Глава 3. Драйверы символьных устройств
About: "По мотивам перевода" Linux Device Driver 2-nd edition.
Перевод: Князев Алексей knzsoft@mail.ru
Дата последнего изменения: 03.08.2004
Авторскую страницу А.Князева можно найти тут :
http://lug.kmv.ru/wiki/index.php?page=knz_ldd2
Архивы в переводе А.Князева лежат тут:
http://lug.kmv.ru/wiki/files/ldd2_ch1.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch2.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch3tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch4.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch5.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch6.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch7.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch8.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch13.tar.bz2
Целью этой главы является написание полноценного драйвера символьного
устройства. Мы начнем с разработки символьного драйвера, потому что
этот класс драйверов подходит для большинства простых аппаратных
устройств. Кроме того, драйверы символьных устройств более просты для
начального понимания, чем, например, классы блочных или сетевых
драйверов устройств. Итак, наша текущая цель – написание модульного
символьного драйвера, но в этой главе, мы не будем говорить о
концепциях построения модулей как таковых.
В этой главе мы покажем фрагменты кода из реального драйвера устройства: scull, сокращение от Simple Character Utility for Loading Localities. scull
это символьный драйвер, который в качестве целевого устройства, на
которое направлено его действие, использует обычную оперативную память
компьютера. Такой необычный выбор устройства приводит к тому, что слово
устройство, в контексте scull, равнозначно выражению "память,
используемая scull".
Основное преимущество драйвера scull заключается в его аппаратной
независимости, т.к. каждый компьютер имеет память. Драйвер scull только
выполняет определенные действия над некоторой частью этой памяти,
распределенной с помощью функции kmalloc(). Каждый из читателей этой
книги может откомпилировать и запустить scull, независимо от того,
какую версию Linux, и какую аппаратную архитектуру компьютера он
использует. С другой стороны, драйвер не делает ничего полезного, кроме
демонстрации интерфейса взаимодействия между ядром и драйвером
символьного устройства.
Архитектура драйвера scull
Первым шагом в написании драйвера является определение его
функциональности (механизма), которая будет предоставлена
пользовательским программам. Определим перечень возможных операций
исходя из того, что нашим “устройством” является часть компьютерной
памяти. Мы можем организовать случайный или последовательный доступ к
устройству, определить множество устройств и т.д.
Для извлечения большей пользы из этого примера, мы попробуем
реализовать scull как шаблон для написания реальных драйверов. Для
этого, мы покажем реализацию нескольких абстрактных драйверов
управления памятью, каждый из которых будет иметь свои особенности.
Исходный код scull реализовывает в виде модулей драйвера следующих устройств:
- scull0..scull3
-
Четыре устройства управления памятью, каждое из которых глобально разделяет и сохраняет память. Под глобальностью разделения
понимается возможность многократного открытия устройства с разделением всех хранящихся в нем данных между всеми файловыми
дескрипторами, открытыми для доступа к устройству. Сохранение памяти устройства понимается дословно – вы можете закрыть и
снова открыть доступ к устройству – данные будут сохранены. Это устройство интересно тем, что мы можем протестировать его
используя перенаправление ввода/вывода и общеизвестные команды, такие как cp, cat. Мы протестируем работу этого
устройства в этой главе.
- scullpipe0..scullpipe3
-
Четыре FIFO (first-in-first-out – первый пришел, первый ушел – очередь)
устройства, которые действуют как общеизвестный системный канал
(pipes). Один процесс считывает данные из канала, в то время как другой
процесс – записывает их. Возможна ситуация соперничества за данные,
когда несколько процессов считывают одно и тоже устройство. В коде
scullpipe будет показано, как можно реализовать блочные и не блочные
операции чтения/записи без использования прерываний. Обычно, реальные
драйвера синхронизируют операции чтения/записи по прерываниям от
устройства, но сами по себе блочные и не блочные операции могут быть
отделены от управления прерываниями и, соответственно, могут быть
изучены отдельно. Вообще, управление прерываниями подробно рассмотрено
в главе 9 - “Управление прерываниями”.
-
scullsingle
scullpriv
sculluid
scullwuid
-
Эти устройства похожи на scull0, но с ограничениями при разрешенной операции open(). Драйвер scullsingle
позволяет только одно открытие доступа к драйверу и только одним из
пользовательских процессов. Драйвер scullpriv позволяет по одному
доступу на каждую виртуальную консоль (или сессию X терминала).
Процессы запущенные на разных консолях/терминалах могут быть различимы
по областям получаемой памяти. Драйвера sculluid и scullwuid
могут быть открыты многократно, но только одним пользователем
одновременно. При этом, если с устройством работает другой
пользователь, sculluid возвращает ошибку “Device Busy” (устройство
занято), в то время как scullwuid просто блокирует вызов open(). Такие варианты реализации драйвера
скорее демонстрируют “политику управления” чем функциональность (см. главу 1), и полезны для рассмотрения именно в
этом ключе.
Каждое из scull устройств демонстрирует различные характеристики
драйвера и имеет свои сложности в реализации. В этой главе охвачена
реализация устройств scull0 – scull3. Реализация более сложных
scull-драйверов представлена в главе 5 “Enhanced Char Driver
Operations”. Так, драйвер scullpipe описан в разделе “A Sample
Implementation: scullpipe”, а другие – в главе “Access Control on
Device File”.
Старший и младший номера устройств
Символьные устройства доступны через специальные символьные файлы
устройств файловой системы Unix. Такие файлы часто называются
интерфейсами символьных устройств. Обычно, они располагаются в каталоге
/dev. Если вы выведете список файлов этого каталога с помощью команды ls -l,
то интерфейсы символьных устройств будут помечены символом “c” в первой
позиции области атрибутов файла, в то время как интерфейсы блочных
устройств имеют символ “b” в этой позиции атрибутов. Эта глава
посвящена символьным устройствам, но информация содержащаяся в данном
разделе применима и к блочным устройствам.
В строках вывода команды ls -l вы увидите два номера
разделенные запятыми перед датой последнего изменения файла, на месте
где обычно располагается размер файла. Эти номера представляют собой
старший и младший номер каждого из устройств. Ниже приведен типичный
пример вывода команды ls -l. В этом списке, старшие номера
устройств представлены числами 1, 4, 7, и 10, тогда как младшие –
числами 1, 3, 5, 64, 65, и 129.
crw-rw-rw- 1 root root 1, 3 Feb 23 1999 null
crw------- 1 root root 10, 1 Feb 23 1999 psaux
crw------- 1 rubini tty 4, 1 Aug 16 22:22 tty1
crw-rw-rw- 1 root dialout 4, 64 Jun 30 11:19 ttyS0
crw-rw-rw- 1 root dialout 4, 65 Aug 16 00:00 ttyS1
crw------- 1 root sys 7, 1 Feb 23 1999 vcs1
crw------- 1 root sys 7, 129 Feb 23 1999 vcsa1
crw-rw-rw- 1 root root 1, 5 Feb 23 1999 zero
Старший номер устройства определяет драйвер связанный с устройством,
т.е. это номер драйвера. Например, устройства /dev/null и /dev/zero
используют драйвер с номером 1, а виртуальные консоли и терминалы –
драйвер номер 4. Также, и vcs1, и vcsa1 управляются драйвером номер 7.
Ядро использует старший номер устройства для диспетчеризации запроса на
требуемый драйвер.
Младший номер устройства используется драйвером, определенном по
старшему номеру. Никакие другие части ядра не используют младший номер
устройства. Наиболее часто, один драйвер управляет разными устройствами
различаемыми кодом драйвера по младшему номеру.
В версии ядра 2.4 предлагается (по желанию) такая новая
характеристика как файловая система устройств или devfs. При ее
использовании, управление и различение устройства упрощается. Но, с
другой стороны, новая файловая система несет с собой некоторые, видимые
пользователю, несовместимости, и пока не принята стандартом de-facto в
linux-дистрибутивах. Все, что говорилось выше не применимо к файловой
системе devfs. Подробнее о файловой системе устройств мы поговорим в
разделе “Файловая система устройств”.
Если мы не используем devfs, то добавление нового драйвера в систему
означает назначение ему старшего номера. Назначение номера драйверу
(модулю) должно производиться при его инициализации вызовом следующей
функции, определенной в <linux/fs.h>
int register_chrdev(unsigned int major, const char *name,
struct file_operations *fops);
По возвращаемому значению можно судить об успехе или неудаче
операции. Отрицательный код сигнализирует об ошибке. 0 или
положительное значение возвращаемого кода говорит об успешном
завершении функции. Параметр major есть запрашиваемый старший номер
устройства. Параметр name – символьное имя вашего устройства, которое
будет отображено в файле /proc/devices. Параметр fops – это указатель
на структуру указателей на функции, обрабатываемые различные,
стандартные запросы к вашему драйверу. Данная структура подробно
объясняется в этой главе позднее, в разделе “Файловые
операции”.
Старший номер устройства представляет собой небольшое целое число,
являющееся индексом в массиве драйверов символьных устройств. Позднее в
этой главе, в разделе “Динамическое распределение старших номеров” мы
объясним, как выбирается старший номер устройства. Ядро версии 2.0
поддерживало 128 устройств, ядра версий 2.2 и 2.4 увеличили их число до
256 (резервируя номера 0 и 255 для особого использования в будущем).
Младшие номера, также, представляют собой восьмибитовую величину. Эти
номера не передаются в функцию register_chardev(), потому что они
используются только для
диспетчеризации устройств в коде драйвера, и системе безынтересны.
Существует серьезное давление от сообщества разработчиков по увеличению
количества возможных устройств, поддерживаемых ядром. Поэтому,
стартовой целью ядра 2.5 являлось увеличение номеров устройств, по
меньшей мере, до 16 бит.
После регистрации драйвера в таблице ядра, все зарегистрированные
драйвером операции связаны со старшим номером, назначенным драйверу.
Какая бы операция не выполнялась над интерфейсным файлом символьного
устройства, связанного со старшим номером драйвера, ядро находит и
вызывает соответствующую функцию драйвера из структуры file_operations.
По этой причине, указатель переданный в функцию register_chrdev()
должен быть глобальным, а не локальным по отношению к функции
инициализации модуля.
Следующим вопросом является имя, по которому программы могут
запрашивать операции с драйвером. Это имя должно принадлежать файлу,
например из каталога /dev, и быть связано со старшими и младшими
номерами.
Командой, создающей файловые интерфейсы устройств, является команда
mknod. Для использования этой команды вы должны обладать привилегиями
суперпользователя. Команде передается три аргумента, в добавлении к
имени создаваемого файла. Например, команда
mknod /dev/scull0 c 254 0
создает символьное устройство (c) со старшим номером 254 и младшим
номером 0. Младшие номера должны быть в диапазоне от 0 до 255 по
историческим причинам (см. выше).
Обратите внимание, что файлы интерфейсов устройств, создаваемые командой mknod,
остаются на диске до их явного удаления, как и любая другая информация
сохраненная на диске. Поэтому, если вы хотите удалить файл устройства,
созданного в предыдущем примере, то можно выполнить rm /dev/scull0.
Динамическое распределение старших номеров устройств
Некоторые старшие номера статически назначаются наиболее общим
устройствам. Список таких устройств может быть найден в файле
Documentation/devices.txt, расположенном в дереве каталогов источников
ядра. По причине того, что многие номера уже назначены, выбор
уникального номера для вашего драйвера может оказаться весьма непростой
задачей. Учитывать следует и то, что в системе могут работать
пользовательские драйверы с назначенными старшими номерами. Вы можете
выбрать старший номер устройства из зарезервированных для
экспериментов, но опять же могут возникнуть проблемы с другими
пользовательскими драйверами. Результаты особенно непредсказуемы после
передачи вашего драйвера в пользование другим людям.
Старшие номера устройств в диапазонах от 60 до 63, от 120 до 127, от
240 до 254 зарезервированы для местного и экспериментального
использования. Эти номера не должны быть назначены реальным
устройствам.
К счастью, вы можете запросить динамическое назначение для старших
номеров устройств. Если параметр major установлен в 0, при вызове
register_chrdev(), то функция регистрации сама выбирает свободный номер
и возвращает его. Возвращенный, в этом случае номер, всегда
положителен. Отрицательное значение всегда говорит об ошибке исполнения
функции. Заметьте, что интерпретация возвращаемого значения функции
register_chardev() несколько отличается при статическом и динамическом
назначении номеров. При статическом назначении функция возвращает ноль
в случае успеха, в то время, как при динамическом назначении, функция
возвращает назначенный номер устройства, или отрицательный номер
ошибки.
При личном использовании драйвера, мы крайне рекомендуем
использовать динамическое назначение старшего номера устройства. С
другой стороны, ваш драйвер станет гораздо более удобным в
использовании сторонними пользователями, если он будет включен в
официальное дерево драйверов, и ему будет назначен уникальный
статический номер.
Неудобство динамического назначения заключается в том, что вы не
можете использовать постоянный файл интерфейса устройства, потому что
нет никакой гарантии, что при следующей регистрации, ваш модуль получит
тот же самый старший номер устройства. Таким образом, вы не сможете
обеспечить загрузку драйвера по требованию, как это описано в главе 11
“kmod and Advanced Modularization”. Это представляет проблему для
нормального использования драйвера – вам придется определять
назначенный номер устройства по содержимому файла /proc/devices.
Для загрузки драйвера, использующего динамическое выделение старшего
номера, можно использовать простой скрипт, в котором, после вызова
команды insmod выполняется чтение, назначенного драйверу, старшего
номера из файла /proc/devices.
Приведем типичный пример файла /proc/devices:
Character devices:
1 mem
2 pty
3 ttyp
4 ttyS
6 lp
7 vcs
10 misc
13 input
14 sound
21 sg
180 usb
Block devices:
2 fd
8 sd
11 sr
65 sd
66 sd
Скрипт для загрузки модуля, которому назначен динамический старший
номер, может быть написан с использованием такого инструмента как awk, который получает информацию из /proc/devices для создания файлов интерфейсов устройств в /dev.
Срипт scull_load, приведенный ниже, представляет собой часть проекта
scull. Пользователь нашего драйвера, распространяемого в виде модуля,
может вызвать такой скрипт вручную или прописать его в системный скрипт
начальной загрузки, такого как rc.local.
#!/bin/sh
module="scull"
device="scull"
mode="664"
# invoke insmod with all arguments we were passed
# and use a pathname, as newer modutils don't look in . by default
/sbin/insmod -f ./$module.o $* || exit 1
# remove stale nodes
rm -f /dev/${device}[0-3]
major=`awk "\\$2==\"$module\" {print \\$1}" /proc/devices`
mknod /dev/${device}0 c $major 0
mknod /dev/${device}1 c $major 1
mknod /dev/${device}2 c $major 2
mknod /dev/${device}3 c $major 3
# give appropriate group/permissions, and change the group.
# Not all distributions have staff; some have "wheel" instead.
group="staff"
grep '^staff:' /etc/group > /dev/null || group="wheel"
chgrp $group /dev/${device}[0-3]
chmod $mode /dev/${device}[0-3]
Данный скрипт может быть адаптирован для загрузки другого
аналогичного драйвера переопределением переменных и редактированием
строк с вызовом команды mknod. В вышеприведенном скрипте создается
четыре интерфейса устройства для драйвера scull.
Последние четыре строки скрипта могут показаться странными: зачем
изменять группу и права доступа на файл интерфейса устройства? Причина
заключается в том, что скрипт может быть запущен только
суперпользователем, поэтому, вновь созданные файлы интерфейса
принадлежат суперпользователю. По умолчанию, принятому в операционной
системе при таком создании файла устройства, права доступа позволяют
запись в устройство только суперпользователю. Все остальные имеют права
только на чтение. Разные устройства требуют разной политики доступа. С
помощью данного скрипта вы можете легко управлять назначением прав на
устройства. По умолчанию, скрипт расширяет права записи на группу – код
доступа “664”. Позднее в разделе “Права доступа на файл устройства”
главы 5 “Enhanced Char Driver Operations”, в коде драйвера sculluid мы
покажем как драйвер может проводить собственную авторизацию для доступа
к устройству. Там же будет приведен скрипт scull_unload, с помощью
которого вы сможете очистить каталог /dev и удалить модуль.
В качестве альтернативы использованию пары скриптов для загрузки и
выгрузки драйвера, вы можете написать инициализационный скрипт,
предназначенный для размещения в специальном каталоге, где лежат
подобные скрипты в вашем дистрибутиве. Как правило, это каталоги
/etc/init.d, /etc/rc.d/init.d или /sbin/init.d. В добавлении к этому,
вам необходимо разместить ссылку на этот скрипт в соответствующих
каталогах инициализации необходимых уровней запуска (см. man chkconfig).
Для полноты источников нашего драйвера мы предлагаем пример такого
инициализационного скрипта, называемого scull.init, который принимает
один из следующих аргументов - “start”, “stop” или “restart” и
одновременно выполняет роль скриптов scull_load и scull_unload.
При условии, что вы работаете с загрузкой и выгрузкой одного
драйвера, вы можете, на этапе разработки, использовать простые скрипты,
построенные с учетом того факта, что алгоритм динамического выбора
старших номеров для драйвера детерминированный (не случаен). Поэтому,
при условии, что вы не работаете одновременно с несколькими такими
драйверами, вы можете запомнить номер, выделяемый вашему драйверу. Еще
раз обратите внимание, что такой трюк не пройдет при одновременном
использовании нескольких драйверов с динамическим выделением для них
старшего номера.
Лучший способ назначения старшего номера устройства, по нашему
мнению, заключается в использовании одновременно динамического и явного
назначения. В качестве умолчания можно использовать динамическое
выделение старшего номера устройства, а опционально, использовать явное
назначение номера, либо во время загрузки модуля, либо, даже, во время
его компиляции. Код который мы предлагаем похож на код, выполняющий
автоопределение адресного диапазона портов. В реализации драйвера scull
используется глобальная переменная scull_major, для сохранения старшего
номера. Переменная инициализируется по значению макроопределения
SCULL_MAJOR, определенному в заголовочном файле scull.h. По умолчанию,
значение SCULL_MAJOR установлено в 0, что означает использование
динамического назначения старшего номера. Пользователь может принять
значение по умолчанию, или явно выбрать определеный номер, либо
редактируя макроопределение SCULL_MAJOR перед компиляцией, либо
передавая значение scull_major параметром через командную строку при
вызове insmod. Последнее можно выполнить и с помощью передачи параметра
в скрипт scull_load.
Что касается инициализационного скрипта scull.init, то по причине
его назначения в автоматическом использовании при загрузке и завершении
соответствующих уровней запуска, он не поддерживает передачи
специальных параметров через командную строку, но поддерживает
конфигурационный файл.
Приведем код, который мы использовали в источнике драйвера scull для получения старшего номера устройства:
result = register_chrdev(scull_major, "scull", &scull_fops);
if (result < 0) {
printk(KERN_WARNING "scull: can't get major %d\n",scull_major);
return result;
}
if (scull_major == 0) scull_major = result; /* dynamic */
Выгрузка драйвера из системы
Когда модуль выгружается из системы, старший номер устройства должен
быть освобожден. Для этого, в теле функции завершения модуля
(cleanup_module()) вызывают следующую функцию:
int unregister_chrdev(unsigned int major, const char *name);
Аргументами, передаваемыми в функцию, являются значение
освобождаемого старшего номера и строка с именем связанного с ним
устройства. Ядро сравнивает переданное в функцию имя с
зарегистрированным для данного номера. Если значения имени не
совпадают, то функция возвращает значение -EINVAL. Ядро, также
возвращает -EINVAL, если значение старшего номера устройства выходит за
допустимый диапазон.
Ошибка освобождения старшего номера в функции завершения модуля
имеет неприятное последействие. При запросе чтения файла /proc/devices
возникнет системная ошибка, при его генерации, потому что указатель
строки с именем устройства указывает на память модуля, которая уже
освобождена. Данная ошибка называется в Linux сообществе “oops”, потому что она возникает при попытке доступа к запрещенному адресному пространству.
Восстановление системы при выгрузке драйвера без освобождения старшего
номера достаточно проблематично, потому что функция strcmp(),
вызываемая в unregister_chrdev() должна разыменовать указатель имени
модуля в памяти, выделенной оригинальному (первичному) модулю. Поэтому,
в случае ошибки освобождения старшего номера необходимо загрузить в
систему сразу два модуля – оригинальный модуль содержащий ошибку и
модуль специально написанный для корректного освобождения номера. Если
вы не изменили код оригинального модуля, то он загрузится в туже самую
область памяти и строка с именем будет расположена в том же самом
месте. Другой безопасной альтернативой написанию специального модуля
исправляющего ошибку является, конечно же, перезагрузка системы.
Возможно, после выгрузки модуля понадобится удаление файлов
интерфейсов выгруженного драйвера. Это может предотвратить возможные
проблемы при обращении к несуществующим драйверам. Данная задача может
быть упрощена использованием скриптов. Для нашего модуля эту работу
может выполнить скрипт scull_unload. В качестве альтернативы можно
вызвать scull.init stop.
dev_t и kdev_t
Итак, мы обговорили смысл и способы назначения старших номеров
устройств. Настало время обсудить младшие номера и их использование
драйвером для дифференциации устройств. Как уже говорилось, один
драйвер может управлять множеством устройств различимых младшими
номерами в файлах интерфейса драйвера.
Каждый раз, когда ядро обращается к драйверу устройства, оно
передает ему информацию о том, над каким именно устройством необходимо
выполнить указанное действие. Старший и младший номера устройства
объединены в простой скалярный тип данных, который используется
драйвером для идентификации конкретного устройства. Объединенные
значения старшего и младшего номеров устройства размещены в поле i_rdev
структуры inode, с которой мы познакомимся позже. Некоторые функции
драйвера получают в качестве первого аргумента указатель на структуру
struct inode. Если вы разыменуете этот указатель, то вы сможете
получить номер устройства в значении поля inode->i_rdev.
Исторически, в системе Unix определен тип dev_t (device type) для
хранения номеров устройства. Определение этого типа размещено в
<sys/types.h>, и, обычно, представляет собой целое число емкостью
16-бит, в которое упаковываются старший и младший номера устройства. На
сегодняшний день потребность в младших номерах устройств превышает
значение в 256, но изменение емкости dev_t вызывает затруднения, потому
что существуют приложения, которые “осведомлены” об исторически
сложившемся размере этого типа и будут работать неправильно при его
изменении.
В Linux ядре используется другой тип – структура kdev_t. Этот тип
данных представляет собой “черный ящик” для функций ядра.
Пользовательские программы не знают о kdev_t вообще, а функции ядра не
должны использовать элементы структуры kdev_t напрямую. Вместо этого,
для работы с этой структурой используется набор макроопределений и
функций ядра. Если размещение данных в kdev_t остается скрытым, то оно
может при необходимости изменяться от версии к версии не требуя
изменений в используемых его драйверах.
Описание kdev_t заключено в заголовочном файле
<linux/kdev_t.h> и хорошо прокомментировано. Если вы
интересуетесь аргументацией этого описания, то чтение комментариев из
этого файла окажется весьма познавательным. Обычно, не возникает
необходимости явного включения этого заголовочного файла в код
источника драйвера, т.к. он включен в заголовочный файл
<linux/fs.h>.
Следующий набор макроопределений и функций предлагается для выполнения операций над kdev_t:
- MAJOR(kdev_t dev);
-
Извлечение старшего номера устройства из структуры kdev_t.
-
- MINOR(kdev_t dev);
-
Извлечение младшего номера устройства из структуры kdev_t.
- MKDEV(int ma, int mi);
-
Создание структуры kdev_t из старшего и младшего номеров устройства.
- kdev_t_to_nr(kdev_t dev);
-
Конвертирует структуру kdev_t в число (dev_t).
- to_kdev_t(int dev);
-
Конвертируем число в структуру kdev_t. Обратите внимание, что тип dev_t не
определен в пространстве ядра, поэтому используется тип int.
Поскольку ваш код должен использовать вышеприведенные макросы и
функции для управления номерами устройства, он (код) останется
работоспособным при изменении внутренней структуры данных.
Файловые операции – обращения к драйверу через файловый интерфейс
В следующих нескольких разделах мы рассмотрим различные операции,
которые драйвер может выполнять по управлению устройствами. Открытое
устройство характеризуется структурой file, а ядро использует структуру
file_operations для доступа к функциям драйвера. Структура,
определенная в заголовочном файле <linux/fs.h> представляет собой
массив указателей на функции драйвера, обрабатывающие стандартные
запросы. Каждый файл интерфейса связан с собственным набором функций,
т.к. для каждого из них определено поле f_op указывающее на структуру
file_operations. Эти механизмы поддерживаются системными вызовами
open(), read() и пр. Если использовать терминологию
объектно-ориентированного программирования, мы можем рассматривать файл
как “объект”, а его функции - “методы”. В следующих главах мы
рассмотрим другие аналогии с объектно-ориентированным программированием
просматриваемые в Linux ядре.
Обычно, указатель на структуру file_operations называется fops. В
аргументах вызова register_chrdev() мы уже видели использование этого
указателя. Каждое поле этой структуры должно быть указателем на функцию
драйвера, выполняющую определенную операцию по обработке одного из
стандартных запросов к драйверу, или иметь значение NULL если такой
запрос не поддерживается драйвером. Поведение ядра при наличии NULL
указателя различно для каждого из запросов и будет уточнено чуть позже.
Именно через структуру file_operations добавляется новая
функциональность в ядро. Добавление разработчиками ядра новых типов
запросов в структуру может, конечно, создать проблемы совместимости для
драйверов устройств. Экземпляр этой структуры для каждого драйвера
обычно описывается с использованием стандартного синтаксиса языка Си.
При добавлении разработчиками ядра новых типов запросов в структуру,
обычно придерживаются правила – добавление новых элементов должно
производится в конец структуры. Тогда, простая перекомпиляция “старого”
драйвера определит значение NULL для новых элементов структуры,
определив для них действия ядра по умолчанию.
Часто, разработчики ядра используют “таговый” формат инициализации
структуры, который позволяет инициализировать поля структуры по имени.
Это снимает большинство проблем связанных с изменением структуры.
Однако, таговая инициализация не является стандартом для языка Си, и
является эксклюзивной особенностью компилятора GNU. Мы вкратце
рассмотрим пример таговой инициализации структуры.
В нижеследующем списке представлены все операции, которые приложение
может производить над устройством. В списке представлено только краткое
описание операции и действие ядра по умолчанию, при нулевом значении
указателя на функцию обработчик. При первом чтении, вы можете
пропустить этот список и вернуться к нему позднее.
В оставшейся части этой главы, после ознакомления с другой важной
структурой данных (такой как структура file, которая включает в себя
указатель на экземпляр file_operations), мы объясним роль наиболее
важных операций и предложим советы, предостережения и реальные примеры
кода. Мы отложим обсуждение других важных операций до последующих глав,
потому, что мы еще не готовы углубиться в такие
темы как управление памятью, блочные операции и асинхронное управление.
В списке представлены операции объявленные в структуре
file_operations для ядра 2.4. Отличия между 2.4 и более ранними
версиями ядра мы рассмотрим в этой главе позднее. Большинство из
представленных операций возвращает 0 в случае успеха, и отрицательное
значение в случае ошибки.
- loff_t (*llseek) (struct file *, loff_t, int);
-
Метод llseek используется для изменения текущего положения позиции
чтения/записи в файле. В случае успешного выполнения функция
возвращает положительное значение новой позиции. Тип loff_t
образован от сочетания “long_offset” (длинное смещение)
имеет не меньше 64 бит емкости даже на 32-битовых платформах. В
случае ошибки возвращается отрицательный код ошибки. Функция должна
изменять положение счетчика в структуре file, которая описывается в
этой главе позднее. Если функция не определена, ядро возвращает
ошибку end-of-file (конец файла).
- ssize_t (*read) (struct file *, char *, size_t, loff_t *);
-
Используется для получения данных из устройства. Если функция не
определена, то системный вызов read() возвращает ошибку -EINVAL
(“Invalid argument”). Неотрицательное значение кода
возврата функции означает количество реально считанных байт. Тип
ssize_t образовано от сочетания “signed size”.
- ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
-
Пишет данные в устройство. Если функция не определена, то системный
вызов write() возвращает ошибку -EINVAL. Неотрицательное значение
кода возврата представляет собой количество реально записанных
байт.
- int (*readdir) (struct file *, void *, filldir_t);
-
Это функция не должна быть определена для устройств. Ее определение
имеет смысл только для драйверов файловых систем.
- unsigned int (*poll) (struct file *, struct poll_table_struct *);
-
Метод poll обеспечивает работу двух системных вызовов poll() и
select(). Оба вызова используются для определения состояния
устройства – доступно ли устройство на чтение или запись, или
оно находится в неком особом состоянии. Любой из этих системных
вызовов может блокироваться до тех пор, пока устройство не станет
доступным на чтение или запись. Если в драйвере не определен метод
poll, то предполагается, что устройство доступно как на чтение, так
и на запись, и не может находиться в каких-то особых состояниях.
Возвращаемое значение представляет собой битовую маску, описывающую
статус устройства.
- int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
-
Системный вызов ioctl() позволяет расширять интерфейс драйвера до
специфических команд, применяемых к устройству. Это может быть,
например, форматирование дорожки гибкого диска, т.к. данная
операция не является ни операцией чтения, ни операцией записи
данных. Операции, добавленные через системный вызов ioctl() не
отражаются в экземпляре структуры fops драйвера. Если данная
операция не определена в драйвере, то системный вызов ioctl()
приведет к ошибке -ENOTTY “No such ioctl for device”.
Неотрицательное значение возвращаемое функцией должно
восприниматься как результат успешной операции.
- int (*mmap) (struct file *, struct vm_area_struct *);
-
Используется для отображения памяти устройства в память пользовательского процесса. Если функция
не определена, то системный вызов mmap() возвращает ошибку -ENODEV.
- int (*open) (struct inode *, struct file *);
-
Данная операция всегда является первой операцией, выполняемой над
файлом устройства. Вам не требуется явно описывать данную функцию.
Если она не определена, то операция открытия файла устройства все
равно пройдет успешно. Просто ваш драйвер не будет об этом
уведомлен.
- int (*flush) (struct file *);
-
Эта операция вызывается когда процесс закрывает свой файловый
дескриптор устройства. Т.е. код данной функции должен завершать все
незавершенные операции над устройством. Не путайте эту операцию с
операцией fsync(), запрашиваемой пользователем. Известно, что на
данный момент эта операция реализована только в коде для сетевой
файловой системы NFS. Если данная операция не определена, то она
просто не вызывается.
- int (*release) (struct inode *, struct file *);
-
Данная операция вызывается при освобождении структуры file. Также
как и операция open(), операция release() может быть не определена
явно. Обратите внимание, что операция release() не вызывается
каждый раз при вызове close(), т.к. структура file может быть
разделена между разными процессами (например, в результате вызова
fork() или dup()). В отличии от функции flash(), функция release()
не вызывается до тех пор, пока не освободится последняя копия
структуры file.
- int (*fsync) (struct inode *, struct dentry *, int);
-
Данный метод драйвера обеспечивает системный вызов fsync(), который
пользователь вызывает для завершения обработки еще необработанных
данных (flush any pending data). Если данный метод не реализован в
драйвере, системный вызов вернет -EINVAL.
- int (*fasync) (int, struct file *, int);
-
Эта операция используется для уведомления устройства об изменении
флага FASYNC. Асинхронные уведомления представляют собой достаточно
сложный материал и описываются в главе 5 “Enhanced Char
Driver Operations”. Данная функция не реализуется для
драйверов не поддерживающих асинхронные уведомления.
- int (*lock) (struct file *, int, struct file_lock *);
-
Метод lock() используется для реализации файловой блокировки.
Блокировка – это обязательная характеристика обычных файлов,
и для большинства драйверов устройств не реализуется.
- ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
- ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
-
Эти методы, добавленные в стадии разработки ядра 2.3, реализуют
множественные (scatter/gather) операции чтения записи. Приложению
может понадобиться простая операция чтения или записи с
использованием множественных областей памяти. Эти системные вызовы
позволяют сделать это без выполнения дополнительных операций
копирования данных в эти области.
- struct module *owner;
-
Это поле не является методом, как другие поля структуры
file_operations. Это указатель на модуль, владеющий этой
структурой. Поле используется ядром для получения счетчика
использования модуля.
Наш драйвер scull реализует только наиболее важные методы и
использует “таговый” формат инициализации экземляра структуры
file_operations:
struct file_operations scull_fops = {
llseek: scull_llseek,
read: scull_read,
write: scull_write,
ioctl: scull_ioctl,
open: scull_open,
release: scull_release,
};
Мы уже говорили о возможности таговой инициализации структур в GNU
компиляторах. Такой синтаксис инициализации является предпочтительным в
плане независимости от дополнений в описании структур. Кроме того,
такая инициализация более читабельна и компактна. Таговая инициализация
позволяет проводить переорганизацию членов структуры без изменения кода
драйвера (требуется простая перекомпиляция), что в некоторых случаях,
увеличивает быстродействие системы. Увеличение быстродействия связано с
расчетом на размещение в кэше наиболее востребованных методов
структуры.
Также, необходимо проинициализировать поле owner структуры
file_operations. В источниках кода ядра, можно увидеть следующий способ
инициализации поля owner:
owner: THIS_MODULE,
Такой способ инициализации работает только для ядра версии 2.4.
Более независимый от версии ядра способ инициализации должен
использовать макроопределение SET_MODULE_OWNER, которое определено в
заголовочном файле <linux/module.h>. В коде модуля scull
инициализация этого поля выполнена с использованием этого макро
следующим образом:
SET_MODULE_OWNER(&scull_fops);
Это макроопределение работает с любой структурой, в которой
определено поле owner. В этой книге мы еще встретимся с этим полем в
несколько иных контекстах.
Структрура file
Структура file, определенная в <linux/fs.h>, является второй, по
важности структурой данных, используемой в драйверах устройств.
Обратите внимание, что структура file не имеет ничего общего со
структурой FILE доступной программам пользовательского пространства.
Структура FILE определена в стандартной библиотеке языка Си, и не видна
из кода ядра. В противоположность этому структура file принадлежит
ядру, и не используется в программах пользователя.
Структура file представляет информацию об открытом файле. Заметьте,
что это не является спецификой именно драйверов устройств – каждый
открытый в системе файл связан со структурой file в пространстве ядра.
Она создается ядром в ответ на системный вызов open() и передается во
все функции работающие с файлом. При закрытии файла системным вызовом
close() код ядра освобождает эту структуру данных. Лежащий на диске
файл представляется в системе структурой inode. При открытии файла,
система дополняет информацию о файле соответствующими логическими
структурами.
В источниках ядра, указатель на структуру file обычно называется
либо file либо filp (“file pointer”). Мы будем использовать название
filp для этого указателя, для предотвращения двусмысленности. Таким
образом, в нашем коде, название file применяется к структуре, а
название filp к указателю на эту структуру.
Наиболее важные поля структуры file описаны ниже. Как и в предыдущем
разделе, вы можете пропустить эти подробности при первом чтении и
вернуться к ним позднее, при необходимости. Например, в следующем
разделе будет представлен реальный код на языке Си и мы обсудим
некоторые из этих полей подробнее.
- mode_t f_mode;
-
Режим открытия файла. Файл может быть открыт на чтение и/или на
запись. Режим открытия указывается битовыми флагами FMODE_READ и
FMODE_WRITE. Возможно, в теле функции ioctl() вы захотите проверить
установленные права на чтение/запись. Однако, необходимости в этом
нет, т.к. ядро проверяет эти права перед вызовом ioctl(). Поэтому,
например, попытка записи без соответствующих прав окончится
неудачей, независимо от того знает об этом драйвер или нет.
- loff_t f_pos;
-
Текущее значение позиции чтения или записи. loff_t представляет
собой 64-битное значение (long long в терминологии gcc). Драйвер
может обратится к этому значению, если потребуется значение текущей
позиции в файле, но он, ни в коем случае не должен изменять это
значение. Изменение этого значения должно производиться только в
функциях read() и write(), которые, последним аргументом, получают
указатель на этот элемент.
- unsigned int f_flags;
-
Имеется набор флагов определенных для файла, таких как O_RDONLY,
O_NONBLOCK, и O_SYNC. Часто, драйверу может понадобиться проверить
флаг запрещения блокировки, в то время остальные флаги используются
значительно реже. В особенности, права на чтение/запись должны
проверяться через f_mode, вместо f_flags. Полный набор флагов
определен в заголовочном файле <linux/fcntl.h>.
- struct file_operations *f_op;
-
Операции, связанные с файлом. Ядро назначает этот указатель в коде
системного вызова open(). Чтение этого указателя производится ядром
при каждом переключении (диспетчеризации) операций. Значение
filp->f_op не сохраняется нигде отдельно для последующих
обращений. Это означает, что вы в любое время можете изменить
операции, связанные с вашим файлом, и они вступят в силу уже при
следующем вызове. Например, код системного вызова open() при
открытии устройства со старшим номером 1 (устройства /dev/null,
/dev/zero и т.д.) заменяет операции в filp->f_op в зависимости
от младшего номера открываемого устройства. Это позволяет
реализовывать различное поведение для одного и того же старшего
номера устройства без перегрузки каждого системного вызова. Такая
возможность замены файловых операций является эквивалентом
перекрытия методов в объектно-ориентированном программировании.
- void *private_data;
-
Код системного вызова open() устанавливает этот указатель в NULL
перед вызовом метода open() вашего драйвера. Драйвер может
использовать это поле по своему собственному усмотрению или не
использовать его вовсе. Можно использовать это поле для указателя
на динамически распределенную область памяти. В этом случае,
необходимо освободить эту память в методе release() драйвера, перед
тем, как ядро уничтожит структуру file. Такой указатель очень
удобен для передачи информации между системными вызовами и
используется в большинстве наших примеров модулей.
- struct dentry *f_dentry;
-
Указатель на структуру элемента каталога, связанного с файлом
(dentry - “directory entry”). Такие структуры добавлены
в целях оптимизации при разработке ядра версии 2.1. Эта структура
мало интересует разработчиков драйверов, за исключением одного
поля: filp->f_dentry->d_inode.
В действительности, структура file имеет еще несколько
малозначительных полей. Поскольку драйвер не заполняет, а использует
структуру file, вы можете, на первом этапе, не вдаваться в эти
подробности.
Методы open() и release()
Теперь, получив краткий обзор полей основополагающих структур
драйвера, мы начнем использовать их в функциях нашего драйвера scull.
Метод open()
Метод open() может быть использован вашим драйвером для проведения
подготовки к дальнейшим операциям с драйвером. Кроме того, в этом
методе, обычно, инкрементируют (увеличивают на 1) счетчик использования
модуля, предотвращая его выгрузку до момента закрытия файла-интерфейса
к модулю. Этот счетчик описан в разделе “Счетчик использования модуля”
главы 2 “Построение и запуск модулей”. Декрементирование (уменьшение на
1) счетчика использования модуля производят в методе release()
драйвера.
В большинстве драйверов, метод open() выполняет следующие задачи:
- Инкрементирование счетчика использования модуля.
- Специфичные
для устройства проверки. Например, проверка готовности устройства или
выявление какие-нибудь других специфичных проблем.
- Инициализация устройства, если оно открывается первый раз.
- Определение младшего номера устройства и соответствующая корректировка поля f_op, при необходимости.
- Распределение и заполнение других структур данных для передачи их через указатель filp->private_data
В драйвере scull большинство из описанных выше задач зависят от
младшего номера открываемого устройства. Поэтому, первой задачей
является идентификация устройства. Мы можем сделать это на основе
анализа поля inode->i_rdev.
Мы уже говорили о том, что ядро не использует младший номер
устройства, и драйвер может использовать его по своему усмотрению. На
практике, различные младшие номера используются для доступа к различным
устройствам управляемым одним драйвером, или для открытия одного и того
же устройства с разными целями. Например, /dev/st0 (младший номер 0) и
/dev/st1 (младший номер 1) ссылаются на различные SCSI tape-приводы
(накопители на магнитной ленте), в то время как /dev/nst0 (младший
номер 128) ссылается на тоже самое физическое устройство, что и
/dev/st0, но реализовывает несколько иной способ управления (лента не
перематывается к началу при закрытии файла устройства). Все файлы
интерфейсов к tape-приводам различаются младшими номерами, которые
используются драйвером для идентификации различных устройств.
Драйверу не известно имя открываемого устройства, только его номер.
Поэтому, пользователь может воспользоваться таким безразличием к имени,
и использовать удобные alias-ы (псевдонимы) для имен файлов
интерфейсов. Если вы создали два файла-интерфейса с одинаковыми парами
старших/младших номеров, то они будут определять одно и тоже
устройство, и не существует способа различить эти файлы из кода
драйвера. Тот же самый эффект получается при использовании жестких или
символических ссылок на файл интерфейса. Надо заметить, что создание
символических ссылок – наиболее популярный способ задания удобных имен
для файлов интерфейсов.
Драйвер scull использует следующую схему назначения младшего номера:
старший полубайт (старшие четыре разряда) определяют тип устройства, а
младший полубайт позволяет вам различить индивидуальные устройства,
если данный тип поддерживает несколько устройств. Таким образом scull0
отличается от scullpipe0 значением старшего полубайта, в то время как
scull0 и scull1 отличаются значением младшего полубайта. В источнике
драйвера определены два макроса (TYPE и NUM) извлекающие требуемую
группу битов из младшего номера устройства.
Вообще, использование битовой карты наиболее типичный случай в схеме
назначения младших номеров устройств. Драйвер IDE, например, использует
старшие два бита для определения номера диска, а младшие шесть бит, для
определения номера дискового раздела.
#define TYPE(dev) (MINOR(dev) >> 4) /* high nibble */
#define NUM(dev) (MINOR(dev) & 0xf) /* low nibble */
Для каждого типа устройства, драйвер scull определяет структуру
file_operation, которая размещается по указателю filp->f_op во время
открытия файла. Следующий код демонстрирует использование различных
fops:
struct file_operations *scull_fop_array[]={
&scull_fops, /* type 0 */
&scull_priv_fops, /* type 1 */
&scull_pipe_fops, /* type 2 */
&scull_sngl_fops, /* type 3 */
&scull_user_fops, /* type 4 */
&scull_wusr_fops /* type 5 */
};
#define SCULL_MAX_TYPE 5
/* In scull_open, the fop_array is used according to TYPE(dev) */
int type = TYPE(inode->i_rdev);
if (type > SCULL_MAX_TYPE) return -ENODEV;
filp->f_op = scull_fop_array[type];
Ядро вызывает требуемый метод open() согласно старшему номеру
устройства. Драйвер scull обрабатывает младший номер с помощью
показанных выше макросов. Макро TYPE используется как индекс в массиве
scull_fop_array для извлечения требуемого набора методов для
открываемого устройства.
В драйвере scull указатель filp->f_op указывает на экземпляр
структуры file_operations определяемой младшим номером устройства.
Затем, если указатель filp->f_op был изменен, вы можете вызвать
новый метод open() самостоятельно. Обычно, драйвер не вызывает методы
из принадлежащей ему структуры file_operations (это делает ядро при
диспетчеризации системных вызовов). Но, если ваш метод open() имеет
дело с различными типами устройств, вам может понадобиться вызов
f_op->open после изменения указателя f_op, согласно младшему номеру
открываемого устройства.
Ниже приведен код для функции scull_open. Он использует макросы TYPE
и NUM, определенные выше, для разделения младшего номера устройства.
int scull_open(struct inode *inode, struct file *filp)
{
Scull_Dev *dev; /* device information */
int num = NUM(inode->i_rdev);
int type = TYPE(inode->i_rdev);
/*
* If private data is not valid, we are not using devfs
* so use the type (from minor nr.) to select a new f_op
*/
if (!filp->private_data && type) {
if (type > SCULL_MAX_TYPE) return -ENODEV;
filp->f_op = scull_fop_array[type];
return filp->f_op->open(inode, filp); /* dispatch to specific open */
}
/* type 0, check the device number (unless private_data valid) */
dev = (Scull_Dev *)filp->private_data;
if (!dev) {
if (num >= scull_nr_devs) return -ENODEV;
dev = &scull_devices[num];
filp->private_data = dev; /* for other methods */
}
MOD_INC_USE_COUNT; /* Before we maybe sleep */
/* now trim to 0 the length of the device if open was write-only */
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY) {
if (down_interruptible(&dev->sem)) {
MOD_DEC_USE_COUNT;
return -ERESTARTSYS;
}
scull_trim(dev); /* ignore errors */
up(&dev->sem);
}
return 0; /* success */
}
Здесь потребуются некоторые дополнительные объяснения. Scull_Dev –
это структура данных используемая драйвером для удержания памяти под
устройство. Позднее, вы познакомитесь с этой структурой подробнее.
Глобальные переменные scull_nr_devs и scull_devices[] представляют
количество доступных устройств и массив указателей на Scull_Dev
соответственно.
Вызовы функций down_interruptible() и up() пока можно упустить из внимания. О них будет рассказано позже.
Код выглядит достаточно скудно, потому что, по соответствующему
системному вызову open(), код этой функции не делает ничего особенного
по управлению устройством. Это не требуется для устройств scull0-3.
Также, заметьте, что мы не проводим никакой особой инициализации при
первом запуске, поэтому, управляя системным счетчиком использования
модуля, мы не используем его значение в коде этой функции.
Ядро может самостоятельно управлять системным счетчиком
использования модуля через поле owner структуры file_operations.
Поэтому, вы можете быть удивлены, встретив в коде приведенной функции
макросы “ручного” управления этим счетчиком. Дело в том, что старые
версии ядер не поддерживали механизм автоматического управления
счетчиком, и для повышения портируемости мы используем ручное
управление. Одновременное использование ручного и автоматического
управления счетчиком под ядрами 2.4 и выше приведет к неправдоподобно
большому значению счетчика, но это не является проблемой, т.к. при
закрытии всех файлов интерфейсов к модулю он, все равно, упадет до
нуля.
Если устройство открывается для записи, то необходимо выполнять
обнуление текущей позиции записи. Драйвер scull оперирует небольшими
объемами памяти, поэтому такой способ управления областью записи
предпочтительнее. Это похоже на открытие на запись обычного файла. В
случае открытия устройства для чтения, такая операция не выполняется.
Позднее код инициализации драйвера станет более понятен, когда вы познакомитесь с другими элементами драйвера scull.
Метод release()
Назначение метода release() противоположно методу open(). Изучая
источники ядра вы можете заметить, что иногда, метод носит название device_close() а не device_release(). Как бы это не называлось, метод должен выполнять следующие задачи:
- Освобождение всей памяти занятой под указателем filp->private_data в методе open()
- По необходимости, выполняются все завершающие действия при последнем закрытии устройства
- Декрементирование (уменьшение на 1) счетчика использования модуля
Наш драйвер scull не управляет реальным оборудованием, поэтому код, требуемый для завершения операций минимален.
The other flavors of the device are closed by different functions, because scull_open substituted a different filp->f_op for each device. We'll see those later.
int scull_release(struct inode *inode, struct file *filp)
{
MOD_DEC_USE_COUNT;
return 0;
}
Обратите внимание, что декрементрирование счетчика использования модуля
необходимо, если вы инкрементируете его в методе open(). Иначе, ядро не
сможет выгрузить модуль, счетчик использования
которого не равен нулю.
Как реализовать корректное управление счетчиком, если файл
интерфейса закрывается не будучи открыт соответствующим методом open().
Такое возможно при использовании системных вызовов dup() и fork(),
создающих копии процесса. Каждая из этих копий закрывается при
завершении программы. Например, большинство программ не открывают
интерфейс stdin, но закрывают его при завершении.
How can the counter remain consistent if sometimes a file is closed without having been opened? After all, the dup and fork system calls will create copies of open files without calling open; each of those copies is then closed at program termination. For example, most programs don't open their stdin file (or device), but all of them end up closing it.
Ответ очень прост. Не каждый системный вызов close() приводит к
вызову метода release(). Метод release() вызывается только в том
случае, если ядро действительно освобождает структуру данных устройства
– отсюда и название – release значит “освобождать”. Ядро содержит
счетчик использования структуры file. Ни dup(), ни fork() не создают
новой структуры file (это делается только в вызове open()), но
увеличивают счетчик использования уже существующей структуры.
Системный вызов close() вызывает метод release() только тогда, когда
счетчик использования структуры file уменьшается до нуля. При этом,
структура уничтожается. Взаимодействия между системным вызовом call() и
методом release() гарантируют корректное состояния счетчика
использования модуля.
Заметьте, что метод flash() вызывается всякий раз, когда приложение
вызывает close(). Однако, немногие драйвера реализовывают метод
flash(), потому что, обычно, завершающие действия требуются только в
методе release() - методе реального закрытия интерфейса.
Завершение приложения автоматически приводит к закрытию связанных с
ним файлов. Т.е. для каждого открытого файла, ядро автоматически
вызывает системный close().
Использование памяти драйвером scull
Перед ознакомлением с операциями read() и write() необходимо
ознакомиться со способом распределения динамической памяти,
используемым драйвером scull. Это поможет лучше понять код драйвера.
В этом разделе мы не будем говорить об управлении оборудованием.
Этому искусству посвящены глава 8 “Управление оборудованием” и глава 9
“Управление прерываниями”. Поэтому, вы можете пропустить этот раздел,
если вам не интересна внутренняя работа памяти-ориентированного
драйвера scull.
Область памяти используемой драйвером scull, также называемой в
данном контексте “устройством”, может иметь переменную длину. Чем
больше вы пишите, тем больше она растет. Усечение этой области может
быть произведено перезаписью в устройство более короткого файла.
Представленная реализация драйвера scull не слишком красива. Более
изящная реализация кода может вызвать проблемы понимания у читателей.
Поэтому, в данном разделе демонстрируются простейшие схемы управления
памятью, которые можно будет применить в методах read() и write(). Мы
будем использовать функции kmalloc() и kfree() не используя
пересортировку целых страниц памяти, хотя это может быть более
эффективно.
Мы не хотим ограничивать предельный размер поглощаемой памяти по
филосовской и практической причинам. С филосовской точки зрения, любые
ограничения на размер хранимых данных – это всегда плохо. С
практической точки зрения, это будет означать, что вы сможете
использовать драйвер scull для временного поглощения требуемого размера
системной памяти для того, чтобы протестировать работу системы в
условиях малого объема физической памяти. Запуск таких тестов поможет
вам понять внутреннюю работу системы. Вы можете использовать команду cp
/dev/zero /dev/scull0 для поглощения драйвером всего свободного объема
памяти. Если вы хотите поглотить строго определенный размер памяти, то
вы можете использовать утилиты dd.
Каждое устройство (область памяти) в драйвере scull представляет
собой связанный список указателей, каждый из которых указывает на
экземпляр структуры Scull_Dev. Каждая такая структура может ссылаться,
по умолчанию, на не более чем на четыре миллиона байт, через массив
промежуточных указателей. Окончательный код источника драйвера
использует массив из 1000 указателей на области по 4000 байт. Мы
называем каждый такой блок памяти квантом (quantum), а массив этих
блоков множеством квантов (quantum set). Схема использования памяти
драйвером scull показана на рис. 3-1.
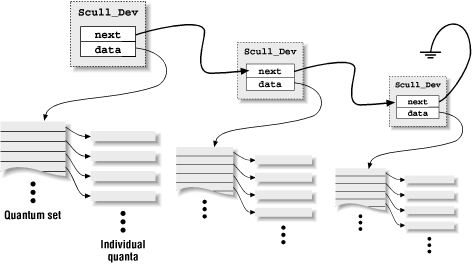
Рис. 3-1. Схема устройства scull
Согласно выбранной схеме хранения данных, запись одного байта
данных, в драйвер scull будет израсходовано восемь или двенадцать байт
памяти: четыре тысячи байт под один квант данных и четыре или восемь
тысяч байт на массив квантовых указателей (в зависимости от размера
указателя на вашей платформе – 32 или 64 бита). При записи большего
объема данных перерасход на список указателей не велик. В одном блоке
Scull_Dev может хранится четыре миллиона байта данных (массив из тысячи
указателей, каждый из которых указывает на квант данных вмещающий
четыре тысячи байт данных). Максимальный объем устройства ограничен
памятью компьютера.
Выбор размера кванта и квантового массива это в большей степени
вопрос политики, а не механизма реализации. Оптимальные значения
размеров зависят от способа использования устройства. Таким образом,
драйвер scull должен предоставлять пользователю механизм управления
этими значениями. Пользователь может изменить эти значения различными
способами: редактированием макросов SCULL_QUANTUM и SCULL_QSET в
заголовочном файле scull.h с последующей перекомпиляцией драйвера,
установкой целых значений параметров scull_quantum и scull_qset при
загрузке модуля, или изменением значения по умолчанию и текущего
значения через механизм, предоставляемый методом ioctl(), во время
работы драйвера.
Использование макро и передачи целого значения для конфигурации
драйвера во время компиляции и загрузки, соответственно, напоминает
выбор старшего номера устройства. Мы используем эту технику для
изменения политики управления устройством.
Остается только один вопрос – выбор значений по умолчанию. Это
вопрос компромисса. При выборе больших размеров кванта и массивов мы
рискуем иметь большие потери памяти из-за не полного заполнения
квантов. С другой стороны, при малых размерах, перерасход памяти может
произойти на систему указателей. Эта проблема аналогичная проблеме
выбора размера кластера для файловой системы.
Помимо этого, необходимо учесть особенности функции kmalloc().
Сейчас, мы не будем касаться этого вопроса, т.к. его подробное описание
вы встретите в разделе “Read Story of kmalloc” главы 7 “Getting Hold of
Memory”.
Наш выбор значений по умолчанию рассчитан на передачу в драйвер достаточно больших объемов данных при тестировании.
Структура данных, используемая для хранения информации устройства выглядит следующим образом:
typedef struct Scull_Dev {
void **data;
struct Scull_Dev *next; /* next list item */
int quantum; /* the current quantum size */
int qset; /* the current array size */
unsigned long size;
devfs_handle_t handle; /* only used if devfs is there */
unsigned int access_key; /* used by sculluid and scullpriv */
struct semaphore sem; /* mutual exclusion semaphore */
} Scull_Dev;
Следующий фрагмент кода показывает показывает использование
структуры Scull_Dev для хранения данных. Приведенная функция
предназначена для освобождения всей области данных драйвера и
вызывается методом scull_open() при открытии устройства на запись.
int scull_trim(Scull_Dev *dev)
{
Scull_Dev *next, *dptr;
int qset = dev->qset; /* "dev" is not null */
int i;
for (dptr = dev; dptr; dptr = next) { /* all the list items */
if (dptr->data) {
for (i = 0; i < qset; i++)
if (dptr->data[i])
kfree(dptr->data[i]);
kfree(dptr->data);
dptr->data=NULL;
}
next=dptr->next;
if (dptr != dev) kfree(dptr); /* all of them but the first */
}
dev->size = 0;
dev->quantum = scull_quantum;
dev->qset = scull_qset;
dev->next = NULL;
return 0;
}
Краткое знакомство с проблемой Race Conditions (состязание)
Теперь, когда вы понимаете работу драйвера по управлению памятью,
настало время обсудить сценарий его работы. Предположим, что имеется
два процесса A и B, открывшие драйвер scull для записи данных. И оба
они пытаются одновременно добавлять данные в устройство. Для
обеспечение этой операции требуется распределение новых квантов.
Поэтому, каждый процесс распределяет требуемое количество памяти и
сохраняет эти указатели в квантовом массиве.
Результат такой операции должен вызывать беспокойство. Оба процесса
работают с одним и тем же устройством scull. Каждый сохраняет
распределенные кванты в одном и том же квантовом массиве. Если сначала
устройство A сохраняет свой указатель, то процесс B перезаписывает этот
указатель впоследствии. Таким образом, память распределенная процессом
A будет потеряна.
Такая ситуация носит название race condition (условия состязания,
или состязание). Результат зависит от того, кто начинает первым. На
однопроцессорной Linux системе, код драйвера scull не должен вызывать
такие проблемы, потому, что процесс, запускающий код ядра не выгружаем
(are not preempted). Однако на SMP системах, жизнь представляется более
сложной. Процессы A и B могут быть запущены на разных процессорах, и их
взаимодействие может вызвать описываемую здесь проблему.
Linux ядро обеспечивает несколько механизмов, позволяющих избежать
такого состязания. Полное описание этих механизмов вы найдете в главе 9
“Управление прерываниями”. В этой главе мы проведем только начальное
знакомство с этими средствами.
Семафоры представляют собой основной механизм доступа к ресурсам. В
простейшем случае, семафоры могут быть использованы для мьютексов
(MUTual EXclusion – взаимоисключения). Процессы, использующие семафоры
в режиме мьютесков предотвращают одновременный запуск одного и того же
кода, или доступ к одним и тем же данным.
Семафоры в Linux определены в заголовочном файле
<asm/semaphore.h>. Они описаны в структуре semaphore, и драйвер
обязан использовать эту структуру только через предлагаемый к ней
интерфейс. В драйвере scull, каждое устройство использует по одному
семафору, определенному в структуре Scull_Dev. Так как устройства
полностью не зависят друг от друга, то нет необходимости навязывать
мьютексы на группу устройств (... there is no need to enforce mutual
exclusion across multiple devices).
Семафоры должны быть проинициализированы перед использованием
передачей числового аргумента в функцию sema_init(). Для приложений,
использующих мьютексы (т.е. для приложений, которые должны
предотвратить одновременный доступ к одним и тем же данным), семафоры
должны быть проинициализированны значением 1, которое означает
разрешение работы семафора. Следующий пример кода инициализационной
функции scull_init() драйвера scull показывает инициализацию семафоров.
for (i=0; i < scull_nr_devs; i++) {
scull_devices[i].quantum = scull_quantum;
scull_devices[i].qset = scull_qset;
sema_init(&scull_devices[i].sem, 1);
}
Процесс, желающий использовать код защищенный семафором, должен
сначала проверить, что данный код не используется другим процессом.
Несмотря на то, что в классической компьютерной науке, функции,
использующие семафоры, часто называются P(), в Linux, используются
названия down() и down_interruptible(). Эти функции проверяют значение
семафора на величину большую нуля. Если это так, то функция
декрементирует значение семафора и завершается. Если значение семафора
равно нулю, то функция засыпает и просыпается через некоторое время,
когда некий другой процесс, использующий семафор, предположительно,
освобождает его.
Функция down_interruptible() может быть прервана сигналом, в то
время как функция down() не принимает сигналы к процессу. Наверное, вы
всегда будете использовать возможность прерывания функции сигналом. В
противном случае, вы рискуете получить неубиваемый процесс, или,
какое-нибудь, другое нежелаемое поведение. Сложность использования
сигнальных прерываний заключается в том, что в теле функции
down_interruptible() необходимо всегда проверять, была ли функция
прервана. Обычно, функция возвращает 0 в случае успеха, и не ноль в
случае неудачного завершения. Если процесс прерывается, то он не
получит семафоров, и, таким образом, нет необходимости вызывать функцию
up(). Поэтому, типичный вызов получения семафора выглядит следующим
образом:
if (down_interruptible (&sem))
return -ERESTARTSYS;
Возвращаемое значение -ERESTARTSYS говорит системе, что операция
была прервана сигналом. Функция ядра, которая вызывает метод устройства
либо повторит вызов, либо вернет приложению ошибку -EINTR, в
зависимости от того, как ваше приложение сконфигурирует обработку
сигналов. Конечно, если ваш код был прерван, то, возможно, ему
понадобится выполнить некоторые завершающие действия перед возвратом.
Процесс, который получает семафор должен всегда освобождать его
впоследствии. Не смотря на то, что в компьютерной науке, функцию,
освобождающую семафор, называют V(), в Linux используется название
up(). Приведем простой пример ее использования:
up (&sem);
Этот код увеличивает значение семафора и будит все процессы, которые ожидают доступного семафора.
При использовании семафоров нужно быть особенно внимательным. Данные
защищаемые семафором должны быть четко определены, и весь код, который
получает доступ к этим данным должен обязательно проверять значение
семафоров. Код, который использует down_interraptible() для получения
семафора, не должен вызывать другую функцию, которая, также, пытается
получить этот семафор. Иначе, вы спровоцируете тупиковую ситуацию. Если
процедура в вашем драйвере, по какой либо причине не освободила
удерживаемый семафор, то дальнейшие попытки получить этот семафор будут
обречены на неудачу.
В драйвере scull семафор используется для защиты доступа к хранимым
в устройстве данным. Любой код, который получает доступ к полю data
структуры Scull_Dev, должен сначала получить семафор. Во избежании
тупиковых ситуаций, получением семафора должны заниматься только методы
драйвера. Внутренние процедуры, такие как scull_trim(), описанная
ранее, должны предполагать, что семафор уже получен. При соблюдении
этих условий, доступ к структуре Scull_Dev будет корректным, и не
приведет к ситуации “race conditions”.
Методы read() и write()
Методы read() и write() выполняют схожие задачи, заключающиеся в
копировании данных из, или в приложение пользователя. Поэтому, их
прототипы очень похожи, и, имеет смысл, рассмотреть их одновременно.
ssize_t read(struct file *filp, char *buff,
size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char *buff,
size_t count, loff_t *offp);
В обоих методах, filp представляет указатель на структуру file, а в
count определяют размер передаваемых данных. Аргумент buff указывает на
буфер данных чтения/записи. Наконец, offp описан, как указатель на
“long offset type”, который указывает на смещение от начала данных
файла для операций чтения/записи. Методы возвращают “signed size type”,
смысл которого будет объяснен позднее.
Главной задачей этих двух методов является передача данных между
адресным пространством ядра и адресным пространством пользовательского
процесса. Такая операция не может быть выполнена через простую передачу
указателей или через функцию memcpy(). Адресное пространство
пользователя не может быть прямо использовано в пространстве ядра по
некоторым причинам.
Одно из серьезных отличий между адресным пространством ядра и
адресным пространством пользователя заключается в том, что пространство
пользователя выгружаемо на диск. Когда ядро получает доступ к указателю
на адресное пространство пользователя, может случиться так, что
страница, связанная с этим указателем не представлена в памяти. В этом
случае возникает исключение page fault. Функции, с которыми мы
знакомимся в этом разделе используют некий скрытый механизм для работы
с такими исключениями. Особенность заключается в том, что процессор
обрабатывает это исключения из уровня ядра. В разделе “Using the ioctl
Argument” главы 5 “Enhanced Char Driver Operation” бы более подробно
остановимся на этом вопросе.
Надо заметить, что реализация ядра Linux 2.0 для x86 использовала
различные механизмы отображения памяти для адресных пространств
пользователя и ядра. Таким образом, указатели адресного пространства
пользователя не могут быть разыменованы в пространстве ядра вообще.
Такая проблема справедлива не только для нашего RAM-драйвера.
Наверное в любом драйвере возникает необходимость копирования данных
между буферами пользователя и пространством ядра, а, возможно, и между
пространством ядра и памятью ввода/вывода.
Такие межпространственные копирования выполняются в Linux с помощью
специальных функций, определенных в <asm/uaccess.h>. Такое
копирование выполняется либо общей функцией, схожей с memcpy(), либо
специальными функциями, оптимизированными на определенный размер данных
(char, short, int, long). С большинством из них мы познакомимся в
разделе “Using the ioctl Argument” главы 5 “Enhanced Char Driver
Operations”.
Код методов read() и write() драйвера scull реализовывает
копирование целых сегментов данных в, и из адресного пространства
пользователя. Для этого используется, описанные ниже, функции ядра,
которые копируют произвольное количество байт.
unsigned long copy_to_user(void *to, const void *from,
unsigned long count);
unsigned long copy_from_user(void *to, const void *from,
unsigned long count);
Еще раз заметим, что несмотря на то, что поведение этих функций
похоже на memcpy(), существует особенность в реализации, связанная с
получением доступа к адресному пространству пользователя из ядра.
Адресуемые пользовательские страницы могут не оказаться в памяти, и
обработчик исключения page fault может перевести процесс в спящее
состояние, до переноса требуемой страницы в физическую память. Такое
может случиться при выгрузке страницы в дисковый своп. Таким образом,
любая функция ядра, которая получает доступ к адресному пространству
пользователя должна быть реентерабельна, и, одновременно с этим, должна
уметь разделять с другими функциями один и тот же блок данных (см.
также раздел “Writing Reentrant Code” в главе 5 “Enhanced Char Driver
Operations”). Вот почему мы используем семафоры для управления
конкурентным доступом к данным.
Назначение этих двух функций заключается копировании неограниченного
объема данных в и из адресного пространства пользователя. При этом
проверяется корректность указателя в адресном пространстве. Если
указатель не корректен, то копирование не выполняется. Если же
некорректность адреса выясняется уже в процессе копирования, то процесс
останавливается. В обоих случаях, функция возвращает количество еще не
скопированных байт памяти. Код драйвера scull возвращает пользователю
ошибку -EFAULT, если результат этой функции не равен нулю.
Тема доступа к пользовательскому пространству и некорректность
указателей подробно обсуждается в разделе “Using the ioctl Argument” в
главе 5 “Enhanced Char Driver Operations”. Однако, стоит сказать уже
сейчас, что если вы уверены в корректности указателя то вы можете
использовать функции __copy_to_user() и __copy_from_user() вместо
вышеуказанных. В этом есть особенный смысл, если вы уже выполнили
проверку указателя.
Метод read() занимается копированием данных из устройства в адресное
пространство пользователя, используя функцию copy_to_user(). Метод
write() копирует данные из пространства пользователя в устройство,
используя copy_from_user(). Для каждого системного вызова read() или
write() определяется количество передаваемых байт, однако драйвер может
передать меньшее количество данных. Об этом мы поговорим чуть позже.
Независимо от количества данных передаваемых этими методами, они
должны изменять значение *offp текущей позиции файла, после успешного
исполнения системного вызова. В большинстве случаев аргумент offp
представляет собой указатель на filp->f_pos. Исключение составляют
случаи использования системных вызовов pread() и pwrite(), которые
выполняют действия эквивалентные вызову lseek() с последующим вызовом
read() или write().
На рисунке 3-2 показано типичная реализация использования аргументов в методе read().
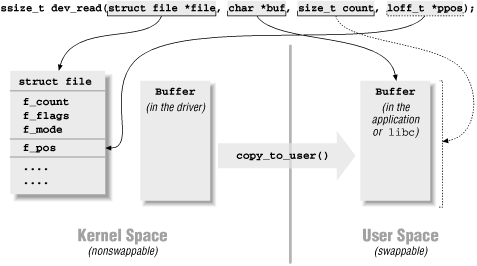
Рис. 3-2. Аргументы метода read
Оба метода, и read(), и write() возвращают отрицательное значение в
случае ошибки. Если возвращаемое значение равно или больше нуля, то это
говорит вызывающей программе о количестве успешно переданных байт. Если
ошибка возникла во время передачи, то возвращается количество
переданных байт, либо ошибка, при повторном вызове функции.
Функции ядра, в случае ошибки, возвращают отрицательное число,
значение которого говорит о типе возникшей ошибке. Об этом мы говорили
в разделе “Обработка ошибок в init_module” главы 2 “Построение и запуск
модулей”. Программы которые работают в пространстве пользователя, в
качестве ошибки, всегда воспринимают только код -1. Для определения
типа ошибки, программы пользователя должны обратиться к переменной
errno. Такое различие в поведение диктуется стандартом POSIX для
системных вызовов.
Метод read()
Возвращаемое значение метода read() интерпретируется вызывающим приложением следующим образом:
- Если значение равно аргументу count переданному
в системный вызов read(), то все запрошенное количество байт было
передано. Это оптимальный вариант.
- Если значение положительно, но меньше чем count,
то только часть данных была прочитана. Это может случиться по
некоторым причинам, зависящим от устройства. Обычно, в этом случае,
пользовательская программа повторяет чтение. Например, если для
чтения вы используете функцию fread(), то библиотечная функция будет
перевызывать системный вызов до тех пор, пока не будет передано
требуемое значение байт.
- Если значение равно 0, значит достигнут конец файла.
- Отрицательное значение означает ошибку. Значение числа определяет тип ошибки,
согласно <linux/errno.h>. Например, -EINTR (системный вызов
прерван) или -EFAULT (неверное значение адреса).
В приведенном списке отсутствует случай “данных нет, но они будут
позднее”. В этом случае, системный вызов read() будет блокирован. Мы не
будем иметь дело с блокируемым вводом до ознакомления с разделом
“Blocking I/O” в главе 5 “Enhanced Char Driver Operations”.
Код драйвера scull поддерживает все эти правила о возвращаемом
значении. При каждом вызове scull_read() передается только один квант
данных. Это делает код короче и понятнее. Если читающая программа хочет
получить большее количество данных, то она повторяет системный вызов.
Если для чтения устройства используются функции из стандартной
библиотеки ввода/вывода (например, функция fread() и пр.), то
приложение даже не уведомляется о квантовом характере читаемых данных.
Если текущая позиция чтения больше, чем размер устройства, то метод
read() драйвера scull возвращает 0, сообщая об отсутствии данных для
чтения. Другими словами, мы находимся в конце файла (end-of-file).
Такая ситуация может возникнуть, если процесс A читает устройство в то
время, когда процесс B открывает его на запись. При открытии на запись,
размер устройства усекается до нуля. Значит, процесс A вдруг
обнаруживает конец файла, и при следующем вызове возвращает 0.
Приведем код метода read():
ssize_t scull_read(struct file *filp, char *buf, size_t count,
loff_t *f_pos)
{
Scull_Dev *dev = filp->private_data; /* the first list item */
Scull_Dev *dptr;
int quantum = dev->quantum;
int qset = dev->qset;
int itemsize = quantum * qset; /* how many bytes in the list item */
int item, s_pos, q_pos, rest;
ssize_t ret = 0;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
if (*f_pos >= dev->size)
goto out;
if (*f_pos + count > dev->size)
count = dev->size - *f_pos;
/* find list item, qset index, and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum; q_pos = rest % quantum;
/* follow the list up to the right position (defined elsewhere) */
dptr = scull_follow(dev, item);
if (!dptr->data)
goto out; /* don't fill holes */
if (!dptr->data[s_pos])
goto out;
/* read only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_to_user(buf, dptr->data[s_pos]+q_pos, count)) {
ret = -EFAULT;
goto out;
}
*f_pos += count;
ret = count;
out:
up(&dev->sem);
return ret;
}
Метод write()
Метод write(), как и метод read() может передать меньше данных, чем
было запрошено. При этом, возвращаемое значение должно удовлетворять
следующим правилам:
- Если значение равно count, значит было передано
все запрошенное количество байт.
- Если значение положительное, но меньше, чем count,
значит была передана только часть запрошенных данных. В этом случае,
программа может повторить запись оставшегося количества данных.
- Если значение равно 0, значит ничего не было записано. Такой результат не
является ошибкой, и нет причин передавать код ошибки. Этот случай мы
рассмотрим подробно в разделе “Blocking I/O” главы 5
“Enhanced Char Driver Operations” при описании
блокируемого ввода/вывода.
- Отрицательное значение является ошибкой. Как и для метода read() значения кодов
ошибок определены в заголовочном файле <linux/errno.h>.
К сожалению, можно встретиться с программами поведение которых
отличается от описанного. Это случается потому, что некоторые
программисты смотрят на метод write(), как на метод, который либо
выполняет полную запись всего требуемого блока данных, либо возвращает
ошибку. Такое ограничение в реализации scull должно быть снято, но мы
не хотим усложнять код более, чем это необходимо.
Код драйвера scull для метода write() выполняет запись одного кванта за одно обращение:
ssize_t scull_write(struct file *filp, const char *buf, size_t count,
loff_t *f_pos)
{
Scull_Dev *dev = filp->private_data;
Scull_Dev *dptr;
int quantum = dev->quantum;
int qset = dev->qset;
int itemsize = quantum * qset;
int item, s_pos, q_pos, rest;
ssize_t ret = -ENOMEM; /* value used in "goto out" statements */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
/* find list item, qset index and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum; q_pos = rest % quantum;
/* follow the list up to the right position */
dptr = scull_follow(dev, item);
if (!dptr->data) {
dptr->data = kmalloc(qset * sizeof(char *), GFP_KERNEL);
if (!dptr->data)
goto out;
memset(dptr->data, 0, qset * sizeof(char *));
}
if (!dptr->data[s_pos]) {
dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL);
if (!dptr->data[s_pos])
goto out;
}
/* write only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_from_user(dptr->data[s_pos]+q_pos, buf, count)) {
ret = -EFAULT;
goto out;
}
*f_pos += count;
ret = count;
/* update the size */
if (dev->size < *f_pos)
dev-> size = *f_pos;
out:
up(&dev->sem);
return ret;
}
Методы readv() и writev()
Unix системы давно поддерживают два альтернативных системных вызова,
называемых readv() и writev(). Это векторные версии принимающие в
качестве параметров массив структур, каждая из которых содержит
указатель на буфер данных и длину буфера. Метод readv() выполняет
заполнение каждого буфера, а метод writev() собирает содержимое каждого
буфера и, потом, записывает эти данные также, как при обычной операции
записи.
Однако, до версии ядра 2.3.44, Linux всегда эмулировал readv() и
writev() через множество вызовов read() и write() соответственно. Если
ваш драйвер не поддерживает управление векторными операциями, то данные
системные вызовы также будут сэмулированы. В некоторых ситуациях, для
повышения эффективности обмена, имеет смысл реализовать эти методы в
драйвере.
Приведем прототип данных векторных операций:
ssize_t (*readv) (struct file *filp, const struct iovec *iov,
unsigned long count, loff_t *ppos);
ssize_t (*writev) (struct file *filp, const struct iovec *iov,
unsigned long count, loff_t *ppos);
Здесь, аргументы filp и ppos имеют то же самое назначение, что и в
методах read() и write(). Структура opvec, определенная в заголовочном
файле <linux/uio.h>, выглядит следующим образом:
struct iovec
{
void *iov_base;
_ _kernel_size_t iov_len;
};
Структура iovec описывает один блок передаваемых данных. Указатель
iov_base указывает на буфер данных, расположенный в адресном
пространстве пользователя, а в iov_len содержится размер этого буфера.
Через параметр count указывают количество блоков iovec. Структуры
создаются вызывающим приложением, но ядро копирует их в адресное
пространство ядра, перед вызовом методов драйвера.
Простейшая реализация векторных операций представляет собой цикл,
который передает адрес и длину каждого из буферов, описанных в iovec, в
методы read() и write(). Однако, иногда, для повышения эффективности
желательно написать более изящную реализацию этих операций. Например,
будет гораздо эффективнее, если метод writev() для накопителя на
магнитной ленте запишет все содержимое структур iovec за один цикл
записи.
Многие драйвера, однако, не получают выгоды от реализации этих
методов. И в нашем драйвере scull они не реализованы. Ядро просто
сэмулирует эти системные вызовы и результат будет тот же самый.
Пробуем новый драйвер
Теперь, когда мы познакомились с кодом четырех описанных методов,
драйвер можно откомпилировать и проверить. Драйвер может сохранить
переданные вами данные, до тех пор, пока вы не перезапишите их новыми
данными. Устройство работает как буфер данных, длина которого
ограничена объемом доступной памяти. Для передачи данных вы можете
использовать системные команды cp или dd перенаправляя ввод/вывод на
тестируемое устройство.
Команда free может быть использована для контроля используемости памяти.
Для контроля расхода квантов при операциях чтения/записи, вы можете
добавить вызов функции printk() в соответствующих местах кода драйвера.
После этого, вы сможете наблюдать, что происходит при передачи больших
блоков данных между приложением и драйвером. Также, вы можете
использовать системную утилиту strace для наблюдения системных вызовов,
осуществляемых приложением, и возвращаемых значений. Например, сделайте
трассировку команды cp или ls -l >/dev/scull0 для наблюдения
квантования чтения/записи. Более подробно, техника мониторинга и
отладки представлена в следующей главе.
Файловая система devfs
Как уже упоминалось в начале этой главы, последние версии ядра Linux
предлагают, специальную файловую систему для взаимодействия с
устройством. Сейчас, эта файловая система доступна в виде
неофициального патча. Вы найдете его в дереве каталогов официального
ядра 2.3.46. Патч можно использовать и в ядре 2.2, но он не входит в
официальные ядра этой ветки.
И хотя эта специализированная файловая система не имеет широкого
распространения, прогрессивные разработчики драйверов могут
использовать новые характеристики, предлагаемые этой системой. Поэтому,
наша версия scull будет использовать devfs, если она будет
поддерживаться операционной системой, эксплуатирующей драйвер. Модуль
использует информацию о конфигурации ядра, во время компиляции для
определения поддержки devfs ядром. Флаг CONFIG_DEVFS_FS в конфигурации
ядра определяет поддержку файловой системы devfs.
Приведем основные характеристики, предоставляемые файловой системой devfs:
- Файл интерфейса к драйверу в /dev автоматически создается при инициализации драйвера и автоматически
удаляется при выгрузке драйвера
- Драйвер устройства может определить имя устройства, владельца и группу, биты
прав доступа. Далее, используя специальные утилиты, вы можете
переопределить владельца и группу и права доступа, но не сможете
изменить имя файла устройства.
- Нет необходимости распределять старший номер для драйвера устройства, и
обрабатывать младший номер устройства.
В результате, не нужно запускать описанные выше скрипты для создания
файлов устройств при загрузке и выгрузке модулей, т.к. драйвер
автономно управляет созданием и уничтожением файлов интерфейсов.
Для управления созданием и уничтожением файловых интерфейсов, драйвер должен вызывать следующие функции:
#include <linux/devfs_fs_kernel.h>
devfs_handle_t devfs_mk_dir (devfs_handle_t dir,
const char *name, void *info);
devfs_handle_t devfs_register (devfs_handle_t dir,
const char *name, unsigned int flags,
unsigned int major, unsigned int minor,
umode_t mode, void *ops, void *info);
void devfs_unregister (devfs_handle_t de);
Реализация файловой системы devfs предлагает и другие функции для
использования в коде драйвера. Они позволяют создавать символические
ссылки, получать доступ к внутренним структурам данных для получения
элементов devfs_handle_t из элементов inode, и пр. Эти функции не
описываются в данной книге, потому что не являются принципиально
значимыми и просты для самостоятельного ознакомления. Любознательные
читатели смогут самостоятельно ознакомиться с этими функциями при
изучении заголовочного файла linux/defs_fs_kernel.h.
Приведем описание аргументов вышеописанных функций:
- dir
-
Имя родительского каталога, в котором
будет создан файл интерфейса устройства. Большинство драйверов
используют значение NULL для этого параметра. В этом случае файл
интерфейса будет создан в каталоге /dev. Для создания собственного
каталога, драйвер может использовать функцию devfs_mk_dir().
- name
-
Имя устройства без указания каталога размещения, т.е. без /dev/, например. Имя может включать символы
слэша, если вы хотите расположить файл интерфейса устройства в
подкаталоге. В этом случае, подкаталог, при необходимости,
автоматически создается в процессе регистрации устройства. В
качестве альтернативы, для указания родительского каталога, вы
можете использовать параметр dir.
- flags
-
Битовая маска для флагов, определенных для файловой системы devfs.
Неплохим выбором, для начала, может быт использование флагов
DEVFS_FL_DEFAULT и DEVFS_FL_AUTO_DEVNUM. Значения применяемых
флагов описано ниже.
- major
- minor
-
Старший и младший номера создаваемого устройства. Не используется, при определении флага
DEVFS_FL_AUTO_DEVNUM.
- mode
-
Режим доступа к устройству
- ops
-
Указатель на структуру file_operations устройства.
- info
-
Значение по умолчанию для указателя filp->private_date. Файловая
система devfs инициализирует указатель в это значение при открытии
устройства. Указатель info переданный в devfs_mk_dir() не
используется devfs, и выступает как указатель на клиентские данные
(“client data” pointer).
- de
-
"devfs entry" – результат предыдущего вызова devfs_register()
Ниже приведены флаги, используемые для определения характеристик
создаваемого файла устройства. И хотя эти флаги коротко и ясно
прокомментированы в заголовочном файле <linux/devfs_fs_kernel.h>,
с некоторыми из этих флагов, имеет смысл познакомиться в рамках этой
книги.
- DEVFS_FL_NONE
- DEVFS_FL_DEFAULT
-
Первый из флагов определен просто как 0 и используется для
повышения читабельности кода. Второе макроопределение, на данный
момент, определено как DEVFS_FL_NONE, и предназначен для
совместимости со следующими реализациями файловой системы devfs.
- DEVFS_FL_AUTO_OWNER
-
При установке этого флага, владельцы устройства устанавливаются по
uid/gid открывающего его процесса. При отсутствии такого процесса,
устройство доступно всем на чтение/запись. Эта характеристика
полезна для интерфейсов tty-устройств, и может быть использована
для предотвращения конкурентного доступа к неразделяемому
устройству. Вопросы политики доступа будут подробнее обсуждаться в
главе 5 “Enhanced Char Driver Operations”.
- DEVFS_FL_SHOW_UNREG
- DEVFS_FL_HIDE
-
Первый из флагов указывает, что файл интерфейса устройства не будет
удален из /dev при выгрузке модуля, точнее после вызова
unregister-процедуры. Второй из флагов говорит, что устройство не
должно быть показано в /dev. Эти флаги, обычно, не используются для
обычных устройств.
- DEVFS_FL_AUTO_DEVNUM
-
Автоматическое распределение старшего и младшего номера устройства.
Номера остаются связанными с именем устройства даже после удаления
устройства. Поэтому, даже после перезагрузки системы, драйвер
сможет получить туже самую пару старшего и младшего номеров.
- DEVFS_FL_NO_PERSISTENCE
-
Установка этого флага отменяет сохранение информации об устройстве после его выгрузки. Между
выгрузкой/загрузкой модулей, возможно сохранять некоторую системную
информацию для обеспечения постоянства некоторых характеристик
устройства, таких как режим доступа,права владения и
старший/младший номера устройств.
Получить и изменить флаги, связанные с устройством, можно во время работы драйвера. Для этого существуют следующие функции:
int devfs_get_flags (devfs_handle_t de, unsigned int *flags);
int devfs_set_flags (devfs_handle_t de, unsigned int flags);
Практическое использование devfs
По причине того, что файловая система devfs поддерживается не всеми
ядрами, ее использование может привести к серьезным проблемам
несовместимости. Поэтому, сейчас будет неправильно заниматься
разработкой только devfs драйверов. Необходимо добавлять поддержку
“старого” способа работы с устройствами, с управлением создания файлов
интерфейсов устройств из пользовательского пространства, и
использования старших/младших номеров устройств из пространства ядра.
Код модуля должен поддерживать devfs только как альтернативу,
используемую при соответствующей поддержке этой файловой системы ядром.
Ниже мы продемонстрируем использование этой альтернативы, добавив к
драйверу scull код поддержки файловой системы devfs. Если ваше ядро
поддерживает devfs, то загрузка драйвера будет производится простым
использованием команды insmod. Описанный выше скрипт scull_load, в этом
случае, не понадобится.
Для размещения всех файловых интерфейсов драйвера scull мы будем
использовать специально созданный каталог. Это в традициях devfs, и нет
смысла нарушать это соглашение. Кроме того, таким образом, мы сможем
продемонстрировать создание и удаление каталогов.
Следующий код функции scull_init() выполняет регистрацию наших устройств.
/* If we have devfs, create /dev/scull to put files in there */
scull_devfs_dir = devfs_mk_dir(NULL, "scull", NULL);
if (!scull_devfs_dir) return -EBUSY; /* problem */
for (i=0; i < scull_nr_devs; i++) {
sprintf(devname, "%i", i);
devfs_register(scull_devfs_dir, devname,
DEVFS_FL_AUTO_DEVNUM,
0, 0, S_IFCHR | S_IRUGO | S_IWUGO,
&scull_fops,
scull_devices+i);
}
Отмена регистрации выполняется следующим кодом функции scull_cleanup():
if (scull_devices) {
for (i=0; i<scull_nr_devs; i++) {
scull_trim(scull_devices+i);
/* the following line is only used for devfs */
devfs_unregister(scull_devices[i].handle);
}
kfree(scull_devices);
}
/* once again, only for devfs */
devfs_unregister(scull_devfs_dir);
Приведенные фрагменты кода компилируются при выполнении следующего
условия: #ifdef CONFIG_DEVFS_FS. Если файловая система devfs не
доступна, в данной версии ядра, то драйвер scull выполняет регистрацию
устройств обычным способом, через вызов функции register_chrdev().
Для поддержки обоих вариантов требуется выполнить еще одну
дополнительную задачу, заключающуюся в инициализации указателей
filp->f_ops и filp->private_data в методе open() драйвера. Первый
указатель, не должен изменяться при использовании devfs, т.к. файловые
операции определяются однократно в devfs_register(). Второй указатель
может быть проинициализирован в методе open() если не используется
devfs.
/*
* If private data is not valid, we are not using devfs
* so use the type (from minor nr.) to select a new f_op
*/
if (!filp->private_data && type) {
if (type > SCULL_MAX_TYPE) return -ENODEV;
filp->f_op = scull_fop_array[type];
return filp->f_op->open(inode, filp); /* dispatch to specific open */
}
/* type 0, check the device number (unless private_data valid) */
dev = (Scull_Dev *)filp->private_data;
if (!dev) {
if (num >= scull_nr_devs) return -ENODEV;
dev = &scull_devices[num];
filp->private_data = dev; /* for other methods */
}
Теперь, если модуль scull будет откомпилирован в системе, ядро
которой поддерживает devfs, то команда ls -l /dev/scull выведет на
экран терминала следующие строки:
crw-rw-rw- 1 root root 144, 1 Jan 1 1970 0
crw-rw-rw- 1 root root 144, 2 Jan 1 1970 1
crw-rw-rw- 1 root root 144, 3 Jan 1 1970 2
crw-rw-rw- 1 root root 144, 4 Jan 1 1970 3
crw-rw-rw- 1 root root 144, 5 Jan 1 1970 pipe0
crw-rw-rw- 1 root root 144, 6 Jan 1 1970 pipe1
crw-rw-rw- 1 root root 144, 7 Jan 1 1970 pipe2
crw-rw-rw- 1 root root 144, 8 Jan 1 1970 pipe3
crw-rw-rw- 1 root root 144, 12 Jan 1 1970 priv
crw-rw-rw- 1 root root 144, 9 Jan 1 1970 single
crw-rw-rw- 1 root root 144, 10 Jan 1 1970 user
crw-rw-rw- 1 root root 144, 11 Jan 1 1970 wuser
Функциональность файловых интерфейсов драйвера scull без поддержки
devfs и с ее поддержкой одинакова. Разница заключается только в именах.
То, что называлось /dev/scull0 теперь называется /dev/scull/0.
Замечания о портируемости кода при использовании devfs
Код драйвера scull несколько усложнен по причинам необходимости его
компиляции и работы под разными версиями ядра – 2.0, 2.2 и 2.4.
Требования совместимости приводят к необходимости использования
директив условной компиляции на основе макроопределения
CONFIG_DEVFS_FS.
К счастью, большинство разработчиков соглашаются, что использование
конструкции #ifdef в теле функции усложняют читабельность кода. В
качестве альтернативы стараются перенести директивы условной компиляции
в заголовочные файлы. Поэтому, поддержка devfs привела к необходимости
создания механизма, позволяющего полностью избежать использования
директив #ifdef в вашем коде. Мы использовали явные механизмы условной
компиляции в коде scull только потому, что старые версии заголовочных
файлов ядра не поддерживали более простой поддержки devfs.
Если вы предполагаете работать только с ядрами версий 2.4, то вы
можете избежать условной компиляции для поддержки devfs вызовом
специальных функций инициализации драйвера. Функции построены так, что
не выполняют никаких действий в случае наличия альтернативы. Так,
например, функция devfs_register_chrdev() не делает ничего, если
используется файловая система devfs, а функция devfs_register() не
выполняет никаких действий, если файловая система devfs не
используется. Следующий пример демонстрирует инициализацию с
использованием этих функций:
#include <devfs_fs_kernel.h>
int init_module()
{
/* request a major: does nothing if devfs is used */
result = devfs_register_chrdev(major, "name", &fops);
if (result < 0) return result;
/* register using devfs: does nothing if not in use */
devfs_register(NULL, "name", /* .... */ );
return 0;
}
Вы можете использовать похожие трюки в собственном заголовочном
файле, при условии, что вы не будете переопределять функций, которые
уже определены в заголовочном файле ядра. Освобождение основного кода
от условных директив компиляции улучшают читабельность этого кода и
уменьшают вероятность ошибок, которые могут быть пропущены
синтаксическим анализатором компилятора. Везде, где используются
директивы условной компиляции, имеется риск опечаток, и других ошибок,
которые останутся незамеченными, если препроцессор вырежет этот код в
той системе, где работает разработчик кода.
Приведем пример того, как за счет усложнения заголовочного файла
scull.h мы избежим директив условной компиляции в коде завершения
модуля. Этот код портируем во все версии ядра, потому что не зависит от
того, знают ли заголовочные файлы ядра о существовании devfs или нет.
#ifdef CONFIG_DEVFS_FS /* only if enabled, to avoid errors in 2.0 */
#include <linux/devfs_fs_kernel.h>
#else
typedef void * devfs_handle_t; /* avoid #ifdef inside the structure */
#endif
На этот счет, мы ничего не определили в sysdep.h, т.к. очень тяжело
реализовать поддержку таких вариантов в наиболее общем случае. Каждый
драйвер должен решать эту задачу по своему. В этой книге мы не
используем поддержку devfs в примерах кода, за исключением кода
драйвера scull. Однако, мы надеемся, что того, что было сказано,
достаточно, чтобы читатели смогли самостоятельно реализовывать
поддержку devfs в своих драйверах.
Вопросы обратной совместимости
В этой главе, мы описали основные элементы интерфейса
программирования ядра версии 2.4. К несчастью, этот интерфейс
претерпевает изменения в процессе разработки. Эти изменения улучшают
ядро, но вызывают сложности у разработчиков при необходимости создания
портируемого кода.
Как описано в этой главе, имеются существенные отличия между
версиями ядра 2.4 и 2.2. Также, имеется много отличий в прототипах
методов file_operations между ядрами 2.2 и 2.0. Также, начиная с версии
2.2 упрощен, но существенно изменен, доступ из ядра к адресному
пространству пользователя. Механизм семафоров был плохо разработан в
ветке 2.0. И, наконец, в ветке 2.1 была добавлена оптимизирующая
структура dentry (directory entry).
Изменения в структуре file_operations
Накопившиеся проблемы привели к изменениям в методах структуры
file_operations. Долгодержащееся ограничение в 2ГБт на размер файла,
вызывало проблемы еще во времена современности ядра 2.0. В результате,
разработчики серии 2.1 начали использовать тип loff_t емкостью в 64
бита для представления длины файла. Поддержка больших файлов не была
полностью реализована вплоть до ядра 2.4, но фундаментальная подготовка
к этому была проведена еще в ветке 2.1.
Другим изменением, введенным разработчиками ядра, начиная с ветки
2.1, стало дополнение аргумента указателя f_pos в методы read() и
write(). Эти изменения были сделаны для соответствия стандарту POSIX на
системные вызовы pread() и pwrite(), в которых явно передавалась
позиция для операций чтения/записи. Не имея такого механизма,
многопоточные программы могли войти в конкуренцию (проблема “race
condition”), при работе с файлами.
Почти все методы ядра 2.0 принимали явно, в качестве аргумента,
указатель inode. Начиная с серии 2.1 разработчики удалили этот параметр
из некоторых методов, по причине редкости его использования. Если вам,
все-таки, понадобится указатель inode, вы можете получить его из
структуры filp.
Прототипы наиболее используемых методов, используемых в структуре file_operations выглядят следующим образом:
- int (*lseek) (struct inode *, struct file *, off_t, int);
-
Заметьте, что в Linux 2.0 этот метод называется lseek, вместо
llseek. Изменение имени связано с поддержкой длинных (long)
значений смещения – 64 бит.
- int (*read) (struct inode *, struct file *, char *, int);
- int (*write) (struct inode *, struct file *, const char *, int);
-
Как уже упоминалось, в ядре 2.0, эти функции использовали указатель inode в
качестве аргумента.
- void (*release) (struct inode *, struct file *);
-
В ядре 2.0 метод release() не мог завершиться ошибкой, поэтому возвращал void.
В структуре file_operations присутствуют много других изменений. Мы
расскажем о них, по мере необходимости, в следующих главах. Сейчас,
имеет смысл, познакомиться с примером портируемого кода, использующего
уже описанные особенности. По причине достаточно существенных
изменений, тяжело привести красивый код учитывающий все особенности.
Простейший способ решения этой задачи заключается в определении
нескольких простых оберточных функций, преобразовывающих старые API в
новые. Эти функции, при компиляции для ядра 2.0, должны заменить методы
в структуре file_operations. Приведем пример, таких оберточных функций,
для драйвера scull.
/*
* The following wrappers are meant to make things work with 2.0 kernels
*/
#ifdef LINUX_20
int scull_lseek_20(struct inode *ino, struct file *f,
off_t offset, int whence)
{
return (int)scull_llseek(f, offset, whence);
}
int scull_read_20(struct inode *ino, struct file *f, char *buf,
int count)
{
return (int)scull_read(f, buf, count, &f->f_pos);
}
int scull_write_20(struct inode *ino, struct file *f, const char *b,
int c)
{
return (int)scull_write(f, b, c, &f->f_pos);
}
void scull_release_20(struct inode *ino, struct file *f)
{
scull_release(ino, f);
}
/* Redefine "real" names to the 2.0 ones */
#define scull_llseek scull_lseek_20
#define scull_read scull_read_20
#define scull_write scull_write_20
#define scull_release scull_release_20
#define llseek lseek
#endif /* LINUX_20 */
Используя такой способ переопределения имен, можно учесть и изменения в названии методов (например, lseek и llseek).
Излишне говорить об осторожности использования таких
переопределений. Эти строки должны стоять до определения структуры
file_operations, но после любого другого использования оригинальных
имен.
Есть еще две несовместимости, относящиеся к изменениям в структуре
file_operations. Одно из них заключается в том, что метод flash() был
добавлен на стадии разработки ядра 2.0. Проблема заключается в том, что
он добавлен в середину описания структуры. Поэтому, лучшим способом
решения этой проблемы является использование синтаксиса тагового
заполнения структуры, доступного в GNU компиляторах.
Другим отличием является способ получения указателя inode из
указателя filp. В то время как современные ядра используют структуру
данных dentry (directory entry), в версии ядра 2.0 такой структуры не
было. Поэтому, в заголовочном файле sysdep.h, мы определили макро,
которое должно разрешить проблемы извлечения inode из filp для разных
версий ядра.
#ifdef LINUX_20
# define INODE_FROM_F(filp) ((filp)->f_inode)
#else
# define INODE_FROM_F(filp) ((filp)->f_dentry->d_inode)
#endif
Счетчик использования модуля
В ветке 2.2 и раньше, Linux ядро не предлагало для модулей никакой
поддержки для счетчика используемости модуля. Модули должны были
выполнять эту работу самостоятельно, не смотря на то, что ядро Linux
ведет учет используемости каждого модуля. Такой способ работы приводил
к ошибкам и дублированию операций. Также, это могло привести к
возникновению проблемам конкуренции доступа к данным (race conditions).
Поэтому, интерфейс для работы со счетчиком использования модуля из
модуля позволяет улучшить качество его кода.
Портируемый код должен использовать старый способ работы со
счетчиком. Это значит, что счетчик использования модуля должен быть
инкрементирован при каждом новом открытии сеанса работы с модулем и
декрементирован при каждом завершении сеанса. Также, портируемый код,
должен учитывать, что поле owner отсутствует в структуре
file_operations в ранних версиях ядра. Простейший способ решения этой
проблемы состоит в использовании SET_MODULE_OWNER, вместо прямого
обращения к полю field. В заголовочном файле sysdep.h мы определили
SET_FILE_OWNER в null, для ядер, которые не поддерживают эту
возможность.
Изменения в поддержке семафоров
Поддержка семафоров началась с ветки 2.0 ядра. В это время,
поддержка SMP систем была достаточно примитивна. При написании
драйверов только для тех версий ядра можно не использовать семафоры
вообще, т.к. эти версии ядер не использовались для многопроцессорных
систем. Однако, если вам, всеже, нужны семафоры, используйте директивы
условной компиляции для учета особенностей различных версий ядра.
Большинство семафорных функций, описанных в этой главе присутствуют
в ядре 2.0. Исключением является функция sema_init(). В версии ядра
2.0, программисты не могли инициализировать семафоры автоматически. В
заголовочном файле sysdep.h мы решаем эту проблему определением функции
sema_init() при компиляции для ядра 2.0.
#ifdef LINUX_20
# ifdef MUTEX_LOCKED /* Only if semaphore.h included */
extern inline void sema_init (struct semaphore *sem, int val)
{
sem->count = val;
sem->waking = sem->lock = 0;
sem->wait = NULL;
}
# endif
#endif /* LINUX_20 */
Изменения в доступе к адресному пространству пользователя из ядра
Доступ к адресному пространству пользователя из ядра был полностью
изменен начиная с серии ядра 2.1. Новый интерфейс лучше и удобнее
организован. В ядре 2.0 функции доступа к памяти выглядят следующим
образом:
void memcpy_fromfs(void *to, const void *from, unsigned long count);
void memcpy_tofs(void *to, const void *from, unsigned long count);
Имена этих функций связаны с историей использования сегментного
регистра FS на i386. Обратите внимание, что функции не возвращают
значений. И если пользователь передает некорректные указатели, то
ошибка не может быть фиксирована кодом модуля. В заголовочном файле
sysdep.h вы найдете преобразования для портируемого кода с
использованием функций copy_to_user() и copy_from_user().
Краткий справочник определений
В этом разделе собраны все определения и заголовочные файлы
описанные в данной главе, за исключением списка полей структур
file_operations и file.
- #include <linux/fs.h>
-
В этом заголовочном файле (fs - “file system”) описаны
важные, для написания драйверов устройств, элементы.
- int register_chrdev(unsigned int major, const char *name, struct file_operations *fops);
-
Функция регистрации драйвера устройства. Если старший номер задан нулем, то функция назначает устройству
динамический старший номер.
- int unregister_chrdev(unsigned int major, const char *name);
-
Функция отмены регистрации вызываемая при выгрузке драйвера. Значение major и name должны быть такими же,
какие были у драйвера во время регистрации.
- kdev_t inode->i_rdev;
-
Номер текущего устройства, доступный из структуры inode.
- int MAJOR(kdev_t dev);
- int MINOR(kdev_t dev);
-
Макросы, используемые для извлечения старшего и младшего номеров
устройства.
- kdev_t MKDEV(int major, int minor);
-
Макро, используемое для построения kdev_t из старшего и младшего номеров устройства.
- SET_MODULE_OWNER(struct file_operations *fops)
-
С помощью данного макро устанавливают поле field в структуре file_operations.
- #include <asm/semaphore.h>
-
Определение функций и типов для использования семафоров.
- void sema_init (struct semaphore *sem, int val);
-
Инициализация семафора в заданное значение. Мьютекс семафоров обычно инициализируют в значение 1.
- int down_interruptible (struct semaphore *sem);
- void up (struct semaphore *sem);
-
Получение и освобождение семафора соответственно. Во время получения семафора
возможен переход в спящее состояние.
- #include <asm/segment.h>
- #include <asm/uaccess.h>
-
В заголовочном файле segment.h определены функции относящиеся к
копированию данных между адресными пространствами пользователя и
ядра. Во время разработки ядра серии 2.1 название этого
заголовочного файла было изменено на uaccess.h.
- unsigned long __copy_from_user (void *to, const void *from, unsigned long count);
- unsigned long __copy_to_user (void *to, const void *from, unsigned long count);
-
Копирование данных между адресными пространствами пользователя и ядра.
- void memcpy_fromfs(void *to, const void *from, unsigned long count);
- void memcpy_tofs(void *to, const void *from, unsigned long count);
-
Эти функции используются для копирования данных между адресными пространствами
пользователя и ядра в ядре серии 2.0.
- #include <linux/devfs_fs_kernel.h>
- devfs_handle_t devfs_mk_dir (devfs_handle_t dir, const char *name, void *info);
- devfs_handle_t devfs_register (devfs_handle_t dir, const char *name, unsigned int flags,
- unsigned int major, unsigned int minor, umode_t mode, void *ops, void *info);
- void devfs_unregister (devfs_handle_t de);
-
Это базовые функции для регистрации устройств с использованием
специальной файловой системы devfs.
|

 LINUX
LINUX