C++ Шаблоны
Код лежит тут
Основы
Этот раздел описывает основные концепции шаблонов C++.
Будут описаны нетипизированные параметры шаблона , члены-шаблоны.
Зачем нужны шаблоны?
В C++ необходимо декларировать переменные, функции, и другие типы.
Для различных типов код порой может выглядеть одинаково.
Особенно когда вы реализуете алгоритмы аналогичные quicksort,
или вы реализуете поведение структур данных,
таких как связанные списки или бинарные деревья.
Если в вашем языке программирования нет шаблонов , на ваш выбор есть следующие альтернативы :
Для каждого типа вам прийдется реализовывать по-новому.
Можно использовать базовый тип Object или void*.
Использовать препроцессор.
Какие недостатки таятся в таком подходе ? :
Избыточность кода .
Вы теряете преимущества проверки типов.
Класс может быть производным от другого класса , что усложняет поддержку кода.
Шаблоны являются решением этих проблем.
Они могут быть использованы для типов , которые еще не определены.
Когда вы используете шаблоны , вы передаете типы как аргументы,явно или неявно.
С использованием шаблонов , вы получаете полноценную проверку типов.
На сегодняшний день шаблоны используются очень широко.
Например , C++ standard library почти целиком состоит из шаблонов.
Она реализует механизмы сортировки для обьектов произвольного типа.
Шаблоны позволяют оптимизировать код.
Введение в Function Templates
Функции-шаблоны реализуют функции , которые могут быть вызваны для различных типов.
Одна функция шаблон представляет семейство функций.
Она выглядит подобно обычной функции.Рассмотрим пример :
Определение шаблона
Следующая функция-шаблон возвращает максимум из 2-х значений:
// basics/max.hpp
template <typename T>
inline T const& max (T const& a, T const& b)
{
// if a < b then use b else use a
return a<b?b:a;
}
У этой функции-шаблона 2 параметра - a и b.
Тип этих параметров определен как шаблонный параметр T.
Синтаксис у таких параметров следующий :
template < comma-separated-list-of-parameters >
В нашем случае списком параметров является typename T.
Используются угловые скобки.
Ключевое слово typename является параметризованным типом.
Это основной тип параметра в шаблонах , хотя позже мы рассмотрим и другие.
Итак , параметр - T. Тип параметра может быть произвольным.
Можно также использовать class вместо typename.
Слово typename появилось позже.
Шаблон max() может быть определен следующим образом :
template <class T>
inline T const& max (T const& a, T const& b)
{
// if a < b then use b else use a
return a<b?b:a;
}
Разницы практически никакой.
Но все же предпочтительнее использовать typename , так сказать , во избежание.
Ключевое слово struct в данном контексте вообще не может быть использовано.
Использование шаблонов
Следующий пример показывает , как использовать функцию-шаблон max():
// basics/max.cpp
#include <iostream>
#include <string>
#include "max.hpp"
int main()
{
int i = 42;
std::cout << "max(7,i): " << ::max(7,i) << std::endl;
double f1 = 3.4;
double f2 = -6.7;
std::cout << "max(f1,f2): " << ::max(f1,f2) << std::endl;
std::string s1 = "mathematics";
std::string s2 = "math";
std::cout << "max(s1,s2): " << ::max(s1,s2) << std::endl;
}
max() вызывается трижды: раз для int,раз для double,
и раз для std::strings.
Вывод:
max(7,i): 42
max(f1,f2): 3.4
max(s1,s2): mathematics
Каждый вызов max() идет с префиксом ::.
При компиляции как правило будут сгенерированы отдельные экземпляры для каждого типа.
Процесс размещения конкретного типа в качестве параметра шаблона называется
instantiation.
Заметьте , что термины instance и instantiate
Попытка вызвать шаблон для неопределенного типа приведет к ошибке :
:
std::complex<float> c1, c2; // doesn't provide operator <
…
max(c1,c2); // ERROR at compile time
Шаблон проходит проверку при компиляции дважды:
Первичная проверка синтаксиса.
При непосредственной инстанциации , шаблон проверяется на валидность параметров.
|
2.2 Argument Deduction
When we call a function template such as max() for some arguments, the template parameters are determined by the arguments we pass. If we pass two ints to the parameter types T const&, the C++ compiler must conclude that T must be int. Note that no automatic type conversion is allowed here. Each T must match exactly. For example:
template <typename T>
inline T const& max (T const& a, T const& b);
…
max(4,7) // OK: T is int for both arguments
max(4,4.2) // ERROR: first T is int, second T is double
There are three ways to handle such an error:
Cast the arguments so that they both match:
max(static_cast<double>(4),4.2) // OK Specify (or qualify) explicitly the type of T:
max<double>(4,4.2) // OK Specify that the parameters may have different types.
For a detailed discussion of these topics, see the next section.
|
2.3 Template Parameters
Function templates have two kinds of parameters:
Template parameters, which are declared in angle brackets before the function template name:
template <typename T> // T is template parameter Call parameters, which are declared in parentheses after the function template name:
… max (T const& a, T const& b) // a and b are call parameters
You may have as many template parameters as you like. However, in function templates (unlike class templates) no default template arguments can be specified.
For example, you could define the max() template for call parameters of two different types:
template <typename T1, typename T2>
inline T1 max (T1 const& a, T2 const& b)
{
return a < b ? b : a;
}
…
max(4,4.2) // OK, but type of first argument defines return type
This may appear to be a good method to enable passing two call parameters of different types to the max() template, but in this example it has drawbacks. The problem is that the return type must be declared. If you use one of the parameter types, the argument for the other parameter might get converted to this type, regardless of the caller's intention. C++ does not provide a means to specify choosing "the more powerful type" (however, you can provide this feature by some tricky template programming, see Section 15.2.4 on page 271). Thus, depending on the call argument order the maximum of 42 and 66.66 might be the double 66.66 or the int 66. Another drawback is that converting the type of the second parameter into the return type creates a new, local temporary object. As a consequence, you cannot return the result by reference.
In our example, therefore, the return type has to be T1 instead of T1 const&.
Because the types of the call parameters are constructed from the template parameters, template and call parameters are usually related. We call this concept function template argument deduction. It allows you to call a function template as you would an ordinary function.
However, as mentioned earlier, you can instantiate a template explicitly for certain types:
template <typename T>
inline T const& max (T const& a, T const& b);
…
max<double>(4,4.2) // instantiate T as double
In cases when there is no connection between template and call parameters and when template parameters cannot be determined, you must specify the template argument explicitly with the call. For example, you can introduce a third template argument type to define the return type of a function template:
template <typename T1, typename T2, typename RT>
inline RT max (T1 const& a, T2 const& b);
However, template argument deduction does not match up return types,
and RT does not appear in the types of the function call parameters. Therefore, RT cannot be deduced. As a consequence, you have to specify the template argument list explicitly. For example:
template <typename T1, typename T2, typename RT>
inline RT max (T1 const& a, T2 const& b);
…
max<int,double,double>(4,4.2) // OK, but tedious
So far, we have looked at cases in which either all or none of the function template arguments were mentioned explicitly. Another approach is to specify only the first arguments explicitly and to allow the deduction process to derive the rest. In general, you must specify all the argument types up to the last argument type that cannot be determined implicitly. Thus, if you change the order of the template parameters in our example, the caller needs to specify only the return type:
template <typename RT, typename T1, typename T2>
inline RT max (T1 const& a, T2 const& b);
…
max<double>(4,4.2) // OK: return type is double
In this example, the call to max<double> explicitly sets RT to double, but the parameters T1 and T2 are deduced to be int and double from the arguments.
Note that all of these modified versions of max() don't lead to significant advantages. For the one-parameter version you can already specify the parameter (and return) type if two arguments of a different type are passed. Thus, it's a good idea to keep it simple and use the one-parameter version of max() (as we do in the following sections when discussing other template issues).
See Chapter 11 for details of the deduction process.

|
2.4 Overloading Function Templates
Like ordinary functions, function templates can be overloaded. That is, you can have different function definitions with the same function name so that when that name is used in a function call, a C++ compiler must decide which one of the various candidates to call. The rules for this decision may become rather complicated, even without templates. In this section we discuss overloading when templates are involved. If you are not familiar with the basic rules of overloading without templates, please look at Appendix B, where we provide a reasonably detailed survey of the overload resolution rules.
The following short program illustrates overloading a function template:
// basics/max2.cpp
// maximum of two int values
inline int const& max (int const& a, int const& b)
{
return a<b?b:a;
}
// maximum of two values of any type
template <typename T>
inline T const& max (T const& a, T const& b)
{
return a<b?b:a;
}
// maximum of three values of any type
template <typename T>
inline T const& max (T const& a, T const& b, T const& c)
{
return max (max(a,b), c);
}
int main()
{
::max(7, 42, 68); // calls the template for three arguments
::max(7.0, 42.0); // calls max<double> (by argument deduction)
::max('a', 'b'); // calls max<char> (by argument deduction)
::max(7, 42); // calls the nontemplate for two ints
::max<>(7, 42); // calls max<int> (by argument deduction)
::max<double>(7, 42); // calls max<double> (no argument deduction)
::max('a', 42.7); // calls the nontemplate for two ints
}
As this example shows, a nontemplate function can coexist with a function template that has the same name and can be instantiated with the same type. All other factors being equal, the overload resolution process normally prefers this nontemplate over one generated from the template. The fourth call falls under this rule:
max(7, 42) // both int values match the nontemplate function perfectly
If the template can generate a function with a better match, however, then the template is selected. This is demonstrated by the second and third call of max():
max(7.0, 42.0) // calls the max<double> (by argument deduction)
max('a', 'b'); // calls the max<char> (by argument deduction)
It is also possible to specify explicitly an empty template argument list. This syntax indicates that only templates may resolve a call, but all the template parameters should be deduced from the call arguments:
max<>(7, 42) // calls max<int> (by argument deduction)
Because automatic type conversion is not considered for templates but is considered for ordinary functions, the last call uses the nontemplate function (while 'a' and 42.7 both are converted to int):
max('a', 42.7) // only the nontemplate function allows different argument types
A more useful example would be to overload the maximum template for pointers and ordinary C-strings:
// basics/max3.cpp
#include <iostream>
#include <cstring>
#include <string>
// maximum of two values of any type
template <typename T>
inline T const& max (T const& a, T const& b)
{
return a < b ? b : a;
}
// maximum of two pointers
template <typename T>
inline T* const& max (T* const& a, T* const& b)
{
return *a < *b ? b : a;
}
// maximum of two C-strings
inline char const* const& max (char const* const& a,
char const* const& b)
{
return std::strcmp(a,b) < 0 ? b : a;
}
int main ()
{
int a=7;
int b=42;
::max(a,b); // max() for two values of type int
std::string s="hey";
std::string t="you";
::max(s,t); // max() for two values of type std::string
int* p1 = &b;
int* p2 = &a;
::max(p1,p2); // max() for two pointers
char const* s1 = "David";
char const* s2 = "Nico";
::max(s1,s2); // max() for two C-strings
}
Note that in all overloaded implementations, we pass all arguments by reference. In general, it is a good idea not to change more than necessary when overloading function templates. You should limit your changes to the number of parameters or to specifying template parameters explicitly. Otherwise, unexpected effects may happen. For example, if you overload the max() template, which passes the arguments by reference, for two C-strings passed by value, you can't use the three-argument version to compute the maximum of three C-strings:
// basics/max3a.cpp
#include <iostream>
#include <cstring>
#include <string>
// maximum of two values of any type (call-by-reference)
template <typename T>
inline T const& max (T const& a, T const& b)
{
return a < b ? b : a;
}
// maximum of two C-strings (call-by-value)
inline char const* max (char const* a, char const* b)
{
return std::strcmp(a,b) < 0 ? b : a;
}
// maximum of three values of any type (call-by-reference)
template <typename T>
inline T const& max (T const& a, T const& b, T const& c)
{
return max (max(a,b), c); // error, if max(a,b) uses call-by-value
}
int main ()
{
::max(7, 42, 68); // OK
const char* s1 = "frederic";
const char* s2 = "anica";
const char* s3 = "lucas";
::max(s1, s2, s3); // ERROR
}
The problem is that if you call max() for three C-strings, the statement
return max (max(a,b), c);
becomes an error. This is because for C-strings, max(a,b) creates a new, temporary local value that may be returned by the function by reference.
This is only one example of code that might behave differently than expected as a result of detailed overload resolution rules. For example, the fact that not all overloaded functions are visible when a corresponding function call is made may or may not matter. In fact, defining a three-argument version of max() without having seen the declaration of a special two-argument version of max() for ints causes the two-argument template to be used by the three-argument version:
// basics/max4.cpp
// maximum of two values of any type
template <typename T>
inline T const& max (T const& a, T const& b)
{
return a<b?b:a;
}
// maximum of three values of any type
template <typename T>
inline T const& max (T const& a, T const& b, T const& c)
{
return max (max(a,b), c); // uses the template version even for ints
} // because the following declaration comes
// too late:
// maximum of two int values
inline int const& max (int const& a, int const& b)
{
return a<b?b:a;
}
We discuss details in Section 9.2 on page 121, but for the moment, as a rule of thumb you should always have all overloaded versions of a function declared before the function is called.
|
2.5 Summary
Template functions define a family of functions for different template arguments. When you pass template arguments, function templates are instantiated for these argument types. You can explicitly qualify the template parameters. You can overload function templates. When you overload function templates, limit your changes to specifying template parameters explicitly. Make sure you see all overloaded versions of function templates before you call them.
|
Chapter 3. Class Templates
Similar to functions, classes can also be parameterized with one or more types. Container classes, which are used to manage elements of a certain type, are a typical example of this feature. By using class templates, you can implement such container classes while the element type is still open. In this chapter we use a stack as an example of a class template.
|
3.1 Implementation of Class Template Stack
As we did with function templates, we declare and define class Stack<> in a header file as follows (we discuss the separation of declaration and definition in different files in Section 7.3 on page 89):
// basics/stack1.hpp
#include <vector>
#include <stdexcept>
template <typename T>
class Stack {
private:
std::vector<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return whether the stack is empty
return elems.empty();
}
};
template <typename T>
void Stack<T>::push (T const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
template<typename T>
void Stack<T>::pop ()
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::pop(): empty stack");
}
elems.pop_back(); // remove last element
}
template <typename T>
T Stack<T>::top () const
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::top(): empty stack");
}
return elems.back(); // return copy of last element
}
As you can see, the class template is implemented by using a class template of the C++ standard library: vector<>. As a result, we don't have to implement memory management, copy constructor, and assignment operator, so we can concentrate on the interface of this class template.
3.1.1 Declaration of Class Templates
Declaring class templates is similar to declaring function templates: Before the declaration, a statement declares an identifier as a type parameter. Again, T is usually used as an identifier:
template <typename T>
class Stack {
…
};
Here again, the keyword class can be used instead of typename:
template <class T>
class Stack {
…
};
Inside the class template, T can be used just like any other type to declare members and member functions. In this example, T is used to declare the type of the elements as vector of Ts, to declare push() as a member function that gets a constant T reference as an argument, and to declare top() as a function that returns a T:
template <typename T>
class Stack {
private:
std::vector<T> elems; // elements
public:
Stack(); // constructor
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
};
The type of this class is Stack<T>, with T being a template parameter. Thus, you have to use Stack<T> whenever you use the type of this class in a declaration. If, for example, you have to declare your own copy constructor and assignment operator, it looks like this
:
template <typename T>
class Stack {
…
Stack (Stack<T> const&); // copy constructor
Stack<T>& operator= (Stack<T> const&); // assignment operator
…
};
However, when the name and not the type of the class is required, only Stack has to be used. This is the case when you specify the name of the class, the constructors, and the destructor.
3.1.2 Implementation of Member Functions
To define a member function of a class template, you have to specify that it is a function template, and you have to use the full type qualification of the class template. Thus, the implementation of the member function push() for type Stack<T> looks like this:
template <typename T>
void Stack<T>::push (T const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
In this case, push_back() of the element vector is called, which appends the element at the end of the vector.
Note that pop_back() of a vector removes the last element but doesn't return it. The reason for this behavior is exception safety. It is impossible to implement a completely exception-safe version of pop() that returns the removed element (this topic was first discussed by Tom Cargill in [CargillExceptionSafety] and is discussed as Item 10 in [SutterExceptional]). However, ignoring this danger, we could implement a pop() that returns the element just removed. To do this, we simply use T to declare a local variable of the element type:
template<typename T>
T Stack<T>::pop ()
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::pop(): empty stack");
}
T elem = elems.back(); // save copy of last element
elems.pop_back(); // remove last element
return elem; // return copy of saved element
}
Because the vectors back() (which returns the last element) and pop_back() (which removes the last element) have undefined behavior when there is no element in the vector, we have to check whether the stack is empty. If it is empty, we throw an exception of type std::out_of_range. This is also done in top(), which returns but does not remove the top element:
template<typename T>
T Stack<T>::top () const
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::top(): empty stack");
}
return elems.back(); // return copy of last element
}
Of course, as for any member function, you can also implement member functions of class templates as an inline function inside the class declaration. For example:
template <typename T>
class Stack {
…
void push (T const& elem) {
elems.push_back(elem); // append copy of passed elem
}
…
};
|
3.2 Use of Class Template Stack
To use an object of a class template, you must specify the template arguments explicitly. The following example shows how to use the class template Stack<>:
// basics/stack1test.cpp
#include <iostream>
#include <string>
#include <cstdlib>
#include "stack1.hpp"
int main()
{
try {
Stack<int> intStack; // stack of ints
Stack<std::string> stringStack; // stack of strings
// manipulate int stack
intStack.push(7);
std::cout << intStack.top() << std::endl;
// manipulate string stack
stringStack.push("hello");
std::cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
}
catch (std::exception const& ex) {
std::cerr << "Exception: " << ex.what() << std::endl;
return EXIT_FAILURE; // exit program with ERROR status
}
}
By declaring type Stack<int>, int is used as type T inside the class template. Thus, intStack is created as an object that uses a vector of ints as elements and, for all member functions that are called, code for this type is instantiated. Similarly, by declaring and using Stack<std::string>, an object that uses a vector of strings as elements is created, and for all member functions that are called, code for this type is instantiated.
Note that code is instantiated only for member functions that are called. For class templates, member functions are instantiated only when they are used. This, of course, saves time and space. It has the additional benefit that you can instantiate a class even for those types that cannot perform all the operations of all the member functions, as long as these member functions are not called. As an example, consider a class in which some member functions use the operator < to sort elements. If you refrain from calling these member functions, you can instantiate the class template for types for which operator < is not defined.
In this example, the default constructor, push(), and top() are instantiated for both int and strings. However, pop() is instantiated only for strings. If a class template has static members, these are instantiated once for each type.
You can use a type of an instantiated class template as any other type, as long as the operations are supported:
void foo (Stack<int> const& s) // parameter s is int stack
{
Stack<int> istack[10]; // istack is array of 10 int stacks
…
}
By using a type definition, you can make using a class template more convenient:
typedef Stack<int> IntStack;
void foo (IntStack const& s) // s is stack of ints
{
IntStack istack[10]; // istack is array of 10 stacks of ints
…
}
Note that in C++ a type definition does define a "type alias" rather than a new type. Thus, after the type definition
typedef Stack<int> IntStack;
IntStack and Stack<int> are the same type and can be used for and assigned to each other.
Template arguments may be any type, such as pointers to floats or even stacks of ints:
Stack<float*> floatPtrStack; // stack of float pointers
Stack<Stack<int> > intStackStack; // stack of stack of ints
The only requirement is that any operation that is called is possible according to this type.
Note that you have to put whitespace between the two closing template brackets. If you don't do this, you are using operator >>, which results in a syntax error:
Stack<Stack<int>> intStackStack; // ERROR: >> is not allowed
|
3.3 Specializations of Class Templates
You can specialize a class template for certain template arguments. Similar to the overloading of function templates (see page 15), specializing class templates allows you to optimize implementations for certain types or to fix a misbehavior of certain types for an instantiation of the class template. However, if you specialize a class template, you must also specialize all member functions. Although it is possible to specialize a single member function, once you have done so, you can no longer specialize the whole class.
To specialize a class template, you have to declare the class with a leading template<> and a specification of the types for which the class template is specialized. The types are used as a template argument and must be specified directly following the name of the class:
template<>
class Stack<std::string> {
…
};
For these specializations, any definition of a member function must be defined as an "ordinary" member function, with each occurrence of T being replaced by the specialized type:
void Stack<std::string>::push (std::string const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
Here is a complete example of a specialization of Stack<> for type std::string:
// basics/stack2.hpp
#include <deque>
#include <string>
#include <stdexcept>
#include "stack1.hpp"
template<>
class Stack<std::string> {
private:
std::deque<std::string> elems; // elements
public:
void push(std::string const&); // push element
void pop(); // pop element
std::string top() const; // return top element
bool empty() const { // return whether the stack is empty
return elems.empty();
}
};
void Stack<std::string>::push (std::string const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
void Stack<std::string>::pop ()
{
if (elems.empty()) {
throw std::out_of_range
("Stack<std::string>::pop(): empty stack");
}
elems.pop_back(); // remove last element
}
std::string Stack<std::string>::top () const
{
if (elems.empty()) {
throw std::out_of_range
("Stack<std::string>::top(): empty stack");
}
return elems.back(); // return copy of last element
}
In this example, a deque instead of a vector is used to manage the elements inside the stack. Although this has no particular benefit here, it does demonstrate that the implementation of a specialization might look very different from the implementation of the primary template.
|
3.4 Partial Specialization
Class templates can be partially specialized. You can specify special implementations for particular circumstances, but some template parameters must still be defined by the user. For example, for the following class template
template <typename T1, typename T2>
class MyClass {
…
};
the following partial specializations are possible:
// partial specialization: both template parameters have same type
template <typename T>
class MyClass<T,T> {
…
};
// partial specialization: second type is int
template <typename T>
class MyClass<T,int> {
…
};
// partial specialization: both template parameters are pointer types
template <typename T1, typename T2>
class MyClass<T1*,T2*> {
…
};
The following example shows which template is used by which declaration:
MyClass<int,float> mif; // uses MyClass<T1,T2>
MyClass<float,float> mff; // uses MyClass<T,T>
MyClass<float,int> mfi; // uses MyClass<T,int>
MyClass<int*,float*> mp; // uses MyClass<T1*,T2*>
If more than one partial specialization matches equally well, the declaration is ambiguous:
MyClass<int,int> m; // ERROR: matches MyClass<T,T>
// and MyClass<T,int>
MyClass<int*,int*> m; // ERROR: matches MyClass<T,T>
// and MyClass<T1*,T2*>
To resolve the second ambiguity, you can provide an additional partial specialization for pointers of the same type:
template <typename T>
class MyClass<T*,T*> {
…
};
For details, see Section 12.4 on page 200.
|
3.5 Default Template Arguments
For class templates you can also define default values for template parameters. These values are called default template arguments. They may even refer to previous template parameters. For example, in class Stack<> you can define the container that is used to manage the elements as a second template parameter, using std::vector<> as the default value:
// basics/stack3.hpp
#include <vector>
#include <stdexcept>
template <typename T, typename CONT = std::vector<T> >
class Stack {
private:
CONT elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return whether the stack is empty
return elems.empty();
}
};
template <typename T, typename CONT>
void Stack<T,CONT>::push (T const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
template <typename T, typename CONT>
void Stack<T,CONT>::pop ()
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::pop(): empty stack");
}
elems.pop_back(); // remove last element
}
template <typename T, typename CONT>
T Stack<T,CONT>::top () const
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::top(): empty stack");
}
return elems.back(); // return copy of last element
}
Note that we now have two template parameters, so each definition of a member function must be defined with these two parameters:
template <typename T, typename CONT>
void Stack<T,CONT>::push (T const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
You can use this stack the same way it was used before. Thus, if you pass a first and only argument as an element type, a vector is used to manage the elements of this type:
template <typename T, typename CONT = std::vector<T> >
class Stack {
private:
CONT elems; // elements
…
};
In addition, you could specify the container for the elements when you declare a Stack object in your program:
// basics/stack3test.cpp
#include <iostream>
#include <deque>
#include <cstdlib>
#include "stack3.hpp"
int main()
{
try {
// stack of ints:
Stack<int> intStack;
// stack of doubles which uses a std::deque<> to mange the elements
Stack<double,std::deque<double> > dblStack;
// manipulate int stack
intStack.push(7);
std::cout << intStack.top() << std::endl;
intStack.pop();
// manipulate double stack
dblStack.push(42.42);
std::cout << dblStack.top() << std::endl;
dblStack.pop();
dblStack.pop();
}
catch (std::exception const& ex) {
std::cerr << "Exception: " << ex.what() << std::endl;
return EXIT_FAILURE; // exit program with ERROR status
}
}
With
Stack<double,std::deque<double> >
you declare a stack for doubles that uses a std::deque<> to manage the elements internally.
|
3.6 Summary
A class template is a class that is implemented with one or more type parameters left open. To use a class template, you pass the open types as template arguments. The class template is then instantiated (and compiled) for these types. For class templates, only those member functions that are called are instantiated. You can specialize class templates for certain types. You can partially specialize class templates for certain types. You can define default values for class template parameters. These may refer to previous template parameters.
|
Chapter 4. Nontype Template Parameters
For function and class templates, template parameters don't have to be types. They can also be ordinary values. As with templates using type parameters, you define code for which a certain detail remains open until the code is used. However, the detail that is open is a value instead of a type. When using such a template, you have to specify this value explicitly. The resulting code then gets instantiated. This chapter illustrates this feature for a new version of the stack class template. In addition, we show an example of nontype function template parameters and discuss some restrictions to this technique.
|
4.1 Nontype Class Template Parameters
In contrast to the sample implementations of a stack in previous chapters, you can also implement a stack by using a fixed-size array for the elements. An advantage of this method is that the memory management overhead, whether performed by you or by a standard container, is avoided. However, determining the best size for such a stack can be challenging. The smaller the size you specify, the more likely it is that the stack will get full. The larger the size you specify, the more likely it is that memory will be reserved unnecessarily. A good solution is to let the user of the stack specify the size of the array as the maximum size needed for stack elements.
To do this, define the size as a template parameter:
// basics/stack4.hpp
#include <stdexcept>
template <typename T, int MAXSIZE>
class Stack {
private:
T elems[MAXSIZE]; // elements
int numElems; // current number of elements
public:
Stack(); // constructor
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return whether the stack is empty
return numElems == 0;
}
bool full() const { // return whether the stack is full
return numElems == MAXSIZE;
}
};
// constructor
template <typename T, int MAXSIZE>
Stack<T,MAXSIZE>::Stack ()
: numElems(0) // start with no elements
{
// nothing else to do
}
template <typename T, int MAXSIZE>
void Stack<T,MAXSIZE>::push (T const& elem)
{
if (numElems == MAXSIZE) {
throw std::out_of_range("Stack<>::push(): stack is full");
}
elems[numElems] = elem; // append element
++numElems; // increment number of elements
}
template<typename T, int MAXSIZE>
void Stack<T,MAXSIZE>::pop ()
{
if (numElems <= 0) {
throw std::out_of_range("Stack<>::pop(): empty stack");
}
--numElems; // decrement number of elements
}
template <typename T, int MAXSIZE>
T Stack<T,MAXSIZE>::top () const
{
if (numElems <= 0) {
throw std::out_of_range("Stack<>::top(): empty stack");
}
return elems[numElems-1]; // return last element
}
The new second template parameter, MAXSIZE, is of type int. It specifies the size of the array of stack elements:
template <typename T, int MAXSIZE>
class Stack {
private:
T elems[MAXSIZE]; // elements
…
};
In addition, it is used in push() to check whether the stack is full:
template <typename T, int MAXSIZE>
void Stack<T,MAXSIZE>::push (T const& elem)
{
if (numElems == MAXSIZE) {
throw "Stack<>::push(): stack is full";
}
elems[numElems] = elem; // append element
++numElems; // increment number of elements
}
To use this class template you have to specify both the element type and the maximum size:
// basics/stack4test.cpp
#include <iostream>
#include <string>
#include <cstdlib>
#include "stack4.hpp"
int main()
{
try {
Stack<int,20> int20Stack; // stack of up to 20 ints
Stack<int,40> int40Stack; // stack of up to 40 ints
Stack<std::string,40> stringStack; // stack of up to 40 strings
// manipulate stack of up to 20 ints
int20Stack.push(7);
std::cout << int20Stack.top() << std::endl;
int20Stack.pop();
// manipulate stack of up to 40 strings
stringStack.push("hello");
std::cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
}
catch (std::exception const& ex) {
std::cerr << "Exception: " << ex.what() << std::endl;
return EXIT_FAILURE; // exit program with ERROR status
}
}
Note that each template instantiation is its own type. Thus, int20Stack and int40Stack are two different types, and no implicit or explicit type conversion between them is defined. Thus, one cannot be used instead of the other, and you cannot assign one to the other.
Again, default values for the template parameters can be specified:
template <typename T = int, int MAXSIZE = 100>
class Stack {
…
};
However, from a perspective of good design, this may not be appropriate in this example. Default values should be intuitively correct. But neither type int nor a maximum size of 100 seems intuitive for a general stack type. Thus, it is better when the programmer has to specify both values explicitly so that these two attributes are always documented during a declaration.
|
4.2 Nontype Function Template Parameters
You can also define nontype parameters for function templates. For example, the following function template defines a group of functions for which a certain value can be added:
// basics/addval.hpp
template <typename T, int VAL>
T addValue (T const& x)
{
return x + VAL;
}
These kinds of functions are useful if functions or operations in general are used as parameters. For example, if you use the Standard Template Library (STL) you can pass an instantiation of this function template to add a value to each element of a collection:
std::transform (source.begin(), source.end(), // start and end of source
dest.begin(), // start of destination
addValue<int,5>); // operation
The last argument instantiates the function template addValue() to add 5 to an int value. The resulting function is called for each element in the source collection source, while it is translated into the destination collection dest.
Note that there is a problem with this example: addValue<int,5> is a function template, and function templates are considered to name a set of overloaded functions (even if the set has only one member). However, according to the current standard, sets of overloaded functions cannot be used for template parameter deduction. Thus, you have to cast to the exact type of the function template argument:
std::transform (source.begin(), source.end(), // start and end of source
dest.begin(), // start of destination
(int(*)(int const&)) addValue<int,5>); // operation
There is a proposal for the standard to fix this behavior so that the cast isn't necessary in this context (see [CoreIssue115] for details), but until then the cast may be necessary to be portable.
|
4.3 Restrictions for Nontype Template Parameters
Note that nontype template parameters carry some restrictions. In general, they may be constant integral values (including enumerations) or pointers to objects with external linkage.
Floating-point numbers and class-type objects are not allowed as nontype template parameters:
template <double VAT> // ERROR: floating-point values are not
double process (double v) // allowed as template parameters
{
return v * VAT;
}
template <std::string name> // ERROR: class-type objects are not
class MyClass { // allowed as template parameters
…
};
Not being able to use floating-point literals (and simple constant floating-point expressions) as template arguments has historical reasons. Because there are no serious technical challenges, this may be supported in future versions of C++ (see Section 13.4 on page 210).
Because string literals are objects with internal linkage (two string literals with the same value but in different modules are different objects), you can't use them as template arguments either:
template <char const* name>
class MyClass {
…
};
MyClass<"hello"> x; // ERROR: string literal "hello" not allowed
You cannot use a global pointer either:
template <char const* name>
class MyClass {
…
};
char const* s = "hello";
MyClass<s> x; // ERROR: s is pointer to object with internal linkage
However, the following is possible:
template <char const* name>
class MyClass {
…
};
extern char const s[] = "hello";
MyClass<s> x; // OK
The global character array s is initialized by "hello" so that s is an object with external linkage.
See Section 8.3.3 on page 109 for a detailed discussion and Section 13.4 on page 209 for a discussion of possible future changes in this area.
|
4.4 Summary
Templates can have template parameters that are values rather than types. You cannot use floating-point numbers, class-type objects, and objects with internal linkage (such as string literals) as arguments for nontype template parameters.
|
Chapter 5. Tricky Basics
This chapter covers some further basic aspects of templates that are relevant to the practical use of templates: an additional use of the typename keyword, defining member functions and nested classes as templates, template template parameters, zero initialization, and some details about using string literals as arguments for function templates. These aspects can be tricky at times, but every day-to-day programmer should have heard of them.
|
5.1 Keyword typename
The keyword typename was introduced during the standardization of C++ to clarify that an identifier inside a template is a type. Consider the following example:
template <typename T>
class MyClass {
typename T::SubType * ptr;
…
};
Here, the second typename is used to clarify that SubType is a type defined within class T. Thus, ptr is a pointer to the type T::SubType.
Without typename, SubType would be considered a static member. Thus, it would be a concrete variable or object. As a result, the expression
T::SubType * ptr
would be a multiplication of the static SubType member of class T with ptr.
In general, typename has to be used whenever a name that depends on a template parameter is a type. This is discussed in detail in Section 9.3.2 on page 130.
A typical application of typename is the access to iterators of STL containers in template code:
// basics/printcoll.hpp
#include <iostream>
// print elements of an STL container
template <typename T>
void printcoll (T const& coll)
{
typename T::const_iterator pos; // iterator to iterate over coll
typename T::const_iterator end(coll.end()); // end position
for (pos=coll.begin(); pos!=end; ++pos) {
std::cout << *pos << ' ';
}
std::cout << std::endl;
}
In this function template, the call parameter is an STL container of type T. To iterate over all elements of the container, the iterator type of the container is used, which is declared as type const_iterator inside each STL container class:
class stlcontainer {
…
typedef … iterator; // iterator for read/write access
typedef … const_iterator; // iterator for read access
…
};
Thus, to access type const_iterator of template type T, you have to qualify it with a leading typename:
typename T::const_iterator pos;
The .template Construct
A very similar problem was discovered after the introduction of typename. Consider the following example using the standard bitset type:
template<int N>
void printBitset (std::bitset<N> const& bs)
{
std::cout << bs.template to_string<char,char_traits<char>,
allocator<char> >();
}
The strange construct in this example is .template. Without that extra use of template, the compiler does not know that the less-than token (<) that follows is not really "less than" but the beginning of a template argument list. Note that this is a problem only if the construct before the period depends on a template parameter. In our example, the parameter bs depends on the template parameter N.
In conclusion, the .template notation (and similar notations such as ->template) should be used only inside templates and only if they follow something that depends on a template parameter. See Section 9.3.3 on page 132 for details.
|
5.2 Using this->
For class templates with base classes, using a name x by itself is not always equivalent to this->x, even though a member x is inherited. For example:
template <typename T>
class Base {
public:
void exit();
};
template <typename T>
class Derived : Base<T> {
public:
void foo() {
exit(); // calls external exit() or error
}
};
In this example, for resolving the symbol exit inside foo(), exit() defined in Base is never considered. Therefore, either you have an error, or another exit() (such as the standard exit()) is called.
We discuss this issue in Section 9.4.2 on page 136 in detail. For the moment, as a rule of thumb, we recommend that you always qualify any symbol that is declared in a base that is somehow dependent on a template parameter with this-> or Base<T>::. If you want to avoid all uncertainty, you may consider qualifying all member accesses (in templates).
|
5.3 Member Templates
Class members can also be templates. This is possible for both nested classes and member functions. The application and advantage of this ability can again be demonstrated with the Stack<> class template. Normally you can assign stacks to each other only when they have the same type, which implies that the elements have the same type. However, you can't assign a stack with elements of any other type, even if there is an implicit type conversion for the element types defined:
Stack<int> intStack1, intStack2; // stacks for ints
Stack<float> floatStack; // stack for floats
…
intStack1 = intStack2; // OK: stacks have same type
floatStack = intStack1; // ERROR: stacks have different types
The default assignment operator requires that both sides of the assignment operator have the same type, which is not the case if stacks have different element types.
By defining an assignment operator as a template, however, you can enable the assignment of stacks with elements for which an appropriate type conversion is defined. To do this you have to declare Stack<> as follows:
// basics/stack5decl.hpp
template <typename T>
class Stack {
private:
std::deque<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return whether the stack is empty
return elems.empty();
}
// assign stack of elements of type T2
template <typename T2>
Stack<T>& operator= (Stack<T2> const&);
};
The following two changes have been made:
We added a declaration of an assignment operator for stacks of elements of another type T2. The stack now uses a deque as an internal container for the elements. Again, this is a consequence of the implementation of the new assignment operator.
The implementation of the new assignment operator looks like this:
// basics/stack5assign.hpp
template <typename T>
template <typename T2>
Stack<T>& Stack<T>::operator= (Stack<T2> const& op2)
{
if ((void*)this == (void*)&op2) { // assignment to itself?
return *this;
}
Stack<T2> tmp(op2); // create a copy of the assigned stack
elems.clear(); // remove existing elements
while (!tmp.empty()) { // copy all elements
elems.push_front(tmp.top());
tmp.pop();
}
return *this;
}
First let's look at the syntax to define a member template. Inside the template with template parameter T, an inner template with template parameter T2 is defined:
template <typename T>
template <typename T2>
…
Inside the member function you may expect simply to access all necessary data for the assigned stack op2. However, this stack has a different type (if you instantiate a class template for two different types, you get two different types), so you are restricted to using the public interface. It follows that the only way to access the elements is by calling top(). However, each element has to become a top element, then. Thus, a copy of op2 must first be made, so that the elements are taken from that copy by calling pop(). Because top() returns the last element pushed onto the stack, we have to use a container that supports the insertion of elements at the other end of the collection. For this reason, we use a deque, which provides push_front() to put an element on the other side of the collection.
Having this member template, you can now assign a stack of ints to a stack of floats:
Stack<int> intStack; // stack for ints
Stack<float> floatStack; // stack for floats
…
floatStack = intStack; // OK: stacks have different types,
// but int converts to float
Of course, this assignment does not change the type of the stack and its elements. After the assignment, the elements of the floatStack are still floats and therefore pop() still returns a float.
It may appear that this function would disable type checking such that you could assign a stack with elements of any type, but this is not the case. The necessary type checking occurs when the element of the (copy of the) source stack is moved to the destination stack:
elems.push_front(tmp.top());
If, for example, a stack of strings gets assigned to a stack of floats, the compilation of this line results in an error message stating that the string returned by tmp.top() cannot be passed as an argument to elems.push_front() (the message varies depending on the compiler, but this is the gist of what is meant):
Stack<std::string> stringStack; // stack of ints
Stack<float> floatStack; // stack of floats
…
floatStack = stringStack; // ERROR: std::string doesn't convert to float
Note that a template assignment operator doesn't replace the default assignment operator. For assignments of stacks of the same type, the default assignment operator is still called.
Again, you could change the implementation to parameterize the internal container type:
// basics/stack6decl.hpp
template <typename T, typename CONT = std::deque<T> >
class Stack {
private:
CONT elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return whether the stack is empty
return elems.empty();
}
// assign stack of elements of type T2
template <typename T2, typename CONT2>
Stack<T,CONT>& operator= (Stack<T2,CONT2> const&);
};
Then the template assignment operator is implemented like this:
// basics/stack6assign.hpp
template <typename T, typename CONT>
template <typename T2, typename CONT2>
Stack<T,CONT>&
Stack<T,CONT>::operator= (Stack<T2,CONT2> const& op2)
{
if ((void*)this == (void*)&op2) { // assignment to itself?
return *this;
}
Stack<T2> tmp(op2); // create a copy of the assigned stack
elems.clear(); // remove existing elements
while (!tmp.empty()) { // copy all elements
elems.push_front(tmp.top());
tmp.pop();
}
return *this;
}
Remember, for class templates, only those member functions that are called are instantiated. Thus, if you avoid assigning a stack with elements of a different type, you could even use a vector as an internal container:
// stack for ints using a vector as an internal container
Stack<int,std::vector<int> > vStack;
…
vStack.push(42);
vStack.push(7);
std::cout << vStack.pop() << std::endl;
Because the assignment operator template isn't necessary, no error message of a missing member function push_front() occurs and the program is fine.
For the complete implementation of the last example, see all the files with a name that starts with "stack6" in the subdirectory basics.
|
5.4 Template Template Parameters
It can be useful to allow a template parameter itself to be a class template. Again, our stack class template can be used as an example.
To use a different internal container for stacks, the application programmer has to specify the element type twice. Thus, to specify the type of the internal container, you have to pass the type of the container and the type of its elements again:
Stack<int,std::vector<int> > vStack; // integer stack that uses a vector
Using template template parameters allows you to declare the Stack class template by specifying the type of the container without respecifying the type of its elements:
stack<int,std::vector> vStack; // integer stack that uses a vector
To do this you must specify the second template parameter as a template template parameter. In principle, this looks as follows
:
// basics/stack7decl.hpp
template <typename T,
template <typename ELEM> class CONT = std::deque >
class Stack {
private:
CONT<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return whether the stack is empty
return elems.empty();
}
};
The difference is that the second template parameter is declared as being a class template:
template <typename ELEM> class CONT
The default value has changed from std::deque<T> to std::deque. This parameter has to be a class template, which is instantiated for the type that is passed as the first template parameter:
CONT<T> elems;
This use of the first template parameter for the instantiation of the second template parameter is particular to this example. In general, you can instantiate a template template parameter with any type inside a class template.
As usual, instead of typename you could use the keyword class for template parameters. However, CONT is used to define a class and must be declared by using the keyword class. Thus, the following is fine:
template <typename T,
template <class ELEM> class CONT = std::deque> // OK
class Stack {
…
};
but the following is not:
template <typename T,
template <typename ELEM> typename CONT = std::deque>
class Stack { // ERROR
…
};
Because the template parameter of the template template parameter is not used, you can omit its name:
template <typename T,
template <typename> class CONT = std::deque >
class Stack {
…
};
Member functions must be modified accordingly. Thus, you have to specify the second template parameter as the template template parameter. The same applies to the implementation of the member function. The push() member function, for example, is implemented as follows:
template <typename T, template <typename> class CONT>
void Stack<T,CONT>::push (T const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
Template template parameters for function templates are not allowed.
Template Template Argument Matching
If you try to use the new version of Stack, you get an error message saying that the default value std::deque is not compatible with the template template parameter CONT. The problem is that a template template argument must be a template with parameters that exactly match the parameters of the template template parameter it substitutes. Default template arguments of template template arguments are not considered, so that a match cannot be achieved by leaving out arguments that have default values.
The problem in this example is that the std::deque template of the standard library has more than one parameter: The second parameter (which describes a so-called allocator) has a default value, but this is not considered when matching std::deque to the CONT parameter.
There is a workaround, however. We can rewrite the class declaration so that the CONT parameter expects containers with two template parameters:
template <typename T,
template <typename ELEM,
typename ALLOC = std::allocator<ELEM> >
class CONT = std::deque>
class Stack {
private:
CONT<T> elems; // elements
…
};
Again, you can omit ALLOC because it is not used.
The final version of our Stack template (including member templates for assignments of stacks of different element types) now looks as follows:
// basics/stack8.hpp
#ifndef STACK_HPP
#define STACK_HPP
#include <deque>
#include <stdexcept>
#include <allocator>
template <typename T,
template <typename ELEM,
typename = std::allocator<ELEM> >
class CONT = std::deque>
class Stack {
private:
CONT<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return whether the stack is empty
return elems.empty();
}
// assign stack of elements of type T2
template<typename T2,
template<typename ELEM2,
typename = std::allocator<ELEM2>
>class CONT2>
Stack<T,CONT>& operator= (Stack<T2,CONT2> const&);
};
template <typename T, template <typename,typename> class CONT>
void Stack<T,CONT>::push (T const& elem)
{
elems.push_back(elem); // append copy of passed elem
}
template<typename T, template <typename,typename> class CONT>
void Stack<T,CONT>::pop ()
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::pop(): empty stack");
}
elems.pop_back(); // remove last element
}
template <typename T, template <typename,typename> class CONT>
T Stack<T,CONT>::top () const
{
if (elems.empty()) {
throw std::out_of_range("Stack<>::top(): empty stack");
}
return elems.back(); // return copy of last element
}
template <typename T, template <typename,typename> class CONT>
template <typename T2, template <typename,typename> class CONT2>
Stack<T,CONT>&
Stack<T,CONT>::operator= (Stack<T2,CONT2> const& op2)
{
if ((void*)this == (void*)&op2) { // assignment to itself?
return *this;
}
Stack<T2> tmp(op2); // create a copy of the assigned stack
elems.clear(); // remove existing elements
while (!tmp.empty()) { // copy all elements
elems.push_front(tmp.top());
tmp.pop();
}
return *this;
}
#endif // STACK_HPP
The following program uses all features of this final version:
// basics/stack8test.cpp
#include <iostream>
#include <string>
#include <cstdlib>
#include <vector>
#include "stack8.hpp"
int main()
{
try {
Stack<int> intStack; // stack of ints
Stack<float> floatStack; // stack of floats
// manipulate int stack
intStack.push(42);
intStack.push(7);
// manipulate float stack
floatStack.push(7.7);
// assign stacks of different type
floatStack = intStack;
// print float stack
std::cout << floatStack.top() << std::endl;
floatStack.pop();
std::cout << floatStack.top() << std::endl;
floatStack.pop();
std::cout << floatStack.top() << std::endl;
floatStack.pop();
}
catch (std::exception const& ex) {
std::cerr << "Exception: " << ex.what() << std::endl;
}
// stack for ints using a vector as an internal container
Stack<int,std::vector> vStack;
…
vStack.push(42);
vStack.push(7);
std::cout << vStack.top() << std::endl;
vStack.pop();
}
The program has the following output:
7
42
Exception: Stack<>::top(): empty stack
7
Note that template template parameters are one of the most recent features required for compilers to conform to the standard. Thus, this program is a good evaluation of the conformity of your compiler regarding template features.
For further discussions and examples of template template parameters, see Section 8.2.3 on page 102 and Section 15.1.6 on page 259.
|
5.5 Zero Initialization
For fundamental types such as int, double, or pointer types, there is no default constructor that initializes them with a useful default value. Instead, any noninitialized local variable has an undefined value:
void foo()
{
int x; // x has undefined value
int* ptr; // ptr points to somewhere (instead of nowhere)
}
Now if you write templates and want to have variables of a template type initialized by a default value, you have the problem that a simple definition doesn't do this for built-in types:
template <typename T>
void foo()
{
T x; // x has undefined value if T is built-in type
}
For this reason, it is possible to call explicitly a default constructor for built-in types that initializes them with zero (or false for bool). That is, int() yields zero. As a consequence you can ensure proper default initialization even for built-in types by writing the following:
template <typename T>
void foo()
{
T x = T(); // x is zero (or false)ifT is a built-in type
}
To make sure that a member of a class template, for which the type is parameterized, gets initialized, you have to define a default constructor that uses an initializer list to initialize the member:
template <typename T>
class MyClass {
private:
T x;
public:
MyClass() : x() { // ensures that x is initialized even for built-in types
}
…
};
|
5.6 Using String Literals as Arguments for Function Templates
Passing string literal arguments for reference parameters of function templates sometimes fails in a surprising way. Consider the following example:
// basics/max5.cpp
#include <string>
// note: reference parameters
template <typename T>
inline T const& max (T const& a, T const& b)
{
return a < b ? b : a;
}
int main()
{
std::string s;
::max("apple","peach"); // OK: same type
::max("apple","tomato"); // ERROR: different types
::max("apple",s); // ERROR: different types
}
The problem is that string literals have different array types depending on their lengths. That is, "apple" and "peach" have type char const[6] whereas "tomato" has type char const[7]. Only the first call is possible because the template expects both parameters to have the same type. However, if you declare nonreference parameters, you can substitute them with string literals of different size:
// basics/max6.cpp
#include <string>
// note: nonreference parameters
template <typename T>
inline T max (T a, T b)
{
return a < b ? b : a;
}
int main()
{
std::string s;
::max("apple","peach"); // OK: same type
::max("apple","tomato"); // OK: decays to same type
::max("apple",s); // ERROR: different types
}
The explanation for this behavior is that during argument deduction array-to-pointer conversion (often called decay) occurs only if the parameter does not have a reference type. This is demonstrated by the following program:
// basics/refnonref.cpp
#include <typeinfo>
#include <iostream>
template <typename T>
void ref (T const& x)
{
std::cout << "x in ref(T const&): "
<< typeid(x).name() << '\n';
}
template <typename T>
void nonref (T x)
{
std::cout << "x in nonref(T): "
<< typeid(x).name() << '\n';
}
int main()
{
ref("hello");
nonref("hello");
}
The example passes a string literal to function templates that declare their parameter to be a reference or nonreference respectively. Both function templates use the typeid operator to print the type of the instantiated parameters. The typeid operator returns an lvalue of type std::type_info, which encapsulates a representation of the type of the expression passed to the typeid operator. The member function name() of std::type_info is intended to return a human-readable text representation of the latter type. The C++ standard doesn't actually say that name() must return something meaningful, but on good C++ implementations, you should get a string that gives a good description of the type of the expression passed to typeid (with some implementations this string is mangled, but a demangler is available to turn it into human-readable text). For example, the output might be as follows:
x in ref(T const&): char [6]
x in nonref(T): const char *
If you encounter a problem involving a mismatch between an array of characters and a pointer to characters, you might have stumbled on this somewhat surprising phenomenon.
There is unfortunately no general solutions to address this problem. Depending on the context, you can
std::make_pair("key","value") // ERROR according to [Standard98]
use nonreferences instead of references (however, this can lead to unnecessary copying) overload using both reference and nonreference parameters (however, this might lead to ambiguities; see Section B.2.2 on page 492) overload with concrete types (such as std::string) overload with array types, for example:
template <typename T, int N, int M>
T const* max (T const (&a)[N], T const (&b)[M])
{
return a < b ? b : a;
} force application programmers to use explicit conversions
In this example it is best to overload max() for strings (see Section 2.4 on page 16). This is necessary anyway because without overloading in cases where the call to max() is valid for string literals, the operation that is performed is a pointer comparison: a<bcompares the addresses of the two string literals and has nothing to do with lexicographical order. This is another reason why it is usually preferable to use a string class such as std::string instead of C-style strings.
See Section 11.1 on page 168 for details.
|
5.7 Summary
To access a type name that depends on a template parameter, you have to qualify the name with a leading typename. Nested classes and member functions can also be templates. One application is the ability to implement generic operations with internal type conversions. However, type checking still occurs. Template versions of assignment operators don't replace default assignment operators. You can also use class templates as template parameters, as so-called template template parameters. Template template arguments must match exactly. Default template arguments of template template arguments are ignored. By explicitly calling a default constructor, you can make sure that variables and members of templates are initialized by a default value even if they are instantiated with a built-in type. For string literals there is an array-to-pointer conversion during argument deduction if and only if the parameter is not a reference.
|
Chapter 6. Using Templates in Practice
Template code is a little different from ordinary code. In some ways templates lie somewhere between macros and ordinary (nontemplate) declarations. Although this may be an oversimplification, it has consequences not only for the way we write algorithms and data structures using templates, but also for the day-to-day logistics of expressing and analyzing programs involving templates.
In this chapter we address some of these practicalities without necessarily delving into the technical details that underlie them. Many of these details are explored in Chapter 10. To keep the discussion simple, we assume that our C++ compilation systems consist of fairly traditional compilers and linkers (C++ systems that don't fall in this category are quite rare).
|
6.1 The Inclusion Model
There are several ways to organize template source code. This section presents the most popular approach as of the time of this writing: the inclusion model.
6.1.1 Linker Errors
Most C and C++ programmers organize their nontemplate code largely as follows:
Classes and other types are entirely placed in header files. Typically, this is a file with a .hpp (or .H, .h, .hh, .hxx) filename extension. For global variables and (noninline) functions, only a declaration is put in a header file, and the definition goes into a so-called dot-C file. Typically, this is a file with a .cpp (or .C, .c, .cc, or .hxx) filename extension.
This works well: It makes the needed type definition easily available throughout the program and avoids duplicate definition errors on variables and functions from the linker.
With these conventions in mind, a common error about which beginning template programmers complain is illustrated by the following (erroneous) little program. As usual for "ordinary code," we declare the template in a header file:
// basics/myfirst.hpp
#ifndef MYFIRST_HPP
#define MYFIRST_HPP
// declaration of template
template <typename T>
void print_typeof (T const&);
#endif // MYFIRST_HPP
print_typeof() is the declaration of a simple auxiliary function that prints some type information. The implementation of the function is placed in a dot-C file:
// basics/myfirst.cpp
#include <iostream>
#include <typeinfo>
#include "myfirst.hpp"
// implementation/definition of template
template <typename T>
void print_typeof (T const& x)
{
std::cout << typeid(x).name() << std::endl;
}
The example uses the typeid operator to print a string that describes the type of the expression passed to it (see Section 5.6 on page 58).
Finally, we use the template in another dot-C file, into which our template declaration is #included:
// basics/myfirstmain.cpp
#include "myfirst.hpp"
// use of the template
int main()
{
double ice = 3.0;
print_typeof(ice); // call function template for type double
}
A C++ compiler will most likely accept this program without any problems, but the linker will probably report an error, implying that there is no definition of the function print_typeof().
The reason for this error is that the definition of the function template print_typeof() has not been instantiated. In order for a template to be instantiated, the compiler must know which definition should be instantiated and for what template arguments it should be instantiated. Unfortunately, in the previous example, these two pieces of information are in files that are compiled separately. Therefore, when our compiler sees the call to print_typeof() but has no definition in sight to instantiate this function for double, it just assumes that such a definition is provided elsewhere and creates a reference (for the linker to resolve) to that definition. On the other hand, when the compiler processes the file myfirst.cpp, it has no indication at that point that it must instantiate the template definition it contains for specific arguments.
6.1.2 Templates in Header Files
The common solution to the previous problem is to use the same approach that we would take with macros or with inline functions: We include the definitions of a template in the header file that declares that template. For our example, we can do this by adding
#include "myfirst.cpp"
at the end of myfirst.hpp or by including myfirst.cpp in every dot-C file that uses the template. A third way, of course, is to do away entirely with myfirst.cpp and rewrite myfirst.hpp so that it contains all template declarations and template definitions:
// basics/myfirst2.hpp
#ifndef MYFIRST_HPP
#define MYFIRST_HPP
#include <iostream>
#include <typeinfo>
// declaration of template
template <typename T>
void print_typeof (T const&);
// implementation/definition of template
template <typename T>
void print_typeof (T const& x)
{
std::cout << typeid(x).name() << std::endl;
}
#endif // MYFIRST_HPP
This way of organizing templates is called the inclusion model. With this in place, you should find that our program now correctly compiles, links, and executes.
There are a few observations we can make at this point. The most notable is that this approach has considerably increased the cost of including the header file myfirst.hpp. In this example, the cost is not the result of the size of the template definition itself, but the result of the fact that we must also include the headers used by the definition of our templatein this case <iostream> and <typeinfo>. You may find that this amounts to tens of thousands of lines of code because headers like <iostream> contain similar template definitions.
This is a real problem in practice because it considerably increases the time needed by the compiler to compile significant programs. We will therefore examine some possible ways to approach this problem in upcoming sections. However, real-world programs quickly end up taking hours to compile and link (we have been involved in situations in which it literally took days to build a program completely from its source code).
Despite this build-time issue, we do recommend following this inclusion model to organize your templates when possible. We examine two alternatives, but in our opinion their engineering deficiencies are more serious than the build-time issue discussed here. They may have other advantages not directly related to the engineering aspects of software development, however.
Another (more subtle) observation about the inclusion approach is that noninline function templates are distinct from inline functions and macros in an important way: They are not expanded at the call site. Instead, when they are instantiated, they create a new copy of a function. Because this is an automatic process, a compiler could end up creating two copies in two different files, and some linkers could issue errors when they find two distinct definitions for the same function. In theory, this should not be a concern of ours: It is a problem for the C++ compilation system to accommodate. In practice, things work well most of the time, and we don't need to deal with this issue at all. For large projects that create their own library of code, however, problems occasionally show up. A discussion of instantiation schemes in Chapter 10 and a close study of the documentation that came with the C++ translation system (compiler) should help address these problems.
Finally, we need to point out that what applies to the ordinary function template in our example also applies to member functions and static data members of class templates, as well as to member function templates.
|
6.2 Explicit Instantiation
The inclusion model ensures that all the needed templates are instantiated. This happens because the C++ compilation system automatically generates those instantiations as they are needed. The C++ standard also offers a construct to instantiate templates manually: the explicit instantiation directive.
6.2.1 Example of Explicit Instantiation
To illustrate manual instantiation, let's revisit our original example that leads to a linker error (see page 62). To avoid this error we add the following file to our program:
// basics/myfirstinst.cpp
#include "myfirst.cpp"
// explicitly instantiate print_typeof() for type double
template void print_typeof<double>(double const&);
The explicit instantiation directive consists of the keyword template followed by the fully substituted declaration of the entity we want to instantiate. In our example, we do this with an ordinary function, but it could be a member function or a static data member. For example:
// explicitly instantiate a constructor of MyClass<> for int
template MyClass<int>::MyClass();
// explicitly instantiate a function template max() for int
template int const& max (int const&, int const&);
You can also explicitly instantiate a class template, which is short for requesting the instantiation of all its instantiatable members. This excludes members that were previously specialized as well as those that were already instantiated:
// explicitly instantiate class Stack<> for int:
template class Stack<int>;
// explicitly instantiate some member functions of Stack<> for strings:
template Stack<std::string>::Stack();
template void Stack<std::string>::push(std::string const&);
template std::string Stack<std::string>::top();
// ERROR: can't explicitly instantiate a member function of a
// class that was itself explicitly instantiated:
template Stack<int>::Stack();
There should be, at most, one explicit instantiation of each distinct entity in a program. In other words, you could explicitly instantiate both print_typeof<int> and print_typeof<double>, but each directive should appear only once in a program. Not following this rule usually results in linker errors that report duplicate definitions of the instantiated entities.
Manual instantiation has a clear disadvantage: We must carefully keep track of which entities to instantiate. For large projects this quickly becomes an excessive burden; hence we do not recommend it. We have worked on several projects that initially underestimated this burden, and we came to regret our decision as the code matured.
However, explicit instantiation also has a few advantages because the instantiation can be tuned to the needs of the program. Clearly, the overhead of large headers is avoided. The source code of template definition can be kept hidden, but then no additional instantiations can be created by a client program. Finally, for some applications it can be useful to control the exact location (that is, the object file) of a template instance. With automatic instantiation, this may not be possible (see Chapter 10 for details).
6.2.2 Combining the Inclusion Model and Explicit Instantiation
To keep the decision open whether to use the inclusion model or explicit instantiation, we can provide the declaration and the definition of templates in two different files. It is common practice to have both files named as header files (using an extension ordinarily used for files that are intended to be #included), and it is probably wise to stick to this convention. (Thus, myfirst.cpp of our motivating example becomes myfirstdef.hpp, with preprocessor guards around the code inserted.) Figure 6.1 demonstrates this for a Stack<> class template.

Now if we want to use the inclusion model, we can simply include the definition header file stackdef.hpp. Alternatively, if we want to instantiate the templates explicitly, we can include the declaration header stack.hpp and provide a dot-C file with the necessary explicit instantiation directives (see Figure 6.2).
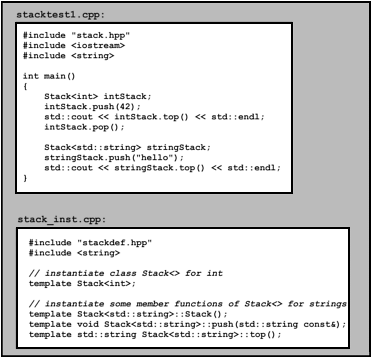
|
6.3 The Separation Model
Both approaches advocated in the previous sections work well and conform entirely to the C++ standard. However, this same standard also provides the alternative mechanism of exporting templates. This approach is sometimes called the C++ template separation model.
6.3.1 The Keyword export
In principle, it is quite simple to make use of the export facility: Define the template in just one file, and mark that definition and all its nondefining declarations with the keyword export. For the example in the previous section, this results in the following function template declaration:
// basics/myfirst3.hpp
#ifndef MYFIRST_HPP
#define MYFIRST_HPP
// declaration of template
export
template <typename T>
void print_typeof (T const&);
#endif // MYFIRST_HPP
Exported templates can be used without their definition being visible. In other words, the point where a template is being used and the point where it is defined can be in two different translation units. In our example, the file myfirst.hpp now contains only the declaration of the member functions of the class template, and this is sufficient to use those members. Comparing this with the original code that was triggering linker errors, we had to add only one export keyword in our code and things now work just fine.
Within a preprocessed file (that is, within a translation unit), it is sufficient to mark the first declaration of a template with export. Later redeclarations, including definitions, implicitly keep that attribute. This is why myfirst.cpp does not need to be modified in our example. The definitions in this file are implicitly exported because they were so declared in the #included header file. On the other hand, it is perfectly acceptable to provide redundant export keywords on template definitions, and doing so may improve the readability of the code.
The keyword export really applies to function templates, member functions of class templates, member function templates, and static data members of class templates. export can also be applied to a class template declaration. It implies that every one of its exportable members is exported, but class templates themselves are not actually exported (hence, their definitions still appear in header files). You can still have implicitly or explicitly defined inline member functions. However, these inline functions are not exported:
export template <typename T>
class MyClass {
public:
void memfun1(); // exported
void memfun2() { // not exported because implicitly inline
…
}
void memfun3(); // not exported because explicitly inline
…
};
template <typename T>
inline void MyClass<T>::memfun3 ()
{
…
}
However, note that the keyword export cannot be combined with inline and must always precede the keyword template. The following is invalid:
template <typename T>
class Invalid {
public:
export void wrong(T); // ERROR: export not followed by template
};
export template<typename T> // ERROR: both export and inline
inline void Invalid<T>::wrong(T)
{
}
export inline T const& max (T const&a, T const& b)
{ // ERROR: both export and inline
return a < b ? b : a;
}
6.3.2 Limitations of the Separation Model
At this point it is reasonable to wonder why we're still advocating the inclusion approach when exported templates seem to offer just the right magic to make things work. There are a few different aspects to this choice.
First, even four years after the standard came out, only one company has actually implemented support for the export keyword.
Therefore, experience with this feature is not as widespread as other C++ features. Clearly, this also means that at this point experience with exported templates is fairly limited, and all our observations will ultimately have to be taken with a grain of salt. It is possible that some of our misgivings will be addressed in the future (and we show how to prepare for that eventuality).
Second, although export may seem quasi-magical, it is not actually magical. Ultimately, the instantiation process has to deal with both the place where a template is instantiated and the place where its definition appears. Hence, although these two seem neatly decoupled in the source code, there is an invisible coupling that the system establishes behind the scenes. This may mean, for example, that if the file containing the definition changes, both that file and all the files that instantiate the templates in that file may need to be recompiled. This is not substantially different from the inclusion approach, but it is no longer obviously visible in the source code. As a consequence, dependency management tools (such as the popular make and nmake programs) that use traditional source-based techniques no longer work. It also means that quite a few bits of extra processing by the compiler are needed to keep all the bookkeeping straight; and in the end, the build times may not be better than those of the inclusion approach.
Finally, exported templates may lead to surprising semantic consequences, the details of which are explained in Chapter 10.
A common misconception is that the export mechanism offers the potential of being able to ship libraries of templates without revealing the source code for their definitions (just like libraries of nontemplate entities).
This is a misconception in the sense that hiding code is not a language issue: It would be equally possible to provide a mechanism to hide included template definitions as to hide exported template definitions. Although this may be feasible (the current implementations do not support this model), it unfortunately creates new challenges in dealing with template compilation errors that need to refer to the hidden source code.
6.3.3 Preparing for the Separation Model
One workable idea is to prepare our sources in such a way that we can easily switch between the inclusion and export models using a harmless dose of preprocessor directives. Here is how it can be done for our simple example:
// basics/myfirst4.hpp
#ifndef MYFIRST_HPP
#define MYFIRST_HPP
// use export if USE_EXPORT is defined
#if defined(USE_EXPORT)
#define EXPORT export
#else
#define EXPORT
#endif
// declaration of template
EXPORT
template <typename T>
void print_typeof (T const&);
// include definition if USE_EXPORT is not defined
#if !defined(USE_EXPORT)
#include "myfirst.cpp"
#endif
#endif // MYFIRST_HPP
By defining or omitting the preprocessor symbol USE_EXPORT, we can now select between the two models. If a program defines USE_EXPORT before it includes myfirst.hpp, the separation model is used:
// use separation model:
#define USE_EXPORT
#include "myfirst.hpp"
…
If a program does not define USE_EXPORT, the inclusion model is used because in this case myfirst.hpp automatically includes the definitions in myfirst.cpp:
// use inclusion model:
#include "myfirst.hpp"
…
Despite this flexibility, we should reiterate that besides the obvious logistical differences, there can be subtle semantic differences between the two models.
Note that we can also explicitly instantiate exported templates. In this case the template definition can be in another file. To be able to choose between the inclusion model, the separation model, and explicit instantion, we can combine the organization controlled by USE_EXPORT with the conventions described in Section 6.2.2 on page 67.
|
6.4 Templates and inline
Declaring short functions to be inline is a common tool to improve the running time of programs. The inline specifier indicates to the implementation that inline substitution of the function body at the point of call is preferred over the usual function call mechanism. However, an implementation is not required to perform this inline substitution at the point of call.
Both function templates and inline functions can be defined in multiple translation units. This is usually achieved by placing the definition in a header file that is included by multiple dot-C files.
This may lead to the impression that function templates are inline by default. However, they're not. If you write function templates that should be handled as inline functions, you should use the inline specifier (unless the function is inline already because it is defined inside a class definition).
Therefore, many short template functions that are not part of a class definition should be declared with inline.
|
6.5 Precompiled Headers
Even without templates, C++ header files can become very large and therefore take a long time to compile. Templates add to this tendency, and the outcry of waiting programmers has in many cases driven vendors to implement a scheme usually known as precompiled headers. This scheme operates outside the scope of the standard and relies on vendor-specific options. Although we leave the details on how to create and use precompiled header files to the documentation of the various C++ compilation systems that have this feature, it is useful to gain some understanding of how it works.
When a compiler translates a file, it does so starting from the beginning of the file and works through to the end. As it processes each token from the file (which may come from #included files), it adapts its internal state, including such things as adding entries to a table of symbols so they may be looked up later. While doing so, the compiler may also generate code in object files.
The precompiled header scheme relies on the fact that code can be organized in such a manner that many files start with the same lines of code. Let's assume for the sake of argument that every file to be compiled starts with the same N lines of code. We could compile these N lines and save the complete state of the compiler at that point in a so-called precompiled header. Then, for every file in our program, we could reload the saved state and start compilation at line N+1. At this point it is worthwhile to note that reloading the saved state is an operation that can be orders of magnitude faster than actually compiling the first N lines. However, saving the state in the first place is typically more expensive than just compiling the N lines. The increase in cost varies roughly from 20 to 200 percent.
The key to making effective use of precompiled headers is to ensure thatas much as possible files start with a maximum number of common lines of code. In practice this means the files must start with the same #include directives, which (as mentioned earlier) consume a substantial portion of our build time. Hence, it can be very advantageous to pay attention to the order in which headers are included. For example, the following two files
#include <iostream>
#include <vector>
#include <list>
…
and
#include <list>
#include <vector>
…
inhibit the use of precompiled headers because there is no common initial state in the sources.
Some programmers decide that it is better to #include some extra unnecessary headers than to pass on an opportunity to accelerate the translation of a file using a precompiled header. This decision can considerably ease the management of the inclusion policy. For example, it is usually relatively straightforward to create a header file named std.hpp that includes all the standard headers
:
#include <iostream>
#include <string>
#include <vector>
#include <deque>
#include <list>
…
This file can then be precompiled, and every program file that makes use of the standard library can then simply be started as follows:
#include "std.hpp"
…
Normally this would take a while to compile, but given a system with sufficient memory, the precompiled header scheme allows it to be processed significantly faster than almost any single standard header would require without precompilation. The standard headers are particularly convenient in this way because they rarely change, and hence the precompiled header for our std.hpp file can be built once.
Otherwise, precompiled headers are typically part of the dependency configuration of a project (for example, they are updated as needed by the popular make tool).
One attractive approach to manage precompiled headers is to create layers of precompiled headers that go from the most widely used and stable headers (for example, our std.hpp header) to headers that aren't expected to change all the time and therefore are still worth precompiling. However, if headers are under heavy development, creating precompiled headers for them can take more time than what is saved by reusing them. A key concept to this approach is that a precompiled header for a more stable layer can be reused to improve the precompilation time of a less stable header. For example, suppose that in addition to our std.hpp header (which we have precompiled), we also define a core.hpp header that includes additional facilities that are specific to our project but nonetheless achieve a certain level of stability:
#include "std.hpp"
#include "core_data.hpp"
#include "core_algos.hpp"
…
Because this file starts with #include "std.hpp", the compiler can load the associated precompiled header and continue with the next line without recompiling all the standard headers. When the file is completely processed, a new precompiled header can be produced. Applications can then use #include "core.hpp" to provide access quickly to large amounts of functionality because the compiler can load the latter precompiled header.
|
6.6 Debugging Templates
Templates raise two classes of challenges when it comes to debugging them. One set of challenges is definitely a problem for writers of templates: How can we ensure that the templates we write will function for any template arguments that satisfy the conditions we document? The other class of problems is almost exactly the opposite: How can a user of a template find out which of the template parameter requirements it violated when the template does not behave as documented?
Before we discuss these issues in depth, it is useful to contemplate the kinds of constraints that may be imposed on template parameters. In this section we deal mostly with the constraints that lead to compilation errors when violated, and we call these constraints syntactic constraints. Syntactic constraints can include the need for a certain kind of constructor to exist, for a particular function call to be unambiguous, and so forth. The other kind of constraint we call semantic constraints. These constraints are much harder to verify mechanically. In the general case, it may not even be practical to do so. For example, we may require that there be a < operator defined on a template type parameter (which is a syntactic constraint), but usually we'll also require that the operator actually defines some sort of ordering on its domain (which is a semantic constraint).
The term concept is often used to denote a set of constraints that is repeatedly required in a template library. For example, the C++ standard library relies on such concepts as random access iterator and default constructible. Concepts can form hierarchies in the sense that one concept can be a refinement of another. The more refined concept includes all the constraints of the other concept but adds a few more. For example, the concept random access iterator refines the concept bidirectional iterator in the C++ standard library. With this terminology in place, we can say that debugging template code includes a significant amount of determining how concepts are violated in the template implementation and in their use.
6.6.1 Decoding the Error Novel
Ordinary compilation errors are normally quite succinct and to the point. For example, when a compiler says "class X has no member 'fun'," it usually isn't too hard to figure out what is wrong in our code (for example, we might have mistyped run as fun). Not so with templates. Consider the following relatively simple code excerpt using the C++ standard library. It contains a fairly small mistake: list<string> is used, but we are searching using a greater<int> function object, which should have been a greater<string> object:
std::list<std::string> coll;
…
// Find the first element greater than "A"
std::list<std::string>::iterator pos;
pos = std::find_if(coll.begin(),coll.end(), // range
std::bind2nd(std::greater<int>(),"A")); // criterion
This sort of mistake commonly happens when cutting and pasting some code and forgetting to adapt parts of it.
A version of the popular GNU C++ compiler reports the following error:
/local/include/stl/_algo.h: In function 'struct _STL::_List_iterator<_STL::basic
_string<char,_STL::char_traits<char>,_STL::allocator<char> >,_STL::_Nonconst_tra
its<_STL::basic_string<char,_STL::char_traits<char>,_STL::allocator<char> > > >
_STL::find_if<_STL::_List_iterator<_STL::basic_string<char,_STL::char_traits<cha
r>,_STL::allocator<char> >,_STL::_Nonconst_traits<_STL::basic_string<char,_STL::
char_traits<char>,_STL::allocator<char> > > >, _STL::binder2nd<_STL::greater<int
> > >(_STL::_List_iterator<_STL::basic_string<char,_STL::char_traits<char>,_STL:
:allocator<char> >,_STL::_Nonconst_traits<_STL::basic_string<char,_STL::char_tra
its<char>,_STL::allocator<char> > > >, _STL::_List_iterator<_STL::basic_string<c
har,_STL::char_traits<char>,_STL::allocator<char> >,_STL::_Nonconst_traits<_STL:
:basic_string<char,_STL::char_traits<char>,_STL::allocator<char> > > >, _STL::bi
nder2nd<_STL::greater<int> >, _STL::input_iterator_tag)':
/local/include/stl/_algo.h:115: instantiated from '_STL::find_if<_STL::_List_i
terator<_STL::basic_string<char,_STL::char_traits<char>,_STL::allocator<char> >,
_STL::_Nonconst_traits<_STL::basic_string<char,_STL::char_traits<char>,_STL::all
ocator<char> > > >, _STL::binder2nd<_STL::greater<int> > >(_STL::_List_iterator<
_STL::basic_string<char,_STL::char_traits<char>,_STL::allocator<char> >,_STL::_N
onconst_traits<_STL::basic_string<char,_STL::char_traits<char>,_STL::allocator<c
har> > > >, _STL::_List_iterator<_STL::basic_string<char,_STL::char_traits<char>
,_STL::allocator<char> >,_STL::_Nonconst_traits<_STL::basic_string<char,_STL::ch
ar_traits<char>,_STL::allocator<char> > > >, _STL::binder2nd<_STL::greater<int>
>)'
testprog.cpp:18: instantiated from here
/local/include/stl/_algo.h:78: no match for call to '(_STL::binder2nd<_STL::grea
ter<int> >) (_STL::basic_string<char,_STL::char_traits<char>,_STL::allocator<cha
r> > &)'
/local/include/stl/_function.h:261: candidates are: bool _STL::binder2nd<_STL::g
reater<int> >::operator ()(const int &) const
A message like this starts looking more like a novel than a diagnostic. It can also be overwhelming to the point of discouraging novice template users. However, with some practice, messages like this become manageable, and the errors are relatively easily located.
The first part of this error message says that an error occurred in a function template instance (with a horribly long name) deep inside the /local/include/stl/_algo.h header. Next, the compiler reports why it instantiated that particular instance. In this case it all started on line 18 of testprog.cpp (which is the file containing our example code), which caused the instantiation of a find_if template on line 115 of the _algo.h header. The compiler reports all this in case we simply were not expecting all these templates to be instantiated. It allows us to determine the chain of events that caused the instantiations.
However, in our example we're willing to believe that all kinds of templates needed to be instantiated, and we just wonder why it didn't work. This information comes in the last part of the message: The part that says "no match for call" implies that a function call could not be resolved because the types of the arguments and the parameter types didn't match. Furthermore, just after this, the line containing "candidates are" explains that there was a single candidate type expecting an integer type (parameter type const int&). Looking back at line 18 of the program, we see std::bind2nd(std::greater<int>(),"A"), which does indeed contain an integer type (<int>) that is not compatible with the string type objects for which we're looking in our example. Replacing <int> with <std::string> makes the problem go away.
There is no doubt that the error message could be better structured. The actual problem could be omitted before the history of the instantiation, and instead of using fully expanded template instantiation names like MyTemplate<YourTemplate<int> >, decomposing the instance as in MyTemplate<T> with T=YourTemplate<int> can reduce the overwhelming length of names. However, it is also true that all the information in this diagnostic could be useful in some situations. It is therefore not surprising that other compilers provide similar information (although some use the structuring techniques mentioned).
6.6.2 Shallow Instantiation
Diagnostics such as those discussed earlier arise when errors are found after a long chain of instantiations. To illustrate this, consider the following somewhat contrived code:
template <typename T>
void clear (T const& p)
{
*p=0; // assumes T is a pointer-like type
}
template <typename T>
void core (T const& p)
{
clear(p);
}
template <typename T>
void middle (typename T::Index p)
{
core(p);
}
template <typename T>
void shell (T const& env)
{
typename T::Index i;
middle<T>(i);
}
class Client {
public:
typedef int Index;
};
Client main_client;
int main()
{
shell(main_client);
}
This example illustrates the typical layering of software development: High-level function templates like shell() rely on components like middle(), which themselves make use of basic facilities like core(). When we instantiate shell(), all the layers below it also need to be instantiated. In this example, a problem is revealed in the deepest layer: core() is instantiated with type int (from the use of Client::Index in middle()) and attempts to dereference a value of that type, which is an error. A good generic diagnostic includes a trace of all the layers that led to the problems, but we observe that so much information can appear unwieldy.
An excellent discussion of the core ideas surrounding this problem can be found in [StroustrupDnE], in which Bjarne Stroustrup identifies two classes of approaches to determine earlier whether template arguments satisfy a set of constraints: through a language extension or through earlier parameter use. We cover the former option to some extent in Section 13.11 on page 218. The latter alternative consists of forcing any errors in shallow instantiations. This is achieved by inserting unused code with no other purpose than to trigger an error if that code is instantiated with template arguments that do not meet the requirements of deeper levels of templates.
In our previous example we could add code in shell() that attempts to dereference a value of type T::Index. For example:
template <typename T>
inline void ignore(T const&)
{
}
template <typename T>
void shell (T const& env)
{
class ShallowChecks {
void deref(T::Index ptr) {
ignore(*ptr);
}
};
typename T::Index i;
middle(i);
}
If T is a type such that T::Index cannot be dereferenced, an error is now diagnosed on the local class ShallowChecks. Note that because the local class is not actually used, the added code does not impact the running time of the shell() function. Unfortunately, many compilers will warn about the fact that ShallowChecks is not used (and neither are its members). Tricks such as the use of the ignore() template can be used to inhibit such warnings, but they add to the complexity of the code.
Clearly, the development of the dummy code in our example can become as complex as the code that implements the actual functionality of the template. To control this complexity it is natural to attempt to collect various snippets of dummy code in some sort of library. For example, such a library could contain macros that expand to code that triggers the appropriate error when a template parameter substitution violates the concept underlying that particular parameter. The most popular such library is the Concept Check Library, which is part of the Boost distribution (see [BCCL]).
Unfortunately, the technique isn't particularly portable (the way errors are diagnosed differs considerably from one compiler to another) and sometimes masks issues that cannot be captured at a higher level.
6.6.3 Long Symbols
The error message analyzed in Section 6.6.1 on page 75 demonstrates another problem of templates: Instantiated template code can result in very long symbols. For example, in the implementation used earlier std::string is expanded to
_STL::basic_string<char,_STL::char_traits<char>,
_STL::allocator<char> >
Some programs that use the C++ standard library produce symbols that contain more than 10,000 characters. These very long symbols can also cause errors or warnings in compilers, linkers, and debuggers. Modern compilers use compression techniques to reduce this problem, but in error messages this is not apparent.
6.6.4 Tracers
So far we have discussed bugs that arise when compiling or linking programs that contain templates. However, the most challenging task of ensuring that a program behaves correctly at run time often follows a successful build. Templates can sometimes make this task a little more difficult because the behavior of generic code represented by a template depends uniquely on the client of that template (certainly much more so than ordinary classes and functions). A tracer is a software device that can alleviate that aspect of debugging by detecting problems in template definitions early in the development cycle.
A tracer is a user-defined class that can be used as an argument for a template to be tested. Often, it is written just to meet the requirements of the template and no more than those requirements. More important, however, a tracer should generate a trace of the operations that are invoked on it. This allows, for example, to verify experimentally the efficiency of algorithms as well as the sequence of operations.
Here is an example of a tracer that might be used to test a sorting algorithm:
// basics/tracer.hpp
#include <iostream>
class SortTracer {
private:
int value; // integer value to be sorted
int generation; // generation of this tracer
static long n_created; // number of constructor calls
static long n_destroyed; // number of destructor calls
static long n_assigned; // number of assignments
static long n_compared; // number of comparisons
static long n_max_live; // maximum of existing objects
// recompute maximum of existing objects
static void update_max_live() {
if (n_created-n_destroyed > n_max_live) {
n_max_live = n_created-n_destroyed;
}
}
public:
static long creations() {
return n_created;
}
static long destructions() {
return n_destroyed;
}
static long assignments() {
return n_assigned;
}
static long comparisons() {
return n_compared;
}
static long max_live() {
return n_max_live;
}
public:
// constructor
SortTracer (intv=0):value(v), generation(1) {
++n_created;
update_max_live();
std::cerr << "SortTracer #" << n_created
<< ", created generation " << generation
<< " (total: " << n_created - n_destroyed
<< ")\n";
}
// copy constructor
SortTracer (SortTracer const& b)
: value(b.value), generation(b.generation+1) {
++n_created;
update_max_live();
std::cerr << "SortTracer #" << n_created
<< ", copied as generation " << generation
<< " (total: " << n_created - n_destroyed
<< ")\n";
}
// destructor
~SortTracer() {
++n_destroyed;
update_max_live();
std::cerr << "SortTracer generation " << generation
<< " destroyed (total: "
<< n_created - n_destroyed << ")\n";
}
// assignment
SortTracer& operator= (SortTracer const& b) {
++n_assigned;
std::cerr << "SortTracer assignment #" << n_assigned
<< " (generation " << generation
<< " = " << b.generation
<< ")\n";
value = b.value;
return *this;
}
// comparison
friend bool operator < (SortTracer const& a,
SortTracer const& b) {
++n_compared;
std::cerr << "SortTracer comparison #" << n_compared
<< " (generation " << a.generation
<< " < " << b.generation
<< ")\n";
return a.value < b.value;
}
int val() const {
return value;
}
};
In addition to the value to sort, value, the tracer provides several members to trace an actual sort: generation traces for each object how many copies it is from the original. The other static members trace the number of creations (constructor calls), destructions, assignment comparisons, and the maximum number of objects that ever existed.
The static members are defined in a separate dot-C file:
// basics/tracer.cpp
#include "tracer.hpp"
long SortTracer::n_created = 0;
long SortTracer::n_destroyed = 0;
long SortTracer::n_max_live = 0;
long SortTracer::n_assigned = 0;
long SortTracer::n_compared = 0;
This particular tracer allows us to track the pattern or entity creation and destruction as well as assignments and comparisons performed by a given template. The following test program illustrates this for the std::sort algorithm of the C++ standard library:
// basics/tracertest.cpp
#include <iostream>
#include <algorithm>
#include "tracer.hpp"
int main()
{
// prepare sample input:
SortTracer input[]={7,3,5,6,4,2,0,1,9,8};
// print initial values:
for (int i=0; i<10; ++i) {
std::cerr << input[i].val() << ' ';
}
std::cerr << std::endl;
// remember initial conditions:
long created_at_start = SortTracer::creations();
long max_live_at_start = SortTracer::max_live();
long assigned_at_start = SortTracer::assignments();
long compared_at_start = SortTracer::comparisons();
// execute algorithm:
std::cerr << "---[ Start std::sort() ]--------------------\n";
std::sort<>(&input[0], &input[9]+1);
std::cerr << "---[ End std::sort() ]----------------------\n";
// verify result:
for (int i=0; i<10; ++i) {
std::cerr << input[i].val() << ' ';
}
std::cerr << "\n\n";
// final report:
std::cerr << "std::sort() of 10 SortTracer's"
<< " was performed by:\n "
<< SortTracer::creations() - created_at_start
<< " temporary tracers\n "
<< "up to "
<< SortTracer::max_live()
<< " tracers at the same time ("
<< max_live_at_start << " before)\n "
<< SortTracer::assignments() - assigned_at_start
<< " assignments\n "
<< SortTracer::comparisons() - compared_at_start
<< " comparisons\n\n";
}
Running this program creates a considerable amount of output, but much can be concluded from the "final report." For one implementation of the std::sort() function, we find the following:
std::sort() of 10 SortTracer's was performed by:
15 temporary tracers
up to 12 tracers at the same time (10 before)
33 assignments
27 comparisons
For example, we see that although 15 temporary tracers were created in our program while sorting, at most two additional tracers existed at any one time.
Our tracer thus fulfills two roles: It proves that the standard sort() algorithm requires no more functionality than our tracer (for example, operators == and > were not needed), and it gives us a sense of the cost of the algorithm. It does not, however, reveal much about the correctness of the sorting template.
6.6.5 Oracles
Tracers are relatively simple and effective, but they allow us to trace the execution of templates only for specific input data and for a specific behavior of its related functionality. We may wonder, for example, what conditions must be met by the comparison operator for the sorting algorithm to be meaningful (or correct), but in our example we have only tested a comparison operator that behaves exactly like less-than for integers.
An extension of tracers is known in some circles as oracles (or run-time analysis oracles). They are tracers that are connected to a so-called inference enginea program that can remember assertions and reasons about them to infer certain conclusions. One such system that was applied to certain parts of a standard library implementation is called MELAS and is discussed in [MusserWangDynaVeri].
Oracles allow us, in some cases, to verify template algorithms dynamically without fully specifying the substituting template arguments (the oracles are the arguments) or the input data (the inference engine may request some sort of input assumption when it gets stuck). However, the complexity of the algorithms that can be analyzed in this way is still modest (because of the limitations of the inference engines), and the amount of work is considerable. For these reasons, we do not delve into the development of oracles, but the interested reader should examine the publication mentioned earlier (and the references contained therein).
6.6.6 Archetypes
We mentioned earlier that tracers often provide an interface that is the minimal requirement of the template they trace. When such a minimal tracer does not generate run-time output, it is sometimes called an archetype. An archetype allows us to verify that a template implementation does not require more syntactic constraints than intended. Typically, a template implementer will want to develop an archetype for every concept identified in the template library.
|
6.7 Afternotes
The organization of source code in header files and dot-C files is a practical consequence of various incarnations of the so-called one-definition rule or ODR. An extensive discussion of this rule is presented in Appendix A.
The inclusion versus separation model debate has been a controversial one. The inclusion model is a pragmatic answer dictated largely by existing practice in C++ compiler implementations. However, the first C++ implementation was different: The inclusion of template definitions was implicit, which created a certain illusion of separation (see Chapter 10 for details on this original model).
[StroustrupDnE] contains a good presentation of Stroustrup's vision for template code organization and the associated implementation challenges. It clearly wasn't the inclusion model. Yet, at some point in the standardization process, it seemed as if the inclusion model was the only viable approach after all. After some intense debates, however, those envisioning a more decoupled model garnered sufficient support for what eventually became the separation model. Unlike the inclusion model, this was a theoretical model not based on any existing implementation. It took more than five years to see its first implementation published (May 2002).
It is sometimes tempting to imagine ways of extending the concept of precompiled headers so that more than one header could be loaded for a single compilation. This would in principle allow for a finer grained approach to precompilation. The obstacle here is mainly the preprocessor: Macros in one header file can entirely change the meaning of subsequent header files. However, once a file has been precompiled, macro processing is completed, and it is hardly practical to attempt to patch a precompiled header for the preprocessor effects induced by other headers.
A fairly systematic attempt to improve C++ compiler diagnostics by adding dummy code in high-level templates can be found in Jeremy Siek's Concept Check Library (see [BCCL]). It is part of the Boost library (see [Boost]).
|
6.8 Summary
Templates challenge the classic compiler-plus-linker model. Therefore there are different approaches to organize template code: the inclusion model, explicit instantiation, and the separation model. Usually, you should use the inclusion model (that is, put all template code in header files). By separating template code into different header files for declarations and definitions, you can more easily switch between the inclusion model and explicit instantiation. The C++ standard defines a separate compilation model for templates (using the keyword export). It is not yet widely available, however. Debugging code with templates can be challenging. Template instances may have very long names. To take advantage of precompiled headers, be sure to keep the same order for #include directives.
|
|
|
|

 LINUX
LINUX