C++ : разработка паттернов
Код лежит тут
Policy-Based разработка классов
Этот раздел описывает policies и policy classes,
гибкую технологию разработки классов, с высокой usability их в последующем.
policy-based class после сборки имеет гибкое поведене на основе большого количества
мелких классов (названных policies),
каждый из которых берет на себя часть функционала.
Каждый policy имеет свой конкретный интерфейс.
Реализовывать такие маленькие классы можно произвольным образом.
Поскольку можно смешивать policies,
можно достичь требуемого поведения за счет комбинации определенного набора элементарных компонентов.
Policies здесь используются повсюду. Генерик SingletonHolder class template (Часть 6)
использует policies для управления временем жизни потоков.
SmartPtr (Часть 7)
построен почти целиком на основе policies.
Енжин в Главе 11
использует policies для выбора various trade-offs.
Генерик Abstract Factory (Gamma et al. 1995)
реализованный в Chapter 9
использует policy для выбора метода создания.
Этот раздел описывает проблемы policies и пути их решения.
|
Многогранность разработки софта
Software engineering, maybe more than any other engineering discipline, exhibits a rich multiplicity: You can do the same thing in many correct ways, and there are infinite nuances between right and wrong. Each path opens up a new world. Once you choose a solution, a host of possible variants appears, on and on at all levelsfrom the system architecture level down to the smallest coding detail. The design of a software system is a choice of solutions out of a combinatorial solution space.
Let's think of a simple, low-level design artifact: a smart pointer (Chapter 7). A smart pointer class can be single threaded or multithreaded, can use various ownership strategies, can make various trade-offs between safety and speed, and may or may not support automatic conversions to the underlying raw pointer type. All these features can be combined freely, and usually exactly one solution is best suited for a given area of your application.
The multiplicity of the design space constantly confuses apprentice designers. Given a software design problem, what's a good solution to it? Events? Objects? Observers? Callbacks? Virtuals? Templates? Up to a certain scale and level of detail, many different solutions seem to work equally well.
The most important difference between an expert software architect and a beginner is the knowledge of what works and what doesn't. For any given architectural problem, there are many competing ways of solving it. However, they scale differently and have distinct sets of advantages and disadvantages, which may or may not be suitable for the problem at hand. A solution that appears to be acceptable on the whiteboard might be unusable in practice.
Designing software systems is hard because it constantly asks you to choose. And in program design, just as in life, choice is hard.
Good, seasoned designers know what choices will lead to a good design. For a beginner, each design choice opens a door to the unknown. The experienced designer is like a good chess player: She can see more moves ahead. This takes time to learn. Maybe this is the reason why programming genius may show at an early age, whereas software design genius tends to take more time to ripen.
In addition to being a puzzle for beginners, the combinatorial nature of design decisions is a major source of trouble for library writers. To implement a useful library of designs, the library designer must classify and accommodate many typical situations, yet still leave the library open-ended so that the application programmer can tailor it to the specific needs of a particular situation.
Indeed, how can one package flexible, sound design components in libraries? How can one let the user configure these components? How does one fight the "evil multiplicity" of design with a reasonably sized army of code? These are the questions that the remainder of this chapter, and ultimately this whole book, tries to answer.
|
Все-в-одном - неверный подход
Implementing everything under the umbrella of a do-it-all interface is not a good solution, for several reasons.
Some important negative consequences are intellectual overhead, sheer size, and inefficiency. Mammoth classes are unsuccessful because they incur a big learning overhead, tend to be unnecessarily large, and lead to code that's much slower than the equivalent handcrafted version.
But maybe the most important problem of an overly rich interface is loss of static type safety. One essential purpose of the architecture of a system is to enforce certain axioms "by design"for example, you cannot create two Singleton objects (see Chapter 6) or create objects of disjoint families (see Chapter 9). Ideally, a design should enforce most constraints at compile time.
In a large, all-encompassing interface, it is very hard to enforce such constraints. Typically, once you have chosen a certain set of design constraints, only certain subsets of the large interface remain semantically valid. A gap grows between syntactically valid and semantically valid uses of the library. The programmer can write an increasing number of constructs that are syntactically valid, but semantically illegal.
For example, consider the thread-safety aspect of implementing a Singleton object. If the library fully encapsulates threading, then the user of a particular, nonportable threading system cannot use the Singleton library. If the library gives access to the unprotected primitive functions, there is the risk that the programmer will break the design by writing code that's syntacticallybut not semanticallyvalid.
What if the library implements different design choices as different, smaller classes? Each class would represent a specific canned design solution. In the smart pointer case, for example, you would expect a battery of implementations: SingleThreadedSmartPtr, MultiThreadedSmartPtr, RefCountedSmartPtr, RefLinkedSmartPtr, and so on.
The problem that emerges with this second approach is the combinatorial explosion of the various design choices. The four classes just mentioned lead necessarily to combinations such as SingleThreadedRefCountedSmartPtr. Adding a third design option such as conversion support leads to exponentially more combinations, which will eventually overwhelm both the implementer and the user of the library. Clearly this is not the way to go. Never use brute force in fighting an exponential.
Not only does such a library incur an immense intellectual overhead, but it also is extremely rigid. The slightest unpredicted customizationsuch as trying to initialize default-constructed smart pointers with a particular valuerenders all the carefully crafted library classes useless.
Designs enforce constraints; consequently, design-targeted libraries must help user-crafted designs to enforce their own constraints, instead of enforcing predefined constraints. Canned design choices would be as uncomfortable in design-targeted libraries as magic constants would be in regular code. Of course, batteries of "most popular" or "recommended" canned solutions are welcome, as long as the client programmer can change them if needed.
These issues have led to an unfortunate state of the art in the library space: Low-level general-purpose and specialized libraries abound, while libraries that directly assist the design of an applicationthe higher-level structuresare practically nonexistent. This situation is paradoxical because any nontrivial application has a design, so a design-targeted library would apply to most applications.
Frameworks try to fill the gap here, but they tend to lock an application into a specific design rather than help the user to choose and customize a design. If programmers need to implement an original design, they have to start from first principlesclasses, functions, and so on.

|
Множественное наследование - это хорошо или плохо ?
A TemporarySecretary class inherits both the Secretary and the Temporary classes. TemporarySecretary has the features of both a secretary and a temporary employee, and possibly some more features of its own. This leads to the idea that multiple inheritance might help with handling the combinatorial explosion of design choices through a small number of cleverly chosen base classes. In such a setting, the user would build a multi-threaded, reference-counted smart pointer class by inheriting some BaseSmartPtr class and two classes: MultiThreaded and RefCounted. Any experienced class designer knows that such a naïve design does not work.
Analyzing the reasons why multiple inheritance fails to allow the creation of flexible designs provides interesting ideas for reaching a sound solution. The problems with assembling separate features by using multiple inheritance are as follows:
Mechanics.
There is no boilerplate code to assemble the inherited components in a controlled manner. The only tool that combines BaseSmartPtr, MultiThreaded, and RefCounted is a language mechanism called multiple inheritance. The language applies simple superposition in combining the base classes and establishes a set of simple rules for accessing their members. This is unacceptable except for the simplest cases. Most of the time, you need to carefully orchestrate the workings of the inherited classes to obtain the desired behavior.
Type information.
The base classes do not have enough type information to carry out their tasks. For example, imagine you try to implement deep copy for your smart pointer class by deriving from a DeepCopy base class. What interface would DeepCopy have? It must create objects of a type it doesn't know yet.
State manipulation.
Various behavioral aspects implemented with base classes must manipulate the same state. This means that they must use virtual inheritance to inherit a base class that holds the state. This complicates the design and makes it more rigid because the premise was that user classes inherit library classes, not vice versa.
Although combinatorial in nature, multiple inheritance by itself cannot address the multiplicity of design choices.
|
Преимущества шаблонов
Templates are a good candidate for coping with combinatorial behaviors because they generate code at compile time based on the types provided by the user.
Class templates are customizable in ways not supported by regular classes. If you want to implement a special case, you can specialize any member functions of a class template for a specific instantiation of the class template. For example, if the template is SmartPtr<T>, you can specialize any member function for, say, SmartPtr<Widget>. This gives you good granularity in customizing behavior.
Furthermore, for class templates with multiple parameters, you can use partial template specialization (as you will see in Chapter 2). Partial template specialization gives you the ability to specialize a class template for only some of its arguments. For example, given the definition
template <class T, class U> class SmartPtr { ... };
you can specialize SmartPtr<T, U> for Widget and any other type using the following syntax:
template <class U> class SmartPtr<Widget, U> { ... };
The innate compile-time and combinatorial nature of templates makes them very attractive for creating design pieces. As soon as you try to implement such designs, you stumble upon several problems that are not self-evident:
You cannot specialize structure.
Using templates alone, you cannot specialize the structure of a class (its data members). You can specialize only functions.
Specialization of member functions does not scale.
You can specialize any member function of a class template with one template parameter, but you cannot specialize individual member functions for templates with multiple template parameters. For example:
template <class T> class Widget
{
void Fun() { .. generic implementation ... }
};
// OK: specialization of a member function of Widget
template <> Widget<char>::Fun()
{
... specialized implementation ...
}
template <class T, class U> class Gadget
{
void Fun() { .. generic implementation ... }
};
// Error! Cannot partially specialize a member class of Gadget
template <class U> void Gadget<char, U>::Fun()
{
... specialized implementation ...
}
The library writer cannot provide multiple default values.
At best, a class template implementer can provide a single default implementation for each member function. You cannot provide several defaults for a template member function.
Now compare the list of drawbacks of multiple inheritance with the list of drawbacks of templates. Interestingly, multiple inheritance and templates foster complementary trade-offs. Multiple inheritance has scarce mechanics; templates have rich mechanics. Multiple inheritance loses type information, which abounds in templates. Specialization of templates does not scale, but multiple inheritance scales quite nicely. You can provide only one default for a template member function, but you can write an unbounded number of base classes.
This analysis suggests that a combination of templates and multiple inheritance could engender a very flexible device, appropriate for creating libraries of design elements.
|
Policies и Policy Classes
Policies and policy classes help in implementing safe, efficient, and highly customizable design elements. A policy defines a class interface or a class template interface. The interface consists of one or all of the following: inner type definitions, member functions, and member variables.
Policies have much in common with traits (Alexandrescu 2000a) but differ in that they put less emphasis on type and more emphasis on behavior. Also, policies are reminiscent of the Strategy design pattern (Gamma et al. 1995), with the twist that policies are compile-time bound.
For example, let's define a policy for creating objects. The Creator policy prescribes a class template of type T. This class template must expose a member function called Create that takes no arguments and returns a pointer to T. Semantically, each call to Create should return a pointer to a new object of type T. The exact mode in which the object is created is left to the latitude of the policy implementation.
Let's define some policy classes that implement the Creator policy. One possible way is to use the new operator. Another way is to use malloc and a call to the placement new operator (Meyers 1998b). Yet another way would be to create new objects by cloning a prototype object. Here are examples of all three methods:
template <class T>
struct OpNewCreator
{
static T* Create()
{
return new T;
}
};
template <class T>
struct MallocCreator
{
static T* Create()
{
void* buf = std::malloc(sizeof(T));
if (!buf) return 0;
return new(buf) T;
}
};
template <class T>
struct PrototypeCreator
{
PrototypeCreator(T* pObj = 0)
:pPrototype_(pObj)
{}
T* Create()
{
return pPrototype_ ? pPrototype_->Clone() : 0;
}
T* GetPrototype() { return pPrototype_; }
void SetPrototype(T* pObj) { pPrototype_ = pObj; }
private:
T* pPrototype_;
};
For a given policy, there can be an unlimited number of implementations. The implementations of a policy are called policy classes. Policy classes are not intended for stand-alone use; instead, they are inherited by, or contained within, other classes.
An important aspect is that, unlike classic interfaces (collections of pure virtual functions), policies' interfaces are loosely defined. Policies are syntax oriented, not signature oriented. In other words, Creator specifies which syntactic constructs should be valid for a conforming class, rather than which exact functions that class must implement. For example, the Creator policy does not specify that Create must be static or virtualthe only requirement is that the class template define a Create member function. Also, Creator says that Create should return a pointer to a new object (as opposed to must). Consequently, it is acceptable that in special cases, Create might return zero or throw an exception.
You can implement several policy classes for a given policy. They all must respect the interface as defined by the policy. The user then chooses which policy class to use in larger structures, as you will see.
The three policy classes defined earlier have different implementations and even slightly different interfaces (for example, PrototypeCreator has two extra functions: GetPrototype and SetPrototype). However, they all define a function called Create with the required return type, so they conform to the Creator policy.
Let's see now how we can design a class that exploits the Creator policy. Such a class will either contain or inherit one of the three classes defined previously, as shown in the following:
// Library code
template <class CreationPolicy>
class WidgetManager : public CreationPolicy
{
...
};
The classes that use one or more policies are called hosts or host classes. In the example above, WidgetManager is a host class with one policy. Hosts are responsible for assembling the structures and behaviors of their policies in a single complex unit.
When instantiating the WidgetManager template, the client passes the desired policy:
// Application code
typedef WidgetManager< OpNewCreator<Widget> > MyWidgetMgr;
Let's analyze the resulting context. Whenever an object of type MyWidgetMgr needs to create a Widget, it invokes Create() for its OpNewCreator<Widget> policy subobject. How ever, it is the user of WidgetManager who chooses the creation policy. Effectively, through its design, WidgetManager allows its users to configure a specific aspect of WidgetManager's functionality.
This is the gist of policy-based class design.
Реализация классов с помощью параметризованных шаблонов
Often, as is the case above, the policy's template argument is redundant. It is awkward that the user must pass OpNewCreator's template argument explicitly. Typically, the host class already knows, or can easily deduce, the template argument of the policy class. In the example above, WidgetManager always manages objects of type Widget, so requiring the user to specify Widget again in the instantiation of OpNewCreator is redundant and potentially dangerous.
In this case, library code can use template template parameters for specifying policies, as shown in the following:
// Library code
template <template <class Created> class CreationPolicy>
class WidgetManager : public CreationPolicy<Widget>
{
...
};
In spite of appearances, the Created symbol does not contribute to the definition of WidgetManager. You cannot use Created inside WidgetManagerit is a formal argument for CreationPolicy (not WidgetManager) and simply can be omitted.
Application code now need only provide the name of the template in instantiating WidgetManager:
// Application code
typedef WidgetManager<OpNewCreator> MyWidgetMgr;
Using template template parameters with policy classes is not simply a matter of convenience; sometimes, it is essential that the host class have access to the template so that the host can instantiate it with a different type. For example, assume WidgetManager also needs to create objects of type Gadget using the same creation policy. Then the code would look like this:
// Library code
template <template <class> class CreationPolicy>
class WidgetManager : public CreationPolicy<Widget>
{
...
void DoSomething()
{
Gadget* pW = CreationPolicy<Gadget>().Create();
...
}
};
Does using policies give you an edge? At first sight, not a lot. For one thing, all implementations of the Creator policy are trivially simple. The author of WidgetManager could certainly have written the creation code inline and avoided the trouble of making WidgetManager a template.
But using policies gives great flexibility to WidgetManager. First, you can change policies from the outside as easily as changing a template argument when you instantiate WidgetManager. Second, you can provide your own policies that are specific to your concrete application. You can use new, malloc, prototypes, or a peculiar memory allocation library that only your system uses. It is as if WidgetManager were a little code generation engine, and you configure the ways in which it generates code.
To ease the lives of application developers, WidgetManager's author might define a battery of often-used policies and provide a default template argument for the policy that's most commonly used:
template <template <class> class CreationPolicy = OpNewCreator>
class WidgetManager ...
Note that policies are quite different from mere virtual functions. Virtual functions promise a similar effect: The implementer of a class defines higher-level functions in terms of primitive virtual functions and lets the user override the behavior of those primitives. As shown above, however, policies come with enriched type knowledge and static binding, which are essential ingredients for building designs. Aren't designs full of rules that dictate before runtime how types interact with each other and what you can and what you cannot do? Policies allow you to generate designs by combining simple choices in a typesafe manner. In addition, because the binding between a host class and its policies is done at compile time, the code is tight and efficient, comparable to its handcrafted equivalent.
Of course, policies' features also make them unsuitable for dynamic binding and binary interfaces, so in essence policies and classic interfaces do not compete.
Реализация классов с шаблонными членами-функциями
An alternative to using template template parameters is to use template member functions in conjunction with simple classes. That is, the policy implementation is a simple class (as opposed to a template class) but has one or more templated members.
For example, we can redefine the Creator policy to prescribe a regular (nontemplate) class that exposes a template function Create<T>. A conforming policy class looks like the following:
struct OpNewCreator
{
template <class T>
static T* Create()
{
return new T;
}
};
This way of defining and implementing a policy has the advantage of being better supported by older compilers. On the other hand, policies defined this way are often harder to talk about, define, implement, and use.
|
Enriched Policies
The Creator policy prescribes only one member function, Create. However, PrototypeCreator defines two more functions: GetPrototype and SetPrototype. Let's analyze the resulting context.
Because WidgetManager inherits its policy class and because GetPrototype and Set-Prototype are public members of PrototypeCreator, the two functions propagate through WidgetManager and are directly accessible to clients.
However, WidgetManager asks only for the Create member function; that's all WidgetManager needs and uses for ensuring its own functionality. Users, however, can exploit the enriched interface.
A user who uses a prototype-based Creator policy class can write the following code:
typedef WidgetManager<PrototypeCreator>
MyWidgetManager;
...
Widget* pPrototype = ...;
MyWidgetManager mgr;
mgr.SetPrototype(pPrototype);
... use mgr ...
If the user later decides to use a creation policy that does not support prototypes, the compiler pinpoints the spots where the prototype-specific interface was used. This is exactly what should be expected from a sound design.
The resulting context is very favorable. Clients who need enriched policies can benefit from that rich functionality, without affecting the basic functionality of the host class. Don't forget that usersand not the librarydecide which policy class to use. Unlike regular multiple interfaces, policies give the user the ability to add functionality to a host class, in a typesafe manner.
|
Деструкторы в Policy Classes
There is an additional important detail about creating policy classes. Most often, the host class uses public inheritance to derive from its policies. For this reason, the user can automatically convert a host class to a policy and later delete that pointer. Unless the policy class defines a virtual destructor, applying delete to a pointer to the policy class has undefined behavior, as shown below.
typedef WidgetManager<PrototypeCreator>
MyWidgetManager;
...
MyWidgetManager wm;
PrototypeCreator<Widget>* pCreator = &wm; // dubious, but legal
delete pCreator; // compiles fine, but has undefined behavior
Defining a virtual destructor for a policy, however, works against its static nature and hurts performance. Many policies don't have any data members, but rather are purely behavioral by nature. The first virtual function added incurs some size overhead for the objects of that class, so the virtual destructor should be avoided.
A solution is to have the host class use protected or private inheritance when deriving from the policy class. However, this would disable enriched policies as well (Section 1.6).
The lightweight, effective solution that policies should use is to define a nonvirtual protected destructor:
template <class T>
struct OpNewCreator
{
static T* Create()
{
return new T;
}
protected:
~OpNewCreator() {}
};
Because the destructor is protected, only derived classes can destroy policy objects, so it's impossible for outsiders to apply delete to a pointer to a policy class. The destructor, however, is not virtual, so there is no size or speed overhead.
|
Функциональность и неполная инсталляция
It gets even better. C++ contributes to the power of policies by providing an interesting feature. If a member function of a class template is never used, it is not even instantiatedthe compiler does not look at it at all, except perhaps for syntax checking.
This gives the host class a chance to specify and use optional features of a policy class. For example, let's define a SwitchPrototype member function for WidgetManager.
// Library code
template <template <class> class CreationPolicy>
class WidgetManager : public CreationPolicy<Widget>
{
...
void SwitchPrototype(Widget* pNewPrototype)
{
CreationPolicy<Widget>& myPolicy = *this;
delete myPolicy.GetPrototype();
myPolicy.SetPrototype(pNewPrototype);
}
};
The resulting context is very interesting:
If the user instantiates WidgetManager with a Creator policy class that supports prototypes, she can use SwitchPrototype. If the user instantiates WidgetManager with a Creator policy class that does not support prototypes and tries to use SwitchPrototype, a compile-time error occurs. If the user instantiates WidgetManager with a Creator policy class that does not support prototypes and does not try to use SwitchPrototype, the program is valid.
This all means that WidgetManager can benefit from optional enriched interfaces but still work correctly with poorer interfacesas long as you don't try to use certain member functions of WidgetManager.
The author of WidgetManager can define the Creator policy in the following manner:
Creator prescribes a class template of one type T that exposes a member function Create. Create should return a pointer to a new object of type T. Optionally, the implementation can define two additional member functionsT* GetPrototype() and SetPrototype(T*)having the semantics of getting and setting a prototype object used for creation. In this case, WidgetManager exposes the SwitchPrototype (T* pNewPrototype) member function, which deletes the current prototype and sets it to the incoming argument.
In conjunction with policy classes, incomplete instantiation brings remarkable freedom to you as a library designer. You can implement lean host classes that are able to use additional features and degrade graciously, allowing for Spartan, minimal policies.
|
Комбинирование Policy Classes
The greatest usefulness of policies is apparent when you combine them. Typically, a highly configurable class uses several policies for various aspects of its workings. Then the library user selects the desired high-level behavior by combining several policy classes.
For example, consider designing a generic smart pointer class. (Chapter 7 builds a full implementation.) Say you identify two design choices that you should establish with policies: threading model and checking before dereferencing. Then you implement a SmartPtr class template that uses two policies, as shown:
template
<
class T,
template <class> class CheckingPolicy,
template <class> class ThreadingModel
>
class SmartPtr;
SmartPtr has three template parameters: the pointee type and two policies. Inside SmartPtr, you orchestrate the two policies into a sound implementation. SmartPtr be comes a coherent shell that integrates several policies, rather than a rigid, canned implementation. By designing SmartPtr this way, you allow the user to configure SmartPtr with a simple typedef:
typedef SmartPtr<Widget, NoChecking, SingleThreaded>
WidgetPtr;
Inside the same application, you can define and use several smart pointer classes:
typedef SmartPtr<Widget, EnforceNotNull, SingleThreaded>
SafeWidgetPtr;
The two policies can be defined as follows:
Checking: The CheckingPolicy<T> class template must expose a Check member function, callable with an lvalue of type T*. SmartPtr calls Check, passing it the pointee object before dereferencing it.
ThreadingModel: The ThreadingModel<T> class template must expose an inner type called Lock, whose constructor accepts a T&. For the lifetime of a Lock object, operations on the T object are serialized.
For example, here is the implementation of the NoChecking and EnforceNotNull policy classes:
template <class T> struct NoChecking
{
static void Check(T*) {}
};
template <class T> struct EnforceNotNull
{
class NullPointerException : public std::exception { ... };
static void Check(T* ptr)
{
if (!ptr) throw NullPointerException();
}
};
By plugging in various checking policy classes, you can implement various behaviors. You can even initialize the pointee object with a default value by accepting a reference to a pointer, as shown:
template <class T> struct EnsureNotNull
{
static void Check(T*& ptr)
{
if (!ptr) ptr = GetDefaultValue();
}
};
SmartPtr uses the Checking policy this way:
template
<
class T,
template <class> class CheckingPolicy,
template <class> class ThreadingModel
>
class SmartPtr
: public CheckingPolicy<T>
, public ThreadingModel<SmartPtr>
{
...
T* operator->()
{
typename ThreadingModel<SmartPtr>::Lock guard(*this);
CheckingPolicy<T>::Check(pointee_);
return pointee_;
}
private:
T* pointee_;
};
Notice the use of both the CheckingPolicy and ThreadingModel policy classes in the same function. Depending on the two template arguments, SmartPtr::operator-> behaves differently on two orthogonal dimensions. Such is the power of combining policies.
If you manage to decompose a class in orthogonal policies, you can cover a large spectrum of behaviors with a small amount of code.
|
Выбор структуры Policy Classes
One of the limitations of templates, mentioned in Section 1.4, is that you cannot use templates to customize the structure of a classonly its behavior. Policy-based designs, however, do support structural customization in a natural manner.
Suppose that you want to support nonpointer representations for SmartPtr. For example, on certain platforms some pointers might be represented by a handlean integral value that you pass to a system function to obtain the actual pointer. To solve this you might "indirect" the pointer access through a policy, say, a Structure policy. The Structure policy abstracts the pointer storage. Consequently, Structure should expose types called PointerType (the type of the pointed-to object) and ReferenceType (the type to which the pointer refers) and functions such as GetPointer and SetPointer.
The fact that the pointer type is not hardcoded to T* has important advantages. For example, you can use SmartPtr with nonstandard pointer types (such as near and far pointers on segmented architectures), or you can easily implement clever solutions such as before and after functions (Stroustrup 2000a). The possibilities are extremely interesting.
The default storage of a smart pointer is a plain-vanilla pointer adorned with the Structure policy interface, as shown in the following code.
template <class T>
class DefaultSmartPtrStorage
{
public:
typedef T* PointerType;
typedef T& ReferenceType;
protected:
PointerType GetPointer() { return ptr_; }
void SetPointer(PointerType ptr) { pointee_ = ptr; }
private:
PointerType ptr_;
};
The actual storage used is completely hidden behind Structure's interface. Now SmartPtr can use a Storage policy instead of aggregating a T*.
template
<
class T,
template <class> class CheckingPolicy,
template <class> class ThreadingModel,
template <class> class Storage = DefaultSmartPtrStorage
>
class SmartPtr;
Of course, SmartPtr must either derive from Storage<T> or aggregate a Storage<T> object in order to embed the needed structure.
|
Полная и неполная Policies
Suppose you create two instantiations of SmartPtr: FastWidgetPtr, a pointer with out checking, and SafeWidgetPtr, a pointer with checking before dereference. An interesting question is, Should you be able to assign FastWidgetPtr objects to SafeWidgetPtr objects? Should you be able to assign them the other way around? If you want to allow such conversions, how can you implement that?
Starting from the reasoning that SafeWidgetPtr is more restrictive than FastWidgetPtr, it is natural to accept the conversion from FastWidgetPtr to SafeWidgetPtr. This is because C++ already supports implicit conversions that increase restrictionsnamely, from non-const to const types.
On the other hand, freely converting SafeWidgetPtr objects to FastWidgetPtr objects is dangerous. This is because in an application, the majority of code would use SafeWidgetPtr and only a small, speed-critical core would use FastWidgetPtr. Allowing only explicit, controlled conversions to FastWidgetPtr would help keep FastWidgetPtr's usage to a minimum.
The best, most scalable way to implement conversions between policies is to initialize and copy SmartPtr objects policy by policy, as shown below. (Let's simplify the code by getting back to only one policythe Checking policy.)
template
<
class T,
template <class> class CheckingPolicy
>
class SmartPtr : public CheckingPolicy<T>
{
...
template
<
class T1,
template <class> class CP1,
>
SmartPtr(const SmartPtr<T1, CP1>& other)
: pointee_(other.pointee_), CheckingPolicy<T>(other)
{ ... }
};
SmartPtr implements a templated copy constructor, which accepts any other instantiation of SmartPtr. The code in bold initializes the components of SmartPtr with the components of the other SmartPtr<T1, CP1> received as arguments.
Here's how it works. (Follow the constructor code.) Assume you have a class ExtendedWidget, derived from Widget. If you initialize a SmartPtr<Widget, NoChecking> with a SmartPtr<ExtendedWidget, NoChecking>, the compiler attempts to initialize a Widget* with an ExtendedWiget* (which works), and a NoChecking with a SmartPtrExtended <Widget, NoChecking>. This might look suspicious, but don't forget that SmartPtr derives from its policy, so in essence the compiler will easily figure out that you initialize a NoChecking with a NoChecking. The whole initialization works.
Now for the interesting part. Say you initialize a SmartPtr<Widget, EnforceNotNull> with a SmartPtr<ExtendedWidget, NoChecking>. The ExtendedWidget* to Widget* conversion works just as before. Then the compiler tries to match SmartPtr<ExtendedWidget, NoChecking> to EnforceNotNull's constructors.
If EnforceNotNull implements a constructor that accepts a NoChecking object, then the compiler matches that constructor. If NoChecking implements a conversion operator to EnforceNotNull, that conversion is invoked. In any other case, the code fails to compile.
As you can see, you have two-sided flexibility in implementing conversions between policies. You can implement a conversion constructor on the left-hand side, or you can implement a conversion operator on the right-hand side.
The assignment operator looks like an equally tricky problem, but fortunately, Sutter (2000) describes a very nifty technique that allows you to implement the assignment operator in terms of the copy constructor. (It's so nifty, you have to read about it. You can see the technique at work in Loki's SmartPtr implementation.)
Although conversions from NoChecking to EnforceNotNull and even vice versa are quite sensible, some conversions don't make any sense at all. Imagine converting a reference-counted pointer to a pointer that supports another ownership strategy, such as destructive copy (à la std::auto_ptr). Such a conversion is semantically wrong. The definition of reference counting is that all pointers to the same object are known and tracked by a unique counter. As soon as you try to confine a pointer to another ownership policy, you break the invariant that makes reference counting work.
In conclusion, conversions that change the ownership policy should not be allowed implicitly and should be treated with maximum care. At best, you can change the ownership policy of a reference-counted pointer by explicitly calling a function. That function succeeds if and only if the reference count of the source pointer is 1.
|
1.12 Decomposing a Class into Policies
The hardest part of creating policy-based class design is to correctly decompose the functionality of a class in policies. The rule of thumb is to identify and name the design decisions that take part in a class's behavior. Anything that can be done in more than one way should be identified and migrated from the class to a policy. Don't forget: Design constraints buried in a class's design are as bad as magic constants buried in code.
For example, consider a WidgetManager class. If WidgetManager creates new Widget objects internally, creation should be deferred to a policy. If WidgetManager stores a collection of Widgets, it makes sense to make that collection a storage policy, unless there is a strong preference for a specific storage mechanism.
At an extreme, a host class is totally depleted of any intrinsic policy. It delegates all design decisions and constraints to policies. Such a host class is a shell over a collection of policies and deals only with assembling the policies into a coherent behavior.
The disadvantage of an overly generic host class is the abundance of template parameters. In practice, it is awkward to work with more than four to six template parameters. Still, they justify their presence if the host class offers complex, useful functionality.
Type definitionstypedef statementsare an essential tool in using classes that rely on policies. Using typedef is not merely a matter of convenience; it ensures ordered use and easy maintenance. For example, consider the following type definition:
typedef SmartPtr
<
Widget,
RefCounted,
NoChecked
>
WidgetPtr;
It would be very tedious to use the lengthy specialization of SmartPtr instead of WidgetPtr in code. But the tediousness of writing code is nothing compared with the major problems in understanding and maintaining that code. As the design evolves, WidgetPtr's definition might changefor example, to use a checking policy other than NoChecked in debug builds. It is essential that all the code use WidgetPtr instead of a hardcoded instantiation of SmartPtr. It's just like the difference between calling a function and writing the equivalent inline code: The inline code technically does the same thing but fails to build an abstraction behind it.
When you decompose a class in policies, it is very important to find an orthogonal decomposition. An orthogonal decomposition yields policies that are completely independent of each other. You can easily spot a nonorthogonal decomposition when various policies need to know about each other.
For example, think of an Array policy in a smart pointer. The Array policy is very simpleit dictates whether or not the smart pointer points to an array. The policy can be defined to have a member function T& ElementAt(T* ptr, unsigned int index), plus a similar version for const T. The non-array policy simply does not define an ElementAt member function, so trying to use it would yield a compile-time error. The ElementAt function is an optional enriched behavior as defined in Section 1.6.
The implementations of two policy classes that implement the Array policy follow.
template <class T>
struct IsArray
{
T& ElementAt(T* ptr, unsigned int index)
{
return ptr[index];
}
const T& ElementAt(T* ptr, unsigned int index) const
{
return ptr[index];
}
};
template <class T> struct IsNotArray {};
The problem is that purpose of the Array policyspecifying whether or not the smart pointer points to an arrayinteracts unfavorably with another policy: destruction. You must destroy pointers to objects using the delete operator, and destroy pointers to arrays of objects using the delete[] operator.
Two policies that do not interact with each other are orthogonal. By this definition, the Array and the Destroy policies are not orthogonal.
If you still need to confine the qualities of being an array and of destruction to separate policies, you need to establish a way for the two policies to communicate. You must have the Array policy expose a Boolean constant in addition to a function, and pass that Boolean to the Destroy policy. This complicates and somewhat constrains the design of both the Array and the Destroy policies.
Nonorthogonal policies are an imperfection you should strive to avoid. They reduce compile-time type safety and complicate the design of both the host class and the policy classes.
If you must use nonorthogonal policies, you can minimize dependencies by passing a policy class as an argument to another policy class's template function. This way you can benefit from the flexibility specific to template-based interfaces. The downside remains that one policy must expose some of its implementation details to other policies. This decreases encapsulation.
|
1.13 Summary
Design is choice. Most often, the struggle is not that there is no way to solve a design problem, but that there are too many ways that apparently solve the problem. You must know which collection of solutions solves the problem in a satisfactory manner. The need to choose propagates from the largest architectural levels down to the smallest unit of code. Furthermore, choices can be combined, which confers on design an evil multiplicity.
To fight the multiplicity of design with a reasonably small amount of code, a writer of a design-oriented library needs to develop and use special techniques. These techniques are purposely conceived to support flexible code generation by combining a small number of primitive devices. The library itself provides a number of such devices. Furthermore, the library exposes the specifications from which these devices are built, so the client can build her own. This essentially makes a policy-based design open-ended. These devices are called policies, and the implementations thereof are called policy classes.
The mechanics of policies consist of a combination of templates with multiple inheritance. A class that uses policiesa host classis a template with many template parameters (often, template template parameters), each parameter being a policy. The host class "indirects" parts of its functionality through its policies and acts as a receptacle that combines several policies in a coherent aggregate.
Classes designed around policies support enriched behavior and graceful degradation of functionality. A policy can provide supplemental functionality that propagates through the host class due to public inheritance. Furthermore, the host class can implement enriched functionality that uses the optional functionality of a policy. If the optional functionality is not present, the host class still compiles successfully, provided the enriched functionality is not used.
The power of policies comes from their ability to mix and match. A policy-based class can accommodate very many behaviors by combining the simpler behaviors that its policies implement. This effectively makes policies a good weapon for fighting against the evil multiplicity of design.
Using policy classes, you can customize not only behavior but also structure. This important feature takes policy-based design beyond the simple type genericity that's specific to container classes.
Policy-based classes support flexibility when it comes to conversions. If you use policy-by-policy copying, each policy can control which other policies it accepts, or converts to, by providing the appropriate conversion constructors, conversion operators, or both.
In breaking a class into policies, you should follow two important guidelines. One is to localize, name, and isolate design decisions in your classthings that are subject to a trade-off or could be sensibly implemented in other ways. The other guideline is to look for orthogonal policies, that is, policies that don't need to interact with each other and that can be changed independently.
|
Chapter 2. Techniques
This chapter presents a host of C++ techniques that are used throughout the book. Because they are of help in various contexts, the techniques presented tend to be general and reusable, so you might find applications for them in other contexts. Some of the techniques, such as partial template specialization, are language features. Others, such as compile-time assertions, come with some support code.
In this chapter you will get acquainted with the following techniques and tools:
Compile-time assertions Partial template specialization Local classes Mappings between types and values (the Int2Type and Type2Type class templates) The Select class template, a tool that chooses a type at compile time based on a Boolean condition Detecting convertibility and inheritance at compile time TypeInfo, a handy wrapper around std::type_info Traits, a collection of traits that apply to any C++ type
Taken in isolation, each technique and its support code might look trivial; the norm is five to ten lines of easy-to-understand code. However, the techniques have an important property: They are "nonterminal"; that is, you can combine them to generate higher-level idioms. Together, they form a strong foundation of services that helps in building powerful architectural structures.
The techniques come with examples, so don't expect the discussion to be dry. As you read through the rest of the book, you might want to return to this chapter for reference.
|
2.1 Compile-Time Assertions
As generic programming in C++ took off, the need for better static checking (and better, more customizable error messages) emerged.
Suppose, for instance, you are developing a function for safe casting. You want to cast from one type to another, while making sure that information is preserved; larger types must not be cast to smaller types.
template <class To, class From>
To safe_reinterpret_cast(From from)
{
assert(sizeof(From) <= sizeof(To));
return reinterpret_cast<To>(from);
}
You call this function using the same syntax as the native C++ casts:
int i = ...;
char* p = safe_reinterpret_cast<char*>(i);
You specify the To template argument explicitly, and the compiler deduces the From template argument from i's type. By asserting on the size comparison, you ensure that the destination type can hold all the bits of the source type. This way, the code above yields either an allegedly correct cast or an assertion at runtime.
Obviously, it would be more desirable to detect such an error during compilation. For one thing, the cast might be on a seldom-executed branch of your program. As you port the application to a new compiler or platform, you cannot remember every potential nonportable part and might leave the bug dormant until it crashes the program in front of your customer.
There is hope; the expression being evaluated is a compile-time constant, which means that you can have the compiler, instead of runtime code, check it. The idea is to pass the compiler a language construct that is legal for a nonzero expression and illegal for an expression that evaluates to zero. This way, if you pass an expression that evaluates to zero, the compiler will signal a compile-time error.
The simplest solution to compile-time assertions (Van Horn 1997), and one that works in C as well as in C++, relies on the fact that a zero-length array is illegal.
#define STATIC_CHECK(expr) { char unnamed[(expr) ? 1 : 0]; }
Now if you write
template <class To, class From>
To safe_reinterpret_cast(From from)
{
STATIC_CHECK(sizeof(From) <= sizeof(To));
return reinterpret_cast<To>(from);
}
...
void* somePointer = ...;
char c = safe_reinterpret_cast<char>(somePointer);
and if on your system pointers are larger than characters, the compiler complains that you are trying to create an array of length zero.
The problem with this approach is that the error message you receive is not terribly informative. "Cannot create array of size zero" does not suggest "Type char is too narrow to hold a pointer." It is very hard to provide customized error messages portably. Error messages have no rules that they must obey; it's all up to the compiler. For instance, if the error refers to an undefined variable, the name of that variable does not necessarily appear in the error message.
A better solution is to rely on a template with an informative name; with luck, the compiler will mention the name of that template in the error message.
template<bool> struct CompileTimeError;
template<> struct CompileTimeError<true> {};
#define STATIC_CHECK(expr) \
(CompileTimeError<(expr) != 0>())
CompileTimeError is a template taking a nontype parameter (a Boolean constant). Compile-TimeError is defined only for the true value of the Boolean constant. If you try to instantiate CompileTimeError<false>, the compiler utters a message such as "Undefined specialization CompileTimeError<false>." This message is a slightly better hint that the error is intentional and not a compiler or a program bug.
Of course, there's a lot of room for improvement. What about customizing that error message? An idea is to pass an additional parameter to STATIC_CHECK and some how make that parameter appear in the error message. The disadvantage that remains is that the custom error message you pass must be a legal C++ identifier (no spaces, cannot start with a digit, and so on). This line of thought leads to an improved CompileTimeError, as shown in the following code. Actually, the name CompileTimeError is no longer suggestive in the new context; as you'll see in a minute, CompileTimeChecker makes more sense.
template<bool> struct CompileTimeChecker
{
CompileTimeChecker(...);
};
template<> struct CompileTimeChecker<false> { };
#define STATIC_CHECK(expr, msg) \
{\
class ERROR_##msg {}; \
(void)sizeof(CompileTimeChecker<(expr) != 0>((ERROR_##msg())));\
}
Assume that sizeof(char) < sizeof(void*). (The standard does not guarantee that this is necessarily true.) Let's see what happens when you write the following:
template <class To, class From>
To safe_reinterpret_cast(From from)
{
STATIC_CHECK(sizeof(From) <= sizeof(To),
Destination_Type_Too_Narrow);
return reinterpret_cast<To>(from);
}
...
void* somePointer = ...;
char c = safe_reinterpret_cast<char>(somePointer);
After macro preprocessing, the code of safe_reinterpret_cast expands to the following:
template <class To, class From>
To safe_reinterpret_cast(From from)
{
{
class ERROR_Destination_Type_Too_Narrow {};
(void)sizeof(
CompileTimeChecker<(sizeof(From) <= sizeof(To))>(
ERROR_Destination_Type_Too_Narrow()));
}
return reinterpret_cast<To>(from);
}
The code defines a local class called ERROR_Destination_Type_Too_Narrow that has an empty body. Then, it creates a temporary value of type CompileTimeChecker< (sizeof(From) <= sizeof(To))>, initialized with a temporary value of type ERROR_ Destination_Type_Too_Narrow. Finally, sizeof gauges the size of the resulting temporary variable.
Now here's the trick. The CompileTimeChecker<true> specialization has a constructor that accepts anything; it's an ellipsis function. This means that if the compile-time expression checked evaluates to true, the resulting program is valid. If the comparison between sizes evaluates to false, a compile-time error occurs: The compiler cannot find a conversion from an ERROR_Destination_Type_Too_Narrow to a CompileTimeChecker<false>. And the nicest thing of all is that a decent compiler outputs an error message such as "Error: Cannot convert ERROR_Destination_Type_Too_Narrow to CompileTimeChecker <false>."
Bingo!
|
2.2 Partial Template Specialization
Partial template specialization allows you to specialize a class template for subsets of that template's possible instantiations set.
Let's first recap total explicit template specialization. If you have a class template Widget,
template <class Window, class Controller>
class Widget
{
... generic implementation ...
};
then you can explicitly specialize the Widget class template as shown:
template <>
class Widget<ModalDialog, MyController>
{
... specialized implementation ...
};
ModalDialog and MyController are classes defined by your application.
After seeing the definition of Widget's specialization, the compiler uses the specialized implementation wherever you define an object of type Widget<ModalDialog,My Controller> and uses the generic implementation if you use any other instantiation of Widget.
Sometimes, however, you might want to specialize Widget for any Window and MyController. Here is where partial template specialization comes into play.
// Partial specialization of Widget
template <class Window>
class Widget<Window, MyController>
{
... partially specialized implementation ...
};
Typically, in a partial specialization of a class template, you specify only some of the template arguments and leave the other ones generic. When you instantiate the class template in your program, the compiler tries to find the best match. The matching algorithm is very intricate and accurate, allowing you to partially specialize in innovative ways. For instance, assume you have a class template Button that accepts one template parameter. Then, even if you specialized Widget for any Window and a specific MyController, you can further partially specialize Widgets for all Button instantiations and My Controller:
template <class ButtonArg>
class Widget<Button<ButtonArg>, MyController>
{
... further specialized implementation ...
};
As you can see, the capabilities of partial template specialization are pretty amazing. When you instantiate a template, the compiler does a pattern matching of existing partial and total specializations to find the best candidate; this gives you enormous flexibility.
Unfortunately, partial template specialization does not apply to functionsbe they member or nonmemberwhich somewhat reduces the flexibility and the granularity of what you can do.
Although you can totally specialize member functions of a class template, you cannot partially specialize member functions. You cannot partially specialize namespace-level (nonmember) template functions. The closest thing to partial specialization for namespace-level template functions is overloading. For practical purposes, this means that you have fine-grained specialization abilities only for the function parametersnot for the return value or for internally used types. For example,
template <class T, class U> T Fun(U obj); // primary template
template <class U> void Fun<void, U>(U obj); // illegal partial
// specialization
template <class T> T Fun (Window obj); // legal (overloading)
This lack of granularity in partial specialization certainly makes life easier for compiler writers, but has bad effects for developers. Some of the tools presented later (such as Int2Type and Type2Type) specifically address this limitation of partial specialization.
This book uses partial template specialization copiously. Virtually the entire typelist facility (Chapter 3) is built using this feature.
|
2.3 Local Classes
Local classes are an interesting and little-known feature of C++. You can define classes right inside functions, as follows:
void Fun()
{
class Local
{
... member variables ...
... member function definitions ...
};
... code using Local ...
}
There are some limitationslocal classes cannot define static member variables and cannot access nonstatic local variables. What makes local classes truly interesting is that you can use them in template functions. Local classes defined inside template functions can use the template parameters of the enclosing function.
The template function MakeAdapter in the following code adapts one interface to another. MakeAdapter implements an interface on the fly with the help of a local class. The local class stores members of generic types.
class Interface
{
public:
virtual void Fun() = 0;
...
};
template <class T, class P>
Interface* MakeAdapter(const T& obj, const P& arg)
{
class Local : public Interface
{
public:
Local(const T& obj, const P& arg)
: obj_(obj), arg_(arg) {}
virtual void Fun()
{
obj_.Call(arg_);
}
private:
T obj_;
P arg_;
};
return new Local(obj, arg);
}
It can be easily proven that any idiom that uses a local class can be implemented using a template class outside the function. In other words, local classes are not an idiom-enabling feature. On the other hand, local classes can simplify implementations and improve locality of symbols.
Local classes do have a unique feature, though: They are final. Outside users cannot derive from a class hidden in a function. Without local classes, you'd have to add an unnamed namespace in a separate translation unit.
Chapter 11 uses local classes to create trampoline functions.
|
2.4 Mapping Integral Constants to Types
A simple template, initially described in Alexandrescu (2000b), can be very helpful to many generic programming idioms. Here it is:
template <int v>
struct Int2Type
{
enum { value = v };
};
Int2Type generates a distinct type for each distinct constant integral value passed. This is because different template instantiations are distinct types; thus, Int2Type<0> is different from Int2Type<1>, and so on. In addition, the value that generates the type is "saved" in the enum member value.
You can use Int2Type whenever you need to "typify" an integral constant quickly. This way you can select different functions, depending on the result of a compile-time calculation. Effectively, you achieve static dispatching on a constant integral value.
Typically, you use Int2Type when both these conditions are satisfied:
You need to call one of several different functions, depending on a compile-time constant. You need to do this dispatch at compile time.
For dispatching at runtime, you can use simple if-else statements or the switch statement. The runtime cost is negligible in most cases. However, you often cannot do this. The if-else statement requires both branches to compile successfully, even when the condition tested by if is known at compile time. Confused? Read on.
Consider this situation: You design a generic container NiftyContainer, which is templated by the type contained:
template <class T> class NiftyContainer
{
...
};
Say NiftyContainer contains pointers to objects of type T. To duplicate an object contained in NiftyContainer, you want to call either its copy constructor (for nonpolymorphic types) or a Clone() virtual function (for polymorphic types). You get this information from the user in the form of a Boolean template parameter.
template <typename T, bool isPolymorphic>
class NiftyContainer
{
...
void DoSomething()
{
T* pSomeObj = ...;
if (isPolymorphic)
{
T* pNewObj = pSomeObj->Clone();
... polymorphic algorithm ...
}
else
{
T* pNewObj = new T(*pSomeObj);
... nonpolymorphic algorithm ...
}
}
};
The problem is that the compiler won't let you get away with this code. For example, because the polymorphic algorithm uses pObj->Clone(), NiftyContainer::DoSomething does not compile for any type that doesn't define a member function Clone(). True, it is obvious at compile time which branch of the if statement executes. However, that doesn't matter to the compilerit diligently tries to compile both branches, even if the optimizer will later eliminate the dead code. If you try to call DoSomething for NiftyContainer<int,false>, the compiler stops at the pObj->Clone() call and says, "Huh?"
It is also possible for the nonpolymorphic branch of the code to fail to compile. If T is a polymorphic type and the nonpolymorphic code branch attempts new T(*pObj), the code might fail to compile. This might happen if T has disabled its copy constructor (by making it private), as a well-behaved polymorphic class should.
It would be nice if the compiler didn't bother about compiling code that's dead anyway, but that's not the case. So what would be a satisfactory solution?
As it turns out, there are a number of solutions, and Int2Type provides a particularly clean one. It can transform ad hoc the Boolean value isPolymorphic into two distinct types corresponding to isPolymorphic's true and false values. Then you can use Int2Type<isPolymorphic> with simple overloading, and voilà!
template <typename T, bool isPolymorphic>
class NiftyContainer
{
private:
void DoSomething(T* pObj, Int2Type<true>)
{
T* pNewObj = pObj->Clone();
... polymorphic algorithm ...
}
void DoSomething(T* pObj, Int2Type<false>)
{
T* pNewObj = new T(*pObj);
... nonpolymorphic algorithm ...
}
public:
void DoSomething(T* pObj)
{
DoSomething(pObj, Int2Type<isPolymorphic>());
}
};
Int2Type comes in very handy as a means to translate a value into a type. You then pass a temporary variable of that type to an overloaded function. The overloads implement the two needed algorithms.
The trick works because the compiler does not compile template functions that are never usedit only checks their syntax. And, of course, you usually perform dispatch at compile time in template code.
You will see Int2Type at work in several places in Loki, notably in Chapter 11, Multimethods. There, the template class is a double-dispatch engine, and the bool template parameter provides the option of supporting symmetric dispatch or not.
|
2.5 Type-to-Type Mapping
As Section 2.2 mentions, partial specialization for template functions does not exist. At times, however, you might need to simulate similar functionality. Consider the following function.
template <class T, class U>
T* Create(const U& arg)
{
return new T(arg);
}
Create makes a new object, passing an argument to its constructor.
Now say there is a rule in your application: Objects of type Widget are untouchable legacy code and must take two arguments upon construction, the second being a fixed value such as -1. Your own classes, derived from Widget, don't have this problem.
How can you specialize Create so that it treats Widget differently from all other types? An obvious solution is to make a separate CreateWidget function that copes with the particular case. Unfortunately, now you don't have a uniform interface for creating Widgets and objects derived from Widget. This renders Create unusable in any generic code.
You cannot partially specialize a function; that is, you can't write something like this:
// Illegal code don't try this at home
template <class U>
Widget* Create<Widget, U>(const U& arg)
{
return new Widget(arg, -1);
}
In the absence of partial specialization of functions, the only tool available is, again, overloading. A solution would be to pass a dummy object of type T and rely on overloading:
template <class T, class U>
T* Create(const U& arg, T /* dummy */)
{
return new T(arg);
}
template <class U>
Widget* Create(const U& arg, Widget /* dummy */)
{
return new Widget(arg, -1);
}
Such a solution would incur the overhead of constructing an arbitrarily complex object that remains unused. We need a light vehicle for transporting the type information about T to Create. This is the role of Type2Type: It is a type's representative, a light identifier that you can pass to overloaded functions.
The definition of Type2Type is as follows.
template <typename T>
struct Type2Type
{
typedef T OriginalType;
};
Type2Type is devoid of any value, but distinct types lead to distinct Type2Type instantiations, which is what we need.
Now you can write the following:
// An implementation of Create relying on overloading
// and Type2Type
template <class T, class U>
T* Create(const U& arg, Type2Type<T>)
{
return new T(arg);
}
template <class U>
Widget* Create(const U& arg, Type2Type<Widget>)
{
return new Widget(arg, -1);
}
// Use Create()
String* pStr = Create("Hello", Type2Type<String>());
Widget* pW = Create(100, Type2Type<Widget>());
The second parameter of Create serves only to select the appropriate overload. Now you can specialize Create for various instantiations of Type2Type, which you map to various types in your application.
|
2.6 Type Selection
Sometimes generic code needs to select one type or another, depending on a Boolean constant.
In the NiftyContainer example discussed in Section 2.4, you might want to use an std::vector as your back-end storage. Obviously, you cannot store polymorphic types by value, so you must store pointers. On the other hand, you might want to store nonpolymorphic types by value, because this is more efficient.
In your class template,
template <typename T, bool isPolymorphic>
class NiftyContainer
{
...
};
you need to store either a vector<T*> (if isPolymorphic is true) or a vector<T> (if isPolymorphic is false). In essence, you need a typedef ValueType that is either T* or T, depending on the value of isPolymorphic.
You can use a traits class template (Alexandrescu 2000a), as follows.
template <typename T, bool isPolymorphic>
struct NiftyContainerValueTraits
{
typedef T* ValueType;
};
template <typename T>
struct NiftyContainerValueTraits<T, false>
{
typedef T ValueType;
};
template <typename T, bool isPolymorphic>
class NiftyContainer
{
...
typedef NiftyContainerValueTraits<T, isPolymorphic>
Traits;
typedef typename Traits::ValueType ValueType;
};
This way of doing things is unnecessarily clumsy. Moreover, it doesn't scale: For each type selection, you must define a new traits class template.
The library class template Select provided by Loki makes type selection available right on the spot. Its definition uses partial template specialization.
template <bool flag, typename T, typename U>
struct Select
{
typedef T Result;
};
template <typename T, typename U>
struct Select<false, T, U>
{
typedef U Result;
};
Here's how it works. If flag evaluates to true, the compiler uses the first (generic) definition and therefore Result evaluates to T. If flag is false, then the specialization enters into action and therefore Result evaluates to U.
Now you can define NiftyContainer::ValueType much more easily.
template <typename T, bool isPolymorphic>
class NiftyContainer
{
...
typedef typename Select<isPolymorphic, T*, T>::Result
ValueType;
...
};
|
2.7 Detecting Convertibility and Inheritance at Compile Time
When you're implementing template functions and classes, a question arises every so often: Given two arbitrary types T and U that you know nothing about, how can you detect whether or not U inherits from T? Discovering such relationships at compile time is key to implementing advanced optimizations in generic libraries. In a generic function, you can rely on an optimized algorithm if a class implements a certain interface. Discovering this at compile time means not having to use dynamic_cast, which is costly at runtime.
Detecting inheritance relies on a more general mechanism, that of detecting convertibility. The more general problem is, How can you detect whether an arbitrary type T supports automatic conversion to an arbitrary type U?
There is a solution to this problem, and it relies on sizeof. There is a surprising amount of power in sizeof: You can apply sizeof to any expression, no matter how complex, and sizeof returns its size without actually evaluating that expression at runtime. This means that sizeof is aware of overloading, template instantiation, conversion ruleseverything that can take part in a C++ expression. In fact, sizeof conceals a complete facility for deducing the type of an expression; eventually, sizeof throws away the expression and returns only the size of its result.
The idea of conversion detection relies on using sizeof in conjunction with overloaded functions. We provide two overloads of a function: One accepts the type to convert to (U), and the other accepts just about anything else. We call the overloaded function with a temporary of type T, the type whose convertibility to U we want to determine. If the function that accepts a U gets called, we know that T is convertible to U; if the fallback function gets called, then T is not convertible to U. To detect which function gets called, we arrange the two overloads to return types of different sizes, and then we discriminate with sizeof. The types themselves do not matter, as long as they have different sizes.
Let's first create two types of different sizes. (Apparently, char and long double do have different sizes, but that's not guaranteed by the standard.) A foolproof scheme would be the following:
typedef char Small;
class Big { char dummy[2]; };
By definition, sizeof(Small) is 1. The size of Big is unknown, but it's certainly greater than 1, which is the only guarantee we need.
Next, we need the two overloads. One accepts a U and returns, say, a Small:
Small Test(U);
How can we write a function that accepts "anything else"? A template is not a solution because the template would always qualify as the best match, thus hiding the conversion. We need a match that's "worse" than an automatic conversionthat is, a conversion that kicks in if and only if there's no automatic conversion. A quick look through the conversion rules applied for a function call yields the ellipsis match, which is the worst of allthe bottom of the list. That's exactly what the doctor prescribed.
Big Test(...);
(Passing a C++ object to a function with ellipses has undefined results, but this doesn't matter. Nothing actually calls the function. It's not even implemented. Recall that sizeof does not evaluate its argument.)
Now we need to apply sizeof to the call of Test, passing it a T:
const bool convExists = sizeof(Test(T())) == sizeof(Small);
That's it! The call of Test gets a default-constructed objectT()and then sizeof extracts the size of the result of that expression. It can be either sizeof(Small) or sizeof(Big), depending on whether or not the compiler found a conversion.
There is one little problem. If T makes its default constructor private, the expression T() fails to compile and so does all of our scaffolding. Fortunately, there is a simple solu-tionjust use a strawman function returning a T. (Remember, we're in the sizeof wonderland where no expression is actually evaluated.) In this case, the compiler is happy and so are we.
T MakeT(); // not implemented
const bool convExists = sizeof(Test(MakeT())) == sizeof(Small);
(By the way, isn't it nifty just how much you can do with functions, like MakeT and Test, that not only don't do anything but don't even really exist at all?)
Now that we have it working, let's package everything in a class template that hides all the details of type deduction and exposes only the result.
template <class T, class U>
class Conversion
{
typedef char Small;
class Big { char dummy[2]; };
static Small Test(U);
static Big Test(...);
static T MakeT();
public:
enum { exists =
sizeof(Test(MakeT())) == sizeof(Small) };
};
Now you can test the Conversion class template by writing
int main()
{
using namespace std;
cout
<< Conversion<double, int>::exists << ' '
<< Conversion<char, char*>::exists << ' '
<< Conversion<size_t, vector<int> >::exists << ' ';
}
This little program prints "1 0 0." Note that although std::vector does implement a constructor taking a size_t, the conversion test returns 0 because that constructor is explicit.
We can implement one more constant inside Conversion: sameType, which is true if T and U represent the same type:
template <class T, class U>
class Conversion
{
... as above ...
enum { sameType = false };
};
We implement sameType through a partial specialization of Conversion:
template <class T>
class Conversion<T, T>
{
public:
enum { exists = 1, sameType = 1 };
};
Finally, we're back home. With the help of Conversion, it is now very easy to determine inheritance:
#define SUPERSUBCLASS(T, U) \
(Conversion<const U*, const T*>::exists && \
!Conversion<const T*, const void*>::sameType)
SUPERSUBCLASS(T, U) evaluates to true if U inherits from T publicly, or if T and U are actually the same type. SUPERSUBCLASS does its job by evaluating the convertibility from a const U* to a const T*. There are only three cases in which const U* converts implicitly to const T*:
T is the same type as U. T is an unambiguous public base of U. T is void.
The last case is eliminated by the second test. In practice it's useful to accept the first case (T is the same as U) as a degenerated case of "is-a" because for practical purposes you can often consider a class to be its own superclass. If you need a stricter test, you can write it this way:
#define SUPERSUBCLASS_STRICT(T, U) \
(SUPERSUBCLASS(T, U) && \
!Conversion<const T, const U>::sameType)
Why does the code add all those const modifiers? The reason is that we don't want the conversion test to fail due to const issues. If template code applies const twice (to a type that's already const), the second const is ignored. In a nutshell, by using const in SUPERSUBCLASS, we're always on the safe side.
Why use SUPERSUBCLASS and not the cuter BASE_OF or INHERITS? For a very practical reason. Initially Loki used INHERITS. But with INHERITS(T, U) it was a constant struggle to say which way the test workeddid it tell whether T inherited U or vice versa? Arguably, SUPERSUBCLASS(T, U) makes it clearer which one is first and which one is second.
|
2.8 A Wrapper Around type_info
Standard C++ provides the std::type_info class, which gives you the ability to investigate object types at runtime. You typically use type_info in conjunction with the typeid operator. The typeid operator returns a reference to a type_info object:
void Fun(Base* pObj)
{
// Compare the two type_info objects corresponding
// to the type of *pObj and Derived
if (typeid(*pObj) == typeid(Derived))
{
... aha, pObj actually points to a Derived object ...
}
...
}
The typeid operator returns a reference to an object of type type_info. In addition to supporting the comparison operators operator== and operator!=, type_info provides two more functions:
The name member function returns a textual representation of a type, in the form of const char*. There is no standardized way of mapping class names to strings, so you shouldn't expect typeid(Widget) to return "Widget". A conforming (but not necessarily award-winning) implementation can have type_info::name return the empty string for all types. The before member function introduces an ordering relationship for type_info objects. Using type_info::before, you can perform indexing on type_info objects.
Unfortunately, type_info's useful capabilities are packaged in a way that makes them unnecessarily hard to exploit. The type_info class disables the copy constructor and assignment operator, which makes storing type_info objects impossible. However, you can store pointers to type_info objects. The objects returned by typeid have static storage, so you don't have to worry about lifetime issues. You do have to worry about pointer identity, though.
The standard does not guarantee that each invocation of, say, typeid(int) returns a reference to the same type_info object. Consequently, you cannot compare pointers to type_info objects. What you should do is to store pointers to type_info objects and compare them by applying type_info::operator== to the dereferenced pointers.
If you want to sort type_info objects, again you must actually store pointers to type_info, and this time you must use the before member function. Consequently, if you want to use STL's ordered containers with type_info, you must write a little functor and deal with pointers.
All this is clumsy enough to mandate a wrapper class around type_info that stores a pointer to a type_info object and provides
All the member functions of type_info Value semantics (public copy constructor and assignment operator) Seamless comparisons by defining operator< and operator==
Loki defines the wrapper class TypeInfo which implements such a handy wrapper around type_info. The synopsis of TypeInfo follows.
class TypeInfo
{
public:
// Constructors/destructors
TypeInfo(); // needed for containers
TypeInfo(const std::type_info&);
TypeInfo(const TypeInfo&);
TypeInfo& operator=(const TypeInfo&);
// Compatibility functions
bool before(const TypeInfo&) const;
const char* name() const;
private:
const std::type_info* pInfo_;
};
// Comparison operators
bool operator==(const TypeInfo&, const TypeInfo&);
bool operator!=(const TypeInfo&, const TypeInfo&);
bool operator<(const TypeInfo&, const TypeInfo&);
bool operator<=(const TypeInfo&, const TypeInfo&);
bool operator>(const TypeInfo&, const TypeInfo&);
bool operator>=(const TypeInfo&, const TypeInfo&);
Because of the conversion constructor that accepts a std::type_info as a parameter, you can directly compare objects of type TypeInfo and std::type_info, as shown:
void Fun(Base* pObj)
{
TypeInfo info = typeid(Derived);
...
if (typeid(*pObj) == info)
{
... pBase actually points to a Derived object ...
}
...
}
The ability to copy and compare TypeInfo objects is important in many situations. The cloning factory in Chapter 8 and one double-dispatch engine in Chapter 11 put TypeInfo to good use.
|
2.9 NullType and EmptyType
Loki defines two very simple types: NullType and EmptyType. You can use them in type calculations to mark certain border cases.
NullType is a class that serves as a null marker for types:
class NullType {};
You usually don't create objects of type NullTypeits only use is to indicate "I am not an interesting type." Section 2.10 uses NullType for cases in which a type must be there syntactically but doesn't have a semantic sense. (For example: "To what type does an int point?") Also, the typelist facility in Chapter 3 uses NullType to mark the end of a typelist and to return "type not found" information.
The second helper type is EmptyType. As you would expect, EmptyType's definition is
struct EmptyType {};
EmptyType is a legal type to inherit from, and you can pass around values of type EmptyType. You can use this insipid type as a default ("don't care") type for a template. The typelist facility in Chapter 3 uses EmptyType in such a way.
|
2.10 Type Traits
Traits are a generic programming technique that allows compile-time decisions to be made based on types, much as you would make runtime decisions based on values (Alexandrescu 2000a). By adding the proverbial "extra level of indirection" that solves many software engineering problems, traits let you take type-related decisions outside the immediate context in which they are made. This makes the resulting code cleaner, more readable, and easier to maintain.
Usually you will write your own trait templates and classes as your generic code needs them. Certain traits, however, are applicable to any type. They can help generic programmers to tailor template code better to the capabilities of a type.
Suppose, for instance, that you implement a copying algorithm:
template <typename InIt, typename OutIt>
OutIt Copy(InIt first, InIt last, OutIt result)
{
for (; first != last; ++first, ++result)
*result = *first;
}
In theory, you shouldn't have to implement such an algorithm, because it duplicates the functionality of std::copy. But you might need to specialize your copying routine for specific types.
Let's say you develop code for a multiprocessor machine that has a very fast BitBlast primitive function, and you would like to take advantage of that primitive whenever possible.
// Prototype of BitBlast in "SIMD_Primitives.h"
void BitBlast(const void* src, void* dest, size_t bytes);
BitBlast, of course, works only for copying primitive types and plain old data structures. You cannot use BitBlast with types having a nontrivial copy constructor. You would like, then, to implement Copy so as to take advantage of BitBlast whenever possible, and fall back on a more general, conservative algorithm for elaborate types. This way, Copy operations on ranges of primitive types will "automagically" run faster.
What you need here are two tests:
If you can find answers to these questions at compile time and if the answer to both questions is yes, you can use BitBlast. Otherwise, you must rely on the generic for loop.
Type traits help in solving such problems. The type traits in this chapter owe a lot to the type traits implementation found in the Boost C++ library (Boost).
2.10.1 Implementing Pointer Traits
Loki defines a class template TypeTraits that collects a host of generic type traits. TypeTraits uses template specialization internally and exposes the results.
The implementation of most type traits relies on total or partial template specialization (Section 2.2). For example, the following code determines whether a type T is a pointer:
template <typename T>
class TypeTraits
{
private:
template <class U> struct PointerTraits
{
enum { result = false };
typedef NullType PointeeType;
};
template <class U> struct PointerTraits<U*>
{
enum { result = true };
typedef U PointeeType;
};
public:
enum { isPointer = PointerTraits<T>::result };
typedef PointerTraits<T>::PointeeType PointeeType;
...
};
The first definition introduces the PointerTraits class template, which says, "T is not a pointer, and a pointee type doesn't apply." Recall from Section 2.9 that NullType is a placeholder type for "doesn't apply" cases.
The second definition (the line in bold) introduces a partial specialization of PointerTraits, a specialization that matches any pointer type. For pointers to anything, the specialization in bold qualifies as a better match than the generic template for any pointer type. Consequently, the specialization enters into action for a pointer, so result evaluates to true. In addition, PointeeType is defined appropriately.
You can now gain some insight into the std::vector::iterator implementationis it a plain pointer or an elaborate type?
int main()
{
const bool
iterIsPtr = TypeTraits<vector<int>::iterator>::isPointer;
cout << "vector<int>::iterator is " <<
iterIsPtr ? "fast" : "smart" << '\n';
}
Similarly, TypeTraits implements an isReference constant and a ReferencedType type definition. For a reference type T, ReferencedType is the type to which T refers; if T is a straight type, ReferencedType is T itself.
Detection of pointers to members (consult Chapter 5 for a description of pointers to members) is a bit different. The specialization needed is as follows:
template <typename T>
class TypeTraits
{
private:
template <class U> struct PToMTraits
{
enum { result = false };
};
template <class U, class V>
struct PToMTraits<U V::*>
{
enum { result = true };
};
public:
enum { isMemberPointer = PToMTraits<T>::result };
...
};
2.10.2 Detection of Fundamental Types
TypeTraits<T> implements an isStdFundamental compile-time constant that says whether or not T is a standard fundamental type. Standard fundamental types consist of the type void and all numeric types (which in turn are floating-point and integral types). TypeTraits defines constants that reveal the categories to which a given type belongs.
At the price of anticipating a bit, it should be said that the magic of typelists (Chapter 3) makes it easy to detect whether a type belongs to a known set of types. For now, all you should know is that the expression
TL::IndexOf<T, TYPELIST_nn(comma-separated list of types)>::value
(where nn is the number of types in the list of types) returns the zero-based position of T in the list, or 1 if T does not figure in the list. For example, the expression
TL::IndexOf<T, TYPELIST_4(signed char, short int,
int, long int)>::value
is greater than or equal to zero if and only if T is a signed integral type.
Following is the definition of the part of TypeTraits dedicated to primitive types.
template <typename T>
class TypeTraits
{
... as above ...
public:
typedef TYPELIST_4(
unsigned char, unsigned short int,
unsigned int, unsigned long int)
UnsignedInts;
typedef TYPELIST_4(signed char, short int, int, long int)
SignedInts;
typedef TYPELIST_3(bool, char, wchar_t) OtherInts;
typedef TYPELIST_3(float, double, long double) Floats;
enum { isStdUnsignedInt =
TL::IndexOf<T, UnsignedInts>::value >= 0 };
enum { isStdSignedInt = TL::IndexOf<T, SignedInts>::value >= 0 };
enum { isStdIntegral = isStdUnsignedInt || isStdSignedInt ||
TL::IndexOf <T, OtherInts>::value >= 0 };
enum { isStdFloat = TL::IndexOf<T, Floats>::value >= 0 };
enum { isStdArith = isStdIntegral || isStdFloat };
enum { isStdFundamental = isStdArith || isStdFloat ||
Conversion<T, void>::sameType };
...
};
Using typelists and TL::IndexOf gives you the ability to infer information quickly about types, without having to specialize a template many times. If you cannot resist the temptation to delve into the details of typelists and TL::IndexOf, take a peek at Chapter 3but don't forget to return here.
The actual implementation of detection of fundamental types is more sophisticated, allowing for vendor-specific extension types (such as int64 or long long).
2.10.3 Optimized Parameter Types
In template code, you sometimes need to answer the following question: Given an arbitrary type T, what is the most efficient way of passing and accepting objects of type T as arguments to functions? In general, the most efficient way is to pass elaborate types by reference and scalar types by value. (Scalar types consist of the arithmetic types described earlier as well as enums, pointers, and pointers to members.) For elaborate types you avoid the overhead of an extra temporary (constructor-plus-destructor calls), and for scalar types you avoid the overhead of the indirection resulting from the reference.
A detail that must be carefully handled is that C++ does not allow references to references. Thus, if T is already a reference, you should not add one more reference to it.
A bit of analysis on the optimal parameter type for a function call engenders the following algorithm. Let's call the parameter type that we look for ParameterType.
If T is a reference to some type, ParameterType is the same as T (unchanged). Reason: References to references are not allowed.
Else:
If T is a scalar type (int, float, etc.), ParameterType is T. Reason: Primitive types are
best passed by value.
Else ParameterType is const T&. Reason: In general, nonprimitive types are best
passed by reference.
One important achievement of this algorithm is that it avoids the reference-to-reference error, which might appear if you combined bind2nd with mem_fun standard library functions.
It is easy to implement TypeTraits::ParameterType using the techniques we already have in hand and the traits defined earlierReferencedType and isPrimitive.
template <typename T>
class TypeTraits
{
... as above ...
public:
typedef Select<isStdArith || isPointer || isMemberPointer,
T, ReferencedType&>::Result
ParameterType;
};
Unfortunately, this scheme fails to pass enumerated types (enums) by value because there is no known way of determining whether or not a type is an enum.
The Functor class template defined in Chapter 5 uses TypeTraits::ParameterType.
2.10.4 Stripping Qualifiers
Given a type T, you can easily get to its constant sibling by simply typing const T. However, doing the opposite (stripping the const off a type) is slightly harder. Similarly, you sometimes might want to get rid of the volatile qualifier of a type.
Consider, for instance, building a smart pointer class SmartPtr (Chapter 7 discusses smart pointers in detail). Although you would like to allow users to create smart pointers to const objectsas in SmartPtr<const Widget>you still need to modify the pointer to Widget you hold internally. In this case, inside SmartPtr you need to obtain Widget from const Widget.
Implementing a "const stripper" is easy, again by using partial template specialization:
template <typename T>
class TypeTraits
{
... as above ...
private:
template <class U> struct UnConst
{
typedef U Result;
};
template <class U> struct UnConst<const U>
{
typedef U Result;
};
public:
typedef UnConst<T>::Result NonConstType;
};
2.10.5 Using TypeTraits
TypeTraits can help you do a lot of interesting things. For one thing, you can now implement the Copy routine to use BitBlast (the problem mentioned in Section 2.10) by simply assembling techniques presented in this chapter. You can use TypeTraits to figure out type information about the two iterators and the Int2Type template for dispatching the call either to BitBlast or to a classic copy routine.
enum CopyAlgoSelector { Conservative, Fast };
// Conservative routine-works for any type
template <typename InIt, typename OutIt>
OutIt CopyImpl(InIt first, InIt last, OutIt result,
Int2Type<Conservative>)
{
for (; first != last; ++first, ++result)
*result = *first;
return result;
}
// Fast routine-works only for pointers to raw data
template <typename InIt, typename OutIt>
OutIt CopyImpl(InIt first, InIt last, OutIt result,
Int2Type<Fast>)
{
const size_t n = last-first;
BitBlast(first, result, n * sizeof(*first));
return result + n;
}
template <typename InIt, typename OutIt>
OutIt Copy(InIt first, InIt last, OutIt result)
{
typedef TypeTraits<InIt>::PointeeType SrcPointee;
typedef TypeTraits<OutIt>::PointeeType DestPointee;
enum { copyAlgo =
TypeTraits<InIt>::isPointer &&
TypeTraits<OutIt>::isPointer &&
TypeTraits<SrcPointee>::isStdFundamental &&
TypeTraits<DestPointee>::isStdFundamental &&
sizeof(SrcPointee) == sizeof(DestPointee) ? Fast :
Conservative };
return CopyImpl(first, last, result, Int2Type<copyAlgo>);
}
Although Copy itself doesn't do much, the interesting part is right in there. The enum value copyAlgo selects one implementation or the other. The logic is as follows: Use BitBlast if the two iterators are pointers, if both pointed-to types are fundamental, and if the pointed-to types are of the same size. The last condition is an interesting twist. If you do this:
int* p1 = ...;
int* p2 = ...;
unsigned int* p3 = ...;
Copy(p1, p2, p3);
then Copy calls the fast routine, as it should, although the source and destination types are different.
The drawback of Copy is that it doesn't accelerate everything that could be accelerated. For example, you might have a plain C-like struct containing nothing but primitive dataa so-called plain old data, or POD, structure. The standard allows bitwise copying of POD structures, but Copy cannot detect "PODness," so it will call the slow routine. Here you have to rely, again, on classic traits in addition to TypeTraits. For instance:
template <typename T> struct SupportsBitwiseCopy
{
enum { result = TypeTraits<T>::isStdFundamental };
};
template <typename InIt, typename OutIt>
OutIt Copy(InIt first, InIt last, OutIt result,
Int2Type<true>)
{
typedef TypeTraits<InIt>::PointeeType SrcPointee;
typedef TypeTraits<OutIt>::PointeeType DestPointee;
enum { useBitBlast =
TypeTraits<InIt>::isPointer &&
TypeTraits<OutIt>::isPointer &&
SupportsBitwiseCopy<SrcPointee>::result &&
SupportsBitwiseCopy<DestPointee>::result &&
sizeof(SrcPointee) == sizeof(DestPointee) };
return CopyImpl(first, last, Int2Type<useBitBlast>);
}
Now, to unleash BitBlast for your POD types of interest, you need only specialize SupportsBitwiseCopy and put a true in there:
template<> struct SupportsBitwiseCopy<MyType>
{
enum { result = true };
};
2.10.6 Wrapping Up
Table 2.1 defines the complete set of traits implemented by Loki.
|
2.11 Summary
A number of techniques form the building blocks of the components presented in this book. Most of the techniques are related to template code.
Compile-time assertions (Section 2.1) help libraries to generate meaningful error messages in templated code. Partial template specialization (Section 2.2) allows you to specialize a template, not for a specific, fixed set of parameters, but for a family of parameters that match a pattern. Local classes (Section 2.3) let you do interesting things, especially inside template functions. Mapping integral constants to types (Section 2.4) eases the compile-time dispatch based on numeric values (notably Boolean conditions). Type-to-type mapping (Section 2.5) allows you to substitute function overloading for function template partial specialization, a feature missing in C++. Type selection (Section 2.6) allows you to select types based on Boolean conditions. Detecting convertibility and inheritance at compile time (Section 2.7) gives you the ability to figure out whether two arbitrary types are convertible to each other, are aliases of the same type, or inherit one from the other. TypeInfo (Section 2.8) implements a wrapper around std::type_info, featuring value semantics and ordering comparisons. The NullType and EmptyType classes (Section 2.9) function as placeholder types in template metaprogramming. The TypeTraits template (Section 2.10) offers a host of general-purpose traits that you can use to tailor code to specific categories of types.
Table 2.1. TypeTraits<T> Members
| isPointer |
Boolean constant |
True if T is a pointer. |
| PointeeType |
Type |
Evaluates to the type to which T points, if T is a pointer. Otherwise, evaluates to NullType. |
| isReference |
Boolean constant |
True if T is a reference. |
| ReferencedType |
Type |
If T is a reference, evaluates to the type to which T refers. Otherwise, evaluates to the type T itself. |
| ParameterType |
Type |
The type that's most appropriate as a parameter of a nonmutable function. Can be either T or const T&. |
| isConst |
Boolean constant |
True if T is a const-qualified type. |
| NonConstType |
Type |
Removes the const qualifier, if any, from type T. |
| isVolatile |
Boolean constant |
True if T is a volatile-qualified type. |
| NonVolatileType |
Type |
Removes the volatile qualifier, if any, from type T. |
| NonQualifiedType |
Type |
Removes both the const and volatile qualifiers, if any, from type T. |
| isStdUnsignedInt |
Boolean constant |
True if T is one of the four unsigned integral types (unsigned char, unsigned short int, unsigned int, or unsigned long int). |
| isStdSignedInt |
Boolean constant |
True if T is one of the four signed integral types (signed char, short int, int, or long int). |
| isStdIntegral |
Boolean constant |
True if T is a standard integral type. |
| isStdFloat |
Boolean constant |
True if T is a standard floating-point type (float, double, or long double). |
| isStdArith |
Boolean constant |
True if T is a standard arithmetic type (integral or floating point). |
| isStdFundamental |
Boolean constant |
True if T is a fundamental type (arithmetic or void). |
|
Chapter 3. Typelists
Typelists are a C++ tool for manipulating collections of types. They offer for types all the fundamental operations that lists of values support.
Some design patterns specify and manipulate collections of types, either related by inheritance or not. Notable examples are Abstract Factory and Visitor (Gamma et al. 1995). If you use traditional coding techniques, you can manipulate collections of types by sheer repetition. This repetition leads to a subtle form of code bloating. Most people don't think it could get any better than that. However, typelists let you automate tasks that you usually confine to your editor's macro capability. Typelists bring power from another planet to C++, enabling it to support new, interesting idioms.
This chapter is dedicated to presenting a complete typelist facility for C++, together with a couple of examples of their use. After reading this chapter, you will
Understanding the typelist concept Understand how typelists can be created and processed Be able to manipulate typelists effectively Know the main uses of typelists and the programming idioms they enable and support
Chapters 9, 10, and 11 use typelists as an enabling technology.
|
3.1 The Need for Typelists
Sometimes you must repeat the same code for a number of types, and templates cannot be of help. Consider, for instance, implementing an Abstract Factory (Gamma et al. 1995). Here you define one virtual function for each type in a collection of types known at design time:
class WidgetFactory
{
public:
virtual Window* CreateWindow() = 0;
virtual Button* CreateButton() = 0;
virtual ScrollBar* CreateScrollBar() = 0;
};
If you want to generalize the concept of Abstract Factory and put it into a library, you have to make it possible for the user to create factories of arbitrary collections of typesnot just Window, Button, and ScrollBar. Templates don't support this feature out of the box.
Although at first Abstract Factory may not seem to provide much opportunity for abstraction and generalization, there are a few things that make the investigation worthwhile:
If you cannot take a stab at generalizing the fundamental concept, you won't be given a chance to generalize the concrete instances of that concept. This is a crucial principle. If the essence escapes generalization, you continue to struggle with the concrete artifacts of that essence. In the Abstract Factory case, although the abstract base class is quite simple, you can get a nasty amount of code duplication when implementing various concrete factories. You cannot easily manipulate the member functions of WidgetFactory (see the previous code). A collection of virtual function signatures is essentially impossible to handle in a generic way. For instance, consider this:
template <class T>
T* MakeRedWidget(WidgetFactory& factory)
{
T* pW = factory.CreateT(); // huh???
pW->SetColor(RED);
return pW;
}
You need to call CreateWindow, CreateButton, or CreateScrollBar, depending on T being a Window, Button, or ScrollBar, respectively. C++ doesn't allow you to do this kind of text substitution. Last, but not least, good libraries have the nice side effect of putting aside endless debates about naming conventions (createWindow, create_window, or CreateWindow?) and little tweaks like that. They introduce a preferred, standardized way of doing things. Abstracting, well, Abstract Factory would have this nice side effect.
Let's put together a wish list. For addressing item 1, it would be nice if we could create a WidgetFactory by passing a parameter list to an AbstractFactory template:
typedef AbstractFactory<Window, Button, ScrollBar> WidgetFactory;
For addressing item 2, we need a template-like invocation for various CreateXxx functions, such as Create<Window>(), Create<Button>(), and so on. Then we can invoke it from generic code:
template <class T>
T* MakeRedWidget(WidgetFactory& factory)
{
T* pW = factory.Create<T>(); // aha!
pW->SetColor(RED);
return pW;
}
However, we cannot fulfill these needs. First, the typedef for WidgetFactory above is not possible because templates cannot have a variable number of parameters. Second, the template syntax Create<Xxx>() is not legal because virtual functions cannot be templates.
By this point, you should see what good abstraction and reuse opportunities we have, and how badly we are constrained in exploiting these opportunities due to language limitations.
Typelists make it possible to create generic Abstract Factories and much more.
|
3.2 Defining Typelists
For a variety of reasons, C++ is a language that leads its users sometimes to say, "These are the smartest five lines of code I ever wrote." Maybe it is its semantic richness or the ever-exciting (and surprising?) way its features interact. In line with this tradition, typelists are fundamentally very simple:
template <class T, class U>
struct Typelist
{
typedef T Head;
typedef U Tail;
};
namespace TL
{
...typelist algorithms ...
}
Everything related to typelists, except the definition of Typelist itself, lives in the TL namespace. In turn, TL is inside the Loki namespace, as is all of Loki's code. To simplify examples, this chapter omits mentioning the TL namespace. You'll have to remember it when using the Typelist.h header. (If you forget, the compiler will remind you.)
Typelist holds two types. They are accessible through the Head and Tail inner names. That's it! We don't need typelists that hold three or more elements, because we already have them. For instance, here's a typelist of three elements holding the three char variants of C++:
typedef Typelist<char, Typelist<signed char, unsigned char> >
CharList;
(Notice the annoying, but required, space between the two > tokens at the end.)
Typelists are devoid of any value: Their bodies are empty, they don't hold any state, and they don't define any functionality. At runtime, typelists don't carry any value at all. Their only raison d'âtre is to carry type information. It follows that any typelist processing must necessarily occur at compile time, not at runtime. Typelists are not meant to be instantiated, although there's no harm in doing this. Thus, whenever this book talks about "a typelist," it really is referring to a typelist type, not a typelist value. Typelist values are not interesting; only their types are of use. (Section 3.13.2 shows how to use typelists to create collections of values.)
The property of templates used here is that a template parameter can be any type, including another instantiation of the same template. This is an old, well-known property of templates, often used to implement ad hoc matrices as vector< vector<double> >. Because Typelist accepts two parameters, we can always extend a given Typelist by replacing one of the parameters with another Typelist, ad infinitum.
There is a little problem, though. We can express typelists of two types or more, but we're unable to express typelists containing zero or one type. What's needed is a null list type, and the NullType class described in Chapter 2 is exactly suited for such uses.
We establish the convention that every typelist must end with a NullType. NullType serves as a useful termination marker, much like the \0 that helps traditional C string functions. Now we can define a typelist of only one element:
// See Chapter 2 for the definition of NullType
typedef Typelist<int, NullType> OneTypeOnly;
The typelist containing the three char variants becomes
typedef Typelist<char, Typelist<signed char,
Typelist<unsigned char, NullType> > > AllCharTypes;
Therefore, we have obtained an open-ended Typelist template that can, by compounding a basic cell, hold any number of types.
Let's see now how we can manipulate typelists. (Again, this means Typelist types, not Typelist objects.) Prepare for an interesting journey. From here on we delve into the underground of C++, a world with strange, new rulesthe world of compile-time programming.
|
3.3 Linearizing Typelist Creation
Right off the bat, typelists are just too LISP-ish to be easy to use. LISP-style constructs are great for LISP programmers, but they don't dovetail nicely with C++ (to say nothing about the spaces between >s that you have to take care of). For instance, here's a typelist of integral types:
typedef Typelist<signed char,
Typelist<short int,
Typelist<int, Typelist<long int, NullType> > > >
SignedIntegrals;
Typelists might be a cool concept, but they definitely need nicer packaging.
In order to linearize typelist creation, the typelist library (see Loki's file Typelist.h) defines a plethora of macros that transform the recursion into simple enumeration, at the expense of tedious repetition. This is not a problem, however. The repetition is done only once, in the library code, and it scales typelists to a large library-defined number (50). The macros look like this:
#define TYPELIST_1(T1) Typelist<T1, NullType>
#define TYPELIST_2(T1, T2) Typelist<T1, TYPELIST_1(T2) >
#define TYPELIST_3(T1, T2, T3) Typelist<T1, TYPELIST_2(T2, T3) >
#define TYPELIST_4(T1, T2, T3, T4) \
Typelist<T1, TYPELIST_3(T2, T3, T4) >
...
#define TYPELIST_50(...) ...
Each macro uses the previous one, which makes it easy for the library user to extend the upper limit, should this necessity emerge.
Now the earlier type definition of SignedIntegrals can be expressed in a much more pleasant way:
typedef TYPELIST_4(signed char, short int, int, long int)
SignedIntegrals;
Linearizing typelist creation is only the beginning. Typelist manipulation is still very clumsy. For instance, accessing the last element in SignedIntegrals requires using SignedIntegrals::Tail::Tail::Head. It's not yet clear how we can manipulate typelists generically. It's time, then, to define some fundamental operations for typelists by thinking of the primitive operations available to lists of values.
|
3.4 Calculating Length
Here's a simple operation. Given a typelist TList, obtain a compile-time constant that evaluates its length. The constant ought to be a compile-time one because typelists are static constructs, so we'd expect all calculations related to typelists to be performed at compile time.
The idea underlying most typelist manipulations is to exploit recursive templates, which are templates that use instantiations of themselves as part of their definition. While doing this, they pass a different template argument list. The recursion obtained this way is stopped with an explicit specialization for a border case.
The code that computes a typelist's length is, again, quite concise:
template <class TList> struct Length;
template <> struct Length<NullType>
{
enum { value = 0 };
};
template <class T, class U>
struct Length< Typelist<T, U> >
{
enum { value = 1 + Length<U>::value };
};
This is the C++ way of saying, "The length of a null typelist is 0. The length of any other typelist is 1 plus the length of the tail of that typelist."
The implementation of Length uses partial template specialization (see Chapter 2) to distinguish between a null type and a typelist. The first specialization of Length is totally specialized and matches only NullType. The second, partial, specialization of Length matches any Typelist<T, U>, including compound typelists, that is, those in which U is in turn a Typelist<V, W>.
The second specialization performs the computation by recursion. It defines value as 1 (which counts the head T) plus the length of the tail of the typelist. When the tail becomes NullType, the first definition is matched, the recursion is stopped, and so is the length calculation, which comes back nicely with the result. Suppose, for example, that you want to define a C-style array that collects pointers to std::type_info objects for all signed integrals. Using Length, you can write
std::type_info* intsRtti[Length<SignedIntegrals>::value];
You allocate four elements for intsRtti through a compile-time calculation.
|
3.5 Intermezzo
You can find early examples of template metaprograms in Veldhuizen (1995). Czarnecki and Eisenecker (2000) discuss this problem in depth and provide a full collection of compile-time simulations for C++ statements.
The conception and implementation of Length resembles a classic recursion example given in computer science classes: the algorithm that computes the length of a singly linked list structure. (There are two major differences, though: The algorithm for Length is performed at compile time, and it operates on types, not on values.)
This naturally leads to the following question: Couldn't we develop a version of Length that's iterative, instead of recursive? After all, iteration is more natural to C++ than recursion. Getting an answer to this question will guide us in implementing the other Typelist facilities.
The answer is no, and for interesting reasons.
Our tools for compile-time programming in C++ are templates, compile-time integer calculations, and type definitions (typedefs). Let's see in what ways each of these tools serves us.
Templatesmore specifically, template specializationprovide the equivalent of if statements at compile time. As seen earlier in the implementation of Length, template specialization enables differentiation between typelists and other types.
Integer calculations allow you to make true value computations, to jump from types to values. However, there is a peculiarity: All compile-time values are immutable. After you've defined an integral constant, say an enumerated value, you cannot change it (that is, assign another value to it).
Type definitions (typedefs) can be seen as introducing named type constants. Again, after definition, they are frozenyou cannot later redefine a typedef'd symbol to hold another type.
These two peculiarities of compile-time calculation make it fundamentally incompatible with iteration. Iteration is about holding an iterator and changing it until some condition is met. Because we don't have mutable entities in the compile-time world, we cannot do any iteration at all. Therefore, although C++ is mostly an imperative language, any compile-time computation must rely on techniques that definitely are reminiscent of pure functional languageslanguages that cannot mutate values. Be prepared to recurse heavily.
|
3.6 Indexed Access
Having access by index to the elements of a typelist would certainly be a desirable feature. It would linearize typelist access, making it easier to manipulate typelists comfortably. Of course, as with all the entities we manipulate in our static world, the index must be a compile-time value.
The declaration of a template for an indexed operation would look like this:
template <class TList, unsigned int index> struct TypeAt;
Let's define the algorithm. Keep in mind that we cannot use mutable, modifiable values.
TypeAt
Inputs: Typelist TList, index i
Output: Inner type Result
If TList is non-null and i is zero, then Result is the head of TList.
Else
If TList is non-null and index i is nonzero, then Result is obtained by applying
TypeAt to the tail of TList and i-1.
Else there is an out-of-bound access that translates into a compile-time error.
Here's the incarnation of the TypeAt algorithm:
template <class Head, class Tail>
struct TypeAt<Typelist<Head, Tail>, 0>
{
typedef Head Result;
};
template <class Head, class Tail, unsigned int i>
struct TypeAt<Typelist<Head, Tail>, i>
{
typedef typename TypeAt<Tail, i - 1>::Result Result;
};
If you try an out-of-bound access, the compiler will complain that there's no specialization defined for TypeAt<NullType, x>, where x is the amount by which you bypass the list size. This message could be a bit more informative, but it's not bad, either.
Loki (file Typelist.h) also defines a variant of TypeAt, called TypeAtNonStrict. TypeAtNonStrict implements the same functionality as TypeAt, with the difference that an out-of-bound access is more forgiving, yielding a user-chosen default type as the result instead of a compile-time error. The generalized callback implementation described in Chapter 5 uses TypeAt-NonStrict.
Indexed access in typelists takes linear time according to the size of the typelist. For lists of values, this method is inefficient (for this reason, std::list does not define an operator[]). However, in the case of typelists, the time is consumed during compilation, and compile time is in a sense "free."
|
3.7 Searching Typelists
How would you search a typelist for a given type? Let's try to implement an IndexOf algorithm that computes the index of a type in a typelist. If the type is not found, the result will be an invalid value, say - 1. The algorithm is a classic linear search implemented recursively.
IndexOf
Inputs: Typelist TList, type T
Output: Inner compile-time constant value
If TList is NullType, then value is -1.
Else
If the head of TList is T, then value is 0.
Else
Compute the result of IndexOf applied to TList's tail and T into a temporary
value temp.
If temp is -1, then value is -1.
Else value is 1 plus temp.
IndexOf is a relatively simple algorithm. Special care is given to propagate the "not found" value (-1) to the result. We need three specializationsone for each branch in the algorithm. The last branch (value's computation from temp) is a numeric calculation that we carry with the conditional operator ?:. Here's the implementation:
template <class TList, class T> struct IndexOf;
template <class T>
struct IndexOf<NullType, T>
{
enum { value = -1 };
};
template <class T, class Tail>
struct IndexOf<Typelist<T, Tail>, T>
{
enum { value = 0 };
};
template <class Head, class Tail, class T>
struct IndexOf<Typelist<Head, Tail>, T>
{
private:
enum { temp = IndexOf<Tail, T>::value };
public:
enum { value = temp == -1 ? -1 : 1 + temp };
};
|
3.8 Appending to Typelists
We need a means to append a type or a typelist to a typelist. Because modifying a typelist is not possible, as discussed previously, we will "return by value" by creating a brand new typelist that contains the result.
Append
Inputs: Typelist TList, type or typelist T
Output: Inner type definition Result
If TList is NullType and T is NullType, then Result is NullType.
Else
If TList is NullType and T is a single (nontypelist) type, then Result is a typelist hav-
ing T as its only element.
Else
If TList is NullType and T is a typelist, Result is T itself.
Else if TList is non-null, then Result is a typelist having TList::Head as its
head and the result of appending T to TList::Tail as its tail.
This algorithm maps naturally to the following code:
template <class TList, class T> struct Append;
template <> struct Append<NullType, NullType>
{
typedef NullType Result;
};
template <class T> struct Append<NullType, T>
{
typedef TYPELIST_1(T) Result;
};
template <class Head, class Tail>
struct Append<NullType, Typelist<Head, Tail> >
{
typedef Typelist<Head, Tail> Result;
};
template <class Head, class Tail, class T>
struct Append<Typelist<Head, Tail>, T>
{
typedef Typelist<Head,
typename Append<Tail, T>::Result>
Result;
};
Note, again, how the last partially specialized version of Append instantiates the Append template recursively, passing it the tail of the list and the type to append.
Now we have a unified Append operation for single types and typelists. For instance, the statement
typedef Append<SignedIntegrals,
TYPELIST_3(float, double, long double)>::Result
SignedTypes;
defines a list containing all signed numeric types in C++.
|
3.9 Erasing a Type from a Typelist
Now for the opposite operation erasing a type from a typelistwe have two options: Erase only the first occurrence, or erase all occurrences of a given type.
Let's think of removing only the first occurrence.
Erase
Input: Typelist TList, type T
Output: Inner type definition Result
If TList is NullType, then Result is NullType.
Else
If T is the same as TList::Head, then Result is TList::Tail.
Else Result is a typelist having TList::Head as its head and the result of applying
Erase to TList::Tail and T as its tail.
Here's how this algorithm maps to C++.
template <class TList, class T> struct Erase;
template <class T> // Specialization 1
struct Erase<NullType, T>
{
typedef NullType Result;
};
template <class T, class Tail> // Specialization 2
struct Erase<Typelist<T, Tail>, T>
{
typedef Tail Result;
};
template <class Head, class Tail, class T> // Specialization 3
struct Erase<Typelist<Head, Tail>, T>
{
typedef Typelist<Head,
typename Erase<Tail, T>::Result>
Result;
};
As in the case of TypeAt, there is no default version of the template. This means you can instantiate Erase only with certain types. For instance, Erase<double, int> yields a compile-time error because there's no match for it. Erase needs its first parameter to be a typelist.
Using our SignedTypes definition, we can now say the following:
// SomeSignedTypes contains the equivalent of
// TYPELIST_6(signed char, short int, int, long int,
// double, long double)
typedef Erase<SignedTypes, float>::Result SomeSignedTypes;
Let's tap into the recursive erase algorithm. The EraseAll template erases all occurrences of a type in a typelist. The implementation is similar to Erase's, with one difference. When detecting a type to erase, the algorithm doesn't stop. EraseAll continues looking for and removing matches down the tail of the list by recursively applying itself:
template <class TList, class T> struct EraseAll;
template <class T>
struct EraseAll<NullType, T>
{
typedef NullType Result;
};
template <class T, class Tail>
struct EraseAll<Typelist<T, Tail>, T>
{
// Go all the way down the list removing the type
typedef typename EraseAll<Tail, T>::Result Result;
};
template <class Head, class Tail, class T>
struct EraseAll<Typelist<Head, Tail>, T>
{
// Go all the way down the list removing the type
typedef Typelist<Head,
typename EraseAll<Tail, T>::Result>
Result;
};
|
3.10 Erasing Duplicates
An important operation on typelists is to erase duplicate values.
The need is to transform a typelist so that each type appears only once. For example, from this:
TYPELIST_6(Widget, Button, Widget, TextField, ScrollBar, Button)
we need to obtain this:
TYPELIST_4(Widget, Button, TextField, ScrollBar)
This processing is a bit more complex, but, as you might guess, we can use Erase to help.
NoDuplicates
Input: Typelist TList
Output: Inner type definition Result
If TList is NullType, then Result is NullType.
Else
Apply NoDuplicates to TList::Tail, obtaining a temporary typelist L1.
Apply Erase to L1 and TList::Head. Obtain L2 as the result.
Result is a typelist whose head is TList::Head and whose tail is L2.
Here's how this algorithm translates to code:
template <class TList> struct NoDuplicates;
template <> struct NoDuplicates<NullType>
{
typedef NullType Result;
};
template <class Head, class Tail>
struct NoDuplicates< Typelist<Head, Tail> >
{
private:
typedef typename NoDuplicates<Tail>::Result L1;
typedef typename Erase<L1, Head>::Result L2;
public:
typedef Typelist<Head, L2> Result;
};
Why was Erase enough when EraseAll would have seemed appropriate? We want to remove all duplicates for a type, right? The answer is that Erase is applied after the recursion to NoDuplicates. This means we erase a type from a list that already has no duplicates, so at most one instance of the type to be erased will appear. This recursive programming is quite interesting.
|
3.11 Replacing an Element in a Typelist
Sometimes a replacement is needed instead of a removal. As you'll see in Section 3.12, replacing a type with another is an important building block for more advanced idioms.
We need to replace type T with type U in a typelist TList.
Replace
Inputs: Typelist TList, type T (to replace), and type U (to replace with)
Output: Inner type definition Result
If TList is NullType, then Result is NullType.
Else
If the head of the typelist TList is T, then Result is a typelist with U as its head and
TList::Tail as its tail.
Else Result is a typelist with TList::Head as its head and the result of applying
Replace to TList, T, and U as its tail.
After you figure out the correct recursive algorithm, the code writes itself:
template <class TList, class T, class U> struct Replace;
template <class T, class U>
struct Replace<NullType, T, U>
{
typedef NullType Result;
};
template <class T, class Tail, class U>
struct Replace<Typelist<T, Tail>, T, U>
{
typedef Typelist<U, Tail> Result;
};
template <class Head, class Tail, class T, class U>
struct Replace<Typelist<Head, Tail>, T, U>
{
typedef Typelist<Head,
typename Replace<Tail, T, U>::Result>
Result;
};
We easily obtain the ReplaceAll algorithm by changing the second specialization for one that recursively applies the algorithm to Tail.
|
3.12 Partially Ordering Typelists
Suppose we want to order a typelist by inheritance relationship. We'd like, for instance, derived types to appear before base types. For example, say we have a class hierarchy like the one in Figure 3.1:
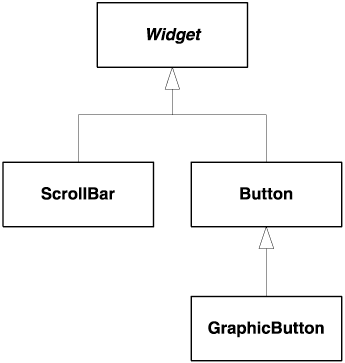
If we have this typelist:
TYPELIST_4(Widget, ScrollBar, Button, GraphicButton)
the challenge is to transform it into
TYPELIST_4(ScrollBar, GraphicButton, Button, Widget)
That is, we need to bring the most derived types to the front and leave the order of sibling types unaltered.
This seems like an exercise of intellectual value only, but there are important practical applications for it. Scanning a typelist ordered with the most derived types first ensures a bottom-up traversal of a class hierarchy. The double-dispatch engine in Chapter 11 applies this important property for figuring out information about types.
When ordering a collection, we need an ordering function. We already have a compile-time means to detect inheritance relationships, described in detail in Chapter 2. Recall that we have a handy macro, SUPERSUBCLASS(T, U), which evaluates to true if U is derived from T. We just have to combine the inheritance detection mechanism with typelists.
We cannot use a full-fledged sorting algorithm here because we don't have a total ordering relationship; we don't have the equivalent of operator< for classes. Two sibling classes cannot be ordered by SUPERSUBCLASS(T, U). We will therefore use a custom algorithm that will bring derived classes to the front and will let other classes remain in the same relative positions.
DerivedToFront
Input: Typelist TList
Output: Inner type definition Result
If TList is NullType, then Result is NullType.
Else
Find the most derived type from TList::Head in TList::Tail. Store it in a
temporary variable TheMostDerived.
Replace TheMostDerived in TList::Tail with TList::Head, obtaining L as the result.
Build the result as a typelist having TheMostDerived as its head and L as its tail.
When this algorithm is applied to a typelist, derived types will migrate to the top of the typelist, and base types will be pushed to the bottom.
There is a piece missing herethe algorithm that finds the most derived type of a given type in a typelist. Because SUPERSUBCLASS yields a compile-time Boolean value, we'll find the little Select class template (also presented in Chapter 2) to be useful. Recall that Select is a template that selects one of two types based on a compile-time Boolean constant.
The MostDerived algorithm accepts a typelist and a type Base and returns the most derived type from Base in the typelist (or possibly Base itself, if no derived type is found). It looks like this:
MostDerived
Input: Typelist TList, type T
Output: Inner type definition Result
If TList is NullType, the result is T.
Else
Apply MostDerived to TList::Tail and Base. Obtain Candidate.
If TList::Head is derived from Candidate, the result is TList::Head.
Else, the result is Candidate.
The implementation of MostDerived is as follows:
template <class TList, class T> struct MostDerived;
template <class T>
struct MostDerived<NullType, T>
{
typedef T Result;
};
template <class Head, class Tail, class T>
struct MostDerived<Typelist<Head, Tail>, T>
{
private:
typedef typename MostDerived<Tail, T>::Result Candidate;
public:
typedef typename Select<
SUPERSUBCLASS(Candidate, Head),
Head, Candidate>::Result Result;
};
The DerivedToFront algorithm uses MostDerived as a primitive. Here is DerivedToFront's implementation:
template <class T> struct DerivedToFront;
template <>
struct DerivedToFront<NullType>
{
typedef NullType Result;
};
template <class Head, class Tail>
struct DerivedToFront< Typelist<Head, Tail> >
{
private:
typedef typename MostDerived<Tail, Head>::Result
TheMostDerived;
typedef typename Replace<Tail,
TheMostDerived, Head>::Result L;
public:
typedef Typelist<TheMostDerived, L> Result;
};
This complex typelist manipulation is of considerable strength. The DerivedToFront transformation effectively automates type processing that otherwise can be performed only with much discipline and attention. Automatic maintenance of parallel class hierarchies, anyone?
|
3.13 Class Generation with Typelists
If, until now, you found typelists intriguing, interesting, or just ugly, you haven't seen anything yet. This section is dedicated to defining fundamental constructs for code generation with typelists. That is, we don't write code anymore; instead, we put the compiler to work generating code for us. These constructs use one of the most powerful constructs of C++, a feature unmatched by any other languagetemplate template parameters.
So far, typelist manipulation has not yielded actual code; the processing has produced only typelists, types, or compile-time numeric constants (as was the case with Length). Let's tap into generating some real code, that is, stuff that leaves traces in the compiled code.
Typelist objects have no use as they are; they are devoid of any runtime state or functionality. An important need in programming with typelists is to generate classes from typelists. Application programmers sometimes need to fill a class with codebe it virtual function signatures, data declarations, or function implementationsin ways directed by a typelist. We will try to automate such processes with typelists.
Because C++ lacks compile-time iteration or recursive macros, the task of adding some code for each type in a typelist is difficult. You can use partial template specialization in ways resembling the algorithms described earlier, but implementing this solution in user code is clumsy and complicated. Loki should be of help with this task.
3.13.1 Generating Scattered Hierarchies
A powerful utility template provided by Loki makes it easy to build classes by applying each type in a typelist to a basic template, provided by the user. This way, the clumsy process of distributing types in the typelist to user code is encapsulated in the library; the user need only define a simple template of one parameter.
The library class template is called GenScatterHierarchy. Although it has a simple definition, GenScatterHierarchy has amazing horsepower under its hood, as you'll see soon. For now, let's look at its definition.
template <class TList, template <class> class Unit>
class GenScatterHierarchy;
// GenScatterHierarchy specialization: Typelist to Unit
template <class T1, class T2, template <class> class Unit>
class GenScatterHierarchy<Typelist<T1, T2>, Unit>
: public GenScatterHierarchy<T1, Unit>
, public GenScatterHierarchy<T2, Unit>
{
public:
typedef Typelist<T1, T2> TList;
typedef GenScatterHierarchy<T1, Unit> LeftBase;
typedef GenScatterHierarchy<T2, Unit> RightBase;
};
// Pass an atomic type (non-typelist) to Unit
template <class AtomicType, template <class> class Unit>
class GenScatterHierarchy : public Unit<AtomicType>
{
typedef Unit<AtomicType> LeftBase;
};
// Do nothing for NullType
template <template <class> class Unit>
class GenScatterHierarchy<NullType, Unit>
{
};
Template template parameters work much as you would expect (see also Chapter 1). You pass a template class Unit to GenScatterHierarchy as its second argument. Internally, GenScatterHierarchy uses its template template parameter Unit just as it would have used any regular template class with one template parameter. The power comes from your abilityas the user of GenScatterHierarchyto pass it a template written by you.
What does GenScatterHierarchy do? If its first template argument is an atomic type (as opposed to a typelist), GenScatterHierarchy passes that type to Unit, and inherits from the resulting class Unit<T>. If GenScatterHierarchy's first template argument is a type list TList, GenScatterHierarchy recurses to GenScatterHierarchy<TList::Head, Unit> and GenScatterHierarchy<TList::Tail, Unit>, and inherits both. GenScatterHierarchy<NullType, Unit> is an empty class.
Ultimately, an instantiation of GenScatterHierarchy ends up inheriting Unit instantiated with every type in the typelist. For instance, consider this code:
template <class T>
struct Holder
{
T value_;
};
typedef GenScatterHierarchy<
TYPELIST_3(int, string, Widget),
Holder>
WidgetInfo;
The inheritance hierarchy generated by WidgetInfo looks like Figure 3.2. We call the class hierarchy in Figure 3.2 scattered, because the types in the typelist are scattered in distinct root classes. This is the gist of GenScatteredHierarchy: It generates a class hierarchy for you by repeatedly instantiating a class template that you provide as a model. Then it collects all such generated classes in a single leaf classin our case, WidgetInfo.
As an effect of inheriting Holder<int>, Holder<string>, and Holder<Widget>, WidgetInfo has one member variable value_ for each type in the typelist. Figure 3.3 shows a likely binary layout of a WidgetInfo object. The layout assumes that empty classes such as GenScatterHierarchy<NullType, Holder> are optimized away and do not occupy any storage in the compound object.
You can do interesting things with WidgetInfo objects. You can, for instance, access the string stored in a WidgetInfo object by writing
WidgetInfo obj;
string name = (static_cast<Holder<string>&>(obj)).value_;
The explicit cast is necessary to disambiguate the member variable name value_. Otherwise, the compiler is confused as to which value_ member you are referring to.
This cast is quite ugly, so let's try to make GenScatterHierarchy easier to use by providing some handy access functions. For instance, a nice member function would access a member by its type. This is quite easy.
// Refer to HierarchyGenerators.h for FieldTraits' definition
template <class T, class H>
typename Private::FieldTraits<H>::Rebind<T>::Result&
Field(H& obj)
{
return obj;
}
Field relies on implicit derived-to-base conversion. If you call Field<Widget>(obj) (obj being of type WidgetInfo), the compiler figures out that Holder<Widget> is a base class of WidgetInfo and simply returns a reference to that part of the compound object.
Why is Field a namespace-level function and not a member function? Well, such highly generic programming must play very carefully with names. Imagine, for instance, that Unit itself defines a symbol with the name Field. Had GenScatterHierarchy itself defined a member function Field, it would have masked Unit's Field member. This would be a major source of annoyance to the user.
There is one more major source of annoyance with Field: You cannot use it when you have duplicate types in your typelists. Consider this slightly modified definition of WidgetInfo:
typedef GenScatterHierarchy<
TYPELIST_4(int, int, string, Widget),
Value>
WidgetInfo;
Now WidgetInfo has two value_ members of type int. If you try to call Field<int> for a WidgetInfo object, the compiler complains about an ambiguity. There is no easy way to solve the ambiguity, because the WidgetInfo ends up inheriting Holder<int> twice through different paths, as shown in Figure 3.4.
We need a means of selecting fields in an instantiation of GenScatterHierarchy by positional index, not by type name. If you could refer to each of the two fields of type int by its position in the typelist (that is, as Field<0>(obj) and Field<1>(obj)), you would get rid of the ambiguity.
Let's implement an index-based field access function. We have to dispatch at compile time between the field index zero, which accesses the head of the typelist, and nonzero, which accesses the tail of the typelist. Dispatching is easy with the help of the little Int2Type template defined in Chapter 2. Recall that Int2Type simply transforms each distinct constant integral into a distinct type. Also, we use Type2Type to transport the result type appropriately, as shown below.
template <class H, typename R>
inline R& FieldHelper(H& obj, Type2Type<R>, Int2Type<0>)
{
typename H::LeftBase& subobj = obj;
return subobj;
}
template <class H, typename R, int i>
inline R& FieldHelper(H& obj, Type2Type<R> tt, Int2Type<i>)
{
typename H::RightBase& subobj = obj;
return FieldHelper(subobj, tt, Int2Type<i- 1>());
}
//Refer to HierarchyGenerators.h for FieldTraits' definition
template <int i, class H>
typename Private::FieldTraits<H>::At<i>::Result&
Field(H& obj)
{
typedef typename Private::FieldTraits<H>::At<i>::Result
Result;
return FieldHelper(obj, Type2Type<Result>(), Int2type<i>());
}
It takes a while to figure out how to write such an implementation, but fortunately explaining it is quite easy. Two overloaded functions called FieldHelper do the actual job. The first one accepts a parameter of type Int2Type<0>, and the second is a template that accepts Int2Type<any integer>. Consequently, the first overload returns the value corresponding to the Unit<T1>&, and the other returns the type at the specified index in the typelist. Field uses a helper template FieldTraits to figure out what type it must return. Field passes that type to FieldHelper through Type2Type.
The second overload of FieldHelper recurses to FieldHelper, passing it the right-hand base of GenScatterHierarchy and Int2Type<index - 1>. This is because field N in a typelist is field N - 1 in the tail of that typelist, for a non-zero N. (And indeed, the N = 0 case is handled by the first overload of FieldHelper.)
For a streamlined interface, we need two additional Field functions: the const versions of the two Field functions defined above. They are similar to their non-const counterparts, except that they accept and return references to const types.
Field makes GenScatterHierarchy very easy to use. Now we can write
WidgetInfo obj;
...
int x = Field<0>(obj).value_; // first int
int y = Field<1>(obj).value_; // second int
The GenScatterHierarchy template is very suitable for generating elaborate classes from typelists by compounding a simple template. You can use GenScatterHierarchy to generate virtual functions for each type in a typelist. Chapter 9, Abstract Factory, uses GenScatterHierarchy to generate abstract creation functions starting from a type list. Chapter 9 also shows how to implement hierarchies generated by GenScatterHierarchy.
3.13.2 Generating Tuples
Sometimes you might need to generate a small structure with unnamed fields, known in some languages (such as ML) as a tuple. A tuple facility in C++ was first introduced by Jakko Järvi (1999a) and then refined by Järvi and Powell (1999b).
What are tuples? Consider the following example.
template <class T>
struct Holder
{
T value_;
};
typedef GenScatterHierarchy<
TYPELIST_3(int, int, int),
Holder>
Point3D;
Working with Point3D is a bit clumsy, because you have to write.value_ after any field access function. What you need here is to generate a structure the same way GenScatterHierarchy does, but with the Field access functions returning references to the value_ members directly. That is, Field<n> should not return a Holder<int>&, but an int& instead.
Loki defines a Tuple template class that is implemented similarly to GenScatterHierarchy but that provides direct field access. Tuple works as follows:
typedef Tuple<TYPELIST_3(int, int, int)>
Point3D;
Point3D pt;
Field<0>(pt) = 0;
Field<1>(pt) = 100;
Field<2>(pt) = 300;
Tuples are useful for creating small anonymous structures that don't have member functions. For example, you can use tuples for returning multiple values from a function:
Tuple<TYPELIST_3(int, int, int)>
GetWindowPlacement(Window&);
The fictitious function GetWindowPlacement allows users to get the coordinates of a window and its position in the window stack using a single function call. The library implementer does not have to provide a distinct structure for tuples of three integers.
You can see other tuple-related functions offered by Loki by looking in the file Tuple.h.
3.13.3 Generating Linear Hierarchies
Consider the following simple template that defines an event handler interface. It only defines an OnEvent member function.
template <class T>
class EventHandler
{
public:
virtual void OnEvent(const T&, int eventId) = 0;
virtual void ~EventHandler() {}
};
To be politically correct, EventHandler also defines a virtual destructor, which is not germane to our discussion, but necessary nonetheless (see Chapter 4 on why).
We can use GenScatterHierarchy to distribute EventHandler to each type in a typelist:
typedef GenScatterHierarchy
<
TYPELIST_3(Window, Button, ScrollBar),
EventHandler
>
WidgetEventHandler;
The disadvantage of GenScatterHierarchy is that it uses multiple inheritance. If you care about optimizing size, GenScatterHierarchy might be inconvenient, because Widget-EventHandler contains three pointers to virtual tables, one for each EventHandler instantiation. If sizeof(EventHandler) is 4 bytes, then sizeof(WidgetEventHandler) will likely be 12 bytes, and it grows as you add types to the typelist. The most space-efficient configuration is to have all virtual functions declared right inside WidgetEventHandler, but this dismisses any code generation opportunities.
A nice configuration that decomposes WidgetEventHandler into one class per virtual function is a linear inheritance hierarchy, as shown in Figure 3.5. By using single inheritance, WidgetEventHandler would have only one vtable pointer, thus maximizing space efficiency.
How can we provide a mechanism that automatically generates a hierarchy like this? A recursive template similar to GenScatterHierarchy can be of help here. There is a difference, though. The user-provided class template must now accept two template parameters. One of them is the current type in the typelist, as in GenScatterHierarchy. The other one is the base from which the instantiation derives. The second template parameter is needed because, as shown in Figure 3.5, the user-defined code now participates in the middle of the class hierarchy, not only at its roots (as was the case with GenScatterHierarchy).
Let's write a recursive template GenLinearHierarchy. It bears a similarity to GenScatterHierarchy, the difference being the way it handles the inheritance relationship and the user-provided template unit.
template
<
class TList,
template <class AtomicType, class Base> class Unit,
class Root = EmptyType // For EmptyType, consult Chapter 2
>
class GenLinearHierarchy;
template
<
class T1,
class T2,
template <class, class> class Unit,
class Root
>
class GenLinearHierarchy<Typelist<T1, T2>, Unit, Root>
: public Unit< T1, GenLinearHierarchy<T2, Unit, Root> >
{
};
template
<
class T,
template <class, class> class Unit,
class Root
>
class GenLinearHierarchy<TYPELIST_1(T), Unit, Root>
: public Unit<T, Root>
{
};
This code is slightly more complicated than GenScatterHierarchy's, but the structure of a hierarchy generated by GenLinearHierarchy is simpler. Let's verify the adage that an image is worth 1,024 words by looking at Figure 3.6, which shows the hierarchy generated by the following code.
template <class T, class Base>
class EventHandler : public Base
{
public:
virtual void OnEvent(T& obj, int eventId);
};
typedef GenLinearHierarchy
<
TYPELIST_3(Window, Button, ScrollBar),
EventHandler
>
MyEventHandler;
In conjunction with EventHandler, GenLinearHierarchy defines a linear, rope-shaped, single-inheritance class hierarchy. Each other node in the hierarchy defines one pure virtual function, as prescribed by EventHandler. Consequently, MyEventHandler defines three virtual functions, as needed. GenLinearHierarchy adds a requirement to its template template parameter: Unit (in our example, EventHandler) must accept a second template argument, and inherit from it. In compensation, GenLinearHierarchy does the laborious task of generating the class hierarchy.
GenScatterHierarchy and GenLinearHierarchy work great in tandem. In most cases, you would generate an interface with GenScatterHierarchy and implement it with GenLinearHierarchy. Chapters 9 and 10 demonstrate concrete uses of these two hierarchy generators.
|
3.14 Summary
Typelists are an important generic programming technique. They add new capabilities for library writers: expressing and manipulating arbitrarily large collections of types, generating data structures and code from such collections, and more.
At compile time, typelists offer most of the primitive functions that lists of values typically implement: add, erase, search, access, replace, erase duplicates, and even partial ordering by inheritance relationship. The code that implements typelist manipulation is confined to a pure functional style because there are no compile-time mutable valuesa type or compile-time constant, once defined, cannot be changed. For this reason, most typelist processing relies on recursive templates and pattern matching through partial template specialization.
Typelists are useful when you have to write the same codeeither declarative or imperativefor a collection of types. They enable you to abstract and generalize entities that escape all other generic programming techniques. For this reason, typelists are the enabling means for genuinely new idioms and library implementations, as you will see in Chapters 9 and 10.
Loki provides two powerful primitives for automatic generation of class hierarchies from typelists: GenScatterHierarchy and GenLinearHierarchy. They generate two basic class structures: scattered (Figure 3.2) and linear (Figure 3.6). The linear class hierarchy structure is the more size efficient one. A scattered class hierarchy has a useful property: All instantiations of the user-defined template (passed as an argument to GenScatter Hierarchy) are roots of the final class, as Figure 3.2 shows.
|
3.15 Typelist Quick Facts
Header file:
Typelist.h.
All typelist utilities reside in namespace Loki::TL. Class template Typelist<Head, Tail> is defined. Typelist creation: Macros TYPELIST_1 to TYPELIST_50 are defined. They accept the number of parameters stated in their name. The upper limit of macros (50) can be extended by the user. For instance:
#define TYPELIST_51(T1, repeat here up to T51) \
Typelist<T1, TYPELIST_50(T2, repeat here up to T51) >
By convention, typelists are properthey always have a simple type (nontypelist) as the first element (the head). The tail can only be a typelist or NullType. The header defines a collection of primitives that operate on typelists. By convention, all the primitives return the result in a nested (inner) public type definition called Result. If the result of the primitive is a value, then its name is value. The primitives are described in Table 3.1. Synopsis of class template GenScatterHierarchy:
template <class TList, template <class> class Unit>
class GenScatterHierarchy;
GenScatterHierarchy generates a hierarchy that instantiates Unit with each type in the typelist TList. An instantiation of GenScatterHierarchy directly or indirectly inherits Unit<T> for each T in TList. The structure of a hierarchy generated by GenScatterHierarchy is depicted in Figure 3.2. Synopsis of class template GenLinearHierarchy:
template <class TList, template <class, class> class Unit>
class GenLinearHierarchy;
GenLinearHierarchy generates a linear hierarchy, depicted in Figure 3.6. GenLinearHierarchy instantiates Unit by passing each type in the typelist TList as Unit's first template argument. Important: Unit must derive publicly from its second template parameter. The overloaded Field functions provide by-type and by-index access to the nodes of the hierarchies. Field<Type>(obj) returns a reference to the Unit instantiation that corresponds to the specified type Type. Field<index>(obj) returns a reference to the Unit instantiation that corresponds to the type found in the typelist at the position specified by the integral constant index.
Table 3.1. Compile-Time Algorithms Operating on Typelists
| Length<TList> |
Computes the length of TList. |
| TypeAt<TList, idx> |
Returns the type at a given position (zero-based) in TList. If the index is greater than or equal to the length of TList, a compile-time error occurs. |
| TypeAtNonStrict<TList, idx> |
Returns the type at a given position (zero-based) in a typelist. If the index is greater than or equal to the length of TList, Null Type is returned. |
| IndexOf<TList, T> |
Returns the index of the first occurrence of type T in typelist TList. If the type is not found, the result is -1. |
| Append<TList, T> |
Appends a type or a typelist to TList. |
| Erase<TList, T> |
Erases the first occurrence, if any, of T in TList. |
| EraseAll<TList, T> |
Erases all occurrences, if any, of T in TList. |
| NoDuplicates<TList> |
Eliminates all the duplicates from TList. |
| Replace<TList, T, U> |
Replaces the first occurrence, if any, of T in TList with U. |
| ReplaceAll<TList, T, U> |
Replaces all occurrences, if any, of T in TList with U. |
| MostDerived<TList, T> |
Returns the most derived type from T in TList. If no such type is found, T is returned. |
| DerivedToFront<TList> |
Brings the most derived types to the front of TList. |
|
|
|

 LINUX
LINUX