Структуры данных и процессы
Каждый процесс в системе имеет свой список открытых файлов ,
рутовую файловую систему , текущую рабочую директорию, и т.д.
Три структуры используются в VFS :
files_struct, fs_struct, namespace
The files_struct is defined in <linux/file.h>. This table's address is pointed to by the files enTRy in the processor descriptor. All per-process information about open files and file descriptors is contained therein. Here it is, with comments:
struct files_struct {
atomic_t count; /* structure's usage count */
spinlock_t file_lock; /* lock protecting this structure */
int max_fds; /* maximum number of file objects */
int max_fdset; /* maximum number of file descriptors */
int next_fd; /* next file descriptor number */
struct file **fd; /* array of all file objects */
fd_set *close_on_exec; /* file descriptors to close on exec() */
fd_set *open_fds; /* pointer to open file descriptors */
fd_set close_on_exec_init; /* initial files to close on exec() */
fd_set open_fds_init; /* initial set of file descriptors */
struct file *fd_array[NR_OPEN_DEFAULT]; /* default array of file objects */
};
fd - указатель на массив открытых файлов.
По умолчанию это массив fd_array.
Поскольку NR_OPEN_DEFAULT равен 32,
сюда входит 32 файловых обьекта.
Если процесс открывает более 32 файлов , ядро выделяет новый массив
и указатель fd указывает на него.
Для оптимизации макрос NR_OPEN_DEFAULT можно увеличить,
Другая структура , связанная с процессом - fs_struct,
которая включает информацию о файловой системе.
Указателем на нее является поле fs в дескрипторе процесса.
Структура определена в <linux/fs_struct.h>.
struct fs_struct {
atomic_t count; /* structure usage count */
rwlock_t lock; /* lock protecting structure */
int umask; /* default file permissions*/
struct dentry *root; /* dentry of the root directory */
struct dentry *pwd; /* dentry of the current directory */
struct dentry *altroot; /* dentry of the alternative root */
struct vfsmount *rootmnt; /* mount object of the root directory */
struct vfsmount *pwdmnt; /* mount object of the current directory */
struct vfsmount *altrootmnt; /* mount object of the alternative root */
};
Эта структура хранит текущую рабочую директорию процесса и его рутовую директорию.
3-я структура - namespace ,
которая определена в <linux/namespace.h> , указателем на которую
является поле namespace дескриптора процесса.
Эта структура была добавлена в версии 2.4.
С ее помощью все файловые системы монтируются в одну иерархическую файловую систему.
struct namespace {
atomic_t count; /* structure usage count */
struct vfsmount *root; /* mount object of root directory */
struct list_head list; /* list of mount points */
struct rw_semaphore sem; /* semaphore protecting the namespace */
};
list - связанный список примонтированных файловых систем
Все эти структуры связаны с конкретным дескриптором процесса.
Как правило , каждый дескриптор указывает на уникальные
files_struct и fs_struct structures.
Для процессов , созданных с флагами CLONE_FILES или CLONE_FS, ,
эти структуры расшариваются.
В каждой структуре имеется счетчик count ,
который предотвращает разрушение этих структур до тех пор , пока они используются.
Структура namespace работает по-другому.
По умолчанию , все процессы работают в одном namespace.
Только если процесс создан с флагом CLONE_NEWNS,
он имеет уникальную структуру namespace.
Файловые системы в Linux
Linux supports a wide range of filesystems, from native filesystems, such as ext2 and ext3, to networked filesystems, such as NFS and Codamore than 50 filesystems alone in the official kernel. The VFS layer provides these disparate filesystems with both a framework for their implementation and an interface for working with the standard system calls. The VFS layer, thus, both makes it clean to implement new filesystems in Linux and allows those filesystems to automatically interoperate via the standard Unix system calls.
This chapter described the purpose of the VFS and discussed its various data structures, including the all-important inode, dentry, and superblock objects. The next chapter, "
The Block I/O Layer," discusses how data physically ends up in a filesystem.
Common Filesystem Interface
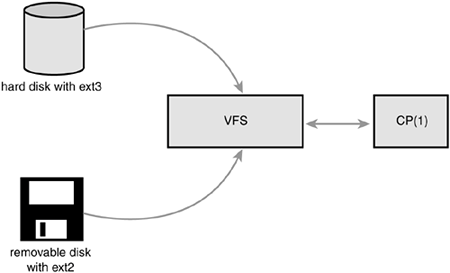
The VFS is the glue that enables system calls such as open(), read(), and write() to work regardless of the filesystem or underlying physical medium. It might not sound impressive these dayswe have long been taking such a feature for grantedbut it is a nontrivial feat for such generic system calls to work across all supported filesystems and media. More so, the system calls work between these different filesystems and mediawe can use standard system calls to copy or move files from one filesystem to another. In older operating systems (think DOS), this would never have worked; any access to a nonnative filesystem would require special tools. It is only because modern operating systems, Linux included, abstract access to the filesystems via a virtual interface that such interoperation and generic access is possible. New filesystems and new varieties of storage media can find their way into Linux, and programs need not be rewritten or even recompiled.
Filesystem Abstraction Layer
Such a generic interface for any type of filesystem is feasible only because the kernel itself implements an abstraction layer around its low-level filesystem interface. This abstraction layer enables Linux to support different filesystems, even if they differ greatly in supported features or behavior. This is possible because the VFS provides a common file model that is capable of representing any conceivable filesystem's general features and behavior. Of course, it is biased toward Unix-style filesystems (you will see what constitutes a Unix-style filesystem later in this chapter). Regardless, wildly different filesystems are still supportable in Linux.
The abstraction layer works by defining the basic conceptual interfaces and data structures that all filesystems support. The filesystems mold their view of concepts such as "this is how I open files" and "this is what a directory is to me" to match the expectations of the VFS. The actual filesystem code hides the implementation details. To the VFS layer and the rest of the kernel, however, each filesystem looks the same. They all support notions such as files and directories, and they all support operations such as creating and deleting files.
The result is a general abstraction layer that enables the kernel to support many types of filesystems easily and cleanly. The filesystems are programmed to provide the abstracted interfaces and data structures the VFS expects; in turn, the kernel easily works with any filesystem and the exported user-space interface seamlessly works on any filesystem.
In fact, nothing in the kernel needs to understand the underlying details of the filesystems, except the filesystems themselves. For example, consider a simple user-space program that does
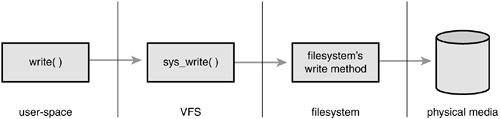
write(f, &buf, len);
This writes the len bytes pointed to by &buf into the current position in the file represented by the file descriptor f. This system call is first handled by a generic sys_write() system call that determines the actual file writing method for the filesystem on which f resides. The generic write system call then invokes this method, which is part of the filesystem implementation, to write the data to the media (or whatever this filesystem does on write). Figure 12.2 shows the flow from user-space's write() call through the data arriving on the physical media. On one side of the system call is the generic VFS interface, providing the frontend to user-space; on the other side of the system call is the filesystem-specific backend, dealing with the implementation details. The rest of this chapter looks at how the VFS achieves this abstraction and provides its interfaces.
Unix Filesystems
Historically, Unix has provided four basic filesystem-related abstractions: files, directory entries, inodes, and mount points.
A filesystem is a hierarchical storage of data adhering to a specific structure. Filesystems contain files, directories, and associated control information. Typical operations performed on filesystems are creation, deletion, and mounting. In Unix, filesystems are mounted at a specific mount point in a global hierarchy known as a namespace. This enables all mounted filesystems to appear as entries in a single tree.
A file is an ordered string of bytes. The first byte marks the beginning of the file and the last byte marks the end of the file. Each file is assigned a human-readable name for identification by both the system and the user. Typical file operations are read, write, create, and delete. The Unix concept of the file is in stark contrast to record-oriented filesystems, such as OpenVMS's Files-11. Record-oriented filesystems provide a richer, more structured representation of files than Unix's simple byte-stream abstraction, at the cost of simplicity and ultimate flexibility.
Files are organized in directories. A directory is analogous to a folder and usually contains related files. Directories can also contain subdirectories; in this fashion, directories may be nested to form paths. Each component of a path is called a directory entry. A path example is "/home/wolfman/butter"the root directory /, the directories home and wolfman, and the file butter are all directory entries, called dentries. In Unix, directories are actually normal files that simply list the files contained therein. Because a directory is a file to the VFS, the same operations performed on files can be performed on directories.
Unix systems separate the concept of a file from any associated information about it, such as access permissions, size, owner, creation time, and so on. This information is sometimes called file metadata (that is, data about the file's data) and is stored in a separate data structure from the file, called the inode. This name is short for index node, although these days the term "inode" is much more ubiquitous.
All this information is tied together with the filesystem's control information, which is stored in the superblock. The superblock is a data structure containing information about the filesystem as a whole. Sometimes the collective data is referred to as filesystem metadata. Filesystem metadata includes information about both the individual files and the filesystem as a whole.
Traditional, Unix filesystems implement these notions as part of their physical on-disk layout. For example, file information is stored as an inode in a separate block on the disk; directories are files; control information is stored centrally in a superblock, and so on. The Linux VFS is designed to work with filesystems that understand and implement such concepts. Non-Unix filesystems, such as FAT or NTFS, still work in Linux, but their filesystem code must provide the appearance of these concepts. For example, even if a filesystem does not support distinct inodes, it must assemble the inode data structure in memory as if it did. Or, if a filesystem treats directories as a special object, to the VFS they must represent directories as mere files. Oftentimes, this involves some special processing done on the fly by the non-Unix filesystems to cope with the Unix paradigm and the requirements of the VFS. Such filesystems still work, however, and usually suffer very little.
VFS Objects and Their Data Structures
The VFS is object-oriented. A family of data structures represents the common file model. These data structures are akin to objects. Because the kernel is programmed strictly in C, without the benefit of a language directly supporting object-oriented paradigms, the data structures are represented as C structures. The structures contain both data and pointers to filesystem-implemented functions that operate on the data.
The four primary object types of the VFS are
The superblock object, which represents a specific mounted filesystem. The inode object, which represents a specific file. The dentry object, which represents a directory entry, a single component of a path. The file object, which represents an open file as associated with a process.
Note that because the VFS treats directories as normal files, there is not a specific directory object. Recall from earlier in this chapter that a dentry represents a component in a path, which might include a regular file. In other words, a dentry is not the same as a directory, but a directory is the same as a file. Got it?
An operations object is contained within each of these primary objects. These objects describe the methods that the kernel invokes against the primary objects. Specifically, there are
The super_operations object, which contains the methods that the kernel can invoke on a specific filesystem, such as read_inode() and sync_fs(). The inode_operations object, which contains the methods that the kernel can invoke on a specific file, such as create() and link(). The dentry_operations object, which contains the methods that the kernel can invoke on a specific directory entry, such as d_compare() and d_delete(). The file object, which contains the methods that a process can invoke on an open file, such as read() and write().
The operations objects are implemented as a structure of pointers to functions that operate on the parent object. For many methods, the objects can inherit a generic function if basic functionality is sufficient. Otherwise, the specific instance of the particular filesystem fills in the pointers with its own filesystem-specific methods.
Again, note that objects refer to structuresnot explicit object data types, such as those in C++ or Java. These structures, however, represent specific instances of an object, their associated data, and methods to operate on themselves. They are very much objects.
Other VFS Objects
The VFS loves structures, and it comprises a couple more than the primary objects previously discussed. Each registered filesystem is represented by a file_system_type structure. This object describes the filesystem and its capabilities. Furthermore, each mount point is represented by the vfsmount structure. This structure contains information about the mount point, such as its location and mount flags.
Finally, three per-process structures describe the filesystem and files associated with a process. They are the file_struct, fs_struct, and namespace structures.
The rest of this chapter concentrates on discussing these objects and the role they play in implementing the VFS layer.
The Superblock Object
The superblock object is implemented by each filesystem, and is used to store information describing that specific filesystem. This object usually corresponds to the filesystem superblock or the filesystem control block, which is stored in a special sector on disk (hence the object's name). Filesystems that are not disk-based (a virtual memorybased filesystem, such as sysfs, for example) generate the superblock on the fly and store it in memory.
The superblock object is represented by struct super_block and defined in <linux/fs.h>. Here is what it looks like, with comments describing each entry:
struct super_block {
struct list_head s_list; /* list of all superblocks */
dev_t s_dev; /* identifier */
unsigned long s_blocksize; /* block size in bytes */
unsigned long s_old_blocksize; /* old block size in bytes */
unsigned char s_blocksize_bits; /* block size in bits */
unsigned char s_dirt; /* dirty flag */
unsigned long long s_maxbytes; /* max file size */
struct file_system_type s_type; /* filesystem type */
struct super_operations s_op; /* superblock methods */
struct dquot_operations *dq_op; /* quota methods */
struct quotactl_ops *s_qcop; /* quota control methods */
struct export_operations *s_export_op; /* export methods */
unsigned long s_flags; /* mount flags */
unsigned long s_magic; /* filesystem's magic number */
struct dentry *s_root; /* directory mount point */
struct rw_semaphore s_umount; /* unmount semaphore */
struct semaphore s_lock; /* superblock semaphore */
int s_count; /* superblock ref count */
int s_syncing; /* filesystem syncing flag */
int s_need_sync_fs; /* not-yet-synced flag */
atomic_t s_active; /* active reference count */
void *s_security; /* security module */
struct list_head s_dirty; /* list of dirty inodes */
struct list_head s_io; /* list of writebacks */
struct hlist_head s_anon; /* anonymous dentries */
struct list_head s_files; /* list of assigned files */
struct block_device *s_bdev; /* associated block device */
struct list_head s_instances; /* instances of this fs */
struct quota_info s_dquot; /* quota-specific options */
char s_id[32]; /* text name */
void *s_fs_info; /* filesystem-specific info */
struct semaphore s_vfs_rename_sem; /* rename semaphore */
};
The code for creating, managing, and destroying superblock objects lives in fs/super.c. A superblock object is created and initialized via the alloc_super() function. When mounted, a filesystem invokes this function, reads its superblock off of the disk, and fills in its superblock object.
Superblock Operations
The most important item in the superblock object is s_op, which is the superblock operations table. The superblock operations table is represented by struct super_operations and is defined in <linux/fs.h>. It looks like this:
struct super_operations {
struct inode *(*alloc_inode) (struct super_block *sb);
void (*destroy_inode) (struct inode *);
void (*read_inode) (struct inode *);
void (*dirty_inode) (struct inode *);
void (*write_inode) (struct inode *, int);
void (*put_inode) (struct inode *);
void (*drop_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*sync_fs) (struct super_block *, int);
void (*write_super_lockfs) (struct super_block *);
void (*unlockfs) (struct super_block *);
int (*statfs) (struct super_block *, struct statfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
int (*show_options) (struct seq_file *, struct vfsmount *);
};
Each item in this structure is a pointer to a function that operates on a superblock object. The superblock operations perform low-level operations on the filesystem and its inodes.
When a filesystem needs to perform an operation on its superblock, it follows the pointers from its superblock object to the desired method. For example, if a filesystem wanted to write to its superblock, it would invoke
sb->s_op->write_super(sb);
where sb is a pointer to the filesystem's superblock. Following that pointer into s_op yields the superblock operations table and ultimately the desired write_super() function, which is then directly invoked. Note how the write_super() call must be passed a superblock, despite the method being associated with one. This is because of the lack of object-oriented support in C. In C++ or C#, a call such as
sb.write_super();
would suffice. In C, there is no way for the method to cleanly obtain its parent, so you have to pass it.
Take a look at the superblock operations, which are specified by super_operations:
struct inode *
alloc_inode(struct super_block *sb)
This function creates and initializes a new inode object under the given superblock. void destroy_inode(struct inode *inode) This function deallocates the given inode. void read_inode(struct inode *inode) This function reads the inode specified by inode->i_ino from disk and fills in the rest of the inode structure. void dirty_inode(struct inode *inode) This function is invoked by the VFS when an inode is dirtied (modified). Journaling filesystems (such as ext3) use this function to perform journal updates.
void write_inode(struct inode *inode,
int wait)
Writes the given inode to disk. The wait parameter specifies whether the operation should be synchronous. void put_inode(struct inode *inode) This function releases the given inode. void drop_inode(struct inode *inode) This function is called by the VFS when the last reference to an inode is dropped. Normal Unix filesystems do not define this function, in which case the VFS simply deletes the inode. The caller must hold the inode_lock. void delete_inode(struct inode *inode) This function deletes the given inode from the disk. void put_super(struct super_block *sb) This function is called by the VFS on unmount to release the given superblock object. void write_super(struct super_block *sb) This function updates the on-disk superblock with the specified superblock. The VFS uses this function to synchronize a modified in-memory superblock with the disk. int sync_fs(struct super_block *sb, int wait) This function synchronizes filesystem metadata with the on-disk filesystem. The wait parameter specifies whether the operation is synchronous. void write_super_lockfs(struct super_block *sb) This function prevents changes to the filesystem, and then updates the on-disk superblock with the specified superblock. It is currently used by LVM (the Logical Volume Manager).
void
unlockfs(struct super_block *sb)
This function unlocks the filesystem against changes as done by write_super_lockfs().
int statfs(struct super_block *sb,
struct statfs *statfs)
This function is called by the VFS to obtain filesystem statistics. The statistics related to the given filesystem are placed in statfs.
int remount_fs(struct super_block *sb,
int *flags, char *data)
This function is called by the VFS when the filesystem is remounted with new mount options. void clear_inode(struct inode *) This function is called by the VFS to release the inode and clear any pages containing related data. void umount_begin(struct super_block *sb) This function is called by the VFS to interrupt a mount operation. It is used by network filesystems, such as NFS.
All these functions are invoked by the VFS, in process context. They may all block if needed.
Some of these functions are optional; a specific filesystem can then set its value in the superblock operations structure to NULL. If the associated pointer is NULL, the VFS either calls a generic function or does nothing, depending on the operation.
The Inode Object
The inode object represents all the information needed by the kernel to manipulate a file or directory. For Unix-style filesystems, this information is simply read from the on-disk inode. If a filesystem does not have inodes, however, the filesystem must obtain the information from wherever it is stored on the disk.
The inode object is represented by struct inode and is defined in <linux/fs.h>. Here is the structure, with comments describing each entry:
struct inode {
struct hlist_node i_hash; /* hash list */
struct list_head i_list; /* list of inodes */
struct list_head i_dentry; /* list of dentries */
unsigned long i_ino; /* inode number */
atomic_t i_count; /* reference counter */
umode_t i_mode; /* access permissions */
unsigned int i_nlink; /* number of hard links */
uid_t i_uid; /* user id of owner */
gid_t i_gid; /* group id of owner */
kdev_t i_rdev; /* real device node */
loff_t i_size; /* file size in bytes */
struct timespec i_atime; /* last access time */
struct timespec i_mtime; /* last modify time */
struct timespec i_ctime; /* last change time */
unsigned int i_blkbits; /* block size in bits */
unsigned long i_blksize; /* block size in bytes */
unsigned long i_version; /* version number */
unsigned long i_blocks; /* file size in blocks */
unsigned short i_bytes; /* bytes consumed */
spinlock_t i_lock; /* spinlock */
struct rw_semaphore i_alloc_sem; /* nests inside of i_sem */
struct semaphore i_sem; /* inode semaphore */
struct inode_operations *i_op; /* inode ops table */
struct file_operations *i_fop; /* default inode ops */
struct super_block *i_sb; /* associated superblock */
struct file_lock *i_flock; /* file lock list */
struct address_space *i_mapping; /* associated mapping */
struct address_space i_data; /* mapping for device */
struct dquot *i_dquot[MAXQUOTAS]; /* disk quotas for inode */
struct list_head i_devices; /* list of block devices */
struct pipe_inode_info *i_pipe; /* pipe information */
struct block_device *i_bdev; /* block device driver */
unsigned long i_dnotify_mask; /* directory notify mask */
struct dnotify_struct *i_dnotify; /* dnotify */
unsigned long i_state; /* state flags */
unsigned long dirtied_when; /* first dirtying time */
unsigned int i_flags; /* filesystem flags */
unsigned char i_sock; /* is this a socket? */
atomic_t i_writecount; /* count of writers */
void *i_security; /* security module */
__u32 i_generation; /* inode version number */
union {
void *generic_ip; /* filesystem-specific info */
} u;
};
An inode represents each file on a filesystem (although an inode object is constructed in memory only as the files are accessed). This includes special files, such as device files or pipes. Consequently, some of the entries in struct inode are related to these special files. For example, the i_pipe enTRy points to a named pipe data structure. If the inode does not refer to a named pipe, this field is simply NULL. Other special file-related fields are i_devices, i_bdev, and i_cdev.
It might occur that a given filesystem does not support a property represented in the inode object. For example, some filesystems might not record an access timestamp. In that case, the filesystem is free to implement the feature however it sees fit; it can store zero for i_atime, make i_atime equal to i_mtime, or whatever floats its boat.
Inode Operations
As with the superblock operations, the inode_operations member is very important. It describes the filesystem's implemented functions that the VFS can invoke on an inode. As with the superblock, inode operations are invoked via
i->i_op->truncate(i)
where i is a reference to a particular inode. In this case, the truncate() operation defined by the filesystem on which i exists is called on the given inode. The inode_operations structure is defined in <linux/fs.h>:
struct inode_operations {
int (*create) (struct inode *, struct dentry *,int);
struct dentry * (*lookup) (struct inode *, struct dentry *);
int (*link) (struct dentry *, struct inode *, struct dentry *);
int (*unlink) (struct inode *, struct dentry *);
int (*symlink) (struct inode *, struct dentry *, const char *);
int (*mkdir) (struct inode *, struct dentry *, int);
int (*rmdir) (struct inode *, struct dentry *);
int (*mknod) (struct inode *, struct dentry *, int, dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char *, int);
int (*follow_link) (struct dentry *, struct nameidata *);
int (*put_link) (struct dentry *, struct nameidata *);
void (*truncate) (struct inode *);
int (*permission) (struct inode *, int);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,
const void *, size_t, int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
};
The following interfaces constitute the various functions that the VFS may perform, or ask a specific filesystem to perform, on a given inode:
int create(struct inode *dir,
struct dentry *dentry, int mode)
The VFS calls this function from the creat() and open() system calls to create a new inode associated with the given dentry object with the specified initial mode.
struct dentry * lookup(struct inode *dir,
struct dentry *dentry)
This function searches a directory for an inode corresponding to a filename specified in the given dentry.
int link(struct dentry *old_dentry,
struct inode *dir,
struct dentry *dentry)
The function is invoked by the link() system call to create a hard link of the file old_dentry in the directory dir with the new filename dentry.
int unlink(struct inode *dir,
struct dentry *dentry)
This function is called from the unlink() system call to remove the inode specified by the directory entry dentry from the directory dir.
int symlink(struct inode *dir,
struct dentry *dentry,
const char *symname)
This function is called from the symlink() system call to create a symbolic link named symname to the file represented by dentry in the directory dir.
int mkdir(struct inode *dir,
struct dentry *dentry, int mode)
This function is called from the mkdir() system call to create a new directory with the given initial mode.
int rmdir(struct inode *dir,
struct dentry *dentry)
This function is called by the rmdir() system call to remove the directory referenced by dentry from the directory dir.
int mknod(struct inode *dir,
struct dentry *dentry,
int mode, dev_t rdev)
This function is called by the mknod() system call to create a special file (device file, named pipe, or socket). The file is referenced by the device rdev and the directory entry dentry in the directory dir. The initial permissions are given via mode.
int rename(struct inode *old_dir,
struct dentry *old_dentry,
struct inode *new_dir,
struct dentry *new_dentry)
This function is called by the VFS to move the file specified by old_dentry from the old_dir directory to the directory new_dir, with the filename specified by new_dentry.
int readlink(struct dentry *dentry,
char *buffer, int buflen)
This function is called by the readlink() system call to copy at most buflen bytes of the full path associated with the symbolic link specified by dentry into the specified buffer.
int follow_link(struct dentry *dentry,
struct nameidata *nd)
This function is called by the VFS to translate a symbolic link to the inode to which it points. The link pointed at by dentry is translated and the result is stored in the nameidata structure pointed at by nd.
int put_link(struct dentry *dentry,
struct nameidata *nd)
This function is called by the VFS to clean up after a call to follow_link(). void truncate(struct inode *inode) This function is called by the VFS to modify the size of the given file. Before invocation, the inode's i_size field must be set to the desired new size. int permission(struct inode *inode, int mask) This function checks whether the specified access mode is allowed for the file referenced by inode. This function returns zero if the access is allowed and a negative error code otherwise. Most filesystems set this field to NULL and use the generic VFS method, which simply compares the mode bits in the inode's objects to the given mask. More complicated filesystems, such as those supporting access control lists (ACLs), have a specific permission() method.
int setattr(struct dentry *dentry,
struct iattr *attr)
This function is called from notify_change() to notify a "change event" after an inode has been modified.
int getattr(struct vfsmount *mnt,
struct dentry *dentry,
struct kstat *stat)
This function is invoked by the VFS upon noticing that an inode needs to be refreshed from disk.
int setxattr(struct dentry *dentry,
const char *name,
const void *value, size_t size,
int flags)
This function is used by the VFS to set the extended attribute name to the value value on the file referenced by dentry.
ssize_t getxattr(struct dentry *dentry,
const char *name,
void *value, size_t size)
This function is used by the VFS to copy into value the value of the extended attribute name for the specified file.
ssize_t listxattr(struct dentry *dentry,
char *list, size_t size)
This function copies the list of all attributes for the specified file into the buffer list.
int removexattr(struct dentry *dentry,
const char *name)
This function removes the given attribute from the given file.
The Dentry Object
As discussed, the VFS treats directories as files. In the path /bin/vi, both bin and vi are filesbin being the special directory file and vi being a regular file. An inode object represents both these components. Despite this useful unification, the VFS often needs to perform directory-specific operations, such as path name lookup. Path name lookup involves translating each component of a path, ensuring it is valid, and following it to the next component.
To facilitate this, the VFS employs the concept of a directory entry (dentry). A dentry is a specific component in a path. Using the previous example, /, bin, and vi are all dentry objects. The first two are directories and the last is a regular file. This is an important point: dentry objects are all components in a path, including files. Resolving a path and walking its components is a nontrivial exercise, time-consuming and rife with string comparisons. The dentry object makes the whole process easier.
Dentries might also include mount points. In the path /mnt/cdrom/foo, the components /, mnt, cdrom, and foo are all dentry objects. The VFS constructs dentry objects on the fly, as needed, when performing directory operations.
Dentry objects are represented by struct dentry and defined in <linux/dcache.h>. Here is the structure, with comments describing each member:
struct dentry {
atomic_t d_count; /* usage count */
unsigned long d_vfs_flags; /* dentry cache flags */
spinlock_t d_lock; /* per-dentry lock */
struct inode *d_inode; /* associated inode */
struct list_head d_lru; /* unused list */
struct list_head d_child; /* list of dentries within */
struct list_head d_subdirs; /* subdirectories */
struct list_head d_alias; /* list of alias inodes */
unsigned long d_time; /* revalidate time */
struct dentry_operations *d_op; /* dentry operations table */
struct super_block *d_sb; /* superblock of file */
unsigned int d_flags; /* dentry flags */
int d_mounted; /* is this a mount point? */
void *d_fsdata; /* filesystem-specific data */
struct rcu_head d_rcu; /* RCU locking */
struct dcookie_struct *d_cookie; /* cookie */
struct dentry *d_parent; /* dentry object of parent */
struct qstr d_name; /* dentry name */
struct hlist_node d_hash; /* list of hash table entries */
struct hlist_head *d_bucket; /* hash bucket */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* short name */
};
Unlike the previous two objects, the dentry object does not correspond to any sort of on-disk data structure. The VFS creates it on the fly from a string representation of a path name. Because the dentry object is not physically stored on the disk, no flag in struct dentry specifies whether the object is modified (that is, whether it is dirty and needs to be written back to disk).
Dentry State
A valid dentry object can be in one of three states: used, unused, or negative.
A used dentry corresponds to a valid inode (d_inode points to an associated inode) and indicates that there are one or more users of the object (d_count is positive). A used dentry is in use by the VFS and points to valid data and, thus, cannot be discarded.
An unused dentry corresponds to a valid inode (d_inode points to an inode), but indicates that the VFS is not currently using the dentry object (d_count is zero). Because the dentry object still points to a valid object, the dentry is kept aroundcachedin case it is needed again. Because the dentry has not been destroyed prematurely, the dentry need not be re-created if it is needed in the future and path name lookups can complete quicker. If it is necessary to reclaim memory, however, the dentry can be discarded because it is not in use.
A negative dentry is not associated with a valid inode (d_inode is NULL) because either the inode was deleted or the path name was never correct to begin with. The dentry is kept around, however, so that future lookups are resolved quickly. Although the dentry is useful, it can be destroyed, if needed, because nothing can actually be using it.
A dentry object can also be freed, sitting in the slab object cache, as discussed in the previous chapter. In that case, there is no valid reference to the dentry object in any VFS or any filesystem code.
The Dentry Cache
After the VFS layer goes through the trouble of resolving each element in a path name into a dentry object and arriving at the end of the path, it would be quite wasteful to throw away all that work. Instead, the kernel caches dentry objects in the dentry cache or, simply, the dcache.
The dentry cache consists of three parts:
Lists of "used" dentries that are linked off their associated inode via the i_dentry field of the inode object. Because a given inode can have multiple links, there might be multiple dentry objects; consequently, a list is used. A doubly linked "least recently used" list of unused and negative dentry objects. The list is insertion sorted by time, such that entries toward the head of the list are newest. When the kernel must remove entries to reclaim memory, the entries are removed from the tail; those are the oldest and presumably have the least chance of being used in the near future. A hash table and hashing function used to quickly resolve a given path into the associated dentry object.
The hash table is represented by the dentry_hashtable array. Each element is a pointer to a list of dentries that hash to the same value. The size of this array depends on the amount of physical RAM in the system.
The actual hash value is determined by d_hash(). This enables filesystems to provide a unique hashing function.
Hash table lookup is performed via d_lookup(). If a matching dentry object is found in the dcache, it is returned. On failure, NULL is returned.
As an example, assume that you are editing a source file in your home directory, /home/dracula/src/the_sun_sucks.c. Each time this file is accessed (for example, when you first open it, later save it, compile it, and so on), the VFS must follow each directory entry to resolve the full path: /, home, dracula, src, and finally the_sun_sucks.c. To avoid this time-consuming operation each time this path name is accessed, the VFS can first try to look up the path name in the dentry cache. If the lookup succeeds, the required final dentry object is obtained without serious effort. Conversely, if the dentry is not in the dentry cache, the VFS must manually resolve the path by walking the filesystem for each component of the path. After this task is completed, the kernel adds the dentry objects to the dcache to speed up any future lookups.
The dcache also provides the front end to an inode cache, the icache. Inode objects that are associated with dentry objects are not freed because the dentry maintains a positive usage count over the inode. This enables dentry objects to pin inodes in memory. As long as the dentry is cached, the corresponding inodes are cached, too. Consequently, when a path name lookup succeeds from cache, as in the previous example, the associated inodes are already cached in memory.
Dentry Operations
The dentry_operations structure specifies the methods that the VFS invokes on directory entries on a given filesystem.
The dentry_operations structure is defined in <linux/dcache.h>:
struct dentry_operations {
int (*d_revalidate) (struct dentry *, int);
int (*d_hash) (struct dentry *, struct qstr *);
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
int (*d_delete) (struct dentry *);
void (*d_release) (struct dentry *);
void (*d_iput) (struct dentry *, struct inode *);
};
The methods are as follows:
int d_revalidate(struct dentry *dentry,
int flags)
This function determines whether the given dentry object is valid. The VFS calls this function whenever it is preparing to use a dentry from the dcache. Most filesystems set this method to NULL because their dentry objects in the dcache are always valid.
int d_hash(struct dentry *dentry,
struct qstr *name)
This function creates a hash value from the given dentry. The VFS calls this function whenever it adds a dentry to the hash table.
int d_compare(struct dentry *dentry,
struct qstr *name1,
struct qstr *name2)
This function is called by the VFS to compare two filenames, name1 and name2. Most filesystems leave this at the VFS default, which is a simple string compare. For some filesystems, such as FAT, a simple string compare is insufficient. The FAT filesystem is not case sensitive and therefore needs to implement a comparison function that disregards case. This function requires the dcache_lock. int d_delete (struct dentry *dentry) This function is called by the VFS when the specified dentry object's d_count reaches zero. This function requires the dcache_lock. void d_release(struct dentry *dentry) This function is called by the VFS when the specified dentry is going to be freed. The default function does nothing.
void d_iput(struct dentry *dentry,
struct inode *inode)
This function is called by the VFS when a dentry object loses its associated inode (say, because the entry was deleted from the disk). By default, the VFS simply calls the iput() function to release the inode. If a filesystem overrides this function, it must also call iput() in addition to performing whatever filesystem-specific work it requires.
The File Object
The final primary VFS object that we shall look at is the file object. The file object is used to represent a file opened by a process. When we think of the VFS from the perspective of user-space, the file object is what readily comes to mind. Processes deal directly with files, not superblocks, inodes, or dentries. It is not surprising that the information in the file object is the most familiar (data such as access mode and current offset) or that the file operations are familiar system calls such as read() and write().
The file object is the in-memory representation of an open file. The object (but not the physical file) is created in response to the open() system call and destroyed in response to the close() system call. All these file-related calls are actually methods defined in the file operations table. Because multiple processes can open and manipulate a file at the same time, there can be multiple file objects in existence for the same file. The file object merely represents a process's view of an open file. The object points back to the dentry (which in turn points back to the inode) that actually represents the open file. The inode and dentry objects, of course, are unique.
The file object is represented by struct file and is defined in <linux/fs.h>. Let's look at the structure, again with comments added to describe each entry:
struct file {
struct list_head f_list; /* list of file objects */
struct dentry *f_dentry; /* associated dentry object */
struct vfsmount *f_vfsmnt; /* associated mounted fs */
struct file_operations *f_op; /* file operations table */
atomic_t f_count; /* file object's usage count */
unsigned int f_flags; /* flags specified on open */
mode_t f_mode; /* file access mode */
loff_t f_pos; /* file offset (file pointer) */
struct fown_struct f_owner; /* owner data for signals */
unsigned int f_uid; /* user's UID */
unsigned int f_gid; /* user's GID */
int f_error; /* error code */
struct file_ra_state f_ra; /* read-ahead state */
unsigned long f_version; /* version number */
void *f_security; /* security module */
void *private_data; /* tty driver hook */
struct list_head f_ep_links; /* list of eventpoll links */
spinlock_t f_ep_lock; /* eventpoll lock */
struct address_space *f_mapping; /* page cache mapping */
};
Similar to the dentry object, the file object does not actually correspond to any on-disk data. Therefore, no flag is in the object to represent whether the object is dirty and needs to be written back to disk. The file object does point to its associated dentry object via the f_dentry pointer. The dentry in turn points to the associated inode, which reflects whether the file is dirty.
File Operations
As with all the other VFS objects, the file operations table is quite important. The operations associated with struct file are the familiar system calls that form the basis of the standard Unix system calls.
The file object methods are specified in file_operations and defined in <linux/fs.h>:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, char *, size_t, loff_t);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
ssize_t (*aio_write) (struct kiocb *, const char *, size_t, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int);
int (*aio_fsync) (struct kiocb *, int);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *,
unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *,
unsigned long, loff_t *);
ssize_t (*sendfile) (struct file *, loff_t *, size_t,
read_actor_t, void *);
ssize_t (*sendpage) (struct file *, struct page *, int,
size_t, loff_t *, int);
unsigned long (*get_unmapped_area) (struct file *, unsigned long,
unsigned long, unsigned long,
unsigned long);
int (*check_flags) (int flags);
int (*dir_notify) (struct file *filp, unsigned long arg);
int (*flock) (struct file *filp, int cmd, struct file_lock *fl);
};
Filesystems can implement unique functions for each of these operations, or they can use a generic method if one exists. The generic methods tend to work fine on normal Unix-based filesystems. A filesystem is under no obligation to implement all these methodsalthough not implementing the basics is sillyand can simply set the method to NULL if not interested.
Here are the individual operations:
loff_t llseek(struct file *file,
loff_t offset, int origin)
This function updates the file pointer to the given offset. It is called via the llseek() system call.
ssize_t read(struct file *file,
char *buf, size_t count,
loff_t *offset)
This function reads count bytes from the given file at position offset into buf. The file pointer is then updated. This function is called by the read() system call.
ssize_t aio_read(struct kiocb *iocb,
char *buf, size_t count,
loff_t offset)
This function begins an asynchronous read of count bytes into buf of the file described in iocb. This function is called by the aio_read() system call.
ssize_t write(struct file *file,
const char *buf, size_t count,
loff_t *offset)
This function writes count bytes from buf into the given file at position offset. The file pointer is then updated. This function is called by the write() system call.
ssize_t aio_write(struct kiocb *iocb,
const char *buf,
size_t count, loff_t offset)
This function begins an asynchronous write of count bytes into buf of the file described in iocb. This function is called by the aio_write() system call.
int readdir(struct file *file, void *dirent,
filldir_t filldir)
This function returns the next directory in a directory listing. This function is called by the readdir() system call.
unsigned int poll(struct file *file,
struct poll_table_struct *poll_table)
This function sleeps, waiting for activity on the given file. It is called by the poll() system call.
int ioctl(struct inode *inode,
struct file *file,
unsigned int cmd,
unsigned long arg)
This function is used to send a command and argument pair to a device. It is used when the file is an open device node. This function is called from the ioctl() system call.
int mmap(struct file *file,
struct vm_area_struct *vma)
This function memory maps the given file onto the given address space and is called by the mmap() system call.
int open(struct inode *inode,
struct file *file)
This function creates a new file object and links it to the corresponding inode object. It is called by the open() system call. int flush(struct file *file) This function is called by the VFS whenever the reference count of an open file decreases. Its purpose is filesystem dependent.
int release(struct inode *inode,
struct file *file)
This function is called by the VFS when the last remaining reference to the file is destroyedfor example, when the last process sharing a file descriptor calls close() or exits. Its purpose is filesystem dependent.
int fsync(struct file *file,
struct dentry *dentry,
int datasync)
This function is called by the fsync() system call to write all cached data for the file to disk.
int aio_fsync(struct kiocb *iocb,
int datasync)
This function is called by the aio_fsync() system call to write all cached data for the file associated with iocb to disk. int fasync(int fd, struct file *file, int on) This function enables or disables signal notification of asynchronous I/O.
int lock(struct file *file, int cmd,
struct file_lock *lock)
This function manipulates a file lock on the given file.
ssize_t readv(struct file *file,
const Pstruct iovec *vector,
unsigned long count,
loff_t *offset)
This function is called by the readv() system call to read from the given file and put the results into the count buffers described by vector. The file offset is then incremented.
ssize_t writev(struct file *file,
const struct iovec *vector,
unsigned long count,
loff_t *offset)
This function is called by the writev() system call to write from the count buffers described by vector into the file specified by file. The file offset is then incremented.
ssize_t sendfile(struct file *file,
loff_t *offset,
size_t size,
read_actor_t actor,
void *target)
This function is called by the sendfile() system call to copy data from one file to another. It performs the copy entirely in the kernel and avoids an extraneous copy to user-space.
ssize_t sendpage(struct file *file,
struct page *page,
int offset, size_t size,
loff_t *pos, int more)
This function is used to send data from one file to another.
unsigned long get_unmapped_area(struct file
*file,
unsigned long addr,
unsigned long len,
unsigned long offset,
unsigned long flags)
This function gets unused address space to map the given file. int check_flags(int flags) This function is used to check the validity of the flags passed to the fcntl() system call when the SETFL command is given. As with many VFS operations, filesystems need not implement check_flags(); currently, only NFS does so. This function enables filesystems to restrict invalid SETFL flags that are otherwise allowed by the generic fcntl() function. In the case of NFS, combining O_APPEND and O_DIRECT is not allowed.
int flock(struct file *filp,
int cmd,
struct file_lock *fl)
This function is used to implement the flock() system call, which provides advisory locking.
Data Structures Associated with Filesystems
In addition to the fundamental VFS objects, the kernel uses other standard data structures to manage data related to filesystems. The first object is used to describe a specific variant of a filesystem, such as ext3 or XFS. The second data structure is used to describe a mounted instance of a filesystem.
Because Linux supports so many different filesystems, the kernel must have a special structure for describing the abilities and behavior of each filesystem.
struct file_system_type {
const char *name; /* filesystem's name */
struct subsystem subsys; /* sysfs subsystem object */
int fs_flags; /* filesystem type flags */
/* the following is used to read the superblock off the disk */
struct super_block *(*get_sb) (struct file_system_type *, int,
char *, void *);
/* the following is used to terminate access to the superblock */
void (*kill_sb) (struct super_block *);
struct module *owner; /* module owning the filesystem */
struct file_system_type *next; /* next file_system_type in list */
struct list_head fs_supers; /* list of superblock objects */
};
The get_sb() function is used to read the superblock from the disk and populate the superblock object when the filesystem is loaded. The remaining functions describe the filesystem's properties.
There is only one file_system_type per filesystem, regardless of how many instances of the filesystem are mounted on the system, or whether the filesystem is even mounted at all.
Things get more interesting when the filesystem is actually mounted, at which point the vfsmount structure is created. This structure is used to represent a specific instance of a filesystemin other words, a mount point.
The vfsmount structure is defined in <linux/mount.h>. Here it is:
struct vfsmount {
struct list_head mnt_hash; /* hash table list */
struct vfsmount *mnt_parent; /* parent filesystem */
struct dentry *mnt_mountpoint; /* dentry of this mount point */
struct dentry *mnt_root; /* dentry of root of this fs */
struct super_block *mnt_sb; /* superblock of this filesystem */
struct list_head mnt_mounts; /* list of children */
struct list_head mnt_child; /* list of children */
atomic_t mnt_count; /* usage count */
int mnt_flags; /* mount flags */
char *mnt_devname; /* device file name */
struct list_head mnt_list; /* list of descriptors */
struct list_head mnt_fslink; /* fs-specific expiry list */
struct namespace *mnt_namespace /* associated namespace */
};
The complicated part of maintaining the list of all mount points is the relation between the filesystem and all the other mount points. The various linked lists in vfsmount keep track of this information.
The vfsmount structure also stores the flags, if any, specified on mount in the mnt_flags field. Table 12.1 is a list of the standard mount flags.
Table 12.1. Listing of Standard Mount FlagsFlag | Description |
|---|
MNT_NOSUID | Forbids setuid and setgid flags on binaries on this filesystem | MNT_NODEV | Forbids access to device files on this filesystem | MNT_NOEXEC | Forbids execution of binaries on this filesystem |
These flags are most useful on removable devices that the administrator does not trust. They are defined in <linux/mount.h>.
Chapter 13. The Block I/O Layer
Block devices are hardware devices distinguished by the random (that is, not necessarily sequential) access of fixed-size chunks of data, called blocks. The most common block device is a hard disk, but many other block devices exist, such as floppy drives, CD-ROM drives, and flash memory. Notice how these are all devices on which you mount a filesystemfilesystems are the lingua franca of block devices.
The other basic type of device is a character device. Character devices, or char devices, are accessed as a stream of sequential data, one byte after another. Example character devices are serial ports and keyboards. If the hardware device is accessed as a stream of data, it is implemented as a character device. On the other hand, if the device is accessed randomly (nonsequentially), it is a block device.
Basically, the difference comes down to whether the device accesses data randomlyin other words, whether the device can seek to one position from another. As an example, consider the keyboard. As a driver, the keyboard provides a stream of data. You type "fox" and the keyboard driver returns a stream with those three letters in exactly that order. Reading the letters out of order, or reading any letter but the next one in the stream, makes little sense. The keyboard driver is thus a char device; the device provides a stream of characters that the user types onto the keyboard. Reading from the keyboard returns a stream first with f, then o, then x, and ultimately end of file (EOF). When no keystrokes are waiting, the stream is empty. A hard drive, conversely, is quite different. The hard drive's driver might ask to read the contents of one arbitrary block and then read the contents of a different block; the blocks need not be consecutive. Therefore, the hard disk's data is accessed randomly, and not as a stream, and thus the hard disk is a block device.
Managing block devices in the kernel requires more care, preparation, and work than managing character devices. Character devices have only one positionthe current onewhereas block devices must be able to navigate back and forth between any location on the media. Indeed, the kernel does not have to provide an entire subsystem dedicated to the management of character devices, but block devices receive exactly that. Such a subsystem is a necessity partly because of the complexity of block devices. A large reason, however, for such extensive support is that block devices are quite performance sensitive; getting every last drop out of your hard disk is much more important than squeezing an extra percent of speed out of your keyboard. Furthermore, as you will see, the complexity of block devices provides a lot of room for such optimizations. The topic of this chapter is how the kernel manages block devices and their requests. This part of the kernel is known as the block I/O layer. Interestingly, revamping the block I/O layer was the primary goal for the 2.5 development kernel. This chapter covers the all-new block I/O layer in the 2.6 kernel.
Anatomy of a Block Device
The smallest addressable unit on a block device is known as a sector. Sectors come in various powers of two, but 512 bytes is the most common size. The sector size is a physical property of the device and the sector is the fundamental unit of all block devicesthe device cannot address or operate on a unit smaller than the sector, although many block devices can transfer multiple sectors at once. Although most block devices have 512-byte sectors, other sizes are common (for example, many CD-ROM discs have 2-kilobyte sectors).
Software has different goals, however, and therefore imposes its own smallest logically addressable unit, which is the block. The block is an abstraction of the filesystemfilesystems can be accessed only in multiples of a block. Although the physical device itself is addressable at the sector level, the kernel performs all disk operations in terms of blocks. Because the device's smallest addressable unit is the sector, the block size can be no smaller than the sector and must be a multiple of a sector. Furthermore, the kernel (like hardware with the sector) needs the block to be a power of two. The kernel also requires that a block be no larger than the page size (see Chapter 11, "Memory Management," and Chapter 19, "Portability"). Therefore, block sizes are a power-of-two multiple of the sector size and are not greater than the page size. Common block sizes are 512 bytes, 1 kilobyte, and 4 kilobytes.
Somewhat confusingly, some people refer to sectors and blocks with different names. Sectors, the smallest addressable unit to the device, are sometimes called "hard sectors" or "device blocks." Meanwhile, blocks, the smallest addressable unit to the filesystem, are sometimes referred to as "filesystem blocks" or "I/O blocks." This chapter continues to call the two notions "sectors" and "blocks," but you should keep these other terms in mind. Figure 13.1 is a diagram of the relationship between sectors and buffers.
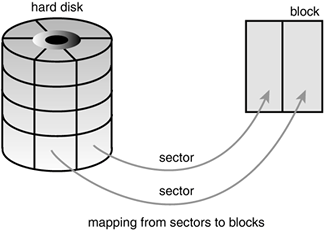
Other terminology, at least with respect to hard disks, is commonterms such as clusters, cylinders, and heads. Those notions are specific only to certain block devices and, for the most part, are invisible to user-space software. The reason that the sector is important to the kernel is because all device I/O must be done in units of sectors. In turn, the higher-level concept used by the kernelblocksis built on top of sectors.
Buffers and Buffer Heads
When a block is stored in memory (say, after a read or pending a write), it is stored in a buffer. Each buffer is associated with exactly one block. The buffer serves as the object that represents a disk block in memory. Recall that a block comprises one or more sectors, but is no more than a page in size. Therefore, a single page can hold one or more blocks in memory. Because the kernel requires some associated control information to accompany the data (such as from which block device and which specific block the buffer is), each buffer is associated with a descriptor. The descriptor is called a buffer head and is of type struct buffer_head. The buffer_head structure holds all the information that the kernel needs to manipulate buffers and is defined in <linux/buffer_head.h>.
Take a look at this structure, with comments describing each field:
struct buffer_head {
unsigned long b_state; /* buffer state flags */
atomic_t b_count; /* buffer usage counter */
struct buffer_head *b_this_page; /* buffers using this page */
struct page *b_page; /* page storing this buffer */
sector_t b_blocknr; /* logical block number */
u32 b_size; /* block size (in bytes) */
char *b_data; /* buffer in the page */
struct block_device *b_bdev; /* device where block resides */
bh_end_io_t *b_end_io; /* I/O completion method */
void *b_private; /* data for completion method */
struct list_head b_assoc_buffers; /* list of associated mappings */
};
The b_state field specifies the state of this particular buffer. It can be one or more of the flags in Table 13.1. The legal flags are stored in the bh_state_bits enumeration, which is defined in <linux/buffer_head.h>.
Table 13.1. bh_state FlagsStatus Flag | Meaning |
|---|
BH_Uptodate | Buffer contains valid data | BH_Dirty | Buffer is dirty (the contents of the buffer are newer than the contents of the block on disk and therefore the buffer must eventually be written back to disk) | BH_Lock | Buffer is undergoing disk I/O and is locked to prevent concurrent access | BH_Req | Buffer is involved in an I/O request | BH_Mapped | Buffer is a valid buffer mapped to an on-disk block | BH_New | Buffer is newly mapped via get_block() and not yet accessed | BH_Async_Read | Buffer is undergoing asynchronous read I/O via end_buffer_async_read() | BH_Async_Write | Buffer is undergoing asynchronous write I/O via end_buffer_async_write() | BH_Delay | Buffer does not yet have an associated on-disk block | BH_Boundary | Buffer forms the boundary of contiguous blocksthe next block is discontinuous |
The bh_state_bits enumeration also contains as the last value in the list a BH_PrivateStart flag. This is not a valid state flag, but instead corresponds to the first usable bit of which other code can make use. All bit values equal to and greater than BH_PrivateStart are not used by the block I/O layer proper, so these bits are safe to use by individual drivers who want to store information in the b_state field. Drivers can base the bit values of their internal flags off this flag and rest assured that they are not encroaching on an official bit used by the block I/O layer.
The b_count field is the buffer's usage count. The value is incremented and decremented by two inline functions, both of which are defined in <linux/buffer_head.h>:
static inline void get_bh(struct buffer_head *bh)
{
atomic_inc(&bh->b_count);
}
static inline void put_bh(struct buffer_head *bh)
{
atomic_dec(&bh->b_count);
}
Before manipulating a buffer head, you must increment its reference count via get_bh() to ensure that the buffer head is not deallocated out from under you. When finished with the buffer head, decrement the reference count via put_bh().
The physical block on disk to which a given buffer corresponds is the b_blocknr-th logical block on the block device described by b_bdev.
The physical page in memory to which a given buffer corresponds is the page pointed to by b_page. More specifically, b_data is a pointer directly to the block (that exists somewhere in b_page), which is b_size bytes in length. Therefore, the block is located in memory starting at address b_data and ending at address (b_data + b_size).
The purpose of a buffer head is to describe this mapping between the on-disk block and the physical in-memory buffer (which is a sequence of bytes on a specific page). Acting as a descriptor of this buffer-to-block mapping is the data structure's only role in the kernel.
Before the 2.6 kernel, the buffer head was a much more important data structure: It was the unit of I/O in the kernel. Not only did the buffer head describe the disk-block-to-physical-page mapping, but it also acted as the container used for all block I/O. This had two primary problems. First, the buffer head was a large and unwieldy data structure (it has shrunken a bit nowadays), and it was neither clean nor simple to manipulate data in terms of buffer heads. Instead, the kernel prefers to work in terms of pages, which are simple and allow for greater performance. A large buffer head describing each individual buffer (which might be smaller than a page) was inefficient. Consequently, in the 2.6 kernel, much work has gone into making the kernel work directly with pages and address spaces instead of buffers. Some of this work is discussed in Chapter 15, "The Page Cache and Page Writeback," where the address_space structure and the pdflush daemons are discussed.
The second issue with buffer heads is that they describe only a single buffer. When used as the container for all I/O operations, the buffer head forces the kernel to break up potentially large block I/O operations (say, a write) into multiple buffer_head structures. This results in needless overhead and space consumption. As a result, the primary goal of the 2.5 development kernel was to introduce a new, flexible, and lightweight container for block I/O operations. The result is the bio structure, which is discussed in the next section.
The bio structure
The basic container for block I/O within the kernel is the bio structure, which is defined in <linux/bio.h>. This structure represents block I/O operations that are in flight (active) as a list of segments. A segment is a chunk of a buffer that is contiguous in memory. Thus, individual buffers need not be contiguous in memory. By allowing the buffers to be described in chunks, the bio structure provides the capability for the kernel to perform block I/O operations of even a single buffer from multiple locations in memory. Vector I/O such as this is called scatter-gather I/O.
Here is struct bio, defined in <linux/bio.h>, with comments added for each field:
struct bio {
sector_t bi_sector; /* associated sector on disk */
struct bio *bi_next; /* list of requests */
struct block_device *bi_bdev; /* associated block device */
unsigned long bi_flags; /* status and command flags */
unsigned long bi_rw; /* read or write? */
unsigned short bi_vcnt; /* number of bio_vecs off */
unsigned short bi_idx; /* current index in bi_io_vec */
unsigned short bi_phys_segments; /* number of segments after coalescing */
unsigned short bi_hw_segments; /* number of segments after remapping */
unsigned int bi_size; /* I/O count */
unsigned int bi_hw_front_size; /* size of the first mergeable segment */
unsigned int bi_hw_back_size; /* size of the last mergeable segment */
unsigned int bi_max_vecs; /* maximum bio_vecs possible */
struct bio_vec *bi_io_vec; /* bio_vec list */
bio_end_io_t *bi_end_io; /* I/O completion method */
atomic_t bi_cnt; /* usage counter */
void *bi_private; /* owner-private method */
bio_destructor_t *bi_destructor; /* destructor method */
};
The primary purpose of a bio structure is to represent an in-flight block I/O operation. To this end, the majority of the fields in the structure are housekeeping related. The most important fields are bi_io_vecs, bi_vcnt, and bi_idx. Figure 13.2 shows the relationship between the bio structure and its friends.
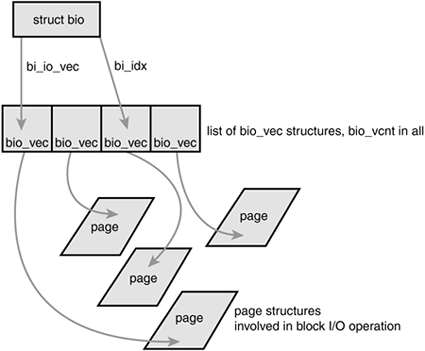
The bi_io_vecs field points to an array of bio_vec structures. These structures are used as lists of individual segments in this specific block I/O operation. Each bio_vec is treated as a vector of the form <page, offset, len>, which describes a specific segment: the physical page on which it lies, the location of the block as an offset into the page, and the length of the block starting from the given offset. The full array of these vectors describes the entire buffer. The bio_vec structure is defined in <linux/bio.h>:
struct bio_vec {
/* pointer to the physical page on which this buffer resides */
struct page *bv_page;
/* the length in bytes of this buffer */
unsigned int bv_len;
/* the byte offset within the page where the buffer resides */
unsigned int bv_offset;
};
In each given block I/O operation, there are bi_vcnt vectors in the bio_vec array starting with bi_io_vecs. As the block I/O operation is carried out, the bi_idx field is used to point to the current index into the array.
In summary, each block I/O request is represented by a bio structure. Each request comprises one or more blocks, which are stored in an array of bio_vec structures. These structures act as vectors and describe each segment's location in a physical page in memory. The first segment in the I/O operation is pointed to by b_io_vec. Each additional segment follows after the first, for a total of bi_vcnt segments in the list. As the block I/O layer submits segments in the request, the bi_idx field is updated to point to the current segment.
The bi_idx field is used to point to the current bio_vec in the list, which helps the block I/O layer keep track of partially completed block I/O operations. A more important usage, however, is to allow the splitting of bio structures. With this feature, drivers such as RAID (Redundant Array of Inexpensive Disks, a hard disk setup that allows single volumes to span multiple disks for performance and reliability purposes) can take a single bio structure, initially intended for a single device, and split it up among the multiple hard drives in the RAID array. All the RAID driver needs to do is copy the bio structure and update the bi_idx field to point to where the individual drive should start its operation.
The bio structure maintains a usage count in the bi_cnt field. When this field reaches zero, the structure is destroyed and the backing memory is freed. Two functions, which follow, manage the usage counters for you.
void bio_get(struct bio *bio)
void bio_put(struct bio *bio)
The former increments the usage count, whereas the latter decrements the usage count (and, if the count reaches zero, destroys the bio structure). Before manipulating an in-flight bio structure, be sure to increment its usage count to make sure it does not complete and deallocate out from under you. When you're finished, decrement the usage count in turn.
Finally, the bi_private field is a private field for the owner (that is, creator) of the structure. As a rule, you can read or write this field only if you allocated the bio structure.
The Old Versus the New
The difference between buffer heads and the new bio structure is important. The bio structure represents an I/O operation, which may include one or more pages in memory. On the other hand, the buffer_head structure represents a single buffer, which describes a single block on the disk. Because buffer heads are tied to a single disk block in a single page, buffer heads result in the unnecessary dividing of requests into block-sized chunks, only to later reassemble them. Because the bio structure is lightweight, it can describe discontiguous blocks, and does not unnecessarily split I/O operations.
Switching from struct buffer_head to struct bio provided other benefits, as well:
The bio structure can easily represent high memory (see Chapter 11), because struct bio deals with only physical pages and not direct pointers. The bio structure can represent both normal page I/O and direct I/O (I/O operations that do not go through the page cachesee Chapter 15 for a discussion on the page cache). The bio structure makes it easy to perform scatter-gather (vectored) block I/O operations, with the data involved in the operation originating from multiple physical pages. The bio structure is much more lightweight than a buffer head because it contains only the minimum information needed to represent a block I/O operation and not unnecessary information related to the buffer itself.
The concept of buffer heads is still required, however; buffer heads function as descriptors, mapping disk blocks to pages. The bio structure does not contain any information about the state of a bufferit is simply an array of vectors describing one or more segments of data for a single block I/O operation, plus related information. In the current setup, the buffer_head structure is still needed to contain information about buffers while the bio structure describes in-flight I/O. Keeping the two structures separate allows each to remain as small as possible.
Request Queues
Block devices maintain request queues to store their pending block I/O requests. The request queue is represented by the request_queue structure and is defined in <linux/blkdev.h>. The request queue contains a doubly linked list of requests and associated control information. Requests are added to the queue by higher-level code in the kernel, such as filesystems. As long as the request queue is nonempty, the block device driver associated with the queue grabs the request from the head of the queue and submits it to its associated block device. Each item in the queue's request list is a single request, of type struct request.
Requests
Individual requests on the queue are represented by struct request, which is also defined in <linux/blkdev.h>. Each request can be composed of more than one bio structure because individual requests can operate on multiple consecutive disk blocks. Note that although the blocks on the disk must be adjacent, the blocks in memory need not beeach bio structure can describe multiple segments (recall, segments are contiguous chunks of a block in memory) and the request can be composed of multiple bio structures.
I/O Schedulers
Simply sending out requests to the block devices in the order that the kernel issues them, as soon as it issues them, results in awful performance. One of the slowest operations in a modern computer is disk seeks. Each seekpositioning the hard disk's head at the location of a specific blocktakes many milliseconds. Minimizing seeks is absolutely crucial to the system's performance.
Therefore, the kernel does not issue block I/O requests to the disk in the order they are received or as soon as they are received. Instead, it performs operations called merging and sorting to greatly improve the performance of the system as a whole. The subsystem of the kernel that performs these operations is called the I/O scheduler.
The I/O scheduler divides the resource of disk I/O among the pending block I/O requests in the system. It does this through the merging and sorting of pending requests in the request queue. The I/O scheduler is not to be confused with the process scheduler (see Chapter 4, "Process Scheduling"), which divides the resource of the processor among the processes on the system. The two subsystems are similar in nature but not the same. Both the process scheduler and the I/O scheduler virtualize a resource among multiple objects. In the case of the process scheduler, the processor is virtualized and shared among the processes on the system. This provides the illusion of virtualization inherent in a multitasking and timesharing operating system, such as any Unix. On the other hand, the I/O scheduler virtualizes block devices among multiple outstanding block requests. This is done to minimize disk seeks and ensure optimum disk performance.
The Job of an I/O Scheduler
An I/O scheduler works by managing a block device's request queue. It decides the order of requests in the queue and at what time each request is dispatched to the block device. It manages the request queue with the goal of reducing seeks, which results in greater global throughput. The "global" modifier here is important. An I/O scheduler, very openly, is unfair to some requests at the expense of improving the overall performance of the system.
I/O schedulers perform two primary actions to minimize seeks: merging and sorting. Merging is the coalescing of two or more requests into one. Consider an example request that is submitted to the queue by a filesystemsay, to read a chunk of data from a file. (At this point, of course, everything is occurring in terms of sectors and blocks and not files, but presume that the requested blocks originate from a chunk of a file.) If a request is already in the queue to read from an adjacent sector on the disk (for example, an earlier chunk of the same file), the two requests can be merged into a single request operating on one or more adjacent on-disk sectors. By merging requests, the I/O scheduler reduces the overhead of multiple requests down to a single request. More importantly, only a single command needs to be issued to the disk and servicing the multiple requests can be done without seeking. Consequently, merging requests reduces overhead and minimizes seeks.
Now, assume your fictional read request is submitted to the request queue, but there is no read request to an adjacent sector. You are therefore unable to merge this request with any other request. Now, you could simply stick this request onto the tail of the queue. But, what if there are other requests to a similar location on the disk? Would it not make sense to insert this new request into the queue at a spot near other requests operating on physically near sectors? In fact, I/O schedulers do exactly this. The entire request queue is kept sorted, sector-wise, so that all seeking activity along the queue moves (as much as possible) sequentially over the sectors of the hard disk. The goal is not just to minimize each individual seek, but to minimize all seeking by keeping the disk head moving in a straight line. This is similar to the algorithm employed in elevatorselevators do not jump all over, wildly, from floor to floor. Instead, they try to move gracefully in a single direction. When the final floor is reached in one direction, the elevator can reverse course and move in the other direction. Because of this similarity, I/O schedulers (or sometimes just their sorting algorithm) are called elevators.
The Linus Elevator
Now let's look at some real-life I/O schedulers. The first I/O scheduler is called the Linus Elevator (yes, Linus has an elevator named after him!). It was the default I/O scheduler in 2.4. In 2.6, it was replaced by the following I/O schedulers that we will look athowever, because this elevator is simpler than the subsequent ones, while performing many of the same functions, it still deserves discussion.
The Linus Elevator performs both merging and sorting. When a request is added to the queue, it is first checked against every other pending request to see whether it is a possible candidate for merging. The Linus Elevator I/O scheduler performs both front and back merging. The type of merging performed depends on the location of the existing adjacent request. If the new request immediately proceeds an existing request, it is front merged. Conversely, if the new request immediately precedes an existing request, it is back merged. Because of the way files are laid out (usually by increasing sector number) and the I/O operations performed in a typical workload (data is normally read from start to finish and not in reverse), front merging is very rare compared to back merging. Nonetheless, the Linus Elevator checks for and performs both types of merge.
If the merge attempt fails, a possible insertion point in the queue (a location in the queue where the new request fits sector-wise between the existing requests) is then sought. If one is found, the new request is inserted there. If a suitable location is not found, the request is added to the tail of the queue. Additionally, if an existing request is found in the queue that is older than a predefined threshold, the new request is added to the tail of the queue even if it can be insertion sorted elsewhere. This prevents many requests to nearby on-disk locations from indefinitely starving requests to other locations on the disk. Unfortunately, this "age" check is not very efficient. It does not provide any real attempt to service requests in a given timeframeit merely stops insertion-sorting requests after a suitable delay. This improves latency but can still lead to request starvation, which was the big must-fix of the 2.4 I/O scheduler.
In summary, when a request is added to the queue, four operations are possible. In order, they are
1. | First, if a request to an adjacent on-disk sector is in the queue, the existing request and the new request are merged into a single request.
| 2. | Second, if a request in the queue is sufficiently old, the new request is inserted at the tail of the queue to prevent starvation of the other, older, requests.
| 3. | Next, if there is a suitable location sector-wise in the queue, the new request is inserted there. This keeps the queue sorted by physical location on disk.
| 4. | Finally, if no such suitable insertion point exists, the request is inserted at the tail of the queue |
The Deadline I/O Scheduler
The Deadline I/O scheduler sought to prevent the starvation caused by the Linus Elevator. In the interest of minimizing seeks, heavy disk I/O operations to one area of the disk can indefinitely starve request operations to another part of the disk. Indeed, a stream of requests to the same area of the disk can result in other far-off requests never being serviced. This starvation is unfair.
Worse, the general issue of request starvation introduces a specific instance of the problem known as writes starving reads. Write operations can usually be committed to disk whenever the kernel gets around to them, entirely asynchronous with respect to the submitting application. Read operations are quite different. Normally, when an application submits a read request, the application blocks until the request is fulfilled. That is, read requests occur synchronously with respect to the submitting application. Although system response is largely unaffected by write latency (the time required to commit a write request), read latency (the time required to commit a read request) is very important. Write latency has little bearing on application performance, but an application must wait, twiddling its thumbs, for the completion of each read request. Consequently, read latency is very important to the performance of the system.
Compounding the problem, read requests tend to be dependent on each other. For example, consider the reading of a large number of files. Each read occurs in small buffered chunks. The application does not start reading the next chunk (or the next file, for that matter) until the previous chunk is read from disk and returned to the application. Worse, both read and write operations require the reading of various metadata, such as inodes. Reading these blocks off the disk further serializes I/O. Consequently, if each read request is individually starved, the total delay to such applications compounds and can grow enormous. Recognizing that the asynchrony and interdependency of read requests results in a much stronger bearing of read latency on the performance of the system, the Deadline I/O scheduler implements several features to ensure that request starvation in general, and read starvation in specific, is minimized.
Note that reducing request starvation comes at a cost to global throughput. Even the Linus Elevator makes this compromise, albeit in a much milder mannerthe Linus Elevator could provide better overall throughput (via a greater minimization of seeks) if it always inserted requests into the queue sector-wise and never checked for old requests and reverted to insertion at the tail of the queue. Although minimizing seeks is very important, indefinite starvation is not good either. The Deadline I/O scheduler, therefore, works harder to limit starvation while still providing good global throughput. Make no mistake: It is a tough act to provide request fairness, yet maximize global throughput.
In the Deadline I/O scheduler, each request is associated with an expiration time. By default, the expiration time is 500 milliseconds in the future for read requests and 5 seconds in the future for write requests. The Deadline I/O scheduler operates similarly to the Linus Elevator in that it maintains a request queue sorted by physical location on disk. It calls this queue the sorted queue. When a new request is submitted to the sorted queue, the Deadline I/O scheduler performs merging and insertion like the Linus Elevator. The Deadline I/O scheduler also, however, inserts the request into a second queue that depends on the type of request. Read requests are sorted into a special read FIFO queue and write requests are inserted into a special write FIFO queue. Although the normal queue is sorted by on-disk sector, these queues are kept FIFO (effectively, they are sorted by time). Consequently, new requests are always added to the tail of the queue. Under normal operation, the Deadline I/O scheduler pulls requests from the head of the sorted queue into the dispatch queue. The dispatch queue is then fed to the disk drive. This results in minimal seeks.
If the request at the head of either the write FIFO queue or the read FIFO queue expires (that is, if the current time becomes greater than the expiration time associated with the request), the Deadline I/O scheduler then begins servicing requests from the FIFO queue. In this manner, the Deadline I/O scheduler attempts to ensure that no request is outstanding longer than its expiration time. See Figure 13.3.
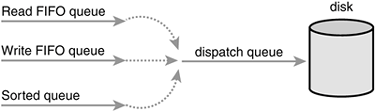
Note that the Deadline I/O scheduler does not make any strict guarantees over request latency. It is capable, however, of generally committing requests on or before their expiration. This prevents request starvation. Because read requests are given a substantially smaller expiration value than write requests, the Deadline I/O scheduler also works to ensure that write requests do not starve read requests. This preference toward read requests provides minimized read latency.
The Deadline I/O scheduler lives in drivers/block/deadline-iosched.c.
The Anticipatory I/O Scheduler
Although the Deadline I/O scheduler does a great job minimizing read latency, it does so at the expense of global throughput. Consider a system undergoing heavy write activity. Every time a read request is submitted, the I/O scheduler quickly rushes to handle the read request. This results in the disk seeking over to where the read is, performing the read operation, and then seeking back to continue the ongoing write operation, repeating this little charade for each read request. The preference toward read requests is a good thing, but the resulting pair of seeks (one to the location of the read request and another back to the ongoing write) is detrimental to global disk throughput. The Anticipatory I/O scheduler aims to continue to provide excellent read latency, but also provide excellent global throughput.
First, the Anticipatory I/O scheduler starts with the Deadline I/O scheduler as its base. Therefore, it is not entirely different. The Anticipatory I/O scheduler implements three queues (plus the dispatch queue) and expirations for each request, just like the Deadline I/O scheduler. The major change is the addition of an anticipation heuristic.
The Anticipatory I/O scheduler attempts to minimize the seek storm that accompanies read requests issued during other disk I/O activity. When a read request is issued, it is handled as usual, within its usual expiration period. After the request is submitted, however, the Anticipatory I/O scheduler does not immediately seek back and return to handling other requests. Instead, it does absolutely nothing for a few milliseconds (the actual value is configurable; by default it is six milliseconds). In those few milliseconds, there is a good chance that the application will submit another read request. Any requests issued to an adjacent area of the disk are immediately handled. After the waiting period elapses, the Anticipatory I/O scheduler seeks back to where it left off and continues handling the previous requests.
It is important to note that the few milliseconds that are spent in anticipation for more requests are well worth it if they minimize even a modest percentage of the back-and-forth seeking that results from the servicing of read requests during other heavy requests. If an adjacent I/O request is issued within the waiting period, the I/O scheduler just saved a pair of seeks. As more and more reads are issued to the same area of disk, many more seeks are prevented.
Of course, if no activity occurs within the waiting period, the Anticipatory I/O scheduler loses and a few milliseconds are wasted. The key to reaping maximum benefit from the Anticipatory I/O scheduler is correctly anticipating the actions of applications and filesystems. This is done via a set of statistics and associated heuristics. The Anticipatory I/O scheduler keeps track of per-process statistics pertaining to block I/O habits in hopes of correctly anticipating the actions of applications. With a sufficiently high percentage of correct anticipations, the Anticipatory I/O scheduler can greatly reduce the penalty of seeking to service read requests, while still providing the attention to such requests that system response requires. This allows the Anticipatory I/O scheduler to minimize read latency, while also minimizing the number and duration of seeks. This results in low system latency and high system throughput.
The Anticipatory I/O scheduler lives in the file drivers/block/as-iosched.c in the kernel source tree. It is the default I/O scheduler in the Linux kernel. It performs well across most workloads. It is ideal for servers, although it performs very poorly on certain uncommon but critical workloads involving seek-happy databases.
The Complete Fair Queuing I/O Scheduler
The Complete Fair Queuing (CFQ) I/O scheduler is an I/O scheduler designed for specialized workloads, but that in practice actually provides good performance across multiple workloads. It is fundamentally different from the previous I/O schedulers that have been covered, however.
The CFQ I/O scheduler assigns incoming I/O requests to specific queues based on the process originating the I/O request. For example, I/O requests from process foo go in foo's queues, and I/O requests from process bar go in bar's queue. Within each queue, requests are coalesced with adjacent requests and insertion sorted. The queues are thus kept sorted sector-wise, as with the other I/O scheduler's queues. The difference with the CFQ I/O scheduler is that there is one queue for each process submitting I/O.
The CFQ I/O scheduler then services the queues round robin, plucking a configurable number of requests (by default, four) from each queue before continuing on to the next. This provides fairness at a per-process level, assuring that each process receives a fair slice of the disk's bandwidth. The intended workload is multimedia, in which such a fair algorithm can guarantee that, for example, an audio player is able to always refill its audio buffers from disk in time. In practice, however, the CFQ I/O scheduler performs well in many scenarios.
The Complete Fair Queuing I/O scheduler lives in drivers/block/cfq-iosched.c. It is recommended for desktop workloads, although it performs reasonably well in nearly all workloads without any pathological corner cases.
The Noop I/O Scheduler
A fourth and final I/O scheduler is the Noop I/O scheduler, so named because it is basically a noopit does not do much. The Noop I/O scheduler does not perform sorting or any other form of seek-prevention whatsoever. In turn, it has no need to implement anything akin to the slick algorithms to minimize request latency that you saw in the previous three I/O schedulers.
The Noop I/O scheduler does perform merging, however, as its lone chore. When a new request is submitted to the queue, it is coalesced with any adjacent requests. Other than this operation, the Noop I/O Scheduler truly is a noop, merely maintaining the request queue in near-FIFO order, from which the block device driver can pluck requests.
The Noop I/O scheduler is not the lazy and worthless I/O scheduler of the bunch; its lack of hard work is with reason. It is intended for block devices that are truly random-access, such as flash memory cards. If a block device has little or no overhead associated with "seeking," then there is no need for insertion sorting of incoming requests, and the Noop I/O scheduler is the ideal candidate.
The Noop I/O scheduler lives in drivers/block/noop-iosched.c. It is intended only for random-access devices.
I/O Scheduler Selection
You have now seen four different I/O schedulers in the 2.6 kernel. Each of these I/O schedulers can be enabled and built into the kernel. By default, block devices use the Anticipatory I/O scheduler. This can be overridden via the boot-time option elevator=foo on the kernel command line, where foo is a valid and enabled I/O Scheduler. See Table 13.2.
Table 13.2. Parameters Given to the elevator OptionParameter | I/O Scheduler |
|---|
as | Anticipatory | cfq | Complete Fair Queuing | deadline | Deadline | noop | Noop |
For example, the kernel command line option elevator=cfq would enable use of the Complete Fair Queuing I/O scheduler for all block devices.
Summary
In this chapter, we discussed the fundamentals of block devices and we looked at the data structures used by the block I/O layer: The bio, representing in-flight I/O; the buffer_head, representing a block-to-page mapping; and the request structure, representing a specific I/O request. We followed the I/O request on its brief but important life, culminating in the I/O scheduler. We discussed the dilemmas involved in scheduling I/O and went over the four I/O schedulers currently in the Linux kernel, as well as the old Linus Elevator from 2.4.
Next up, we will tackle the process address space.
Chapter 14. The Process Address Space
Chapter 11, "Memory Management," looked at how the kernel manages physical memory. In addition to managing its own memory, the kernel also has to manage the process address spacethe representation of memory given to each user-space process on the system. Linux is a virtual memory operating system, and thus the resource of memory is virtualized among the processes on the system. To an individual process, the view is as if it alone has full access to the system's physical memory. More importantly, the address space of even a single process can be much larger than physical memory. This chapter discusses how the kernel manages the process address space.
The process address space consists of the linear address range presented to each process and, more importantly, the addresses within this space that the process is allowed to use. Each process is given a flat 32- or 64-bit address space, with the size depending on the architecture. The term "flat" describes the fact that the address space exists in a single range. (As an example, a 32-bit address space extends from the address 0 to 429496729.) Some operating systems provide a segmented address space, with addresses existing not in a single linear range, but instead in multiple segments. Modern virtual memory operating systems generally have a flat memory model and not a segmented one. Normally, this flat address space is unique to each process. A memory address in one process's address space tells nothing of that memory address in another process's address space. Both processes can have different data at the same address in their respective address spaces. Alternatively, processes can elect to share their address space with other processes. We know these processes as threads.
A memory address is a given value within the address space, such as 4021f000. This particular value identifies a specific byte in a process's 32-bit address space. The interesting part of the address space is the intervals of memory addresses, such as 08048000-0804c000, that the process has permission to access. These intervals of legal addresses are called memory areas. The process, through the kernel, can dynamically add and remove memory areas to its address space.
The process can access a memory address only in a valid memory area. Memory areas have associated permissions, such as readable, writable, and executable, that the associated process must respect. If a process accesses a memory address not in a valid memory area, or if it accesses a valid area in an invalid manner, the kernel kills the process with the dreaded "Segmentation Fault" message.
Memory areas can contain all sorts of goodies, such as
A memory map of the executable file's code, called the text section A memory map of the executable file's initialized global variables, called the data section A memory map of the zero page (a page consisting of all zeros, used for purposes such as this) containing uninitialized global variables, called the bss section A memory map of the zero page used for the process's user-space stack (do not confuse this with the process's kernel stack, which is separate and maintained and used by the kernel) An additional text, data, and bss section for each shared library, such as the C library and dynamic linker, loaded into the process's address space Any memory mapped files Any shared memory segments Any anonymous memory mappings, such as those associated with malloc()
All valid addresses in the process address space exist in exactly one area; memory areas do not overlap. As you can see, there is a separate memory area for each different chunk of memory in a running process: the stack, the object code, global variables, mapped file, and so on.
The Memory Descriptor
The kernel represents a process's address space with a data structure called the memory descriptor. This structure contains all the information related to the process address space. The memory descriptor is represented by struct mm_struct and defined in <linux/sched.h>.
Let's look at the memory descriptor, with comments added describing each field:
struct mm_struct {
struct vm_area_struct *mmap; /* list of memory areas */
struct rb_root mm_rb; /* red-black tree of VMAs */
struct vm_area_struct *mmap_cache; /* last used memory area */
unsigned long free_area_cache; /* 1st address space hole */
pgd_t *pgd; /* page global directory */
atomic_t mm_users; /* address space users */
atomic_t mm_count; /* primary usage counter */
int map_count; /* number of memory areas */
struct rw_semaphore mmap_sem; /* memory area semaphore */
spinlock_t page_table_lock; /* page table lock */
struct list_head mmlist; /* list of all mm_structs */
unsigned long start_code; /* start address of code */
unsigned long end_code; /* final address of code */
unsigned long start_data; /* start address of data */
unsigned long end_data; /* final address of data */
unsigned long start_brk; /* start address of heap */
unsigned long brk; /* final address of heap */
unsigned long start_stack; /* start address of stack */
unsigned long arg_start; /* start of arguments */
unsigned long arg_end; /* end of arguments */
unsigned long env_start; /* start of environment */
unsigned long env_end; /* end of environment */
unsigned long rss; /* pages allocated */
unsigned long total_vm; /* total number of pages */
unsigned long locked_vm; /* number of locked pages */
unsigned long def_flags; /* default access flags */
unsigned long cpu_vm_mask; /* lazy TLB switch mask */
unsigned long swap_address; /* last scanned address */
unsigned dumpable:1; /* can this mm core dump? */
int used_hugetlb; /* used hugetlb pages? */
mm_context_t context; /* arch-specific data */
int core_waiters; /* thread core dump waiters */
struct completion *core_startup_done; /* core start completion */
struct completion core_done; /* core end completion */
rwlock_t ioctx_list_lock; /* AIO I/O list lock */
struct kioctx *ioctx_list; /* AIO I/O list */
struct kioctx default_kioctx; /* AIO default I/O context */
};
The mm_users field is the number of processes using this address space. For example, if two threads share this address space, mm_users is equal to two. The mm_count field is the primary reference count for the mm_struct. All mm_users equate to one increment of mm_count. Thus, in the previous example, mm_count is only one. Only when mm_users reaches zero (when both threads exit) is mm_count decremented. When mm_count finally reaches zero, there are no remaining references to this mm_struct and it is freed. Having two counters enables the kernel to differentiate between the main usage counter (mm_count) and the number of processes using the address space (mm_users).
The mmap and mm_rb fields are different data structures that contain the same thing: all the memory areas in this address space. The former stores them in a linked list, whereas the latter stores them in a red-black tree. A red-black tree is a type of binary tree; like all binary trees, searching for a given element is an O(log n) operation. For further discussion on red-black trees, see "Lists and Trees of Memory Areas," later in this chapter.
Although the kernel would normally avoid the extra baggage of using two data structures to organize the same data, the redundancy comes in handy here. The mmap data structure, as a linked list, allows for simple and efficient traversing of all elements. On the other hand, the mm_rb data structure, as a red-black tree, is more suitable to searching for a given element. Memory areas are discussed in more detail later in this chapter.
All of the mm_struct structures are strung together in a doubly linked list via the mmlist field. The initial element in the list is the init_mm memory descriptor, which describes the address space of the init process. The list is protected from concurrent access via the mmlist_lock, which is defined in kernel/fork.c. The total number of memory descriptors is stored in the mmlist_nr global integer, which is defined in the same place.
Allocating a Memory Descriptor
The memory descriptor associated with a given task is stored in the mm field of the task's process descriptor. Thus, current->mm is the current process's memory descriptor. The copy_mm() function is used to copy a parent's memory descriptor to its child during fork(). The mm_struct structure is allocated from the mm_cachep slab cache via the allocate_mm() macro in kernel/fork.c. Normally, each process receives a unique mm_struct and thus a unique process address space.
Processes may elect to share their address spaces with their children by means of the CLONE_VM flag to clone().The process is then called a thread. Recall from Chapter 3, "Process Management," that this is essentially the only difference between normal processes and so-called threads in Linux; the Linux kernel does not otherwise differentiate between them. Threads are regular processes to the kernel that merely share certain resources.
In the case that CLONE_VM is specified, allocate_mm() is not called and the process's mm field is set to point to the memory descriptor of its parent via this logic in copy_mm():
if (clone_flags & CLONE_VM) {
/*
* current is the parent process and
* tsk is the child process during a fork()
*/
atomic_inc(¤t->mm->mm_users);
tsk->mm = current->mm;
}
Destroying a Memory Descriptor
When the process associated with a specific address space exits, the exit_mm() function is invoked. This function performs some housekeeping and updates some statistics. It then calls mmput(), which decrements the memory descriptor's mm_users user counter. If the user count reaches zero, mmdrop() is called to decrement the mm_count usage counter. If that counter is finally zero, then the free_mm() macro is invoked to return the mm_struct to the mm_cachep slab cache via kmem_cache_free(), because the memory descriptor does not have any users.
The mm_struct and Kernel Threads
Kernel threads do not have a process address space and therefore do not have an associated memory descriptor. Thus, the mm field of a kernel thread's process descriptor is NULL. This is pretty much the definition of a kernel threadprocesses that have no user context.
This lack of an address space is fine, because kernel threads do not ever access any user-space memory (whose would they access?). Because kernel threads do not have any pages in user-space, they do not really deserve their own memory descriptor and page tables (page tables are discussed later in the chapter). Despite this, kernel threads need some of the data, such as the page tables, even to access kernel memory. To provide kernel threads the needed data, without wasting memory on a memory descriptor and page tables, or wasting processor cycles to switch to a new address space whenever a kernel thread begins running, kernel threads use the memory descriptor of whatever task ran previously.
Whenever a process is scheduled, the process address space referenced by the process's mm field is loaded. The active_mm field in the process descriptor is then updated to refer to the new address space. Kernel threads do not have an address space and mm is NULL. Therefore, when a kernel thread is scheduled, the kernel notices that mm is NULL and keeps the previous process's address space loaded. The kernel then updates the active_mm field of the kernel thread's process descriptor to refer to the previous process's memory descriptor. The kernel thread can then use the previous process's page tables as needed. Because kernel threads do not access user-space memory, they make use of only the information in the address space pertaining to kernel memory, which is the same for all processes.
Memory Areas
Memory areas are represented by a memory area object, which is stored in the vm_area_struct structure and defined in <linux/mm.h>. Memory areas are often called virtual memory areas or VMA's in the kernel.
The vm_area_struct structure describes a single memory area over a contiguous interval in a given address space. The kernel treats each memory area as a unique memory object. Each memory area shares certain properties, such as permissions and a set of associated operations. In this manner, the single VMA structure can represent multiple types of memory areasfor example, memory-mapped files or the process's user-space stack. This is similar to the object-oriented approach taken by the VFS layer (see Chapter 12, "The Virtual Filesystem"). Here's the structure, with comments added describing each field:
struct vm_area_struct {
struct mm_struct *vm_mm; /* associated mm_struct */
unsigned long vm_start; /* VMA start, inclusive */
unsigned long vm_end; /* VMA end , exclusive */
struct vm_area_struct *vm_next; /* list of VMA's */
pgprot_t vm_page_prot; /* access permissions */
unsigned long vm_flags; /* flags */
struct rb_node vm_rb; /* VMA's node in the tree */
union { /* links to address_space->i_mmap or i_mmap_nonlinear */
struct {
struct list_head list;
void *parent;
struct vm_area_struct *head;
} vm_set;
struct prio_tree_node prio_tree_node;
} shared;
struct list_head anon_vma_node; /* anon_vma entry */
struct anon_vma *anon_vma; /* anonymous VMA object */
struct vm_operations_struct *vm_ops; /* associated ops */
unsigned long vm_pgoff; /* offset within file */
struct file *vm_file; /* mapped file, if any */
void *vm_private_data; /* private data */
};
Recall that each memory descriptor is associated with a unique interval in the process's address space. The vm_start field is the initial (lowest) address in the interval and the vm_end field is the first byte after the final (highest) address in the interval. That is, vm_start is the inclusive start and vm_end is the exclusive end of the memory interval. Thus, vm_end vm_start is the length in bytes of the memory area, which exists over the interval [vm_start, vm_end). Intervals in different memory areas in the same address space cannot overlap.
The vm_mm field points to this VMA's associated mm_struct. Note each VMA is unique to the mm_struct to which it is associated. Therefore, even if two separate processes map the same file into their respective address spaces, each has a unique vm_area_struct to identify its unique memory area. Conversely, two threads that share an address space also share all the vm_area_struct structures therein.
VMA Flags
The vm_flags field contains bit flags, defined in <linux/mm.h>, that specify the behavior of and provide information about the pages contained in the memory area. Unlike permissions associated with a specific physical page, the VMA flags specify behavior for which the kernel is responsible, not the hardware. Furthermore, vm_flags contains information that relates to each page in the memory area, or the memory area as a whole, and not specific individual pages. Table 14.1 is a listing of the possible vm_flags values.
Table 14.1. VMA FlagsFlag | Effect on the VMA and its pages |
|---|
VM_READ | Pages can be read from | VM_WRITE | Pages can be written to | VM_EXEC | Pages can be executed | VM_SHARED | Pages are shared | VM_MAYREAD | The VM_READ flag can be set | VM_MAYWRITE | The VM_WRITE flag can be set | VM_MAYEXEC | The VM_EXEC flag can be set | VM_MAYSHARE | The VM_SHARE flag can be set | VM_GROWSDOWN | The area can grow downward | VM_GROWSUP | The area can grow upward | VM_SHM | The area is used for shared memory | VM_DENYWRITE | The area maps an unwritable file | VM_EXECUTABLE | The area maps an executable file | VM_LOCKED | The pages in this area are locked | VM_IO | The area maps a device's I/O space | VM_SEQ_READ | The pages seem to be accessed sequentially | VM_RAND_READ | The pages seem to be accessed randomly | VM_DONTCOPY | This area must not be copied on fork() | VM_DONTEXPAND | This area cannot grow via mremap() | VM_RESERVED | This area must not be swapped out | VM_ACCOUNT | This area is an accounted VM object | VM_HUGETLB | This area uses hugetlb pages | VM_NONLINEAR | This area is a nonlinear mapping |
Let's look at some of the more important and interesting flags in depth. The VM_READ, VM_WRITE, and VM_EXEC flags specify the usual read, write, and execute permissions for the pages in this particular memory area. They are combined as needed to form the appropriate access permissions that a process accessing this VMA must respect. For example, the object code for a process might be mapped with VM_READ and VM_EXEC, but not VM_WRITE. On the other hand, the data section from an executable object would be The VM_SHARED flag specifies whether the memory area contains a mapping that is shared among multiple processes. If the flag is set, it is intuitively called a shared mapping. If the flag is not set, only a single process can view this particular mapping, and it is called a private mapping. mapped VM_READ and VM_WRITE, but VM_EXEC would make little sense. Meanwhile, a read-only memory mapped data file would be mapped with only the VM_READ flag.
The VM_IO flag specifies that this memory area is a mapping of a device's I/O space. This field is typically set by device drivers when mmap() is called on their I/O space. It specifies, among other things, that the memory area must not be included in any process's core dump. The VM_RESERVED flag specifies that the memory region must not be swapped out. It is also used by device driver mappings.
The VM_SEQ_READ flag provides a hint to the kernel that the application is performing sequential (that is, linear and contiguous) reads in this mapping. The kernel can then opt to increase the read-ahead performed on the backing file. The VM_RAND_READ flag specifies the exact opposite: that the application is performing relatively random (that is, not sequential) reads in this mapping. The kernel can then opt to decrease or altogether disable read-ahead on the backing file. These flags are set via the madvise() system call with the MADV_SEQUENTIAL and MADV_RANDOM flags, respectively. Read-ahead is the act of reading sequentially ahead of requested data, in hopes that the additional data will be needed soon. Such behavior is beneficial if applications are reading data sequentially. If data access patterns are random, however, read-ahead is not effective.
VMA Operations
The vm_ops field in the vm_area_struct structure points to the table of operations associated with a given memory area, which the kernel can invoke to manipulate the VMA. The vm_area_struct acts as a generic object for representing any type of memory area, and the operations table describes the specific methods that can operate on this particular instance of the object.
The operations table is represented by struct vm_operations_struct and is defined in <linux/mm.h>:
struct vm_operations_struct {
void (*open) (struct vm_area_struct *);
void (*close) (struct vm_area_struct *);
struct page * (*nopage) (struct vm_area_struct *, unsigned long, int);
int (*populate) (struct vm_area_struct *, unsigned long, unsigned long,
pgprot_t, unsigned long, int);
};
Here's a description for each individual method:
void open(struct vm_area_struct *area) This function is invoked when the given memory area is added to an address space. void close(struct vm_area_struct *area) This function is invoked when the given memory area is removed from an address space.
struct page * nopage(struct vm_area_sruct *area,
unsigned long address,
int unused)
This function is invoked by the page fault handler when a page that is not present in physical memory is accessed.
int populate(struct vm_area_struct *area,
unsigned long address,
unsigned long len, pgprot_t prot,
unsigned long pgoff, int nonblock)
This function is invoked by the remap_pages() system call to prefault a new mapping.
Lists and Trees of Memory Areas
As discussed, memory areas are accessed via both the mmap and the mm_rb fields of the memory descriptor. These two data structures independently point to all the memory area objects associated with the memory descriptor. In fact, they both contain pointers to the very same vm_area_struct structures, merely represented in different ways.
The first field, mmap, links together all the memory area objects in a singly linked list. Each vm_area_struct structure is linked into the list via its vm_next field. The areas are sorted by ascended address. The first memory area is the vm_area_struct structure to which mmap points. The last structure points to NULL.
The second field, mm_rb, links together all the memory area objects in a red-black tree. The root of the red-black tree is mm_rb, and each vm_area_struct structure in this address space is linked to the tree via its vm_rb field.
A red-black tree is a type of balanced binary tree. Each element in a red-black tree is called a node. The initial node is called the root of the tree. Most nodes have two children: a left child and a right child. Some nodes have only one child, and the final nodes, called leaves, have no children. For any node, the elements to the left are smaller in value, whereas the elements to the right are larger in value. Furthermore, each node is assigned a color (red or black, hence the name of this tree) according to two rules: The children of a red node are black and every path through the tree from a node to a leaf must contain the same number of black nodes. The root node is always red. Searching of, insertion to, and deletion from the tree is an O(log(n)) operation.
The linked list is used when every node needs to be traversed. The red-black tree is used when locating a specific memory area in the address space. In this manner, the kernel uses the redundant data structures to provide optimal performance regardless of the operation performed on the memory areas.
Memory Areas in Real Life
Let's look at a particular process's address space and the memory areas inside. For this task, I'm using the useful /proc filesystem and the pmap(1) utility. The example is a very simple user-space program, which does absolutely nothing of value, except act as an example:
int main(int argc, char *argv[])
{
return 0;
}
Take note of a few of the memory areas in this process's address space. Right off the bat, you know there is the text section, data section, and bss. Assuming this process is dynamically linked with the C library, these three memory areas also exist for libc.so and again for ld.so. Finally, there is also the process's stack.
The output from /proc/<pid>/maps lists the memory areas in this process's address space:
rml@phantasy:~$ cat /proc/1426/maps
00e80000-00faf000 r-xp 00000000 03:01 208530 /lib/tls/libc-2.3.2.so
00faf000-00fb2000 rw-p 0012f000 03:01 208530 /lib/tls/libc-2.3.2.so
00fb2000-00fb4000 rw-p 00000000 00:00 0
08048000-08049000 r-xp 00000000 03:03 439029 /home/rml/src/example
08049000-0804a000 rw-p 00000000 03:03 439029 /home/rml/src/example
40000000-40015000 r-xp 00000000 03:01 80276 /lib/ld-2.3.2.so
40015000-40016000 rw-p 00015000 03:01 80276 /lib/ld-2.3.2.so
4001e000-4001f000 rw-p 00000000 00:00 0
bfffe000-c0000000 rwxp fffff000 00:00 0
The data is in the form
start-end permission offset major:minor inode file
The pmap(1) utility formats this information in a bit more readable manner:
rml@phantasy:~$ pmap 1426
example[1426]
00e80000 (1212 KB) r-xp (03:01 208530) /lib/tls/libc-2.3.2.so
00faf000 (12 KB) rw-p (03:01 208530) /lib/tls/libc-2.3.2.so
00fb2000 (8 KB) rw-p (00:00 0)
08048000 (4 KB) r-xp (03:03 439029) /home/rml/src/example
08049000 (4 KB) rw-p (03:03 439029) /home/rml/src/example
40000000 (84 KB) r-xp (03:01 80276) /lib/ld-2.3.2.so
40015000 (4 KB) rw-p (03:01 80276) /lib/ld-2.3.2.so
4001e000 (4 KB) rw-p (00:00 0)
bfffe000 (8 KB) rwxp (00:00 0) [ stack ]
mapped: 1340 KB writable/private: 40 KB shared: 0 KB
The first three rows are the text section, data section, and bss of libc.so, the C library. The next two rows are the text and data section of our executable object. The following three rows are the text section, data section, and bss for ld.so, the dynamic linker. The last row is the process's stack.
Note how the text sections are all readable and executable, which is what you expect for object code. On the other hand, the data section and bss (which both contain global variables) are marked readable and writable, but not executable. The stack is, naturally, readable, writable, and executablenot of much use otherwise.
The entire address space takes up about 1340KB, but only 40KB are writable and private. If a memory region is shared or nonwritable, the kernel keeps only one copy of the backing file in memory. This might seem like common sense for shared mappings, but the nonwritable case can come as a bit of a surprise. If you consider the fact that a nonwritable mapping can never be changed (the mapping is only read from), it is clear that it is safe to load the image only once into memory. Therefore, the C library need only occupy 1212KB in physical memory, and not 1212KB multiplied by every process using the library. Because this process has access to about 1340KB worth of data and code, yet consumes only about 40KB of physical memory, the space savings from such sharing is substantial.
Note the memory areas without a mapped file that are on device 00:00 and inode zero. This is the zero page. The zero page is a mapping that consists of all zeros. By mapping the zero page over a writable memory area, the area is in effect "initialized" to all zeros. This is important in that it provides a zeroed memory area, which is expected by the bss. Because the mapping is not shared, as soon as the process writes to this data a copy is made (à la copy-on-write) and the value updated from zero.
Each of the memory areas that are associated with the process corresponds to a vm_area_struct structure. Because the process was not a thread, it has a unique mm_struct structure referenced from its task_struct.
Manipulating Memory Areas
The kernel often has to find whether any memory areas in a process address space match a given criteria, such as whether a given address exists in a memory area. These operations are frequent, and form the basis of the mmap() routine, which is covered in the next section. A handful of helper functions are defined to assist these jobs.
These functions are all declared in <linux/mm.h>.
find_vma()
The find_vma() function is defined in mm/mmap.c.
The function searches the given address space for the first memory area whose vm_end field is greater than addr. In other words, this function finds the first memory area that contains addr or begins at an address greater than addr. If no such memory area exists, the function returns NULL. Otherwise, a pointer to the vm_area_struct structure is returned. Note that because the returned VMA may start at an address greater than addr, the given address does not necessarily lie inside the returned VMA. The result of the find_vma() function is cached in the mmap_cache field of the memory descriptor. Because of the probability of an operation on one VMA being followed by more operations on that same VMA, the cached results have a decent hit rate (about 3040% in practice). Checking the cached result is quick. If the given address is not in the cache, you must search the memory areas associated with this memory descriptor for a match. This is done via the red-black tree:
struct vm_area_struct * find_vma(struct mm_struct *mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
if (mm) {
vma = mm->mmap_cache;
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
struct rb_node *rb_node;
rb_node = mm->mm_rb.rb_node;
vma = NULL;
while (rb_node) {
struct vm_area_struct * vma_tmp;
vma_tmp = rb_entry(rb_node,
struct vm_area_struct, vm_rb);
if (vma_tmp->vm_end > addr) {
vma = vma_tmp;
if (vma_tmp->vm_start <= addr)
break;
rb_node = rb_node->rb_left;
} else
rb_node = rb_node->rb_right;
}
if (vma)
mm->mmap_cache = vma;
}
}
return vma;
}
The initial check of mmap_cache tests whether the cached VMA contains the desired address. Note that simply checking whether the VMA's vm_end field is bigger than addr would not ensure that this is the first such VMA that is larger than addr. Thus, for the cache to be useful here, the given addr must lie in the VMAthankfully, this is just the sort of scenario in which consecutive operations on the same VMA would occur.
If the cache does not contain the desired VMA, the function must search the red-black tree. If the current VMA's vm_end is larger than addr, the function follows the left child; otherwise, it follows the right child. The function terminates as soon as a VMA is found that contains addr. If such a VMA is not found, the function continues traversing the tree and returns the first VMA it found that starts after addr. If no VMA is ever found, NULL is returned.
find_vma_prev()
The find_vma_prev() function works the same as find_vma(), but it also returns the last VMA before addr. The function is also defined in mm/mmap.c and declared in <linux/mm.h>:
struct vm_area_struct * find_vma_prev(struct mm_struct *mm, unsigned long addr,
struct vm_area_struct **pprev)
The pprev argument stores a pointer to the VMA preceding addr.
find_vma_intersection()
The find_vma_intersection() function returns the first VMA that overlaps a given address interval. The function is defined in <linux/mm.h> because it is inline:
static inline struct vm_area_struct *
find_vma_intersection(struct mm_struct *mm,
unsigned long start_addr,
unsigned long end_addr)
{
struct vm_area_struct *vma;
vma = find_vma(mm, start_addr);
if (vma && end_addr <= vma->vm_start)
vma = NULL;
return vma;
}
The first parameter is the address space to search, start_addr is the start of the interval, and end_addr is the end of the interval.
Obviously, if find_vma() returns NULL, so would find_vma_intersection(). If find_vma() returns a valid VMA, however, find_vma_intersection() returns the same VMA only if it does not start after the end of the given address range. If the returned memory area does start after the end of the given address range, the function returns NULL.
mmap() and do_mmap(): Creating an Address Interval
The do_mmap() function is used by the kernel to create a new linear address interval. Saying that this function creates a new VMA is not technically correct, because if the created address interval is adjacent to an existing address interval, and if they share the same permissions, the two intervals are merged into one. If this is not possible, a new VMA is created. In any case, do_mmap() is the function used to add an address interval to a process's address spacewhether that means expanding an existing memory area or creating a new one.
The do_mmap() function is declared in <linux/mm.h>:
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
This function maps the file specified by file at offset offset for length len. The file parameter can be NULL and offset can be zero, in which case the mapping will not be backed by a file. In that case, this is called an anonymous mapping. If a file and offset are provided, the mapping is called a file-backed mapping.
The addr function optionally specifies the initial address from which to start the search for a free interval.
The prot parameter specifies the access permissions for pages in the memory area. The possible permission flags are defined in <asm/mman.h> and are unique to each supported architecture, although in practice each architecture defines the flags listed in Table 14.2.
Table 14.2. Page Protection FlagsFlag | Effect on the Pages in the New Interval |
|---|
PROT_READ | Corresponds to VM_READ | PROT_WRITE | Corresponds to VM_WRITE | PROT_EXEC | Corresponds to VM_EXEC | PROT_NONE | Page cannot be accessed |
The flags parameter specifies flags that correspond to the remaining VMA flags. These flags are also defined in <asm/mman.h>. See Table 14.3.
Table 14.3. Page Protection FlagsFlag | Effect on the New Interval |
|---|
MAP_SHARED | The mapping can be shared | MAP_PRIVATE | The mapping cannot be shared | MAP_FIXED | The new interval must start at the given address addr | MAP_ANONYMOUS | The mapping is not file-backed, but is anonymous | MAP_GROWSDOWN | Corresponds to VM_GROWSDOWN | MAP_DENYWRITE | Corresponds to VM_DENYWRITE | MAP_EXECUTABLE | Corresponds to VM_EXECUTABLE | MAP_LOCKED | Corresponds to VM_LOCKED | MAP_NORESERVE | No need to reserve space for the mapping | MAP_POPULATE | Populate (prefault) page tables | MAP_NONBLOCK | Do not block on I/O |
If any of the parameters are invalid, do_mmap() returns a negative value. Otherwise, a suitable interval in virtual memory is located. If possible, the interval is merged with an adjacent memory area. Otherwise, a new vm_area_struct structure is allocated from the vm_area_cachep slab cache, and the new memory area is added to the address space's linked list and red-black tree of memory areas via the vma_link() function. Next, the total_vm field in the memory descriptor is updated. Finally, the function returns the initial address of the newly created address interval.
The mmap() System Call
The do_mmap() functionality is exported to user-space via the mmap() system call. The mmap() system call is defined as
void * mmap2(void *start,
size_t length,
int prot,
int flags,
int fd,
off_t pgoff)
This system call is named mmap2() because it is the second variant of mmap(). The original mmap() took an offset in bytes as the last parameter; the current mmap2() receives the offset in pages. This enables larger files with larger offsets to be mapped. The original mmap(), as specified by POSIX, is available from the C library as mmap(), but is no longer implemented in the kernel proper, whereas the new version is available as mmap2(). Both library calls use the mmap2() system call, with the original mmap() converting the offset from bytes to pages.
munmap() and do_munmap(): Removing an Address Interval
The do_munmap() function removes an address interval from a specified process address space. The function is declared in <linux/mm.h>:
int do_munmap(struct mm_struct *mm, unsigned long start, size_t len)
The first parameter specifies the address space from which the interval starting at address start of length len bytes is removed. On success, zero is returned. Otherwise, a negative error code is returned.
The munmap() System Call
The munmap() system call is exported to user-space as a means to allow processes to remove address intervals from their address space; it is the complement of the mmap() system call:
int munmap(void *start, size_t length)
The system call is defined in mm/mmap.c and acts as a very simple wrapper to do_munmap():
asmlinkage long sys_munmap(unsigned long addr, size_t len)
{
int ret;
struct mm_struct *mm;
mm = current->mm;
down_write(&mm->mmap_sem);
ret = do_munmap(mm, addr, len);
up_write(&mm->mmap_sem);
return ret;
}
Page Tables
Although applications operate on virtual memory that is mapped to physical addresses, processors operate directly on those physical addresses. Consequently, when an application accesses a virtual memory address, it must first be converted to a physical address before the processor can resolve the request. Performing this lookup is done via page tables. Page tables work by splitting the virtual address into chunks. Each chunk is used as an index into a table. The table points to either another table or the associated physical page.
In Linux, the page tables consist of three levels. The multiple levels allow a sparsely populated address space, even on 64-bit machines. If the page tables were implemented as a single static array, their size on even 32-bit architectures would be enormous. Linux uses three levels of page tables even on architectures that do not support three levels in hardware (for example, some hardware uses only two levels or implements a hash in hardware). Using three levels is a sort of "greatest common denominator"architectures with a less complicated implementation can simplify the kernel page tables as needed with compiler optimizations.
The top-level page table is the page global directory (PGD). The PGD consists of an array of pgd_t types. On most architectures, the pgd_t type is an unsigned long. The entries in the PGD point to entries in the second-level directory, the PMD.
The second-level page table is the page middle directory (PMD). The PMD is an array of pmd_t types. The entries in the PMD point to entries in the PTE.
The final level is called simply the page table and consists of page table entries of type pte_t. Page table entries point to physical pages.
In most architectures, page table lookups are handled (at least to some degree) by hardware. In normal operation, hardware can handle much of the responsibility of using the page tables. The kernel must set things up, however, in such a way that the hardware is happy and can do its thing. Figure 14.1 diagrams the flow of a virtual to physical address lookup using page tables.
Each process has its own page tables (threads share them, of course). The pgd field of the memory descriptor points to the process's page global directory. Manipulating and traversing page tables requires the page_table_lock, which is located inside the associated memory descriptor.
Page table data structures are quite architecture dependent and thus are defined in <asm/page.h>.
Because nearly every access of a page in virtual memory must be resolved to its corresponding address in physical memory, the performance of the page tables is very critical. Unfortunately, looking up all these addresses in memory can be done only so quickly. To facilitate this, most processors implement a translation lookaside buffer, or simply TLB, which acts as a hardware cache of virtual-to-physical mappings. When accessing a virtual address, the processor first checks whether the mapping is cached in the TLB. If there is a hit, the physical address is immediately returned. Otherwise, if there is a miss, the page tables are consulted for the corresponding physical address.
Nonetheless, page table management is still a criticaland evolvingpart of the kernel. Changes to this area in 2.6 include allocating parts of the page table out of high memory. Future possibilities include shared page tables with copy-on-write semantics. In that scheme, page tables would be shared between parent and child across a fork(). When the parent or the child attempted to modify a particular page table entry, a copy would be created and the two processes would no longer share that entry. Sharing page tables would remove the overhead of copying the page table entries on fork().
Conclusion
In this suspense-laden chapter, we looked at the abstraction of virtual memory provided to each process. We looked at how the kernel represents the process address space (via struct mm_struct) and how the kernel represents regions of memory within that space (struct vm_area_struct). We covered how the kernel creates (via mmap()) and destroys (via munmap()) these memory regions. Finally, we covered page tables. Because Linux is a virtual memorybased operating system, these concepts are essential to its operation and process model.
The next chapter covers the page cache, a general in-memory data cache used to fulfill all page I/O, and how the kernel performs page-based data writeback. Hold on!
Chapter 16. Modules
Despite being "monolithic," in the sense of the whole kernel running in a single protection domain, the Linux kernel is modular, allowing the dynamic insertion and removal of code from the kernel at run-time. Related subroutines, data, and entry and exit points are grouped together in a single binary image, a loadable kernel object, called a module. Support for modules allows systems to have only a minimal base kernel image, with optional features and drivers supplied via module. Modules also provide easy removal and reloading of kernel code, facilitate debugging, and allow for the loading of new drivers on demand in response to the hotplugging of new devices.
This chapter looks at the magic behind modules in the kernel and how you can write your very own module.
Building Modules
In 2.6, building modules is easier than ever, thanks to the new "kbuild" build system. The first decision in building modules is deciding where the module source is to live. You can add the module source to the kernel source proper, either as a patch or by eventually merging your code into the official tree. Alternatively, you can maintain and build your module source outside the source tree.
At Home in the Source Tree
Ideally, your module is an official part of Linux and thus lives in the kernel source tree. Getting your work into the kernel proper may require more maintenance at first, but it is usually the preferred solution.
The first step is deciding where in the kernel source tree your module is to live. Drivers are stored in subdirectories of the drivers/ directory in the root of the kernel source tree. Inside, they are further organized by class, type, and eventually specific driver. Character devices live in drivers/char/, whereas block devices live in drivers/block/ and USB devices live in drivers/usb/. The rules are not hard and fast because many USB devices are character devices. But the organization is fairly understandable and accurate.
Assume you have a character device and want to store it in drivers/char/. Inside this directory are numerous C source files and a handful of other directories. Drivers with only one or two source files might simply stick their source in this directory. Drivers with multiple source files and other accompanying junk might create a new subdirectory. There is no hard and fast rule.
Presume that you want to create your own subdirectory. In this fantasy, your driver is for a fishing pole with a computer interface, the Fish Master XL 2000 Titanium, so you need to create a fishing subdirectory inside drivers/char/.
Now you need to add a line to the Makefile in drivers/char/. So you edit drivers/char/Makefile and add
obj-m += fishing/
This causes the build system to descend into the fishing/ subdirectory whenever it compiles modules. More likely, your driver's compilation is contingent on a specific configuration option; for example, perhaps CONFIG_FISHING_POLE (see the section "Managing Configuration Options" later in this chapter for how to add a new con-figuration option). In that case, you would instead add the line
obj-$(CONFIG_FISHING_POLE) += fishing/
Finally, inside drivers/char/fishing/, you add a new Makefile with the following line:
obj-m += fishing.o
The build system will now descend into fishing/ and build the module fishing.ko from fishing.c. Yes, you write an extension of .o but the module is compiled as .ko.
Again, more likely, your fishing pole driver's compilation is conditional on a configuration option. So you probably want to do the following:
obj-$(CONFIG_FISHING_POLE) += fishing.o
One day, your fishing pole driver may get so complicatedautodetection of fishing line test is just the latest "must have"that it grows to occupy more than one source file. No problem, anglers! You simply make your Makefile read
obj-$(CONFIG_FISHING_POLE) += fishing.o
fishing-objs := fishing-main.o fishing-line.o
Now, fishing-main.c and fishing-line.c will be compiled and linked into fishing.ko.
Finally, you may need to pass to gcc additional compile flags during the build process solely for your file. To do so, simply add a line such as the following to your Makefile:
EXTRA_CFLAGS += -DTITANIUM_POLE
If you opted to place your source file(s) in drivers/char/ and not create a new subdirectory, you would merely place the preceding lines (that you placed in your Makefile in drivers/char/fishing/) into drivers/char/Makefile.
To compile, run the kernel build process as usual. If your module's build was conditioned on a configuration option, as it was with CONFIG_FISHING_POLE, make sure that the option is enabled before beginning.
Living Externally
If you prefer to maintain and build your module outside the kernel source tree, to live the life of an outsider, simply create a Makefile in your own source directory like the single line
obj-m := fishing.o
This compiles fishing.c into fishing.ko. If your source spans multiple files, then two lines will suffice:
obj-m := fishing.o
fishing-objs := fishing-main.o fishing-line.o
This compiles fishing-main.c and fishing-line.c into fishing.ko.
The main difference in living externally is the build process. Because your module lives outside the kernel tree, you need to instruct make on how to find the kernel source files and base Makefile. This is also easy:
make -C /kernel/source/location SUBDIRS=$PWD modules
where /kernel/source/location is the location of your configured kernel source tree. Recall that you should not store your working copy of the kernel source tree in /usr/src/linux but somewhere else, easily accessible, in your home directory.
Installing Modules
Compiled modules are installed into /lib/modules/version/kernel/. For example, with a kernel version of 2.6.10, the compiled fishing pole module would live at /lib/modules/2.6.10/kernel/drivers/char/fishing.ko if you stuck it directly in drivers/char/.
The following build command is used to install compiled modules into the correct location:
make modules_install
Naturally, this needs to be run as root.
Generating Module Dependencies
The Linux module utilities understand dependencies. This means that module chum can depend on module bait and when you load the chum module, the bait module is automatically loaded. This dependency information must be generated. Most Linux distributions generate the mapping automatically and keep it up to date on each boot. To build the module dependency information, as root simply run
depmod
To perform a quick update, rebuilding only the information for modules newer than the dependency information itself, run as root
depmod -A
The module dependency information is stored in the file /lib/modules/version/modules.dep.
Loading Modules
The simplest way to load a module is via insmod. This utility is very basic. It simply asks the kernel to load the module you specify. The insmod program does not perform any dependency resolution or advanced error checking. Usage is trivial. As root, simply run
insmod module
where module is the name of the module that you want to load. To load the fishing pole module, you would run
insmod fishing
In like fashion, to remove a module, you use the rmmod utility. As root, simply run
rmmod module
For example,
rmmod fishing
removes the fishing pole module.
These utilities, however, are trivial and unintelligent. The utility modprobe provides dependency resolution, intelligent error checking and reporting, and more advanced features and options. Its use is highly encouraged.
To insert a module into the kernel via modprobe, run as root
modprobe module [ module parameters ]
where module is the name of the module to load. Any following arguments are taken as parameters to pass to the module on load. See the section "Module Parameters" for a discussion on module parameters.
The modprobe command attempts to load not only the requested module, but also any modules on which it depends. Consequently, it is the preferred mechanism for loading kernel modules.
The modprobe command can also be used to remove modules from the kernel. Again, as root, run
modprobe r modules
where modules specifies one or more modules to remove. Unlike rmmod, modprobe also removes any modules on which the given module depends, if they are unused.
Section eight of the Linux manual pages provides a reference on their other, less used, options.
Managing Configuration Options
An earlier section in this chapter looked at compiling the fishing pole module only if the CONFIG_FISHING_POLE configuration option was set. Configuration options have been discussed in earlier chapters, too, but now let's look at actually adding a new one, continuing with the fishing pole example.
Thanks to the new "kbuild" system in the 2.6 kernel, adding new configuration options is very easy. All you have to do is add an entry to the Kconfig file responsible for the neck of the kernel source tree. For drivers, this is usually the very directory in which the source lives. If the fishing pole driver lives in drivers/char/, then you use drivers/char/Kconfig.
If you created a new subdirectory and want a new Kconfig file to live there, you have to source it from an existing Kconfig. You do this by adding a line such as
source "drivers/char/fishing/Kconfig"
to the existing Kconfig file, say drivers/char/Kconfig.
Entries in Kconfig are easy to add. The fishing pole module would look like
config FISHING_POLE
tristate "Fish Master XL support"
default n
help
If you say Y here, support for the Fish Master XL 2000 Titanium with
computer interface will be compiled into the kernel and accessible via
device node. You can also say M here and the driver will be built as a
module named fishing.ko.
If unsure, say N.
The first line defines what configuration option this entry represents. Note that the CONFIG_ prefix is assumed and not written.
The second line states that this option is a tristate, meaning that it can be built into the kernel (Y), built as a module (M), or not built at all (N). To disable the option of building as a modulesay, if this option represented a feature and not a moduleuse the directive bool instead of tristate. The quoted text following the directive provides the name of this option in the various configuration utilities.
The third line specifies the default for this option, which is off.
The help directive signifies that the rest of the test, indented as it is, is the help text for this entry. The various configuration tools can display this text when requested. Because this text is for users and developers building their own kernels, it can be succinct and to the point. Home users do not typically build kernels and, if they did, they could probably understand the configuration help as is.
There are other options, too. The depends directive specifies options that must be set before this option can be set. If the dependencies are not met, the option is disabled. For example, if you added the directive
depends on FISH_TANK
to the config entry, the module could not be enabled until the CONFIG_FISH_TANK module is enabled.
The select directive is like depends, except it forces the given option on if this option is selected. It should not be used as frequently as depends because it automatically enables other configuration options. Use is as simple as depends:
select BAIT
The configuration option CONFIG_BAIT is automatically enabled when CONFIG_ FISHING_POLE is enabled.
For both select and depends, you can request multiple options via &&. With depends, you can also specify that an option not be enabled by prefixing the option with an exclamation mark. For example,
depends on DUMB_DRIVERS && !NO_FISHING_ALLOWED
specifies that the driver depends on CONFIG_DUMB_DRIVERS being set and CONFIG_NO_ FISHING_ALLOWED being unset.
The TRistate and bool options can be followed by the directive if, which makes the entire option conditional on another configuration option. If the condition is not met, the configuration option is not only disabled but does not even appear in the configuration utilities. For example, the directive
bool "Deep Sea Mode" if OCEAN
instructs the configuration system to display this option only if CONFIG_X86 is set. Presumably, deep sea mode is available only if CONFIG_OCEAN is enabled.
The if directive can also follow the default directive, enforcing the default only if the conditional is met.
The configuration system exports several meta-options to help make configuration easier. The option CONFIG_EMBEDDED is enabled only if the user specified that he or she wishes to see options designed for disabling key features (presumably to save precious memory on embedded systems). The option CONFIG_BROKEN_ON_SMP is used to specify a driver that is not SMP-safe. Normally this option is not set, forcing the user to explicitly acknowledge the brokenness. New drivers, of course, should not use this flag. Finally, the CONFIG_EXPERIMENTAL option is used to flag options that are experimental or otherwise of beta quality. The option defaults to off, again forcing users to explicitly acknowledge the risk before they enable your driver.
Module Parameters
The Linux kernel provides a simple framework, allowing drivers to declare parameters that the user can specify on either boot or module load and then have these parameters exposed in your driver as global variables. These module parameters also show up in sysfs (see Chapter 17," kobjects and sysfs"). Consequently, creating and managing module parameters that can be specified in a myriad of convenient ways is trivial.
Defining a module parameter is done via the macro module_param():
module_param(name, type, perm);
where name is the name of both the parameter exposed to the user and the variable holding the parameter inside your module. The type argument holds the parameter's data type; it is one of byte, short, ushort, int, uint, long, ulong, charp, bool, or invbool. These types are, respectively, a byte, a short integer, an unsigned short integer, an integer, an unsigned integer, a long integer, an unsigned long integer, a pointer to a char, a Boolean, and a Boolean whose value is inverted from what the user specifies. The byte type is stored in a single char and the Boolean types are stored in variables of type int. The rest are stored in the corresponding primitive C types. Finally, the perm argument specifies the permissions of the corresponding file in sysfs. The permissions can be specified in the usual octal format, for example 0644 (owner can read and write, group can read, everyone else can read), or by ORing together the usual S_Ifoo defines, for example S_IRUGO | S_IWUSR (everyone can read, user can also write). A value of zero disables the sysfs entry altogether.
The macro does not declare the variable for you. You must do that before using the macro. Therefore, typical use might resemble
/* module parameter controlling the capability to allow live bait on the pole */
static int allow_live_bait = 1; /* default to on */
module_param(allow_live_bait, bool, 0644); /* a Boolean type */
This would be in the outermost scope of your module's source file. In other words, allow_live_bait is global.
It is possible to have the internal variable named differently than the external parameter. This is accomplished via module_param_named():
module_param_named(name, variable, type, perm);
where name is the externally viewable parameter name and variable is the name of the internal global variable. For example,
static unsigned int max_test = DEFAULT_MAX_LINE_TEST;
module_param_named(maximum_line_test, max_test, int, 0);
Normally, you would use a type of charp to define a module parameter that takes a string. The kernel copies the string provided by the user into memory and points your variable to the string. For example,
static char *name;
module_param(name, charp, 0);
If so desired, it is also possible to have the kernel copy the string directly into a character array that you supply. This is done via module_param_string():
module_param_string(name, string, len, perm);
where name is the external parameter name, string is the internal variable name, len is the size of the buffer named by string (or some smaller size, but that does not make much sense), and perm is the sysfs permissions (or zero to disable a sysfs entry altogether). For example,
static char species[BUF_LEN];
module_param_string(specifies, species, BUF_LEN, 0);
You can accept a comma-separated list of parameters that are stored in a C array via module_param_array():
module_param_array(name, type, nump, perm);
where name is again the external parameter and internal variable name, type is the data type, and perm is the sysfs permissions. The new argument, nump, is a pointer to an integer where the kernel will store the number of entries stored into the array. Note that the array pointed to by name must be statically allocated. The kernel determines the array's size at compile-time and ensures that it does not cause an overrun. Use is simple. For example,
static int fish[MAX_FISH];
static int nr_fish;
module_param_array(fish, int, &nr_fish, 0444);
You can name the internal array something different than the external parameter with module_param_array_named():
module_param_array_named(name, array, type, nump, perm);
The parameters are identical to the other macros.
Finally, you can document your parameters by using MODULE_PARM_DESC():
static unsigned short size = 1;
module_param(size, ushort, 0644);
MODULE_PARM_DESC(size, "The size in inches of the fishing pole " \
"connected to this computer.");
All these macros require the inclusion of <linux/moduleparam.h>.
Exported Symbols
When modules are loaded, they are dynamically linked into the kernel. As with user-space, dynamically linked binaries can call only into external functions that are explicitly exported for use. In the kernel, this is handled via special directives called EXPORT_ SYMBOL() and EXPORT_SYMBOL_GPL().
Functions that are exported are available for use by modules. Functions that are not exported cannot be invoked from modules. The linking and invoking rules are much more stringent for modules than code in the core kernel image. Core code can call any non-static interface in the kernel because all core source files are linked into a single base image. Exported symbols, of course, must be non-static too.
The set of kernel symbols that are exported are known as the exported kernel interfaces or even (gasp) the kernel API.
Exporting a symbol is easy. After the function is declared, it is usually followed by an EXPORT_SYMBOL(). For example,
/*
* get_pirate_beard_color - return the color of the current pirate's beard.
* pirate is a global variable accessible to this function.
* the color is defined in <linux/beard_colors.h>.
*/
int get_pirate_beard_color(void)
{
return pirate->beard->color;
}
EXPORT_SYMBOL(get_pirate_beard_color);
Presuming that get_pirate_beard_color() is also declared in an accessible header file, any module can now access it.
Some developers want their interfaces accessible to only GPL-compliant modules. This is enforced by the kernel linker through use of the MODULE_LICENSE(). If you wanted the previous function accessible to only modules that labeled themselves as GPL licensed, you would use instead
EXPORT_SYMBOL_GPL(get_pirate_beard_color);
If your code is configurable as a module, you must ensure that when compiled as a module all interfaces that it uses are exported. Otherwise linking errors (and a broken module) will result.
Wrapping Up Modules
This chapter looked at writing, building, loading, and unloading modules. We discussed what modules are and how Linux, despite being "monolithic," can load modular code dynamically. We discussed module parameters and exported symbols. We used a fictional fishing pole module (a creative device, if you will) to illustrate writing a module and adding features such as parameters to it.
The next chapter looks at kobjects and the sysfs filesystem, which are of paramount utility to device drivers and, consequently, modules.
Hello, World!
Unlike development on core subsystems of the kernelmuch of what has been discussed thus farmodule development is more like writing a new application, at least in that modules have entry points and exit points and live in their own files.
It might be trite and cliché, but it would be a travesty of the highest order to have the opportunity to write a Hello, World! program and not capitalize on the occasion.
Ladies and gentlemen, the kernel module Hello, World:
/*
* hello.c Hello, World! As a Kernel Module
*/
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
/*
* hello_init the init function, called when the module is loaded.
* Returns zero if successfully loaded, nonzero otherwise.
*/
static int hello_init(void)
{
printk(KERN_ALERT "I bear a charmed life.\n");
return 0;
}
/*
* hello_exit the exit function, called when the module is removed.
*/
static void hello_exit(void)
{
printk(KERN_ALERT "Out, out, brief candle!\n");
}
module_init(hello_init);
module_exit(hello_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Shakespeare");
This is as simple a kernel module as one can get. The hello_init() function is registered via module_init() as this module's entry point. It is invoked by the kernel when the module is loaded. The call to module_init() is not really a function call at all but a macro that assigns its sole parameter as the initialization function for this module. All init functions must have the form
int my_init(void);
Because init functions are typically not directly called by external code, you need not export the function, and it can be marked as static.
Init functions return an int. If initialization (or whatever your init function does) was successful, the function returns zero. On failure, it returns nonzero.
This init function merely prints a simple message and returns zero. Init functions in real world modules typically register resources, allocate data structures, and so on. Even if this file were compiled statically into the kernel image, the init function would be kept and run on kernel boot.
The hello_exit() function is registered as this module's exit point via module_exit(). The kernel invokes hello_exit() when the module is removed from memory. Exit functions might clean up resources, ensure that hardware is in a consistent state, and so on before returning. After the exit function returns, the module is unloaded.
Exit functions must have the form
void my_exit(void);
As with the init function, you probably want to mark it static.
If this file were compiled into the static kernel image, the exit function would not be included and it would never be invoked (because, if it were not a module, the code could never be removed from memory).
The MODULE_LICENSE() macro specifies the copyright license for this file. Loading a non-GPL module into memory results in the tainted flag being set in the kernel. This flag is also just for informational purposes, but many kernel developers give bug reports less credence when the tainted flag is set in the oops. Further, non-GPL modules cannot invoke GPL-only symbols (see the section "Exported Symbols" later in this chapter).
Finally, the MODULE_AUTHOR() macro specifies this file's author. The value of this macro is entirely for informational purposes.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX