Visitor
Здесь обсуждается паттерн под названием Visitor(Gamma et al. 1995).
Visitor очень гибок:
можно добавлять виртуальную функцию в иерархический класс без его рекомпиляции.
Но за это приходится расплачиваться другим:
вы не сможете добавить в иерархию без рекомпиляции всех его клиентов.
Visitor совсем не интуитивен:
нужно быть весьма осторожным и тщательным при его реализации.
В этой главе :
Вы поймете, как работает Visitor
Узнаете,когда нужно применять Visitor,
и что особенно важно-когда не нужно :-)
Понимание базовой реализации visitor (GoF-реализация)
Поймете, как обойти недостатки GoF Visitor implementation
|
Основы Visitor
Пусть у вас есть класс с иерархией,которую нужно модифицировать.
Можно пойти двумя путями:либо добавлением новых классов,
либо добавлением новых виртуальных функций.
Добавить новый класс легко.
Вы наследуетесь от базового класса и реализуете необходимые виртуальные функции.
Не нужно рекомпилировать всю иерархию.
С добавлением новых виртуальных функций возникают проблемы.
Прийдется манипулировать такими полиморфическими вещами,
как указатель на базовый класс,вам прийдется добавлять виртуальную функцию в базовый класс,
и возможно,во множество его наследников.Это тяжко.Прийдется все пересобирать по новой.
Пусть у вас есть иерархия, в которую как раз часто нужно добавлять виртуальные функции.
Вот тут вам на помощь и приходит Visitor.
Он позволяет легко добавлять виртуальные функции.
Предположим,что вы разрабатываете редактор документов.
Элементы документа,такие как параграф,битмап и т.д.,
унаследованы от базового класса DocElement.
Документ представляет из себя структурированный набор указателей на DocElement.
Вам нужен итератор для управления такой структурой,
Параметрами документа также могут быть число символов, слов,образов.
Это можно обьединить в классе DocStats.
class DocStats
{
unsigned int
chars_,
nonBlankChars_,
words_,
images_;
...
public:
void AddChars(unsigned int charsToAdd)
{
chars_ += charsToAdd;
}
...similarly defined AddWords, AddImages...
// Display the statistics to the user in a dialog box
void Display();
};
If you used a classic object-oriented approach to grabbing statistics, you would define a virtual function in DocElement that deals with gathering statistics.
class DocElement
{
...
// This member function helps the "Statistics" feature
virtual void UpdateStats(DocStats& statistics) = 0;
};
Then each concrete document element would define the function in its own way. For example, class Paragraph and class RasterBitmap, which are derived from DocElement, would implement UpdateStats as follows:
void Paragraph::UpdateStats(DocStats& statistics)
{
statistics.AddChars(number of characters in the paragraph);
statistics.AddWords(number of words in the paragraph);
}
void RasterBitmap::UpdateStats(DocStats& statistics)
{
// A raster bitmap counts as one image
// and nothing else (no characters etc.)
statistics.AddImages(1);
}
Finally, the driver function would look like this:
void Document::DisplayStatistics()
{
DocStats statistics;
for (each DocElement in the document)
{
element->UpdateStats(statistics);
}
statistics.Display();
}
This is a fairly good implementation of the Statistics feature, but it has a number of disadvantages.
It requires DocElement and its derivees to have access to the DocStats definition. Consequently, every time you modify DocStats, you must recompile the whole DocElement hierarchy. The actual operations of gathering statistics are spread throughout the UpdateStats implementations. A maintainer debugging or enhancing the Statistics feature must search and edit multiple files. The implementation technique does not scale with respect to adding other operations that are similar to gathering statistics. To add an operation such as "increase font size by one point," you will have to add another virtual function to DocElement (and suffer all of the hassles that this implies).
A solution that breaks the dependency of DocElement on DocStats is to move all operations into the DocStats class and let it figure out what to do for each concrete type. This implies that DocStats has a member function void UpdateStats(DocElement&). The document then simply iterates through its elements and calls UpdateStats for each of them.
This solution effectively makes DocStats invisible to DocElement. However, now DocStats depends on each concrete DocElement that it needs to process. If the object hierarchy is more stable than its operations, the dependency is not very annoying. Now the problem is that the implementation of UpdateStats has to rely on the so-called type switch. A type switch occurs whenever you query a polymorphic object on its concrete type and perform different operations with it depending on what that concrete type is. DocStats::UpdateStats is bound to do such a type switch, as in the following:
void DocStats::UpdateStats(DocElement& elem)
{
if (Paragraph* p = dynamic_cast<Paragraph*>(&elem))
{
chars_ += p->NumChars();
words_ += p->NumWords();
}
else if (dynamic_cast<RasterBitmap*>(&elem))
{
++images_;
}
else ...
add one 'if' statement for each type of object you inspect
}
(The definition of p inside the if test is legal because of to a little-known addition to C++. You can define and test a variable right in an if statement. The lifetime of that variable extends to that if statement and its else part, if any. Although it's not an essential feature and writing cute code per se is not recommended, the feature was invented especially to support type switches, so why not reap the benefits?)
Whenever you see something like this, a mental alarm bell should go off. Type switching is not at all a desirable solution. (Chapter 8 presents a detailed argument.) Code that relies on type switching is hard to understand, hard to extend, and hard to maintain. It's also open to insidious bugs. For example, what if you put the dynamic_cast for a base class before the dynamic_cast for a derived class? The first test will match derived objects, so the second one will never succeed. One of the goals of polymorphism is to eliminate type switches because of all the problems they have.
Here's where the Visitor pattern can be helpful. You need new functions to act virtual, but you don't want to add a new virtual function for each operation. To effect this, you must implement a unique bouncing virtual function in the DocElement hierarchy, a function that "teleports" work to a different hierarchy. The DocElement hierarchy is called the visited hierarchy, and the operations belong to a new visitor hierarchy.
Each implementation of the bouncing virtual function calls a different function in the visitor hierarchy. That's how visited types are selected. The functions in the visitor hierarchy called by the bouncing function are virtual. That's how operations are selected.
Following are a few lines of code to illustrate this idea. First, we define an abstract class DocElementVisitor that defines an operation for each type of object in the DocElement hierarchy.
class DocElementVisitor
{
public:
virtual void VisitParagraph(Paragraph&) = 0;
virtual void VisitRasterBitmap(RasterBitmap&) = 0;
... other similar functions ...
};
Next we add the bouncing virtual function, called Accept, to the class DocElement hierarchy, one that takes a DocElementVisitor& and invokes the appropriate VisitXxx function on its parameter.
class DocElement
{
public:
virtual void Accept(DocElementVisitor&) = 0;
...
};
void Paragraph::Accept(DocElementVisitor& v)
{
v.VisitParagraph(*this);
}
void RasterBitmap::Accept(DocElementVisitor& v)
{
v.VisitRasterBitmap(*this);
}
Now here's DocStats in all its splendor:
class DocStats : public DocElementVisitor
{
public:
virtual void VisitParagraph(Paragraph& par)
{
chars_ += par.NumChars();
words_ += par.NumWords();
}
virtual void VisitRasterBitmap(RasterBitmap&)
{
++images_;
}
...
};
(Of course, a real-world implementation would likely pull out the functions' implementations from the class definition to a separate source file.)
This small example also illustrates a drawback of Visitor: You don't really add virtual member functions. True virtual functions have full access to the object for which they're defined, whereas from inside VisitParagraph you can access only the public part of Paragraph.
The driver function Document::DisplayStatistics creates a DocStats object and invokes Accept on each DocElement, passing that DocStats object as a parameter. As the DocStats object visits various concrete DocElements, it gets nicely filled up with the appropriate datano type switching needed!
void Document::DisplayStatistics()
{
DocStats statistics;
for (each DocElement in the document)
{
element->Accept(statistics);
}
statistics.Display();
}
Let's analyze the resulting context. We have added a new hierarchy, rooted in DocElementVisitor. This is a hierarchy of operationseach of its classes is actually an operation, like DocStatsis. Adding a new operation becomes as easy as deriving a new class from DocElementVisitor. No element of the DocElement hierarchy needs to be changed.
For instance, let's add a new operation, IncrementFontSize, as a helper in implementing an Increase Font Size hot key or toolbar button.
class IncrementFontSize : public DocElementVisitor
{
public:
virtual void VisitParagraph(Paragraph& par)
{
par.SetFontSize(par.GetFontSize() + 1);
}
virtual void VisitRasterBitmap(RasterBitmap&)
{
// nothing to do
}
...
};
That's it. No change to the DocElement class hierarchy is needed, and there is no change to the other operations. You just add a new class. DocElement::Accept bounces IncrementFontSize objects just as well as it bounces DocStats objects. The resulting class structure is represented in Figure 10.1.
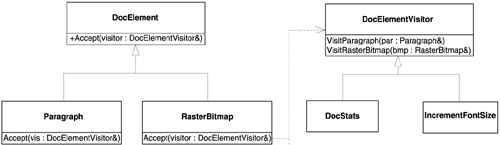
Recall that, by default, new classes are easy to add, whereas new virtual member functions are not easy. We transformed classes into functions by bouncing back from the DocElement hierarchy to the DocElementVisitor hierarchy; thus, DocElementVisitor's derivatives are objectified functions. This is how the Visitor design pattern works.

|
10.2 Overloading and the Catch-All Function
Although not germane to the Visitor pattern, leveraging C++ overloading (or not) has a tremendous impact on implementing designs that use Visitor.
In DocElementVisitor, we defined one member function per type visited: VisitParagraph(Paragraph&), VisitRasterBitmap(RasterBitmap&), and so on. These functions foster a kind of redundancy. The name of the element visited is also encoded in the function name.
Usually it's best to avoid redundancy. We can get rid of it by leveraging C++ overloading. We simply name all the functions Visit and leave it to the compiler to figure out which overload of Visit to call based on the type of the parameter passed to it. So an alternative DocElementVisitor definition looks like this:
class DocElementVisitor
{
public:
virtual void Visit(Paragraph&) = 0;
virtual void Visit(RasterBitmap&) = 0;
... other similar functions ...
};
It also becomes simpler to define all the Accept member functions. They now exhibit a nice uniformity.
void Paragraph::Accept(DocElementVisitor& v)
{
v.Visit(*this);
}
void RasterBitmap::Accept(DocElementVisitor& v)
{
v.Visit(*this);
}
They look so similar that you might be tempted to factor them out in the base class DocElement. Wrong. The similarity is only a mirage. Actually, the functions are quite different: The static type of *this in Paragraph::Accept is Paragraph&, and in RasterBitmap:: Accept it's RasterBitmap&. It is this static type that helps the compiler figure out which overload of DocElementVisitor::Visit to call. If you implement Accept in DocElement, the static type of *this would be DocElement&, which doesn't provide the compiler with the needed type information. So base class factoring is not an option. It actually invalidates our design.
Using overloading introduces an interesting idea. Let's assume that all DocElement derivatives implement Accept by simply bouncing to DocElementVisitor::Visit. Then we can provide DocElementVisitor with the following catch-all overload.
class DocElementVisitor
{
public:
... as above ...
virtual void Visit(DocElement&) = 0;
};
When will this overload be called? If you directly derive a new class from DocElement and don't provide an appropriate Visit overload for it in DocElementVisitor, then overloading rules and automatic derived-to-base conversions come into play. The reference to the unknown class will be automatically converted to a reference to the DocElement base class, and the catch-all member function will be called. If you don't put the catch-all in there, you'll get a compile-time error. Whether you prefer this way or the other depends on the concrete situation.
You can do a lot of things inside the catch-all overload. Refer, for example, to John Vlissides' work (Vlissides 1998, 1999). You can take contingency measures, do something very generic, or fall back to a type switch (hack by using dynamic_cast) to find out the actual type of the DocElement.
|
10.3 An Implementation Refinement: The Acyclic Visitor
So you have decided to use Visitor. Let's get pragmatic. In a real-life project, how should you organize the code?
A dependency analysis of the earlier example reveals the following:
For the DocElement class definition to compile, it must know about the DocElementVisitor because DocElementVisitor appears in the DocElement::Accept member function signature. A forward declaration would suffice. For the DocElementVisitor class definition to compile, it has to know about all the concrete classes (at least) in the DocElement hierarchy because the class names appear in DocElementVisitor's VisitXxx member functions.
This type of dependency is called a cyclic dependency. Cyclic dependencies are well-known maintenance bottlenecks. DocElement needs DocElementVisitor, and Doc ElementVisitor needs all of DocElement's hierarchy. Consequently, DocElement depends on its own subclasses. Actually, this is a cyclic name dependency; that is, the class definitions depend only on their names in order to compile. Thus, a sensible division of classes into files would look like this:
// File DocElementVisitor.h
class DocElement;
class Paragraph;
class RasterBitmap;
... forward declarations for all DocElement derivatives ...
class DocElementVisitor
{
virtual void VisitParagraph(Paragraph&) = 0;
virtual void VisitRasterBitmap(RasterBitmap&) = 0;
... other similar functions ...
};
// File DocElement.h
class DocElementVisitor;
class DocElement
{
public:
virtual void Accept(DocElementVisitor&) = 0;
...
};
Furthermore, each one-line Accept implementation needs the definition of DocElement Visitor, and each concrete visitor has to include its classes of interest. All this leads to an intricate map of dependencies.
What becomes really cumbersome is adding new derivatives to DocElements. But hold on, we're not supposed to add any new elements to the DocElement hierarchy. Visitor applies best to stable hierarchies to which you want to add operations without touching them. Recall, however, that Visitor can do this for you at the expense of making it hard to add derivatives to the visited hierarchy (in our example, the hierarchy rooted in DocElement).
But life is change. Let's face it, here on Earth, there's no such thing as a stable hierarchy. Occasionally you will have to add a new class to the DocElement hierarchy. For the previous example, here's what you must do to add a class VectorGraphic derived from DocElement:
Go to DocElementVisitor.h and add a new forward declaration for VectorGraphic. Add a new pure overload to DocElementVisitor, as follows:
class DocElementVisitor
{
... as before ...
virtual void VisitVectorGraphic(VectorGraphic&) = 0;
};
Go to every concrete visitor and implement VisitVectorGraphic. Depending on the task, the function can be a do-nothing function. Alternatively, you can define DocElementVisitor::VisitVectorGraphic as a do-nothing, as opposed to a pure, function, but in this case, the compiler won't remind you if you don't implement it in concrete visitors. Implement Accept in the VectorGraphic class. Don't forget to do this. If you derive directly from DocElement and forget to implement Accept, there's no problemyou'll get a compile-time error. But if you derive from another class, such as Graphic, and if that class defines Accept, the compiler won't utter a word about your forgetting to make VectorGraphic visitable. This bug won't be detected until runtime, when you notice that your Visitor framework refuses to call any implementation of VisitVectorGraphic. Quite a nasty bug to deal with.
Corollary:
All of the DocElement and DocElementVisitor hierarchies will be recompiled, and you need to add a considerable amount of mechanical code, all simply to keep things working. Depending on the size of the project, this requirementcould range from being annoying to being totally unacceptable.
Robert Martin (1996) invented an interesting variation of the Visitor pattern that leverages dynamic_cast to eliminate cyclicity. His approach defines a strawman base class, BaseVisitor, for the visitor hierarchy. BaseVisitor is only a carrier of type information. It doesn't have any content; therefore, it is totally decoupled. The visited hierarchy's Accept member function accepts a reference to BaseVisitor and applies dynamic_cast against it to detect a matching visitor. If Accept finds a match, it jumps from the visited hierarchy to the visitor hierarchy.
This might sound weird at first, but it's very simple. Let's see how we can implement an acyclic visitor for our DocElement/DocElementVisitor design. First, we define a visitor archetypal base class, the strawman.
class DocElementVisitor
{
public:
virtual void ~DocElementVisitor() {}
};
The do-nothing virtual destructor does two important things. First, it gives DocElementVisitor RTTI (runtime type information) capabilities. (Only types with at least one virtual function support dynamic_cast.) Second, the virtual destructor ensures correct polymorphic destruction of DocElementVisitor objects. A polymorphic hierarchy without virtual destructors engenders undefined behavior if a derived object is destroyed via a pointer to a base object. Thus, we nicely solve two dangerous problems with one line of code.
The DocElement class definition remains the same. Of interest to us is its definition of the Accept(DocElementVisitor&) pure virtual function.
Then, for each derived class in the visited hierarchy (the one rooted in DocElement), we define a small visiting class that has only one function, VisitXxxx. For instance, for Paragraph, we define the following:
class ParagraphVisitor
{
public:
virtual void VisitParagraph(Paragraph&) = 0;
};
The Paragraph::Accept implementation looks like this:
void Paragraph::Accept(Visitor& v)
{
if (ParagraphVisitor* p =
dynamic_cast<ParagraphVisitor*>(&v))
{
p->VisitParagraph(*this);
}
else
{
optionally call a catch-all function
}
}
The prima donna here is dynamic_cast, which enables the runtime system to figure out whether v is actually a subobject of an object that also implements ParagraphVisitor and, if so, to obtain a pointer to that ParagraphVisitor.
RasterBitmap and the other DocElement-derived classes define similar implementations of Accept. Finally, a concrete visitor derives from DocElementVisitor and the archetypal visitors of all classes that are of interest to it. For instance:
class DocStats :
public DocElementVisitor, // Required
public ParagraphVisitor, // Wants to visit Paragraph objects
public RasterBitmapVisitor // Wants to visit RasterBitmap
// objects
{
public:
void VisitParagraph(Paragraph& par)
{
chars_ += par.NumChars();
words_ += par.NumWords();
}
void VisitRasterBitmap(RasterBitmap&)
{
++images_;
}
};
The resulting class structure is presented in Figure 10.2. The horizontal dotted lines depict dependency layers, and the vertical ones depict the insulation between hierarchies. Notice how dynamic_cast provides the means to jump magically from one hierarchy to the other by leveraging the strawman DocElementVisitor class.
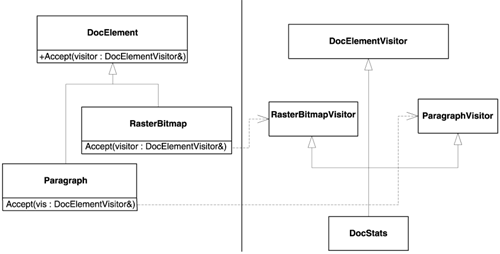
The described structure encompasses a lot of details and interactions. However, the basic structure is simple. Let's recap everything by analyzing an event flow. We assume that we have a pointer, pDocElem, to a DocElement whose dynamic ("real") type is Paragraph. Then we do the following:
DocStats stats;
pDocElem->Accept(stats);
The following events happen, in order.
The stats object is automatically converted to a reference to DocElementVisitor because it inherits this class publicly. The virtual function Paragraph::Accept is called. Paragraph::Accept attempts a dynamic_cast<ParagraphVisitor*> against the address of the DocElementVisitor object that it received. Because that object's dynamic type is DocStats and because DocStats inherits publicly from both DocElementVisitor and ParagraphVisitor, the cast succeeds. (Here is where the teleporting occurs!) Now Paragraph::Accept has obtained a pointer to the ParagraphVisitor part of the DocStats object. Paragraph::Accept will invoke the virtual function VisitParagraph on that pointer. The virtual call reaches DocStats::VisitParagraph. DocStats::VisitParagraph also receives as its parameter a reference to the visited paragraph. The visit is completed.
Let's examine the new dependency chart.
DocElement's class definition depends on DocElementVisitor by name. Dependency by name means that a forward declaration of DocElementVisitor is enough. ParagraphVisitorand, in general, all XxxVisitor base classesdepends by name on the classes that it visits. The Paragraph::Accept implementation fully depends on ParagraphVisitor. Full dependency means that the full class definition is needed in order to compile the code. Any concrete visitor's class definition fully depends on DocElementVisitor and on all of the base visitors XxxVisitor that it wants to visit.
The Acyclic Visitor pattern eliminates cyclic dependencies but in exchange leaves you with even more work to do. Basically, from now on, you must maintain two parallel sets of classes: the visited hierarchy rooted in DocElement; and the visitor classes XxxVisitor, one for each concrete visited class. Maintaining two parallel class hierarchies is not desirable because it requires much discipline and attention.
A note on efficiency in comparing the "plain" Visitor with the Acyclic Visitor: In the latter, there's one extra dynamic cast in the path. Its cost in time might be constant or might increase logarithmically or linearly with the number of polymorphic classes in the program, depending on your compiler vendor. The cost might be important if efficiency is an issue. So in some cases you might be forced to use the "plain" Visitor and to maintain cyclic dependencies.
Because of this overall grim picture, Visitor is, unsurprisingly, a controversial pattern. Even Ralph Gamma of GoF fame says that on his list of bottom-ten patterns, Visitor is at the very bottom (Vlissides 1999).
Visitor is clumsy, rigid, hard to extend, and hard to maintain. However, with perseverance and diligence we can put together a Visitor library implementation that is win-win: easy to use, extend, and maintain. The next sections show how.
|
10.4 A Generic Implementation of Visitor
Let's divide the implementation into two major units:
Table 10.1. Component Names
| BaseVisitable |
Library |
The root of all hierarchies that can be visited |
| Visitable |
Library |
A mix-in class that confers visitable properties to a class in the visitable hierarchy |
| DocElement |
Application |
A sample classthe root of the hierarchy we want to make visitable |
| Paragraph,RasterBitmap |
Application |
Two sample visitable concrete classes, derived from DocElement |
| Accept |
Library and application |
The member function that's called for visiting the visitable hierarchy |
| BaseVisitor |
Library |
The root of the visitor hierarchy |
| Visitor |
Library |
A mix-in class that confers visitor properties to a class in the visitor hierarchy |
| Statistics |
Application |
A sample visitor concrete class |
| Visit |
Library and application |
The member function that is called back by the visitable elements, for its visitors |
The approach is simple and consistent: We try to factor out as much code as possible into the library. If we succeed in doing that, we will be rewarded with simplified dependencies. That is, instead of the two partsvisitor and visitabledepending on each other, both will depend on the library. This is good because the library is supposed to be much more immutable than the application.
We first try to implement a generic Acyclic Visitor, since it has better behavior with regard to dependency and insulation. Later, we'll tweak it for performance. In the end, we return to implementing a classic GoF Visitor that is speedier at the expense of some flexibility.
In the discussion on implementation, the names listed and defined in Table 10.1 apply. Some of the names in the table actually describe class templates, or, better said, will become class templates as we increasingly make our code more generic. For now, it's important to define the entities that the names represent.
Let's focus on the visitor hierarchy first. Here things are quite simplewe must provide some base classes for the user, classes that define a Visit operation for a given type. In addition, we must provide the strawman class that's used by the dynamic cast as required by the Acyclic Visitor pattern. Here it is:
class BaseVisitor
{
public:
virtual ~BaseVisitor() {}
};
That's not a lot of reuse, but somebody has to write this little class.
Now we provide a simple class template Visitor. Visitor<T> defines a pure virtual function for visiting an object of type T.
template <class T>
class Visitor
{
public:
virtual void Visit(T&) = 0;
};
In the general case, Visitor<T>::Visit might return something other than void. Visitor<T>::Visit can pass a useful result via Visitable::Accept. Consequently, let's add a second template parameter to Visitor:
template <class T, typename R = void>
class Visitor
{
public:
typedef R ReturnType;
virtual ReturnType Visit(T&) = 0;
};
Whenever you want to visit a hierarchy, you first derive your ConcreteVisitor from BaseVisitor, and as many Visitor instantiations as types you want to visit.
class SomeVisitor :
public BaseVisitor // required
public Visitor<RasterBitmap>,
public Visitor<Paragraph>
{
public:
void Visit(RasterBitmap&); // visit a RasterBitmap
void Visit(Paragraph &); // visit a Paragraph
};
The code looks clean, simple, and easy to use. Its structure makes it clear which classes your code visits. Even better, the compiler does not allow you to instantiate SomeVisitor if you don't define all the Visit functions. There is a name dependency between SomeVisitor's class definition and the names of the classes it visits (RasterBitmap and Paragraph). This dependency is quite understandable, because SomeVisitor knows about these types and needs to do specific operations on them.
We have now concluded the visitor side of the implementation. We defined a simple base class that acts as the boot for dynamic_cast (BaseVisitor) and a class template (Visitor) that generates a pure virtual function (Visit) for each visited type.
The code we have written so far, in spite of its small quantity, has fairly good reuse potential. The Visitor class template generates a separate type for each visited class. The library client is relieved of the burden of littering the implementation with all those little classes such as ParagraphVisitor and RasterBitmapVisitor. The types generated by the Visitor class template will ensure the link with the Visitable classes.
This brings us to the visitable hierarchy. As discussed in the previous section, the visitable hierarchy in an Acyclic Visitor implementation has the following responsibilities:
To carry the first responsibility we add a pure virtual function to the BaseVisitable class and require DocElementand in general any root of a visitable hierarchy in the application spaceto inherit from it. BaseVisitable looks like this:
template <typename R = void>
class BaseVisitable
{
public:
typedef R ReturnType;
virtual ~BaseVisitable() {}
virtual ReturnType Accept(BaseVisitor&) = 0;
};
Trivial. Things become interesting when we try to carry the second responsibility, that is, to implement Accept in the library (not in the client). The Accept function implementation is not big, but it's annoying to have each client class take care of it. It would be nice if its code belonged to the library. As prescribed by the Acyclic Visitor pattern, if T is a visited class, T::Accept's implementation applies dynamic_cast<Vistor<T>*> to the BaseVisitor. If the cast succeeds, T::Accept bounces back to the Visitor<T>::Visit. However, as mentioned in Section 10.2, simply defining Accept in the Base Visitable class does not work, because the static type of *this in BaseVisitable does not provide the appropriate information to visitors.
We need a way to implement Accept in the library and to inject this function into the application's DocElement hierarchy. Alas, C++ has no such direct mechanism. There are workarounds that use virtual inheritance, but they are less than stellar and have non-negligible costs. We have to resort to a macro and require each class in the visitable hierarchy to use that macro inside the class definition.
Using macros, with all the clumsiness they bring, is not an easy decision to make, but any other solution does not add much commodity, at considerable expense in time and space. Because C++ programmers are known to be practical people, efficiency is reason enough for relying on macros from time to time instead of using esoteric but ineffective techniques.
The single most important rule in defining a macro is to let it do as little as possible by itself and to forward to a "real" entity (function, class) as quickly as possible. We define the macro for visitable classes as follows:
#define DEFINE_VISITABLE() \
virtual ReturnType Accept(BaseVisitor& guest) \
{ return AcceptImpl(*this, guest); }
The client must insert DEFINE_VISITABLE() in each class of the visitable hierarchy. DEFINE_VISITABLE() defines the Accept member function to forward to another functionAcceptImpl. AcceptImpl is a template function parameterized with the type of *this. This way AcceptImpl gains access to the much-needed static type. We define AcceptImpl in the very base of the hierarchy, in BaseVisitor. This way, all derivatives will have access to it. Here's the changed BaseVisitable class:
template <typename R = void>
class BaseVisitable
{
public:
typedef R ReturnType;
virtual ~BaseVisitable() {}
virtual ReturnType Accept(BaseVisitor&) = 0;
protected: // Give access only to the hierarchy
template <class T>
static ReturnType AcceptImpl(T& visited, BaseVisitor& guest)
{
// Apply the Acyclic Visitor
if (Visitor<T>* p = dynamic_cast<Visitor<T>*>(&guest))
{
return p->Visit(visited);
}
return ReturnType();
}
};
The fact that we have managed to move AcceptImpl to the library is important. It's not only a matter of automating the client's job. The presence of AcceptImpl in the library gives us the opportunity to adjust its implementation depending on various design constraints, as will become clear later.
The resulting design of Visitor/Visitable hides a great many details from the user, doesn't have annoying usage caveats, and works like a charm. Here's the current codebase for our generic Acyclic Visitor implementation.
// Visitor part
class BaseVisitor
{
public:
virtual ~BaseVisitor() {}
};
template <class T, typename R = void>
class Visitor
{
public:
typedef R ReturnType; // Available for clients
virtual ReturnType Visit(T&) = 0;
};
// Visitable part
template <typename R = void>
class BaseVisitable
{
public:
typedef R ReturnType;
virtual ~BaseVisitable() {}
virtual R Accept(BaseVisitor&) = 0;
protected:
template <class T>
static ReturnType AcceptImpl(T& visited, BaseVisitor& guest)
{
// Apply the Acyclic Visitor
if (Visitor<T>* p =
dynamic_cast<Visitor<T>*>(&guest))
{
return p->Visit(visited);
}
return ReturnType();
}
};
#define DEFINE_VISITABLE() \
virtual ReturnType Accept(BaseVisitor& guest) \
{ return AcceptImpl(*this, guest); }
Ready for a test drive? Here it is:
class DocElement : public BaseVisitable<>
{
public:
DEFINE_VISITABLE()
};
class Paragraph : public DocElement
{
public:
DEFINE_VISITABLE()
};
class MyConcreteVisitor :
public BaseVisitor, // required
public Visitor<DocElement>,// visits DocElements
public Visitor<Paragraph> // visits Paragraphs
{
public:
void Visit(DocElement&) { std::cout << "Visit(DocElement&) \n"; }
void Visit(Paragraph&) { std::cout << "Visit(Paragraph&) \n"; }
};
int main()
{
MyConcreteVisitor visitor;
Paragraph par;
DocElement* d = ∥ // "hide" the static type of 'par'
d->Accept(visitor);
}
This little program will output
Visit(Paragraph&)
which means that everything works just fine.
Of course, this toy example doesn't show very much about the power of the codebase we've put together. However, given all the pains we've been through in implementing visitors from scratch in the previous sections, it's clear we now have a device that makes it easy to create visitable hierarchies correctly and to visit them.
Let us review the actions you must carry out to define a visitable hierarchy.
Derive the root of your hierarchy from BaseVisitable<YourReturnType>. Add to each class SomeClass in the visitable hierarchy the DEFINE_VISITABLE() macro. (By now your hierarchy is ready to be visitedhowever, no dependency of any Visitor class is in sight!) Derive each concrete visitor SomeVisitor from BaseVisitor. Also, for each class X that you need to visit, derive SomeVisitor from Visitor<X, YourReturnType>. Provide overrides for the Visit member function for each visited type.
The resulting dependency chart is simple. The class definition of SomeVisitor depends by name on each visited class. The implementations of the Visit member functions fully depend on the classes they manipulate.
That's pretty much it. Compared with the previously discussed implementations, this one leaves us much better off. With the help of our Visitor implementation, we now have an ordered way to make visitable hierarchies, and we have reduced client code and dependencies to the bare necessity.
In special cases, you might prefer to implement Accept directly rather than to use the DEFINE_VISITABLE macro. Suppose you define a Section class, derived from DocElement, which contains several Paragraphs. For a Section object, you would like to visit each Paragraph in that Section. In this case, you might want to implement Accept manually: class Section : public DocElement
// Won't use the DEFINE_VISITABLE() macro
// because it's going to implement Accept by itself
{
...
virtual ReturnType Accept(BaseVisitor& v)
{
for (each paragraph in this section)
{
current_paragraph->Accept(v);
}
}
};
As you can see, there's nothing you cannot do when you use the Visitor implementation. The code we defined only frees you from the grunt work you would have to do if you started from scratch.
We have finished defining the kernel Visitor implementation, which includes pretty much anything that is germane to basic visiting needs. But read on, there's a lot more to come.
|
10.6 Hooking Variations
Visitor has a number of variations and customizations. This section is dedicated to mapping the hooks that you might need so that you can add these to the implementation that we've put in place.
10.6.1 The Catch-All Function
We discussed the catch-all function in Section 10.2. A Visitor may encounter an unknown type derived from the base class (in our example, DocElement). In this case, you may want either a compile-time error to occur or a default action to be carried out at runtime.
Let's analyze the catch-all issue for the GoF Visitor and the Acyclic Visitor implementations provided by our generic components.
For the GoF Visitor, things are quite simple. If you include the root class of your hierarchy in the typelist you pass to CyclicVisitor, then you give yourself the opportunity to implement the catch-all function. Otherwise, you take the compile-time error route. The following code illustrates the two options:
// Forward declarations needed for the GoF Visitor
class DocElement; // Root class
class Paragraph;
class RasterBitmap;
class VectorizedDrawing;
typedef CyclicVisitor
<
void, // Return type
TYPELIST_3(Paragraph, RasterBitmap, VectorizedDrawing)
>
StrictVisitor; // No catch-all operation;
// will issue a compile-time error if you try
// visiting an unknown type
typedef CyclicVisitor
<
void, // return type
TYPELIST_4(DocElement, Paragraph, RasterBitmap,
VectorizedDrawing)
>
NonStrictVisitor; // Declares Visit(DocElement&), which will be
// called whenever you try visiting
// an unknown type
All this was quite easy. Now let's talk about the catch-all function within our Acyclic Visitor generic implementation.
In Acyclic Visitor an interesting twist occurs. Although essentially catch-all is all about visiting an unknown class by a known visitor, the problem appears reversed: An unknown visitor visits a known class!
Let's look again at our AcceptImpl implementation for Acyclic Visitor.
template <typename R = void >
class BaseVisitable
{
... as above ...
template <class T>
static ReturnType AcceptImpl(T& visited,
BaseVisitor& guest)
{
if (Visitor<T>* p =
dynamic_cast<Visitor<T>*>(&guest))
{
return p->Visit(visited);
}
return ReturnType(); // Attention here!
}
};
Suppose you add a VectorizedDrawing to your DocElement hierarchy in a sneaky wayyou don't notify any concrete visitors about it. Whenever VectorizedDrawing is visited, the dynamic cast to Visitor<VectorizedDrawing> fails. This is because your existing concrete visitors are not aware of the new type, so they didn't derive from Visitor<VectorizedDrawing>. Because the dynamic cast fails, the code takes the alternate route and returns the default value of ReturnType. Here's the exact place where the catch-all function can enter into action.
Because our AcceptImpl function hardcodes the return ReturnType() action, it quite rigidly imposes a design constraint without leaving room for variation. Therefore, let's put a policy in place that dictates the catch-all behavior:
template
<
typename R = void,
template <typename, class> class CatchAll = DefaultCatchAll
>
class BaseVisitable
{
... as above ...
template <class T>
static ReturnType AcceptImpl(T& visited,
BaseVisitor& guest)
{
if (Visitor<T>* p =
dynamic_cast<Visitor<T>*>(&guest))
{
return p->Visit(visited);
}
// Changed
return CatchAll<R, T>::OnUnknownVisitor(visited, guest);
}
};
The CatchAll policy can do whatever the design requires. It can return a default value or error code, throw an exception, call a virtual member function for the visited object, try more dynamic casts, and so on. The implementation of OnUnknownVisitor depends largely on the concrete design needs. In some cases, you might want to enforce visitation for all the types in the hierarchy. In other cases, you might want to visit some types freely and to ignore all others silently. The Acyclic Visitor implementation favors the second approach, so the default CatchAll looks like this:
template <class R, class Visited>
struct DefaultCatchAll
{
static R OnUnknownVisitor(Visited&, BaseVisitor&)
{
// Here's the action that will be taken when
// there is a mismatch between a Visitor and a Visited.
// The stock behavior is to return a default value
return R();
}
};
Should you need a different behavior, all you have to do is plug a different template into BaseVisitable.
10.6.2 Nonstrict Visitation
Maybe it's human nature, but the have-your-cake-and-eat-it-too ideal is every programmer's mantra. If possible, programmers would like a fast, noncoupled, flexible visitor that would read their minds and figure out whether an omission is a simple mistake or a deliberate decision. On the other hand, unlike their customers, programmers are practical, down-to-earth people, with whom you can haggle about trade-offs.
Following this line of thought, the flexibility of CatchAll renders users of GoF Visitor envious. As it is now, the GoF Visitor implementation is strictit declares one pure virtual function for each type visited. You must derive from BaseVisitor and implement each and every Visit overload, and if you don't, you cannot compile your code.
However, sometimes you don't really want to visit each type in the list. You don't want the framework to be so strict about it. You want options: Either you implement Visit for a type, or OnUnknownVisitor will be automatically called for your CatchAll implementation.
For this kind of situation, Loki introduces a class called BaseVisitorImpl. It inherits BaseVisitor and uses typelist techniques for accommodating typelists. You can look up its implementation in Loki (file Visitor.h).
|
10.7 Summary
This chapter discussed the Visitor pattern and the problems it addresses. Essentially, Visitor allows you to add virtual functions to a class hierarchy without modifying the classes in that hierarchy. In some cases, Visitor can lead to a clever, extensible design.
However, Visitor has a bunch of problems, to the point that its use with any but the most stable class hierarchies is unjustifiably hard. Acyclic Visitor is of help, at the expense of a decrease in efficiency.
By using careful design and advanced implementation techniques, you can ensure that the generic Visitor components get the best out of the Visitor pattern. Although the implementation fully preserves Visitor's power, it mitigates most of its shortcomings.
In an application, Acyclic Visitor should be the variant of choice, unless you need all the speed you can get. If speed is important, you can use a generic implementation of the GoF Visitor that keeps maintenance low (a single, clear point of maintenance) and compile-time cost reasonable.
The generic implementation leverages advanced C++ programming techniques, such as dynamic casts, typelists, and partial specialization. The outcome is that all the common, repetitive parts of implementing visitors for any concrete need have been absorbed by the library.
|
10.8 Visitor Generic Components Quick Facts
To implement the Acyclic Visitor, use BaseVisitor (as the strawman base class), Visitor, and Visitable:
class BaseVisitor;
template <class T, typename R = void>
class Visitor;
template
<
typename R = void,
template<class, class> CatchAll = DefaultCatchAll
>
class BaseVisitable;
The first template parameter of Visitor and BaseVisitable is the return type of the Visit and Accept member functions, respectively. It defaults to void (this is the return type assumed in the GoF book examples and in most Visitor descriptions). The second template parameter of BaseVisitable is the policy for handling the catch-all issue (see Section 10.2). Derive the root of your hierarchy from BaseVisitable. Then use the macro DEFINE_VISITABLE() in each class in the hierarchy, or provide a handmade implementation of Accept(BaseVisitor&). Derive your concrete Visitor classes from BaseVisitor. Also derive your concrete visitor from Visitor<T>, for each type T you are interested in visiting. For the GoF Visitor, use the CyclicVisitor template:
template <typename R, class TList>
class CyclicVisitor;
Specify the types visited in the TList template argument. Use CyclicVisitor with your code just as you would use a classic GoF visitor. If you need to implement only part of a GoF Visitor (the nonstrict variant), derive your visitable hierarchy from BaseVisitorImpl. BaseVisitorImpl implements all the Visit overloads to call OnUnknownVisitor. You can override part of this behavior. The OnUnknownVisitor static member function of the CatchAll policy provides a catch-all sink for Acyclic Visitor. If you use BaseVisitorImpl, it will provide a catch-all for the GoF Visitor, too. The stock implementation of OnUnknownVisitor returns a default-constructed value of the return type you chose. You can override this behavior by providing custom implementations of CatchAll.
|
Chapter 11. Multimethods
This chapter defines, discusses, and implements multimethods in the context of C++.
The C++ virtual function mechanism allows dispatching of a call depending on the dynamic type of one object. The multimethods feature allows dispatching of a function call depending on the types of multiple objects. A universally good implementation requires language support, which is the route that languages such as CLOS, ML, Haskell, and Dylan have taken. C++ lacks such support, so its emulation is left to library writers.
This chapter discusses some typical solutions and some generic implementations of each. The solutions feature various trade-offs in speed, flexibility, and dependency management. To describe the technique of dispatching a function call depending on multiple objects, this book uses the terms multimethod (borrowed from CLOS) and multiple dispatch. A particularization of multiple dispatch for two objects is known as double dispatch.
Implementing multimethods is a problem that's as fascinating as it is dreaded, one that has stolen lots of hours of good, healthy sleep from designers and programmers.
The topics of this chapter include
Defining multimethods Identifying situations in which the need for multiobject polymorphism appears Discussing and implementing three double dispatchers that foster different trade-offs Enhancing double-dispatch engines
After reading this chapter, you will have a firm grasp of the typical situations for which multimethods are the way to go. In addition, you will be able to use and extend several robust generic components, provided by Loki, that implement multimethods.
This chapter limits discussion to multimethods for two objects (double dispatch). You can use the underlying techniques to extend the number of supported objects to three or more. It is likely, though, that in most situations you can get away with dispatching depending on two objects, and therefore you'll be able to use Loki directly.
|
11.1 What Are Multimethods?
In C++, polymorphism essentially means that a given function call can be bound to different implementations, depending on compile-time or runtime contextual issues.
Two types of polymorphism are implemented in C++:
Compile-time polymorphism, supported by overloading and template functions
Runtime polymorphism, implemented with virtual functions
Overloading is a simple form of polymorphism that allows multiple functions with the same name to coexist in a scope. If the functions have different parameter lists, the compiler can differentiate among them at compile time. Overloading is simple syntactic sugar, a convenient syntactic abbreviation.
Template functions are a static dispatch mechanism. They offer more sophisticated compile-time polymorphism.
Virtual member function calls allow the C++ runtime support, instead of the compiler, to decide which actual function implementation to call. Virtual functions bind a name to a function implementation at runtime. The function called depends on the dynamic type of the object for which you make the virtual call.
Let's now see how these three mechanisms for polymorphism scale to multiple objects. Overloading and template functions scale to multiple objects naturally. Both features allow multiple parameters, and intricate compile-time rules govern function selection.
Unfortunately, virtual functionsthe only mechanism that implements runtime polymorphism in C++are tailored for one object only. Even the call syntaxobj.Fun (arguments)gives obj a privileged role over arguments. (In fact, you can think of obj as nothing more than one of Fun's arguments, accessible inside Fun as *this. The Dylan language, for example, accepts the dot call syntax only as a particular expression of a general function-call mechanism.)
We define multimethods or multiple dispatch as the mechanism that dispatches a function call to different concrete functions depending on the dynamic types of multiple objects involved in the call. Because we can take compile-time multiobject polymorphism for granted, we need only implement runtime multiobject polymorphism. Don't be worried; there's a lot left to talk about.
|
11.2 When Are Multimethods Needed?
Detecting the need for multimethods is simple. You have an operation that manipulates multiple polymorphic objects through pointers or references to their base classes. You would like the behavior of that operation to vary with the dynamic type of more than one of those objects.
Collisions form a typical category of problems best solved with multimethods. For instance, you might write a video game in which moving objects are derived from a Game Object abstract class. You would like their collision to behave differently depending on which two types collide: a space ship with an asteroid, a ship with a space station, or an asteroid with a space station.
For example, suppose you want to mark overlapping areas of drawing objects. You write a drawing program that allows its users to define rectangles, circles, ellipses, polygons, and other shapes. The basic design is an object-oriented classic: Define an abstract class Shape and have all the concrete shapes derive from it; then manipulate a drawing as a collection of pointers to Shape.
Now say the client comes and asks for a nice-to-have feature: If two closed shapes intersect, the intersection should be drawn in a way different from each of the two shapes. For instance, the intersection area could be hatched, as in Figure 11.1.
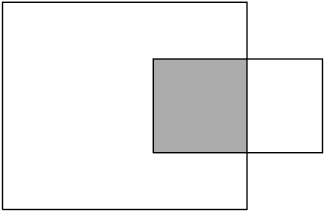
Finding a single algorithm that will hatch any intersection is difficult. For instance, the algorithm that hatches the intersection between an ellipse and a rectangle is very different (and much more complex) from the one that hatches the intersection between two rectangles. Besides, an overly general algorithm (for instance, one that operates at a pixel level) is likely to be highly inefficient, since some intersections (such as rectangle-rectangle) are trivial.
What you need here is a battery of algorithms, each specialized for two shape types, such as rectangle-rectangle, rectangle-polygon, polygon-polygon, ellipse-rectangle, ellipse-polygon, and ellipse-ellipse. At runtime, as the user moves shapes on the screen, you'd like to pick up and fire the appropriate algorithms, which in turn will quickly compute and hatch the overlapping areas.
Because you manipulate all drawing objects as pointers to Shape, you don't have the type information necessary to select the suitable algorithm. You have to start from pointers to Shape only. Because you have two objects involved, simple virtual functions cannot solve this problem. You have to use double dispatch.
|
11.3 Double Switch-on-Type: Brute Force
The most straightforward approach to a double dispatch implementation is to implement a double switch-on-type. You try to dynamic cast the first object against each of the possible left-hand types in succession. For each branch, you do the same with the second argument. When you have discovered the types of both objects, you know which function to call. The code looks like this:
// various intersection algorithms
void DoHatchArea1(Rectangle&, Rectangle&);
void DoHatchArea2(Rectangle&, Ellipse&);
void DoHatchArea3(Rectangle&, Poly&);
void DoHatchArea4(Ellipse&, Poly&);
void DoHatchArea5(Ellipse&, Ellipse&);
void DoHatchArea6(Poly&, Poly&);
void DoubleDispatch(Shape& lhs, Shape& rhs)
{
if (Rectangle* p1 = dynamic_cast<Rectangle*>(&lhs))
{
if (Rectangle* p2 = dynamic_cast<Rectangle*>(&rhs))
DoHatchArea1(*p1, *p2);
else if (Ellipse p2 = dynamic_cast<Ellipse*>(&rhs))
DoHatchArea2(*p1, *p2);
else if (Poly p2 = dynamic_cast<Poly*>(&rhs))
DoHatchArea3(*p1, *p2);
else
Error("Undefined Intersection");
}
else if (Ellipse* p1 = dynamic_cast<Ellipse*>(&lhs))
{
if (Rectangle* p2 = dynamic_cast<Rectangle*>(&rhs))
DoHatchArea2(*p2, *p1);
else if (Ellipse* p2 = dynamic_cast<Ellipse*>(&rhs))
DoHatchArea5(*p1, *p2);
else if (Poly* p2 = dynamic_cast<Poly*>(&rhs))
DoHatchArea4(*p1, *p2);
else
Error("Undefined Intersection");
}
else if (Poly* p1 = dynamic_cast<Poly*>(&lhs))
{
if (Rectangle* p2 = dynamic_cast<Rectangle*>(&rhs))
DoHatchArea2(*p2, *p1);
else if (Ellipse* p2 = dynamic_cast<Ellipse*>(&rhs))
DoHatchArea4(*p2, *p1);
else if (Poly* p2 = dynamic_cast<Poly*>(&rhs))
DoHatchArea6(*p1, *p2);
else
Error("Undefined Intersection");
}
else
{
Error("Undefined Intersection");
}
}
Whew! It's been quite a few lines. As you can see, the brute-force approach asks you to write a lot of (allegedly trivial) code. You can count on any dependable C++ programmer to put together the appropriate web of if statements. In addition, the solution has the advantage of being fast if the number of possible classes is not too high. From a speed perspective, DoubleDispatch implements a linear search in the set of possible types. Because the search is unrolleda succession of if-else statements as opposed to a loopthe speed is very good for small sets.
One problem with the brute-force approach is sheer code size, which makes the code unmaintainable as the number of classes grows. The code just given deals with only three classes, yet it's already of considerable size. The size grows exponentially as you add more classes. Imagine how the code of DoubleDispatch would look for a hierarchy of 20 classes!
Another problem is that DoubleDispatch is a dependency bottleneckits implementation must know of the existence of all classes in a hierarchy. It is best to keep the dependency net as loose as possible, and DoubleDispatch is a dependency hog.
The third problem with DoubleDispatch is that the order of the if statements matters. This is a very subtle and dangerous problem. Imagine, for instance, you derive class RoundedRectangle (a rectangle with rounded corners) from Rectangle. You then edit DoubleDispatch and insert the additional if statement at the end of each if-else statement, right before the Error call. You have just introduced a bug.
The reason is that if you pass DoubleDispatch a pointer to a RoundedRectangle, the dynamic_cast<Rectangle*> succeeds. Because that test is before the test for dynamic_cast<RoundedRectangle*>, the first test will "eat" both Rectangles and Rounded Rectangles. The second test will never get a chance. Most compilers don't warn about this.
A candidate solution would be to change the tests as follows:
void DoubleDispatch(Shape& lhs, Shape& rhs)
{
if (typeid(lhs) == typeid(Rectangle))
{
Rectangle* p1 = dynamic_cast<Rectangle*>(&lhs);
...
}
else ...
}
The tests are now for the exact type instead of the exact or derived type. The typeid comparison shown in this code fails if lhs is a RoundedRectangle, so the tests continue. Ultimately, the test against typeid(RoundedRectangle) succeeds.
Alas, this fixes one aspect but breaks another: DoubleDispatch is too rigid now. If you didn't add support for a type in DoubleDispatch, you would like DoubleDispatch to fire on the closest base type. This is what you'd normally expect when using inheritanceby default, derived objects do what base objects do unless you override some behavior. The problem is that the typeid-based implementation of DoubleDispatch fails to preserve this property. The rule of thumb that results from this fact is that you must still use dynamic_cast in DoubleDispatch and "sort" the if tests so that the most derived classes are tried first.
This adds two more disadvantages to the brute-force implementation of multimethods. First, the dependency between DoubleDispatch and the Shape hierarchy deepensDoubleDispatch must know about not only classes but also the inheritance relationships between classes. Second, maintaining the appropriate ordering of dynamic casts puts a supplemental burden on the shoulders of the maintainer.
|
11.4 The Brute-Force Approach Automated
Because in some situations the speed of the brute-force approach can be unbeatable, it's worth paying attention to implementing such a dispatcher. Here's where typelists can be of help.
Recall from Chapter 3 that Loki defines a typelist facilitya collection of structures and compile-time algorithms that allow you to manipulate collections of types. A brute-force implementation of multimethods can use a client-provided typelist that specifies the classes in the hierarchy (in our example, Rectangle, Poly, Ellipse, etc.). Then a recursive template can generate the sequence of if-else statements.
In the general case, we can dispatch on different collections of types, so the typelist for the left-hand operand can differ from the one for the right-hand operand.
Let's try outlining a StaticDispatcher class template that performs the type deduction algorithm and then fires a function in another class. Explanations follow the code.
template
<
class Executor,
class BaseLhs,
class TypesLhs,
class BaseRhs = BaseLhs,
class TypesRhs = TypesLhs
typename ResultType = void
>
class StaticDispatcher
{
typedef typename TypesLhs::Head Head;
typedef typename TypesLhs::Tail Tail;
public:
static ResultType Go(BaseLhs& lhs, BaseRhs& rhs,
Executor exec)
{
if (Head* p1 = dynamic_cast<Head*>(&lhs))
{
return StaticDispatcher<Executor, BaseLhs,
NullType, BaseRhs, TypesRhs>::DispatchRhs(
*p1, rhs, exec);
}
else
{
return StaticDispatcher<Executor, BaseLhs,
Tail, BaseRhs, TypesRhs>::Go(
lhs, rhs, exec);
}
}
...
};
If you are familiar with typelists, the workings of StaticDispatcher are seen to be quite simple. StaticDispatcher has surprisingly little code for what it does.
StaticDispatcher has six template parameters. Executor is the type of the object that does the actual processingin our example, hatching the intersection area. We'll discuss what Executor looks like a bit later.
BaseLhs and BaseRhs are the base types of the arguments on the left-hand side and the right-hand side, respectively. TypesLhs and TypesRhs are typelists containing the possible derived types for the two arguments. The default values of BaseRhs and TypesRhs foster a dispatcher for types in the same class hierarchy, as is the case with the drawing program example.
ResultType is the type of the result of the double-dispatch operation. In the general case, the dispatched function can return an arbitrary type. StaticDispatcher supports this dimension of genericity and forwards the result to the caller.
StaticDispatcher::Go tries a dynamic cast to the first type found in the TypesLhs typelist, against the address of lhs. If the dynamic cast fails, Go delegates to the remainder (tail) of TypesLhs in a recursive call to itself. (This is not a true recursive call, because each time we have a different instantiation of StaticDispatcher.)
The net effect is that Go performs a suite of if-else statements that apply dynamic_cast to each type in the typelist. When a match is found, Go invokes DispatchRhs. DispatchRhs does the second and last step of the type deductionfinding the dynamic type of rhs.
template <...>
class StaticDispatcher
{
... as above ...
template <class SomeLhs>
static ResultType DispatchRhs(SomeLhs& lhs, BaseRhs& rhs,
Executor exec)
{
typedef typename TypesRhs::Head Head;
typedef typename TypesRhs::Tail Tail;
if (Head* p2 = dynamic_cast<Head*>(&rhs))
{
return exec.Fire(lhs, *p2);
}
else
{
return StaticDispatcher<Executor, SomeLhs,
NullType, BaseRhs, Tail>::DispatchRhs(
lhs, rhs, exec);
}
}
};
DispatchRhs performs the same algorithm for rhs as Go applied for lhs. In addition, when the dynamic cast on rhs succeeds, DispatchRhs calls Executor::Fire, passing it the two discovered types. Again, the code that the compiler generates is a suite of if-else statements. Interestingly, the compiler generates one such suite of if-else statements for each type in TypesLhs. Effectively, StaticDispatcher manages to generate an exponential amount of code with two typelists and a fixed codebase. This is an asset, but also a potential dangertoo much code can hurt compile times, program size, and total execution time.
To treat the limit conditions that stop the compile-time recursion, we need to specialize StaticDispatcher for two cases: The type of lhs is not found in TypesLhs, and the type of rhs is not found in TypesRhs.
The first case (error on lhs) appears when you invoke Go on a StaticDispatcher with NullType as TypesLhs. This is the sign that the search depleted TypesLhs. (Recall from Chapter 3 that NullType is used to signal the last element in any typelist.)
template
<
class Executor,
class BaseLhs,
class BaseRhs,
class TypesRhs,
typename ResultType
>
class StaticDispatcher<Executor, BaseLhs, NullType,
BaseRhs, TypesRhs, ResultType>
{
static void Go(BaseLhs& lhs, BaseRhs& rhs, Executor exec)
{
exec.OnError(lhs, rhs);
}
};
Error handling is elegantly delegated to the Executor class, as you will see later in the discussion on Executor.
The second case (error on rhs) appears when you invoke DispatchRhs on a Static Dispatcher with NullType as TypesRhs. Hence the following specialization:
template
<
class Executor,
class BaseLhs,
class TypesLhs,
class BaseRhs,
class TypesRhs,
typename ResultType
>
class StaticDispatcher<Executor, BaseLhs, TypesLhs,
BaseRhs, NullType, ResultType>
{
public:
static void DispatchRhs(BaseLhs& lhs, BaseRhs& rhs,
Executor& exec)
{
exec.OnError(lhs, rhs);
}
};
It is time now to discuss what Executor must implement to take advantage of the double-dispatch engine we have just defined.
StaticDispatcher deals only with type discovery. After finding the right types and objects, it passes them to a call of Executor::Fire. To differentiate these calls, Executor must implement several overloads of Fire. For example, the Executor class for hatching shape intersections is as follows:
class HatchingExecutor
{
public:
// Various intersection algorithms
void Fire(Rectangle&, Rectangle&);
void Fire(Rectangle&, Ellipse&);
void Fire(Rectangle&, Poly&);
void Fire(Ellipse&, Poly&);
void Fire(Ellipse&, Ellipse&);
void Fire(Poly&, Poly&);
// Error handling routine
void OnError(Shape&, Shape&);
};
You use HatchingExecutor with StaticDispatcher as shown in the following code:
typedef StaticDispatcher<HatchingExecutor, Shape,
TYPELIST_3(Rectangle, Ellipse, Poly)> Dispatcher;
Shape *p1 = ...;
Shape *p2 = ...;
HatchingExecutor exec;
Dispatcher::Go(*p1, *p2, exec);
This code invokes the appropriate Fire overload in the HatchingExecutor class. You can see the StaticDispatcher class template as a mechanism that achieves dynamic overloadingit defers overloading rules to runtime. This makes StaticDispatcher remarkably easy to use. You just implement HatchingExecutor with the overloading rules in mind, and then you use StaticDispatcher as a black box that does the magic of applying overloading rules at runtime.
As a nice side effect, StaticDispatcher will unveil any overloading ambiguities at compile time. For instance, assume you don't declare HatchingExecutor::Fire(Ellipse&, Poly&). Instead, you declare HatchingExecutor::Fire(Ellipse&, Shape&) and Hatching Executor::Fire(Shape&, Poly&). Calling HatchingExecutor::Fire with an Ellipse and a Poly would result in an ambiguityboth functions compete to handle the call. Remarkably, StaticDispatcher signals the same error for you and with the same level Multimethods Chapter 11 of detail. StaticDispatcher is a tool that's very consistent with the existing C++ overloading rules.
What happens in the case of a runtime errorfor instance, if you pass a Circle as one of the arguments of StaticDispatcher::Go? As hinted earlier, StaticDispatcher handles border cases by simply calling Executor::OnError with the original (not cast) lhs and rhs. This means that, in our example, HatchingExecutor::OnError (Shape&, Shape&) is the error handling routine. You can use this routine to do whatever you find appropriatewhen it's called, it means that StaticDispatcher gave up on finding the dynamic types.
As discussed in the previous section, inheritance adds problems to a bruteforce dispatcher. That is, the following instantiation of StaticDispatcher has a bug:
typedef StaticDispatcher
<
SomeExecutor,
Shape,
TYPELIST_4(Rectangle, Ellipse, Poly, RoundedRectangle)
>
MyDispatcher;
If you pass a RoundedRectangle to MyDispatcher, it will be considered a Rectangle. The dynamic_cast<Rectangle*> succeeds on a pointer to a RoundedRectangle, and because the dynamic_cast<RoundedRectangle*> is lower on the food chain, it will never be given a chance. The correct instantiation is
typedef StaticDispatcher
<
SomeExecutor,
Shape,
TYPELIST_4(RoundedRectangle, Ellipse, Poly, Rectangle)
>
Dispatcher;
The general rule is to put the most derived types at the front of the typelist.
It would be nice if this transformation could be applied automatically, and typelists do support that. We have a means to detect inheritance at compile time (Chapter 2), and typelists can be sorted. This led to the DerivedToFront compile-time algorithm in Chapter 3.
All we have to do to take advantage of automatic sorting is to modify the implementation of StaticDispatcher as follows:
template <...>
class StaticDispatcher
{
typedef typename DerivedToFront<
typename TypesLhs::Head>::Result Head;
typedef typename DerivedToFront<
typename TypesLhs::Tail>::Result Tail;
public:
... as above ...
};
After all this handy automation, don't forget that all we have obtained is the code generation part. The dependency problems are still with us. Although it makes it very easy to implement brute-force multimethods, StaticDispatcher still has a dependency on all the types in the hierarchy. Its advantages are speed (if there are not too many types in the hierarchy) and nonintrusivenessyou don't have to modify a hierarchy to use StaticDispatcher with it.
|
11.5 Symmetry with the Brute-Force Dispatcher
When you hatch the intersection between two shapes, you might want to do it differently if you have a rectangle covering an ellipse than if you have an ellipse covering a rectangle. Or, on the contrary, you might need to hatch the intersection area the same way when an ellipse and a rectangle intersect, no matter which covers which. In the latter case, you need a symmetric multimethoda multimethod that is insensitive to the order in which you pass its arguments.
Symmetry applies only when the two parameter types are identical (in our case, BaseLhs is the same as BaseRhs, and LhsTypes is the same as RhsTypes).
The brute-force StaticDispatcher defined previously is asymmetric; that is, it doesn't offer any built-in support for symmetric multimethods. For example, assume you define the following classes:
class HatchingExecutor
{
public:
void Fire(Rectangle&, Rectangle&);
void Fire(Rectangle&, Ellipse&);
...
// Error handler
void OnError(Shape&, Shape&);
};
typedef StaticDispatcher
<
HatchingExecutor,
Shape,
TYPELIST_3(Rectangle, Ellipse, Poly)
>
HatchingDispatcher;
The HatchingDispatcher does not fire when passed an Ellipse as the left-hand parameter and a Rectangle as the right-hand parameter. Even though from your HatchingExecutor's viewpoint it doesn't matter who's first and who's second, HatchingDispatcher will insist that you pass objects in a certain order.
We can fix the symmetry in the client code by reversing arguments and forwarding from one overload to another:
class HatchingExecutor
{
public:
void Fire(Rectangle&, Ellipse&);
// Symmetry assurance
void Fire(Ellipse& lhs, Rectangle& rhs)
{
// Forward to Fire(Rectangle&, Ellipse&)
// by switching the order of arguments
Fire(rhs, lhs);
}
...
};
These little forwarding functions are hard to maintain. Ideally, StaticDispatcher would provide itself optional support for symmetry through an additional bool template parameter, which is worth looking into.
The need is to have StaticDispatcher reverse the order of arguments when invoking the callback, for certain cases. What are those cases? Let's analyze the previous example. Expanding the template argument lists from their default values, we get the following instantiation:
typedef StaticDispatcher
<
HatchingExecutor,
Shape,
TYPELIST_2(Rectangle, Ellipse, Poly), // TypesLhs
Shape,
TYPELIST_2(Rectangle, Ellipse, Poly), // TypesRhs
void
>
HatchingDispatcher;
An algorithm for selecting parameter pairs for a symmetric dispatcher can be as follows: Combine the first type in the first typelist (TypesLhs) with each type in the second typelist (TypesRhs). This gives three combinations: Rectangle-Rectangle, Rectangle-Ellipse, and Rectangle-Poly. Next, combine the second type in Types Lhs (Ellipse) with types in TypesRhs. However, because the first combination (Rectangle-Ellipse) has already been made in the first step, this time start with the second element in Types Rhs. This step yields Ellipse-Ellipse and Ellipse-Poly. The same reasoning applies to the next step: Poly in TypesLhs must be combined only with types starting with the third one in TypesRhs. This gives only one combination, Poly-Poly, and the algorithm stops here.
Following this algorithm, you implement only the functions for the selected combination, as follows:
class HatchingExecutor
{
public:
void Fire(Rectangle&, Rectangle&);
void Fire(Rectangle&, Ellipse&);
void Fire(Rectangle&, Poly&);
void Fire(Ellipse&, Ellipse&);
void Fire(Ellipse&, Poly&);
void Fire(Poly&, Poly&);
// Error handler
void OnError(Shape&, Shape&);
};
StaticDispatcher must detect all by itself the combinations that were eliminated by the algorithm just discussed, namely Ellipse-Rectangle, Poly-Rectangle, and Poly-Ellipse. For these three combinations, StaticDispatcher must reverse the arguments. For all others, StaticDispatcher forwards the call just as it did before.
What's the Boolean condition that determines whether or not argument swapping is needed? The algorithm selects the types in TL2 only at indices greater than or equal to the index of the type in TL1. Therefore, the condition is as follows:
For two types T and U, if the index of U in TypesRhs is less than the index of T in TypesLhs, then the arguments must be swapped.
For example, say T is Ellipse and U is Rectangle. Then T's index in TypesLhs is 1 and U's index in TypesRhs is 0. Consequently, Ellipse and Rectangle must be swapped before invoking Executor::Fire, which is correct.
The typelist facility already provides the IndexOf compile-time algorithm that returns the position of a type in a typelist. We can then write the swapping condition easily.
First, we must add a new template parameter that says whether the dispatcher is symmetric. Then, we add a simple little traits class template, InvocationTraits, which either swaps the arguments or does not swap them when calling the Executor::Fire member function. Here is the relevant excerpt.
template
<
class Executor,
bool symmetric,
class BaseLhs,
class TypesLhs,
class BaseRhs = BaseLhs,
class TypesRhs = TypesLhs,
typename ResultType = void
>
class StaticDispatcher
{
template <bool swapArgs, class SomeLhs, class SomeRhs>
struct InvocationTraits
{
static void DoDispatch(SomeLhs& lhs, SomeRhs& rhs,
Executor& exec)
{
exec.Fire(lhs, rhs);
}
};
template <class SomeLhs, class SomeRhs>
struct InvocationTraits<True, SomeLhs, SomeRhs>
{
static void DoDispatch(SomeLhs& lhs, SomeRhs& rhs,
Executor& exec)
{
exec.Fire(rhs, lhs); // swap arguments
}
}
public:
static void DispatchRhs(BaseLhs& lhs, BaseRhs& rhs,
Executor exec)
{
if (Head* p2 = dynamic_cast<Head*>(&rhs))
{
enum { swapArgs = symmetric &&
IndexOf<Head, TypesRhs>::result <
IndexOf<BaseLhs, TypesLhs>::result };
typedef InvocationTraits<swapArgs, BaseLhs, Head>
CallTraits;
return CallTraits::DoDispatch(lhs, *p2);
}
else
{
return StaticDispatcher<Executor, BaseLhs,
NullType, BaseRhs, Tail>::DispatchRhs(
lhs, rhs, exec);
}
}
};
Support for symmetry adds some complexity to StaticDispatcher, but it certainly makes things much easier for StaticDispatcher's user.
|
11.6 The Logarithmic Double Dispatcher
If you want to avoid the heavy dependencies accompanying the brute-force solution, you must look into a more dynamic approach. Instead of generating code at compile time, you must keep a runtime structure and use runtime algorithms that help in dynamically dispatching function calls depending on types.
RTTI (runtime type information) can be of further help here because it provides not only dynamic_cast and type identification, but also a runtime ordering of types, through the before member function of std::type_info. What before offers is an ordering relationship on all types in a program. We can use this ordering relationship for fast searches of types.
The implementation here is similar to the one found in Item 31 of Scott Meyers's More Effective C++ (1996a), with some improvements: The casting step when invoking a handler is automated, and the implementation herein aims at being generic.
We will avail ourselves of the OrderedTypeInfo class, described in Chapter 2. OrderedTypeInfo is a wrapper providing exactly the same functionality as std::type_info. In addition, OrderedTypeInfo provides value semantics and a caveat-free less-than operator. You can thus store OrderedTypeInfo objects in standard containers, which is of interest to this chapter.
Meyers's approach was simple: For each pair of std::type_info objects you want to dispatch upon, you register a pointer to a function with the double dispatcher. The double dispatcher stores the information in a std::map. At runtime, when invoked with two unknown objects, the double dispatcher performs a fast search (logarithmic time) for type discovery, and if it finds an entry, fires the appropriate pointer to a function.
Let's define the structure of a generic engine operating on these principles. We must templatize the engine with the base types of the two arguments (left-hand side and right-hand side). We call this engine BasicDispatcher, because we will use it as the base device for several more advanced double dispatchers.
template <class BaseLhs, class BaseRhs = BaseLhs,
typename ResultType = void>
class BasicDispatcher
{
typedef std::pair<OrderedTypeInfo, OrderedTypeInfo>
KeyType;
typedef ResultType (*CallbackType)(BaseLhs&, BaseRhs&);
typedef CallbackType MappedType;
typedef std::map<KeyType, MappedType> MapType;
MapType callbackMap_;
public:
...
};
The key type in the map is a std::pair of two OrderedTypeInfo objects. The std::pair class supports ordering, so we don't have to provide a custom ordering functor.
BasicDispatcher can be more general if we templatize the callback type. In general, the callback does not have to be a function. It can be, for example, a functor (refer to the introduction of Chapter 5 for a discussion of functors). BasicDispatcher can accommodate functors by transforming its inner CallbackType type definition into a template parameter.
An important improvement is to change the std::map type to a more efficient structure. Matt Austern (2000) explains that the standard associative containers have a slightly narrower area of applicability than one might think. In particular, a sorted vector in combination with binary search algorithms (such as std::lower_bound) might perform much better, in both space and time, than an associative container. This happens when the number of accesses is much larger than the number of insertions. So we should take a close look at the typical usage pattern of a double-dispatcher object.
Most often, a double dispatcher is a write-once, read-many type of structure. Typically, a program sets the callbacks once and then uses the dispatcher many, many times. This is in keeping with the virtual functions mechanism, which double dispatchers extend. You decide, at compile time, which functions are virtual and which are not.
It seems as if we're better off with a sorted vector. The disadvantages of a sorted vector are linear-time insertions and linear-time deletions, and a double dispatcher is not typically concerned about the speed of either. In exchange, a vector offers about twice the lookup speed and a much smaller working set, so it is definitely a better choice for a double dispatcher.
Loki saves the trouble of maintaining a sorted vector by hand by defining an AssocVector class template. AssocVector is a drop-in replacement for std::map (it supports the same set of member functions), implemented on top of std::vector. AssocVector differs from a map in the behavior of its erase functions (AssocVector::erase invalidates all iterators into the object) and in the complexity guarantees of insert and erase (linear as opposed to constant). Because of the high degree of compatibility of AssocVector with std::map, we'll continue to use the term map to describe the data structure held by the double dispatcher.
Here is the revised definition of BasicDispatcher:
template
<
class BaseLhs,
class BaseRhs = BaseLhs,
typename ResultType = void,
typename CallbackType = ResultType (*)(BaseLhs&, BaseRhs&)
>
class BasicDispatcher
{
typedef std::pair<TypeInfo, TypeInfo>
KeyType;
typedef CallbackType MappedType;
typedef AssocVector<KeyType, MappedType> MapType;
MapType callbackMap_;
public:
...
};
The registration function is easy to define. This is all we need:
template <...>
class BasicDispatcher
{
... as above ...
template <class SomeLhs, SomeRhs>
void Add(CallbackType fun)
{
const KeyType key(typeid(SomeLhs), typeid(SomeRhs));
callbackMap_[key] = fun;
}
};
The types SomeLhs and SomeRhs are the concrete types for which you need to dispatch the call. Just like std::map, AssocVector overloads operator[] to find a key's corresponding mapped type. If the entry is missing, a new element is inserted. Then operator[] returns a reference to that new or found element, and Add assigns fun to it.
The following is an example of using Add:
typedef BasicDispatcher<Shape> Dispatcher;
// Hatches the intersection between a rectangle and a polygon
void HatchRectanglePoly(Shape& lhs, Shape& rhs)
{
Rectangle& rc = dynamic_cast<Rectangle&>(lhs);
Poly& pl = dynamic_cast<Poly&>(rhs);
... use rc and pl ...
}
...
Dispatcher disp;
disp.Add<Rectangle, Poly>(HatchRectanglePoly);
The member function that does the search and invocation is simple:
template <...>
class BasicDispatcher
{
... as above ...
ResultType Go(BaseLhs& lhs, BaseRhs& rhs)
{
MapType::iterator i = callbackMap_.find(
KeyType(typeid(lhs), typeid(rhs));
if (i == callbackMap_.end())
{
throw std::runtime_error("Function not found");
}
return (i->second)(lhs, rhs);
}
};
11.6.1 The Logarithmic Dispatcher and Inheritance
BasicDispatcher does not work correctly with inheritance. If you register only HatchRectanglePoly(Shape& lhs, Shape& rhs) with BasicDispatcher, you get proper dispatching only for objects of type Rectangle and Polynothing else. If, for instance, you pass references to a RoundedRectangle and a Poly to BasicDispatcher::Go, BasicDispatcher will reject the call.
The behavior of BasicDispatcher is not in keeping with inheritance rules, according to which derived types must by default act like their base types. It would be nice if BasicDispatcher accepted calls with objects of derived classes, as long as these calls were unambiguous per C++'s overloading rules.
There are quite a few things you can do to correct this problem, but to date there is no complete solution. You must be careful to register all the pairs of types with Basic Dispatcher.
11.6.2 The Logarithmic Dispatcher and Casts
BasicDispatcher is usable, but not quite satisfactory. Although you register a function that handles the intersection between a Rectangle and a Poly, that function must accept arguments of the base type, Shape&. It is awkward and error-prone to ask client code (HatchRectanglePoly's implementation) to cast the Shape references back to the correct types.
On the other hand, the callback map cannot hold a different function or functor type for each element, so we must stick to a uniform representation. Item 31 in More Effective C++ (Meyers 1996a) discusses this issue, too. No function-pointer-to-function-pointer cast helps because after you exit FnDoubleDispatcher::Add, you've lost the static type information, so you don't know what to cast to. (If this sounds confusing, try spinning some code and you'll immediately figure it out.)
We will implement a solution to the casting problem in the context of simple callback functions (not functors). That is, the CallbackType template argument is a pointer to a function.
An idea that could help is using a trampoline function, also known as a thunk. Trampoline functions are small functions that perform little adjustments before calling other functions. They are commonly used by C++ compiler writers to implement features such as covariant return types and pointer adjustments for multiple inheritance.
We can use a trampoline function that performs the appropriate cast and then calls a function of the proper signature, thus making life much easier for the client. The problem, however, is that callbackMap_ must now store two pointers to functions: one to the pointer provided by the client, and one to the pointer to the trampoline function. This is worrisome in terms of speed. Instead of an indirect call through a pointer, we have two. In addition, the implementation becomes more complicated.
An interesting bit of wizardry saves the day. A template can accept a pointer to a function as a nontype template parameter. (Most often in this book, nontype template parameters are integral values.) A template is allowed to accept pointers to global objects, including functions, as nontype template parameters. The only condition is that the function whose address is used as a template argument must have external linkage. You can easily transform static functions in functions with external linkage by removing static and putting them into unnamed namespaces. For example, what you would write as
static void Fun();
in pre-namespace C++, you can write using an anonymous namespace as
namespace
{
void Fun();
}
Using a pointer to a function as a nontype template argument means that we no longer need to store it in the map. This essential aspect needs thorough understanding. The reason we don't need to store the pointer to a function is that the compiler has static knowledge about it. Thus, the compiler can hardcode the function address in the trampo line code.
We implement this idea in a new class that uses BasicDispatcher as its back end. The new class, FnDispatcher, is tuned for dispatching to functions onlynot to functors. FnDispatcher aggregates BasicDispatcher privately and provides appropriate forwarding functions.
The FnDispatcher::Add template function accepts three template parameters. Two represent the left-hand-side and the right-hand-side types for which the dispatch is registered (ConcreteLhs and ConcreteRhs). The third template parameter (callback) is the pointer to a function. The added FnDispatcher::Add overloads the template Add with only two template parameters, defined earlier.
template <class BaseLhs, class BaseRhs = BaseLhs,
ResultType = void>
class FnDispatcher
{
BaseDispatcher<BaseLhs, BaseRhs, ResultType> backEnd_;
...
public:
template <class ConcreteLhs, class ConcreteRhs,
ResultType (*callback)(ConcreteLhs&, ConcreteRhs&)>
void Add()
{
struct Local // see Chapter 2
{
static ResultType Trampoline(BaseLhs& lhs, BaseRhs& rhs)
{
return callback(
dynamic_cast<ConcreteLhs&>(lhs),
dynamic_cast<ConcreteRhs&>(rhs));
}
};
return backEnd_.Add<ConcreteLhs, ConcreteRhs>(
&Local::Trampoline);
}
};
Using a local structure, we define the trampoline right inside Add. The trampoline casts the arguments to the right types and then forwards to callback. Then, the Add function uses backEnd_'s Add function (defined by BaseDispatcher) to add the trampoline to callbackMap_.
As far as speed is concerned, the trampoline does not incur additional overhead. Although it looks like an indirect call, the call to callback is not. As explained before, the compiler hardwires callback's address right into Trampoline so there is no second indirection. A clever compiler can even inline the call to callback if possible.
Using the newly defined Add function is simple:
typedef FnDispatcher<Shape> Dispatcher;
// Possibly in an unnamed namespace
void HatchRectanglePoly(Rectangle& lhs, Poly& rhs)
{
...
}
Dispatcher disp;
disp.Add<Rectangle, Poly, Hatch>();
Because of its Add member function, FnDispatcher is easy to use. FnDispatcher also exposes an Add function similar to the one defined by BaseDispatcher, so you still can use this function if you need to.
|
11.7 FnDispatcher and Symmetry
Because of FnDispatcher's dynamism, adding support for symmetry is much easier than it was with the static StaticDispatcher.
All we have to do to support symmetry is to register two trampolines: one that calls the executor in normal order, and one that swaps the parameters before calling. We add a new template parameter to Add, as shown.
template <class BaseLhs, class BaseRhs = BaseLhs,
typename ResultType = void>
class FnDispatcher
{
...
template <class ConcreteLhs, class ConcreteRhs,
ResultType (*callback)(ConcreteLhs&, ConcreteRhs&),
bool symmetric>
bool Add()
{
struct Local
{
... Trampoline as before ...
static void TrampolineR(BaseRhs& rhs, BaseLhs& lhs)
{
return Trampoline(lhs, rhs);
}
};
Add<ConcreteLhs, ConcreteRhs>(&Local::Trampoline);
if (symmetric)
{
Add<ConcreteRhs, ConcreteLhs>(&Local::TrampolineR);
}
}
};
Symmetry with FnDispatcher has function-level granularityfor each function you register, you can decide whether or not you want symmetric dispatching.
|
11.8 Double Dispatch to Functors
As described earlier, the trampoline trick works nicely with pointers to nonstatic functions. Anonymous namespaces provide a clean way to replace static functions with nonstatic functions that are not visible outside the current compilation unit.
Sometimes, however, you need your callback objects (the CallbackType template parameter of BasicDispatcher) to be more substantial than simple pointers to functions. For instance, you might want each callback to hold some state, and functions cannot hold much state (only static variables). Consequently, you need to register functors, and not functions, with the double dispatcher.
Functors (Chapter 5) are classes that overload the function call operator, operator(), thus imitating simple functions in call syntax. Additionally, functors can use member variables for storing and accessing state. Unfortunately, the trampoline trick cannot work with functors, precisely because functors hold state and simple functions do not. (Where would the trampoline hold the state?)
Client code can use BasicDispatcher directly, instantiated with the appropriate functor type.
struct HatchFunctor
{
void operator()(Shape&, Shape&)
{
...
}
};
typedef BasicDispatcher<Shape, Shape, void, HatchFunctor>
HatchingDispatcher;
HatchFunctor::operator() itself cannot be virtual, because BasicDispatcher needs a functor with value semantics, and value semantics don't mix nicely with runtime polymorphism. However, HatchFunctor::operator() can forward a call to a virtual function.
The real disadvantage is that the client loses some automation that the dispatcher could donamely, taking care of the casts and providing symmetry.
It seems as if we're back to square one, but only if you haven't read Chapter 5 on generalized functors. Chapter 5 defines a Functor class template that can aggregate any kind of functor and pointers to functions, even other Functor objects. You can even define specialized Functor objects by deriving from the FunctorImpl class. We can define a Functor to take care of the casts. Once the casts are confined to the library, we can implement symmetry easily.
Let's define a FunctorDispatcher that dispatches to any Functor objects. This dispatcher will aggregate a BasicDispatcher that stores Functor objects.
template <class BaseLhs, class BaseRhs = BaseLhs,
typename ResultType = void>
class FunctorDispatcher
{
typedef Functor<ResultType,
TYPELIST_2(BaseLhs&, BaseRhs&)>
FunctorType;
typedef BasicDispatcher<BaseLhs, BaseRhs, ResultType,
FunctorType>
BackEndType;
BackEndType backEnd_;
public:
...
};
FunctorDispatcher uses a BasicDispatcher instantiation as its back end. BasicDispatcher stores objects of type FunctorType, which are Functors that accept two parameters (BaseLhs and BaseRhs) and return a ResultType.
The FunctorDispatcher::Add member function defines a specialized FunctorImpl class by deriving from it. The specialized class (Adapter, shown below) takes care of casting the arguments to the right types; in other words, it adapts the argument types from BaseLhs and BaseRhs to SomeLhs and SomeRhs.
template <class BaseLhs, class BaseRhs = BaseLhs,
ResultType = void>
class FunctorDispatcher
{
... as above ...
template <class SomeLhs, class SomeRhs, class Fun>
void Add(const Fun& fun)
{
typedef
FunctorImpl<ResultType, TYPELIST_2(BaseLhs&, BaseRhs&)>
FunctorImplType;
class Adapter : public FunctorImplType
{
Fun fun_;
virtual ResultType operator()(BaseLhs& lhs, BaseRhs& rhs)
{
return fun_(
dynamic_cast<SomeLhs&>(lhs),
dynamic_cast<SomeRhs&>(rhs));
}
virtual FunctorImplType* Clone()const
{ return new Adapter; }
public:
Adapter(const Fun& fun) : fun_(fun) {}
};
backEnd_.Add<SomeLhs, SomeRhs>(
FunctorType((FunctorImplType*)new Adapter(fun));
}
};
The Adapter class does exactly what the trampoline function did. Because functors have state, Adapter aggregates a Fun objectsomething that was impossible with a simple trampoline function. The Clone member function, with obvious semantics, is required by Functor.
FunctorDispatcher::Add has remarkably broad uses. You can use it to register not only pointers to functions, but also almost any functor you want, even generalized functors. The only requirements for the Fun type in Add is that it accept the function-call operator with arguments of types SomeLhs and SomeRhs and that it return a type convertible to ResultType. The following example registers two different functors to a FunctorDispatcher object.
typedef FunctorDispatcher<Shape> Dispatcher;
struct HatchRectanglePoly
{
void operator()(Rectangle& r, Poly& p)
{
...
}
};
struct HatchEllipseRectangle
{
void operator()(Ellipse& e, Rectangle& r)
{
...
}
};
...
Dispatcher disp;
disp.Add<Rectangle, Poly>(HatchRectanglePoly());
disp.Add<Ellipse, Rectangle>(HatchEllipseRectangle());
The two functors don't have to be related in any way (as with inheriting from a common base). All they have to do is to implement operator() for the types that they advertise to handle.
Implementing symmetry with FunctorDispatcher is similar to implementing symmetry in FnDispatcher. FunctorDispatcher::Add defines a new ReverseAdapter object that does the casts and reverses the order of calls.
|
11.9 Converting Arguments: static_cast or dynamic_cast?
All the previous code has performed casting with the safe dynamic_cast. But in the case of dynamic_cast, safety comes at a cost in runtime efficiency.
At registration time, you already know that your function or functor will fire for a pair of specific, known types. Through the mechanism it implements, the double dispatcher knows the actual types when an entry in the map is found. It seems a waste, then, to have dynamic_cast check again for correctness when a simple static_cast achieves the same result in much less time.
There are, however, two cases in which static_cast may fail and the only cast to rely on is dynamic_cast. The first occurs when you're using virtual inheritance. Consider the following class hierarchy:
class Shape { ... };
class Rectangle : virtual public Shape { ... };
class RoundedShape : virtual public Shape { ... };
class RoundedRectangle : public Rectangle,
public RoundedShape { ... };
Figure 11.2 displays a graphical representation of the relationships between classes in this hierarchy.
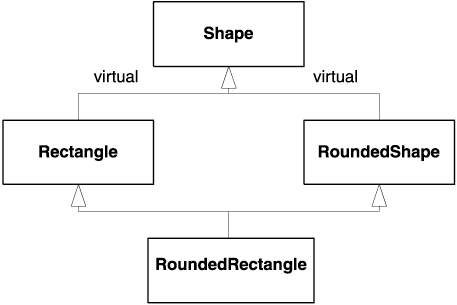
This may not be a very smart class hierarchy, but one thing about designing class libraries is that you never know what your clients might need to do. There are definitely reasonable situations in which a diamond-shaped class hierarchy is needed, in spite of all its caveats. Consequently, the double dispatchers we defined should work with diamond-shaped class hierarchies.
The dispatchers actually work fine as of now. But if you try to replace the dynamic_casts with static_casts, you will get compile-time errors whenever you try to cast a Shape& to any of Rectangle&, RoundedShape&, and RoundedRectangle&. The reason is that virtual inheritance works very differently from plain inheritance. Virtual inheritance provides a means for several derived classes to share the same base class object. The compiler cannot just lay out a derived object in memory by gluing together a base object with whatever the derived class adds.
In some implementations of multiple inheritance, each derived object stores a pointer to its base object. When you cast from derived to base, the compiler uses that pointer. But the base object does not store pointers to its derived objects. From a pragmatic viewpoint, all this means that after you cast an object of derived type to a virtual base type, there's no compile-time mechanism for getting back to the derived object. You cannot static_cast from a virtual base to an object of derived type.
However, dynamic_cast uses more advanced means to retrieve the relationships between classes and works nicely even in the presence of virtual bases. In a nutshell, you must use dynamic_cast if you have a hierarchy using virtual inheritance.
Second, let's analyze the situation with a similar class hierarchy, but one that doesn't use virtual inheritanceonly plain multiple inheritance.
class Shape { ... };
class Rectangle : public Shape { ... };
class RoundedShape : public Shape { ... };
class RoundedRectangle : public Rectangle,
public RoundedShape { ... };
Figure 11.3 shows the resulting inheritance graph.
Although the shape of the class hierarchy is the same, the structure of the objects is very different. RoundedRectangle now has two distinct subobjects of type Shape. This means that converting from RoundedRectangle to Shape is now ambiguous: Which Shape do you meanthat in the RoundedShape or that in the Rectangle? Similarly, you cannot even static cast a Shape& to a RoundedRectangle& because the compiler doesn't know which Shape subobject to consider.
We're facing trouble again. Consider the following code:
RoundedRectangle roundRect;
Rectangle& rect = roundRect; // Unambiguous implicit conversion
Shape& shape1 = rect;
RoundedShape& roundShape = roundRect; // Unambiguous implicit
// conversion
Shape& shape2 = roundShape;
SomeDispatcher d;
Shape& someOtherShape = ...;
d.Go(shape1, someOtherShape);
d.Go(shape2, someOtherShape);
Here, it is essential that the dispatcher use dynamic_cast to convert the Shape& to a Rounded Shape&. If you try to register a trampoline for converting a Shape& to a RoundedRectangle&, a compile-time error occurs due to ambiguity.
There is no trouble at all if the dispatcher uses dynamic_cast. A dynamic_cast<Rounded Rectangle&> applied to any of the two base Shape subobjects of a RoundedRectangle leads to the correct object. As you can see, nothing beats a dynamic cast. The dynamic_cast operator is designed to reach the right object in a class hierarchy, no matter how intricate its structure is.
The conclusion that consolidates these findings is this: You cannot use static_cast with a double dispatcher in a class hierarchy that has multiple occurrences of the same base class, whether or not it is through virtual inheritance.
This might give you a strong incentive to use dynamic_cast in all dispatchers. However, there are two supplemental considerations.
Very few class hierarchies in the real world foster a diamond-shaped inheritance graph. Such class hierarchies are very complicated, and their problems tend to outweigh their advantages. That's why most designers avoid them whenever possible. dynamic_cast is much slower than static_cast. Its power comes at a cost. There are many clients who have simple class hierarchies and who require high speed. Committing the double dispatcher to dynamic_cast leaves these clients with two options: Reimplement the whole dispatcher from scratch, or rely on some embarrassing surgery into library code.
The solution that Loki adopts is to make casting a policyCastingPolicy. (Refer to Chapter 1 for a description of policies.) Here, the policy is a class template with two parameters: the source and the destination type. The only function the policy exposes is a static function called Cast. The following is the DynamicCaster policy class.
template <class To, class From>
struct DynamicCaster
{
static To& Cast(From& obj)
{
return dynamic_cast<To&>(obj);
}
};
The dispatchers FnDispatcher and FunctorDispatcher use CastingPolicy according to the guidelines described in Chapter 1. Here is the modified FunctorDispatcher class. The changes are shown in bold.
template
<
class BaseLhs,
class BaseRhs = BaseLhs,
ResultType = void,
template <class, class> class CastingPolicy = DynamicCaster
>
class FunctorDispatcher
{
...
template <class SomeLhs, class SomeRhs, class Fun>
void Add(const Fun& fun)
{
class Adapter : public FunctorType::Impl
{
Fun fun_;
virtual ResultType operator()(BaseLhs& lhs,
BaseRhs& rhs)
{
return fun_(
CastingPolicy<SomeLhs, BaseLhs>::Cast(lhs),
CastingPolicy<SomeRhs, BaseRhs>::Cast(rhs));
}
... as before ...
};
backEnd_.Add<SomeLhs, SomeRhs>(
FunctorType(new Adapter(fun));
}
};
Cautiously, the casting policy defaults to DynamicCaster.
Finally, you can do a very interesting thing with casting policies. Consider the hierarchy in Figure 11.4. There are two categories of casts within this hierarchy. Some do not involve a diamond-shaped structure, so static_cast is safe. Namely, static_cast suffices for casting a Shape& to a Triangle&. On the other hand, you cannot static_cast a Shape& to Rectangle& and any of its derivatives; you must use dynamic_cast.
Suppose you define your own casting policy template for this class hierarchy, namely ShapeCast. You can make it default to dynamic_cast. You can then specialize the policy for the special cases:
template <class To, class From>
struct ShapeCaster
{
static To& Cast(From& obj)
{
return dynamic_cast<To&>(obj);
}
};
template<>
class ShapeCaster<Triangle, Shape>
{
static Triangle& Cast(Shape& obj)
{
return static_cast<Triangle&>(obj);
}
};
You now get the best of both worldsspeedy casts whenever you can, and safe casts whenever you must.
|
11.10 Constant-Time Multimethods: Raw Speed
Maybe you have considered the static dispatcher but found it too coupled, have tried the map-based dispatcher but found it too slow. You cannot settle for less: You need absolute speed and absolute scalability, and you're ready to pay for it.
The price to pay in this case is changing your classes. You are willing to allow the double dispatcher to plant some hooks in your classes so that it leverages them later.
This opportunity gives a fresh perspective to implementing a double-dispatch engine. The support for casts remains the same. The means of storing and retrieving handlers must be changed, howeverlogarithmic time is not constant time.
To find a better dispatching mechanism, let's ask ourselves again, What is double dispatching? You can see it as finding a handler function (or functor) in a two-dimensional space. On one axis are the types of the left-hand operator. On the other axis are the types of the right-hand operator. At the intersection between two types, you find their respective handler function. Figure 11.5 illustrates double dispatch for two class hierarchiesone of Shapes and one of DrawingDevices. The handlers can be drawing functions that know how to render each concrete Shape object on each concrete DrawingDevice object.
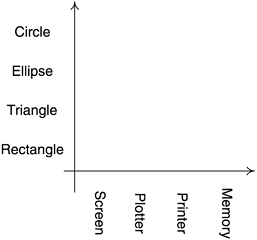
It doesn't take long to figure out that if you need constant-time searches in this two-dimensional space, you must rely on indexed access in a two-dimensional matrix.
The idea takes off swiftly. Each class must bear a unique integral value, which is the index in the dispatcher matrix. That integral value must be accessible for each class in constant time. A virtual function can help here. When you issue a double-dispatch call, the dispatcher fetches the two indices from the two objects, accesses the handler in the matrix, and launches the handler. Cost: two virtual calls, one matrix indexing operation, and a call through a pointer to a function. The cost is constant.
It seems as if the idea should work quite nicely, but some of its details are not easy to get right. For instance, maintaining indices is very likely to be uncomfortable. For each class, you must assign a unique integral ID and hope that you can detect any duplicates at compile time. The integral IDs must start from zero and have no gapsotherwise, we would waste matrix storage.
A much better solution is to move index management to the dispatcher itself. Each class stores a static integral variable; initially, its value is -1, meaning "unassigned." A virtual function returns a reference to that static variable, allowing the dispatcher to change it at runtime. As you add new handlers to the matrix, the dispatcher accesses the ID and, if it is -1, assigns the next available slot in the matrix to it.
Here's the gist of this implementationa simple macro that you must plant in each class of your class hierarchy.
#define IMPLEMENT_INDEXABLE_CLASS(SomeClass)
static int& GetClassIndexStatic()\
{\
static int index = -1;\
return index;\
}\
virtual int& GetClassIndex()\
{\
assert(typeid(*this) == typeid(SomeClass));\
return GetClassIndexStatic();\
}
You must insert this macro in the public portion of each class for which you want to support multiple dispatch.
The BasicFastDispatcher class template exposes exactly the same functionality as the previously defined BasicDispatcher but uses different storage and retrieval mechanisms.
template
<
class BaseLhs,
class BaseRhs = BaseLhs,
typename ResultType = void,
typename CallbackType = ResultType (*)(BaseLhs&, BaseRhs&)
>
class BasicFastDispatcher
{
typedef std::vector<CallbackType> Row;
typedef std::vector<Row> Matrix;
Matrix callbacks_;
int columns_;
public:
BasicFastDispatcher() : columns_(0) {}
template <class SomeLhs, SomeRhs>
void Add(CallbackType pFun)
{
int& idxLhs = SomeLhs::GetClassIndexStatic();
if (idxLhs < 0)
{
callbacks_.push_back(Row());
idxLhs = callbacks_.size() - 1;
}
else if (callbacks_.size() <= idxLhs)
{
callbacks_.resize(idxLhs + 1);
}
Row& thisRow = callbacks_[idxLhs];
int& idxRhs = SomeRhs::GetClassIndexStatic();
if (idxRhs < 0)
{
thisRow.resize(++columns_);
idxRhs = thisRow.size() - 1;
}
else if (thisRow.size() <= idxRhs)
{
thisRow.resize(idxRhs + 1);
}
thisRow[idxRhs] = pFun;
}
};
The callback matrix is implemented as a vector of vectors of MappedType. The BasicFastDispatcher::Add function performs the following sequence of actions:
Fetches the ID of each class by calling GetClassIndexStatic. Performs initialization and adjustments if one or both indices were not initialized. For uninitialized indices, Add expands the matrix to accommodate one extra element. Inserts the callback at the correct position in the matrix.
The columns_ member variable tallies the number of columns added so far. Strictly speaking, columns_ is redundant; a search for the maximum row length in the matrix would yield the same result. However, column_'s convenience justifies its presence.
The BasicFastDispatcher::Go is easy to implement now. The main difference is that Go uses the virtual function GetClassIndex.
template <...>
class BasicFastDispatcher
{
... as above ...
ResultType Go(BaseLhs& lhs, BaseRhs& rhs)
{
int& idxLhs = lhs.GetClassIndex();
int& idxRhs = rhs.GetClassIndex();
if (idxLhs < 0 || idxRhs < 0 ||
idxLhs >= callbacks_.size() ||
idxRhs >= callbacks_[idxLhs].size() ||
callbacks_[idxLhs][idxRhs] == 0)
{
... error handling goes here ...
}
return callbacks_[idxLhs][idxRhs].callback_(lhs, rhs);
}
};
Let's recap this section. We defined a matrix-based dispatcher that reaches callback objects in constant time by assigning an integral index to each class. In addition, it performs automatic initialization of its support data (the indices corresponding to the classes). Users of BasicFastDispatcher must add a one-macro line, IMPLEMENT_INDEXABLE_CLASS (YourClass), to each class that is to use BasicFastDispatcher.
|
11.11 BasicDispatcher and BasicFastDispatcher as Policies
BasicFastDispatcher (matrix based) is preferable to BasicDispatcher (map based) when speed is a concern. However, the nice advanced classes FnDispatcher and FunctorDispatcher are built around BasicDispatcher. Should we develop two new classesFnFastDispatcher and FunctorFastDispatcherthat use BasicFastDispatcher as their back end?
A better idea is to try to adapt FnDispatcher and FunctorDispatcher to use either BasicDispatcher or BasicFastDispatcher, depending on a template parameter. That is, make the dispatcher a policy for the classes FnDispatcher and FunctorDispatcher, much as we did with the casting strategy.
The task of morphing the dispatcher into a policy is eased by the fact that Basic Dispatcher and BasicFastDispatcher have the same call interface. This makes replacing one with the other as easy as changing a template argument.
The following is the revised declaration of FnDispatcher (FunctorDispatcher's declaration is similar). The changes are shown in bold.
template
<
class BaseLhs,
class BaseRhs = BaseLhs,
typename ResultType = void,
template <class, class>
class CastingPolicy = DynamicCaster,
template <class, class, class, class>
class DispatcherBackend = BasicDispatcher
>
class FnDispatcher; // similarly for FunctorDispatcher
Table 11.1. DispatcherBackend Policy Requirements
| copy, assign, swap, destroy |
|
Value semantics. |
| backEnd.Add<SomeLhs, SomeRhs>(callback) |
void |
Add a callback to the backEnd object for types SomeLhs and SomeRhs. |
| backEnd.Go(BaseLhs&, BaseRhs&) |
ResultType |
Performs a lookup and a dispatch for the two objects. Throws std::runtime_error if a handler is not found. |
| backEnd.Remove<SomeLhs, SomeRhs>() |
bool |
Removes the callback for the types SomeLhs and SomeRhs. Returns true if there was a callback. |
| backEnd.HandlerExists<SomeLhs, SomeRhs>() |
bool |
Returns true if a callback is registered for the types SomeLhs and SomeRhs. No callback is added. |
The two classes themselves undergo very few changes.
Let's clarify the DispatcherBackend policy requirements. First of all, obviously, DispatcherBackend must be a template with four parameters. The parameter semantics are, in order
In Table 11.1, BackendType represents an instantiation of the dispatcher back-end template, and backEnd represents a variable of that type. The table contains functions that we haven't mentioned yetdon't worry. A complete dispatcher must come with functions that remove callbacks and that do a "passive" lookup without calling the callback. These are trivial to implement; you can see them in Loki's source code, file MultiMethods.h.
|
11.12 Looking Forward
Generalization is right around the corner. We can take our findings regarding double dispatch and apply them to implementing true generic multiple dispatch.
It's actually quite easy. This chapter defines three types of double dispatchers:
A static dispatcher, driven by two typelists A map-based dispatcher, driven by a map keyed by a pair of std::type_info objects
A matrix-based dispatcher, driven by a matrix indexed with unique numeric class IDs
It's easy to generalize these dispatchers as follows. You can generalize the static dispatcher to one driven by a typelist of typelists, instead of two typelists. Yes, you can define a typelist of typelists because any typelist is a type. The following typedef defines a typelist of three typelists, possible participants in a triple-dispatch scenario. Remarkably, the resulting typelist is actually easy to read.
typedef TYPELIST_3
(
TYPELIST_3(Shape, Rectangle, Ellipse),
TYPELIST_3(Screen, Printer, Plotter),
TYPELIST_3(File, Socket, Memory)
)
ListOfLists;
You can generalize the map-based dispatcher to one that is keyed by a vector of std:: type_info objects (as opposed to a std::pair). That vector's size will be the number of objects involved in the multiple-dispatch operation. A possible synopsis of a generalized BasicDispatcher is as follows:
template
<
class ListOfTypes,
typename ResultType,
typename CallbackType
>
class GeneralBasicDispatcher;
The ListOfTypes template parameter is a typelist containing the base types involved in the multiple dispatch. For instance, our earlier example of hatching intersections between two shapes would have used a TYPELIST_2(Shape, Shape).
You can generalize the matrix-based dispatcher by using a multidimensional array. You can build a multidimensional array with a recursive class template. The existing scheme of assigning numeric IDs to types works just as it is. This has the nice effect that if you modify a hierarchy once to support double dispatch, you don't have to modify it again to support multiple dispatch.
All these possible extensions need the usual amount of work to get all the details right. A particularly nasty problem related to multiple dispatch and C++ is that there's no uniform way to represent functions with a variable number of arguments.
As of now, Loki implements double dispatch only. The interesting generalizations just suggested are left in the dreaded form of the exercise for . . . you know.
|
11.13 Summary
Multimethods are generalized virtual functions. Whereas the C++ runtime support dispatches virtual functions on a per-class basis, multimethods are dispatched depending on multiple classes simultaneously. This allows you to implement virtual functions for collections of types instead of one type at a time.
By their nature, multimethods are best implemented as a language feature. C++ lacks such a feature, but there are several ways to implement it in libraries.
Multimethods are needed in applications that call algorithms that depend on the type of two or more objects. Typical examples include collisions between polymorphic objects, intersections, and displaying objects on various target devices.
This chapter limits discussion to the defining of multimethods for two objects. An object that takes care of selecting the appropriate function to call is called a double dispatcher. The types of dispatchers discussed are as follows:
The brute-force dispatcher.
This dispatcher relies on static type information (provided in the form of a typelist) and does a linear unrolled search for the correct types. Once the types are found, the dispatcher calls an overloaded member function in a handler object.
The map-based dispatcher.
This uses a map keyed by std::type_info objects. The mapped value is a callback (either a pointer to a function or a functor). The type discovery algorithm performs a binary search.
The constant-time dispatcher.
This is the fastest dispatcher of all, but it requires you to modify the classes on which it acts. The change is to add a macro to each class that you want to use with the constant-time dispatcher. The cost of a dispatch is two virtual calls, a couple of numeric tests, and a matrix element access.
On top of the last two dispatchers, higher-level facilities can be implemented:
Automated conversions.
(Not to be confused with automatic conversions.) Because of their uniformity, the dispatchers above require the client to cast the objects from their base types to their derived types. A casting layer can provide a trampoline function that takes care of these conversions.
Symmetry.
Some double-dispatch applications are symmetric in nature. They dispatch on the same base type on both sides of the double-dispatch operation, and they don't care about the order of elements. For instance, in a collision detector it doesn't matter whether a spaceship hits a torpedo or a torpedo hits a spaceshipthe behavior is the same. Implementing support for symmetry in the library makes client code smaller and less exposed to errors.
The brute-force dispatcher supports these higher-level features directly. This is possible because the brute-force dispatcher has extensive type information available. The other two dispatchers use different methods and add an extra layer to implement automated conversions and symmetry. Double dispatchers for functions implement this extra layer differently (and more efficiently) than double dispatchers for functors.
Table 11.2 compares the three dispatcher types defined in this chapter. As you can see, none of the presented implementations is ideal. You should choose the solution that best fits your needs for a given situation.
Table 11.2. Comparison of Various Implementations of Double Dispatch
| Speed for few classes |
Best |
Modest |
Good |
| Speed for many classes |
Low |
Good |
Best |
| Dependency introduced |
Heavy |
Low |
Low |
| Alteration of existing classes needed |
None |
None |
Add a macro to each class |
| Compile-time safety |
Best |
Good |
Good |
| Runtime safety |
Best |
Good |
Good |
|
11.14 Double Dispatcher Quick Facts
Loki defines three basic double dispatchers: StaticDispatcher, BasicDispatcher, and BasicFastDispatcher. StaticDispatcher's declaration:
template
<
class Executor,
class BaseLhs,
class TypesLhs,
class BaseRhs = BaseLhs,
class TypesRhs = TypesLhs,
typename ResultType = void
>
class StaticDispatcher;
where
BaseLhs is the base left-hand type.
TypesLhs is a typelist containing the set of concrete types involved in the double dispatch on the left-hand side.
BaseRhs is the base right-hand type.
TypesRhs is a typelist containing the set of concrete types involved in the double dispatch on the right-hand side.
Executor is a class that provides the functions to be invoked after type discovery. Executor must provide an overloaded member function Fire for each combination of types in TypesLhs and TypesRhs.
ResultType is the type returned by the Executor::Fire overloaded functions. The returned value will be forwarded as the result of StaticDispatcher::Go.
Executor must provide a member function OnError(BaseLhs&, BaseRhs&) for error handling. StaticDispatcher calls Executor::OnError when it encounters an unknown type. Example (assume Rectangle and Ellipse inherit Shape, and Printer and Screen inherit OutputDevice):
struct Painter
{
bool Fire(Rectangle&, Printer&);
bool Fire(Ellipse&, Printer&);
bool Fire(Rectangle&, Screen&);
bool Fire(Ellipse&, Screen&);
bool OnError(Shape&, OutputDevice&);
};
typedef StaticDispatcher
<
Painter,
Shape,
TYPELIST_2(Rectangle, Ellipse),
OutputDevice,
TYPELIST_2(Printer&, Screen),
bool
>
Dispatcher;
StaticDispatcher implements the Go member function, which takes a BaseLhs&, a BaseRhs&, and an Executor&, and executes the dispatch. Example (using the previous definitions):
Dispatcher disp;
Shape* pSh = ...;
OutputDevice* pDev = ...;
bool result = disp.Go(*pSh, *pDev);
BasicDispatcher and BasicFastDispatcher implement dynamic dispatchers that allow users to add handler functions at runtime. BasicDispatcher finds a handler in logarithmic time. BasicFastDispatcher finds a handler in constant time but requires the user to change the definitions of all dispatched classes. Both classes implement the same interface, illustrated here for BasicDispatcher.
template
<
class BaseLhs,
class BaseRhs = BaseLhs,
typename ResultType = void,
typename CallbackType = ResultType (*)(BaseLhs&, BaseRhs&)
>
class BasicDispatcher;
where
CallbackType is the type of object that handles the dispatch.
BasicDispatcher and BasicFastDispatcher store and invoke objects of this type.
All other parameters have the same meaning as for StaticDispatcher.
The two dispatchers implement the functions described in Table 11.1. In addition to the three basic dispatchers, Loki also defines two advanced layers: FnDispatcher and FunctorDispatcher. They use one of BasicDispatcher or BasicFastDispatcher as a policy. FnDispatcher and FunctorDispatcher have similar declarations, as shown here.
template
<
class BaseLhs,
class BaseRhs = BaseLhs,
ResultType = void,
template <class To, class From>
class CastingPolicy = DynamicCast
template <class, class, class, class>
class DispatcherBackend = BasicDispatcher
>
class FnDispatcher;
where
BaseLhs and BaseRhs are the base classes of the two hierarchies involved in the double dispatch.
ResultType is the type returned by the callbacks and the dispatcher.
CastingPolicy is a class template with two parameters. It must implement a static member function Cast that accepts a reference to From and returns a reference to To. The stock implementations DynamicCaster and StaticCaster use dynamic_cast and static_cast, respectively.
DispatcherBackend is a class template that implements the same interface as BasicDispatcher and BasicFastDispatcher, described in Table 11.1.
Both FnDispatcher and FunctorDispatcher provide an Add member function or their primitive handler type. For FnDispatcher the primitive handler type is ResultType (*)(BaseLhs&, BaseRhs&). For FunctorDispatcher, the primitive handler type is Functor<ResultType, TYPELIST_2(BaseLhs&, Base Rhs&)>. Refer to Chapter 5 for a description of Functor. In addition, FnDispatcher provides a template function to register callbacks with the engine:
void Add<SomeLhs, SomeRhs,
ResultType (*callback)(SomeLhs&, SomeRhs&),
bool symmetric>();
If you register handlers with the Add member function shown in the previous code, you benefit from automated casting and optional symmetry. FunctorDispatcher provides a template Add member function:
template <class SomeLhs, class SomeRhs, class F>
void Add(const F& fun);
F can be any of the types accepted by the Functor object (see Chapter 5), including another Functor instantiation. An object of type F must accept the function-call operator with arguments of types BaseLhs& and BaseRhs& and return a type convertible to ResultType. If no handler is found, all dispatch engines throw an exception of type std::runtime_error.
|
A Minimalist Multithreading Library
A multithreaded program has multiple points of execution at the same time. Practically, this means that in a multithreaded program you can have multiple functions running at once. On a multiprocessor computer, different threads might run literally simultaneously. On a single-processor machine, a multithreading-capable operating system will apply time slicingit chops each thread at short time intervals, suspends it, and gives another thread some processor time. Multithreading gives the user the impression that multiple things happen at once. For instance, a word processor can verify grammar while letting the user enter text.
Users don't like to see the hourglass cursor, so we programmers must write multithreaded programs. Unfortunately, as pleasing as it is to users, multithreading is traditionally very hard to program, and even harder to debug. Moreover, multithreading pervades application design. Making a library work safely in the presence of multiple threads cannot be done from the outside; it must be built in, even if the library does not use threads of its own.
It follows that the components provided in this book cannot ignore the threading issue. (Well, they actually could, in which case most of them would be useless in the presence of multiple threads.) Because modern applications increasingly use multithreaded execution, it would be a pity to sweep multithreading under the rug out of laziness.
This appendix provides tools and techniques that establish a sound ground for writing portable multithreaded object-oriented applications in C++. It does not provide a comprehensive introduction to multithreaded programminga fascinating domain in itself. Trying to discuss a complete threading library en passant in this book would be a futile, doomed effort. The focus here is on figuring out the minimal abstractions that allow us to write multithreaded components.
Loki's threading abilities are scarce compared with the host of amenities that a modern operating system provides, because its concern is only to provide thread-safe components. On the bright side, the synchronization concepts defined in this appendix are higher level than the traditional mutexes and semaphores and might help in the design of any object-oriented multithreaded application.
|
A.1 A Critique of Multithreading
The advantages of multithreading on multiprocessor machines are obvious. But when executed on a single processor, multithreading may seem a bit silly. Why would you want to slow down the processor with time-slicing algorithms? Obviously, you won't get any net gain. No miracle can occurthere's still only one processor, so overall multithreading will actually slightly reduce efficiency because of the additional swapping and bookkeeping.
The reason that multithreading is important even on single-processor machines is efficient resource use. In a typical modern computer, there are many more resources than the processor. You have devices such as disk drives, modems, network cards, and printers. Because they are physically independent, these resources can work at the same time. For instance, there is no reason why the processor cannot compute while the disk spins and while the printer prints. However, this is exactly what would happen if your application and operating system committed exclusively to a single-threaded execution model. And you wouldn't be happy if your application didn't allow you to do anything while transferring data from the Internet through the modem.
In the same vein, even the processor might be unused for extended periods of time. As you are editing a 3D image, the short intervals between your mouse moves and clicks are little eternities to the processor. It would be nice if the drawing program could use those idle times to do something useful, such as ray tracing or computing hidden lines.
The main alternative to multithreading is asynchronous execution. Asynchronous execution fosters a callback model: You start an operation and register a function to be called when the operation completes. The main disadvantage of asynchronous execution compared with using multithreading is that it leads to state-rich programs. By using asynchronous execution, you cannot follow an algorithm from one point to another; you can only store a state and let the callbacks change that state. Maintaining such state is troublesome in all but the simplest operations.
True threads don't have this problem. Each thread has an implicit state given by its execution point (the statement where the thread currently executes). You can easily follow what a thread does because it's just like following a simple function. The execution point is exactly what you have to manage by hand in asynchronous execution. (The main question in asynchronous programming is "Where am I now?") In conclusion, multithreaded programs can follow the synchronous execution model, which is good.
On the other hand, threads are exposed to big problems as soon as they start sharing resources, such as data in memory. Because threads can be interrupted at any time by other threads (yes, that's any time, including in the middle of an assignment to a variable), operations that you thought were atomic are not. Unorganized access of threads to a piece of data is always lethal to that data.
In single-threaded programming, data health is usually guaranteed at the entry and at the exit of a function. For instance, the assignment operator (operator=) of a String class assumes the String object is valid upon entry and at exit of the operator. With multithreaded programming, you must make sure that the String object is valid even during the assignment operation, because another thread may interrupt an assignment and do another operation against the String object. Whereas single-threaded programming accustoms you to think of functions as atomic operations, in multithreaded programming you must state explicitly which operations are atomic. In conclusion, multithreaded programs have big trouble sharing resources, which is bad.
Most programming techniques for multithreading focus on providing synchronization objects that enable you to serialize access to shared resources. Whenever you do an operation that must be atomic, you lock a synchronization object. If other threads try to lock the same synchronization object, they are put on hold. You modify the data (and leave it in a coherent state) and then unlock the synchronization object. At that moment, some other thread will be able to lock the synchronization object and gain access to the data. This effectively makes every thread work on consistent data.
The following sections define various locking objects. The synchronization objects provided herein are not comprehensive, yet you can do a great deal of multithreaded programming by using them.
|
A.2 Loki's Approach
To deal with threading issues, Loki defines the ThreadingModel policy. ThreadingModel prescribes a template with one argument. That argument is a C++ type for which you need to access threading amenities:
template <typename T>
class SomeThreadingModel
{
...
};
The following sections progressively fill ThreadingModel with concepts and functionality. Loki defines a single threading model that is the default for most of Loki.
|
A.3 Atomic Operations on Integral Types
Assuming x is a variable of type int, consider this statement:
++x;
It might seem awkward that a book focused on design analyzes a simple increment statement, but this is the thing with multithreadinglittle issues affect big designs.
To increment x, the processor has to do three operations:
Fetch the variable from memory. Increment the variable inside the arithmetic logic unit (ALU) of the processor. The ALU is the only place where an operation can take place; memory does not have arithmetic capabilities of its own. Write the variable back to memory.
Because the first operation reads, the second modifies, and the third writes the data, this troika is known as a read-modify-write (RMW) operation.
Now suppose this increment happens in a multiprocessor architecture. To maximize efficiency, during the modify part of the RMW operation the processor unlocks the memory bus. This way another processor can access the memory while the first increments the variable, leading to better resource use.
Unfortunately, another processor can start an RMW operation against the same integer. For instance, assume there are two increments on x, which initially has value 0, performed by two processors P1 and P2 in the following sequence:
P1 locks the memory bus and fetches x. P1 unlocks the memory bus. P2 locks the memory bus and fetches x (which is still 0). At the same time, P1 increments x inside its ALU. The result is 1. P2 unlocks the memory bus. P1 locks the memory bus and writes 1 to x. At the same time, P2 increments x inside its ALU. Because P2 fetched a 0, the result is, again, 1. P1 unlocks the memory bus. P2 locks the memory bus and writes 1 to x. P2 unlocks the memory bus.
The net result is that although two increment operations have been applied to x starting from 0, the final value is 1. This is an erroneous result. Worse, neither processor (thread) can figure out that the increment failed and will retry it. In a multithreaded world, nothing is atomicnot even a simple increment of an integer.
There are a number of ways to make the increment operation atomic. The most efficient way is to exploit processor capabilities. Some processors offer locked-bus operationsthe RMW operation takes place as described previously, except that the memory bus is locked throughout the operation. This way, when P2 fetches x from memory, it will be after its increment by P1 has completed.
This low-level functionality is usually packaged by operating systems in C functions that provide atomic increment and atomic decrement operations.
If an OS defines atomic operations, it usually does so for the integral type that has the width of the memory busmost of the time, int. The threading subsystem of Loki (file Threads.h) defines the type IntType inside each ThreadingModel implementation.
The primitives for atomic operations, still inside ThreadingModel, are outlined in the following:
template <typename T>
class SomeThreadingModel
{
public:
typedef int IntType; // or another type as dictated by the platform
static IntType AtomicAdd(volatile IntType& lval, IntType val);
static IntType AtomicSubtract(volatile IntType & lval, IntType val);
... similar definitions for AtomicMultiply, AtomicDivide,
... AtomicIncrement, AtomicDecrement ...
static void AtomicAssign(volatile IntType & lval, IntType val);
static void AtomicAssign(IntType & lval, volatile IntType & val);
};
These primitives get the value to change as the first parameter (notice the pass by non-const reference and the use of volatile), and the other operand (absent in the case of unary operators) as the second parameter. Each primitive returns a copy of the volatile destination. The returned value is very useful when you're using these primitives because you can inspect the actual result of the operation. If you inspect the volatile value after the operation,
volatile int counter;
...
SomeThreadingModel<Widget>::AtomicAdd(counter, 5);
if (counter == 10) ...
then your code does not inspect counter immediately after the addition because another thread can modify counter between the call to AtomicAdd and the if statement. Most of the time, you need to see what value counter has immediately after your call to AtomicAdd, in which case you write
if (AtomicAdd(counter, 5) == 10) ...
The two AtomicAssign functions are necessary because even the copy operation can be nonatomic. For instance, if your machine bus is 32 bits wide and long has 64 bits, copying a long value involves two memory accesses.
|
A.4 Mutexes
Edgar Dijkstra has proven that in the presence of multithreading, the thread scheduler of the operating system must provide certain synchronization objects. Without them, writing correct multithreaded applications is impossible.
Mutexes are fundamental synchronization objects that allow threads to access shared resources in an ordered manner. This section defines the notion of a mutex. The rest of Loki does not use mutexes directly; instead, it defines higher-level means of synchronization that can be easily implemented with mutexes.
Mutex is a collocation of Mutual Exclusive, a phrase that describes the functioning of this primitive object: A mutex allows threads mutually exclusive access to a resource.
The basic functions of a mutex are Acquire and Release. Each thread that needs exclusive access to a resource (such as a shared variable) acquires the mutex. Only one thread can acquire the mutex. After one thread acquires it, all other threads that invoke Acquire block in a wait state (the function Acquire does not return). When the thread that owns the mutex calls the Release function, the thread scheduler chooses one of the threads that is in a wait state on the same mutex and gives that thread the ownership of the mutex.
The observable effect is that mutexes are access serialization devices: The portion of code between a call to mtx.Acquire() and a call to mtx.Release() is atomic with respect to the mtx object. Any other attempt to acquire the mtx object must wait until the atomic operation finishes.
It follows that you should allocate one mutex object for each resource you want to share between threads. The resources you might want to share include, notably, C++ objects. Every nonatomic operation with these resources must start with acquiring the mutex and end with releasing the mutex. The nonatomic operations that you might want to perform include, notably, non-const member functions of thread-safe objects.
For instance, imagine you have a BankAccount class that provides functions such as Deposit and Withdraw. These operations do more than add to and subtract from a double member variable; they also log additional information regarding the transaction. If BankAccount is to be accessed from multiple threads, the two operations must certainly be atomic. Here's how you can do this:
class BankAccount
{
public:
void Deposit(double amount, const char* user)
{
mtx_.Acquire();
... perform deposit transaction ...
mtx_.Release();
}
void Withdraw(double amount, const char* user)
{
mtx_.Acquire();
... perform withdrawal transaction ...
mtx_.Release();
}
...
private:
Mutex mtx_;
...
};
As you probably have figured out (if you didn't know already), failing to call Release for each Acquire you issue has deadly effects. You lock the mutex and leave it locked all other threads trying to acquire it block forever. In the previous code, you must implement Deposit and Withdraw very carefully with regard to exceptions and premature returns.
To mitigate this problem, many C++ threading APIs define a Lock object that you can initialize with a mutex. The Lock object's constructor calls Acquire, and its destructor calls Release. This way, if you allocate a Lock object on the stack, you can count on correct pairing of Acquire and Release, even in the presence of exceptions.
For portability reasons, Loki does not define mutexes on its own. It's likely you already use a multithreading library that defines its own mutexes. It would be awkward to duplicate their functionality. Instead, Loki relies on higher-level locking semantics that are implemented in terms of mutexes.
|
A.5 Locking Semantics in Object-Oriented Programming
Synchronization objects are associated with shared resources. In an object-oriented program, resources are objects. Therefore, in an object-oriented program, synchronization objects are associated with application objects.
It follows that each shared object should aggregate a synchronization object and lock it appropriately in every mutating member function, much as the BankAccount example does. This is a correct way to structure an object supporting multithreading. The structure fostering one synchronization object per object is known as object-level locking.
However, sometimes the size and the overhead of storing one mutex per object are too big. In this case, a synchronization strategy that keeps only one mutex per class can help.
Consider, for example, a String class. From time to time, you might need to perform a locking operation on a String object. However, you don't want each String to carry a mutex object; that would make Strings big and their copying costly. In this case, you can use a static mutex object for all Strings. Whenever a String object performs a locking operation, that operation will block all locking operations for all String objects. This strategy fosters class-level locking.
Loki defines two implementations of the ThreadingModel policy: ClassLevelLockable and ObjectLevelLockable. They encapsulate class-level locking and object-level locking semantics, respectively. The synopsis is presented here.
template <typename Host>
class ClassLevelLockable
{
public:
class Lock
{
public:
Lock();
Lock(Host& obj);
...
};
...
};
template <typename Host>
class ObjectLevelLockable
{
public:
class Lock
{
public:
Lock(Host& obj);
...
};
...
};
Technically, Lock keeps a mutex locked. The difference between the two implementations is that you cannot construct an ObjectLevelLockable<T>::Lock without passing a T object to it. The reason is that ObjectLevelLockable uses per-object locking.
The Lock nested class locks the object (or the entire class, in the case of ClassLevelLockable) for the lifetime of a Lock object.
In an application, you inherit one of the implementations of ThreadingModel. Then you use the inner class Lock directly. For example,
class MyClass : public ClassLevelLockable <MyClass>
{
...
};
Table A.1. Implementations of ThreadingModel
| SingleThreaded |
No threading strategy at all. The Lock and ReadLock classes are empty mock-ups. |
| ObjectLevelLockable |
Object-level locking semantics. One mutex per object is stored. The Lock inner class locks the mutex (and implicitly the object). |
| ClassLevelLockable |
Class-level locking semantics. One mutex per class is stored. The Lock inner class locks the mutex (and implicitly all objects of a type). |
The exact locking strategy depends on the ThreadingModel implementation you choose to derive from. Table A.1 summarizes the available implementations.
You can define synchronized member functions very easily, as outlined in the following example:
class BankAccount : public ObjectLevelLockable<BankAccount>
{
public:
void Deposit(double amount, const char* user)
{
Lock lock(*this);
... perform deposit transaction ...
}
void Withdraw(double amount, const char* user)
{
Lock lock(*this);
... perform withdrawal transaction ...
}
...
};
You no longer have any problem with premature returns and exceptions; the correct pairing of lock/unlock operations on the mutex is guaranteed by language invariants.
The uniform interface supported by the dummy interface SingleThreaded gives syntactic consistency. You can write your code assuming a multithreading environment, and then easily change design decisions by modifying the threading model.
The ThreadingModel policy is used in Chapter 4 (Small-Object Allocation), Chapter 5 (Generalized Functors), and Chapter 6 (Implementing Singletons).
|
A.6 Optional volatile Modifier
C++ provides the volatile type modifier, with which you should qualify each variable that you share with multiple threads. However, in a single-threaded model, it's best not to use volatile because it prevents the compiler from performing some important optimizations.
That's why Loki defines the inner class VolatileType. Inside SomeThreadingModel<Widget>, VolatileType evaluates to volatile Widget for ClassLevelLockable and ObjectLevelLockable, and to plain Widget for SingleThreaded. You can see VolatileType at work in Chapter 6.
|
A.7 Semaphores, Events, and Other Good Things
Loki's support for multithreading stops here. General multithreading libraries provide a richer set of synchronization objects and functions such as semaphores, events, and memory barriers. Also, the function that starts a new thread is conspicuously absent from Lokiwitness to the fact that Loki aims to be thread safe but not to use threads itself.
It is possible that a future version of Loki will provide a complete threading model. Multithreading is a domain that can greatly benefit from generic programming techniques. However, competition is heavy herecheck out ACE (Adaptive Communication Environment) for a great, very portable multithreading library (Schmidt 2000).
|
A.8 Summary
Threads are absent from standard C++. However, synchronization issues in multithreaded programs pervade application and library design. The trouble is, the threading models supported by various operating systems are very different. Therefore, Loki defines a high-level synchronization mechanism having a minimal interaction with a threading model provided from the outside.
The ThreadingModel policy and the three class templates that implement ThreadingModel define a platform for building generic components that support different threading models. At compile time, you can select support for object-level locking, class-level locking, or no locking at all.
The object-level locking strategy allocates one synchronization object per application object. The class-level locking strategy allocates one synchronization object per class. The former strategy is faster; the second uses a smaller amount of resources.
All implementations of ThreadingModel support a unique syntactic interface. This makes it easy for the library and for client code to use a uniform syntax. You can adjust locking support for a class without incurring changes to its implementation. For the same purpose, Loki defines a do-nothing implementation that supports a single-threaded model.
|
|
|

 LINUX
LINUX