Введение в Linux Kernel
После 3 десятков лет использования , юникс остается одной из самых мощных и , я бы сказал ,
элегантных операционных систем.
С момента создания в 1969 году , праотцы Dennis Ritchie и Ken Thompson
заслуженно превратились в легенды.
Unix вырос из другой операционной системы - Multics,
которая была разработана ранее в стенах Bell Laboratories.
Когда проект Multics был завершен,
разработчики Bell Laboratories' Computer Sciences Research Center оказались как бы не у дел.
И летом 1969 они разработали новую файловую систему , которая плавно перешла в Unix.
Thompson апробировал ее на PDP-7.
Затем в 1971 Unix был портирован на PDP-11,
и в 1973, операционная система была переписана на C.
Первый Unix за стенами Bell получил название Sixth Edition, более известное как V6.
Другие компании портировали Unix на другие машины.
В 1977 Bell Labs обьединила все уже существующие версии юникса в единую систему - Unix System III;
в 1982, AT&T реализовала System V.
Простота Unix вкупе с прилагаемыми исходниками привлекло к разработке сторонние организации.
Наиболее влиятельной из них был University of California at Berkeley.
Вариант Unix от Berkeley был назван Berkeley Software Distributions (BSD).
Первый Berkeley Unix был 3BSD в 1979.
Серия 4BSD : 4.0BSD, 4.1BSD, 4.2BSD, and 4.3BSD, последовала за 3BSD.
В этих версиях появилась виртуальная память , пейджинг , TCP/IP.
В 1993, был реализован 4.4BSD.
Сегодня BSD включает в себя такие клоны , как Darwin, Dragonfly BSD, FreeBSD, NetBSD, OpenBSD
.
В восьмидесятых и 90-х годах, крупные компании стали разрабатывать свои собственные коммерческие версии Unix.
Среди них были : Digital's Tru64, Hewlett Packard's HP-UX, IBM's AIX, Sequent's DYNIX/ptx, SGI's IRIX, Sun's Solaris.
Дизайн Unix , многолетний вклад большого числа разработчиков сделали Unix мощной и устойчивой операционной системой.
К числу важнейших характеристик юникса относятся - простота:
в Unix ограниченное число системных вызовов . Далее ,
в юниксе все представляет из себя файл .
это упрощает манипуляцию данными и устройствами с помощью простого набора системных вызовов:
open(), read(), write(), ioctl(), and close().
Ядро и системные утилиты написана на C , что делает Unix портабельным и доступным для широкого круга разработчиков.
Создание процесса в Unix очень быстрое за счет уникального fork() .
Unix обеспечивает механизм меж-процессного взаимодействия (IPC) ,
что позволяет делать простые утилиты ,
которые делают что-то одно , но очень хорошо.
На сегодняшний день Unix поддерживает : multitasking, multithreading, virtual memory,
demand paging, shared libraries + demand loading, TCP/IP networking.
Unix масштабируем до нескольких сотен процессоров,
и в то же время Unix способен работать на очень маленьких устройствах.
Хотя Unix уже давно не чисто исследовательский проект.
Секрет Unix - в простоте и элегантности его дизайна.
Сила его базируется на решениях , которые были сделаны еще Dennis Ritchie, Ken Thompson,
и другими разработчиками.
Пока не пришел Linus: Введение в Linux
Linux был создан Линусом Торвальдсом в 1991 как операционная система для компьютера
с процессором Intel 80386 , который в тот момент был наиболее продвинутым.
Линусу , тогда студенту University of Helsinki,
крайне нужна была свободная непроприетарная Unix-система.
Microsoft's DOS использовался Торвальдсом исключительно для поиграть в Prince of Persia:-)
Линус использовал Minix, но был ограничен в ее использовании лицензионным соглашением.
В результате Линус сделал то , что сделал бы на его месте другой ученик :
он решил написать собственную операционную систему.
Он начал писать простой терминальный эмулятор , который использовался для коннекта с большой Юниксовой системой
в его тогда еще школе.
Со временем эмулятор развился и эволюционировал и стал превращаться в юникс.
Первая версия была выложена им в 1991.
После этого популярность Линукса взлетела.
Linux обзавелся большим количеством пользователей.
Linux стал быстро наполняться измененным и улучшенным кодом.
В силу лицензии Linux мгновенно стал коллективным проектом.
Сегодня Linux работает на следующих платформах : AMD x86-64, ARM, Compaq Alpha, CRIS, DEC VAX, H8/300, Hitachi SuperH, HP PA-RISC,
IBM S/390, Intel IA-64, MIPS, Motorola 68000, PowerPC, SPARC, UltraSPARC, v850.
Он может работать на гигантских кластерах.
Коммерческий интерес к Linux сегодня очень высок.
Novell и Red Hat,IBM реализуют решения для Linux-устройств,
десктопов, и серверов.
Linux - это юниксовый клон , но это не юникс.
Хотя Linux вырос из юникса и использовал его Unix API (POSIX).
Одна из главных особенностей Linux - в том , что это не-коммерческий продукт ,
а коллективный проект независимых разработчиков.
Linus по-прежнему остается создателем и maintainer ядра.
Любой может внести вклад в Linux.
Linux kernel свободно и открыто.
Ядро находится под лицензией GNU General Public License (GPL) version 2.0.
Вы вольны брать исходники и делать с ними все что угодно.
Linux многолик.
В его основе лежат ядро, C library, компилятор, toolchain, базовые системные утилиты,
такие как login или shell.
В Linux включена графическая система X Window System implementation , включая GNOME.
Существуют тысячи свободных и коммерческих приложений под Linux.
Когда в этой книге я буду говорить Linux ,
как правило это будет означать Linux kernel.
Термин Linux как правило в этой книге будет ссылаться в основном на ядро.
Обзор операционных систем и ядер
Из-за разношерстности точное определение , что же такое операционная система , дать довольно сложно.
Пользователь , глядя на экран , думает , что там и находится операционная система.
Операционная система - это часть системы , отвественной за базовое использование и администрирование.
Сюда входят ядро , драйверы устройств,загрузчик, shell ,файловая система.
Тема этой книги - ядро.
Пользовательский интерфейс - внешняя часть операционной системы , ядро - ее внутренняя часть.
Ядро - это софт , который обеспечивает базовые сервисы для всех частей системы,
управляет железом, раздает системные ресурсы.
Ядро в свою очередь - это что-то типа супервизора или главного администратора,
внутри самой операционной системы.
Типичным компонентом ядра являются системные прерывания для обслуживания запросов-прерываний,
а также шедулер для распределения времени процессора на несколько процессов,
управление памятью системы , системные сервисы такие как сетевое обслуживание
и меж-процессная коммуникация.
В новейших системах с защитой памяти,
ядро включает в себя защищенную и недоступную для простого смертного область памяти и называется
kernel-space.
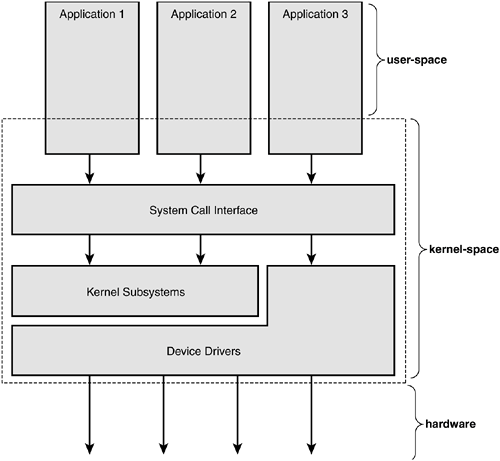
В то время как пользовательские приложения выполняются в совершенно другом адрессном пространстве - user-space.
Приложения пользователя не могут выполнить определенные системные вызовы,
получить доступ напрямую к железу.
Ядро работает в kernel mode, все остальные пользовательские приложения - в user mode.
Приложения взаимодействуют с ядром через
system calls
(see Figure 1.1).
Приложения вызывают стандартные функции , которые лежат в C library.
Если взять printf() , она делает форматирование и буфферизацию
данных и вызывает в свою очередь write() для вывода данных на консоль.
Или библиотечная функция open()
не делает ничего , кроме системного вызова open().
Другие C library функции , такие как strcpy(), вообще не должны трогать системные вызовы.
Когда вызывается системный вызов ,
ядро работает в process context.
Ядро управляет железом. Делает это на всех архитектурах , которые поддерживает.
Когда железу нужно взаимодействовать с ядром , срабатывает прерывание ,
которое асинхронно притормаживает ядро.
У каждого прерывания есть свой номер.
Этот номер используется для вызова подпрограммы interrupt handler
для обработки этого прерывания.
Например , при нажатии контроллер клавиатуры генерит прерывание и дает знать системе ,
что у него в буффере новые данные.
Ядро ловит номер прерывания и выполняет соответствующий хэндлер.
Хэндлер обрабатывает контроллер клавиатуры и позволяет последнему принимать новые нажатия.
В момент обработки этого прерывания все остальные отключаются.
Прерывание НЕ выполняется в process context.
Оно выполняется в специальном interrupt context ,
которое не имеет ничего общего с другими процессами.
Вообще говоря , в текущий момент времени линукс может выполнять одно из трех :
kernel-space : process context
kernel-space : interrupt context
user-space: пользовательский процесс
|
Linux-версии юникс-ядер
Owing to their common ancestry and same API, modern Unix kernels share various design traits. With few exceptions, a Unix kernel is typically a monolithic static binary. That is, it exists as a large single-executable image that runs in a single address space. Unix systems typically require a system with a paged memory-management unit; this hardware enables the system to enforce memory protection and to provide a unique virtual address space to each process.
See the bibliography for my favorite books on the design of the classic Unix kernels.
|
Operating kernels can be divided into two main design camps: the monolithic kernel and the microkernel. (A third camp, exokernel, is found primarily in research systems but is gaining ground in real-world use.)
Monolithic kernels involve the simpler design of the two, and all kernels were designed in this manner until the 1980s. Monolithic kernels are implemented entirely as single large processes running entirely in a single address space. Consequently, such kernels typically exist on disk as single static binaries. All kernel services exist and execute in the large kernel address space. Communication within the kernel is trivial because everything runs in kernel mode in the same address space: The kernel can invoke functions directly, as a user-space application might. Proponents of this model cite the simplicity and performance of the monolithic approach. Most Unix systems are monolithic in design.
Microkernels, on the other hand, are not implemented as single large processes. Instead, the functionality of the kernel is broken down into separate processes, usually called servers. Idealistically, only the servers absolutely requiring such capabilities run in a privileged execution mode. The rest of the servers run in user-space. All the servers, though, are kept separate and run in different address spaces. Therefore, direct function invocation as in monolithic kernels is not possible. Instead, communication in microkernels is handled via message passing: An interprocess communication (IPC) mechanism is built into the system, and the various servers communicate and invoke "services" from each other by sending messages over the IPC mechanism. The separation of the various servers prevents a failure in one server from bringing down another.
Likewise, the modularity of the system allows one server to be swapped out for another. Because the IPC mechanism involves quite a bit more overhead than a trivial function call, however, and because a context switch from kernel-space to user-space or vice versa may be involved, message passing includes a latency and throughput hit not seen on monolithic kernels with simple function invocation. Consequently, all practical microkernel-based systems now place most or all the servers in kernel-space, to remove the overhead of frequent context switches and potentially allow for direct function invocation. The Windows NT kernel and Mach (on which part of Mac OS X is based) are examples of microkernels. Neither Windows NT nor Mac OS X run any microkernel servers in user-space in their latest versions, defeating the primary purpose of microkernel designs altogether.
Linux is a monolithic kernelthat is, the Linux kernel executes in a single address space entirely in kernel mode. Linux, however, borrows much of the good from microkernels: Linux boasts a modular design with kernel preemption, support for kernel threads, and the capability to dynamically load separate binaries (kernel modules) into the kernel. Conversely, Linux has none of the performance-sapping features that curse microkernel designs: Everything runs in kernel mode, with direct function invocationnot message passingthe method of communication. Yet Linux is modular, threaded, and the kernel itself is schedulable. Pragmatism wins again. |
As Linus and other kernel developers contribute to the Linux kernel, they decide how best to advance Linux without neglecting its Unix roots (and more importantly, the Unix API). Consequently, because Linux is not based on any specific Unix, Linus and company are able to pick and choose the best solution to any given problemor at times, invent new solutions! Here is an analysis of characteristics that differ between the Linux kernel and other Unix variants:
Linux supports the dynamic loading of kernel modules. Although the Linux kernel is monolithic, it is capable of dynamically loading and unloading kernel code on demand. Linux has symmetrical multiprocessor (SMP) support. Although many commercial variants of Unix now support SMP, most traditional Unix implementations did not. The Linux kernel is preemptive. Unlike traditional Unix variants, the Linux kernel is capable of preempting a task even if it is running in the kernel. Of the other commercial Unix implementations, Solaris and IRIX have preemptive kernels, but most traditional Unix kernels are not preemptive. Linux takes an interesting approach to thread support: It does not differentiate between threads and normal processes. To the kernel, all processes are the samesome just happen to share resources. Linux provides an object-oriented device model with device classes, hotpluggable events, and a user-space device filesystem (sysfs). Linux ignores some common Unix features that are thought to be poorly designed, such as STREAMS, or standards that are brain dead. Linux is free in every sense of the word. The feature set Linux implements is the result of the freedom of Linux's open development model. If a feature is without merit or poorly thought out, Linux developers are under no obligation to implement it. To the contrary, Linux has adopted an elitist attitude toward changes: Modifications must solve a specific real-world problem, have a sane design, and have a clean implementation. Consequently, features of some other modern Unix variants, such as pageable kernel memory, have received no consideration.
Despite any differences, Linux remains an operating system with a strong Unix heritage.
Linux Kernel Versions
Linux kernels come in two flavors: stable or development. Stable kernels are production-level releases suitable for widespread deployment. New stable kernel versions are released typically only to provide bug fixes or new drivers. Development kernels, on the other hand, undergo rapid change where (almost) anything goes. As developers experiment with new solutions, often-drastic changes to the kernel are made.
Linux kernels distinguish between stable and development kernels with a simple naming scheme (see Figure 1.2). Three numbers, each separated by a dot, represent Linux kernels. The first value is the major release, the second is the minor release, and the third is the revision. The minor release also determines whether the kernel is a stable or development kernel; an even number is stable, whereas an odd number is development. Thus, for example, the kernel version 2.6.0 designates a stable kernel. This kernel has a major version of two, has a minor version of six, and is revision zero. The first two values also describe the "kernel series"in this case, the 2.6 kernel series.

Development kernels have a series of phases. Initially, the kernel developers work on new features and chaos ensues. Over time, the kernel matures and eventually a feature freeze is declared. At that point, no new features can be submitted. Work on existing features, however, can continue. After the kernel is considered nearly stabilized, a code freeze is put into effect. When that occurs, only bug fixes are accepted. Shortly thereafter (one hopes), the kernel is released as the first version of a new stable series. For example, the development series 1.3 stabilized into 2.0 and 2.5 stabilized into 2.6.
|
Well, not exactly. Technically speaking, the previous description of the kernel development process is true. Indeed, historically the process has proceeded exactly as described. In the summer of 2004, however, at the annual invite-only Linux Kernel Developers Summit, a decision was made to prolong the development of the 2.6 kernel without introducing a 2.7 development series in the near future. The decision was made because the 2.6 kernel is well received, it is generally stable, and no large intrusive features are on the horizon. Additionally, perhaps most importantly, the current 2.6 maintainer system that exists between Linus Torvalds and Andrew Morton is working out exceedingly well. The kernel developers believe that this process can continue in such a way that the 2.6 kernel series both remains stable and receives new features. Only time will tell, but so far, the results look good. |
This book is based on the 2.6 stable kernel series.
Chapter 2. Getting Started with the Kernel
In this chapter, we introduce some of the Basics of the Linux kernel: where to get its source, how to compile it, and how to install the new kernel. We then go over some kernel assumptions, differences between the kernel and user-space programs, and common methods used in the kernel.
The kernel has some intriguing differences over other beasts, but certainly nothing that cannot be tamed. Let's tackle it.
Obtaining the Kernel Source
The current Linux source code is always available in both a complete tarball and an incremental patch from the official home of the Linux kernel, http://www.kernel.org.
Unless you have a specific reason to work with an older version of the Linux source, you always want the latest code. The repository at kernel.org is the place to get it, along with additional patches from a number of leading kernel developers.
Installing the Kernel Source
The kernel tarball is distributed in both GNU zip (gzip) and bzip2 format. Bzip2 is the default and preferred format, as it generally compresses quite a bit better than gzip. The Linux kernel tarball in bzip2 format is named linux-x.y.z.tar.bz2, where x.y.z is the version of that particular release of the kernel source. After downloading the source, uncompressing and untarring it is simple. If your tarball is compressed with bzip2, run
$ tar xvjf linux-x.y.z.tar.bz2
If it is compressed with GNU zip, run
$ tar xvzf linux-x.y.z.tar.gz
This uncompresses and untars the source to the directory linux-x.y.z.
|
The kernel source is typically installed in /usr/src/linux. Note that you should not use this source tree for development. The kernel version that your C library is compiled against is often linked to this tree. Besides, you do not want to have to be root to make changes to the kernelinstead, work out of your home directory and use root only to install new kernels. Even when installing a new kernel, /usr/src/linux should remain untouched. |
Using Patches
Throughout the Linux kernel community, patches are the lingua franca of communication. You will distribute your code changes in patches as well as receive code from others as patches. More relevant to the moment is the incremental patches that are provided to move from one version of the kernel source to another. Instead of downloading each large tarball of the kernel source, you can simply apply an incremental patch to go from one version to the next. This saves everyone bandwidth and you time. To apply an incremental patch, from inside your kernel source tree, simply run
$ patch p1 < ../patch-x.y.z
Generally, a patch to a given version of the kernel is applied against the previous version.
Generating and applying patches is discussed in much more depth in later chapters.
The Kernel Source Tree
The kernel source tree is divided into a number of directories, most of which contain many more subdirectories. The directories in the root of the source tree, along with their descriptions, are listed in Table 2.1.
Table 2.1. Directories in the Root of the Kernel Source TreeDirectory | Description |
|---|
arch | Architecture-specific source | crypto | Crypto API | Documentation | Kernel source documentation | drivers | Device drivers | fs | The VFS and the individual file systems | include | Kernel headers | init | Kernel boot and initialization | ipc | Interprocess communication code | kernel | Core subsystems, such as the scheduler | lib | Helper routines | mm | Memory management subsystem and the VM | net | Networking subsystem | scripts | Scripts used to build the kernel | security | Linux Security Module | sound | Sound subsystem | usr | Early user-space code (called initramfs) |
A number of files in the root of the source tree deserve mention.The file COPYING is the kernel license (the GNU GPL v2). CREDITS is a listing of developers with a more than trivial amount of code in the kernel. MAINTAINERS lists the names of the individuals who maintain subsystems and drivers in the kernel. Finally, Makefile is the base kernel Makefile.
Building the Kernel
Building the kernel is easy. In fact, it is surprisingly easier than compiling and installing other system-level components, such as glibc. The 2.6 kernel series introduces a new configuration and build system, which makes the job even easier and is a welcome improvement over 2.4.
Because the Linux source code is available, it follows that you are able to configure and custom tailor it before compiling. Indeed, it is possible to compile support into your kernel for just the features and drivers you require. Configuring the kernel is a required step before building it. Because the kernel offers a myriad of features and supports tons of varied hardware, there is a lot to configure. Kernel configuration is controlled by configuration options, which are prefixed by CONFIG in the form CONFIG_FEATURE. For example, symmetrical multiprocessing (SMP) is controlled by the configuration option CONFIG_SMP. If this option is set, SMP is enabled; if unset, SMP is disabled. The configure options are used both to decide which files to build and to manipulate code via preprocessor directives.
Configuration options that control the build process are either Booleans or tristates. A Boolean option is either yes or no. Kernel features, such as CONFIG_PREEMPT, are usually Booleans. A tristate option is one of yes, no, or module. The module setting represents a configuration option that is set, but is to be compiled as a module (that is, a separate dynamically loadable object). In the case of tristates, a yes option explicitly means to compile the code into the main kernel image and not a module. Drivers are usually represented by tristates.
Configuration options can also be strings or integers. These options do not control the build process but instead specify values that kernel source can access as a preprocessor macro. For example, a configuration option can specify the size of a statically allocated array.
Vendor kernels, such as those provided by Novell and Red Hat, are precompiled as part of the distribution. Such kernels typically enable a good cross section of the needed kernel features and compile nearly all the drivers as modules. This provides for a great base kernel with support for a wide range of hardware as separate modules. Unfortunately, as a kernel hacker, you will have to compile your own kernels and learn what modules to include or not include on your own.
Thankfully, the kernel provides multiple tools to facilitate configuration. The simplest tool is a text-based command-line utility:
$ make config
This utility goes through each option, one by one, and asks the user to interactively select yes, no, or (for tristates) module. Because this takes a long time, unless you are paid by the hour, you should use an ncurses-based graphical utility:
$ make menuconfig
Or an X11-based graphical utility:
$ make xconfig
Or, even better, a gtk+-based graphical utility:
$ make gconfig
These three utilities divide the various configuration options into categories, such as "Processor type and features." You can move through the categories, view the kernel options, and of course change their values.
The command
$ make defconfig
creates a configuration based on the defaults for your architecture. Although these defaults are somewhat arbitrary (on i386, they are rumored to be Linus's configuration!), they provide a good start if you have never configured the kernel before. To get off and running quickly, run this command and then go back and ensure that configuration options for your hardware are enabled.
The configuration options are stored in the root of the kernel source tree, in a file named .config. You may find it easier (as most of the kernel developers do) to just edit this file directly. It is quite easy to search for and change the value of the configuration options. After making changes to your configuration file, or when using an existing configuration file on a new kernel tree, you can validate and update the configuration:
$ make oldconfig
You should always run this before building a kernel, in fact. After the kernel configuration is set, you can build it:
$ make
Unlike kernels before 2.6, you no longer need to run make dep before building the kernelthe dependency tree is maintained automatically. You also do not need to specify a specific build type, such as bzImage, or build modules separately, as you did in old versions. The default Makefile rule will handle everything!
Minimizing Build Noise
A trick to minimize build noise, but still see warnings and errors, is to redirect the output from make(1):
$ make > ../some_other_file
If you do need to see the build output, you can read the file. Because the warnings and errors are output to standard error, however, you normally do not need to. In fact, I just do
$ make > /dev/null
which redirects all the worthless output to that big ominous sink of no return, /dev/null.
Spawning Multiple Build Jobs
The make(1) program provides a feature to split the build process into a number of jobs. Each of these jobs then runs separately and concurrently, significantly speeding up the build process on multiprocessing systems. It also improves processor utilization because the time to build a large source tree also includes some time spent in I/O wait (time where the process is idle waiting for an I/O request to complete).
By default, make(1) spawns only a single job. Makefiles all too often have their dependency information screwed up. With incorrect dependencies, multiple jobs can step on each other's toes, resulting in errors in the build process. The kernel's Makefiles, naturally, have no such coding mistakes. To build the kernel with multiple jobs, use
$ make -jn
where n is the number of jobs to spawn. Usual practice is to spawn one or two jobs per processor. For example, on a dual processor machine, one might do
$ make j4
Using utilities such as the excellent distcc(1) or ccache(1) can also dramatically improve kernel build time.
Installing the Kernel
After the kernel is built, you need to install it. How it is installed is very architecture and boot loader dependentconsult the directions for your boot loader on where to copy the kernel image and how to set it up to boot. Always keep a known-safe kernel or two around in case your new kernel has problems!
As an example, on an x86 using grub, you would copy arch/i386/boot/bzImage to /boot, name it something like vmlinuz-version, and edit /boot/grub/grub.conf with a new entry for the new kernel. Systems using LILO to boot would instead edit /etc/lilo.conf and then rerun lilo(8).
Installing modules, thankfully, is automated and architecture-independent. As root, simply run
% make modules_install
to install all the compiled modules to their correct home in /lib.
The build process also creates the file System.map in the root of the kernel source tree. It contains a symbol lookup table, mapping kernel symbols to their start addresses. This is used during debugging to translate memory addresses to function and variable names.
A Beast of a Different Nature
The kernel has several differences compared to normal user-space applications that, although not making it necessarily harder to program than user-space, certainly provide unique challenges to kernel development.
These differences make the kernel a beast of a different nature. Some of the usual rules are bent; other rules are entirely new. Although some of the differences are obvious (we all know the kernel can do anything it wants), others are not so obvious. The most important of these differences are
The kernel does not have access to the C library. The kernel is coded in GNU C. The kernel lacks memory protection like user-space. The kernel cannot easily use floating point. The kernel has a small fixed-size stack. Because the kernel has asynchronous interrupts, is preemptive, and supports SMP, synchronization and concurrency are major concerns within the kernel. Portability is important.
Let's briefly look at each of these issues because all kernel development must keep them in mind.
No libc
Unlike a user-space application, the kernel is not linked against the standard C library (or any other library, for that matter). There are multiple reasons for this, including some chicken-and-the-egg situations, but the primary reason is speed and size. The full C libraryor even a decent subset of itis too large and too inefficient for the kernel.
Do not fret: Many of the usual libc functions have been implemented inside the kernel. For example, the common string manipulation functions are in lib/string.c. Just include <linux/string.h> and have at them.
|
When I talk about header files hereor elsewhere in this bookI am referring to the kernel header files that are part of the kernel source tree. Kernel source files cannot include outside headers, just as they cannot use outside libraries. |
Of the missing functions, the most familiar is printf(). The kernel does not have access to printf(), but it does have access to printk(). The printk() function copies the formatted string into the kernel log buffer, which is normally read by the syslog program. Usage is similar to printf():
printk("Hello world! A string: %s and an integer: %d\n", a_string, an_integer);
One notable difference between printf() and printk() is that printk() allows you to specify a priority flag. This flag is used by syslogd(8) to decide where to display kernel messages. Here is an example of these priorities:
printk(KERN_ERR "this is an error!\n");
We will use printk() tHRoughout this book. Later chapters have more information on printk().
GNU C
Like any self-respecting Unix kernel, the Linux kernel is programmed in C. Perhaps surprisingly, the kernel is not programmed in strict ANSI C. Instead, where applicable, the kernel developers make use of various language extensions available in gcc (the GNU Compiler Collection, which contains the C compiler used to compile the kernel and most everything else written in C on a Linux system).
The kernel developers use both ISO C99 and GNU C extensions to the C language. These changes wed the Linux kernel to gcc, although recently other compilers, such as the Intel C compiler, have sufficiently supported enough gcc features that they too can compile the Linux kernel. The ISO C99 extensions that the kernel uses are nothing special and, because C99 is an official revision of the C language, are slowly cropping up in a lot of other code. The more interesting, and perhaps unfamiliar, deviations from standard ANSI C are those provided by GNU C. Let's look at some of the more interesting extensions that may show up in kernel code.
Inline Functions
GNU C supports inline functions. An inline function is, as its name suggests, inserted inline into each function call site. This eliminates the overhead of function invocation and return (register saving and restore), and allows for potentially more optimization because the compiler can optimize the caller and the called function together. As a downside (nothing in life is free), code size increases because the contents of the function are copied to all the callers, which increases memory consumption and instruction cache footprint. Kernel developers use inline functions for small time-critical functions. Making large functions inline, especially those that are used more than once or are not time critical, is frowned upon by the kernel developers.
An inline function is declared when the keywords static and inline are used as part of the function definition. For example:
static inline void dog(unsigned long tail_size)
The function declaration must precede any usage, or else the compiler cannot make the function inline. Common practice is to place inline functions in header files. Because they are marked static, an exported function is not created. If an inline function is used by only one file, it can instead be placed toward the top of just that file.
In the kernel, using inline functions is preferred over complicated macros for reasons of type safety.
Inline Assembly
The gcc C compiler enables the embedding of assembly instructions in otherwise normal C functions. This feature, of course, is used in only those parts of the kernel that are unique to a given system architecture.
The asm() compiler directive is used to inline assembly code.
The Linux kernel is programmed in a mixture of C and assembly, with assembly relegated to low-level architecture and fast path code. The vast majority of kernel code is programmed in straight C.
Branch Annotation
The gcc C compiler has a built-in directive that optimizes conditional branches as either very likely taken or very unlikely taken. The compiler uses the directive to appropriately optimize the branch. The kernel wraps the directive in very easy-to-use macros, likely() and unlikely().
For example, consider an if statement such as the following:
if (foo) {
/* ... */
}
To mark this branch as very unlikely taken (that is, likely not taken):
/* we predict foo is nearly always zero ... */
if (unlikely(foo)) {
/* ... */
}
Conversely, to mark a branch as very likely taken:
/* we predict foo is nearly always nonzero ... */
if (likely(foo)) {
/* ... */
}
You should only use these directives when the branch direction is overwhelmingly a known priori or when you want to optimize a specific case at the cost of the other case. This is an important point: These directives result in a performance boost when the branch is correctly predicted, but a performance loss when the branch is mispredicted. A very common usage for unlikely() and likely() is error conditions. As one might expect, unlikely() finds much more use in the kernel because if statements tend to indicate a special case.
No Memory Protection
When a user-space application attempts an illegal memory access, the kernel can trap the error, send SIGSEGV, and kill the process. If the kernel attempts an illegal memory access, however, the results are less controlled. (After all, who is going to look after the kernel?) Memory violations in the kernel result in an oops, which is a major kernel error. It should go without saying that you must not illegally access memory, such as dereferencing a NULL pointerbut within the kernel, the stakes are much higher!
Additionally, kernel memory is not pageable. Therefore, every byte of memory you consume is one less byte of available physical memory. Keep that in mind next time you have to add one more feature to the kernel!
No (Easy) Use of Floating Point
When a user-space process uses floating-point instructions, the kernel manages the transition from integer to floating point mode. What the kernel has to do when using floating-point instructions varies by architecture, but the kernel normally catches a trap and does something in response.
Unlike user-space, the kernel does not have the luxury of seamless support for floating point because it cannot trap itself. Using floating point inside the kernel requires manually saving and restoring the floating point registers, among possible other chores. The short answer is: Don't do it; no floating point in the kernel.
Small, Fixed-Size Stack
User-space can get away with statically allocating tons of variables on the stack, including huge structures and many-element arrays. This behavior is legal because user-space has a large stack that can grow in size dynamically (developers of older, less intelligent operating systemssay, DOSmight recall a time when even user-space had a fixed-sized stack).
The kernel stack is neither large nor dynamic; it is small and fixed in size. The exact size of the kernel's stack varies by architecture. On x86, the stack size is configurable at compile-time and can be either 4 or 8KB. Historically, the kernel stack is two pages, which generally implies that it is 8KB on 32-bit architectures and 16KB on 64-bit architecturesthis size is fixed and absolute. Each process receives its own stack.
The kernel stack is discussed in much greater detail in later chapters.
Synchronization and Concurrency
The kernel is susceptible to race conditions. Unlike a single-threaded user-space application, a number of properties of the kernel allow for concurrent access of shared resources and thus require synchronization to prevent races. Specifically,
Linux is a preemptive multi-tasking operating system. Processes are scheduled and rescheduled at the whim of the kernel's process scheduler. The kernel must synchronize between these tasks. The Linux kernel supports multiprocessing. Therefore, without proper protection, kernel code executing on two or more processors can access the same resource. Interrupts occur asynchronously with respect to the currently executing code. Therefore, without proper protection, an interrupt can occur in the midst of accessing a shared resource and the interrupt handler can then access the same resource. The Linux kernel is preemptive. Therefore, without protection, kernel code can be preempted in favor of different code that then accesses the same resource.
Typical solutions to race conditions include spinlocks and semaphores.
Later chapters provide a thorough discussion of synchronization and concurrency.
Portability Is Important
Although user-space applications do not have to aim for portability, Linux is a portable operating system and should remain one. This means that architecture-independent C code must correctly compile and run on a wide range of systems, and that architecture-dependent code must be properly segregated in system-specific directories in the kernel source tree.
A handful of rulessuch as remain endian neutral, be 64-bit clean, do not assume the word or page size, and so ongo a long way. Portability is discussed in extreme depth in a later chapter.
So Here We Are
The kernel is indeed a unique and inimitable beast: No memory protection, no tried-and-true libc, a small stack, a huge source tree. The Linux kernel plays by its own rules, running with the big boys and stopping just long enough to break the customs with which we are familiar. Despite this, however, the kernel is just a program. It is not very different from the usual, the accustomed, the status quo. Do not be afraid: Stand up to it, call it names, push it around.
Realizing that the kernel is not as daunting as first appearances might suggest is the first step on the road to having everything just make sense. To reach that utopia, however, you have to jump in, read the source, hack the source, and not be disheartened.
The introduction in the previous chapter and the basics in this chapter willI hopelay the foundation for the monument of knowledge we will construct throughout the rest of this book. In the following chapters, we will look at specific concepts of and subsystems in the kernel.
Chapter 3. Process Management
The process is one of the fundamental abstractions in Unix operating systems. A process is a program (object code stored on some media) in execution. Processes are, however, more than just the executing program code (often called the text section in Unix). They also include a set of resources such as open files and pending signals, internal kernel data, processor state, an address space, one or more threads of execution, and a data section containing global variables. Processes, in effect, are the living result of running program code.
Threads of execution, often shortened to threads, are the objects of activity within the process. Each thread includes a unique program counter, process stack, and set of processor registers. The kernel schedules individual threads, not processes. In traditional Unix systems, each process consists of one thread. In modern systems, however, multithreaded programsthose that consist of more than one threadare common. As you will see later, Linux has a unique implementation of threads: It does not differentiate between threads and processes. To Linux, a thread is just a special kind of process.
On modern operating systems, processes provide two virtualizations: a virtualized processor and virtual memory. The virtual processor gives the process the illusion that it alone monopolizes the system, despite possibly sharing the processor among dozens of other processes.
Chapter 4, "Process Scheduling," discusses this virtualization. Virtual memory lets the process allocate and manage memory as if it alone owned all the memory in the system. Virtual memory is covered in
Chapter 11, "Memory Management." Interestingly, note that threads share the virtual memory abstraction while each receives its own virtualized processor.
A program itself is not a process; a process is an active program and related resources. Indeed, two or more processes can exist that are executing the same program. In fact, two or more processes can exist that share various resources, such as open files or an address space.
A process begins its life when, not surprisingly, it is created. In Linux, this occurs by means of the fork() system call, which creates a new process by duplicating an existing one. The process that calls fork() is the parent, whereas the new process is the child. The parent resumes execution and the child starts execution at the same place, where the call returns. The fork() system call returns from the kernel twice: once in the parent process and again in the newborn child.
Often, immediately after a fork it is desirable to execute a new, different, program. The exec*() family of function calls is used to create a new address space and load a new program into it. In modern Linux kernels, fork() is actually implemented via the clone() system call, which is discussed in a following section.
Finally, a program exits via the exit() system call. This function terminates the process and frees all its resources. A parent process can inquire about the status of a terminated child via the wait4() system call, which enables a process to wait for the termination of a specific process. When a process exits, it is placed into a special zombie state that is used to represent terminated processes until the parent calls wait() or waitpid().
Another name for a process is a task. The Linux kernel internally refers to processes as tasks. In this book, I will use the terms interchangeably, although when I say task I am generally referring to a process from the kernel's point of view.
Process Descriptor and the Task Structure
The kernel stores the list of processes in a circular doubly linked list called the task list. Each element in the task list is a process descriptor of the type struct task_struct, which is defined in <linux/sched.h>. The process descriptor contains all the information about a specific process.
The task_struct is a relatively large data structure, at around 1.7 kilobytes on a 32-bit machine. This size, however, is quite small considering that the structure contains all the information that the kernel has and needs about a process. The process descriptor contains the data that describes the executing programopen files, the process's address space, pending signals, the process's state, and much more (see Figure 3.1).
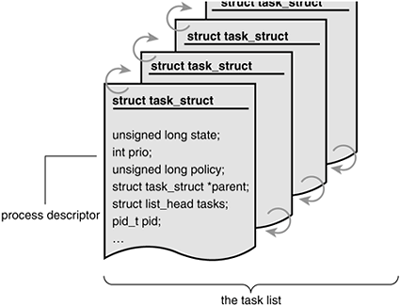
Allocating the Process Descriptor
The task_struct structure is allocated via the slab allocator to provide object reuse and cache coloring (see
Chapter 11, "Memory Management"). Prior to the 2.6 kernel series, struct task_struct was stored at the end of the kernel stack of each process. This allowed architectures with few registers, such as x86, to calculate the location of the process descriptor via the stack pointer without using an extra register to store the location. With the process descriptor now dynamically created via the slab allocator, a new structure, struct thread_info, was created that again lives at the bottom of the stack (for stacks that grow down) and at the top of the stack (for stacks that grow up). See Figure 3.2. The new structure also makes it rather easy to calculate offsets of its values for use in assembly code.
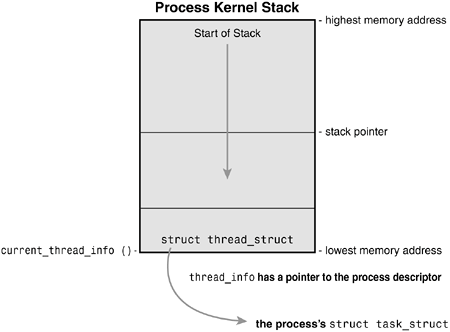
The thread_info structure is defined on x86 in <asm/thread_info.h> as
struct thread_info {
struct task_struct *task;
struct exec_domain *exec_domain;
unsigned long flags;
unsigned long status;
__u32 cpu;
__s32 preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
unsigned long previous_esp;
__u8 supervisor_stack[0];
};
Each task's tHRead_info structure is allocated at the end of its stack. The task element of the structure is a pointer to the task's actual task_struct.
Storing the Process Descriptor
The system identifies processes by a unique process identification value or PID. The PID is a numerical value that is represented by the opaque type pid_t, which is typically an int. Because of backward compatibility with earlier Unix and Linux versions, however, the default maximum value is only 32,768 (that of a short int), although the value can optionally be increased to the full range afforded the type. The kernel stores this value as pid inside each process descriptor.
This maximum value is important because it is essentially the maximum number of processes that may exist concurrently on the system. Although 32,768 might be sufficient for a desktop system, large servers may require many more processes. The lower the value, the sooner the values will wrap around, destroying the useful notion that higher values indicate later run processes than lower values. If the system is willing to break compatibility with old applications, the administrator may increase the maximum value via /proc/sys/kernel/pid_max.
Inside the kernel, tasks are typically referenced directly by a pointer to their task_struct structure. In fact, most kernel code that deals with processes works directly with struct task_struct. Consequently, it is very useful to be able to quickly look up the process descriptor of the currently executing task, which is done via the current macro. This macro must be separately implemented by each architecture. Some architectures save a pointer to the task_struct structure of the currently running process in a register, allowing for efficient access. Other architectures, such as x86 (which has few registers to waste), make use of the fact that struct thread_info is stored on the kernel stack to calculate the location of thread_info and subsequently the task_struct.
On x86, current is calculated by masking out the 13 least significant bits of the stack pointer to obtain the thread_info structure. This is done by the current_thread_info() function. The assembly is shown here:
movl $-8192, %eax
andl %esp, %eax
This assumes that the stack size is 8KB. When 4KB stacks are enabled, 4096 is used in lieu of 8192.
Finally, current dereferences the task member of thread_info to return the task_struct:
current_thread_info()->task;
Contrast this approach with that taken by PowerPC (IBM's modern RISC-based microprocessor), which stores the current task_struct in a register. Thus, current on PPC merely returns the value stored in the register r2. PPC can take this approach because, unlike x86, it has plenty of registers. Because accessing the process descriptor is a common and important job, the PPC kernel developers deem using a register worthy for the task.
Process State
The state field of the process descriptor describes the current condition of the process (see Figure 3.3). Each process on the system is in exactly one of five different states. This value is represented by one of five flags:
TASK_RUNNING
The process is runnable; it is either currently running or on a runqueue waiting to run (runqueues are discussed in
Chapter 4, "Scheduling"). This is the only possible state for a process executing in user-space; it can also apply to a process in kernel-space that is actively running.
TASK_INTERRUPTIBLE
The process is sleeping (that is, it is blocked), waiting for some condition to exist. When this condition exists, the kernel sets the process's state to TASK_RUNNING. The process also awakes prematurely and becomes runnable if it receives a signal.
TASK_UNINTERRUPTIBLE
This state is identical to TASK_INTERRUPTIBLE except that it does not wake up and become runnable if it receives a signal. This is used in situations where the process must wait without interruption or when the event is expected to occur quite quickly. Because the task does not respond to signals in this state, TASK_UNINTERRUPTIBLE is less often used than TASK_INTERRUPTIBLE.
TASK_ZOMBIE
The task has terminated, but its parent has not yet issued a wait4() system call. The task's process descriptor must remain in case the parent wants to access it. If the parent calls wait4(), the process descriptor is deallocated.
TASK_STOPPED
Process execution has stopped; the task is not running nor is it eligible to run. This occurs if the task receives the SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal or if it receives any signal while it is being debugged.
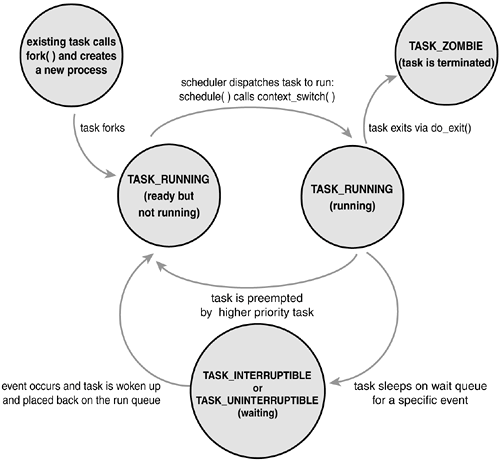
Manipulating the Current Process State
Kernel code often needs to change a process's state. The preferred mechanism is using
set_task_state(task, state); /* set task 'task' to state 'state' */
This function sets the given task to the given state. If applicable, it also provides a memory barrier to force ordering on other processors (this is only needed on SMP systems). Otherwise, it is equivalent to
task->state = state;
The method set_current_state(state) is synonymous to set_task_state(current, state).
Process Context
One of the most important parts of a process is the executing program code. This code is read in from an executable file and executed within the program's address space. Normal program execution occurs in user-space. When a program executes a system call (see
Chapter 5, "System Calls") or triggers an exception, it enters kernel-space. At this point, the kernel is said to be "executing on behalf of the process" and is in process context. When in process context, the current macro is valid. Upon exiting the kernel, the process resumes execution in user-space, unless a higher-priority process has become runnable in the interim, in which case the scheduler is invoked to select the higher priority process.
System calls and exception handlers are well-defined interfaces into the kernel. A process can begin executing in kernel-space only through one of these interfacesall access to the kernel is through these interfaces.
The Process Family Tree
A distinct hierarchy exists between processes in Unix systems, and Linux is no exception. All processes are descendents of the init process, whose PID is one. The kernel starts init in the last step of the boot process. The init process, in turn, reads the system initscripts and executes more programs, eventually completing the boot process.
Every process on the system has exactly one parent. Likewise, every process has zero or more children. Processes that are all direct children of the same parent are called siblings. The relationship between processes is stored in the process descriptor. Each task_struct has a pointer to the parent's task_struct, named parent, and a list of children, named children. Consequently, given the current process, it is possible to obtain the process descriptor of its parent with the following code:
struct task_struct *my_parent = current->parent;
Similarly, it is possible to iterate over a process's children with
struct task_struct *task;
struct list_head *list;
list_for_each(list, ¤t->children) {
task = list_entry(list, struct task_struct, sibling);
/* task now points to one of current's children */
}
The init task's process descriptor is statically allocated as init_task. A good example of the relationship between all processes is the fact that this code will always succeed:
struct task_struct *task;
for (task = current; task != &init_task; task = task->parent)
;
/* task now points to init */
In fact, you can follow the process hierarchy from any one process in the system to any other. Oftentimes, however, it is desirable simply to iterate over all processes in the system. This is easy because the task list is a circular doubly linked list. To obtain the next task in the list, given any valid task, use:
list_entry(task->tasks.next, struct task_struct, tasks)
Obtaining the previous works the same way:
list_entry(task->tasks.prev, struct task_struct, tasks)
These two routines are provided by the macros next_task(task) and prev_task(task), respectively. Finally, the macro for_each_process(task) is provided, which iterates over the entire task list. On each iteration, task points to the next task in the list:
struct task_struct *task;
for_each_process(task) {
/* this pointlessly prints the name and PID of each task */
printk("%s[%d]\n", task->comm, task->pid);
}
Note: It can be expensive to iterate over every task in a system with many processes; code should have good reason (and no alternative) before doing so.
Process Creation
Process creation in Unix is unique. Most operating systems implement a spawn mechanism to create a new process in a new address space, read in an executable, and begin executing it. Unix takes the unusual approach of separating these steps into two distinct functions: fork() and exec(). The first, fork(), creates a child process that is a copy of the current task. It differs from the parent only in its PID (which is unique), its PPID (parent's PID, which is set to the original process), and certain resources and statistics, such as pending signals, which are not inherited. The second function, exec(), loads a new executable into the address space and begins executing it. The combination of fork() followed by exec() is similar to the single function most operating systems provide.
Copy-on-Write
Traditionally, upon fork() all resources owned by the parent are duplicated and the copy is given to the child. This approach is significantly naïve and inefficient in that it copies much data that might otherwise be shared. Worse still, if the new process were to immediately execute a new image, all that copying would go to waste. In Linux, fork() is implemented through the use of copy-on-write pages. Copy-on-write (or COW) is a technique to delay or altogether prevent copying of the data. Rather than duplicate the process address space, the parent and the child can share a single copy. The data, however, is marked in such a way that if it is written to, a duplicate is made and each process receives a unique copy. Consequently, the duplication of resources occurs only when they are written; until then, they are shared read-only. This technique delays the copying of each page in the address space until it is actually written to. In the case that the pages are never writtenfor example, if exec() is called immediately after fork()they never need to be copied. The only overhead incurred by fork() is the duplication of the parent's page tables and the creation of a unique process descriptor for the child. In the common case that a process executes a new executable image immediately after forking, this optimization prevents the wasted copying of large amounts of data (with the address space, easily tens of megabytes). This is an important optimization because the Unix philosophy encourages quick process execution.
fork()
Linux implements fork() via the clone() system call. This call takes a series of flags that specify which resources, if any, the parent and child process should share (see the section on "
The Linux Implementation of Threads" later in this chapter for more about the flags). The fork(), vfork(), and __clone() library calls all invoke the clone() system call with the requisite flags. The clone() system call, in turn, calls do_fork().
The bulk of the work in forking is handled by do_fork(), which is defined in kernel/fork.c. This function calls copy_process(), and then starts the process running. The interesting work is done by copy_process():
It calls dup_task_struct(), which creates a new kernel stack, thread_info structure, and task_struct for the new process. The new values are identical to those of the current task. At this point, the child and parent process descriptors are identical. It then checks that the new child will not exceed the resource limits on the number of processes for the current user. Now the child needs to differentiate itself from its parent. Various members of the process descriptor are cleared or set to initial values. Members of the process descriptor that are not inherited are primarily statistically information. The bulk of the data in the process descriptor is shared. Next, the child's state is set to TASK_UNINTERRUPTIBLE, to ensure that it does not yet run. Now, copy_process() calls copy_flags() to update the flags member of the task_struct. The PF_SUPERPRIV flag, which denotes whether a task used super-user privileges, is cleared. The PF_FORKNOEXEC flag, which denotes a process that has not called exec(), is set. Next, it calls get_pid() to assign an available PID to the new task. Depending on the flags passed to clone(), copy_process() then either duplicates or shares open files, filesystem information, signal handlers, process address space, and namespace. These resources are typically shared between threads in a given process; otherwise they are unique and thus copied here. Next, the remaining timeslice between the parent and its child is split between the two (this is discussed in
Chapter 4). Finally, copy_process() cleans up and returns to the caller a pointer to the new child.
Back in do_fork(), if copy_process() returns successfully, the new child is woken up and run. Deliberately, the kernel runs the child process first. In the common case of the child simply calling exec() immediately, this eliminates any copy-on-write overhead that would occur if the parent ran first and began writing to the address space.
vfork()
The vfork() system call has the same effect as fork(), except that the page table entries of the parent process are not copied. Instead, the child executes as the sole thread in the parent's address space, and the parent is blocked until the child either calls exec() or exits. The child is not allowed to write to the address space. This was a welcome optimization in the old days of 3BSD when the call was introduced because at the time copy-on-write pages were not used to implement fork(). Today, with copy-on-write and child-runs-first semantics, the only benefit to vfork() is not copying the parent page tables entries. If Linux one day gains copy-on-write page table entries there will no longer be any benefit. Because the semantics of vfork() are tricky (what, for example, happens if the exec() fails?) it would be nice if vfork() died a slow painful death. It is entirely possible to implement vfork() as a normal fork()in fact, this is what Linux did until 2.2.
The vfork() system call is implemented via a special flag to the clone() system call:
In copy_process(), the task_struct member vfork_done is set to NULL. In do_fork(), if the special flag was given, vfork_done is pointed at a specific address. After the child is first run, the parentinstead of returningwaits for the child to signal it through the vfork_done pointer. In the mm_release() function, which is used when a task exits a memory address space, vfork_done is checked to see whether it is NULL. If it is not, the parent is signaled. Back in do_fork(), the parent wakes up and returns.
If this all goes as planned, the child is now executing in a new address space and the parent is again executing in its original address space. The overhead is lower, but the design is not pretty.
The Linux Implementation of Threads
Threads are a popular modern programming abstraction. They provide multiple threads of execution within the same program in a shared memory address space. They can also share open files and other resources. Threads allow for concurrent programming and, on multiple processor systems, true parallelism.
Linux has a unique implementation of threads. To the Linux kernel, there is no concept of a thread. Linux implements all threads as standard processes. The Linux kernel does not provide any special scheduling semantics or data structures to represent threads. Instead, a thread is merely a process that shares certain resources with other processes. Each thread has a unique task_struct and appears to the kernel as a normal process (which just happens to share resources, such as an address space, with other processes).
This approach to threads contrasts greatly with operating systems such as Microsoft Windows or Sun Solaris, which have explicit kernel support for threads (and sometimes call threads lightweight processes). The name "lightweight process" sums up the difference in philosophies between Linux and other systems. To these other operating systems, threads are an abstraction to provide a lighter, quicker execution unit than the heavy process. To Linux, threads are simply a manner of sharing resources between processes (which are already quite lightweight). For example, assume you have a process that consists of four threads. On systems with explicit thread support, there might exist one process descriptor that in turn points to the four different threads. The process descriptor describes the shared resources, such as an address space or open files. The threads then describe the resources they alone possess. Conversely, in Linux, there are simply four processes and thus four normal task_struct structures. The four processes are set up to share certain resources.
Threads are created like normal tasks, with the exception that the clone() system call is passed flags corresponding to specific resources to be shared:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
The previous code results in behavior identical to a normal fork(), except that the address space, filesystem resources, file descriptors, and signal handlers are shared. In other words, the new task and its parent are what are popularly called threads.
In contrast, a normal fork() can be implemented as
clone(SIGCHLD, 0);
And vfork() is implemented as
clone(CLONE_VFORK | CLONE_VM | SIGCHLD, 0);
The flags provided to clone() help specify the behavior of the new process and detail what resources the parent and child will share. Table 3.1 lists the clone flags, which are defined in <linux/sched.h>, and their effect.
Table 3.1. clone() FlagsFlag | Meaning |
|---|
CLONE_FILES | Parent and child share open files. | CLONE_FS | Parent and child share filesystem information. | CLONE_IDLETASK | Set PID to zero (used only by the idle tasks). | CLONE_NEWNS | Create a new namespace for the child. | CLONE_PARENT | Child is to have same parent as its parent. | CLONE_PTRACE | Continue tracing child. | CLONE_SETTID | Write the TID back to user-space. | CLONE_SETTLS | Create a new TLS for the child. | CLONE_SIGHAND | Parent and child share signal handlers and blocked signals. | CLONE_SYSVSEM | Parent and child share System V SEM_UNDO semantics. | CLONE_THREAD | Parent and child are in the same thread group. | CLONE_VFORK | vfork() was used and the parent will sleep until the child wakes it. | CLONE_UNTRACED | Do not let the tracing process force CLONE_PTRACE on the child. | CLONE_STOP | Start process in the TASK_STOPPED state. | CLONE_SETTLS | Create a new TLS (thread-local storage) for the child. | CLONE_CHILD_CLEARTID | Clear the TID in the child. | CLONE_CHILD_SETTID | Set the TID in the child. | CLONE_PARENT_SETTID | Set the TID in the parent. | CLONE_VM | Parent and child share address space. |
Kernel Threads
It is often useful for the kernel to perform some operations in the background. The kernel accomplishes this via kernel threadsstandard processes that exist solely in kernel-space. The significant difference between kernel threads and normal processes is that kernel threads do not have an address space (in fact, their mm pointer is NULL). They operate only in kernel-space and do not context switch into user-space. Kernel threads are, however, schedulable and preemptable as normal processes.
Linux delegates several tasks to kernel threads, most notably the pdflush task and the ksoftirqd task. These threads are created on system boot by other kernel threads. Indeed, a kernel thread can be created only by another kernel thread. The interface for spawning a new kernel thread from an existing one is
int kernel_thread(int (*fn)(void *), void * arg, unsigned long flags)
The new task is created via the usual clone() system call with the specified flags argument. On return, the parent kernel thread exits with a pointer to the child's task_struct. The child executes the function specified by fn with the given argument arg. A special clone flag, CLONE_KERNEL, specifies the usual flags for kernel threads: CLONE_FS, CLONE_FILES, and CLONE_SIGHAND. Most kernel threads pass this for their flags parameter.
Typically, a kernel thread continues executing its initial function forever (or at least until the system reboots, but with Linux you never know). The initial function usually implements a loop in which the kernel thread wakes up as needed, performs its duties, and then returns to sleep.
We will discuss specific kernel threads in more detail in later chapters.
Process Termination
It is sad, but eventually processes must die. When a process terminates, the kernel releases the resources owned by the process and notifies the child's parent of its unfortunate demise.
Typically, process destruction occurs when the process calls the exit() system call, either explicitly when it is ready to terminate or implicitly on return from the main subroutine of any program (that is, the C compiler places a call to exit() after main() returns). A process can also terminate involuntarily. This occurs when the process receives a signal or exception it cannot handle or ignore. Regardless of how a process terminates, the bulk of the work is handled by do_exit(), which completes a number of chores:
First, it set the PF_EXITING flag in the flags member of the task_struct. Second, it calls del_timer_sync() to remove any kernel timers. Upon return, it is guaranteed that no timer is queued and that no timer handler is running. Next, if BSD process accounting is enabled, do_exit() calls acct_process() to write out accounting information. Now it calls __exit_mm() to release the mm_struct held by this process. If no other process is using this address space (in other words, if it is not shared), then deallocate it. Next, it calls exit_sem(). If the process is queued waiting for an IPC semaphore, it is dequeued here. It then calls __exit_files(), __exit_fs(), exit_namespace(), and exit_sighand() to decrement the usage count of objects related to file descriptors, filesystem data, the process namespace, and signal handlers, respectively. If any usage counts reach zero, the object is no longer in use by any process and it is removed. Subsequently, it sets the task's exit code, stored in the exit_code member of the task_struct, to the code provided by exit() or whatever kernel mechanism forced the termination. The exit code is stored here for optional retrieval by the parent. It then calls exit_notify() to send signals to the task's parent, reparents any of the task's children to another thread in their thread group or the init process, and sets the task's state to TASK_ZOMBIE. Finally, do_exit() calls schedule() to switch to a new process (see
Chapter 4). Because TASK_ZOMBIE tasks are never scheduled, this is the last code the task will ever execute.
The code for do_exit() is defined in kernel/exit.c.
At this point, all objects associated with the task (assuming the task was the sole user) are freed. The task is not runnable (and in fact no longer has an address space in which to run) and is in the TASK_ZOMBIE state. The only memory it occupies is its kernel stack, the thread_info structure, and the task_struct structure. The task exists solely to provide information to its parent. After the parent retrieves the information, or notifies the kernel that it is uninterested, the remaining memory held by the process is freed and returned to the system for use.
Removal of the Process Descriptor
After do_exit() completes, the process descriptor for the terminated process still exists but the process is a zombie and is unable to run. As discussed, this allows the system to obtain information about a child process after it has terminated. Consequently, the acts of cleaning up after a process and removing its process descriptor are separate. After the parent has obtained information on its terminated child, or signified to the kernel that it does not care, the child's task_struct is deallocated.
The wait() family of functions are implemented via a single (and complicated) system call, wait4(). The standard behavior is to suspend execution of the calling task until one of its children exits, at which time the function returns with the PID of the exited child. Additionally, a pointer is provided to the function that on return holds the exit code of the terminated child.
When it is time to finally deallocate the process descriptor, release_task() is invoked. It does the following:
First, it calls free_uid() to decrement the usage count of the process's user. Linux keeps a per-user cache of information related to how many processes and files a user has opened. If the usage count reaches zero, the user has no more open processes or files and the cache is destroyed. Second, release_task() calls unhash_process() to remove the process from the pidhash and remove the process from the task list. Next, if the task was ptraced, release_task() reparents the task to its original parent and removes it from the ptrace list. Ultimately, release_task(), calls put_task_struct() to free the pages containing the process's kernel stack and thread_info structure and deallocate the slab cache containing the task_struct.
At this point, the process descriptor and all resources belonging solely to the process have been freed.
The Dilemma of the Parentless Task
If a parent exits before its children, some mechanism must exist to reparent the child tasks to a new process, or else parentless terminated processes would forever remain zombies, wasting system memory. The solution, hinted upon previously, is to reparent a task's children on exit to either another process in the current thread group or, if that fails, the init process. In do_exit(), notify_parent() is invoked, which calls forget_original_parent() to perform the reparenting:
struct task_struct *p, *reaper = father;
struct list_head *list;
if (father->exit_signal != -1)
reaper = prev_thread(reaper);
else
reaper = child_reaper;
if (reaper == father)
reaper = child_reaper;
This code sets reaper to another task in the process's thread group. If there is not another task in the thread group, it sets reaper to child_reaper, which is the init process. Now that a suitable new parent for the children is found, each child needs to be located and reparented to reaper:
list_for_each(list, &father->children) {
p = list_entry(list, struct task_struct, sibling);
reparent_thread(p, reaper, child_reaper);
}
list_for_each(list, &father->ptrace_children) {
p = list_entry(list, struct task_struct, ptrace_list);
reparent_thread(p, reaper, child_reaper);
}
This code iterates over two lists: the child list and the ptraced child list, reparenting each child. The rationale behind having both lists is interesting; it is a new feature in the 2.6 kernel. When a task is ptraced, it is temporarily reparented to the debugging process. When the task's parent exits, however, it must be reparented along with its other siblings. In previous kernels, this resulted in a loop over every process in the system looking for children. The solution, as noted previously, is simply to keep a separate list of a process's children that are being ptracedreducing the search for one's children from every process to just two relatively small lists.
With the process successfully reparented, there is no risk of stray zombie processes. The init process routinely calls wait() on its children, cleaning up any zombies assigned to it.
Chapter 4. Process Scheduling
The previous chapter discussed processes, the operating system abstraction of active program code. This chapter discusses the process scheduler, the chunk of code that puts those processes to work.
The process scheduler is the component of the kernel that selects which process to run next. The process scheduler (or simply the scheduler, to which it is often shortened) can be viewed as the subsystem of the kernel that divides the finite resource of processor time between the runnable processes on a system. The scheduler is the basis of a multitasking operating system such as Linux. By deciding what process can run, the scheduler is responsible for best utilizing the system and giving the impression that multiple processes are executing simultaneously.
The idea behind the scheduler is simple. To best utilize processor time, assuming there are runnable processes, a process should always be running. If there are more runnable processes than processors in a system, some processes will not be running at a given moment. These processes are waiting to run. Deciding what process runs next, given a set of runnable processes, is a fundamental decision that the scheduler must make.
A multitasking operating system is one that can simultaneously interleave execution of more than one process. On single processor machines, this gives the illusion of multiple processes running concurrently. On multiprocessor machines, this also enables processes to actually run concurrently, in parallel, on different processors. On either machine, it also enables many processes to run in the background, not actually executing until work is available. These tasks, although in memory, are not runnable. Instead, such processes utilize the kernel to block until some event (keyboard input, network data, some time in the future, and so on) occurs. Consequently, a modern Linux system may have 100 processes in memory but only one in a runnable state.
Multitasking operating systems come in two flavors: cooperative multitasking and preemptive multitasking. Linux, like all Unix variants and most modern operating systems, provides preemptive multitasking. In preemptive multitasking, the scheduler decides when a process is to cease running and a new process is to resume running. The act of involuntarily suspending a running process is called preemption. The time a process runs before it is preempted is predetermined, and it is called the timeslice of the process. The timeslice, in effect, gives each runnable process a slice of the processor's time. Managing the timeslice enables the scheduler to make global scheduling decisions for the system. It also prevents any one process from monopolizing the processor. As we shall see, this timeslice is dynamically calculated in the Linux process scheduler to provide some interesting benefits.
Conversely, in cooperative multitasking, a process does not stop running until it voluntary decides to do so. The act of a process voluntarily suspending itself is called yielding. Processes are supposed to yield often, but the operating system cannot enforce this. The shortcomings of this approach are numerous: The scheduler cannot make global decisions regarding how long processes run, processes can monopolize the processor for longer than the user desires, and a hung process that never yields can potentially bring down the entire system. Thankfully, most operating systems designed in the last decade have provided preemptive multitasking, with Mac OS 9 and earlier being the most notable (and embarrassing) exceptions. Of course, Unix has been preemptively multitasked since the beginning.
During the 2.5 kernel development series, the Linux kernel received a scheduler overhaul. A new scheduler, commonly called the O(1) scheduler because of its algorithmic behavior, solved the shortcomings of the previous Linux scheduler and introduced powerful new features and performance characteristics. This chapter discusses the fundamentals of scheduler design and how they apply to the new O(1) scheduler and its goals, design, implementation, algorithms, and related system calls.
Policy
Policy is the behavior of the scheduler that determines what runs when. A scheduler's policy often determines the overall feel of a system and is responsible for optimally utilizing processor time. Therefore, it is very important.
I/O-Bound Versus Processor-Bound Processes
Processes can be classified as either I/O-bound or processor-bound. The former is characterized as a process that spends much of its time submitting and waiting on I/O requests. Consequently, such a process is often runnable, but for only short durations because it will eventually block waiting on more I/O (this is any type of I/O, such as keyboard activity, and not just disk I/O).
Conversely, processor-bound processes spend much of their time executing code. They tend to run until they are preempted because they do not block on I/O requests very often. Because they are not I/O-driven, however, system response does not dictate that the scheduler run them often. A scheduler policy for processor-bound processes, therefore, tends to run such processes less frequently but (optimally, to them) for longer durations. The ultimate example of a processor-bound process is one executing an infinite loop.
Of course, these classifications are not mutually exclusive. Processes can exhibit both behaviors simultaneously: The X Window server, for example, is both processor-intense and I/O-intense. Other processes may be I/O-bound but dive into periods of intense processor action. A good example of this is a word processor, which normally sits waiting for key presses but at any moment might peg the processor in a rabid fit of spell checking.
The scheduling policy in a system must attempt to satisfy two conflicting goals: fast process response time (low latency) and maximal system utilization (high throughput). To satisfy these at-odds requirements, schedulers often employ complex algorithms to determine the most worthwhile process to run while not compromising fairness to other, lower priority, processes. The scheduler policy in Unix variants tends to explicitly favor I/O-bound processes, thus providing good process response time. Linux, aiming to provide good interactive response, optimizes for process response (low latency), thus favoring I/O-bound processes over processor-bound processors. As you will see, this is done in a creative manner that does not neglect processor-bound processes.
Process Priority
A common type of scheduling algorithm is priority-based scheduling. The idea is to rank processes based on their worth and need for processor time. Processes with a higher priority run before those with a lower priority, whereas processes with the same priority are scheduled round-robin (one after the next, repeating). On some systems, Linux included, processes with a higher priority also receive a longer timeslice. The runnable process with timeslice remaining and the highest priority always runs. Both the user and the system may set a process's priority to influence the scheduling behavior of the system.
Linux builds on this idea and provides dynamic priority-based scheduling. This concept begins with an initial base priority and then enables the scheduler to increase or decrease the priority dynamically to fulfill scheduling objectives. For example, a process that is spending more time waiting on I/O than running is clearly I/O bound. Under Linux, it receives an elevated dynamic priority. As a counterexample, a process that continually uses up its entire timeslice is processor boundit would receive a lowered dynamic priority.
The Linux kernel implements two separate priority ranges. The first is the nice value, a number from -20 to +19 with a default of 0. Larger nice values correspond to a lower priorityyou are being nice to the other processes on the system. Processes with a lower nice value (higher priority) run before processes with a higher nice value (lower priority). The nice value also helps determine how long a timeslice the process receives. A process with a nice value of -20 receives the maximum possible timeslice, whereas a process with a nice value of 19 receives the minimum possible timeslice. Nice values are the standard priority range used in all Unix systems.
The second range is the real-time priority. The values are configurable, but by default range from 0 to 99. All real-time processes are at a higher priority than normal processes. Linux implements real-time priorities in accordance with POSIX standards on the matter. Most modern Unix systems implement a similar scheme.
Timeslice
The timeslice is the numeric value that represents how long a task can run until it is preempted. The scheduler policy must dictate a default timeslice, which is not a trivial exercise. Too long a timeslice causes the system to have poor interactive performance; the system will no longer feel as if applications are concurrently executed. Too short a timeslice causes significant amounts of processor time to be wasted on the overhead of switching processes because a significant percentage of the system's time is spent switching from one process with a short timeslice to the next. Furthermore, the conflicting goals of I/O-bound versus processor-bound processes again arise: I/O-bound processes do not need longer timeslices (although they do like to run often), whereas processor-bound processes crave long timeslices (to keep their caches hot, for example).
With this argument, it would seem that any long timeslice would result in poor interactive performance. In many operating systems, this observation is taken to heart, and the default timeslice is rather lowfor example, 20ms. Linux, however, takes advantage of the fact that the highest priority process always runs. The Linux scheduler bumps the priority of interactive tasks, enabling them to run more frequently. Consequently, the Linux scheduler offers a relatively high default timeslice (see Table 4.1, later in this chapter). Furthermore, the Linux scheduler dynamically determines the timeslice of a process based on priority. This enables higher-priority (allegedly more important) processes to run longer and more often. Implementing dynamic timeslices and priorities provides robust scheduling performance.
Table 4.1. Scheduler TimeslicesType of Task | Nice Value | Timeslice Duration |
|---|
Initially created | parent's | half of parent's | Minimum Priority | +19 | 5ms (MIN_TIMESLICE) | Default Priority | 0 | 100ms (DEF_TIMESLICE) | Maximum Priority | 20 | 800ms (MAX_TIMESLICE) |
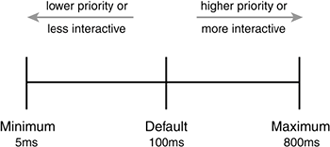
Note that a process does not have to use all its timeslice at once. For example, a process with a 100-millisecond timeslice does not have to run for 100 milliseconds in one go or risk losing the remaining timeslice. Instead, the process can run on five different reschedules for 20 milliseconds each. Thus, a large timeslice also benefits interactive tasks: Although they do not need such a large timeslice all at once, it ensures they remain runnable for as long as possible.
When a process's timeslice runs out, the process is considered expired. A process with no timeslice is not eligible to run until all other processes have exhausted their timeslices (that is, they all have zero timeslice remaining). At that point, the timeslices for all processes are recalculated. The Linux scheduler employs an interesting algorithm for handling timeslice exhaustion that is discussed later in this chapter.
Process Preemption
As mentioned, the Linux operating system is preemptive. When a process enters the TASK_RUNNING state, the kernel checks whether its priority is higher than the priority of the currently executing process. If it is, the scheduler is invoked to preempt the currently executing process and run the newly runnable process. Additionally, when a process's timeslice reaches zero, it is preempted and the scheduler is again invoked to select a new process.
The Scheduling Policy in Action
Consider a system with two runnable tasks: a text editor and a video encoder. The text editor is I/O-bound because it spends nearly all its time waiting for user key presses (no matter how fast the user types, it is not that fast). Despite this, when the text editor does receive a key press, the user expects the editor to respond immediately. Conversely, the video encoder is processor-bound. Aside from reading the raw data stream from the disk and later writing the resulting video, the encoder spends all its time applying the video codec to the raw data, easily using 100% of the processor. The video encoder does not have any strong time constraints on when it runsif it started running now or in half a second, the user could not tell and would not care. Of course, the sooner it finishes the better, but latency is not a primary concern.
In this scenario example, ideally the scheduler gives the text editor a higher priority and larger timeslice than the video encoder receives because the text editor is interactive. This ensures that the text editor has plenty of timeslice available. Furthermore, because the text editor has a higher priority, it is capable of preempting the video encoder when neededsay, the instant the user presses a key. This guarantees that the text editor is capable of responding to user key presses immediately. This is to the detriment of the video encoder, but because the text editor runs only intermittently, when the user presses a key, the video encoder can monopolize the remaining time. This optimizes the performance of both applications.
The Linux Scheduling Algorithm
In the previous sections, we discussed process scheduling theory in the abstract, with only occasional mention of how Linux applies a given concept to reality. With the foundation of scheduling now built, we can dive into Linux's very own process scheduler.
The Linux scheduler is defined in kernel/sched.c. The scheduler algorithm and supporting code went through a large rewrite early in the 2.5 kernel development series.
Consequently, the scheduler code is entirely new and unlike the scheduler in previous kernels. The new scheduler was designed to accomplish specific goals:
Implement fully O(1) scheduling. Every algorithm in the new scheduler completes in constant-time, regardless of the number of running processes. Implement perfect SMP scalability. Each processor has its own locking and individual runqueue. Implement improved SMP affinity. Attempt to group tasks to a specific CPU and continue to run them there. Only migrate tasks from one CPU to another to resolve imbalances in runqueue sizes. Provide good interactive performance. Even during considerable system load, the system should react and schedule interactive tasks immediately. Provide fairness. No process should find itself starved of timeslice for any reasonable amount of time. Likewise, no process should receive an unfairly high amount of timeslice. Optimize for the common case of only one or two runnable processes, yet scale well to multiple processors, each with many processes.
The new scheduler accomplished these goals.
Runqueues
The basic data structure in the scheduler is the runqueue. The runqueue is defined in kernel/sched.c as struct runqueue. The runqueue is the list of runnable processes on a given processor; there is one runqueue per processor. Each runnable process is on exactly one runqueue. The runqueue additionally contains per-processor scheduling information. Consequently, the runqueue is the primary scheduling data structure for each processor.
Let's look at the structure, with comments describing each field:
struct runqueue {
spinlock_t lock; /* spin lock that protects this runqueue */
unsigned long nr_running; /* number of runnable tasks */
unsigned long nr_switches; /* context switch count */
unsigned long expired_timestamp; /* time of last array swap */
unsigned long nr_uninterruptible; /* uninterruptible tasks */
unsigned long long timestamp_last_tick; /* last scheduler tick */
struct task_struct *curr; /* currently running task */
struct task_struct *idle; /* this processor's idle task */
struct mm_struct *prev_mm; /* mm_struct of last ran task */
struct prio_array *active; /* active priority array */
struct prio_array *expired; /* the expired priority array */
struct prio_array arrays[2]; /* the actual priority arrays */
struct task_struct *migration_thread; /* migration thread */
struct list_head migration_queue; /* migration queue*/
atomic_t nr_iowait; /* number of tasks waiting on I/O */
};
Because runqueues are the core data structure in the scheduler, a group of macros are used to obtain the runqueue associated with a given processor or process. The macro cpu_rq(processor) returns a pointer to the runqueue associated with the given processor; the macro this_rq() returns the runqueue of the current processor; and the macro task_rq(task) returns a pointer to the runqueue on which the given task is queued.
Before a runqueue can be manipulated, it must be locked (locking is discussed in depth in Chapter 8, "Kernel Synchronization Introduction"). Because each runqueue is unique to the current processor, it is rare when a processor desires to lock a different processor's runqueue. (It does happen, however, as we will see.) The locking of the runqueue prohibits any changes to it while the lock-holder is reading or writing the runqueue's members. The most common runqueue locking scenario is when you want to lock the runqueue on which a specific task runs. In that case, the task_rq_lock() and task_rq_unlock() functions are used:
struct runqueue *rq;
unsigned long flags;
rq = task_rq_lock(task, &flags);
/* manipulate the task's runqueue, rq */
task_rq_unlock(rq, &flags);
Alternatively, the method this_rq_lock() locks the current runqueue and rq_unlock() unlocks the given runqueue:
struct runqueue *rq;
rq = this_rq_lock();
/* manipulate this process's current runqueue, rq */
rq_unlock(rq);
To avoid deadlock, code that wants to lock multiple runqueues needs always to obtain the locks in the same order: by ascending runqueue address. (Again, Chapter 8 offers a full explanation.) For example,
/* to lock ... */
if (rq1 == rq2)
spinlock(&rq1->lock);
else {
if (rq1 < rq2) {
spin_lock(&rq1->lock);
spin_lock(&rq2->lock);
} else {
spin_lock(&rq2->lock);
spin_lock(&rq1->lock);
}
}
/* manipulate both runqueues ... */
/* to unlock ... */
spin_unlock(&rq1->lock);
if (rq1 != rq2)
spin_unlock(&rq2->lock);
These steps are made automatic by the double_rq_lock() and double_rq_unlock() functions. The preceding steps would then become
double_rq_lock(rq1, rq2);
/* manipulate both runqueues ... */
double_rq_unlock(rq1, rq2);
A quick example should help you see why the order of obtaining the locks is important. The topic of deadlock is covered in Chapters 8 and 9 because this is not a problem unique to the runqueues; nested locks always need to be obtained in the same order. The spin locks are used to prevent multiple tasks from simultaneously manipulating the runqueues. They work like a key to a door. The first task to reach the door grabs the key and enters the door, locking the door behind it. If another task reaches the door and finds it locked (because another task is already inside), it must sit and wait for the first task to exit the door and return the key. This waiting is called spinning because the task actually sits in a tight loop, repeatedly checking for the return of the key. Now, consider if one task wants to lock the first runqueue and then the second while another task wants to lock the second runqueue and then the first. Assume the first task succeeds in locking the first runqueue while simultaneously the second task succeeds in locking the second runqueue. Now the first task tries to lock the second runqueue and the second task tries to lock the first runqueue. Neither task succeeds because the other task holds the lock. Both tasks sit, waiting forever for each other. Like an impasse creating a traffic deadlock, this out-of-order locking results in the tasks waiting for each other, forever, and thus deadlocking. If both tasks obtained the locks in the same order, this scenario could not happen. See Chapters 8 and 9 for the full scoop on locking.
The Priority Arrays
Each runqueue contains two priority arrays, the active and the expired array. Priority arrays are defined in kernel/sched.c as struct prio_array. Priority arrays are the data structures that provide O(1) scheduling. Each priority array contains one queue of runnable processors per priority level. These queues contain lists of the runnable processes at each priority level. The priority arrays also contain a priority bitmap used to efficiently discover the highest-priority runnable task in the system.
struct prio_array {
int nr_active; /* number of tasks in the queues */
unsigned long bitmap[BITMAP_SIZE]; /* priority bitmap */
struct list_head queue[MAX_PRIO]; /* priority queues */
};
MAX_PRIO is the number of priority levels on the system. By default, this is 140. Thus, there is one struct list_head for each priority. BITMAP_SIZE is the size that an array of unsigned long typed variables would have to be to provide one bit for each valid priority level. With 140 priorities and 32-bit words, this is five. Thus, bitmap is an array with five elements and a total of 160 bits.
Each priority array contains a bitmap field that has at least one bit for every priority on the system. Initially, all the bits are zero. When a task of a given priority becomes runnable (that is, its state is set to TASK_RUNNING), the corresponding bit in the bitmap is set to one. For example, if a task with priority seven is runnable, then bit seven is set. Finding the highest priority task on the system is therefore only a matter of finding the first set bit in the bitmap. Because the number of priorities is static, the time to complete this search is constant and unaffected by the number of running processes on the system. Furthermore, each supported architecture in Linux implements a fast find first set algorithm to quickly search the bitmap. This method is called sched_find_first_bit(). Many architectures provide a find-first-set instruction that operates on a given word. On these systems, finding the first set bit is as trivial as executing this instruction at most a couple of times.
Each priority array also contains an array named queue of struct list_head queues, one queue for each priority. Each list corresponds to a given priority and in fact contains all the runnable processes of that priority that are on this processor's runqueue. Finding the next task to run is as simple as selecting the next element in the list. Within a given priority, tasks are scheduled round robin.
The priority array also contains a counter, nr_active. This is the number of runnable tasks in this priority array.
Recalculating Timeslices
Many operating systems (older versions of Linux included) have an explicit method for recalculating each task's timeslice when they have all reached zero. Typically, this is implemented as a loop over each task, such as
for (each task on the system) {
recalculate priority
recalculate timeslice
}
The priority and other attributes of the task are used to determine a new timeslice. This approach has some problems:
It potentially can take a long time. Worse, it scales O(n) for n tasks on the system. The recalculation must occur under some sort of lock protecting the task list and the individual process descriptors. This results in high lock contention. The nondeterminism of a randomly occurring recalculation of the timeslices is a problem with deterministic real-time programs. It is just gross (which is a quite legitimate reason for improving something in the Linux kernel).
The new Linux scheduler alleviates the need for a recalculate loop. Instead, it maintains two priority arrays for each processor: both an active array and an expired array. The active array contains all the tasks in the associated runqueue that have timeslice left. The expired array contains all the tasks in the associated runqueue that have exhausted their timeslice. When each task's timeslice reaches zero, its timeslice is recalculated before it is moved to the expired array. Recalculating all the timeslices is then as simple as just switching the active and expired arrays. Because the arrays are accessed only via pointer, switching them is as fast as swapping two pointers. This is performed in schedule():
struct prio_array *array = rq->active;
if (!array->nr_active) {
rq->active = rq->expired;
rq->expired = array;
}
This swap is a key feature of the new O(1) scheduler. Instead of recalculating each processes priority and timeslice all the time, the O(1) scheduler performs a simple two-step array swap. This resolves the previously discussed problems.
schedule()
The act of picking the next task to run and switching to it is implemented via the schedule() function. This function is called explicitly by kernel code that wants to sleep and it is invoked whenever a task is to be preempted. The schedule() function is run independently by each processor. Consequently, each CPU makes its own decisions on what process to run next.
The schedule() function is relatively simple for all it must accomplish. The following code determines the highest priority task:
struct task_struct *prev, *next;
struct list_head *queue;
struct prio_array *array;
int idx;
prev = current;
array = rq->active;
idx = sched_find_first_bit(array->bitmap);
queue = array->queue + idx;
next = list_entry(queue->next, struct task_struct, run_list);
First, the active priority array is searched to find the first set bit. This bit corresponds to the highest priority task that is runnable. Next, the scheduler selects the first task in the list at that priority. This is the highest priority runnable task on the system and is the task the scheduler will run. See Figure 4.2.
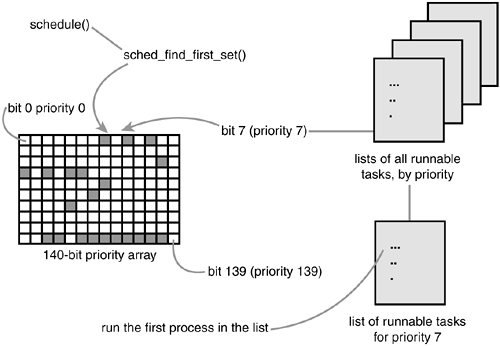
If prev does not equal next, then a new task has been selected to run. The function context_switch() is called to switch from prev to next. Context switching is discussed in a subsequent section.
Two important points should be noted from the previous code. First, it is very simple and consequently quite fast. Second, the number of processes on the system has no effect on how long this code takes to execute. There is no loop over any list to find the most suitable process. In fact, nothing affects how long the schedule() code takes to find a new task. It is constant in execution time.
Calculating Priority and Timeslice
At the beginning of this chapter, you saw how priority and timeslice are used to influence the decisions that the scheduler makes. Additionally, you learned about I/O-bound and processor-bound tasks and why it is beneficial to boost the priority of interactive tasks. Now it's time to look at the actual code that implements this design.
Processes have an initial priority that is called the nice value. This value ranges from 20 to +19 with a default of zero. Nineteen is the lowest and 20 is the highest priority. This value is stored in the static_prio member of the process's task_struct. The variable is called the static priority because it does not change from what the user specifies. The scheduler, in turn, bases its decisions on the dynamic priority that is stored in prio. The dynamic priority is calculated as a function of the static priority and the task's interactivity.
The method effective_prio() returns a task's dynamic priority. The method begins with the task's nice value and computes a bonus or penalty in the range 5 to +5 based on the interactivity of the task. For example, a highly interactive task with a nice value of ten can have a dynamic priority of five. Conversely, a mild processor hog with a nice value of ten can have a dynamic priority of 12. Tasks that are only mildly interactiveat some theoretical equilibrium of I/O versus processor usagereceive no bonus or penalty and their dynamic priority is equal to their nice value.
Of course, the scheduler does not magically know whether a process is interactive. It must use some heuristic that is capable of accurately reflecting whether a task is I/O bound or processor bound. The most indicative metric is how long the task sleeps. If a task spends most of its time asleep, then it is I/O bound. If a task spends more time runnable than sleeping, it is certainly not interactive. This extends to the extreme: A task that spends nearly all the time sleeping is completely I/O bound, whereas a task that spends nearly all its time runnable is completely processor bound.
To implement this heuristic, Linux keeps a running tab on how much time a process is spent sleeping versus how much time the process spends in a runnable state. This value is stored in the sleep_avg member of the task_struct. It ranges from zero to MAX_SLEEP_AVG, which defaults to 10 milliseconds. When a task becomes runnable after sleeping, sleep_avg is incremented by how long it slept, until the value reaches MAX_SLEEP_AVG. For every timer tick the task runs, sleep_avg is decremented until it reaches zero.
This metric is surprisingly accurate. It is computed based not only on how long the task sleeps but also on how little it runs. Therefore, a task that spends a great deal of time sleeping, but also continually exhausts its timeslice, will not be awarded a huge bonusthe metric works not just to award interactive tasks but also to punish processor-bound tasks. It is also not vulnerable to abuse. A task that receives a boosted priority and timeslice quickly loses the bonus if it turns around and hogs the processor. Finally, the metric provides quick response. A newly created interactive process quickly receives a large sleep_avg. Despite this, because the bonus or penalty is applied against the initial nice value, the user can still influence the system's scheduling decisions by changing the process's nice value.
Timeslice, on the other hand, is a much simpler calculation. It is based on the static priority. When a process is first created, the new child and the parent split the parent's remaining timeslice. This provides fairness and prevents users from forking new children to get unlimited timeslice. After a task's timeslice is exhausted, however, it is recalculated based on the task's static priority. The function task_timeslice() returns a new timeslice for the given task. The calculation is a simple scaling of the static priority into a range of timeslices. The higher a task's priority, the more timeslice it receives per round of execution. The maximum timeslice, which is given to the highest priority tasks (a nice value of -20), is 800 milliseconds. Even the lowest-priority tasks (those with a nice value of +19) receive at least the minimum timeslice, MIN_TIMESLICE, which is either 5 milliseconds or one timer tick (see Chapter 10, Timers and Time Management), whichever is larger. Tasks with the default priority (a nice value of zero) receive a timeslice of 100 milliseconds. See Table 4.1.
The scheduler provides one additional aide to interactive tasks: If a task is sufficiently interactive, when it exhausts its timeslice it will not be inserted into the expired array, but instead reinserted back into the active array. Recall that timeslice recalculation is provided via the switching of the active and the expired arrays. Normally, as processes exhaust their timeslices, they are moved from the active array to the expired array. When there are no more processes in the active array, the two arrays are switched: The active becomes the expired, and the expired becomes the active. This provides O(1) timeslice recalculation. It also provides the possibility that an interactive task can become runnable but fail to run again until the array switch occurs because the task is stuck in the expired array. Reinserting interactive tasks back into the active array alleviates this problem. The task does not run immediately, but is scheduled round robin with the other tasks at its priority. The logic to provide this feature is implemented in scheduler_tick(), which is called via the timer interrupt (discussed in Chapter 10, "Timers and Time Management"):
struct task_struct *task;
struct runqueue *rq;
task = current;
rq = this_rq();
if (!--task->time_slice) {
if (!TASK_INTERACTIVE(task) || EXPIRED_STARVING(rq))
enqueue_task(task, rq->expired);
else
enqueue_task(task, rq->active);
}
First, the code decrements the process's timeslice and checks whether it is now zero. If it is, the task is expired and it needs to be inserted into an array, so this code first checks whether the task is interactive via the TASK_INTERACTIVE() macro. This macro computes whether a task is "interactive enough" based on its nice value. The lower the nice value (the higher the priority) the less interactive a task needs to be. A nice +19 task can never be interactive enough to be reinserted. Conversely, a nice 20 task would need to be a heavy processor hog not to be reinserted. A task at the default nice value, zero, needs to be relatively interactive to be reinserted, but it is not too difficult. Next, the EXPIRED_STARVING() macro checks whether there are processes on the expired array that are starvingthat is, if the arrays have not been switched in a relatively long time. If they have not been switched recently, reinserting the current task into the active array further delays the switch, additionally starving the tasks on the expired array. If this is not the case, the process can be inserted into the active array. Otherwise, it is inserted into the expired array, which is the normal practice.
Sleeping and Waking Up
Tasks that are sleeping (blocked) are in a special non-runnable state. This is important because without this special state, the scheduler would select tasks that did not want to run or, worse, sleeping would have to be implemented as busy looping. A task sleeps for a number of reasons, but always while it is waiting for some event. The event can be a specified amount of time, more data from a file I/O, or another hardware event. A task can also involuntarily go to sleep when it tries to obtain a contended semaphore in the kernel (this is covered in Chapter 9, "Kernel Synchronization Methods"). A common reason to sleep is file I/Ofor example, the task issued a read() request on a file, which needs to be read in from disk. As another example, the task could be waiting for keyboard input. Whatever the case, the kernel behavior is the same: The task marks itself as sleeping, puts itself on a wait queue, removes itself from the runqueue, and calls schedule() to select a new process to execute. Waking back up is the inverse: the task is set as runnable, removed from the wait queue, and added back to the runqueue.
As discussed in the previous chapter, two states are associated with sleeping, TASK_INTERRUPTIBLE and TASK_UNINTERRUPTIBLE. They differ only in that tasks in the TASK_UNINTERRUPTIBLE state ignore signals, whereas tasks in the TASK_INTERRUPTIBLE state wake up prematurely and respond to a signal if one is issued. Both types of sleeping tasks sit on a wait queue, waiting for an event to occur, and are not runnable.
Sleeping is handled via wait queues. A wait queue is a simple list of processes waiting for an event to occur. Wait queues are represented in the kernel by wake_queue_head_t. Wait queues are created statically via DECLARE_WAITQUEUE() or dynamically via init_waitqueue_head(). Processes put themselves on a wait queue and mark themselves not runnable. When the event associated with the wait queue occurs, the processes on the queue are awakened. It is important to implement sleeping and waking correctly, to avoid race conditions.
Some simple interfaces for sleeping used to be in wide use. These interfaces, however, have races: It is possible to go to sleep after the condition becomes true. In that case, the task might sleep indefinitely. Therefore, the recommended method for sleeping in the kernel is a bit more complicated:
/* 'q' is the wait queue we wish to sleep on */
DECLARE_WAITQUEUE(wait, current);
add_wait_queue(q, &wait);
while (!condition) { /* condition is the event that we are waiting for */
set_current_state(TASK_INTERRUPTIBLE); /* or TASK_UNINTERRUPTIBLE */
if (signal_pending(current))
/* handle signal */
schedule();
}
set_current_state(TASK_RUNNING);
remove_wait_queue(q, &wait);
The task performs the following steps to add itself to a wait queue:
Creates a wait queue entry via DECLARE_WAITQUEUE(). Adds itself to a wait queue via add_wait_queue(). This wait queue awakens the process when the condition for which it is waiting occurs. Of course, there needs to be code elsewhere that calls wake_up() on the queue when the event actually does occur. Changes the process state to TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE. If the state is set to TASK_INTERRUPTIBLE, a signal wakes the process up. This is called a spurious wake up (a wake-up not caused by the occurrence of the event). So check and handle signals. Tests whether the condition is true. If it is, there is no need to sleep. If it is not true, the task calls schedule(). When the task awakens, it again checks whether the condition is true. If it is, it exits the loop. Otherwise, it again calls schedule() and repeats. Now that the condition is true, the task can set itself to TASK_RUNNING and remove itself from the wait queue via remove_wait_queue().
If the condition occurs before the task goes to sleep, the loop terminates, and the task does not erroneously go to sleep. Note that kernel code often has to perform various other tasks in the body of the loop. For example, it might need to release locks before calling schedule() and reacquire them after or react to other events.
Waking is handled via wake_up(), which wakes up all the tasks waiting on the given wait queue. It calls try_to_wake_up(), which sets the task's state to TASK_RUNNING, calls activate_task() to add the task to a runqueue, and sets need_resched if the awakened task's priority is higher than the priority of the current task. The code that causes the event to occur typically calls wake_up() afterward. For example, when data arrives from the hard disk, the VFS calls wake_up() on the wait queue that holds the processes waiting for the data.
An important note about sleeping is that there are spurious wake-ups. Just because a task is awakened does not mean that the event for which the task is waiting has occurred; sleeping should always be handled in a loop that ensures that the condition for which the task is waiting has indeed occurred. Figure 4.3 depicts the relationship between each scheduler state.
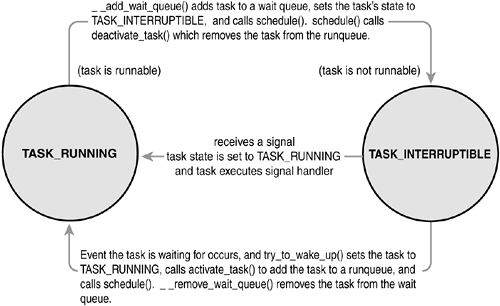
The Load Balancer
As discussed, the Linux scheduler implements separate runqueues and locking for each processor on a symmetrical multiprocessing system. That is, each processor maintains its own list of processes and operates the scheduler on only those tasks. The entire scheduling system is, in effect, unique to each processor. How, then, does the scheduler enforce any sort of global scheduling policy on multiprocessing systems? What if the runqueues become unbalanced, say with five processes on one processor's runqueue, but only one on another? The solution is the load balancer, which works to ensure that the runqueues are balanced. The load balancer compares the current processor's runqueue to the other runqueues in the system. If it finds an imbalance, it pulls processes from the busier runqueue to the current runqueue. Ideally, every runqueue will have the same number of processes. That is a lofty goal, but the load balancer comes close.
The load balancer is implemented in kernel/sched.c as load_balance(). It has two methods of invocation. It is called by schedule() whenever the current runqueue is empty. It is also called via timer: every 1 millisecond when the system is idle and every 200 milliseconds otherwise. On uniprocessor systems, load_balance() is never called and in fact is not even compiled into the kernel image because there is only a single runqueue and thus no balancing is needed.
The load balancer is called with the current processor's runqueue locked and with interrupts disabled to protect the runqueues from concurrent access. In the case where schedule() calls load_balance(), its job is pretty clear because the current runqueue is empty and finding any process and pulling it onto this runqueue is advantageous. When the load balancer is called via timer, however, its job might be less apparent: It needs to resolve any imbalance between the runqueues to keep them about even. See Figure 4.4.
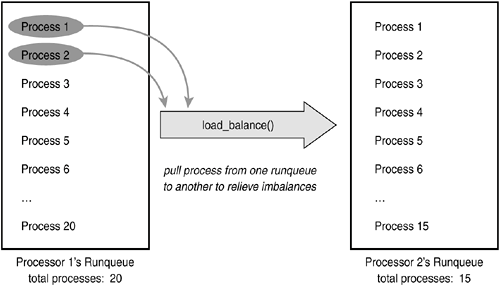
The load_balance() function and related methods are fairly large and complicated, although the steps they perform are comprehensible:
1. | First, load_balance() calls find_busiest_queue() to determine the busiest runqueue. In other words, this is the runqueue with the greatest number of processes in it. If there is no runqueue that has at least 25% more processes than the current, find_busiest_queue() returns NULL and load_balance() returns. Otherwise, the busiest runqueue is returned.
| 2. | Second, load_balance() decides from which priority array on the busiest runqueue it wants to pull. The expired array is preferred because those tasks have not run in a relatively long time and thus are most likely not in the processor's cache (that is, they are not "cache hot"). If the expired priority array is empty, the active one is the only choice.
| 3. | Next, load_balance() finds the highest priority (smallest value) list that has tasks, because it is more important to fairly distribute high-priority tasks than lower-priority ones.
| 4. | Each task of the given priority is analyzed to find a task that is not running, not prevented to migrate via processor affinity, and not cache hot. If the task meets this criteria, pull_task() is called to pull the task from the busiest runqueue to the current runqueue.
| 5. | As long as the runqueues remain imbalanced, the previous two steps are repeated and more tasks are pulled from the busiest runqueue to the current. Finally, when the imbalance is resolved, the current runqueue is unlocked and load_balance()returns. |
Here is load_balance(), slightly cleaned up but otherwise in all its glory:
static int load_balance(int this_cpu, runqueue_t *this_rq,
struct sched_domain *sd, enum idle_type idle)
{
struct sched_group *group;
runqueue_t *busiest;
unsigned long imbalance;
int nr_moved;
spin_lock(&this_rq->lock);
group = find_busiest_group(sd, this_cpu, &imbalance, idle);
if (!group)
goto out_balanced;
busiest = find_busiest_queue(group);
if (!busiest)
goto out_balanced;
nr_moved = 0;
if (busiest->nr_running > 1) {
double_lock_balance(this_rq, busiest);
nr_moved = move_tasks(this_rq, this_cpu, busiest,
imbalance, sd, idle);
spin_unlock(&busiest->lock);
}
spin_unlock(&this_rq->lock);
if (!nr_moved) {
sd->nr_balance_failed++;
if (unlikely(sd->nr_balance_failed > sd->cache_nice_tries+2)) {
int wake = 0;
spin_lock(&busiest->lock);
if (!busiest->active_balance) {
busiest->active_balance = 1;
busiest->push_cpu = this_cpu;
wake = 1;
}
spin_unlock(&busiest->lock);
if (wake)
wake_up_process(busiest->migration_thread);
sd->nr_balance_failed = sd->cache_nice_tries;
}
} else
sd->nr_balance_failed = 0;
sd->balance_interval = sd->min_interval;
return nr_moved;
out_balanced:
spin_unlock(&this_rq->lock);
if (sd->balance_interval < sd->max_interval)
sd->balance_interval *= 2;
return 0;
}
Preemption and Context Switching
Context switching, the switching from one runnable task to another, is handled by the context_switch() function defined in kernel/sched.c. It is called by schedule() when a new process has been selected to run. It does two basic jobs:
Calls switch_mm(), which is defined in <asm/mmu_context.h>, to switch the virtual memory mapping from the previous process's to that of the new process. Calls switch_to(), defined in <asm/system.h>, to switch the processor state from the previous process's to the current's. This involves saving and restoring stack information and the processor registers.
The kernel, however, must know when to call schedule(). If it called schedule() only when code explicitly did so, user-space programs could run indefinitely. Instead, the kernel provides the need_resched flag to signify whether a reschedule should be performed (see Table 4.2). This flag is set by scheduler_tick() when a process runs out of timeslice, and by TRy_to_wake_up() when a process that has a higher priority than the currently running process is awakened. The kernel checks the flag, sees that it is set, and calls schedule() to switch to a new process. The flag is a message to the kernel that the scheduler should be invoked as soon as possible because another process deserves to run. Upon returning to user-space or returning from an interrupt, the need_resched flag is checked. If it is set, the kernel invokes the scheduler before continuing.
Table 4.2. Functions for Accessing and Manipulating need_reschedFunction | Purpose |
|---|
set_tsk_need_resched() | Set the need_resched flag in the given process | clear_tsk_need_resched() | Clear the need_resched flag in the given process | need_resched() | Test the value of the need_resched flag; return true if set and false otherwise |
The flag is per-process, and not simply global, because it is faster to access a value in the process descriptor (because of the speed of current and high probability of it being in a cache line) than a global variable. Historically, the flag was global before the 2.2 kernel. In 2.2 and 2.4, the flag was an int inside the task_struct. In 2.6, it was moved into a single bit of a special flag variable inside the tHRead_info structure. As you can see, the kernel developers are never satisfied.
User Preemption
User preemption occurs when the kernel is about to return to user-space, need_resched is set, and therefore, the scheduler is invoked. If the kernel is returning to user-space, it knows it is in a safe quiescent state. In other words, if it is safe to continue executing the current task, it is also safe to pick a new task to execute. Consequently, whenever the kernel is preparing to return to user-space either on return from an interrupt or after a system call, the value of need_resched is checked. If it is set, the scheduler is invoked to select a new (more fit) process to execute. Both the return paths for return from interrupt and return from system call are architecture dependent and typically implemented in assembly in entry.S (which, aside from kernel entry code, also contains kernel exit code).
In short, user preemption can occur
Kernel Preemption
The Linux kernel, unlike most other Unix variants and many other operating systems, is a fully preemptive kernel. In non-preemptive kernels, kernel code runs until completion. That is, the scheduler is not capable of rescheduling a task while it is in the kernelkernel code is scheduled cooperatively, not preemptively. Kernel code runs until it finishes (returns to user-space) or explicitly blocks. In the 2.6 kernel, however, the Linux kernel became preemptive: It is now possible to preempt a task at any point, so long as the kernel is in a state in which it is safe to reschedule.
So when is it safe to reschedule? The kernel is capable of preempting a task running in the kernel so long as it does not hold a lock. That is, locks are used as markers of regions of non-preemptibility. Because the kernel is SMP-safe, if a lock is not held, the current code is reentrant and capable of being preempted.
The first change in supporting kernel preemption was the addition of a preemption counter, preempt_count, to each process's thread_info. This counter begins at zero and increments once for each lock that is acquired and decrements once for each lock that is released. When the counter is zero, the kernel is preemptible. Upon return from interrupt, if returning to kernel-space, the kernel checks the values of need_resched and preempt_count. If need_resched is set and preempt_count is zero, then a more important task is runnable and it is safe to preempt. Thus, the scheduler is invoked. If preempt_count is nonzero, a lock is held and it is unsafe to reschedule. In that case, the interrupt returns as usual to the currently executing task. When all the locks that the current task is holding are released, preempt_count returns to zero. At that time, the unlock code checks whether need_resched is set. If so, the scheduler is invoked. Enabling and disabling kernel preemption is sometimes required in kernel code and is discussed in Chapter 9.
Kernel preemption can also occur explicitly, when a task in the kernel blocks or explicitly calls schedule(). This form of kernel preemption has always been supported because no additional logic is required to ensure that the kernel is in a state that is safe to preempt. It is assumed that the code that explicitly calls schedule() knows it is safe to reschedule.
Kernel preemption can occur
When an interrupt handler exits, before returning to kernel-space When kernel code becomes preemptible again If a task in the kernel explicitly calls schedule() If a task in the kernel blocks (which results in a call to schedule())
Real-Time
Linux provides two real-time scheduling policies, SCHED_FIFO and SCHED_RR. The normal, not real-time scheduling policy is SCHED_NORMAL. SCHED_FIFO implements a simple first-in, first-out scheduling algorithm without timeslices. A runnable SCHED_FIFO task is always scheduled over any SCHED_NORMAL tasks. When a SCHED_FIFO task becomes runnable, it continues to run until it blocks or explicitly yields the processor; it has no timeslice and can run indefinitely. Only a higher priority SCHED_FIFO or SCHED_RR task can preempt a SCHED_FIFO task. Two or more SCHED_FIFO tasks at the same priority run round robin, but again only yielding the processor when they explicitly choose to do so. If a SCHED_FIFO task is runnable, all tasks at a lower priority cannot run until it finishes.
SCHED_RR is identical to SCHED_FIFO except that each process can run only until it exhausts a predetermined timeslice. That is, SCHED_RR is SCHED_FIFO with timeslicesit is a real-time round-robin scheduling algorithm. When a SCHED_RR task exhausts its timeslice, any other real-time processes at its priority are scheduled round robin. The timeslice is used only to allow rescheduling of same-priority processes. As with SCHED_FIFO, a higher-priority process always immediately preempts a lower-priority one, and a lower-priority process can never preempt a SCHED_RR task, even if its timeslice is exhausted.
Both real-time scheduling policies implement static priorities. The kernel does not calculate dynamic priority values for real-time tasks. This ensures that a real-time process at a given priority always preempts a process at a lower priority.
The real-time scheduling policies in Linux provide soft real-time behavior. Soft real-time refers to the notion that the kernel tries to schedule applications within timing deadlines, but the kernel does not promise to always be able to achieve these goals. Conversely, hard real-time systems are guaranteed to meet any scheduling requirements within certain limits. Linux makes no guarantees on the ability to schedule real-time tasks. Despite not having a design that guarantees hard real-time behavior, the real-time scheduling performance in Linux is quite good. The 2.6 Linux kernel is capable of meeting very stringent timing requirements.
Real-time priorities range inclusively from zero to MAX_RT_PRIO minus one. By default, MAX_RT_PRIO is 100therefore, the default real-time priority range is zero to 99. This priority space is shared with the nice values of SCHED_NORMAL tasks: They use the space from MAX_RT_PRIO to (MAX_RT_PRIO + 40). By default, this means the 20 to +19 nice range maps directly onto the priority space from 100 to 139.
Scheduler-Related System Calls
Linux provides a family of system calls for the management of scheduler parameters. These system calls allow manipulation of process priority, scheduling policy, and processor affinity, as well as provide an explicit mechanism to yield the processor to other tasks.
Various booksand your friendly system man pagesprovide reference to these system calls (which are all implemented in the C library without much wrapperthey just invoke the system call). Table 4.3 lists the system calls and provides a brief description. How system calls are implemented in the kernel is discussed in Chapter 5, "System Calls."
Table 4.3. Scheduler-Related System CallsSystem Call | Description |
|---|
nice() | Sets a process's nice value | sched_setscheduler() | Sets a process's scheduling policy | sched_getscheduler() | Gets a process's scheduling policy | sched_setparam() | Sets a process's real-time priority | sched_getparam() | Gets a process's real-time priority | sched_get_priority_max() | Gets the maximum real-time priority | sched_get_priority_min() | Gets the minimum real-time priority | sched_rr_get_interval() | Gets a process's timeslice value | sched_setaffinity() | Sets a process's processor affinity | sched_getaffinity() | Gets a process's processor affinity | sched_yield() | Temporarily yields the processor |
Scheduling Policy and Priority-Related System Calls
The sched_setscheduler() and sched_getscheduler() system calls set and get a given process's scheduling policy and real-time priority, respectively. Their implementation, like most system calls, involves a lot of argument checking, setup, and cleanup. The important work, however, is merely to read or write the policy and rt_priority values in the process's task_struct.
The sched_setparam() and sched_getparam() system calls set and get a process's real-time priority. These calls merely encode rt_priority in a special sched_param structure. The calls sched_get_priority_max() and sched_get_priority_min() return the maximum and minimum priorities, respectively, for a given scheduling policy. The maximum priority for the real-time policies is MAX_USER_RT_PRIO minus one; the minimum is one.
For normal tasks, the nice() function increments the given process's static priority by the given amount. Only root can provide a negative value, thereby lowering the nice value and increasing the priority. The nice() function calls the kernel's set_user_nice() function, which sets the static_prio and prio values in the task's task_struct as appropriate.
Processor Affinity System Calls
The Linux scheduler enforces hard processor affinity. That is, although it tries to provide soft or natural affinity by attempting to keep processes on the same processor, the scheduler also enables a user to say, "This task must remain on this subset of the available processors no matter what." This hard affinity is stored as a bitmask in the task's task_struct as cpus_allowed. The bitmask contains one bit per possible processor on the system. By default, all bits are set and, therefore, a process is potentially runnable on any processor. The user, however, via sched_setaffinity(), can provide a different bitmask of any combination of one or more bits. Likewise, the call sched_getaffinity() returns the current cpus_allowed bitmask.
The kernel enforces hard affinity in a very simple manner. First, when a process is initially created, it inherits its parent's affinity mask. Because the parent is running on an allowed processor, the child thus runs on an allowed processor. Second, when a processor's affinity is changed, the kernel uses the migration threads to push the task onto a legal processor. Finally, the load balancer pulls tasks to only an allowed processor. Therefore, a process only ever runs on a processor whose bit is set in the cpus_allowed field of its process descriptor.
Yielding Processor Time
Linux provides the sched_yield() system call as a mechanism for a process to explicitly yield the processor to other waiting processes. It works by removing the process from the active array (where it currently is, because it is running) and inserting it into the expired array. This has the effect of not only preempting the process and putting it at the end of its priority list, but also putting it on the expired listguaranteeing it will not run for a while. Because real-time tasks never expire, they are a special case. Therefore, they are merely moved to the end of their priority list (and not inserted into the expired array). In earlier versions of Linux, the semantics of the sched_yield() call were quite different; at best, the task was moved only to the end of its priority list. The yielding was often not for a very long time. Nowadays, applications and even kernel code should be certain they truly want to give up the processor before calling sched_yield().
Kernel code, as a convenience, can call yield(), which ensures that the task's state is TASK_RUNNING, and then call sched_yield(). User-space applications use the sched_yield()system call.
Scheduler Finale
The process scheduler is an important part of the kernel because running processes is (for most of us, at least) the point of using the computer in the first place. Juggling the demands of process scheduling are nontrivial, however: A large number of runnable processes, scalability concerns, tradeoffs between latency and throughput, and the demands of various workloads make a one-size-fits-all algorithm hard to find. The Linux kernel's new process scheduler, however, comes very close to appeasing all parties and providing an optimal solution for all cases with perfect scalability and ever-apparent charm.
Remaining issues include fine tuning (or even totally replacing) the interactivity estimator, which is a godsend when it makes correct predictions and a total pain when it guesses wrong. Work on alternatives continues; one day we will likely see a new implementation in the mainline kernel.
Improved behavior on NUMA (non-uniform memory architecture) machines is of growing importance as the prevalence of NUMA machines increases. Support for scheduler domains, a scheduler abstraction used to describe process topology, was merged into the mainline kernel early in the 2.6 series.
This chapter looked at theory behind process scheduling and the specific implementation, algorithms, and interfaces used by the current Linux kernel. The next chapter covers the primary interface that the kernel provides to running processes: system calls.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX