Глава 5. Дополнительные операции в драйвере символьного устройства.
About: "По мотивам перевода" Linux Device Driver 2-nd edition.
Перевод: Князев Алексей knzsoft@mail.ru
Дата последнего изменения: 03.08.2004
Авторскую страницу А.Князева можно найти тут :
http://lug.kmv.ru/wiki/index.php?page=knz_ldd2
Архивы в переводе А.Князева лежат тут:
http://lug.kmv.ru/wiki/files/ldd2_ch1.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch2.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch3tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch4.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch5.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch6.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch7.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch8.tar.bz2
http://lug.kmv.ru/wiki/files/ldd2_ch13.tar.bz2
Содержание:
- Системный вызов ioctl()
- Выбор команд ioctl()
- Возвращаемое значение
- Предопределенные команды
- Использование аргумента команды в ioctl()
- Концепция "мандатов" (capabilities) и привилегированные операции
- Реализация команд ioctl()
- Управление устройством не используя ioctl()
- Блокировка ввода/вывода
- Уход в сон и пробуждение
- Углубленный взгляд на очередь ожидания
- Написание реентерабельного кода
- Блокируемые и неблокируемые операции
- Пример реализации: scullpipe
- Системные вызовы poll() и select()
- Взаимодействие с методами read() и write()
- Flushing - принудительный сброс выходного буфера
- Структуры данных для poll() и select()
- Асинхронные уведомления (Asynchronous Notification)
- Взгляд со стороны драйвера
- Seeking a Device - перемещение по данным в устройстве
- Реализация метода llseek()
- Дополнительное управление доступом к файлу устройства
- Устройства single-open - одно открытие за раз
- Отступление в проблему Race Conditions (борьба за ресурсы)
- Ограничение доступа по принципу "Один пользователь за раз"
- Блокировка метода open() как альтернатива EBUSY
- Клонирование устройства в методе open()
- Вопросы обратной совместимости
- Очереди ожидания в Linux 2.2 и 2.0
- Асинхронные уведомления
- Метод fsync()
- Доступ к пространству пользователя в ядре Linux 2.0
- "Мандаты" (Capabilities) в ядре 2.0
- Метод select() в ядре Linux 2.0
- Перемещение по файлу в ядре Linux 2.0
- Ядро 2.0 и SMP
- Краткий справочник определений
В главе 3, "Драйверы символьных устройств", мы создали самодостаточный драйвер символьного устройства,
с которым пользователь может производить операции чтения/записи. Но реальное устройство предлагает большую
функциональность, чем синхронное чтение и запись. Теперь, когда мы овладели техникой отладки мы можем благополучно
двигаться вперед и реализовывать новые, более сложные операции.
Обычно, в дополнении к операциям чтения и записи, существует необходимость выполнения различных операций по управлению
оборудованием через драйвер устройства. Операции управления, обычно поддерживаются через метод ioctl(). Альтернативный
способ управления заключается в передачи специальной управляющей последовательности в цикле записи в устройство. Тогда,
через анализ этой последовательности можно будет выполнить действия аналогичные прямому вызову ioctl(). По возможности,
следует избегать этой устаревшей техники управления устройством через передачу команд в цикле записи, т.к. это требует
резервирования нескольких байт данных в потоке записи для управляющих команд. Кроме того, реализация управления
устройством через цикл записи более сложно в реализации, чем управление через механизм ioctl(). Несмотря на неудобства,
управление через цикл записи используется, например, для tty и других устройств. Мы опишем это более подробно в
разделе "Управление устройствами без ioctl()".
Как мы упоминали в предыдущей главе, системный вызов ioctl() предлагает устройство-зависимые точки входа в драйвер
для передачи команд управления. Коды передаваемые через механизм ioctl() устройство-зависимы, т.е. уникальны для каждого
типа управляемого оборудования. Операции управления обычно недоступны через файловую абстракцию чтения/записи. Например,
все, что вы пишете в последовательный порт воспринимается как коммуникационные данные, и вы не можете изменить скорость
передачи данных записью кода в устройство. Таким образом, механизм ioctl() специально предназначен для управления
каналами ввода/вывода.
Другая важная особенность реальных устройств (не таких как scull) заключается в том, что при обмене данными между
устройствами требуется тот или иной механизм синхронизации. Концепции блочного ввода/вывода и асинхронного обмена
поясняются в этой главе на примере модификации scull устройства. Драйвер использует взаимодействие между различными
процессами для создания асинхронных событий. Как и в случае оригинального scull, нам не потребуется специального
оборудования для тестирования драйвера. Мы не будем работать с реальным устройством до главы 8 "Управление
оборудованием".
Системный вызов ioctl()
Вызов функции ioctl() в пользовательском процессе определяется следующим прототипом:
int ioctl(int fd, int cmd, ...);
Благодаря неопределенному списку параметров, данный прототип выгодно выделяется в списке системных вызовов Unix,
которые, обычно, представлены фиксированным числом формальных параметров. Однако, в реальной системе, системный
вызов не может иметь переменное число параметров. Системные вызовы должны иметь строго определенное количество
аргументов, так как пользовательские программы могут получить доступ к ним только через аппаратные "ворота"
(hardware gates), как подчеркнуто в разделе "User Space and Kernel Space" главы 2 "Создание и
запуск модулей". Поэтому, точки в прототипе, означают не переменное число параметров, а просто один необязательный
(опциональный) аргумент, обычно определяемый как char *argp. Точки в прототипе используются только для предотвращения
проверки типов в процессе компиляции. Действительный тип третьего аргумента зависит от передаваемой в процедуру команды,
которая определяется вторым аргументом. Некоторые команды не имеют аргументов, некоторые используют целый аргумент,
а некоторые берут в качестве аргумента указатель на структуру данных. Использование указателя позволяет передавать
в системный вызов ioctl() произвольное количество требуемых данных. Таким образом, это одна из возможностей обмена
произвольного объема данных между пользовательским процессом и процессом, работающем в ядре.
С другой стороны, функция ioctl() драйвера получает аргументы согласно следующему объявлению:
int (*ioctl) (struct inode *inode, struct file *filp,
unsigned int cmd, unsigned long arg);
Указатели inode и filp представляют собой значения соответствующие файловому дескриптору fd, переданному пользовательским
процессом, и полностью совпадают с параметрами, передаваемыми в системный вызов open(). Аргумент cmd передается от
пользователя неизменным, а необязательный аргумент arg передается в форме unsigned long, что может соответствовать
как целому значению, так и указателю. Если вызывающая программа не передает третий аргумент, то значение arg, полученное
драйвером имеет неопределенное значение.
Так как проверка типов передаваемых аргументов запрещена, компилятор не сможет предупредить вас о возможной ошибке,
и программист не узнает о ней до момента исполнения ошибочного кода. Этот недостаток есть небольшая плата за ту
функциональность, которую обеспечивает системный вызов ioctl().
Как вы можете предположить, реализация метода ioctl(), в большинстве случаев строится на основе оператора switch,
который обеспечивает ветвление, согласно значению аргумента cmd. Различные команды имеют различные числовые значения,
которым, обычно, дают символические имена для улучшения читабельности кода. Символические имена задаются через
директиву define препроцессора. Обычно, такие имена задаются в заголовочных файлах драйвера. Так для драйвера scull
они описаны в файле scull.h. Если пользовательская программа, хочет использовать те же символические имена, то
достаточно подключить к ней соответствующий заголовочный файл.
Выбор команд ioctl()
Перед реализацией функции ioctl() для нашего драйвера, мы должны определиться в кодах, которые будут соответствовать
используемым командам. К сожалению, простой выбор номеров, начинающихся с единицы не всегда работает хорошо.
Нумерация команд, должна быть, по возможности, уникальна в пределах операционной системы, для того, чтобы
предотвратить ошибки, которые могут возникнуть при ошибочном обращении к другому устройству. Такие ошибки не
настолько невероятны, как может показаться на первый взгляд. Если нумерация кодов команд, передаваемых в ioctl()
будет уникальна, то при обращении к "чужому" устройству вызывающая программа просто получит код ошибки
EINVAL, что, конечно же, предпочтительнее, нежели непредсказуемая настройка ошибочно адресованного устройства.
В помощь программистам, создающим уникальные коды команд для ioctl() было предложено соглашение, согласно которому коды
команд были разделены на несколько битовых полей. Первые версии Linux использовали 16-битовую нумерацию кодов.
Старшие восемь бит являлись "магическими" числами связанными с устройством, а младшие восемь бит представляли
коды команд для данного устройства. Так случилось, согласно собственным словам Линуса Торвальдса, по причине
его невежественности ("clueless"). Лучшее решение для использования битовых полей было найдено немного
позднее. К несчастью, в некоторых драйверах еще используется старое соглашение. В наших программах мы будем
использовать исключительно новое соглашение о нумерации кодов команд.
Для выбора кодов команд для передачи в ioctl() вашего драйвера, согласно новому соглашению, вы должны сначала
просмотреть файлы include/asm/ioctl.h и Documentation/ioctl-number.txt. В заголовочном файле определяется
использование битовых полей: тип ("магический номер"), порядковый номер команды, направление передачи и
размер аргумента. Файл ioctl-number.txt содержит список "магических номеров" используемых в ядре. Вам
необходимо выбрать номер отличающийся от зарезервированных в файле, для избежания перекрытия номеров. Также, в
этом текстовом файле содержится список причин, по которым, данное соглашение о нумерации кодов команд должно
быть использовано.
Согласно старому, не рекомендуемому сейчас, соглашению выбор нумерации кодов для ioctl() был проще: автор выбирал
"магический" восьмибитовый код для драйвера, например "k" (шестнадцатеричное значение – 0x6b)
и добавлял порядковый номер команды.
#define SCULL_IOCTL1 0x6b01
#define SCULL_IOCTL2 0x6b02
/* .... */
Конечно же, и приложение, и драйвер должны использовать одно и тоже соглашение о нумерации кодов команд. Выбрав
способ нумерации остается только организовать оператор switch в драйвере. Однако, способ нумерации, предложенный в
этом примере, хоть и имеет свои основания в традициях Unix, не должен более использоваться. Приведенный пример –
не более чем демонстрация того, как выглядит определение кодов команд в заголовочном файле драйвера.
Новый способ определения номеров команд использует четыре битовых поля, которые имеют описанное ниже значения. Все
новые, используемые здесь, макросимволы определены в <linux/ioctl.h>.
- type
-
Магическое число. Выбор номера необходимо осуществлять после
ознакомления с файлом ioctl-number.txt. Именно этот выбранный номер,
необходимо, в дальнейшем, использовать везде, где он потребуется для
вашего драйвера. Данное поле имеет емкость в восемь бит
(_IOC_TYPEBITS).
- number
-
Порядковый номер. Емкость – восемь бит (_IOC_NRBITS).
- direction
-
Направление передачи данных, если данная команда вызывает пересылку
данных. Возможные значения: _IOC_NONE (нет передачи данных),
_IOC_READ, _IOC_WRITE, и _IOC_READ | _IOC_WRITE (данные передаются в
обоих направлениях). Точкой наблюдения передачи данных является
приложение. Таким образом _IOC_READ означает чтение данных из
устройства, так, что драйвер должен писать в пользовательский
процесс. Обратите внимание, что это поле представляет собой битовую
маску, поэтому и _IOC_READ и _IOC_WRITE могут быть извлечены
используя логическую операцию AND.
- size
-
Размер передаваемых данных. Емкость этого поля архитектурно-зависима
и, сейчас, лежит в диапазоне от 8 до 14 бит. Вы можете определить
его значение для вашей архитектуры из макро _IOC_SIZEBITS. Если вы
создаете портируемый драйвер, то значение этого поля не должно
превышать 255. Использование данного поля не является обязательным.
Если вы передаете больший размер данных, то вы можете просто
игнорировать его. Скоро, мы увидим пример использования этого поля.
В заголовочном файле <asm/ioctl.h>, который включен в <linux/ioctl.h>, определены следующие макросы,
которые помогут вам установить номер команды: _IO(type,nr), _IO(type,nr,dataitem), _IOW(type,nr,dataitem) и
_IOWR(type,nr,dataitem). Каждое макро соответсвует одному возможному значению для направления передачи. Поля
type и number передаются как аргументы, а поле size вычисляется как sizeof() над аргументом dataitem. В заголовочном
файле, также, определены макросы для декодирования номеров: _IOC_DIR(nr), _IOC_TYPE(nr), _IOC_NR(nr) и _IOC_SIZE(nr).
Ниже приведен пример некоторых ioctl-команд, определенных в драйвере scull. В частности команд, которые
устанавливают и получают параметры конфигурирования драйвера.
/* Use 'k' as magic number */
#define SCULL_IOC_MAGIC 'k'
#define SCULL_IOCRESET _IO(SCULL_IOC_MAGIC, 0)
/*
* S means "Set" through a ptr
* T means "Tell" directly with the argument value
* G means "Get": reply by setting through a pointer
* Q means "Query": response is on the return value
* X means "eXchange": G and S atomically
* H means "sHift": T and Q atomically
*/
#define SCULL_IOCSQUANTUM _IOW(SCULL_IOC_MAGIC, 1, scull_quantum)
#define SCULL_IOCSQSET _IOW(SCULL_IOC_MAGIC, 2, scull_qset)
#define SCULL_IOCTQUANTUM _IO(SCULL_IOC_MAGIC, 3)
#define SCULL_IOCTQSET _IO(SCULL_IOC_MAGIC, 4)
#define SCULL_IOCGQUANTUM _IOR(SCULL_IOC_MAGIC, 5, scull_quantum)
#define SCULL_IOCGQSET _IOR(SCULL_IOC_MAGIC, 6, scull_qset)
#define SCULL_IOCQQUANTUM _IO(SCULL_IOC_MAGIC, 7)
#define SCULL_IOCQQSET _IO(SCULL_IOC_MAGIC, 8)
#define SCULL_IOCXQUANTUM _IOWR(SCULL_IOC_MAGIC, 9, scull_quantum)
#define SCULL_IOCXQSET _IOWR(SCULL_IOC_MAGIC,10, scull_qset)
#define SCULL_IOCHQUANTUM _IO(SCULL_IOC_MAGIC, 11)
#define SCULL_IOCHQSET _IO(SCULL_IOC_MAGIC, 12)
#define SCULL_IOCHARDRESET _IO(SCULL_IOC_MAGIC, 15) /* debugging tool */
#define SCULL_IOC_MAXNR 15
Последняя команда, HARDRESET, используется для сброса счетчика использования модуля в 0, так, что модуль может
быть выгружен при возникновении каких-нибудь проблем со счетчиком. В действительном коде драйвера, также определены
команды между IOCHQSET и HARDRESET, которые не показаны здесь.
Мы выбрали для реализации оба способа передачи параметров – по указателю и явному значению, хотя по
установившемуся соглашению ioctl() должен обмениваться значениями по указателю. Также, не имеет значения, какой
способ будет использоваться для возврата целого значения – через указатель или через механизм возврата
функции (return). Но последнее будет работать только для возврата положительных целых значений, т.к.
отрицательное значение воспринимается ядром как ошибка и используется для передачи errno в пространство пользователя.
Операции "exchange" (обмен) и "shift" (смена) не являются необходимыми для нашего драйвера scull. Мы
реализовали "exchange" для того, чтобы показать, как драйвер может соединять различную функциональность
в одной атомарной операции. "shift" мы реализовали как пару "tell" (сказать) и "query"
(запросить). Бывают случаи, когда атомарные операции типа test-and-set, наподобии этой, необходимы, в особенности,
когда приложение должно установить или снять блокировки.
Фрагмент кода называется атомарным, когда он выполняется как одна инструкция, без каких-бы то ни было прерываний.
Порядковый номер команд не имеет какого-то специфического значения. Он используется только для различения
команд. Вообще, вы можете даже использовать одинаковые номера команд для операций чтения и записи, так как, реальный
вычисляемый ioctl-номер таких команд будет различаться битами направления передачи ("direction" bits).
Значение параметра cmd в ioctl-вызове не анализируется ядром, и врядли такой анализ будет производиться в
будущем. Поэтому, в принципе, вы можете не пользоваться таким сложным способом определения номеров, и просто явно
определить набор скалярных номеров (скалярный, т.е. не состоящих из частей – битовых полей). С другой стороны,
если вы выберите такой способ определения номеров команд, вы не получите выгоды от использования битовых полей.
Заголовочный файл <linux/kd.h> представляет собой пример такого назначения номеров в старом стиле. Во время
написания этого файла другой технологии определения номеров в Linux просто не было. Теперь, приведение этого файла
к современному виду приведет к серьезным проблемам несовместимости.
Возвращаемое значение
В реализации ioctl() для анализа номеров команд обычно используется оператор switch. Возникает вопрос о реализации
блока default при передаче в системный вызов некорректного кода команды. Данный вопрос является спорным. Некоторые
функции ядра возвращают, в этом случае, вполне логичное значение -EINVAL ("Invalid argument"), потому
что переданный аргумент действительно некорректен. Однако, согласно стандарту POSIX, в этом случае, необходимо
возвращать значение -ENOTTY. С даннной ошибкой должно быть связано текстовое сообщение "Not a typewriter".
Данное правило распространялось на все ранние библиотеки до libc5 включительно. Только начиная с libc6 сообщение,
связанное с этой ошибкой, было изменено на более корректное – "Inappropriate ioctl for device".
Большинство современных Linux систем построены на основе libc6, и мы призываем вас придерживаться стандарта и
использовать в качестве кода ошибки значение -EINVAL.
Предопределенные команды
Некоторые из команд системного вызова ioctl распознаются ядром, что означает декодирование номеров команд до
вызова ioctl-функции вашего драйвера. Поэтому, в случае если вы выбрали такие номера для своих ioctl-команд, вызов
вашей ioctl-функции драйвера не произойдет, и приложение получит неожидаемый ответ на системный запрос.
Предопределенные команды подразделяются на три группы:
-
Команды, которые могут быть использованы для любых типов файлов (обычных, файлов интерфейсов устройств,
FIFO, или сокетов)
-
Команды, которые могут быть использованы только для обычных файлов
-
Команды, связанные с определенным типом файловых систем
Команды из последней группы реализуются драйверами файловых систем (см. команду chattr). Разработчикам драйверов
наиболее интересны команды из первой группы, которые обозначаются магической литерой "T". Знакомство с
другими предопределенными командами предоставляется интересующимся читателям в качестве упражнения (команда
ext2_ioctl, реализующая append-only и immutable флаги, наверное, наиболее интересна).
Следующие ioctl команды предопределены для любых типов файлов:
- FIOCLEX
-
Установка флага close-on-exec (File Ioctl CLose on EXec). Установка этого флага приведет к
закрытию файлового дескриптора, если вызывающий процесс выполняет новую программу.
- FIONCLEX
-
Сброс флага close-on-exec.
- FIOASYNC
-
Установка или сброс асинхронных уведомлений для файла (как описано в разделе "Асинхронное уведомление"
позднее в этой главе). Заметьте, что ядра, до версии 2.2.4 некорректно использовали эту команду для
модификации флага O_SYNC. И установка и сброс асинхронных уведомлений могут быть выполнены другими путями,
поэтому, в действительности, никто не использует команду FIOASYNC. Объявление этой команды служит более
целям полноты описания.
- FIONBIO
-
"File IOctl Non-Blocking I/O" (описано позднее в этой главе, в разделе "Blocking and Nonblocking
Operations"). Этот вызов изменяет значение флага O_NONBLOCK в поле filp->f_flags. Третий аргумент в
этом системном вызове используется для передачи информации об установке или сбросе данного флага. Смысл этого
флага будет объяснен в этой главе позднее. Заметьте, что данный флаг может быть также изменен системным
вызовом fcntl(), используя команду F_SETFL в качестве его параметра.
Последний элемент в этом списке знакомит нас с новым системным вызовом fcntl(), который выглядит схожим с ioctl().
Схожесть заключается в том, что оба системных вызова получают, среди прочего, аргумент команду, и дополнительный
(необязательный) аргумент. Различия этих вызовов имеют, главным образом, исторические причины. Когда разработчики
Unix обдумывали проблему управления операциями ввода/вывода, то они решили, что файлы и устройства будут различаться.
В то время, только устройства ttys управлялись через вызовы ioctl(), что и объясняет тот факт, почему код ошибки -ENOTTY
был определен для некорректной ioctl() команды. С тех пор многое изменилось, но системный вызов fcntl() остался во
имя обратной совместимости.
Использование аргумента команды в ioctl()
Перед тем, как мы рассмотрим реализацию кода вызова ioctl() для драйвера scull, необходимо обсудить использование
дополнительного аргумента для команды, переданной в ioctl(). Если это целое число, то все просто – оно
используется по прямому назначению. Однако, если это указатель, то мы должны учитывать различия в адресных
пространствах ядра и пользовательских процессов.
Когда указатель используется для ссылки в пространство пользователя, то мы должны быть уверены в его корректности,
и в том, что требуемая страница виртуальной памяти, в данный момент, является отображенной в пространство физической
памяти. Если код пытается обратиться за пределы доступного адресного пространства, то процессор вырабатывает исключение.
Исключения в коде ядра приводят к сообщению oops для всех ядер вплоть до версии 2.0.x. Версии 2.1 и более поздние,
обрабатывают это исключение немного более изящно. Но, в любом случае, ответственность за использование некорректных
указателей из адресного пространства пользователя должно лежать на коде ядра, который должен корректно обрабатывать
эту ситуацию и возвращать ошибку, не доводя дело до исключительных ситуаций.
Проверка корректности адреса в ядрах до версии 2.2.x реализуется через вызов функции access_ok(), которая описана в
заголовочном файле <asm/uaccess.h>:
int access_ok(int type, const void *addr, unsigned long size);
Первый аргумент должен иметь значение либо VERIFY_READ, либо VERIFY_WRITE, в зависимости от того, собираемся мы
читать или писать в память пользовательского адресного пространства. Аргумент addr указывает на адрес адресного
пространства пользователя, а аргумент size – количество байт тестируемого диапазона адресов, начиная с адреса
addr. Например, если в реализации ioctl() необходимо прочитать целое значение из адресного пространства пользователя,
то значение size будет равно sizeof(int). Если вам требуется и чтение и запись по заданному диапазону адресов, то в
качестве первого аргумента необходимо задавать VERIFY_WRITE, т.к. это значение является надмножеством для VERIFY_READ.
В отличии от большинства функций, access_ok() возвращает булево значение: 1 – в случае успешной проверки, и 0
– в случае неудачи. Если проверка адреса не удалась, то драйвер обычно возвращает код ошибки -EFAULT.
Имеется пара интересных вещей, которые необходимо знать о работе функции access_ok(). Прежде всего, функция не
выполняет полной проверки для заданного диапазона адресов – определяется только принадлежность заданного
диапазона тому множеству адресов, которые доступны для данного процесса. Таким образом, функция access_ok() может
гарантировать, что заданный диапазон адресов не принадлежит пространству ядра. Кроме того, необходимо помнить, что в
большинстве случаев вы не столкнетесь с необходимостью прямого вызова access_ok(), т.к. процедуры доступа к памяти,
которые будут описаны позднее, выполняют эту проверку за вас. Тем не менее, мы продемонстрируем использование этой
функции как в чисто учебных целях, так и по причинам обратной совместимости, о которых мы расскажем в конце этой главы.
Модуль scull использует битовые поля в номере команды, передаваемой в ioctl(), для проверки аргументов перед
диспетчерезацией в операторе switch:
int err = 0, tmp;
int ret = 0;
/*
* extract the type and number bitfields, and don't decode
* wrong cmds: return ENOTTY (inappropriate ioctl) before access_ok()
*/
if (_IOC_TYPE(cmd) != SCULL_IOC_MAGIC) return -ENOTTY;
if (_IOC_NR(cmd) > SCULL_IOC_MAXNR) return -ENOTTY;
/*
* the direction is a bitmask, and VERIFY_WRITE catches R/W
* transfers. `Type' is user oriented, while
* access_ok is kernel oriented, so the concept of "read" and
* "write" is reversed
*/
if (_IOC_DIR(cmd) & _IOC_READ)
err = !access_ok(VERIFY_WRITE, (void *)arg, _IOC_SIZE(cmd));
else if (_IOC_DIR(cmd) & _IOC_WRITE)
err = !access_ok(VERIFY_READ, (void *)arg, _IOC_SIZE(cmd));
if (err) return -EFAULT;
После вызова access_ok() драйвер может безопасно выполнять передачу данных из одного адресного пространства в другое
(ядро и пользовательский процесс). В добавлении к функциям copy_from_user() и copy_to_user(), выполняющим такую
передачу данных, программист может использовать множество функций, которые оптимизированы для наиболее
часто используемых размеров данных – один, два, четыре, или восемь байт (для 64-х разрядной платформы). Приведем
список этих функций, описанных в заголовочном файле <asm/uaccess.h>.
-
put_user(datum, ptr) __put_user(datum, ptr)
-
Данные макросы пишут datum в адресное пространство пользователя. Они относительно быстрее, и должны
быть использованы вместо copy_to_user() везде, где требуется передача скалярного значения. Так как при
расширении этих макроопределений не выполняется проверка типов, то вы можете передать любой тип указателя
в put_user() из адресного пространства пользователя. Размер передаваемых данных зависит от типа аргумента
ptr и определяется во время компиляции, используя специальные псевдофункции, определенные в gcc, и на
которых не стоит сейчас акцентировать внимание. В результате, если ptr указатель на char, то будет
передан один байт данных. То же для двух, четырех, и, возможно, восьми байт.
-
put_user() проверяет возможность записи по данному адресу памяти. В случае успешного завершения возвращается
0, и -EFAULT в случае ошибки. __put_user() выполняет меньшее количество проверок (не выполняется вызов
access_ok()), но определенные ошибки неправильной адресации могут быть определены данным вызовом. Таким образом,
__put_user() должен быть использован только если регион памяти был уже проверен вызовом access_ok().
-
В общем, можно сказать, что при необходимости многократного обращения к одному региону памяти, вызов
access_ok() следует производить только перед первым обращением к региону, и использовать __put_user() в
дальнейшем.
-
get_user(local, ptr) __get_user(local, ptr)
-
Эти макросы используются для получения одного элемента данных из адресного пространства пользователя.
Их поведение схоже с макросами put_user() и __put_user(), но передача данных производится в
обратном направлении. Полученное из адресного пространства пользователя значение сохраняется в локальной
переменной local. Возвращаемое макросом значение определяет успешность выполнения операции. Макрос
__get_user() следует использовать только в том случае, если корректность адреса была уже проверена вызовом
access_ok().
Если попытка выполнения передачи данных с помощью описанных выше макросов приводит, на этапе компиляции, к сообщению
типа "conversion to non-scalar type requested", то размер передаваемого аргумента не соответствует
размерам обрабатываемым макросом. В этом случае, необходимо воспользоваться функциями copy_to_user() и copy_from_user().
Концепция "мандатов" (capabilities) и привилегированные операции
Доступ к устройству определяется атрибутами прав доступа к файловому интерфейсу устройства, и драйвер, обычно, не
содержит кода дополнительного контроля доступа. Однако, возможны ситуации, когда некоторые операции должны быть
запрещены для части пользователей, имеющих разрешения чтения/записи на устройство. Например, не каждый пользователь
накопителя на магнитной ленте должен иметь возможность изменять размер блока, установленного для этого устройства
по умолчанию. Т.е. необходимо различать настройку и обычное использование устройства. В подобных случаях, драйверу
необходимо осуществлять дополнительные проверки прав доступа к устройству различных пользователей на некоторые
конкретные операции.
Традиционно, системы Unix, допускают привилегированные операции только для суперпользователя. Привилегии можно
рассматривать как концепцию "все-или-ничего" (all-or-nothing) – суперпользователю можно абсолютно все,
но остальные пользователи являются крайне ограниченными на права доступа к системе. Ядро Linux, начиная с версии
2.2, предоставляет более гибкую концепцию, которою можно называть мандатной (capabilities). Мне затруднительно
подобрать точный перевод английского слова capabilities – это, например, можно попробовать перевести как
концепция потенциальных возможностей. Выбирайте сами, а лучше используйте оригинальный английский вариант –
capability-based system. Так вот, такие системы отклоняют правило “все-или-ничего”, и разделяют
привилегированные операции по различным подгруппам. В этом случае, некоторые пользователи (или программы) могут
получить права на выполнение некоторых специфических привилегированных операций, не получая прав на другие
привилегированные операции. Такая концепция пока мало используется в пространстве пользователя, но широко
используется в пространстве ядра.
Полный набор таких "мандатов" (capabilities) может быть найден в заголовочном файле <linux/capability.h>.
Рассмотрим некоторые элементы, которые могут быть интересны разработчику драйверов:
- CAP_DAC_OVERRIDE
-
Дает возможность перекрытия ограничений доступа к файлам и каталогам.
- CAP_NET_ADMIN
-
Позволяет выполнять сетевые задачи администрирования, включая те, которые определяют сетевой интерфейс.
- CAP_SYS_MODULE
-
Дает возможность загружать или выгружать модули ядра.
- CAP_SYS_RAWIO
-
Дает возможность выполнения операций "сырого" (raw) ввода/вывода. Например, обращение к портам
устройства, или прямое взаимодействие с устройствами USB.
- CAP_SYS_ADMIN
-
Особый мандат “catch-all” (владеть-всем), который обеспечивает доступ ко многим операциям
системного администрирования.
-
Прим. переводчика: Судя по всему, в оригинале какое-то недоразумение. Мандат CAP_SYS_ADMIN в
моем текущем ядре 2.4.26, согласно комментариям в файле <linux/capability.h> дает возможность только
на использование системной функции reboot(). Зато определение CAP_SYS_PACCT действительно позволяет получить
доступ к нескольким десяткам операций системного администрирования.
- CAP_SYS_TTY_CONFIG
-
Дает возможность выполнения задач конфигурирования tty.
Перед выполнением привилегированной операции, драйвер устройства должен проверить, что вызывающий процесс имеет
соответствующий “мандат”. Такую проверку можно осуществить с помощью функции capable(), определенной
в заголовочном файле <sys/sched.h>:
int capable(int capability);
В примере драйвера scull, любой пользователь имеет права на получение информации о размерах кванта или массива квантов.
Однако, только привилегированный пользователь может изменять эти значения, т.к. неверный выбор значений для этих
параметров может отрицательно сказаться на производительности системы. При необходимости, драйвер scull проверяет
уровень привилегированности пользователя следующим способом:
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
Выбор мандата определяется из следующих соображений. Если в файле <linux/capability.h> отсутствует более
специфический для данной привилегии мандат, то выбирается общий – CAP_SYS_ADMIN.
Реализация команд ioctl()
Реализация ioctl() в драйвере scull очень проста. Данный системный вызов используется для передачи и получения
некоторых настроечных параметров драйвера. Опустив часть почти повторяющегося кода, приведем реализацию наиболее
интересных команд метода ioctl():
switch(cmd) {
#ifdef SCULL_DEBUG
case SCULL_IOCHARDRESET:
/*
* reset the counter to 1, to allow unloading in case
* of problems. Use 1, not 0, because the invoking
* process has the device open.
*/
while (MOD_IN_USE)
MOD_DEC_USE_COUNT;
MOD_INC_USE_COUNT;
/* don't break: fall through and reset things */
#endif /* SCULL_DEBUG */
case SCULL_IOCRESET:
scull_quantum = SCULL_QUANTUM;
scull_qset = SCULL_QSET;
break;
case SCULL_IOCSQUANTUM: /* Set: arg points to the value */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
ret = __get_user(scull_quantum, (int *)arg);
break;
case SCULL_IOCTQUANTUM: /* Tell: arg is the value */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
scull_quantum = arg;
break;
case SCULL_IOCGQUANTUM: /* Get: arg is pointer to result */
ret = __put_user(scull_quantum, (int *)arg);
break;
case SCULL_IOCQQUANTUM: /* Query: return it (it's positive) */
return scull_quantum;
case SCULL_IOCXQUANTUM: /* eXchange: use arg as pointer */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
tmp = scull_quantum;
ret = __get_user(scull_quantum, (int *)arg);
if (ret == 0)
ret = __put_user(tmp, (int *)arg);
break;
case SCULL_IOCHQUANTUM: /* sHift: like Tell + Query */
if (! capable (CAP_SYS_ADMIN))
return -EPERM;
tmp = scull_quantum;
scull_quantum = arg;
return tmp;
default: /* redundant, as cmd was checked against MAXNR */
return -ENOTTY;
}
return ret;
Шесть способов передачи и приема аргументов выглядят, с точки зрения пользовательского процесса, следующим образом:
int quantum;
ioctl(fd,SCULL_IOCSQUANTUM, &quantum);
ioctl(fd,SCULL_IOCTQUANTUM, quantum);
ioctl(fd,SCULL_IOCGQUANTUM, &quantum);
quantum = ioctl(fd,SCULL_IOCQQUANTUM);
ioctl(fd,SCULL_IOCXQUANTUM, &quantum);
quantum = ioctl(fd,SCULL_IOCHQUANTUM, quantum);
Конечно, в обычном драйвере, наверное, не реализуется такой
калейдоскоп передачи параметров. Здесь, мы ставим целью только
демонстрацию всех возможных способов передачи.
Управление устройством не используя ioctl()
Управление некоторыми устройствами удачнее реализуется через запись управляющей последовательности в само
устройство. Такая техника, например, используется для драйвера консоли, в который передаются, так называемые
эскейп-последовательности (esc-последовательности), используемые для перемещения курсора, изменения цвета, и
выполнения других конфигурационных задач. Выгода такого способа управления заключается в том, что пользователи,
имеющие права на запись в устройство могут участвовать в управлении им не приобретая специальных привилегий, и
не используя специальных программ, реализующих ioctl() вызовы.
Например, программа setterm (см. man setterm) управляет конфигурацией консоли (или другого терминала) передачей
esc-последовательностей. Дополнительным преимуществом такого управления является простота удаленного управления
устройством. Управляющая программа и управляемое устройство могут размещаться на разных компьютерах, т.к. управление
может осуществляться простым перенаправлением потока данных.
Неприятной стороной такого управления устройством являются
дополнительные ограничения по управлению устройством.
Например, вы должны быть уверены, что управляющие последовательности не
окажутся внутри потока данных передаваемых в
устройство. Это справедливо и для tty. Несмотря на то, что текстовый
дисплей предназначен для отображения только символов ASCII, иногда, в
потоке передаваемых данных, могут оказаться управляющие символы,
влияющие на настройку консоли. Это может случиться,
например, при выполнении операции grep над бинарными файлами -
извлекаемые строки могут содержать все, что угодно, в том
числе и коды, воспринимаемые консолью как управляющие. Так, например,
это может закончиться изменением шрифтов в
консоли.
Символ CTRL-N устанавливает альтернативный шрифт в консоли, состоящий из графических символов, не
являющихся дружественными по отношению к вводу символов в вашей командной оболочке. Если вы столкнулись с этой
проблемой, то передайте в консоль (командой echo) символ CTRL-O для восстановления исходного шрифта.
Управление посредством записи в устройство лучшим образом подходит для устройств, работа которых, в основном, состоит в
отклике на принимаемые ими команды. К таким устройствам, прежде всего, следует отнести различные робототехнические
устройства.
Например, от нечего делать, авторами оригинального английского материала этой книги, был написан драйвер, управляющий
перемещением камеры по двум осям. "Устройством" для данного драйвера является пара старых шаговых двигателей,
для которых, обычное понимание операций чтения/записи не имеет смысла. Поэтому, переданные в операции записи данные,
драйвер интерпретирует как ASCII команды и преобразует их в электрические импульсы управления шаговыми двигателями. Эта
идея схожа с концепцией управления модемом через последовательность AT-команд. Различие заключается лишь в том, что
используемый для соединения с устройством последовательный порт используется не только для передачи команд, но и для
передачи данных. Неоспоримым преимуществом такого способа управления является возможность использования стандартных
команд типа cat для управления устройством, не утруждая себя написанием и использованием специальных программ
реализующих системные вызовы ioctl.
При написании командно-ориентированных драйверов, не имеет смысла реализовывать метод ioctl(). Добавление команд в
интерпретатор проще в реализации и использовании, нежели расширение функциональности драйвера через механизм ioctl(),
прежде всего тем, что может не потребует исправление в пользовательской программе в обязательном порядке. Возможно,
стоит напомнить, что при реализации управления драйвером через механизм ioctl(), вам потребуется специальная программа
пользовательского уровня для предоставления интерфейса управления, в то время как реализация управления через метод
write() драйвера, позволит использовать стандартный набор утилит Unix (echo, cat и пр.) для взаимодействия с устройством.
Блокировка ввода/вывода
В реализации отклика на чтение в драйвере может возникнуть проблема, когда, с одной стороны,
данные еще не кончились (т.е. нет конца файла), но, в данный момент, еще не готовы.
Наверное вы уже догадались, что в этом случае, необходимо отправить вызывающий процесс в спящее состояние ("go
to sleep waiting for data"). В этом разделе мы покажем как перевести процесс в спящее состояние, как его
разбудить, и как приложение может определить готовность данных. Затем мы применим эту же концепцию к операции записи.
Прежде чем продемонстрировать код, мы объясним некоторые концепции.
Уход в сон и пробуждение
Всегда, когда процесс должен ждать какого-либо события (ожидание данных, или завершение другого процесса), он должен
быть погружен в спящее состояние. Это означает, что система приостанавливает исполнение процесса, освобождая
процессор для исполнения других процессов. Позже, когда ожидаемое событие реализуется, процесс будет разбужен и
продолжит свою работу. В этом разделе будет обсуждаться реализация этого механизма для ядра 2.4.
Позднее, в разделе "Вопросы обратной совместимости" мы рассмотрим особенности более ранних версий.
Существует несколько способов управления переводом процесса в спящее состояние и его пробуждения. Каждый из этих
способов используется в разных контекстах. Однако, все эти способы используют один и тот же тип данных –
очередь ожидания (wait_queue_head_t). Очередь ожидания – это очередь процессов, ожидающих какого-либо события.
Очередь ожидания описывается и инициализируется следующим образом:
wait_queue_head_t my_queue;
init_waitqueue_head (&my_queue);
Даже если очередь ожидания описана статически (static), т.е. она определена не как автоматическая переменная или
часть динамически распределенной структуры данных, то, по прежнему, возможна инициализация очереди на этапе компиляции:
DECLARE_WAIT_QUEUE_HEAD (my_queue);
Наиболее общей ошибкой является игнорирование процедуры инициализации очереди ожидания. Возможно, это следствие того,
что в ранних версиях ядра такая инициализации не требовалась. Если вы забудете выполнить такую инициализацию то
результат работы с очередью будет непредсказуемым.
После того, как очередь ожидания описана и проинициализирована, ее можно использовать для перевода процесса в
спящее состояние. Такой перевод осуществляется вызовом одной из sleep_on-функций:
- sleep_on(wait_queue_head_t *queue);
-
Функция выполняет перевод процесса в спящее состояние. Недостатком использования такого способа
приостановки выполнения процесса является невозможность его прерывания. Т.е. процесс становится
неубиваемым, если ожидаемое им событие не может случиться.
-
interruptible_sleep_on(wait_queue_head_t *queue);
-
Прерываемый вариант. Работает также как и sleep_on(), но переведенный в сон процесс может быть
прерван сигналом. Разработчики драйверов использовали такую форму вызова достаточно долгое время до
появления, описанной ниже, альтернативы wait_event_interruptible().
-
sleep_on_timeout(wait_queue_head_t *queue, long timeout);
-
interruptible_sleep_on_timeout(wait_queue_head_t *queue, long timeout);
-
Поведение этих двух функций сходно с поведением функций описанных выше, с той лишь разницей, что
уснувший процесс может находится в состоянии сна не дольше заданного таймаута. Таймаут определен в
джифисах (jiffies) – 0.01 сек. Подробнее об этом будет рассказано в главе 6 "Flow of Time".
-
void wait_event(wait_queue_head_t queue, int condition);
-
int wait_event_interruptible(wait_queue_head_t queue, int condition);
-
Эти макросы предоставляют наиболее предпочтительный способ перевода процесса в сон до момента удовлетворения
заданного условия. Макросы связывают ожидание события и проверку его возникновения способом, позволяющим избежать
проблемы "race condition" (борьба за ресурсы). Код будет спать до момента возникновения условия,
которое может быть задано любым логическим выражением языка Си, вычисляемым в true (истина).
-
Данные макросы расширяются в цикл while, который перевычисляет условие перед каждым повторением тела цикла.
Такое поведение отличается от вызова функции или простого макро, где аргументы вычисляются только в момент
вызова. Последниее макро реализуется как выражение, которое возвращает ноль в случае успеха, и -ERESTARTSYS,
если цикл прерывается сигналом.
Стоит заметить, что в большинстве случаев разработчики драйверов должны всегда использовать прерываемые варианты этих
функций/макросов. Непрерываемые версии предоставляются для случаев, когда обработка сигналов нежелательна, либо опасна.
Например, при ожидании страницы данных из пространства свопа. В большинстве драйверов не возникает подобных ситуаций.
Понятно, что перевод в состояние сна только половина проблемы. Пробуждение - вторая часть этой проблемы. Как правило,
если одна часть драйвера спит, то существует другая его часть, которая может выполнить пробуждение, при возникновении
определенного события. Как правило, драйвер пробуждает спящие куски кода в своем обработчике прерываний при получении новой
порции данных. Однако, возможен и другой сценарий.
Поскольку существует несколько способов перевода в спящее состояние, то существует и более одного способа пробуждения.
Рассмотрим список высокоуровневых фукнций, предоставляемых ядром, для пробуждения процесса.
-
wake_up(wait_queue_head_t *queue);
-
Данная функция будит все процессы, которые ожидают данной очереди.
-
wake_up_interruptible(wait_queue_head_t *queue);
-
Данная функция будит только те процессы, которые находятся в прерываемом сне. Все остальные процессы, которые
заснули по заданной очереди событий, но были переведены в сон с помощью "непрерываемых" функций,
останутся в спящем состоянии.
-
wake_up_sync(wait_queue_head_t *queue);
wake_up_interruptible_sync(wait_queue_head_t *queue);
-
Обычно, вызов wake_up() может привести к немедленному переупорядочиванию очереди, означающему, что другие
процессы могут быть запущены до того, как вызов wake_up() завершится. "Синхронный" вариант вызова помечает разбуженные
процессы запускаемыми, но не переупорядочивает очередь. Это используется для предотвращения переупорядочивания очереди,
в случае, если текущему процессу известно о переводе в сон, что позволяет использовать принудительное
переупорядочивание. Заметьте, что разбуженные процессы могут быть немедленно запущены на другом процессоре, и
использование этих функций должно предотвращать ситуацию mutual exclusion ("взаимное исключение").
-
Примечание переводчика: Перевод последнего абзаца, наверное, неверен. Привожу оригинал. "Normally, a wake_up call
can cause an immediate reschedule to happen, meaning that other processes might run before
wake_up returns. The "synchronous" variants instead make any awakened processes runnable, but do not reschedule the CPU.
This is used to avoid rescheduling when the current process is known to be going to sleep, thus forcing a reschedule
anyway. Note that awakened processes could run immediately on a different processor, so these functions should not be
expected to provide mutual exclusion."
Если ваш драйвер использует interruptible_sleep_on(), то имеется небольшое отличие между вызовами wake_up() и
wake_up_interruptible(). Однако, чтобы быть последовательным, используя interruptible_sleep_on() для перевода в сон,
следует использовать wake_up_interruptible() для пробуждения.
В качестве примера использования очереди ожидания, вообразите, что вы хотите перевести процесс в сон, при чтении вашего
устройства, и разбудить его, когда кто-нибудь еще осуществляет запись в устройство. Следующий код реализовывает
описанную функциональность:
DECLARE_WAIT_QUEUE_HEAD(wq);
ssize_t sleepy_read (struct file *filp, char *buf, size_t count,
loff_t *pos)
{
printk(KERN_DEBUG "process %i (%s) going to sleep\n",
current->pid, current->comm);
interruptible_sleep_on(&wq);
printk(KERN_DEBUG "awoken %i (%s)\n", current->pid, current->comm);
return 0; /* EOF */
}
ssize_t sleepy_write (struct file *filp, const char *buf, size_t count,
loff_t *pos)
{
printk(KERN_DEBUG "process %i (%s) awakening the readers...\n",
current->pid, current->comm);
wake_up_interruptible(&wq);
return count; /* succeed, to avoid retrial */
}
Вы можете использовать этот код в качестве примера управления переводом в сон и пробуждением процесса. Для тестирования
можно использовать обычную команду cat с перенаправлением ввода/вывода.
Вы должны помнить, что пробуждение процесса может быть связано не с тем событием, которого он ожидал. Процес может быть
разбужет по другим причинам, например, в результате получения сигнала. Поэтому, спящий код должен проверять необходимое
условие после пробуждения. Подробнее это рассмотрено в разделе "Простая реализация: scullpipe" в этой главе
позднее.
Углубленный взгляд на очередь ожидания
Ранее мы обсудили все то, что должны знать большинство разработчиков драйверов для управления переводов процессов в сон
и их пробуждением. Однако, некоторым читателям захочется узнать об этом немного больше. В этом разделе мы попытаемся, в
общих чертах, удовлетворить их любопытство. Все остальные могут пропустить этот раздел не боясь упустить что-либо
важное.
Тип wait_queue_head_t, в действительности, очень простая структура, определенная в <linux/wait.h>. Она содержит
только переменную lock и связанный список спящих процессов. Индивидуальные элементы данных списка представлены типом
wait_queue_t, который представляет собой обычный список, определенный в <linux/list.h>, и описан в разделе
"Связанные списки" в главе 10 "Judicious Use of Data Types". Обычно, структуры wait_queue_t
распределяются в стеке такими функциями, как interruptible_sleep_on(). Эти структуры оказываются в стеке просто потому,
что они описаны как автоматические переменные в соответствующих функциях. Как правило, у программиста не возникает
необходимости использования этих структур.
Однако, в некоторых приложениях, может потребоваться прямая работа с переменными wait_queue_t. Для этого, имеет смысл
рассмотреть то, что происходит внутри таких функций, как interruptible_sleep_on(). Ниже приведена упрощенная версия
реализации interruptible_sleep_on() для перевода процесса в сон:
void simplified_sleep_on(wait_queue_head_t *queue)
{
wait_queue_t wait;
init_waitqueue_entry(&wait, current);
current->state = TASK_INTERRUPTIBLE;
add_wait_queue(queue, &wait);
schedule();
remove_wait_queue (queue, &wait);
}
Представленный здесь код создает новую переменную wait типа wait_queue_t, которая будет рассположена в стеке, и
инициализирует ее. Для текущего процесса, current->state устанавливается в значение TASK_INTERRUPTIBLE, означающем,
что процесс уходит в прерываемый сон. Затем, элемент очереди ожидания добавляется к очереди queue (аргумент
wait_queue_head_t *). Затем вызывается диспетчер schedule(), который переключает процессор на какую-либо другую задачу.
Функция schedule() завершится только тогда, когда кто-нибудь еще разбудит данный процесс и установит его состояние
current->state в значение TASK_RUNNING. После этого, элемент очереди wait удаляется из очереди queue, и сон
завершается.
На рисунке 5-1 показаны элементы структур данных очередей ожидания, и их использование процессами.
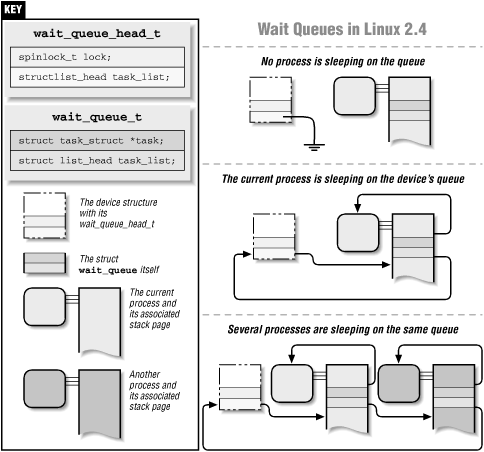
Беглый анализ кода ядра показывает, что огромное количество процедур уходит в сон самостоятельно, используя код, похожий
на тот, что показан в предыдущем примере. Большая часть этих реализаций относит нас к эпохе ядра 2.2.3, еще до появления
макроса wait_event(). Как уже говорилось, использование макроса wait_event() является предпочтительным способом перевода
процесса в сон до возникновения нужного события, потому что использование функции interruptible_sleep_on() может
привести к нежелательной проблеме борьбы за ресурсы (race condition). В разделе "Going to Sleep Without Races"
главы 9 "Interrupt Handling" мы подробно остановимся на причинах, приводящих к race condition при засыпании.
Кратко можно сказать лишь о том, что проблема может возникнуть за время между тем, как код драйвер решил заснуть по
interruptible_sleep_on() и заснул.
Есть еще одна причина, по которой необходимо реализовывать явный
вызов диспетчера (scheduler). Возможна ситуация, когда,
во время сна, несколько процессов ждут одного и того же события
(exclusive sleep). При вызове wake_up() все эти процессы будут пытаться
продолжить
выполнение. Предположим, что ожидаемое этими процессами событие состоит
в получении некоего атомарного куска данных.
Тогда, только один процесс может обратиться к этим данным. Все
остальные процессы, должны просто проснуться, проверить
доступность данных и вернуться в спящее состояние.
Такая ситуация иногда называется проблемой "громоподобного стада" (thundering herd problem). В условиях
высокой высокой производительности системы, такая проблема приводит к заметным и бесполезным затратам вычислительных
ресурсов. Создание большого количества готовых к запуску процессов, которые не могут выполнять полезной работы приводят
к пустой перегрузки процессора из-за затрат на переключение контекстов процесса. Ситуация будет намного проще, если
такие процессы останутся в спящем состоянии.
По этим причинам, во время разработки ядра серии 2.3 была добавлена концепция эксклюзивного сна (exclusive sleep). Если
процессы спят в таком эксклюзивном режиме, то они сообщают ядру о необходимости будить только один из них. В результате,
в таких ситуациях, улучшается производительность системы.
Приведем пример кода, демонстрирующего переход в эксклюзивный сон. Приводимый код очень похож на пример ухода в обычный
сон.
void simplified_sleep_exclusive(wait_queue_head_t *queue)
{
wait_queue_t wait;
init_waitqueue_entry(?wait, current);
current->state = TASK_INTERRUPTIBLE | TASK_EXCLUSIVE;
add_wait_queue_exclusive(queue, &wait);
schedule();
remove_wait_queue (queue, &wait);
}
Добавление флага TASK_EXCLUSIVE в поле current->state текущей задачи уже показывает, что процесс находится в эклюзивном
ожидании. Однако, также необходимо вызвать функцию add_wait_queue_exclusive(). Эта функция добавляет процесс в конец
очереди ожидания, после всех остальных процессов в очереди. В результате, все остальные процессы, находящиеся в
неэксклюзивном сне оказываются в начале очереди, где они всегда будут разбужены. Как только wake_up() встречает первый
эксклюзивно спящий процесс, то его работа по пробуждению процессов останавливатся.
Внимательный читатель может предположить и другие причины для явного управления очередью ожидания и диспетчером
(explicitly). В то время как функции, похожие на sleep_on(), будут блокировать процессы только по одной очереди
ожидания, прямая работа с очередями позволяет установить сон по нескольким очередям одновременно. В большинстве случаев
это не нужно. Однако, при необходимости, вы можете воспользоваться приведенным выше способом.
Для более глубокого ознакомления с кодом по очередям ожидания, ознакомтесь с файлами <linux/sched.h> и
kernel/sched.c.
Написание реентерабельного кода
Когда процесс уходит в спящее состояние, драйвер продолжает работать и может быть вызван другим процессом. Давайте
рассмотрим пример консольного драйвера. Пока приложение ожидает ввода с клавиатуры на tty1, пользователь может
переключиться на tty2 и запустить новый shell. Теперь оба командных интерпретатора ожидают ввода с клавиатуры в драйвере
консоли, хотя они спят по различным очередям ожидания: одна очередь связана с tty1, а другая - с tty2. Каждый процесс
блокируется функцией interruptible_sleep_on(), но драйвер может принимать и отвечать на запросы с других tty-устройств.
Конечно, на системах SMP, множественные одновременные обращения к драйверу могут возникнуть даже при неспящих процессах.
Такие ситуации могут быть безболезненно обработаны реентерабельным кодом. Реентерабельным называется код, который не
содержит информацию о своем состоянии в глобальных переменных, и, таким образом, способен управлять данными от разных
задач, не смешивая их. Если вся информация о текущем статусе будет специфична для текущего обрабатываемого процесса, то
взаимовлияния процессов ни когда не случится.
Если вам потребуется статусная информации, то вы можете сохранить ее либо в локальных переменных функции драйвера
(каждый процесс имеет свою собственную страницу стека в пространстве ядра, в которой будут сохранены локальные
переменные), либо вы можете воспользоваться указателем private_date в структуре, на которую указывает filp.
Использование локальных переменных предпочтительнее, потому что иногда, одни и теже указатели filp могут быть разделены
между двумя процессами, обычно между родительским процессом (parent) и ребенком (child).
Если вам необходимо сохранить большое количество статусных данных, то вы можете удержать их под локально описанным
указателем, и использовать kmalloc() для распределения необходимого пространства памяти. В этом случае, вы не должны
забывать освобождать эту память через вызов kfree(), потому что работая в пространстве ядра мы не можем полагаться на
правило "при завершении процесса, вся связанная с ним память автоматически освобождается". Использование
локальных переменных для распределения множества элементов данных не рекомендуется, потому что данные могут не
уместиться в одной странице памяти, распределенной под пространство стека.
Реентерабельной должна быть любая функция удовлетворяющая одному из двух условий. Во-первых, если она вызывает диспетчер
(schedule), например, неявно, через обращение к sleep_on() или wake_up(). Во-вторых, если она копирует данные в, или из
пространства пользователя, потому что обращение в пространство пользователя может привести к page-fault, и процесс уйдет
в сон до тех пор, пока ядро не подгрузит требуемую страницу из стека. Каждая функция, которая вызывает другие такие
функции, также должна быть реентерабельной. Например, если функция sample_read() вызывает функцию sample_getdata(),
которая может быть блокирована, то sample_read(), также как и sample_getdata() должна быть реентерабельна, потому что
ничто не запрещает вызвать ее какому-нибудь другому процессу, во время ее обработки спящего процесса.
Кроме того, конечно, код который спит всегда должен помнить, что состояние системы может измениться во время его сна.
Поэтому, драйвер должен проверить все элементы своего окружения, которые могли измениться.
Блокируемые и неблокируемые операции
Прежде чем мы рассмотрим реализацию полнофункциональных методов чтения и записи, необходимо ознакомиться со значеним
флага O_NONBLOCK в поле filp->f_flags. Этот флаг определен в заголовочном файле <linux/fcntl.h>, который
автоматически включен в <linux/fs.h>.
Название флага просходит от "open-nonblock", потому что он может
быть определено во время открытия драйвера, и
первоначально, мог быть определен только там. Если вы просмотрите код
источника, то вы найдете несколько ссылок на флаг
O_NDELAY. Это альтернативное имя для флага O_NONBLOCK, принятое для
совместимости с кодом System V. Флаг, по умолчанию,
сброшен, потому что сон, является нормальным состоянием процесса
ожидающего данные. В случае разрешения блокировки, для поддержания
стандартной семантики, следует реализовывать следующее поведение:
- Если процесс вызывает системный вызов read(), но данные еще
не доступы, то процесс должен быть блокирован. Процесс пробуждается,
как только появляются какие-нибудь данные, которые и передаются
процессу, даже если количество доступных данных меньше, чем запрошено
аргументом count.
-
Если процесс вызывает системный вызов write(), но буфер для данных еще не готов, то процесс должен быть
блокирован, и для блокировки должна быть использована другая очередь ожидания, нежели для чтения. Когда данные
будут переданы в устройство, и выходной буфер опустеет, то процесс просыпается и системный вызов write() успешно
завершается, хотя данные могут быть записаны только частично, если в буфере недостаточно места для тех count
байт, которые были запрошены.
Оба эти утверждения предполагают, что присутствуют как входной, так и выходной буфера. Большинство драйверов устройств,
действительно, имеют их. Входной буфер требуется для того, чтобы избежать потери данных тогда, когда их никто не читает.
Также, данные не могут быть потеряны и при записи, потому что если системный вызов не принимает данные, то они остаются
в буфере пространства пользователя. Кроме того, выходной буфер почти всегда полезен для повышения производительности
передачи данных в устройство.
Выигрыш в производительности от реализации выходного буфера в драйвере происходит от уменьшения количества переключений
контекста и переходов между уровнями ядра/приложение. Для медленных устройств без выходного буфера, за один системный
вызов могут быть переданы только один или несколько символов. Рассмотрим работу двух процессов с драйвером. Пока один
процесс заснул по write(), другой процесс работает (первое переключение контекста). Когда первый процесс просыпается, он
возобновляет свою работу (второе переключение контекста). Когда вызов write() завершается (переход из пространства ядра
в пространство пользователя), то процесс вызывает write() повторно для передачи следующей порции данных (переход из
пространства пользователя в пространство ядра). Вызов блокируется и все начинается сначала. И так до тех пор, пока не
будут переданы все данные. Если выходной буфер достаточно большой, то передача всех данных производится за один вызов
write(). Буферизованные данные будут переданы в устройство позднее, в "свободное" время, без необходимости
возврата в пространство пользователя для второго и последующих вызовов. Выбор подходящего размера выходного буфера
представляет собой задачу, специфическую для каждого конкретного устройства.
Мы не используем входной буфер в драйвере scull, потому что данные уже доступны при вызове read(). Также, мы не
используем выходного буфера, потому что данные просто копируются в область памяти связанной с устройством. Наше
устройство, по определению, уже является буфером, поэтому дополнительный буфер будет явно излишним. Мы увидим
использование буферов в главе 9 "Interrupt Handling", в разделе "Interrupt-Driven I/O".
Поведение вызовов read() и write() различаются при определении флага O_NONBLOCK. В этом случае, системные вызовы просто
возвращают -EAGAIN если процесс вызвал read() при отсутствии входных данных, или если он вызвал write() в то время,
когда в системе недостаточно памяти для распределения выходного буфера.
Как вы можете предположить, неблокируемые операции вовращают управление вызывающему процессу немедленно, позволяя
приложению периодически опрашивать готовность системы принять, или передать данные. Приложения должны быть внимательны
при использовании функций из stdio, работая с неблокируемыми файлами, потому что они могут легко ошибиться, приняв
неблокируемый возврат за EOF. Необходимо всегда проверять errno.
В действительности, флаг O_NONBLOCK имеет большое значение и для системного вызова open(). Это может быть полезным,
когда системный вызов может быть блокирован на долгое время. Например, при открытии FIFO, в который еще не было записи,
или при получении доступа к файлу с незаконченной блокировкой (with a pending lock). Обычно, открытие устройства
заканчивается либо удачно, либо неудачно, и не требует ожидания внешних событий. Однако, иногда, открытие устройства
требует продолжительной инициализации, и вы можете добавить поддержку O_NONBLOCK для вызова open(), для немедленного
получения результата -EAGAIN ("try it again" - попытайся снова). Мы рассмотрим одну такую реализацию в разделе
"Блокировка системного вызова open() как альтернатива EBUSY" позднее в этой главе.
Некоторые драйвера могут, также, реализовать специальную семантику для O_NONBLOCK. Например, открытие устройства
накопителя на магнитной ленте, обычно блокируется до тех пор, пока лента не будет вставлена. Если такое устройство
открывается с использованием флага O_NONBLOCK, то оно открывается немедленно, независимо от того, вставлена магнитная
лента или нет.
Надо заметить, что флаг O_NONBLOCK влияет только на операции read(), write() и open().
Пример реализации: scullpipe
Четыре устройства /dev/scullpipe являются частью scullmodule и используются для демонстрации реализации блочного
ввода/вывода.
Процесс блокированный по системному вызову read() просыпается при появлении данных. Обычно, из устройства поступает
прерывание, сообщающее об этом событии, и драйвер будит ожидающий процесс при обработке этого прерывания. Драйвер scull
работает немного иначе. Ему не требуется какое-либо специальное оборудование или обработчик прерываний. Мы будем
использовать один процесс передающий данные в драйвер, что будет приведет к пробуждению другого процесса, читающего
данные из этого драйвера. Такая реализация очень похожа на работу FIFO (или "named pipe" - именованной трубы).
Отсюда и название драйвера - scullpipe.
Драйвер устройства использует структуру, которая включает две очереди ожидания и буфер. Размер буфера конфигурируется
обычными способами (на этапе компиляции, во время загрузки или исполнения).
typedef struct Scull_Pipe {
wait_queue_head_t inq, outq; /* read and write queues */
char *buffer, *end; /* begin of buf, end of buf */
int buffersize; /* used in pointer arithmetic */
char *rp, *wp; /* where to read, where to write */
int nreaders, nwriters; /* number of openings for r/w */
struct fasync_struct *async_queue; /* asynchronous readers */
struct semaphore sem; /* mutual exclusion semaphore */
devfs_handle_t handle; /* only used if devfs is there */
} Scull_Pipe;
Предствленная ниже реализация системного вызова read() управляет как блокируемым, так и не блокируемым вводом. Позднее,
в разделе "Seeking a Device" мы объясним начальную строчку кода, которая может привести читателей в
замешательство.
size_t scull_p_read (struct file *filp, char *buf, size_t count,
loff_t *f_pos)
{
Scull_Pipe *dev = filp->private_data;
if (f_pos != &filp->f_pos) return -ESPIPE;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
while (dev->rp == dev->wp) { /* nothing to read */
up(&dev->sem); /* release the lock */
if (filp->f_flags & O_NONBLOCK)
return -EAGAIN;
PDEBUG("\"%s\" reading: going to sleep\n", current->comm);
if (wait_event_interruptible(dev->inq, (dev->rp != dev->wp)))
return -ERESTARTSYS; /* signal: tell the fs layer to handle it */
/* otherwise loop, but first reacquire the lock */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
}
/* ok, data is there, return something */
if (dev->wp > dev->rp)
count = min(count, dev->wp - dev->rp);
else /* the write pointer has wrapped, return data up to dev->end */
count = min(count, dev->end - dev->rp);
if (copy_to_user(buf, dev->rp, count)) {
up (&dev->sem);
return -EFAULT;
}
dev->rp += count;
if (dev->rp == dev->end)
dev->rp = dev->buffer; /* wrapped */
up (&dev->sem);
/* finally, awaken any writers and return */
wake_up_interruptible(&dev->outq);
PDEBUG("\"%s\" did read %li bytes\n",current->comm, (long)count);
return count;
}
Обратите внимание на оператор PDEBUG. При компиляции вы можете разрешить выдачу драйвером отладочных сообщений, которые
упростят наблюдение за работой устройства.
Также, обратите внимание на использование семафоров для защиты критических кусков кода. Код драйвера scull должен
избегать погружения в сон при удержании семафора. В противном случае, процесс передающий данные в драйвер не сможет
этого сделать, и произойдет взаимная блокировка - deadlock. Приведенный код, при ожидании требуемых данных, использует
wait_event_interruptible() для перевода процесса в сон. Однако, код должен проверить доступность данных после
пробуждения. Может оказаться так, что кто-нибудь еще захватит данные между тем, как произойдет пробуждение и получение
семафора.
Имеет смысл напомнить, что процесс может уйти в сон либо вызывая, явно или неявно, диспетчер (scheduler), либо при
передаче данных в/из пользовательского пространства. В последнем случае, процесс может заснуть, если пользовательские
данные, в текущий момент, не представлены в оперативной памяти. Если scull засыпает при копировании данных между
пространствами ядра и пользовательского процесса, то он заснет при удержании семафора устройства. Удержание семафора в
этом случае оправдано, так как предотвращает взаимную блокировку системы (deadlock), и препятствует изменению
передаваемого блока данных во время сна драйвера.
Оператор if, за которым следует interruptible_sleep_on() ответственнен за обрабокту сигнала. Этот оператор гарантирует
правильную и ожидаемую реакцию на сигналы, которые могут быть ответственны за пробуждение процесса (т.к. мы находимся в
прерываемом сне). Если сигнал пришел, и не был блокирован процессом, то правильное поведение позволит верхним слоям ядра
обработать это событие. В помощь этому, драйвер возвращает -ERESTARTSYS. Это значение используется слоем виртуальной
файловой системы VFS (Virtual File System), который либо вызовет системный вызов повторно, либо возвратит -EINR
пользовательскому процессу. Мы будем использовать тот же самый оператор для обработки сигнала в каждой read() и write()
реализации. Так как signal_pending() появился только в ядре версии 2.1.57, то мы, в нашем заголовочном файле sysdep.h
определили его для более ранних версий ядра, для сохранения совместимости нашего кода с такими ядрами.
Реализация для вызова write() похожа на реализацию вызова read(). И так же как для read() мы объясним значение первой
строки кода позднее. Особенностью этого кода является то, что он никогда полностью не заполняет буфер, всегда оставляя
"дырку" хотя бы для одного байта. Таким образом, когда буфер пуст, то wp и rp эквиваленты, когда же в буфере
появляются данные, эти элементы всегда различаются.
static inline int spacefree(Scull_Pipe *dev)
{
if (dev->rp == dev->wp)
return dev->buffersize - 1;
return ((dev->rp + dev->buffersize - dev->wp) % dev->buffersize) - 1;
}
ssize_t scull_p_write(struct file *filp, const char *buf, size_t count,
loff_t *f_pos)
{
Scull_Pipe *dev = filp->private_data;
if (f_pos != &filp->f_pos) return -ESPIPE;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
/* Make sure there's space to write */
while (spacefree(dev) == 0) { /* full */
up(&dev->sem);
if (filp->f_flags & O_NONBLOCK)
return -EAGAIN;
PDEBUG("\"%s\" writing: going to sleep\n",current->comm);
if (wait_event_interruptible(dev->outq, spacefree(dev) > 0))
return -ERESTARTSYS; /* signal: tell the fs layer to handle it */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
}
/* ok, space is there, accept something */
count = min(count, spacefree(dev));
if (dev->wp >= dev->rp)
count = min(count, dev->end - dev->wp); /* up to end-of-buffer */
else /* the write pointer has wrapped, fill up to rp-1 */
count = min(count, dev->rp - dev->wp - 1);
PDEBUG("Going to accept %li bytes to %p from %p\n",
(long)count, dev->wp, buf);
if (copy_from_user(dev->wp, buf, count)) {
up (&dev->sem);
return -EFAULT;
}
dev->wp += count;
if (dev->wp == dev->end)
dev->wp = dev->buffer; /* wrapped */
up(&dev->sem);
/* finally, awaken any reader */
wake_up_interruptible(&dev->inq); /* blocked in read() and select() */
/* and signal asynchronous readers, explained later in Chapter 5 */
if (dev->async_queue)
kill_fasync(&dev->async_queue, SIGIO, POLL_IN);
PDEBUG("\"%s\" did write %li bytes\n",current->comm, (long)count);
return count;
}
По нашему замыслу, рассматриваемый драйвер не реализует блокирование в системном вызове open(). Эта деталь отличает его
от реализации FIFO. Если вам интересно познакомиться с реальным положением вещей, то вы можете рассмотреть код из файла
fs/pipe.c в каталоге источников ядра.
Для того, чтобы протестировать блокировку операций в драйвере scullpipe, вы можете задействовать драйвер из нескольких
программ, используя обычное перенаправление ввода/вывода. Тестирование неблокируемой активности значительно сложнее,
потому что обычные программы не используют неблокируемые операции. В нашем каталоге источников misc-progs, вы найдете
простую программу nbtest, которую можно использовать для тестирования таких операций. Все, что делает эта программа, это
копирование своего ввода на свой вывод, используя неблокируемый ввод/вывод и выполняя задержку между повторами. Время
задержки передается в программу через командную строку, и, по умолчанию, равно одной секунде.
int main(int argc, char **argv)
{
int delay=1, n, m=0;
if (argc>1) delay=atoi(argv[1]);
fcntl(0, F_SETFL, fcntl(0,F_GETFL) | O_NONBLOCK); /* stdin */
fcntl(1, F_SETFL, fcntl(1,F_GETFL) | O_NONBLOCK); /* stdout */
while (1) {
n=read(0, buffer, 4096);
if (n>=0)
m=write(1, buffer, n);
if ((n<0 || m<0) && (errno != EAGAIN))
break;
sleep(delay);
}
perror( n<0 ? "stdin" : "stdout");
exit(1);
}
Системные вызовы poll() и select()
Приложения, которые используют неблокируемый ввод/вывод, также, часто используют системные вызовы poll() и select(). Эти
системные вызовы, во многом, равнофункциональны. И тот и другой позволяют процессам определить возможность открытия
файлов на чтение или запись без блокировки. Таким образом, они часто используются приложениями, которые должны
использовать множество входных или выходных потоков без блокировки какого либо из них. Одна и та же функциональность
предлагается двумя различными функциями, потому что они были реализованы в Unix практически одновременно двумя
различными группами. select() был реализован в BSD Unix, а poll() - в Systev V.
Поддержка каждого из этих системных вызовов требует реализации в драйвере соответвующей функции. В версии 2.0 ядра был
реализован только интерфейс для метода select(), и системный вызов poll() не был доступен из пользовательского
пространства. Однако начиная с версии 2.1.23, ядро предоставляло интерфейс для обоих методов, который был основан на
реализации системного вызова poll(), который предоставлял более обширные возможности управления, нежели select().
Реализация метода poll(), обслуживающего системные вызовы poll() и select(), имеет следующий прототип:
unsigned int (*poll) (struct file *, poll_table *);
Этот метод драйвера будет вызван пользовательским процессом как при обращении к системному вызову poll(), так и при
обращении к select(). В метод передается файловый дескриптор, связанный с драйвером. Реализация этого метода драйвера
строится на выполнении следующих двух шагов:
-
Вызов poll_wait() на основе одной или нескольких очередей ожидания (wait queues), который может показать изменения
в статусе опроса (in the poll status).
-
Возвращение битовой маски, описывающей операции, которые могут быть выполнены без блокировки в данный момент времени
(на момент опроса).
Обе эти операции достаточно просты, и выглядят очень схожим образом во всех драйверах. Однако, они опираются на
информацию, которая может получена только из конкретного драйвера, поэтому метод должен быть реализован индивидуально
для каждого драйвера.
Структура poll_table, второй аргумент в методе poll(), используется в ядре для реализации вызовов poll() и select().
Структура описана в <linux/poll.h>, которая предоставляется источниками ядра. Разработчикам драйверов нет
необходимости знать что-либо о ее внутренностях. Эту структуру можно рассматривать как совершенно &qout;прозрачный"
объект. Она передается в метод драйвера, так, что каждый элемент очереди событий, который может разбудить процесс и
измениь статус операции poll(), может быть добавлен в структуру poll_table с помощью вызова poll_wait():
void poll_wait (struct file *, wait_queue_head_t *, poll_table *);
Вторая задача, выполняемая методом poll() заключается в возвращении битовой маски, описывающей операции, которые могут
быть выполнены немедленно. Например, если устройство имеет доступные данные, и метод read() может быть выполнен без
ухода в спящее состояние, то метод poll() должен отразить этот факт в битовой маске. Для определения возможных операций
можно использовать некоторые флаги, определенные в <linux/poll.h>:
- POLLIN
-
Этот бит должен быть установлен, если устройство может быть прочитано без блокировки.
- POLLRDNORM
-
Этот бит должне быть установлен, если данные ("normal" data) доступны для чтения. Доступное для чтения
устройство возвращает (POLLIN | POLLRDNORM).
- POLLRDBAND
-
Этот бит показывает, что на чтение из устройства доступно out-of-band данных (т.е. некий избыток данных). В данный
момент это используется только в одном месте Linux ядра - в коде сетевого транспорта протокола DECnet. Этот бит, в
общем, не применим к драйверам устройств.
- POLLPRI
-
Флаг указывает на то, что высокоприоритетные данные (out-of-band) могут быть прочитаны без блокировки. Данные бит
воспринимается вызовом select() как возникновение в файле условия исключения (exception condition).
- POLLHUP
-
Когда процесс, читающий это устройство, достигает конца файла (end-of-file), то драйвер должен устрановить POLLHUP
(hang-up). Процесс, вызывающий select(), будет уведомлен, что устройство доступно для чтения, как продиктовано
функциональностью метода select().
- POLLERR
-
Флаг указывает на возникновение ошибки в устройстве. При вызове poll() устройство определяется как готовое и к чтению,
и к записи, т.к. и при чтении и при записи устройство возвратит код ошибки без блокировки.
- POLLOUT
-
Этот бит устанавливается в том случае, если устройство может быть прочитано без блокировки.
- POLLWRNORM
-
Этот бит имеет тот же самый смысл, что и POLLOUT, и, в действительности, имеет тот же самый номер. Устройство, готовое
к запими возвращает (POLLOUT | POLLWRNORM).
- POLLWRBAND
-
Как и POLLRDBAND, этот бит означает, что данные с ненулевым приоритетом могут быть записаны в устройство. Этот бит
используется только в реализации poll() для дейтаграмм (datagram), т.к. только дейтаграммы могут передавать out-of-band
данные.
Наверное, нет смысла уточнять, что флаги POLLRDBAND и POLLWRBAND имеют смысл только для файловых дескрипторов связанных
с сокетами. Другие драйвера обычно не используют эти флаги.
Описание метода poll() весьма обширное, и имеет смысл просто познакомиться с одним из практических примеров его
реализации. Рассмотрим реализацию метода poll() для драйвера scullpipe:
unsigned int scull_p_poll(struct file *filp, poll_table *wait)
{
Scull_Pipe *dev = filp->private_data;
unsigned int mask = 0;
/*
* Циклический буфер. Предполагается, что буфер полный, если "wp" правее "rp".
* "left" равен 0, если буфер пуст, и равен 1
* если буфер совершенно заполнен.
*/
int left = (dev->rp + dev->buffersize - dev->wp) % dev->buffersize;
poll_wait(filp, &dev->inq, wait);
poll_wait(filp, &dev->outq, wait);
if (dev->rp != dev->wp) mask |= POLLIN | POLLRDNORM; /* readable */
if (left != 1) mask |= POLLOUT | POLLWRNORM; /* writable */
return mask;
}
Этот код просто добавляет две очереди событий scullpipe в таблицу poll_table, и устанавливает соответствующие биты в
маске, в зависимости от того, доступно ли устройство на чтение или на запись.
Как вы можете видеть, приведенный код метода poll() не поддерживает end-of-file. Метод poll() должен возвращать флаг
POLLHUP, когда устройство достигло конца файла. Если же программа пользователя обратится к системному вызову select(), то
файл, в этом случае, определится как доступный для чтения. В обоих случаях, приложение пользователя будет знать, что оно
может вызвать системный вызов read() без риска быть заблокированным. В случае же действительного конца файла, вызов
read() вернет 0 символизируя end-of-file.
Если обратиться к настоящей реализации FIFO (очередь), то читающий процесс увидит конец файла тогда, когда все пишущие в
файл процессы, закроют файл. В отличии от этого, процесс читающий драйвер scullpipe никогда не увидит конца файла.
Поведение различно потому, что FIFO намеревается организовать коммуникационный канал между двумя процессами, в то время
как scullpipe является "мусорным ведром" в которое кто угодно может положить данные, и хотя бы один процесс
может их прочитать.
Реализация end-of-file тем же способом, как это сделано для FIFO будет означат необходимость проверки поля
dev->nwriters как в методе read(), так и в методе poll(). При этом, если нет процессов, которые открыли бы устройство
для записи, то методы должны будут сообщить о конце файла, как было описано выше. К несчастью, если читающий процесс
откроет устройство scullpipe раньше, то он сразу увидит конец файла без шансов дождаться каких-либо данных. Лучшим
способом устранения этой проблемы является реализация блокировки в методе open(). Эту задачу мы оставим читателю в
качестве упражнения.
Взаимодействие с методами read() и write()
Назначение системных вызовов poll() и select() заключается в предоставлении информации о блокировке операций
ввода/вывода. В этом отношении, они дополняют методы read() и write(). Более важным является то, что методы poll() и
select() позволяют приложению одновременно обрабатывать несколько потоков данных. Данную функциональность мы не
реализовали в драйвере scull.
Корректная реализация этих трех системных вызовов будет залогом корректно работающего приложения. Попробуем подвести
итог всему изложенному по этому вопросу.
Чтение данных из устройства
- Если во входном буфере присутствуют данные, то системный вызов read() может быть выполнен без какой-либо
ощутимой задержки, даже, если объем доступных данных меньше того, что запрашивает приложение.
- Если во входном буфере нет данных, то, по умолчанию, системный вызов read() будет блокирован до тех пор,
пока в буфере не появиться по меньшей мере одного байта данных. С другой стороны, если установлен флаг
O_NONBLOCK, то метод read() выполнится без задержки, но с кодом ошибки -EAGAIN (некоторые старые вырсии System V
возвратят, в этом случае, 0). Поэтому, при запрещении блокировки имеет смысл опрашивать готовность устройства с
помощью системного вызова poll()
- При достижении конца файла, метод read() должен без задержки возвратить значение 0, независимо от того
установлен ли флаг O_NONBLOCK, или нет. Метод poll() в этом случае должен возвращать флаг POLLHUP.
Запись данных в устройство
- Если в выходном буфере имеется свободное место, то системный вызов write() должен быть выполнен без
какой-либо ощутимой задержки. Буфер может принять меньше данных, чем передается приложением, но он должен быть
готов принять как минимум один байт данных. В этом случае, системный вызов poll() должен определить, что
устройство готово для записи.
- Если выходной буфер полон, то по умолчанию, системный вызов write() будет блокирован до тех пор, пока в
буфере не освободится сколько нибудь места. Если установлен флаг O_NONBLOCK, то метод write() в этом случае,
завершится немедленно с кодом ошибки -EAGAIN (некоторые старые версии System V возвратят, в этом случае, 0).
Метод poll(), при полном буфере, должен возвратить, что устройство не готово для записи. Если же устройство не
может принять больше данных, то метод write() возвращает -ENOSPC ("No space left on device" - нет
осталось места на устройстве), независимо от того, установлен ли флаг O_NONBLOCK, или нет.
- Никогда не выполняйте ожидание передачи данных перед возвратом в системном вызове write(), даже если флаг
O_NONBLOCK не установлен. Дело в том, что многие приложения используют метод select() для определения возможной
блокировки записи. Поэтому, если сообщается, что устройство готово к записи, то запись, соответственно, не
должна блокироваться. Если же программа, использующая устройство, хочет убедиться что данные переданные в
выходной буфер были в действительности отправлены в устройство, то драйвер должен предоставить для такой проверки
метод fsync(). Например, сменные устройства должны иметь реализацию метода fsync().
Несмотря на то, что мы сформулировали несколько удачных основных правил обработки чтения записи, необходимо помнить, что
каждое устройство, в своем роде, уникально, и в некоторых случаях необходимо немного отходить от намеченных правил.
Например, такое запись-ориентированное устройство как накопитель на магнитной ленте не может выполнять частичную запись
данных.
Flushing - принудительный сброс выходного буфера
Как мы видели, метод write() не производит полное слежение за выходным потоком данных. Функция ядра fsync(), вызываемая
одноименным системным вызовом заполняет эту прореху. Прототип этого метода выглядит следующим образом:
int (*fsync) (struct file *file, struct dentry *dentry, int datasync);
Если некоторому приложению потребуется уверенность в том, что данные были действительно переданы в устройство, то
необходимо будет воспользоваться системным вызовом fsync(), и соответствующий метод драйвера должен быть реализован.
Метод fsync() завершает свою работу только тогда, когда данные из буфера будут полностью сброшены на устройство. Такая
операция носит название flush. Операция может занять какое-то время, независимо от того, установлен флаг O_NONBLOCK, или
нет. Аргумент datasync представлен только в ядрах серии 2.4, и используется для различия между системными вызовами
fsync() и fdatasync(). Аргумент представляет интерес только для кода файловых систем, и может быть проигнорирован другими
драйверами.
Метод fsync() не содержит ничего необычного. Исполнение данного системного вызова не критично во времени, поэтому его
реализация в драйвере может быть выполнена в произвольном авторском вкусе. Как правило, этот метод не реализовывается
для драйверов символьных устройств. Драйвера блочных устройств, в другой стороны, всегда реализовывают метод общего
назначения block_fsync(), который сбрасывает все блоки данных в устройство ожидая завершения ввода/вывода.
Структуры данных для poll() и select()
Действительная реализация системных вызовов poll() и select() достаточно проста. Всегда, когда приложение пользователя
вызывает любую из этих функций, ядро вызывает метод poll() для всех файлов, связанных с данным системным вызовом,
передаваю каждому из них одну и ту же таблицу poll_table. Это массив структур poll_table_entry общего назначения,
связанный с каждым определенным вызовом poll() или select(). Каждый элемент poll_table_entry содержит указатель на
структуру файл для открытого устройства, указатель на wait_queue_head_t, и элемент wait_queue_t. Когда драйвер вызывает
poll_wait, один из этих элементов заполняется информацией из драйвера, и элемент очереди ожидания укладывается в очередь
драйвера. Указатель на wait_queue_head_t используется для получения текущей очереди ожидания, в которой зарегистрирован
элемент текущей таблицы опроса (poll table). Это необходимо для того, чтобы free_wait() мог удалить элемент из очереди
перед пробуждением.
Примечание переводчика: В последнем абзаце я не совсем уверен, поэтому приведу оригинальный текст. "...
Whenever a user application calls either function, the kernel invokes the poll method of all files referenced
by the system call, passing the same poll_table to each of them. The structure is, for all practical purposes, an array
of poll_table_entry structures allocated for a specific poll or selectcall. Each poll_table_entry contains the struct
file pointer for the open device, a wait_queue_head_t pointer, and a wait_queue_t entry. When a driver calls poll_wait,
one of these entries gets filled in with the information provided by the driver, and the wait queue entry gets put onto
the driver's queue. The pointer to wait_queue_head_t is used to track the wait queue where the current poll table entry
is registered, in order for free_wait to be able to dequeue the entry before the wait queue is awakened."
Если ни один из опрошенных драйверов не выдал готовность операций ввода/вывода к исполнению без блокировки, то вызов
poll() просто засыпает до тех пор, пока одна, или несколько, очередей не будут готовы проснуться.
В реализации метода poll() интересно то, что файловые операции могут быть вызваны с NULL-указателем для аргумента
poll_table. Такая ситуация может произойти по паре причин. Если приложение вызвавшее poll() установила значение таймаута
в 0 (т.е никаких ожиданий), то нет причин для накопления очередей ожиданий, и система просто ничего не делает. Также,
poll_table_pointer может быть установлен в NULL сразу после того как какой-нибудь опрошенный драйвер показал возможность
операции ввода/вывода. Так как ядро знает, где и какое неожидаемое событие возникло, то оно не выстраивает список
очередей ожидания. Прим. переводчика: Опять что то не совсем понятное "Since the kernel knows at that point
that no wait will occur, it does not build up a list of wait queues."
Когда вызов poll() завершается, то структура poll_table уничтожается из памяти, и все элементы очереди ожидания,
предварительно добавленные в таблицу опроса, удаляются из таблицы и соответствующих очередей ожиданий.
В действительности, рассмотренный только что механизм, чуть более сложен, потому что таблица опроса poll_table не совсем
массив, а скорее множество одной или нескольких страниц, каждая из которых содержит массив. Это усложнение позволяет
избегать ограничения на максимальное количество дескрипторов, обрабатываемых системными вызовами poll() или select(), и
связанное с небольшим размером самой страницы.
На рисунке 5-2 изображены структуры данных учавствующие в механизме опроса. Вообще, на рисунке представлена упрощенная
схема реальных структур данных, потому что здесь проигнорирована многостраничная природа таблицы опросы, и неучтен
файловый указатель, который является частью каждого элемента poll_table_entry. Те читатели, которых заинтересовало
реальное положение дел могут познакомиться с файлами <linux/poll.h> и fs/select.c из каталога источников ядра.
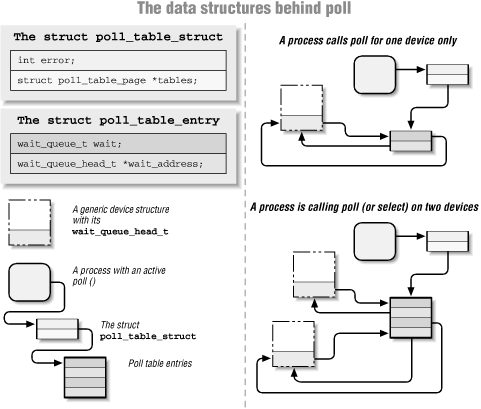
Асинхронные уведомления (Asynchronous Notification)
Несмотря на то, что в большинстве случаев для управления устройством достаточно механизмов блокируемых/неблокируемых
операций и метода select(), все же, возникают ситуации когда такая техника управления становится недостаточной. Скоро мы
рассмотрим такие случаи подробнее.
Например, давайте вообразим, что некий процесс выполняет цикл продолжительных вычислений с ниским приоритетом, требуя,
по возможности, подкачки новых данных. Если входным каналом данных являются данные с клавиатуры, то вы можете послать
приложению сигнал - символ "INTR" (обычно, комбинация клавиш CTRL+C). Такая возможность передачи сигнала
является частью tty-абстракции, являющейся программным слоем, который не используется для общего класса символьных
устройств. Поэтому, для асинхронных уведомлений, нам требуется что-то еще. Кроме того, входные данные должны имет
возможность генерировать прерывания - не только CTRL+C.
Программы пользователя должны выполнить следующие два шага для разрешения асинхронных уведомлений из входного файла.
Во-первых, они должны определить процесс как "владелец" файла. Для этого процесс должен выполнить системный
вызов fcntl() с передачей в него команды F_SETOWN. В результате, идентификатор процесса (process ID) владельца
сохранится в поле filp->f_owner для дальнейшего использования. Этот шаг необходим только для того, чтобы ядро знало о
том какой процесс требует уведомления. Для того, чтобы разрешить ассинхронное уведомление, пользовательские программы
должны установить в устройстве флаг FASYNC. Установка этого флага производится передачей команды F_SETFL в системный
вызов fcntl().
После выполнения этих двух системных вызовов, входной файл может потребовать доставку сигнала SIGIO при получении новой
порции данных. Сигнал посылается процессу сохраненному в filp->f_owner (или группе процессов, если значение отрицательно).
Например, следующие строки кода в пользовательской программе разрешают асинхронные уведомления текущего процесса при
получение новой порции данных на входной файл stdin:
signal(SIGIO, &input_handler); /* глупый пример; вызов sigaction() предпочтительнее */
fcntl(STDIN_FILENO, F_SETOWN, getpid());
oflags = fcntl(STDIN_FILENO, F_GETFL);
fcntl(STDIN_FILENO, F_SETFL, oflags | FASYNC);
Программа под именем asynctest, в источниках к данной книге, является простой программой демонстрирующей чтение stdin.
Она может быть использована для проверки асинхронных возможностей драйвера scullpipe. Программа во многом похожа на
стандартную программу cat, но не завершает свою работу по достижении конца файла (end-of-file).
Заметьте однако, что не все устройства поддерживают асинхронное уведомление, и вы можете ошибиться в выборе устройства.
Приложения обычно предполагают, что возможности асинхронного уведомления доступны только на сокетах и устройствах tty.
Например, pipes (трубы) и FIFO (очереди) не поддерживают эту возможность, по крайней мере, на текущем ядре 2.4.х. Мышь,
наоборот, поддерживает асинхронное уведомление, потому что некоторые программы ожидают, что мышь может послать сигнал
SIGIO, как это делают устройства tty.
Однако имеется одна старая проблема с входным уведомлением. Когда процесс получает SIGIO, он не знает, в каком из входных
файлов появились новые данные. Т.е. если некий процесс может получить асинхронные уведомления от нескольких файлов, то
приложение должно будет еще проанализировать результаты poll() или select() запросов, чтобы разобраться в том, что
случилось.
Взгляд со стороны драйвера
Для нас, более уместным, будет являться рассмотрение того, как драйвер устройства может реализовать асинхронную передачу
сигнала. В следующем списке представлена детальная последовательность операций с точки зрения ядра.
- При выполнении команды F_SETOWN системным вызовом fcntl() ничего не происходит, кроме передачи значения полю
filp->f_owner.
- При выполнении системным вызовом fcntl() команды F_SETFL для установки флага FASYNC, вызывается метод
драйвера fasync(). Этот метод вызывается свякий раз, когда флаг FASYNC добавляется или убирается из поля
filp->f_flags. Таким образом, код драйвера уведомляется об установке или сбросе данного флага, что необходимо
для правильного функционирования драйвера. Флаг очищается по умолчанию при открытии файла. Скоро мы рассмотрим
стандартную реализацию этого метода в драйвере.
- При получении новых данных, сигнал SIGIO должен быть послан всем процессам, которые зарегистрировали
асинхронное уведомление для данного файла.
В то время как реализация первого шага тривиальна - драйвер не должен что-либо делать - другие шаги связаны с обработкой
динамических структур данных для поддержки приложений-клиентов, запросивших асинхронное уведомление. Причем, таких
приложений может быть сколько угодно. Однако, эти динамические структуры не завися то особенностей конкретного
устройства, и ядро предлагает походящую реализацию общего назначение, так что вы не должны переписывать однотипный код
для каждого драйвера.
Общая реализация предлагаемая Linux основана на одной структуре данных и двух функциях, которые вызываются на втором и
третьем шагах, описанных выше. В заголовочном файле <linux/fs.h>, содержатся необходимые описания. Интересующая
нас структура данных носит название facync_struct. Так же, как мы работали с очередями ожидания, нам необходимо вставить
указатель на эту структуру в структуру данных специфическую для устройства. В действительности, мы уже видели такое поле
в разделе "Простая реализация scullpipe"
Описанные выше функции, вызываемые драйвером, соответствуют следующим прототипам:
int fasync_helper(int fd, struct file *filp,
int mode, struct fasync_struct **fa);
void kill_fasync(struct fasync_struct **fa, int sig, int band);
Функция fasync_helper() вызывается для добавления или извлечения файлов из списка, который интересен процессам при
установке или сбросе флага FASYNC для открытого файла. Все аргументы этой функции, за исключением последнего,
предоставляются для передачи в метод fasync() и могут быть переданы в него напрямую. Функция kill_async() используется
для передачи сигнала списку интересующихся процессов при получении новых данных. Вторым аргументом идентифицируется
передаваемый сигнал (обычно SIGIO). Третий аргумент определяет способ передачи (band), который, как правило, равен
POLL_IN, но который может быть использован для указания срочности ("urgent") или отложенности (out-of-band)
передачи данных в сетевом коде.
Рассмотрим реализацию метода fasync() в драйвере scullpipe:
int scull_p_fasync(fasync_file fd, struct file *filp, int mode)
{
Scull_Pipe *dev = filp->private_data;
return fasync_helper(fd, filp, mode, &dev->async_queue);
}
Ясно, что вся работа выполняется в вызове fasync_helper(). Однако, реализовать в fasync_helper() всю функциональность
было бы невозможно, потому что данная функция требует корректного указателя на структуру fasync_struct *, представленную
в данном примере как &dev->async_queue. Данный указатель может быть предоставлен только каждым конкретным
драйвером устройства.
При появлении новых данных должен быть вызван следующий оператор для передачи асинхронного сигнала читающему процессу.
Так как новые данные для процесса, читающего драйвер scullpipe, передаются из процесса записывающего в этот драйвер, то
данный оператор размещают в методе write() драйвера scullpipe.
if (dev->async_queue)
kill_fasync(&dev->async_queue, SIGIO, POLL_IN);
В описании данного механизма мы опустили еще одну деталь. Мы должны вызвать наш метод fasync() при закрытии файла для
удаления файла из списка активных процессов ждущих асинронное уведомление на чтение данного файла. И хотя этот вызов
требуется только в случае, если поле filp->f_flags имеет установленным бит FASYNC, но не будет никакого вреда, если
вызов fasync() будет произведен в любом случае, что обычно и делается. Следующие строки, например, являются частью
метода close() для драйвера scullpipe:
/* remove this filp from the asynchronously notified filp's */
/* удаление данного filp из списка для асинхронного уведомления */
scull_p_fasync(-1, filp, 0);
Структура данных, лежащая в основе операций асинхронного уведомления во многом идентична структуре wait_queue, потому
что обе ситуации связаны с ожиданием некоторого события. Различие состоит в том, что структура file используется вместо
структуры task_struct. Структура file используется для получения f_owner определяющей процес, которому необходимо
передать уведомляющий сигнал.
Seeking a Device - перемещение по данным в устройстве
Сложная часть данной главы закончилась. Теперь мы рассмотрим метод llseek(), который полезен для получения общей
файловой картины устройства и, к тому же, прост в реализации.
Реализация метода llseek()
На методе llseek() построена реализация двух системных вызовов: llseek() и lseek(). Мы уже говорили, что если метод
llseek() не реализован в драйвере, то реализация по умолчанию, используемая в этом случае ядром, выполняет перемещение
от начала в файла в нужную позицию простым изменением поля filp->f_pos - текущей позицией чтения/записи в файле.
Заметьте, что для правильной работы системного вызова lseek() необходимо, чтобы методы read() и write() корректно
изменяли текущее значение смещения в файле, которое они принимают в качестве аргумента - этот аргумент обычно является
указателем на filp->f_pos.
Вам может понадобиться собственная реализация метода llseek() для вашего драйвера, если операция перемещения по файлу
устройства связана с некой реальной физической операцией над устройством, или, если перемещение за пределы конца файла,
которое не учтено в методе по умолчанию, может оказаться для вашего устройства нежелательным. Простой пример реализации
данного метода можно увидеть в драйвере scull:
loff_t scull_llseek(struct file *filp, loff_t off, int whence)
{
Scull_Dev *dev = filp->private_data;
loff_t newpos;
switch(whence) {
case 0: /* SEEK_SET */
newpos = off;
break;
case 1: /* SEEK_CUR */
newpos = filp->f_pos + off;
break;
case 2: /* SEEK_END */
newpos = dev->size + off;
break;
default: /* can't happen */
return -EINVAL;
}
if (newpos<0) return -EINVAL;
filp->f_pos = newpos;
return newpos;
}
Единственной устройство-специфической операцией в данном коде является получение текущего размера файла устройства. В
драйвере scull работа методов read() и write() взаимосвязана, и показана в разделе "Методы read() и write()"
главы 3 "Драйверы символьных устройств".
Показанная только что реализация имеет смысл для драйвера scull, который управляет простой областью данных из
оперативной памяти. Однако, большая часть драйверов управляют, скорее, потоком данных. Представьте себе последовательный
порт или клавиатуру. Для таких устройств, операция перемещения файлового указателя не имеет смысла. В этом случае вам
также потребуется определение собственного метода llseek() в драйвере, так как функция предоставляемая ядром по
умолчанию позволяет перемещение указателя. Код, запрещающий перемещение, будет выглядеть следующим образом:
loff_t scull_p_llseek(struct file *filp, loff_t off, int whence)
{
return -ESPIPE; /* unseekable */
}
Именно эта функция используется в драйвере scullpipe, который управляет областью данных, произвольное перемещение по
которой невозможно. Код возвращаемой этим методом ошибки воспринимается как "illegal seek" (перемещение
невозможно), хотя символическое определение идентификатора ошибки происходит от "is a pipe". Позиция файлового
указателя для таких устройств бессмыслена, и ни метод read() ни метод write() не утруждают себя его изменением при
передаче данных.
Интересно заметить, что с тех пор, как в множество поддерживаемых системных вызовов были добавлены вызовы pread() и
pwrite(), то вызов lseek() перестал быть единственным способом, которым может воспользоваться программа пользователя для
произвольного перемещения файлового указателя. Правильная реализация драйвера устройства с неперемещаемым файловым
указателем должна обрабатывать, по возможности, нормальные операции read() и write(), запрещая, при этом, операции
pread() и pwrite(). При этом, первой строкой в методах read() и write() должна быть следующая стока, которая не была
сразу объяснена при ознакомлении с этими методами для scullpipe:
if (f_pos != &filp->f_pos) return -ESPIPE;
Дополнительно управление доступом к файлу устройства
Управление доступом для некоторых устройств может оказаться жизнено важной задачей. Использование устройства должно быть
запрещено неавторизованным пользователям (такие ограничения накладываются битовой маской разрешений доступа
предоставляемой файловой системой), и, кроме того, доступ должен быть ограничен только одним из авторизованных
пользователей за раз (в данный момент времен).
Проблема схожа с использованием tty-устройств. В случае с tty, процесс входа пользователя в систему изменяет владельца
устройства для того, чтобы предотвратить взаимовлияние или слежение за течением данных в tty. Однако, использование
привилегированной программы для изменение владельца устройства при каждом его открытии непрактично, за исключением
случая получения уникального доступа к нему.
Ни один из рассмотренных выше примеров не реализовывал дополнительное управление доступом к устройству кроме того, что
определяла битовая маска разрешений, предоставляемая файловой системой. Если системный вызов open() перенаправлял запрос
к драйверу, то операция завершалась успешно. Теперь, мы рассмотрим несколько техник, позволяющих реализовать
дополнительные проверки для разрешения доступа к устройству.
Каждое из устройств, описанных в этом разделе имеет схожее поведение с основополагающим устройством scull, т.е.
неким устройством общего применения, просто реализующем распределение памяти. Разница заключается только в
дополнительном управлении доступом, реализованном в методах open() и close().
Устройства single-open - одно открытие за раз
Один из грубых способов дополнительного управления доступом к устройству состоит в запрещении его открытия в случае,
если оно уже открыто одним из процессов. Такие устройства носят название single-open devices. Следует избегать такой
техники, так как она тормозит активность пользователя. Возможно, пользователь захочет запустить два различных процесса,
один из которых пишет, другой читает одно и то же устройство. Например, одни процесс пишет данные, а другой читает
статус-информацию о состоянии устройства. В некоторых случаях, пользователь может разрешить такую задачу с помощью
shell-скрипта, запуская требуемые процессы поочередно. Другими словами, реализация такого single-open поведения приводит
к созданию политики, которая может определить способ получения того, что требуется пользователю устройства.
Устройства позволяющие одновременное открытие только одним процессом имеют нежелательные свойства, но легки в реализации
ограничения доступа. Продемонстрируем данную реализацию на примере методов open() и close() для драйвера scullsingle.
Системный вызов open() ограничивает доступ на основе глобального флага занятости устройства:
int scull_s_open(struct inode *inode, struct file *filp)
{
Scull_Dev *dev = &scull_s_device; /* device information */
int num = NUM(inode->i_rdev);
if (!filp->private_data && num > 0)
return -ENODEV; /* not devfs: allow 1 device only */
spin_lock(&scull_s_lock);
if (scull_s_count) {
spin_unlock(&scull_s_lock);
return -EBUSY; /* already open */
}
scull_s_count++;
spin_unlock(&scull_s_lock);
/* then, everything else is copied from the bare scull device */
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY)
scull_trim(dev);
if (!filp->private_data)
filp->private_data = dev;
MOD_INC_USE_COUNT;
return 0; /* success */
}
С другой стороны, системный вызов close() снимает флаг занятости с устройства.
int scull_s_release(struct inode *inode, struct file *filp)
{
scull_s_count--; /* release the device */
MOD_DEC_USE_COUNT;
return 0;
}
Обычно, мы рекомендуем размещеть флаг открытия scull_s_count устройства внутри структуры устройства, которая в данном
коде представлена структурой Scull_Dev. Такой подход концептуален, так как данная структура принадлежит устройству.
Такой же подход к размещению рекомендуется и для флага scull_s_lock, который будет объяснен в следующем подразделе.
Однако, драйвер scull использует для этих целей отдельные глобальные переменные, что позволяет минимизировать
повторяющийся код для разных драйверов семейства scull.
Отступление в проблему Race Conditions (борьба за ресурсы)
Рассмотрим внимательнее только что показанную обработку переменной scull_s_count. Здесь производится два различных
действия: (1) - проверяется значение переменной и операция открытия запрещается, если ее значение не равно 0, и (2) -
значение переменной инкрементируется для указания занятости устройства. На однопроцессорной системе такая проверка
безопасна, так как другие процессы не могут быть запущены между выполнением этих двух операций.
Проблема возникает в мире систем SMP. Если два процесса на двух разных процессорах пытаются одновременно открыть
устройство, то возможно, что они оба проверят значение scull_s_count перед тем, как оно будет изменено. При этом, в
лучшем случае для вашего устройства не сработает концепция single-open, а в худшем - неожидаемый одновременный
доступ может разрушить структуру данных, что может привести к краху системы.
Другими словами - налицо проблема Race Conditions (одновременного доступа к ресурсам). Подробно данная проблема была
рассмотрена в главе 3 "Драйвера символьных устройств", где было показано что защита разделяемой структуры
данных может быть реализована с помощью семафоров. В общем случае, семафоры могут оказаться слишком дорогим решением,
потому что могут привести переводу вызывающего процесса в спящее состояние. Имеется более дешевое решение этой проблемы,
состоящее в быстрой проверке переменной статуса.
Вместо этого, драйвер scullsingle использует другой механизм блокировки, называемый спинлоком (spinlock). Данный
механизм не приведет к погружению процесса в сон. Вместо этого, если блокировка не доступна, то код спинлока будет
просто повторен снова и снова, пока блокировка не освободится. Отсюда и название - одним из значений английского слова
"spin" является значение "волчок". Таким образом, накладные расходы на такой способ блокировки
невелики, но потенциально они могут привести к пустой и длительной загрузке процессора в цикле ожидания, если блокировка
уже запущена на другом процессоре. Другим преимуществом спинлоков перед семаформами является тот факт, что на
однопроцессорной системе, где подобная проблема просто не может возникнуть, можно воспользоваться директивами компиляции
для устранения спинлоков, хотя перерасход на обработку спинлока в однопроцессорной системе будет совсем незначителен.
Семафоры используются для более глобальной защиты ресурсов, которая необходима даже на однопроцессорной системе.
Спинлоки могут быть идеальным механизмом для защиты небольших критически важных элементов данных. Процессы должны
удерживать спинлоки на минимально возможное время, и никогда не должны уходить в сон во время удержания такой
блокировки. Таким образом, основной драйвер scull, который обменивается данными с пользовательским пространством, и
может, поэтому, запросто заснуть, не является подходящим местом для использования спинлоков. Но, с другой стороны,
спинлоки замечательно работают для реализации механизма ограничения доступа в драйвере scull_s_single, хотя в главе 9
"Обработка прерываний" мы рассмотрим, возможно, более оптимальное решение для этой проблемы.
Спинлоки описываются типом spinlock_t, который определен в заголовочном файле <linux/spinlock.h>. Перед
использованием, спинлоки должны быть инициализированы:
spin_lock_init(spinlock_t *lock);
Начало критической секции кода должно быть предварено блокировкой с помощью функции spin_lock():
spin_lock(spinlock_t *lock);
Освобождение блокировки реализуется с помощью функции spin_unlock():
spin_unlock(spinlock_t *lock);
Спинлоки могут быть более сложными, чем в рассмотреном нами случае. Такие варианты использования спинлоков будут
нами детально рассмотрены в главе 9 "Обработка прерываний". Однако, в рассмотренном примере, простой вариант
использования спинлоков достаточен, и во всех наших примерах по дополнительному управлению доступом мы будем
использовать спинлоки именно таким простым способом.
Внимательный читатель может заметить, что использование scull_s_count предохраняется спинлоком только при открытии
драйвера, т.е в функции scull_s_open(). При закрытии драйвера, в методе scull_s_close() такая предосторожность не
используется, так как этот код совершенно безопасен по причине того, что не может существовать второго процесса
уменьшающего значение флага scull_s_count.
Ограничение доступа по принципу "Один пользователь за раз"
Следующий способ ограничения доступа, который мы сейчас рассмотрим, позволяют одному пользователю открывать устройство
много раз из разных процессов, но устройство может быть открыто только одним пользователем за раз. Т.е. до тех пор пока
один пользователь использует устройство хотя бы в одном из своих процессов, любой другой пользователь не сможет получить
доступ к этому устройству. Такое устройство может быть легко протестировано, так как пользователь может читать и писать
данные в устройство одновременно из нескольких процессов. Единственное, нужно понимать, что пользователь несет некоторую
ответственность за целостность данных при организации множественного доступа к устройству. Такое управление доступом
реализуется добавлением специальной проверки в метод open() драйвера. Понятно, что такая проверка будет выполнена после
всех проверок выполняемых файловой системой на основе битов разрешения доступа к файлу устройства. Именно такая политика
доступа используется для устройств tty, но реализуется не за счет обращения к внешним привелигированным программам.
Такая политика доступа несколько сложнее в реализации, нежели политика single-open устройства. В этом случае нам
необходимо слежение как за счетчиком использования модуля, так и за uid ("user ID" - идентификатор
пользователя) владельца ("owner") устройства. Как уже говорилось раньше, лучшим местом для хранения такой
информации является структура устройства, однако для минимизации повторяемого кода в наших примерах мы будем использовать
для ее хранения глобальную переменную. Обсуждаемое здесь устройство называется sculluid.
Вызов open() разрешает доступ при первом открытии файла, и запоминает владельца устройства. Теперь этот пользователь
может открыть данное устройство произвольное количество раз, используя разные процессы для параллельного доступа к этому
устройству. В то же самое время, никакой другой пользователь не сможет открыть данное устройство. Вариант метода open()
для данного случая во многом похож на тот код, который был приведен ранее, для устройства с политикой single-open,
поэтому здесь мы приведем только измененную часть кода, а не весь метод целиком:
spin_lock(&scull_u_lock);
if (scull_u_count &&
(scull_u_owner != current->uid) && /* allow user */
(scull_u_owner != current->euid) && /* allow whoever did su */
!capable(CAP_DAC_OVERRIDE)) { /* still allow root */
spin_unlock(&scull_u_lock);
return -EBUSY; /* -EPERM would confuse the user */
}
if (scull_u_count == 0)
scull_u_owner = current->uid; /* grab it */
scull_u_count++;
spin_unlock(&scull_u_lock);
В качестве кода возврата при невыполнении приведенного условия мы используем значение -EBUSY, а не -EPERM. Это
подчеркивает тот факт, что пользователь имеет право доступа к устройству, но на данный момент оно занято.
"Permition denied" используется, обычно, как ошибка при проверке прав доступа к /dev-файлу устройства, в то
время как "Device busy" корректно отображает тот факт, что устройство занято другим пользователем.
Приведенный код проверяет не только идентификатор пользователя (uid), но и эффективный идентификатор пользователя
(euid), что позволяет открывать устройство процессам использующим требуемую замену идентификатора пользователя. Проверка
возможности перекрытия прав доступа к файлам и каталогам (CAP_DAC_OVERRIDE), дополнительно позволяет ослабить жесткую
политику доступа к устройству.
Код метода close() не показан для этого случая, потому что все, что он делает сводится к декрементированию счетчика
открытия файла.
Блокировка метода open() как альтернатива EBUSY
В случае, когда доступ к устройству запрещен, наиблее осмысленным является возврат ошибки занятости устройства, но
возможны ситуации, когда вы можете предпочесть ожидание устройства.
Например, если коммуникационный канал передачи данных используется одновремено как для периодической посылки отчетов,
согласно диспетчеру crontab, и для случайного использования пользователем, то, наверное, при занятости канала, имеет
смысл немного задержать передачу периодического отчета, нежели пропустить его вовсе.
Вообще, правильный выбор сильно зависит от назначения устройства, и определяется на этапе разработки его драйвера.
Альтернативой передачи значения занятости (-EBUSY), как вы уже догадались, является блокировка метода open().
Устройство scullwuid представляет собой вариант sculluid, который ожидает устройство при открытии, вместо того, чтобы
возвратить код занятости (-EBUSY). Отличие кода заключено только в следующей части:
spin_lock(&scull_w_lock);
while (scull_w_count &&
(scull_w_owner != current->uid) && /* allow user */
(scull_w_owner != current->euid) && /* allow whoever did su */
!capable(CAP_DAC_OVERRIDE)) {
spin_unlock(&scull_w_lock);
if (filp->f_flags & O_NONBLOCK) return -EAGAIN;
interruptible_sleep_on(&scull_w_wait);
if (signal_pending(current)) /* a signal arrived */
return -ERESTARTSYS; /* tell the fs layer to handle it */
/* else, loop */
spin_lock(&scull_w_lock);
}
if (scull_w_count == 0)
scull_w_owner = current->uid; /* grab it */
scull_w_count++;
spin_unlock(&scull_w_lock);
Как вы могли догадаться, реализация снова построена на использовании очереди ожидания. Очереди ожидания создаются для
составления списка процессов, которые должны спать при ожидании некоторого события.
Метод release() драйвера, выполняет пробуждение всех, еще не проснувшихся, процессов:
int scull_w_release(struct inode *inode, struct file *filp)
{
scull_w_count--;
if (scull_w_count == 0)
wake_up_interruptible(&scull_w_wait); /* awaken other uid's */
MOD_DEC_USE_COUNT;
return 0;
}
Проблема реализации блокировки в методе open() состоит в том, что пользователь должен учитывать предположение о том, что
происходит все не совсем гладко. Взаимодействие пользователя с драйвером может быть построено на использовании готовых
команд, таких как cp и tar, которые не могут добавить флаг O_NONBLOCK при вызове open(). Кто-то, кто выполняет резервное
копирование на накопитель на магнитной ленте, стоящий в другой комнате, предпочтет получить сообщение "device or
resource busy", вместо того, чтобы ломать голову над тем, почему безмолствует жесткий диск при выполнении
резервного копирования.
Этот сорт проблем, связанный с различием фукнциональности и политики для одного и того же устройства, лучшим образом
решается созданием множества файловых интерфейсов, реализующих различную политику для одного устройства. В качестве
примера такой практики можно привести реализацию драйвера для накопителя на магнитной ленте в Linux, который
предоставляет множество файловых интерфейсов для одного и того же устройства. Различные файловые интерфейсы позволяют, в
последнем случае, производить запись с компрессией, или без компрессии данных, или использовать автоматическую перемотку
при закрытии устройства.
Клонирование устройства в методе open()
Другой техникой управления уточненным доступом состоит в создании различных копий устройства, в зависимости от процесса,
который его открывает.
Ясно, что реализация такой техники возможна только в том случае, если устройство не зажато рамками физического
устройства. Так, устройство scull, как раз является отличным примером такого "программного" устройства.
Внутренняя реализация /dev/tty использует похожую технику, для того чтобы предоставить процессам различную точку зрения
на элемент /dev-интерфейса. Когда копии устройства создается программным драйвером, мы называем из виртуальными
устройствами - как виртуальные консоли, использующие одно физическое устройство tty.
Хотя необходимость в таком способе управления доступом достаточно редка, рассмотрение его реализации хорошо
демонстрирует факт того, как код ядра может изменить точку зрения приложения на окружающий мир (т.е. на компьютер).
Данная тема достаточно экзотична, поэтому, если она вам не интересна, то вы можете смело приступить к изучению
следующего раздела.
Файловый интерфейс /dev/scullpriv реализует виртуальное устройство из пакета scull. Реализация scullpriv использует
младший номер процесса, управляющего tty, как ключ доступа к виртуальному устройству. Конечно, вы можете легко изменить
код источника драйвера для использования любого другого целого значения в качестве ключа. Каждый способ определения
ключа является следствием различной политики. Например, использование в качестве ключа идентификатора пользователя (uid)
приведет к различным виртуальным устройствам для каждого пользователя, в то время как использование в качестве ключа
идентификатора процесса (pid) позволит создать для каждого процесса свое виртуальное устройство.
Использование в качестве ключа код управляющего терминала позволит упростить процесс тестирования устройства используя
обычное перенаправление ввода/вывода. Устройство будет разделяться между всеми комаднами запущенными на одном
виртуальном терминале, и закроет доступ для команд запущенных на другом терминале.
Приведем код метода open(). Он должен найти соответсвующее виртуальное устройство, и, возможно, создать его.
Заключительная часть функции не показана, потому что она совпадает с кодом общим для основного драйвера scull, который
уже был приведен выше.
/* The clone-specific data structure includes a key field */
/* Структура данных, специфичная для каждого из клонов драйвера,
включающая поле ключа */
struct scull_listitem {
Scull_Dev device;
int key;
struct scull_listitem *next;
};
/* The list of devices, and a lock to protect it */
/* Список устройств и спинлок для его защиты */
struct scull_listitem *scull_c_head;
spinlock_t scull_c_lock;
/* Look for a device or create one if missing */
/* Поиск устройства или его создание, при необходимости */
static Scull_Dev *scull_c_lookfor_device(int key)
{
struct scull_listitem *lptr, *prev = NULL;
for (lptr = scull_c_head; lptr && (lptr->key != key); lptr = lptr->next)
prev=lptr;
if (lptr) return &(lptr->device);
/* not found */
lptr = kmalloc(sizeof(struct scull_listitem), GFP_ATOMIC);
if (!lptr) return NULL;
/* initialize the device */
memset(lptr, 0, sizeof(struct scull_listitem));
lptr->key = key;
scull_trim(&(lptr->device)); /* initialize it */
sema_init(&(lptr->device.sem), 1);
/* place it in the list */
if (prev) prev->next = lptr;
else scull_c_head = lptr;
return &(lptr->device);
}
int scull_c_open(struct inode *inode, struct file *filp)
{
Scull_Dev *dev;
int key, num = NUM(inode->i_rdev);
if (!filp->private_data && num > 0)
return -ENODEV; /* not devfs: allow 1 device only */
if (!current->tty) {
PDEBUG("Process \"%s\" has no ctl tty\n",current->comm);
return -EINVAL;
}
key = MINOR(current->tty->device);
/* look for a scullc device in the list */
spin_lock(&scull_c_lock);
dev = scull_c_lookfor_device(key);
spin_unlock(&scull_c_lock);
if (!dev) return -ENOMEM;
/* then, everything else is copied from the bare scull device */
/* остаток кода скопируйте из примера для фундаментального scull устройства */
Метод release() не делает ничего особенного. Мы бы могли просто "уничтожить" или "освободить" устройство при
закрытии последнего, связанного с ним файлового интерфейса, но в данном коде мы не поддержали счетчик
открытия устройства для того, чтобы упростить его тестирование. Если устройство будет освобождаться по закрытию
последнего файлового интерфейска, связанного с устройством, то вы не сможете прочитать теже самые данные, которые были
записаны в устройство, до тех пор пока вы не будете держать некий фоновый процесс, который будет удерживать его открытым
на время записи с последующим чтением. Поэтому, данный пример драйвера просто удерживает данные, так, что при следующем
открытии устройства вы сможете найти в нем последние данные. Устройство освобождается при вызове scull_cleanup().
Приведем реализацию метода release() для /dev/scullpriv, который закрывает обсуждение методов устройства в данной книге.
int scull_c_release(struct inode *inode, struct file *filp)
{
/*
* Nothing to do, because the device is persistent.
* A `real' cloned device should be freed on last close
*/
/* Ничего не делаем, так как хотим сохранить данные устройства.
* В реальности, клонируемые устройства должны уничтожаться
* при закрытии последнего файлового интерфейса
*/
MOD_DEC_USE_COUNT;
return 0;
}
Вопросы обратной совместимости
В процессе развития ядра, с изменением номера его ветки, могут измениться некоторые элементы набора API ядра. Поэтому,
если вы заботитесь о том чтобы ваш драйвер написанный для ядра 2.4 мог бы исполняться и в ветках 2.2 и 2.0, то в этом
разделе вы сможете найти необходимую информацию по вопросам совместимости для тех элементов, которые обсуждались в этой
главе.
Очереди ожидания в Linux 2.2 и 2.0
Относительно небольшая часть материала этой главы подверглась изменениям на этапе разработки ядра 2.3. Значительное
изменение касается очередей ожидания. Ядро 2.2 имело другую и значительно более простую реализацию очередей ожидания, но
в ней не хватало некоторых важных характеристик, таких как возможности эксклюзивного сна. Новая реализация очередей
ожидания была представлена в ядре 2.3.1.
Реализация очереди ожидания в ядре 2.2 использовала переменные типа struct wait_queue *, вместо wait_queue_head_t. Этот
указатель должен был быть проинициализирован в NULL перед первым использованием. Типичное описание и инициализация
очереди ожидания выглядела следующим образом:
struct wait_queue *my_queue = NULL;
Различные функции для перевода в сон и пробуждения выглядят аналогично, за исключением типа переменной для указания
самой очереди ожидания. В результате, написания кода, который бы мог работать как на ядре 2.4, так и на ядрах 2.2 и 2.0,
можно упростить, если использовать следующий кусок кода, который представлен в нашем заголовочном файле sysdep.h, и
используемый нами для компиляции наших примеров.
# define DECLARE_WAIT_QUEUE_HEAD(head) struct wait_queue *head = NULL
typedef struct wait_queue *wait_queue_head_t;
# define init_waitqueue_head(head) (*(head)) = NULL
Синхронные версии для набора функций wake_up() были добавлены в ядре 2.3.29, поэтому в заголовочном файле sysdep.h мы
предоставили макросы с этими именами, которые вы можете использовать для поддержки этой функциональности в портируемом
коде. Эти макросы расширяются в обычные вызовы wake_up(), так как в ранних версиях ядра отсутствовали другие механизмы.
Версии sleep_on() с поддержкой таймаута были добавлены в ядро на момент выпуска версии 2.1.127. Другие элементы
интерфейса очереди ожидания остались практически без изменений. Предоставленный нами заголовочный файл sysdep.h
определяет необходимые макросы, для того, чтобы вы могли компилировать и запускать ваши модули на ядрах 2.4 2.2 и 2.0 не
загрязняя код модуля множеством директив условной компиляции.
Макро wait_event() не был представлен в ядре 2.0, поэтому, для тех кому это может понадобиться, мы представили его
реализацию в заголовочном файле sysdep.h.
Асинхронные уведомления
В работе асинхронных уведомлений были сделаны небольшие изменения в версиях ядра 2.2 и 2.4.
В ядре 2.3.21, функция kill_fasync() получила свой третий аргумент. До этого, функция kill_fasync() имела следующую
сигнатуру вызова:
kill_fasync(struct fasync_struct *queue, int signal);
Предоставляемый нами заголовочный файл sysdep.h позаботился об этом изменении.
В ядре 2.2 изменился тип первого аргумента для метода fasync(). В ядре 2.0, вместо целого значения файлового дескриптора
передавался указатель на структуру inode:
int (*fasync) (struct inode *inode, struct file *filp, int on);
Для решения этой проблемы несовместимости мы используем тот же самый прием, что и для методов read() и write():
использование оберточной функции, при компиляции для ядра 2.0.
To solve this incompatibility, we use the same approach taken for read and write: use of a wrapper function when the
module is compiled under 2.0 headers.
Аргумент inode также передается в метод fasync(), когда он вызывается из метода release(). Это предпочтительнее передачи
значения -1, используемое в более поздних версиях ядра. Примечание переводчика: попробуйте сами прочитать
последнее предложение - "... The inode argument to the fasync method was also passed in when called from the
release method, rather than the -1 value used with later kernels."
Метод fsync()
Третий аргумент (целое значение datasync) был добавлен в метод fsync() при разработке серии ядра 2.3, означая, что для
написания портируемого кода нам необходимо написать функцию-обертку для старых версия ядра. Однако, разработчики,
которые попытаются написать портируемый код для метода fsync(), могут попасться в ловушку: по меньшей пере один из
дистрибьютеров, имя которого нам не известно, пропатчил свое ядро 2.2 fsync()-API из ядра 2.4. Разработчики ядра обычно
пытаются избежать изменений API в стабильных ветках ядра, но они не могут проконтролировать действия дистрибьютеров.
Доступ к пространству пользователя в ядре Linux 2.0
Способ управления памятью имел отличия в ядрах 2.0. Система управления виртуальной памятью уже была реализована в Linux к
тому времени, но само управление памятью несколько отличалось. Ключевые изменения в системе управления памятью произошли
во время открытия ветки ядра 2.1, что принесло значительное улучшение производительности, но, к несчастью,
сопровождалось множеством проблем совместимости, которые добавили головной боли разработчикам драйверов.
Функции, используемые для доступа к памяти в ядре 2.0 выглядели следующим образом:
- verify_area(int mode, const void *ptr, unsigned long size);
-
Работа этой функции схоже с работой access_ok(), но выполняла более обширные проверки и работала медленнее.
Функция возвращает 0 в случае успеха, и -EFAULT при обнаружении ошибки. Еще в недавних версиях заголовков ядра
данная функция была определена, но уже являлась оберткой над access_ok(). При работе в ядре 2.0, вызов
verify_area() не был опциональным (необязательным). Безопасный доступ к пространству пользователя не мог быть
произведен без явной, предварительной проверки указателя.
- put_user(datum, ptr)
-
Макро put_user() выглядит во многом похоже на его современный эквивалент. Различие заключалось в том, что не
производилась проверка адреса, и не было возвращаемого значения.
- get_user(ptr)
-
Это макро получало значение по заданному адресу, и отдавало его в качестве возвращаемого значения. Проверки
корректности передаваемого в макро указателя не производилось.
Вызов фукции verify_area() должен был вызываться явно, потому что функции копирования в/из пространства пользователя не
выполняли такой проверки. Однако, ядро 2.1, к счастью, форсировала проблемы несовместимости для функций get_user() и
put_user(), тем, что задачу проверки адресов пользовательского пространства оставила процессору и его окружению, потому
что ядро потому, что ядро было не готово управлять ловушками и процессорными исключениями, генерируемыми во время
копирования данных в пространство пользователя.
В качестве примера использования старых вызовов, рассмотрим еще раз код драйвера scull. Версия scull использующая API
ядра 2.0 может вызывать verify_area() следующим способом:
int err = 0, tmp;
/*
* extract the type and number bitfields, and don't decode
* wrong cmds: return ENOTTY before verify_area()
*/
if (_IOC_TYPE(cmd) != SCULL_IOC_MAGIC) return -ENOTTY;
if (_IOC_NR(cmd) > SCULL_IOC_MAXNR) return -ENOTTY;
/*
* the direction is a bit mask, and VERIFY_WRITE catches R/W
* transfers. `Type' is user oriented, while
* verify_area is kernel oriented, so the concept of "read" and
* "write" is reversed
*/
if (_IOC_DIR(cmd) & _IOC_READ)
err = verify_area(VERIFY_WRITE, (void *)arg, _IOC_SIZE(cmd));
else if (_IOC_DIR(cmd) & _IOC_WRITE)
err = verify_area(VERIFY_READ, (void *)arg, _IOC_SIZE(cmd));
if (err) return err;
Теперь, можно использовать get_user() и put_user() следующим образом:
case SCULL_IOCXQUANTUM: /* eXchange: use arg as pointer */
tmp = scull_quantum;
scull_quantum = get_user((int *)arg);
put_user(tmp, (int *)arg);
break;
default: /* redundant, as cmd was checked against MAXNR */
return -ENOTTY;
}
return 0;
Здесь показана только маленькая часть кода оператора switch из метода ioctl(), т.к. отличие между версиями 2.2 и более
поздними небольшие.
Жизнь разработчиков драйверов была бы относительно проще при решении вопросов совместимости, если бы put_user() и
get_user() не были бы реализованы как макросы во всех версиях ядра Linux, и их интерфейс не был бы изменен. В
результате, прямое решение с использованием макросов не может быть реализовано.
Одно из решений состоит в определении нового множества версии-независимых макросов. Так, в нашем заголовочном файле
sysdep.h определены макросы с использованием в имени символов верхнего регистра, т.е. GET_USER(), __GET_USER() и пр.
Аргументы совпадают с аргументами для макросов, определенных в ядре 2.4, но вызывающие программы должны предварительно
использовать проверку адреса с помощью verify_area(), как это требуется в ядре 2.0.
"Мандаты" (Capabilities) в ядре 2.0
Ядро 2.0 не поддерживает концепцию мандатов (capabilities) вообще. Вся проверка прав выглядела достаточно просто -
суперпользователю разрешены все операции. Для этой цели использовалась функция suser(). Она не имела аргументов, и
возвращала ненулевое значение если процесс имел привилегии суперпользователя.
Функция suser() существует в последующих версиях ядер, но ее использование выглядет несколько необычно. Лучшим решением
для данной проблемы совместимости является определение для ядра 2.0 макроса capable(), что мы и сделали в нашем
заголовочном файле sysdep.h:
# define capable(anything) suser()
Код, написанный с использованием этого макроса, будет портируемым, и сможет работать на современных,
мандатно-ориентированных системах.
Метод select() в ядре Linux 2.0
Ядро 2.0 не поддерживает системный вызов poll(), и доступен только метод select() в стиле BSD. Поэтому, соответсвующий
метод драйвера назывался select(), и работал несколько иначе, хотя выполняемые действия были почти идентичны.
В метод select передается указатель на select_table, который должен быть передан в select_wait(), в случае, если
вызывающий процесс должен дождаться одного из затребованных условий SEL_IN, SEL_OUT или SEL_EX.
Драйвер scull решает данную несовместимость объявлением специального метода select(), который используется при
компиляции для ядра 2.0:
#ifdef __USE_OLD_SELECT__
int scull_p_poll(struct inode *inode, struct file *filp,
int mode, select_table *table)
{
Scull_Pipe *dev = filp->private_data;
if (mode == SEL_IN) {
if (dev->rp != dev->wp) return 1; /* readable */
PDEBUG("Waiting to read\n");
select_wait(&dev->inq, table); /* wait for data */
return 0;
}
if (mode == SEL_OUT) {
/*
* The buffer is circular; it is considered full
* if "wp" is right behind "rp". "left" is 0 if the
* buffer is empty, and it is "1" if it is completely full.
*/
int left = (dev->rp + dev->buffersize - dev->wp) % dev->buffersize;
if (left != 1) return 1; /* writable */
PDEBUG("Waiting to write\n");
select_wait(&dev->outq, table); /* wait for free space */
return 0;
}
return 0; /* never exception-able */
}
#else /* Use poll instead, already shown */
Используемый здесь препроцессорный символ __USE_OLD_SELECT__ устанавливается в нашем заголовочном файле sysdep.h
согласно версии ядра.
Перемещение по файлу в ядре Linux 2.0
До версии ядра 2.1 метод llseek() назывался lseek() и имел другие аргументы, в отличии от текущей реализации. По этой
причине, работая под ядром 2.0 мы не могли перемещаться по файлу размером более 2 ГБт, несмотря на то, что системный
вызов llseek() уже поддерживался.
Прототип этой файловой операции в ядре 2.0 имел следующий вид:
int (*lseek) (struct inode *inode, struct file *filp , off_t off, int whence);
Поэтому решение данного вопроса совместимости для ядер 2.0 и 2.2 обычно заключается в определении различных реализаций
метода перемещения по файлу для этих двух интерфейсов.
Ядро 2.0 и SMP
Ядро Linux 2.0 практически не поддерживала SMP системы, поэтому вопросы борьбы за ресурсы (race conditions), упомянутые
в данной главе, обычно не актуальны для этой версии ядра. Так, ядро 2.0 не имело реализации spinlock, но так как,
на данном ядре в данный момент времени только один процессор обрабатывал код ядра, то необходимости в такой блокировке
не существовало.
Краткий справочник определений
Рассмотрим вкратце заголовочные файлы и символы представленные в данной главе.
- #include <linux/ioctl.h>
-
Данный заголовочный файл описывает все макросимволы используемые для определения команд ioctl. Включен в
заголовочный файл <linux/fs.h>.
- _IOC_NRBITS
_IOC_TYPEBITS
_IOC_SIZEBITS
_IOC_DIRBITS
-
Количество бит, доступных для различных битовых полей в командах ioctl. Имеются также, четыре макроса, которые
определяют MASK (маску), и четыре макросы для определения SHIFT (смещения), но они предназначены, главным
образом для внутреннего использования. Наиболее интересным для проверки является значение _IOC_SIZEBITS, потому
что его значение может быть различным на разных архитектурах.
- _IOC_NONE
_IOC_READ
_IOC_WRITE
-
Возможные значения для битового поля "direction" (направление). Возможно OR (ИЛИ) объединение полей
_IOC_READ и _IOC_WRITE, для определения операции чтения/записи. The values are 0 based.
- _IOC(dir,type,nr,size)
_IO(type,nr)
_IOR(type,nr,size)
_IOW(type,nr,size)
_IOWR(type,nr,size)
-
Макросы, используемые для создания номеров команд ioctl.
- _IOC_DIR(nr)
_IOC_TYPE(nr)
_IOC_NR(nr)
_IOC_SIZE(nr)
-
Макросы, используемые для декодирования номеров команд ioctl. Например, _IOC_TYPE(nr) возвращает OR (ИЛИ)
комбинацию флагов _IOC_READ и _IOC_WRITE.
- #include <asm/uaccess.h>
int access_ok(int type, const void *addr, unsigned long size);
-
Функция для проверки корректности указателя из адресного пространства пользователя. access_ok() возвращает
ненулевое значение, если указатель корректен.
- VERIFY_READ
VERIFY_WRITE
-
Возможные значения для аргумента type в функции access_ok(). VERIFY_WRITE является надмножеством для
VERIFY_READ.
- #include <asm/uaccess.h>
int put_user(datum,ptr);
int get_user(local,ptr);
int __put_user(datum,ptr);
int __get_user(local,ptr);
-
Макросы, используемые для сохранения или получение данных из адресного пространства пользователя. Количество
передаваемых байт определяется sizeof(*ptr). Версии put_user() и get_user() проверяют корректность указателя
вызовом функции access_ok(), в то время как версии __put_user() и __get_user() предполагают, что вызов
access_ok() уже был произведен.
- #include <linux/capability.h>
-
Определяет различные CAP_ символы для "мандатов" (capabilities), используемых в ядрах версии 2.2 и
более поздних.
- int capable(int capability);
-
Возвращает ненулевое значение, если процесс имеет соответствующий "мандат" (capability).
- #include <linux/wait.h>
typedef struct { /* ... */ } wait_queue_head_t;
void init_waitqueue_head(wait_queue_head_t *queue);
DECLARE_WAIT_QUEUE_HEAD(queue);
-
Определения для поддержки очередей ожидания в Linux. Элемент wait_queue_head_t должен быть явно
проинициализирован либо с помощью init_waitqueue_head() во время исполнения, либо с помощью
DECLARE_WAIT_QUEUE_HEAD() на этапе компиляции.
- #include <linux/sched.h>
void interruptible_sleep_on(wait_queue_head_t *q);
void sleep_on(wait_queue_head_t *q);
void interruptible_sleep_on_timeout(wait_queue_head_t *q, long timeout);
void sleep_on_timeout(wait_queue_head_t *q, long timeout);
-
Вызвав любую из этих функций вы можете перевести текущий процесс в состояние сна на заданную очередь. Обычно,
останавливают выбор на прерываемой (interruptible) форме для реализации блокируемого чтения/записи.
- void wake_up(struct wait_queue **q);
void wake_up_interruptible(struct wait_queue **q);
void wake_up_sync(struct wait_queue **q);
void wake_up_interruptible_sync(struct wait_queue **q);
-
Эти функции пробуждают процессы, которые пребывают в состоянии сна из очереди q. Прерываемая форма
(_interruptible) пробуждает только прерываемые процессы. _sync-версии не переупорядочивают очередь CPU перед
завершением вызова.
- typedef struct { /* ... */ } wait_queue_t;
init_waitqueue_entry(wait_queue_t *entry, struct task_struct *task);
-
Тип wait_queue_t используется когда сон происходит без вызова sleep_on(). Элементы очереди ожидания должны быть
проинициализированы перед использованием. Аргумент task почти всегда указывает на текущую задачу.
- void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait);
void remove_wait_queue(wait_queue_head_t *q, wait_queue_t *wait);
-
Данные функции добавляют элемент в очередь ожидания. Функция add_wait_queue_exclusive() добавляет элемент в
конец очереди для эксклюзивного ожидания. Элементы должны быть удалены из очереди с помощью функции
remove_wait_queue() после пробуждения.
- void wait_event(wait_queue_head_t q, int condition);
int wait_event_interruptible(wait_queue_head_t q, int condition);
-
Эти два макроса переводят процесс в спящее состояние по данной очереди ожидания до тех пор, пока значение
заданного условия не станет истинным.
- void schedule(void);
-
Эта функция выбирает процесс из очереди выполнения. Выбранный процесс может быть, или не быть, текущим. Обычно,
вам не придется вызывать эту функцию явно, так как sleep_on() сама выполняет этот вызов.
- #include <linux/poll.h>
void poll_wait(struct file *filp, wait_queue_head_t *q, poll_table *p)
-
Эта функция кладет текущий процесс в очередь ожидания не выполняя немедленного переупорядочивания очереди CPU.
Функция разработана для использования в методе poll() драйверов устройств.
- int fasync_helper(struct inode *inode, struct file *filp, int mode, struct fasync_struct **fa);
-
Данная функция является помошником в реализации метода fasync(). Аргумент mode совпадает с тем, что передается в
метод fasync(), в то время как аргумент fa указывает на специфическую для драйвера структуру fasync_struct *.
- void kill_fasync(struct fasync_struct *fa, int sig, int band);
-
Если драйвер поддерживает асинхронные уведомления, то эта функция может быть использована для посылки сигнала
процессу, зарегистрированному в fa.
- #include <linux/spinlock.h>
typedef struct { /* ... */ } spinlock_t;
void spin_lock_init(spinlock_t *lock);
-
Тип spinlock_t определяет спинлок, который должен быть проинициализирован с помощью функции spin_lock_init()
перед использованием.
- spin_lock(spinlock_t *lock);
spin_unlock(spinlock_t *lock);
-
Функция spin_lock() используется для установки блокировки на заданный lock. Для снятия блокировки с заданного
lock используется функция spin_unlock().
|

 LINUX
LINUX