple processors. The tasklet interface is simpler to use and implement compared to softirqs. |
3.8.2.2. IRQ Structures
Three main structures contain all the information related to IRQ's: irq_desc_t, irqaction, and hw_interrupt_type. Figure 3.18 illustrates how they interrelate.
Struct irq_desc_t
The irq_desc_t structure is the primary IRQ descriptor. irq_desc_t structures are stored in a globally accessible array of size NR_IRQS (whose value is architecture dependent) called irq_desc.
-----------------------------------------------------------------------
include/linux/irq.h
60 typedef struct irq_desc {
61 unsigned int status; /* IRQ status */
62 hw_irq_controller *handler;
63 struct irqaction *action; /* IRQ action list */
64 unsigned int depth; /* nested irq disables */
65 unsigned int irq_count; /* For detecting broken interrupts */
66 unsigned int irqs_unhandled;
67 spinlock_t lock;
68 } ____cacheline_aligned irq_desc_t;
69
70 extern irq_desc_t irq_desc [NR_IRQS];
-----------------------------------------------------------------------
Line 61
The value of the status field is determined by setting flags that describe the status of the IRQ line. Table 3.9 shows the flags.
Table 3.9. irq_desc_t->field FlagsFlag | Description |
|---|
IRQ_INPROGRESS | Indicates that we are in the process of executing the handler for that IRQ line. | IRQ_DISABLED | Indicates that the IRQ is disabled by software so that its handler is not executed even if the physical line itself is enabled. | IRQ_PENDING | A middle state that indicates that the occurrence of the interrupt has been acknowledged, but the handler has not been executed. | IRQ_REPLAY | The previous IRQ has not been acknowledged. | IRQ_AUTODETECT | The state the IRQ line is set when being probed. | IRQ_WAITING | Used when probing. | IRQ_LEVEL | The IRQ is level triggered as opposed to edge triggered. | IRQ_MASKED | This flag is unused in the kernel code. | IRQ_PER_CPU | Used to indicate that the IRQ line is local to the CPU calling. |
Line 62
The handler field is a pointer to the hw_irq_controller. The hw_irq_ controller is a typedef for hw_interrupt_type structure, which is the interrupt controller descriptor used to describe low-level hardware.
Line 63
The action field holds a pointer to the irqaction struct. This structure, described later in more detail, keeps track of the interrupt handler routine to be executed when the IRQ is enabled.
Line 64
The depth field is a counter of nested IRQ disables. The IRQ_DISABLE flag is cleared only when the value of this field is 0.
Lines 6566
The irq_count field, along with the irqs_unhandled field, identifies IRQs that might be stuck. They are used in x86 and PPC64 in the function note_interrupt() (arch/<arch>/kernel/irq.c).
Line 67
The lock field holds the spinlock to the descriptor.
Struct irqaction
The kernel uses the irqaction struct to keep track of interrupt handlers and the association with the IRQ. Let's look at the structure and the fields we will view in later sections:
-----------------------------------------------------------------------
include/linux/interrupt.h
35 struct irqaction {
36 irqreturn_t (*handler) (int, void *, struct pt_regs *);
37 unsigned long flags;
38 unsigned long mask;
39 const char *name;
40 void *dev_id;
41 struct irqaction *next;
42 };
------------------------------------------------------------------------
Line 36
The field handler is a pointer to the interrupt handler that will be called when the interrupt is encountered.
Line 37
The flags field can hold flags such as SA_INTERRUPT, which indicates the interrupt handler will run with all interrupts disabled, or SA_SHIRQ, which indicates that the handler might share an IRQ line with another handler.
Line 39
The name field holds the name of the interrupt being registered.
Struct hw_interrupt_type
The hw_interrupt_type or hw_irq_controller structure contains all the data related to the system's interrupt controller. First, we look at the structure, and then we look at how it is implemented for a couple of interrupt controllers:
-----------------------------------------------------------------------
include/linux/irq.h
40 struct hw_interrupt_type {
41 const char * typename;
42 unsigned int (*startup)(unsigned int irq);
43 void (*shutdown)(unsigned int irq);
44 void (*enable)(unsigned int irq);
45 void (*disable)(unsigned int irq);
46 void (*ack)(unsigned int irq);
47 void (*end)(unsigned int irq);
48 void (*set_affinity)(unsigned int irq, cpumask_t dest);
49 };
------------------------------------------------------------------------
Line 41
The typename holds the name of the Programmable Interrupt Controller (PIC). (PICs are discussed in detail later.)
Lines 4248
These fields hold pointers to PIC-specific programming functions.
Now, let's look at our PPC controller. In this case, we look at the PowerMac's PIC:
-----------------------------------------------------------------------
arch/ppc/platforms/pmac_pic.c
170 struct hw_interrupt_type pmac_pic = {
171 " PMAC-PIC ",
172 NULL,
173 NULL,
174 pmac_unmask_irq,
175 pmac_mask_irq,
176 pmac_mask_and_ack_irq,
177 pmac_end_irq,
178 NULL
179 };
------------------------------------------------------------------------
As you can see, the name of this PIC is PMAC-PIC, and it has four of the six functions defined. The pmac_unamsk_irq and the pmac_mask_irq functions enable and disable the IRQ line, respectively. The function pmac_mask_and_ack_irq acknowledges that an IRQ has been received, and pmac_end_irq takes care of cleaning up when we are done executing the interrupt handler.
-----------------------------------------------------------------------
arch/i386/kernel/i8259.c
59 static struct hw_interrupt_type i8259A_irq_type = {
60 "XT-PIC",
61 startup_8259A_irq,
62 shutdown_8259A_irq,
63 enable_8259A_irq,
64 disable_8259A_irq,
65 mask_and_ack_8259A,
66 end_8259A_irq,
67 NULL
68 };
------------------------------------------------------------------------
The x86 8259 PIC is called XT-PIC, and it defines the first five functions. The first two, startup_8259A_irq and shutdown_8259A_irq, start up and shut down the actual IRQ line, respectively.
3.8.2.3. An Interrupt Example: System Timer
The system timer is the heartbeat for the operating system. The system timer and its interrupt are initialized during system initialization at boot-up time. The initialization of an interrupt at this time uses interfaces different to those used when an interrupt is registered at runtime. We point out these differences as we go through the example.
As more complex support chips are produced, the kernel designer has gained several options for the source of the system timer. The most common timer implementation for the x86 architecture is the Programmable Interval Time (PIT) and, for the PowerPC, it is the decrementer.
The x86 architecture has historically implemented the PIT with the Intel 8254 timer. The 8254 is used as a 16-bit down counterinterrupting on terminal count. That is, a value is written to a register and the 8254 decrements this value until it gets to 0. At that moment, it activates an interrupt to the IRQ 0 input on the 8259 interrupt controller, which was previously mentioned in this section.
The system timer implemented in the PowerPC architecture is the decrementer clock, which is a 32-bit down counter that runs at the same frequency as the CPU. Similar to the 8259, it activates an interrupt at its terminal count. Unlike the Intel architecture, the decrementer is built in to the processor.
Every time the system timer counts down and activates an interrupt, it is known as a tick. The rate or frequency of this tick is set by the HZ variable.
|
HZ is a variation on the abbreviation for Hertz (Hz), named for Heinrich Hertz (1857-1894). One of the founders of radio waves, Hertz was able to prove Maxwell's theories on electricity and magnetism by inducing a spark in a wire loop. Marconi then built on these experiments leading to modern radio. In honor of the man and his work the fundamental unit of frequency is named after him; one cycle per second is equal to one Hertz.
HZ is defined in include/asm-xxx/param.h. Let's take a look at what these values are in our x86 and PPC.
-----------------------------------------------------------------------
include/asm-i386/param.h
005 #ifdef __KERNEL__
006 #define HZ 1000 /* internal
kernel timer frequency */
-----------------------------------------------------------------------
-----------------------------------------------------------------------
include/asm-ppc/param.h
008 #ifdef __KERNEL__
009 #define HZ 100 /* internal
kernel timer frequency */
-----------------------------------------------------------------------
The value of HZ has been typically 100 across most architectures, but as machines become faster, the tick rate has increased on certain models. Looking at the two main architectures we are using for this book, we can see (above) the default tick rate for both architectures is 1000. The period of 1 tick is 1/HZ. Thus the period (or time between interrupts) is 1 millisecond. We can see that as the value of HZ goes up, we get more interrupts in a given amount of time. While this yields better resolution from the timekeeping functions, it is important to note that more of the processor time is spent answering the system timer interrupts in the kernel. Taken to an extreme, this could slow the system response to user mode programs. As with all interrupt handling, finding the right balance is key. |
We now begin walking through the code with the initialization of the system timer and its associated interrupts. The handler for the system timer is installed near the end of kernel initialization; we pick up the code segments as start_kernel(), the primary initialization function executed at system boot time, first calls trap_init(), then init_IRQ(), and finally time_init():
init/main.c
386 asmlinkage void __init start_kernel(void)
387 {
...
413 trap_init();
...
415 init_IRQ();
...
419 time_init();
...
}
-----------------------------------------------------------------------
Line 413
The macro trap_init() initializes the exception entries in the Interrupt Descriptor Table (IDT) for the x86 architecture running in protected mode. The IDT is a table set up in memory. The address of the IDT is set in the processor's IDTR register. Each element of the interrupt descriptor table is one of three gates. A gate is an x86 protected mode address that consists of a selector, an offset, and a privilege level. The gate's purpose is to transfer program control. The three types of gates in the IDT are system, where control is transferred to another task; interrupt, where control is passed to an interrupt handler with interrupts disabled; and trap, where control is passed to the interrupt handler with interrupts unchanged.
The PPC is architected to jump to specific addresses, depending on the exception. The function trap_init() is a no-op for the PPC. Later in this section, as we continue to follow the system timer code, we will contrast the PPC interrupt table with the x86 interrupt descriptor table initialized next.
-----------------------------------------------------------------------
arch/i386/kernel/traps.c
900 void __init trap_init(void)
901 {
902 #ifdef CONFIG_EISA
903 if (isa_readl(0x0FFFD9) == 'E'+('I'<<8)+('S'<<16)+('A'<<24)) {
904 EISA_bus = 1;
905 }
906 #endif
907
908 #ifdef CONFIG_X86_LOCAL_APIC
909 init_apic_mappings();
910 #endif
911
912 set_trap_gate(0,÷_error);
913 set_intr_gate(1,&debug);
914 set_intr_gate(2,&nmi);
915 set_system_gate(3,&int3); /* int3-5 can be called from all */
916 set_system_gate(4,&overflow);
917 set_system_gate(5,&bounds);
918 set_trap_gate(6,&invalid_op);
919 set_trap_gate(7,&device_not_available);
920 set_task_gate(8,GDT_ENTRY_DOUBLEFAULT_TSS);
921 set_trap_gate(9,&coprocessor_segment_overrun);
922 set_trap_gate(10,&invalid_TSS);
923 set_trap_gate(11,&segment_not_present);
924 set_trap_gate(12,&stack_segment);
925 set_trap_gate(13,&general_protection);
926 set_intr_gate(14,&page_fault);
927 set_trap_gate(15,&spurious_interrupt_bug);
928 set_trap_gate(16,&coprocessor_error);
929 set_trap_gate(17,&alignment_check);
930 #ifdef CONFIG_X86_MCE
931 set_trap_gate(18,&machine_check);
932 #endif
933 set_trap_gate(19,&simd_coprocessor_error);
934
935 set_system_gate(SYSCALL_VECTOR,&system_call) ;
936
937 /*
938 * default LDT is a single-entry callgate to lcall7 for iBCS
939 * and a callgate to lcall27 for Solaris/x86 binaries
940 */
941 set_call_gate(&default_ldt[0],lcall7);
942 set_call_gate(&default_ldt[4],lcall27);
943
944 /*
945 * Should be a barrier for any external CPU state.
846 */
947 cpu_init();
948
949 trap_init_hook();
950 }
-----------------------------------------------------------------------
Line 902
Look for EISA signature. isa_readl() is a helper routine that allows reading the EISA bus by mapping I/O with ioremap().
Lines 908910
If an Advanced Programmable Interrupt Controller (APIC) exists, add its address to the system fixed address map. See include/asm-i386/fixmap.h for "special" system address helper routines; set_fixmap_nocache().init_apic_mappings() uses this routine to set the physical address of the APIC.
Lines 912935
Initialize the IDT with trap gates, system gates, and interrupt gates.
Lines 941942
These special intersegment call gates support the Intel Binary Compatibility Standard for running other UNIX binaries on Linux.
Line 947
For the currently executing CPU, initialize its tables and registers.
Line 949
Used to initialize system-specific hardware, such as different kinds of APICs. This is a no-op for most x86 platforms.
Line 415
The call to init_IRQ() initializes the hardware interrupt controller. Both x86 and PPC architectures have several device implementations. For the x86 architecture, we explore the i8259 device. For PPC, we explore the code associated with the Power Mac.
The PPC implementation of init_IRQ() is in arch/ppc/kernel/irq.c. Depending on the particular hardware configuration, init_IRQ() calls one of several routines to initialize the PIC. For a Power Mac configuration, the function pmac_pic_init() in arch/ppc/platforms/pmac_pic.c is called for the G3, G4, and G5 I/O controllers. This is a hardware-specific routine that tries to identify the type of I/O controller and set it up appropriately. In this example, the PIC is part of the I/O controller device. The process for interrupt initialization is similar to x86, with the minor difference being the system timer is not started in the PPC version of init_IRQ(), but rather in the time_init() function, which is covered later in this section.
The x86 architecture has fewer options for the PIC. As previously discussed, the older systems use the cascaded 8259, while the later systems use the IOAPIC architecture. This code explores the APIC with the emulated 8259 type controllers:
-----------------------------------------------------------------------
arch/i386/kernel/i8259.c
342 void __init init_ISA_irqs (void)
343 {
344 int i;
345 #ifdef CONFIG_X86_LOCAL_APIC
346 init_bsp_APIC();
347 #endif
348 init_8259A(0);
...
351 for (i = 0; i < NR_IRQS; i++) {
352 irq_desc[i].status = IRQ_DISABLED;
353 irq_desc[i].action = 0;
354 irq_desc[i].depth = 1;
355
356 if (i < 16) {
357 /*
358 * 16 old-style INTA-cycle interrupts:
359 */
360 irq_desc[i].handler = &i8259A_irq_type;
361 } else {
362 /*
363 * 'high' PCI IRQs filled in on demand
364 */
365 irq_desc[i].handler = &no_irq_type;
366 }
367 }
368 }
...
409
410 void __init init_IRQ(void)
411 {
412 int i;
413
414 /* all the set up before the call gates are initialized */
415 pre_intr_init_hook();
...
422 for (i = 0; i < NR_IRQS; i++) {
423 int vector = FIRST_EXTERNAL_VECTOR + i;
424 if (vector != SYSCALL_VECTOR)
425 set_intr_gate(vector, interrupt[i]) ;
426 }
...
431 intr_init_hook();
...
437 setup_timer();
...
}
-----------------------------------------------------------------------
Line 410
This is the function entry point called from start_kernel(), which is the primary kernel initialization function called at system startup.
Lines 342348
If the local APIC is available and desired, initialize it and put it in virtual wire mode for use with the 8259. Then, initialize the 8259 device using register I/O in init_8259A(0).
Lines 422426
On line 424, syscalls are not included in this loop because they were already installed earlier in TRap_init(). Linux uses an Intel interrupt gate (kernel-initiated code) as the descriptor for interrupts. This is set with the set_intr_gate() macro (on line 425). Exceptions use the Intel system gate and trap gate set by the set_system_gate() and set_trap_gate(), respectively. These macros can be found in arch/i386/kernel/traps.c.
Line 431
Set up interrupt handlers for the local APIC (if used) and call setup_irq() in irq.c for the cascaded 8259.
Line 437
Start the 8253 PIT using register I/O.
Line 419
Now, we follow time_init() to install the system timer interrupt handler for both PPC and x86. In PPC, the system timer (abbreviated for the sake of this discussion) initializes the decrementer:
-----------------------------------------------------------------------
arch/ppc/kernel/time.c
void __init time_init(void)
{
...
317 ppc_md.calibrate_decr();
...
351 set_dec(tb_ticks_per_jiffy);
...
}
-----------------------------------------------------------------------
Line 317
Figure the proper count for the system HZ value.
Line 351
Set the decrementer to the proper starting count.
The interrupt architecture of the PowerPC and its Linux implementation does not require the installation of the timer interrupt. The decrementer interrupt vector comes in at 0x900. The handler call is hard coded at this location and it is not shared:
-----------------------------------------------------------------------
arch/ppc/kernel/head.S
/* Decrementer */
479 EXCEPTION(0x900, Decrementer, timer_interrupt, EXC_XFER_LITE)
-----------------------------------------------------------------------
More detail on the EXCEPTION macro for the decrementer is given later in this section. The handler for the decrementer is now ready to be executed when the terminal count is reached.
The following code snippets outline the x86 system timer initialization:
-----------------------------------------------------------------------
arch/i386/kernel/time.c
void __init time_init(void)
{
...
340 time_init_hook();
}
-----------------------------------------------------------------------
The function time_init() flows down to time_init_hook(), which is located in the machine-specific setup file setup.c:
-----------------------------------------------------------------------
arch/i386/machine-default/setup.c
072 static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT, 0, "timer", NULL, NULL};
...
081 void __init time_init_hook(void)
082 {
083 setup_irq(0, &irq0);
084 }
-----------------------------------------------------------------------
Line 72
We initialize the irqaction struct that corresponds to irq0.
Lines 8184
The function call setup_irq(0, &irq0) puts the irqaction struct containing the handler timer_interrupt() on the queue of shared interrupts associated with irq0.
This code segment has a similar effect to calling request_irq() for the general case handler (those not loaded at kernel initialization time). The initialization code for the timer interrupt took a shortcut to get the handler into irq_desc[]. Runtime code uses disable_irq(), enable_irq(), request_irq(), and free_irq() in irq.c. All these routines are utilities to work with IRQs and touch an irq_desc struct at one point.
Interrupt Time
For PowerPC, the decrementer is internal to the processor and has its own interrupt vector at 0x900. This contrasts the x86 architecture where the PIT is an external interrupt coming in from the interrupt controller. The PowerPC external controller comes in on vector 0x500. A similar situation would arise in the x86 architecture if the system timer were based on the local APIC.
Tables 3.10 and 3.11 describe the interrupt vector tables of the x86 and PPC architectures, respectively.
Table 3.10. x86 Interrupt Vector TableVector Number/IRQ | Description |
|---|
0 | Divide error | 1 | Debug extension | 2 | NMI interrupt | 3 | Breakpoint | 4 | INTO-detected overflow | 5 | BOUND range exceeded | 6 | Invalid opcode | 7 | Device not available | 8 | Double fault | 9 | Coprocessor segment overrun (reserved) | 10 | Invalid task state segment | 11 | Segment not present | 12 | Stack fault | 13 | General protection | 14 | Page fault | 15 | (Intel reserved. Do not use.) | 16 | Floating point error | 17 | Alignment check | 18 | Machine check* | 1931 | (Intel reserved. Do not use.) | 32255 | Maskable interrupts |
Table 3.11. PPC Offset of Interrupt VectorOffset (Hex) | Interrupt Type |
|---|
00000 | Reserved | 00100 | System reset | 00200 | Machine check | 00300 | Data storage | 00400 | Instruction storage | 00500 | External | 00600 | Alignment | 00700 | Program | 00800 | Floating point unavailable | 00900 | Decrementer | 00A00 | Reserved | 00B00 | Reserved | 00C00 | System call | 00D00 | Trace | 00E00 | Floating point assist | 00E10 | Reserved | … | … | 00FFF | Reserved | 01000 | Reserved, implementation specific | … | … | 02FFF | (End of interrupt vector locations) |
Note the similarities between the two architectures. These tables represent the hardware. The software interface to the Intel exception interrupt vector table is the Interrupt Descriptor Table (IDT) that was previously mentioned in this chapter.
As we proceed, we can see how the Intel architecture handles a hardware interrupt by way of an IRQ, to a jump table in entry.S, to a call gate (descriptor), to finally the handler code. Figure 3.19 illustrates this.
PowerPC, on the other hand, vectors to specific offsets in memory where the code to jump to the appropriate handler is located. As we see next, the PPC jump table in head.S is indexed by way of being fixed in memory. Figure 3.20 illustrates this.
This should become clearer as we now explore the PPC external (offset 0x500) and timer (offset 0x900) interrupt handlers.
Processing the PowerPC External Interrupt Vector
As previously discussed, the processor jumps to address 0x500 in the event of an external interrupt. Upon further investigation of the EXCEPTION() macro in the file head.S, we can see the following lines of code is linked and loaded such that it is mapped to this memory region at offset 0x500. This architected jump table has the same effect as the x86 IDT:
-----------------------------------------------------------------------
arch/ppc/kernel/head.S
453 /* External interrupt */
454 EXCEPTION(0x500, HardwareInterrupt, do_IRQ, EXC_XFER_LITE)
The third parameter, do_IRQ(), is called next. Let's take a look at this function.
arch/ppc/kernel/irq.c
510 void do_IRQ(struct pt_regs *regs)
511 {
512 int irq, first = 1;
513 irq_enter();
...
523 while ((irq = ppc_md.get_irq(regs)) >= 0) {
524 ppc_irq_dispatch_handler(regs, irq);
525 first = 0;
526 }
527 if (irq != -2 && first)
528 /* That's not SMP safe ... but who cares ? */
529 ppc_spurious_interrupts++;
530 irq_exit();
531 }
-----------------------------------------------------------------------
Lines 513530
Indicate to the preemption code that we are in a hardware interrupt.
Line 523
Read from the interrupt controller a pending interrupt and convert to an IRQ number (until all interrupts are handled).
Line 524
The ppc_irq_dispatch_handler() handles the interrupt. We look at this function in more detail next.
The function ppc_irq_dispatch_handler() is nearly identical to the x86 function do_IRQ():
-----------------------------------------------------------------------
arch/ppc/kernel/irq.c
428 void ppc_irq_dispatch_handler(struct pt_regs *regs, int irq)
429 {
430 int status;
431 struct irqaction *action;
432 irq_desc_t *desc = irq_desc + irq;
433
434 kstat_this_cpu.irqs[irq]++;
435 spin_lock(&desc->lock);
436 ack_irq(irq);
...
441 status = desc->status & ~(IRQ_REPLAY | IRQ_WAITING);
442 if (!(status & IRQ_PER_CPU))
443 status |= IRQ_PENDING; /* we _want_ to handle it */
...
449 action = NULL;
450 if (likely(!(status & (IRQ_DISABLED | IRQ_INPROGRESS)))) {
451 action = desc->action;
452 if (!action || !action->handler) {
453 ppc_spurious_interrupts++;
454 printk(KERN_DEBUG "Unhandled interrupt %x, disabled\n",irq);
455 /* We can't call disable_irq here, it would deadlock */
456 ++desc->depth;
457 desc->status |= IRQ_DISABLED;
458 mask_irq(irq);
459 /* This is a real interrupt, we have to eoi it,
460 so we jump to out */
461 goto out;
462 }
463 status &= ~IRQ_PENDING; /* we commit to handling */
464 if (!(status & IRQ_PER_CPU))
465 status |= IRQ_INPROGRESS; /* we are handling it */
466 }
567 desc->status = status;
...
489 for (;;) {
490 spin_unlock(&desc->lock);
491 handle_irq_event(irq, regs, action);
492 spin_lock(&desc->lock);
493
494 if (likely(!(desc->status & IRQ_PENDING)))
495 break;
496 desc->status &= ~IRQ_PENDING;
497 }
498 out:
499 desc->status &= ~IRQ_INPROGRESS;
...
511 }
-----------------------------------------------------------------------
Line 432
Get the IRQ from parameters and gain access to the appropriate irq_desc.
Line 435
Acquire the spinlock on the IRQ descriptor in case of concurrent accesses to the same interrupt by different CPUs.
Line 436
Send an acknowledgment to the hardware. The hardware then reacts accordingly, preventing further interrupts of this type from being processed until this one is finished.
Lines 441443
The flags IRQ_REPLAY and IRQ_WAITING are cleared. In this case, IRQ_REPLAY indicates that the IRQ was dropped earlier and is being resent. IRQ_WAITING indicates that the IRQ is being tested. (Both cases are outside the scope of this discussion.) In a uniprocessor system, the IRQ_PENDING flag is set, which indicates that we commit to handling the interrupt.
Line 450
This block of code checks for conditions under which we would not process the interrupt. If IRQ_DISABLED or IRQ_INPROGRESS are set, we can skip over this block of code. The IRQ_DISABLED flag is set when we do not want the system to respond to a particular IRQ line being serviced. IRQ_INPROGRESS indicates that an interrupt is being serviced by a processor. This is used in the case a second processor in a multiprocessor system tries to raise the same interrupt.
Lines 451462
Here, we check to see if the handler exists. If it does not, we break out and jump to the "out" label in line 498.
Lines 463465
At this point, we cleared all three conditions for not servicing the interrupt, so we are committing to doing so. The flag IRQ_INPROGRESS is set and the IRQ_PENDING flag is cleared, which indicates that the interrupt is being handled.
Lines 489497
The interrupt is serviced. Before an interrupt is serviced, the spinlock on the interrupt descriptor is released. After the spinlock is released, the routine handle_irq_event() is called. This routine executes the interrupt's handler. Once done, the spinlock on the descriptor is acquired once more. If the IRQ_PENDING flag has not been set (by another CPU) during the course of the IRQ handling, break out of the loop. Otherwise, service the interrupt again.
Processing the PowerPC System Timer Interrupt
As noted in timer_init(), the decrementer is hard coded to 0x900. We can assume the terminal count has been reached and the handler timer_interrupt() in arch/ppc/kernel/time.c is called at this time:
-----------------------------------------------------------------------
arch/ppc/kernel/head.S
/* Decrementer */
479 EXCEPTION(0x900, Decrementer, timer_interrupt, EXC_XFER_LITE)
-----------------------------------------------------------------------
Here is the timer_interrupt() function.
-----------------------------------------------------------------------
arch/ppc/kernel/time.c
145 void timer_interrupt(struct pt_regs * regs)
146 {
...
152 if (atomic_read(&ppc_n_lost_interrupts) != 0)
153 do_IRQ(regs);
154
155 irq_enter();
...
159 if (!user_mode(regs))
160 ppc_do_profile(instruction_pointer(regs));
...
165 write_seqlock(&xtime_lock);
166
167 do_timer(regs);
...
189 if (ppc_md.set_rtc_time(xtime.tv_sec+1 + time_offset) == 0)
...
195 write_sequnlock(&xtime_lock);
...
198 set_dec(next_dec);
...
208 irq_exit();
209 }
-----------------------------------------------------------------------
Line 152
If an interrupt was lost, go back and call the external handler at 0x900.
Line 159
Do kernel profiling for kernel routing debug.
Lines 165 and 195
Lock out this block of code.
Line 167
This code is the same function used in the x86 timer interrupt (coming up next).
Line 189
Update the RTC.
Line 198
Restart the decrementer for the next interrupt.
Line 208
Return from the interrupt.
The interrupted code now runs as normal until the next interrupt.
Processing the x86 System Timer Interrupt
Upon activation of an interrupt (in our example, the PIT has counted down to 0 and activated IRQ0), the interrupt controller activates an interrupt line going into the processor. The assembly code in enTRy.S has an entry point that corresponds to each descriptor in the IDT. IRQ0 is the first external interrupt and is vector 32 in the IDT. The code is then ready to jump to entry point 32 in the jump table in enTRy.S:
-----------------------------------------------------------------------
arch/i386/kernel/entry.S
385 vector=0
386 ENTRY(irq_entries_start)
387 .rept NR_IRQS
388 ALIGN
389 1: pushl $vector-256
390 jmp common_interrupt
391 .data
392 .long 1b
393 .text
394 vector=vector+1
395 .endr
396
397 ALIGN
398 common_interrupt:
399 SAVE_ALL
400 call do_IRQ
401 jmp ret_from_intr
-----------------------------------------------------------------------
This code is a fine piece of assembler magic. The repeat construct .rept (on line 387), and its closing statement (on line 395) create the interrupt jump table at compile time. Notice that as this block of code is repeatedly created, the vector number to be pushed at line 389 is decremented. By pushing the vector, the kernel code now knows what IRQ it is working with at interrupt time.
When we left off the code trace for x86, the code jumps to the proper entry point in the jump table and saves the IRQ on the stack. The code then jumps to the common handler at line 398 and calls do_IRQ() (arch/i386/kernel/irq.c) at line 400. This function is almost identical to ppc_irq_dispatch_handler(), which was described in the section, "Processing the PowerPC External Interrupt Vector" so we will not repeat it here.
Based on the incoming IRQ, the function do_irq() accesses the proper element of irq_desc and jumps to each handler in the chain of action structures. Here, we have finally made it to the actual handler function for the PIT: timer_interrupt(). See the following code segments from time.c. Maintaining the same order as in the source file, the handler starts at line 274:
-----------------------------------------------------------------------
arch/i386/kernel/time.c
274 irqreturn_t timer_interrupt(int irq, void *dev_id, struct pt_regs *regs)
275 {
...
287 do_timer_interrupt(irq, NULL, regs);
...
290 return IRQ_HANDLED;
291 }
-----------------------------------------------------------------------
Line 274
This is the entry point for the system timer interrupt handler.
Line 287
This is the call to do_timer_interrupt().
-----------------------------------------------------------------------
arch/i386/kernel/time.c
208 static inline void do_timer_interrupt(int irq, void *dev_id,
209 struct pt_regs *regs)
210 {
...
227 do_timer_interrupt_hook(regs);
...
250 }
------------------------------------------------------------
Line 227
Call to do_timer_interrupt_hook(). This function is essentially a wrapper around the call to do_timer(). Let's look at it:
-----------------------------------------------------------------------
include/asm-i386/mach-default/do_timer.h
016 static inline void do_timer_interrupt_hook(struct pt_regs *regs)
017 {
018 do_timer(regs);
...
025 x86_do_profile(regs);
...
030 }
------------------------------------------------------------------
Line 18
This is where the call to do_timer() gets made. This function performs the bulk of the work for updating the system time.
Line 25
The x86_do_profile() routine looks at the eip register for the code that was running before the interrupt. Over time, this data indicates how often processes are running.
At this point, the system timer interrupt returns from do_irq()to enTRy.S for system housekeeping and the interrupted thread resumes.
As previously discussed, the system timer is the heartbeat of the Linux operating system. Although we have used the timer as an example for interrupts in this chapter, its use is prevalent throughout the entire operating system.
|
Project: current System Variable
This chapter explored the task_struct and current, which is the system variable that points to the currently executing task's task_struct. This project's goal is to reinforce the idea that the kernel is an orderly yet ever-changing series of linked structures that are created and destroyed as programs run. As we have seen, the task_struct structure is one of the most important structures the kernel owns, in that it has all the information needed for any given task. This project module accesses that structure just as the kernel does and serves as a base for future explorations for the reader.
In this project, we access the current task_struct and print various elements from that structure. Starting with the file include/linux/sched.h, we find the task_struct. Using sched.h, we reference current->pid and current->comm., the current process ID and name, and follow these structures to the parent's pid and comm. Next, we borrow a routine from printk() and send a message back to the current tty terminal we are using.
See the following code:
NOTE
From running the first program (hellomod), what do you think the name of the current process will be when the initialization routine prints out current->comm? What will be the name of the parent process? See the following code discussion.
Project Source Code
-----------------------------------------------------------------------
currentptr.c
001 #include <linux/module.h>
002 #include <linux//kernel.h>
003 #include <linux/init.h>
004 #include <linux/sched.h>
005 #include <linux/tty.h>
006
007 void tty_write_message1(struct tty_struct *, char *);
008
009 static int my_init( void )
010 {
011
012 char *msg="Hello tty!";
013
014 printk("Hello, from the kernel...\n");
015 printk("parent pid =%d(%s)\n",current->parent->pid
,current->parent->comm);
016 printk("current pid =%d(%s)\n",current->pid,current->comm);
017
018 tty_write_message1(current->signal->tty,msg);
019 return 0;
020 }
022 static void my_cleanup( void )
{
printk("Goodbye, from the kernel...\n");
}
027 module_init(my_init);
028 module_exit(my_cleanup);
// This routine was borrowed from <printk.c>
032 void tty_write_message1(struct tty_struct *tty, char *msg)
{
if (tty && tty->driver->write)
tty->driver->write(tty, 0, msg, strlen(msg));
return;
037 }
-----------------------------------------------------------------------
Line 4
sched.h contains struct task_struct {}, which is where we reference the process ID (->pid), and the name of the current task (->comm.), as well as the pointer to the parent PID (->parent), which references the parent task structure. We also find a pointer to the signal structure, which contains a reference to the tty structure (see lines 1822).
Line 5
tty.h contains struct tty_struct {}, which is used by the routine we borrowed from printk.c (see lines 3237).
Line 12
This is the simple message string we want to send back to our terminal.
Line 15
Here, we reference the parent PID and its name from our current task structure. The answer to the previous question is that the parent of our task is the current shell program; in this case, it was Bash.
Line 16
Here, we reference the current PID and its name from our current task structure. To answer the other half of the previous question, we entered insmod on the Bash command line and that is printed out as the current process.
Line 18
This is a function borrowed from kernel/printk.c. It is used to redirect messages to a specific tty. To illustrate our current point, we pass this routine the tty_struct of the tty (window or command line) from where we invoke our program. This is referenced by way of current->signal->tty. The msg parm is the string we declared on line 12.
Lines 3238
The tty write function checks that the tty exists and then calls the appropriate device driver with the message.
Running the Code
Compile and insmod() the code as in the first project.
|
|
|
|
|

 LINUX
LINUX