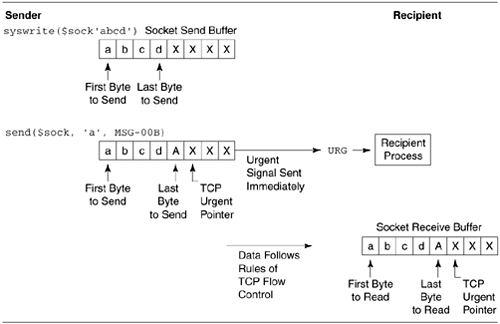
TCP is fundamentally stream based. Data
placed by the sending process into the operating system's TCP
transmit buffer is received by the other end and read by the
receiving process in exactly the same order in which it was
sent. But what if the sending process detects some exceptional
condition and it needs to alert the receiver immediately?
Vanilla TCP can't handle this well because all data has equal
priority, and the urgent message will have to wait its turn
behind all the data sent before it. This is where TCP "urgent"
data fits in. This facility, more commonly known as
"out-of-band" data, makes it possible, in a limited and highly
qualified manner, to send and receive TCP messages that are
delivered ahead of the ordinary TCP stream.
To illustrate the use of such a facility,
consider a terminal-based application that allows the user to
queue a stream of long-running commands to be executed on the
server. After he issues several commands, and while the server
is still chewing through them, the user changes his mind and
decides to cancel by hitting the interrupt key. But the
commands have already been sent to the server and are in the
TCP receive queue waiting for processing. Somehow the client
must transmit a cancel signal to the server immediately,
without queuing a cancel command behind other normal-priority
data. One way to accomplish this is to use TCP urgent data to
notify the server to clear its list of pending commands and to
ignore commands already received but not yet read. We develop
just such an application in the course of this chapter.
You can send a single byte of TCP urgent data
over a connected socket by calling send() with the
MSG_OOB flag:
This looks simple enough, but there is
significant complexity lurking under the surface. Although the
term "out-of-band data" implies that it is transmitted outside
the normal data stream, this is not the case.
Because of the way TCP urgent data works,
there are numerous caveats and restrictions on its
use:
Caveat 3 is the real kicker. If the receiver
calls recv() with MSG_OOB before the urgent
data has arrived, the call will fail with an
EWOULDBLOCK error. The alternatives are to just
ignore the urgent data or to perform one or more normal reads
until the urgent data arrives. The work needed to implement
the latter option is eased slightly by the fact that
sysread() stops automatically at the urgent pointer
boundary. We'll see examples of this later.
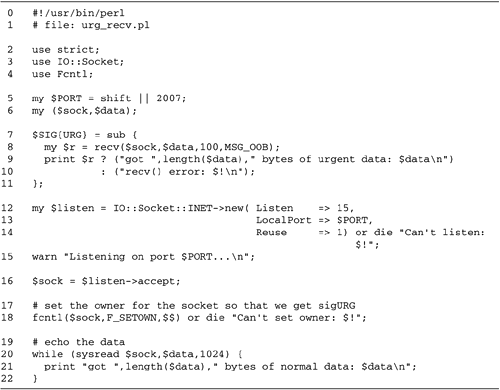
We will write a client/server pair to
illustrate the basics of urgent data. The client connects to
the server via TCP and sends a stream of lines containing
normal (nonurgent) data, with a small pause between each line.
The server reads the lines and prints them to standard
output.
The twist is that the client intercepts
interrupt key (^C) presses and sends out 1 byte of urgent data
containing the character "!". The server retrieves
the urgent data when it comes in and prints a warning message
to that effect.
When we run the client, it runs for thirty
iterations (about 30 s) and quits. If we hit the interrupt key
a couple of times during that period, we see the following
messages:
When we run the server and client together
and interrupt the client twice, we see output like this:
Notice that the urgent data never appears in
the normal data stream read by sysread().
As written, there is a potential race
condition in this server. It is possible for urgent data to
come in during or soon after the call to accept(),
but before fcntl() has set the owner of the socket.
In this case, the server misses the urgent data signal. This
may or may not be an issue for your application. If it is, you
could either
By default, TCP urgent data can be recovered
only by calling recv() with the MSG_OOB
flag. Internally, the operating system extracts and reserves
incoming urgent data so that it doesn't mingle with the normal
data stream.
However, if you would prefer that the urgent
data remain inline and appear amidst the normal data, you can
use the SO_OOBLINE option. This option can be set
with the IO::Socket sockopt() method or using the
built-in setsockopt() function. Sockets with this
option set return urgent data inline. The URG signal
continues to be sent, but calling recv() with
MSG_OOB can no longer be used to retrieve the urgent
data and, in fact, will return an EINVAL error.
Running the server and client together and
generating a couple of interrupts now shows this pattern:
Notice that the urgent data always appears at
the beginning of the data returned by a sysread()
call. This is no coincidence. A feature of the urgent data API
is that reads terminate at the urgent data pointer even if the
caller requested more data. In the case of inline data, the
next byte read by sysread() will be the urgent data
itself. In the case of out-of-band data, the next byte read
will be the character that follows the urgent data.
Regrettably, this server needs to use a trick
because of an idiosyncrasy of select(). Many
implementations of select() continue to indicate that
a socket has urgent data to read even after the program has
called recv(), but calling recv() a second
time fails with an EINVAL error because the urgent
data buffer has already been emptied. This condition persists
until at least 1 byte of normal data has been read from the
socket and, unless handled properly, the program goes into a
tight loop after receiving urgent data.
The most common use of urgent data is to mark
a section of the TCP stream as invalid so that it can be
discarded. For example, the UNIX rlogin (remote login) server uses
this feature to accommodate the user's urgent request to kill
a runaway remote program. It isn't sufficient for the rlogin server to terminate the
program, because it may have already transmitted substantial
output to the rlogin client at
the user's end of the connection. The server must tell the
client to ignore all output up to the point at which the user
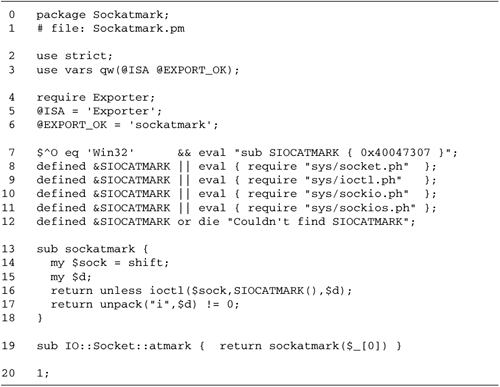
hit the interrupt key. This is where the sockatmark()
function comes in:
This looks simple, but there's a hitch. The
particular header file needed is not standard across all
operating systems and is variously named sys/ioctl.ph, sys/socket.ph, sys/sockio. ph, or sys/sockios.ph. This makes it
difficult to write portable code. Furthermore, none of these
converted header files is part of the standard Perl
distribution, but they must be created manually using a
finicky and sometimes unreliable Perl script called h2ph. This tool is documented in the
online POD documentation, but the capsule usage is as
follows:
This assumes that you are using a UNIX system
that keeps its header files in /usr/include. Users of other
operating systems that have a C or C++ compiler installed must
locate their compiler's header directory and run h2ph from there. Even then, h2ph occasionally generates incorrect
Perl code and the resulting .ph
files may need to be patched by hand.
Having generated the converted header files,
we're still stuck with having to guess which one contains the
SIOCATMARK constant. One approach is to try several
possibilities until one works. The following code snippet
first uses a hard-coded value for Win32 systems, and then
tries a series of possible .ph
file paths. If none succeeds, it dies.
We now have all the ingredients necessary to
write a client/server pair that does something useful with
urgent data. This server implements "travesty," a Markov chain
algorithm that analyzes a text document and generates a new
document that preserves all the word-pair (tuple) frequencies
of the original. The result is a completely incomprehensible
document that has an eerie similarity to the writing style of
the original. For example, here's an excerpt from the text
generated after running the previous chapter through the
travesty algorithm:
The results of running Ernest Hemingway
through the wringer are similarly amusing. Oddly, James
Joyce's later works seem to be entirely unaffected by this
translation.
The client/server pair in this example
divides the work in the classical manner. The client runs the
user interface. It prompts the user for commands to load text
files into the analyzer, generate the travesty, and reset the
word frequency tables. The server does the heavy lifting,
constructing the Markov model from uploaded files and
generating travesties of arbitrary length.
TCP urgent data is useful in this application
because it frequently takes longer for the server to analyze
the word tuple frequencies in an uploaded text file than for
the client to upload it. The user may wish to abort the upload
midway, in which case the client must send the server an
urgent signal to stop processing the file and to ignore all
data sent from the time the user interrupted the process.
Conversely, once the tuple frequency tables
are created, the server has the ability to generate travesty
text far faster than the network can transfer it. We would
like the user to be able to interrupt the incoming text
stream, again by issuing an urgent data signal.
The client/server pair requires three
external modules in addition to the standard ones: Sockatmark,
which we have already seen; Text::Travesty, the travesty
generator; and IO::Getline, the nonblocking replacement for
Perl's getline() function, which we developed in Chapter
13 (Figure
13.2). In this case we won't be using IO::Getline for its
nonblocking features, but for its ability to clear its
internal line buffer when the flush() method is
called.
The travesty algorithm is encapsulated in a
small module named Text::Travesty. Its source code list is in
Appendix A; it may also be available on CPAN. It is adapted
from a small demo application that comes in the eg/ directory of the Perl
distribution. Like other modules in this book, it is
object-oriented. You start by creating a new Text::Travesty
object with Text::Travesty->new():
Once the text is analyzed, you can generate a
travesty with calls to generate() or
pretty_text():
Both methods take a numeric argument that
indicates the length of the generated travesty, measured in
words. The difference between the two methods is that
generate() creates unwrapped raw text, while
pretty_text() invokes Perl's Text::Wrap module to
create nicely indented and wrapped paragraphs.
In addition to its main purpose of showing
the handling of urgent data, the travesty server illustrates a
number of common design motifs in client/server
communications.
After loading the required modules, we set up
two signal handlers. The CHLD handler is the usual
one used in accept-and-fork servers. We initially tell Perl to
ignore URG signals. We'll reenable them in the places
where they have meaning, during the uploading and downloading
of large data streams.
We now create a new Text::Travesty object and
an IO::Getline wrapper for the socket. Recall from Chapter
13 that IO::Getline has nonblocking behavior by default.
In this application, we don't use its nonblocking features, so
we turn blocking back on after creating the wrapper. The
IO::Getline wrapper is global to the package so as to allow
the URG handler to find it; since this server uses a
different process to service each incoming connection, this
use of a global won't cause problems.
Having finished our initialization, we write
our welcome banner to the client, using result code 200.
Notice that the IO::Getline module accepts all the object
methods of IO::Socket, including syswrite(). This
makes the code easier to read than would calling the getline
object's handle() method each time to recover the
underlying socket.
We're now going to accept uploaded data from
the client by calling $gl->getline() repeatedly
until we encounter a line consisting of a dot, or until we are
interrupted by an URG signal.
Before exiting, we transmit a code 202
message giving the number of unique words we processed,
regardless of whether the upload was interrupted. Notice that
we treat interrupted file transfers just as if the uploaded
file ended early. We leave the travesty generator in whatever
state it happened to be in when the URG signal was
received. Because the travesty generator is not affected by
the analysis of a partial file, this causes no harm and might
be construed as a feature. Another application might want to
reset itself to a known state.
We're going to transmit the mangled text now.
As in the previous subroutine, we enter an I/O loop wrapped in
an eval{}, and again install a local URG
handler that runs do_urgent() and dies. If the socket
enters urgent mode, our download loop is terminated
immediately. This time, however, our URG handler also
sets a local variable named $abort to true. The loop
calls the travesty object's pretty_text() method to
generate up to 500 words, replaces newline characters with the
CRLF sequence, and writes out the resulting text. At the end
of the loop, we transmit a lone dot.
If the transmission was aborted, we must tell
the client to discard data left in the socket stream. We do
this by sending an urgent data byte back to the client using
this idiom:
We now begin to upload the text file to the
server. As in the server code, the upload is done in an
eval{} block, but in this case it is the INT
signal that we catch. Before entering the block, we set a
local variable $abort to false. Within the block we
create a local INT handler that prints a warning,
sets $abort to true, and dies, causing the
eval{} block to terminate. By declaring the handler
local, we temporarily replace the original INT
handler, and restore it automatically when the eval{}
block is finished. Within the block itself we read from the
text file one line at a time and send it to the server. When
the file is finished, we send the server a "."
character.
The last step is to read the response line
from the server and print the number of unique words
successfully processed.
We are now ready to read the travesty from
the server. The logic is similar to the do_analyze()
subroutine. We set the local variable $abort to a
false value and enter a loop that is wrapped in an
eval{}. For the duration of the loop, the default
INT handler is replaced with one that increments
$abort and dies, terminating the eval{}
block. The loop accepts lines from the server, removes the
CRLF pairs with chomp(), and prints them to standard
output with proper newlines. The loop terminates normally when
it encounters a line consisting of one dot.
To test the travesty client/server, I
launched the server on one machine and the client on another,
in both cases leaving the DEBUG constant true so that
I could see debugging messages.
The next step was to test that I could
interrupt uploads. I ran the analyze command again, but this
time hit the interrupt key before the analysis was
complete:
The message indicates that only 879 of 2,658
unique words were processed this time, confirming that the
upload was aborted prematurely. Meanwhile, on the server's
side of the connection, the server's do_urgent()
URG handler emitted the following debug messages as
it discarded all data through to the urgent pointer:
The final test was to confirm that I could
interrupt travesty generation. I issued the command generate 20000 to generate a very
long 20,000-word travesty, then hit the interrupt key as soon
as text started to appear.
As expected, the transmission was interrupted
and the client's URG signal handler printed out a
series of debug messages as it discarded data leading up to
the server's urgent data.
Because of the difficulty in using h2ph to
generate the .ph files required by the Sockatmark.pm module, I
have recently written a C-language extension module names
IO::Sockatmark. It is available on CPAN, and on this book's
companion site. If you have encounter problems getting the
pure-Perl version of Sockatmark.pm to work, I suggest you
replace it with IO::Sockatmark. You will need a C compiler to
do this.
The modifications required to use
IO::Sockatmark in the "travesty" code examples are very minor.
In Figures
17.6 and 17.7,
simply change:
Up to now we have focused exclusively on
applications that use the TCP protocol and have said little
about the User Datagram Protocol, or UDP. This is because TCP
is generally easier to use, more reliable, and more familiar
to programmers who are used to dealing with files and pipes.
On the Internet, TCP-based applications protocols outnumber
those based on UDP by a factor of at least 10 to 1.
Nevertheless, UDP is extremely useful for
certain applications, and sometimes can do things that would
be difficult, if not impossible, for a TCP-based service to
achieve. The next few chapters introduce UDP, discuss the
design of UDP-based servers, and show how to use UDP for
broadcasting and multicasting applications.
Our client takes up to two command-line
arguments: the name of the daytime host to query and a port to
connect to. By default, the program tries to contact a server
running on the local host using the standard daytime service
port number (13). Here's a sample session:
The client is different from the TCP-based
programs we are more familiar with. Figure
18.1 shows the complete code for this program.
Lines 15: Load modules We begin by
turning on strict code checking and then bring in the
standard Socket library and its line-end constants. We set
$/ to CRLF, not because we'll be
performing line-oriented reads, but in order for the
chomp() call at the end of the script to remove the
terminating CRLF properly.
Lines 68: Define constants We
define some constant values. DEFAULT_HOST is the
name of the host to contact if not specified on the command
line; we use the loopback address, "localhost."
DEFAULT_PORT is the port to contact if not
overridden on the command line; it can be either the port
number or a symbolic service name. We use "daytime" as the
service name.
UDP data is transmitted and received as
discrete messages. MAX_MSG_LEN specifies the
maximum size of a message. Since the daytime strings are
only a few characters, it is safe to set this constant to a
relatively small value of 100 bytes.
Lines 910: Read command-line
arguments We read the command-line arguments into the
$host and $port global variables; if these
variables are not provided, we use the defaults.
Lines 1113: Get protocol and port
We use getprotobyname() to get the protocol number
for UDP and call getservbyname() to look up the
port number for the daytime service. If the user provided
the port number directly, we skip the last step. We declare
an empty variable named $data to receive the
message transmitted by the remote host.
Line 14: Create the socket We create
the socket by calling Perl's built-in socket()
function. We use AF_INET for the domain, creating
an Internet socket, SOCK_DGRAM for the type,
creating a datagram-style socket, and the previously derived
protocol number for UDP.
If successful, socket() returns a
true value and assigns a socket to the filehandle.
Otherwise, the call returns undef and we die with
an error message.
Line 15: Create the destination
address The final preparatory step is to create the
destination address for outgoing messages. We call
inet_aton() to turn the hostname into a packed
string and pack this with the port into a
sockaddr_in structure, using the function of the
same name.
Line 16: Send the request We now
have a socket and a destination address. The next step is to
send a message to the server to tell it that it has a
customer waiting. With the daytime service, one can send any
message (even an empty one) and the server will respond with
the time of day.
To send the message, we call the
send() function. send() takes four
arguments: the socket name, the message to send, the message
flags, and the destination to send it to. For the message
contents we use the string "What time is it?" but any string
would do. We pass a 0 for the message flags in order to
accept the defaults. For the destination address, we use the
packed sockaddr_in address that we built
earlier.
If the message is correctly queued for
delivery, send() returns a true value. Otherwise,
we die with an error message.
Line 17: Receive response The
message has now been sent (or at least successfully queued),
so we wait for a response using the recv()
function. Like send(), this call also takes several
arguments, including the socket, a variable in which to
store the received data, and a numeric value indicating the
maximum length of the message that we will receive.
If a message is received, recv()
copies up to MAX_MSG_LEN bytes of it into
$data. In case of an error, recv() returns
undef, and we exit with an error message.
Otherwise, recv() returns the packed address of the
sender. We don't do anything with the sender's address but
will put it to good use in the server examples given in
later sections.
Lines 1819: Print the response We
remove the CRLF at the end of the message with
chomp() and print its contents to standard output.
Creating and Using UDP Sockets
As shown in the example of the last section,
UDP datagrams are sent and received via sockets. However,
unlike TCP sockets, there is no step in which you
connect() the socket or accept() an incoming
connection. Instead, you can start transmitting and receiving
messages via the socket as soon as you create it.
UDP Socket Creation
To create a UDP socket, call
socket() with an address family of AF_INET,
a socket type of SOCK_DGRAM, and the UDP protocol
number. The AF_INET and SOCK_DGRAM constants
are defined and exported by default by the Socket module, but
you should use getprotobyname(" udp ") to fetch the
protocol number. Here is the idiom using the built-in
socket() function:
socket(SOCK, AF_INET, SOCK_DGRAM, scalar getprotobyname('udp'))
or die "socket() failed: $!";
The send() and recv()
Functions
Once you have created a UDP socket, you can
use it as an endpoint for communication immediately. The
send() function is used to transmit datagrams, and
recv() is used to receive them. We've seen
send() and recv() before in the context of
sending and receiving TCP urgent data (Chapter
17). To send a datagram, the idiom is this:
$bytes = send (SOCK,$message,$flags,$dest_addr);
Using socket SOCK, send()
sends the message data that is contained in $message
to the destination indicated by $dest_addr. The
$flags argument, which in addition to controlling TCP
out-of-band data can be used to adjust esoteric routing
parameters, should be set to 0. The destination address must
be a packed socket address created by sockaddr_in().
Like all other INET addresses, the address includes the port
number and IP address of the destination.
send() will return the number of
bytes successfully queued for delivery. If for some reason it
couldn't queue the message, send() returns
undef and sets $! to the relevant error
message. Note that a positive response from send()
does not mean that the message
was successfully delivered, or even that it was placed on the
network wire. All this means is that the operating system has
successfully copied the message into the local send buffer.
UDP is unreliable and
guarantees nothing.
Having used a socket to send a message to one
destination address, a program can turn right around and use
send() to send a second message to a different
destination. Unlike TCP, in the UDP protocol there is no
long-term relationship between a socket and its peer.
To receive a UDP message, call
recv(). This function also takes four arguments, and
uses this idiom:
$sender = recv (SOCK,$data,$max_size,$flags);
In this case $data is a scalar that
receives the contents of the message, $max_size is
the maximum size of the datagram that you can accept, and
$flags should once again be set to 0. The
recv() call will block until a datagram is received.
On receipt of a message, recv() returns the message
contents in $data and the packed address of the
sender in the function result. The sender address is provided
so that you can reply to the sender.
If the received datagram is larger than
$max_size, it will be truncated. If some error
occurs, recv() returns undef and sets
$! to the appropriate error code.
If you are familiar with the C-language
socket API, you should know that the Perl recv()
function is actually implemented on top of the C language
recvfrom() call, not the recv() call
itself.
Binding a UDP Socket
By default, the operating system assigns to a
new UDP socket an unused ephemeral port number and a wildcard
IP address of INADDR_ANY. Clients can usually accept
this default, because when the client transmits a request to a
server, its UDP datagram contains this return address,
allowing the server to return a response.
However, a server application usually wants
to bind its socket to a well-known port so that clients can
rendezvous with it. To do this, call bind() in the
same way you would with a TCP socket. For example, to bind a
UDP socket to port 8000, you might use the following code
fragment:
my $local_addr = sockaddr_in(8000,INADDR_ANY);
bind (SOCK,$local_addr) or die "bind(): $!";
Once a UDP socket is bound, many systems do
not allow it to be rebound to a different address.
Connecting a UDP Socket
Although it seems like an oxymoron, it is possible to call
connect() with a UDP socket. No actual connection is
attempted; instead the system stores the specified destination
address of the connect() function and uses this as
the destination for all subsequent calls to send().
You can retrieve this address using
getpeername().
After the UDP socket is connected,
send() will accept only the first three arguments.
You should not try to specify a destination address as the
fourth argument, or you will get an "invalid argument" error.
This is convenient for clients that wish to communicate only
with a single UDP server. After connecting the socket, clients
can send() to the same server multiple times without
having to give the destination address repeatedly.
Should you wish to change the destination
address, you may do so by calling connect() again
with the new address. Although the C-language equivalent of
this call allows you to dissolve the association by connecting
to a NULL address, Perl does not provide easy access to this
functionality.
A nice side effect of connecting a datagram
socket is that such a socket can receive messages only from
the designated peer. Messages sent to the socket from other
hosts or from other ports on the peer host are ignored. This
can add a modicum of security to a client program. However,
connecting a datagram socket does not change its basic
behavior: It remains message oriented and unreliable.
Servers that typically must receive and send
messages to multiple clients should generally not connect their sockets.
UDP Errors
UDP errors are a little unusual because they
can occur asynchronously. Consider what happens when you use
send() to transmit a UDP datagram to aremote host
that has no program listening on the specified port. With TCP,
you would get a "connection refused" (ECONNREFUSED)
error on the call to connect(). Similarly, a problem
at the remote end, such as the server going down, will be
reported synchronously the next time you read or write to the
socket.
UDP is different. The return value from
send() tells you nothing about whether the message
was delivered at the remote end, because send()
simply returns true if the message is successfully queued by
the operating system. In the event that no server is listening
at the other end and you go on to call recv(), the
call blocks forever, because no reply from the host is
forthcoming.
Asynchronous Errors
There is, however, a way to recover some
information on UDP communications errors. If a UDP socket has
been connected, it is possible to receive asynchronous errors. These are errors
that occur at some point after sending a datagram, and include
ECONNREFUSED errors, host unreachable messages from
routers, and other problems.
Asynchronous errors are not detected by
send(), because this always reports success if the
datagram was successfully queued. Instead, after an
asynchronous error occurs, the next call to recv()
returns an undef value and sets $! to the
appropriate error message. It is also possible to recover and
clear the asynchronous error by calling getsockopt()
with the SO_ERROR command.
You may also use select() on a UDP
socket to determine whether an asynchronous error is
available. The socket will appear to be readable, and
recv() will not block.
The implementation of UDP on Linux systems
differs somewhat from this description. On such systems,
asynchronous errors are always returned regardless of whether
or not a socket is connected. In addition, if the network is
sufficiently fast, it is sometimes possible for
send() to detect and report datagram delivery errors
as well.
Dropped Packets and
Fragmentation
The most common UDP errors are not easily
detected. As described in Chapter
3, UDP messages can be lost in transit or arrive in a
different order from that in which they were sent. Because
there is no flow control in the UDP protocol and each host has
only finite buffer space for received datagrams, if a host
receives datagrams faster than the application can read them,
then excess datagrams will be dropped silently.
Although datagrams can, in theory, be as
large as 65,535 bytes, in practice the size is limited by the
maximum transmission unit (MTU) of the network media. Beyond
this size, the datagram will be fragmented into multiple
pieces, and the receiving operating system will try to
reassemble it. If any of the pieces were lost in transmission,
then the whole datagram is discarded.
On Ethernet networks, the MTU is 1,500 bytes.
However, some of the links that a datagram may traverse across
the Internet may use an MTU as small as 576 bytes. For this
reason, it's best to keep UDP messages smaller than this
limit.
Provided that a datagram is received at all,
its contents are guaranteed by a checksum that the TCP/IP
protocol places on each packetthat is, if the application
hasn't deliberately turned off the UDP checksum.
Sending to Multiple Hosts
One of the nice features of UDP is that the
same socket can be used to send to and receive messages from
multiple hosts. To illustrate this, let's rewrite the daytime
client so that it can ask for the time from multiple
hosts.
The revised client reads a list of hostnames
from the command line and sends a daytime request to each one.
It then enters a loop in which it calls recv()
repeatedly to read any responses returned by the server. The
loop quits when the number of responses received matches the
number of requests sent, or until a preset timeout occurs. As
it receives each response, the client prints the name of the
remote host and the time it returned. Figure
18.3 lists the code for the revised daytime client, udp_daytime_multi.pl.

Lines 17: Initialize script We
bring in the IO::Socket module and its constants. We again
declare the MAX_MSG_LEN constant and define a
timeout of 10 seconds for the receipt of all the responses.
As before, we set the input record separator to
CRLF.
Line 8: Set up a signal handler We
will use alarm() to set the timeout on received
responses, so we install an ALRM signal handler,
which simply dies with an appropriate message.
Line 9: Create socket We call
IO::Socket::INET->new() with a Proto argument of " udp
" to create a UDP socket. Because we will specify the
destination address within send() and don't want
IO::Socket to perform an automatic connect(), we do
not provide PeerPort or
PeerAddr arguments.
Line 10: Look up the daytime port We
look up the port number for the UDP version of the daytime
service using getservbyname().
Lines 1120: Send request to all
hosts We now send a request to each host that is given
on the command line. For each host we use
inet_aton() to translate its name into a packed IP
address, and sockaddr_in() to create a suitable
destination address.
We now send a request to the time-of-day
server running on the indicated host. As before, the exact
content of the request is irrelevant. If send()
reports that the message was successfully queued, we bump up
the $host_count counter. Otherwise, we warn about
the error.
Lines 2132: Wait for responses We
are now going to wait for up to TIMEOUT seconds for
all the responses to come in. If we get all the responses we
are expecting, we leave the loop early. We call
alarm() to set the timeout and enter a loop that
decrements $host_count each time through. Within
the body of the loop, we call recv(). If
recv() returns false, then an error has occurred
and we print the contents of $! and go on to the
next iteration of the loop.
If recv() succeeds, it places the
received message into $daytime. We now attempt to
recover the hostname of the sender of the message we just
received. Recall that IO::Socket::INET conveniently
remembers the peer address from themost recent invocation of
recv(). We fetch this address by calling
peeraddr() and pass it to gethostbyaddr()
to translate it into a DNS name. If gethostbyaddr()
fails, we call the socket's peerhost() method to
translate the packed peer address into a dotted-quad IP
address string.
We remove the terminal CRLF from
$daytime and print the time and the name of the
host that reported it.
Line 33: Turn off the alarm On
principle, we deactivate the alarm after the loop is done.
This isn't strictly necessary because the program will exit
immediately anyway.
Here is what I saw when I ran the client
against several machines located in various parts of the
world. Notice that we got a delayed " Connection
refused " message from one of the machines, but we can't
easily determine which one generated the error (except by a
process of elimination). Finally, notice that the responses
don't come back in the same order in which we submitted the
requests!
% udp_daytime_multi.pl sunsite.auc.dk rtfm.mit.edu wuarchive.wustl.edu
prep.ai.mit.edu
sent to sunsite.auc.dk...
sent to rtfm.mit.edu...
sent to wuarchive.wustl.edu...
sent to prep.ai.mit.edu...
Waiting for responses...
PENGUIN-LUST.MIT.EDU: Thu Aug 17 05:57:50 2000
wuarchive.wustl.edu: Thu Aug 17 04:57:52 2000
Connection refused
sunsite.auc.dk: Thu Aug 17 11:57:54 2000
Aside from the time-zone differences, the
three machines that responded reported the same time, plus or
minus a few seconds. It is likely that they are running XNTP
servers, a UDP-based protocol for synchronizing clocks with an
authoritative source.
UDP Servers
UDP servers are generally much simpler in
design than their TCP brethren. A typical UDP server is a
simple loop that receives a message from an incoming client,
processes it, and transmits a response. A server may handle
requests from different clients with each iteration of the
loop.
Because there's no long-term relationship
between client and server, there's no need to manage
connections, maintain concurrency, or retain state for an
extended time. By the same token, a UDP server must be careful
to process each transaction quickly or it may delay the
response to waiting requests.
We will look at UDP servers in more detail in
Chapter
19. In this chapter, we show a very simple example of a
UDP client/server pair.
A UDP Reverse-Echo Server
For this example, we reimplement the
reverse-echo server from Chapter
4 (Figure
4.2). As you recall, this server reads lines of input from
the socket, reverses them, and echoes them back. Figure
18.4 lists the code.
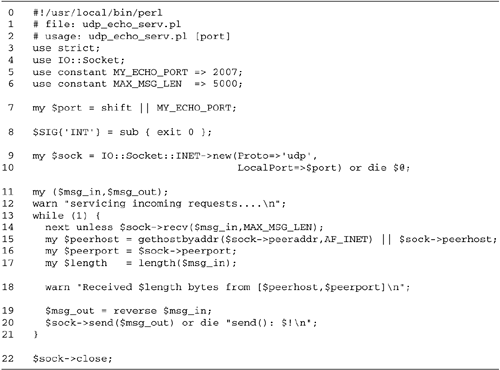
Lines 17: Initialize module We load
the IO::Socket module and initialize our constants. The
MY_ECHO_PORT constant should be set to an unused
port on your system. We allow our port number to be changed
at runtime using a command-line argument. If this argument
is present, we recover it and store it in $port.
Line 8: Install INT handler We
install an INT handler so that the server exits
gracefully when the interrupt key is pressed. Microsoft
Windows users will want to comment this out to avoid Dr.
Watson errors.
Lines 910: Create the socket We
call IO:Socket::INET->new() to create a UDP
socket bound to the port specified on the command line. The
LocalPort argument is
required to bind to the correct port, but as with TCP
sockets there's no need to provide LocalAddr explicitly.
IO::Socket::INET assumes INADDR_ANY, allowing the
socket to receive messages on any of the host's network
interfaces.
Lines 1121: Main loop We enter an
infinite loop. Each time through the loop we call the
socket's recv() method, copying the message into
$msg_in. If for some reason we encounter an error,
we just continue with the next iteration of the loop.
After accepting a message, we call the
socket's peeraddr() method to recover the packed
address of the sender, and attempt to translate it into a
DNS hostname as before. If this fails, we retrieve the
dotted-quad form of the peer's IP address. The call to
peerport() returns the sender's port number. We
print a status message to standard error and generate a
response consisting of the client's message reversed
end-to-end.
We now take advantage of another trick in
the IO::Socket module. As mentioned earlier, if you call the
send() method immediately after recv(),
IO::Socket uses the stored peer address as its default
destination. This means that we do not have to explicitly
pass the destination address to send(). This
reduces the idiom to a succinct:
$sock->send($msg_out) or die "send(): $!\n"; # (line 21)
Line 22: Close the socket Although
this statement is never reached, we call the socket's
close() method at the end of the script.
UDP Echo Client
We need a client to go along with this
server. A suitable one is shown in Figure
18.5.
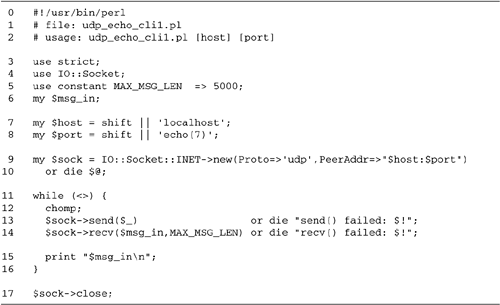
Lines 18: Initialization We load
the IO::Socket module and initialize our constants and
global variables. We use the standard " echo "
service port as our default. This can be overridden on the
command line, for instance to talk to the reverse-echo
server discussed in the previous section.
Lines 910: Create socket We create
a new IO::Socket::INET object, requesting the UDP protocol
and specifying a PeerAddr
that combines the selected hostname and port number. Because
we know in advance that the socket will be used to send
messages to only one single host, we allow IO::Socket to
call connect().
Lines 1116: Main loop We read a
line of input from standard input, then remove the terminal
newline and send() it to the server. We don't need
to specify a destination address, because the default
destination has been set with connect(). We then
call recv() to receive a response and print it to
standard output.
Line 17: Close the socket The loop
exits when standard input is closed. We close the socket by
calling its close() method.
I launched the echo server from the previous
section on the machine brie.cshl.org and ran the client on
another machine, being careful to specify port 2007 rather
than the default echo port. The transcript from the client
session looked like this:
% udp_echo_cli1.pl brie.cshl.org 2007
hello there
ereht olleh
what's up?
?pu s'tahw
goodbye
eybdoog
^D
Meanwhile, on the server machine, these
messages were printed.
% udp_echo_serv.pl
servicing incoming requests....
Received 11 bytes from [brie.cshl.org,1048]
Received 10 bytes from [brie.cshl.org,1048]
Received 7 bytes from [brie.cshl.org,1048]
If other clients had sent requests during the
same period of time, the server would have processed them as
well and printed an appropriate status message.
Increasing the Robustness of UDP
Applications
Because UDP is unreliable, problems arise
when you least expect them. Although the echo client of Figure
18.5 looks simple, it actually contains a hidden bug. To
bring out this bug, try pointing the client at an echo server
running on a remote UNIX host somewhere on the Internet.
Instead of typing directly into the client, redirect its
standard input from a large text file, such as /usr/dict/words:
% udp_echo_cli1.pl wuarchive.wustl.edu echo </usr/dict/words
If the quality of your connection is
excellent, you may see the entire contents of the file scroll
by and the command-line prompt reappear after the last line is
echoed. More likely, though, you will see the program get part
way through the text file and then hang indefinitely. What
happened?
Remember that UDP is an unreliable protocol.
Any datagram sent to the remote server may fail to reach its
destination, and any datagram returned from the server to the
local host may vanish into the ether. If the remote server is
very busy, it may not be able to keep up with the flow of
incoming packets, resulting in buffer overrun errors.
Our echo client doesn't take these
possibilities into account. After we send() the
message, we blithely call recv(), assuming that a
response will be forthcoming. If the response never arrives,
we block indefinitely, making the script hang.
This is yet another example of deadlock. We
won't get a message from the server until we send it one to
echo back, but we can't do that because we're waiting for a
message from the server!
As with TCP, we can avoid deadlock either by
timing out the call to recv() or by using some form
of concurrency to decouple the input from the output.
Timing Out UDP Receives
It's straightforward to time out a call to
recv() using an eval{} block and an
ALRM handler:
eval {
local $SIG{ALRM} = sub { die "timeout\n" };
alarm($timeout);
$result = $sock->recv($msg_in,max_msg_LEN);
alarm(0);
};
if ($@) {
die $@ unless $@ eq "timeout\n";
warn "Timed out!\n";
}
We wrap recv() in an eval{}
block and set a local ALRM handler that invokes
die(). Just prior to making the system call, we call
the alarm() function with the desired timeout value.
If the function returns normally, we call alarm(0) to
cancel the alarm. Otherwise, if the alarm clock goes off
before the function returns, the ALRM handler runs
and we die. But since this fatal error is trapped within an
eval{} block, the effect is to abort the entire block
and to leave the error message in the $@ variable.
Our last step is to examine this variable and issue a warning
if a timeout occurred or die if the variable contains an
unexpected error.
Using a variant of this strategy, we can
design a version of the echo client that transmits a message
and waits up to a predetermined length of time for a response.
If the recv() call times out, we try again by
retransmitting the request. If a predetermined number of
retransmissions fail, we give up.
Figure
18.6 shows a modified version of the echo client, udp_echo_cli2.pl.

Lines 115: Initialize module, create
socket The main changes are two new constants to control
the timeouts. TIMEOUT specifies the time, in
seconds, that the client will allow recv() to wait
for a message. We set it to 2 seconds. MAX_RETRIES
is the number of times the client will try to retransmit a
message before it assumes that the remote server is not
answering.
Lines 1630: Main loop We now place
a do{} loop around the calls to send() and
recv(). The do{} loop retransmits the
outgoing message every time a timeout occurs, up to
MAX_RETRIES times. Within the do{} loop,
we call send() to transmit the message as before,
but recv() is wrapped in an eval{} block.
The only difference between this code and the generic idiom
is that the local ALRM handler bumps up a variable
named $retries each time it is invoked. This allows
us to track the number of timeouts. After the
eval{} block completes, we check whether the number
of retries is greater than the maximum retry setting. If so
we issue a short warning and die.
The easiest way to test the new and improved
echo client is to point it at a port that isn't running the
echo service, for example, 2008 on the local
host:
% udp_echo_cli2.pl localhost 2008
anyone home?
Retrying...1
Retrying...2
Retrying...3
Retrying...4
Retrying...5
timeout
Duplicates and Out-of-Sequence
Datagrams
While this timeout code fixes the problem
with deadlocks, it opens the door on a new one: duplicates.
Instead of being lost, it is possible that the missing
response was merely delayed and that it will arrive later. In
this case, the program will receive an extra message that it
isn't prepared to deal with.
If you are sufficiently dexterous and are
using a UNIX machine, you can demonstrate this with the
reverse-echo server/echo client pair from Figures
18.4 and 18.6.
Launch the echo server and echo clients in separate windows.
Type a few lines into the echo client to get things going. Now
suspend the echo server by typing ^Z, and go back to the
client window and type another line. The client will begin to
generate timeout messages. Quickly go back to the server
window and resume the server by typing the fg command. The client will recover
from the timeout and print the server's response.
Unfortunately, the client and server are now hopelessly out of
synch! The responses the client displays are those from the
retransmitted requests, not the current request.
Another problem that we can encounter in UDP
communications is out-of-sequence datagrams, in which two
datagrams arrive in a different order from that in which they
were sent. The general technique for dealing with both these
problems is to attach a sequence number to each outgoing
message and design the client/server protocol in such a way
that the server returns the same sequence number in its
response. In this section, we develop a better echo client
that implements this scheme. In so doing, we show how
select() can be used with UDP sockets to implement
timeouts and prevent deadlock.
To implement a sequence number scheme, both
client and server have to agree on the format of the messages.
Our scheme is a simple one. Each request from client to server
consists of a sequence number followed by a " : "
character, a space, and a payload of arbitrary length.
Sequence numbers begin at 0 and count upward. For example, in
this message, the sequence number is 42 and the
payload is " the meaning of life ":
42: the meaning of life
The reverse-echo server generates a response
that preserves this format. The server's response to the
sample request given earlier would be:
42: efil fo gninaem eht
The modifications to the reverse-echo server
of Figure
18.4 are trivial. We simply replace line 19 with a few
lines of code that detect messages having the sequence
number/payload format and generate an appropriately formatted
response.
if ( $msg_in =~ /^(\d+): (.*)/ ) {
$msg_out = "$1: ".reverse $2;
} else {
$msg_out = reverse $msg_in;
}
For backward compatibility, messages that are
not in the proper format are simply reversed as before.
Another choice would be to have the server discard
unrecognized messages.
All the interesting changes are in the
client, which we will call udp_echo_cli3.pl (Figure
18.7). Our strategy is to maintain a hash named
%PENDING to contain a record of every request that
has been sent. The hash is indexed by the sequence number of
the outgoing request and contains both a copy of the original
request and a counter that keeps track of the number of times
the request has been sent.

A global variable $seqout is
incremented by 1 every time we generate a new request, and
another global, $seqin, keeps track of the sequence
number of the last response received from the server so that
we can detect out-of-order responses.
We must abandon the send-and-wait paradigm of
the earlier UDP clients and assume that responses from the
server can arrive at unpredictable times. To do this, we use
select() with a timeout to multiplex between
STDIN and the socket. Whenever the user types a new
request (i.e., a string to be reversed), we bump up the
$seqout variable and create a new request entry in
the %PENDING array.
Whenever a response comes in from the server,
we check its sequence number to see if it corresponds to a
request that we have made. If it does, we print the response
and delete the request from %PENDING. If a response
comes in whose sequence number is not found in %PENDING, then
it is a duplicate response, which we discard. We store the
most recent sequence number of an incoming response in
$seqin, and use it to detect out-of-order responses.
In the case of this client, we simply warn about out-of-order
responses, but don't take any more substantial action.
If the call to select() times out
before any new messages arrive, we check the %PENDING
array to see if there is still one or more unsatisfied
requests. If so, we retransmit the requests and bump up the
counter for the number of times the request has been
tried.
In order to mix line-oriented reads from
STDIN with multiplexing, we take advantage of the
IO::Getline module that we developed in Chapter
13 (Figure
13.2). Let's walk through the code now:
Lines 19: Load modules, define
constants We bring in the IO::Socket, IO::Select, and
IO::Getline modules.
Lines 1012: Define the structure of the
%PENDING hash The %PENDING hash is indexed
by request sequence number. Its values are two-element array
references containing the original request and the number of
times the request has been sent. We use symbolic constants
for the indexes of this array reference, such that
$PENDING{$seqno}[REQUEST] is the text of the
request and $PENDING{$seqno}[TRIES] is the number
of times the request has been sent to the server.
Lines 1318: Global variables
$seqout is the master counter that is used to
assign unique sequence numbers to each outgoing request.
$seqin keeps track of the sequence number of the
last response we received. The server $host and
$port are read from the command line as before.
Lines 1922: Create socket, IO::Select
objects, and IO::Getline objects We create a UDP socket
as before. If successful, we create an IO::Select set
initialized to contain the socket and STDIN, as
well as an IO::Getline object wrapped around STDIN.
Lines 2325: The select() loop We
now enter the main loop of the program. Each time through
the loop we call the select set's can_read() method
with the desired timeout. This returns a list of filehandles
that are ready for reading, or if the timeout expired, an
empty list. We loop through each of the filehandles that are
ready for reading. There are only two possibilities. One is
that the user has typed something and STDIN has
some data for us to read. The other is that a message has
been received and we can call recv() on the socket
without blocking.
Lines 2632: Handle input on STDIN
If STDIN is ready to read, we fetch a line from its
IO::Getline wrapper by calling the getline()
method. Recall that the syntax for
IO::Getline->getline() works like
read(). It copies the line into a scalar variable
(in this case, $_) and returns a result code
indicating the success of the operation.
If getline() returns false, we
know we've encountered the end of file and we exit the loop.
Otherwise, we check whether we got a complete line by
looking at the line length returned by getline(),
and if so, remove the terminating end-of-line sequence and
call send_message() with the message text and a new
sequence number.
Lines 3337: Handle a message on the
socket If the socket is ready to read, then we've
received a response from the server. We retrieve it by
calling the socket's recv() method and pass the
message to our receive_message() subroutine.
Lines 3941: Handle retries If
@ready is empty, then we have timed out. We call
the do_retries() subroutine to retransmit any
requests that are pending.
Lines 4249: The send_message()
subroutine This subroutine is responsible for transmitting a
request to the server given a unique sequence number and the
text of the request. We construct the message using the
simple format discussed earlier and send() it to
the server.
We then add the request to the
%PENDING hash. This subroutine is also called on to
retransmit requests, so rather than setting the
TRIES field to 1, we increment it and let Perl take
care of creating the field if it doesn't yet exist.
Lines 5066: The receive_message()
subroutine This subroutine is responsible for processing an
incoming response. We begin by parsing the sequence number
and the payload. If it doesn't fit the format, we print a
warning and return. Having recovered the response's sequence
number, we check to see whether it is known to the
%PENDING hash. If not, this response is presumably
a duplicate. We print a warning and return. We check to see
whether the sequence number of this response is greater than
the sequence number of the last one. If not, we print a
warning, but don't take any other action.
If all these checks pass, then we have a
valid response. We print it out, remember its sequence
number, and delete the request from the %PENDING
hash.
Lines 6777: The do_retries()
subroutine This subroutine is responsible for retransmitting
pending requests whose responses are late. We loop through
the keys of the %PENDING hash and examine each
one's TRIES field. If TRIES is greater
than the MAX_RETRIES constant, then we print a
warning that we are giving up on the request and delete it
from %PENDING. Otherwise, we invoke
send_message() on the request in order to
retransmit it.
To test udp_echo_cli3.pl, I modified the
reverse-echo server to make it behave unreliably. The
modification occurs at line 20 of Figure
18.4 and consists of this:
for (1..3) {
$sock->send($msg_out) or die "send(): $!\n" if rand() > 0.7;
}
Instead of sending a single response as
before, we now send a variable number of responses using
Perl's rand() function to generate a random coin
flip. Sometimes the server sends one response, sometimes none,
and sometimes several.
When we run udp_echo_cli3.pl against this
unreliable server, we see output like the following. In this
transcript, the user input is bold, standard error is italic,
and the output of the script is roman.
% udp_echo_cli3.pl localhost 2007
hello there
0: retrying...
hello there => ereht olleh
Discarding duplicate message seqno = 0
Discarding duplicate message seqno = 0
this is unreliable communications
1: retrying...
this is unreliable communications => snoitacinummoc elbailernu si siht
but it works anyway
2: retrying...
but it works anyway => yawyna skrow ti tub
Discarding duplicate message seqno = 2
Discarding duplicate message seqno = 2
Even though some responses were dropped and
others were duplicated, the client still managed to associate
the correct response with each request.
A cute thing about this client is that it
will work with unmodified UDP echo servers. This is because we
designed the message protocol in such a way that the protocol
is correct even if the server just returns the incoming
message without modification.
As written in Figure
18.7, the client is slightly inefficient because we time
out can_read(), even when there's nothing in
%PENDING to wait for. We can fix this problem by
modifying line 23 of Figure
18.7 to read this way:
my @ready = $select->can_read ( %PENDING ? TIMEOUT : () );
If %PENDING is nonempty, we call
can_read() with a timeout. Otherwise, we pass an
empty list for the arguments, causing can_read() to
block indefinitely until either the socket or STDIN
are ready to read.
Chapter 19. UDP Servers
TCP provides reliable connection-oriented
network service, but at the cost of some overhead in setting
up and tearing down connections and maintaining the fidelity
of the data stream. As we have seen, there's also programmer
overhead: TCP server applications have to go to some lengths
to handle multiple concurrent clients.
Sometimes 100 percent reliability isn't
necessary. Perhaps the application can tolerate an occasional
dropped or out-of-order packet, or perhaps it can simply
retransmit a message that hasn't been acknowledged. In such
cases, UDP offers a simple, lightweight solution.

An Internet Chat System
This chapter develops a useful UDP version of
an Internet chat system. Like other chat systems that might be
familiar to you, the software consists of a server that
manages multiple discussion groups called "channels." Users
log into the server using a command-line client, join whatever
channels they are interested in, and begin exchanging public
messages. Any public message that a user sends is echoed by
the server to all members of the user's current channel. The
server also supports private messages, which are sent to a
single user only by using his or her login name. The system
notifies users whenever someone joins or departs one of the
channels they are monitoring.
A Sample Session
Figure
19.1 shows a sample session with the chat client. As
always, keyboard input is in a bold font and output from the
program is in normal font.

We begin by invoking the client with the name
of the server to connect to. The program prompts us for a
nickname, logs in, and prints a confirmation message. We then
issue the /channels command
to fetch the list of available channels. This client, like
certain other command-line chat clients, expects all commands
to begin with the " / " character. Anything else we
type is assumed to be a public message to be transmitted to
the current channel. The system replies with the names of five
channels, a brief description, and the number of users that
belong to each one (a single user may be a member of multiple
channels at once, so the sum of these numbers may not reflect
the total number of users on the system).
We join the Weather channel using the /join command, at which point we
begin to see public messages from other users, as well as join
and departure notifications. We participate briefly in the
conversation and then issue the /users command to view the users
who currently belong to the channel. This command lists users'
nicknames, the length of time that they have been on the
system, and the channels that they are subscribed to.
We send a private message to one of the users
using the /private command,
/join the Hobbies channel
briefly, and finally log out using /quit.
In addition to the commands shown in the
example (Figure
19.1), there's also a /part command that allows one to
depart a channel. Otherwise, the list of subscribed channels
just grows every time you join one.
Chat System Design
The chat system is message oriented. Clients
send prearranged messages to the server to log in, join a
channel, send a public message, and so forth. The server sends
messages back to the client whenever an event of interest
occurs, such as another user posting a public message to a
subscribed channel.
Event Codes
In all our previous examples, we have passed
information between client and server in text form. For
example, in the travesty server, the server's welcome message
was the text string "100." However, some Internet protocols
pass command codes and other numeric data in binary form. To
illustrate such systems, the chat server uses binary codes
rather than human-readable ones.
In this system, all communication between
client and server is via a series of binary messages. Each
message consists of an integer event code packed with a
message string. For example, to create a public message using
the SEND_PUBLIC message constant, we call
pack() with the format "na*":
$message = pack("na*",SEND_PUBLIC,"hello, anyone here?");
To retrieve the code and the message string,
we call unpack() with the same format:
($code,$data) = unpack("na*",$message);
We use the " n " format to pack the
event code in platform-independent "network" byte order. This
ensures that clients and servers can communicate even if their
hosts don't share the same byte order.
The various event codes are defined as
constants in a .pm file that is
shared between the client and server source trees. The code
for packing and unpacking messages is encapsulated in a module
named ChatObjects::Comm. A brief description of each of the
messages is given in Table
19.1.
Table 19.1. Event
Codes
| ERROR |
<error
message> |
Server reports an
error |
| LOGIN_REQ |
<nickname> |
Client requests a
login |
| LOGIN_ACK |
<nickname> |
Server acknowledges
successful login |
| LOGOFF |
<nickname> |
Client signals a
signoff |
| JOIN_REQ |
<title>
|
Client requests to
join channel <title> |
| JOIN_ACK |
<title>
<count> |
Server acknowledges
join of channel <title>, currently
containing <count> users |
| PART_REQ |
<title>
|
Client requests to
depart channel |
| PART_ACK |
<title>
|
Server acknowledges
departure |
| SEND_PUBLIC
|
<text>
|
Client sends public
message |
| PUBLIC_MSG
|
<title>
<user> <text> |
User
<user> has sent message
<text> on channel <title>
|
| SEND_PRIVATE
|
<user>
<text> |
Client sends private
message <text> to user
<user> |
| PRIVATE_MSG
|
<user>
<text> |
User
<user> has sent private message
<text> |
| USER_JOINS
|
<channel>
<user> |
User has joined
indicated channel |
| USER_PARTS
|
<channel>
<user> |
User has departed
indicated channel |
| LIST_CHANNELS
|
|
Client requests a list
of all channel titles |
| CHANNEL_ITEM
|
<channel>
<count> <desc> |
Sent in response to a
LIST_CHANNELS request |
| |
|
Channel
<channel> has <count>
users and description <desc> |
| LIST_USERS
|
|
Client requests a list
of users in current channel |
| USER_ITEM |
<user>
<timeon> <channel 1> <channel
2>...<channel n> |
Sent in response to a
LIST_USERS request. User <user>
has been online for <timeon> seconds and
is subscribed to channels <channel 1>
through <channel n>
|
User Information
The system must maintain a certain amount of
state information about each active user: the channels she has
subscribed to, her nickname, her login time, and the address
and port her client is bound to. While this information could
be maintained on either the client or the server side, it's
probably better that the server keep track of this
information. It reduces the server's dependency on the
client's implementing the chat protocol correctly, and it
allows for more server-side features to be added later. For
example, since the server is responsible for subscribing users
to a channel, it is easy to limit the number or type of
channels that a user can join. This information is maintained
by objects of class ChatObjects::User.
Channel Information
One other item of information that the server
tracks is the list of channels and associated information. In
addition to the title, channels maintain a human-readable
description and a list of the users currently subscribed. This
simplifies the task of sending a message to all members of the
channel. This information is maintained by objects of class
ChatObjects::Channel.
Concurrency
We assume that each transaction that the
server is called upon to handlelogging in a user, sending a
public message, listing channelscan be disposed of rapidly.
Therefore, the server has a single-threaded design that
receives and processes messages on a first-come, first-served
basis. Messages come in from users in any order, so the server
must keep track of each user's address and associate it with
the proper ChatObjects::User object.
On the other end, the client will be
communicating with only one server. However, it needs to
process input from both the server and the user, so uses a
simple select() loop to multiplex between the two
sources of input.
The object classes used by the server are
designed for subclassing. This enables us to modify the chat
system to take advantage of multicasting in the next
chapter.
The Chat Server
The chat server is more complicated than the
chat client because it must keep track of each user that logs
in and each user's changing channel membership. When a user
enters or leaves a channel, the server must transmit a
notification to that effect to every remaining member of the
channel. Likewise, when a user sends a public message while
enrolled in a channel, that message must be duplicated and
sent to each member of the channel in turn.
To simplify user management, we create two
utility classes, ChatObjects::User and ChatObjects::Channel. A
new ChatObjects::User object is created each time a user logs
in to the system and destroyed when the user logs out. The
class remembers the address and port number of the client's
socket as well as the user's nickname, login time, and channel
subscriptions. It also provides method calls for joining and
departing channels, sending messages to other users, and
listing users and channels. Since most of the server consists
of sending the appropriate messages to users, most of the code
is found in the ChatObjects::User class.
ChatObjects::Channel is a small class that
keeps track of each channel. It maintains the channel's name
and description, as well as the list of subscribers. The
subscriber list is used in broadcasting public messages and
notifying members when a user enters or leaves the
channel.
The Main Server Script
Let's walk through the main body of the
server first (Figure
19.5).

Lines 18: Load modules The program
begins by loading various ChatObjects modules, including
ChatObjects::ChatCodes, ChatObjects::Comm, and
ChatObjects::User. It also defines a DEBUG constant
that can be set to a true value to turn on debug messages.
Lines 914: Define channels We now
create five channels by invoking the
ChatObjects::Channel->new() method. The method
takes two arguments corresponding to the channel title and
description.
Lines 1524: Create the dispatch
table We define a dispatch table, named
%DISPATCH, similar to the ones used in the client
application. Each key in the table is a numeric event code,
and each value is the name of a ChatObject::User method.
With the exception of the initial login, all interaction
with the remote user goes through a ChatObjects::User
object, so it makes sense to dispatch to method calls rather
than to anonymous subroutines, as we did in the client.
Here is a typical entry in the dispatch
table:
SEND_PUBLIC() => 'send_public',
This is interpreted to mean that whenever a
client sends us a SEND_PUBLIC message, we will call
the corresponding ChatObject::User object's
send_public() method.
Lines 2528: Create a new ChatObjects::
Comm object We get the port from the command line and
use it to initialize a new ChatObjects::Comm object with the
arguments LocalPort=>$port. Internally this
creates a UDP protocol IO::Socket object bound to the
desired port. Unlike in the client code, in the server we do
not specify a peer host or port to connect with, because
this would disable our ability to receive messages from
multiple hosts.
Lines 2932: Process incoming messages,
handle login requests The main server loop calls the
ChatObject::Server object's recv_event()
repeatedly. This method calls recv() on the
underlying socket, parses the message, and returns the event
code, the event message, and the packed address of the
client that sent the message.
Login requests receive special treatment
because there isn't yet a ChatObjects::User object
associated with the client's address. If the event code is
LOGIN_REQ, then we pass the address, the event
text, and our ChatObjects::Comm object to a
do_login() subroutine. It will create a new
ChatObjects::User object and send the client a
LOGIN_ACK.
Lines 3335: Look up the user Any
other event code must be from a user who has logged in
earlier. We call the class method
ChatObjects::User->lookup_byaddr() to find a
ChatObjects::User object that is associated with the
client's address. If there isn't one, it means that the
client hasn't logged in, and we issue an error message by
sending an event of type ERROR.
Lines 3639: Handle event If we were
successful in identifying the user corresponding to the
client address, we look up the event code in the dispatch
table and treat it as a method call on the user object. The
event data, if any, is passed to the method to deal with as
appropriate. If the event code is unrecognized, we complain
by issuing an ERROR event. In either case, we're
finished processing the transaction, so we loop back and
wait for another incoming request.
Lines 4045: Handle logins The
do_login() subroutine is called to handle new user
registration. It receives the peer's packed address, the
ChatObjects::Comm object, and the LOGIN_REQ event
data, which contains the nickname that the user desires to
register under.
It is certainly possible for two users to
request the same nickname. We check for this eventuality by
calling the ChatObjects::User class method
lookup_byname(). If there is already a user
registered under this name, then we issue an error.
Otherwise, we invoke ChatObjects::User->new() to
create a new user object.
The ChatObjects::User Class
Most of the server application logic is
contained in the ChatObjects::User module (Figure
19.6). This object mediates all events transmitted to a
particular user and keeps track of the set of channels in
which a user is enrolled.

The set of enrolled channels is implemented
as an array. Although the user may belong to multiple
channels, one of those channels is special because it receives
all public messages that the user sends out. In this
implementation, the current channel is the first element in
the array; it is always the channel that the user subscribed
to most recently.
Lines 14: Bring in required modules
The module turns on strict type checking and brings in the
ChatObjects::ChatCodes and Socket modules.
Lines 56: Overload the quote
operator One of Perl's nicer features is the ability to
overload certain operators so that a method call is invoked
automatically. In the case of the ChatObjects::User class,
it would be nice if the object were replaced with the user's
nickname whenever the object is used in a string context.
This would allow the string " Your name is $user "
to interpolate automatically to " Your name is
rufus " rather than to " Your name is
ChatObjects::User=HASH(0x82b81b0). "
We use the overload pragma to
implement this feature, telling Perl to interpolate the
object into double-quoted strings by calling its
nickname() method and to fall back to the default
behavior for all other operators.
Lines 79: Set up package globals
The module needs to look up registered users in two ways: by
their nicknames and by the addresses of their clients. Two
in-memory globals keep track of users. The
%NICKNAMES hash indexes the user objects by the
users' nicknames. %ADDRESSES, in contrast, indexes
the objects by the packed addresses of their clients.
Initially these hashes are empty.
Lines 1022: The new() method The
new() method creates new ChatObjects::User objects.
It is passed three arguments: the packed address of the
user's client, the user's nickname, and a ChatObjects::Comm
object to use in sending messages to the user. We store
these attributes into a blessed hash, along with a record of
the user's login time and an empty anonymous array. This
array will eventually contain the list of channels that the
user belongs to.
Having created the object, we invoke the
server object's send_event() method to return a
LOGIN_ACK message to the user, being sure to use
the three-argument form of send_event() so that the
message goes to the correct client. We then stash the new
object into the %NICKNAMES and %ADDRESSES
hashes and return the object to the caller.
There turns out to be a slight trick
required to make the %ADDRESSES hash work properly.
Occasionally Perl's recv() call returns a packed
socket address that contains extraneous junk in the unused
fields of the underlying C data structure. This junk is
ignored by the send() call and is discarded when
sockaddr_in() is used to unpack the address into
its port and IP address components.
The problem arises when comparing two
addresses returned by recv() for equality, because
differences in the junk data may cause the addresses to
appear to be different, when in fact they share the same
port numbers and IP addresses. To avoid this issue, we call
a utility subroutine named key(), which turns the
packed address into a reliable key containing the port
number and IP address.
Lines 2332: Look up objects by name and
address The lookup_byname() and
lookup_byaddr() methods are class methods that are
called to retrieve ChatObjects::User objects based on the
nickname of the user and her client's address, respectively.
These methods work by indexing into %NICKNAMES and
%ADDRESSES. For the reasons already explained, we
must pass the packed address to key() in order to
turn it into a reliable value that can be used for indexing.
The users() method returns a list of all currently
logged-in users.
Lines 3338: Various accessors The
next block of code provides access to user data. The
address(), nickname(), timeon(),
and channels() methods return the user's address,
nickname, login time, and channel set.
current_channel() returns the channel that the user
subscribed to most recently.
Lines 3943: Send an event to the
user The ChatObjects::User send() method is a
convenience method that accepts an event code and the event
data and passes that to the ChatObject::Server object's
send_event() method. The third argument to
send_event() is the user's stored address to be
used as the destination for the datagram that carries the
event.
Lines 4450: Handle user logout When
the user logs out, the logout() method is invoked.
This method removes the user from all subscribed channels
and then deletes the object from the %NICKNAMES and
%ADDRESSES hashes. These actions remove all memory
references to the object and cause Perl to destroy the
object and reclaim its space.
Lines 5165: The join() method The
join() method is invoked when the user has
requested to join a channel. It is passed the title of the
channel.
The join() method begins by
looking up the selected channel object using the
ChatObjects::Channel lookup() method. If no channel
with the indicated name is identified, we issue an error
event by calling our send() method. Otherwise, we
call our channels() method to retrieve the current
list of channels that the user is enrolled in. If we are not
already enrolled in the channel, we call the channel
object's add() method to notify other users that we
are joining the channel. If we already belong to the
channel, we delete it from its current position in the
channels array so that it will be moved to the top of the
list in the next part of the code. We make the channel
object current by making it the first element of the
channels array, and send the client a JOIN_ACK
event.
Lines 6680: The part() method The
part() method is called when a user is departing a
channel; it is similar to join() in structure and
calling conventions.
If the user indeed belongs to the selected
channel, we call the corresponding channel object's
remove() method to notify other users that the user
is leaving. We then remove the channel from the channels
array and send the user a PART_ACK event. The
removed channel may have been the current channel, in which
case we issue a JOIN_ACK for the new current
channel, if any.
Lines 8189: Send a public message
The send_public() method handles the
PUBLIC_MSG event. It takes a line of text, looks up
the current channel, and calls the channel's
message() method. If there is no current channel,
indicating that the user is not enrolled in any channel,
then we return an error message.
Lines 90101: Send a private message
The send_private() method handles a request to send
a private message to a user. We receive the data from a
PRIVATE_MSG event and parse it into the recipient's
nickname and the message text. We then call our
lookup_byname() method to turn the nickname into a
user object. If no one by that name is registered, we issue
an error message. Otherwise, we call the user object's
send() method to transmit a PRIVATE_MSG
event directly to the user.
This method takes advantage of the fact
that user objects call nickname() automatically
when interpolated into strings. This is the result of
overloading the double-quote operator at the beginning of
the module.
Lines 102111: List users enrolled in
the current channel The list_users() method
generates and transmits a series of USER_ITEM
events to the client. Each event contains information about
users enrolled in the current channel (including the present
user).
We begin by recovering the current channel.
If none is defined (because the user is enrolled in no
channels at all), we send an ERROR event.
Otherwise, we retrieve all the users on the current channel
by calling its users() method, and transmit a
USER_ITEM event containing the user nickname, the
length of time the user has been registered with the system
(measured in seconds), and a space-delimited list of the
channels the user is enrolled in.
Like the user class, ChatObjects::Channel
overloads the double-quoted operator so that its
title() method is called when the object is
interpolated into double-quoted strings. This allows us to
use the object reference directly in the data passed to
send().
Lines 112115: Listchannels
list_channels() returns a list of the available
channels by sending the user a series of
CHANNEL_ITEM events. It calls the
ChatObjects::Channel class's channels() method to
retrieve the list of all channels, and incorporates each
channel into a CHANNEL_ITEM event. The event
contains the information returned by the channel objects'
info() method. In the current implementation, this
consists of the channel title, the number of enrolled users,
and the human-readable description of the channel.
Line 116118: Turn a packed client
address into a hash key As previously explained, the
system recv() call can return random junk in the
unused parts of the socket address structure, complicating
the comparison of client addresses. The key()
method normalizes the address into a string suitable for use
as a hash key by unpacking the address with
sockaddr_in() and then rejoining the host address
and port with a " : " character. Two packets sent
from the same host and socket will have identical keys.
Because we have a method named
join(), we must qualify the built-in function of
the same name as CORE::join() in order to avoid the
ambiguity.
The ChatObjects::Channel Class
Last, we look at the ChatObjects::Channel
class (Figure
19.7). The most important function of this class is to
broadcast messages to all current members of the channel
whenever a member joins, leaves, or sends a public message.
The class does this by iterating across each currently
enrolled user, invoking their send() methods to
transmit the appropriate event.

Lines 13: Bring in modules The
module begins by loading the ChatObjects::User and
ChatObjects::ChatCodes modules.
Lines 47: Overload double-quoted string
operator As in ChatObjects::User, we want to be able to
interpolate channel objects directly into strings. We
overload the double-quoted string operator so that it
invokes the object's title() method, and tell Perl
to fall back to the default behavior for other operators.
At this point we also define a package
global named %CHANNELS. It will hold the definitive
list of channel objects indexed by title for later lookup
operations.
Lines 816: Object constructor The
new() class method is called to create a new
instance of the ChannelObjects::Channel class. We take the
title and description for the new channel and incorporate
them into a blessed hash, along with an empty anonymous hash
that will eventually contain the list of users enrolled in
the channel. We stash the new object in the
%CHANNELS hash and return it.
Lines 1722: Look up a channel by
title The lookup() method returns the
ChatObjects::Channel object that has the indicated title. We
retrieve the title from the subroutine argument array and
use it to index into the %CHANNELS array. The
channels() method fetches all the channel titles by
returning the keys of the %CHANNELS hash.
Lines 2325: Various accessors The
title() and description() methods return
the channel's title and description, respectively. The
users() method returns a list of all users enrolled
in the channel. The keys of the users hash are users'
nicknames, and its values are the corresponding
ChatObjects::User objects.
Lines 2630: Return information for the
CHANNEL_ITEM event The info() method
provides data to be incorporated into the
CHANNEL_ITEM event. In the current version of
ChatObjects::Channel, info() returns a
space-delimited string containing the channel title, the
number of users currently enrolled, and the description of
the channel. In the next chapter we will override
info() to return a multicast address for the
channel as well.
Lines 3135: Send an event to all
enrolled users The send_to_all() method is the
crux of the whole application. Given an event code and the
data associated with it, this method sends the event to all
enrolled users. We do this by calling users() to
get the up-to-date list of ChatObject::User objects and
sending the event code and data to each one via its
send() method. This results in one datagram being
sent for each enrolled user, with no issues of blocking or
concurrency control.
Lines 3642: Enroll a user The
add() method is called when a user wishes to join a
channel. We first check that the user is not already a
member, in which case we do nothing. Otherwise, we use the
send_to_all() method to send a USER_JOINS
event to each member and add the new user to the users hash.
Lines 4349: Remove a user The
remove() method is called to remove a user from the
channel. We check that the user is indeed a member of the
channel, delete the user from the users hash, and then send
a USER_PARTS message to all the remaining
enrollees.
Lines 5055: Send a public message
The message() method is called when a user sends a
public message. We are called with the name of the user who
is sending the message and retransmit the message to each of
the members of the group (including the sender) with the
send_to_all() method.
Notice that the server makes no attempt to
verify that each user receives the events it transmits. This
is typical of a UDP server, and appropriate for an application
like this one, which doesn't require 100 percent
precision.
Detecting Dead Clients
There is, however, a significant problem with
the chat server as it is currently written. A client might
crash for some reason before sending a LOGOFF event
to the server, or a LOGOFF event might be sent but
get lost on the network. In this case, the server will think
that the user is logged in and continue to send messages to
the client. Over long periods of time, the server may fill up
with such phantom users. There are a number of solutions to
this problem:
-
The server times
out inactive users Each time the server receives an
event from a user, such as joining or departing a channel,
it records the time the event occurred in the corresponding
ChatObjects::User object. At periodic intervals, the server
checks all users for those who have been silent for a long
time and deletes them. This has the disadvantage of logging
out "lurkers" who are monitoring chat channels but not
participating in them.
-
The server pings
clients The server could send a PING event
to each client at regular intervals. The clients are
expected to respond to the event by returning a
PING_ACK. If a client fails to acknowledge some
number of consecutive pings, the user is automatically
logged out.
-
The clients ping
the server Instead of the server pinging clients and
expecting an acknowledgment, clients could send the server a
STILL_HERE event at regular intervals.
Periodically, the server checks that each user is still
sending STILL_HERE events and logs out any that
have fallen silent.
Adding STILL_HERE Events to the
Chat System
The third solution we listed represents a
good compromise between simplicity and effectiveness. It
requires small changes to the following files:
-
ChatObjects/ChatCodes.pm We add a
STILL_HERE event code for the client to use to
transmit periodic confirmations that it is still active.
-
ChatObjects/TimedUser.pm We define
a new ChatObjects::TimedUser class, which inherits from
ChatObjects::User. This class adds the ability to record the
time of a STILL_HERE event and to return the number
of seconds since the last such event.
-
chat_client.pl The top-level client
application must be modified to generate STILL_HERE
events at roughly regular intervals.
-
chat_server.pl The top-level server
application must handle STILL_HERE events and
perform periodic checks for defunct clients.
Modifications to
ChatObjects::ChatCodes
The modifications to ChatObjects::ChatCodes
are minimal. We simply define a new STILL_HERE
constant and add it to the @EXPORTS list:
@EXPORT = qw(
ERROR
LOGIN_REQ LOGIN_ACK
...
STILL_HERE
);
...use constant USER_ITEM => 190;
use constant STILL_HERE => 200;
1;
The ChatObjects::TimedUser
Subclass
We next define ChatObjects::TimedUser, a
simple subclass of ChatObjects::User (Figure
19.8). This class overrides the original new()
method to add a stillhere
instance variable. A new still_here() method updates
the variable with the current time, and
inactivity_interval() returns the number of seconds
since still_here() was last called.
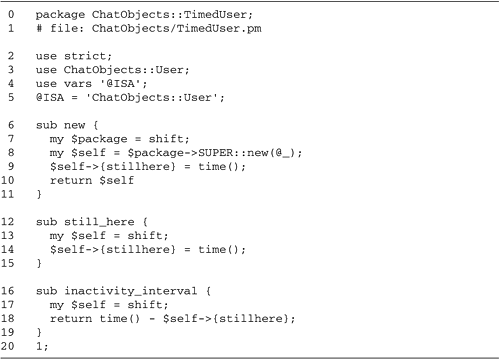
ChatObjects::TimedUser will be used by the
modified server instead of ChatObjects::User.
The Modified chat_client.pl Program
Next we modify chat_client.pl in order to issue
periodic STILL_HERE events. Figure
19.9 shows the first half of the modified script (the rest
is identical to the original given in Figure
19.2). The relevant changes are as follows:
Line 8: Define an ALIVE_INTERVAL
constant We define a constant called
ALIVE_INTERVAL, which contains the interval at
which we issue STILL_HERE events. This interval
must be shorter than the period the server uses to time out
inactive clients. We choose 30 seconds for
ALIVE_INTERVAL and 120 seconds for the server
timeout period, meaning that the client must miss four
consecutive STILL_HERE events over a period of 2
minutes before the server will assume that it's defunct.
Line 38: Create a timer for
STILL_HERE events The global variable
$last_alive contains the time that we last sent a
STILL_HERE event. This is used to determine when we
should issue the next one.
Line 47: Add a select() timeout We
want to send the STILL_HERE event at regular
intervals even when neither STDIN nor the server
have data to read. To achieve this, we add a timeout to our
call to the IO::Select object's can_read() method
so that if no data is received within that period of time,
we will still have the opportunity to send the event in a
timely fashion.
Lines 5558: Send STILL_HERE event
Each time through the main loop, we check whether it is time
to send a new STILL_HERE event. If so, we send the
event and record the current time in $last_alive.
The Modified chat_server.pl Program
Figure
19.10 shows the chat_server.pl script modified to
support auto logout of defunct clients. The modifications are
as follows:

Line 6: Use ChatObjects::TimedUser
We bring in the ChatObjects::TimedUser module to have access
to its still_here() and
inactivity_interval() methods.
Lines 910: Define auto-logout
parameters We define an AUTO_LOGOUT constant of
120 seconds. If a client fails to send a STILL_HERE
message within that interval, it will be logged out
automatically. We also define an interval of 30 seconds for
checking all currently logged-in users of the system. This
imposes a smaller burden on the system than would doing the
check every time a message comes in.
Line 26: Dispatch on the
STILL_HERE event We add an entry to the
%DISPATCH dispatch table that invokes the current
ChatObject::TimedUser object's still_here() method
when the STILL_HERE event is received.
Line 32: Keep track of the check
time As in the client, we need to keep track of the next
time to check for inactive clients. We do this using a
global variable named $next_check, which is set to
the current time plus CHECK_INTERVAL.
Lines 4345: Call the
auto_logoff() method at regular intervals We then
add a continue{} block to the bottom of the main
loop. The block checks whether it is time to check for
defunct users. If so, we call a new subroutine named
auto_logoff() and update $next_check.
Lines 4956: Check for inactive users
and log them off The auto_logoff() method loops
through each currently registered user returned by the
ChatObjects::TimedUser->users() method (which is
inherited from its parent). We call each user object's
inactivity_interval() method to retrieve the number
of seconds since the client has sent a STILL_HERE
event. If the interval exceeds AUTO_LOGOUT, we call
the object's logout() method to unregister the user
and free up memory.
Unlike the client, we do not time out the
call to $server->recv_event(). If the server is
totally inactive, then defunct clients are not recognized and
pruned until an event is received and the
auto_logoff() function gets a chance to run. On an
active server, this issue is not noticeable; but if it bothers
you, you can wrap the server object's recv_event() in
a call to select().
Chapter 20. Broadcasting
In this chapter we look at one of the
advanced features of the UDP protocolits ability to address
messages to more than one recipient via broadcasting. This
chapter introduces this technology and develops a tool that
makes it easier to work with from Perl. We end by enhancing
the Internet chat client from Chapter
19 to allow it to locate a server at runtime using
broadcasts.
Unicasting versus Broadcasting
Consider an application in which information
must be sent to many clients simultaneously. An Internet
teleconferencing system is one example. Another is a server
that sends out periodic time synchronization signals. You
could implement such a system using conventional network
protocols in a couple of ways:
-
Using TCP
Accept incoming connections from clients that wish to
subscribe to the service, and create a connected socket for
each one. Call syswrite() on each socket every time
you need to send information.
-
Using UDP
Accept incoming messages from clients and add each client's
IP address and port number to a list of subscribers. Each
time we want to send information, we iterate over each
client's destination address and call send() on the
socket, just like we did in the chat server in Chapter
19 (Figure
19.5).
Both these solutions are known as
"unicasting" because each transmitted message is addressed to
a single destination. To send identical messages to more than
one destination, we have to call syswrite() or
send() multiple times. Although unicast approaches
are effective in many cases, they have a number of
disadvantages:
-
Unicast is
inefficient for large networks. In unicast
applications, it may be necessary to transmit multiple
copies of the same information across the local area network
and its routers. In a video-streaming application, for
example, the same frame of video may have to be
retransmitted thousands of times.
-
The destination
must be known in advance. By definition, to send a
unicast message the sender must know the address of the
recipient. However, there are a handful of cases in which it
is impossible to know the recipient's address in advance.
For example, in the Dynamic Host Configuration Protocol
(DHCP), a newly booted computer must contact a server to
obtain its name and IP address. However, in a classic
chicken-and-egg problem, the client doesn't know the
server's IP address in advance, and the server can't send a
unicast message back to it unless it has an IP address.
-
Unicast doesn't
allow anonymity. A corollary of (2) is that a host
receiving unicast messages can't be anonymous. The peer
needs its socket and IP address in order to get messages to
it. However, there are many applications, including the
video-streaming application that we have been discussing, in
which it is neither necessary nor desirable for the server
to know which clients are receiving the video stream.
Broadcasting and multicasting (the next
chapter's topic) break out of the unicast paradigm by allowing
a single message transmitted by a host to be delivered to
multiple addresses. The server does not need to maintain
multiple sockets or to call send() or
syswrite() several times. Each message is placed on
the local area network only once, and distributed to the other
machines on the LAN in a way designed to minimize the burden
on the network.
Furthermore, broadcasting and multicasting
allow "resource discovery," a process that allows one host to
contact another without knowing its address in advance. This
same feature enables anonymous listeners to receive messages
without making their presence known to the sender.
Broadcasting Explained
Broadcasting is an old technology that dates
back to the earliest versions of TCP/IP. It is a nonselective
form of the UDP protocol in which messages placed on the local
subnet are received and processed by each host on the network.
Because broadcasting is gregarious, it is strictly limited to
the local subnet. Unless deliberately configured otherwise,
routers refuse to forward broadcast packets across subnet
boundaries.
Broadcasting is implemented using a special
IP address known as the "broadcast address." As explained in
Chapter
3, the broadcast address is an IP address whose host part
is replaced by all ones. For example, for the class C network
192.168.3.124, the host part of the address is the last byte,
making its broadcast address 192.168.3.255. Strictly speaking,
this is known as the "subnet directed broadcast address,"
because the address is specific to the subnetwork. There are
several other types of broadcast addresses, the only one of
which still regularly being used is the "all-ones" broadcast
address, 255.255.255.255. We will discuss this address
later.
To broadcast a message, an application sends
out a UDP datagram directed toward a network port and the
broadcast address for the network. The message will be
distributed to all hosts on the local network and picked up by
any broadcast-capable network cards (Figure
20.1). The message is then passed up to the operating
system, which checks whether some process has bound to the
port that the message is addressed to. If there is such a
socket, the message is handed off to the program that owns it.
Otherwise, the message is discarded.
Broadcasting is indiscriminate. All
broadcast-capable interface cards attached to the network
receive broadcast packets and pass them up to the operating
system for processing. This is in contrast to unicast packets,
which are ordinarily filtered by the card and never reach the
operating system. Thus, excessive use of broadcasting can have
a performance impact on all locally connected hosts because it
forces the operating system to examine and dispose of each
irrelevant packet.
Broadcast Applications
Despite its limitations, broadcasting is
extremely useful. Network broadcasts are used in the following
categories of application:
-
Resource Discovery Broadcasts are
frequently used when you know that there is a server out
there somewhere but you don't know its IP address in
advance. For example, the DHCP uses broadcasts to locate a
DHCP server and to retrieve network configuration
information for a client that is booting. Similarly, the
Network Information System (NIS) clients use broadcasts to
locate an appropriate NIS server on the local network.
-
Route Information Routers must
exchange information in order to maintain their internal
routing tables in a consistent state. Some routing protocols
use periodic broadcasts to advertise routes and to advise
other routers of changes in the network topology.
-
Time Information The Network Time
Protocol (NTP) can be configured so that a central time
server periodically broadcasts the time across the LAN. This
allows interested hosts to synchronize their internal clocks
to the millisecond.
Broadcasting is a core part of the IPv4
protocol and is available on any operating system that
supports TCP/IP networking.
Sending and Receiving
Broadcasts
Broadcasting a message is simply a matter of
sending a UDP message to the broadcast address for your
subnet. A simple way to see broadcasts in action is to use the
ping program to send an ICMP
ping request to the broadcast address. The following example
illustrates what happened when I pinged the broadcast address
for my office's 143.48.31.0/24 network:
% ping 143.48.31.255
PING 143.48.31.255 (143.48.31.255): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=4.9 ms
64 bytes from 143.48.31.46: icmp_seq=0 ttl=255 time=5.4 ms (DUP!)
64 bytes from 143.48.31.52: icmp_seq=0 ttl=255 time=5.9 ms (DUP!)
64 bytes from 143.48.31.47: icmp_seq=0 ttl=255 time=6.4 ms (DUP!)
64 bytes from 143.48.31.48: icmp_seq=0 ttl=255 time=6.9 ms (DUP!)
64 bytes from 143.48.31.30: icmp_seq=0 ttl=255 time=7.4 ms (DUP!)
64 bytes from 143.48.31.40: icmp_seq=0 ttl=255 time=7.9 ms (DUP!)
64 bytes from 143.48.31.33: icmp_seq=0 ttl=255 time=8.4 ms (DUP!)
64 bytes from 143.48.31.39: icmp_seq=0 ttl=255 time=9.0 ms (DUP!)
64 bytes from 143.48.31.31: icmp_seq=0 ttl=255 time=9.5 ms (DUP!)
64 bytes from 143.48.31.35: icmp_seq=0 ttl=255 time=10.0 ms (DUP!)
64 bytes from 143.48.31.36: icmp_seq=0 ttl=255 time=10.5 ms (DUP!)
64 bytes from 143.48.31.32: icmp_seq=0 ttl=255 time=11.0 ms (DUP!)
64 bytes from 143.48.31.37: icmp_seq=0 ttl=255 time=11.6 ms (DUP!)
64 bytes from 143.48.31.43: icmp_seq=0 ttl=255 time=12.1 ms (DUP!)
64 bytes from 143.48.31.57: icmp_seq=0 ttl=255 time=12.6 ms (DUP!)
64 bytes from 143.48.31.55: icmp_seq=0 ttl=255 time=13.1 ms (DUP!)
64 bytes from 143.48.31.58: icmp_seq=0 ttl=255 time=13.6 ms (DUP!)
64 bytes from 143.48.31.254: icmp_seq=0 ttl=255 time=14.1 ms (DUP!)
64 bytes from 143.48.31.45: icmp_seq=0 ttl=255 time=14.6 ms (DUP!)
64 bytes from 143.48.31.34: icmp_seq=0 ttl=255 time=15.1 ms (DUP!)
64 bytes from 143.48.31.38: icmp_seq=0 ttl=255 time=15.6 ms (DUP!)
64 bytes from 143.48.31.59: icmp_seq=0 ttl=60 time=19.1 ms (DUP!)
64 bytes from 143.48.31.60: icmp_seq=0 ttl=128 time=16.6 ms (DUP!)
64 bytes from 143.48.31.251: icmp_seq=0 ttl=255 time=17.1 ms (DUP!)
64 bytes from 143.48.31.252: icmp_seq=0 ttl=255 time=17.6 ms (DUP!)
--- 143.48.31.255 ping statistics ---
1 packets transmitted, 1 packets received, +25 duplicates, 0% packet
loss round-trip min/avg/max = 4.9/11.2/17.6 ms
A total of 26 hosts responded to the single
ping packet, including the machine I was pinging from. The
machines that replied to the ping include Windows 98 laptops,
a laser printer, some Linux workstations, and servers from Sun
and Compaq. Every machine on the subnet received the ping
packet, and each responded as if it had been pinged
individually. Although one of the machines that responded was
a router (143.48.31.254), it did not forward the broadcast. We
did not see replies from machines outside the subnet.
Interestingly, the host I ran the ping on did
not respond via its network interface of 143.48.31.42, but on
its loopback interface, 127.0.0.1. This illustrates the fact
that the operating system is free to choose the most efficient
route to a destination and is not limited to responding to
messages on the same interface that it received them on.
Sending Broadcasts
There are four simple steps to sending
broadcast packets:
-
Create a UDP
socket. Create a UDP socket in the normal way, either
by using Perl's built-in socket() function or with
the IO::Socket module.
-
Set the socket's
SO_BROADCAST option. The designers of the
socket API wanted to add some protection against programs
inadvertently transmitting to the broadcast address, so they
required that the SO_BROADCAST socket option be set
to true before a socket can be used for broadcasting. Use
either the built-in setsockopt() call or the
IO::Socket unified sockopt() method.
-
Discover the
broadcast address for your subnet (optional). The
broadcast address is different from location to location.
You could just hard code the appropriate address for your
subnet (or ask the user to enter it at runtime). For
portability, however, you might want to discover the
appropriate broadcast address programatically. We discuss
how to do this later.
-
Call
send() to send data to the broadcast
address. Use sockaddr_in() to create a
packed destination address with the broadcast address and
the port of your choosing. Pass the packed address to
send() to broadcast the message throughout the
subnet.
Figure
20.2 shows a simple echo client based on the multiplexing
client from Chapter
18. It reads user input from STDIN and broadcasts
the data to a hard-coded broadcast address. As responses come
in, it prints the IP address and port number of each
respondent and the length of the data received back.

Lines 13: Bring in modules Load
definitions from IO::Socket and IO::Select.
Lines 45: Choose an IP address and
port We get the address and port from the command line.
If not given, we default to a hard-coded broadcast address
and the UDP echo service port. We will see in the next
section how to discover the appropriate broadcast address
automatically.
Lines 68: Create a UDP socket and
enable broadcasting We call
IO::Socket::INET-new() to create a new UDP protocol
socket. No other arguments are necessary. We then notify the
operating system that we intend to broadcast over this
socket by calling its sockopt() method with
SO_BROADCAST set to true.
The last line of this section creates a
packed destination address from the port number and the
broadcast address.
Lines 916: Select loop The body of
the code is a select loop over the socket and
STDIN. Each time through the loop, we call
do_stdin() if there's data to be read from the
user, and do_socket() if there's a message ready to
receive on the socket.
Lines 1721: Broadcast user data via the
socket The do_stdin() function reads some data
from STDIN, exiting the script on end of file or
other error. We then send the data to the packed broadcast
address created in line 8.
Lines 2228: Read responses from
socket If select() indicates that the socket
has messages to read, we call recv(), saving the
peer's packed address and the message itself in local
variables. We unpack the peer's address, translate the host
portion in it into a dotted-quad form, and print a message
to standard output.
Here is what I got when I ran this program on
the same subnet that we pinged in the previous section:
% broadcast_echo_cli.pl 143.48.31.255
hi there
received 9 bytes from 143.48.31.42:7
received 9 bytes from 143.48.31.36:7
received 9 bytes from 143.48.31.34:7
received 9 bytes from 143.48.31.32:7
received 9 bytes from 143.48.31.40:7
received 9 bytes from 143.48.31.60:7
received 9 bytes from 143.48.31.33:7
received 9 bytes from 143.48.31.31:7
received 9 bytes from 143.48.31.39:7
received 9 bytes from 143.48.31.35:7
received 9 bytes from 143.48.31.38:7
received 9 bytes from 143.48.31.37:7
this works
received 11 bytes from 143.48.31.42:7
received 11 bytes from 143.48.31.34:7
received 11 bytes from 143.48.31.32:7
received 11 bytes from 143.48.31.36:7
received 11 bytes from 143.48.31.35:7
received 11 bytes from 143.48.31.33:7
received 11 bytes from 143.48.31.31:7
received 11 bytes from 143.48.31.38:7
received 11 bytes from 143.48.31.37:7
received 11 bytes from 143.48.31.39:7
received 11 bytes from 143.48.31.40:7
received 11 bytes from 143.48.31.60:7
If you run this example program, replace the
address on the command line with the broadcast address
suitable for your network. Each time the client broadcasts a
message, it receives a dozen responses, each corresponding to
an echo server running on a machine in the local subnet. As it
happens, the machine that I ran the client program on
(143.48.31.42) also runs an echo server, so it is also one of
the machines to respond. Broadcast packets always loop back in
this way.
The echo service is commonly active on UNIX
systems, and in fact all the responses seen here correspond to
various UNIX and Linux hosts on my office network. The Windows
machines and the laser printer that responded to the ping test
do not run the echo server, so they didn't respond.
Receiving Broadcasts
In contrast to sending broadcast messages,
you do not need to do anything special to receive them. Any of
the UDP servers used as examples in this book, including the
earliest ones from Chapter
18, respond to messages directed to the broadcast address.
In fact, without resorting to very-low-level tricks, it is
impossible to distinguish between UDP messages directed to
your program via the broadcast address and those directed to
its unicast address.
Enhancing the Chat Client to
Support Resource Discovery
We now have all the ingredients on hand to
add a useful feature to the UDP chat client developed in Chapter
19. If the client is launched without specifying a target
server, it broadcasts requests to the chat port on whatever
networks it finds itself attached to. It waits for responses
from any chat servers that might be listening, and if a
response is forthcoming from a host within a set time, the
client connects to it and proceeds as before. In the case of
multiple responses, the client binds to whichever server
answers first. This is a simple form of resource
discovery.
You'll find the code listing for the revised
chat client in Figure
20.4. It is derived from the timed chat client of Chapter
19 (Figures
19.8, 19.9,
and 19.10).
Parts of the code that haven't changed are omitted from the
listing.

Line 8: Load the IO::Interface
module We will use IO::Interface to derive the client's
subnet-directed broadcast address(es), so we load the
module, importing the interface flag constants at the same
time.
Line 37: No default server address
In previous incarnations of this client, we defaulted to
localhost if the chat host
was not specified on the command line. In this version, we
assume no default, using an empty string for the server name
if none was specified on the command line.
Lines 4041: Call find_server() to
search for a server If no server address was specified on
the command line, we call a new internal subroutine
find_server() to locate one. If
find_server() returns undef, we die.
Lines 6485: Find a server via
broadcasts All the interesting work is in the
find_server() subroutine. It begins by creating a
new UDP socket. This socket happens to be distinct from the
one that will ultimately be used to communicate with the
server, but there's no reason they can't be the same. After
creating the socket, we set its SO_BROADCAST option
to a true value so that we can broadcast over it.
We now look for network interfaces to
broadcast on. We get the list of interfaces by calling the
socket's if_list() method and loop over them, looking
for those that have the IFF_BROADCAST option set in
their interface flags. For each broadcast-capable interface,
we fetch its broadcast IP address, create a packed target
address using the specified chat server port number, and send
a message to it.
It doesn't matter what message we send to the
server, because we care only whether a server responds at all.
In this case, we send a message containing binary 0 in network
order. Since this corresponds to none of the chat messages
defined in the ChatCodes package, we expect the server to
respond with a message code of ERROR. A more formal
way to do this would be to define explicit messages that
client and server could exchange for this purpose, but that
would have required changes at the server end as well.
The client has broadcast the request to all
its attached broadcast-capable interfaces, and now it must
wait for responses. We use IO::Select to wait for up to 3
seconds for incoming messages. If no response is received
before the timeout, we return undef. Otherwise, we
read the first message, unpack it, and see if it contains the
expected ERROR code from the chat server (if not, it
may indicate that some other type of server is listening on
the port). We now return the address of the sender by calling
sockaddr_in() to unpack the peer name returned from
recv(), and inet_ntoa() to turn the address
into human-readable dotted-quad form.
If two or more chat servers received the
broadcast, the client binds to the first one. The responses
sent by other servers are discarded along with the socket when
the subroutine goes out of scope.
When we run the modified chat client on a
host that is attached to two networks, we see the client send
broadcast packets to both networks. After a short interval,
the client receives a response from a server on one of the
networks and selects it. The remainder of the chat session
proceeds as usual.
% broadcast_chat_client.pl
Broadcasting for a server on 192.168.3.255
Broadcasting for a server on 192.168.8.255
Found a server at 192.168.3.2
Your nickname: lincoln
trying to log in (1)...
Log in successful. Welcome lincoln.
Chapter 21. Multicasting
In the previous chapter, we discussed using
broadcasting to transmit a UDP message to all hosts on the
local area network. The examples in that chapter revealed two
of broadcasting's greatest limitations: the fact that it
cannot be routed beyond the local subnet and its inability to
be targeted to selected hosts. Broadcasting is strictly an
all-or-nothing affair and works only across the local
subnetwork.
This chapter discusses multicasting, a newer
technology designed specifically for streaming video, audio,
and conferencing applications. Unlike broadcasting, multicast
messages are routable; that is, they can be transmitted across
subnet boundaries or even across the Internet. Furthermore,
multicasting gives you great flexibility in selecting which
hosts will receive particular messages. A single multicast
message created by a host will be cleverly replicated by
routers as needed, and delivered to a single recipient, or a
dozen, or thousands.
This chapter describes multicasting, how it
works, and how to use it in your applications. As a practical
example, we use multicasting to reimplement the chat server
from Chapter
19.
Multicast Basics
Multicasting relies on a series of reserved
IP addresses in the upper end of the IP address space between
addresses 224.0.0.0 and 239.255.255.255. When a packet is sent
to one of these addresses, it is not routed in the normal way
to a single machine, but instead is distributed through the
network to all machines that have registered their interest in
receiving transmissions on that address. These IP addresses
are known in the multicasting world as "groups" because each
address refers to a group of machines.
In effect, multicast groups act much like
mailing lists. A process joins one or more groups, and the
multicasting system makes sure that copies of the messages
directed to the group are routed to each member of the group.
Later, the process can drop its membership, and the incoming
messages will cease.
Like all other TCP/IP applications,
multicasting uses the combination of port number and address
to find the correct program to deliver a packet to. Before a
socket can receive a multicast message, it must bind to a port
just as a socket in a conventional unicast server application
must do. This means that the same multicast group can be used
for different applications (or different components of the
same application) so long as everyone agrees in advance on
which ports to use. For example, multicast address 226.0.1.8
can be used to receive a video stream on port 1908 and
simultaneously to run an interactive whiteboard application on
port 2455.
There are more than 26 million multicast
addresses in the reserved range and 65,536 port numbers, which
gives the Internet about 17 trillion channels to use in
multicasting. However, the number of multicast groups that a
single socket can join simultaneously is usually limited by
the operating systems to about 20.
A variety of applications that require
one-to-many connectivity use multicasting. Examples of
multicast applications for which source code is available
include VIC, a videoconferencing system from Lawrence Berkeley
National Laboratory; RAT, an audio streaming system from
University College London; and WB, a networked whiteboard
system also from Lawrence Berkeley. In addition, the network
time protocol daemon, xntpd,
can be configured to multicast the current time throughout the
LAN. Used in conjunction with LAN-wide multicast routing, this
allows one to synchronize all the machines in an organization
to a single network time signal. You can find these and a
large number of other Open Source multicast-related tools at
http://www-mice.cs.ucl.ac.uk/multimedia/software/.
Like broadcasting, current implementation of
TCP/IP multicasting is compatible with only the UDP protocol.
A number of active research projects are addressing the need
for a reliable connection-oriented multicasting facility.
Multicasting is discussed in RFCs 1112, 2236, 1458, and others
listed among the references of Appendix
D.
Reserved Multicast Addresses
Multicast space isn't quite the untramelled
wilderness that the last section might imply. Some address
ranges are reserved for special purposes or for well-known
applications. These addresses are not available for general
use (Table
21.1). If you are designing a new multicast application
rather than writing a client or server for an existing one,
you should avoid these addresses in order to prevent potential
conflicts.
The 255 addresses in the range 224.0.0.0
through 224.0.0.255 are reserved for local administrative
tasks, specifically the exchange of router messages. Messages
sent to these addresses are never routed beyond the local area
network.
Table 21.1. Reserved Multicast
Ranges
| 224.0.0.0224.0.0.255 |
Local
administration |
| 224.0.1.0224.0.1.26 |
Various audio, video,
and database application |
| 224.0.2.1 |
BSD "rwho"
service |
| 224.0.2.2 |
SUN RPC services |
| 224.0.3.0224.0.4.255 |
RFE conferencing
system |
| 224.0.5.0224.0.5.127 |
CDPD groups |
| 224.0.6.0224.0.6.255 |
Cornell ISIS
project |
| 224.1.0.0224.1.255.255 |
ST multicast
groups |
| 224.2.0.0224.2.255.255 |
Multimedia conference
calls |
| 224.3.0.0224.251.255.255 |
UNASSIGNED |
| 224.252.0224.251.255.255 |
DIS transient
groups |
| 225.0.0.0231.255.255.255 |
UNASSIGNED |
| 232.0.0.0232.255.255.255 |
VMTP transient
groups |
| 233.0.0.0238.255.255.255 |
UNASSIGNED |
| 239.0.0.0239.255.255.255 |
Administrative
scoping |
224.0.0.1 is the "all-hosts" group. A message
sent to this address is transmitted to all the hosts on the
local area network, but is not forwarded by any multicast
routers. Thus the all-hosts group is the multicast equivalent
of the broadcast address.
224.0.0.2 is the "all-routers" group. All
multicast-capable routers are required to join this group at
startup time.
Other addresses in this range are reserved
for the use of specific router types. For example, 224.0.0.4
is the "all DVMRP routers" group, joined by routers using the
DVMRP protocol. 224.0.0.5 is reserved for OSPF routers,
224.0.0.9 for RIP2 routers, and so on.
Other addresses in multicast space are
reserved for well-known applications, and although some of
them are not much used, you're advised to avoid them. You'll
find a more comprehensive list of well-known addresses at http://www.isi.cdn/in-notes/iana/assignments/mnln-castaddresses.
Three large blocks of multicast addresses are unassigned and
are safe for you to use for development:
-
224.3.0.0224.251.255.255 (16,318,464
addresses)
-
225.0.0.0231.255.255.255 (117,440,512
addresses)
-
233.0.0.0238.255.255.255 (100,663,296
addresses)
Multicast Addresses and Hardware
Filtering
Recall from the last chapter that one of the
limitations of broadcasting is that it forces every host on
the LAN to process each packet. Multicasting is more efficient
than this. When an application joins a multicast group, the
host's network interface card is configured to receive
multicast packets bound for that group, a process called
"imperfect hardware filtering." The interface hands off
received packets to the operating system, which then delivers
them to the correct application (Figure
21.1).
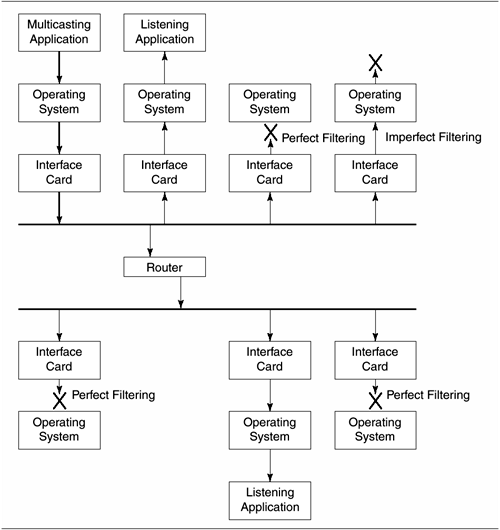
The filtering performed by the interface card
is "imperfect" because it uses a hashing scheme to choose
which packets to accept. This scheme occasionally allows some
irrelevant packets (those bound for groups the host has not
joined) through as well. However, any irrelevant packets are
discarded by the operating system in a second "perfect
software filtering" step. Hence, multicasting is not as
efficient as unicasting, in which the network card perfectly
filters out packets bound for irrelevant IP addresses; but it
is much more efficient than broadcasting, in which the card
exercises no discrimination.
From the application programming standpoint,
you do not have to worry about multicast hardware filtering,
except to know that heavy use of multicasting would not have
the same impact on your network that a similar level of
broadcasting would.
Multicasting Across WANs
Unlike broadcasts, multicasts were designed
to be routed. Multicast packets can be routed between subnets
or across wide area networks (WANs). A specialized multicast
routing protocol supervises this process.
When an application joins a multicast group,
its host sends a message to the local router to inform it of
that fact. The router then forwards that group's multicast
messages from the WAN to the host's subnet. As additional
hosts in the subnet join the same group, the router keeps
track of them, both passively by receiving join messages and
actively by periodically polling the subnet for each host's
membership list. When an application departs from a multicast
group, its host sends a depart message to the local router.
When the last host has departed from a multicast group, the
router stops forwarding the corresponding packets.
Multicast routers periodically exchange
information about the groups that the adjacent routers wish to
receive, collaboratively building a tree that describes how
multicast messages on a particular group should be
distributed. This allows messages transmitted to a multicast
group to be distributed in an efficient manner to just those
networks and hosts that are interested in receiving them.
In order for any of this to work, however,
you must be equipped with multicast-capable routers. Many
newer routers, such as those from Cisco systems, are multicast
capable, but some are not. Another option is to build a router
from a UNIX host that is capable of multicast routing. For
example, recent versions of the Linux operating system have
built-in multicast routing capabilities, although this feature
must usually be enabled by recompiling the kernel. You would
also need the mrouted router
daemon to take advantage of this functionality.
It is also possible to work around a
nonmulticast-capable router by tunneling through it using
ordinary unicast packets. The mrouted daemon can do this, provided
that it is running on hosts on each subnet that you wish to
share multicast packets.
To send or receive multicasts across the
Internet, you may create a private multicast network by
tunneling between LANs using mrouted or the equivalent.
Alternatively, you can participate in the public multicast
network, MBONE, which is used by a loose coalition of public
and private organizations for Internet-based broadcasting
services. In addition to providing an Internet-wide
multicasting backbone, MBONE provides a simple
session-announcement service that notifies you when certain
public activities, such as a video conference, are scheduled
to occur. Session announcements also provide information about
the multicast addresses and ports on which the session will be
transmitted so that client software can be configured properly
to receive the information.
Joining the MBONE requires the cooperation of
your Internet Service Provider and possibly the network
provider as well. Appendix
D contains more sources of information on setting up
multicast routing and connecting with the MBONE.
Multicast TTLs
Since multicast messages can be routed, you
need a way to control how far they can go. You wouldn't want a
whiteboard application intended for interdepartmental
conferences in your organization to be multicast across the
Internet.
Multicasting uses a simple but effective
technique to control the scope of messages. Each packet
contains a time-to-live (TTL) field that is set to an
arbitrary positive integer between 1 and 255. Every time the
packet crosses a router, its TTL is decremented by 1. When the
TTL reaches 0, the packet is discarded.
By default, multicast packets have a TTL of
1, meaning that they won't be routed across subnets. As soon
as they hit the first router, their TTL reaches 0 and they
expire. To arrange for a packet to be forwarded, set its TTL
to a higher value. In general, a packet can cross TTL-1
routers.
To provide finer control over routing of
multicast packets, an organization can assign "threshold"
values to each outgoing interface of a multicast router. The
router will forward the packet only if its TTL matches or
exceeds the threshold. To illustrate this, consider the
hypothetical company in Figure
21.2. It has three departments, each of which is large
enough to contain several subnets. Each department's subnets
are connected with a departmental router (labeled A, B, and
C), and the departments are interconnected via the central
interdepartmental router "D." Router D also acts as the
gateway to the Internet. Each departmental router uses the
default threshold of 1 on the subnet interfaces, but a
threshold of 3 on the interface that connects it to the
central router. Similarly, the central router has a threshold
of 31 on the interface that connects it to the Internet. This
setup allows the scope of a packet to be precisely controlled
by its TTL. Packets with TTLs between 1 and 3 are forwarded
within a department's subnets, but can't travel to other
departments because they don't meet the threshold criterion of
3 required to be forwarded beyond the departmental router.
Packets with TTLs between 4 and 32 can travel among the
departments, but won't be forwarded to the Internet. The
router threshold values control the scope of multicast
applications, preventing applications intended for use only
within a subnet, department, or organization from spilling
over into places they're not wanted.
Table
21.2 lists common TTL thresholds and their associated
scopes. These values are conventions, and the exact
definitions of "site," "organization," and "department" are up
to you to determine.
Table 21.2. Conventional TTL
Thresholds
| 0 |
Restricted to the same
host |
| 1 |
Restricted to the same
subnet |
| <32 |
Restricted to the same
site, organization, or department |
| <64 |
Restricted to the same
region |
| <128 |
Restricted to the same
continent |
| <255 |
Unrestricted in scope;
global |
Using Multicast
The remainder of this chapter shows you how
to use multicasting in Perl applications.
Sending Multicast Messages
Sending a multicast message is as
straighforward as creating a UDP socket and sending a message
to the desired multicast address. Unlike broadcasting
messages, to send multicast messages you don't have to get
permission from the operating system first.
Recall from Chapter
20 that we were able to identify all the hosts on the
local area subnet by pinging the broadcast address. We can use
the same trick to identify multicast-capable hosts by sending
a packet to the all-hosts group, 224.0.0.1:
% ping 224.0.0.1
PING 224.0.0.1 (224.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=1.0 ms
64 bytes from 143.48.31.47: icmp_seq=0 ttl=255 time=1.2 ms (DUP!)
64 bytes from 143.48.31.46: icmp_seq=0 ttl=255 time=1.3 ms (DUP!)
64 bytes from 143.48.31.55: icmp_seq=0 ttl=255 time=1.5 ms (DUP!)
64 bytes from 143.48.31.43: icmp_seq=0 ttl=255 time=1.7 ms (DUP!)
64 bytes from 143.48.31.61: icmp_seq=0 ttl=255 time=1.9 ms (DUP!)
64 bytes from 143.48.31.33: icmp_seq=0 ttl=255 time=2.1 ms (DUP!)
64 bytes from 143.48.31.36: icmp_seq=0 ttl=255 time=2.2 ms (DUP!)
64 bytes from 143.48.31.45: icmp_seq=0 ttl=255 time=2.8 ms (DUP!)
64 bytes from 143.48.31.32: icmp_seq=0 ttl=255 time=3.0 ms (DUP!)
64 bytes from 143.48.31.48: icmp_seq=0 ttl=255 time=3.1 ms (DUP!)
64 bytes from 143.48.31.58: icmp_seq=0 ttl=255 time=3.3 ms (DUP!)
64 bytes from 143.48.31.57: icmp_seq=0 ttl=255 time=3.5 ms (DUP!)
64 bytes from 143.48.31.40: icmp_seq=0 ttl=255 time=3.7 ms (DUP!)
64 bytes from 143.48.31.39: icmp_seq=0 ttl=255 time=3.9 ms (DUP!)
64 bytes from 143.48.31.31: icmp_seq=0 ttl=255 time=4.0 ms (DUP!)
64 bytes from 143.48.31.34: icmp_seq=0 ttl=255 time=4.5 ms (DUP!)
64 bytes from 143.48.31.37: icmp_seq=0 ttl=255 time=4.7 ms (DUP!)
64 bytes from 143.48.31.38: icmp_seq=0 ttl=255 time=4.9 ms (DUP!)
64 bytes from 143.48.31.41: icmp_seq=0 ttl=64 time=5.1 ms (DUP!)
64 bytes from 143.48.31.35: icmp_seq=0 ttl=255 time=5.2 ms (DUP!)
As in the earlier broadcast example, a
variety of machines responded to the ping, including the
loopback device (127.0.0.1) and a mixture of UNIX and Windows
machines. Unlike the broadcast example, two laser printers on
the subnetwork did not respond
to the multicast call, presumably because they are not
multicast capable. Similarly, we could ping 224.0.0.2, the
all-routers group, to discover all multicast-capable routers
on the LAN, 224.0.0.4 to discover all DVMRP routers, and so
forth.
For a Perl script to send a multicast
message, it has only to create a UDP socket and send to the
desired group address. To illustrate this, we can use the
broadcast echo client from the previous chapter (Figure
20.2) to discover all multicast-capable hosts on the local
subnet that are running an echo server. The program doesn't
need modification; instead of giving the broadcast address as
the command-line argument, we just use the address for the
all-hosts group:
broadcast_echo_cli.pl 224.0.0.1
hi there
received 9 bytes from 143.48.31.42:7
received 9 bytes from 143.48.31.30:7
received 9 bytes from 143.48.31.40:7
Interestingly, the list of servers that
respond to the echo client is much smaller than it was for
either the multicast ping test or the broadcast ping test of
the previous chapter. After some investigation, the difference
turned out to be nine Solaris machines whose kernels were not
configured for multicasting. Apparently there was sufficient
low-level multicasting code built into the kernel of these
machines to allow them to respond to ICMP ping messages, but
not to higher-level multicasts.
Socket Options for Multicast
Send
By default, when you issue a multicast
message, it is sent from the default interface with a TTL of
1. In addition, the message "loops back" to the same host you
sent it in the same manner that broadcast packets do. You can
change one or more of these defaults using a set of three
IP-level socket options that are specific for
multicasting.
IP_MULTICAST_TTL The
IP_MULTICAST_TTL option gets or sets the TTL for
outgoing packets on this socket. Its argument must be an
integer between 1 and 255, packed into binary using the "I"
format.
IP_MULTICAST_LOOP
IP_MULTICAST_LOOP activates or deactivates the
loopback property of multicast messages. Its argument, if
true, causes outgoing multicast messages to loop back so that
they are received by the host (the default behavior). If
false, this behavior is suppressed. Note that this has nothing
to do with the loopback interface.
IP_MULTICAST_IF The
IP_MULTICAST_IF socket option allows you to control
which network interface the multicast message will be issued
from, much as you can control where broadcast packets go by
choosing the appropriate broadcast address. The argument is
the packed IP address of the interface created using
inet_aton(). If an interface is not explicitly set,
the operating system picks an appropriate one for you.
There is a "gotcha" when using
getsockopt() to retrieve the value of
IP_MULTICAST_IF under the Linux operating system.
This OS accepts the packed 4-byte interface address as the
argument to setsockopt() but returns a 12-byte
ip_mreqn structure from calls to
getsockopt() (see the following description of the
related ip_mreq structure). This undocumented
behavior is a bug that will be fixed in kernel versions 2.4
and higher. We work around this behavior in the IO::Multicast
module developed in the next section.
Unlike all the other socket options we have
seen so far, the multicast options apply not to the socket at
the SOL_SOCKET level but to the IP protocol layer
(which is responsible for routing packets and other functions
related to IP addresses). The second argument passed to
getsockopt() and setsockopt() must be the
protocol number for the IP layer, which you can retrieve by
calling getprotobyname() using 'IP' as the
protocol name. This example illustrates how to turn off
loopback for a socket named $soc:
my $ip_level = getprotobyname('IP') or die "Can't get protocol: $!";
setsockopt($sock,$ip_level,IP_MULTICAST_LOOPBACK,0);
Because the IO::Socket->sockopt()
method assumes the SOL_SOCKET level, you cannot use
it for multicast options. However, you can use IO::Socket's
setsockopt() and getsockopt() methods, which
are just thin wrappers around the underlying Perl function
calls.
The multicast option constants are defined in
the system header file netinet/in.h. To get access to the
proper values for your operating system, you must use the
h2ph tool to convert the system
header files.
Receiving Multicast Messages
Multicast messages are sent to the
combination of a multicast group address and a port. To
receive them, your program must create a UDP socket, bind it
to the appropriate port, and then join the socket to one or
more multicast addresses.
A single socket can belong to multiple
multicast groups simultaneously, in which case the socket
receives all messages sent to any of the groups that it
currently belongs to. The socket also continues to receive
messages directed to its unicast address. The number of groups
that a socket can belong to is limited by the operating
system; a limit of 20 is typical.
Two new socket options allow you to join or
leave multicast groups: IP_ADD_MEMBERSHIP and
IP_DROP_MEMBERSHIP.
IP_ADD_MEMBERSHIP Join a multicast
group, thereby receiving all group transmissions directed to
the port the socket is bound to. The argument is a packed
binary string consisting of the desired multicast address
concatenated to the address of the local interface (derived
from a C structure called an ip_mreq). This allows
you to control not only what multicast groups to join but also
on which interface to receive their messages. If you are
willing to accept multicast transmissions on any interface,
use INADDR_ANY as the local interface address.
The outgoing multicast interface (set by
IP_MULTICAST_IF) is not tied in any way to the
interface used to receive multicast packets. You can send
multicast packets from one network interface and receive them
on another.
IP_DROP_MEMBERSHIP Leave a multicast
group, terminating membership in the group. The argument is
identical to the one used by IP_ADD_MEMBERSHIP.
As with IP_MULTICAST_IF and the
other options discussed earlier, the
IP_ADD_MEMBERSHIP and IP_DROP_MEMBERSHIP
options apply to the IP layer, so you must pass
setsockopt() an option level equal to the IP protocol
number returned by getprotobyname().
These two options may sound more complicated
than they are. The only tricky part is creating the
ip_mreq argument to pass to setsockopt().
You can do by passing the group address to
inet_aton() and then concatenating the result with
the INADDR_ANY constant. This code snippet shows how
to join a multicast group, in this case the one with address
225.1.1.3:
my $mcast_addr = inet_aton('225.1.1.3');
my $local_addr = INADDR_ANY;
my $ip_mreq = $mcast_addr . $local_addr;
my $ip_level = getprotobyname('IP') or die "Can't get protocol: $!";
setsockopt($sock,$ip_level,IP_ADD_MEMBERSHIP,$ip_mreq)
or die "Can't join group: $!";
You drop membership in a group in the same
way, using the IP_DROP_MEMBERSHIP constant. You do
not have to drop membership in all groups before exiting the
program. The operating system will take care of this for you
when the socket is destroyed.
Oddly, there is no way to ask the operating
system what multicast groups a socket is a member of. You have
to keep track of this yourself.
The IO::Socket::Multicast
Module
This section develops a small module that
makes getting and setting multicasting options more
convenient. As in the IO::Interface module discussed in the
previous chapter, it is a pure-Perl solution that gets system
constants from h2ph-generated.ph files. You'll find
a C-language version of IO::Multicast on CPAN, and if you have
a C or C++ compiler handy, I recommend that you install it
rather than hassling with h2ph.
IO::Socket::Multicast is a descendent of
IO::Socket::INET. It implements all its parents' methods and
adds several new methods related to multicasting. As a
convenience, this module makes UDP, rather than TCP, the
default protocol for new socket objects.
|
$socket->mcast_ttl([$ttl])
Get or set the socket's multicast time
to live. If you provide an integer argument, it will be
used to set the TTL and the method returns true if the
attempt was successful. Without an argument,
mcast_ttl() returns the current value of the
TTL.
$socket->mcast_loopback([$boolean])
Get or set the loopback property on
outgoing multicast packets. Provide a true value to
enable loopbacking, false to inhibit it. The method
returns true if it was successful. Without an argument,
the method returns the current loopback setting.
$socket->mcast_if([$if])
Get or set the interface for outgoing
multicast packets. For your convenience, you can use
either the interface device name, such as eth0,
or its dotted-quad interface address. The method returns
true if the attempt to set the interface was successful.
Without any argument, it returns the current interface,
or if no interface is set, it returns undef (in
which case the operating system chooses an appropriate
interface automatically).
$socket->mcast_add($multicast_group
[,$interface])
Join a multicast group, allowing the
socket to receive messages multicast to that group.
Specify the group address using
dotted-quad form (e.g., "225.0.0.3"). The optional
second argument allows you to tell the operating system
which network interface to use to receive the group. If
not specified, the OS listens on all multicast-capable
interfaces. For your convenience, you can use either the
interface device name or the interface address.
This method returns true if the group
was successfully added; otherwise, it returns false. In
case of failure, $! contains additional
information.
You may call mcast_add() more
than once in order to join multiple groups.
$socket->mcast_drop($multicast_group
[,$interface])
Drop membership in a multicast group,
disabling the socket's reception of messages to that
group. Specify the group using its dotted-quad address.
If you specified the interface in mcast_add(),
you must again specify that interface when leaving the
group.
You may use either a device name or an IP address to
specify the interface.
This method returns true if the group
was added successfully, and false in case of an error,
such as dropping a group to which the socket does not
already belong. |
Figure
21.3 contains the complete code for the IO::Socket::
Multicast module. We'll walk through the relevant bits.

Lines 17: Module setup The first
part of the module consists of boilerplate module
declarations and bookkeeping. Among other things, we bring
in the IO::Interface module developed in the previous
chapter and declare this module a subclass of
IO::Socket::INET.
Lines 812: Bring in Socket and .ph definitions We next load
functions from the Socket module and from netinet/in.ph. As in the
IO::Interface module, to avoid clashing prototype warnings
from duplicate functions defined in the .ph file, we call the Socket
module's import() method manually. netinet/in.ph contains definitions
for the various IFF_MULTICAST socket options.
We call getprotobyname() to
retrieve the IP protocol number for use with
setsockopt() and getsockopt(). If the
protocol number isn't available for some reason, we default
to 0, which is a common value for this constant.
Lines 1322: The new() and
configure() methods We override the
IO::Socket::INET new() and configure()
methods so as to make UDP the default protocol if no Proto argument is given
explicitly.
Lines 2329: mcast_add() The
mcast_add() method receives the socket, the
multicast group address, and the optional local interface to
receive on. If an interface is specified, the method calls
the internal function get_if_addr() to deal
appropriately with the alternative ways that the interface
can be specified. If no interface is specified, then
get_if_addr() returns "0.0.0.0", the dotted-quad
form of the INADDR_ANY wildcard address.
We then build an ip_mreq structure
by concatenating the binary forms of the group and local IP
address, and pass this to setsockopt() with a
socket level of $IP_LEVEL and a command of
IP_ADD_MEMBERSHIP.
Lines 3036: mcast_drop() This
method contains the same code as mcast_add(),
except that at the very end it calls setsockopt()
with a command of IP_DROP_MEMBERSHIP.
Lines 3747: mcast_if() This
method assigns or retrieves the interface for outgoing
multicast messages. If the caller has specified an
interface, we turn it into an address by calling
get_if_addr(), translate it into its packed binary
version using inet_aton(), and call
setsockopt() with the IP_MULTICAST_IF
command.
For retrieving the interface, things are
slightly more complicated because of buggy behavior under
the Linux operating system, where getsockopt()
returns a 12-byte ip_mreqn structure rather than
the expected 4-byte packed IP address of the interface (I
found this out by examining the kernel source code). The
desired information resides in the second field of this
structure, beginning at byte number 4. We test the length of
the getsockopt() result, and if it is larger than
4, we extract the address using substr(). We then
call an internal routine named find_interface() to
turn this IP address into an interface device name.
Lines 4856: The mcast_loopback ()
method The mcast_loopback() method is more
straightforward. If a second argument is supplied, it calls
setsockopt() with a command of
IP_MULTICAST_LOOP and an argument of 1 to turn
loopback on and 0 to turn loopback off. If no argument is
supplied, then the method calls getsockopt() to
retrieve the loopback setting. getsockopt() returns
the setting as a packed binary string, so we convert it into
a human-readable number by unpacking it using the "
I " (unsigned integer) format.
Lines 5765: mcast_ttl() The
mcast_ttl() method gets or sets the TTL on outgoing
multicast messages. If a TTL value is specified, we pack it
into a binary integer with the " I " format and
pass it to setsockopt() with the
IP_MULTICAST_TTL command. If no value is passed, we
reverse the process.
Lines 6675: get_if_addr()
function The last two functions are used internally.
get_if_addr() allows the caller to specify network
interfaces using either a dotted IP address or the device
name. The function takes two arguments consisting of the
socket and the interface. If the interface argument is
empty, then the function returns "0.0.0.0," which is the
dotted-quad equivalent of the INADDR_ANY wildcard.
If the interface looks like a dotted-quad address by pattern
match, then the function returns it unmodified.
Otherwise, we assume that the argument is a
device name. We call the socket's if_addr() method
(created by IO::Interface) to retrieve the corresponding
interface address. If this is unsuccessful, we die with an
error message. As a consistency check, we call the
if_flags() method to confirm that the interface is
multicast-capable; if it is not, we die. Otherwise, we
return the interface address.
Lines 7682: find_interface()
function The last function performs the reverse of
get_if_addr(), returning the interface device name
corresponding to an IP address. It retrieves the list of
device names by calling the socket's if_list()
method (defined in IO::Interface) and loops over them until
it finds the one with the desired IP address.
Sample Multicast Applications
We'll look at two example multicast
applications. One is a simple time-of-day server, which
intermittently broadcasts the current time to whoever is
interested. The other is a reworking of Chapter
19's chat system.
Time-of-Day Multicasting
Server
The first example application is a server
that intermittently transmits its hostname and the time of day
to a predetermined port and multicast address. Client
applications that wish to receive these time-of-day messages
join the group and echo what they receive to standard output.
You might use something like this to monitor the status of
your organization's servers; if a server stops sending status
messages, it might be an early warning that it had gone
offline.
Thanks to the IO::Socket::Multicast module,
both client and server applications are less than 25 lines of
code. We'll look at the server first (Figure
21.4).
Lines 14: Load modules We load the
IO::Socket and IO::Socket::Multicast modules. We also bring
in the Sys::Hostname module, a standard part of the Perl
distribution that allows you to determine the hostname in a
OS-independent way.
Lines 58: Get arguments We choose
an interval of 15 seconds between transmissions. We then
read the port, multicast group address, and the TTL for
transmissions from the command line; if they're not defined,
we assume reasonable defaults. For the port, we arbitrarily
choose 2070. For the multicast group, we choose
224.225.226.227, one of the many unassigned groups. For TTL,
we choose 31, which, by convention, is an organization-wide
scope (messages will stay within the organization but will
not be forwarded to the outside world).
Lines 912: Set up socket We create
a new multicasting UDP socket by calling
IO::Socket::Multicast->new() and set the
multicast TTL for outgoing messages by calling the socket's
mcast_ttl() method.
Lines 1316: Prepare to transmit
messages We create a packed destination address using
inet_aton() and sockaddr_in(>), using
the multicast address and port specified on the command
line. We also retrieve the name of the host and store it in
a variable for later use.
Lines 1724: Main loop The server
now enters its main loop. We want to transmit on even
multiples of PERIOD seconds, so we use the
% operator to compute the modulus of
time() over PERIOD. If we are at an even
multiple of PERIOD, then we create a status message
consisting of the local time followed by a slash and the
hostname, producing this type of format:
Mon May 29 19:05:15 2000/pesto.cshl.org
We send a copy of the message to the socket
using send() with the multicast destination set up
previously. After transmitting the message, we sleep for 1
second and loop again.
Time-of-Day Multicast Client
We'll now look at a client that can receive
messages from the server (Figure
21.5).

Lines 13: Load modules We bring in
IO::Socket and IO::Socket::Multicast modules as before.
Lines 45: Retrieve command-line
arguments We fetch the port and multicast address from
the command line. If these arguments are not provided, we
default to the values used by the server.
Lines 710: Set up socket Next we
set up the socket we'll use for receiving multicast
messages. We create a UDP socket using
IO::Socket::Multicast->new, passing the LocalPort argument to
bind() the socket to the desired port. The newly
created socket is now ready to receive unicast messages
directed to that port, but not multicasts. To enable
reception of group messages, we call mcast_add()
with the specified multicast group address.
Lines 1116: Client main loop The
remainder of the client is a simple loop that calls
recv() to receive messages on the socket. We unpack
the sender's address using sockaddr_in() and print
the address and the message body to standard output.
To test the client, I ran the server on
several machines on my LAN, and the client on my desktop
system. The client's output over a period of 45 seconds was
this (blank lines have been inserted between intervals to aid
readability):
% time_of_day_cli.pl
143.48.31.66: Wed Aug 23 13:31:00 2000/swiss
143.48.31.45: Wed Aug 23 13:31:00 2000/feta.cshl.org
143.48.31.54: Wed Aug 23 10:31:00 2000/pesto
143.48.31.47: Wed Aug 23 13:31:00 2000/turunmaa.cshl.org
143.48.31.43: Wed Aug 23 13:31:00 2000/romano.cshl.org
143.48.31.69: Wed Aug 23 13:31:00 2000/munster.cshl.org
143.48.31.63: Wed Aug 23 13:31:00 2000/whey.cshl.org
143.48.31.66: Wed Aug 23 13:31:15 2000/swiss
143.48.31.69: Wed Aug 23 13:31:15 2000/munster.cshl.org
143.48.31.63: Wed Aug 23 13:31:15 2000/whey.cshl.org
143.48.31.44: Wed Aug 23 13:31:15 2000/edam.cshl.org
143.48.31.45: Wed Aug 23 13:31:15 2000/feta.cshl.org
143.48.31.54: Wed Aug 23 10:31:15 2000/pesto
143.48.31.47: Wed Aug 23 13:31:15 2000/turunmaa.cshl.org
143.48.31.43: Wed Aug 23 13:31:15 2000/romano.cshl.org
143.48.31.66: Wed Aug 23 13:31:30 2000/swiss
143.48.31.43: Wed Aug 23 13:31:30 2000/romano.cshl.org
143.48.31.69: Wed Aug 23 13:31:30 2000/munster.cshl.org
143.48.31.63: Wed Aug 23 13:31:30 2000/whey.cshl.org
143.48.31.44: Wed Aug 23 13:31:30 2000/edam.cshl.org
143.48.31.45: Wed Aug 23 13:31:30 2000/feta.cshl.org
143.48.31.54: Wed Aug 23 10:31:30 2000/pesto
143.48.31.47: Wed Aug 23 13:31:30 2000/turunmaa.cshl.org
All the machines on my office network are
supposed to have their internal clocks synchronized by the
network time protocol. The fact that " pesto " is off
by several hours relative to the others suggests that
something is wrong with this machine's time-zone setting. The
example client was unexpectedly useful in identifying a
problem.
Another thing to notice is that we don't see
a transmission from edam.cshl.org in the first group but
transmissions from it appear later. It may have missed a time
interval (the sleep() function is only accurate to
plus or minus 1 second), or the multicast message from that
machine may have been lost. Multicast messages, like other UDP
messages, are unreliable.
Multicast Chat System
We'll now use multicasting to redesign the
architecture of the UDP-based Internet chat system developed
in Chapter
19. Recall that the heart of the system was five lines of
code from the server's ChatObjects::Channel module:
sub send_to_all {
my $self = shift;
my ($code,$text) = @_;
$_->send($code,$text) foreach $self->users;
}
Given a message code and message body,
send_to_all() looks up each registered user and sends
it a copy of the message. The socket transmission is done by a
ChatObjects::User object, which maintains a copy of the
client's address and port number.
The weakness of this system is that if there
are a great many registered users, the server sends out an
equally large number of UDP packets, loading its local network
and routers. This system can probably scale to support
thousands of registered users, but not tens of thousands
(depending on how "chatty" they are).
In the reimplemented version, we'll replace
the server's send_to_all() method with a version that
looks like this:
sub send_to_all {
my $self = shift;
my ($code,$text) = @_;
my $dest = $self->mcast_dest;
my $comm = $self->comm;
$comm->send_event($code,$text,$dest) || warn $!;
}
Instead of looking up each client and sending
it a unicast message, we make one call to the communication
object's send_event() method, using as the
destination a multicast group address. We'll go over the
details of this method when we walk through the code.
Let's look at the revised chat protocol from
the client's point of view. In the original version of this
system, the client did all its communication via a single UDP
socket permanently assigned to the server. In the new version,
we alter this paradigm:
-
The client creates
a socket for communicating with the server. This is
the same as the original application. One socket will be
used for all messages sent by the client to the server;
we'll call this the control socket.
-
The client creates
a second socket for receiving multicasts. When the
client logs in, the server responds with two messages, one
acknowledging successful login and the other providing the
port number on which to listen for multicasts. The client
responds by creating a second socket and binding it to the
indicated port. The client now select()s over the
multicast socket as well as over standard input and the
control socket.
-
The client adds
multicast groups to subscribe to channels. There is a
one-to-one correspondence between chat channels and
multicast groups. When the client subscribes to a new chat
channel, the server responds with an acknowledgment that
contains the multicast group address on which public
messages to that group will be transmitted. The client adds
the group to the socket using
mcast_add().
-
The client drops
multicast groups to depart channels. The client calls
mcast_drop() when it wants to depart a
channel.
-
The client sends
public messages as before. To send a public message,
the client sends it to the server and the server retransmits
it as a multicast. Therefore, the client code for sending a
public message is unchanged from the original
version.
From the server's point of view, the
following changes are needed:
-
The server has both
a port and a multicast port. In addition to the port
used to receive control messages from clients, the server is
configured with a port used for its multicast messages. This
could have been the same as the control port, but it was
cleaner to keep the two distinct.
-
The multicast port
is sent to the client at login time. We need a new
message to send to the client at login time to tell it what
port to use for receiving multicasts.
-
Each chat channel
has a multicast group address. Each chat group has a
distinct multicast address. To send a message to all members
of a channel, the server looks up its corresponding group
address and sends a single message to that
address.
A feature of this design is that the client
sends public messages to the server using conventional
unicasting, and the server retransmits the message to members
of the channel via multicast. A reasonable alternative would
be to make the client responsible for sending public messages
directly to the relevant multicast address. Either
architecture would work, and both would achieve the main goal
of avoiding congestion on the server's side of the
connection.
I chose the first architecture for two
reasons. First, I wanted to avoid too radical a rewriting of
the client, which would have been necessary if the burden of
keeping track of which channels the user belonged to had been
shifted to the client side. Second, I wanted to leave the way
open for the server to exercise editorial control over the
clients' content. Many chat systems have a "muzzling" function
that allows the server administrator to silence a user who is
becoming abusive. Because all public messages are forced to
pass through the server, it would be possible to add this
feature later. A final consideration is the TTL on outgoing
multicasts, which could have different meanings on different
clients' networks. Having the server issue all the multicasts
enforces uniformity on the scope of public messages.
We'll walk through the server first, and then
the client. The first change is very minor (Figure
21.6). We add a new event code constant named
SET_MCAST_PORT to ChatObjects::ChatCodes. This is the
message sent by the server to the client to tell it what port
to bind to in order to receive multicast transmissions.
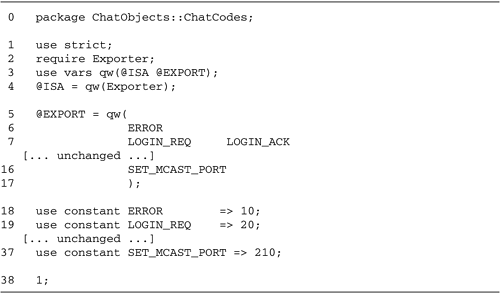
Next we look at the server script (Figure
21.7). It is very similar to the original version, so
we'll just go over the parts that are different.

Lines 47: Load multicast subclasses of
modules Instead of loading the ChatObjects::Channel and
ChatObjects::Comm modules, we load slightly modified
subclasses named ChatObjects::MChannel and
ChatObjects::MComm respectively.
Lines 1921: Read command-line
arguments We read three arguments from the command line
corresponding to the control port, the multicast port, and
the TTL on outgoing public messages. If the multicast port
isn't provided, we use the control port plus one. If the TTL
isn't provided, we choose the organization-wide scope of 31.
Line 22: Create a new communications
object We call ChatObjects::MComm->new() to
create a new communications (comm) object. As in the
original version of this server, we use the comm object as
an intermediary for sending and receiving events from
clients. Its primary job is to pack and unpack chat system
messages using the binary format we designed. This subclass
of the original ChatObjects::Comm takes three arguments: the
control port, the multicast port, and the TTL for outgoing
multicast messages.
Lines 2330: Create a bunch of
channels We create several chat channels in the form of
ChatObjects::MChannel objects. The constructor for this
subclass takes four arguments, the title and description of
the channel, as before, and two new arguments consisting of
a multicast group address for the channel and the comm
object. We arbitrarily use group addresses in the range
225.1.0.1 through 225.1.0.5 for this purpose.
Lines 3243: Main loop The server
main loop is identical to the earlier version.
Lines 4450: Handle logins The
do_login() is slightly modified. After successfully
logging in the user and creating a corresponding
ChatObjects::User object, we call the user object's
send() method to send the client a
SET_MCAST_PORT event. The argument for this event
is the multicast port, which we retrieve from the comm
object's mport() method (we could also get the
value from the $mport global variable).
Figure
21.8 lists the code for the ChatObjects::MComm module. It
is a subclass of ChatObjects::Comm that overrides the
new() constructor and adds one method,
mport().
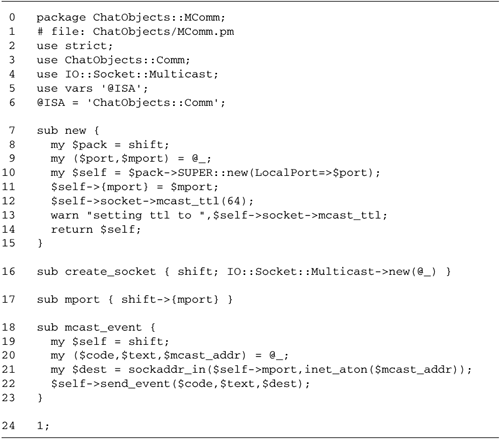
Lines 16: Load modules We tell Perl
that ChatObjects::MComm is a subclass of ChatObjects::Comm
and load ChatObjects::Comm and IO::Socket. We also load
IO::Socket::Multicast so as to have access to the various
mcast_ methods.
Lines 715: Override new() method
We replace ChatObjects::Comm->new() with a new
version. We begin this version by invoking the parent
class's new() method to construct the control
socket. When this is done, we remember the multicast port
argument in the object hash and set the TTL on outgoing
messages by calling mcast_ttl() on the control
socket.
Line 16: The create_socket()
method We override our parent's create_socket()
method with one that creates a suitable
IO::Socket::Multicast object, rather than IO::Socket::INET.
Line 17: The mport() method This
new method looks up the multicast port in the object hash
and returns it.
Lines 1823: The mcast_event()
method This new method is responsible for sending an event
message, given the event code, the event text, and the
multicast destination address. We use sockaddr_in()
to create a suitable packed destination address using our
multicast port and multicast IP address, and pass the event
code, text, and address to our inherited
send_event() method.
We turn now to the ChatObjects::MChannel
module (Figure
21.9). This module, which is responsible for transmitting
public messages to all currently enrolled members of a
channel, requires the most extensive changes.

Lines 26: Load modules We declare
ChatObjects::MChannel as a subclass of ChatObjects::Channel,
so that Perl falls back to the parent class for any methods
that aren't explicitly defined in this class.
Lines 713: Override new() method
We override the new() method to save information
about the channel's multicast address and the comm object to
use for outgoing messages. We begin by invoking the parent
class's new() method. We then copy the method's
third and fourth arguments into hash keys named mcast_addr and comm, respectively.
Lines 1415: mcast_addr() and
comm() accessors We define two accessors named
mcast_addr() and comm(), to retrieve the
multicast address for the channel and the comm object,
respectively.
Lines 1620: info() method We
override the channel's info() method, which sends
descriptive information about the channel to the client.
Previously this method returned the name of the channel, the
number of users enrolled, and the description. We modify
this slightly so that the dotted-quad multicast IP address
for the channel occupies a position between the user count
and the description.
Lines 2126: mcast_dest() method
The mcast_dest() method returns the packed binary
destination address for the multicast group. It retrieves
the multicast port from the server object and uses
sockaddr_in() to combine it with the dotted-quad
address returned by mcast_addr(). We explicitly put
sockaddr_in() into a scalar context so that it
packs the port and IP address together, rather than
attempting to unpack its argument.
Lines 2733: send_to_all() method
The send_to_all() method is called whenever it's
necessary to send a message to all members of a channel.
Such messages are sent when a user joins or departs a
channel, as well as when a user sends a public message to
the channel. We call mcast_dest() to get the packed
binary address for multicasts directed to the channel, and
then pass this destination, along with the event code and
content, to the comm object's send_event() method.
Note that the ChatObject::MComm class doesn't
itself define the send_event() method. This is
inherited from the parent class and is used to send both
unicast messages to individual clients and multicast messages
to all channel subscribers.
Only a few parts of the client application
need to be modified to support multicasting, so we list only
the relevant portions of the source code (Figure
21.10). The full source code for the modified client is in
Appendix
A.

Lines 19: Load modules In addition
to the IO::Socket and IO::Select modules, we now load
ChatObjects::MComm and IO::Socket::Multicast in order to
gain access to mcast_add() and friends.
Lines 2336: Define handlers for server
events The %MESSAGES hash maps server events to
subroutines that are invoked to handle the events. We add
SET_MCAST_PORT to the list of handled events,
making its handler the new create_msocket()
subroutine.
Lines 3742: Initialize the control and
multicast sockets We read the command-line arguments to
get the default server address and control port. We then
create a standard ChatObjects::Comm object, which holds the
server unicast address and port. We store this in
$comm. This will be used to exchange chat messages
with the server. For multicast messages we will later create
a ChatObjects::MComm object.
Lines 4154: Log in and enter select
loop We now attempt to log into the server. If
successful, we create an IO::Select object on the control
socket and STDIN and enter the main loop of the
client, handling user commands and server messages. This
part of the program hasn't changed from the original but is
repeated here in order to provide context.
Lines 5967: Handle the
SET_MCAST_PORT message The
create_msocket() subroutine is responsible for
handling SET_MCAST_PORT messages sent from the
server. It must do two things: create a new
ChatObjects::MComm object bound to the indicated port and
add the new comm object's socket to the list of filehandles
monitored by the client's main select() loop.
The function first examines the port number
sent by the server in the message body and refuses to handle
the message unless it is numeric. If the $msocket
global variable is already defined, the function removes it
from the list of handles monitored by the global IO::Select
object (currently, this never happens, but a future
iteration of this server might change the multicast port
dynamically).
The next step is to create a new comm
object to handle incoming multicasts. We call
ChatObjects::MComm->new() to create a new
communications object wrapped around a multicasting UDP
socket.
The last step is to add the newly created
socket to the list that the global IO::Select object
monitors.
Lines 124136: Join and part
channels The join_part() subroutine is called
to handle the server's JOIN_ACK and
PART_ACK message codes. The subroutine parses the
message from the server, which contains the affected
channel's multicast address. In the case of a
JOIN_ACK message, we tell the multicast socket to
join the group by calling its mcast_add() method.
Otherwise, we call mcast_drop().
Lines 137142: List a channel A
last, trivial change is to the list_channel()
method, which lists information about a channel in response
to a CHANNEL_ITEM message. The format of this
message was changed to include the channel's multicast
address, so the regular expression that parses it must
change accordingly.
The new multicast-enabled version of the chat
server works well on a local area network and between subnets
separated by multicast routers. It will not work across the Internet unless
the ISPs at both ends route multicast packets or you set up a
multicast tunnel with mrouted
or equivalent.
One limitation of this client is that only
one user can run it on the same machine at the same time. This
is because only one socket can be bound to the multicast port
at a time. We could work around this limitation by setting the
Reuse option during creation
of the multicast socket. This would allow multiple sockets to
bind to the same port but would create a situation in which,
whenever one user subscribed to a channel, all other users on
the machine would start to receive messages on that channel as
well. To prevent this, the client would have to keep track of
the channels it subscribed to and filter out messages coming
from irrelevant ones.
Perhaps a better solution would be to
allocate a range of ports for use by the chat system and have
each client run through the allowed ports until it finds a
free one that it can bind to. Alternatively, the server could
keep track of the ports and IP addresses used by each client
and use the SET_MCAST_PORT message to direct the
client toward an unclaimed port.
Chapter 22. UNIX-Domain Sockets
In previous chapters we focused on TCP/IP
sockets, which were designed to allow processes on different
hosts to communicate. Sometimes, however, you'd like two or
more processes on the same host to exchange messages. Although
TCP/IP sockets can be used for this purpose (and often are),
an alternative is to use UNIX-domain sockets, which were
designed to support local communications.
The advantage of UNIX-domain sockets over
TCP/IP for local interprocess communication is that they are
more efficient and are guaranteed to be private to the
machine. A TCP/IP-based service intended for local
communications would have to check the source address of each
incoming client to accept only those originating from the
local host.
Once set up, UNIX-domain sockets look and act
much like TCP/IP sockets. The process of reading and writing
to them is the same, and the same concurrency-managing
techniques that work with TCP/IP sockets apply equally well to
UNIX-domain sockets. In fact, you can write an application for
UNIX-domain sockets and then reengineer it for use on the
network just by changing the way it sets up its sockets.
Using UNIX-Domain Sockets
Like TCP/IP sockets, two applications that
wish to communicate must rendezvous at an agreed-on name.
Instead of using the combination of IP address and port number
for rendezvous, UNIX-domain sockets use a path on the local
file system, such as /dev/log.
They are created automatically when the socket is bound and
appear in UNIX directory listings with an "s" at the
beginning of the permission string. For example:
% ls -l /dev/log
srw-rw-rw- 1 root root 0 Jun 17 16:21 /dev/log
The socket files are not automatically
removed after the socket is closed, and must be unlinked
manually.
The Perl documentation occasionally refers to
these files as "fifo's" because they follow first-in-first-out
rules: The first byte of data written by a sending application
is the first byte of data read by the receiver. UNIX-domain
sockets are similar in many ways to UNIX pipes (Chapter
2), and in fact the two are frequently implemented on top
of a common code base.
The "UNIX" in UNIX-domain sockets is apt.
Although a few platforms, such as OS/2, have facilities
similar to UNIX-domain sockets, most operating systems,
including Windows and Macintosh, do not support them. However,
Windows users can get UNIX-domain sockets by installing the
free Cygwin32 compatibility library. This library is available
from http://www.cygnus.com/cygwin/.
UNIX-domain sockets are used by the standard
UNIX syslog daemon (Chapter
12), the Berkeley lpd printer service, and a number of
newer applications such as the XMMS MP3 player (http://www.xmms.org/). In the syslog system,
client applications write log messages to a UNIX-domain
socket, such as /dev/log. As
described in Chapter
14, the syslog daemon reads these messages, filters them
according to their severity, and writes them to one or several
log files. The lpd printer daemon uses a similar strategy to
receive print jobs from clients.
XMMS has a more interesting use for
UNIX-domain sockets. By creating and monitoring a UNIX-domain
socket, XMMS can exchange information with clients. Among
other things, clients can send XMMS commands to play a song or
change its volume, or retrieve information from XMMS about
what it's currently doing. Doug MacEachern's Xmms module,
available from CPAN, provides a Perl interface to XMMS
sockets.
Perl provides both a function-oriented and an
object-oriented interface to UNIX-domain sockets. We'll look
at each in turn.
Function-Oriented Interface to
UNIX-Domain Sockets
Creating UNIX-domain sockets with the
function-oriented interface is similar to creating TCP/IP
sockets. You call socket() to create the socket,
connect() to make an outgoing connection, or
bind(), listen(), and accept() to
accept incoming connections.
To create a UNIX-domain socket, call
socket() with a domain type of AF_UNIX and a
protocol of PF_UNSPEC (protocol unspecified). These
constants are exported by the socket module. You are free to
create either SOCK_STREAM or SOCK_DGRAM
sockets:
use Socket;
socket(S, AF_UNIX, SOCK_STREAM, PF_UNSPEC)
or die "Can't create stream socket: $!
socket(D, AF_UNIX, SOCK_DGRAM, PF_UNSPEC)
or die "Can't create datagram socket: $!
Having created the socket, we can make an
outgoing connection to a waiting server by calling
connect(). The chief difference is that we must
create the rendezvous address using a pathname and the utility
function sockaddr_un (). This code fragment tries to
connect to a server listening at the address /tmp/daytime:
my $dest = sockaddr_un('/tmp/daytime');
connect(S,$dest) or die "Can't connect: $!";
A UNIX-domain address is simply a pathname
that has been padded to a fixed length with nulls and can be
created with sockaddr_un(). The members of the
sockaddr_un() family of functions are similar to
their IP counterparts:
|
$packed_addr
= sockaddr_un($path)
($path) =
sockaddr_un($packed_addr)
In a scalar context,
sockaddr_un() takes a file pathname and turns
it into a UNIX-domain destination address suitable for
bind() and connect(). In an array
context, the sockaddr_un() reverses this
operation, which is handy for interpreting the return
value of recv() and
getsockname(). |
If this context-specific behavior makes you
nervous, you can use the pack_sockaddr_un() and
unpack_sockaddr_un() functions instead:
|
$packed_addr
= pack_sockaddr_un($path)
pack_sockaddr_un() packs a
file path into a UNIX domain address regardless of array
or scalar context.
$path =
unpack_sockaddr_un($packed_addr)
unpack_sockaddr_un()
transforms a packed UNIX-domain socket into a file path,
regardless of array or scalar
context. |
Servers must bind to a UNIX-domain address by
calling bind() with the desired rendezvous address.
This example binds to the socket named /tmp/daytime:
bind(S,sockaddr_un('/tmp/daytime')) or die "Can't bind: $!";
If successful, bind() returns a true
value. Common reasons for failure include:
"address already in use" (EADDRINUSE)
The rendezvous point already exists, as a regular file, a
regular directory, or a socket created by a previous
invocation of your script. UNIX-domain servers must unlink the
socket file before they exit.
"permission denied" (EACCES)
Permissions deny the current process the ability to create the
socket file at the selected location. The same rules that
apply to creating a file for writing apply to UNIX-domain
sockets. On UNIX systems the /tmp directory is often chosen by
unprivileged scripts as the location for sockets.
"not a directory" (ENOTDIR) The
selected path included a component that was not a valid
directory. Additional errors are possible if the selected path
is not local. For example, socket addresses on read-only
filesystems or network-mounted filesystems are disallowed.
Once a UNIX-domain socket is created and
initialized, it can be used like a TCP/IP socket. Programs can
call read(), sysread(), print(), or
syswrite() to communicate in a stream-oriented
fashion, or send() and recv() to use a
message-oriented API. Servers may accept new incoming
connections with listen() and accept().
The functions that return socket addresses,
such as getpeername(), getsockname(), and
recv(), return packed UNIX-domain addresses when used
with UNIX-domain sockets. These must be unpacked with
sockaddr_un() or unpack_sockaddr_un() to
retrieve a human-readable file path.
You should be aware that some versions of
Perl have a bug in the routines that return socket names. On
such versions, the array forms of sockaddr_un() and
unpack_sockaddr_un() will fail. This is not as bad as
it sounds because UNIX-domain applications don't need to
recover this information as frequently as TCP/IP applications
do. However, if you do need to recover the pathname of the
local or remote socket, you can work around the Perl bug by
applying unpack() with a format of "x2z" to
the value returned by getpeername() or
getsockname():
$path = unpack "x2z",getpeername(S);
Another thing to be aware of is that a
UNIX-domain socket created by a client can connect()
without calling bind(), just as one can with a TCP/IP
socket. In this case, the system creates an invisible endpoint
for communication, and getsockname() returns a path
of length 0. This is roughly equivalent to the operating
system's method of using ephemeral ports for outgoing TCP/IP
connections.
Object-Oriented Interface to
UNIX-Domain Sockets
The standard IO::Socket module provides
object-oriented access to UNIX-domain sockets. Simply create
an object of type IO::Socket::UNIX, and use it as you would a
TCP/IP-based IO::Socket object. Compared to IO::Socket::INET,
the main change is the new() object constructor,
which takes a different set of named arguments.
IO::Socket::UNIX adds the hostpath() and
peerpath() methods (described next) and does not
support the TCP/IP-specific sockaddr(),
sockport(), sockhost(>),
peeraddr(), or peerport() methods.
|
$socket =
IO::Socket::UNIX-new('/path/to/socket')
The single-argument form of
IO::Socket::UNIX->new() attempts to connect
to the indicated UNIX-domain socket, assuming a socket
type of SOCK_STREAM. If successful, it returns
an IO::Socket::UNIX object.
$socket =
IO::Socket::UNIX-new(arg1 => val1, arg2 =>
val2,...)
The named-argument form of
new() takes a set of name=> value
pairs and creates a new IO::Socket::UNIX object. The
recognized arguments are listed in Table
22.1.
$path =
$socket->hostpath()
The hostpath() method returns
the path to the UNIX socket at the local end. The method
returns undef for unbound sockets.
$path =
$socket- peerpat>()
peerpath() returns the path to
the UNIX socket at the remote end. The method returns
undef for unconnected
sockets. |
Table
22.1 lists the arguments recognized by IO::
Socket::UNIX->new(). Typical scenarios include:
-
Create a socket and connect() it
to the process listening on /var/log.
$socket = IO::Socket::UNIX->new(Type=>SOCK_STREAM,
Peer=>'/dev/log');
-
Create a listening socket bound to /tmp/mysock. Allow up to
SOMAXCONN incoming connections to wait in the
incoming queue.
$socket = IO::Socket::UNIX->new(Type => SOCK_STREAM,
Local => '/tmp/mysock',
Listen => SOMAXCONN);
-
Create a UNIX-domain socket for use with
outgoing datagram transmissions.
$socket = IO::Socket::UNIX->new(Type => SOCK_DGRAM);
-
Create a UNIX-domain socket bound to /tmp/mysock for use with incoming
datagram transmissions.
$socket = IO::Socket::UNIX->new(Type => SOCK_DGRAM,
Local=> '/tmp/mysock');
Table 22.1. Arguments to
IO::Socket::UNIX->new()
| Type |
Socket type, defaults
to SOCK_STREAM |
SOCK_STREAM or
SOCK_DGRAM |
| Local |
Local socket path |
<path>
|
| Peer |
Remote socket path |
<path>
|
| Listen |
Queue size for
listen |
<integer>
|
UNIX-Domain Sockets and File
Permissions
Because UNIX-domain sockets use physical
files as rendezvous points, the access mode of the socket file
affects what processes are allowed access to it. This can be
used to advantage as an access control mechanism.
When the bind() function (and the
IO::Socket::UNIX->new() method) creates the socket
file, the permissions of the resulting file are determined by
the process's current umask. If umask is 0000, then the socket
file is created with octal mode 0777 (all bits turned on). A
directory listing shows world-writable symbolic permissions of
srwxrwxrwx. This means that any
process can connect to the socket and send and receive
messages using it.
To restrict access to the socket, prior to
creating it you can modify the umask using Perl's built-in
umask() function. For example, a umask of octal 0117
creates socket files with permissions of srw-rw----, allowing socket access
only to processes running with the same user and group as the
server. 0177 is even more restrictive and forbids access to
all processes not running with the same user ID as the server.
For example, a server running as root might want to create its
sockets using this umask to prevent any client that does not
also have root privileges from connecting.
If you encounter difficulties using
UNIX-domain sockets, inspect the permissions of the socket
files and adjust the umask if they are not what you want. In
the examples that follow, we explicitly set the umask to 0111
prior to creating the socket. This creates a world-writable
socket, allowing any process to connect, but turns off the
execute bits, which are not relevant for socket files. An
alternative strategy is to call the Perl chmod()
function explicitly.
Server applications are free to use the
peer's socket path as a form of authentication. Before
servicing a request, they can recover the peer path and insist
that the socket file be owned by a particular user or group,
or that it has been created in a particular directory that
only a designated user or group has access to.
A "Wrap" Server
As a sample application we'll use the
standard Text::Wrap module to create a simple text-formatting
server. The server accepts a chunk of text input, reformats it
into narrow 30-column paragraphs, and returns the reformatted
text to the client. The server, named wrap_serv.pl uses the standard
forking architecture and the IO::Socket::UNIX library. The
client, wrap_cli.pl, uses a
simple design that sends the entire input file to the server,
shuts down the socket for writing, and then reads back the
reformatted data. The following is an example of the output
from the client after feeding it an excerpt from the beginning
of this chapter:
% wrap_cli.pl ../ch22.txt
Connected to /tmp/wrapserv...
In previous chapters we have focused on
TCP/IP sockets, which were designed to allow processes on
different hosts to communicate. Sometimes, however, you'd
like two or more processes on the same host to exchange
messages. Although TCP/IP sockets can be used for this
purpose (and often are), an alternative is to use
UNIX-domain sockets, which were designed to support local
communications.
The advantage of UNIX-domain sockets over
TCP/IP for local interprocess
communication...
The Text::Wrap Server
Figure
22.1 lists wrap_serv.pl. It
uses the forking design familiar from previous chapters. For
simplicity, the server doesn't autobackground itself, write a
PID file, or add any of the other frills discussed earlier,
but this would be simple to add with the Daemon module
developed in Chapter
14.

Lines 14: Import modules We load
the IO::Socket module and import the fill()
subroutine from Text::Wrap. Since this is a forking server,
we import the WNOHANG constant from POSIX for use
in the CHLD handler. We also bring in the POSIX
:signal_h set to block and unblock signals. This
facility will be used in the call to fork().
Lines 58: Define constants We
define a SOCK_PATH constant containing the
UNIX-domain socket path and various format settings to be
passed to Text::Wrap.
Lines 912: Set up variables We
retrieve the socket path from the command line or default to
the one in SOCK_PATH. We set the Text::Wrap
$columns variable to the column width defined in
COLUMNS.
Lines 1316: Install signal handlers
The CHLD signal reaps all child processes using a
variant of the waitpid() loop that we saw earlier.
This server must also unlink the UNIX-domain socket file
before it terminates, and for this reason we intercept the
INT and TERM signals with a handler that
unlinks the file and then terminates normally.
Lines 1718: Set umask We explicitly
set the umask to octal 0111 so that the listening
socket will be created world readable and writable. This
allows any process on the local host to communicate with the
server. (The leading 0 is crucial for making
0111 interpreted as an octal constant. If omitted,
Perl interprets this as decimal 111, which is
something else entirely.)
Lines 1921: Create listening socket
We call IO::Socket::UNIX->new() to create a
UNIX-domain listening socket on the selected socket address
path. The Listen argument
is set to the SOMAXCONN constant exported by the
Socket and IO::Socket modules.
Lines 2232: accept() loop The
accept() loop is identical to similar loops used in
TCP/IP servers. We do, however, call fork() through
a launch_child() wrapper for reasons that we will
discuss next. The interact() function is
responsible for communication with the client and is run in
the child process.
Lines 3342: launch_child()
subroutine launch_child() is a wrapper around
fork(). Because the parent server process has
INT and TERM handlers that unlink the
socket file, we must be careful to remove these handlers
from the children; otherwise, the file might be unlinked
prematurely. Using the same strategy we developed in the
Daemon module of Chapter
14, we create a POSIX:: SigSet containing the
INT, CHLD, and TERM signals and
invoke sigprocmask() to block the signals
temporarily. With the signals now safely blocked, we
fork(), and reset each of the handlers to the
default behavior in the child. We now unblock signals by
calling sigprocmask() again and return the child's
PID.
Lines 4348: interact() subroutine
The routine that does all the real work is only six lines
long. It retrieves the connected socket from its argument
list, reads the list of text lines to format from the
socket, and calls chomp() to remove the newlines,
if any. It then passes the lines to the Text::Wrap
fill() function, sends the result across the
socket, and closes the socket.
The Text::Wrap Client
Figure
22.2 lists wrap_cli.pl,
which is a mere 12 lines long.
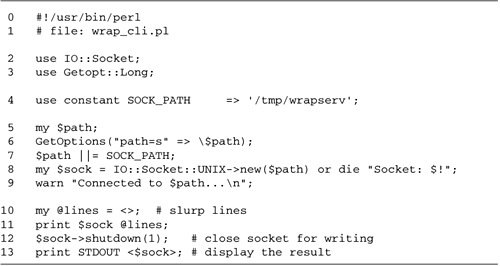
Lines 13: Import modules We bring
in the IO::Socket and Getopt::Long modules. The latter is
used for processing command-line switches.
Line 4: Define SOCK_PATH constant
We define a constant containing the default path to the
UNIX-domain socket.
Lines 57: Process command-line
arguments The client allows the user to manually set the
path to the socket by providing a $path argument.
We call GetOptions() to parse the command-line
looking for this argument. If not provided, we default to
the value of SOCK_PATH.
Lines 89: Open socket We call the
one-argument form of IO::Socket::UNIX->new() to
create a new UNIX-domain socket and attempt to connect to
the address at $path. We don't need to set our
umask before calling new(), because we will not be
binding to a local address.
Lines 1012: Read text lines and send
them to server We use <> to read all the
lines from STDIN and/or the command-line argument
list into an array named @lines, and send them over
the socket to the server. We then invoke
shutdown(1) to close the write-half of the socket
and indicate to the server that we have no more data to
submit.
Line 13: Print the results We read
the reformatted lines from the socket and print them to
STDOUT.
Using UNIX-Domain Sockets for
Datagrams
UNIX-domain sockets can be used to send and
receive datagrams. When creating the socket (or accepting
IO::Socket::UNIX's default), instead of specifying a type of
SOCK_STREAM, create the socket with
SOCK_DGRAM. You will now be able to use
send() and recv() to transmit messages over
the socket without establishing a long-term connection.
Because UNIX-domain sockets are local to the
host, there are some important differences between using
UNIX-domain sockets to send datagrams locally and using the
UDP protocol to send datagrams across the network. On the plus
side, UNIX-domain datagrams are reliable and sequenced. Unlike
with the UDP protocol, you can count on the UNIX-domain
datagrams reaching their destinations and arriving in the same
order you sent them. On the minus side, two-way communication
is only possible if both processes bind() to a path.
If the client forgets to do so, then it will be able to send
messages to the server, but the server will not receive a peer
address that can be used to reply.
To illustrate using datagrams across
UNIX-domain sockets, we'll develop a simple variation on the
daytime server. This server acts much like the standard
daytime server by returning a string containing the current
local date and time in response to incoming requests. However,
in a nod to globalization, it also looks at the incoming
message for a string indicating the time zone, and if the
string is present, it returns the date and time relative to
that zone.
The server is called localtime_serv.pl and the client
localtime_cli.pl. The client
takes an optional time-zone argument on the command line. The
following excerpt shows the client being used to fetch the
time in the current time zone, in Eastern Europe, and in
Anchorage, Alaska:
% ./localtime_cli.pl
Sat Jun 17 18:06:14 2000
% ./localtime_cli.pl Europe/Warsaw
Sat Jun 17 22:06:24 2000
% ./localtime_cli.pl America/Anchorage
Sat Jun 17 14:06:57 2000
UNIX-Domain Daytime Server
Figure
22.3 lists localtime_serv.pl. It follows the
general outline of the single-threaded datagram servers
discussed in Chapter
18.
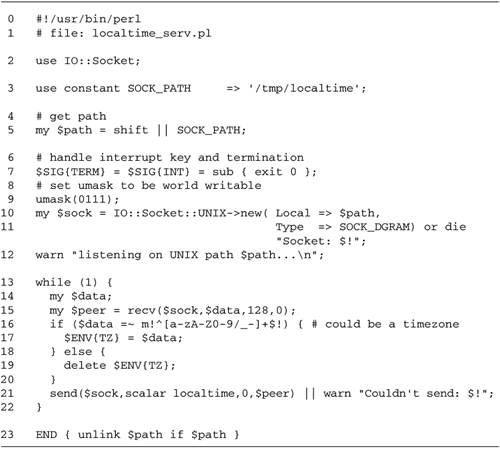
Lines 16: Server setup We load the
IO::Socket module and choose a default path for the socket.
We then read the command line for an alternative socket
path, should the user desire to change it.
Line 7: Install TERM and
INT handlers As in the connection-oriented example,
we need to delete the socket file before exiting. In the
previous case we did this by unlinking the file in the
TERM and INT signal handlers.
For variety, in this example we will
accomplish the same thing by defining an END{}
block that unlinks the path when the script terminates.
However, to prevent the script from terminating prematurely,
we must still install an interrupt handler that intercepts
the TERM and INT signals and calls
exit() so that the process terminates in an orderly
fashion.
Lines 812: Create socket We set our
umask to 0111 so that the socket will be world
writable and call IO::Socket::UNIX->new() to
create the socket and bind it to the designated path. Unlike
the previous example, where we allowed IO::Socket::UNIX to
default to a connection-oriented socket, we pass
new() a Type
argument of SOCK_DGRAM. Because this is a
message-oriented socket, we do not provide a Listen argument.
Lines 1322: Transaction loop We
enter an infinite loop. Each time through the loop we call
recv() to return a message of up to 128 bytes
(which is as long as a time zone specifier is likely to
get). The value returned from recv() is the path to
the peer's socket.
We examine the contents of the message, and
if its format is compatible with a time-zone specifier, we
use it to set the TZ environment variable, which
contains the current time zone. Otherwise, we delete this
variable, which causes Perl to default to the local time
zone.
Using the peer's path, we now call
send() to return to the peer a datagram containing
the output of localtime(). If for some reason
send() returns a false value, we issue a
warning.
Line 23: END{} block The script's
END{} block unlinks the socket file if
$path is not empty.
UNIX-Domain Daytime Client
A client to match the daytime server is shown
in Figure
22.4.

Lines 14: Load modules We load the
IO::Socket and Getopt::Long modules. We also bring in the
tmpnam() function from the POSIX module. This handy
routine chooses unique names for temporary files; we'll use
it to generate a file path for our local socket.
Lines 56: Constants We define a
constant containing the default path to use for the server's
socket, and a TIMEOUT value containing the maximum
time we will wait for a response from the server.
Lines 710: Select pathnames for local
and remote sockets We process command-line options
looking for a --path argument. If none is defined,
we default to the same path for the server socket that the
server uses.
We also need a pathname for the local
socket so that the server can talk back to us, but we don't
want to hard code the path because another user might want
to run the client at the same time. Instead, we call
POSIX::tmpnam() to return a unique temporary
filename for the local socket.
Line 11: Signal handlers We will
unlink the local socket in an END{} block as in the
server. For this reason, we intercept the INT and
TERM signals.
Lines 1216: Create socket We set
our umask as before and call
IO::Socket::UNIX->new() to create the socket,
providing both Local and
Type arguments to create a
SOCK_DGRAM socket bound to the temporary pathname
returned by tmpnam().
Lines 1718: Prepare to transmit
request We recover the requested time zone from the
command line. If none is provided, we create a message
consisting of a single space (we must send at least 1 byte
of data to the server in order for it to respond). We use
sockaddr_un() to create a valid destination address
for use with send().
Lines 1927: Send request and receive
response We call send() to send the message
containing the requested time zone to the server.
We now want to call recv() to read
the response from the server, but we don't know for sure
that the server is listening. So instead of calling
recv() and waiting indefinitely for a response, we
wrap the call in an eval{} block using the
technique shown in Chapter
5. On entry into the eval{}, we set a handler
for the ALRM signal, which calls die(). We
then set an alarm clock for TIMEOUT seconds using
alarm() and call recv(). If
recv() returns before the alarm expires, we print
the returned data. Otherwise, we die with an error
message.
Line 28: END{} block As in the
server, we unlink the local socket after we are done.
If you wish to watch the client's timeout
mechanism work, start the server and immediately suspend it
using the suspend key (^Z on UNIX systems). When the
client sends a request to the server, it will not get a
response and will issue a timeout error.

 LINUX
LINUX