sysfs
The sysfs filesystem is an in-memory virtual filesystem that provides a view of the kobject object hierarchy. It enables users to view the device topology of their system as a simple filesystem. Using attributes, kobjects can export files that allow kernel variables to be read from and optionally written to.
Although the intended purpose of the device model was initially to provide a device topology for power management reasons, a quite spectacular offshoot was sysfs. To facilitate debugging, the device model's developer decided to export the tree as a file-system. This quickly proved quite useful, at first as a replacement for device-related files that previously found themselves in /proc, and later as a powerful view into the system's object hierarchy. Indeed, sysfs, originally called driverfs, predated kobjects. Eventually sysfs made it clear that a new object model would be quite beneficial, and kobject was born. Today, every system with a 2.6 kernel has sysfs and nearly all have it mounted.
The magic behind sysfs is simply tying kobjects to directory entries via the dentry variable inside each kobject. Recall from Chapter 12, "The Virtual Filesystem," that the dentry structure represents directory entries. By linking kobjects to dentries, kobjects trivially map to directories. Exporting the kobjects as a filesystem is now as easy as building a tree of the dentries in memory. But wait! kobjects already form a tree, our beloved device model. With kobjects mapping to dentries and the object hierarchy already forming an in-memory tree, sysfs became trivial.
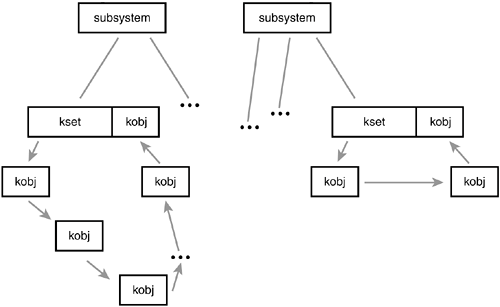
Figure 17.2 is a partial view of the sysfs filesystem as mounted at /sys.

The root of the sysfs contains seven directories: block, bus, class, devices, firmware, module, and power. The block directory contains one directory for each of the registered block devices on the system. Each of those directories, in turn, contains any partitions on the block device. The bus directory provides a view of the system buses. The class directory contains a view of the devices on the system organized by high-level function. The devices directory is a view of the device topology of the system. It maps directly to the hierarchy of device structures inside the kernel. The firmware directory contains a system-specific tree of low-level subsystems such as ACPI, EDD, EFI, and so on. The power directory contains system-wide power management data.
The most important directory is devices, which exports the device model to the world. The directory structure is the actual device topology of the system. Much of the data in other directories is simply alternative organizations of the data in the devices directory. For example, /sys/class/net/ organizes devices by the high-level concept of registered network interfaces. Inside this directory might be the subdirectory eth0, which contains the symlink device back to the actual device directory in devices.
Take a look at /sys on any Linux systems that you have access to. Such an accurate view into the system's device is pretty neat, and seeing the interconnection between the high-level concepts in class versus the low-level physical devices in devices and the actual drivers in bus is very informative. The whole experience is even more rewarding when you realize that this data is free, that this is the very representation of the system maintained inside the kernel.
Adding and Removing kobjects from sysfs
Initialized kobjects are not automatically exported to sysfs. To represent a kobject to sysfs, you use kobject_add():
int kobject_add(struct kobject *kobj);
The kobject's location in sysfs depends on the kobject's location in the object hierarchy. If the kobject's parent pointer is set, the kobject will map to a subdirectory in sysfs inside its parent. If the parent pointer is not set, the kobject will map to a subdirectory inside kset->kobj. If neither the parent nor the kset fields are set in the given kobject, the kobject is assumed to have no parent and will map to a root-level directory in sysfs. This is almost assuredly what you want, so one or both of parent and kset should be set appropriately before kobject_add() is called. Regardless, the name of the directory representing the kobject in sysfs is given by kobj->k_name.
Rather than call both kobject_init() and kobject_add(), you can call kobject_register():
int kobject_register(struct kobject *kobj)
This function both initializes the given kobject and adds it to the object hierarchy.
Removing a kobject's sysfs representation is done via kobject_del():
void kobject_del(struct kobject *kobj);
The function kobject_unregister() combines both kobject_del() and kobject_put():
void kobject_unregister(struct kobject * kobj)
All four of these functions are defined in lib/kobject.c and declared in <linux/kobject.h>.
Adding Files to sysfs
kobjects map to directories, and the complete object hierarchy maps nicely to the complete sysfs directory structure, but what about files? sysfs is nothing but a pretty tree without files to provide actual data.
Default Attributes
A default set of files is provided via the ktype field in kobjects and ksets. Consequently, all kobjects of the same type have the same default set of files populating their sysfs directories. The kobj_type structure contains a member, default_attrs, that is an array of attribute structures. Attributes map kernel data to files in sysfs.
The attribute structure is defined in <linux/sysfs.h>:
/* attribute structure - attributes map kernel data to a sysfs file */
struct attribute {
char *name; /* attribute's name */
struct module *owner; /* owning module, if any */
mode_t mode; /* permissions */
};
The name member provides the name of this attribute. This will be the filename of the resulting file in sysfs. The owner member points to a module structure representing the owning module, if any. If a module does not own this attribute, this field is NULL. The mode member is a mode_t type that specifies the permissions for the file in sysfs. Read-only attributes probably want to set this to S_IRUGO if they are world readable and S_IRUSR if they are only owner readable. Writable attributes probably want to set mode to S_IRUGO | S_IWUSR. All files and directories in sysfs are owned by uid zero and gid zero.
Although default_attrs lists the default attributes, sysfs_ops describes how to use them. The sysfs_ops member is a pointer to a structure of the same name, which is defined in <linux/sysfs.h>:
struct sysfs_ops {
/* method invoked on read of a sysfs file */
ssize_t (*show) (struct kobject *kobj,
struct attribute *attr,
char *buffer);
/* method invoked on write of a sysfs file */
ssize_t (*store) (struct kobject *kobj,
struct attribute *attr,
const char *buffer,
size_t size);
};
The show() method is invoked on read. It must copy the value of the attribute given by attr into the buffer provided by buffer. The buffer is PAGE_SIZE bytes in length; on x86, PAGE_SIZE is 4096 bytes. The function should return the size in bytes of data actually written into buffer on success or a negative error code on failure.
The store() method is invoked on write. It must read the size bytes from buffer into the variable represented by the attribute attr. The size of the buffer is always PAGE_SIZE or smaller. The function should return the size in bytes of data read from buffer on success or a negative error code on failure.
Because this single set of functions must handle file I/O requests on all attributes, they typically need to maintain some sort of generic mapping to invoke a handler specific to each attribute.
Creating New Attributes
Generally, the default attributes provided by the ktype associated with a kobject are sufficient. Indeed, because all the kobjects of the same ktype are supposed to be relatedif not identical in nature as in, say, all partitionsthe same set of attributes should satisfy all kobjects. This not only simplifies life, but also provides code consolidation and a uniform look and feel to sysfs directories of related objects.
Nonetheless, often some specific instance of a kobject is somehow special. It wants or even needs its own attributesperhaps to provide data or functionality not shared by the more general ktype. To this end, the kernel provides the sysfs_create_file() interface for adding new attributes on top of the default set:
int sysfs_create_file(struct kobject *kobj, const struct attribute *attr);
This badboy will associate the attribute structure pointed at by attr with the kobject pointed at by kobj. Before it is invoked, the given attribute should be filled out. This function returns zero on success and a negative error code otherwise.
Note that the sysfs_ops specified in the kobject's ktype is invoked to handle this new attribute. The existing default show() and store() methods must be capable of handling the newly created attribute.
In addition to creating actual files, it is possible to create symbolic links. Creating a symlink in sysfs is very easy:
int sysfs_create_link(struct kobject *kobj, struct kobject *target, char *name);
This function creates a link named name in the directory mapped from kobj to the directory mapped from target. This function returns zero on success and a negative error code otherwise.
Destroying New Attributes
Removing an attribute is handled via sysfs_remove_file():
void sysfs_remove_file(struct kobject *kobj, const struct attribute *attr);
Upon call return, the given attribute will no longer appear in the given kobject's directory.
Symbolic links created with sysfs_create_link() may be removed with sysfs_remove_link():
void sysfs_remove_link(struct kobject *kobj, char *name);
Upon return, the symbolic link name in the directory mapped from kobj is removed.
All four of these functions are declared in <linux/kobject.h>. The sysfs_create_file() and sysfs_remove_file() functions are defined in fs/sysfs/file.c. The sysfs_create_link() and sysfs_remove_link() functions are defined in fs/sysfs/symlink.c.
sysfs Conventions
The sysfs filesystem is currently the place for implementing functionality previously reserved for ioctl() calls on device nodes or the procfs filesystem. These days, the chic thing to do is implement such functionality as sysfs attributes in the appropriate directory. For example, instead of a new ioctl() on a device node, add a sysfs attribute in the driver's sysfs directory. Such an approach avoids the type-unsafe use of obscure ioctl() arguments and the haphazard mess of /proc.
To keep sysfs clean and intuitive, however, developers must follow certain conventions.
First, sysfs attributes should export one value per file. Values should be text-based and map to simple C types. The goal is to avoid the highly structured or highly messy representation of data we have today in /proc. Providing one value per file makes reading and writing trivial from the command line and enables C programs to easily slurp the kernel's data from sysfs into their own variables. In situations where the one-value-per-file rule results in an inefficient representation of data, it is acceptable to place multiple values of the same type in one file. Delineate them as appropriate; a simple space probably makes the most sense. Ultimately, think of sysfs attributes as mapping to individual kernel variables (as they usually do) and keep in mind ease of manipulation from user-space, particularly from the shell.
Second, organize data in sysfs in a clean hierarchy. Correctly parent kobjects so that they map intuitively into the sysfs tree. Associate attributes with the correct kobject and keep in mind that the kobject hierarchy exists not only in the kernel but also as an exported tree to user-space. Keep the sysfs tree sane!
Finally, keep in mind that sysfs provides a kernel-to-user service and is thus some sort of user-space ABI. User programs may come to rely on the existence, location, value, and behavior of sysfs directories and files. Changing existing files in any way is discouraged, and modifying the behavior of a given attribute but keeping its name and location is surely begging for trouble.
These simple conventions should allow sysfs to provide a rich and intuitive interface to user-space. Use sysfs correctly and user-space developers will not curse your existence but praise your beautiful code.
The Kernel Events Layer
The Kernel Event Layer implements a kernel-to-user notification system on top ofyou guessed itkobjects. After the release of 2.6.0, it became clear that a mechanism for pushing events out of the kernel and up into user-space was needed, particularly for desktop systems that yearned for a more integrated and asynchronous system. The idea was to have the kernel push events up the stack: Hard drive full! Processor is overheating! Partition mounted! Pirate ship on the horizon!
Just kidding about the last one.
Early revisions of the event layer came and went, and it was not long before the whole thing was tied intimately to kobjects and sysfs. The result, it turns out, is pretty neat. The Kernel Event Layer models events as signals emitting from objectsspecifically, kobjects. Because kobjects map to sysfs paths, the source of each event is a sysfs path. If the event in question has to do with your first hard drive, then /sys/block/hda is the source address. Internally, inside the kernel, we model the event as originating from the backing kobject.
Each event is given a verb or action string representing the signal. The strings are terms such as modified or unmounted that describe what happened.
Finally, each event has an optional payload. Rather than pass an arbitrary string to user-space that provides the payload, the kernel event layer represents payloads as sysfs attributes.
Internally, the kernel events go from kernel-space out to user-space via netlink. Netlink is a high-speed multicast socket used to transmit networking information. Using netlink means that obtaining kernel events from user-space is as simple as blocking on a socket. The intention is for user-space to implement a system daemon that listens on the socket, processes any read events, and transmits the events up the system stack. One possible proposal for such a user-space daemon is to tie the events into D-BUS, which already implements a system-wide messaging bus. In this manner, the kernel can emit signals just as any other component in the system.
To send events out to user-space from your kernel code, use kobject_uevent():
int kobject_uevent(struct kobject *kobj,
enum kobject_action action,
struct attribute *attr);
The first parameter specifies the kobject that is emitting this signal. The actual kernel event will contain the sysfs path to which this kobject maps.
The second parameter specifies the action or verb describing this signal. The actual kernel event will contain a string that maps to the provided enum kobject_action value. Rather than directly provide the string, the function uses an enumeration to encourage value reuse, provide type safety, and prevent typos and other mistakes. The enumerations are defined in <linux/kobject_uevent.c> and have the form KOBJ_foo. Current values include KOBJ_MOUNT, KOBJ_UNMOUNT, KOBJ_ADD, KOBJ_REMOVE, and KOBJ_CHANGE. These values map to the strings "mount", "unmount", "add", "remove", and "change", respectively. Adding new action values is acceptable, so long as an existing value is insufficient.
The final parameter is an optional pointer to an attribute structure. This can be seen as the "payload" of the event. If the action value is insufficient in describing the event, the event can point at a specific file in sysfs that provides more information.
This function allocates memory and thus can sleep. An atomic version is provided that is identical to the non-atomic variant, except that it allocates memory via GFP_ATOMIC:
int kobject_uevent_atomic(struct kobject *kobj,
enum kobject_action action,
struct attribute *attr);
Using the standard non-atomic interface is encouraged if possible. The parameters and behavior are otherwise the same between both functions.
Using kobjects and attributes not only encourages events that fit nicely in a sysfs-based world, but also encourages the creation of new kobjects and attributes to represent objects and data not yet exposed through sysfs.
Both these functions are defined in lib/kobject_uevent.c and declared in <linux/kobject_uevent.h>.
Chapter 18. Debugging
One of the defining factors that sets apart kernel development from user-space development is the hardship associated with debugging. It is difficult, at least relative to user-space, to debug the kernel. To complicate the matter, the stakes are much higher. A fault in the kernel could bring the whole system downhard.
Growing successful at debugging the kerneland ultimately, becoming successful at kernel development as a wholeis largely a function of your experience and understanding of the operating system. Sure, looks and charm help, too, but to successfully debug kernel issues, you need to understand the kernel. You have to start somewhere, however, so this chapter looks at approaches to debugging the kernel.
Binary Searching to Find the Culprit Change
It is usually useful to know when a bug was introduced into the kernel source. If you know that a bug occurred in version 2.6.10, but not 2.4.9, then you have a clear picture of the changes that occurred to cause the bug. The bug fix is often as simple as reverting or otherwise fixing the bad change.
Many times, however, you do not know what kernel version introduced the bug. You know that the bug is in the current kernel, but it seemed to have always have been in the current kernel! It takes some investigative work, but with a little effort, you can find the offending change. With the change in hand, the bug fix is usually near.
To start, you need a reliably reproducible problempreferably, a bug that you can verify immediately after boot. Next, you need a known-good kernel. You might already know this. For example, if you know a couple months back the kernel worked, grab a kernel from that period. If you are wrong, try an earlier release. It shouldn't be too hardunless the bug has existed foreverto find a kernel without the bug.
Next, you need a known-bad kernel. To make things easier, start with the earliest kernel you know to have the bug.
Now, you begin a binary search from the known-bad kernel down to the known-good kernel. Let's look at an example. Assume the latest known-good kernel is 2.4.11 and the earliest known-bad is 2.4.20. Start by picking a kernel in the middle, such as 2.4.15. Test 2.4.15 for the bug. If 2.4.15 works, then you know the problem began in a later kernel, so try a kernel in between 2.4.15 and 2.4.20say, 2.4.17. On the other hand, if 2.4.15 does not work, you know the problem is in an earlier kernel, so you might try 2.4.13. Rinse and repeat.
Eventually you should narrow the problem down to two kernelsone of which has the bug and one of which does not. You then have a clear picture of the changes that caused the bug.
This approach beats looking at every kernel!
When All Else Fails: The Community
Perhaps you have tried everything that you can think of. You have slaved over the keyboard for countless hoursindeed, perhaps countless daysand the solution still escapes you. If the bug is in the mainstream Linux kernel, you can always elicit the help of the other developers in the kernel community.
A brief, but complete, email sent to the kernel mailing list describing the bug and your findings might help aid in discovery of a solution. After all, no one likes bugs.
Chapter 20, "Patches, Hacking, and the Community," specifically addresses the community and its primary forum, the Linux Kernel Mailing List (LKML).
What You Need to Start
So, you are ready to start bug hunting? It might be a long and frustrating journey. Some bugs have perplexed the entire kernel development community for months. Fortunately, for every one of these evil bugs, there are many simple bugs with an equally simple fix. With luck, all your bugs will remain simple and trivial. You will not know that, however, until you start investigating. For that, you need
A bug. It might sound silly, but you need a well-defined and specific bug. It helps if it is reliably reproducible (at least for someone), but unfortunately bugs are not always well behaved or well defined. A kernel version on which the bug exists (presumably in the latest kernel, or who cares?). Even better is if you know the kernel version where the bug first appeared. You will learn how to figure that out if you do not know it. Some good luck, kernel hacking skill, or a combination thereof.
If you cannot reproduce the bug, many of the following approaches become worthless. It is rather crucial that you be able to duplicate the problem. If you cannot, fixing the bug is limited to conceptualizing the problem and finding a flaw in the code. This does often happen (yep, the Linux kernel developers are that good), but chances of success are obviously much more favorable if you can reproduce the problem.
It might seem strange that there would be a bug that someone cannot reproduce. In user-space programs, bugs are quite often a lot more straightforward. For example, doing foo makes me core dump. The kernel is an entirely different beast. The interactions between the kernel, user-space, and hardware can be quite delicate. Race conditions might rear their ugly heads only once in a million iterations of an algorithm. Poorly designed or even miscompiled code can result in acceptable performances on some systems, but terrible performances on others. It is very common for some specific configuration, on some random machine, under some odd workload, to trigger a bug otherwise unseen. The more information you have when tackling a bug, the better. Many times, if you can reliably reproduce the bug, you are more than halfway home.
Bugs in the Kernel
Bugs in the kernel are as varied as bugs in user-space applications. They occur for a myriad of reasons and manifest themselves in just as many forms. Bugs range from clearly incorrect code (for example, not storing the correct value in the proper place) to synchronization errors (for example, not properly locking a shared variable). They manifest themselves as everything from poor performance to incorrect behavior to corrupt data.
Often, it is a long chain of events that leads from the error in the code to the error witnessed by the user. For example, a shared structure without a reference count might cause a race condition. Without proper accounting, one process might free the structure while another process still wants to use it. Later on, the second process may attempt to use the no longer existent structure through a now invalid pointer. This might result in a NULL pointer dereference, reading of garbage data, or nothing bad at all (if the data was not yet overwritten). The NULL pointer dereference causes an oops, whereas the garbage data leads to corruption (and then bad behavior or an oops). The user reports the oops or incorrect behavior. The kernel developer must then work backward from the error and see that the data was accessed after it was freed, there was a race, and the fix is proper reference counting on the shared structure. It probably needs locking, too.
Debugging the kernel might sound difficult, but in reality, the kernel is not unlike any other large software project. The kernel does have unique issues, such as timing constraints and race conditions, which are a consequence of allowing multiple threads of execution inside the kernel. I assure you that with a little effort and understanding, you can debug kernel problems (and perhaps even enjoy the challenge).
printk()
The kernel print function, printk(), behaves almost identically to the C library printf() function. Indeed, throughout this book we have not made use of any real differences. For most intentions, this is fine; printk() is simply the name of the kernel's formatted print function. It does have some differences, however.
The Robustness of printk()
One property of printk() quickly taken for granted is its robustness. The printk() function is callable from just about anywhere in the kernel at any time. It can be called from interrupt or process context. It can be called while a lock is held. It can be called simultaneously on multiple processors, yet it does not require the caller to hold a lock.
It is a resilient function. This is important because the usefulness of printk() rests on the fact that it is always there and always works.
The Nonrobustness of printk()
A chink in the armor of printk()'s robustness does exist. It is unusable before a certain point in the kernel boot process, prior to console initialization. Indeed, if the console is not initialized, where is the output supposed to go?
This is normally not an issue, unless you are debugging issues very early in the boot process (for example, in setup_arch(), which performs architecture-specific initialization). Such debugging is a challenge to begin with, and the absence of any sort of print method only compounds the problem.
There is some hope, but not a lot. Hardcore architecture hackers use the hardware that does work (say, a serial port) to communicate with the outside world. Trust methis is not fun for most people. Some supported architectures do implement a sane solution, howeverand others (i386 included) have patches available that also save the day.
The solution is a printk() variant that can output to the console very early in the boot process: early_printk(). The behavior is the same as printk(), only the name and its capability to work earlier are changed. This is not a portable solution, however, because not all supported architectures have such a method implemented. It might become your best friend, though, if it does.
Unless you need to write to the console very early in the boot process, you can rely on printk() to always work.
Loglevels
The major difference between printk() and printf() is the capability of the former to specify a loglevel. The kernel uses the loglevel to decide whether to print the message to the console. The kernel displays all messages with a loglevel below a specified value on the console.
You specify a loglevel like this:
printk(KERN_WARNING "This is a warning!\n");
printk(KERN_DEBUG "This is a debug notice!\n");
printk("I did not specify a loglevel!\n");
The KERN_WARNING and KERN_DEBUG strings are simple defines found in <linux/ kernel.h>. They expand to a string such as "<4>" or "<7>" that is concatenated onto the front of the printk() message. The kernel then decides which messages to print on the console based on this specified loglevel and the current console loglevel, console_loglevel. Table 18.1 is a full listing of the available loglevels.
Table 18.1. Available LoglevelsLoglevel | Description |
|---|
KERN_EMERG | An emergency condition; the system is probably dead | KERN_ALERT | A problem that requires immediate attention | KERN_CRIT | A critical condition | KERN_ERR | An error | KERN_WARNING | A warning | KERN_NOTICE | A normal, but perhaps noteworthy, condition | KERN_INFO | An informational message | KERN_DEBUG | A debug messagetypically superfluous |
If you do not specify a loglevel, it defaults to DEFAULT_MESSAGE_LOGLEVEL, which is currently KERN_WARNING. Because this value might change, you should always specify a loglevel for your messages.
The kernel defines the most important loglevel, KERN_EMERG, as <0> and it defines KERN_DEBUG, the least critical loglevel, as <7>. For example, after the preprocessor is done, the previous examples resemble the following:
printk("<4>This is a warning!\n");
printk("<7>This is a debug notice!\n");
printk("<4>did not specify a loglevel!\n");
The avenue that you take with your printk() loglevels is up to you. Of course, normal messages that you intend to keep around should have the appropriate loglevel. But the debugging messages you sprinkle everywhere when trying to get a handle on a problemadmit it, we all do it and it workscan have any loglevel you want. One option is to leave your default console loglevel where it is, and make all your debugging messages KERN_CRIT or so. Conversely, you can make the debugging messages KERN_DEBUG and change your console loglevel. Each has pros and cons; you decide.
Loglevels are defined in <linux/kernel.h>.
The Log Buffer
Kernel messages are stored in a circular buffer of size LOG_BUF_LEN. This size is configurable at compile time via the CONFIG_LOG_BUF_SHIFT option. The default for a uniprocessor machine is 16KB. In other words, the kernel can simultaneously store 16KB of kernel messages. As messages are read in user-space, they are removed from the queue. If the message queue is at this maximum and another call to printk() is made, the new message overwrites the oldest one. The log buffer is called circular because the reading and writing occur in a circular pattern.
Using a circular buffer has multiple advantages. Because it is easy to simultaneously write to and read from a circular buffer, even interrupt context can easily use printk(). Furthermore, it makes log maintenance easy. If there are too many messages, new messages simply overwrite the older ones. If there is a problem that results in the generation of many messages, the log simply overwrites itself in lieu of uncontrollably consuming memory. The lone disadvantage of a circular bufferthe possibility of losing messagesis a small price to pay for the simplicity and robustness it affords.
syslogd and klogd
On a standard Linux system, the user-space klogd daemon retrieves the kernel messages from the log buffer and feeds them into the system log file via the syslogd daemon. To read the log, the klogd program can either read the /proc/kmsg file or call the syslog() system call. By default, it uses the /proc approach. In either case, klogd blocks until there are new kernel messages to read. It then wakes up, reads any new messages, and processes them. By default, it sends the messages to the syslogd daemon.
The syslogd daemon appends all the messages it receives to a file, which is by default /var/log/messages. It is configurable via /etc/syslog.conf.
You can have klogd change the console loglevel when it loads by specifying the -c flag when you start it.
A Note About printk() and Kernel Hacking
When you first start developing kernel code, you most likely will often transpose printf() for printk(). This transposition is only natural, as you cannot deny years of experience using printf() in user-space programs. With luck, this mistake will not last long because the repeated linker errors will eventually grow rather annoying.
Someday, you might find yourself accidentally using printk() instead of printf() in your user-space code. When that day comes, you can say you are a true kernel hacker.
Oops
An oops is the usual way a kernel communicates to the user that something bad happened. Because the kernel is the supervisor of the entire system, it cannot simply fix itself or kill itself as it can when user-space goes awry. Instead, the kernel issues an oops. This involves printing an error message to the console, dumping the contents of the registers, and providing a back trace. A failure in the kernel is hard to manage, so the kernel must jump through many hoops to issue the oops and clean up after itself. Often, after an oops the kernel is in an inconsistent state. For example, the kernel could have been in the middle of processing important data when the oops occurred. It might have held a lock or been in the middle of talking to hardware. The kernel must gracefully back out of its current context and try to resume control of the system. In many cases, this is not possible. If the oops occurred in interrupt context, the kernel cannot continue and it panics. A panic results in an instant halt of the system. If the oops occurred in the idle task (pid zero) or the init task (pid one), the result is also a panic because the kernel cannot continue without these important processes. If the oops occurs in any other process, however, the kernel kills the process and tries to continue executing.
An oops might occur for multiple reasons, including a memory access violation or an illegal instruction. As a kernel developer, you will often deal with (and undoubtedly cause) oopses.
What follows is an oops example from a PPC machine, in the timer handler of the tulip network interface card:
Oops: Exception in kernel mode, sig: 4
Unable to handle kernel NULL pointer dereference at virtual address 00000001
NIP: C013A7F0 LR: C013A7F0 SP: C0685E00 REGS: c0905d10 TRAP: 0700
Not tainted
MSR: 00089037 EE: 1 PR: 0 FP: 0 ME: 1 IR/DR: 11
TASK = c0712530[0] 'swapper' Last syscall: 120
GPR00: C013A7C0 C0295E00 C0231530 0000002F 00000001 C0380CB8 C0291B80 C02D0000
GPR08: 000012A0 00000000 00000000 C0292AA0 4020A088 00000000 00000000 00000000
GPR16: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
GPR24: 00000000 00000005 00000000 00001032 C3F7C000 00000032 FFFFFFFF C3F7C1C0
Call trace:
[c013ab30] tulip_timer+0x128/0x1c4
[c0020744] run_timer_softirq+0x10c/0x164
[c001b864] do_softirq+0x88/0x104
[c0007e80] timer_interrupt+0x284/0x298
[c00033c4] ret_from_except+0x0/0x34
[c0007b84] default_idle+0x20/0x60
[c0007bf8] cpu_idle+0x34/0x38
[c0003ae8] rest_init+0x24/0x34
PC users might marvel at the number of registers (a whopping 32!). An oops on x86, which you might be more familiar with, is a little simpler. The important information, however, is identical for all the architectures: the contents of the registers and the back trace.
The back trace shows the exact function call chain leading up to the problem. In this case, you can see exactly what happened: The machine was idle and executing the idle loop, cpu_idle(), which calls default_idle() in a loop. The timer interrupt occurred, which resulted in the processing of timers. A timer handler, the tulip_timer() function, was executed, which performed a NULL pointer dereference. You can even use the offsets (those numbers such as 0x128/0x1c4 to the right of the functions) to find exactly the offending line.
The register contents can be equally useful, although less commonly so. With a decoded copy of the function in assembly, the register values help you re-create the exact events leading to the problem. Seeing an unexpected value in a register might shine some light on the root of the issue. In this case, you can see which registers held NULL (a value of all zeros) and discover which variable in the function had the unexpected value. In situations such as this, the problem is often a racein this case, between the timer and some other part of this network card. Debugging a race condition is always a challenge.
ksymoops
The previous oops is said to be decoded because the memory addresses are translated into the functions they represent. An undecoded version of the previous oops is shown here:
NIP: C013A7F0 LR: C013A7F0 SP: C0685E00 REGS: c0905d10 TRAP: 0700
Not tainted
MSR: 00089037 EE: 1 PR: 0 FP: 0 ME: 1 IR/DR: 11
TASK = c0712530[0] 'swapper' Last syscall: 120
GPR00: C013A7C0 C0295E00 C0231530 0000002F 00000001 C0380CB8 C0291B80 C02D0000
GPR08: 000012A0 00000000 00000000 C0292AA0 4020A088 00000000 00000000 00000000
GPR16: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
GPR24: 00000000 00000005 00000000 00001032 C3F7C000 00000032 FFFFFFFF C3F7C1C0
Call trace: [c013ab30] [c0020744] [c001b864] [c0007e80] [c00061c4]
[c0007b84] [c0007bf8] [c0003ae8]
The addresses in the back trace need to be converted into symbolic names. This is done via the ksymoops command in conjunction with the System.map generated during kernel compile. If you are using modules, you also need some module information. ksymoops tries to figure out most of this information, so you can usually invoke it via
ksymoops saved_oops.txt
The program then spits out a decoded version of the oops. If the default information ksymoops uses is unacceptable, or you want to provide alternative locations for the information, the program understands various options. Its manual page has a lot of information that you should read before using.
The ksymoops program most likely came with your distribution.
kallsyms
Thankfully, dealing with ksymoops is no longer a requirement. This is a big deal, because although developers might have had little problem using it, end users often mismatched System.map files or failed to decode oopses altogether.
The 2.5 development kernel introduced the kallsyms feature, which is enabled via the CONFIG_KALLSYMS configuration option. This option loads the symbolic kernel name of memory address mapping into the kernel image, so the kernel can print predecoded back traces. Consequently, decoding oopses no longer requires System.map or ksymoops. On the downside, the size of the kernel increases a bit because the address-to-symbol mappings must reside in permanently mapped kernel memory. It is worth the memory use, however, at least during development.
Kernel Debugging Options
Multiple configure options that you can set during compile to aid in debugging and testing kernel code are available. These options are in the Kernel Hacking menu of the Kernel Configuration Editor. They all depend on CONFIG_DEBUG_KERNEL. When hacking on the kernel, consider enabling as many of these options as practical.
Some of the options are rather useful, enabling slab layer debugging, high-memory debugging, I/O mapping debugging, spin-lock debugging, and stack-overflow checking. One of the most useful settings, however, is sleep-inside-spinlock checking, which actually does much more.
Atomicity Debugging
Starting with 2.5, the kernel has an excellent infrastructure for detecting all sorts of atomicity violations. Recall from Chapter 8, "Kernel Synchronization Introduction," that atomic refers to something's capability to execute without division; the code completes without interruption or it does not complete at all. Code that holds a spin lock or has disabled kernel preemption is atomic. Code cannot sleep while atomicsleeping while holding a lock is a recipe for deadlock.
Thanks to kernel preemption, the kernel has a central atomicity counter. The kernel can be set such that if a task sleeps while atomic, or even does something that might sleep, the kernel will print a warning and provide a back trace. Potential bugs that are detectable include calling schedule() while holding a lock, issuing a blocking memory allocation while holding a lock, or sleeping while holding a reference to per-CPU data. This debugging infrastructure catches a lot of bugs and is highly recommended.
The following options make the best use of this feature:
CONFIG_PREEMPT=y
CONFIG_DEBUG_KERNEL=y
CONFIG_KALLSYMS=y
CONFIG_SPINLOCK_SLEEP=y
Asserting Bugs and Dumping Information
A number of kernel routines make it easy to flag bugs, provide assertions, and dump information. Two of the most common are BUG() and BUG_ON(). When called, they cause an oops, which results in a stack trace and an error message dumped to the kernel. Why these statements cause an oops is architecture-dependent. Most architectures define BUG() and BUG_ON() as illegal instructions, which result in the desired oops. You normally use these routines as assertions, to flag situations that should not happen:
if (bad_thing)
BUG();
Or, even better,
BUG_ON(bad_thing);
Most kernel developers believe that BUG_ON() is easier to read and more self-documenting compared to BUG(). Also, BUG_ON() wraps its assertion in an unlikely() statement. Do note that some developers have discussed the idea of having an option to compile BUG_ON() statements away, saving space in embedded kernels. This means that your assertion inside a BUG_ON() should not have any side effects.
A more critical error is signaled via panic(). A call to panic() prints an error message and then halts the kernel. Obviously, you want to use it only in the worst of situations:
if (terrible_thing)
panic("foo is %ld!\n", foo);
Sometimes, you just want a simple stack trace issued on the console to help you in debugging. In those cases, dump_stack() is used. It simply dumps the contents of the registers and a function back trace to the console:
if (!debug_check) {
printk(KERN_DEBUG "provide some information...\n");
dump_stack();
}
Magic SysRq Key
A possible lifesaver is the Magic SysRq Key, which is enabled via the CONFIG_MAGIC_SYSRQ configure option. The SysRq (system request) key is a standard key on most keyboards. On the i386 and PPC, it is accessible via Alt-PrintScreen. When this configure option is enabled, special combinations of keys enable you to communicate with the kernel regardless of what else it is doing. This enables you to perform some useful tasks in the face of a dying system.
In addition to the configure option, there is a sysctl to toggle this feature on and off. To turn it on:
echo 1 > /proc/sys/kernel/sysrq
From the console, you can hit SysRq-h for a list of available options. SysRq-s syncs dirty buffers to disk, SysRq-u unmounts all file systems, and SysRq-b reboots the machine. Issuing these three key combinations in a row is a safer way to reboot a dying machine than simply hitting the machine reset switch.
If the machine is badly locked, it might not respond to any Magic SysRq combinations, or it might fail to complete a given command. With luck, however, these options might save your data or aid in debugging. Table 18.2 is a listing of the supported SysRq commands.
Table 18.2. Supporting SysRq CommandsKey Command | Description |
|---|
SysRq-b | Reboot the machine | SysRq-e | Send a SIGTERM to all processes except init | SysRq-h | Display SysRq help on the console | SysRq-i | Send a SIGKILL to all processes except init | SysRq-k | Secure Access Key: kill all programs on this console | SysRq-l | Send a SIGKILL to all processes including init | SysRq-m | Dump memory information to console | SysRq-o | Shut down the machine | SysRq-p | Dump registers to console | SysRq-r | Turn off keyboard raw mode | SysRq-s | Sync all mounted file systems to disk | SysRq-t | Dump task information to console | SysRq-u | Unmount all mounted file systems |
The file Documentation/sysrq.txt in the kernel source tree has more information. The actual implementation is in drivers/char/sysrq.c. The Magic SysRq Key is a vital tool for aiding in debugging or saving a dying system. Because it provides powerful capabilities to any user on the console, however, you should exercise caution on important machines. For your development machine, however, it is a great help.
The Saga of a Kernel Debugger
Many kernel developers have long demanded an in-kernel debugger. Unfortunately, Linus does not want a debugger in his tree. He believes that debuggers lead to bad fixes by misinformed developers. No one can argue with his logica fix derived from real understanding of the code is certainly more likely to be correct. Nonetheless, plenty of kernel developers want an official in-kernel debugger. Because it is unlikely to happen anytime soon, a number of patches have arisen that add kernel-debugging support to the standard Linux kernel. Despite being external unofficial patches, these tools are quite well featured and powerful. Before you delve into these solutions, however, it's a good idea to look at how much help the standard Linux debugger, gdb, will give you.
gdb
You can use the standard GNU debugger to glimpse inside a running kernel. Starting the debugger on the kernel is about the same as debugging a running process:
gdb vmlinux /proc/kcore
The vmlinux file is the uncompressed kernel image stored in the root of the build directory, not the compressed zImage or bzImage.
The optional /proc/kcore parameter acts as a core file, to let gdb actually peak into the memory of the running kernel. You need to be root to read it.
You can issue just about any of the gdb commands for reading information. For example, to print the value of a variable:
p global_variable
To disassemble a function:
disassemble function
If you compile the kernel with the -g flag (add -g to the CFLAGS variable in the kernel Makefile), gdb is able to provide much more information. For example, you can dump the contents of structures and follow pointers. You also get a much larger kernel, so do not routinely compile with debugging information included.
Unfortunately, this is about the limit of what gdb can do. It cannot modify kernel data in any way. It is unable to single-step through kernel code or set breakpoints. The inability to modify kernel data structures is a large downside. Although it is undoubtedly useful for it to disassemble functions on occasion, it would be much more useful if it could modify data, too.
kgdb
kgdb is a patch that enables gdb to fully debug the kernel remotely over a serial line. It requires two computers. The first runs a kernel patched with kgdb. The second debugs the first over the serial line (a null modem cable connecting the two machines) using gdb. With kgdb, the entire feature set of gdb is accessible: reading and writing any variables, settings breakpoints, setting watch points, single stepping, and so on! Special versions of kgdb even allow function execution.
Setting up kgdb and the serial line is a little tricky, but when complete, debugging is simple. The patch installs plenty of documentation in Documentation/check it out.
Different people maintain the kgdb patch for various architectures and kernel releases. Searching online is your best bet for finding a patch for a given kernel.
kdb
An alternative to kgdb is kdb. Unlike kgdb, kdb is not a remote debugger. kdb is a kernel patch that extensively modifies the kernel to allow direct debugging on the host system. It provides variable modification, breakpoints, and single-stepping, among other things. Running the debugger is simple: Just hit the break key on the console. The debugger also automatically executes when the kernel oopses. Much documentation is available in Documentation/kdb, after the patch is applied.
kdb is available at http://oss.sgi.com/.
Poking and Probing the System
As you gain experience in kernel debugging, you gain little tricks to help you poke and probe the kernel for answers. Because kernel debugging can prove rather challenging, every little tip and trick helps. Let's look at a couple.
Using UID as a Conditional
If the code you are developing is process-related, sometimes you can develop alternative implementations without breaking the existing code. This is helpful if you are rewriting an important system call and would like a fully functional system with which to debug it. For example, assume you are rewriting the fork() algorithm to take advantage of an exciting new feature. Unless you get everything right on the first try, it would not be easy to debug the system: A nonfunctioning fork() system call is certain to result in a nonfunctioning system. As always, there is hope.
Often, it is safe to keep the remaining algorithm in place and construct your replacement on the side. You can achieve this by using the user id (UID) as a conditional with which to decide which algorithm to use:
if (current->uid != 7777) {
/* old algorithm .. */
} else {
/* new algorithm .. */
}
All users except UID 7777 will use the old algorithm. You can create a special user, with UID 7777, for testing the new algorithm. This makes it much easier to test critical process-related code.
Using Condition Variables
If the code in question is not in process context, or if you want a more global method of controlling the feature, you can use a condition variable. This approach is even simpler than using the UID. Simply create a global variable and use it as a conditional check in your code. If the variable is zero, you follow one code path. If it is nonzero, you follow another. The variable can be set via an interface you export or a poke from the debugger.
Using Statistics
Sometimes you want to get a feel for how often a specific event is occurring. Sometimes you want to compare multiple events and generate some ratios for comparison. You can do this easily by creating statistics and a mechanism to export their values.
For instance, say you want to look at the occurrence of foo and the occurrence of bar. In a file, ideally the one where these events occur, declare two global variables:
unsigned long foo_stat = 0;
unsigned long bar_stat = 0;
For each occurrence of these events, increment the appropriate variable. Then export the data however you feel fit. For example, you can create a file in /proc with the values or write a system call. Alternatively, simply read them via a debugger.
Note that this approach is not particularly SMP-safe. Ideally, you would use atomic operations. For a trivial one-time debugging statistic, however, you normally do not need such protection.
Rate Limiting Your Debugging
Often, you want to stick some debugging checks (with some corresponding print statements) in an area to sniff out a problem. In the kernel, however, some functions are called many times per second. If you stick a call to printk() in such a function, the system is overwhelmed with debugging output and quickly grows unusable.
Two relatively simple tricks exist to prevent this problem. The first is rate limiting, which is useful when you want to watch the progression of an event, but the event occurs rather often. To prevent a deluge of debugging output, you print your debug message (or do whatever you are doing) only every few seconds. For example,
static unsigned long prev_jiffy = jiffies; /* rate limiting */
if (time_after(jiffies, prev_jiffy + 2*HZ)) {
prev_jiffy = jiffies;
printk(KERN_ERR "blah blah blah\n");
}
In this example, the debug message is printed at most every two seconds. This prevents any flood of information on the console and the computer remains usable. You might need the rate limiting to be larger or smaller, depending on your needs.
Another sticky situation arises if you are looking for any occurrence of an event. Unlike the previous example, you do not want to monitor the progress of the kernel, but simply receive a notification when something happens. Perhaps you want to receive this notice only once or twice. This is an especially sticky problem if after the check is triggered once, it is triggered a lot. The solution here is not to rate limit the debugging, but occurrence limit it:
static unsigned long limit = 0;
if (limit < 5) {
limit++;
printk(KERN_ERR "blah blah blah\n");
}
This example caps the debugging output to five. After five such messages, the conditional is always false.
In both examples, the variables should be static and local to the function, as shown. This enables the variable's values to persist across function calls.
Neither of these examples are SMP- or preempt-safe, although a quick switch to atomic operators will make them safe. Frankly, however, this is just debugging code, so why go through the trouble?
Appendix A. Linked Lists
A linked list is a data structure that allows the storage and manipulation of a variable number of nodes of data. Unlike a static array, the elements in a linked list are dynamically created. This enables the creation of a variable number of elements that are unknown at compile time. Because the elements are created at different times, they do not necessarily occupy contiguous regions in memory. Therefore, the elements need to be linked together, so each element contains a pointer to the next element. As elements are added or removed from the list, the pointer to the next node is simply adjusted.
The simplest data structure representing such a linked list would look similar to the following:
/* an element in a linked list */
struct list_element {
void *data; /* the payload */
struct list_element *next; /* pointer to the next element */
};
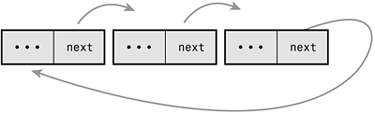
Figure A.1 is a linked list.

In some linked lists, each element also contains a pointer to the previous element. These lists are called doubly linked lists because they are linked both forward and backward. Linked lists, similar to the one in Figure A.1, that do not have a pointer to the previous element are called singly linked lists.
A data structure representing a doubly linked list would look similar to this:
/* an element in a linked list */
struct list_element {
void *data; /* the payload */
struct list_element *next; /* pointer to the next element */
struct list_element *prev; /* pointer to the previous element */
};
Figure A.2 is a doubly linked list.

Circular Linked Lists
Normally, because the last element in a linked list has no next element, it is set to point to a special value, usually NULL, to indicate it is the last element in the list. In some linked lists, the last element does not point to a special value. Instead, it points back to the first value. This linked list is called a circular linked list because the links are cyclic. Circular linked lists can come in both doubly and singly linked versions. In a circular doubly linked list, the first node's "previous" pointer points to the last node. Figures A.3 and A.4 are singly and doubly circular linked lists, respectively.
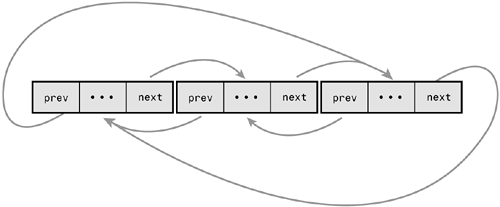
The Linux kernel's standard linked list implementation is a circular doubly linked list. Going with this type of linked list provides the greatest flexibility.
Moving Through a Linked List
Movement through a linked list occurs linearly. You visit one element, follow the next pointer, and visit the next element. Rinse and repeat. This is the easiest method of moving through a linked list, and the one by which linked lists are best suited. Linked lists are usually not used when random access is an important goal. Instead, you use linked lists when iterating over the whole list is important and the dynamic addition and removal of elements is required.
Often the first element is represented by a special pointercalled the headthat makes it quick and easy to find. In a noncircular-linked list, the last element is delineated by its next pointer being NULL. In a circular-linked list, the last element is delineated by the fact that it points to the head element. Traversing the list, therefore, occurs linearly through each element from the first to the last. In a doubly linked list, movement can also occur backward, linearly from the last element to the first. Of course, given a specific element in the list, you can go back and forth any number of elements, too. You need not traverse the whole list.
The Linux Kernel's Implementation
The Linux kernel has a unique approach to traversing linked lists. When traversing a linked list, unless ordering is important, it does not matter if you start at the head element; in fact, it doesn't matter where you start at all! All that matters is that you visit each and every node. Indeed, we do not even need the concept of a first and last node. If a circular linked list simply contains a collection of unordered data, any element can be the head element. To traverse the list, simply pick an element and follow the pointers until you get back to the original element. This removes the need for a special head pointer. Additionally, the routines for manipulating a linked list are simplified. Each routine simply needs a pointer to a single element in the listany element. The kernel hackers are particularly proud of this clever implementation.
Linked lists in the kernel, as with any complex program, are common. For example, the kernel uses a linked list to store the task list: Each process's task_struct is an element in the linked list.
The Linked-List Structure
In the old days, there were multiple implementations of linked lists in the kernel. A single, powerful linked list implementation was needed to remove duplicate code. During the 2.1 kernel development series, the official kernel linked-list implementation was introduced. All existing uses of linked lists now use the official implementation: All new users must use the existing interface, we are serious about this, do not reinvent the wheel.
The linked-list code is declared in <linux/list.h> and the data structure is simple:
struct list_head {
struct list_head *next
struct list_head *prev;
};
Note the curious name, list_head. The name takes a cue from the fact that there is no head node. Instead, because the list can be traversed starting with any given element, each element is in effect a head. Thus, the individual nodes are all called list heads.
The next pointer points to the next element in the list and the prev pointer points to the previous element. Thanks to the kernel's elegant list implementation with no concept of start or finish, you can ignore any concept of first and last element. Consider the list a big cycle with no start or finish.
A list_head by itself is worthless; it is normally embedded inside your own structure:
struct my_struct {
struct list_head list;
unsigned long dog;
void *cat;
};
The list needs to be initialized before it can be used. Because most of the elements are created dynamically (probably why you need a linked list), the most common way of initializing the linked list is at runtime:
struct my_struct *p;
/* allocate my_struct .. */
p->dog = 0;
p->cat = NULL;
INIT_LIST_HEAD(&p->list);
If the structure is statically created at compile time, and you have a direct reference to it, you can simply do this:
struct my_struct mine = {
.list = LIST_HEAD_INIT(mine.list),
.dog = 0,
.cat = NULL
};
To declare and initialize a static list directly, use
static LIST_HEAD(fox);
This declares and initializes a static list named fox.
You should never actually need to play with the internal members of the linked list. Instead, just embed the structure in your data, and you can make use of the linked list interface to easily manipulate and traverse your data.
Manipulating Linked Lists
A family of functions is provided to manipulate linked lists. They all take pointers to one or more list_head structures. The functions are implemented as inlines in generic C and can be found in <linux/list.h>.
Interestingly, all these functions are O(1). This means they execute in constant time, regardless of the size of the list or any other inputs. For example, it takes the same amount of time to add or remove an entry to or from a list whether that list has 3 or 3,000 entries. This is perhaps not surprising, but still good to know.
To add a node to a linked list:
list_add(struct list_head *new, struct list_head *head)
This function adds the new node to the given list immediately after the head node. Because the list is circular and generally has no concept of first or last nodes, you can pass any element for head. If you do pass the "last" element, however, this function can be used to implement a stack.
To add a node to the end of a linked list:
list_add_tail(struct list_head *new, struct list_head *head)
This function adds the new node to the given list immediately before the head node. As with list_add(), because the lists are circular you can generally pass any element for head. This function can be used to implement a queue, however, if you do indeed pass the "first" element.
To delete a node from a linked list,
list_del(struct list_head *entry)
This function removes the element entry from the list. Note, it does not free any memory belonging to enTRy or the data structure in which it is embedded; this function merely removes the element from the list. After calling this, you would typically destroy your data structure and the list_head inside it.
To delete a node from a linked list and reinitialize it,
list_del_init(struct list_head *entry)
This function is the same as list_del(), except it also reinitializes the given list_head with the rationale that you no longer want the entry in the list, but you can reuse the data structure itself.
To move a node from one list to another,
list_move(struct list_head *list, struct list_head *head)
This function removes the list entry from its linked list and adds it to the given list after the head element.
To move a node from one list to the end of another,
list_move_tail(struct list_head *list, struct list_head *head)
This function does the same as list_move(), but inserts the list element before the head enTRy.
To check if a list is empty,
list_empty(struct list_head *head)
This returns nonzero if the given list is empty; otherwise it returns zero.
To splice two unconnected list together:
list_splice(struct list_head *list, struct list_head *head)
This function splices together two lists by inserting the list pointed to by list to the given list after the element head.
To splice two unconnected lists together and reinitialize the old list,
list_splice_init(struct list_head *list, struct list_head *head)
This function works the same as list_splice(), except that the emptied list pointed to by list is reinitialized.
|
If you happen to already have the next and prev pointers available, you can save a couple cycles (specifically, the dereferences to get the pointers) by calling the internal list functions directly. Every previously discussed function actually does nothing except find the next and prev pointers and then call the internal functions. The internal functions generally have the same name as their wrappers, except they are prefixed by double underscores. For example, rather than call list_del(list), you can call __list_del(prev, next). This is useful only if the next and previous pointers are already dereferenced. Otherwise, you are just writing ugly code. See <linux/list.h> for the exact interfaces. |
Traversing Linked Lists
Now you know how to declare, initialize, and manipulate a linked list in the kernel. This is all very well and good, but it is meaningless if you have no way to access your data! The linked lists are just containers that holds your important data; you need a way to use lists to move around and access the actual structures that contain the data. The kernel (thank goodness) provides a very nice set of interfaces for traversing linked lists and referencing the data structures that include them.
Note that, unlike the list manipulation routines, iterating over a linked list in its entirety is clearly an O(n) operation, for n entries in the list.
The simplest way to iterate over a list is with the list_for_each() macro. The macro takes two parameters, both list_head structures. The first is a pointer used to point to the current entry; it is a temporary variable that you must provide. The second is a list_head in the list you want to traverse. On each iteration of the loop, the first parameter points to the next entry in the list, until each entry has been visited. Usage is as follows:
struct list_head *p;
list_for_each(p, list) {
/* p points to an entry in the list */
}
Well, that is still worthless! A pointer to the list structure is usually no good; what we need is a pointer to the structure that contains the list. For example, with the previous my_struct example, we want a pointer to each my_struct, not a pointer to the list member in the structure. The macro list_entry() is provided, which returns the structure that contains a given list_head. It takes three parameters: a pointer to the given element, the type of structure in which the list is embedded, and the member name of the list within that structure.
Consider the following example:
struct list_head *p;
struct my_struct *my;
list_for_each(p, &mine->list) {
/* my points to the structure in which the list is embedded */
my = list_entry(p, struct my_struct, list);
}
The list_for_each() macro expands to a simple for loop. For example, the previous use expands to
for (p = mine->list->next; p != mine->list; p = p->next)
The list_for_each() macro also uses processor prefetching, if the processor supports such a feature, to prefetch subsequent entries into memory before they are actually referenced. Prefetching improves memory bus utilization on modern pipelined processors. To not perform prefetching, the macro __list_for_each() works just identically to this for loop. Unless you know the list is very small or empty, you should always use the prefetching version. You should never hand code the loop; always use the provided macros.
If you need to iterate through the list backward, you can use list_for_each_prev(), which follows the prev pointers instead of the next pointer.
Note that nothing prevents removal of list entries from the list while you are traversing it. Normally, the list needs some sort of lock to prevent concurrent access. The macro list_for_each_safe(), however, uses temporary storage to make traversing the list safe from removals:
struct list_head *p, *n;
struct my_struct *my;
list_for_each_safe(p, n, &mine->list) {
/* my points to each my_struct in the list */
my = list_entry(p, struct my_struct, list);
}
This macro provides protection from only removals. You probably require additional locking protection to prevent concurrent manipulation of the actual list data.
Appendix B. Kernel Random Number Generator
The Linux kernel implements a strong random number generator that is theoretically capable of generating true random numbers. The random number generator gathers environmental noise from device drivers into an entropy pool. This pool is accessible from both user processes and the kernel as a source of data that is not only random but also non-deterministic to an outside attacker. Such numbers are of use in various applications, most notably cryptography.
True random numbers differ from the pseudo-random numbers generated by functions such as those found in the C library. Pseudo-random numbers are created by a deterministic function. Although the function may generate a sequence of numbers that exhibit some properties of a true random number, they are only statistically random. Pseudo-random numbers are deterministic: Knowing one number in the sequence provides information about the rest of the sequence. In fact, the initial value of the sequence (known as the seed) usually determines the entire sequence. For applications that need truly random and non-deterministic numbers, such as cryptography, a pseudo-random number is usually unacceptable.
As opposed to a pseudo-random number, a true random is produced independently of its generating function. Further, knowing some value in a sequence of truly random numbers does not enable an external party to deduce future values from the generator because the generator is non-deterministic.
From physics, entropy is a measurement of disorder and randomness in a system. In thermodynamics, entropy is measured in energy per unit temperature (Joules/Kelvin). When Claude Shannon, the founder of information theory, looked for a term to represent randomness in information, the great mathematician John von Neumann supposedly suggested he use the term entropy because no one really understand what that meant anyhow. Shannon agreed, and today the term is sometimes called Shannon entropy. In hindsight, some scientists find the dual use confusing, and prefer simply the term uncertainty when discussing information. Kernel hackers, on the other hand, think entropy sounds cool and encourage its use.
In discussions of random number generators, Shannon entropy is an important property. It is measured in bits per symbol; high entropy implies there is little useful information (but lots of random junk) in a sequence of characters. The kernel maintains an entropy pool that is fed data obtained from non-deterministic device events. Ideally, this pool is entirely random. To help keep track of the entropy in the pool, the kernel keeps a measurement of the uncertainty of the data in the pool. As the kernel feeds data into the pool, it estimates the amount of randomness in the data that it is adding. Conversely, the kernel keeps track of entropy as it is removed from the pool. This measurement is called the entropy estimate. Optionally, the kernel can refuse a request for a random number if the entropy estimate is zero.
The kernel random number generator was introduced in kernel version 1.3.30 and lives at drivers/char/random.c in the kernel source.
Design and Implementation
Computers are predictable devices. Indeed, it is hard to find randomness in a system whose behavior is entirely programmed. The environment of the machine, however, is full of noise that is accessible and non-deterministic. Such sources include the timing of various hardware devices and user interaction. For example, the time between key presses, the movement of the mouse, the timingparticularly the low-order bits of such timingbetween certain interrupts, and the time taken to complete a block I/O request are all both non-deterministic and not measurable by an outside attacker. Randomness from these values is taken and fed into the entropy pool. The pool grows to become a random and unpredictable mixture of noise. As the values are added to the pool, an estimate of the randomness is calculated and a tally is kept. This allows the kernel to keep track of the entropy in the pool. Figure B.1 is a diagram of the flow of entropy into and out of the pool.
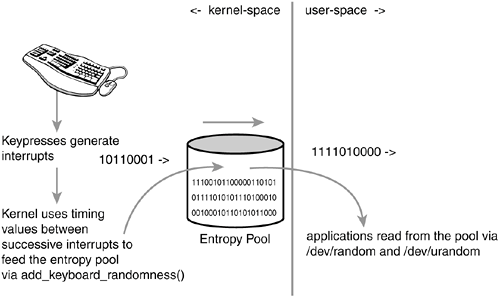
The kernel provides a set of interfaces to allow access to the entropy pool, both from within the kernel and from user-space. When the interfaces are accessed, the kernel first takes the SHA hash of the pool. SHA (Secure Hash Algorithm) is a message digest algorithm developed by the National Security Agency (NSA) and made a U.S. federal standard by NIST (via FIPS 186). A message digest is an algorithm that takes a variable-sized input (small or large) and outputs a fixed-size hash value (typically 128 or 160 bits) that is a "digest" of the original input. From the outputted hash value, the input cannot be reconstructed. Further, trivial manipulations to the input (for example, changing a single character) result in a radically different hash value. Message digest algorithms have various uses, including data verification and fingerprinting. Other message digest algorithms include MD4 and MD5. The SHA hash, not the raw contents of the pool, is returned to the user; the contents of the entropy pool are never directly accessible. It is assumed impossible to derive any information about the state of the pool from the SHA hash. Therefore, knowing some values from the pool does not lend any knowledge to past or future values. Nonetheless, the kernel can use the entropy estimate to refuse to return data if the pool has zero entropy. As entropy is read from the pool, the entropy estimate is decreased in response to how much information is now known about the pool.
When the estimate reaches zero, the kernel can still return random numbers. Theoretically, however, an attacker is then capable of inferring future output given prior output. This would require that the attacker have nearly all the prior outputs from the entropy pool and that the attacker successfully perform cryptanalysis on SHA. Because SHA is believed to be secure, this possibility is not feasible. To high-security cryptography users who accept no risk, however, the entropy estimate ensures the strength of the random numbers. To the vast majority of users this extra assurance is not needed.
|
A criterion for kernel features in Linux is that they cannot be also be implemented in user-space. Tossing things in the kernel "because we can" is not acceptable. At first glance, a random number generator and entropy pool have no place in the kernel. Three conditions, however, all but require it live in the kernel. First, the random number generator needs access to system timings, such as interrupts and user input. It is not possible for user-space to access such timings without exporting various interfaces and hooks to notify user-space of these events. Even if the data were exported, use would be neither clean nor fast. Second, the random number generator must be secure. Although the system could run as root and institute various security measures, the kernel provides a much safer home for the entropy pool. Finally, the kernel itself needs access to the data. It is neither practical nor clean for the kernel to have to obtain the values from a user-space agent. Therefore, the random number generator lives happily in the kernel. |
The Dilemma of System Startup
When the kernel first boots, it completes a series of actions that are almost entirely predictable. Consequently, an attacker is able to infer much about the state of the entropy pool at boot. Worse, each boot is largely similar to the next and the pool would initialize to largely the same contents on each boot. This reduces the accuracy of the entropy estimate, which has no way of knowing that the entropy contributed during the boot sequence is less predictable than entropy contributed at other times.
To offset this problem, most Linux systems save some information from the entropy pool across system shutdowns. They do this by saving the contents of the entropy pool on each shutdown. When the system boots, the data is read and fed into /dev/urandom. This effectively loads the previous contents of the pool into the current pool, without increasing the entropy estimate.
Therefore, an attacker cannot predict the state of the entropy pool without knowledge of both the current state of the system and the previous state of the system.
Interfaces to Input Entropy
The kernel exports a family of interfaces to facilitate feeding data into the entropy pool. They are called by the appropriate kernel subsystems or drivers. They are
void add_interrupt_randomness(int irq)
void add_keyboard_randomness(unsigned char scancode)
void add_mouse_randomness(__u32 mouse_data)
add_interrupt_randomness()is called by the interrupt system whenever an interrupt is received whose handler was registered with SA_SAMPLE_RANDOM. The parameter irq is the interrupt number. The random number generator uses the timing between interrupts as a source of noise. Note that not all devices are suitable for this; if the device generates interrupts deterministically (for example, the timer interrupt) or may be influenced by an outside attacker (for example, a network device) it should not feed the pool. An acceptable device is a hard disk, which generates interrupts at an unpredictable rate.
add_keyboard_randomness() uses the scancode and the timing between successive key presses to feed the entropy pool. Interestingly, the routine is smart enough to ignore autorepeat (when the user holds a key down) because both the scancode and timing interval would then be constant, contributing no entropy. The sole parameter is the scancode of the pressed key.
add_mouse_randomness() uses the mouse position as well as the timing between interrupts to feed the pool. The parameter mouse_data is the hardware-reported position of the mouse.
All three of these routines add the supplied data to the entropy pool, calculate an estimate of the entropy of the given data, and increment the entropy estimate by this amount.
All these exported interfaces use the internal function add_timer_randomness() to feed the pool. This function calculates the timing between successive events of the same time and adds the delay to the pool. For example, the timing between two successive disk interrupts is largely randomespecially when measured very precisely. Often, the low-order bits are electrical noise. After this function feeds the pool, it calculates how much randomness was present in the data. It does this by calculating the first-, second-, and third-order deltas from the previous timing and first- and second-order deltas. The greatest of these deltas, rounded down to 12 bits, is used as the entropy estimate.
Interfaces to Output Entropy
The kernel exports one interface for obtaining random data from within the kernel:
void get_random_bytes(void *buf, int nbytes)
This function stores nbytes worth of random data in the buffer pointed to by buf. The function returns the values, whether or not the entropy estimate is zero. This is less of a concern to the kernel than user-space cryptography applications. The random data is suitable for a handful of kernel tasks, most notably in networking, where the random data seeds the initial TCP sequence number.
Kernel code can do the following to receive a word-size helping of randomness:
unsigned long rand;
get_random_bytes(&rand, sizeof (unsigned long));
For user-space processes, the kernel provides two character devices, /dev/random and /dev/urandom, for obtaining entropy. The first, /dev/random, is more suitable when very strong random numbers are desired, as in high-security cryptographic applications. It returns only up to the maximum number of bits of random data noted by the entropy estimate. When the entropy estimate reaches zero, /dev/random blocks and does not return the remaining data until the entropy estimate is sufficiently positive. Conversely, the device /dev/urandom does not have this feature and is generally just as secure. Both devices return numbers from the same pool.
Reading from either file is simple. Here is an example of a user-space function that an application can use to extract a word of entropy:
unsigned long get_random(void)
{
unsigned long seed;
int fd;
fd = open("/dev/urandom", O_RDONLY);
if (fd == -1) {
perror("open");
return 0;
}
if (read(fd, &seed, sizeof (seed)) < 0) {
perror("read");
seed = 0;
}
if (close(fd))
perror("close");
return seed;
}
Alternatively, you can easily read bytes bytes into the file file by using the dd(1) program:
dd if=/dev/urandom of=file count=1 bs=bytes
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

 LINUX
LINUX