|
Один из самых главных и полезных инструментов отладки
сетей и работающих в них приложений - это утилита ping. Ее основное назначение
- проверить наличие связи между двумя хостами.
Прежде необходимо разъяснить несколько моментов,
касающихся ping. Во-первых, по словам Майка Муусса, слово «ping» не расшифровывается
как «packet internet groper» (проводящий межсетевые пакеты). Своим названием
эта программа обязана звуку, который издает сонар, устанавливаемый на подводных
лодках. История создания программы ping изложена в статье «The Story of the
Ping Program» Муусса на Web-странице http://ftp.arl.mil/-mike/ping/html. Там
же приведен и ее исходный текст.
Во-вторых, эта утилита не использует ни TCP, ни
UDP, поэтому для нее нет никакого хорошо известного порта. Для проверки наличия
связи ping пользуется функцией эхо-контроля, имеющейся в протоколе ICMP. Помните
(совет 14), что, хотя сообщения ICMP передаются в IP-датаграммах, ICMP считается
не отдельным протоколом, а частью IP.
Примечание: В RFC 792 [Postel 1981] на первой
странице сказано: «1СМР использует базовую поддержку IP, как если бы это был
протокол более высокого уровня, однако в действительности ICMP является неотъемлемой
частью IP и должен быть реализован в каждом IP-модуле».
Таким образом, структура пакета, посылаемого ping,
имеет такой вид, как на рис. 4.1. Показанная на рис. 4.2 ICMP-часть сообщения
состоит из восьмибайтного ICMP-заголовка и n байт дополнительной информации.
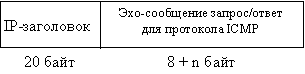
Рис. 4.1. Формат пакета ping
Обычно в качестве значения n - числа дополнительных
байтов в пакете ping выбирается 56 (UNIX) или 32 (Windows), но эту величину
можно изменить с помощью флагов -s (UNIX) или -l (Windows).
В некоторых версиях ping пользователь может задавать
значения дополнительных данных или даже указывать, что они должны генерироваться
псевдослучайным образом. По умолчанию в большинстве версий дополнительные данные
циклически переставляемый по кругу набор байтов.
Примечание: Задание конкретных данных бывает
полезно при отладке ошибок, зависящих от данных.
UNIX - версия ping помещает временной штамп
(структуру timeval) в первые восемь байт дополнительных данных (при условии,
конечно, что пользователь не задал меньшее количество). Когда программа ping
получает эхо-ответ, она использует этот временной штамп для вычисления периода
кругового обращения (RTT). Windows-версия ping этого не делает (вывод основан
на анализе информации, полученной с помощью программы tcpdump), но в тексте
примера ping, поставляемого в составе компилятора Visual C++, этот алгоритм
присутствует.

Рис. 4.2. Пакет эхо – сообщения
запрос/ответ протокола ICMP
Поскольку поля идентификатор и порядковый номер
не задействованы ни в эхо-запросе, ни в эхо-ответе, ping использует их для идентификации
полученных ICMP-ответов. Так как для IP-датаграмм нет специального порта, они
доставляются каждому процессу, который открыл простой (raw) сокет с указанием
протокола ICMP (совет 40). Поэтому ping помещает свой идентификатор процесса
в поле идентификатор, так что каждый запущенный экземпляр способен отличить
ответы на свои запросы. Таким образом, поле идентификатор в этом случае можно
представить как аналог номера порта.
Таким же образом ping помещает в поле порядковый
номер значение счетчика для того, чтобы связать ответ с запросом. Именно это
значение ping показывает как icmp_seq.
Обычно первое ваше действие при пропадании связи
с удаленным хостом - это запуск ping с указанием адреса этого хоста (хост
«пингуется»). Предположим, что нужно связаться с хостом А с помощью программы
telnet, но соединение не устанавливается из-за истечения тайм-аута. Причин может
быть несколько: проблема в сети между двумя хостами, не работает сам хост А,
проблема в удаленном стеке TCP/IP или не запущен сервер telnet.
Сначала следует проверить, «пингуя» хост А, что
он достижим. Если работа ping Проходит нормально, то можно сказать, что с сетью
все в порядке, а проблема, вероятно, связана с самим хостом А. Если же невозможно
«достучаться» до хоста А с помощью ping, то требуется «пропинговать» ближайший
маршрутизатор, чтобы понять, удается ли достичь хотя бы границы собственной
сети. Если это получается, то воспользуйтесь программой traceroute (совет 35),
чтобы выяснить, насколько далеко можно продвинуться по маршруту от вашего хоста
к хосту А. Часто это помогает идентифицировать сбойный маршрутизатор или хотя
бы сделать предположение о месте возникновения ошибки.
Поскольку ping работает на уровне протокола IP,
она не зависит от правильности конфигурации TCP или UDP. Поэтому иногда полезно
«пропинговать» свой собственный хост, чтобы проверить правильность установки
сетевого программного обеспечения. Сначала можно указать ping возвратный адрес
localhost (127.0.0.1), чтобы убедиться в работе хотя бы части сетевой поддержки.
Если при этом проблем не возникает, то следует «пропинговать» один или несколько
сетевых интерфейсов и удостовериться, что они правильно сконфигурированы.
Попробуйте «пропинговать» хост netcom4.netcom.com,
который находится от вас в десяти переходах (рис. 4.3).
bsd: $ ping netcom4.netcom.com
PING netcom4.netcom.com (199.183.9.104): 56 data bytes
64 bytes from 199.183.9.104: icmp_seq=0 tt1=245 time=598.554 ms
64 bytes from 199.183.9.104: icmp_seq=1 tt1=245 time=550.081 ms
64 bytes from 199.183.9.104: icmp_seq=2 tt1=245 time=590.079 ms
64 bytes from 199.183.9.104: icmp_seq=3 tt1=245 time=530.114 ms
64 bytes from 199.183.9.104: icmp_seq=5 tt1=245 time=480.137 ms
64 bytes from 199.183.9.104: icmp_seq=6 tt1=245 time=540.081 ms
64 bytes from 199.183.9.104: icmp_seq=7 tt1=245 time=580.084 ms
64 bytes from 199.183.9.104: icmp_seq=8 tt1=245 time=490.078 ms
64 bytes from 199.183.9.104: icmp_seq=9 tt1=245 time=560.090 ms
64 bytes from 199.183.9.104: icmp_seq=10 tt1=245 time=490.090 ms
^C завершили ping вручную
- - - netcom4.netcom.com ping statistics - - -
12 packets transmitted, 10 packets received, 16% packet loss
round-trip min/avg/max/stddev = 480.137/540.939/598.554/40.871 ms
bsd: $
Рис. 4.З. Короткий прогон ping
Прежде всего, RTT для разных пакетов мало меняется
и остается в пределах 500 мс. Как следует из последней строки, RTT модифицируется
в диапазоне от 480,137 мс до 598,554 мс со стандартным отклонением 40,871 мс.
Тест слишком рано прерван, чтобы можно было сделать какие-то выводы, но и при
более длительном прогоне (около 2 мин) результат существенно не изменится. Так
что можно предположить, что нагрузка на сеть постоянная. Значительный разброс
RTT это, как правило, признак изменяющейся загрузки сети. При повышенной загрузке
возрастает длина очереди в маршрутизаторе, а вместе с ней - и RTT. При уменьшении
загрузки очередь сокращается, что приводит к уменьшению RTT.
Далее из рис. 4.3 видно, что на эхо-запрос ICMP
с порядковым номером 4 не пришел ответ. Это означает, что запрос либо ответ
был потерян одним из промежуточных маршрутизаторов. По данным сводной статистики,
было послано 12 запросов (0-11) и получено лишь, 10 ответов. Один из пропавших
ответов имеет порядковый номер 4, второй - 11 (вероятно, он был засчитан как
пропавший, поскольку не вовремя прервана работа ping).
Утилита ping - это один из важнейших инструментов
тестирования связи в сети. Поскольку для ее работы требуется лишь функционирование
самых нижних уровней сетевых служб, она полезна для проверки связи в условиях,
когда сервисы более высокого уровня, такие как TCP, или программы прикладного
уровня типа telnet не работают.
С помощью ping часто удается сделать выводы об условиях
в сети, наблюдая за значениями и дисперсией RTT и за числом потерянных ответов.
Из всех имеющихся в нашем распоряжении мощных и
полезных средств отладки сетевых приложений и поиска неисправностей в сети наиболее
интересны сетевые анализаторы (их еще называют сниферами). Традиционно сетевой
анализатор - дорогое специализированное устройство, но современные рабочие станции
вполне способны выполнять их функции в рамках отдельного процесса.
Сегодня сниферы есть для большинства сетевых операционных
систем. Иногда в операционную систему входит снифер, предлагаемый поставщиком
(программа snoop в Solaris или программы iptrace/ipreport в AIX), а иногда пользуются
программами третьих фирм, например tcpdump.
Из инструментов, предназначенных только для диагностики,
сниферы постепенно превратились в средства для исследований и обучения. Например,
они постоянно используются для изучения динамики и взаимодействий в сетях. В
книгах [Stevens 1994, Stevens 1996] рассказано, как использовать tcpdump, чтобы
разобраться в работе сетевых протоколов. Наблюдая за данными, которые посылает
протокол, вы можете глубже понять его функционирование на практике, а заодно
увидеть, когда некоторая конкретная реализация работает не в соответствии со
спецификацией.
В этом разделе будет рассмотрена утилита tcpdump.
Как уже отмечалось, есть и другие программно реализованные сетевые анализаторы.
Некоторые из них лучше форматируют выходные данные, но у tcpdump есть одно неоспоримое
преимущество - она работает практически во всех UNIX-системах и в Windows. Поскольку
исходные тексты tcpdump опубликованы, ее можно при необходимости адаптировать
для специальных целей или перенести на новую платформу.
Код tcpdump вы можете найти на сайте http://www-nrg.ee.lbl.gov/nrg.html,
а исходные тексты и исполняемый код для Windows WinDump - http://netgroup-serv.polito.it/windump.
Посмотрим, как работает программа t cpdump и на
каком уровне протоколов она перехватывает пакеты. Как и большинство сетевых
анализаторов, tcpdump состоит из двух компонент: первая работает в ядре и занимается
перехватом и, возможно фильтрацией пакетов, а вторая действует в адресном пространстве
пользователя и определяет интерфейс пользователя, а также выполняет форматирование
и фильтрацию пакетов, если последнее не делается ядром.
Пользовательская компонента tcpdump взаимодействует
с компонентой в ядре при помощи библиотеки libpcap (библиотека для перехвата
пакетов), которая абстрагирует системно-зависимые детали общения с канальным
уровнем стека протоколов. Например, в системах на основе BSD libpcap взаимодействует
с пакетным фильтром BSD (BSD packet filter - BPF) [McCanne and Jacobson 1993].
BPF исследует каждый пакет, проходящий через канальный уровень, и сопоставляет
его с фильтром, заданным пользователем. Если пакет удовлетворяет критерию фильтрации,
то его копия помещается в выделенный ядром буфер, который ассоциируется с данным
фильтром. Когда буфер заполняется или истекает заданный пользователем тайм-аут,
содержимое буфера передается приложению с помощью libpcap.
Этот процесс изображен на рис. 4.4. Показано, как
tcpdump и любая другая программа считывают необработанные пакеты с помощью BPF,
а также изображено еще одно приложение, читающее данные из стека TCP/IP, как
обычно.
Примечание: Хотя на этом рисунке и tcpdump,
и программа используют библиотеку libpcap, можно напрямую общаться с ВРF или
иным интерфейсом, о чем будет сказано ниже. Достоинство libpcap в том, что она
предоставляет системно-независимые средства доступа к необработанным пакетам.
В настоящее время эта библиотека поддерживает BPF; интерфейс канального провайдера
(data link provider interface – DLPI); систему SunOS NIT; потоковую NIT; сокеты
типа SOCK_PACKET, применяемые в системе Linux; интерфейс snoop (IRIX) и разработанный
в Стэнфордском университете интерфейс enet. В дистрибутив WinDump входит также
версия libpcap для Windows.
Обратите внимание, что BPF перехватывает сетевые
пакеты на уровне драйвера устройства, то есть сразу после того, как они считаны
с носителя. Это не то же самое что чтение из простого сокета. В ситуации с простым
сокетом вы получаете IР-датаграммы, уже обработанные уровнем IP и переданные
непосредственно приложению минуя транспортный уровень (TCP или UDP). Об этом
рассказывается в совете 40.
Начиная с версии 2.0, архитектура WinDump очень
напоминает используемую в системах BSD. Эта программа пользуется специальным
NDIS-драйвером (NDIS- Network Driver Interface Specification - спецификация
стандартного интерфейса сетевых адаптеров), предоставляющим совместимый с BPF
фильтр и интерфейс. В архитектуре WinDump NDIS-драйвер фактически представляет
собой часть стека протоколов, но функционирует он так же, как показано на рис.
4.4, только надо заменить BPF на пакетный драйвер NDIS.
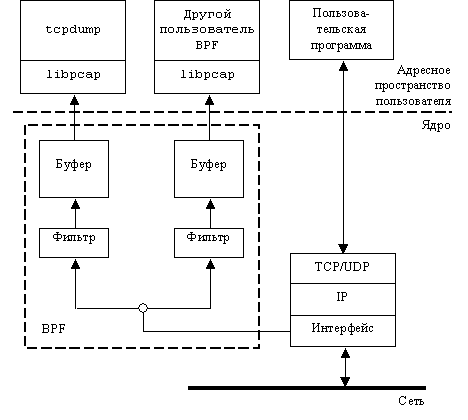
Рис. 4.4. Перехват пакетов с помощью
BPF
Другие операционные системы используют несколько
иные механизмы. В системах, производных от SVR4, для доступа к простым сокетам
применяется интерфейс DLPI [Unix International 1991]. DLPI - это не зависящий
от протокола, основанный на системе STREAMS [Ritchie 1984] интерфейс к канальному
уровню, С помощью DLPI можно напрямую получить доступ к канальному уровню, но
по соображениям эффективности обычно вставляют в поток STREAMS-модули pfmod
и bufmod. Модуль bufmod предоставляет услуги по буферизации сообщений и увеличивает
эффективность за счет ограничения числа контекстных переключений, требуемых
для доставки данных.
Примечание: Это аналогично чтению полного
буфера из сокета вместо побайтного чтения.
Модуль pfmod - это фильтр, аналогичный BPF. Поскольку
он несовместим с фильтром BPF, tcpdump вставляет этот модуль в поток, а фильтрацию
выполняет в пространстве пользователя. Это не столь эффективно, как при использовании
BPF, так как в пространство пользователя приходится передавать каждый пакет,
даже если он не нужен программе tcpdump.
На рис. 4.5 показаны tcpdump без модуля pf mod
и приложение, которое получает необработанные пакеты с использованием находящегося
в ядре фильтра.
На рис. 4.5 также представлены приложения, пользующиеся
библиотекой libpcap, но, как и в случае BPF, это необязательно. Для отправки
сообщений непосредственно в поток и получения их обратно можно было бы воспользоваться
вызовами getmsg и putmsg. Книга [Rago 1993] - отличный источник информации о
программировании системы STREAMS, DLPI и системных вызовах getmsg и putmsq.
Более краткое обсуждение вопроса можно найти в главе 33 книги [Stevens 1998].
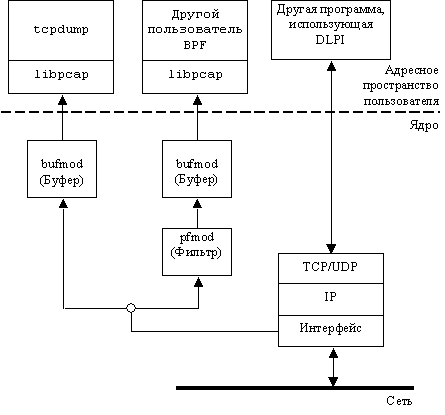
Рис. 4.5. Перехват пакетов с помощью
DLPI
Наконец, есть еще и архитектура Linux. В этой системе
доступ к необработанным сетевым пакетам производится через интерфейс сокетов
типа SOCK_PACKET. Для использования этого простого механизма надо открыть подобный
сокет, привязать к нему требуемый сетевой интерфейс, включить режим пропускания
всех пакетов (promiscuous mode) и читать из сокета.
Примечание: Начиная с версии 2.2 ядра Linux,
рекомендуется несколько другой интерфейс, но последняя версия libpcap по-прежнему
поддерживает описанный выше.
Например, строка
s = socket( AF_INET, SOCK_PACKET, htons( ETH_P_ALL
) );
открывает сокет, предоставляющий доступ ко всем
Ethernet-пакетам. В качестве третьего параметра можно также указать ЕТН_Р_IР
(пакеты IP), ETH_P_IPV6 (пакеты IPv6) или ETH_P_ARP (пакеты ARP). Будем считать,
что этот интерфейс аналогичен простым сокетам (SOCK_RAW), только доступ производится
к канальному, а не сетевому (IP) уровню.
К сожалению, несмотря на простоту и удобство этого
интерфейса, он не очень эффективен. В отличие от обычных сокетов, ядро в этом
случае не осуществляет никакой буферизации, так что каждый пакет доставляется
приложением сразу после поступления. Отсутствует также фильтрация на уровне
ядра (если не считать параметра ЕТН_Р_* ). Поэтому фильтровать приходится на
прикладном уровне, а это означает, что приложение должно получать все пакеты
без исключения.
Прежде всего для использования tcpdump надо получить
разрешение. Поскольку применение сетевых анализаторов небезопасно, по умолчанию
tcpdump конфигурируется с полномочиями суперпользователя root.
Примечание: К системе Windows это не относится.
Коль скоро NDIS-драйвер для перехвата пакетов установлен, воспользоваться программой
WinDump может любой.
Во многих случаях лучше дать возможность всем пользователям
работать с программой tcpdump, не передавая им полномочия суперпользователя.
Это делается по-разному, в зависимости от версии UNIX и документировано в руководстве
по tcpdump. В большинстве случаев надо либо предоставить всем права на чтение
из сетевого интерфейса, либо сделать tcpdump setuid-программой.
Проще всего вызвать tcpdump вообще без параметров.
Тогда она будет перехватывать все сетевые пакеты и выводить о них информацию.
Однако полезнее, указать какой-нибудь фильтр, чтобы видеть только нужные пакеты
и не отвлекаться на остальные. Например, если требуются лишь пакеты, полученные
от хоста bsd или отправленные ему, то можно вызвать tcpdump так:
tcpdump host bsd
Если же нужны пакеты, которыми обмениваются хосты
bsd и sparc, то можно использовать такой фильтр:
host bsd and host spare
или сокращенно -
host bsd and spare
Язык для задания фильтров достаточно богат и позволяет
фильтровать, например, по следующим атрибутам:
- протокол;
- хост отправления и/или назначения;
- сеть отправления и/или назначения;
- Ethernet-адрес отправления и/или назначения;
- порт отправления и/или назначения;
- размер пакета;
- пакеты, вещаемые на всю локальную сеть
или на группу (как в Ethernet так, и в IP);
- пакет, используемый в качестве шлюза указанным
хостом.
Кроме того, можно проверять конкретные биты или
байты в заголовках протоколов. Например, чтобы отбирать только TCP-сегменты,
в которых выставлен бит срочных данных, следует использовать фильтр
tcp[ 13 ] & 16
Чтобы понять последний пример, надо знать, что
четвертый бит четырнадцатого байта заголовка TCP - это бит срочности.
Поскольку разрешается использовать булевские операторы
and (или &&), or (или || ) и not (или !) для комбинирования простых
предикатов, можно задавать фильтры произвольной сложности. Ниже приведен пример
фильтра, отбирающего ICMP-пакеты, приходящие из внешней сети:
icmp and not src net localnet
Примеры более сложных фильтров рассматриваются
в документации по tcpdump.
Информация, выдаваемая программой tcpdump, зависит
от протокола. Рассмотрим несколько примеров, которые помогут составить представление
о том, что можно получить от tcpdump для наиболее распространенных протоколов.
Документация, поставляемая вместе с программой, содержит исчерпывающие сведения
о формате выдачи.
Первый пример - это трассировка сеанса по протоколу
SMTP (Simple Mail Transfer Protocol - простой протокол электронной почты), то
есть процедура отправки электронного письма. Распечатка на рис. 4.6 в точности
соответствует выдаче tcpdump, только добавлены номера строк, напечатанные курсивом,
удалено имя домена хоста bsd и перенесены длинные строки, не уместившиеся на
странице.
Для получения трассировки послано письмо пользователю
с адресом в домен gte. net. Таким образом, адрес имел вид user@gte.net.
Строки 1-4 относятся к поиску адреса SMTP-сервера,
обслуживающего домен gte. net. Это пример выдачи, генерируемой tcpdump
для запросов и ответов сервиса DNS. В строке 1 bsd запрашивает у сервера имен
своего сервис-провайдера (nsl. ix.netcom.com) имя или имена почтового сервера
gte.net. В первом находится временной штамп пакета (12:54:32.920881). Поскольку
разрешающая способность таймера на машине bsd составляет 1 мкс, показано шесть
десятичных знаков. Вы видите, что пакет ушел из порта 1067 на bsd в порт 53
(domain) на машине nsl. Далее, дается информация о данных в пакете. Первое поле
(45801) -
1 12:54:32.920881 bsd.1067 > nsl.ix.netcom.com.domain:
45801+ MX? gte.net. (25)
2 12:54:33.254981 nsl.ix.netcom.com.domain > bsd.1067:
45801 5/4/9 (371) (DF)
3 12:54:33.256127 bsd.1068 > nsl.ix.netcom.com.domain:
45802+ A? mtapop2.gte.net. (33)
4 12:54:33.534962 nsl.ix.netcom.com.domain > bsd.1068:
45802 1/4/4 (202) (DF)
5 12:54:33.535737 bsd.1059 > mtapop2.gte.net.smtp:
S 585494507:585494507(0) win 16384
<mss 1460,nop,wscale 0,nop,nop,
timestamp 6112 0> (DF)
6 12:54:33.784963 mtapop2.gte.net.smtp > bsd.1059:
S1257159392:1257159392(0) ack 585494509 win 49152
<mss 1460,nop,wscale 0,nop,nop,
timestamp 7853753 6112> (DF)
7 12:54:33.785012 bsd.1059 > mtapop2.gte.net.smtp:
.ack 1 win 17376 <nop,nop,
timestamp 6112 7853753> (DF)
8 12:54:34.235066 mtapop2.gte.net.smtp > bsd.1059:
P 1:109(108) ack 1 win 49152
<nop,nop,timestamp 7853754 6112> (DF)
9 12:54:34.235277 bsd.1059 > mtapop2.gte.net.smtp:
P 1:19(10) ack 109 win 17376
<nop,nop,timestamp 6113 7853754> (DF)
14 строк опущено
24 12:54:36.675105 bsd.1059 > mtapop2.gte.net.smtp:
F 663:663(0) ack 486 3win 17376
<nop,nop,timestamp 6118 7853758> (DF)
25 12:54:36.685080 mtapop2.gte.net.smtp > bsd.1059:
F 486:486(0) ack 663 win 49152
<nop,nop,timestamp 7853758 6117> (DF)
26 12:54:36.685126 bsd.1059 > mtapop2.gte.net.smtp:
. ack 487 win 17376
<nop,nop,timestamp 6118 7853758> (DF)
27 12:54:36.934985 mtapop2.gte3.net.smtp > bsd.1059:
F 486:486(0) ack 664 win 49152
<nop,nop,timestamp 7853759 6118> (DF)
28 12:54:36.935020 bsd.1059 > mtapop2.gte.net.smtp:
. ack 487 win 17376
<nop,nop,timestamp 6118 7853759> (DF)
Рис. 4.6. Трассировка SMTP-сеанса с
включением обмена по протоколам DNS и TCP
Это номер запроса, используемый функциями разрешения
имен на bsd для сопоставления ответов с запросами. Знак «+» означает, что функция
разрешения задает опрос DNS-сервером других серверов, если у него нет информации
об ответе. Строка «MX?» показывает, что это запрос о записи почтового обмена
для сети, имя которой стоит в следующем поле (gte.net). Строка «(25)» свидетельствует
о том, что длина запроса - 25 байт.
Строка 2 - это ответ на запрос в строке 1. Число
45801 - это номер запроса, к которому относится ответ. Следующие три поля, разделенные
косой чертой, - количество записей в ответе, записей от сервера имен (полномочного
агента) и прочих записей. Строка «(371)» показывает, что ответ содержит 371
байт. И, наконец, строка «(DF)» означает, что в IP-заголовке ответа был поднят
бит «Don't fragment» (не фрагментировать). Итак, эти две строки иллюстрируют
использование системы DNS для поиска обработчиков почты (об этом кратко упоминалось
в совете 29).
Если в двух первых строках было выяснено имя обработчика
почты для сети gte.net, то в двух последующих выясняется его программа tcpdump
IP-адрес. «А?» в строке 3 указывает, что это запрос IP-адреса хоста mtapop2.gte.net
- одного из почтовых серверов компании GTE.
Строки 5-28 содержат детали обмена по протоколу
SMTP. Процедура трехстороннего квитирования между хостами bsd и mtapop2 начинается
в строке 5 и заканчивается строкой 7. Первое поле после временного штампа и
имен хостов - это поле flags. «S» в строке 5 указывает, что в сегменте установлен
флаг SYN. Другие возможные значения флага: «F» (FIN), «U» (URG), «P» (PUSH),
«R» (RST) и «.» (нет флагов). Далее идут порядковые номера первого и последнего
байтов, а за ними в скобках - число байтов данных. Эти поля могут вызвать некоторое
недоумение, так как «порядковый номер последнего» - это первый неиспользованный
порядковый номер, но только в том случае, когда в пакете есть данные. Удобнее
всего считать, что первое число - это порядковый номер первого байта в сегменте
(SYN или информационном), а второе - порядковый номер первого байта плюс число
байтов данных в сегменте. Следует отметить, что по умолчанию показываются реальные
порядковые номера для SYN-сегментов и смещения - для последующих сегментов (так
удобнее следить). Это поведение можно изменить с помощью опции - S в командной
строке.
Во всех сегментах, кроме первого SYN, имеется поле
АСК, показывающее, какой следующий порядковый номер ожидает отправитель. Это
поле (в виде ack nnn), как и раньше, по умолчанию содержит смещение относительно
порядкового номера, указанного в сегменте SYN.
За полем АСК идет поле window. Это количество байтов
данных, которое готов принять удаленный хост. Обычно оно отражает объем свободной
памяти в буферах соединения.
И, наконец, в угловых скобках указаны опции TCP.
Основные опции рассматриваются в RFC 793 [Postel 1981b] и RFC 1323 [Jacobson
et al. 1992]. Они обсуждаются также в книге [Stevens 1994], а их полный перечень
можно найти на Web-странице http://www.isi.edu/in-notes/iana/assignments/tcp-parameters.
В строках 8-23 показан диалог между программой
sendmail на bsd и SMTP сервером на машине mtapop2. Большая часть этих строк
опущена. Строки 24-28 отражают процедуру разрыва соединения. Сначала bsd посылает
FIN в строке 24 затем приходит FIN от mtapop2 (строка 25). Заметьте, что в строке
27 mtapop повторно посылает FIN. Это говорит о том, что хост не получил от bsd
подтверждения АСК на свой первый FIN, и еще раз подчеркивает важность состояния
ТIME-WAIT (совет 22).
Теперь посмотрим, что происходит при обмене UDP-датаграммами.
С помощью клиента udphelloc (совет 4) следует послать один нулевой байт в порт
сервера времени дня в домене netсоm.com:
bsd: $ udphelloc netcom4.netcom.com daytime
Thu Sep 16 15:11:49 1999
bsd: $
Хост netcom4 возвращает дату и время в UDP-датаграмме.
Программа tcpdump печатает следующее:
18:12:23.130009 bsd.1127 > nectom4.netcom.com.daytime:
udp 1
18:12:23.389284 nectom4.netcom.com.daytime >
bsd.1127: udp 26
Отсюда видно, что bsd послал netcom4 UDP-датаграмму
длиной один байт, a netcom4 ответил датаграммой длиной 26 байт.
Протокол обмена ICMP-пакетами аналогичен. Ниже
приведена трассировка одного запроса, генерируемого программой ping с хоста
bsd на хост netcom4:
1 06:21:28.690390 bsd > netcom4.netcom.com: icmp:
echo request
2 06:21:29.400433 netcom4.netcom.com > bsd: icmp:
echo reply
Строка icmp: означает, что это ICMP-датаграмма,
а следующий за ней текст описывает тип этой датаграммы.
Один из недостатков tcpdump - это неполная поддержка
вывода собственно данных. Часто во время отладки сетевых приложений необходимо
знать, какие данные посылаются. Эту информацию можно получить, задав в командной
строке опции -s и -х, но данные будут выведены только в шестнадцатеричном формате.
Опция -х показывает, что содержимое пакета нужно выводить в шестнадцатеричном
виде. Опция -s сообщает, сколько данных из пакета выводить. По умолчанию tcpdump
выводит только первые 68 байт (в системе SunOS NIT - 96 байт). Этого достаточно
для заголовков большинства протоколов. Повторим предыдущий пример, касающийся
UDP, но здесь нужно выводить также следующие данные:
tcpdump -х -s 100 -l
После удаления строк, относящихся к DNS, и исключения
имени домена из адреса хоста bsd получается следующий результат:
1 12:57:53.299924 bsd.1053 > netcom4.netcom.com.daytime:
udp 1
4500 001d 03d4 0000 4011 17al c7b7 c684
c7b7 0968 041d 000d 0009 9c56 00
2 12:57:53.558921 netcom4.netcom.com.daytime >
bsd.1053: udp 26
4500 0036 f0c8 0000 3611 3493 c7b7 0968
c7b7 c684 000d 041d 0022 765a 5375 6e20
5365 7020 3139 2030 393a 3537 3a34 3220
3139 3939 0a0d
Последний байт в первом пакете - это нулевой байт,
который udphelloc посылает хосту netcom4. Последние 26 байт второго пакета -
это полученный ответ. Интерпретировать приведенные в нем шестнадцатеричные цифры
довольно трудно.
Авторы tcpdump не хотели давать ASCII-представление
данных, так как полагали, что это упростит кражу паролей для технически неподготовленных
лиц. Теперь многие считают, что широкое распространение программ для кражи паролей
сделало это опасение неактуальным. Поэтому есть основания полагать, что в последующие
версии tcpdump будет включена поддержка вывода в коде ASCII*.(* Начиная с версии
3.5 tcpdump позволяет выводить и ASCII-представление. Для этого надо одновременно
указать опции -X и -х. - Прим. автора.)
А пока многие сетевые программисты упражняются
в написании фильтр, преобразующих выдачу tcpdump в код ASCII. Несколько подобных
программ есть в Internet. Показанный в листинге 4.1 сценарий Perl запускает
tcpdump, перенаправляет ее вывод к себе и перекодирует данные в ASCII.
Листинг 4.1. Perl-сценарий для фильтрации выдачи
tcpdump
tcpd
1 #! /usr/bin/perl5
2 $tcpdump = "/usr/sbin/tcpdump";
3 open( TCPD, "$tcpdump 8ARGV |" )
||
4 die "не могу запустить tcpdump: \$!\\n";
5 $| = 1;
6 while ( <TCPD> )
7 {
8 if ( /^\t/ }
9 {
10 chop;
11 $str = $_;
12 $str =~ tr / \t//d;
13 $str = pack "H*" , $str;
14 $str =~ tr/\x0-\xlf\x7f-\xff/./;
15 printf "\t%-40s\t%s\n", substr(
$_, 4 ), $str;
16 }
17 else
18 {
19 print;
20 }
21 }
Если еще раз прогнать последний пример, но вместо
tcpdump использоват tcpd, то получится следующее:
1 12:58:56.428052 bsd.1056 > netcom4.netcom.com.daytime:
udp 1
4500 OOld 03d7 0000 4011 179e c7b7 c684 E.......@....
c7b7 0968 041d OOOd 0009 9c56 00 ..-h......S.
2 12:58:56.717128 netcom4.netcom.com.daytime >
bsd.1053: udp 26
4500 0036 lOfl 0000 3611 146b c7b7 0968 E..6....6..k..h
c7b7 c684 OOOd 0420 0022 7656 5375 6e20 ......."rVSun
5365 7020 3139 2030 393a 3538 3a34 3620 Sep 19
09:58:46
3139 3939 OaOd 1999..
Программа tcpdump - это незаменимый инструмент
для изучения того, что происходит в сети. Если знать, что в действительности
посылается или принимается «по проводам», то трудные, на первый взгляд, ошибки
удается легко найти и исправить. Эта программа представляет собой также важный
инструмент для исследований динамики сети, а равно средство обучения. В последнем
качестве она широко применяется в книгах серии «TCP/IP Illustrated», написанных
Стивенсом.
Утилита traceroute - это важный инструмент для
нахождения ошибок маршрутизации, изучения трафика в Internet и исследования
топологии сети. Как и многие другие распространенные сетевые инструменты, traceroute
была разработана коллективом лаборатории Лоренса Беркли в Университете Калифорнии.
Примечание: В комментариях к исходному тексту
Ван Джекобсон, автор программы traceroute, пишет: «Я пытался найти ошибку в
работе алгоритма маршрутизации в течение 48 бессонных часов, и этот код родился
как-то сам собой».
Идея traceroute проста. Программа пытается определить
маршрут между двумя хостами в сети, заставляя каждый промежуточный маршрутизатор
посылать ICMP-сообщение об ошибке хосту-отправителю. Далее об этом механизме
будет сказано подробнее. Сначала нужно несколько раз запустить программу и посмотреть,
что она выдает. Проследим маршрут между хостом bsd и компьютером в Университете
города Тампа на юге Флориды (рис. 4.7). Как обычно, перенесены строки, не умещающиеся
на странице.
Число слева в каждой строке - это номер промежуточного
узла. За ним идет имя хоста или маршрутизатора в этом узле и далее - IP-адрес
узла. Если узнать имя не удается, то traceroute печатает только IP-адрес. Такая
ситуация наблюдается в узле 13. Как видно, по умолчанию программа пыталась определить
имя хоста или маршрутизатора трижды, а три числа, следующие за IP-адресом, -
это Периоды кругового обращения (RTT) для каждой из трех попыток. Если при оче-РеДной
попытке на запрос никто не отвечает или ответ теряется, то вместо времена печатается
«*».
Хотя компьютер ziggy.usf.edu расположен в соседнем
городе, в Internet между ними находится 14 узлов. Сначала данные проходят через
два маршрутизатора, в Тампе, относящихся к сети net com. net (это сервис-провайдер,
через которого выходит в Internet), потом еще через два маршрутизатора, а затем
через маршрутизатор netcom.net в узле МАЕ-EAST (узел 5) в сеть, находящуюся
в Вашингтоне, округ Колумбия. Узел МАЕ-EAST - это точка пересечения сетей, в
которой сервис-провайдеры передают друг другу Internet-трафик. Далее покидает
узел МАЕ-EAST и попадает в сеть sprintlink.net. От маршрутизатора сети Sprintlink
в узле MAE-EAST он пролегает вдоль восточного побережья до домена usf.edu (узел
13). И наконец на шаге 14 маршрут подходит к компьютеру ziggy.
bsd: $ tracerout ziggy, usf. edu
traceroute to ziggy. usf. edu (131. 247. 1. 40), 30 hops max,
40 byte packets
1 tam-f1-pm8. netcom. net (163. 179. 44. 15)
128. 960 ms 139. 230ms 129. 483 ms
2 tam-f1-qwl. netcom. net (163. 179. 44. 254)
139. 436 ms 129.226ms 129.570 ms
3 nl-0.mig-fl-qwl.Netcom.net (165.236.144.110)
279.582 ms 199.325 ms 289.611 ms
4 a5-0-0-6.was-dc-qwl.Netcom.net (163.179.235.121)
179.505 ms 229.543 ms 179.422 ms
5 h1-0.mae-east.netcom.net (163.179.220.182)
189.258 ms 179.211 ms 169.605 ms
6 s1-mae-e-f0-0.sprintlink.net (192.41.177.241)
189.999 ms 179.399 ms 189.472 ms
7 s1-bb4-dc-1-0-0.sprintlink.net (144.228.10.41)
180.048 ms 179.388 ms 179.562 ms
8 s1-bb10-rly-2-3.sprintlink.net (144.232.7.153)
199.433 ms 179.390 ms 179.468 ms
9 s1-bb11-rly-9-0.sprintlink.net (144.232.0.46)
199.259 ms 189.315 ms 179.459 ms
10 s1-bb10-orl-1-0.sprintlink.net (144.232.9.62)
189.987 ms 199.508 ms 219.252 ms
11 s1-qw3-orl-4-0-0.sprintlink.net (144.232.2.154)
219.307 ms 209.382 ms 209.502 ms
12 s1-usf-1-0-0.sprintlink.net (144.232.154.14)
209.518 ms 199.288 ms 219.495 ms
13 131.247.254.36 (131.247.254.36) 209.318ms 199.281ms 219.588ms
14 ziggy.usf.edu (131.247.1.40) 209.591 ms * 210.159 ms
Рис. 4.7. Маршрут до хостаziggy.usf.edu,
прослеженный traceroute
Посмотрим, как далеко от bsd отстоит Калифорнийский
университет в Лос-Анджелесе. Понятно, что географически он находится на другом
конце страны, в Калифорнии. А если выполнить traceroute до хоста panther в Калифорнийском
университете, то получится результат, показанный на рис. 4.8.
На этот раз маршрут проходит только через 13 промежуточных
узлов и достигает домена ucla. edu на шаге 11. Таким образом, топологически
bsd ближе к Калифорнийскому университету, чем к Университету на юге Флориды.
Примечание: Университет Чепмена, расположенный
также вблизи Лос-Анджелеса, находится всего в девяти промежуточных шагах от
bsd. Это связано с тем, что домен chapman, edu, как и bsd, подключен к Internet
через сеть netcom.net, и весь трафик проходи по этой опорной сети.
А теперь разберемся, как работает traceroute. Вспомним
(совет 22), что в IP-датаграмме есть поле TTL, которое уменьшается на единицу
каждым промежуточным
bsd: $ traceroute panther.cs.ucla.edu
traceroute to panther.cs-ucla.edu (131.179.128.25),
30 hops max, 40 bytes packets
1 tam-f1-pm8.netcom.net (163.179.44.15)
178.957 ms 129.049 ms 129.585 ms
2 tam-f1-gw1.netcom.net (163.179.44.254)
1390435 ms 139.258 ms 139.434 ms
3 h1-0.mig-f1-gw1.netcom.net (165.236.144.110)
139.538 ms 149.202 ms 139.488 ms
4 a5-0-0-7.was-dc-gw1.netcom.net (163.179.235.121)
189.535 ms 179.496 ms 168.699 ms
5 h2-0.mae-east.netcom.net (163.179.136.10)
180.040 ms 189.308 ms 169.479 ms
6 cpe3-fddi-0.Washington.cw.net (192.41.177.180)
179.186 ms 179.368 ms 179.631 ms
7 core5-hssi6-0-0.Washington.cw.net (204.70.1.21)
199.268 ms 179.537 ms 189.694 ms
8 corerouter2.Bloomington.cw.net (204.70.9.148)
239.441 ms 239.560 ms 239.417 ms
9 bordercore3.Bloomington.cw.net (166.48.180.1)
239.322 ms 239.348 ms 249.302 ms
10 ucla-internet –t-3.Bloomington.cw.net (166.48.181.254)
249.989 ms 249.384 ms 249.662 ms
11 cbn5-t3-1.cbn.ucla.edu (169.232.1.34)
258.756 ms 259.370 ms 249.487 ms
12 131.179.9.6 (131.179.9.6) 249.457 ms 259.238 ms 249.666 ms
13 Panther.CS.UCLA.EDU (131.179.128.25) 259.256 ms 259.184 ms*
bsd: $
Рис. 4.8. Маршрут до хоста panther.cs.ucla.edu,
прослеженный traceroute
маршрутизатором. Когда маршрутизатор получает датаграмму,
у которой в поле TTL находится единица (или нуль), он отбрасывает ее и посылает
отправителю ICМР-сообщение «истекло время в пути».
Программа traceroute использует это свойство. Сначала
она посылает получателю UDP-датаграмму, в которой TTL установлено в единицу.
Когда датаграмма доходит до первого маршрутизатора, тот определяет, что поле
TTL равно единице, отбрасывает датаграмму и посылает отправителю ICМР-сообщение.
как вы узнаете адрес первого промежуточного узла (из поля «адрес отправителя»
в заголовке ICMP). И traceroute пытается выяснить его имя с помощью Функции
gethostbyaddr. Чтобы получить информацию о втором узле, traceroute Повторяет
процедуру, на этот раз установив TTL равным двум. Маршрутизатор в первом промежуточном
узле уменьшит TTL на единицу и отправит датаграмму Дальше. Но второй маршрутизатор
определит единицу в поле TTL, отбросит датаграмму и пошлет ICМР-сообщение отправителю.
Повторяя эти действия, но увеличивая каждый раз значение TTL, traceroute может
построить весь маршрут От отправителя к получателю.
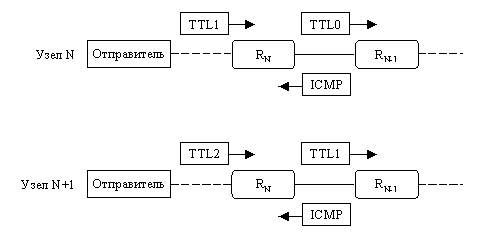
Рис. 4.9. Маршрутизатор N ошибочно
переправляет датаграмму с TTL, равным нулю
Когда датаграмма с достаточно большим начальным
значением TTL наконец доходит до получателя, TTL будет равно единице, но, поскольку
дальше переправлять датаграмму некуда, стек TCP/IP попытается доставить ее ожидающему
приложению. Однако traceroute установлено в качестве порта назначения такое
значение, которое вряд ли кем-то используется, поэтому хост-получатель вернет
ICMP-сообщение «порт недоступен». Получив такое сообщение, tracerout определяет,
что конечный получатель обнаружен, и трассировку можно завершить.
Поскольку протокол UDP ненадежен (совет 1), не
исключена возможность потери датаграмм. Поэтому traceroute пытается «достучаться»
до каждого промежуточного хоста или маршрутизатора несколько раз, то есть посылает
несколько датаграмм с одним и тем же значением TTL. По умолчанию делается три
попытки, но это можно изменить с помощью опции -q.
Кроме того, tracerout нужно определить, сколько
времени ждать IСМР - сообщения после каждой попытки. По умолчанию время
ожидания - 5 с, но это значение можно изменить с помощью опции -w. Если в течение
этого времени IСМР-сообщение не получено, то вместо значения RTT печатается
звездочка (*).
В описанном процессе могут быть некоторые трудности:
traceroute полагается на то, что маршрутизаторы будут, как положено, отбрасывать
IP-датаграммы, в которых TTL равно единице, и посылать при этом ICMP-сообщение
«истекло время в пути». К сожалению, некоторые маршрутизаторы таких сообщений
не посылают, и тогда печатаются звездочки. Есть также маршрутизаторы, которые
посылают сообщение, но с тем значением TTL, которое обнаружили во входящей датаграмме.
Поскольку оно оказалось равным нулю, то датаграмма будет отброшена первым узлом
на обратном пути (если, конечно, это не случилось на первом шаге). Результате
точно такой же, как если бы ICMP-сообщение не посылалось вовсе.
Некоторые маршрутизаторы ошибочно переправляют
далее датаграммы, в которых TTL равно нулю. Если такое происходит, то следующий
маршрутизатор, например N + 1, отбросит датаграмму и вернет ICMP-сообщение «истекло
врем в пути». На дальнейшей итерации маршрутизатор N + 1 получит датаграмму
со значением TTL, равным единице, и вернет обычное ICMP-сообщение. Таким образом,
маршрутизатор N + 1 появится дважды: первый раз в результате ошибки
предыдущего маршрутизатора, а второй - после корректного отбрасывания датаграммы
с истекшим временем работы. Такая ситуация изображена на рис. 4.9, а ее видимое
проявление - в строках, соответствующих узлам 5 и 6 на рис. 4.10.
bed: $ traceroute syrup.hill.com
traceroute to syrup.hil1.corn (208.162.106.3),
30 hops max, 40 byte packets
1 tam-fl-pm5.netcom.net (163.179.44.11)
129.120 ms 139.263 ms 129.603 ms
2 tarn-fl-gwl.netcom.net (163.179.44.254)
29.584 ms 129.328 ms 149.578 ms
3 hl-O.mig-fl-gwl.netcom.net (165.236.144.110)
219.595 ms 229.306 ms 209.602 ms
4 a5-0-0-7.was-dc-gwl.netcom.net (163.179.235.121)
179.248 ms 179.521 ms 179.694 ms
5 h2-0.mae-east.netcom.net (163.179.136.10)
179.274 ms 179.325 ms 179.623 ms
6 h2-0.mae-east.netcom.net (163.179.136.10)
169.443 ms 199.318 ms 179.601 ms
7 cpe3-fddi-0.washington.cw.net (192.41.177.180) 189.529 ms
core6-seria!5-l-0.Washington.cw.net
(204.70.1.221) 209.496 ms 209.247 ms
8 bordercore2.Boston.cw.net (166.48.64.1)
209.486 ms 209.332 ms 209.598 ms
9 hill-associatesinc-internet.Boston.cw.net (166.48.67.54)
229.602 ms 219.510 ms *
10 syrup.hill.corn (208.162.106.3) 239.744 ms 239.348 m 219.607 ms
bsd: $
Рис. 4.10. Выдача traceroute с повторяющимися
узлами
На рис. 4.10 показано еще одно интересное явление.
Вы видите, что в узле 7 маршрут изменился после первой попытки. Возможно, это
было вызвано тем, что маршрутизатор в узле 6 выполнил какие-то действия по балансированию
нагрузки. А возможно, что узел среЗ-fddi-0 .washington.cw.net за время, прошедшее
с момента первой попытки, успел «отключиться», и вместо него был использован
маршрутизатор с адресом core6-serial5-l-0.Washington.cw.net.
Еще одна проблема, встречающаяся, к сожалению,
все чаще, состоит в том, что маршрутизаторы полностью блокируют все ICMP-сообщения.
Некоторые организации, ошибочно полагая, что ICMP-сообщения несут какую-то опасность,
отключают их. В таких условиях traceroute становится бесполезной, поскольку
первый же такой узел, встретившийся на маршруте к получателю, с точки зрения
traceroute Ведет себя как «черная дыра». Никакая информация от последующих узлов
не доходит, так как этот маршрутизатор отбрасывает и сообщение «истекло время
в пути», и сообщение «порт недоступен».
Следующая проблема при работе с traceroute - это
асимметрия маршрутов. Запуская traceroute, вы получаете маршрут от пункта отправления
до пункта назначения, но нет гарантии, что датаграмма, отправленная из пункта
назначении будет следовать тем же маршрутом. Хотя кажется естественным предположении
о том, что почти все маршруты одинаковы, в действительности, как показано в
работе [Paxson 1997], 49% изученных маршрутов демонстрируют асимметрию хотя
бы в одном промежуточном узле.
Примечание: С помощью опции -s, которая
устанавливает режим свободной маршрутизации, заданной источником (loose source
routing) oт пункта назначения в пункт отправления, теоретически можно получить
оба маршрута. Но, как отмечает Джекобсон в комментариях к исходному тексту trace-route,
количество маршрутизаторов, которые некорректно выполняют маршрутизацию, заданную
источником, настолько велико, что этот метод на практике не работает. В главе
8 книги [Stevens 1994] объясняетсясуть метода и приводится пример его успешного
применения.
В другой работе Паксон отмечает, что асимметричные
маршруты возникают также из-за эффекта «горячей картофелины» [Paxson 1995].
Примечание: Этот эффект состоит в следующем.
Предположим, что хост А, расположенный на восточном побережье Соединенных Штатов,
отправляет датаграмму хосту В на западном побережье. Хост А подключен к Internet
через провайдера 1, а хост В - через провайдера 2. Допустим, что у обоих
провайдеров есть опорные сети, проходящие через всю страну. Поскольку полоса
пропускания опорной сети - это дефицитный ресурс, провайдер 1 пытается доставить
датаграмму хосту в сети провайдера 2, пользуясь его же опорной сетью. Но точно
также, когда хост В отвечает, провайдер 2 пытается доставить ответ на противоположное
побережье, пользуясь опорной сетью провайдера 1. Отсюда и асимметрия.
Программа tracert в системе Windows
До сих пор описывалась UNIX-версия программы traceroute.
Очень похожее средство - tracert - есть и в различных версиях операционной системы
Windows. Программа tracert работает аналогично traceroute, но для определения
маршрута используются не UDP-датаграммы, а эхо-запросы протокола ICMP (как в
программе ping). В результате хост-получатель возвращает эхо-ответ ICMP, а не
сообщение о недоступности порта. Промежуточные маршрутизаторы по-прежнему возвращают
сообщение «истекло время в пути».
Примечание: В последних версиях traсеrоutе
есть опция -1, имитирующая такое же поведение. Подобную версию можно получить
на сайте ftp://ftp.ee.lbl.gov/traceroute.tar.Z.
Наверное, это изменение сделано исходя из соображения
о том, что UDP-датаграммы часто отфильтровываются маршрутизаторами, тогда как
эхо-запросы и эхо-ответы ICMP, используемые программой ping, менее подвержены
этому.Исходная версия traceroute также применяла эхо-запросы для определения
маршрута, но потом они были заменены UDP-датаграммами, поскольку многие маршрутизаторы
строго следовали предписанию RFC 792 [Postel 1981], требующему не посылать
ICMP-сообщения в ответ на ICMP-сообщения [Jacobson 1999]. Действующее ныне RFC
1122 [Braden 1989] указывает, что ICMP-сообщение не должно посылаться в ответ
на ICMP-сообщение об ошибке, но tracert по-прежнему встречает трудности в старых
моделях маршрутизаторов.
В RFC 1393 [Malkin 1993] предложено добавить новую
опцию в протокол IP и отдельное ICMP-сообщение, чтобы гарантировать надежность
traceroute (а заодно и решить некоторые другие задачи), но, так как в маршрутизаторы
и программное обеспечение хостов пришлось бы вносить изменения, этот метод не
получил распространения.
Утилита traceroute - очень полезный инструмент
для диагностики сетевых ошибок, изучения маршрутизации и исследования топологии
сети. Топология Internet нередко достаточно запутанна, и это может быть причиной
неожиданного поведения приложений. С помощью traceroute зачастую удается обнаружить
аномалии в сети, из-за которых программа ведет себя странно.
Программы traceroute и tracert работают путем отправки
хосту назначения датаграммы с последовательно увеличивающимся значением в поле
TTL. Затем они отслеживают приходящие от промежуточных маршрутизаторов ICMP-сообщения
«истекло время в пути». Разница в том, что traceroute посылает UDP-датаграммы,
a tracert - эхо-запросы ICMP.
Часто необходимо иметь утилиту, которая может посылать
произвольный объем данных другой (или той же самой) машине по протоколу TCP
или UDP и собирать статистическую информацию о полученных результатах. В этой
книге уже написано несколько программ такого рода. В этом разделе вы познакомитесь
с готовым инструментом, обладающим той же функциональностью. Подобное средство
можно использовать для тестирования собственного приложения или для получения
информации о производительности конкретного стека TCP/IP или сети. Такая информация
может оказаться бесценной на этапе создания прототипа.
Этот инструмент - программа ttcp, бесплатно распространяемая
Лабораторией баллистических исследований армии США (BRL - Ballistics Research
Laboratory). Ее авторы Майк Муусс (автор программы ping) и Терри Слэттери. Эта
утилита доступна на множестве сайтов в Internet. В книге будет использована
версия, которую Джон Лин модифицировал с целью включения дополнительной статистики;
ее можно получить по анонимному FTP с сайта gwen.cs.purdue.edu из каталога /pub/lin.
Версия без модификаций Лина находится, например, на сайте ftp.sgi.com в каталоге
sgi/ src/ttcp, в состав ее дистрибутива входит также страница руководства.
У программы ttcp есть несколько опций, позволяющих
управлять: объемом Посылаемых данных, длиной отдельных операций записи и считывания,
размерами буферов приема и передачи сокета, включением или отключением алгоритма
Нейгла и даже выравниванием буферов в памяти. На рис. 4.11 приведена информация
о порядке использования ttcp. Дается перевод на русский язык, хотя оригинальная
программа, естественно, выводит справку по-английски.
Порядок вызова:ttcp -t [-опции] хост [ < in ]
ttcp -r [-опции > out]
Часто используемые опции:
-1 ## длина в байтах буферов,
в которые происходит считывание из сети и запись в сеть (по умолчанию 8192)
-u использовать UDP, а не TCP
-p ## номер порта, в который надо посылать данные или прослушивать (по умолчанию
5001)
-s -t: отправить данные в сеть
-r: считать (и отбросить) все данные из сети
-А выравнивать начало каждого буфера на эту границу(по умолчанию 16384)
-O считать, что буфер начинается с этого смещения относительно границы (по
умолчанию 0)
-v печатать более подробную статистику
-d установить опцию сокета SO_DEBUG
-b ## установить размер буфера сокета (если поддерживает операционная система)
-f X формат для вычисления скорости обмена: к,К = кило (бит, байт);
m,М = мега; g,G = гига
Опции, употребляемые вместе с -t:
-n ## число буферов, записываемых в сеть (по умолчанию 2048)
-D не буферизовать запись по протоколу TCP (установить опцию сокета TCP_NODELAY)
Опции, употребляемые вместе с -r:
-В для -s, выводить только полные блоки в соответствии с опцией -1 (для TAR)
-Т "touch": обращаться к каждому прочитанному байту
Рис. 4.11. Порядок вызова ttcp
Поэкспериментируем с размером буфера передачи сокета.
Сначала прогоним тест с размером буфера, выбранным по умолчанию, чтобы получить
точку отсче В одном окне запустим экземпляр ttcp-потребителя:
bsd: $ ttcp –rsv
а в другом - экземпляр, играющий роль источника:
bsd: $ ttcp -tsv bsd
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5013
tcp -> bsd
ttcp-t: socket
ttcp-t: connect
ttcp-t: 16777216 bytes in 1.341030 real seconds
= 12217.474628 KB/sec (95.449021 Mb/sec)
ttcp-t: 16777216 bytes in 0.00 CPU seconds
= 16384000.000000 KB/cpu sec
ttcp-t: 2048 I/O calls, msec/call = 0.67, calls/sec
= 1527.18
ttcp-t: buffer address 0x8050000
bsd: $
Как видите, ttcp дает информацию о производительности.
Для передачи 16 Мб потребовалось около 1,3 с.
Примечание: Аналогичная статистика печатается
принимающим процессом, но поскольку цифры, по существу, такие же, они здесь
не приводятся.
Также был выполнен мониторинг обмена с помощью
tcpdump. Вот типичная строка выдачи:
13:05:44.084576 bsd.1061 > bsd.5013: . 1:1449(1448)
ack Iwinl7376 <nop,nop,timestamp 11306 11306>
(DF)
Из нее видно, что TCP посылает сегменты по 1448
байт. Теперь следует установить размер буфера передачи равным 1448 байт, и повторить
эксперимент. Приемник данных нужно оставить без изменения.
bsd: $ ttcp -tsvb 1448 bsd
ttcp-t: socket
ttcp-t: sndbuf
ttcp-t: connect
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5013,
sockbufsize=1448 tcp -> bsd
ttcp-t: 16777216 bytes in 2457.246699 real seconds
= 6.667625 KB/sec (0.052091 Mb/sec)
ttcp-t: 16777216 bytes in 0.00 CPU seconds
= 16384000.000000 KB/cpu sec
ttcp-t: 2048 I/O calls, msec/call = 1228.62, calls/sec
= 0.83 ttcp-t: buffer address 0x8050000
bds: $
На этот раз передача заняла почти 41 мин. Следует
отметить, что, хотя по часам для передачи потребовалось больше 40 мин, время,
затраченное процессором, Попрежнему очень мало, даже не поддается измерению.
Поэтому, что бы ни произошло, это не связано с загрузкой процессора.
Теперь посмотрим, что показывает tcpdump. На рис.
4.12 приведены четыре типичные строки:
16:03:57.168093 bsd.1187 > bsd.5013: Р 8193:9641(1448)
ack 1 win 17376 <nор,ор,timestamp 44802 44802> (DF)
16:03:57.368034 bsd.5013 > bsd.1187: . ack 9641 win 17376
<nop,nор,timestamp 44802 44802> (DF)
16:03:57.368071 bsd.1187. > bsd.5013: P 9641:11089(1448)
ack 1 win;17376 <nop,nор,timestamp 44802 44802> (DF)
16:03:57.568038 bsd.5013 > bsd. 1187: .ack 11089 win 17376
<nop,nор,timestamp 44802 44802> (DF)
Рис. 4.12. Типичная выдача tcpdump
для запуска ttcp -tsvb 1448 bsd
Обратите внимание, что время между последовательными
сегментами составляет почти 200 мс. Возникает подозрение, что тут замешано взаимодействие
между алгоритмами Нейгла и отложенного подтверждения (совет 24). И действительно
именно АСК задерживаются.
Эту гипотезу можно проверить, отключив алгоритм
Нейгла с помощью опции -D. Повторим эксперимент:
bsd: $ ttcp -tsvDb 1448 bsd
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5013,
sockbufsize=1448 tcp -> bsd ttcp-t socket ttcp-t
sndbuf ttcp-t: connect
ttcp-t: nodelay
ttcp-t: 16777216 bytes in 2457.396882 real seconds
= 6.667218 KB/sec (0.052088 Mb/sec)
ttcp-t: 16777216 bytes in 0.00 CPU seconds
= 16384000.000000 KB/cpu sec
ttcp-t: 2048 I/O calls, msec/call = 1228.70, calls/sec
= 0.83 ttcp-t: buffer address 0x8050000
bds: $
Как ни странно, ничего не изменилось.
Примечание: Это пример того, как опасно
делать поспешные заключения. Стоило немного подумать и стало бы ясно, что алгоритм
Нейгла тут ни при чем, так как посылаются заполненные сегменты. В частности,
этому служит самый первый тест, - чтобы определить величину MSS.
В совете 39 будут рассмотрены средства трассировки
системных вызовов. Тогда вы вернетесь к этому примеру и обнаружите, что выполняемая
ttcp операция записи не возвращает управление в течение примерно 1,2 с. Косвенное
указание на это видно и из выдачи ttcp, где каждый вызов операции ввода/вывода
занимает приблизительно 1,228 мс. Но, как говорилось в совете 15, TCP обычно
не блокирует операции записи, пока буфер передачи не окажется заполненным. Таким
образом, становится понятно, что происходит. Когда ttcp записывает 8192 байта,
ядро копирует первые 1448 байт в буфер сокета, после чего блокирует процесс,
так как места в буфере больше нет. TCP посылает все эти байты в одном сегменте,
но послать больше не может, так как в буфере ничего не осталось.
Примечание: Из рис. 4.12 видно, что дело
обстоит именно так, поскольку в каждом отправленном сегменте задан флаг PSH,
а стеки, берущие начало в системе BSD, устанавливают этот флаг только тогда,
когда выполненная операция передачи опустошает буфер.
Поскольку приемник данных ничего не посылает в
ответ, запускается механизм отложенного подтверждения, из-за которого АСК не
возвращается до истечения тайм-аута в 200 мс.
В первом тесте TCP мог продолжать посылать заполненные
сегменты данных, поскольку буфер передачи был достаточно велик (16 Кб на машине
bsd) для сохранения нескольких сегментов. Трассировка системных вызовов для
этого теста показывает, что на операцию записи уходит около 0,3 мс.
Этот пример наглядно демонстрирует, как важно, чтобы
буфер передачи отправителя был, по крайней мере, не меньше буфера приема получателя.
Хотя получатель был готов принимать данные и дальше, но в выходном буфере отправителя
задержался последний посланный сегмент. Забыть про него нельзя, пока не придет
АСК, говорящий о том, что данные дошли до получателя. Поскольку размер одного
сегмента значительно меньше, чем буфер приема (16 Кб), его получение не приводит
к обновлению окна (совет 15). Поэтому АСК задерживается на 200 мс. Подробнее
о размерах буферов рассказано в совете 32.
Однако смысл этого примера в том, чтобы показать,
как можно использовать ttcp для проверки эффекта установки тех или иных параметров
TCP-соединения. Вы также видели, как анализ информации, полученной от ttcp,
tcpdump и программы трассировки системных вызовов, может объяснить работу TCP.
Следует упомянуть о том, как использовать программу
ttcp для организации «сетевого конвейера» между хостами. Например, скопировать
всю иерархию каталогов с хоста А на хост В. На хосте В вводите команду
ttcp -rB | tar -xpf -
на хосте А - команду
tar -cf - каталог | ttcp -t A
Можно распространить конвейер на несколько машин,
если на промежуточных запустить команду
ttcp -r | ttcp -t следующий_узел
В этом разделе показано, как пользоваться программой
ttcp для экспериментирования с различными параметрами TCP-соединения, ttcp можно
применять также в целях тестирования собственных приложений, предоставляя для
них источник или приемник данных, работающий по протоколу TCP либо UDP. И, наконец,
вы видели, как использовать ttcp для организации сетевого конвейера между двумя
или более машинами.
В сетевом (и не только) программировании часто
необходимо определить, какой Процесс открыл файл или сокет. Особенно это важно
в сетевом окружении, поскольку, как было показано в совете 16, при завершении
процесса, работавшего с сокетом, FIN не будет послан, если другой процесс держит
этот сокет открытым.
Хотя ситуация, когда другой процесс держит сокет
открытым, выглядит странно, но она часто возникает, особенно при работе в UNIX.
Происходит вот что: один процесс принимает соединение и запускает другой процесс,
который будет работать с этим соединением (кстати, именно это и делает inetd
- совет 17). Если процесс, принявший соединение, не закроет сокет после создания
процесса - потомка, то счетчик ссылок на это сокет будет равен двум. Поэтому
после того как потомок закроет сокет, соединение останется открытым, и FIN не
будет послан. |
Та же проблема может возникнуть и по другой причине.
Предположим, что хост клиента, работавшего с созданным процессом, аварийно остановился,
в результате чего потомок «завис». Такая ситуация обсуждалась в совете 10. Если
процесс, принимающий соединения, завершит работу, то перезапустить его будет
невозможно (если, конечно, не была задана опция сокета SO_REUSEADDR, - совет
23), так как локальный порт уже привязан к созданному процессу.
В этих и некоторых других случаях необходимо знать,
какой процесс (или процессы) держит сокет открытым. Утилита netstat (совет 38)
сообщает, что некоторый процесс занимает данный порт или адрес, но что это за
процесс, неизвестно. В некоторых версиях UNIX для ответа на этот вопрос есть
программа f stat. Виктор Абель (Victor Abell) написал свободно распространяемую
программу lsof, работающую почти во всех версиях UNIX.
Примечание: Дистрибутив Isof можно получить
по анонимному FTP с сайта vic.cc.purdue.edu из каталога pub/tools/unix/lsof.
lsof - это исключительно гибкая программа; руководство
по ней занимает 26 печатных страниц. С ее помощью можно получить "самую
разнообразную информацию об открытых файлах. Как и в случае tcpdump, предоставление
единого интерфейса к нескольким диалектам UNIX - это существенное достоинство.
Рассмотрим некоторые возможности lsof, полезные в сетевом программировании.
В руководстве приводится подробная информация и о других ее применениях.
Предположим, что после выполнения команды netstat
-af inet (совет 38) вы обнаруживаете, что некоторый процесс прослушивает порт
6000:
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address
(state)
Tcp 0 0 *.6000 *.*
LISTEN
Порт 6000 не относится к хорошо известным (совет
18), поэтому возникает вопрос: что же его прослушивает? Как уже упоминалось,
в netstat по этому поводу ничего не говорится - она лишь сообщает о наличии
прослушивающего процесса. Зато программа lsof не испытывает никаких затруднений:
bsd# lsof -i TCP:6000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE
NAME
XF86_Mach 253 root 0u inetOxf5d98840 0t0 TCP *:6000
(LISTEN)
bsd#
Следует отметить, что вы запускали lsof от имени
пользователя root. Это необходимо, потому что используемая версия lsof сконфигурирована
для перечисления файлов, принадлежащих только данному пользователю, за исключением
ситуации, когда ее запускает root. Это свойство направлено на обеспечение безопасности,
но его можно отключить во время компиляции программы. Далее надо отмети, что
процесс был запущен пользователем root с помощью команды XF86_Mach. Это ваш
Х-сервер.
Опция -i TCP: 6000 означает, что lsof должна искать
открытые ТСР-сокеты, привязанные к порту 6000. Можно было бы показать все ТСР-сокеты
с помощью опции -i TCP или все TCP- и UDP-сокеты - с помощью опции -i.
Предположим, что вы еще раз запустили nets tat
и обнаружили, что кто-то открыл FTP-соединение с хостом vie. ее. purdue. edu:
Active Internet connections
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp 0 0 bsd.1124 vie.cc.purdue.edu. ftp ESTABLISHED
Выяснить, кто это сделал, поможет lsof:
bsd# Isof -i @vic.cc.purdue.edu
COMMAND PID USER FD TYPE DEVICE SIZE/OFF
NODE NAME
ftp 450 jcs 3u inet 0xf5d99f00 0t0 TCP
bsd:1124->
vie.cc.purdue.edu:ftp ESTABLISHED
bsd#
Как обычно, в имени машины bsd опущен домен и строка
разбита на две. Из полученной выдачи видно, что FTP-соединение открыл пользователь
jcs.
Необходимо подчеркнуть, что lsof может выдать информацию
только об открытых файлах. Собственно говоря, название программы - аббревиатура
list open files (перечислить открытые файлы). Это, в частности, означает, что
с ее помощью нельзя получить информацию о TCP-соединениях, находящихся в состоянии
TIME-WAIT (совет 22), поскольку с ними не связан никакой открытый сокет или
файл.
Здесь показано, как можно воспользоваться утилитой
lsof для получения ответа на разнообразные вопросы об открытых файлах. К сожалению,
нет версии lsof для Windows.
Ядро операционной системы ведет разнообразную статистику
об объектах, имеющих отношение к сети. Эту информацию можно получить с помощью
программы netstat. Существует четыре вида запросов.
Во-первых, можно получить сведения об активных
сокетах. Хотя netstat дает информацию о разных типах сокетов, интерес представляют
только сокеты из адресных доменов inet (AF_INET) и UNIX (AF_LOCAL или AF_UNIX).
Можно потребовать вывести все типы сокетов или выбрать один тип, указав адресное
семейство с помощью опции -f.
По умолчанию серверы, сокеты которых привязаны
к адресу INADDR_ANY, не выводятся, но этот режим можно отключить с помощью опции
-а. Например, если нужны TCP/UDP-сокеты, то можно вызвать netstat так:
bsd: $ netstat -f inet
Active Internet connections
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp 0 0 localhost.domain *.*
LISTEN
tcp 0 0 bsd.domain *.*
LISTEN
udp 0 0 localhost.domain *.*
udp 0 0 bsd.domain *.*
bsd: $
Здесь показан только сервер доменных имен (named),
работающий на машине bsd. Если же нужно вывести все серверы, то программа запускается
таким образом:
bsd: $ netstat -af inet
Active Internet connections
Proto Recv-Q Send-Q Local Address Foreign Address
(state)
tcp 0 0 *.6000 *.*
LISTEN
tcp 0 0 *.smtp *.*
LISTEN
tcp 0 0 *.printer *.*
LISTEN
tcp 0 0 *.rlnum *.*
LISTEN
tcp 0 0 *.tcpmux *.*
LISTEN
tcp 0 0 *.chargen *.*
LISTEN
tcp 0 0 *.discard *.*
LISTEN
tcp 0 0 *.echo *.*
LISTEN
tcp 0 0 *.time *.*
LISTEN
tcp 0 0 *.daytime *.*
LISTEN
tcp 0 0 *.finger *.*
LISTEN
tcp 0 0 *.login *.* LISTEN
tcp 0 0 *.cmd *.*
LISTEN
tcp 0 0 *.telnet *.*
LISTEN
tcp 0 0 *.ftp *.*
LISTEN
tcp 0 0 *.1022 *.*
LISTEN
tcp 0 0 *.2049 *.*
LISTEN
tcp 0 0 *.1023 *.*
LISTEN
tcp 0 0 localhost.domain *.*
LISTEN
tcp 0 0 bsd.domain *.*
LISTEN
udp 0 0 *.udpecho *.*
udp 0 0 *.chargen *.*
udp 0 0 *.discard *.*
udp 0 0 *.echo *.*
udp 0 0 *.time *.*
udp 0 0 *.ntalk *.*
udp 0 0 *.biff *.*
udp 0 0 *.1011 *.*
udp 0 0 *.nfsd *.*
udp 0 0 *.1023 *.*
udp 0 0 *. sunrpc *.*
udp 0 0 *.1024 *.*
udp 0 0 localhost. Domain *.*
udp 0 0 bsd. domain *.*
udp 0 0 *.syslog *.*
bsd: $
Если бы вы запустили программу lsof (совет 37),
то обнаружили, что боль-щинство этих «серверов» - в действительности inetd (совет
17), ожидающий Прихода соединений или датаграмм в порты стандартных сервисов.
Слово «LISTEN» в колонке state для TCP-соединений означает, что сервер ждет
запроса Щ соединение от клиента.
Если обратиться к серверу эхо-контроля с помощью
telnet:
bbd: $ telnet bsd echo
то появится соединение в состоянии ESTABLISHED:
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp 0 0 bsd.echo bsd.1035
ESTABLISHED
tcp 0 0 bsd.1035 bsd.echo
ESTABLISHED
tTcp 0 0 *.echo *.*
LISTEN
Здесь опущены строки, не относящиеся к серверу
эхо-контроля. Обратите внимание, что, поскольку вы соединились с локальной машиной,
в выдаче netstat соединение присутствует дважды: один раз для клиента, а другой
- для сервера. Заметьте также, что inetd продолжает прослушивать порт в ожидании
дальнейших соединений.
Примечание: Последнее замечание требует
еще нескольких пояснений. Хотя telnet-клиент подсоединился к порту 7 (порт эхо)
и фактически использует его в качестве порта назначения, хост продолжает прослушивать
этот порт. Это нормально, так как с точки зрения TCP соединение - это четверка,
состоящая из локальных IP-адреса и порта и удаленных IP-адреса и порта (совет
23). Как видите, inetd прослушивает порт на универсальном «псевдоадресе» INADDR_ANY,
что показано звездочкой в колонке LocalAddress, тогда как IP-адрес для установленного
соединения равен bsd. Если бы, вы создали одно дополнительное соединение с помощью
telnet, то получили бы еще две строки, аналогичныепервым двум, только порт клиента
был бы отличен от 1035.
Завершите работу клиента и снова запустите netstat.
Вот что вы получите:
Proto Recv-Q Send-Q Local Address Foreign Address
(state)
tcp 0 0 bsd.1035 bsd.echo
TIME_WAIT
Как видно, клиентская сторона соединения находится
в состоянии TIME-WAIT (совет 22). В колонке state могут появляться и другие
состояния, подробнее 0 них рассказывается в RFC 793 [Postel 1981b].
С помощью netstat можно также получить информацию
об интерфейсах. Такой пример был приведен в совете 7. Основная информация выдается
при наличии опции -i:
bsd: $ netstat -i
Name Mtu Network Address
Ipkts Ierrs Opkts Oerrs Coll
ed0 1500 <Link> 00.00.cO.54.53.73 40841
0 5793 0 0
ed0 1500 172.30 bsd 40841 0
5793 0 0
tun0 *1500 <Link> 397
0 451 0 0
tun0 *1500 205.184.142 205.184.142.171 397 0
451 0 0
sl0 * 552 <Link> 0
0 0 0 0
lo0 16384 <Link> 353
0 353 0 0
lo0 16384 127 localhost 353 0
353 0 0
Отсюда видно, что в машине bsd сконфигурировано
четыре интерфейса. Первый – ed0- это адаптер сети Ethernet. Он входит в
частную (RFC 1918 [Rekhter Moskowitz et al. 1996]) сеть 172.30.0.0. Адрес 00.00.с0.54.73
- это первый в списке МАС-адресов (media access control - контроль доступа к
носителю) данной сетевой карты. Через этот интерфейс прошло 40841 входных пакетов
и 5793 выходных; не было зарегистрировано ни ошибок, ни коллизий. MTU (совет
7) составляет 1500 байт - максимальное значение для сетей Ethernet.
Интерфейс tun0 - это телефонный канал, по которому
связь осуществляется по протоколу РРР (Point-to-Point Protocol). Он входит в
сеть 205.184.142.0. MTU для этого интерфейса также составляет 1500 байт.
Интерфейс sl0 - это телефонный канал, по которому
связь осуществляется по протоколу SLIP (Serial Line Internet Protocol), RFC
1055 [Romkey 1988]. Это еще один, ныне устаревший протокол двухточечного соединения
по телефонным линиям. Данный интерфейс в машине bsd не используется.
Наконец, есть еще возвратный интерфейс 1o0. О нем
уже неоднократно говорилось.
В сочетании с опцией -i можно также задать опции
-b или -d. Тогда будет напечатано количество байт, прошедших через интерфейс
в обе стороны, или число отброшенных пакетов.
Кроме того, netstat может дать маршрутную таблицу.
Назначьте опцию -n, чтобы получить не символические имена, а IP-адреса; так
лучше видно, в какие сети маршрутизируются пакеты.
Интерфейсы и соединения, выведенные на рис. 4.13,
показаны и на рис. 4.14. Интерфейс 1оО не показан, так как полностью находится
внутри машины bsd.
bsd: $ netstat -rn
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 163.179.44.41 UGSc 2 0 tun0
127.0.0.1 127.0.0.1 UH 1 34 lo0
163.179.44.41 205.184.142.171 UH 3 0 tunO
172.30 linkt#l UC 0 0 ed0
172.30.0.1 0:0:c0:54:53:73 UHLW 0 132 lo0
Рис. 4.13. Маршрутная таблица, выведенная
программой netstart
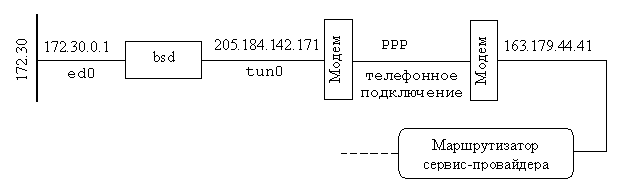
Рис. 4.14. Информация об интерфейсах
и хостах, выведенная программой netstat
Прежде чем знакомиться с отдельными элементами этой
выдачи, обсудим назначение колонок. В первой колонке находится пункт назначения
маршрута. Это может быть конкретный хост, сеть или маршрут по умолчанию.
В колонке Flags печатаются различные флаги, большая
часть которых зависит от реализации. Следует упомянуть только следующие:
- U - маршрут задействован («UP»);
- Н - маршрут к хосту. Если этот флаг отсутствует,
то речь идет о маршруте к сети (или к подсети, если используется бесклассовая
междоменная маршрутизация CIDR - совет 2);
- G - непрямой маршрут. Иными словами, пункт
назначения не связан напрямую с данным хостом, к нему следует добираться через
промежуточный маршрутизатор или шлюз (G - gateway).
Легко сделать ошибку, полагая, что флаги Н и G
взаимоисключающие, то есть маршрут может идти либо к хосту (Н), либо к промежуточному
шлюзу (G). Флаг Н означает, что адрес в первой колонке представляет собой полный
IP-адрес хоста. Если флага Н нет, то адрес в этой колонке не содержит идентификатора
хоста, иными словами, он - адрес сети. Флаг G показывает, достижим ли адрес,
проставленный в первой колонке, непосредственно с данного хоста или необходимо
пройти через промежуточный маршрутизатор.

Рис. 4.15. H2 выступает в роли шлюза
к H3
Вполне возможно, что для некоторого маршрута будут
одновременно установлены флаги G и Н. Рассмотрим, например, две сети, изображенные
на рис. 4.15. Хосты H1 и Н2 подключены к сети Ethernet с адресом 172.20. Хост
Н3 соединен с Н2 по РРР-линии с сетевым адресом 198.168.2.
Маршрут к НЗ в маршрутной таблице HI будет выглядеть
так:
Destination Gateway Flags Refs Use Netif Expire
192.168.2.2 172.20.10.2 UGH 0 0 edO
Флаг Н установлен потому, что 192.168.2.2 - полный
адрес хоста. А флаг G - так как HI не имеет прямого соединения с Н3 и должен
идти через хост Н2 (172.20.10.2). Обратите внимание, что на рис. 4.13 для маршрута
к хосту 163.179.44.41 нет флага G, поскольку этот хост напрямую подключен к
интерфейсу tun0 (205.184.142.171) в машине bsd.
На рис. 2.9 в маршрутной таблице H1 не должно быть
записи для Н3. Вместо нее присутствует запись для подсети 190.50.2, поскольку
именно в этом состоит смысл организации подсетей - уменьшить размеры маршрутных
таблиц. Запись в маршрутной таблице HI для этой подсети выглядела бы так:
Destination Gateway Flags Refs Use Netif Expire
190.50.2 190.50.1.4 UG 0 0 edO
Флаг Н не установлен, так как 190.50.2 - адрес
подсети, а не отдельного хоста. Имеется флаг G, так как Н3 не соединен напрямую
с HI. Датаграммы от Н3 к H1 должны проходить через маршрутизатор R1 (190.50.1.4).
Смысл колонки Gateway зависит от того, есть флаг
G или нет. Если маршрут непрямой (флаг G есть), то в колонке Gateway находится
IP-адрес следующего узла (шлюза). Если же флага G нет, то в этой колонке печатается
информация о том, как достичь напрямую подсоединенного пункта назначения. Во
многих реализациях это всегда IP-адрес интерфейса, к которому и подсоединен
пункт казна»; чтения. В реализациях, производных от BSD, это может быть также
МАС-адрес, как, показано в последней строке на рис. 4.13. В таком случае будет
установлен флаг L
Колонка Refs содержит счетчик ссылок на маршрут,
то есть количество активных пользователей этого маршрута.
Колонка Use указывает, сколько пакетов было послано
по этому маршруту, а колонка Netif содержит имя ассоциированного сетевого интерфейса,
который представляет собой тот же объект, о котором вы получаете информацию
с помощью опции -i.
Теперь, разобравшись, что означают колонки, печатаемые
командой netstat -rn, вернемся к рис. 4.13.
Первая строка на этом рисунке описывает маршрут
по умолчанию. Именно по нему отсылаются датаграммы, когда в маршрутной таблице
нет более точного маршрута. Например, если выполнить команду ping netcom4. netcom.
com, то получится такой результат:
bsd: $ ping netcom4.netcom.com
PING netcom4.netcom.com (199.183.9.104): 56 data
bytes
64 bytes from 199.183.9.104: icmp_seq=0 ttl=248
time=268.604 ms
...
Поскольку нет маршрута ни до хоста 199.183.9.104,
ни до сети, содержащей этой хост, эхо-запросы ICMP (совет 33) посылаются по
маршруту по умолчанию. В соответствии с первой строкой выдачи netstat шлюз для
этого маршрута имеет адрес 163.179.44.41, туда и посылается датаграмма. Строка
3 на рис. 4.13 показывает, что есть прямой маршрут к хосту 163.179.44.41, и
отсылать ему Дата граммы следует через интерфейс с IP-адресом 205.184.142.171.
Строка 2 в выдаче - это маршрут для возвратного
адреса (127.0.0.1). Поскольку это адрес хоста, установлен флаг Н. Так как хост
подсоединен напрямую, то имеется и флаг G. А в колонке Gateway вы видите IP-адрес
интерфейса 1о0.
В строке 4 представлен маршрут к локальной сети
Ethernet. В связи с тем, что на машине bsd установлена операционная система,
производная от BSD, в колонке Gateway находится строка Link#l. В других системах
был бы просто напечатан IP-адрес интерфейса, подсоединенного к локальной сети
(172.30.0.1).
С помощью netstat можно получить статистику протоколов.
Если задать опцию -s, то netstat напечатает статистические данные по протоколам
IP, ICMP, IGMP, UDP и TCP. Если нужен какой-то один протокол, то его можно указать
посредством опции -р. Так, для получения статистики по протоколу UDP следует
ввести следующую команду:
bsd: $ netstat -sp udp
udp:
82 datagrams received
0 with incomplete header
0 with bad data length field
0 with bad checksum
1 dropped due to no socket
0 broadcast/multicast datagrams dropped due to
no socket
0 dropped due to full socket buffers
0 not for hashed pcb
81 delivered
82 datagrams output
bsd: $
Ниже дается перевод на русский язык, программа
netstat использует английский.
udp:
82 датаграмм получено
0 с неполным заголовком
0 с неправильным значением в поле длины данных
0 с неправильной контрольной суммой
1 отброшено из-за отсутствия сокета
0 отброшено широковещательных/групповых датаграмм
из-за отсутствия сокета
0 отброшено из-за переполнения буфера сокета О
не для хэшированного блока
управления протоколом
81 доставлено
82 отправлено датаграмм
Можно отменить печать строк с нулевыми значениями,
если дважды задать опцию -s:
bsd: $ netstat -ssp udp
udp:
82 datagrams received
1 dropped due to no socket
81 delivered
82 datagrams output
bsd: $
Периодический просмотр статистики TCP оказывает
очень «отрезвляющее» действие. На машине bsd netstat выводит для TCP 45 статистических
показателей. Вот строки с ненулевыми значениями, которые были получены при запуске
netstat-ssp tcp:
tcp:
446 packets sent
190 data packets (40474 bytes)
213 ack-only packets (166 delayed)
18 window update packets
32 control packets
405 packets received
193 acks (for 40488 bytes)
12 duplicate acks
302 packets (211353 bytes) received in sequence
10 completely duplicate packets (4380 bytes)
22 out-of-order packets (16114 bytes)
2 window update packets
20 connection requests
2 connection accepts
13 connections established (including accepts)
22 connection closed (including 0 drops)
3 connections updated cached RTT on close
3 connections updated cached RTT variance on
close
2 embryonic connections dropped
193 segments updated rtt (of 201 attempts)
31 correct ACK header predictions
180 correct data packet header predictions
Далее дается перевод статистической информации
на русский язык.
tcp:
446 пакетов послано
190 пакетов данных (40474 байта)
213 пакетов, содержащих только ack (166 отложенных)
18 пакетов с обновлением окна
32 контрольных пакета
405 пакетов принято
193 ack (на 40488 байт)
12 повторных ack
302 пакета (211353 байта) получено по порядку
10 пакетов - полных дубликатов (4380 байт)
22 пакета не по порядку (16114 байта)
2 пакета с обновлением окна
20 запросов на соединение
2 приема соединения
13 соединений установлено (включая принятые)
22 соединения закрыто (включая 0 сброшенных)
3 соединения при закрытии обновили RTT в кэше
3 соединения при закрытии обновили дисперсию
RTT в кэше
2 эмбриональных соединения сброшено
193 сегмента обновили rtt (из 201 попыток)
31 правильное предсказание заголовка АСК
180 правильных предсказаний заголовка пакета с
данными
Эта статистика получена после перезагрузки машины
bsd и последовавших за ней отправки и получения нескольких сообщений по электронной
почте, а также чтения нескольких телеконференций. Если предположить, что такие
события, как доставка пакетов не по порядку или получение дубликатов пакетов,
происходят очень редко, то полученная информация полностью развеет эти иллюзии.
Так, из 405 полученных пакетов 10 оказались дубликатами, а 22 пришли не по порядку.
Примечание: В работе [Bennett et al. 1999]
показано, что приход пакетов не по порядку не обязательно свидетельствует о
неисправности. Также объясняется, почему в будущем следует ожидать широкого
распространения этого явления.
Выше рассмотрено, как работает программа netstat
в системе UNIX. В Windows тоже есть аналогичная программа, принимающая в основном
те же опции и выдающая такие же данные. Формат выдачи очень напоминает то, что
вы видели, хотя состав информации не такой полный.
Здесь приведены утилита netstat и те сведения о
системе, которые можно получить с ее помощью, netstat сообщает об активных сокетах,
о сконфигурированных сетевых интерфейсах, о маршрутной таблице и о статистике
протоколов. Иными словами, она выдает отчеты о самых разнообразных аспектах
сетевой подсистемы, причем в различных форматах.
Иногда при отладке сетевых приложений нужно уметь
трассировать обращения к ядру операционной системы. Вы уже встречались с подобной
ситуацией в совете 36 и вскоре вернетесь к этому примеру.
В большинстве операционных систем есть разные способы
трассировки системных вызовов. В BSD это утилита ktrace, в SVR4 (и Solaris)
- truss, а в Linux- strace.
Все эти программы похожи, поэтому остановимся только
на ktrace. Беглого знакомства с руководством по truss или strace должно быть
достаточно для применения аналогичной методики в других системах.
Первый пример - это вариация на тему первой версии
программы shutdownc (листинг 3.1), которая разработана в совете 16. Идея программ
badclient и shutdownc та же: читаются данные из стандартного ввода, пока не
будет получен признак конца файла. В этот момент вы вызываете shutdown для отправки
FIN-сегмента удаленному хосту, а затем продолжаете читать от него данные, пока
не получите EOF, что служит признаком прекращения передачи удаленным хостом.
Текст программы badclient приведен в листинге 4.2.
Листинг 4.2. Некорректный эхо-клиент
badcllent.с
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 fd_set readmask;
6 fd_set allreads;
7 int rc;
8 int len;
9 char lin[ 1024 ] ;
10 char lout[ 1024 ] ;
11 INIT();
12 s = tcp_client( argv[ optind ], argv[ optind
+ 1 ] ) ;
13 FD_ZERO( &allreads );
14 FD_SET( 0, &allreads );
15 FD_SET( s, &allreads );
16 for ( ;; )
17 {
18 readmask = allreads;
19 rc = select( s + 1, &readmask, NULL,
NULL, NULL };
20 if ( rc <= 0 )
21 error( 1, errno, "select вернула (%d)",
rc );
22 if ( FD_ISSET( s, kreadmask ) )
23 {
24 rc = recv( s, lin, sizeof( lin ) - 1, 0
);
25 if ( rc < 0 )
26 error( 1, errno, "ошибка вызова recv"
);
27 if ( rc == 0 )
28 error( 1, 0, "сервер отсоединился\n"
);
29 lin[ rc] = '\0';
30 if ( fputst lin, stdout ) )
31 error( 1, errno, "ошибка вызова fputs"
);
32 }
33 if ( FD_ISSET( 0, &readmask ) )
34 {
35 if ( fgets( lout, sizeof( lout ), stdin
) == NULL )
36 {
37 if ( shutdown( s, 1 ) )
38 error( 1, errno, "ошибка вызова
shutdown" );
39 }
40 else
41 {
42 len = strlen( lout );
43 rc = send( s, lout, len, 0 );
44 if ( rc< 0 )
45 error( 1, errno, "ошибка вызова
send" );
46 }
47 }
48 }
49 }
22-32 Если select показывает, что произошло событие
чтения на соединении, пытаемся читать данные. Если получен признак конца файла,
то удаленный хост прекратил передачу, поэтому завершаем работу. В противном
случае выводим только что прочитанные данные на stdout.
33-47 Если select показывает, что произошло событие
чтения на стандартном вводе, вызываем f gets для чтения данных. Если f gets
возвращает NULL, что является признаком ошибки или конца файла, то вызываем
shutdown, чтобы сообщить удаленному хосту о прекращении передачи. В противном
случае посылаем только что прочитанные данные.
А теперь посмотрим, что произойдет при запуске
программы badcl lent. В качестве сервера в этом эксперименте будет использоваться
программа tcpecho (листинг 3.2). Следует напомнить (совет 16), что вы можете
задать число секунд, на которое tcpecho должна задержать отправку ответа на
запрос. Установите задержку в 30 с. Запустив клиент, напечатайте hello и сразу
нажмите Ctrl+D, таким образом посылается fgets признак конца файла.
|
bsd: $ tcpecho 9000 30
спустя 30 с
tcpecho: ошибка вызова recv:
Connection reset by peer (54)
bsd: $
|
bsd: $ badclient bad 9000
hello
^D
badclient: сервер отсоединился
bsd: $
|
Как видите, badclient завершает сеанс сразу же
с сообщением о том, что сервер отсоединился. Но tcpecho продолжает работать
и «спит», пока не истечет 30 с таим-аута. После этого программа получает от
своего партнера ошибку Connection reset by peer.
Это удивительно. Ожидалось, что tcpecho через 30
с пошлет эхо-ответ, а затем завершит сеанс, прочтя признак конца файла. Вместо
этого badclient завершает работу немедленно, a tcpecho получает ошибку чтения.
Правильнее начать исследование проблемы с использования
tcpdump (совет 34), чтобы понять, что же на самом деле посылают и принимают
обе программы. Выдача tcpdump приведена на рис. 4.16. Здесь опущены строки,
относящиеся к фазе установления соединения, и разбиты длинные строки.
1 18:39:48.535212 bsd.2027 > bsd.9000:
Р 1:7(6) ack 1 win 17376 <nop,nop,timestamp 742414 742400> (DF)
2 18:39:48.546773 bsd.9000 > bsd.2027:
. ack 7 win 17376 <nop,пор,timestamp 742414 742414> (DF)
3 18:39:49.413285 bsd.2027 > bsd.9000:
F 7:7(0) ack 1 win 17376 <nop, пор, timestamp 742415 742414> (DF)
4 18:39:49.413311 bsd.9000 > bsd.2027:
. ack 8 win 17376 <nop,пор,timestamp 742415 742415> (DF)
5 18:40:18.537119 bsd.9000 > bsd.2027:
P 1:7(6) ack 8 win 17376 <nop,пор,timestamp 742474 742415> (DF)
6 18:40:18.537180 bsd.2027 > bsd.9000:
R 2059690956:2059690956(0) win 0
Рис. 4.16. Текст, выведенный tcpdump для программы badclient
Все выглядит нормально, кроме последней строки.
Программа badclient посылает tcpecho строку hello (строка 1), а спустя секунду
появляется сегмент FIN, посланный в результате shutdown (строка 3). Программа
tcpecho в обоих случаях отвечает сегментом АСК (строки 2 и 4). Через 30 с после
того, как badclient отправила hello, tcpecho отсылает эту строку назад (строка
5), но другая сторона вместо того, чтобы послать АСК, возвращает RST (строка
б), что и приводит к печати сообщения Connection reset by peer. RST был послан,
поскольку программа badcl ient уже завершила сеанс.
Но все же видно, что tcpecho ничего не сделала
для преждевременного завершения работы клиента, так что вся вина целиком лежит
на badclient. Посмотрим, что же происходит внутри badclient, поможет в этом
трассировка системных вызовов.
Повторим эксперимент, только на этот раз следует
запустить программу так:
bsd: $ ktrace badclient bed 9000
При этом badclient работает, как и раньше, но дополнительно
вы получаете трассу выполняемых системных вызовов. По умолчанию трасса записывается
в файл ktrace. out. Для печати содержимого этого файла надо воспользоваться
программой kdump. Результаты показаны на рис. 4.17, в котором опущено несколько
начальных вызовов, относящихся к запуску приложения и установлению соединения.
Первые два поля в каждой строке - это идентификатор
процесса и имя исполняемой программы. В строке 1 вы видите вызов read с дескриптором
fd, равным (stdin). В строке 2 читается шесть байт (GIO - сокращение от
general I/O - общий ввод/вывод), содержащих hello\n. В строке 3 показано,
что вызов re вернул 6 - число прочитанных байтов. Аналогично из строк 4-6 видно,
программа badclient писала в дескриптор 3, который соответствует сокету, соединному
с tcpecho. Далее, в строках 7 и 8 показан вызов select, вернувший едини
1 4692 badclient CALL read(0,0x804e000,0x10000)
2 4692 badclient GIO fd 0 read 6 bytes
"hello
"
3 4692 badclient RET read 6
4 4692 badclient CALL sendto(0x3,0xefbfce68,0x6,0,0,0)
5 4692 badclient GIO fd 3 wrote 6 bytes
"hello
"
6 4692 badclient RET sendto 6
7 4692 badclient CALL select(0x4,0xefbfd6f0,0 , 0, 0)
8 4692 badclient RET select 1
9 4692 badclient CALL read(0,0x804e000,0x10000)
10 4692 badclient GIO fd 0 read 0 bytes
""
11 4692 badclient RET read 0
12 4692 badclient CALL shutdown(0x3,0xl)
13 4692 badclient RET shutdown 0
14 4692 badclient CALL select(0x4,0xefbfd6fO,0,0,0)
15 4692 badclient RET select 1
16 4692 badclient CALL shutdown(0x3,0xl)
17 4692 badclient RET shutdown 0
18 4692 badclient CALL select(0x4,0xefbfd6fO,0,0,0)
19 4692 badclient RET select 2
20 4692 badclient CALL recvfrom(0x3,0xefbfd268,0x3ff,0,0,0)
21 4692 badclient GIO fd 3 read 0 bytes
""
22 4692 badclient RET recvfrom 0
23 4692 badclient CALL write(0x2,0xefbfc6f4,0xb)
24 4692 badclient GIO fd 2 wrote 11 bytes
"badclient: "
25 4692 badclient RET write 11/0xb
26 4692 badclient CALL write(0x2,Oxefbfc700,0x14)
27 4692 badclient GIO fd 2 wrote 20 bytes
"server disconnected
"
28 4692 badclient RET write 20/0x14
29 4692 badclient CALL exit(0xl)
Рис. 4.17. Результаты прогона badclient
под управлением ktrace
Это означает, что произошло одно событие. В строках
9-11 badclient прочитала EOF из stdin и вызвала shutdown (строки 12 и 13).
До сих пор все шло нормально, но вот в строках
14-17 вас поджидает сюрприз: select возвращает одиночное событие, и снова вызывается
shutdown. Ознакомившись с листингом 4.2, вы видите, что такое возможно только
при условии, если дескриптор 0 снова готов для чтения. Но read не вызывается,
как можно было бы ожидать, ибо fgets в момент нажатия Ctrl+D отметила, что поток
находится в конце файла, поэтому она возвращается, не выполняя чтения.
Примечание: Вы можете убедиться в этом,
познакомившись с эталонной реализацией fgets (на основе fgetc) в книге [Kemighan
andRitchie 19881
В строках 18 и 19 select возвращает информацию
о событиях на обоих дескрипторах stdin и сокете. В строках 20-22 видно, что
recvfrom возвращает нуль (конец файла), а оставшаяся часть трассы показывает,
как badclient выводит сообщение об ошибке и завершает сеанс.
Теперь ясно, что произошло: select показывает,
что стандартный ввод готов для чтения в строке 15, поскольку вы забыли вызвать
FD_CLR для stdin после первого обращения к shutdown. А следующий (уже второй)
вызов shutdown вынуждает TCP закрыть соединение.
Примечание: В этом можно убедиться, посмотрев
код на странице 1014 книги [Wright and Stevens 1995], где показано, что в результате
обращения к shutdown вызывается функция tcp_usrclosee. Если shutdown уже вызывался
раньше, то соединение находится в состоянии FIN-WAIT-2 и tcp_usrclosed вызывает
функцию soisdisconnected (строка 444 на странице 1021). Этот вызов окончательно
закрывает сокет и заставляет select вернуть событие чтения. А в результате будет
прочитан EOF.
Поскольку соединение закрыто, recvf rom возвращает
нуль, то есть признак конца файла, и badclient выводит сообщение «сервер отсоединился»
и завершает сеанс.
Ключ к пониманию событий в этом примере дал второй
вызов shutdown. Легко обнаружилось отсутствующее обращение к FD_CLR.
Следующая ситуация - это продолжение примера из
совета 36. Помните, что при размере буфера равном MSS соединения, время передачи
16 Мб возросло с 1,3 с до почти 41 мин.
На рис. 4.18 приведена репрезентативная выборка
из результатов прогона ktrace для этого примера.
12512 ttcp 0.000023 CALL write(0x3,0x8050000, 0x2000)
12512 ttcp 1.199605 GIO fd 3 wrote 8192 bytes
“”
12512 ttcp 0.000442 RET write 8192/0x2000
12512 ttcp 0.000022 CALL write(0x3,0x8050000 , 0x2000)
12512 ttcp 1.199574 GIO fd 3 wrote 8192 bytes
“”
12512 ttcp 0.000442 RET write 8192/0x2000
12512 ttcp 0.000023 CALL write(0x3,0x8050000 , 0x2000)
12512 ttcp 1.199514 GIO fd 3 wrote 8192 bytes
“”
12512 ttcp 0.000432 RET write 8192/0x2000
Рис. 4.18. Выборка из результатов проверки
ttcp -tsvb 1448 bsd под управлением ktrace
Вызвана kdump со следующими опциями:
kdump -R -m -l
для печати интервалов времени между вызовами и запрета
вывода 8 Кб данных, ассоциированных с каждым системным вызовом.
Время каждой операции записи колеблется около значения
1,2 с. На рис. 4.19 для сравнения приведены результаты эталонного теста. На
этот раз разброс значений несколько больше, но среднее время записи составляет
менее 0,5 мс.
Большее время в записях типа GIO на рис. 4.18 по
сравнению с временем на рис. 4.19 наводит на мысль, что операции записи блокировались
в ядре (совет 36). Тогда становится понятна истинная причина столь резкого увеличения
времени передачи.
12601 ttcp 0.000033 CALL write(0x3,0x8050000, 0x2000) 12601 ttcp 0.000279
GIO fd 3 wrote 8192 bytes
“”
12601 ttcp 0.000360 RET write 8192/0x2000
12601 ttcp 0.000033 CALL write(0x3,0x8050000, 0x2000)
12601 ttcp 0.000527 GIO fd 3 wrote 8192 bytes
“”
12601 ttcp 0.000499 RET write 8192/0x2000
12601 ttcp 0.000032 CALL write(0x3,0x8050000, 0x2000)
12601 ttcp 0.000282 GIO fd 3 wrote 8192 bytes
“”
12601 ttcp 0.000403 RET write 8192/0x2000
Рис. 4.19. Репрезентативная выборка
из результатов проверки ttcp –tsvbsd под управлением ktrace
Здесь описано два способа применения утилиты трассировки
системных вызовов. В первом примере ошибку удалось обнаружить путем анализа
системных вызовов, выполненных приложением. Во втором примере надо было отслеживать
не очередность системных вызовов, а время выполнения некоторых из них.
Ранее уже говорилось о том, что для выяснения причин
аномального поведения программы часто бывает необходимо сопоставить результаты,
полученные от различных утилит. Программы трассировки системных вызовов, такие
как ktrace, truss и strace, - это еще одно средство анализа в арсенале сетевого
программиста.
Иногда необходимо знать, какие сообщения приходят
в протоколе ICMP. Конечно, для их перехвата всегда можно воспользоваться программой
tcpdump или Другим сетевым анализатором, но иногда простой инструмент оказывается
более Удобным. Применение tcpdump влечет за собой некоторое снижение производительности,
а также угрозу безопасности, хотя прослушивание ICMP-сообщений совершенно безобидно
и ненакладно.
Во-первых, для работы такового сетевого анализатора,
как tcpdump, нужно перевести сетевой интерфейс в режим пропускания. Это увеличивает
нагрузку на центральный процессор, так как прерывание будет возникать при проходе
через интерфейс каждого пакета Ethernet, даже если он адресован не той машине,
на которой работает анализатор.
Во-вторых, во многих организациях применение сетевых
анализаторов ограничено или вообще запрещено из-за потенциальной опасности перехвата
информации и кражи паролей. Поэтому чтение ICMP-сообщений там более приемлемо.
В данном разделе разработан инструмент, который
позволяет отслеживать ICMP-сообщения и не имеет недостатков, присущих сетевому
анализатору общего назначения. Это позволит изучить простые сокеты, с которыми
вы пока не сталкивались.
В совете 33 упоминалось, что ICMP-сообщения транспортируются
в составе датаграмм. Обычно содержимое ICMP-сообщения зависит от его типа, но
интерес представляют только поля icmp_type и icmp_code, показанные на рис. 4.20.
Дополнительные поля будут рассмотрены в связи с сообщениями о недоступности
ресурса.

Рис. 4.20. Общий формат ICMP-сообщения
Часто возникают недоразумения при ответе на вопрос,
что такое простые сокеты и для чего они нужны. Простые сокеты нельзя использовать
для перехвата TCP-сегментов или UDP-датаграмм, поскольку они таким сокетам не
передаются. Не годятся они и для получения всех ICMP-сообщений. Например, в
системах, производных от BSD, эхо-запросы ICMP, запросы о временном штампе и
запросы маски адреса полностью обрабатываются ядром и не передаются простым
сокетам. В общем случае простой сокет получает все IP-датаграммы, в заголовках
которых указан неизвестный ядру протокол, большинство ICMP-сообщений и все без
исключения ICMP-сообщения.
Важно также отметить, что в простой сокет поступает
вся IP-датаграмма целиком, включая заголовок. Ваша программа должна будет пропускать
IP-заголовок.
Чтение ICMP-сообщений
Начнем с включаемых в программу файлов и функции
main (листинг 4.3).
Листинг 4.3. Функция main программы icmp
icmp.с
1 #include <sys/types.h>
2 #include <netinet/in_systm.h>
3 #include <netinet/in.h>
4 #include <netinet/ip.h>
5 #include <netinet/ip_icmp.h>
6 #include <netinet/udp.h>
7 #include <etcp.h>
8 int main (int args, char **argv)
9 {
10 SOCKET s;
11 struct protoent *pp;
12 int rc;
13 char icmpdg [1024];
14 INIT ();
15 pp = getprotobyname (“icmp“);
16 if (pp == NULL)
17 error ( 1, errno, “ошибка вызова getprotobyname”
);
18 s = socket (AF_INET, SOCK_RAW, pp->p_proto);
19 if (!isvalidsock (s))
20 error ( 1, errno, “ошибка вызова socket”
);
21 for ( ; ; )
22 {
23 rc = recvform (s, icmpdg, sizeof (icmpdg)),
0,
24 NULL, NULL);
25 if ( rc < 0 )
26 error ( 1, errno, “ошибка вызова recvfrom”
);
27 print_dg (icmpdg, rc);
28 }
29 }
Открытие простого сокета
15-20 Поскольку использован простой сокет, надо
указать нужный протокол. Вызов фуекции getprotobyname возвращает структуру,
содержащую номер протокола ICMP. Обратите внимание, что в качестве типа указана
константа SOCK_RAW, а не SOCK_STREAM или SOCK_DGRAM, как раньше.
Цикл обработки событий
21-28 Читаем каждую IP-диаграмму, используя recvform,
как и в случае UDP-датаграмм. Для печати поступающих ICMP-сообщений вызываем
функцию print_dg.
Печать ICMP-сообщений
Далее рассмотрим форматирование и печать ICMP-сообщений.
Это делает функция print_dg, показанная в листинге 4.4. Передаваемый этой функции
буфер имеет структуру, показанную на рис. 4.21.
Из рис. 4.21 видно, что буфер содержит IP-заголовок,
за которым идет собственно ICMP-сообщение.
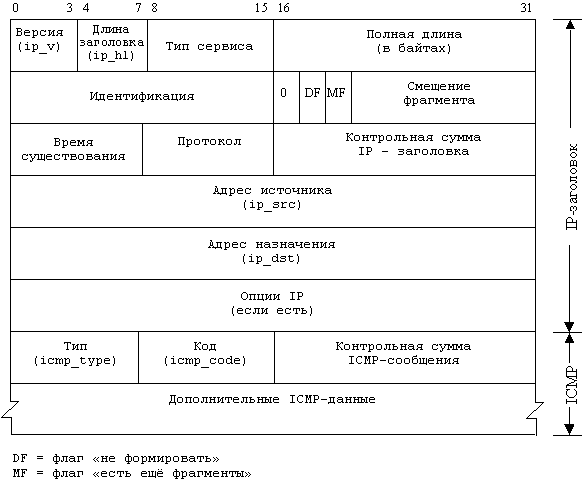
Рис.4.21. ICMP-сообщение, передаваемое
функции print_dg
Листинг 4.4. Функция printjdg
icmp.с
1 static void print_dg( char *dg, int len )
2 {
3 struct ip *ip;
4 struct icmp *icmp;
5 struct hostent *hp;
6 char *hname;
7 int hl;
8 static char *redirect_code[] =
9 {
10 "сеть", "хост",
11 "тип сервиса и сеть", "тип
сервиса и хост"
12 };
13 static char *timexceed_code [ ] =
14 {
15 "транзите", "сборке"
16 }
17 static char *param_code[] =
18 {
19 "Плохой IP-заголовок", "Нет
обязательной опции"
20 };
21 ip = ( struct ip * )dg;
22 if ( ip->ip_v !=4)
23 {
24 error( 0, 0, "IP-датаграмма не версии
4\n" );
25 return;
26 }
27 hl = ip->ip_hl « 2; /* Длина IP-заголовка
в байтах. */
28 if ( len < hl + ICMP_MINLEN )
29 {
30 error( 0, 0, "short datagram (%d bytes)
from %s\n",
31 len, inet_ntoa( ip->ip_src ) );
32 return;
33 }
34 hp = gethostbyaddr( ( char * )&ip->ip_src,
4, AF_INET );
35 if ( hp == NULL )
36 hname = "";
37 else
38 hname = hp->h_name;
39 icmp = ( struct icmp * }( dg + hl ); /* ICMP-пакет.
*/
40 printf( "ICMP %s (%d) от %s (%s)\n",
41 get_type( icmp->icmp_type ),
42 icmp->icmp_type, hname, inet_ntoa( ip->ip_src
) );
43 if ( icmp->icmp_type == ICMP_UNREACH )
44 print_unreachable( icmp );
45 else if ( icmp->icmp_type == ICMP_REDIRECT
)
46 printf( "\tПеренаправление на %s\n",
icmp->icmp_code <=
47 redirect_code[ icmp->icmp_code ] : "Некорректный
код" );
48 else if ( icmp->icmp_type == ICMP_TIMXCEED
)
49 printf( "\tTTL == 0 при %s\n",
icmp->icmp_code <= 1 ?
50 timexceed_code[ icmp->icmp_code] : "Некорректный
код" );
51 else if ( icmp->icmp_type == ICMP_PARAMPROB
)
52 printf ( "\t%s\n", icmp->icmp_code
<= 1 ?
53 param_code[ icmp->icmp_code ] : "Некорректный
код" );
54 }
Получение указателя на IP-заголовок
и проверка корректности пакета
21 Записываем в переменную ip указатель на только
что прочитанную датаграмму, приведенный к типу struct ip *.
22-26 Поле ip_v - это версия протокола IP. Если
протокол не совпадает с IPv4, то печатаем сообщение об ошибке и выходим.
27-33 Поле ip_hl содержит длину заголовка в 32-байтных
словах. Умножаем его на 4, чтобы получить длину в байтах, и сохраняем результат
в переменной hl. Затем проверяем, что длина ICMP-сообщения не меньше минимально
допустимой величины.
Получение имени хоста отправителя
34-38 Используем адрес источника в ICMP-сообщении,
чтобы найти имя хоста отправителя. Если gethostbyaddr вернет NULL, то записываем
в hname пустую строку, в обратном случае - имя хоста.
Пропуск IP-заголовка и печать отправителя
и типа
39-42 Устанавливаем указатель icmp на первый байт,
следующий за IP-заголовком. Этот указатель используется далее для получения
типа ICMP-сообщения (icmp_type) и печати типа, адреса и имени хоста отправителя.
Для получения ASCII-представления типа ICMP вызываем функцию get_type, текст
которой приведен в листинге 4.5.
Печать информации, соответствующей типу
43-44 Если это одно из ICMP-сообщений о недоступности,
то вызываем функцию print_unreachable (листинг 4.6) для печати дополнительной
информации.
45-47 Если это сообщение о перенаправлении, то получаем
тип перенаправления из поля icmp_code и печатаем его.
48-50 Если это сообщение об истечении времени существования,
из поля icmp_code узнаем, произошло ли это во время транзита или сборки датаграммы,
и печатаем результат.
51-53 Если это сообщение о некорректном параметре,
из поля icmp_code определяем, в чем ошибка, и печатаем результат.
Функция get_type очевидна. Вы проверяете допустимость
кода типа и возвращаете указатель на соответствующую строку (листинг 4.5).
Листинг 4.5. Функция getjype
icmp.c
1 static char *get_type( unsigned icmptype )
2 {
3 static char *type[] =
4 {
5 "Эхо-ответ",
/* 0*/
6 "ICMP Тип 1",
/* 1*/
7 "ICMP Тип 2",
/* 2*/
8 "Пункт назначения недоступен",
/* 3*/
9 "Источник приостановлен",
/* 4*/
10 "Перенаправление",
/* 5*/
11 "ICMP Тип 6",
/* 6*/
12 "ICMP Тип 7",
/* 7*/
13 "Эхо-запрос",
/* 8*/
14 "Отклик маршрутизатора",
/* 9*/
15 "Поиск маршрутизаторов",
/* 10*/
16 "Истекло время существования",
/* 11*/
17 "Неверный параметр",
/* 12*/
18 "Запрос временного штампа",
/* 13*/
19 "Ответ на запрос временного штампа",
/* 14*/
20 "Запрос информации",
/* 15*/
21 "Ответ на запрос информации",
/* 16*/
22 "Запрос маски адреса",
/* 17*/
23 "Ответ на запрос маски адреса"
/* 18*/
24 }
25 if ( icmptype < ( sizeof( type ) / sizeof
( type[ 0 ]) ) )
26 return type[ icmptype ];
27 return "НЕИЗВЕСТНЫЙ ТИП";
28 }
Последняя функция - это print_unreachable. ICMP-сообщения
о недоступности содержат IP-заголовок и первые восемь байт той IP-датаграммы,
из-за которой было сгенерировано сообщение о недоступности. Это позволяет узнать
адреса и номера портов отправителя и предполагаемого получателя недоставленного
сообщения.
Структура IP-датаграммы, прочитанной из простого
сокета в составе ICMP-сообщения о недоступности, показана на рис. 4.22. Та часть,
которую уже обработала функция print_dg, заштрихована, она не передается в print_unreachable.
Приведены также входной параметр функции print_unreachable - icmp и локальные
переменные ip и udp.
Рис. 4.22. ICMP-сообщение о недоступности
Функция print_unreachable извлекает информацию
из заголовка и первых восьми байт включенной IP-датаграммы. Хотя вы пометили
байты как UDP-заголовок, это мог быть и заголовок TCP: номера портов в обоих
случаях находятся в одной и той же позиции. Формат UDP-заголовка показан на
рис. 4.23.

Рис. 4.23. UDP-заголовок
Текст функции print_unreachable приведен в листинге
4.6.
Листинг4.6. Функцияprint_unreachable
icmp.с
1 static void print_unreachable( struct icmp *icmp )
2 {
3 struct ip *ip;
4 struct udphdr *udp;
5 char laddr[ 15 + 1 ] ;
6 static char *unreach[] =
7 {
8 "Сеть недоступна",
/* 0 */
9 "Хост недоступен",
/* 1 */
10 "Протокол недоступен",
/* 2 */
11 "Порт недоступен",
/* 3 */
12 "Нужна фрагментация, поднят бит DF",
/* 4 */
13 "Ошибка маршрутизации от источника",
/* 5 */
14 "Сеть назначения неизвестна",
/* 6 */
15 "Хост назначения неизвестен",
/* 7 */
16 "Хост источника изолирован",
/* 8 */
17 "Сеть назначения закрыта администратором
", /* 9 */
18 "Хост назначения закрыт администратором
", /* 10 */
19 "Сеть недоступна для типа сервиса",
/* 11 */
20 "Хост недоступен для типа сервиса",
/* 12 */
21 "Связь запрещена администратором",
/* 13 */
22 "Нарушение предшествования хостов",
/* 14 */
23 "Действует отсечка предшествования"
/* 15 */
24 };
25 ip = ( struct ip * )( ( char * )icmp + 8 );
26 udp = ( struct udphdr *)((char *)ip + (ip->ip_hl
« 2 ) );
27 strcpy( laddr, inet_ntoa( ip->ip_src )
);
28 printf( "\t%s\n\tИст.: %s.%d, Назн.:
%s.%d\n",
29 icmp->icmp_code < ( sizeof( unreach
) /
30 sizeof( unreach[ 0 ] ) )?
31 unreach[ icmp->icmp_code ] : "Некорректный
код",
32 laddr, ntohs( udp->uh_sport ),
33 inet_ntoa( ip->ip_dst ), ntohs( udp->uh_dport
) );
34 }
Установка указателей и получение адреса источника
25-26 Начинаем с установки указателей ip и udp
соответственно на IP-заголовок и первые восемь байт вложенной IP-датаграммы.
27 Копируем адрес источника из IP-заголовка в локальную
переменную laddr.
Печать адресов, портов и типа сообщения
28-33 Печатаем адреса и номера портов источника
и назначения, а также уточненный тип сообщения о недоступности.
В качестве примера использования программы ICMP
приведено несколько юследних ICMP-сообщений, полученных при запуске traceroute
(совет 35).
traceroute -q 1 netcom4.netcom.com
Опция -q 1 означает, что traceroute должна посылать
пробный запрос только один раз, а не три, как принято по умолчанию.
ICMP Истекло время существования (11) от hl-0.mig-fl-gwl.icg.net
(165.236.144.110)
TTL == 0 во время транзита
ICMP Истекло время существования (11) от sl0-0-0.dfw-tx-
gwl.icg.net (165.236.32.74)
TTL == 0 во время транзита
ICMP Истекло время существования (11) от dfw-tx-gw2.icg.net
(163.179.1.133)
TTL == 0 во время транзита
ICMP Пункт назначения недоступен (3) от netcom4.netcom.com
(199.183.9.104)
Порт недоступен
Ист. 205.184.-142.71.45935, Назн. 199.183.9.104.33441
Обычно нет необходимости следить с помощью icmp
за работой traceroute, но это может быть очень полезно для поиска причин отсутствия
связи.
В этом разделе разработан инструмент для перехвата
и печати ICMP-сообщений. Такая программа помогает при диагностике ошибок сети
и маршрутизации.
В ходе разработки программы icmp использованы простые
сокеты. Здесь вы познакомились с форматами IP- и UDP-датаграмм, а также со структурой
ICMP-сообщений.
В сетевых конференциях чаще всего задают вопрос:
«Какие книги нужно читать, чтобы освоить TCP/IP?». В подавляющем большинстве
ответов упоминаются книги Ричарда Стивенса.
В этой книге много ссылок на работы Стивенса. Для
сетевых программистов этот автор написал две серии книг: «TCP/IP Illustrated»
в трех томах и «UNIX Network Programming» в двух. Они преследуют разные цели,
поэтому рассмотрим их по отдельности.
Как следует из названия, серия «TCP/IP Illustrated»
трактует работу наиболее распространенных протоколов из семейства TCP/IP и программ,
в которых они применяются. В совете 14 говорилось, что основное средство для
исследования - это программа tcpdump. Запуская небольшие тестовые программы
и наблюдая за генерируемым ими сетевым трафиком, вы постепенно начинаете понимать,
как на практике функционируют протоколы.
Используя различные операционные системы, Стивенс
показывает, что реализации в них одного и того же протокола приводят к тонким
отличиям в его работе. Еще важнее, что вы учитесь ставить собственные эксперименты,
а затем интерпретировать их результаты, отвечая тем самым на возникающие вопросы.
Поскольку в каждом томе семейство протоколов TCP/IP
рассматривается под разными углами зрения, имеет смысл кратко охарактеризовать
каждую книгу.
Том 1: Протоколы
В этом томе описываются классические протоколы
TCP/IP и их взаимосвязи. Сначала рассматриваются протоколы канального уровня,
такие как Ethernet, SLIP и РРР. Далее автор переходит к протоколам АКР и RARP
(Reverse Address Resolution Protocol - протокол определения адреса по местоположению
узла сети) и рассматривает их в качестве связующего звена между канальным и
межсетевым уровнями.
Несколько глав посвящено протоколу IP и его связям
с ICMP и маршрутизацией. Также анализируются утилиты ping и traceroute, работающие
на уровне IP.
Далее речь идет о протоколе UDP и смежных вопросах:
широковещании и протоколе IGMP. Описываются также основанные на UDP протоколы:
DNS, TFTP (Trivial File Transfer Protocol - тривиальный протокол передачи файлов)
и ВООТР (Bootstrap Protocol - протокол начальной загрузки по сети).
Восемь глав посвящено протоколу TCP. В нескольких
главах обсуждаются распространенные приложения на базе TCP, такие как telnet,
rlogin, FTP, SMTP (электронная почта) и NFS.
Том 2: Реализация
Второй том, написанный в соавторстве с Гэри Райтом
(Gary Wright), - это практически построчное описание сетевого кода из операционной
системы 4.4BSD. Поскольку код из системы BSD широко признан как эталонная реализация,
эта книга незаменима для тех, кто хочет лучше разбираться в реализации основных
протоколов семейства TCP/IP.
В книге рассматривается реализация нескольких протоколов
канального уровня (Ethernet, SLIP и возвратный интерфейс), протокола IP, маршрутизации,
протоколов ICMP, IGMP, UDP и TCP, группового вещания, уровня сокетов, а также
несколько смежных тем. Поскольку автор приводит реальный код, читатель может
получить представление о том, какие проблемы возникают при реализации сложной
сетевой системы, и на какие компромиссы приходится идти.
Том 3: TCP для транзакций, HTTP,
NNTP и протоколы в адресном домене UNIX
Третий том - это продолжение первого и второго.
Он начинается с описания протокола Т/ТСР и принципов его функционирования. Это
описание построено так же, как и в первом томе. Далее приводится реализация
Т/ТСР - по типу второго тома.
Во второй части рассматриваются два популярных
прикладных протокола. HTTP (Hypertext Transfer Protocol - протокол передачи
гипертекста) и NNTP (Network News Transfer Protocol - сетевой протокол передачи
новостей), которые составляют основу сети World Wide Web и сетевых телеконференций
Usenet соответственно.
И, наконец, исследуются сокеты в адресном домене
UNIX и их реализация. По сути, это продолжение второго тома, не включенное в
него из-за ограничений на объем издания.
В серии «UNIX Network Programming» приведена трактовка
TCP/IP для прикладных программистов. Здесь рассматриваются не сами протоколы,
а их применение для построения сетевых приложений.
Том 1. Сетевые API: Сокеты и XTI
Эта книга должна быть у каждого сетевого программиста.
В ней очень подробно рассматривается программирование TCP/IP с помощью API сокетов
и XTI. Помимо традиционных тем, обсуждаемых в изданиях по программированию в
архитектуре клиент-сервер, в данной книге затрагиваются групповое вещание, маршрутизирующие
сокеты, неблокирующий ввод/вывод, протокол IPv6 и его работу совместно с IPv4,
простые сокеты, программирование на канальном уровне и сокета в адресном домене
UNIX.
В этом томе есть особенно ценная глава, в которой
сравниваются различные модели построения клиентов и серверов. В приложениях
описываются виртуальные сети и техника отладки.
Том 2: Межпроцессное взаимодействие
Во втором томе детально рассмотрены различные механизмы
межпроцессного взаимодействия. Помимо таких традиционных средств, как каналы
и FIFO в UNIX, очереди сообщений, семафоры и разделяемая память, впервые появившиеся
в системе SysV, обсуждаются и более современные методы межпроцессного взаимодействия,
предложенные в стандарте POSIX.
Имеется прекрасное введение в изучение стандартизованных
POSIX-потоков (threads) и использования в них таких примитивов синхронизации,
как мьютексы, условные переменные и блокировки чтения-записи. Для тех, кто интересуется
работой системных механизмов, Стивенс приводит реализацию нескольких примитивов
синхронизации и очередей сообщений в стандарте POSIX.
Заканчивается книга главами об RPC (Remote Procedure
Calls - вызовы удаленных процедур) и подсистеме Solaris Doors.
Был запланирован и третий том, в котором предполагалось рассмотреть приложения,
но, к несчастью, Стивене скончался, не успев его завершить. Частично материал,
который он хотел включить в третий том, можно найти в первом издании книги «UNIX
Network Programming» [Stevens 1990].
Начинающие программисты часто спрашивают более
опытных коллег, откуда тем столько всего известно. Конечно, знания и опыт приобретаются
разными способами, но один из самых важных, хотя и недооцениваемых, - это чтение
программ, написанных мастерами.
Расширяющееся движение за открытые исходные тексты
облегчает эту задачу. Чтение и разбор высококачественного кода имеют множество
плюсов, самое очевидное - это ознакомление с подходом, выбранным экспертом для
решения задачи. Вы можете применить такую методику в своих программах, немного
ее модифицировав и адаптировав. При этом вырабатываются собственные приемы.
1И когда-нибудь будут читать уже ваш код и восхищаться красивым решением.
Не так очевидно, хотя в некоторых отношениях более
важно осознание того, что нет никакой магии. Начинающие программисты иногда
склонны думать, что код операционной системы или реализации протоколов непостижим,
он создается высшими силами, а простым смертным нечего и пытаться в нем разобраться.
Но, читая код, вы понимаете, что это просто образец хорошей (по большей части,
стандартной) практики инженерного проектирования, и вам это тоже под силу.
Короче говоря, изучая код, вы приходите к выводу,
что глубокое и таинственное - в действительности вопрос применения стандартных
приемов, овладеваете этими приемами и учитесь применять их на практике. Читать
код нелегко. Для этого требуется высокая концентрация внимания, но усилия окупаются
сторицей.
Есть несколько источников хорошего кода, но лучше
получить еще и комментарии. Книга Лионса «A Commentary on the UNIX Operating
System» [Lions 1977] давно уже ходила в списках. Недавно благодаря усилиям нескольких
людей, в частности Денниса Ричи, и великодушию компании SCO, которая сейчас
владеет исходными текстами UNIX, эта книга стала доступна широкой публике.
Примечание: Первоначально книгу могли приобрести
только держатели лицензии на исходные тексты UNIX, но подпольная ксерокопия
(или копия с ксерокопии) была вожделенным призом для многих программистов в
дни становления UNIX.
В книге приведен код очень ранней (шестой) версии
операционной системы UNIX, в которой не было сетевых компонент, кроме TTY-терминалов
с разделением времени. Тем не менее стоит изучить этот код, даже если вы не
интересуетесь системой UNIX, поскольку это прекрасный пример конструирования
программного обеспечения.
Еще одна отличная книга по операционным системам,
включающая исходные тексты, - это «Operating Systems: Design and Implementation»
[Tanenbaum and Woodhull, 1997]. В ней описана операционная система MINIX. Хотя
в самом тексте сетевой код не приводится, но он есть на прилагаемом компакт-диске.
Для тех, кого больше интересуют сетевые задачи,
предназначен второй том книги «TCP/IP Illustrated» [Wright and Stevens 1995].
Она упоминалась в совете 41.
В этой книге описывается код из системы BSD, на
базе которой создано несколько современных систем с открытыми исходными текстами
(FreeBSD, OpenBSD, NetBSD). Она дает прекрасный материал для экспериментов с
кодом. Оригинальный код системы 4.4BSD Lite можно получить с FTP-сервера компании
Walnut Creek CD-ROM (ftp://ftp.cdrom.eom/pub/4.4BSD-Lite).
Во втором томе книги «Работа в сетях: TCP/IP» [Comer
and Stevens 1999 описан другой стек TCP/IP. Как и в предыдущей, в ней приводится
подробно! объяснение принципа работы кода. Код можно загрузить из сети.
Есть много и других источников кода, хотя, как
правило, он не сопровождаете; пояснениями в виде книги. Начать можно с открытых
систем UNIX или Linux. Для всех подобных проектов исходные тексты доступны на
CD-ROM или через FTP.
В проекте GNU, основанном фондом Free Software
Foundation, имеется исходный текст переписанных с нуля реализаций большинства
стандартных утилит UNIX. Это тоже отличный материал для изучения.
Информацию об этих проектах можно найти на следующих
сайтах:
В каждом из этих источников есть огромное количество
исходных текстов, связанных с сетевым программированием, и их стоит изучить,
даже если UNIX не находится в сфере ваших интересов.
Один из лучших способов изучения сетевого программирования
(да и любого другого) - это чтение программ, написанных людьми, уже достигшими
верши] мастерства. До недавнего времени было нелегко получить доступ к исходным
текстам операционных систем и их сетевых подсистем. Но в связи с распространением
движения за открытость исходных текстов ситуация изменилась. Ко, нескольких
реализаций стека TCP/IP и соответствующих утилит (telnet, FTI inetd и т.д.)
доступен для проектов FreeBSD и Linux. Здесь приведены лишь некоторые источники,
в Internet можно найти множество других.
Особенно полезны книги, в которых есть не только код, но
и подробные комментарии к нему.
Ранее говорилось, что спецификации семейства протоколов
TCP/IP и связанные с ними архитектурные вопросы Internet содержатся в серии
документов, объединенных названием Request for Comments (RFC - Предложения для
обсуждения). На самом деле, RFC, впервые появившиеся в 1969 году, - это не только
спецификации протоколов. Их можно назвать рабочими документами, в которых обсуждаются
разнообразные аспекты компьютерных коммуникаций и сетей. Не все RFC чисто технические,
в них встречаются забавные наблюдения, пародии стихи и просто различные высказывания.
К концу 1999 года было более 2000 при своенных RFC номеров, правда, некоторые
из них так и не были опубликованы.
Хотя не в каждом RFC содержится какой-либо стандарт
Internet, любой стандарт Internet опубликован в виде RFC. Материалам, входящим
в подсерию RFC дается дополнительная метка «STDxxxx». Текущий список стандартов
и тех RFC которые находятся на пути принятия в качестве стандарта, опубликован
в документе STD0001.
Не следует, однако, думать, что RFC, не упомянутые
в документе STD0001 лишены технической ценности. В некоторых описываются идеи
пока еще разрабатываемых протоколов или направления исследовательских работ.
Другие содержат информацию или отчеты о деятельности многочисленных рабочих
групп, созданных по решению IETF (Internet Engineering Task Force - проблемная
группа проектирования Internet).
Получить копии RFC можно разными путями, но самый
простой - зайти на Web-страницу редактора RFC http://www.rfc-editor.org. На
этой странице есть основанное на заполнении форм средство загрузки, значительно
упрощающее поиск. Есть также поиск по ключевым словам, позволяющий найти нужные
RFC, если их номер неизвестен. Там же можно получить документы из подсерий STD,
FYI и ВСР (Best Current Practices - лучшие современные решения).
RFC можно также переписать по FTP с сайта ftp.isi.edu
из каталога in-notes/ и из других FTP-архивов.
Если у вас нет доступа по протоколам HTTP или FTP,
то можно заказать копии RFC по электронной почте. Подробные инструкции о том,
как сделать заказ, а также список FTP-сайтов вы получите, послав электронное
сообщение по адресу rfc-info@isi.edu, включив одну строку:
help: ways_to_get_rfcs
Какой бы способ вы ни выбрали, прежде всего надо
загрузить текущий указатель RFC (файл rfс-index. txt). После публикации ни номер,
ни текст RFC уже не изменяются, так что единственный способ модифицировать RFC
- это выпустить другое RFC, заменяющее предыдущее. Для каждого RFC в указателе
отмечено, есть ли для него заменяющее RFC и если есть, то его номер. Там же
указаны RFC, которые обновляют, но не замещают прежние.
И, наконец, различные компании поставляют RFC на
CD. Так, Walnut Creek CD-ROM (http://www.cdrom.com) и InfoMagic (http://www.infomagic.com)
предлагают компакт-диски, на которых записаны как RFC, так и другие документы,
относящиеся к Internet. Разумеется, перечень RFC на таких дисках быстро становится
неполным, но, поскольку RFC сами по себе не подлежат изменению, диск может устареть
только в том смысле, что не содержит последних RFC.
Одно из самых ценных мест в Internet в плане получения
советов и информации - это конференции Usenet, посвященные сетевому программированию.
Существуют конференции практически по любому аспекту сетевых технологий от прокладки
кабелей (comp.dcom.cabling) до синхронизирующего сетевого протокола NTP (comp.protocols.time.ntp).
Замечательная конференция, относящаяся к протоколам
семейства TCP/IP и программированию с их помощью, - comp.protocols.tcp-ip. Всего
лишь несколько минут, ежедневно потраченных на просмотр сообщений в этой конференции,
даст массу полезной информации, советов и приемов. Обсуждаемые темы варьируются
от подключения к сети машины под управлением Windows до тонких технических вопросов
по протоколам TCP/IP, их реализации и работы.
В самом начале знакомства с конференциями по сетям
вызвать недоумение может даже простое их перечисление (а их не меньше 70). Лучше
всего начать с конференции comp.protocols.tcp-ip и, возможно, одной из конференций
по конкретной операционной системе, например, comp.os.linux.networking или comp.ms -
windows.programmer.tools.winsock. Сообщения в этих конференциях могут содержать
ссылки на другие, более специальные конференции, которые тоже могут быть вам
интересны или полезны.
Один из лучших способов чему-то научиться в сетевых
конференциях - это отвечать на вопросы. Изложив свои знания по конкретному вопросу
в форме, понятной для других, вы сами глубже разберетесь в проблеме. Небольшое
усилие, требуемое для составления ответа из 50-100 слов, окупится многократно.
Отличное введение в систему конференций Usenet
находится на сайте Информационного центра Usenet (http://metalab.unc.edu/usenet-i/).
На этом сайте есть статьи по истории и использованию Usenet, а также краткая
статистика для большинства конференций, в том числе среднее число сообщений
в день, среднее число читателей, адрес модератора (если таковой есть), где хранится
архив (если он ведется) и ссылки на часто задаваемые вопросы (FAQ) для каждой
конференции. На сайте Информационного центра Usenet есть поисковая система,
позволяющая найти конференции, в которых обсуждается интересующая вас тема.
Выше упоминалось, что во многих конференциях ведутся
FAQ, с которыми стоит ознакомиться, прежде чем задавать вопрос. Если задать
вопрос, на который уже есть ответ в FAQ, то, скорее всего, вас к нему и отошлют,
а, может быть, и пожурят за нежелание потрудиться самому.
Следует упомянуть еще о двух ценных ресурсах, связанных
с сетевыми конференциями. Первый - это сайт DejaNews (http://www.deja.com).
Примечание: В мае 1999 сайт Deja News изменил
свое название на Deja.com. Владельцы объясняют это расширением спектра услуг.
В этом разделе говорится только о первоначальных услугах по архивации сообщений
из сетевых конференций и поиску в архивах.
На этом сайте хранятся архивы примерно 45000 дискуссионных
форумов, включая конференции Usenet и собственные конференции Deja Community
Discussions. Владельцы Deja.com утверждают, что примерно две трети всех архивов
составляют сообщения из конференций Usenet. На конец 1999 года в архивах хранились
сообщения, начиная с марта 1995 года.
Поисковая система сайта Power Search позволяет
искать ответ на конкретный вопрос или информацию по некоторой проблеме в отдельной
конференции, в группе или даже во всех конференциях по ключевому слову, теме,
автору или диапазону дат. Второй ценный ресурс - это список ресурсов по TCP/IP
(TCP/IP Resources List) Юри Раца (Uri Raz), который каждые две недели рассылается
в конференцию comp.protocols.tcp-ip и некоторые более специальные. Этот список
- отличная отправная точка для тех, кто ищет конкретную информацию или общий
обзор TCP/IP и соответствующих API.
В списке имеются ссылки на книги по этому вопросу
и другим, касающимся сетей; онлайновые ресурсы (к примеру, страницы IETF и сайты,
где размещаются FAQ); онлайновые книги и журналы, учебники по TCP/IP; источники
информации по протоколу IPv6; домашние страницы многих популярных книг по сетям;
домашние страницы книжных издательств; домашние страницы проекта GNU и открытых
операционных систем; поисковые машины с описанием способов работы с ними и
конференции, посвященные сетям.
Самая последняя редакция списка находится на сайтах:
- http://www.private.org.il/tcpip_rl.html;
- http://www.best.com.il/~mphunter/tcpip_resources.html;
Также информация может быть загружена по FTP с
сайтов:
- ftp://rtfra.mit.edu/pub/usenet-by-group/news.answers/internet/tcp-ip/resource-list;
- ftp://rtfm.mit.edu/pub/usenet-by-hierarchy/comp/protocols/tcp-ip/TCP-IP_Resources_List.
Особую ценность списку ресурсов по TCP/IP придает
тот факт, что автор регулярно обновляет его. Это немаловажно, так как ссылки
в Web имеют тенденцию быстро устаревать.
Заголовочный файл etcp.h
Почти все программы в этой книге начинаются с заголовочного файла etcp. h (листинг
П1.1). Он подключает и другие необходимые файлы, в том числе skel. h (листинг
П2.1), а также определения некоторых констант, типов данных и прото-типов.
Листинг П1.1. Заголовочный файл etcp, h
еtcp.h
1 #ifndef _ETCP_H_
2 #define _ЕТСР_Н_
3 /* Включаем стандартные заголовки. */
4 #include <errno.h>
5 #include <stdlib.h>
6 #include <unistd.h>
7 #include <stdio.h>
8 #include <stdarg.h>
9 #include <string.h>
10 #include <netdb.h>
11 #include <signal.h>
12 #include <fcntl.h>
13 #include <sys/socket.h>
14 #include <sys/wait.h>
15 #include <sys/time.h>
16 #include <sys/resource.h>
17 #include <sys/stat.h>
18 #include <netinet/in.h>
19 #include <arpa/inet.h>
20 #include "skel.h"
21 #define TRUE 1
22 #define FALSE 0
23 #define NLISTEN 5 /* Максимальное число ожидающих соединений. */
24 #define NSMB 5 /* Число буферов в разделяемой памяти. */
25 #tdefine SMBUFSZ256/* Размер буфера в разделяемой памяти. */
26 extern char *program_name; /* Для сообщений об ошибках. */
27 #ifdef _SVR4
28 #define bzero(b,n) memset( ( b ), 0, ( n ) )
29 #endif
30 typedef void ( *tofunc_t ) ( void * ) ;
31 void error( int, int, char*, ... );
32 int readn( SOCKET, char *, size_t );
33 int readvrect SOCKET, char *, size_t ) ;
34 int readcrlf( SOCKET, char *, size_t ) ;
35 int readline( SOCKET, char *, size_t ) ;
36 int tcp_server( char *, char * };
37 int tcp_client ( char *, char * ) ;
38 int udp_server ( char *, char * } ;
39 int udp_client( char *, char *, struct sockaddr_in * );
40 int tselect( int, fd_set *, fd_set *, fd_set *);
41 unsigned int timeout( tofunc_t, void *, int );
42 void untimeout( unsigned int );
43 void init_smb( int ) ;
44 void *smballoc( void ) ;
45 void smbfree( void * ) ;
46 void smbsendf SOCKET, void * );
47 void *smbrecv( SOCKET ) ;
48 void set_address ( char *, char *, struct sockaddr_in *', char *
) ;
49 #endif /* _ETCP_H_ */
Функция daemon
Функция daemon, которая использована в программе
tcpmux, входит в стандартную библиотеку, поставляемую с системой BSD. Для систем
SVR4 приводится версия, текст которой показан в листинге П1.2.
Листинг П1.2. Функция daemon
daemon.с
1 int daemon( int nocd, int noclose )
2 (
3 struct rlimit rlim;
4 pid_t pid;
5 int i;
6 mask( 0 ); /* Очистить маску создания файлов. */
7 /* Получить максимальное число открытых файлов. */
8 if ( getrlimit( RLIMIT_NOFILE, &rlim ) < 0 )
9 error( 1, errno, "getrlimit failed" );
10 /* Стать лидером сессии, потеряв при этом управляющий терминал... */
11 pid = fork();
12 if ( pid < 0 )
13 return -1;
14 if ( pid != 0 )
15 exit( 0 ) ;
16 setsid();
17 /* ... и гарантировать, что больше его не будет. */
18 signal( SIGHUP, SIG_IGN );
19 pid = fork(};
20 if ( pid < 0 )
21 return -1;
22 if ( pid != 0 )
23 exit( 0 );
24 * Сделать текущим корневой каталог, ее ли не требовалось обратное */
25 if ( !nocd )
26 chdir( "/" ) ;
27 /*
28 * Если нас не просили этого не делать, закрыть все файлы.
29 * Затем перенаправить stdin, stdout и stderr
30 * на /dev/null.
31 */
32 if (!noclose }
33 {
34 #if 0 /* Заменить на 1 для закрытия всех файлов. */
35 if ( rlim.rlim_max == RLIM_INFINITY )
3 rlim.rlim_max = 1024;
37 for ( i = 0; i < rlim.rlim_max; i++ )
38 close( i );
39 endif
40 i = open( "/dev/null", 0_RDWR );
41 f ( i < 0 )
42 return -1;
43 up2( i, 0 ) ;
44 up2( i, 1 };
45 up2( i, 2 );
46 f ( i > 2 )
47 close( i ) ;
48 }
49 return 0;
50 }
Функция signal
В этой книге уже упоминалось, что в некоторых версиях
UNIX функция s ignal реализована на основе семантики ненадежных сигналов. В
таком случае для получения семантики надежных сигналов следует использовать
функцию sigaction. Чтобы повысить переносимость, необходимо реализовать signal
с помощью sigaction (листинг П1.3)
Листинг П 1.3. Функция signal
signal. c
/* signal - надежная версия для SVR4 и некоторых других
систем. */
1 typedef void sighndlr_t( int );
2 sighndlr_t *signal( int sig, sighndlr_t *hndlr )
3 {
4 struct sigaction act;
5 struct sigaction xact;
6 act.sa_handler = hndlr;
7 act.sa_flags =0;
8 sigemptyset( &act.sa_mask );
9 if ( sigaction( sig, &act, &xact ) < 0 )
10 return SIG_ERR;
11 return xact.sa_handler;
12 }
Albitz, P. and Liu, С. 1998. DNS and BIND, 3rd Edition. O'Reilly &
Associates, Sebastopol, Calif.
Baker, R, ed. 1995. «Requirements for IP Version 4 Routers», RFC 1812 (June).
Banga, G. and Mogul, J. C. 1998. «Scalable Kernel Performance for Internet
Servers Under Realistic Loads», Proceedings of the 1998 USENIX Annual Technica
Conference, New Orleans, LA.
http://www.cs.rice.edu/~gaurav/my_p.apers/usenix98.ps
Bennett, J. C. R., Partridge, C., and Shectman, N. 1999. «Packet Reordering
Is Not Pathological Network Behavior», IEEE/ACM Transactions on Networking,
vol. 7, no. 6, pp. 789-798 (Dec.).
Braden, R. T. 1985. «Towards a Transport Service for Transaction Processina
Applications», RFC 955 (Sept.).
Braden, R. T. 1992a. «Extending TCP for Transactions-Concepts,» RFC 1379 (Nov.).
Braden, R. T. 1992b. «TIME-WAIT Assassination Hazards in TCP,» RFC 133 (May).
Braden, R. T. 1994. «T/TCP—TCP Extensions for Transactions, Functional Speci-fication»,
RFC 1644 (July).
Braden, R. T, ed. 1989. «Requirements for Internet Hosts—Communicatior Layers»,
RFC 1122 (Oct.).
Brown, C. 1994. UNIX Distributed Programming. Prentice Hall, Englewood
Cliffc
NJ.
Castro, E. 1998. Peri and CGI for the World Wide Web: Visual QuickStart
Guide Peachpit Press, Berkeley, Calif.
Clark, D. D. 1982. «Window and Acknowledgement Strategy in TCP», RFC 813
(July).
Cohen, D. 1981. «On Holy Wars and a Plea for Peace», IEEE Computer Magazine,
vol. 14, pp. 48-54 (Oct.).
Comer, D. E. 1995. Internetworking with TCP/IP Volume I: Principles, Protocols,
апd Architecture, Third Edition. Prentice Hall, Englewood
Cliffs, NJ.
Comer, D. E. and Lin, J. C. 1995. «TCP Buffering and Performance Over an ATM
Network» Journal of Internetworking: Research and Experience, vol. 6,
no. 1, pp. 1-13 (Mar.).
ftp://gwen.cs.purdue.edu/pub/lin/TCP.atm.ps.
Comer, D. E. and Stevens, D. L. 1999. Internetworking with TCP/IP Volume
II: Design, Implementation, and Internals, Third Edition. Prentice Hall,
Englewood Cliffs, NJ.
Fuller, V, Li, T, Yu, J., and Varadhan, K. 1993. «Classless Inter-Domain Routing
(CIDR): An Address Assignment», RFC 1519 (Sept.).
Gallatin, A., Chase, J., and Yocum, K. 1999. «Trapeze/IP: TCP/IP at Near-Gigabit
Speeds», 1999 Usenix Technical Conference (Freenix track), Monterey,
Calif.
http://www.cs.duke.edu/ari/publications/tcpgig.ps
Haverlock, P. 2000. Private communication.
Hinden, R. M. 1993. «Applicability Statement for the Implementation of Classless
Inter-Domain Routing (CIDR)», RFC 1517 (Sept.).
Huitema, C. 1995. Routing in the Internet. Prentice Hall, Englewood
Cliffs, NJ.
International Standards Organization 1984. «OSI—Basic Reference Model», ISO
7498, International Standards Organization, Geneva.
Jacobson, V. 1988. «Congestion Avoidance and Control», Proc. of SIGCOMM
'88 i; vol. 18, no. 4, pp. 314-329 (Aug.).
http://www-nrg.ee.ibl.gov/nrg.html
Jacobson, V. 1999. «Re: Traceroute History: Why UDP?», Message-ID <79m7m4$reh$l
©dog.ee.lbl.gov>, Usenet, comp.protocols.tcp-ip (Feb.).
http://www.kohala.com/start/vanj99Feb08.txt
Jacobson, V., Braden, R. Т., and Borman, D. 1992. «TCP Extensions for High
Performance», RFC 1323 (May).
Jain, B.N. and Agrawala, A. K. 1993. Open Systems Interconnection: Its Architecture
and Protocols, Revised Edition. McGraw-Hill, N.Y.
Kacker, M. 1998. Private communication.
Kacker, M. 1999. Private communication.
Kantor, B. and Lapsley, P. 1986. «Network News Transfer Protocol», RFC 977
(Feb.).
Kernighan, B. W. and Pike, R. 1999. The Practice of Programming. Addison-Wesley,
Reading, Mass.
Kernighan, B. W. and Ritchie, D. M. 1988. The С Programming
Language, Second Edition. Prentice Hall, Englewood Cliffs, NJ.
Knuth, D. E. 1998. The Art of Computer Programming, Volume 2, Seminumerical
Algorithms, Third Edition. Addison-Wesley, Reading, Mass.
Lehey, G. 1996. The Complete FreeBSD. Walnut Creek CDROM, Walnut Creek,
Calif.
Lions, J. 1977. Lions' Commentary on UNIX 6th Edition with Source Code.
Peer-to-Peer Communications, San Jose, Calif.
Lotter, M. K. 1988. «TCP Port Service Multiplexer (TCPMUX)», RFC 1078 (Nov.).
Mahdavi, J. 1997. «Enabling High Performance Data Transfers on Hosts: (Notes
for Users and System Administrators)», Technical Note (Dec.).
http://www.psc.edu/networking/perf_tune.html
Malkin, G. 1993. «Traceroute Using an IP Option», RFC 1393 (Jan.).
McCanne, S. and Jacobson, V. 1993. «The BSD Packet Filter: A New Architecture
for User-Level Packet Capture», Proceedings of the 1993 Winter USENIX Conference,
pp. 259-269, San Diego, Calif.
ftp://ftp.ee.lbl.gov/papers/bpf-usenix93-ps.Z
Miller, B. P., Koski, D., Lee, C. P., Maganty, V, Murthy, R., Natarajan, A,
and Steidi, J. 1995. «Fuzz Revisited: A Re-examination of the Reliability of
UNIX Utilities and Services», CS-TR-95-1268, University of Wisconsin (Apr.).
ftp://grilled.cs.wise.edu/technical_papers/fuzz-revisited.ps.
Minshall, G., Saito, Y., Mogul, J. C., and Verghese, B. 1999. «Application
Performance Pitfalls and TCP's Nagle Algorithm», ACM SIGMETRICS Workshop
on Internet Server Performance, Atlanta, Ga..
http://www.cc.gatech.edu/fac/Ellen.Zegura/wisp99/papers/minshall.ps
Mogul, J. and Postel, J. B. 1985. «Internet Standard Subnetting Procedure»,
RFC 950 (Aug.).
Nagle, J. 1984. «Congestion Control in IP/TCP Internetworks», RFC 896 (Jan.).
Oliver, M. 2000. Private communication. ;
Padlipsky, M. A. 1982. «A Perspective on the ARPANET Reference Model,» RFC
871 (Sept.).
Partridge, C. 1993. «Jacobson on TCP in 30 Instruction», Message-ID I
<1993Sep8.213239.28992 @sics.se>, Usenet, comp.protocols.tcp-ip Newsgroup
(Sept.).http://www-nrg.ee. ibl .gov/nrg-email.html
Partridge, C. and Pink, S. 1993. «A Faster UDP», IEEE/ACM Transactions оп
Networking, vol. 1, no. 4, pp. 427-440 (Aug.).
http://www.ir.bbn.com/~craig/udp.ps
Patchett, C. and Wright, M. 1998. The CGI/PerI Cookbook. John Wiley
& Sons, N.Y.
Paxson, V. 1995. «Re: Traceroute and TTL», Message-ID <48407@dog.ee.lbl.gov>,
Usenet, comp.protocols.tcp-ip (Sept.).
ftp://ftp.ee.Ibl.gov/email/paxson.95sep29.txt
Paxson, V. 1997. «End-to-End Routing Behavior in the Internet», IEEE/ACM
Transactions on Networking, vol. 5, no. 5, pp. 601-615 (Oct.).
ftp://ftp.ee.Ibl.gOv/papers/vp-routing-TON.ps.Z
Plummer, W. W. 1978. «TCP Checksum Function Design», IEN 45 (June)
Reprinted as an appendix to RFC 1071.
Postel, J. B. 1981. «Internet Control Message Protocol», RFC 792 (Sept.).
Postel, J. В., ed. 1981a. «Internet Protocol», RFC 791 (Sept.).
Postel, J. В., ed. 1981b. «Transmission Control Protocol», RFC 793 (Sept.).
Quinn, B. and Shute, D. 1996. Windows Sockets Network Programming. Addison-Wesley,
Reading, Mass.
Rago, S. A. 1993. UNIX System V Network Programming. Addison-Wesley,
Reading, Mass.H
Rago, S. A. 1996. «Re: Sockets vs TLL» Message-ID <50pcds$jl8@prologic.plc.com>,
Usenet, comp.protocols.tcp-ip (Oct.).
Rekhter, Y. and Li, T. 1993. «An Architecture for IP Address Allocation with
CIDR»,
RFC 1518 (Sept.).
Rekhter, Y, Moskowitz, R. G., Karrenberg, D., Groot, G. J. de, and Lear, E.
1996.
«Address Allocation of Private Internets», RFC 1918 (Feb.).
Reynolds, J. K. and Postel, J. B. 1985. «File Transfer Protocol (FTP)», RFC
959 ,
(Oct.).
Richter, J. 1997. Advanced Windows, Third Edition. Microsoft Press,
Redmond, Wash.
Ritchie, D. M. 1984. «A Stream Input-Output System», AT&T Bell Laboratories
Technicaljoumal, vol. 63, no. No. 8 Part 2, pp. 1897-1910 (Oct.).
http://cm.bell-labs.com/cm/cs/who/dmr/st.ps
Romkey, J. L. 1988. «A Nonstandard for Transmission of IP Datagrams Over Seria
Lines: SLIP», RFC 1055 Qune).
Saltzer, J. H., Reed, D. P., and Clark, D. D. 1984. «End-to-End Arguments ir
System Design», ACM Transactions in Computer Science, vol. 2, no. 4,
pp. 277-288 (Nov.)
http://web.mit.edu/Saltzer/www/publications
Sedgewick, R. 1998. Algorithms in C, Third Edition, Parts 1-4. Addison-Wesley
Reading, Mass.
Semke, J., Mahdavi, J., and Mathis, M. 1998. «Automatic TCP Buffer Tuning»
Computer Communications Review, vol. 28, no. 4, pp. 315-323 (Oct.).
http://www.psc.edu/networking
/ftp/papers/autotune-sigcomm98.ps
Srinivasan, R. 1995. «XDR: External Data Representation Standard», RFC 1832
(Aug.)
Stevens.W. R. 1990. UNIX Network Programming. Prentice Hall, Englewood
Cliffs
Stevens, W. R. 1994. TCP/IP Illustrated, Volume 1: The Protocols. Addison-Wesley
Reading, Mass.
Stevens, W. R. 1996. TCP/IP Illustrated, Volume 3: TCP for Transactions,
HTTP NNTP, and the UNIX Domain Protocols. Addison-Wesley, Reading, Mass.
Stevens, W. R. 1998. UNIX Network Programming, Volume 1, Second Edition,
Networking APIs: Sockets and XTI. Prentice Hall, Upper Saddle River, NJ.
Stevens, W. R. 1999. UNIX Network Programming, Volume 2, Second Edition,
Interprocess Communications. Prentice Hall, Upper Saddle River, NJ.
Stone, J., Greenwald, M., Partridge, C., and Hughes, J. 1998. «Performance
oi Checksums and CRC's Over Real Data», IEEE/ACM Transactions on Networking,
vol. 6 no. 5, pp. 529-543 (Oct.).
Tanenbaum, A. S. 1996. Computer Networks, Third Edition. Prentice Hall
Englewood Cliffs, NJ.
Tanenbaum, A. S. and Woodhull, A. S. 1997. Operating Systems: Design ana
Implementation, Second Edition. Prentice Hall, Upper Saddle River, NJ.
Torek, C. 1994. «Re: Delay in Re-Using TCP/IP Port», Message-ID <199501010028.QAA16863
©elf.bsdi.com>, Usenet, comp.unix.wizards (Dec.).
http://www.kohala.corn/start/torek.94dec31
.txt
Unix International 1991. «Data Link Provider Interface Specification,» Revision
2.0.0, Unix International, Parsippany, NJ. (Aug.).
http://www.whitefang.com/rin/docs/dlpi-ps
http://www.opengroup.org/publications/catalog/c
81 l.htm
Varghese, G. and Lauck, A. 1997. «Hashed and Hierarchical Timing Wheels: Efficient
Data Structures for Implementing a Timer Facility», IEEE/ACM Transactions
on Networking, vol.5, no. 6, pp. 824-834 (Dec.).
http://www.cere-wusti.edu/-varghese/PAPERS/twheel.ps.Z
Wall, L., Christiansen, T, and Schwartz, R. L. 1996. Programming Peri, Secona
Edition. O'Reilly & Associates, Sebastopol, Calif.
WinSock Group 1997. «Windows Sockets 2 Application Programming Interface»,
Revision 2.2.1, The Winsock Group (May).
http://www.stardust.com/wsresource/winsock2/ws2docs.html
Wright, G. R. and Stevens, W. R. 1995. TCP/IP Illustrated, Volume 2: The
Implementation. Addison-Wesley, Reading, Mass.
| 
 LINUX
LINUX