CHAPTER 5 Filesystem-Based Concepts
The UNIX filesystem hierarchy contains a number of different filesystem types
including disk-based filesystems such as VxFS and UFS and also pseudo
filesystems such as procfs and tmpfs. This chapter describes concepts that relate
to filesystems as a whole such as disk partitioning, mounting and unmounting of
filesystems, and the main commands that operate on filesystems such as mkfs,
mount, fsck, and df.
What_fs in a Filesystem?
At one time, filesystems were either disk based in which all files in the filesystem
were held on a physical disk, or were RAM based. In the latter case, the filesystem
only survived until the system was rebooted. However, the concepts and
implementation are the same for both. Over the last 10 to 15 years a number of
pseudo filesystems have been introduced, which to the user look like filesystems,
but for which the implementation is considerably different due to the fact that
they have no physical storage. Pseudo filesystems will be presented in more detail
in Chapter 11. This chapter is primarily concerned with disk-based filesystems.
A UNIX filesystem is a collection of files and directories that has the following
properties:
86 UNIX Filesystems.Evolution, Design, and Implementation
It has a root directory (/) that contains other files and directories. Most
disk-based filesystems will also contain a lost+found directory where
orphaned files are stored when recovered following a system crash.
Each file or directory is uniquely identified by its name, the directory in
which it resides, and a unique identifier, typically called an inode.
By convention, the root directory has an inode number of 2 and the
lost+found directory has an inode number of 3. Inode numbers 0 and 1
are not used. File inode numbers can be seen by specifying the -i option to
ls.
It is self contained. There are no dependencies between one filesystem
and any other.
A filesystem must be in a clean state before it can be mounted. If the system
crashes, the filesystem is said to be dirty. In this case, operations may have been
only partially completed before the crash and therefore the filesystem structure
may no longer be intact. In such a case, the filesystem check program fsck must
be run on the filesystem to check for any inconsistencies and repair any that it
finds. Running fsck returns the filesystem to its clean state. The section
Repairing Damaged Filesystems, later in this chapter, describes the fsck program
in more detail.
The Filesystem Hierarchy
There are many different types of files in a complete UNIX operating system.
These files, together with user home directories, are stored in a hierarchical tree
structure that allows files of similar types to be grouped together. Although the
UNIX directory hierarchy has changed over the years, the structure today still
largely reflects the filesystem hierarchy developed for early System V and BSD
variants.
For both root and normal UNIX users, the PATH shell variable is set up during
login to ensure that the appropriate paths are accessible from which to run
commands. Because some directories contain commands that are used for
administrative purposes, the path for root is typically different from that of
normal users. For example, on Linux the path for a root and non root user may
be:
# echo $PATH
/usr/sbin:/sbin:/bin:/usr/bin:/usr/local/bin:/usr/bin/X11:/root/bin
$ echo $PATH
/home/spate/bin:/usr/bin:/bin:/usr/bin/X11:/usr/local/bin:
/home/spate/office52/program
The following list shows the main UNIX directories and the type of files that
reside in each directory. Note that this structure is not strictly followed among the
different UNIX variants but there is a great deal of commonality among all of
them.
/usr. This is the main location of binaries for both user and administrative
purposes.
/usr/bin. This directory contains user binaries.
/usr/sbin. Binaries that are required for system administration purposes are
stored here. This directory is not typically on a normal user_fs path. On some
versions of UNIX, some of the system binaries are stored in /sbin.
/usr/local. This directory is used for locally installed software that is
typically separate from the OS. The binaries are typically stored in
/usr/local/bin.
/usr/share. This directory contains architecture-dependent files including
ASCII help files. The UNIX manual pages are typically stored in
/usr/share/man.
/usr/lib. Dynamic and shared libraries are stored here.
/usr/ucb. For non-BSD systems, this directory contains binaries that
originated in BSD.
/usr/include. User header files are stored here. Header files used by the
kernel are stored in /usr/include/sys.
/usr/src. The UNIX kernel source code was once held in this directory
although this hasn_ft been the case for a long time, Linux excepted.
/bin. Has been a symlink to /usr/bin for quite some time.
/dev. All of the accessible device files are stored here.
/etc. Holds configuration files and binaries which may need to be run before
other filesystems are mounted. This includes many startup scripts and
configuration files which are needed when the system bootstraps.
/var. System log files are stored here. Many of the log files are stored in
/var/log.
/var/adm. UNIX accounting files and system login files are stored here.
/var/preserve. This directory is used by the vi and ex editors for storing
backup files.
/var/tmp. Used for user temporary files.
/var/spool. This directory is used for UNIX commands that provide
spooling services such as uucp, printing, and the cron command.
/home. User home directories are typically stored here. This may be
/usr/home on some systems. Older versions of UNIX and BSD often store
user home directories under /u.
88 UNIX Filesystems.Evolution, Design, and Implementation
/tmp. This directory is used for temporary files. Files residing in this
directory will not necessarily be there after the next reboot.
/opt. Used for optional packages and binaries. Third-party software vendors
store their packages in this directory.
When the operating system is installed, there are typically a number of
filesystems created. The root filesystem contains the basic set of commands,
scripts, configuration files, and utilities that are needed to bootstrap the system.
The remaining files are held in separate filesystems that are visible after the
system bootstraps and system administrative commands are available.
For example, shown below are some of the mounted filesystems for an active
Solaris system:
/proc on /proc read/write/setuid
/ on /dev/dsk/c1t0d0s0 read/write/setuid
/dev/fd on fd read/write/setuid
/var/tmp on /dev/vx/dsk/sysdg/vartmp read/write/setuid/tmplog
/tmp on /dev/vx/dsk/sysdg/tmp read/write/setuid/tmplog
/opt on /dev/vx/dsk/sysdg/opt read/write/setuid/tmplog
/usr/local on /dev/vx/dsk/sysdg/local read/write/setuid/tmplog
/var/adm/log on /dev/vx/dsk/sysdg/varlog read/write/setuid/tmplog
/home on /dev/vx/dsk/homedg/home read/write/setuid/tmplog
During installation of the operating system, there is typically a great deal of
flexibility allowed so that system administrators can tailor the number and size
of filesystems to their specific needs. The basic goal is to separate those
filesystems that need to grow from the root filesystem, which must remain stable.
If the root filesystem becomes full, the system becomes unusable.
Disks, Slices, Partitions, and Volumes
Each hard disk is typically split into a number of separate, different sized units
called partitions or slices. Note that is not the same as a partition in PC
terminology. Each disk contains some form of partition table, called a VTOC
(Volume Table Of Contents) in SVR4 terminology, which describes where the
slices start and what their size is. Each slice may then be used to store bootstrap
information, a filesystem, swap space, or be left as a raw partition for database
access or other use.
Disks can be managed using a number of utilities. For example, on Solaris and
many SVR4 derivatives, the prtvtoc and fmthard utilities can be used to edit
the VTOC to divide the disk into a number of slices. When there are many disks,
this hand editing of disk partitions becomes tedious and very error prone.
For example, here is the output of running the prtvtoc command on a root
disk on Solaris:
# prtvtoc /dev/rdsk/c0t0d0s0
* /dev/rdsk/c0t0d0s0 partition map
Filesystem-Based Concepts 89
*
* Dimensions:
* 512 bytes/sector
* 135 sectors/track
* 16 tracks/cylinder
* 2160 sectors/cylinder
* 3882 cylinders
* 3880 accessible cylinders
*
* Flags:
* 1: unmountable
* 10: read-only
*
* First Sector Last
* Partition Tag Flags Sector Count Sector Mount Dir
0 2 00 0 788400 788399 /
1 3 01 788400 1049760 1838159
2 5 00 0 8380800 8380799
4 0 00 1838160 4194720 6032879 /usr
6 4 00 6032880 2347920 8380799 /opt
The partition tag is used to identify each slice such that c0t0d0s0 is the slice that
holds the root filesystem, c0t0d0s4 is the slice that holds the /usr filesystem,
and so on.
The following example shows partitioning of an IDE-based, root Linux disk.
Although the naming scheme differs, the concepts are similar to those shown
previously.
# fdisk /dev/hda
Command (m for help): p
Disk /dev/hda: 240 heads, 63 sectors, 2584 cylinders
Units = cylinders of 15120 * 512 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 3 22648+ 83 Linux
/dev/hda2 556 630 567000 6 FAT16
/dev/hda3 4 12 68040 82 Linux swap
/dev/hda4 649 2584 14636160 f Win95 Ext'd (LBA)
/dev/hda5 1204 2584 10440328+ b Win95 FAT32
/dev/hda6 649 1203 4195737 83 Linux
Logical volume managers provide a much easier way to manage disks and create
new slices (called logical volumes). The volume manager takes ownership of the
disks and gives out space as requested. Volumes can be simple, in which case the
volume simply looks like a basic raw disk slice, or they can be mirrored or striped.
For example, the following command can be used with the VERITAS Volume
Manager, VxVM, to create a new simple volume:
# vxassist make myvol 10g
# vxprint myvol
90 UNIX Filesystems.Evolution, Design, and Implementation
Disk group: rootdg
TY NAME ASSOC KSTATE LENGTH PLOFFS STATE
v myvol fsgen ENABLED 20971520 ACTIVE
pl myvol-01 myvol ENABLED 20973600 ACTIVE
sd disk12-01 myvol-01 ENABLED 8378640 0 -
sd disk02-01 myvol-01 ENABLED 8378640 8378640 -
sd disk03-01 myvol-01 ENABLED 4216320 16757280 -
VxVM created the new volume, called myvol, from existing free space. In this
case, the 1GB volume was created from three separate, contiguous chunks of disk
space that together can be accessed like a single raw partition.
Raw and Block Devices
With each disk slice or logical volume there are two methods by which they can
be accessed, either through the raw (character) interface or through the block
interface. The following are examples of character devices:
# ls -l /dev/vx/rdsk/myvol
crw------ 1 root root 86, 8 Jul 9 21:36 /dev/vx/rdsk/myvol
# ls -lL /dev/rdsk/c0t0d0s0
crw------ 1 root sys 136, 0 Apr 20 09:51 /dev/rdsk/c0t0d0s0
while the following are examples of block devices:
# ls -l /dev/vx/dsk/myvol
brw------ 1 root root 86, 8 Jul 9 21:11 /dev/vx/dsk/myvol
# ls -lL /dev/dsk/c0t0d0s0
brw------ 1 root sys 136, 0 Apr 20 09:51 /dev/dsk/c0t0d0s0
Note that both can be distinguished by the first character displayed (b or c) or
through the location of the device file. Typically, raw devices are accessed
through /dev/rdsk while block devices are accessed through /dev/dsk. When
accessing the block device, data is read and written through the system buffer
cache. Although the buffers that describe these data blocks are freed once used,
they remain in the buffer cache until they get reused. Data accessed through the
raw or character interface is not read through the buffer cache. Thus, mixing the
two can result in stale data in the buffer cache, which can cause problems.
All filesystem commands, with the exception of the mount command, should
therefore use the raw/character interface to avoid this potential caching problem.
Filesystem Switchout Commands
Many of the commands that apply to filesystems may require filesystem specific
processing. For example, when creating a new filesystem, each different
Filesystem-Based Concepts 91
filesystem may support a wide range of options. Although some of these options
will be common to most filesystems, many may not be.
To support a variety of command options, many of the filesystem-related
commands are divided into generic and filesystem dependent components. For
example, the generic mkfs command that will be described in the next section, is
invoked as follows:
# mkfs -F vxfs -o ...
The -F option (-t on Linux) is used to specify the filesystem type. The -o option
is used to specify filesystem-specific options. The first task to be performed by
mkfs is to do a preliminary sanity check on the arguments passed. After this has
been done, the next job is to locate and call the filesystem specific mkfs function.
Take for example the call to mkfs as follows:
# mkfs -F nofs /dev/vx/rdsk/myvol
mkfs: FSType nofs not installed in the kernel
Because there is no filesystem type of nofs, the generic mkfs command is unable
to locate the nofs version of mkfs. To see how the search is made for the
filesystem specific mkfs command, consider the following:
# truss -o /tmp/truss.out mkfs -F nofs /dev/vx/rdsk/myvol
mkfs: FSType nofs not installed in the kernel
# grep nofs /tmp/truss.out
execve("/usr/lib/fs/nofs/mkfs", 0x000225C0, 0xFFBEFDA8) Err#2 ENOENT
execve("/etc/fs/nofs/mkfs", 0x000225C0, 0xFFBEFDA8) Err#2 ENOENT
sysfs(GETFSIND, "nofs") Err#22 EINVAL
In this case, the generic mkfs command assumes that commands for the nofs
filesystem will be located in one of the two directories shown above. In this case,
the files don_ft exist. As a finally sanity check, a call is made to sysfs() to see if
there actually is a filesystem type called nofs.
Consider the location of the generic and filesystem-specific fstyp commands
in Solaris:
# which fstyp
/usr/sbin/fstyp
# ls /usr/lib/fs
autofs/ fd/ lofs/ nfs/ proc/ udfs/ vxfs/
cachefs/ hsfs/ mntfs/ pcfs/ tmpfs/ ufs/
# ls /usr/lib/fs/ufs/fstyp
/usr/lib/fs/ufs/fstyp
# ls /usr/lib/fs/vxfs/fstyp
/usr/lib/fs/vxfs/fstyp
Using this knowledge it is very straightforward to write a version of the generic
fstyp command as follows:
1 #include
2 #include
3 #include
4
5 main(int argc, char **argv)
6 {
7 char cmd[256];
8
9 if (argc != 4 && (strcmp(argv[1], "-F") != 0)) {
10 printf("usage: myfstyp -F fs-type\n");
11 exit(1);
12 }
13 sprintf(cmd, "/usr/lib/fs/%s/fstyp", argv[2]);
14 if (execl(cmd, argv[2], argv[3], NULL) < 0) {
15 printf("Failed to find fstyp command for %s\n",
16 argv[2]);
17 }
18 if (sysfs(GETFSTYP, argv[2]) < 0) {
19 printf("Filesystem type %s doesn_ft exist\n",
20 argv[2]);
21 }
22 }
This version requires that the filesystem type to search for is specified. If it is
located in the appropriate place, the command is executed. If not, a check is made
to see if the filesystem type exists as the following run of the program shows:
# myfstyp -F vxfs /dev/vx/rdsk/myvol
vxfs
# myfstyp -F nofs /dev/vx/rdsk/myvol
Failed to find fstyp command for nofs
Filesystem type "nofs" doesn_ft exist
Creating New Filesystems
Filesystems can be created on raw partitions or logical volumes. For example, in
the prtvtoc output shown above, the root (/) filesystem was created on the raw
disk slice /dev/rdsk/c0t0d0s0 and the /usr filesystem was created on the
raw disk slice /dev/rdsk/c0t0d0s4.
The mkfs command is most commonly used to create a new filesystem,
although on some platforms the newfs command provides a more friendly
interface and calls mkfs internally. The type of filesystem to create is passed to
mkfs as an argument. For example, to create a VxFS filesystem, this would be
achieved by invoking mkfs -F vxfs on most UNIX platforms. On Linux, the
call would be mkfs -t vxfs.
The filesystem type is passed as an argument to the generic mkfs command
(-F or -t). This is then used to locate the switchout command by searching
well-known locations as shown above. The following two examples show how to
Filesystem-Based Concepts 93
create a VxFS filesystem. In the first example, the size of the filesystem to create is
passed as an argument. In the second example, the size is omitted, in which case
VxFS determines the size of the device and creates a filesystem of that size.
# mkfs -F vxfs /dev/vx/rdsk/vol1 25g
version 4 layout
52428800 sectors, 6553600 blocks of size 4096,
log size 256 blocks unlimited inodes, largefiles not supported
6553600 data blocks, 6552864 free data blocks
200 allocation units of 32768 blocks, 32768 data blocks
# mkfs -F vxfs /dev/vx/rdsk/vol1
version 4 layout
54525952 sectors, 6815744 blocks of size 4096,
log size 256 blocks unlimited inodes, largefiles not supported
6815744 data blocks, 6814992 free data blocks
208 allocation units of 32768 blocks, 32768 data blocks
The following example shows how to create a UFS filesystem. Note that although
the output is different, the method of invoking mkfs is similar for both VxFS and
UFS.
# mkfs -F ufs /dev/vx/rdsk/vol1 54525952
/dev/vx/rdsk/vol1: 54525952 sectors in 106496 cylinders of
16 tracks, 32 sectors
26624.0MB in 6656 cyl groups (16 c/g, 4.00MB/g, 1920 i/g)
super-block backups (for fsck -F ufs -o b=#) at:
32, 8256, 16480, 24704, 32928, 41152, 49376, 57600, 65824,
74048, 82272, 90496, 98720, 106944, 115168, 123392, 131104,
139328, 147552, 155776, 164000,
...
54419584, 54427808, 54436032, 54444256, 54452480, 54460704,
54468928, 54477152, 54485376, 54493600, 54501824, 54510048,
The time taken to create a filesystem differs from one filesystem type to another.
This is due to how the filesystems lay out their structures on disk. In the example
above, it took UFS 23 minutes to create a 25GB filesystem, while for VxFS it took
only half a second. Chapter 9 describes the implementation of various filesystems
and shows how this large difference in filesystem creation time can occur.
Additional arguments can be passed to mkfs through use of the -o option, for
example:
# mkfs -F vxfs -obsize=8192,largefiles /dev/vx/rdsk/myvol
version 4 layout
20971520 sectors, 1310720 blocks of size 8192,
log size 128 blocks
unlimited inodes, largefiles not supported
1310720 data blocks, 1310512 free data blocks
40 allocation units of 32768 blocks, 32768 data blocks
94 UNIX Filesystems.Evolution, Design, and Implementation
For arguments specified using the -o option, the generic mkfs command will
pass the arguments through to the filesystem specific mkfs command without
trying to interpret them.
Mounting and Unmounting Filesystems
The root filesystem is mounted by the kernel during system startup. Each
filesystem can be mounted on any directory in the root filesystem, except /. A
mount point is simply a directory. When a filesystem is mounted on that
directory, the previous contents of the directory are hidden for the duration of the
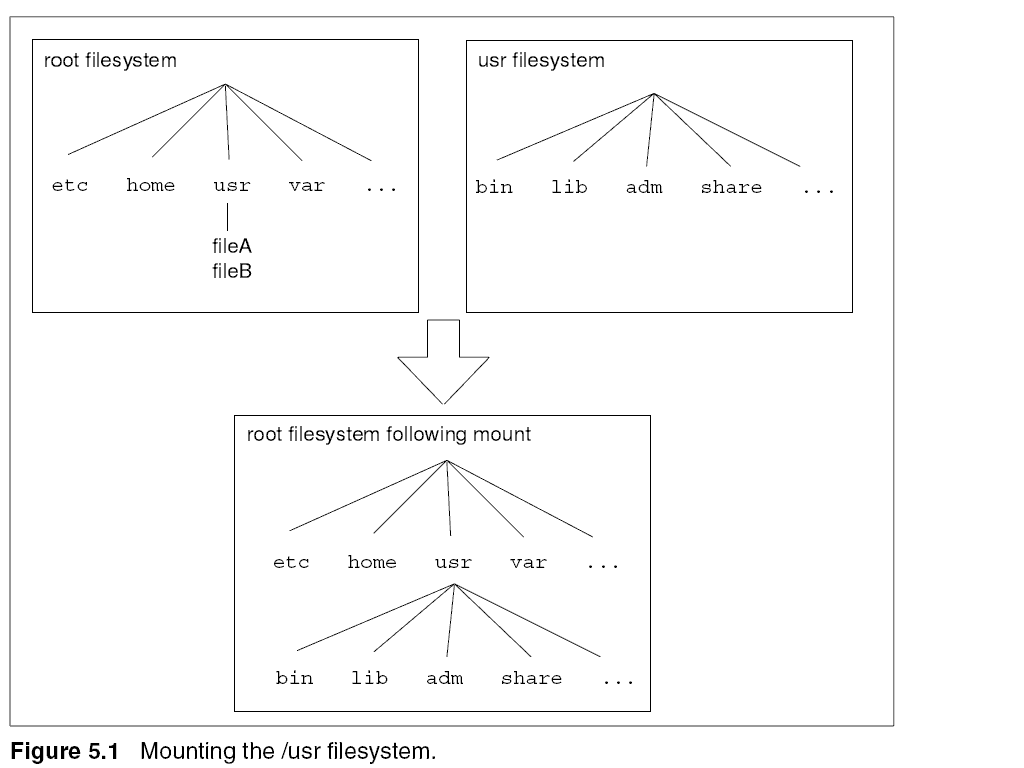
mount, as shown in Figure 5.1.
In order to mount a filesystem, the filesystem type, the device (slice or logical
volume), and the mount point must be passed to the mount command. In the
example below, a VxFS filesystem is mounted on /mnt1. Running the mount
command by itself shows all the filesystems that are currently mounted, along
with their mount options:
# mount -F vxfs /dev/vx/dsk/vol1 /mnt1
# mount | grep mnt1
/mnt1 on /dev/vx/dsk/vol1 read/write/setuid/delaylog/
nolargefiles/ioerror=mwdisable/dev=1580006
on Tue Jul 3 09:40:27 2002
Note that the mount shows default mount options as well as options that were
explicitly requested. On Linux, the -t option is used to specify the filesystem
type so the command would be invoked with mount -t vxfs.
As with mkfs, the mount command is a switchout command. The generic
mount runs first and locates the filesystem-specific command to run, as the
following output shows. Note the use of the access() system call. There are a
number of well-known locations for which the filesystem-dependent mount
command can be located.
1379: execve("/usr/sbin/mount", 0xFFBEFD8C, 0xFFBEFDA4) argc = 5
...
1379: access("/usr/lib/fs/vxfs/mount", 0) Err#2 ENOENT
1379: execve("/etc/fs/vxfs/mount", 0xFFBEFCEC, 0xFFBEFDA4) argc = 3
...
1379: mount("/dev/vx/dsk/vol1", "/mnt1", MS_DATA|MS_OPTIONSTR,
"vxfs", 0xFFBEFBF4, 12) = 0
...
When a filesystem is mounted, an entry is added to the mount table, which is a file
held in /etc that records all filesystems mounted, the devices on which they
reside, the mount points on which they_fre mounted, and a list of options that
were passed to mount or which the filesystem chose as defaults.
TEAMFLY
The actual name chosen for the mount table differs across different versions of
UNIX. On all System V variants, it is called mnttab, while on Linux and BSD
variants it is called mtab.
Shown below are the first few lines of /etc/mnttab on Solaris followed by
the contents of a /etc/mtab on Linux:
# head -6 /etc/mnttab
/proc /proc proc rw,suid,dev=2f80000 995582515
/dev/dsk/c1t0d0s0 / ufs rw,suid,dev=1d80000,largefiles 995582515
fd /dev/fd fd rw,suid,dev=3080000 995582515
/dev/dsk/c1t1d0s0 /space1 ufs ro,largefiles,dev=1d80018 995582760
/dev/dsk/c1t2d0s0 /rootcopy ufs ro,largefiles,dev=1d80010
995582760
/dev/vx/dsk/sysdg/vartmp /var/tmp vxfs rw,tmplog,suid,nolargefiles
995582793
# cat /etc/mtab
/dev/hda6 / ext2 rw 0 0
none /proc proc rw 0 0
usbdevfs /proc/bus/usb usbdevfs rw 0 0
/dev/hda1 /boot ext2 rw 0 0
none /dev/pts devpts rw,gid=5,mode=620 0 0
All versions of UNIX provide a set of routines for manipulating the mount table,
either for adding entries, removing entries, or simply reading them. Listed below
are two of the functions that are most commonly available:
#include < stdio.h>
#include < sys/mnttab.h>
int getmntent(FILE *fp, struct mnttab *mp);
int putmntent(FILE *iop, struct mnttab *mp);
The getmntent(L) function is used to read entries from the mount table while
putmntent(L) can be used to remove entries. Both functions operate on the
mnttab structure, which will contain at least the following members:
char *mnt_special; /* The device on which the fs resides */
char *mnt_mountp; /* The mount point */
char *mnt_fstype; /* The filesystem type */
char *mnt_mntopts; /* Mount options */
char *mnt_time; /* The time of the mount */
Using the getmntent(L) library routine, it is very straightforward to write a
simple version of the mount command that, when run with no arguments,
displays the mounted filesystems by reading entries from the mount table. The
program, which is shown below, simply involves opening the mount table and
then making repeated calls to getmntent(L) to read all entries.
1 #include < stdio.h>
2 #include < sys/mnttab.h>
3
4 main()
5 {
6 struct mnttab mt;
7 FILE *fp;
8
9 fp = fopen("/etc/mnttab", _gr_h);
10
11 printf("%-15s%-10s%-30s\n",
12 "mount point", "fstype", "device");
13 while ((getmntent(fp, &mt)) != -1) {
14 printf("%-15s%-10s%-30s\n", mt.mnt_mountp,
15 mt.mnt_fstype, mt.mnt_special);
16 }
17 }
Each time getmntent(L) is called, it returns the next entry in the file. Once all
entries have been read, -1 is returned. Here is an example of the program
running:
$ mymount | head -7
/proc proc /proc
Filesystem-Based Concepts 97
/ ufs /dev/dsk/c1t0d0s0
/dev/fd fd fd
/space1 ufs /dev/dsk/c1t1d0s0
/var/tmp vxfs /dev/vx/dsk/sysdg/vartmp
/tmp vxfs /dev/vx/dsk/sysdg/tmp
On Linux, the format of the mount table is slightly different and the
getmntent(L) function operates on a mntent structure. Other than minor
differences with field names, the following program is almost identical to the one
shown above:
1 #include < stdio.h>
2 #include < mntent.h>
3
4 main()
5 {
6 struct mntent *mt;
7 FILE *fp;
8
9 fp = fopen("/etc/mtab", "r");
10
11 printf("%-15s%-10s%-30s\n",
12 "mount point", "fstype", "device");
13 while ((mt = getmntent(fp)) != NULL) {
14 printf("%-15s%-10s%-30s\n", mt->mnt_dir,
15 mt->mnt_type, mt->mnt_fsname);
16 }
17 }
Following is the output when the program runs:
$ lmount
mount point fstype device
/ ext2 /dev/hda6
/proc proc none
/proc/bus/usb usbdevfs usbdevfs
/boot ext2 /dev/hda1
/dev/pts devpts none
/mnt1 vxfs /dev/vx/dsk/myvol
To unmount a filesystem either the mount point or the device can be passed to the
umount command, as the following examples show:
# umount /mnt1
# mount | grep mnt1
# mount -F vxfs /dev/vx/dsk/vol1 /mnt1
# mount | grep mnt1
/mnt1 on /dev/vx/dsk/vol1 read/write/setuid/delaylog/ ...
# umount /dev/vx/dsk/vol1
# mount | grep mnt1
After each invocation of umount, the entry is removed from the mount table.
98 UNIX Filesystems.Evolution, Design, and Implementation
Mount and Umount System Call Handling
As the preceding examples showed, the mount and umount commands result in
a call to the mount() and umount() system calls respectively.
#include < sys/types.h>
#include < sys/mount.h>
int mount(const char *spec, const char *dir, int mflag, /*
char *fstype, const char *dataptr, int datalen */ ...);
#include
int umount(const char *file);
Usually there should never be a direct need to invoke either the mount() or
umount() system calls. Although many of the arguments are self explanatory,
the handling of per-filesystem options, as pointed to by dataptr, is not typically
published and often changes. If applications have a need to mount and unmount
filesystems, the system(L) library function is recommended as a better choice.
Mounting Filesystems Automatically
As shown in the next section, after filesystems are created, it is typically left to the
system to mount them during bootstrap. The virtual filesystem table, called
/etc/vfstab on System V variants and /etc/fstab on BSD variants,
contains all the necessary information about each filesystem to be mounted.
This file is partially created during installation of the operating system. When
new filesystems are created, the system administrator will add new entries
ensuring that all the appropriate fields are entered correctly. Shown below is an
example of the vfstab file on Solaris:
# cat /etc/vfstab
...
fd - /dev/fd fd - no -
/proc - /proc proc - no -
/dev/dsk/c0t0d0s0 /dev/rdsk/c0t0d0s0 / ufs 1 no -
/dev/dsk/c0t0d0s6 /dev/rdsk/c0t0d0s6 /usr ufs 1 no -
/dev/dsk/c0t0d0s4 /dev/rdsk/c0t0d0s4 /c ufs 2 yes -
...
Here the fields are separated by spaces or tabs. The first field shows the block
device (passed to mount), the second field shows the raw device (passed to
fsck), the third field specifies the mount point, and the fourth specifies the
filesystem type. The remaining three fields specify the order in which the
filesystems will be checked, whether they should be mounted during bootstrap,
and what options should be passed to the mount command.
Here is an example of a Linux fstab table:
# cat /etc/fstab
LABEL=/ / ext2 defaults 1 1
LABEL=/boot /boot ext2 defaults 1 2
/dev/cdrom /mnt/cdrom iso9660 noauto,owner,ro 0 0
/dev/fd0 /mnt/floppy auto noauto,owner 0 0
none /proc proc defaults 0 0
none /dev/pts devpts gid=5,mode=620 0 0
/dev/hda3 swap swap defaults 0 0
/SWAP swap swap defaults 0 0
The first four fields describe the device, mount point, filesystem type, and options
to be passed to mount. The fifth field is related to the dump command and records
which filesystems need to be backed up. The sixth field is used by the fsck
program to determine the order in which filesystems should be checked during
bootstrap.
Mounting Filesystems During Bootstrap
Once filesystems are created and entries placed in /etc/vfstab, or equivalent,
there is seldom need for administrator intervention. This file is accessed during
system startup to mount all filesystems before the system is accessible to most
applications and users.
When the operating system bootstraps, the kernel is read from a well-known
location of disk and then goes through basic initialization tasks. One of these tasks
is to mount the root filesystem. This is typically the only filesystem that is
mounted until the system rc scripts start running.
The init program is spawned by the kernel as the first process (process ID of
1). By consulting the inittab(F) file, it determines which commands and
scripts it needs to run to bring the system up further. This sequence of events can
differ between one system and another. For System V-based systems, the rc
scripts are located in /etc/rcX.d where X corresponds to the run level at which
init is running.
Following are a few lines from the inittab(F) file:
$ head -9 inittab
ap::sysinit:/sbin/autopush -f /etc/iu.ap
ap::sysinit:/sbin/soconfig -f /etc/sock2path
fs::sysinit:/sbin/rcS sysinit
is:3:initdefault:
p3:s1234:powerfail:/usr/sbin/shutdown -y -i5 -g0
sS:s:wait:/sbin/rcS
s0:0:wait:/sbin/rc0
s1:1:respawn:/sbin/rc1
s2:23:wait:/sbin/rc2
Of particular interest is the last line. The system goes multiuser at init state 2.
This is achieved by running the rc2 script which in turn runs all of the scripts
found in /etc/rc2.d. Of particular interest is the script S01MOUNTFSYS. This is
100 UNIX Filesystems.Evolution, Design, and Implementation
the script that is responsible for ensuring that all filesystems are checked for
consistency and mounted as appropriate. The mountall script is responsible for
actually mounting all of the filesystems.
The layout of files and scripts used on non-System V variants differs, but the
concepts are the same.
Repairing Damaged Filesystems
A filesystem can typically be in one of two states, either clean or dirty. To mount a
filesystem it must be clean, which means that it is structurally intact. When
filesystems are mounted read/write, they are marked dirty to indicate that there
is activity on the filesystem. Operations may be pending on the filesystem during
a system crash, which could leave the filesystem with structural damage. In this
case it can be dangerous to mount the filesystem without knowing the extent of
the damage. Thus, to return the filesystem to a clean state, a filesystem-specific
check program called fsck must be run to repair any damage that might exist.
For example, consider the following call to mount after a system crash:
# mount -F vxfs /dev/vx/dsk/vol1 /mnt1
UX:vxfs mount: ERROR: /dev/vx/dsk/vol1 is corrupted. needs checking
The filesystem is marked dirty and therefore the mount fails. Before it can be
mounted again, the VxFS fsck program must be run as follows:
# fsck -F vxfs /dev/vx/rdsk/vol1
log replay in progress
replay complete marking super-block as CLEAN
VxFS is a transaction-based filesystem in which structural changes made to the
filesystem are first written to the filesystem log. By replaying the transactions in
the log, the filesystem returns to its clean state.
Most UNIX filesystems are not transaction-based, and therefore the whole
filesystem must be checked for consistency. In the example below, a full fsck is
performed on a UFS filesystem to show the type of checks that will be performed.
UFS on most versions of UNIX is not transaction-based although Sun has added
journaling support to its version of UFS.
# fsck -F ufs -y /dev/vx/rdsk/myvol
** /dev/vx/dsk/myvol
** Last Mounted on /mnt1
** Phase 1 Check Blocks and Sizes
** Phase 2 Check Pathnames
** Phase 3 Check Connectivity
** Phase 4 Check Reference Counts
** Phase 5 Check Cyl groups
61 files, 13 used, 468449 free (41 frags, 58551 blocks, 0
.0% fragmentation)
Running fsck is typically a non-interactive task performed during system
initialization. Interacting with fsck is not something that system administrators
will typically need to do. Recording the output of fsck is always a good idea in
case fsck fails to clean the filesystem and support is needed by filesystem
vendors and/or developers.
The Filesystem Debugger
When things go wrong with filesystems, it is necessary to debug them in the same
way that it is necessary to debug other applications. Most UNIX filesystems have
shipped with the filesystem debugger, fsdb, which can be used for that purpose.
It is with good reason that fsdb is one of the least commonly used of the UNIX
commands. In order to use fsdb effectively, knowledge of the filesystem
structure on disk is vital, as well as knowledge of how to use the filesystem
specific version of fsdb. Note that one version of fsdb does not necessarily bear
any resemblance to another.
In general, fsdb should be left well alone. Because it is possible to damage the
filesystem beyond repair, its use should be left for filesystem developers and
support engineers only.
Per Filesystem Statistics
In the same way that the stat() system call can be called to obtain per-file
related information, the statvfs() system call can be invoked to obtain
per-filesystem information. Note that this information will differ for each
different mounted filesystem so that the information obtained for, say, one VxFS
filesystem, will not necessarily be the same for other VxFS filesystems.
#include < sys/types.h>
#include < sys/statvfs.h>
int statvfs(const char *path, struct statvfs *buf);
int fstatvfs(int fildes, struct statvfs *buf);
Both functions operate on the statvfs structure, which contains a number of
filesystem-specific fields including the following:
u_long f_bsize; /* file system block size */
u_long f_frsize; /* fundamental filesystem block
(size if supported) */
fsblkcnt_t f_blocks; /* total # of blocks on file system
in units of f_frsize */
fsblkcnt_t f_bfree; /* total # of free blocks */
fsblkcnt_t f_bavail; /* # of free blocks avail to
non-super-user */
fsfilcnt_t f_files; /* total # of file nodes (inodes) */
102 UNIX Filesystems.Evolution, Design, and Implementation
fsfilcnt_t f_ffree; /* total # of free file nodes */
fsfilcnt_t f_favail; /* # of inodes avail to non-suser*/
u_long f_fsid; /* file system id (dev for now) */
char f_basetype[FSTYPSZ]; /* fs name null-terminated */
u_long f_flag; /* bit mask of flags */
u_long f_namemax; /* maximum file name length */
char f_fstr[32]; /* file system specific string */
The statvfs(L) function is not available on Linux. In its place is the
statfs(L) function that operates on the statfs structure. The fields of this
structure are very similar to the statvfs structure, and therefore implementing
commands such as df require very little modification if written for a system
complying with the Single UNIX Specification.
The following program provides a simple implementation of the df command
by invoking statvfs(L) to obtain per filesystem statistics as well as locating
the entry in the /etc/vfstab file:
1 #include < stdio.h>
2 #include < sys/types.h>
3 #include < sys/statvfs.h>
4 #include < sys/mnttab.h>
5
6 #define Kb (stv.f_frsize / 1024)
7
8 main(int argc, char **argv)
9 {
10 struct mnttab mt, mtp;
11 struct statvfs stv;
12 int blocks, used, avail, capacity;
13 FILE *fp;
14
15 statvfs(argv[1], &stv);
16
17 fp = fopen("/etc/mnttab", "r");
18 memset(&mtp, 0, sizeof(struct mnttab));
19 mtp.mnt_mountp = argv[1];
20 getmntany(fp, &mt, &mtp);
21
22 blocks = stv.f_blocks * Kb;
23 used = (stv.f_blocks - stv.f_bfree) * Kb;
24 avail = stv.f_bfree * Kb;
25 capacity = ((double)used / (double)blocks) * 100;
26 printf("Filesystem kbytes used "
27 "avail capacity Mounted on\n");
28 printf("%-22s%-7d%8d%8d %2d%% %s\n",
29 mt.mnt_special, blocks, used, avail,
30 capacity, argv[1]);
31 }
In the output shown next, the df command is run first followed by output from
the example program:
$ df -k /h
Filesystem kbytes used avail capacity Mounted on
/dev/vx/dsk/homedg/h 7145728 5926881 1200824 84% /h
$ mydf /h
Filesystem kbytes used avail capacity Mounted on
/dev/vx/dsk/homedg/h 7145728 5926881 1218847 82% /h
In practice, there is a lot of formatting work needed by df due to the different
sizes of device names, mount paths, and the additional information displayed
about each filesystem.
Note that the preceding program has no error checking. As an exercise,
enhance the program to add error checking. On Linux the program needs
modification to access the /etc/mtab file and to use the statfs(L) function.
The program can be enhanced further to display all entries on the mount table as
well as accept some of the other options that df provides.
User and Group Quotas
Although there may be multiple users of a filesystem, it is possible for a single
user to consume all of the space within the filesystem. User and group quotas
provide the mechanisms by which the amount of space used by a single user or all
users within a specific group can be limited to a value defined by the
administrator.
Quotas are based on the number of files used and the number of blocks. Some
filesystems have a limited number of inodes available. Even though the amount
of space consumed by a user may be small, it is still possible to consume all of the
files in the filesystem even though most of the free space is still available.
Quotas operate around two limits that allow the user to take some action if the
amount of space or number of disk blocks start to exceed the administrator
defined limits:
Soft Limit. If the user exceeds the limit defined, there is a grace period that
allows the user to free up some space. The quota can be exceeded during this
time. However, after the time period has expired, no more files or data blocks
may be allocated.
Hard Limit. When the hard limit is reached, regardless of the grace period, no
further files or blocks can be allocated.
The grace period is set on a per-filesystem basis. For the VxFS filesystem, the
default is seven days. The soft limit allows for users running applications that
may create a lot of temporary files that only exist for the duration of the
application. If the soft limit is exceeded, no action is taken. After the application
exits, the temporary files are removed, and the amount of files and/or disk blocks
goes back under the soft limit once more. Another circumstance when the soft
limit is exceeded occurs when allocating space to a file. If files are written to
104 UNIX Filesystems.Evolution, Design, and Implementation
sequentially, some filesystems, such as VxFS, allocate large extents (contiguous
data blocks) to try to keep file data in one place. When the file is closed, the
portion of the extent unused is freed.
In order for user quotas to work, there must be a file called quotas in the root
directory of the filesystem. Similarly, for group quotas, the quotas.grp file
must be present. Both of these files are used by the administrator to set quota
limits for users and/or groups. If both user and group quotas are used, the
amount of space allocated to a user is the lower of the two limits.
There are a number of commands to administer quotas. Those shown here are
provided by VxFS. UFS provides a similar set of commands. Each command can
take a -u or -g option to administer user and group quotas respectively.
vxedquota. This command can be used to edit the quota limits for users and
groups.
vxrepquota. This command provides a summary of the quota limits
together with disk usage.
vxquot. This command displays file ownership and usage summaries.
vxquota. This command can be used to view quota limits and usage.
vxquotaon. This command turns on quotas for a specified VxFS filesystem.
vxquotaoff. This command turns off quotas for the specified filesystem.
Quota checks are performed when the filesystem is mounted. This involves
reading all inodes on disk and calculating usage for each user and group if
needed.
Summary
This chapter described the main concepts applicable to filesystems as a whole,
how they are created and mounted, and how they are repaired if damaged by a
system crash or other means. Although the format of some of the mount tables
differs between one system and the next, the location of the files differ only
slightly, and the principles apply across all systems.
In general, unless administrating a UNIX-based machine, many of the
commands here will not be used by the average UNIX user. However, having a
view of how filesystems are managed helps gain a much better understanding of
filesystems overall.
CHAPTER 6 UNIX Kernel Concepts
This chapter covers the earlier versions of UNIX up to 7th Edition and
describes the main kernel concepts, with particular reference to the kernel
structures related to filesystem activity and how the main file access-based
system calls were implemented.
The structures, kernel subsystems, and flow of control through the research
edition UNIX kernels are still largely intact after more than 25 years of
development. Thus, the simple approaches described in this chapter are
definitely a prerequisite to understanding the more complex UNIX
implementations found today.
5th to 7th Edition Internals
From the mid 1980s onwards, there have been a number of changes in the
UNIX kernel that resulted in the mainstream kernels diverging in their
implementation. For the first fifteen years of UNIX development, there wasn_ft
a huge difference in the way many kernel subsystems were implemented, and
therefore understanding the principles behind these earlier UNIX versions
will help readers understand how the newer kernels have changed.
The earliest documented version of UNIX was 6th Edition, which can be
106 UNIX Filesystems.Evolution, Design, and Implementation
seen in John Lions_f book Lions_f Commentary on UNIX 6th Edition.with source
code [LION96]. It is now also possible to download free versions of UNIX
from 5th Edition onwards. The kernel source base is very small by today_fs
standards. With less than 8,000 lines of code for the whole kernel, it is easily
possible to gain an excellent understanding of how the kernel worked. Even
the small amounts of assembler code do not need significant study to
determine their operation.
This chapter concentrates on kernel principles from a filesystem
perspective. Before describing the newer UNIX implementations, it is first
necessary to explain some fundamental UNIX concepts. Much of the
description here centers around the period covering 5th to 7th Edition UNIX,
which generally covers the first ten years of UNIX development. Note that the
goal here is to avoid swamping the reader with details; therefore, little
knowledge of UNIX kernel internals is required in order to read through the
material with relative ease.
Note that at this early stage, UNIX was a uniprocessor-based kernel. It
would be another 10 years before mainstream multiprocessor-based UNIX
versions first started to appear.
The UNIX Filesystem
Before describing how the different kernel structures work together, it is first
necessary to describe how the original UNIX filesystem was stored on disk.
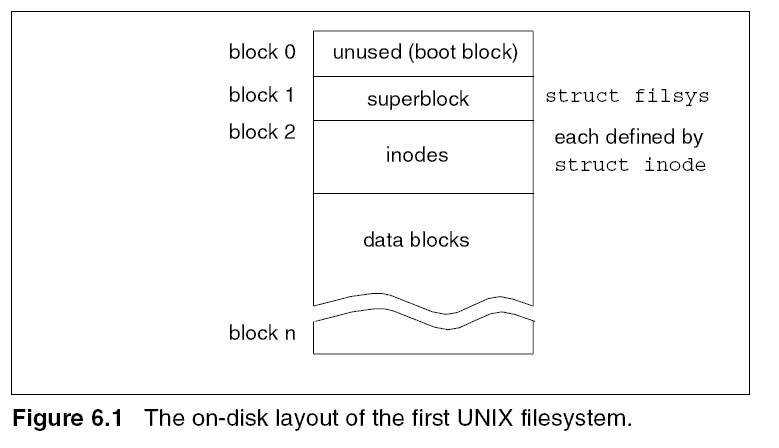
Figure 6.1 shows the layout of various filesystem building blocks. The first
(512 byte) block was unused. The second block (block 1) held the superblock, a
structure that holds information about the filesystem as a whole such as the
number of blocks in the filesystem, the number of inodes (files), and the
number of free inodes and data blocks. Each file in the filesystem was
represented by a unique inode that contained fields such as:
i_mode. This field specifies whether the file is a directory (IFDIR), a block
special file (IFBLK), or a character special file (IFCHR). Note that if one
of the above modes was not set, the file was assumed to be a regular file.
This would later be replaced by an explicit flag, IFREG.
i_nlink. This field recorded the number of hard links to the file. When
this field reaches zero, the inode is freed.
i_uid. The file_fs user ID.
i_gid. The file_fs group ID.
i_size. The file size in bytes.
i_addr. This field holds block addresses on disk where the file_fs data
blocks are held.
i_mtime. The time the file was last modified.
i_atime. The time that the file was last accessed.
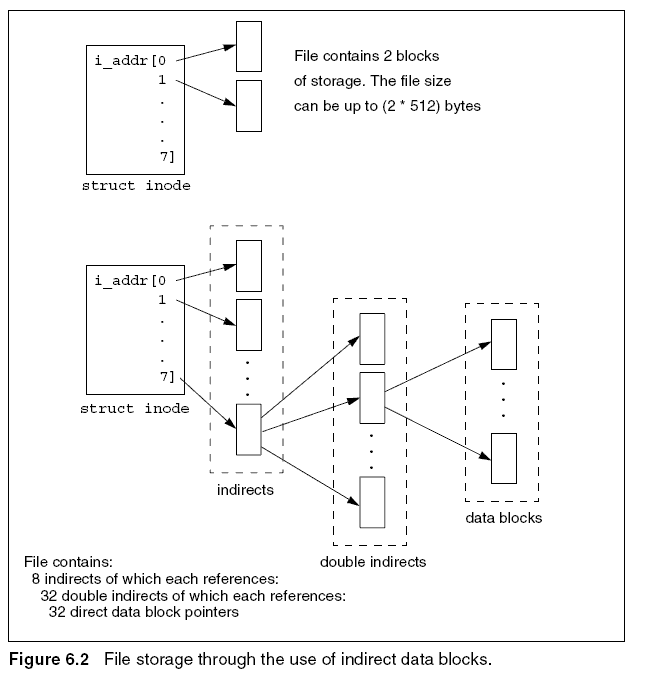
The i_addr field was an array of 8 pointers. Each pointer could reference a
single disk block, giving 512 bytes of storage or could reference what is called
an indirect block. Each indirect block contained 32 pointers, each of which
could point to a 512 byte block of storage or a double indirect block. Double
indirects point to indirect data blocks. Figure 6.2 shows the two extremes
whereby data blocks are accessed directly from the inode or from double
indirects.
In the first example, the inode directly references two data blocks. The file
size in this case will be between 513 and 1024 bytes in size. If the size of the
file is less than 512 bytes, only a single data block is needed. Elements 2 to 7 of
the i_addr[] array will be NULL in this case.
The second example shows the maximum possible file size. Each element
of i_addr[] references an indirect block. Each indirect block points to 32
double indirect blocks, and each double indirect block points to 32 data
blocks. This gives a maximum file size of 32 * 32 * 32 = 32,768 data blocks.
Filesystem-Related Kernel Structures
This section describes the main structures used in the UNIX kernel that are
related to file access, from the file descriptor level down to issuing read and
write calls to the disk driver.
User Mode and Kernel Mode
Each UNIX process is separated both from other processes and from the
kernel through hardware-protection mechanisms. Thus, one process is unable
to access the address space of another and is unable to either read from or
write to the kernel data structures.
When a process is running it can either be in user mode or kernel mode.
When in user mode it runs on its own stack and executes instructions from
the application binary or one of the libraries that it may be linked with. In
order to execute a system call, the process transfers to kernel mode by issuing
a special hardware instruction. When in the kernel, all arguments related to
the system call are copied into the kernel_fs address space. Execution proceeds
on a separate kernel stack. A context switch (a switch to another user process)
can take place prior to returning to the user process if the timeslice of that
process has been exceeded or if the process goes to sleep (for example, while
waiting for an I/O operation).
The mechanisms for transferring control between user and kernel mode are
dependent on the hardware architecture.
Information about each process is divided between two different kernel
structures. The proc structure is always present in memory, while the user
structure holds information that is only needed when the process is running.
Thus, when a process is not running and is eligible to be swapped out, all
structures related to the process other than the proc structure may be written
to the swap device. Needless to say, the proc structure must record
information about where on the swap device the other process-related
structures are located.
The proc structure does not record information related to file access.
However the user structure contains a number of important
file-access-related fields, namely:
u_cdir. The inode of the current working directory is stored here. This is
used during pathname resolution when a user specifies a relative
pathname.
u_uid/u_gid. The process user ID and group ID used for permissions
checking for file-access-based system calls. Similarly, u_euid and
>u_egid hold the effective user and group IDs.
u_ofile. This array holds the process file descriptors. This is described in
more detail later.
u_arg. An array of system call arguments set up during the transition
from user to kernel mode when invoking a system call.
u_base. This field holds the address of a user space buffer in which to read
data from or write data to when processing a system call such as read()
or write().
u_count. The number of bytes to read or write is held here. It is
decremented during the I/O operation and the result can be passed back
to the user.
u_offset. This field records the offset within the file for the current read
or write operation.
u_error. When processing a system call, this field is set if an error is
encountered. The value of u_error is then passed back to the user
when the system call returns.
There are other fields which have significance to file-access-based calls.
However, these fields became redundant over the years and to avoid bloating
this section, they won_ft be described further.
Users familiar with the chroot() system call and later versions of UNIX
may have been wondering why there is no u_rdir to hold the current,
per-process root director.at this stage in UNIX development, chroot() had
not been implemented.
File Descriptors and the File Table
The section File Descriptors, in Chapter 2, described how file descriptors are
returned from system calls such as open(). The u_ofile[] array in the user
structure is indexed by the file descriptor number to locate a pointer to a
file structure.
In earlier versions of UNIX, the size of the u_ofile[] array was hard
coded and had NOFILE elements. Because the stdin, stdout, and stderr
file descriptors occupied slots 0, 1, and 2 within the array, the first file
descriptor returned in response to an open() system call would be 3. For the
early versions of UNIX, NOFILE was set at 15. This would then make its way
to 20 by the time that 7th Edition appeared.
The file structure contains more information about how the file was
opened and where the current file pointer is positioned within the file for
reading or writing. It contained the following members:
f_flag. This flag was set based on how the file was opened. If open for
reading it was set to FREAD, and if open for writing it was set to FWRITE.
f_count. Each file structure had a reference count. This field is further
described below.
f_inode. After a file is opened, the inode is read in from disk and stored in
an in-core inode structure. This field points to the in-core inode.
f_offset. This field records the offset within the file when reading or
writing. Initially it will be zero and will be incremented by each
subsequent read or write or modified by lseek().
The file structure contains a reference count. Calls such as dup() result in a
new file descriptor being allocated that points to the same file table entry as
the original file descriptor. Before dup() returns, the f_count field is
incremented.
Although gaining access to a running 5th Edition UNIX system is a little
difficult 27 years after it first appeared, it is still possible to show how these
concepts work in practice on more modern versions of UNIX. Take for
example the following program running on Sun_fs Solaris version 8:
#include < fcntl.h>
main()
{
int fd1, fd2;
fd1 = open("/etc/passwd", O_RDONLY);
fd2 = dup(fd1);
printf("fd1 = %d, fd2 = %d\n", fd1, fd2);
pause();
}
The crash program can be used to analyze various kernel structures. In this
case, it is possible to run the preceding program, locate the process with
crash, and then display the corresponding user and file structures.
First of all, the program is run in the background, which displays file
descriptor values of 3 and 4 as expected. The crash utility is then run and the
proc command is used in conjunction with grep to locate the process in
question as shown here:
# ./mydup&
[1] 1422
fd1 = 3, fd2 = 4
# crash
dumpfile = /dev/mem, namelist = /dev/ksyms, outfile = stdout
> proc ! grep mydup
37 s 1422 1389 1422 1389 0 46 mydup load
The process occupies slot 37 (consider this as an array of proc structures).
The slot number can be passed to the user command that displays the user
area corresponding to the process. Not all of the structure is shown here
although it easy to see some relevant information about the process including
the list of file descriptors. Note that file descriptor values 0, 1, and 2 all point
to the same file table entry. Also, because a call was made to dup() in the
program, entries 3 and 4 in the array point to the same file table entry.
> user 37
PER PROCESS USER AREA FOR PROCESS 37
PROCESS MISC:
command: mydup, psargs: ./mydup
start: Sat Jul 28 08:50:16 2001
mem: 90, type: exec su-user
vnode of current directory: 300019b5468
OPEN FILES, FLAGS, AND THREAD REFCNT:
[0]: F 30000adad68, 0, 0 [1]: F 30000adad68, 0, 0
[2]: F 30000adad68, 0, 0 [3]: F 30000adb078, 0, 0
[4]: F 30000adb078, 0, 0
...
Finally, the file command can be used to display the file table entry
corresponding to these file descriptors. Note that the reference count is now 2,
the offset is 0 because no data has been read and the flags hold FREAD as
indicated by the read flag displayed.
> file 30000adb078
ADDRESS RCNT TYPE/ADDR OFFSET FLAGS
30000adb078 2 UFS /30000aafe30 0 read
With the exception that this file structure points to a vnode as opposed to the
old in-core inode, the main structure has remained remarkably intact for
UNIX_fs 30+ year history.
The Inode Cache
Each file is represented on disk by an inode. When a file is opened, the inode
must be retrieved from disk. Operations such as the stat() system call
retrieve much of the information they require from the inode structure.
The inode must remain in memory for the duration of the open and is
typically written back to disk if any operations require changes to the inode
structure. For example, consider writing 512 bytes of data at the end of the file
that has an existing size of 512 bytes and therefore one block allocated
(referenced by i_addr[0]). This will involve changing i_size to 1024
bytes, allocating a new block to the file, and setting i_addr[1] to point to
this newly allocated block. These changes will be written back to disk.
After the file has been closed and there are no further processes holding the
file open, the in-core inode can be freed.
If the inode were always freed on close, however, it would need to be read
in again from disk each time the file is opened. This is very costly, especially
considering that some inodes are accessed frequently such as the inodes for /,
/usr, and /usr/bin. To prevent this from happening, inodes are retained in
an inode cache even when the inode is no longer in use. Obviously if new
inodes need to be read in from disk, these unused, cached inodes will need to
be reallocated.
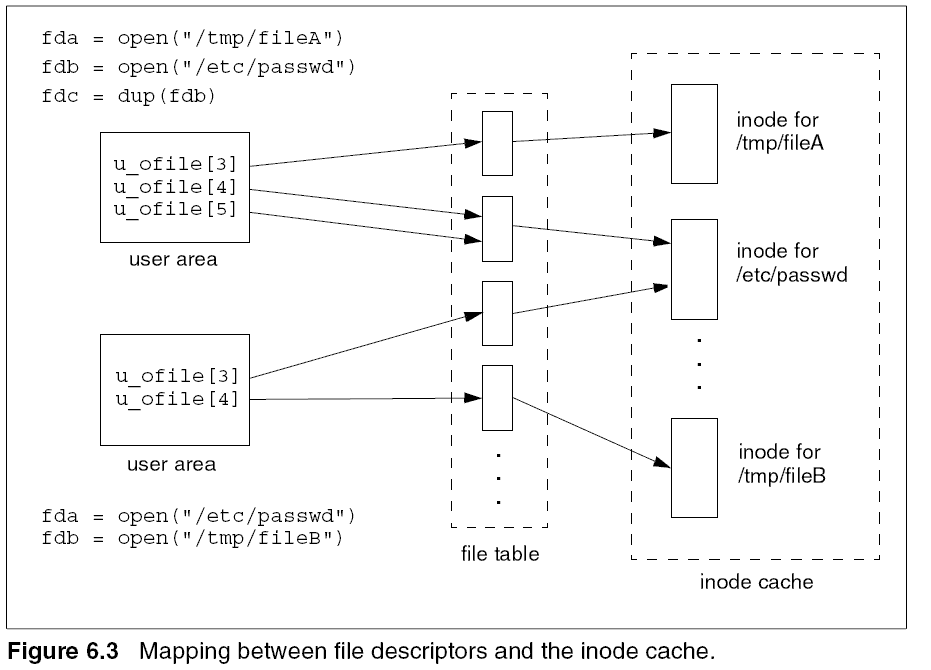
Figure 6.3 shows the linkage between file descriptors and inodes. The top
process shows that by calling dup(), a new file descriptor is allocated
resulting in fdb and fdc both pointing to the same file table entry. The file
table entry then points to the inode for /etc/passwd.
For the bottom process, the open of /etc/passwd results in allocation of
both a new file descriptor and file table entry. The file table entry points to the
same in-core copy of the inode for this file as referenced by the top process. To
handle these multiple references, the i_count field is used. Each time a file is
opened, i_count is incremented and subsequently decremented on each
close. Note that the inode cannot be released from the inode cache until after
the last close.
The Buffer Cache
Devices were and still are accessed by the device ID and block number.
Device IDs are constructed from the device major number and minor number.
The major number has traditionally been nothing more than an entry into an
array of vectors pointing to device driver entry points. Block special files are
accessed through the bdevsw[] array while character special files are
accessed through the cdevsw[] array. Both arrays were traditionally hard
coded into the kernel. Filesystems access the disk through the block driver
interface for which the disk driver exports a strategy function that is called by
the filesystem.
Each driver, through its exported strategy function, accepts a buf structure
that contains all the necessary information required to perform the I/O.
The
buf structure has actually changed very little over the years. Around 5th
Edition it contained the following fields:
int b_flags;
struct buf *b_forw;
struct buf *b_back;
struct buf *av_forw;
struct buf *av_back;
int b_dev;
char *b_addr;
char *b_blkno;
char b_error;
char *b_resid;
The b_forw and b_back fields can be used by the device driver to chain
related buffers together. After I/O is complete and the buffer is freed, the
av_forw and av_back fields are used to hold the buffer on the free list. Note
that buffers on the free list retain their identity until reused and thus act as a
cache of recently accessed blocks. The b_dev and b_blkno fields are used to
associate the buffer with a particular device and block number, while the
b_addr field points to an in-core buffer that holds the data read or to be
written. The b_wcount, b_error, and b_resid fields are used during I/O
and will be described in the section Putting It All Together later in this chapter.
The b_flags field contains information about the state of the buffer. Some
of the possible flags are shown below:
B_WRITE. A call to the driver will cause the buffer contents to be written to
block b_blkno within the device specified by b_dev.
B_READ. A call to the driver will read the block specified by b_blkno and
b_dev into the buffer data block referenced by b_addr.
B_DONE. I/O has completed and the data may be used.
B_ERROR. An error occurred while reading or writing.
B_BUSY. The buffer is currently in use.
B_WANTED. This field is set to indicate that another process wishes to use
this buffer. After the I/O is complete and the buffer is relinquished, the
kernel will wake up the waiting process.
When the kernel bootstraps, it initializes an array of NBUF buffers to comprise
the buffer cache. Each buffer is linked together through the av_forw and
av_back fields and headed by the bfreelist pointer.
The two main interfaces exported by the buffer cache are bread() and
bwrite() for reading and writing respectively. Both function declarations
are shown below:
struct buf *
bread(int dev, int blkno)
void
bwrite(struct buf *bp);
Considering bread() first, it must make a call to getblk() to search for a
buffer in the cache that matches the same device ID and block number. If the
buffer is not in the cache, getblk() takes the first buffer from the free list,
sets its identity to that of the device (dev) and block number (blkno), and
returns it.
When bread() retrieves a buffer from getblk(), it checks to see if the
B_DONE flag is set. If this is the case, the buffer contents are valid and the
buffer can be returned. If B_DONE is not set, the block must be read from disk.
In this case a call is made to the disk driver strategy routine followed by a call
to iowait() to sleep until the data has been read
One final point worthy of mention at this stage is that the driver strategy
interface is asynchronous. After the I/O has been queued, the device driver
returns. Performing I/O is a time-consuming operation, so the rest of the
system could be doing something else while the I/O is in progress. In the case
shown above, a call is made to iowait(), which causes the current process
to sleep until the I/O is complete. The asynchronous nature of the strategy
function allowed read ahead to be implemented whereby the kernel could start
an asynchronous read of the next block of the file so that the data may already
be in memory when the process requests it. The data requested is read, but
before returning to the user with the data, a strategy call is made to read the
next block without a subsequent call to iowait().
To perform a write, a call is made to bwrite(), which simply needs to
invoke the two line sequence previously shown.
After the caller has finished with the buffer, a call is made to brelse(),
which takes the buffer and places it at the back of the freelist. This ensures
that the oldest free buffer will be reassigned first.
Mounting Filesystems
The section The UNIX Filesystem, earlier in this chapter, showed how
filesystems were laid out on disk with the superblock occupying block 1 of
the disk slice. Mounted filesystems were held in a linked list of mount
structures, one per filesystem with a maximum of NMOUNT mounted
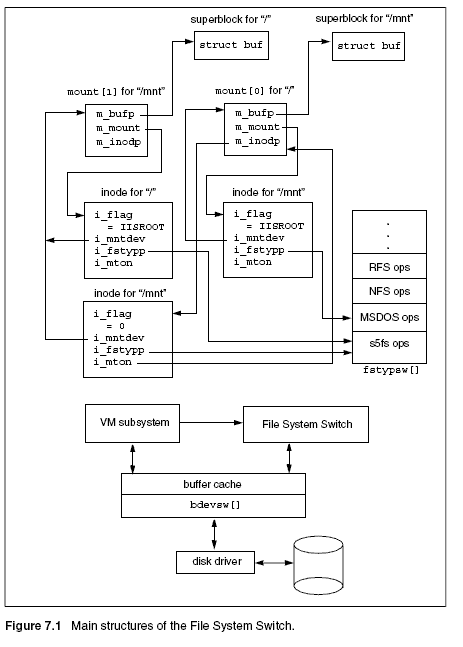
filesystems. Each mount structure has three elements, namely:
m_dev. This field holds the device ID of the disk slice and can be used in a
simple check to prevent a second mount of the same filesystem.
m_buf. This field points to the superblock (struct filsys), which is
read from disk during a mount operation.
m_inodp. This field references the inode for the directory onto which this
filesystem is mounted. This is further explained in the section Pathname
Resolution later in this chapter.
The root filesystem is mounted early on during kernel initialization. This
involved a very simple code sequence that relied on the root device being
hard coded into the kernel. The block containing the superblock of the root
filesystem is read into memory by calling bread(); then the first mount
structure is initialized to point to the buffer.
Any subsequent mounts needed to come in through the mount() system
call. The first task to perform would be to walk through the list of existing
mount structures checking m_dev against the device passed to mount(). If
the filesystem is mounted already, EBUSY is returned; otherwise another
mount structure is allocated for the new mounted filesystem.
System Call Handling
Arguments passed to system calls are placed on the user stack prior to
invoking a hardware instruction that then transfers the calling process from
user mode to kernel mode. Once inside the kernel, any system call handler
needs to be able to access the arguments, because the process may sleep
awaiting some resource, resulting in a context switch, the kernel needs to
copy these arguments into the kernel address space.
The sysent[] array specifies all of the system calls available, including
the number of arguments.
By executing a hardware trap instruction, control is passed from user space
to the kernel and the kernel trap() function runs to determine the system
call to be processed. The C library function linked with the user program
stores a unique value on the user stack corresponding to the system call. The
kernel uses this value to locate the entry in sysent[] to understand how
many arguments are being passed.
For a read() or write() system call, the arguments are accessible as
follows:
fd = u.u_ar0[R0]
u_base = u.u_arg[0]
u_count = u.u_arg[1]
This is a little strange because the first and subsequent arguments are
accessed in a different manner. This is partly due to the hardware on which
5th Edition UNIX was based and partly due to the method that the original
authors chose to handle traps.
If any error is detected during system call handling, u_error is set to
record the error found. For example, if an attempt is made to mount an
already mounted filesystem, the mount system call handler will set u_error
to EBUSY. As part of completing the system call, trap() will set up the r0
register to contain the error code, that is then accessible as the return value of
the system call once control is passed back to user space.
For further details on system call handling in early versions of UNIX,
[LION96] should be consulted. Steve Pate_fs book UNIX Internals.A Practical
Approach [PATE96] describes in detail how system calls are implemented at an
assembly language level in System V Release 3 on the Intel x86 architecture.
Pathname Resolution
System calls often specify a pathname that must be resolved to an inode
before the system call can continue. For example, in response to:
fd = open("/etc/passwd", O_RDONLY);
the kernel must ensure that /etc is a directory and that passwd is a file
within the /etc directory.
Where to start the search depends on whether the pathname specified is
absolute or relative. If it is an absolute pathname, the search starts from
rootdir, a pointer to the root inode in the root filesystem that is initialized
during kernel bootstrap. If the pathname is relative, the search starts from
u_cdir, the inode of the current working directory. Thus, one can see that
changing a directory involves resolving a pathname to a base directory
component and then setting u_cdir to reference the inode for that directory.
The routine that performs pathname resolution is called namei(). It uses
fields in the user area as do many other kernel functions. Much of the work of
namei() involves parsing the pathname to be able to work on one
component at a time. Consider, at a high level, the sequence of events that
must take place to resolve /etc/passwd.
if (absolute pathname) {
dip = rootdir
} else {
dip = u.u_cdir
}
loop:
name = next component
scan dip for name / inode number
iput(dip)
dip = iget() to read in inode
if last component {
return dip
} else {
goto loop
}
This is an oversimplification but it illustrates the steps that must be
performed. The routines iget() and iput() are responsible for retrieving
an inode and releasing an inode respectively. A call to iget() scans the
inode cache before reading the inode from disk. Either way, the returned
inode will have its hold count (i_count) increased. A call to iput()
decrements i_count and, if it reaches 0, the inode can be placed on the free
list.
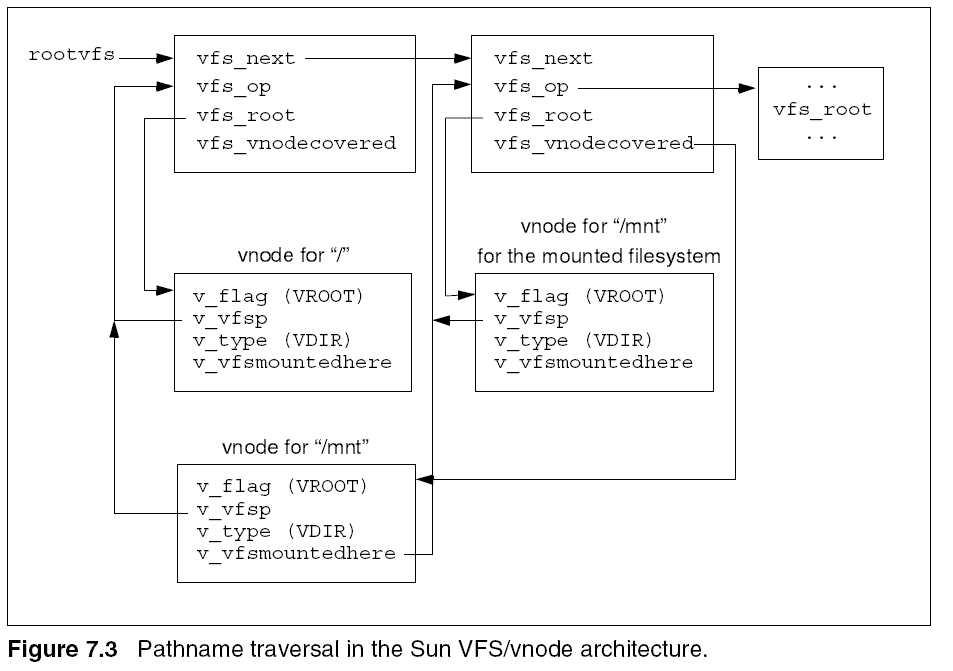
To facilitate crossing mount points, fields in the mount and inode
structures are used. The m_inodp field of the mount structure points to the
directory inode on which the filesystem is mounted allowing the kernel to
perform a _g.._f_f traversal over a mount point. The inode that is mounted on has
the IMOUNT flag set that allows the kernel to go over a mount point.
Putting It All Together
In order to describe how all of the above subsystems work together, this
section will follow a call to open() on /etc/passwd followed by the
read() and close() system calls.
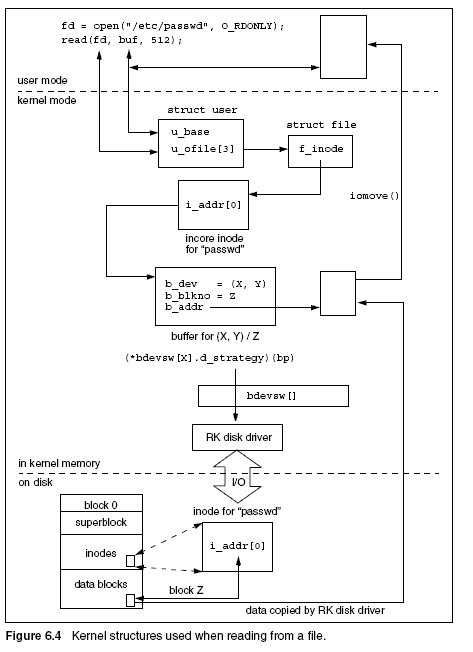
Figure 6.4 shows the main structures involved in actually performing the
read. It is useful to have this figure in mind while reading through the
following sections.
Opening a File
The open() system call is handled by the open() kernel function. Its first
task is to call namei() to resolve the pathname passed to open(). Assuming
the pathname is valid, the inode for passwd is returned. A call to open1() is
then made passing the open mode. The split between open() and open1()
allows the open() and creat() system calls to share much of the same
code.
First of all, open1() must call access() to ensure that the process can
access the file according to ownership and the mode passed to open(). If all
is fine, a call to falloc() is made to allocate a file table entry. Internally this
invokes ufalloc() to allocate a file descriptor from u_ofile[]. The newly
allocated file descriptor will be set to point to the newly allocated file table
entry. Before returning from open1(), the linkage between the file table entry
and the inode for passwd is established as was shown in Figure 6.3.
Reading the File
The read() and write() systems calls are handled by kernel functions of
the same name. Both make a call to rdwr() passing FREAD or FWRITE. The
role of rdwr() is fairly straightforward in that it sets up the appropriate
fields in the user area to correspond to the arguments passed to the system
call and invokes either readi() or writei() to read from or write to the
file. The following pseudo code shows the steps taken for this initialization.
Note that some of the error checking has been removed to simplify the steps
taken.
get file pointer from user area
set u_base to u.u_arg[0]; /* user supplied buffer */
set u_count to u.u_arg[1]; /* number of bytes to read/write */
if (reading) {
readi(fp->f_inode);
} else {
writei(fp->f_inode);
}
The internals of readi() are fairly straightforward and involve making
repeated calls to bmap() to obtain the disk block address from the file offset.
The bmap() function takes a logical block number within the file and returns
the physical block number on disk. This is used as an argument to bread(),
which reads in the appropriate block from disk. The uiomove() function
then transfers data to the buffer specified in the call to read(), which is held
in u_base. This also increments u_base and decrements u_count so that
the loop will terminate after all the data has been transferred.
If any errors are encountered during the actual I/O, the b_flags field of
the buf structure will be set to B_ERROR and additional error information
may be stored in b_error. In response to an I/O error, the u_error field of
the user structure will be set to either EIO or ENXIO.
The b_resid field is used to record how many bytes out of a request size
of u_count were not transferred. Both fields are used to notify the calling
process of how many bytes were actually read or written.
Closing the File
The close() system call is handled by the close() kernel function. It
performs little work other than obtaining the file table entry by calling
getf(), zeroing the appropriate entry in u_ofile[], and then calling
closef(). Note that because a previous call to dup() may have been made,
the reference count of the file table entry must be checked before it can be
freed. If the reference count (f_count) is 1, the entry can be removed and a
call to closei() is made to free the inode. If the value of f_count is greater
than 1, it is decremented and the work of close() is complete.
To release a hold on an inode, iput() is invoked. The additional work
performed by closei() allows a device driver close call to be made if the
file to be closed is a device.
As with closef(), iput() checks the reference count of the inode
(i_count). If it is greater than 1, it is decremented, and there is no further
work to do. If the count has reached 1, this is the only hold on the file so the
inode can be released. One additional check that is made is to see if the hard
link count of the inode has reached 0. This implies that an unlink() system
call was invoked while the file was still open. If this is the case, the inode can
be freed on disk.
Summary
This chapter concentrated on the structures introduced in the early UNIX
versions, which should provide readers with a basic grounding in UNIX
kernel principles, particularly as they apply to how filesystems and files are
accessed. It says something for the design of the original versions of UNIX
that many UNIX based kernels still bear a great deal of similarity to the
original versions developed over 30 years ago.
Lions_f book Lions_f Commentary on UNIX 6th Edition [LION96] provides a
unique view of how 6th Edition UNIX was implemented and lists the
complete kernel source code. For additional browsing, the source code is
available online for download.
For a more concrete explanation of some of the algorithms and more details
on the kernel in general, Bach_fs book The Design of the UNIX Operating System
[BACH86] provides an excellent overview of System V Release 2. Pate_fs book
UNIX Internals.A Practical Approach [PATE96] describes a System V Release 3
variant. The UNIX versions described in both books bear most resemblance to
the earlier UNIX research editions.
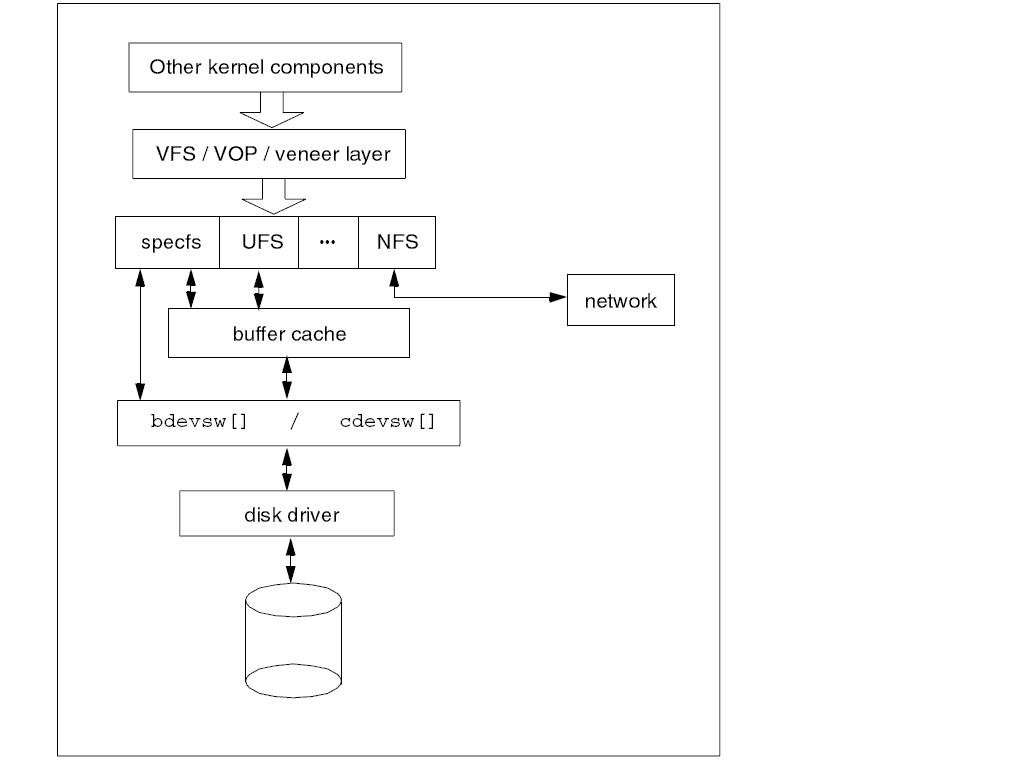
CHAPTER 7 Development of the SVR4 VFS/Vnode Architecture
The development of the File System Switch (FSS) architecture in SVR3, the Sun
VFS/vnode architecture in SunOS, and then the merge between the two to
produce SVR4, substantially changed the way that filesystems were accessed and
implemented. During this period, the number of filesystem types increased
dramatically, including the introduction of commercial filesystems such as VxFS
that allowed UNIX to move toward the enterprise computing market.
SVR4 also introduced a number of other important concepts pertinent to
filesystems, such as tying file system access with memory mapped files, the
DNLC (Directory Name Lookup Cache), and a separation between the traditional
buffer cache and the page cache, which also changed the way that I/O was
performed.
This chapter follows the developments that led up to the implementation of
SVR4, which is still the basis of Sun_fs Solaris operating system and also freely
available under the auspices of Caldera_fs OpenUNIX.
The Need for Change
The research editions of UNIX had a single filesystem type, as described in
Chapter 6. The tight coupling between the kernel and the filesystem worked well
122 UNIX Filesystems.Evolution, Design, and Implementation
at this stage because there was only one filesystem type and the kernel was single
threaded, which means that only one process could be running in the kernel at the
same time.
Before long, the need to add new filesystem types.including non-UNIX
filesystems.resulted in a shift away from the old style filesystem
implementation to a newer, cleaner architecture that clearly separated the
different physical filesystem implementations from those parts of the kernel that
dealt with file and filesystem access.
Pre-SVR3 Kernels
With the exception of Lions_f book on 6th Edition UNIX [LION96], no other UNIX
kernels were documented in any detail until the arrival of System V Release 2
that was the basis for Bach_fs book The Design of the UNIX Operating System
[BACH86]. In his book, Bach describes the on-disk layout to be almost identical
to that of the earlier versions of UNIX.
There was little change between the research editions of UNIX and SVR2 to
warrant describing the SVR2 filesystem architecture in detail. Around this time,
most of the work on filesystem evolution was taking place at the University of
Berkeley to produce the BSD Fast File System which would, in time, become UFS.
The File System Switch
Introduced with System V Release 3.0, the File System Switch (FSS) architecture
introduced a framework under which multiple different filesystem types could
coexist in parallel.
The FSS was poorly documented and the source code for SVR3-based
derivatives is not publicly available. [PATE96] describes in detail how the FSS
was implemented. Note that the version of SVR3 described in that book
contained a significant number of kernel changes (made by SCO) and therefore
differed substantially from the original SVR3 implementation. This section
highlights the main features of the FSS architecture.
As with earlier UNIX versions, SVR3 kept the mapping between file
descriptors in the user area to the file table to in-core inodes. One of the main
goals of SVR3 was to provide a framework under which multiple different
filesystem types could coexist at the same time. Thus each time a call is made to
mount, the caller could specify the filesystem type. Because the FSS could
support multiple different filesystem types, the traditional UNIX filesystem
needed to be named so it could be identified when calling the mount command.
Thus, it became known as the s5 (System V) filesystem. Throughout the
USL-based development of System V through to the various SVR4 derivatives,
little development would occur on s5. SCO completely restructured their
s5-based filesystem over the years and added a number of new features.
The boundary between the filesystem-independent layer of the kernel and the
filesystem-dependent layer occurred mainly through a new implementation of
the in-core inode. Each filesystem type could potentially have a very different
on-disk representation of a file. Newer diskless filesystems such as NFS and RFS
had different, non-disk-based structures once again. Thus, the new inode
contained fields that were generic to all filesystem types such as user and group
IDs and file size, as well as the ability to reference data that was
filesystem-specific. Additional fields used to construct the FSS interface were:
i_fsptr. This field points to data that is private to the filesystem and that is
not visible to the rest of the kernel. For disk-based filesystems this field
would typically point to a copy of the disk inode.
i_fstyp. This field identifies the filesystem type.
i_mntdev. This field points to the mount structure of the filesystem to which
this inode belongs.
i_mton. This field is used during pathname traversal. If the directory
referenced by this inode is mounted on, this field points to the mount
structure for the filesystem that covers this directory.
i_fstypp. This field points to a vector of filesystem functions that are called
by the filesystem-independent layer.
The set of filesystem-specific operations is defined by the fstypsw structure. An
array of the same name holds an fstypsw structure for each possible filesystem.
The elements of the structure, and thus the functions that the kernel can call into
the filesystem with, are shown in Table 7.1.
When a file is opened for access, the i_fstypp field is set to point to the
fstypsw[] entry for that filesystem type. In order to invoke a filesystem-specific
function, the kernel performs a level of indirection through a macro that accesses
the appropriate function. For example, consider the definition of FS_READI()
that is invoked to read data from a file:
#define FS_READI(ip) (*fstypsw[(ip)->i_fstyp].fs_readi)(ip)
All filesystems must follow the same calling conventions such that they all
understand how arguments will be passed. In the case of FS_READI(), the
arguments of interest will be held in u_base and u_count. Before returning to
the filesystem-independent layer, u_error will be set to indicate whether an
error occurred and u_resid will contain a count of any bytes that could not be
read or written.
Mounting Filesystems
The method of mounting filesystems in SVR3 changed because each filesystem_fs
superblock could be different and in the case of NFS and RFS, there was no
superblock per se. The list of mounted filesystems was moved into an array of
mount structures that contained the following elements:
m_flags. Because this is an array of mount structures, this field was used to
indicate which elements were in use. For filesystems that were mounted,
m_flags indicates whether the filesystem was also mounted read-only.
m_fstyp. This field specified the filesystem type.
m_bsize. The logical block size of the filesystem is held here. Each filesystem
could typically support multiple different block sizes as the unit of allocation
to a file.
m_dev. The device on which the filesystem resides.
m_bufp. A pointer to a buffer containing the superblock.
m_inodp. With the exception of the root filesystem, this field points to the
inode on which the filesystem is mounted. This is used during pathname
traversal.
m_mountp. This field points to the root inode for this filesystem.
m_name. The file system name.
Figure 7.1 shows the main structures used in the FSS architecture. There are a
number of observations worthy of mention:
The structures shown are independent of filesystem type. The mount and
inode structures abstract information about the filesystems and files that
they represent in a generic manner. Only when operations go through the
FSS do they become filesystem-dependent. This separation allows the FSS
to support very different filesystem types, from the traditional s5 filesystem
to DOS to diskless filesystems such as NFS and RFS.
Although not shown here, the mapping between file descriptors, the user
area, the file table, and the inode cache remained as is from earlier versions
of UNIX.
The Virtual Memory (VM) subsystem makes calls through the FSS to obtain
a block map for executable files. This is to support demand paging. When a
process runs, the pages of the program text are faulted in from the executable
file as needed. The VM makes a call to FS_ALLOCMAP() to obtain this
mapping. Following this call, it can invoke the FS_READMAP() function to
read the data from the file when handling a page fault.
There is no clean separation between file-based and filesystem-based
operations. All functions exported by the filesystem are held in the same
fstypsw structure.
The FSS was a big step away from the traditional single filesystem-based UNIX
kernel. With the exception of SCO, which retained an SVR3-based kernel for
many years after the introduction of SVR3, the FSS was short lived, being
replaced by the better Sun VFS/vnode interface introduced in SVR4.
The Sun VFS/Vnode Architecture
Developed on Sun Microsystem_fs SunOS operating system, the world first came
to know about vnodes through Steve Kleiman_fs often-quoted Usenix paper
_gVnodes: An Architecture for Multiple File System Types in Sun UNIX_h [KLEI86].
The paper stated four design goals for the new filesystem architecture:
The filesystem implementation should be clearly split into a filesystem
independent and filesystem-dependent layer. The interface between the two
should be well defined.
It should support local disk filesystems such as the 4.2BSD Fast File System
(FSS), non-UNIX like filesystems such as MS-DOS, stateless filesystems
such as NFS, and stateful filesystems such as RFS.
It should be able to support the server side of remote filesystems such as
NFS and RFS.
Filesystem operations across the interface should be atomic such that
several operations do not need to be encompassed by locks.
One of the major implementation goals was to remove the need for global data,
allowing the interfaces to be re-entrant. Thus, the previous style of storing
filesystem-related data in the user area, such as u_base and u_count, needed to
be removed. The setting of u_error on error also needed removing and the new
interfaces should explicitly return an error value.
The main components of the Sun VFS architecture are shown in Figure 7.2.
These components will be described throughout the following sections.
The architecture actually has two sets of interfaces between the
filesystem-independent and filesystem-dependent layers of the kernel. The VFS
interface was accessed through a set of vfsops while the vnode interface was
accessed through a set of vnops (also called vnodeops). The vfsops operate on a
filesystem while vnodeops operate on individual files.
Because the architecture encompassed non-UNIX- and non disk-based
filesystems, the in-core inode that had been prevalent as the memory-based
representation of a file over the previous 15 years was no longer adequate. A new
type, the vnode was introduced. This simple structure contained all that was
needed by the filesystem-independent layer while allowing individual
filesystems to hold a reference to a private data structure; in the case of the
disk-based filesystems this may be an inode, for NFS, an rnode, and so on.
The fields of the vnode structure were:
v_flag. The VROOT flag indicates that the vnode is the root directory of a
filesystem, VNOMAP indicates that the file cannot be memory mapped,
VNOSWAP indicates that the file cannot be used as a swap device, VNOMOUNT
indicates that the file cannot be mounted on, and VISSWAP indicates that the
file is part of a virtual swap device.
v_count. Similar to the old i_count inode field, this field is a reference
count corresponding to the number of open references to the file.
v_shlockc. This field counts the number of shared locks on the vnode.
v_exlockc. This field counts the number of exclusive locks on the vnode.
v_vfsmountedhere. If a filesystem is mounted on the directory referenced
by this vnode, this field points to the vfs structure of the mounted
filesystem. This field is used during pathname traversal to cross filesystem
mount points.
v_op. The vnode operations associated with this file type are referenced
through this pointer.
v_vfsp. This field points to the vfs structure for this filesystem.
v_type. This field specifies the type of file that the vnode represents. It can be
set to VREG (regular file), VDIR (directory), VBLK (block special file), VCHR
(character special file), VLNK (symbolic link), VFIFO (named pipe), or
VXNAM (Xenix special file).
v_data. This field can be used by the filesystem to reference private data
such as a copy of the on-disk inode.
There is nothing in the vnode that is UNIX specific or even pertains to a local
filesystem. Of course not all filesystems support all UNIX file types. For example,
the DOS filesystem doesn_ft support symbolic links. However, filesystems in the
VFS/vnode architecture are not required to support all vnode operations. For
those operations not supported, the appropriate field of the vnodeops vector will
be set to fs_nosys, which simply returns ENOSYS.
The uio Structure
One way of meeting the goals of avoiding user area references was to package all
I/O-related information into a uio structure that would be passed across the
vnode interface. This structure contained the following elements:
uio_iov. A pointer to an array of iovec structures each specifying a base
user address and a byte count.
uio_iovcnt. The number of iovec structures.
uio_offset. The offset within the file that the read or write will start from.
uio_segflg. This field indicates whether the request is from a user process
(user space) or a kernel subsystem (kernel space). This field is required by
the kernel copy routines.
uio_resid. The residual count following the I/O.
Because the kernel was now supporting filesystems such as NFS, for which
requests come over the network into the kernel, the need to remove user area
access was imperative. By creating a uio structure, it is easy for NFS to then make
a call to the underlying filesystem.
The uio structure also provides the means by which the readv() and
writev() system calls can be implemented. Instead of making multiple calls into
the filesystem for each I/O, several iovec structures can be passed in at the same
time.
The VFS Layer
The list of mounted filesystems is maintained as a linked list of vfs structures. As
with the vnode structure, this structure must be filesystem independent. The
vfs_data field can be used to point to any filesystem-dependent data structure,
for example, the superblock.
Similar to the File System Switch method of using macros to access
filesystem-specific operations, the vfsops layer utilizes a similar approach. Each
filesystem provides a vfsops structure that contains a list of functions applicable
to the filesystem. This structure can be accessed from the vfs_op field of the vfs
structure. The set of operations available is:
vfs_mount. The filesystem type is passed to the mount command using the
-F option. This is then passed through the mount() system call and is used
to locate the vfsops structure for the filesystem in question. This function
can be called to mount the filesystem.
vfs_unmount. This function is called to unmount a filesystem.
vfs_root. This function returns the root vnode for this filesystem and is
called during pathname resolution.
vfs_statfs. This function returns filesystem-specific information in
response to the statfs() system call. This is used by commands such as
df.
vfs_sync. This function flushes file data and filesystem structural data to
disk, which provides a level of filesystem hardening by minimizing data loss
in the event of a system crash.
vfs_fid. This function is used by NFS to construct a file handle for a
specified vnode.
vfs_vget. This function is used by NFS to convert a file handle returned by a
previous call to vfs_fid into a vnode on which further operations can be
performed.
The Vnode Operations Layer
All operations that can be applied to a file are held in the vnode operations vector
defined by the vnodeops structure. The functions from this vector follow:
vop_open. This function is only applicable to device special files, files in the
namespace that represent hardware devices. It is called once the vnode has
been returned from a prior call to vop_lookup.
vop_close. This function is only applicable to device special files. It is called
once the vnode has been returned from a prior call to vop_lookup.
vop_rdwr. Called to read from or write to a file. The information about the
I/O is passed through the uio structure.
vop_ioctl. This call invokes an ioctl on the file, a function that can be
passed to device drivers.
vop_select. This vnodeop implements select().
vop_getattr. Called in response to system calls such as stat(), this
vnodeop fills in a vattr structure, which can be returned to the caller via
the stat structure.
vop_setattr. Also using the vattr structure, this vnodeop allows the
caller to set various file attributes such as the file size, mode, user ID, group
ID, and file times.
vop_access. This vnodeop allows the caller to check the file for read, write,
and execute permissions. A cred structure that is passed to this function
holds the credentials of the caller.
vop_lookup. This function replaces part of the old namei()
implementation. It takes a directory vnode and a component name and
returns the vnode for the component within the directory.
vop_create. This function creates a new file in the specified directory
vnode. The file properties are passed in a vattr structure.
Development of the SVR4 VFS/Vnode Architecture 131
vop_remove. This function removes a directory entry.
vop_link. This function implements the link() system call.
vop_rename. This function implements the rename() system call.
vop_mkdir. This function implements the mkdir() system call.
vop_rmdir. This function implements the rmdir() system call.
vop_readdir. This function reads directory entries from the specified
directory vnode. It is called in response to the getdents() system call.
vop_symlink. This function implements the symlink() system call.
vop_readlink. This function reads the contents of the symbolic link.
vop_fsync. This function flushes any modified file data in memory to disk. It
is called in response to an fsync() system call.
vop_inactive. This function is called when the filesystem-independent
layer of the kernel releases its last hold on the vnode. The filesystem can then
free the vnode.
vop_bmap. This function is used for demand paging so that the virtual
memory (VM) subsystem can map logical file offsets to physical disk offsets.
vop_strategy. This vnodeop is used by the VM and buffer cache layers to
read blocks of a file into memory following a previous call to vop_bmap().
vop_bread. This function reads a logical block from the specified vnode and
returns a buffer from the buffer cache that references the data.
vop_brelse. This function releases the buffer returned by a previous call to
vop_bread.
If a filesystem does not support some of these interfaces, the appropriate entry in
the vnodeops vector should be set to fs_nosys(), which, when called, will
return ENOSYS. The set of vnode operations are accessed through the v_op field
of the vnode using macros as the following definition shows:
#define VOP_INACTIVE(vp, cr) \
(*(vp)->v_op->vop_inactive)(vp, cr)
Pathname Traversal
Pathname traversal differs from the File System Switch method due to differences
in the structures and operations provided at the VFS layer. Consider the example
shown in Figure 7.3 and consider the following two scenarios:
1. A user types _gcd /mnt_f_f to move into the mnt directory.
2. A user is in the directory /mnt and types _gcd .._f_f to move up one level.
In the first case, the pathname is absolute, so a search will start from the root
directory vnode. This is obtained by following rootvfs to the first vfs structure
and invoking the vfs_root function. This returns the root vnode for the root
filesystem (this is typically cached to avoid repeating this set of steps). A scan is
then made of the root directory to locate the mnt directory. Because the
vfs_mountedhere field is set, the kernel follows this link to locate the vfs
structure for the mounted filesystem through which it invokes the vfs_root
function for that filesystem. Pathname traversal is now complete so the u_cdir
field of the user area is set to point to the vnode for /mnt to be used in
subsequent pathname operations.
In the second case, the user is already in the root directory of the filesystem
mounted on /mnt (the v_flag field of the vnode is set to VROOT). The kernel
locates the mounted on vnode through the vfs_vnodecovered field. Because
this directory (/mnt in the root directory) is not currently visible to users (it is
hidden by the mounted filesystem), the kernel must then move up a level to the
root directory. This is achieved by obtaining the vnode referenced by _g.._f_f in the
/mnt directory of the root filesystem.
Once again, the u_cdir field of the user area will be updated to reflect the
new current working directory.
The Veneer Layer
To provide more coherent access to files through the vnode interface, the
implementation provided a number of functions that other parts of the kernel
could invoke. The set of functions is:
vn_open. Open a file based on its file name, performing appropriate
The Sun VFS/vnode interface was a huge success. Its merger with the File System
Switch and the SunOS virtual memory subsystem provided the basis for the SVR4
VFS/vnode architecture. There were a large number of other UNIX vendors who
implemented the Sun VFS/vnode architecture. With the exception of the read and
write paths, the different implementations were remarkably similar to the original
Sun VFS/vnode implementation.
The SVR4 VFS/Vnode Architecture
System V Release 4 was the result of a merge between SVR3 and Sun
Microsystems_f SunOS. One of the goals of both Sun and AT&T was to merge the
Sun VFS/vnode interface with AT&T_fs File System Switch.
The new VFS architecture, which has remained largely unchanged for over 15
years, introduced and brought together a number of new ideas, and provided a
clean separation between different subsystems in the kernel. One of the
fundamental changes was eliminating the tight coupling between the filesystem
and the VM subsystem which, although elegant in design, was particularly
complicated resulting in a great deal of difficulty when implementing new
filesystem types.
Changes to File Descriptor Management
A file descriptor had previously been an index into the u_ofile[] array.
Because this array was of fixed size, the number of files that a process could have
134 UNIX Filesystems.Evolution, Design, and Implementation
open was bound by the size of the array. Because most processes do not open a
lot of files, simply increasing the size of the array is a waste of space, given the
large number of processes that may be present on the system.
With the introduction of SVR4, file descriptors were allocated dynamically up
to a fixed but tunable limit. The u_ofile[] array was removed and replaced by
two new fields, u_nofiles, which specified the number of file descriptors that
the process can currently access, and u_flist, a structure of type ufchunk that
contains an array of NFPCHUNK (which is 24) pointers to file table entries. After
all entries have been used, a new ufchunk structure is allocated, as shown in
Figure 7.4.
The uf_pofile[] array holds file descriptor flags as set by invoking the
fcntl() system call.
The maximum number of file descriptors is constrained by a per-process limit
defined by the rlimit structure in the user area.
There are a number of per-process limits within the u_rlimit[] array. The
u_rlimit[RLIMIT_NOFILE] entry defines both a soft and hard file descriptor
limit. Allocation of file descriptors will fail once the soft limit is reached. The
setrlimit() system call can be invoked to increase the soft limit up to that of
the hard limit, but not beyond. The hard limit can be raised, but only by root.
The Virtual Filesystem Switch Table
Built dynamically during kernel compilation, the virtual file system switch table,
underpinned by the vfssw[] array, contains an entry for each filesystem that
can reside in the kernel. Each entry in the array is defined by a vfssw structure
as shown below:
struct vfssw {
char *vsw_name;
int (*vsw_init)();
struct vfsops *vsw_vfsops;
}
The vsw_name is the name of the filesystem (as passed to mount -F). The
vsw_init() function is called during kernel initialization, allowing the
filesystem to perform any initialization it may require before a first call to
mount().
Operations that are applicable to the filesystem as opposed to individual files
are held in both the vsw_vfsops field of the vfssw structure and subsequently
in the vfs_ops field of the vfs structure.
The fields of the vfs structure are shown below:
vfs_mount. This function is called to mount a filesystem.
vfs_unmount. This function is called to unmount a filesystem.
vfs_root. This function returns the root vnode for the filesystem. This is
used during pathname traversal.
vfs_statvfs. This function is called to obtain per-filesystem-related
statistics. The df command will invoke the statvfs() system call on
filesystems it wishes to report information about. Within the kernel,
statvfs() is implemented by invoking the statvfs vfsop.
vfs_sync. There are two methods of syncing data to the filesystem in SVR4,
namely a call to the sync command and internal kernel calls invoked by the
fsflush kernel thread. The aim behind fsflush invoking vfs_sync is to
flush any modified file data to disk on a periodic basis in a similar way to
which the bdflush daemon would flush dirty (modified) buffers to disk.
This still does not prevent the need for performing a fsck after a system
crash but does help harden the system by minimizing data loss.
vfs_vget. This function is used by NFS to return a vnode given a specified
file handle.
vfs_mountroot. This entry only exists for filesystems that can be mounted
as the root filesystem. This may appear to be a strange operation. However,
in the first version of SVR4, the s5 and UFS filesystems could be mounted as
root filesystems and the root filesystem type could be specified during UNIX
installation. Again, this gives a clear, well defined interface between the rest
of the kernel and individual filesystems.
There are only a few minor differences between the vfsops provided in SVR4 and
those introduced with the VFS/vnode interface in SunOS. The vfs structure with
SVR4 contained all of the original Sun vfs fields and introduced a few others
including vfs_dev, which allowed a quick and easy scan to see if a filesystem
was already mounted, and the vfs_fstype field, which is used to index the
vfssw[] array to specify the filesystem type.
Changes to the Vnode Structure and VOP Layer
The vnode structure had some subtle differences. The v_shlockc and
v_exlockc fields were removed and replaced by additional vnode interfaces to
handle locking. The other fields introduced in the original vnode structure
remained and the following fields were added:
v_stream. If the file opened references a STREAMS device, the vnode field
points to the STREAM head.
v_filocks. This field references any file and record locks that are held on
the file.
v_pages. I/O changed substantially in SVR4 with all data being read and
written through pages in the page cache as opposed to the buffer cache,
which was now only used for meta-data (inodes, directories, etc.). All pages
in-core that are part of a file are linked to the vnode and referenced through
this field.
The vnodeops vector itself underwent more change. The vop_bmap(), the
vop_bread(), vop_brelse(), and vop_strategy() functions were
removed as part of changes to the read and write paths. The vop_rdwr() and
vop_select() functions were also removed. There were a number of new
functions added as follows:
vop_read. The vop_rdwr function was split into separate read and write
vnodeops. This function is called in response to a read() system call.
vop_write. The vop_rdwr function was split into separate read and write
vnodeops. This function is called in response to a write() system call.
vop_setfl. This function is called in response to an fcntl() system call
where the F_SETFL (set file status flags) flag is specified. This allows the
filesystem to validate any flags passed.
vop_fid. This function was previously a VFS-level function in the Sun
VFS/vnode architecture. It is used to generate a unique file handle from
which NFS can later reference the file.
vop_rwlock. Locking was moved under the vnode interface, and filesystems
implemented locking in a manner that was appropriate to their own internal
implementation. Initially the file was locked for both read and write access.
Later SVR4 implementations changed the interface to pass one of two flags,
namely LOCK_SHARED or LOCK_EXCL. This allowed for a single writer but
multiple readers.
vop_rwunlock. All vop_rwlock invocations should be followed by a
subsequent vop_rwunlock call.
vop_seek. When specifying an offset to lseek(), this function is called to
determine whether the filesystem deems the offset to be appropriate. With
sparse files, seeking beyond the end of file and writing is a valid UNIX
operation, but not all filesystems may support sparse files. This vnode
operation allows the filesystem to reject such lseek() calls.
vop_cmp. This function compares two specified vnodes. This is used in the
area of pathname resolution.
vop_frlock. This function is called to implement file and record locking.
vop_space. The fcntl() system call has an option, F_FREESP, which
allows the caller to free space within a file. Most filesystems only implement
freeing of space at the end of the file making this interface identical to
truncate().
vop_realvp. Some filesystems, for example, specfs, present a vnode and hide
the underlying vnode, in this case, the vnode representing the device. A call
to VOP_REALVP() is made by filesystems when performing a link()
system call to ensure that the link goes to the underlying file and not the
specfs file, that has no physical representation on disk.
vop_getpage. This function is used to read pages of data from the file in
response to a page fault.
vop_putpage. This function is used to flush a modified page of file data to
disk.
vop_map. This function is used for implementing memory mapped files.
vop_addmap. This function adds a mapping.
vop_delmap. This function deletes a mapping.
vop_poll. This function is used for implementing the poll() system call.
vop_pathconf. This function is used to implement the pathconf() and
fpathconf() system calls. Filesystem-specific information can be returned,
such as the maximum number of links to a file and the maximum file size.
The vnode operations are accessed through the use of macros that reference the
appropriate function by indirection through the vnode v_op field. For example,
here is the definition of the VOP_LOOKUP() macro:
#define VOP_LOOKUP(vp,cp,vpp,pnp,f,rdir,cr) \
(*(vp)->v_op->vop_lookup)(vp,cp,vpp,pnp,f,rdir,cr)
The filesystem-independent layer of the kernel will only access the filesystem
through macros. Obtaining a vnode is performed as part of an open() or
creat() system call or by the kernel invoking one of the veneer layer functions
when kernel subsystems wish to access files directly. To demonstrate the mapping
between file descriptors, memory mapped files, and vnodes, consider the
following example:
1 #include < sys/types.h>
2 #include < sys/stat.h>
3 #include < sys/mman.h>
4 #include < fcntl.h>
5 #include < unistd.h>
6
7 #define MAPSZ 4096
8
9 main()
10 {
11 char *addr, c;
12 int fd1, fd2;
138 UNIX Filesystems.Evolution, Design, and Implementation
13
14 fd1 = open("/etc/passwd", O_RDONLY);
15 fd2 = dup(fd1);
16 addr = (char *)mmap(NULL, MAPSZ, PROT_READ,
17 MAP_SHARED, fd1, 0);
18 close(fd1);
19 c = *addr;
20 pause();
21 }
A file is opened and then dup() is called to duplicate the file descriptor. The file
is then mapped followed by a close of the first file descriptor. By accessing the
address of the mapping, data can be read from the file.
The following examples, using crash and adb on Solaris, show the main
structures involved and scan for the data read, which should be attached to the
vnode through the v_pages field. First of all, the program is run and crash is
used to locate the process:
# ./vnode&
# crash
dumpfile = /dev/mem, namelist = /dev/ksyms, outfile = stdout
> p ! grep vnode
35 s 4365 4343 4365 4343 0 46 vnode load
> u 35
PER PROCESS USER AREA FOR PROCESS 35
PROCESS MISC:
command: vnode, psargs: ./vnode
start: Fri Aug 24 10:55:32 2001
mem: b0, type: exec
vnode of current directory: 30000881ab0
OPEN FILES, FLAGS, AND THREAD REFCNT:
[0]: F 30000adaa90, 0, 0 [1]: F 30000adaa90, 0, 0
[2]: F 30000adaa90, 0, 0 [4]: F 30000adac50, 0, 0
...
The p (proc) command displays the process table. The output is piped to grep
to locate the process. By running the u (user) command and passing the process
slot as an argument, the file descriptors for this process are displayed. The first
file descriptor allocated (3) was closed and the second (4) retained as shown
above.
The entries shown reference file table slots. Using the file command, the
entry for file descriptor number 4 is displayed followed by the vnode that it
references:
> file 30000adac50
ADDRESS RCNT TYPE/ADDR OFFSET FLAGS
30000adac50 1 UFS /30000aafe30 0 read
> vnode -l 30000aafe30
VCNT VFSMNTED VFSP STREAMP VTYPE RDEV VDATA VFILOCKS
VFLAG
3 0 104440b0 0 f 30000aafda0 0 -
Development of the SVR4 VFS/Vnode Architecture 139
mutex v_lock: owner 0 waiters 0
Condition variable v_cv: 0
The file table entry points to a vnode that is then displayed using the vnode
command. Unfortunately the v_pages field is not displayed by crash. Looking
at the header file that corresponds to this release of Solaris, it is possible to see
where in the structure the v_pages field resides. For example, consider the
surrounding fields:
...
struct vfs *v_vfsp; /* ptr to containing VFS */
struct stdata *v_stream; /* associated stream */
struct page *v_pages; /* vnode pages list */
enum vtype v_type; /* vnode type */
...
The v_vfsp and v_type fields are displayed above so by dumping the area of
memory starting at the vnode address, it is possible to display the value of
v_pages. This is shown below:
> od -x 30000aafe30 8
30000aafe30: 000000000000 cafe00000003 000000000000 0000104669e8
30000aafe50: 0000104440b0 000000000000 0000106fbe80 0001baddcafe
There is no way to display page structures in crash, so the Solaris adb command
is used as follows:
# adb -k
physmem 3ac5
106fbe80$ < page
106fbe80: vnode hash vpnext
30000aafe30 1073cb00 106fbe80
106fbe98: vpprev next prev
106fbe80 106fbe80 106fbe80
106fbeb0: offset selock lckcnt
0 0 0
106fbebe: cowcnt cv io_cv
0 0 0
106fbec4: iolock_state fsdata state
0 0 0
Note that the offset field shows a value of 0 that corresponds to the offset
within the file that the program issues the mmap() call for.
Pathname Traversal
The implementation of namei() started to become incredibly complex in some
versions of UNIX as more and more functionality was added to a UNIX kernel
implementation that was really inadequate to support it. [PATE96] shows how
140 UNIX Filesystems.Evolution, Design, and Implementation
namei() was implemented in SCO OpenServer, a derivative of SVR3 for which
namei() became overly complicated. With the addition of new vnodeops,
pathname traversal in SVR4 became greatly simplified.
Because one of the goals of the original Sun VFS/vnode architecture was to
support non-UNIX filesystems, it is not possible to pass a full pathname to the
filesystem and ask it to resolve it to a vnode. Non-UNIX filesystems may not
recognize the _g/_f_f character as a pathname component separator, DOS being a
prime example. Thus, pathnames are resolved one component at a time.
The lookupname() function replaced the old namei() function found in
earlier versions of UNIX. This takes a pathname structure and returns a vnode (if
the pathname is valid). Internally, lookupname() allocates a pathname
structure and calls lookuppn() to actually perform the necessary parsing and
component lookup. The steps performed by lookuppn() are as follows:
if (absolute_pathname) {
dirvp = rootdir
} else {
dirvp = u.u_cdir
}
do {
name = extract string from pathname
newvp = VOP_LOOKUP(dirvp, name, ...)
if not last component {
dirvp = newvp
}
} until basename of pathname reached
return newvp
This is a fairly simple task to perform. Obviously, users can add all sorts of
character combinations, and _g._f_f and _g.._f_f in the specified pathname, so there is a
lot of string manipulation to perform which complicates the work of
lookuppn().
The Directory Name Lookup Cache
The section The Inode Cache in Chapter 6 described how the inode cache provided
a means by which to store inodes that were no longer being used. This helped
speed up access during pathname traversal if an inode corresponding to a
component in the pathname was still present in the cache.
Introduced initially in 4.2BSD and then in SVR4, the directory name lookup cache
(DNLC) provides an easy and fast way to get from a pathname to a vnode. For
example, in the old inode cache method, parsing the pathname
/usr/lib/fs/vxfs/bin/mkfs would involve working on each component of
the pathname one at a time. The inode cache merely saved going to disk during
processing of iget(), not to say that this isn_ft a significant performance
enhancement. However it still involved a directory scan to locate the appropriate
inode number. With the DNLC, a search may be made by the name component
alone. If the entry is cached, the vnode is returned. At hit rates over 90 percent,
this results in a significant performance enhancement.
The DNLC is a cache of ncache structures linked on an LRU (Least Recently
Used) list. The main elements of the structure are shown below and the linkage
between elements of the DNLC is shown in Figure 7.5.
name. The pathname stored.
namelen. The length of the pathname.
vp. This field points to the corresponding vnode.
dvp. The credentials of the file_fs owner.
The ncache structures are hashed to improve lookups. This alleviates the need
for unnecessary string comparisons. To access an entry in the DNLC, a hash value
is calculated from the filename and parent vnode pointer. The appropriate entry
in the nc_hash[] array is accessed, through which the cache can be searched.
There are a number of DNLC-provided functions that are called by both the
filesystem and the kernel.
dnlc_enter. This function is called by the filesystem to add an entry to the
DNLC. This is typically called during pathname resolution on a successful
VOP_LOOKUP() call. It is also called when a new file is created or after other
operations which involve introducing a new file to the namespace such as
creation of hard and symbolic links, renaming of files, and creation of
directories.
dnlc_lookup. This function is typically called by the filesystem during
pathname resolution. Because pathnames are resolved one entry at a time,
the parent directory vnode is passed in addition to the file name to search
for. If the entry exists, the corresponding vnode is returned, otherwise NULL
is returned.
dnlc_remove. Renaming of files and removal of files are functions for which
the entry in the DNLC must be removed.
dnlc_purge_vp. This function can be called to remove all entries in the cache
that reference the specified vnode.
dnlc_purge_vfsp. When a filesystem is to be unmounted, this function is
called to remove all entries that have vnodes associated with the filesystem
that is being unmounted.
dnlc_purge1. This function removes a single entry from the DNLC. SVR4
does not provide a centralized inode cache as found in earlier versions of
UNIX. Any caching of inodes or other filesystem-specific data is the
responsibility of the filesystem. This function was originally implemented to
handle the case where an inode that was no longer in use has been removed
from the inode cache.
As mentioned previously, there should be a hit rate of greater than 90 percent in
the DNLC; otherwise it should be tuned appropriately. The size of the DNLC is
determined by the tunable ncsize and is typically based on the maximum
number of processes and the maximum number of users.
Filesystem and Virtual Memory Interactions
With the inclusion of the SunOS VM subsystem in SVR4, and the integration
between the filesystem and the Virtual Memory (VM) subsystem, the SVR4 VFS
architecture radically changed the way that I/O took place. The buffer cache
changed in usage and a tight coupling between VM and filesystems together
with page-based I/O involved changes throughout the whole kernel from
filesystems to the VM to individual disk drivers.
Consider the old style of file I/O that took place in UNIX up to and including
SVR3. The filesystem made calls into the buffer cache to read and write file data.
For demand paging, the File System Switch architecture provided filesystem
interfaces to aid demand paging of executable files, although all file data was still
read and written through the buffer cache.
This was still largely intact when the Sun VFS/vnode architecture was
introduced. However, in addition to their VFS/vnode implementation, Sun
Microsystems introduced a radically new Virtual Memory subsystem that was, in
large part, to become the new SVR4 VM.
The following sections describe the main components and features of the SVR4
VM together with how file I/O takes place. For a description of the SunOS
implementation, consult the Usenix paper _gVirtual Memory Architecture in
SunOS_h [GING87].
An Overview of the SVR4 VM Subsystem
The memory image of each user process is defined by an as (address space)
structure that references a number of segments underpinned by the seg structure.
Consider a typical user process. The address space of the process will include
separate segments for text, data, and stack, in addition to various libraries, shared
memory, and memory-mapped files as shown pictorially in Figure 7.6.
The seg structure defines the boundaries covering each segment. This includes
the base address in memory together with the size of the segment.
There are a number of different segment types. Each segment type has an array
of segment-related functions in the same way that each vnode has an array of
vnode functions. In the case of a page fault, the kernel will call the fault()
function for the specified segment causing the segment handler to respond by
reading in the appropriate data from disk. When a process is forked, the dup()
function is called for each segment and so on.
For those segments such as process text and data that are backed by a file, the
segvn segment type is used. Each segvn segment has associated private,
per-segment data that is accessed through the s_data field of the seg structure.
This particular structure, segvn_data, contains information about the segment
as well as the underlying file. For example, segvn segment operations need to
know whether the segment is read-only, read/write, or whether it has execute
access so that it can respond accordingly to a page fault. As well as referencing the
vnode backing the segment, the offset at which the segment is mapped to the file
must be known. As a hypothetical example, consider the case where user text is
held at an offset of 0x4000 from the start of the executable file. If a page fault
occurs within the text segment at the address s_base + 0x2000, the segment
page fault handler knows that the data must be read from the file at an offset of
0x4000 + 0x2000 = 0x6000.
After a user process starts executing, there will typically be no physical pages
of data backing these segments. Thus, the first instruction that the process
executes will generate a page fault within the segment covering the instruction.
The kernel page fault handler must first determine in which segment the fault
occurred. This is achieved using the list of segments referenced by the process as
structure together with the base address and the size of each segment. If the
address that generated the page fault does not fall within the boundaries of any of
the process segments, the process will be posted a SIGSEGV, which will typically
result in the process dumping core.
To show how these structures are used in practice, consider the following
invocation of the sleep(1) program:
$ /usr/bin/sleep 100000&
Using crash, the process can be located and the list of segments can be displayed
as follows:
# crash
dumpfile = /dev/mem, namelist = /dev/ksyms, outfile = stdout
> p ! grep sleep
32 s 7719 7694 7719 7694 0 46 sleep load
> as -f 32
PROC PAGLCK CLGAP VBITS HAT HRM RSS
SEGLST LOCK SEGS SIZE LREP TAIL NSEGS
32 0 0 0x0 0x4f958 0x0
0xb10070 0x7fffefa0 0xb5aa50 950272 0 0xb3ccc0 14
BASE SIZE OPS DATA
0x 10000 8192 segvn_ops 0x30000aa46b0
0x 20000 8192 segvn_ops 0x30000bfa448
0x 22000 8192 segvn_ops 0x30000b670f8
0xff280000 679936 segvn_ops 0x30000aa4e40
0xff336000 24576 segvn_ops 0x30000b67c50
0xff33c000 8192 segvn_ops 0x30000bfb260
0xff360000 16384 segvn_ops 0x30000bfac88
0xff372000 16384 segvn_ops 0x30000bface0
0xff380000 16384 segvn_ops 0x30001af3f48
0xff3a0000 8192 segvn_ops 0x30000b677d8
0xff3b0000 8192 segvn_ops 0x30000b239d8
0xff3c0000 131072 segvn_ops 0x30000b4c5e0
0xff3e0000 8192 segvn_ops 0x30000b668b8
0xffbee000 8192 segvn_ops 0x30000bfad38
There are 14 different segment types used to construct the address space, all of
which are segvn type segments. Looking at the highlighted segment, the segvn
private data structure associated with this segment can be displayed within adb
as follows:
0x30000aa4e40$ < segvn
30000aa4e40: lock
30000aa4e40: wwwh
0
30000aa4e48: pageprot prot maxprot
0 015 017
30000aa4e4b: type offset vp
02 0 30000749c58
30000aa4e60: anon_index amp vpage
0 0 0
30000aa4e78: cred swresv advice
30000429b68 0 0
The vnode representing the file backing this segment together with the offset
within the file are displayed. The vnode and inode commands can be used to
display both the vnode and the underlying UFS inode:
30000749c58$ < vnode
30000749c60: flag refcnt vfsmnt
1000 63 0
30000749c70: op vfsp stream
ufs_vnodeops 104440b0 0
30000749c88: pages type rdev
107495e0 1 0
30000749ca0: data filocks shrlocks
30000749bc8 0 0
...
30000749bc8$ < inode
...
30000749ce0: number diroff ufsvfs
50909 0 3000016ee18
...
Finally, the following library is displayed whose inode number matches the inode
displayed above.
# ls -i /usr/lib/libc.so.1
50909 /usr/lib/libc.so.1
An interesting exercise to try is to run some of the programs presented in the
book, particularly those that use memory-mapped files, map the segments
displayed back to the specific file on disk, and note the file offsets and size of the
segments in question.
The segvn segment type is of most interest to filesystem writers. Other
segments include seg_u for managing user areas, seg_kmem for use by the kernel
virtual memory allocator, and seg_dev, which is used to enable applications to
memory-map devices.
The kernel address space is managed in a similar manner to the user address
space in that it has its own address space structure referenced by the kernel
variable k_as. This points to a number of different segments, one of which
represents the SVR4 page cache that is described later in this chapter.
Anonymous Memory
When a process starts executing, the data section may be modified and therefore,
once read from the file, loses its file association thereafter. All such segvn
segments contain a reference to the original file where the data must be read from
but also contain a reference to a set of anonymous pages.
Every anonymous page has reserved space on the swap device. If memory
becomes low and anonymous pages need to be paged out, they can be written to
the swap device and read back into memory at a later date. Anonymous pages
are described by the anon structure, which contains a reference count as well as a
pointer to the actual page. It also points to an entry within an si_anon[] array
for which there is one per swap device. The location within this array determines
the location on the swap device where the page of memory will be paged to if
necessary. This is shown pictorially in Figure 7.7.
File I/O through the SVR4 VFS Layer
SVR4 implemented what is commonly called the page cache through which all file
data is read and written. This is actually a somewhat vague term because the
page cache differs substantially from the fixed size caches of the buffer cache,
DNLC, and other types of caches.
The page cache is composed of two parts, a segment underpinned by the
seg_map segment driver and a list of free pages that can be used for any purpose.
Thus, after a page of file data leaves the cache, it is added to the list of free pages.
While the page is on the free list, it still retains its identity so that if the kernel
wishes to locate the same data prior to the page being reused, the page is
removed from the free list and the data does not need to be re-read from disk.
The main structures used in constructing the page cache are shown in Figure 7.8.
The segmap structure is part of the kernel address space and is underpinned
by the segmap_data structure that describes the properties of the segment. The
size of the segment is tunable and is split into MAXBSIZE (8KB) chunks where
each 8KB chunk represents an 8KB window into a file. Each chunk is referenced
by an smap structure that contains a pointer to a vnode for the file and the offset
within the file. Thus, whereas the buffer cache references file data by device and
block number, the page cache references file data by vnode pointer and file offset.
Two VM functions provide the basis for performing I/O in the new SVR4
model. The first function, shown below, is used in a similar manner to getblk()
to essentially return a new entry in the page cache or return a previously cached
entry:
addr_t
segmap_getmap(struct seg *seg, vnode_t *vp, uint_t *offset);
The seg argument is always segkmap. The remaining two arguments are the
vnode and the offset within the vnode where the data is to be read from or written
to. The offset must be in 8KB multiples from the start of the file.
The address returned from segmap_getmap() is a kernel virtual address
within the segmap segment range s_base to s_base + s_size. When the
page cache is first initialized, the first call to segmap_getmap() will result in the
first smap structure being used. The sm_vp and sm_off fields are updated to
hold the vnode and offset passed in, and the virtual address corresponding to this
entry is returned. After all slots in the segmap window have been used, the
segmap driver must reuse one of the existing slots. This works in a similar
manner to the buffer cache where older buffers are reused when no free buffers
are available. After a slot is reallocated, the pages backing that slot are placed on
the free list. Thus, the page cache essentially works at two levels with the page
free list also acting as a cache.
The segmap_release() function, shown below, works in a similar way to
brelse() by allowing the entry to be reused:
int segmap_release(struct seg *seg, addr_t addr, u_int flags)
This is where the major difference between SVR4 and other UNIX kernels comes
into play. The virtual address returned by segmap_getmap() will not have any
associated physical pages on the first call with a specific vnode and offset.
Consider the following code fragment, which is used by the filesystem to read
from an offset of 8KB within a file and read 1024 bytes:
kaddr = segmap_getmap(segkmap, vp, 8192);
uiomove(kaddr, 1024, UIO_READ, uiop);
segmap_release(segkmap, kaddr, SM_FREE);
The uiomove() function is called to copy bytes from one address to another.
Because there are no physical pages backing kaddr, a page fault will occur.
Because the kernel address space, referenced by kas, contains a linked list of
segments each with a defined start and end address, it is easy for the page fault
handling code to determine which segment fault handler to call to satisfy the page
fault. In this case the s_fault() function provided with the segmap driver will
be called as follows:
segkmap->s_ops->fault(seg, addr, ssize, type, rw);
By using the s_base and addr arguments passed to the fault handler, the
appropriate vnode can be located from the corresponding smap structure. A call
is then made to the filesystem_fs VOP_GETPAGE() function, which must allocate
the appropriate pages and read the data from disk before returning. After this is
all complete, the page fault is satisfied and the uiomove() function continues.
A pictorial view of the steps taken when reading a file through the VxFS
filesystem is shown in Figure 7.9.
To write to a file, the same procedure is followed up to the point where
segmap_release() is called. The flags argument determines what happens to
the pages once the segment is released. The values that flags can take are:
SM_WRITE. The pages should be written, via VOP_PUTPAGE(), to the file once
the segment is released.
SM_ASYNC. The pages should be written asynchronously.
SM_FREE. The pages should be freed.
SM_INVAL. The pages should be invalidated.
SM_DONTNEED. The filesystem has no need to access these pages again.
If no flags are specified, the call to VOP_PUTPAGE() will not occur. This is the
default behavior when reading from a file.
Memory-Mapped File Support in SVR4
A call to mmap() will result in a new segvn segment being attached to the calling
process_f address space. A call will be made to the filesystem VOP_MAP() function,
which performs some level of validation before calling the map_addr() function
to actually initialize the process address space with the new segment.
Page faults on the mapping result in a very similar set of steps to page faults on
the segmap segment. The segvn fault handler is called with the process address
space structure and virtual address. Attached to the private data of this segment
will be the vnode, the offset within the file that was requested of mmap(), and a
set of permissions to indicate the type of mapping.
In the simple case of a memory read access, the segvn driver will call
VOP_GETPAGE() to read in the requested page from the file. Again, the
filesystem will allocate the page and read in the contents from disk.
In the following program, /etc/passwd is mapped. The following text then
shows how to display the segments for this process and from there show the
segvn segment for the mapped region and show how it points back to the passwd
150 UNIX Filesystems.Evolution, Design, and Implementation
file so that data can be read and written as appropriate. The program is very
straightforward, mapping an 8KB chunk of the file from a file offset of 0.
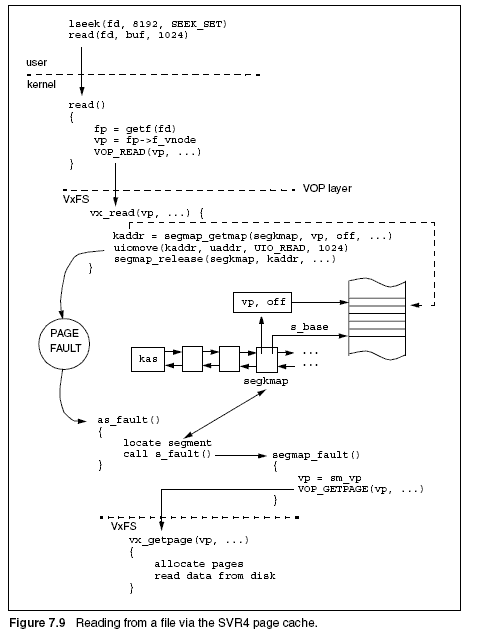 |
1 #include < sys/types.h>
2 #include < sys/stat.h>
3 #include < sys/mman.h>
Figure 7.9 Reading from a file via the SVR4 page cache.
VxFS
vx_getpage(vp, ...)
{
allocate pages
read data from disk
}
segmap_fault()
{
vp = sm_vp
VOP_GETPAGE(vp, ...)
}
as_fault()
{
locate segment
call s_fault()
}
read()
{
fp = getf(fd)
vp = fp->f_vnode
VOP_READ(vp, ...)
}
4 #include < fcntl.h>
5 #include < unistd.h>
6
7 #define MAPSZ 4096
8
9 main()
10 {
11 char *addr, c;
12 int fd;
13
14 fd = open("/etc/passwd", O_RDONLY);
15 addr = (char *)mmap(NULL, MAPSZ,
16 PROT_READ, MAP_SHARED, fd, 0);
17 printf("addr = 0x%x\n", addr);
18 c = *addr;
19 pause();
20 }
After running the program, it can be located with crash as follows. Using the
program slot, the as (address space) for the process is then displayed.
# mydup&
addr = 0xff390000
# crash
> p ! grep mydup
38 s 4836 4800 4836 4800 0 46 map load
> p -f 38
PROC TABLE SIZE = 1882
SLOT ST PID PPID PGID SID UID PRI NAME FLAGS
38 s 4836 4800 4836 4800 0 46 map load
Session: sid: 4800, ctty: vnode(30001031448) maj(24) min(1)
Process Credentials: uid: 0, gid: 1, real uid: 0, real gid: 1
as: 300005d8ff8
...
From within adb the address space can be displayed by invoking the as macro.
This shows a pointer to the list of segments corresponding to this process. In this
case there are 12 segments. The seglist macro then displays each segment in
the list. In this case, only the segment corresponding to the mapped file is
displayed. This is located by looking at the base address of the segment that
corresponds to the address returned from mmap(), which is displayed above.
300005d8ff8$ < as
...
300005d9040: segs size tail
30000b5a2a8 e0000 30000b5a190
300005d9058: nsegs lrep hilevel
12 0 0
...
30000b5a2a8$ < seglist
...
30000b11f80: base size as
ff390000 2000 300005d8ff8
152 UNIX Filesystems.Evolution, Design, and Implementation
30000b11f98: next prev ops
30000b5a4a0 30000b5b8c0 segvn_ops
30000b11fb0: data
30000b4d138
...
Note that in addition to the base address, the size of the segment corresponds to
the size of the mapping requested, in this case 8KB. The data field points to
private segment-specific data. This can be displayed using the segvn macro as
follows:
30000b4d138$ < segvn
...
30000b4d143: type offset vp
01 0 30000aafe30
...
Of most interest here, the vp field points to the vnode from which this segment is
backed. The offset field gives the offset within the file which, as specified to
mmap(), is 0.
The remaining two macro calls display the vnode referenced previously and
the UFS inode corresponding to the vnode.
30000aafe30$ < vnode
30000aafe38: flag refcnt vfsmnt
0 3 0
30000aafe48: op vfsp stream
ufs_vnodeops 104440b0 0
30000aafe60: pages type rdev
106fbe80 1 0
30000aafe78: data filocks shrlocks
30000aafda0 0 0
30000aafda0$ < inode
...
30000aafeb8: number diroff ufsvfs
129222 0 3000016ee18
...
As a check, the inode number is displayed and also displayed below:
# ls -i /etc/passwd
129222 /etc/passwd
Flushing Dirty Pages to Disk
There are a number of cases where modified pages need to be written to disk.
This may result from the pager finding pages to steal, an explicit call to msync(),
or when a process exits and modified pages within a mapping need to be written
back to disk. The VOP_PUTPAGE() vnode operation is called to write a single
page back to disk.
Development of the SVR4 VFS/Vnode Architecture 153
The single page approach may not be ideal for filesystems such as VxFS that
can have multipage extents. The same also holds true for any filesystem where the
block size is greater than the page size. Rather than flush a single dirty page to
disk, it is preferable to flush a range of pages. For VxFS this may cover all dirty
pages within the extent that may be in memory. The VM subsystem provides a
number of routines for manipulating lists of pages. For example, the function
pvn_getdirty_range() can be called to gather all dirty pages in the specified
range. All pages within this range are gathered together in a linked list and
passed to a filesystem-specified routine, that can then proceed to write the page
list to disk.
Page-Based I/O
Prior to SVR4, all I/O went through the buffer cache. Each buffer pointed to a
kernel virtual address where the data could be transferred to and from. With the
change to a page-based model for file I/O in SVR4, the filesystem deals with
pages for file data I/O and may wish to perform I/O to more than one page at a
time. For example, as described in the previous section, a call back into the
filesystem from pvn_getdirty_range() passes a linked list of page
structures. However, these pages do not typically have associated kernel virtual
addresses. To avoid an unnecessary use of kernel virtual address space and an
increased cost in time to map these pages, the buffer cache subsystem as well as
the underlying device drivers were modified to accept a list of pages. In this case,
the b_pages field is set to point to the linked list of pages and the B_PAGES field
must be set.
At the stage that the filesystem wishes to perform I/O, it will typically have a
linked list of pages into which data needs to be read or from which data needs to
be written. To prevent duplication across filesystems, the kernel provides a
function, pageio_setup(), which allocates a buf structure, attaches the list of
pages to b_pages, and initializes the b_flags to include B_PAGES. This is used
by the driver the indicate that page I/O is being performed and that b_pages
should be used and not b_addr. Note that this buffer is not part of the buffer
cache.
The I/O is actually performed by calling the driver strategy function. If the
filesystem needs to wait for the I/O completion, it must call biowait(), passing
the buf structure as an argument. After the I/O is complete, a call to
pageio_done() will free the buffer, leaving the page list intact.
Adoption of the SVR4 Vnode Interface
Although many OS vendors implemented the VFS/vnode architecture within the
framework of their UNIX implementations, the SVR4 style of page I/O, while
elegant and efficient in usage of the underlying memory, failed to gain
widespread adoption. In part this was due to the closed nature in which SVR4
was developed because the implementation was not initially documented. An
additional reason was due to the amount of change that was needed both to the
VM subsystem as well as every filesystem supported.
154 UNIX Filesystems.Evolution, Design, and Implementation
Summary
The period between development of both SVR3 and SunOS and the transition to
SVR4 saw a substantial investment in both the filesystem framework within the
kernel and the development of individual filesystems. The VFS/vnode
architecture has proved to be immensely popular and has been ported in one
way or another to most versions of UNIX. For further details of SVR4.0,
Goodheart and Cox_fs book The Magic Garden Explained: The Internals of System V
Release 4, An Open Systems Design [GOOD94] provides a detailed account of SVR4
kernel internals. For details on the File System Switch (FSS) architecture, Pate_fs
book UNIX Internals.A Practical Approach [PATE96] is one of the few references.
| 
 LINUX
LINUX